LlamaIndex
@@ -102,9 +198,10 @@ for chunk in chat_completion: ```python from llama_index.llms.openai import OpenAI -llm = OpenAI(api_bese="http://localhost:3000/v1", model="meta-llama/Meta-Llama-3-8B-Instruct", api_key="dummy") +llm = OpenAI(api_bese="http://localhost:3000/v1", model="meta-llama/Llama-3.2-1B-Instruct", api_key="dummy") ... ``` +
+
+
+[](https://github.com/bentoml/OpenLLM/blob/main/LICENSE)
+[](https://pypi.org/project/openllm)
+[](https://results.pre-commit.ci/latest/github/bentoml/OpenLLM/main)
+[](https://twitter.com/bentomlai)
+[](https://l.bentoml.com/join-slack)
+
+OpenLLM allows developers to run **any open-source LLMs** (Llama 3.3, Qwen2.5, Phi3 and [more](#supported-models)) or **custom models** as **OpenAI-compatible APIs** with a single command. It features a [built-in chat UI](#chat-ui), state-of-the-art inference backends, and a simplified workflow for creating enterprise-grade cloud deployment with Docker, Kubernetes, and [BentoCloud](#deploy-to-bentocloud).
+
+Understand the [design philosophy of OpenLLM](https://www.bentoml.com/blog/from-ollama-to-openllm-running-llms-in-the-cloud).
+
+## Get Started
+
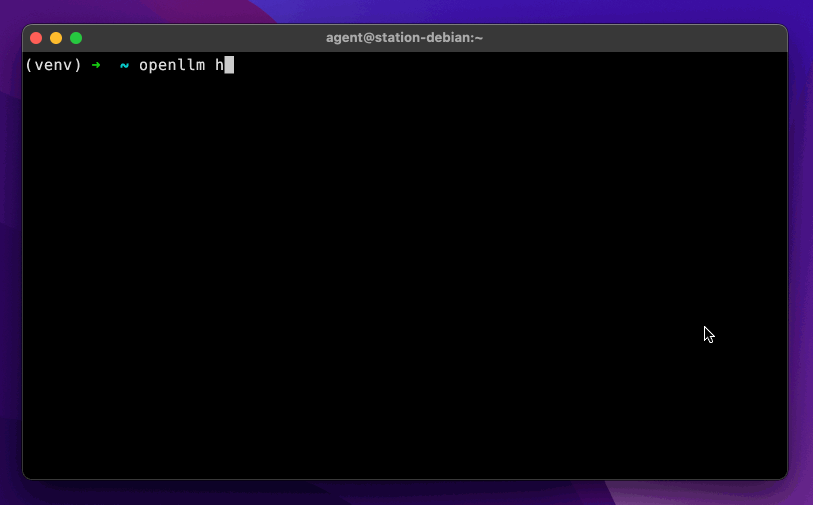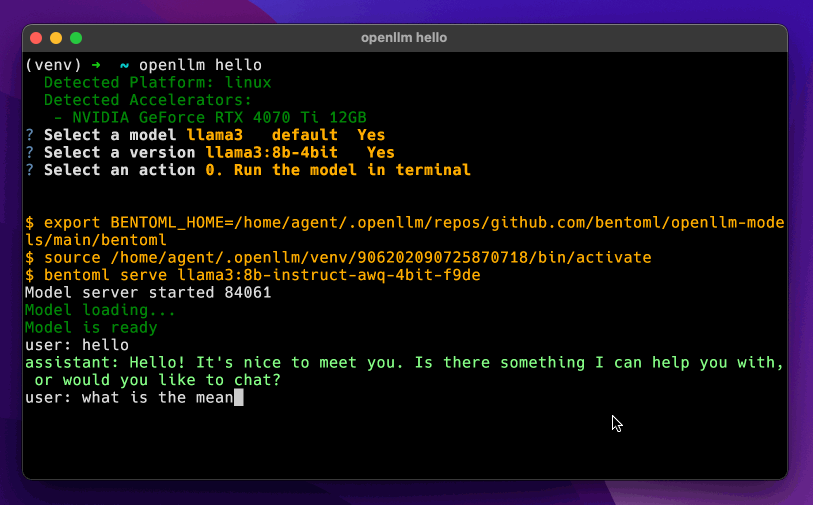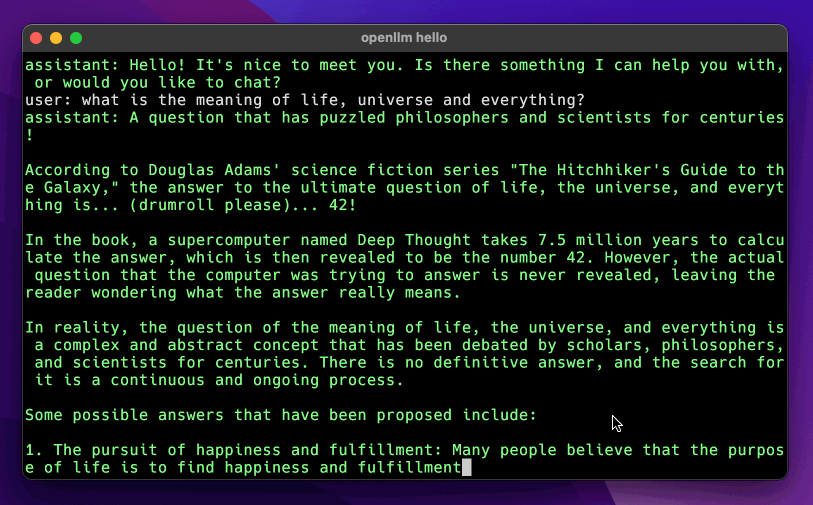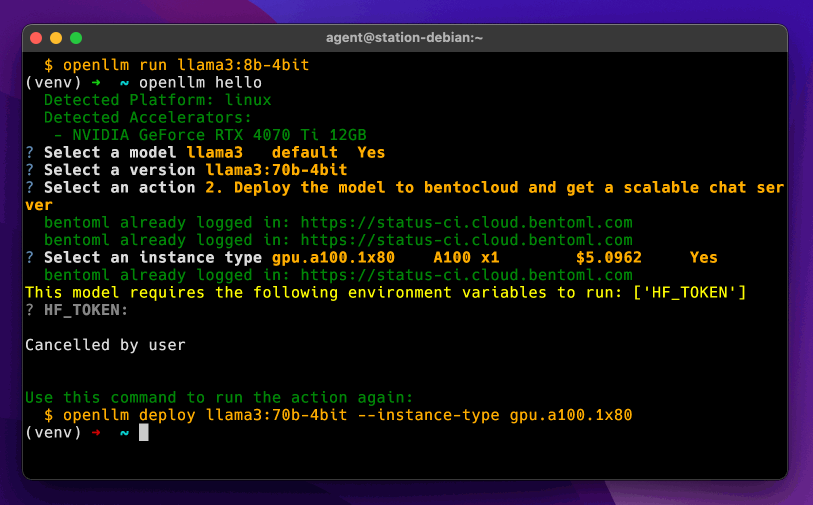
+Run the following commands to install OpenLLM and explore it interactively.
+
+```bash
+pip install openllm # or pip3 install openllm
+openllm hello
+```
+
+
+
+## Supported models
+
+OpenLLM supports a wide range of state-of-the-art open-source LLMs. You can also add a [model repository to run custom models](#set-up-a-custom-repository) with OpenLLM.
+
+🦾 OpenLLM: Self-Hosting LLMs Made Easy
+| Model | +Parameters | +Required GPU | +Start a Server | +
|---|---|---|---|
| {{key}} | +{{value['version'] | upper}} | +{{value['pretty_gpu']}} | +{{value['command']}} |
+
+
+
+
+OpenAI Python client
+ +```python +from openai import OpenAI + +client = OpenAI(base_url='http://localhost:3000/v1', api_key='na') + +# Use the following func to get the available models +# model_list = client.models.list() +# print(model_list) + +chat_completion = client.chat.completions.create( + model="meta-llama/Llama-3.2-1B-Instruct", + messages=[ + { + "role": "user", + "content": "Explain superconductors like I'm five years old" + } + ], + stream=True, +) +for chunk in chat_completion: + print(chunk.choices[0].delta.content or "", end="") +``` + +
+
+
+
+## Chat UI
+
+OpenLLM provides a chat UI at the `/chat` endpoint for the launched LLM server at http://localhost:3000/chat.
+
+