Compare commits
2 Commits
fix-mlx-qu
...
parth/decr
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6b2abfb433 | ||
|
|
805ed4644c |
@@ -190,7 +190,7 @@ if(MLX_ENGINE)
|
|||||||
install(TARGETS mlx mlxc
|
install(TARGETS mlx mlxc
|
||||||
RUNTIME_DEPENDENCIES
|
RUNTIME_DEPENDENCIES
|
||||||
DIRECTORIES ${CUDAToolkit_BIN_DIR} ${CUDAToolkit_BIN_DIR}/x64 ${CUDAToolkit_LIBRARY_DIR}
|
DIRECTORIES ${CUDAToolkit_BIN_DIR} ${CUDAToolkit_BIN_DIR}/x64 ${CUDAToolkit_LIBRARY_DIR}
|
||||||
PRE_INCLUDE_REGEXES cublas cublasLt cudart nvrtc nvrtc-builtins cudnn nccl openblas gfortran
|
PRE_INCLUDE_REGEXES cublas cublasLt cudart nvrtc cudnn nccl
|
||||||
PRE_EXCLUDE_REGEXES ".*"
|
PRE_EXCLUDE_REGEXES ".*"
|
||||||
RUNTIME DESTINATION ${OLLAMA_INSTALL_DIR} COMPONENT MLX
|
RUNTIME DESTINATION ${OLLAMA_INSTALL_DIR} COMPONENT MLX
|
||||||
LIBRARY DESTINATION ${OLLAMA_INSTALL_DIR} COMPONENT MLX
|
LIBRARY DESTINATION ${OLLAMA_INSTALL_DIR} COMPONENT MLX
|
||||||
|
|||||||
18
Dockerfile
@@ -32,7 +32,7 @@ ENV PATH=/${VULKANVERSION}/x86_64/bin:$PATH
|
|||||||
FROM --platform=linux/arm64 almalinux:8 AS base-arm64
|
FROM --platform=linux/arm64 almalinux:8 AS base-arm64
|
||||||
# install epel-release for ccache
|
# install epel-release for ccache
|
||||||
RUN yum install -y yum-utils epel-release \
|
RUN yum install -y yum-utils epel-release \
|
||||||
&& dnf install -y clang ccache git \
|
&& dnf install -y clang ccache \
|
||||||
&& yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/sbsa/cuda-rhel8.repo
|
&& yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/sbsa/cuda-rhel8.repo
|
||||||
ENV CC=clang CXX=clang++
|
ENV CC=clang CXX=clang++
|
||||||
|
|
||||||
@@ -149,7 +149,6 @@ COPY CMakeLists.txt CMakePresets.json .
|
|||||||
COPY ml/backend/ggml/ggml ml/backend/ggml/ggml
|
COPY ml/backend/ggml/ggml ml/backend/ggml/ggml
|
||||||
COPY x/ml/backend/mlx x/ml/backend/mlx
|
COPY x/ml/backend/mlx x/ml/backend/mlx
|
||||||
COPY go.mod go.sum .
|
COPY go.mod go.sum .
|
||||||
COPY MLX_VERSION .
|
|
||||||
RUN curl -fsSL https://golang.org/dl/go$(awk '/^go/ { print $2 }' go.mod).linux-$(case $(uname -m) in x86_64) echo amd64 ;; aarch64) echo arm64 ;; esac).tar.gz | tar xz -C /usr/local
|
RUN curl -fsSL https://golang.org/dl/go$(awk '/^go/ { print $2 }' go.mod).linux-$(case $(uname -m) in x86_64) echo amd64 ;; aarch64) echo arm64 ;; esac).tar.gz | tar xz -C /usr/local
|
||||||
ENV PATH=/usr/local/go/bin:$PATH
|
ENV PATH=/usr/local/go/bin:$PATH
|
||||||
RUN go mod download
|
RUN go mod download
|
||||||
@@ -157,6 +156,14 @@ RUN --mount=type=cache,target=/root/.ccache \
|
|||||||
cmake --preset 'MLX CUDA 13' -DBLAS_INCLUDE_DIRS=/usr/include/openblas -DLAPACK_INCLUDE_DIRS=/usr/include/openblas \
|
cmake --preset 'MLX CUDA 13' -DBLAS_INCLUDE_DIRS=/usr/include/openblas -DLAPACK_INCLUDE_DIRS=/usr/include/openblas \
|
||||||
&& cmake --build --parallel ${PARALLEL} --preset 'MLX CUDA 13' \
|
&& cmake --build --parallel ${PARALLEL} --preset 'MLX CUDA 13' \
|
||||||
&& cmake --install build --component MLX --strip --parallel ${PARALLEL}
|
&& cmake --install build --component MLX --strip --parallel ${PARALLEL}
|
||||||
|
COPY . .
|
||||||
|
ARG GOFLAGS="'-ldflags=-w -s'"
|
||||||
|
ENV CGO_ENABLED=1
|
||||||
|
ARG CGO_CFLAGS
|
||||||
|
ARG CGO_CXXFLAGS
|
||||||
|
RUN mkdir -p dist/bin
|
||||||
|
RUN --mount=type=cache,target=/root/.cache/go-build \
|
||||||
|
go build -tags mlx -trimpath -buildmode=pie -o dist/bin/ollama-mlx .
|
||||||
|
|
||||||
FROM base AS build
|
FROM base AS build
|
||||||
WORKDIR /go/src/github.com/ollama/ollama
|
WORKDIR /go/src/github.com/ollama/ollama
|
||||||
@@ -165,14 +172,12 @@ RUN curl -fsSL https://golang.org/dl/go$(awk '/^go/ { print $2 }' go.mod).linux-
|
|||||||
ENV PATH=/usr/local/go/bin:$PATH
|
ENV PATH=/usr/local/go/bin:$PATH
|
||||||
RUN go mod download
|
RUN go mod download
|
||||||
COPY . .
|
COPY . .
|
||||||
# Clone mlx-c headers for CGO (version from MLX_VERSION file)
|
|
||||||
RUN git clone --depth 1 --branch "$(cat MLX_VERSION)" https://github.com/ml-explore/mlx-c.git build/_deps/mlx-c-src
|
|
||||||
ARG GOFLAGS="'-ldflags=-w -s'"
|
ARG GOFLAGS="'-ldflags=-w -s'"
|
||||||
ENV CGO_ENABLED=1
|
ENV CGO_ENABLED=1
|
||||||
ENV CGO_CFLAGS="-I/go/src/github.com/ollama/ollama/build/_deps/mlx-c-src"
|
ARG CGO_CFLAGS
|
||||||
ARG CGO_CXXFLAGS
|
ARG CGO_CXXFLAGS
|
||||||
RUN --mount=type=cache,target=/root/.cache/go-build \
|
RUN --mount=type=cache,target=/root/.cache/go-build \
|
||||||
go build -tags mlx -trimpath -buildmode=pie -o /bin/ollama .
|
go build -trimpath -buildmode=pie -o /bin/ollama .
|
||||||
|
|
||||||
FROM --platform=linux/amd64 scratch AS amd64
|
FROM --platform=linux/amd64 scratch AS amd64
|
||||||
# COPY --from=cuda-11 dist/lib/ollama/ /lib/ollama/
|
# COPY --from=cuda-11 dist/lib/ollama/ /lib/ollama/
|
||||||
@@ -180,6 +185,7 @@ COPY --from=cuda-12 dist/lib/ollama /lib/ollama/
|
|||||||
COPY --from=cuda-13 dist/lib/ollama /lib/ollama/
|
COPY --from=cuda-13 dist/lib/ollama /lib/ollama/
|
||||||
COPY --from=vulkan dist/lib/ollama /lib/ollama/
|
COPY --from=vulkan dist/lib/ollama /lib/ollama/
|
||||||
COPY --from=mlx /go/src/github.com/ollama/ollama/dist/lib/ollama /lib/ollama/
|
COPY --from=mlx /go/src/github.com/ollama/ollama/dist/lib/ollama /lib/ollama/
|
||||||
|
COPY --from=mlx /go/src/github.com/ollama/ollama/dist/bin/ /bin/
|
||||||
|
|
||||||
FROM --platform=linux/arm64 scratch AS arm64
|
FROM --platform=linux/arm64 scratch AS arm64
|
||||||
# COPY --from=cuda-11 dist/lib/ollama/ /lib/ollama/
|
# COPY --from=cuda-11 dist/lib/ollama/ /lib/ollama/
|
||||||
|
|||||||
@@ -1 +0,0 @@
|
|||||||
v0.4.1
|
|
||||||
41
README.md
@@ -48,7 +48,7 @@ ollama run gemma3
|
|||||||
|
|
||||||
## Model library
|
## Model library
|
||||||
|
|
||||||
Ollama supports a list of models available on [ollama.com/library](https://ollama.com/library "ollama model library")
|
Ollama supports a list of models available on [ollama.com/library](https://ollama.com/library 'ollama model library')
|
||||||
|
|
||||||
Here are some example models that can be downloaded:
|
Here are some example models that can be downloaded:
|
||||||
|
|
||||||
@@ -79,7 +79,7 @@ Here are some example models that can be downloaded:
|
|||||||
| Code Llama | 7B | 3.8GB | `ollama run codellama` |
|
| Code Llama | 7B | 3.8GB | `ollama run codellama` |
|
||||||
| Llama 2 Uncensored | 7B | 3.8GB | `ollama run llama2-uncensored` |
|
| Llama 2 Uncensored | 7B | 3.8GB | `ollama run llama2-uncensored` |
|
||||||
| LLaVA | 7B | 4.5GB | `ollama run llava` |
|
| LLaVA | 7B | 4.5GB | `ollama run llava` |
|
||||||
| Granite-3.3 | 8B | 4.9GB | `ollama run granite3.3` |
|
| Granite-3.3 | 8B | 4.9GB | `ollama run granite3.3` |
|
||||||
|
|
||||||
> [!NOTE]
|
> [!NOTE]
|
||||||
> You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
|
> You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
|
||||||
@@ -260,38 +260,6 @@ Finally, in a separate shell, run a model:
|
|||||||
./ollama run llama3.2
|
./ollama run llama3.2
|
||||||
```
|
```
|
||||||
|
|
||||||
## Building with MLX (experimental)
|
|
||||||
|
|
||||||
First build the MLX libraries:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
cmake --preset MLX
|
|
||||||
cmake --build --preset MLX --parallel
|
|
||||||
cmake --install build --component MLX
|
|
||||||
```
|
|
||||||
|
|
||||||
When building with the `-tags mlx` flag, the main `ollama` binary includes MLX support for experimental features like image generation:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
go build -tags mlx .
|
|
||||||
```
|
|
||||||
|
|
||||||
Finally, start the server:
|
|
||||||
|
|
||||||
```
|
|
||||||
./ollama serve
|
|
||||||
```
|
|
||||||
|
|
||||||
### Building MLX with CUDA
|
|
||||||
|
|
||||||
When building with CUDA, use the preset "MLX CUDA 13" or "MLX CUDA 12" to enable CUDA with default architectures:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
cmake --preset 'MLX CUDA 13'
|
|
||||||
cmake --build --preset 'MLX CUDA 13' --parallel
|
|
||||||
cmake --install build --component MLX
|
|
||||||
```
|
|
||||||
|
|
||||||
## REST API
|
## REST API
|
||||||
|
|
||||||
Ollama has a REST API for running and managing models.
|
Ollama has a REST API for running and managing models.
|
||||||
@@ -322,7 +290,6 @@ See the [API documentation](./docs/api.md) for all endpoints.
|
|||||||
|
|
||||||
### Web & Desktop
|
### Web & Desktop
|
||||||
|
|
||||||
- [Onyx](https://github.com/onyx-dot-app/onyx)
|
|
||||||
- [Open WebUI](https://github.com/open-webui/open-webui)
|
- [Open WebUI](https://github.com/open-webui/open-webui)
|
||||||
- [SwiftChat (macOS with ReactNative)](https://github.com/aws-samples/swift-chat)
|
- [SwiftChat (macOS with ReactNative)](https://github.com/aws-samples/swift-chat)
|
||||||
- [Enchanted (macOS native)](https://github.com/AugustDev/enchanted)
|
- [Enchanted (macOS native)](https://github.com/AugustDev/enchanted)
|
||||||
@@ -526,7 +493,7 @@ See the [API documentation](./docs/api.md) for all endpoints.
|
|||||||
### Database
|
### Database
|
||||||
|
|
||||||
- [pgai](https://github.com/timescale/pgai) - PostgreSQL as a vector database (Create and search embeddings from Ollama models using pgvector)
|
- [pgai](https://github.com/timescale/pgai) - PostgreSQL as a vector database (Create and search embeddings from Ollama models using pgvector)
|
||||||
- [Get started guide](https://github.com/timescale/pgai/blob/main/docs/vectorizer-quick-start.md)
|
- [Get started guide](https://github.com/timescale/pgai/blob/main/docs/vectorizer-quick-start.md)
|
||||||
- [MindsDB](https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/integrations/handlers/ollama_handler/README.md) (Connects Ollama models with nearly 200 data platforms and apps)
|
- [MindsDB](https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/integrations/handlers/ollama_handler/README.md) (Connects Ollama models with nearly 200 data platforms and apps)
|
||||||
- [chromem-go](https://github.com/philippgille/chromem-go/blob/v0.5.0/embed_ollama.go) with [example](https://github.com/philippgille/chromem-go/tree/v0.5.0/examples/rag-wikipedia-ollama)
|
- [chromem-go](https://github.com/philippgille/chromem-go/blob/v0.5.0/embed_ollama.go) with [example](https://github.com/philippgille/chromem-go/tree/v0.5.0/examples/rag-wikipedia-ollama)
|
||||||
- [Kangaroo](https://github.com/dbkangaroo/kangaroo) (AI-powered SQL client and admin tool for popular databases)
|
- [Kangaroo](https://github.com/dbkangaroo/kangaroo) (AI-powered SQL client and admin tool for popular databases)
|
||||||
@@ -669,7 +636,6 @@ See the [API documentation](./docs/api.md) for all endpoints.
|
|||||||
- [llama.cpp](https://github.com/ggml-org/llama.cpp) project founded by Georgi Gerganov.
|
- [llama.cpp](https://github.com/ggml-org/llama.cpp) project founded by Georgi Gerganov.
|
||||||
|
|
||||||
### Observability
|
### Observability
|
||||||
|
|
||||||
- [Opik](https://www.comet.com/docs/opik/cookbook/ollama) is an open-source platform to debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards. Opik supports native integration to Ollama.
|
- [Opik](https://www.comet.com/docs/opik/cookbook/ollama) is an open-source platform to debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards. Opik supports native integration to Ollama.
|
||||||
- [Lunary](https://lunary.ai/docs/integrations/ollama) is the leading open-source LLM observability platform. It provides a variety of enterprise-grade features such as real-time analytics, prompt templates management, PII masking, and comprehensive agent tracing.
|
- [Lunary](https://lunary.ai/docs/integrations/ollama) is the leading open-source LLM observability platform. It provides a variety of enterprise-grade features such as real-time analytics, prompt templates management, PII masking, and comprehensive agent tracing.
|
||||||
- [OpenLIT](https://github.com/openlit/openlit) is an OpenTelemetry-native tool for monitoring Ollama Applications & GPUs using traces and metrics.
|
- [OpenLIT](https://github.com/openlit/openlit) is an OpenTelemetry-native tool for monitoring Ollama Applications & GPUs using traces and metrics.
|
||||||
@@ -678,5 +644,4 @@ See the [API documentation](./docs/api.md) for all endpoints.
|
|||||||
- [MLflow Tracing](https://mlflow.org/docs/latest/llms/tracing/index.html#automatic-tracing) is an open source LLM observability tool with a convenient API to log and visualize traces, making it easy to debug and evaluate GenAI applications.
|
- [MLflow Tracing](https://mlflow.org/docs/latest/llms/tracing/index.html#automatic-tracing) is an open source LLM observability tool with a convenient API to log and visualize traces, making it easy to debug and evaluate GenAI applications.
|
||||||
|
|
||||||
### Security
|
### Security
|
||||||
|
|
||||||
- [Ollama Fortress](https://github.com/ParisNeo/ollama_proxy_server)
|
- [Ollama Fortress](https://github.com/ParisNeo/ollama_proxy_server)
|
||||||
|
|||||||
28
api/types.go
@@ -127,20 +127,6 @@ type GenerateRequest struct {
|
|||||||
// each with an associated log probability. Only applies when Logprobs is true.
|
// each with an associated log probability. Only applies when Logprobs is true.
|
||||||
// Valid values are 0-20. Default is 0 (only return the selected token's logprob).
|
// Valid values are 0-20. Default is 0 (only return the selected token's logprob).
|
||||||
TopLogprobs int `json:"top_logprobs,omitempty"`
|
TopLogprobs int `json:"top_logprobs,omitempty"`
|
||||||
|
|
||||||
// Experimental: Image generation fields (may change or be removed)
|
|
||||||
|
|
||||||
// Width is the width of the generated image in pixels.
|
|
||||||
// Only used for image generation models.
|
|
||||||
Width int32 `json:"width,omitempty"`
|
|
||||||
|
|
||||||
// Height is the height of the generated image in pixels.
|
|
||||||
// Only used for image generation models.
|
|
||||||
Height int32 `json:"height,omitempty"`
|
|
||||||
|
|
||||||
// Steps is the number of diffusion steps for image generation.
|
|
||||||
// Only used for image generation models.
|
|
||||||
Steps int32 `json:"steps,omitempty"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// ChatRequest describes a request sent by [Client.Chat].
|
// ChatRequest describes a request sent by [Client.Chat].
|
||||||
@@ -874,20 +860,6 @@ type GenerateResponse struct {
|
|||||||
// Logprobs contains log probability information for the generated tokens,
|
// Logprobs contains log probability information for the generated tokens,
|
||||||
// if requested via the Logprobs parameter.
|
// if requested via the Logprobs parameter.
|
||||||
Logprobs []Logprob `json:"logprobs,omitempty"`
|
Logprobs []Logprob `json:"logprobs,omitempty"`
|
||||||
|
|
||||||
// Experimental: Image generation fields (may change or be removed)
|
|
||||||
|
|
||||||
// Image contains a base64-encoded generated image.
|
|
||||||
// Only present for image generation models.
|
|
||||||
Image string `json:"image,omitempty"`
|
|
||||||
|
|
||||||
// Completed is the number of completed steps in image generation.
|
|
||||||
// Only present for image generation models during streaming.
|
|
||||||
Completed int64 `json:"completed,omitempty"`
|
|
||||||
|
|
||||||
// Total is the total number of steps for image generation.
|
|
||||||
// Only present for image generation models during streaming.
|
|
||||||
Total int64 `json:"total,omitempty"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// ModelDetails provides details about a model.
|
// ModelDetails provides details about a model.
|
||||||
|
|||||||
@@ -14,7 +14,6 @@ extern NSString *SystemWidePath;
|
|||||||
@interface AppDelegate () <NSWindowDelegate, WKNavigationDelegate, WKUIDelegate>
|
@interface AppDelegate () <NSWindowDelegate, WKNavigationDelegate, WKUIDelegate>
|
||||||
@property(strong, nonatomic) NSStatusItem *statusItem;
|
@property(strong, nonatomic) NSStatusItem *statusItem;
|
||||||
@property(assign, nonatomic) BOOL updateAvailable;
|
@property(assign, nonatomic) BOOL updateAvailable;
|
||||||
@property(assign, nonatomic) BOOL systemShutdownInProgress;
|
|
||||||
@end
|
@end
|
||||||
|
|
||||||
@implementation AppDelegate
|
@implementation AppDelegate
|
||||||
@@ -41,13 +40,6 @@ bool firstTimeRun,startHidden; // Set in run before initialization
|
|||||||
}
|
}
|
||||||
|
|
||||||
- (void)applicationDidFinishLaunching:(NSNotification *)aNotification {
|
- (void)applicationDidFinishLaunching:(NSNotification *)aNotification {
|
||||||
// Register for system shutdown/restart notification so we can allow termination
|
|
||||||
[[[NSWorkspace sharedWorkspace] notificationCenter]
|
|
||||||
addObserver:self
|
|
||||||
selector:@selector(systemWillPowerOff:)
|
|
||||||
name:NSWorkspaceWillPowerOffNotification
|
|
||||||
object:nil];
|
|
||||||
|
|
||||||
// if we're in development mode, set the app icon
|
// if we're in development mode, set the app icon
|
||||||
NSString *bundlePath = [[NSBundle mainBundle] bundlePath];
|
NSString *bundlePath = [[NSBundle mainBundle] bundlePath];
|
||||||
if (![bundlePath hasSuffix:@".app"]) {
|
if (![bundlePath hasSuffix:@".app"]) {
|
||||||
@@ -286,18 +278,7 @@ bool firstTimeRun,startHidden; // Set in run before initialization
|
|||||||
[NSApp activateIgnoringOtherApps:YES];
|
[NSApp activateIgnoringOtherApps:YES];
|
||||||
}
|
}
|
||||||
|
|
||||||
- (void)systemWillPowerOff:(NSNotification *)notification {
|
|
||||||
// Set flag so applicationShouldTerminate: knows to allow termination.
|
|
||||||
// The system will call applicationShouldTerminate: after posting this notification.
|
|
||||||
self.systemShutdownInProgress = YES;
|
|
||||||
}
|
|
||||||
|
|
||||||
- (NSApplicationTerminateReply)applicationShouldTerminate:(NSApplication *)sender {
|
- (NSApplicationTerminateReply)applicationShouldTerminate:(NSApplication *)sender {
|
||||||
// Allow termination if the system is shutting down or restarting
|
|
||||||
if (self.systemShutdownInProgress) {
|
|
||||||
return NSTerminateNow;
|
|
||||||
}
|
|
||||||
// Otherwise just hide the app (for Cmd+Q, close button, etc.)
|
|
||||||
[NSApp hide:nil];
|
[NSApp hide:nil];
|
||||||
[NSApp setActivationPolicy:NSApplicationActivationPolicyAccessory];
|
[NSApp setActivationPolicy:NSApplicationActivationPolicyAccessory];
|
||||||
return NSTerminateCancel;
|
return NSTerminateCancel;
|
||||||
|
|||||||
101
cmd/cmd.go
@@ -46,9 +46,8 @@ import (
|
|||||||
"github.com/ollama/ollama/types/syncmap"
|
"github.com/ollama/ollama/types/syncmap"
|
||||||
"github.com/ollama/ollama/version"
|
"github.com/ollama/ollama/version"
|
||||||
xcmd "github.com/ollama/ollama/x/cmd"
|
xcmd "github.com/ollama/ollama/x/cmd"
|
||||||
"github.com/ollama/ollama/x/create"
|
|
||||||
xcreateclient "github.com/ollama/ollama/x/create/client"
|
|
||||||
"github.com/ollama/ollama/x/imagegen"
|
"github.com/ollama/ollama/x/imagegen"
|
||||||
|
imagegenclient "github.com/ollama/ollama/x/imagegen/client"
|
||||||
)
|
)
|
||||||
|
|
||||||
const ConnectInstructions = "To sign in, navigate to:\n %s\n\n"
|
const ConnectInstructions = "To sign in, navigate to:\n %s\n\n"
|
||||||
@@ -94,87 +93,15 @@ func CreateHandler(cmd *cobra.Command, args []string) error {
|
|||||||
p := progress.NewProgress(os.Stderr)
|
p := progress.NewProgress(os.Stderr)
|
||||||
defer p.Stop()
|
defer p.Stop()
|
||||||
|
|
||||||
// Validate model name early to fail fast
|
|
||||||
modelName := args[0]
|
|
||||||
name := model.ParseName(modelName)
|
|
||||||
if !name.IsValid() {
|
|
||||||
return fmt.Errorf("invalid model name: %s", modelName)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check for --experimental flag for safetensors model creation
|
|
||||||
experimental, _ := cmd.Flags().GetBool("experimental")
|
|
||||||
if experimental {
|
|
||||||
// Get Modelfile content - either from -f flag or default to "FROM ."
|
|
||||||
var reader io.Reader
|
|
||||||
filename, err := getModelfileName(cmd)
|
|
||||||
if os.IsNotExist(err) || filename == "" {
|
|
||||||
// No Modelfile specified or found - use default
|
|
||||||
reader = strings.NewReader("FROM .\n")
|
|
||||||
} else if err != nil {
|
|
||||||
return err
|
|
||||||
} else {
|
|
||||||
f, err := os.Open(filename)
|
|
||||||
if err != nil {
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
defer f.Close()
|
|
||||||
reader = f
|
|
||||||
}
|
|
||||||
|
|
||||||
// Parse the Modelfile
|
|
||||||
modelfile, err := parser.ParseFile(reader)
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("failed to parse Modelfile: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Extract FROM path and configuration
|
|
||||||
var modelDir string
|
|
||||||
mfConfig := &xcreateclient.ModelfileConfig{}
|
|
||||||
|
|
||||||
for _, cmd := range modelfile.Commands {
|
|
||||||
switch cmd.Name {
|
|
||||||
case "model":
|
|
||||||
modelDir = cmd.Args
|
|
||||||
case "template":
|
|
||||||
mfConfig.Template = cmd.Args
|
|
||||||
case "system":
|
|
||||||
mfConfig.System = cmd.Args
|
|
||||||
case "license":
|
|
||||||
mfConfig.License = cmd.Args
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
if modelDir == "" {
|
|
||||||
modelDir = "."
|
|
||||||
}
|
|
||||||
|
|
||||||
// Resolve relative paths based on Modelfile location
|
|
||||||
if !filepath.IsAbs(modelDir) && filename != "" {
|
|
||||||
modelDir = filepath.Join(filepath.Dir(filename), modelDir)
|
|
||||||
}
|
|
||||||
|
|
||||||
quantize, _ := cmd.Flags().GetString("quantize")
|
|
||||||
return xcreateclient.CreateModel(xcreateclient.CreateOptions{
|
|
||||||
ModelName: modelName,
|
|
||||||
ModelDir: modelDir,
|
|
||||||
Quantize: quantize,
|
|
||||||
Modelfile: mfConfig,
|
|
||||||
}, p)
|
|
||||||
}
|
|
||||||
|
|
||||||
var reader io.Reader
|
var reader io.Reader
|
||||||
|
|
||||||
filename, err := getModelfileName(cmd)
|
filename, err := getModelfileName(cmd)
|
||||||
if os.IsNotExist(err) {
|
if os.IsNotExist(err) {
|
||||||
if filename == "" {
|
if filename == "" {
|
||||||
// No Modelfile found - check if current directory is an image gen model
|
// No Modelfile found - check if current directory is an image gen model
|
||||||
if create.IsTensorModelDir(".") {
|
if imagegen.IsTensorModelDir(".") {
|
||||||
quantize, _ := cmd.Flags().GetString("quantize")
|
quantize, _ := cmd.Flags().GetString("quantize")
|
||||||
return xcreateclient.CreateModel(xcreateclient.CreateOptions{
|
return imagegenclient.CreateModel(args[0], ".", quantize, p)
|
||||||
ModelName: modelName,
|
|
||||||
ModelDir: ".",
|
|
||||||
Quantize: quantize,
|
|
||||||
}, p)
|
|
||||||
}
|
}
|
||||||
reader = strings.NewReader("FROM .\n")
|
reader = strings.NewReader("FROM .\n")
|
||||||
} else {
|
} else {
|
||||||
@@ -207,7 +134,7 @@ func CreateHandler(cmd *cobra.Command, args []string) error {
|
|||||||
}
|
}
|
||||||
spinner.Stop()
|
spinner.Stop()
|
||||||
|
|
||||||
req.Model = modelName
|
req.Model = args[0]
|
||||||
quantize, _ := cmd.Flags().GetString("quantize")
|
quantize, _ := cmd.Flags().GetString("quantize")
|
||||||
if quantize != "" {
|
if quantize != "" {
|
||||||
req.Quantize = quantize
|
req.Quantize = quantize
|
||||||
@@ -600,7 +527,7 @@ func RunHandler(cmd *cobra.Command, args []string) error {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// Check if this is an image generation model
|
// Check if this is an image generation model
|
||||||
if slices.Contains(info.Capabilities, model.CapabilityImage) {
|
if slices.Contains(info.Capabilities, model.CapabilityImageGeneration) {
|
||||||
if opts.Prompt == "" && !interactive {
|
if opts.Prompt == "" && !interactive {
|
||||||
return errors.New("image generation models require a prompt. Usage: ollama run " + name + " \"your prompt here\"")
|
return errors.New("image generation models require a prompt. Usage: ollama run " + name + " \"your prompt here\"")
|
||||||
}
|
}
|
||||||
@@ -1815,22 +1742,15 @@ func NewCLI() *cobra.Command {
|
|||||||
rootCmd.Flags().BoolP("version", "v", false, "Show version information")
|
rootCmd.Flags().BoolP("version", "v", false, "Show version information")
|
||||||
|
|
||||||
createCmd := &cobra.Command{
|
createCmd := &cobra.Command{
|
||||||
Use: "create MODEL",
|
Use: "create MODEL",
|
||||||
Short: "Create a model",
|
Short: "Create a model",
|
||||||
Args: cobra.ExactArgs(1),
|
Args: cobra.ExactArgs(1),
|
||||||
PreRunE: func(cmd *cobra.Command, args []string) error {
|
PreRunE: checkServerHeartbeat,
|
||||||
// Skip server check for experimental mode (writes directly to disk)
|
RunE: CreateHandler,
|
||||||
if experimental, _ := cmd.Flags().GetBool("experimental"); experimental {
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
return checkServerHeartbeat(cmd, args)
|
|
||||||
},
|
|
||||||
RunE: CreateHandler,
|
|
||||||
}
|
}
|
||||||
|
|
||||||
createCmd.Flags().StringP("file", "f", "", "Name of the Modelfile (default \"Modelfile\")")
|
createCmd.Flags().StringP("file", "f", "", "Name of the Modelfile (default \"Modelfile\")")
|
||||||
createCmd.Flags().StringP("quantize", "q", "", "Quantize model to this level (e.g. q4_K_M)")
|
createCmd.Flags().StringP("quantize", "q", "", "Quantize model to this level (e.g. q4_K_M)")
|
||||||
createCmd.Flags().Bool("experimental", false, "Enable experimental safetensors model creation")
|
|
||||||
|
|
||||||
showCmd := &cobra.Command{
|
showCmd := &cobra.Command{
|
||||||
Use: "show MODEL",
|
Use: "show MODEL",
|
||||||
@@ -1985,7 +1905,6 @@ func NewCLI() *cobra.Command {
|
|||||||
} {
|
} {
|
||||||
switch cmd {
|
switch cmd {
|
||||||
case runCmd:
|
case runCmd:
|
||||||
imagegen.AppendFlagsDocs(cmd)
|
|
||||||
appendEnvDocs(cmd, []envconfig.EnvVar{envVars["OLLAMA_HOST"], envVars["OLLAMA_NOHISTORY"]})
|
appendEnvDocs(cmd, []envconfig.EnvVar{envVars["OLLAMA_HOST"], envVars["OLLAMA_NOHISTORY"]})
|
||||||
case serveCmd:
|
case serveCmd:
|
||||||
appendEnvDocs(cmd, []envconfig.EnvVar{
|
appendEnvDocs(cmd, []envconfig.EnvVar{
|
||||||
|
|||||||
@@ -1555,7 +1555,7 @@ func TestShowInfoImageGen(t *testing.T) {
|
|||||||
ParameterSize: "10.3B",
|
ParameterSize: "10.3B",
|
||||||
QuantizationLevel: "FP8",
|
QuantizationLevel: "FP8",
|
||||||
},
|
},
|
||||||
Capabilities: []model.Capability{model.CapabilityImage},
|
Capabilities: []model.Capability{model.CapabilityImageGeneration},
|
||||||
Requires: "0.14.0",
|
Requires: "0.14.0",
|
||||||
}, false, &b)
|
}, false, &b)
|
||||||
if err != nil {
|
if err != nil {
|
||||||
|
|||||||
@@ -116,7 +116,7 @@ func generateInteractive(cmd *cobra.Command, opts runOptions) error {
|
|||||||
Prompt: ">>> ",
|
Prompt: ">>> ",
|
||||||
AltPrompt: "... ",
|
AltPrompt: "... ",
|
||||||
Placeholder: "Send a message (/? for help)",
|
Placeholder: "Send a message (/? for help)",
|
||||||
AltPlaceholder: "Press Enter to send",
|
AltPlaceholder: `Use """ to end multi-line input`,
|
||||||
})
|
})
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return err
|
return err
|
||||||
|
|||||||
62
docs/api.md
@@ -16,7 +16,6 @@
|
|||||||
- [Generate Embeddings](#generate-embeddings)
|
- [Generate Embeddings](#generate-embeddings)
|
||||||
- [List Running Models](#list-running-models)
|
- [List Running Models](#list-running-models)
|
||||||
- [Version](#version)
|
- [Version](#version)
|
||||||
- [Experimental: Image Generation](#image-generation-experimental)
|
|
||||||
|
|
||||||
## Conventions
|
## Conventions
|
||||||
|
|
||||||
@@ -59,15 +58,6 @@ Advanced parameters (optional):
|
|||||||
- `keep_alive`: controls how long the model will stay loaded into memory following the request (default: `5m`)
|
- `keep_alive`: controls how long the model will stay loaded into memory following the request (default: `5m`)
|
||||||
- `context` (deprecated): the context parameter returned from a previous request to `/generate`, this can be used to keep a short conversational memory
|
- `context` (deprecated): the context parameter returned from a previous request to `/generate`, this can be used to keep a short conversational memory
|
||||||
|
|
||||||
Experimental image generation parameters (for image generation models only):
|
|
||||||
|
|
||||||
> [!WARNING]
|
|
||||||
> These parameters are experimental and may change in future versions.
|
|
||||||
|
|
||||||
- `width`: width of the generated image in pixels
|
|
||||||
- `height`: height of the generated image in pixels
|
|
||||||
- `steps`: number of diffusion steps
|
|
||||||
|
|
||||||
#### Structured outputs
|
#### Structured outputs
|
||||||
|
|
||||||
Structured outputs are supported by providing a JSON schema in the `format` parameter. The model will generate a response that matches the schema. See the [structured outputs](#request-structured-outputs) example below.
|
Structured outputs are supported by providing a JSON schema in the `format` parameter. The model will generate a response that matches the schema. See the [structured outputs](#request-structured-outputs) example below.
|
||||||
@@ -1877,55 +1867,3 @@ curl http://localhost:11434/api/version
|
|||||||
"version": "0.5.1"
|
"version": "0.5.1"
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## Experimental Features
|
|
||||||
|
|
||||||
### Image Generation (Experimental)
|
|
||||||
|
|
||||||
> [!WARNING]
|
|
||||||
> Image generation is experimental and may change in future versions.
|
|
||||||
|
|
||||||
Image generation is now supported through the standard `/api/generate` endpoint when using image generation models. The API automatically detects when an image generation model is being used.
|
|
||||||
|
|
||||||
See the [Generate a completion](#generate-a-completion) section for the full API documentation. The experimental image generation parameters (`width`, `height`, `steps`) are documented there.
|
|
||||||
|
|
||||||
#### Example
|
|
||||||
|
|
||||||
##### Request
|
|
||||||
|
|
||||||
```shell
|
|
||||||
curl http://localhost:11434/api/generate -d '{
|
|
||||||
"model": "x/z-image-turbo",
|
|
||||||
"prompt": "a sunset over mountains",
|
|
||||||
"width": 1024,
|
|
||||||
"height": 768
|
|
||||||
}'
|
|
||||||
```
|
|
||||||
|
|
||||||
##### Response (streaming)
|
|
||||||
|
|
||||||
Progress updates during generation:
|
|
||||||
|
|
||||||
```json
|
|
||||||
{
|
|
||||||
"model": "x/z-image-turbo",
|
|
||||||
"created_at": "2024-01-15T10:30:00.000000Z",
|
|
||||||
"completed": 5,
|
|
||||||
"total": 20,
|
|
||||||
"done": false
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
##### Final Response
|
|
||||||
|
|
||||||
```json
|
|
||||||
{
|
|
||||||
"model": "x/z-image-turbo",
|
|
||||||
"created_at": "2024-01-15T10:30:15.000000Z",
|
|
||||||
"image": "iVBORw0KGgoAAAANSUhEUg...",
|
|
||||||
"done": true,
|
|
||||||
"done_reason": "stop",
|
|
||||||
"total_duration": 15000000000,
|
|
||||||
"load_duration": 2000000000
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|||||||
@@ -21,7 +21,6 @@ ollama pull glm-4.7:cloud
|
|||||||
To use Ollama with tools that expect the Anthropic API (like Claude Code), set these environment variables:
|
To use Ollama with tools that expect the Anthropic API (like Claude Code), set these environment variables:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
export ANTHROPIC_AUTH_TOKEN=ollama # required but ignored
|
|
||||||
export ANTHROPIC_BASE_URL=http://localhost:11434
|
export ANTHROPIC_BASE_URL=http://localhost:11434
|
||||||
export ANTHROPIC_API_KEY=ollama # required but ignored
|
export ANTHROPIC_API_KEY=ollama # required but ignored
|
||||||
```
|
```
|
||||||
@@ -248,13 +247,12 @@ curl -X POST http://localhost:11434/v1/messages \
|
|||||||
[Claude Code](https://code.claude.com/docs/en/overview) can be configured to use Ollama as its backend:
|
[Claude Code](https://code.claude.com/docs/en/overview) can be configured to use Ollama as its backend:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_API_KEY=ollama claude --model qwen3-coder
|
ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_API_KEY=ollama claude --model qwen3-coder
|
||||||
```
|
```
|
||||||
|
|
||||||
Or set the environment variables in your shell profile:
|
Or set the environment variables in your shell profile:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
export ANTHROPIC_AUTH_TOKEN=ollama
|
|
||||||
export ANTHROPIC_BASE_URL=http://localhost:11434
|
export ANTHROPIC_BASE_URL=http://localhost:11434
|
||||||
export ANTHROPIC_API_KEY=ollama
|
export ANTHROPIC_API_KEY=ollama
|
||||||
```
|
```
|
||||||
|
|||||||
@@ -275,73 +275,6 @@ curl -X POST http://localhost:11434/v1/chat/completions \
|
|||||||
- [x] `dimensions`
|
- [x] `dimensions`
|
||||||
- [ ] `user`
|
- [ ] `user`
|
||||||
|
|
||||||
### `/v1/images/generations` (experimental)
|
|
||||||
|
|
||||||
> Note: This endpoint is experimental and may change or be removed in future versions.
|
|
||||||
|
|
||||||
Generate images using image generation models.
|
|
||||||
|
|
||||||
<CodeGroup dropdown>
|
|
||||||
|
|
||||||
```python images.py
|
|
||||||
from openai import OpenAI
|
|
||||||
|
|
||||||
client = OpenAI(
|
|
||||||
base_url='http://localhost:11434/v1/',
|
|
||||||
api_key='ollama', # required but ignored
|
|
||||||
)
|
|
||||||
|
|
||||||
response = client.images.generate(
|
|
||||||
model='x/z-image-turbo',
|
|
||||||
prompt='A cute robot learning to paint',
|
|
||||||
size='1024x1024',
|
|
||||||
response_format='b64_json',
|
|
||||||
)
|
|
||||||
print(response.data[0].b64_json[:50] + '...')
|
|
||||||
```
|
|
||||||
|
|
||||||
```javascript images.js
|
|
||||||
import OpenAI from "openai";
|
|
||||||
|
|
||||||
const openai = new OpenAI({
|
|
||||||
baseURL: "http://localhost:11434/v1/",
|
|
||||||
apiKey: "ollama", // required but ignored
|
|
||||||
});
|
|
||||||
|
|
||||||
const response = await openai.images.generate({
|
|
||||||
model: "x/z-image-turbo",
|
|
||||||
prompt: "A cute robot learning to paint",
|
|
||||||
size: "1024x1024",
|
|
||||||
response_format: "b64_json",
|
|
||||||
});
|
|
||||||
|
|
||||||
console.log(response.data[0].b64_json.slice(0, 50) + "...");
|
|
||||||
```
|
|
||||||
|
|
||||||
```shell images.sh
|
|
||||||
curl -X POST http://localhost:11434/v1/images/generations \
|
|
||||||
-H "Content-Type: application/json" \
|
|
||||||
-d '{
|
|
||||||
"model": "x/z-image-turbo",
|
|
||||||
"prompt": "A cute robot learning to paint",
|
|
||||||
"size": "1024x1024",
|
|
||||||
"response_format": "b64_json"
|
|
||||||
}'
|
|
||||||
```
|
|
||||||
|
|
||||||
</CodeGroup>
|
|
||||||
|
|
||||||
#### Supported request fields
|
|
||||||
|
|
||||||
- [x] `model`
|
|
||||||
- [x] `prompt`
|
|
||||||
- [x] `size` (e.g. "1024x1024")
|
|
||||||
- [x] `response_format` (only `b64_json` supported)
|
|
||||||
- [ ] `n`
|
|
||||||
- [ ] `quality`
|
|
||||||
- [ ] `style`
|
|
||||||
- [ ] `user`
|
|
||||||
|
|
||||||
### `/v1/responses`
|
### `/v1/responses`
|
||||||
|
|
||||||
> Note: Added in Ollama v0.13.3
|
> Note: Added in Ollama v0.13.3
|
||||||
|
|||||||
@@ -110,7 +110,7 @@ More Ollama [Python example](https://github.com/ollama/ollama-python/blob/main/e
|
|||||||
import { Ollama } from "ollama";
|
import { Ollama } from "ollama";
|
||||||
|
|
||||||
const client = new Ollama();
|
const client = new Ollama();
|
||||||
const results = await client.webSearch("what is ollama?");
|
const results = await client.webSearch({ query: "what is ollama?" });
|
||||||
console.log(JSON.stringify(results, null, 2));
|
console.log(JSON.stringify(results, null, 2));
|
||||||
```
|
```
|
||||||
|
|
||||||
@@ -213,7 +213,7 @@ models](https://ollama.com/models)\n\nAvailable for macOS, Windows, and Linux',
|
|||||||
import { Ollama } from "ollama";
|
import { Ollama } from "ollama";
|
||||||
|
|
||||||
const client = new Ollama();
|
const client = new Ollama();
|
||||||
const fetchResult = await client.webFetch("https://ollama.com");
|
const fetchResult = await client.webFetch({ url: "https://ollama.com" });
|
||||||
console.log(JSON.stringify(fetchResult, null, 2));
|
console.log(JSON.stringify(fetchResult, null, 2));
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@@ -111,9 +111,7 @@
|
|||||||
"/integrations/zed",
|
"/integrations/zed",
|
||||||
"/integrations/roo-code",
|
"/integrations/roo-code",
|
||||||
"/integrations/n8n",
|
"/integrations/n8n",
|
||||||
"/integrations/xcode",
|
"/integrations/xcode"
|
||||||
"/integrations/onyx",
|
|
||||||
"/integrations/marimo"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -22,7 +22,7 @@ Please refer to the [GPU docs](./gpu).
|
|||||||
|
|
||||||
## How can I specify the context window size?
|
## How can I specify the context window size?
|
||||||
|
|
||||||
By default, Ollama uses a context window size of 4096 tokens.
|
By default, Ollama uses a context window size of 2048 tokens.
|
||||||
|
|
||||||
This can be overridden with the `OLLAMA_CONTEXT_LENGTH` environment variable. For example, to set the default context window to 8K, use:
|
This can be overridden with the `OLLAMA_CONTEXT_LENGTH` environment variable. For example, to set the default context window to 8K, use:
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 174 KiB |
{kind=link}
|
Before Width: | Height: | Size: 80 KiB |
{kind=link}
|
Before Width: | Height: | Size: 230 KiB |
{kind=link}
|
Before Width: | Height: | Size: 178 KiB |
{kind=link}
|
Before Width: | Height: | Size: 186 KiB |
{kind=link}
|
Before Width: | Height: | Size: 100 KiB |
{kind=link}
|
Before Width: | Height: | Size: 306 KiB |
{kind=link}
|
Before Width: | Height: | Size: 300 KiB |
{kind=link}
|
Before Width: | Height: | Size: 211 KiB |
@@ -2,12 +2,6 @@
|
|||||||
title: Claude Code
|
title: Claude Code
|
||||||
---
|
---
|
||||||
|
|
||||||
Claude Code is Anthropic's agentic coding tool that can read, modify, and execute code in your working directory.
|
|
||||||
|
|
||||||
Open models can be used with Claude Code through Ollama's Anthropic-compatible API, enabling you to use models such as `qwen3-coder`, `gpt-oss:20b`, or other models.
|
|
||||||
|
|
||||||
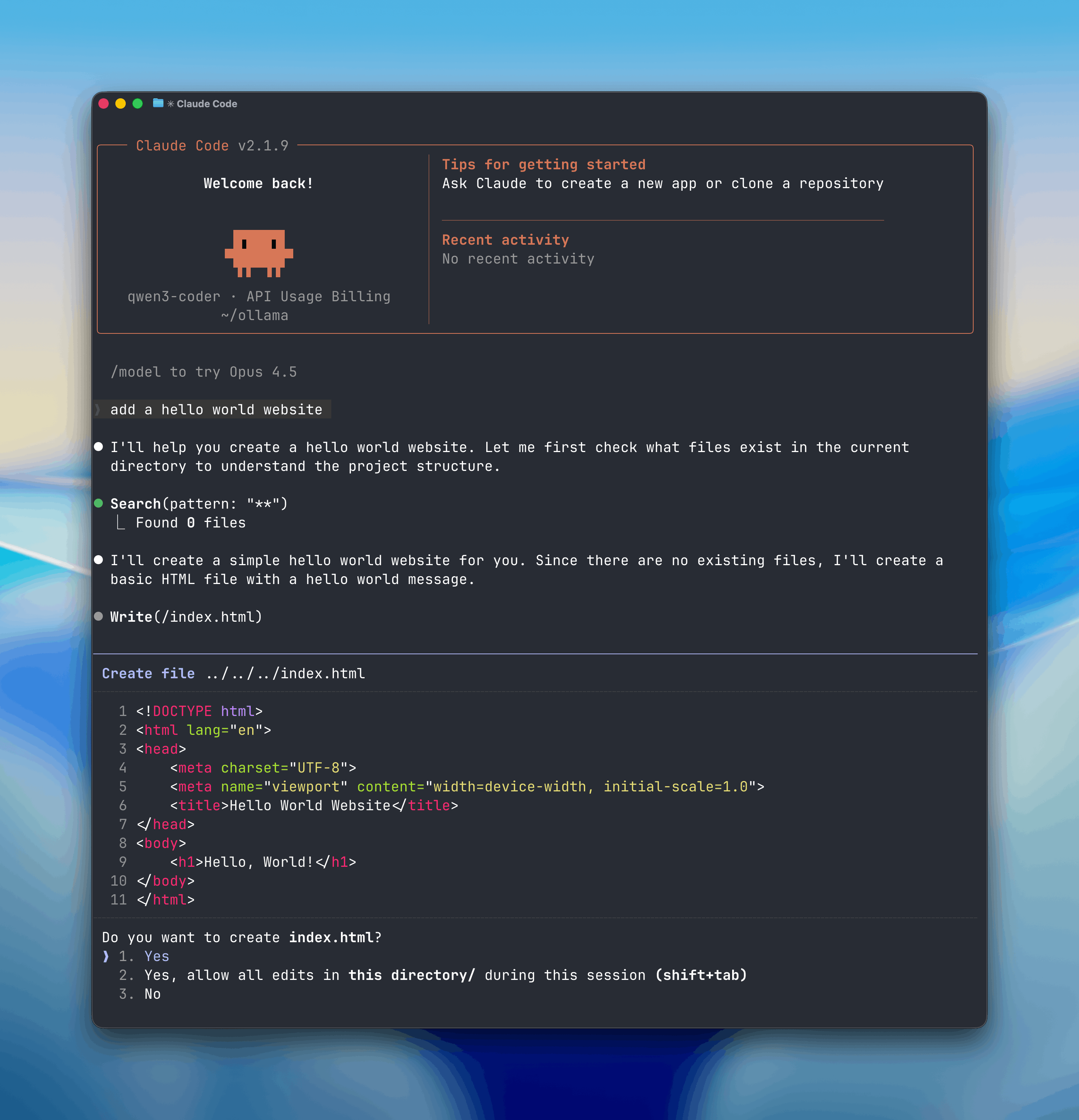
|
|
||||||
|
|
||||||
## Install
|
## Install
|
||||||
|
|
||||||
Install [Claude Code](https://code.claude.com/docs/en/overview):
|
Install [Claude Code](https://code.claude.com/docs/en/overview):
|
||||||
@@ -31,24 +25,22 @@ Claude Code connects to Ollama using the Anthropic-compatible API.
|
|||||||
1. Set the environment variables:
|
1. Set the environment variables:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
export ANTHROPIC_AUTH_TOKEN=ollama
|
|
||||||
export ANTHROPIC_BASE_URL=http://localhost:11434
|
export ANTHROPIC_BASE_URL=http://localhost:11434
|
||||||
|
export ANTHROPIC_API_KEY=ollama
|
||||||
```
|
```
|
||||||
|
|
||||||
2. Run Claude Code with an Ollama model:
|
2. Run Claude Code with an Ollama model:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
claude --model gpt-oss:20b
|
claude --model qwen3-coder
|
||||||
```
|
```
|
||||||
|
|
||||||
Or run with environment variables inline:
|
Or run with environment variables inline:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_BASE_URL=http://localhost:11434 claude --model gpt-oss:20b
|
ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_API_KEY=ollama claude --model qwen3-coder
|
||||||
```
|
```
|
||||||
|
|
||||||
**Note:** Claude Code requires a large context window. We recommend at least 32K tokens. See the [context length documentation](/context-length) for how to adjust context length in Ollama.
|
|
||||||
|
|
||||||
## Connecting to ollama.com
|
## Connecting to ollama.com
|
||||||
|
|
||||||
1. Create an [API key](https://ollama.com/settings/keys) on ollama.com
|
1. Create an [API key](https://ollama.com/settings/keys) on ollama.com
|
||||||
@@ -75,4 +67,3 @@ claude --model glm-4.7:cloud
|
|||||||
### Local models
|
### Local models
|
||||||
- `qwen3-coder` - Excellent for coding tasks
|
- `qwen3-coder` - Excellent for coding tasks
|
||||||
- `gpt-oss:20b` - Strong general-purpose model
|
- `gpt-oss:20b` - Strong general-purpose model
|
||||||
- `gpt-oss:120b` - Larger general-purpose model for more complex tasks
|
|
||||||
@@ -1,73 +0,0 @@
|
|||||||
---
|
|
||||||
title: marimo
|
|
||||||
---
|
|
||||||
|
|
||||||
## Install
|
|
||||||
|
|
||||||
Install [marimo](https://marimo.io). You can use `pip` or `uv` for this. You
|
|
||||||
can also use `uv` to create a sandboxed environment for marimo by running:
|
|
||||||
|
|
||||||
```
|
|
||||||
uvx marimo edit --sandbox notebook.py
|
|
||||||
```
|
|
||||||
|
|
||||||
## Usage with Ollama
|
|
||||||
|
|
||||||
1. In marimo, go to the user settings and go to the AI tab. From here
|
|
||||||
you can find and configure Ollama as an AI provider. For local use you
|
|
||||||
would typically point the base url to `http://localhost:11434/v1`.
|
|
||||||
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/marimo-settings.png"
|
|
||||||
alt="Ollama settings in marimo"
|
|
||||||
width="50%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
2. Once the AI provider is set up, you can turn on/off specific AI models you'd like to access.
|
|
||||||
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/marimo-models.png"
|
|
||||||
alt="Selecting an Ollama model"
|
|
||||||
width="50%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
3. You can also add a model to the list of available models by scrolling to the bottom and using the UI there.
|
|
||||||
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/marimo-add-model.png"
|
|
||||||
alt="Adding a new Ollama model"
|
|
||||||
width="50%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
4. Once configured, you can now use Ollama for AI chats in marimo.
|
|
||||||
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/marimo-chat.png"
|
|
||||||
alt="Configure code completion"
|
|
||||||
width="50%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
4. Alternatively, you can now use Ollama for **inline code completion** in marimo. This can be configured in the "AI Features" tab.
|
|
||||||
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/marimo-code-completion.png"
|
|
||||||
alt="Configure code completion"
|
|
||||||
width="50%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
|
|
||||||
## Connecting to ollama.com
|
|
||||||
|
|
||||||
1. Sign in to ollama cloud via `ollama signin`
|
|
||||||
2. In the ollama model settings add a model that ollama hosts, like `gpt-oss:120b`.
|
|
||||||
3. You can now refer to this model in marimo!
|
|
||||||
@@ -1,63 +0,0 @@
|
|||||||
---
|
|
||||||
title: Onyx
|
|
||||||
---
|
|
||||||
|
|
||||||
## Overview
|
|
||||||
[Onyx](http://onyx.app/) is a self-hostable Chat UI that integrates with all Ollama models. Features include:
|
|
||||||
- Creating custom Agents
|
|
||||||
- Web search
|
|
||||||
- Deep Research
|
|
||||||
- RAG over uploaded documents and connected apps
|
|
||||||
- Connectors to applications like Google Drive, Email, Slack, etc.
|
|
||||||
- MCP and OpenAPI Actions support
|
|
||||||
- Image generation
|
|
||||||
- User/Groups management, RBAC, SSO, etc.
|
|
||||||
|
|
||||||
Onyx can be deployed for single users or large organizations.
|
|
||||||
|
|
||||||
## Install Onyx
|
|
||||||
|
|
||||||
Deploy Onyx with the [quickstart guide](https://docs.onyx.app/deployment/getting_started/quickstart).
|
|
||||||
|
|
||||||
<Info>
|
|
||||||
Resourcing/scaling docs [here](https://docs.onyx.app/deployment/getting_started/resourcing).
|
|
||||||
</Info>
|
|
||||||
|
|
||||||
## Usage with Ollama
|
|
||||||
|
|
||||||
1. Login to your Onyx deployment (create an account first).
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/onyx-login.png"
|
|
||||||
alt="Onyx Login Page"
|
|
||||||
width="75%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
2. In the set-up process select `Ollama` as the LLM provider.
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/onyx-ollama-llm.png"
|
|
||||||
alt="Onyx Set Up Form"
|
|
||||||
width="75%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
3. Provide your **Ollama API URL** and select your models.
|
|
||||||
<Note>If you're running Onyx in Docker, to access your computer's local network use `http://host.docker.internal` instead of `http://127.0.0.1`.</Note>
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/onyx-ollama-form.png"
|
|
||||||
alt="Selecting Ollama Models"
|
|
||||||
width="75%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
You can also easily connect up Onyx Cloud with the `Ollama Cloud` tab of the setup.
|
|
||||||
|
|
||||||
## Send your first query
|
|
||||||
<div style={{ display: 'flex', justifyContent: 'center' }}>
|
|
||||||
<img
|
|
||||||
src="/images/onyx-query.png"
|
|
||||||
alt="Onyx Query Example"
|
|
||||||
width="75%"
|
|
||||||
/>
|
|
||||||
</div>
|
|
||||||
@@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
title: Linux
|
title: "Linux"
|
||||||
---
|
---
|
||||||
|
|
||||||
## Install
|
## Install
|
||||||
@@ -13,15 +13,14 @@ curl -fsSL https://ollama.com/install.sh | sh
|
|||||||
## Manual install
|
## Manual install
|
||||||
|
|
||||||
<Note>
|
<Note>
|
||||||
If you are upgrading from a prior version, you should remove the old libraries
|
If you are upgrading from a prior version, you should remove the old libraries with `sudo rm -rf /usr/lib/ollama` first.
|
||||||
with `sudo rm -rf /usr/lib/ollama` first.
|
|
||||||
</Note>
|
</Note>
|
||||||
|
|
||||||
Download and extract the package:
|
Download and extract the package:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
curl -fsSL https://ollama.com/download/ollama-linux-amd64.tar.zst \
|
curl -fsSL https://ollama.com/download/ollama-linux-amd64.tgz \
|
||||||
| sudo tar x -C /usr
|
| sudo tar zx -C /usr
|
||||||
```
|
```
|
||||||
|
|
||||||
Start Ollama:
|
Start Ollama:
|
||||||
@@ -41,8 +40,8 @@ ollama -v
|
|||||||
If you have an AMD GPU, also download and extract the additional ROCm package:
|
If you have an AMD GPU, also download and extract the additional ROCm package:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
curl -fsSL https://ollama.com/download/ollama-linux-amd64-rocm.tar.zst \
|
curl -fsSL https://ollama.com/download/ollama-linux-amd64-rocm.tgz \
|
||||||
| sudo tar x -C /usr
|
| sudo tar zx -C /usr
|
||||||
```
|
```
|
||||||
|
|
||||||
### ARM64 install
|
### ARM64 install
|
||||||
@@ -50,8 +49,8 @@ curl -fsSL https://ollama.com/download/ollama-linux-amd64-rocm.tar.zst \
|
|||||||
Download and extract the ARM64-specific package:
|
Download and extract the ARM64-specific package:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
curl -fsSL https://ollama.com/download/ollama-linux-arm64.tar.zst \
|
curl -fsSL https://ollama.com/download/ollama-linux-arm64.tgz \
|
||||||
| sudo tar x -C /usr
|
| sudo tar zx -C /usr
|
||||||
```
|
```
|
||||||
|
|
||||||
### Adding Ollama as a startup service (recommended)
|
### Adding Ollama as a startup service (recommended)
|
||||||
@@ -113,11 +112,7 @@ sudo systemctl status ollama
|
|||||||
```
|
```
|
||||||
|
|
||||||
<Note>
|
<Note>
|
||||||
While AMD has contributed the `amdgpu` driver upstream to the official linux
|
While AMD has contributed the `amdgpu` driver upstream to the official linux kernel source, the version is older and may not support all ROCm features. We recommend you install the latest driver from https://www.amd.com/en/support/linux-drivers for best support of your Radeon GPU.
|
||||||
kernel source, the version is older and may not support all ROCm features. We
|
|
||||||
recommend you install the latest driver from
|
|
||||||
https://www.amd.com/en/support/linux-drivers for best support of your Radeon
|
|
||||||
GPU.
|
|
||||||
</Note>
|
</Note>
|
||||||
|
|
||||||
## Customizing
|
## Customizing
|
||||||
@@ -146,8 +141,8 @@ curl -fsSL https://ollama.com/install.sh | sh
|
|||||||
Or by re-downloading Ollama:
|
Or by re-downloading Ollama:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
curl -fsSL https://ollama.com/download/ollama-linux-amd64.tar.zst \
|
curl -fsSL https://ollama.com/download/ollama-linux-amd64.tgz \
|
||||||
| sudo tar x -C /usr
|
| sudo tar zx -C /usr
|
||||||
```
|
```
|
||||||
|
|
||||||
## Installing specific versions
|
## Installing specific versions
|
||||||
|
|||||||
@@ -131,7 +131,7 @@ func TestAPIToolCalling(t *testing.T) {
|
|||||||
t.Errorf("unexpected tool called: got %q want %q", lastToolCall.Function.Name, "get_weather")
|
t.Errorf("unexpected tool called: got %q want %q", lastToolCall.Function.Name, "get_weather")
|
||||||
}
|
}
|
||||||
|
|
||||||
if _, ok := lastToolCall.Function.Arguments.Get("location"); !ok {
|
if _, ok := lastToolCall.Function.Arguments["location"]; !ok {
|
||||||
t.Errorf("expected tool arguments to include 'location', got: %s", lastToolCall.Function.Arguments.String())
|
t.Errorf("expected tool arguments to include 'location', got: %s", lastToolCall.Function.Arguments.String())
|
||||||
}
|
}
|
||||||
case <-ctx.Done():
|
case <-ctx.Done():
|
||||||
|
|||||||
@@ -1464,12 +1464,6 @@ type CompletionRequest struct {
|
|||||||
|
|
||||||
// TopLogprobs specifies the number of most likely alternative tokens to return (0-20)
|
// TopLogprobs specifies the number of most likely alternative tokens to return (0-20)
|
||||||
TopLogprobs int
|
TopLogprobs int
|
||||||
|
|
||||||
// Image generation fields
|
|
||||||
Width int32 `json:"width,omitempty"`
|
|
||||||
Height int32 `json:"height,omitempty"`
|
|
||||||
Steps int32 `json:"steps,omitempty"`
|
|
||||||
Seed int64 `json:"seed,omitempty"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// DoneReason represents the reason why a completion response is done
|
// DoneReason represents the reason why a completion response is done
|
||||||
@@ -1518,15 +1512,6 @@ type CompletionResponse struct {
|
|||||||
|
|
||||||
// Logprobs contains log probability information if requested
|
// Logprobs contains log probability information if requested
|
||||||
Logprobs []Logprob `json:"logprobs,omitempty"`
|
Logprobs []Logprob `json:"logprobs,omitempty"`
|
||||||
|
|
||||||
// Image contains base64-encoded image data for image generation
|
|
||||||
Image string `json:"image,omitempty"`
|
|
||||||
|
|
||||||
// Step is the current step in image generation
|
|
||||||
Step int `json:"step,omitempty"`
|
|
||||||
|
|
||||||
// TotalSteps is the total number of steps for image generation
|
|
||||||
TotalSteps int `json:"total_steps,omitempty"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (s *llmServer) Completion(ctx context.Context, req CompletionRequest, fn func(CompletionResponse)) error {
|
func (s *llmServer) Completion(ctx context.Context, req CompletionRequest, fn func(CompletionResponse)) error {
|
||||||
|
|||||||
@@ -8,7 +8,6 @@ import (
|
|||||||
"math/rand"
|
"math/rand"
|
||||||
"net/http"
|
"net/http"
|
||||||
"strings"
|
"strings"
|
||||||
"time"
|
|
||||||
|
|
||||||
"github.com/gin-gonic/gin"
|
"github.com/gin-gonic/gin"
|
||||||
|
|
||||||
@@ -442,7 +441,6 @@ type ResponsesWriter struct {
|
|||||||
stream bool
|
stream bool
|
||||||
responseID string
|
responseID string
|
||||||
itemID string
|
itemID string
|
||||||
request openai.ResponsesRequest
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (w *ResponsesWriter) writeEvent(eventType string, data any) error {
|
func (w *ResponsesWriter) writeEvent(eventType string, data any) error {
|
||||||
@@ -480,9 +478,7 @@ func (w *ResponsesWriter) writeResponse(data []byte) (int, error) {
|
|||||||
|
|
||||||
// Non-streaming response
|
// Non-streaming response
|
||||||
w.ResponseWriter.Header().Set("Content-Type", "application/json")
|
w.ResponseWriter.Header().Set("Content-Type", "application/json")
|
||||||
response := openai.ToResponse(w.model, w.responseID, w.itemID, chatResponse, w.request)
|
response := openai.ToResponse(w.model, w.responseID, w.itemID, chatResponse)
|
||||||
completedAt := time.Now().Unix()
|
|
||||||
response.CompletedAt = &completedAt
|
|
||||||
return len(data), json.NewEncoder(w.ResponseWriter).Encode(response)
|
return len(data), json.NewEncoder(w.ResponseWriter).Encode(response)
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -527,12 +523,11 @@ func ResponsesMiddleware() gin.HandlerFunc {
|
|||||||
|
|
||||||
w := &ResponsesWriter{
|
w := &ResponsesWriter{
|
||||||
BaseWriter: BaseWriter{ResponseWriter: c.Writer},
|
BaseWriter: BaseWriter{ResponseWriter: c.Writer},
|
||||||
converter: openai.NewResponsesStreamConverter(responseID, itemID, req.Model, req),
|
converter: openai.NewResponsesStreamConverter(responseID, itemID, req.Model),
|
||||||
model: req.Model,
|
model: req.Model,
|
||||||
stream: streamRequested,
|
stream: streamRequested,
|
||||||
responseID: responseID,
|
responseID: responseID,
|
||||||
itemID: itemID,
|
itemID: itemID,
|
||||||
request: req,
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// Set headers based on streaming mode
|
// Set headers based on streaming mode
|
||||||
@@ -546,66 +541,3 @@ func ResponsesMiddleware() gin.HandlerFunc {
|
|||||||
c.Next()
|
c.Next()
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
type ImageWriter struct {
|
|
||||||
BaseWriter
|
|
||||||
}
|
|
||||||
|
|
||||||
func (w *ImageWriter) writeResponse(data []byte) (int, error) {
|
|
||||||
var generateResponse api.GenerateResponse
|
|
||||||
if err := json.Unmarshal(data, &generateResponse); err != nil {
|
|
||||||
return 0, err
|
|
||||||
}
|
|
||||||
|
|
||||||
// Only write response when done with image
|
|
||||||
if generateResponse.Done && generateResponse.Image != "" {
|
|
||||||
w.ResponseWriter.Header().Set("Content-Type", "application/json")
|
|
||||||
return len(data), json.NewEncoder(w.ResponseWriter).Encode(openai.ToImageGenerationResponse(generateResponse))
|
|
||||||
}
|
|
||||||
|
|
||||||
return len(data), nil
|
|
||||||
}
|
|
||||||
|
|
||||||
func (w *ImageWriter) Write(data []byte) (int, error) {
|
|
||||||
code := w.ResponseWriter.Status()
|
|
||||||
if code != http.StatusOK {
|
|
||||||
return w.writeError(data)
|
|
||||||
}
|
|
||||||
|
|
||||||
return w.writeResponse(data)
|
|
||||||
}
|
|
||||||
|
|
||||||
func ImageGenerationsMiddleware() gin.HandlerFunc {
|
|
||||||
return func(c *gin.Context) {
|
|
||||||
var req openai.ImageGenerationRequest
|
|
||||||
if err := c.ShouldBindJSON(&req); err != nil {
|
|
||||||
c.AbortWithStatusJSON(http.StatusBadRequest, openai.NewError(http.StatusBadRequest, err.Error()))
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
if req.Prompt == "" {
|
|
||||||
c.AbortWithStatusJSON(http.StatusBadRequest, openai.NewError(http.StatusBadRequest, "prompt is required"))
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
if req.Model == "" {
|
|
||||||
c.AbortWithStatusJSON(http.StatusBadRequest, openai.NewError(http.StatusBadRequest, "model is required"))
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
var b bytes.Buffer
|
|
||||||
if err := json.NewEncoder(&b).Encode(openai.FromImageGenerationRequest(req)); err != nil {
|
|
||||||
c.AbortWithStatusJSON(http.StatusInternalServerError, openai.NewError(http.StatusInternalServerError, err.Error()))
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
c.Request.Body = io.NopCloser(&b)
|
|
||||||
|
|
||||||
w := &ImageWriter{
|
|
||||||
BaseWriter: BaseWriter{ResponseWriter: c.Writer},
|
|
||||||
}
|
|
||||||
|
|
||||||
c.Writer = w
|
|
||||||
c.Next()
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -961,154 +961,3 @@ func TestRetrieveMiddleware(t *testing.T) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestImageGenerationsMiddleware(t *testing.T) {
|
|
||||||
type testCase struct {
|
|
||||||
name string
|
|
||||||
body string
|
|
||||||
req api.GenerateRequest
|
|
||||||
err openai.ErrorResponse
|
|
||||||
}
|
|
||||||
|
|
||||||
var capturedRequest *api.GenerateRequest
|
|
||||||
|
|
||||||
testCases := []testCase{
|
|
||||||
{
|
|
||||||
name: "image generation basic",
|
|
||||||
body: `{
|
|
||||||
"model": "test-model",
|
|
||||||
"prompt": "a beautiful sunset"
|
|
||||||
}`,
|
|
||||||
req: api.GenerateRequest{
|
|
||||||
Model: "test-model",
|
|
||||||
Prompt: "a beautiful sunset",
|
|
||||||
},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "image generation with size",
|
|
||||||
body: `{
|
|
||||||
"model": "test-model",
|
|
||||||
"prompt": "a beautiful sunset",
|
|
||||||
"size": "512x768"
|
|
||||||
}`,
|
|
||||||
req: api.GenerateRequest{
|
|
||||||
Model: "test-model",
|
|
||||||
Prompt: "a beautiful sunset",
|
|
||||||
Width: 512,
|
|
||||||
Height: 768,
|
|
||||||
},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "image generation missing prompt",
|
|
||||||
body: `{
|
|
||||||
"model": "test-model"
|
|
||||||
}`,
|
|
||||||
err: openai.ErrorResponse{
|
|
||||||
Error: openai.Error{
|
|
||||||
Message: "prompt is required",
|
|
||||||
Type: "invalid_request_error",
|
|
||||||
},
|
|
||||||
},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "image generation missing model",
|
|
||||||
body: `{
|
|
||||||
"prompt": "a beautiful sunset"
|
|
||||||
}`,
|
|
||||||
err: openai.ErrorResponse{
|
|
||||||
Error: openai.Error{
|
|
||||||
Message: "model is required",
|
|
||||||
Type: "invalid_request_error",
|
|
||||||
},
|
|
||||||
},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
endpoint := func(c *gin.Context) {
|
|
||||||
c.Status(http.StatusOK)
|
|
||||||
}
|
|
||||||
|
|
||||||
gin.SetMode(gin.TestMode)
|
|
||||||
router := gin.New()
|
|
||||||
router.Use(ImageGenerationsMiddleware(), captureRequestMiddleware(&capturedRequest))
|
|
||||||
router.Handle(http.MethodPost, "/api/generate", endpoint)
|
|
||||||
|
|
||||||
for _, tc := range testCases {
|
|
||||||
t.Run(tc.name, func(t *testing.T) {
|
|
||||||
req, _ := http.NewRequest(http.MethodPost, "/api/generate", strings.NewReader(tc.body))
|
|
||||||
req.Header.Set("Content-Type", "application/json")
|
|
||||||
|
|
||||||
defer func() { capturedRequest = nil }()
|
|
||||||
|
|
||||||
resp := httptest.NewRecorder()
|
|
||||||
router.ServeHTTP(resp, req)
|
|
||||||
|
|
||||||
if tc.err.Error.Message != "" {
|
|
||||||
var errResp openai.ErrorResponse
|
|
||||||
if err := json.Unmarshal(resp.Body.Bytes(), &errResp); err != nil {
|
|
||||||
t.Fatal(err)
|
|
||||||
}
|
|
||||||
if diff := cmp.Diff(tc.err, errResp); diff != "" {
|
|
||||||
t.Fatalf("errors did not match:\n%s", diff)
|
|
||||||
}
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
if resp.Code != http.StatusOK {
|
|
||||||
t.Fatalf("expected status 200, got %d: %s", resp.Code, resp.Body.String())
|
|
||||||
}
|
|
||||||
|
|
||||||
if diff := cmp.Diff(&tc.req, capturedRequest); diff != "" {
|
|
||||||
t.Fatalf("requests did not match:\n%s", diff)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestImageWriterResponse(t *testing.T) {
|
|
||||||
gin.SetMode(gin.TestMode)
|
|
||||||
|
|
||||||
// Test that ImageWriter transforms GenerateResponse to OpenAI format
|
|
||||||
endpoint := func(c *gin.Context) {
|
|
||||||
resp := api.GenerateResponse{
|
|
||||||
Model: "test-model",
|
|
||||||
CreatedAt: time.Unix(1234567890, 0).UTC(),
|
|
||||||
Done: true,
|
|
||||||
Image: "dGVzdC1pbWFnZS1kYXRh", // base64 of "test-image-data"
|
|
||||||
}
|
|
||||||
data, _ := json.Marshal(resp)
|
|
||||||
c.Writer.Write(append(data, '\n'))
|
|
||||||
}
|
|
||||||
|
|
||||||
router := gin.New()
|
|
||||||
router.Use(ImageGenerationsMiddleware())
|
|
||||||
router.Handle(http.MethodPost, "/api/generate", endpoint)
|
|
||||||
|
|
||||||
body := `{"model": "test-model", "prompt": "test"}`
|
|
||||||
req, _ := http.NewRequest(http.MethodPost, "/api/generate", strings.NewReader(body))
|
|
||||||
req.Header.Set("Content-Type", "application/json")
|
|
||||||
|
|
||||||
resp := httptest.NewRecorder()
|
|
||||||
router.ServeHTTP(resp, req)
|
|
||||||
|
|
||||||
if resp.Code != http.StatusOK {
|
|
||||||
t.Fatalf("expected status 200, got %d: %s", resp.Code, resp.Body.String())
|
|
||||||
}
|
|
||||||
|
|
||||||
var imageResp openai.ImageGenerationResponse
|
|
||||||
if err := json.Unmarshal(resp.Body.Bytes(), &imageResp); err != nil {
|
|
||||||
t.Fatalf("failed to unmarshal response: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
if imageResp.Created != 1234567890 {
|
|
||||||
t.Errorf("expected created 1234567890, got %d", imageResp.Created)
|
|
||||||
}
|
|
||||||
|
|
||||||
if len(imageResp.Data) != 1 {
|
|
||||||
t.Fatalf("expected 1 image, got %d", len(imageResp.Data))
|
|
||||||
}
|
|
||||||
|
|
||||||
if imageResp.Data[0].B64JSON != "dGVzdC1pbWFnZS1kYXRh" {
|
|
||||||
t.Errorf("expected image data 'dGVzdC1pbWFnZS1kYXRh', got %s", imageResp.Data[0].B64JSON)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -1,6 +1,7 @@
|
|||||||
package parsers
|
package parsers
|
||||||
|
|
||||||
import (
|
import (
|
||||||
|
"regexp"
|
||||||
"strings"
|
"strings"
|
||||||
"unicode"
|
"unicode"
|
||||||
|
|
||||||
@@ -13,114 +14,243 @@ const (
|
|||||||
Nemotron3NanoCollectingThinking Nemotron3NanoParserState = iota
|
Nemotron3NanoCollectingThinking Nemotron3NanoParserState = iota
|
||||||
Nemotron3NanoSkipWhitespaceAfterThinking
|
Nemotron3NanoSkipWhitespaceAfterThinking
|
||||||
Nemotron3NanoCollectingContent
|
Nemotron3NanoCollectingContent
|
||||||
|
Nemotron3NanoCollectingToolCalls
|
||||||
)
|
)
|
||||||
|
|
||||||
const (
|
const (
|
||||||
nemotronThinkClose = "</think>"
|
nemotronThinkClose = "</think>"
|
||||||
nemotronToolCallOpen = "<tool_call>"
|
nemotronToolCallOpen = "<tool_call>"
|
||||||
|
nemotronToolCallClose = "</tool_call>"
|
||||||
)
|
)
|
||||||
|
|
||||||
type Nemotron3NanoParser struct {
|
type Nemotron3NanoParser struct {
|
||||||
state Nemotron3NanoParserState
|
state Nemotron3NanoParserState
|
||||||
buffer strings.Builder
|
buffer strings.Builder
|
||||||
toolParser *Qwen3CoderParser
|
tools []api.Tool
|
||||||
}
|
}
|
||||||
|
|
||||||
func (p *Nemotron3NanoParser) HasToolSupport() bool { return true }
|
func (p *Nemotron3NanoParser) HasToolSupport() bool { return true }
|
||||||
func (p *Nemotron3NanoParser) HasThinkingSupport() bool { return true }
|
func (p *Nemotron3NanoParser) HasThinkingSupport() bool { return true }
|
||||||
|
|
||||||
func (p *Nemotron3NanoParser) Init(tools []api.Tool, lastMessage *api.Message, thinkValue *api.ThinkValue) []api.Tool {
|
func (p *Nemotron3NanoParser) Init(tools []api.Tool, lastMessage *api.Message, thinkValue *api.ThinkValue) []api.Tool {
|
||||||
p.toolParser = &Qwen3CoderParser{}
|
p.tools = tools
|
||||||
p.toolParser.Init(tools, nil, nil)
|
|
||||||
|
|
||||||
|
// thinking is enabled if user requests it
|
||||||
thinkingEnabled := thinkValue != nil && thinkValue.Bool()
|
thinkingEnabled := thinkValue != nil && thinkValue.Bool()
|
||||||
|
|
||||||
prefill := lastMessage != nil && lastMessage.Role == "assistant"
|
prefill := lastMessage != nil && lastMessage.Role == "assistant"
|
||||||
|
|
||||||
if !thinkingEnabled || (prefill && lastMessage.Content != "") {
|
if !thinkingEnabled {
|
||||||
p.state = Nemotron3NanoCollectingContent
|
p.state = Nemotron3NanoCollectingContent
|
||||||
} else {
|
return tools
|
||||||
p.state = Nemotron3NanoCollectingThinking
|
|
||||||
}
|
}
|
||||||
|
|
||||||
|
if prefill && lastMessage.Content != "" {
|
||||||
|
p.state = Nemotron3NanoCollectingContent
|
||||||
|
return tools
|
||||||
|
}
|
||||||
|
|
||||||
|
p.state = Nemotron3NanoCollectingThinking
|
||||||
return tools
|
return tools
|
||||||
}
|
}
|
||||||
|
|
||||||
|
type nemotronEvent interface {
|
||||||
|
isNemotronEvent()
|
||||||
|
}
|
||||||
|
|
||||||
|
type nemotronEventThinkingContent struct {
|
||||||
|
content string
|
||||||
|
}
|
||||||
|
|
||||||
|
type nemotronEventContent struct {
|
||||||
|
content string
|
||||||
|
}
|
||||||
|
|
||||||
|
type nemotronEventToolCall struct {
|
||||||
|
toolCall api.ToolCall
|
||||||
|
}
|
||||||
|
|
||||||
|
func (nemotronEventThinkingContent) isNemotronEvent() {}
|
||||||
|
func (nemotronEventContent) isNemotronEvent() {}
|
||||||
|
func (nemotronEventToolCall) isNemotronEvent() {}
|
||||||
|
|
||||||
func (p *Nemotron3NanoParser) Add(s string, done bool) (content string, thinking string, calls []api.ToolCall, err error) {
|
func (p *Nemotron3NanoParser) Add(s string, done bool) (content string, thinking string, calls []api.ToolCall, err error) {
|
||||||
if p.state == Nemotron3NanoCollectingContent {
|
p.buffer.WriteString(s)
|
||||||
return p.toolParser.Add(s, done)
|
events := p.parseEvents()
|
||||||
|
|
||||||
|
var toolCalls []api.ToolCall
|
||||||
|
var contentSb strings.Builder
|
||||||
|
var thinkingSb strings.Builder
|
||||||
|
for _, event := range events {
|
||||||
|
switch event := event.(type) {
|
||||||
|
case nemotronEventToolCall:
|
||||||
|
toolCalls = append(toolCalls, event.toolCall)
|
||||||
|
case nemotronEventThinkingContent:
|
||||||
|
thinkingSb.WriteString(event.content)
|
||||||
|
case nemotronEventContent:
|
||||||
|
contentSb.WriteString(event.content)
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
if p.state == Nemotron3NanoSkipWhitespaceAfterThinking {
|
return contentSb.String(), thinkingSb.String(), toolCalls, nil
|
||||||
s = strings.TrimLeftFunc(s, unicode.IsSpace)
|
}
|
||||||
if s == "" {
|
|
||||||
return "", "", nil, nil
|
func (p *Nemotron3NanoParser) parseEvents() []nemotronEvent {
|
||||||
|
var all []nemotronEvent
|
||||||
|
|
||||||
|
keepLooping := true
|
||||||
|
for keepLooping {
|
||||||
|
var events []nemotronEvent
|
||||||
|
events, keepLooping = p.eat()
|
||||||
|
if len(events) > 0 {
|
||||||
|
all = append(all, events...)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return all
|
||||||
|
}
|
||||||
|
|
||||||
|
// emitWithPartialCheck extracts unambiguous content before a potential partial tag
|
||||||
|
func (p *Nemotron3NanoParser) emitWithPartialCheck(bufStr, tag string) (unambiguous, ambiguous string) {
|
||||||
|
if overlapLen := overlap(bufStr, tag); overlapLen > 0 {
|
||||||
|
beforePartialTag := bufStr[:len(bufStr)-overlapLen]
|
||||||
|
trailingLen := trailingWhitespaceLen(beforePartialTag)
|
||||||
|
return bufStr[:len(beforePartialTag)-trailingLen], bufStr[len(beforePartialTag)-trailingLen:]
|
||||||
|
}
|
||||||
|
wsLen := trailingWhitespaceLen(bufStr)
|
||||||
|
return bufStr[:len(bufStr)-wsLen], bufStr[len(bufStr)-wsLen:]
|
||||||
|
}
|
||||||
|
|
||||||
|
func (p *Nemotron3NanoParser) eat() ([]nemotronEvent, bool) {
|
||||||
|
bufStr := p.buffer.String()
|
||||||
|
if bufStr == "" {
|
||||||
|
return nil, false
|
||||||
|
}
|
||||||
|
|
||||||
|
switch p.state {
|
||||||
|
case Nemotron3NanoCollectingThinking:
|
||||||
|
if strings.Contains(bufStr, nemotronThinkClose) {
|
||||||
|
split := strings.SplitN(bufStr, nemotronThinkClose, 2)
|
||||||
|
thinking := strings.TrimRightFunc(split[0], unicode.IsSpace)
|
||||||
|
p.buffer.Reset()
|
||||||
|
remainder := strings.TrimLeftFunc(split[1], unicode.IsSpace)
|
||||||
|
p.buffer.WriteString(remainder)
|
||||||
|
// Transition to whitespace-skipping state if buffer is empty,
|
||||||
|
// otherwise go directly to content collection
|
||||||
|
if remainder == "" {
|
||||||
|
p.state = Nemotron3NanoSkipWhitespaceAfterThinking
|
||||||
|
} else {
|
||||||
|
p.state = Nemotron3NanoCollectingContent
|
||||||
|
}
|
||||||
|
if thinking != "" {
|
||||||
|
return []nemotronEvent{nemotronEventThinkingContent{content: thinking}}, true
|
||||||
|
}
|
||||||
|
return nil, true
|
||||||
|
}
|
||||||
|
unambig, ambig := p.emitWithPartialCheck(bufStr, nemotronThinkClose)
|
||||||
|
p.buffer.Reset()
|
||||||
|
p.buffer.WriteString(ambig)
|
||||||
|
if unambig != "" {
|
||||||
|
return []nemotronEvent{nemotronEventThinkingContent{content: unambig}}, false
|
||||||
|
}
|
||||||
|
return nil, false
|
||||||
|
|
||||||
|
// We only want to skip whitespace between thinking and content
|
||||||
|
case Nemotron3NanoSkipWhitespaceAfterThinking:
|
||||||
|
bufStr = strings.TrimLeftFunc(bufStr, unicode.IsSpace)
|
||||||
|
p.buffer.Reset()
|
||||||
|
p.buffer.WriteString(bufStr)
|
||||||
|
if bufStr == "" {
|
||||||
|
return nil, false
|
||||||
}
|
}
|
||||||
p.state = Nemotron3NanoCollectingContent
|
p.state = Nemotron3NanoCollectingContent
|
||||||
return p.toolParser.Add(s, done)
|
return nil, true
|
||||||
}
|
|
||||||
|
|
||||||
// Nemotron3NanoCollectingThinking - buffer and look for end markers
|
case Nemotron3NanoCollectingContent:
|
||||||
p.buffer.WriteString(s)
|
if strings.Contains(bufStr, nemotronToolCallOpen) {
|
||||||
bufStr := p.buffer.String()
|
split := strings.SplitN(bufStr, nemotronToolCallOpen, 2)
|
||||||
|
content := strings.TrimRightFunc(split[0], unicode.IsSpace)
|
||||||
// Look for end of thinking: </think> or <tool_call> (model may skip </think>)
|
p.buffer.Reset()
|
||||||
thinkIdx := strings.Index(bufStr, nemotronThinkClose)
|
p.buffer.WriteString(split[1])
|
||||||
toolIdx := strings.Index(bufStr, nemotronToolCallOpen)
|
p.state = Nemotron3NanoCollectingToolCalls
|
||||||
|
if content != "" {
|
||||||
var endIdx int = -1
|
return []nemotronEvent{nemotronEventContent{content: content}}, true
|
||||||
var remainder string
|
}
|
||||||
|
return nil, true
|
||||||
if thinkIdx != -1 && (toolIdx == -1 || thinkIdx < toolIdx) {
|
|
||||||
endIdx = thinkIdx
|
|
||||||
remainder = strings.TrimLeftFunc(bufStr[thinkIdx+len(nemotronThinkClose):], unicode.IsSpace)
|
|
||||||
} else if toolIdx != -1 {
|
|
||||||
endIdx = toolIdx
|
|
||||||
remainder = bufStr[toolIdx:] // Include <tool_call> tag
|
|
||||||
}
|
|
||||||
|
|
||||||
if endIdx != -1 {
|
|
||||||
thinking = strings.TrimRightFunc(bufStr[:endIdx], unicode.IsSpace)
|
|
||||||
p.buffer.Reset()
|
|
||||||
|
|
||||||
if remainder == "" {
|
|
||||||
p.state = Nemotron3NanoSkipWhitespaceAfterThinking
|
|
||||||
} else {
|
|
||||||
p.state = Nemotron3NanoCollectingContent
|
|
||||||
content, _, calls, err = p.toolParser.Add(remainder, done)
|
|
||||||
}
|
}
|
||||||
return content, thinking, calls, err
|
unambig, ambig := p.emitWithPartialCheck(bufStr, nemotronToolCallOpen)
|
||||||
|
p.buffer.Reset()
|
||||||
|
p.buffer.WriteString(ambig)
|
||||||
|
if unambig != "" {
|
||||||
|
return []nemotronEvent{nemotronEventContent{content: unambig}}, false
|
||||||
|
}
|
||||||
|
return nil, false
|
||||||
|
|
||||||
|
case Nemotron3NanoCollectingToolCalls:
|
||||||
|
if strings.Contains(bufStr, nemotronToolCallClose) {
|
||||||
|
split := strings.SplitN(bufStr, nemotronToolCallClose, 2)
|
||||||
|
remaining := strings.TrimLeftFunc(split[1], unicode.IsSpace)
|
||||||
|
p.buffer.Reset()
|
||||||
|
p.buffer.WriteString(remaining)
|
||||||
|
|
||||||
|
var events []nemotronEvent
|
||||||
|
if tc, err := p.parseToolCall(split[0]); err == nil {
|
||||||
|
events = append(events, nemotronEventToolCall{toolCall: tc})
|
||||||
|
}
|
||||||
|
|
||||||
|
if !strings.Contains(remaining, nemotronToolCallOpen) {
|
||||||
|
p.state = Nemotron3NanoCollectingContent
|
||||||
|
}
|
||||||
|
return events, true
|
||||||
|
}
|
||||||
|
return nil, false
|
||||||
}
|
}
|
||||||
|
|
||||||
// No end marker - emit unambiguous thinking
|
return nil, false
|
||||||
thinking = p.emitThinking(bufStr)
|
|
||||||
return "", thinking, nil, nil
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// emitThinking returns unambiguous thinking content, keeping potential partial tags in buffer
|
var (
|
||||||
func (p *Nemotron3NanoParser) emitThinking(bufStr string) string {
|
nemotronFunctionRegex = regexp.MustCompile(`<function=([^>]+)>`)
|
||||||
// Check for partial </think> or <tool_call> at end
|
nemotronParameterRegex = regexp.MustCompile(`<parameter=([^>]+)>\n?([\s\S]*?)\n?</parameter>`)
|
||||||
thinkOverlap := overlap(bufStr, nemotronThinkClose)
|
)
|
||||||
toolOverlap := overlap(bufStr, nemotronToolCallOpen)
|
|
||||||
maxOverlap := max(thinkOverlap, toolOverlap)
|
|
||||||
|
|
||||||
if maxOverlap > 0 {
|
func (p *Nemotron3NanoParser) parseToolCall(content string) (api.ToolCall, error) {
|
||||||
unambiguous := bufStr[:len(bufStr)-maxOverlap]
|
toolCall := api.ToolCall{}
|
||||||
unambiguous = strings.TrimRightFunc(unambiguous, unicode.IsSpace)
|
|
||||||
p.buffer.Reset()
|
// Extract function name
|
||||||
p.buffer.WriteString(bufStr[len(bufStr)-maxOverlap:])
|
fnMatch := nemotronFunctionRegex.FindStringSubmatch(content)
|
||||||
return unambiguous
|
if len(fnMatch) < 2 {
|
||||||
|
return toolCall, nil
|
||||||
|
}
|
||||||
|
toolCall.Function.Name = fnMatch[1]
|
||||||
|
|
||||||
|
// Extract parameters
|
||||||
|
toolCall.Function.Arguments = api.NewToolCallFunctionArguments()
|
||||||
|
paramMatches := nemotronParameterRegex.FindAllStringSubmatch(content, -1)
|
||||||
|
for _, match := range paramMatches {
|
||||||
|
if len(match) >= 3 {
|
||||||
|
paramName := match[1]
|
||||||
|
paramValue := strings.TrimSpace(match[2])
|
||||||
|
|
||||||
|
// Try to parse as typed value based on tool definition
|
||||||
|
toolCall.Function.Arguments.Set(paramName, p.parseParamValue(paramName, paramValue))
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// No partial tags - emit all but trailing whitespace
|
return toolCall, nil
|
||||||
wsLen := trailingWhitespaceLen(bufStr)
|
}
|
||||||
if wsLen > 0 {
|
|
||||||
unambiguous := bufStr[:len(bufStr)-wsLen]
|
func (p *Nemotron3NanoParser) parseParamValue(paramName string, raw string) any {
|
||||||
p.buffer.Reset()
|
// Find the matching tool to get parameter type
|
||||||
p.buffer.WriteString(bufStr[len(bufStr)-wsLen:])
|
var paramType api.PropertyType
|
||||||
return unambiguous
|
for _, tool := range p.tools {
|
||||||
}
|
if tool.Function.Parameters.Properties != nil {
|
||||||
|
if prop, ok := tool.Function.Parameters.Properties.Get(paramName); ok {
|
||||||
// Nothing to hold back
|
paramType = prop.Type
|
||||||
p.buffer.Reset()
|
break
|
||||||
return bufStr
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return parseValue(raw, paramType)
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -8,8 +8,6 @@ import (
|
|||||||
"github.com/ollama/ollama/api"
|
"github.com/ollama/ollama/api"
|
||||||
)
|
)
|
||||||
|
|
||||||
// TestNemotron3NanoParser tests Nemotron-specific behavior (thinking support).
|
|
||||||
// Tool call parsing is tested in qwen3coder_test.go since Nemotron delegates to Qwen3CoderParser.
|
|
||||||
func TestNemotron3NanoParser(t *testing.T) {
|
func TestNemotron3NanoParser(t *testing.T) {
|
||||||
tests := []struct {
|
tests := []struct {
|
||||||
name string
|
name string
|
||||||
@@ -19,6 +17,18 @@ func TestNemotron3NanoParser(t *testing.T) {
|
|||||||
expectedThinking string
|
expectedThinking string
|
||||||
expectedCalls []api.ToolCall
|
expectedCalls []api.ToolCall
|
||||||
}{
|
}{
|
||||||
|
{
|
||||||
|
name: "simple content - no thinking",
|
||||||
|
input: "Hello, how can I help you?",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Hello, how can I help you?",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "simple content - thinking disabled",
|
||||||
|
input: "Hello, how can I help you?",
|
||||||
|
thinkValue: &api.ThinkValue{Value: false},
|
||||||
|
expectedContent: "Hello, how can I help you?",
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "thinking then content",
|
name: "thinking then content",
|
||||||
input: "Let me think about this...</think>\nHere is my answer.",
|
input: "Let me think about this...</think>\nHere is my answer.",
|
||||||
@@ -33,6 +43,69 @@ func TestNemotron3NanoParser(t *testing.T) {
|
|||||||
expectedThinking: "Step 1: Analyze\nStep 2: Process\nStep 3: Conclude",
|
expectedThinking: "Step 1: Analyze\nStep 2: Process\nStep 3: Conclude",
|
||||||
expectedContent: "The answer is 42.",
|
expectedContent: "The answer is 42.",
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "simple tool call",
|
||||||
|
input: "<tool_call>\n<function=get_weather>\n<parameter=city>\nParis\n</parameter>\n</function>\n</tool_call>",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "Paris"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "content then tool call",
|
||||||
|
input: "Let me check the weather.\n<tool_call>\n<function=get_weather>\n<parameter=city>\nNYC\n</parameter>\n</function>\n</tool_call>",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Let me check the weather.",
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "NYC"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "tool call with multiple parameters",
|
||||||
|
input: "<tool_call>\n<function=book_flight>\n<parameter=from>\nSFO\n</parameter>\n<parameter=to>\nNYC\n</parameter>\n</function>\n</tool_call>",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "book_flight",
|
||||||
|
Arguments: testArgs(map[string]any{
|
||||||
|
"from": "SFO",
|
||||||
|
"to": "NYC",
|
||||||
|
}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "multiple tool calls",
|
||||||
|
input: "<tool_call>\n<function=get_weather>\n<parameter=city>\nSan Francisco\n</parameter>\n</function>\n</tool_call>\n" +
|
||||||
|
"<tool_call>\n<function=get_weather>\n<parameter=city>\nNew York\n</parameter>\n</function>\n</tool_call>",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "San Francisco"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "New York"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "thinking then tool call",
|
name: "thinking then tool call",
|
||||||
input: "I should check the weather...</think>\n<tool_call>\n<function=get_weather>\n<parameter=city>\nParis\n</parameter>\n</function>\n</tool_call>",
|
input: "I should check the weather...</think>\n<tool_call>\n<function=get_weather>\n<parameter=city>\nParis\n</parameter>\n</function>\n</tool_call>",
|
||||||
@@ -62,6 +135,19 @@ func TestNemotron3NanoParser(t *testing.T) {
|
|||||||
},
|
},
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "tool call with multiline parameter value",
|
||||||
|
input: "<tool_call>\n<function=create_note>\n<parameter=content>\nLine 1\nLine 2\nLine 3\n</parameter>\n</function>\n</tool_call>",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "create_note",
|
||||||
|
Arguments: testArgs(map[string]any{"content": "Line 1\nLine 2\nLine 3"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "empty thinking block - immediate close",
|
name: "empty thinking block - immediate close",
|
||||||
input: "</think>\nHere is my answer.",
|
input: "</think>\nHere is my answer.",
|
||||||
@@ -75,6 +161,18 @@ func TestNemotron3NanoParser(t *testing.T) {
|
|||||||
thinkValue: &api.ThinkValue{Value: false},
|
thinkValue: &api.ThinkValue{Value: false},
|
||||||
expectedContent: "</think>\nSome content after spurious tag.",
|
expectedContent: "</think>\nSome content after spurious tag.",
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "tool call with no function name - returns empty tool call",
|
||||||
|
input: "<tool_call>\n<function=>\n</function>\n</tool_call>",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{{Function: api.ToolCallFunction{Name: "", Arguments: api.NewToolCallFunctionArguments()}}},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "content with newlines preserved",
|
||||||
|
input: "Line 1\n\nLine 2\n\n\nLine 3",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Line 1\n\nLine 2\n\n\nLine 3",
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "thinking with only whitespace after close tag",
|
name: "thinking with only whitespace after close tag",
|
||||||
input: "My thoughts...</think> \n\t\n Content here.",
|
input: "My thoughts...</think> \n\t\n Content here.",
|
||||||
@@ -82,6 +180,25 @@ func TestNemotron3NanoParser(t *testing.T) {
|
|||||||
expectedThinking: "My thoughts...",
|
expectedThinking: "My thoughts...",
|
||||||
expectedContent: "Content here.",
|
expectedContent: "Content here.",
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "unicode content",
|
||||||
|
input: "Hello 世界! 🌍 Ñoño",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Hello 世界! 🌍 Ñoño",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "tool call with numeric parameter",
|
||||||
|
input: "<tool_call>\n<function=set_temp>\n<parameter=value>\n42\n</parameter>\n</function>\n</tool_call>",
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "set_temp",
|
||||||
|
Arguments: testArgs(map[string]any{"value": "42"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
}
|
}
|
||||||
|
|
||||||
for _, tt := range tests {
|
for _, tt := range tests {
|
||||||
@@ -116,8 +233,6 @@ func TestNemotron3NanoParser(t *testing.T) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// TestNemotron3NanoParser_Streaming tests streaming behavior for thinking support.
|
|
||||||
// Tool call streaming is tested in qwen3coder_test.go.
|
|
||||||
func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
||||||
tests := []struct {
|
tests := []struct {
|
||||||
name string
|
name string
|
||||||
@@ -127,6 +242,18 @@ func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
|||||||
expectedThinking string
|
expectedThinking string
|
||||||
expectedCalls []api.ToolCall
|
expectedCalls []api.ToolCall
|
||||||
}{
|
}{
|
||||||
|
{
|
||||||
|
name: "streaming content character by character",
|
||||||
|
chunks: []string{"H", "e", "l", "l", "o", ",", " ", "w", "o", "r", "l", "d", "!"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Hello, world!",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "streaming content small tokens",
|
||||||
|
chunks: []string{"Hel", "lo", ", ", "how ", "can", " I", " help", " you", " today", "?"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Hello, how can I help you today?",
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "streaming thinking then content - granular",
|
name: "streaming thinking then content - granular",
|
||||||
chunks: []string{"Let", " me", " th", "ink", " about", " this", "...", "<", "/", "think", ">", "\n", "Here", " is", " my", " answer", "."},
|
chunks: []string{"Let", " me", " th", "ink", " about", " this", "...", "<", "/", "think", ">", "\n", "Here", " is", " my", " answer", "."},
|
||||||
@@ -141,6 +268,45 @@ func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
|||||||
expectedThinking: "Step 1: Analyze\nStep 2: Process",
|
expectedThinking: "Step 1: Analyze\nStep 2: Process",
|
||||||
expectedContent: "The answer.",
|
expectedContent: "The answer.",
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "streaming tool call - highly granular",
|
||||||
|
chunks: []string{"<", "tool", "_", "call", ">", "\n", "<", "func", "tion", "=", "get", "_", "weather", ">", "\n", "<", "param", "eter", "=", "city", ">", "\n", "Par", "is", "\n", "</", "param", "eter", ">", "\n", "</", "func", "tion", ">", "\n", "</", "tool", "_", "call", ">"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "Paris"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "streaming content then tool call - granular",
|
||||||
|
chunks: []string{"Let", " me", " check", " the", " weather", ".", "\n<", "tool_call", ">", "\n", "<function=", "get_weather", ">", "\n", "<parameter=", "city", ">", "\n", "NYC", "\n", "</parameter>", "\n", "</function>", "\n", "</tool_call>"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Let me check the weather.",
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "NYC"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "tool call tag split character by character",
|
||||||
|
chunks: []string{"<", "t", "o", "o", "l", "_", "c", "a", "l", "l", ">", "\n", "<", "f", "u", "n", "c", "t", "i", "o", "n", "=", "t", "e", "s", "t", ">", "\n", "<", "/", "f", "u", "n", "c", "t", "i", "o", "n", ">", "\n", "<", "/", "t", "o", "o", "l", "_", "c", "a", "l", "l", ">"},
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "test",
|
||||||
|
Arguments: api.NewToolCallFunctionArguments(),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "thinking close tag split character by character",
|
name: "thinking close tag split character by character",
|
||||||
chunks: []string{"I", "'", "m", " ", "t", "h", "i", "n", "k", "i", "n", "g", ".", ".", ".", "<", "/", "t", "h", "i", "n", "k", ">", "\n", "D", "o", "n", "e", "!"},
|
chunks: []string{"I", "'", "m", " ", "t", "h", "i", "n", "k", "i", "n", "g", ".", ".", ".", "<", "/", "t", "h", "i", "n", "k", ">", "\n", "D", "o", "n", "e", "!"},
|
||||||
@@ -155,6 +321,22 @@ func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
|||||||
expectedThinking: "Thinking...",
|
expectedThinking: "Thinking...",
|
||||||
expectedContent: "Content here.",
|
expectedContent: "Content here.",
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "tool call with multiple parameters - streaming",
|
||||||
|
chunks: []string{"<tool_", "call>\n", "<function", "=book_", "flight>", "\n<para", "meter=", "from>\n", "SFO\n", "</param", "eter>", "\n<param", "eter=to", ">\nNYC", "\n</para", "meter>", "\n</func", "tion>\n", "</tool_", "call>"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "book_flight",
|
||||||
|
Arguments: testArgs(map[string]any{
|
||||||
|
"from": "SFO",
|
||||||
|
"to": "NYC",
|
||||||
|
}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "thinking then content then tool call - streaming",
|
name: "thinking then content then tool call - streaming",
|
||||||
chunks: []string{"Ana", "lyzing", " your", " request", "...", "</", "think", ">\n", "I'll", " check", " that", " for", " you", ".", "\n", "<tool", "_call", ">\n", "<function", "=search", ">\n", "<parameter", "=query", ">\n", "test", " query", "\n</", "parameter", ">\n", "</function", ">\n", "</tool", "_call", ">"},
|
chunks: []string{"Ana", "lyzing", " your", " request", "...", "</", "think", ">\n", "I'll", " check", " that", " for", " you", ".", "\n", "<tool", "_call", ">\n", "<function", "=search", ">\n", "<parameter", "=query", ">\n", "test", " query", "\n</", "parameter", ">\n", "</function", ">\n", "</tool", "_call", ">"},
|
||||||
@@ -170,6 +352,45 @@ func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
|||||||
},
|
},
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "multiple tool calls - streaming",
|
||||||
|
chunks: []string{
|
||||||
|
"<tool_call>", "\n", "<function=", "get_weather>", "\n",
|
||||||
|
"<parameter=", "city>\n", "San Fran", "cisco\n", "</parameter>", "\n",
|
||||||
|
"</function>", "\n", "</tool_call>", "\n",
|
||||||
|
"<tool_", "call>\n", "<function", "=get_weather", ">\n",
|
||||||
|
"<param", "eter=city", ">\nNew", " York\n", "</parameter>\n",
|
||||||
|
"</function>\n", "</tool_call>",
|
||||||
|
},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "San Francisco"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "get_weather",
|
||||||
|
Arguments: testArgs(map[string]any{"city": "New York"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "tool call with multiline parameter - streaming",
|
||||||
|
chunks: []string{"<tool_call>\n", "<function=", "create_note>\n", "<parameter=", "content>\n", "Line 1", "\nLine", " 2\n", "Line 3", "\n</parameter>\n", "</function>\n", "</tool_call>"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "create_note",
|
||||||
|
Arguments: testArgs(map[string]any{"content": "Line 1\nLine 2\nLine 3"}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "empty thinking block",
|
name: "empty thinking block",
|
||||||
chunks: []string{"</think>", "\n", "Just content."},
|
chunks: []string{"</think>", "\n", "Just content."},
|
||||||
@@ -177,6 +398,12 @@ func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
|||||||
expectedThinking: "",
|
expectedThinking: "",
|
||||||
expectedContent: "Just content.",
|
expectedContent: "Just content.",
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "empty input chunks interspersed",
|
||||||
|
chunks: []string{"Hello", "", " ", "", "world", "", "!"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Hello world!",
|
||||||
|
},
|
||||||
{
|
{
|
||||||
name: "tool call immediately after think close - no content",
|
name: "tool call immediately after think close - no content",
|
||||||
chunks: []string{"Analyzing...", "</think>", "\n", "<tool_call>", "\n<function=test>\n</function>\n", "</tool_call>"},
|
chunks: []string{"Analyzing...", "</think>", "\n", "<tool_call>", "\n<function=test>\n</function>\n", "</tool_call>"},
|
||||||
@@ -191,6 +418,25 @@ func TestNemotron3NanoParser_Streaming(t *testing.T) {
|
|||||||
},
|
},
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
name: "tool call with empty parameter value",
|
||||||
|
chunks: []string{"<tool_call>\n<function=test>\n<parameter=name>\n", "\n</parameter>\n</function>\n</tool_call>"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedCalls: []api.ToolCall{
|
||||||
|
{
|
||||||
|
Function: api.ToolCallFunction{
|
||||||
|
Name: "test",
|
||||||
|
Arguments: testArgs(map[string]any{"name": ""}),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "partial tool call tag at end - buffered",
|
||||||
|
chunks: []string{"Here's some content", "<tool"},
|
||||||
|
thinkValue: nil,
|
||||||
|
expectedContent: "Here's some content",
|
||||||
|
},
|
||||||
}
|
}
|
||||||
|
|
||||||
for _, tt := range tests {
|
for _, tt := range tests {
|
||||||
@@ -326,65 +572,3 @@ func TestNemotron3NanoParser_WithTools(t *testing.T) {
|
|||||||
t.Errorf("calls mismatch (-got +want):\n%s", diff)
|
t.Errorf("calls mismatch (-got +want):\n%s", diff)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// TestNemotron3NanoParser_ToolCallWithoutThinkClose tests the case where thinking is enabled
|
|
||||||
// but the model outputs content + tool call WITHOUT the </think> tag.
|
|
||||||
// The parser should still parse the tool call (content before is treated as thinking).
|
|
||||||
func TestNemotron3NanoParser_ToolCallWithoutThinkClose(t *testing.T) {
|
|
||||||
chunks := []string{
|
|
||||||
"Let", " me", " analyze", " this", ".", "\n",
|
|
||||||
"<tool_call>", "\n",
|
|
||||||
"<function=get_weather>", "\n",
|
|
||||||
"<parameter=city>", "Paris", "</parameter>", "\n",
|
|
||||||
"</function>", "\n",
|
|
||||||
"</tool_call>",
|
|
||||||
}
|
|
||||||
|
|
||||||
p := &Nemotron3NanoParser{}
|
|
||||||
p.Init(nil, nil, &api.ThinkValue{Value: true}) // thinking ENABLED but model doesn't output </think>
|
|
||||||
|
|
||||||
var allContent string
|
|
||||||
var allThinking string
|
|
||||||
var allCalls []api.ToolCall
|
|
||||||
|
|
||||||
for _, chunk := range chunks {
|
|
||||||
content, thinking, calls, err := p.Add(chunk, false)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("unexpected error: %v", err)
|
|
||||||
}
|
|
||||||
allContent += content
|
|
||||||
allThinking += thinking
|
|
||||||
allCalls = append(allCalls, calls...)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Drain
|
|
||||||
content, thinking, calls, err := p.Add("", true)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("unexpected error on done: %v", err)
|
|
||||||
}
|
|
||||||
allContent += content
|
|
||||||
allThinking += thinking
|
|
||||||
allCalls = append(allCalls, calls...)
|
|
||||||
|
|
||||||
// The parser was in thinking mode, so text before <tool_call> is emitted as thinking.
|
|
||||||
expectedThinking := "Let me analyze this."
|
|
||||||
|
|
||||||
expectedCalls := []api.ToolCall{
|
|
||||||
{
|
|
||||||
Function: api.ToolCallFunction{
|
|
||||||
Name: "get_weather",
|
|
||||||
Arguments: testArgs(map[string]any{"city": "Paris"}),
|
|
||||||
},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
if allContent != "" {
|
|
||||||
t.Errorf("expected no content (text was streamed as thinking), got: %q", allContent)
|
|
||||||
}
|
|
||||||
if diff := cmp.Diff(allThinking, expectedThinking); diff != "" {
|
|
||||||
t.Errorf("thinking mismatch (-got +want):\n%s", diff)
|
|
||||||
}
|
|
||||||
if diff := cmp.Diff(allCalls, expectedCalls, argsComparer); diff != "" {
|
|
||||||
t.Errorf("calls mismatch (-got +want):\n%s", diff)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -91,37 +91,6 @@ func TestQwenParserStreaming(t *testing.T) {
|
|||||||
},
|
},
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
{
|
|
||||||
desc: "tool call tags split character by character",
|
|
||||||
steps: []step{
|
|
||||||
{input: "<", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "t", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "o", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "o", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "l", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "_", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "c", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "a", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "l", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "l", wantEvents: []qwenEvent{}},
|
|
||||||
{input: ">", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "a", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "b", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "c", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "<", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "/", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "t", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "o", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "o", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "l", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "_", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "c", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "a", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "l", wantEvents: []qwenEvent{}},
|
|
||||||
{input: "l", wantEvents: []qwenEvent{}},
|
|
||||||
{input: ">", wantEvents: []qwenEvent{qwenEventRawToolCall{raw: "abc"}}},
|
|
||||||
},
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
desc: "trailing whitespace between content and tool call",
|
desc: "trailing whitespace between content and tool call",
|
||||||
steps: []step{
|
steps: []step{
|
||||||
|
|||||||
@@ -630,10 +630,6 @@ func nameFromToolCallID(messages []Message, toolCallID string) string {
|
|||||||
|
|
||||||
// decodeImageURL decodes a base64 data URI into raw image bytes.
|
// decodeImageURL decodes a base64 data URI into raw image bytes.
|
||||||
func decodeImageURL(url string) (api.ImageData, error) {
|
func decodeImageURL(url string) (api.ImageData, error) {
|
||||||
if strings.HasPrefix(url, "http://") || strings.HasPrefix(url, "https://") {
|
|
||||||
return nil, errors.New("image URLs are not currently supported, please use base64 encoded data instead")
|
|
||||||
}
|
|
||||||
|
|
||||||
types := []string{"jpeg", "jpg", "png", "webp"}
|
types := []string{"jpeg", "jpg", "png", "webp"}
|
||||||
|
|
||||||
// Support blank mime type to match /api/chat's behavior of taking just unadorned base64
|
// Support blank mime type to match /api/chat's behavior of taking just unadorned base64
|
||||||
@@ -737,60 +733,3 @@ func FromCompleteRequest(r CompletionRequest) (api.GenerateRequest, error) {
|
|||||||
DebugRenderOnly: r.DebugRenderOnly,
|
DebugRenderOnly: r.DebugRenderOnly,
|
||||||
}, nil
|
}, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
// ImageGenerationRequest is an OpenAI-compatible image generation request.
|
|
||||||
type ImageGenerationRequest struct {
|
|
||||||
Model string `json:"model"`
|
|
||||||
Prompt string `json:"prompt"`
|
|
||||||
N int `json:"n,omitempty"`
|
|
||||||
Size string `json:"size,omitempty"`
|
|
||||||
ResponseFormat string `json:"response_format,omitempty"`
|
|
||||||
Seed *int64 `json:"seed,omitempty"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// ImageGenerationResponse is an OpenAI-compatible image generation response.
|
|
||||||
type ImageGenerationResponse struct {
|
|
||||||
Created int64 `json:"created"`
|
|
||||||
Data []ImageURLOrData `json:"data"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// ImageURLOrData contains either a URL or base64-encoded image data.
|
|
||||||
type ImageURLOrData struct {
|
|
||||||
URL string `json:"url,omitempty"`
|
|
||||||
B64JSON string `json:"b64_json,omitempty"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// FromImageGenerationRequest converts an OpenAI image generation request to an Ollama GenerateRequest.
|
|
||||||
func FromImageGenerationRequest(r ImageGenerationRequest) api.GenerateRequest {
|
|
||||||
req := api.GenerateRequest{
|
|
||||||
Model: r.Model,
|
|
||||||
Prompt: r.Prompt,
|
|
||||||
}
|
|
||||||
// Parse size if provided (e.g., "1024x768")
|
|
||||||
if r.Size != "" {
|
|
||||||
var w, h int32
|
|
||||||
if _, err := fmt.Sscanf(r.Size, "%dx%d", &w, &h); err == nil {
|
|
||||||
req.Width = w
|
|
||||||
req.Height = h
|
|
||||||
}
|
|
||||||
}
|
|
||||||
if r.Seed != nil {
|
|
||||||
if req.Options == nil {
|
|
||||||
req.Options = map[string]any{}
|
|
||||||
}
|
|
||||||
req.Options["seed"] = *r.Seed
|
|
||||||
}
|
|
||||||
return req
|
|
||||||
}
|
|
||||||
|
|
||||||
// ToImageGenerationResponse converts an Ollama GenerateResponse to an OpenAI ImageGenerationResponse.
|
|
||||||
func ToImageGenerationResponse(resp api.GenerateResponse) ImageGenerationResponse {
|
|
||||||
var data []ImageURLOrData
|
|
||||||
if resp.Image != "" {
|
|
||||||
data = []ImageURLOrData{{B64JSON: resp.Image}}
|
|
||||||
}
|
|
||||||
return ImageGenerationResponse{
|
|
||||||
Created: resp.CreatedAt.Unix(),
|
|
||||||
Data: data,
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -4,7 +4,6 @@ import (
|
|||||||
"encoding/json"
|
"encoding/json"
|
||||||
"fmt"
|
"fmt"
|
||||||
"math/rand"
|
"math/rand"
|
||||||
"time"
|
|
||||||
|
|
||||||
"github.com/ollama/ollama/api"
|
"github.com/ollama/ollama/api"
|
||||||
)
|
)
|
||||||
@@ -266,9 +265,9 @@ type ResponsesText struct {
|
|||||||
type ResponsesTool struct {
|
type ResponsesTool struct {
|
||||||
Type string `json:"type"` // "function"
|
Type string `json:"type"` // "function"
|
||||||
Name string `json:"name"`
|
Name string `json:"name"`
|
||||||
Description *string `json:"description"` // nullable but required
|
Description string `json:"description,omitempty"`
|
||||||
Strict *bool `json:"strict"` // nullable but required
|
Strict bool `json:"strict,omitempty"`
|
||||||
Parameters map[string]any `json:"parameters"` // nullable but required
|
Parameters map[string]any `json:"parameters,omitempty"`
|
||||||
}
|
}
|
||||||
|
|
||||||
type ResponsesRequest struct {
|
type ResponsesRequest struct {
|
||||||
@@ -476,16 +475,11 @@ func convertTool(t ResponsesTool) (api.Tool, error) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
var description string
|
|
||||||
if t.Description != nil {
|
|
||||||
description = *t.Description
|
|
||||||
}
|
|
||||||
|
|
||||||
return api.Tool{
|
return api.Tool{
|
||||||
Type: t.Type,
|
Type: t.Type,
|
||||||
Function: api.ToolFunction{
|
Function: api.ToolFunction{
|
||||||
Name: t.Name,
|
Name: t.Name,
|
||||||
Description: description,
|
Description: t.Description,
|
||||||
Parameters: params,
|
Parameters: params,
|
||||||
},
|
},
|
||||||
}, nil
|
}, nil
|
||||||
@@ -522,60 +516,17 @@ func convertInputMessage(m ResponsesInputMessage) (api.Message, error) {
|
|||||||
|
|
||||||
// Response types for the Responses API
|
// Response types for the Responses API
|
||||||
|
|
||||||
// ResponsesTextField represents the text output configuration in the response.
|
|
||||||
type ResponsesTextField struct {
|
|
||||||
Format ResponsesTextFormat `json:"format"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// ResponsesReasoningOutput represents reasoning configuration in the response.
|
|
||||||
type ResponsesReasoningOutput struct {
|
|
||||||
Effort *string `json:"effort,omitempty"`
|
|
||||||
Summary *string `json:"summary,omitempty"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// ResponsesError represents an error in the response.
|
|
||||||
type ResponsesError struct {
|
|
||||||
Code string `json:"code"`
|
|
||||||
Message string `json:"message"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// ResponsesIncompleteDetails represents details about why a response was incomplete.
|
|
||||||
type ResponsesIncompleteDetails struct {
|
|
||||||
Reason string `json:"reason"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type ResponsesResponse struct {
|
type ResponsesResponse struct {
|
||||||
ID string `json:"id"`
|
ID string `json:"id"`
|
||||||
Object string `json:"object"`
|
Object string `json:"object"`
|
||||||
CreatedAt int64 `json:"created_at"`
|
CreatedAt int64 `json:"created_at"`
|
||||||
CompletedAt *int64 `json:"completed_at"`
|
Status string `json:"status"`
|
||||||
Status string `json:"status"`
|
Model string `json:"model"`
|
||||||
IncompleteDetails *ResponsesIncompleteDetails `json:"incomplete_details"`
|
Output []ResponsesOutputItem `json:"output"`
|
||||||
Model string `json:"model"`
|
Usage *ResponsesUsage `json:"usage,omitempty"`
|
||||||
PreviousResponseID *string `json:"previous_response_id"`
|
// TODO(drifkin): add `temperature` and `top_p` to the response, but this
|
||||||
Instructions *string `json:"instructions"`
|
// requires additional plumbing to find the effective values since the
|
||||||
Output []ResponsesOutputItem `json:"output"`
|
// defaults can come from the model or the request
|
||||||
Error *ResponsesError `json:"error"`
|
|
||||||
Tools []ResponsesTool `json:"tools"`
|
|
||||||
ToolChoice any `json:"tool_choice"`
|
|
||||||
Truncation string `json:"truncation"`
|
|
||||||
ParallelToolCalls bool `json:"parallel_tool_calls"`
|
|
||||||
Text ResponsesTextField `json:"text"`
|
|
||||||
TopP float64 `json:"top_p"`
|
|
||||||
PresencePenalty float64 `json:"presence_penalty"`
|
|
||||||
FrequencyPenalty float64 `json:"frequency_penalty"`
|
|
||||||
TopLogprobs int `json:"top_logprobs"`
|
|
||||||
Temperature float64 `json:"temperature"`
|
|
||||||
Reasoning *ResponsesReasoningOutput `json:"reasoning"`
|
|
||||||
Usage *ResponsesUsage `json:"usage"`
|
|
||||||
MaxOutputTokens *int `json:"max_output_tokens"`
|
|
||||||
MaxToolCalls *int `json:"max_tool_calls"`
|
|
||||||
Store bool `json:"store"`
|
|
||||||
Background bool `json:"background"`
|
|
||||||
ServiceTier string `json:"service_tier"`
|
|
||||||
Metadata map[string]any `json:"metadata"`
|
|
||||||
SafetyIdentifier *string `json:"safety_identifier"`
|
|
||||||
PromptCacheKey *string `json:"prompt_cache_key"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
type ResponsesOutputItem struct {
|
type ResponsesOutputItem struct {
|
||||||
@@ -599,39 +550,18 @@ type ResponsesReasoningSummary struct {
|
|||||||
}
|
}
|
||||||
|
|
||||||
type ResponsesOutputContent struct {
|
type ResponsesOutputContent struct {
|
||||||
Type string `json:"type"` // "output_text"
|
Type string `json:"type"` // "output_text"
|
||||||
Text string `json:"text"`
|
Text string `json:"text"`
|
||||||
Annotations []any `json:"annotations"`
|
|
||||||
Logprobs []any `json:"logprobs"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type ResponsesInputTokensDetails struct {
|
|
||||||
CachedTokens int `json:"cached_tokens"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type ResponsesOutputTokensDetails struct {
|
|
||||||
ReasoningTokens int `json:"reasoning_tokens"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
type ResponsesUsage struct {
|
type ResponsesUsage struct {
|
||||||
InputTokens int `json:"input_tokens"`
|
InputTokens int `json:"input_tokens"`
|
||||||
OutputTokens int `json:"output_tokens"`
|
OutputTokens int `json:"output_tokens"`
|
||||||
TotalTokens int `json:"total_tokens"`
|
TotalTokens int `json:"total_tokens"`
|
||||||
InputTokensDetails ResponsesInputTokensDetails `json:"input_tokens_details"`
|
|
||||||
OutputTokensDetails ResponsesOutputTokensDetails `json:"output_tokens_details"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// derefFloat64 returns the value of a float64 pointer, or a default if nil.
|
// ToResponse converts an api.ChatResponse to a Responses API response
|
||||||
func derefFloat64(p *float64, def float64) float64 {
|
func ToResponse(model, responseID, itemID string, chatResponse api.ChatResponse) ResponsesResponse {
|
||||||
if p != nil {
|
|
||||||
return *p
|
|
||||||
}
|
|
||||||
return def
|
|
||||||
}
|
|
||||||
|
|
||||||
// ToResponse converts an api.ChatResponse to a Responses API response.
|
|
||||||
// The request is used to echo back request parameters in the response.
|
|
||||||
func ToResponse(model, responseID, itemID string, chatResponse api.ChatResponse, request ResponsesRequest) ResponsesResponse {
|
|
||||||
var output []ResponsesOutputItem
|
var output []ResponsesOutputItem
|
||||||
|
|
||||||
// Add reasoning item if thinking is present
|
// Add reasoning item if thinking is present
|
||||||
@@ -655,7 +585,6 @@ func ToResponse(model, responseID, itemID string, chatResponse api.ChatResponse,
|
|||||||
output = append(output, ResponsesOutputItem{
|
output = append(output, ResponsesOutputItem{
|
||||||
ID: fmt.Sprintf("fc_%s_%d", responseID, i),
|
ID: fmt.Sprintf("fc_%s_%d", responseID, i),
|
||||||
Type: "function_call",
|
Type: "function_call",
|
||||||
Status: "completed",
|
|
||||||
CallID: tc.ID,
|
CallID: tc.ID,
|
||||||
Name: tc.Function.Name,
|
Name: tc.Function.Name,
|
||||||
Arguments: tc.Function.Arguments,
|
Arguments: tc.Function.Arguments,
|
||||||
@@ -669,90 +598,25 @@ func ToResponse(model, responseID, itemID string, chatResponse api.ChatResponse,
|
|||||||
Role: "assistant",
|
Role: "assistant",
|
||||||
Content: []ResponsesOutputContent{
|
Content: []ResponsesOutputContent{
|
||||||
{
|
{
|
||||||
Type: "output_text",
|
Type: "output_text",
|
||||||
Text: chatResponse.Message.Content,
|
Text: chatResponse.Message.Content,
|
||||||
Annotations: []any{},
|
|
||||||
Logprobs: []any{},
|
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
var instructions *string
|
|
||||||
if request.Instructions != "" {
|
|
||||||
instructions = &request.Instructions
|
|
||||||
}
|
|
||||||
|
|
||||||
// Build truncation with default
|
|
||||||
truncation := "disabled"
|
|
||||||
if request.Truncation != nil {
|
|
||||||
truncation = *request.Truncation
|
|
||||||
}
|
|
||||||
|
|
||||||
tools := request.Tools
|
|
||||||
if tools == nil {
|
|
||||||
tools = []ResponsesTool{}
|
|
||||||
}
|
|
||||||
|
|
||||||
text := ResponsesTextField{
|
|
||||||
Format: ResponsesTextFormat{Type: "text"},
|
|
||||||
}
|
|
||||||
if request.Text != nil && request.Text.Format != nil {
|
|
||||||
text.Format = *request.Text.Format
|
|
||||||
}
|
|
||||||
|
|
||||||
// Build reasoning output from request
|
|
||||||
var reasoning *ResponsesReasoningOutput
|
|
||||||
if request.Reasoning.Effort != "" || request.Reasoning.Summary != "" {
|
|
||||||
reasoning = &ResponsesReasoningOutput{}
|
|
||||||
if request.Reasoning.Effort != "" {
|
|
||||||
reasoning.Effort = &request.Reasoning.Effort
|
|
||||||
}
|
|
||||||
if request.Reasoning.Summary != "" {
|
|
||||||
reasoning.Summary = &request.Reasoning.Summary
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
return ResponsesResponse{
|
return ResponsesResponse{
|
||||||
ID: responseID,
|
ID: responseID,
|
||||||
Object: "response",
|
Object: "response",
|
||||||
CreatedAt: chatResponse.CreatedAt.Unix(),
|
CreatedAt: chatResponse.CreatedAt.Unix(),
|
||||||
CompletedAt: nil, // Set by middleware when writing final response
|
Status: "completed",
|
||||||
Status: "completed",
|
Model: model,
|
||||||
IncompleteDetails: nil, // Only populated if response incomplete
|
Output: output,
|
||||||
Model: model,
|
|
||||||
PreviousResponseID: nil, // Not supported
|
|
||||||
Instructions: instructions,
|
|
||||||
Output: output,
|
|
||||||
Error: nil, // Only populated on failure
|
|
||||||
Tools: tools,
|
|
||||||
ToolChoice: "auto", // Default value
|
|
||||||
Truncation: truncation,
|
|
||||||
ParallelToolCalls: true, // Default value
|
|
||||||
Text: text,
|
|
||||||
TopP: derefFloat64(request.TopP, 1.0),
|
|
||||||
PresencePenalty: 0, // Default value
|
|
||||||
FrequencyPenalty: 0, // Default value
|
|
||||||
TopLogprobs: 0, // Default value
|
|
||||||
Temperature: derefFloat64(request.Temperature, 1.0),
|
|
||||||
Reasoning: reasoning,
|
|
||||||
Usage: &ResponsesUsage{
|
Usage: &ResponsesUsage{
|
||||||
InputTokens: chatResponse.PromptEvalCount,
|
InputTokens: chatResponse.PromptEvalCount,
|
||||||
OutputTokens: chatResponse.EvalCount,
|
OutputTokens: chatResponse.EvalCount,
|
||||||
TotalTokens: chatResponse.PromptEvalCount + chatResponse.EvalCount,
|
TotalTokens: chatResponse.PromptEvalCount + chatResponse.EvalCount,
|
||||||
// TODO(drifkin): wire through the actual values
|
|
||||||
InputTokensDetails: ResponsesInputTokensDetails{CachedTokens: 0},
|
|
||||||
// TODO(drifkin): wire through the actual values
|
|
||||||
OutputTokensDetails: ResponsesOutputTokensDetails{ReasoningTokens: 0},
|
|
||||||
},
|
},
|
||||||
MaxOutputTokens: request.MaxOutputTokens,
|
|
||||||
MaxToolCalls: nil, // Not supported
|
|
||||||
Store: false, // We don't store responses
|
|
||||||
Background: request.Background,
|
|
||||||
ServiceTier: "default", // Default value
|
|
||||||
Metadata: map[string]any{},
|
|
||||||
SafetyIdentifier: nil, // Not supported
|
|
||||||
PromptCacheKey: nil, // Not supported
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -772,7 +636,6 @@ type ResponsesStreamConverter struct {
|
|||||||
responseID string
|
responseID string
|
||||||
itemID string
|
itemID string
|
||||||
model string
|
model string
|
||||||
request ResponsesRequest
|
|
||||||
|
|
||||||
// State tracking (mutated across Process calls)
|
// State tracking (mutated across Process calls)
|
||||||
firstWrite bool
|
firstWrite bool
|
||||||
@@ -805,12 +668,11 @@ func (c *ResponsesStreamConverter) newEvent(eventType string, data map[string]an
|
|||||||
}
|
}
|
||||||
|
|
||||||
// NewResponsesStreamConverter creates a new converter with the given configuration.
|
// NewResponsesStreamConverter creates a new converter with the given configuration.
|
||||||
func NewResponsesStreamConverter(responseID, itemID, model string, request ResponsesRequest) *ResponsesStreamConverter {
|
func NewResponsesStreamConverter(responseID, itemID, model string) *ResponsesStreamConverter {
|
||||||
return &ResponsesStreamConverter{
|
return &ResponsesStreamConverter{
|
||||||
responseID: responseID,
|
responseID: responseID,
|
||||||
itemID: itemID,
|
itemID: itemID,
|
||||||
model: model,
|
model: model,
|
||||||
request: request,
|
|
||||||
firstWrite: true,
|
firstWrite: true,
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -855,120 +717,25 @@ func (c *ResponsesStreamConverter) Process(r api.ChatResponse) []ResponsesStream
|
|||||||
return events
|
return events
|
||||||
}
|
}
|
||||||
|
|
||||||
// buildResponseObject creates a full response object with all required fields for streaming events.
|
|
||||||
func (c *ResponsesStreamConverter) buildResponseObject(status string, output []any, usage map[string]any) map[string]any {
|
|
||||||
var instructions any = nil
|
|
||||||
if c.request.Instructions != "" {
|
|
||||||
instructions = c.request.Instructions
|
|
||||||
}
|
|
||||||
|
|
||||||
truncation := "disabled"
|
|
||||||
if c.request.Truncation != nil {
|
|
||||||
truncation = *c.request.Truncation
|
|
||||||
}
|
|
||||||
|
|
||||||
var tools []any
|
|
||||||
if c.request.Tools != nil {
|
|
||||||
for _, t := range c.request.Tools {
|
|
||||||
tools = append(tools, map[string]any{
|
|
||||||
"type": t.Type,
|
|
||||||
"name": t.Name,
|
|
||||||
"description": t.Description,
|
|
||||||
"strict": t.Strict,
|
|
||||||
"parameters": t.Parameters,
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
if tools == nil {
|
|
||||||
tools = []any{}
|
|
||||||
}
|
|
||||||
|
|
||||||
textFormat := map[string]any{"type": "text"}
|
|
||||||
if c.request.Text != nil && c.request.Text.Format != nil {
|
|
||||||
textFormat = map[string]any{
|
|
||||||
"type": c.request.Text.Format.Type,
|
|
||||||
}
|
|
||||||
if c.request.Text.Format.Name != "" {
|
|
||||||
textFormat["name"] = c.request.Text.Format.Name
|
|
||||||
}
|
|
||||||
if c.request.Text.Format.Schema != nil {
|
|
||||||
textFormat["schema"] = c.request.Text.Format.Schema
|
|
||||||
}
|
|
||||||
if c.request.Text.Format.Strict != nil {
|
|
||||||
textFormat["strict"] = *c.request.Text.Format.Strict
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
var reasoning any = nil
|
|
||||||
if c.request.Reasoning.Effort != "" || c.request.Reasoning.Summary != "" {
|
|
||||||
r := map[string]any{}
|
|
||||||
if c.request.Reasoning.Effort != "" {
|
|
||||||
r["effort"] = c.request.Reasoning.Effort
|
|
||||||
} else {
|
|
||||||
r["effort"] = nil
|
|
||||||
}
|
|
||||||
if c.request.Reasoning.Summary != "" {
|
|
||||||
r["summary"] = c.request.Reasoning.Summary
|
|
||||||
} else {
|
|
||||||
r["summary"] = nil
|
|
||||||
}
|
|
||||||
reasoning = r
|
|
||||||
}
|
|
||||||
|
|
||||||
// Build top_p and temperature with defaults
|
|
||||||
topP := 1.0
|
|
||||||
if c.request.TopP != nil {
|
|
||||||
topP = *c.request.TopP
|
|
||||||
}
|
|
||||||
temperature := 1.0
|
|
||||||
if c.request.Temperature != nil {
|
|
||||||
temperature = *c.request.Temperature
|
|
||||||
}
|
|
||||||
|
|
||||||
return map[string]any{
|
|
||||||
"id": c.responseID,
|
|
||||||
"object": "response",
|
|
||||||
"created_at": time.Now().Unix(),
|
|
||||||
"completed_at": nil,
|
|
||||||
"status": status,
|
|
||||||
"incomplete_details": nil,
|
|
||||||
"model": c.model,
|
|
||||||
"previous_response_id": nil,
|
|
||||||
"instructions": instructions,
|
|
||||||
"output": output,
|
|
||||||
"error": nil,
|
|
||||||
"tools": tools,
|
|
||||||
"tool_choice": "auto",
|
|
||||||
"truncation": truncation,
|
|
||||||
"parallel_tool_calls": true,
|
|
||||||
"text": map[string]any{"format": textFormat},
|
|
||||||
"top_p": topP,
|
|
||||||
"presence_penalty": 0,
|
|
||||||
"frequency_penalty": 0,
|
|
||||||
"top_logprobs": 0,
|
|
||||||
"temperature": temperature,
|
|
||||||
"reasoning": reasoning,
|
|
||||||
"usage": usage,
|
|
||||||
"max_output_tokens": c.request.MaxOutputTokens,
|
|
||||||
"max_tool_calls": nil,
|
|
||||||
"store": false,
|
|
||||||
"background": c.request.Background,
|
|
||||||
"service_tier": "default",
|
|
||||||
"metadata": map[string]any{},
|
|
||||||
"safety_identifier": nil,
|
|
||||||
"prompt_cache_key": nil,
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func (c *ResponsesStreamConverter) createResponseCreatedEvent() ResponsesStreamEvent {
|
func (c *ResponsesStreamConverter) createResponseCreatedEvent() ResponsesStreamEvent {
|
||||||
return c.newEvent("response.created", map[string]any{
|
return c.newEvent("response.created", map[string]any{
|
||||||
"response": c.buildResponseObject("in_progress", []any{}, nil),
|
"response": map[string]any{
|
||||||
|
"id": c.responseID,
|
||||||
|
"object": "response",
|
||||||
|
"status": "in_progress",
|
||||||
|
"output": []any{},
|
||||||
|
},
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
func (c *ResponsesStreamConverter) createResponseInProgressEvent() ResponsesStreamEvent {
|
func (c *ResponsesStreamConverter) createResponseInProgressEvent() ResponsesStreamEvent {
|
||||||
return c.newEvent("response.in_progress", map[string]any{
|
return c.newEvent("response.in_progress", map[string]any{
|
||||||
"response": c.buildResponseObject("in_progress", []any{}, nil),
|
"response": map[string]any{
|
||||||
|
"id": c.responseID,
|
||||||
|
"object": "response",
|
||||||
|
"status": "in_progress",
|
||||||
|
"output": []any{},
|
||||||
|
},
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -995,10 +762,9 @@ func (c *ResponsesStreamConverter) processThinking(thinking string) []ResponsesS
|
|||||||
|
|
||||||
// Emit delta
|
// Emit delta
|
||||||
events = append(events, c.newEvent("response.reasoning_summary_text.delta", map[string]any{
|
events = append(events, c.newEvent("response.reasoning_summary_text.delta", map[string]any{
|
||||||
"item_id": c.reasoningItemID,
|
"item_id": c.reasoningItemID,
|
||||||
"output_index": c.outputIndex,
|
"output_index": c.outputIndex,
|
||||||
"summary_index": 0,
|
"delta": thinking,
|
||||||
"delta": thinking,
|
|
||||||
}))
|
}))
|
||||||
|
|
||||||
// TODO(drifkin): consider adding
|
// TODO(drifkin): consider adding
|
||||||
@@ -1017,10 +783,9 @@ func (c *ResponsesStreamConverter) finishReasoning() []ResponsesStreamEvent {
|
|||||||
|
|
||||||
events := []ResponsesStreamEvent{
|
events := []ResponsesStreamEvent{
|
||||||
c.newEvent("response.reasoning_summary_text.done", map[string]any{
|
c.newEvent("response.reasoning_summary_text.done", map[string]any{
|
||||||
"item_id": c.reasoningItemID,
|
"item_id": c.reasoningItemID,
|
||||||
"output_index": c.outputIndex,
|
"output_index": c.outputIndex,
|
||||||
"summary_index": 0,
|
"text": c.accumulatedThinking,
|
||||||
"text": c.accumulatedThinking,
|
|
||||||
}),
|
}),
|
||||||
c.newEvent("response.output_item.done", map[string]any{
|
c.newEvent("response.output_item.done", map[string]any{
|
||||||
"output_index": c.outputIndex,
|
"output_index": c.outputIndex,
|
||||||
@@ -1133,10 +898,8 @@ func (c *ResponsesStreamConverter) processTextContent(content string) []Response
|
|||||||
"output_index": c.outputIndex,
|
"output_index": c.outputIndex,
|
||||||
"content_index": c.contentIndex,
|
"content_index": c.contentIndex,
|
||||||
"part": map[string]any{
|
"part": map[string]any{
|
||||||
"type": "output_text",
|
"type": "output_text",
|
||||||
"text": "",
|
"text": "",
|
||||||
"annotations": []any{},
|
|
||||||
"logprobs": []any{},
|
|
||||||
},
|
},
|
||||||
}))
|
}))
|
||||||
}
|
}
|
||||||
@@ -1150,7 +913,6 @@ func (c *ResponsesStreamConverter) processTextContent(content string) []Response
|
|||||||
"output_index": c.outputIndex,
|
"output_index": c.outputIndex,
|
||||||
"content_index": 0,
|
"content_index": 0,
|
||||||
"delta": content,
|
"delta": content,
|
||||||
"logprobs": []any{},
|
|
||||||
}))
|
}))
|
||||||
|
|
||||||
return events
|
return events
|
||||||
@@ -1182,10 +944,8 @@ func (c *ResponsesStreamConverter) buildFinalOutput() []any {
|
|||||||
"status": "completed",
|
"status": "completed",
|
||||||
"role": "assistant",
|
"role": "assistant",
|
||||||
"content": []map[string]any{{
|
"content": []map[string]any{{
|
||||||
"type": "output_text",
|
"type": "output_text",
|
||||||
"text": c.accumulatedText,
|
"text": c.accumulatedText,
|
||||||
"annotations": []any{},
|
|
||||||
"logprobs": []any{},
|
|
||||||
}},
|
}},
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
@@ -1207,7 +967,6 @@ func (c *ResponsesStreamConverter) processCompletion(r api.ChatResponse) []Respo
|
|||||||
"output_index": c.outputIndex,
|
"output_index": c.outputIndex,
|
||||||
"content_index": 0,
|
"content_index": 0,
|
||||||
"text": c.accumulatedText,
|
"text": c.accumulatedText,
|
||||||
"logprobs": []any{},
|
|
||||||
}))
|
}))
|
||||||
|
|
||||||
// response.content_part.done
|
// response.content_part.done
|
||||||
@@ -1216,10 +975,8 @@ func (c *ResponsesStreamConverter) processCompletion(r api.ChatResponse) []Respo
|
|||||||
"output_index": c.outputIndex,
|
"output_index": c.outputIndex,
|
||||||
"content_index": 0,
|
"content_index": 0,
|
||||||
"part": map[string]any{
|
"part": map[string]any{
|
||||||
"type": "output_text",
|
"type": "output_text",
|
||||||
"text": c.accumulatedText,
|
"text": c.accumulatedText,
|
||||||
"annotations": []any{},
|
|
||||||
"logprobs": []any{},
|
|
||||||
},
|
},
|
||||||
}))
|
}))
|
||||||
|
|
||||||
@@ -1232,31 +989,26 @@ func (c *ResponsesStreamConverter) processCompletion(r api.ChatResponse) []Respo
|
|||||||
"status": "completed",
|
"status": "completed",
|
||||||
"role": "assistant",
|
"role": "assistant",
|
||||||
"content": []map[string]any{{
|
"content": []map[string]any{{
|
||||||
"type": "output_text",
|
"type": "output_text",
|
||||||
"text": c.accumulatedText,
|
"text": c.accumulatedText,
|
||||||
"annotations": []any{},
|
|
||||||
"logprobs": []any{},
|
|
||||||
}},
|
}},
|
||||||
},
|
},
|
||||||
}))
|
}))
|
||||||
}
|
}
|
||||||
|
|
||||||
// response.completed
|
// response.completed
|
||||||
usage := map[string]any{
|
|
||||||
"input_tokens": r.PromptEvalCount,
|
|
||||||
"output_tokens": r.EvalCount,
|
|
||||||
"total_tokens": r.PromptEvalCount + r.EvalCount,
|
|
||||||
"input_tokens_details": map[string]any{
|
|
||||||
"cached_tokens": 0,
|
|
||||||
},
|
|
||||||
"output_tokens_details": map[string]any{
|
|
||||||
"reasoning_tokens": 0,
|
|
||||||
},
|
|
||||||
}
|
|
||||||
response := c.buildResponseObject("completed", c.buildFinalOutput(), usage)
|
|
||||||
response["completed_at"] = time.Now().Unix()
|
|
||||||
events = append(events, c.newEvent("response.completed", map[string]any{
|
events = append(events, c.newEvent("response.completed", map[string]any{
|
||||||
"response": response,
|
"response": map[string]any{
|
||||||
|
"id": c.responseID,
|
||||||
|
"object": "response",
|
||||||
|
"status": "completed",
|
||||||
|
"output": c.buildFinalOutput(),
|
||||||
|
"usage": map[string]any{
|
||||||
|
"input_tokens": r.PromptEvalCount,
|
||||||
|
"output_tokens": r.EvalCount,
|
||||||
|
"total_tokens": r.PromptEvalCount + r.EvalCount,
|
||||||
|
},
|
||||||
|
},
|
||||||
}))
|
}))
|
||||||
|
|
||||||
return events
|
return events
|
||||||
|
|||||||
@@ -850,7 +850,7 @@ func TestFromResponsesRequest_Images(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func TestResponsesStreamConverter_TextOnly(t *testing.T) {
|
func TestResponsesStreamConverter_TextOnly(t *testing.T) {
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
// First chunk with content
|
// First chunk with content
|
||||||
events := converter.Process(api.ChatResponse{
|
events := converter.Process(api.ChatResponse{
|
||||||
@@ -916,7 +916,7 @@ func TestResponsesStreamConverter_TextOnly(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func TestResponsesStreamConverter_ToolCalls(t *testing.T) {
|
func TestResponsesStreamConverter_ToolCalls(t *testing.T) {
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
events := converter.Process(api.ChatResponse{
|
events := converter.Process(api.ChatResponse{
|
||||||
Message: api.Message{
|
Message: api.Message{
|
||||||
@@ -952,7 +952,7 @@ func TestResponsesStreamConverter_ToolCalls(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func TestResponsesStreamConverter_Reasoning(t *testing.T) {
|
func TestResponsesStreamConverter_Reasoning(t *testing.T) {
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
// First chunk with thinking
|
// First chunk with thinking
|
||||||
events := converter.Process(api.ChatResponse{
|
events := converter.Process(api.ChatResponse{
|
||||||
@@ -1267,7 +1267,7 @@ func TestToResponse_WithReasoning(t *testing.T) {
|
|||||||
Content: "The answer is 42",
|
Content: "The answer is 42",
|
||||||
},
|
},
|
||||||
Done: true,
|
Done: true,
|
||||||
}, ResponsesRequest{})
|
})
|
||||||
|
|
||||||
// Should have 2 output items: reasoning + message
|
// Should have 2 output items: reasoning + message
|
||||||
if len(response.Output) != 2 {
|
if len(response.Output) != 2 {
|
||||||
@@ -1638,7 +1638,7 @@ func TestFromResponsesRequest_ShorthandFormats(t *testing.T) {
|
|||||||
|
|
||||||
func TestResponsesStreamConverter_OutputIncludesContent(t *testing.T) {
|
func TestResponsesStreamConverter_OutputIncludesContent(t *testing.T) {
|
||||||
// Verify that response.output_item.done includes content field for messages
|
// Verify that response.output_item.done includes content field for messages
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
// First chunk
|
// First chunk
|
||||||
converter.Process(api.ChatResponse{
|
converter.Process(api.ChatResponse{
|
||||||
@@ -1686,7 +1686,7 @@ func TestResponsesStreamConverter_OutputIncludesContent(t *testing.T) {
|
|||||||
|
|
||||||
func TestResponsesStreamConverter_ResponseCompletedIncludesOutput(t *testing.T) {
|
func TestResponsesStreamConverter_ResponseCompletedIncludesOutput(t *testing.T) {
|
||||||
// Verify that response.completed includes the output array
|
// Verify that response.completed includes the output array
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
// Process some content
|
// Process some content
|
||||||
converter.Process(api.ChatResponse{
|
converter.Process(api.ChatResponse{
|
||||||
@@ -1730,7 +1730,7 @@ func TestResponsesStreamConverter_ResponseCompletedIncludesOutput(t *testing.T)
|
|||||||
|
|
||||||
func TestResponsesStreamConverter_ResponseCreatedIncludesOutput(t *testing.T) {
|
func TestResponsesStreamConverter_ResponseCreatedIncludesOutput(t *testing.T) {
|
||||||
// Verify that response.created includes an empty output array
|
// Verify that response.created includes an empty output array
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
events := converter.Process(api.ChatResponse{
|
events := converter.Process(api.ChatResponse{
|
||||||
Message: api.Message{Content: "Hi"},
|
Message: api.Message{Content: "Hi"},
|
||||||
@@ -1757,7 +1757,7 @@ func TestResponsesStreamConverter_ResponseCreatedIncludesOutput(t *testing.T) {
|
|||||||
|
|
||||||
func TestResponsesStreamConverter_SequenceNumbers(t *testing.T) {
|
func TestResponsesStreamConverter_SequenceNumbers(t *testing.T) {
|
||||||
// Verify that events include incrementing sequence numbers
|
// Verify that events include incrementing sequence numbers
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
events := converter.Process(api.ChatResponse{
|
events := converter.Process(api.ChatResponse{
|
||||||
Message: api.Message{Content: "Hello"},
|
Message: api.Message{Content: "Hello"},
|
||||||
@@ -1791,7 +1791,7 @@ func TestResponsesStreamConverter_SequenceNumbers(t *testing.T) {
|
|||||||
|
|
||||||
func TestResponsesStreamConverter_FunctionCallStatus(t *testing.T) {
|
func TestResponsesStreamConverter_FunctionCallStatus(t *testing.T) {
|
||||||
// Verify that function call items include status field
|
// Verify that function call items include status field
|
||||||
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b", ResponsesRequest{})
|
converter := NewResponsesStreamConverter("resp_123", "msg_456", "gpt-oss:20b")
|
||||||
|
|
||||||
events := converter.Process(api.ChatResponse{
|
events := converter.Process(api.ChatResponse{
|
||||||
Message: api.Message{
|
Message: api.Message{
|
||||||
|
|||||||
@@ -5,7 +5,6 @@ import (
|
|||||||
"fmt"
|
"fmt"
|
||||||
"io"
|
"io"
|
||||||
"os"
|
"os"
|
||||||
"strings"
|
|
||||||
)
|
)
|
||||||
|
|
||||||
type Prompt struct {
|
type Prompt struct {
|
||||||
@@ -37,11 +36,10 @@ type Terminal struct {
|
|||||||
}
|
}
|
||||||
|
|
||||||
type Instance struct {
|
type Instance struct {
|
||||||
Prompt *Prompt
|
Prompt *Prompt
|
||||||
Terminal *Terminal
|
Terminal *Terminal
|
||||||
History *History
|
History *History
|
||||||
Pasting bool
|
Pasting bool
|
||||||
pastedLines []string
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func New(prompt Prompt) (*Instance, error) {
|
func New(prompt Prompt) (*Instance, error) {
|
||||||
@@ -176,8 +174,6 @@ func (i *Instance) Readline() (string, error) {
|
|||||||
case CharEsc:
|
case CharEsc:
|
||||||
esc = true
|
esc = true
|
||||||
case CharInterrupt:
|
case CharInterrupt:
|
||||||
i.pastedLines = nil
|
|
||||||
i.Prompt.UseAlt = false
|
|
||||||
return "", ErrInterrupt
|
return "", ErrInterrupt
|
||||||
case CharPrev:
|
case CharPrev:
|
||||||
i.historyPrev(buf, ¤tLineBuf)
|
i.historyPrev(buf, ¤tLineBuf)
|
||||||
@@ -192,23 +188,7 @@ func (i *Instance) Readline() (string, error) {
|
|||||||
case CharForward:
|
case CharForward:
|
||||||
buf.MoveRight()
|
buf.MoveRight()
|
||||||
case CharBackspace, CharCtrlH:
|
case CharBackspace, CharCtrlH:
|
||||||
if buf.IsEmpty() && len(i.pastedLines) > 0 {
|
buf.Remove()
|
||||||
lastIdx := len(i.pastedLines) - 1
|
|
||||||
prevLine := i.pastedLines[lastIdx]
|
|
||||||
i.pastedLines = i.pastedLines[:lastIdx]
|
|
||||||
fmt.Print(CursorBOL + ClearToEOL + CursorUp + CursorBOL + ClearToEOL)
|
|
||||||
if len(i.pastedLines) == 0 {
|
|
||||||
fmt.Print(i.Prompt.Prompt)
|
|
||||||
i.Prompt.UseAlt = false
|
|
||||||
} else {
|
|
||||||
fmt.Print(i.Prompt.AltPrompt)
|
|
||||||
}
|
|
||||||
for _, r := range prevLine {
|
|
||||||
buf.Add(r)
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
buf.Remove()
|
|
||||||
}
|
|
||||||
case CharTab:
|
case CharTab:
|
||||||
// todo: convert back to real tabs
|
// todo: convert back to real tabs
|
||||||
for range 8 {
|
for range 8 {
|
||||||
@@ -231,28 +211,13 @@ func (i *Instance) Readline() (string, error) {
|
|||||||
case CharCtrlZ:
|
case CharCtrlZ:
|
||||||
fd := os.Stdin.Fd()
|
fd := os.Stdin.Fd()
|
||||||
return handleCharCtrlZ(fd, i.Terminal.termios)
|
return handleCharCtrlZ(fd, i.Terminal.termios)
|
||||||
case CharCtrlJ:
|
case CharEnter, CharCtrlJ:
|
||||||
i.pastedLines = append(i.pastedLines, buf.String())
|
|
||||||
buf.Buf.Clear()
|
|
||||||
buf.Pos = 0
|
|
||||||
buf.DisplayPos = 0
|
|
||||||
buf.LineHasSpace.Clear()
|
|
||||||
fmt.Println()
|
|
||||||
fmt.Print(i.Prompt.AltPrompt)
|
|
||||||
i.Prompt.UseAlt = true
|
|
||||||
continue
|
|
||||||
case CharEnter:
|
|
||||||
output := buf.String()
|
output := buf.String()
|
||||||
if len(i.pastedLines) > 0 {
|
|
||||||
output = strings.Join(i.pastedLines, "\n") + "\n" + output
|
|
||||||
i.pastedLines = nil
|
|
||||||
}
|
|
||||||
if output != "" {
|
if output != "" {
|
||||||
i.History.Add(output)
|
i.History.Add(output)
|
||||||
}
|
}
|
||||||
buf.MoveToEnd()
|
buf.MoveToEnd()
|
||||||
fmt.Println()
|
fmt.Println()
|
||||||
i.Prompt.UseAlt = false
|
|
||||||
|
|
||||||
return output, nil
|
return output, nil
|
||||||
default:
|
default:
|
||||||
|
|||||||
@@ -60,7 +60,7 @@ _build_darwin() {
|
|||||||
cmake --install $BUILD_DIR --component MLX
|
cmake --install $BUILD_DIR --component MLX
|
||||||
# Override CGO flags to point to the amd64 build directory
|
# Override CGO flags to point to the amd64 build directory
|
||||||
MLX_CGO_CFLAGS="-O3 -I$(pwd)/$BUILD_DIR/_deps/mlx-c-src -mmacosx-version-min=14.0"
|
MLX_CGO_CFLAGS="-O3 -I$(pwd)/$BUILD_DIR/_deps/mlx-c-src -mmacosx-version-min=14.0"
|
||||||
MLX_CGO_LDFLAGS="-ldl -lc++ -framework Accelerate -mmacosx-version-min=14.0"
|
MLX_CGO_LDFLAGS="-L$(pwd)/$BUILD_DIR/lib/ollama -lmlxc -lmlx -Wl,-rpath,@executable_path -lc++ -framework Accelerate -mmacosx-version-min=14.0"
|
||||||
else
|
else
|
||||||
BUILD_DIR=build
|
BUILD_DIR=build
|
||||||
cmake --preset MLX \
|
cmake --preset MLX \
|
||||||
@@ -71,12 +71,10 @@ _build_darwin() {
|
|||||||
cmake --install $BUILD_DIR --component MLX
|
cmake --install $BUILD_DIR --component MLX
|
||||||
# Use default CGO flags from mlx.go for arm64
|
# Use default CGO flags from mlx.go for arm64
|
||||||
MLX_CGO_CFLAGS="-O3 -I$(pwd)/$BUILD_DIR/_deps/mlx-c-src -mmacosx-version-min=14.0"
|
MLX_CGO_CFLAGS="-O3 -I$(pwd)/$BUILD_DIR/_deps/mlx-c-src -mmacosx-version-min=14.0"
|
||||||
MLX_CGO_LDFLAGS="-lc++ -framework Metal -framework Foundation -framework Accelerate -mmacosx-version-min=14.0"
|
MLX_CGO_LDFLAGS="-L$(pwd)/$BUILD_DIR/lib/ollama -lmlxc -lmlx -Wl,-rpath,@executable_path -lc++ -framework Metal -framework Foundation -framework Accelerate -mmacosx-version-min=14.0"
|
||||||
fi
|
fi
|
||||||
GOOS=darwin GOARCH=$ARCH CGO_ENABLED=1 CGO_CFLAGS="$MLX_CGO_CFLAGS" CGO_LDFLAGS="$MLX_CGO_LDFLAGS" go build -tags mlx -o $INSTALL_PREFIX .
|
GOOS=darwin GOARCH=$ARCH CGO_ENABLED=1 CGO_CFLAGS="$MLX_CGO_CFLAGS" CGO_LDFLAGS="$MLX_CGO_LDFLAGS" go build -tags mlx -o $INSTALL_PREFIX/ollama-mlx .
|
||||||
# Copy MLX libraries to same directory as executable for dlopen
|
GOOS=darwin GOARCH=$ARCH CGO_ENABLED=1 go build -o $INSTALL_PREFIX .
|
||||||
cp $INSTALL_PREFIX/lib/ollama/libmlxc.dylib $INSTALL_PREFIX/
|
|
||||||
cp $INSTALL_PREFIX/lib/ollama/libmlx.dylib $INSTALL_PREFIX/
|
|
||||||
done
|
done
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -84,10 +82,12 @@ _sign_darwin() {
|
|||||||
status "Creating universal binary..."
|
status "Creating universal binary..."
|
||||||
mkdir -p dist/darwin
|
mkdir -p dist/darwin
|
||||||
lipo -create -output dist/darwin/ollama dist/darwin-*/ollama
|
lipo -create -output dist/darwin/ollama dist/darwin-*/ollama
|
||||||
|
lipo -create -output dist/darwin/ollama-mlx dist/darwin-*/ollama-mlx
|
||||||
chmod +x dist/darwin/ollama
|
chmod +x dist/darwin/ollama
|
||||||
|
chmod +x dist/darwin/ollama-mlx
|
||||||
|
|
||||||
if [ -n "$APPLE_IDENTITY" ]; then
|
if [ -n "$APPLE_IDENTITY" ]; then
|
||||||
for F in dist/darwin/ollama dist/darwin-*/lib/ollama/*; do
|
for F in dist/darwin/ollama dist/darwin-*/lib/ollama/* dist/darwin/ollama-mlx; do
|
||||||
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier ai.ollama.ollama --options=runtime $F
|
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier ai.ollama.ollama --options=runtime $F
|
||||||
done
|
done
|
||||||
|
|
||||||
@@ -154,6 +154,7 @@ _build_macapp() {
|
|||||||
mkdir -p dist/Ollama.app/Contents/Resources
|
mkdir -p dist/Ollama.app/Contents/Resources
|
||||||
if [ -d dist/darwin-amd64 ]; then
|
if [ -d dist/darwin-amd64 ]; then
|
||||||
lipo -create -output dist/Ollama.app/Contents/Resources/ollama dist/darwin-amd64/ollama dist/darwin-arm64/ollama
|
lipo -create -output dist/Ollama.app/Contents/Resources/ollama dist/darwin-amd64/ollama dist/darwin-arm64/ollama
|
||||||
|
lipo -create -output dist/Ollama.app/Contents/Resources/ollama-mlx dist/darwin-amd64/ollama-mlx dist/darwin-arm64/ollama-mlx
|
||||||
for F in dist/darwin-amd64/lib/ollama/*mlx*.dylib ; do
|
for F in dist/darwin-amd64/lib/ollama/*mlx*.dylib ; do
|
||||||
lipo -create -output dist/darwin/$(basename $F) $F dist/darwin-arm64/lib/ollama/$(basename $F)
|
lipo -create -output dist/darwin/$(basename $F) $F dist/darwin-arm64/lib/ollama/$(basename $F)
|
||||||
done
|
done
|
||||||
@@ -165,27 +166,28 @@ _build_macapp() {
|
|||||||
cp -a dist/darwin/ollama dist/Ollama.app/Contents/Resources/ollama
|
cp -a dist/darwin/ollama dist/Ollama.app/Contents/Resources/ollama
|
||||||
cp dist/darwin/*.so dist/darwin/*.dylib dist/Ollama.app/Contents/Resources/
|
cp dist/darwin/*.so dist/darwin/*.dylib dist/Ollama.app/Contents/Resources/
|
||||||
fi
|
fi
|
||||||
|
cp -a dist/darwin/ollama-mlx dist/Ollama.app/Contents/Resources/ollama-mlx
|
||||||
chmod a+x dist/Ollama.app/Contents/Resources/ollama
|
chmod a+x dist/Ollama.app/Contents/Resources/ollama
|
||||||
|
|
||||||
# Sign
|
# Sign
|
||||||
if [ -n "$APPLE_IDENTITY" ]; then
|
if [ -n "$APPLE_IDENTITY" ]; then
|
||||||
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier ai.ollama.ollama --options=runtime dist/Ollama.app/Contents/Resources/ollama
|
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier ai.ollama.ollama --options=runtime dist/Ollama.app/Contents/Resources/ollama
|
||||||
for lib in dist/Ollama.app/Contents/Resources/*.so dist/Ollama.app/Contents/Resources/*.dylib dist/Ollama.app/Contents/Resources/*.metallib ; do
|
for lib in dist/Ollama.app/Contents/Resources/*.so dist/Ollama.app/Contents/Resources/*.dylib dist/Ollama.app/Contents/Resources/*.metallib dist/Ollama.app/Contents/Resources/ollama-mlx ; do
|
||||||
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier ai.ollama.ollama --options=runtime ${lib}
|
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier ai.ollama.ollama --options=runtime ${lib}
|
||||||
done
|
done
|
||||||
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier com.electron.ollama --deep --options=runtime dist/Ollama.app
|
codesign -f --timestamp -s "$APPLE_IDENTITY" --identifier com.electron.ollama --deep --options=runtime dist/Ollama.app
|
||||||
fi
|
fi
|
||||||
|
|
||||||
rm -f dist/Ollama-darwin.zip
|
rm -f dist/Ollama-darwin.zip
|
||||||
ditto -c -k --norsrc --keepParent dist/Ollama.app dist/Ollama-darwin.zip
|
ditto -c -k --keepParent dist/Ollama.app dist/Ollama-darwin.zip
|
||||||
(cd dist/Ollama.app/Contents/Resources/; tar -cf - ollama *.so *.dylib *.metallib 2>/dev/null) | gzip -9vc > dist/ollama-darwin.tgz
|
(cd dist/Ollama.app/Contents/Resources/; tar -cf - ollama ollama-mlx *.so *.dylib *.metallib 2>/dev/null) | gzip -9vc > dist/ollama-darwin.tgz
|
||||||
|
|
||||||
# Notarize and Staple
|
# Notarize and Staple
|
||||||
if [ -n "$APPLE_IDENTITY" ]; then
|
if [ -n "$APPLE_IDENTITY" ]; then
|
||||||
$(xcrun -f notarytool) submit dist/Ollama-darwin.zip --wait --timeout 20m --apple-id "$APPLE_ID" --password "$APPLE_PASSWORD" --team-id "$APPLE_TEAM_ID"
|
$(xcrun -f notarytool) submit dist/Ollama-darwin.zip --wait --timeout 20m --apple-id "$APPLE_ID" --password "$APPLE_PASSWORD" --team-id "$APPLE_TEAM_ID"
|
||||||
rm -f dist/Ollama-darwin.zip
|
rm -f dist/Ollama-darwin.zip
|
||||||
$(xcrun -f stapler) staple dist/Ollama.app
|
$(xcrun -f stapler) staple dist/Ollama.app
|
||||||
ditto -c -k --norsrc --keepParent dist/Ollama.app dist/Ollama-darwin.zip
|
ditto -c -k --keepParent dist/Ollama.app dist/Ollama-darwin.zip
|
||||||
|
|
||||||
rm -f dist/Ollama.dmg
|
rm -f dist/Ollama.dmg
|
||||||
|
|
||||||
|
|||||||
@@ -50,17 +50,12 @@ func (r registryChallenge) URL() (*url.URL, error) {
|
|||||||
return redirectURL, nil
|
return redirectURL, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
func getAuthorizationToken(ctx context.Context, challenge registryChallenge, originalHost string) (string, error) {
|
func getAuthorizationToken(ctx context.Context, challenge registryChallenge) (string, error) {
|
||||||
redirectURL, err := challenge.URL()
|
redirectURL, err := challenge.URL()
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return "", err
|
return "", err
|
||||||
}
|
}
|
||||||
|
|
||||||
// Validate that the realm host matches the original request host to prevent sending tokens cross-origin.
|
|
||||||
if redirectURL.Host != originalHost {
|
|
||||||
return "", fmt.Errorf("realm host %q does not match original host %q", redirectURL.Host, originalHost)
|
|
||||||
}
|
|
||||||
|
|
||||||
sha256sum := sha256.Sum256(nil)
|
sha256sum := sha256.Sum256(nil)
|
||||||
data := []byte(fmt.Sprintf("%s,%s,%s", http.MethodGet, redirectURL.String(), base64.StdEncoding.EncodeToString([]byte(hex.EncodeToString(sha256sum[:])))))
|
data := []byte(fmt.Sprintf("%s,%s,%s", http.MethodGet, redirectURL.String(), base64.StdEncoding.EncodeToString([]byte(hex.EncodeToString(sha256sum[:])))))
|
||||||
|
|
||||||
|
|||||||
@@ -1,113 +0,0 @@
|
|||||||
package server
|
|
||||||
|
|
||||||
import (
|
|
||||||
"context"
|
|
||||||
"strings"
|
|
||||||
"testing"
|
|
||||||
"time"
|
|
||||||
)
|
|
||||||
|
|
||||||
func TestGetAuthorizationTokenRejectsCrossDomain(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
realm string
|
|
||||||
originalHost string
|
|
||||||
wantMismatch bool
|
|
||||||
}{
|
|
||||||
{"https://example.com/token", "example.com", false},
|
|
||||||
{"https://example.com/token", "other.com", true},
|
|
||||||
{"https://example.com/token", "localhost:8000", true},
|
|
||||||
{"https://localhost:5000/token", "localhost:5000", false},
|
|
||||||
{"https://localhost:5000/token", "localhost:6000", true},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.originalHost, func(t *testing.T) {
|
|
||||||
ctx, cancel := context.WithTimeout(context.Background(), 100*time.Millisecond)
|
|
||||||
defer cancel()
|
|
||||||
|
|
||||||
challenge := registryChallenge{Realm: tt.realm, Service: "test", Scope: "repo:x:pull"}
|
|
||||||
_, err := getAuthorizationToken(ctx, challenge, tt.originalHost)
|
|
||||||
|
|
||||||
isMismatch := err != nil && strings.Contains(err.Error(), "does not match")
|
|
||||||
if tt.wantMismatch && !isMismatch {
|
|
||||||
t.Errorf("expected domain mismatch error, got: %v", err)
|
|
||||||
}
|
|
||||||
if !tt.wantMismatch && isMismatch {
|
|
||||||
t.Errorf("unexpected domain mismatch error: %v", err)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestParseRegistryChallenge(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
input string
|
|
||||||
wantRealm, wantService, wantScope string
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
`Bearer realm="https://auth.example.com/token",service="registry",scope="repo:foo:pull"`,
|
|
||||||
"https://auth.example.com/token", "registry", "repo:foo:pull",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
`Bearer realm="https://r.ollama.ai/v2/token",service="ollama",scope="-"`,
|
|
||||||
"https://r.ollama.ai/v2/token", "ollama", "-",
|
|
||||||
},
|
|
||||||
{"", "", "", ""},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
result := parseRegistryChallenge(tt.input)
|
|
||||||
if result.Realm != tt.wantRealm || result.Service != tt.wantService || result.Scope != tt.wantScope {
|
|
||||||
t.Errorf("parseRegistryChallenge(%q) = {%q, %q, %q}, want {%q, %q, %q}",
|
|
||||||
tt.input, result.Realm, result.Service, result.Scope,
|
|
||||||
tt.wantRealm, tt.wantService, tt.wantScope)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestRegistryChallengeURL(t *testing.T) {
|
|
||||||
challenge := registryChallenge{
|
|
||||||
Realm: "https://auth.example.com/token",
|
|
||||||
Service: "registry",
|
|
||||||
Scope: "repo:foo:pull repo:bar:push",
|
|
||||||
}
|
|
||||||
|
|
||||||
u, err := challenge.URL()
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("URL() error: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
if u.Host != "auth.example.com" {
|
|
||||||
t.Errorf("host = %q, want %q", u.Host, "auth.example.com")
|
|
||||||
}
|
|
||||||
if u.Path != "/token" {
|
|
||||||
t.Errorf("path = %q, want %q", u.Path, "/token")
|
|
||||||
}
|
|
||||||
|
|
||||||
q := u.Query()
|
|
||||||
if q.Get("service") != "registry" {
|
|
||||||
t.Errorf("service = %q, want %q", q.Get("service"), "registry")
|
|
||||||
}
|
|
||||||
if scopes := q["scope"]; len(scopes) != 2 {
|
|
||||||
t.Errorf("scope count = %d, want 2", len(scopes))
|
|
||||||
}
|
|
||||||
if q.Get("ts") == "" {
|
|
||||||
t.Error("missing ts")
|
|
||||||
}
|
|
||||||
if q.Get("nonce") == "" {
|
|
||||||
t.Error("missing nonce")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Nonces should differ between calls
|
|
||||||
u2, _ := challenge.URL()
|
|
||||||
if q.Get("nonce") == u2.Query().Get("nonce") {
|
|
||||||
t.Error("nonce should be unique per call")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestRegistryChallengeURLInvalid(t *testing.T) {
|
|
||||||
challenge := registryChallenge{Realm: "://invalid"}
|
|
||||||
if _, err := challenge.URL(); err == nil {
|
|
||||||
t.Error("expected error for invalid URL")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -95,11 +95,48 @@ func (p *blobDownloadPart) UnmarshalJSON(b []byte) error {
|
|||||||
}
|
}
|
||||||
|
|
||||||
const (
|
const (
|
||||||
numDownloadParts = 16
|
// numDownloadParts is the default number of concurrent download parts for standard downloads
|
||||||
|
numDownloadParts = 16
|
||||||
|
// numHFDownloadParts is the reduced number of concurrent download parts for HuggingFace
|
||||||
|
// downloads to avoid triggering rate limits (HTTP 429 errors). See GitHub issue #13297.
|
||||||
|
numHFDownloadParts = 4
|
||||||
minDownloadPartSize int64 = 100 * format.MegaByte
|
minDownloadPartSize int64 = 100 * format.MegaByte
|
||||||
maxDownloadPartSize int64 = 1000 * format.MegaByte
|
maxDownloadPartSize int64 = 1000 * format.MegaByte
|
||||||
)
|
)
|
||||||
|
|
||||||
|
// isHuggingFaceURL returns true if the URL is from a HuggingFace domain.
|
||||||
|
// This includes:
|
||||||
|
// - huggingface.co (main domain)
|
||||||
|
// - *.huggingface.co (subdomains like cdn-lfs.huggingface.co)
|
||||||
|
// - hf.co (shortlink domain)
|
||||||
|
// - *.hf.co (CDN domains like cdn-lfs.hf.co, cdn-lfs3.hf.co)
|
||||||
|
func isHuggingFaceURL(u *url.URL) bool {
|
||||||
|
if u == nil {
|
||||||
|
return false
|
||||||
|
}
|
||||||
|
host := strings.ToLower(u.Hostname())
|
||||||
|
return host == "huggingface.co" ||
|
||||||
|
strings.HasSuffix(host, ".huggingface.co") ||
|
||||||
|
host == "hf.co" ||
|
||||||
|
strings.HasSuffix(host, ".hf.co")
|
||||||
|
}
|
||||||
|
|
||||||
|
// getNumDownloadParts returns the number of concurrent download parts to use
|
||||||
|
// for the given URL. HuggingFace URLs use reduced concurrency (default 4) to
|
||||||
|
// avoid triggering rate limits. This can be overridden via the OLLAMA_HF_CONCURRENCY
|
||||||
|
// environment variable. For non-HuggingFace URLs, returns the standard concurrency (16).
|
||||||
|
func getNumDownloadParts(u *url.URL) int {
|
||||||
|
if isHuggingFaceURL(u) {
|
||||||
|
if v := os.Getenv("OLLAMA_HF_CONCURRENCY"); v != "" {
|
||||||
|
if n, err := strconv.Atoi(v); err == nil && n > 0 {
|
||||||
|
return n
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return numHFDownloadParts
|
||||||
|
}
|
||||||
|
return numDownloadParts
|
||||||
|
}
|
||||||
|
|
||||||
func (p *blobDownloadPart) Name() string {
|
func (p *blobDownloadPart) Name() string {
|
||||||
return strings.Join([]string{
|
return strings.Join([]string{
|
||||||
p.blobDownload.Name, "partial", strconv.Itoa(p.N),
|
p.blobDownload.Name, "partial", strconv.Itoa(p.N),
|
||||||
@@ -271,7 +308,11 @@ func (b *blobDownload) run(ctx context.Context, requestURL *url.URL, opts *regis
|
|||||||
}
|
}
|
||||||
|
|
||||||
g, inner := errgroup.WithContext(ctx)
|
g, inner := errgroup.WithContext(ctx)
|
||||||
g.SetLimit(numDownloadParts)
|
concurrency := getNumDownloadParts(directURL)
|
||||||
|
if concurrency != numDownloadParts {
|
||||||
|
slog.Info(fmt.Sprintf("using reduced concurrency (%d) for HuggingFace download", concurrency))
|
||||||
|
}
|
||||||
|
g.SetLimit(concurrency)
|
||||||
for i := range b.Parts {
|
for i := range b.Parts {
|
||||||
part := b.Parts[i]
|
part := b.Parts[i]
|
||||||
if part.Completed.Load() == part.Size {
|
if part.Completed.Load() == part.Size {
|
||||||
|
|||||||
194
server/download_test.go
Normal file
@@ -0,0 +1,194 @@
|
|||||||
|
package server
|
||||||
|
|
||||||
|
import (
|
||||||
|
"net/url"
|
||||||
|
"testing"
|
||||||
|
|
||||||
|
"github.com/stretchr/testify/assert"
|
||||||
|
)
|
||||||
|
|
||||||
|
func TestIsHuggingFaceURL(t *testing.T) {
|
||||||
|
tests := []struct {
|
||||||
|
name string
|
||||||
|
url string
|
||||||
|
expected bool
|
||||||
|
}{
|
||||||
|
{
|
||||||
|
name: "nil url",
|
||||||
|
url: "",
|
||||||
|
expected: false,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface.co main domain",
|
||||||
|
url: "https://huggingface.co/some/model",
|
||||||
|
expected: true,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "cdn-lfs.huggingface.co subdomain",
|
||||||
|
url: "https://cdn-lfs.huggingface.co/repos/abc/123",
|
||||||
|
expected: true,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "cdn-lfs3.hf.co CDN domain",
|
||||||
|
url: "https://cdn-lfs3.hf.co/repos/abc/123",
|
||||||
|
expected: true,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "hf.co shortlink domain",
|
||||||
|
url: "https://hf.co/model",
|
||||||
|
expected: true,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "uppercase HuggingFace domain",
|
||||||
|
url: "https://HUGGINGFACE.CO/model",
|
||||||
|
expected: true,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "mixed case HF domain",
|
||||||
|
url: "https://Cdn-Lfs.HF.Co/repos",
|
||||||
|
expected: true,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "ollama registry",
|
||||||
|
url: "https://registry.ollama.ai/v2/library/llama3",
|
||||||
|
expected: false,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "github.com",
|
||||||
|
url: "https://github.com/ollama/ollama",
|
||||||
|
expected: false,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "fake huggingface domain",
|
||||||
|
url: "https://nothuggingface.co/model",
|
||||||
|
expected: false,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "fake hf domain",
|
||||||
|
url: "https://nothf.co/model",
|
||||||
|
expected: false,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface in path not host",
|
||||||
|
url: "https://example.com/huggingface.co/model",
|
||||||
|
expected: false,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
for _, tc := range tests {
|
||||||
|
t.Run(tc.name, func(t *testing.T) {
|
||||||
|
var u *url.URL
|
||||||
|
if tc.url != "" {
|
||||||
|
var err error
|
||||||
|
u, err = url.Parse(tc.url)
|
||||||
|
if err != nil {
|
||||||
|
t.Fatalf("failed to parse URL: %v", err)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
got := isHuggingFaceURL(u)
|
||||||
|
assert.Equal(t, tc.expected, got)
|
||||||
|
})
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
func TestGetNumDownloadParts(t *testing.T) {
|
||||||
|
tests := []struct {
|
||||||
|
name string
|
||||||
|
url string
|
||||||
|
envValue string
|
||||||
|
expected int
|
||||||
|
description string
|
||||||
|
}{
|
||||||
|
{
|
||||||
|
name: "nil url returns default",
|
||||||
|
url: "",
|
||||||
|
envValue: "",
|
||||||
|
expected: numDownloadParts,
|
||||||
|
description: "nil URL should return standard concurrency",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "ollama registry returns default",
|
||||||
|
url: "https://registry.ollama.ai/v2/library/llama3",
|
||||||
|
envValue: "",
|
||||||
|
expected: numDownloadParts,
|
||||||
|
description: "Ollama registry should use standard concurrency",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface returns reduced default",
|
||||||
|
url: "https://huggingface.co/model/repo",
|
||||||
|
envValue: "",
|
||||||
|
expected: numHFDownloadParts,
|
||||||
|
description: "HuggingFace should use reduced concurrency",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "hf.co CDN returns reduced default",
|
||||||
|
url: "https://cdn-lfs3.hf.co/repos/abc/123",
|
||||||
|
envValue: "",
|
||||||
|
expected: numHFDownloadParts,
|
||||||
|
description: "HuggingFace CDN should use reduced concurrency",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface with env override",
|
||||||
|
url: "https://huggingface.co/model/repo",
|
||||||
|
envValue: "2",
|
||||||
|
expected: 2,
|
||||||
|
description: "OLLAMA_HF_CONCURRENCY should override default",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface with higher env override",
|
||||||
|
url: "https://huggingface.co/model/repo",
|
||||||
|
envValue: "8",
|
||||||
|
expected: 8,
|
||||||
|
description: "OLLAMA_HF_CONCURRENCY can be set higher than default",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface with invalid env (non-numeric)",
|
||||||
|
url: "https://huggingface.co/model/repo",
|
||||||
|
envValue: "invalid",
|
||||||
|
expected: numHFDownloadParts,
|
||||||
|
description: "Invalid OLLAMA_HF_CONCURRENCY should fall back to default",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface with invalid env (zero)",
|
||||||
|
url: "https://huggingface.co/model/repo",
|
||||||
|
envValue: "0",
|
||||||
|
expected: numHFDownloadParts,
|
||||||
|
description: "Zero OLLAMA_HF_CONCURRENCY should fall back to default",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "huggingface with invalid env (negative)",
|
||||||
|
url: "https://huggingface.co/model/repo",
|
||||||
|
envValue: "-1",
|
||||||
|
expected: numHFDownloadParts,
|
||||||
|
description: "Negative OLLAMA_HF_CONCURRENCY should fall back to default",
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: "non-huggingface ignores env",
|
||||||
|
url: "https://registry.ollama.ai/v2/library/llama3",
|
||||||
|
envValue: "2",
|
||||||
|
expected: numDownloadParts,
|
||||||
|
description: "OLLAMA_HF_CONCURRENCY should not affect non-HF URLs",
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
for _, tc := range tests {
|
||||||
|
t.Run(tc.name, func(t *testing.T) {
|
||||||
|
// Set or clear the environment variable
|
||||||
|
if tc.envValue != "" {
|
||||||
|
t.Setenv("OLLAMA_HF_CONCURRENCY", tc.envValue)
|
||||||
|
}
|
||||||
|
|
||||||
|
var u *url.URL
|
||||||
|
if tc.url != "" {
|
||||||
|
var err error
|
||||||
|
u, err = url.Parse(tc.url)
|
||||||
|
if err != nil {
|
||||||
|
t.Fatalf("failed to parse URL: %v", err)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
got := getNumDownloadParts(u)
|
||||||
|
assert.Equal(t, tc.expected, got, tc.description)
|
||||||
|
})
|
||||||
|
}
|
||||||
|
}
|
||||||
@@ -41,7 +41,6 @@ var (
|
|||||||
errCapabilityVision = errors.New("vision")
|
errCapabilityVision = errors.New("vision")
|
||||||
errCapabilityEmbedding = errors.New("embedding")
|
errCapabilityEmbedding = errors.New("embedding")
|
||||||
errCapabilityThinking = errors.New("thinking")
|
errCapabilityThinking = errors.New("thinking")
|
||||||
errCapabilityImage = errors.New("image generation")
|
|
||||||
errInsecureProtocol = errors.New("insecure protocol http")
|
errInsecureProtocol = errors.New("insecure protocol http")
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -77,7 +76,7 @@ func (m *Model) Capabilities() []model.Capability {
|
|||||||
|
|
||||||
// Check for image generation model via config capabilities
|
// Check for image generation model via config capabilities
|
||||||
if slices.Contains(m.Config.Capabilities, "image") {
|
if slices.Contains(m.Config.Capabilities, "image") {
|
||||||
return []model.Capability{model.CapabilityImage}
|
return []model.Capability{model.CapabilityImageGeneration}
|
||||||
}
|
}
|
||||||
|
|
||||||
// Check for completion capability
|
// Check for completion capability
|
||||||
@@ -160,7 +159,6 @@ func (m *Model) CheckCapabilities(want ...model.Capability) error {
|
|||||||
model.CapabilityVision: errCapabilityVision,
|
model.CapabilityVision: errCapabilityVision,
|
||||||
model.CapabilityEmbedding: errCapabilityEmbedding,
|
model.CapabilityEmbedding: errCapabilityEmbedding,
|
||||||
model.CapabilityThinking: errCapabilityThinking,
|
model.CapabilityThinking: errCapabilityThinking,
|
||||||
model.CapabilityImage: errCapabilityImage,
|
|
||||||
}
|
}
|
||||||
|
|
||||||
for _, cap := range want {
|
for _, cap := range want {
|
||||||
@@ -777,7 +775,7 @@ func pullWithTransfer(ctx context.Context, mp ModelPath, layers []Layer, manifes
|
|||||||
Realm: challenge.Realm,
|
Realm: challenge.Realm,
|
||||||
Service: challenge.Service,
|
Service: challenge.Service,
|
||||||
Scope: challenge.Scope,
|
Scope: challenge.Scope,
|
||||||
}, base.Host)
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
if err := transfer.Download(ctx, transfer.DownloadOptions{
|
if err := transfer.Download(ctx, transfer.DownloadOptions{
|
||||||
@@ -852,7 +850,7 @@ func pushWithTransfer(ctx context.Context, mp ModelPath, layers []Layer, manifes
|
|||||||
Realm: challenge.Realm,
|
Realm: challenge.Realm,
|
||||||
Service: challenge.Service,
|
Service: challenge.Service,
|
||||||
Scope: challenge.Scope,
|
Scope: challenge.Scope,
|
||||||
}, base.Host)
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
return transfer.Upload(ctx, transfer.UploadOptions{
|
return transfer.Upload(ctx, transfer.UploadOptions{
|
||||||
@@ -918,7 +916,7 @@ func makeRequestWithRetry(ctx context.Context, method string, requestURL *url.UR
|
|||||||
|
|
||||||
// Handle authentication error with one retry
|
// Handle authentication error with one retry
|
||||||
challenge := parseRegistryChallenge(resp.Header.Get("www-authenticate"))
|
challenge := parseRegistryChallenge(resp.Header.Get("www-authenticate"))
|
||||||
token, err := getAuthorizationToken(ctx, challenge, requestURL.Host)
|
token, err := getAuthorizationToken(ctx, challenge)
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return nil, err
|
return nil, err
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -54,7 +54,7 @@ func TestModelCapabilities(t *testing.T) {
|
|||||||
Capabilities: []string{"image"},
|
Capabilities: []string{"image"},
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
expectedCaps: []model.Capability{model.CapabilityImage},
|
expectedCaps: []model.Capability{model.CapabilityImageGeneration},
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
name: "model with completion capability",
|
name: "model with completion capability",
|
||||||
@@ -242,24 +242,6 @@ func TestModelCheckCapabilities(t *testing.T) {
|
|||||||
checkCaps: []model.Capability{"unknown"},
|
checkCaps: []model.Capability{"unknown"},
|
||||||
expectedErrMsg: "unknown capability",
|
expectedErrMsg: "unknown capability",
|
||||||
},
|
},
|
||||||
{
|
|
||||||
name: "model missing image generation capability",
|
|
||||||
model: Model{
|
|
||||||
ModelPath: completionModelPath,
|
|
||||||
Template: chatTemplate,
|
|
||||||
},
|
|
||||||
checkCaps: []model.Capability{model.CapabilityImage},
|
|
||||||
expectedErrMsg: "does not support image generation",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "model with image generation capability",
|
|
||||||
model: Model{
|
|
||||||
Config: model.ConfigV2{
|
|
||||||
Capabilities: []string{"image"},
|
|
||||||
},
|
|
||||||
},
|
|
||||||
checkCaps: []model.Capability{model.CapabilityImage},
|
|
||||||
},
|
|
||||||
}
|
}
|
||||||
|
|
||||||
for _, tt := range tests {
|
for _, tt := range tests {
|
||||||
|
|||||||
170
server/routes.go
@@ -51,7 +51,7 @@ import (
|
|||||||
"github.com/ollama/ollama/types/model"
|
"github.com/ollama/ollama/types/model"
|
||||||
"github.com/ollama/ollama/version"
|
"github.com/ollama/ollama/version"
|
||||||
"github.com/ollama/ollama/x/imagegen"
|
"github.com/ollama/ollama/x/imagegen"
|
||||||
xserver "github.com/ollama/ollama/x/server"
|
imagegenapi "github.com/ollama/ollama/x/imagegen/api"
|
||||||
)
|
)
|
||||||
|
|
||||||
const signinURLStr = "https://ollama.com/connect?name=%s&key=%s"
|
const signinURLStr = "https://ollama.com/connect?name=%s&key=%s"
|
||||||
@@ -164,6 +164,29 @@ func (s *Server) scheduleRunner(ctx context.Context, name string, caps []model.C
|
|||||||
return runner.llama, model, &opts, nil
|
return runner.llama, model, &opts, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// ScheduleImageGenRunner schedules an image generation model runner.
|
||||||
|
// This implements the imagegenapi.RunnerScheduler interface.
|
||||||
|
func (s *Server) ScheduleImageGenRunner(c *gin.Context, modelName string, opts api.Options, keepAlive *api.Duration) (llm.LlamaServer, error) {
|
||||||
|
m := &Model{
|
||||||
|
Name: modelName,
|
||||||
|
ShortName: modelName,
|
||||||
|
ModelPath: modelName, // For image gen, ModelPath is just the model name
|
||||||
|
Config: model.ConfigV2{
|
||||||
|
Capabilities: []string{"image"},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
runnerCh, errCh := s.sched.GetRunner(c.Request.Context(), m, opts, keepAlive)
|
||||||
|
var runner *runnerRef
|
||||||
|
select {
|
||||||
|
case runner = <-runnerCh:
|
||||||
|
case err := <-errCh:
|
||||||
|
return nil, err
|
||||||
|
}
|
||||||
|
|
||||||
|
return runner.llama, nil
|
||||||
|
}
|
||||||
|
|
||||||
func signinURL() (string, error) {
|
func signinURL() (string, error) {
|
||||||
pubKey, err := auth.GetPublicKey()
|
pubKey, err := auth.GetPublicKey()
|
||||||
if err != nil {
|
if err != nil {
|
||||||
@@ -191,6 +214,12 @@ func (s *Server) GenerateHandler(c *gin.Context) {
|
|||||||
return
|
return
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Check if this is a known image generation model
|
||||||
|
if imagegen.ResolveModelName(req.Model) != "" {
|
||||||
|
imagegenapi.HandleGenerateRequest(c, s, req.Model, req.Prompt, req.KeepAlive, streamResponse)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
name := model.ParseName(req.Model)
|
name := model.ParseName(req.Model)
|
||||||
if !name.IsValid() {
|
if !name.IsValid() {
|
||||||
// Ideally this is "invalid model name" but we're keeping with
|
// Ideally this is "invalid model name" but we're keeping with
|
||||||
@@ -220,12 +249,6 @@ func (s *Server) GenerateHandler(c *gin.Context) {
|
|||||||
return
|
return
|
||||||
}
|
}
|
||||||
|
|
||||||
// Handle image generation models
|
|
||||||
if slices.Contains(m.Capabilities(), model.CapabilityImage) {
|
|
||||||
s.handleImageGenerate(c, req, name.String(), checkpointStart)
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
if req.TopLogprobs < 0 || req.TopLogprobs > 20 {
|
if req.TopLogprobs < 0 || req.TopLogprobs > 20 {
|
||||||
c.AbortWithStatusJSON(http.StatusBadRequest, gin.H{"error": "top_logprobs must be between 0 and 20"})
|
c.AbortWithStatusJSON(http.StatusBadRequest, gin.H{"error": "top_logprobs must be between 0 and 20"})
|
||||||
return
|
return
|
||||||
@@ -1102,7 +1125,7 @@ func GetModelInfo(req api.ShowRequest) (*api.ShowResponse, error) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// For image generation models, populate details from imagegen package
|
// For image generation models, populate details from imagegen package
|
||||||
if slices.Contains(m.Capabilities(), model.CapabilityImage) {
|
if slices.Contains(m.Capabilities(), model.CapabilityImageGeneration) {
|
||||||
if info, err := imagegen.GetModelInfo(name.String()); err == nil {
|
if info, err := imagegen.GetModelInfo(name.String()); err == nil {
|
||||||
modelDetails.Family = info.Architecture
|
modelDetails.Family = info.Architecture
|
||||||
modelDetails.ParameterSize = format.HumanNumber(uint64(info.ParameterCount))
|
modelDetails.ParameterSize = format.HumanNumber(uint64(info.ParameterCount))
|
||||||
@@ -1110,22 +1133,6 @@ func GetModelInfo(req api.ShowRequest) (*api.ShowResponse, error) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// For safetensors LLM models (experimental), populate details from config.json
|
|
||||||
if m.Config.ModelFormat == "safetensors" && slices.Contains(m.Config.Capabilities, "completion") {
|
|
||||||
if info, err := xserver.GetSafetensorsLLMInfo(name.String()); err == nil {
|
|
||||||
if arch, ok := info["general.architecture"].(string); ok && arch != "" {
|
|
||||||
modelDetails.Family = arch
|
|
||||||
}
|
|
||||||
if paramCount, ok := info["general.parameter_count"].(int64); ok && paramCount > 0 {
|
|
||||||
modelDetails.ParameterSize = format.HumanNumber(uint64(paramCount))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
// Get torch_dtype directly from config.json for quantization level
|
|
||||||
if dtype, err := xserver.GetSafetensorsDtype(name.String()); err == nil && dtype != "" {
|
|
||||||
modelDetails.QuantizationLevel = dtype
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
if req.System != "" {
|
if req.System != "" {
|
||||||
m.System = req.System
|
m.System = req.System
|
||||||
}
|
}
|
||||||
@@ -1208,27 +1215,7 @@ func GetModelInfo(req api.ShowRequest) (*api.ShowResponse, error) {
|
|||||||
return resp, nil
|
return resp, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
if slices.Contains(m.Capabilities(), model.CapabilityImage) {
|
if slices.Contains(m.Capabilities(), model.CapabilityImageGeneration) {
|
||||||
// Populate tensor info if verbose
|
|
||||||
if req.Verbose {
|
|
||||||
if tensors, err := xserver.GetSafetensorsTensorInfo(name.String()); err == nil {
|
|
||||||
resp.Tensors = tensors
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return resp, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// For safetensors LLM models (experimental), populate ModelInfo from config.json
|
|
||||||
if m.Config.ModelFormat == "safetensors" && slices.Contains(m.Config.Capabilities, "completion") {
|
|
||||||
if info, err := xserver.GetSafetensorsLLMInfo(name.String()); err == nil {
|
|
||||||
resp.ModelInfo = info
|
|
||||||
}
|
|
||||||
// Populate tensor info if verbose
|
|
||||||
if req.Verbose {
|
|
||||||
if tensors, err := xserver.GetSafetensorsTensorInfo(name.String()); err == nil {
|
|
||||||
resp.Tensors = tensors
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return resp, nil
|
return resp, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -1600,12 +1587,13 @@ func (s *Server) GenerateRoutes(rc *ollama.Registry) (http.Handler, error) {
|
|||||||
r.GET("/v1/models", middleware.ListMiddleware(), s.ListHandler)
|
r.GET("/v1/models", middleware.ListMiddleware(), s.ListHandler)
|
||||||
r.GET("/v1/models/:model", middleware.RetrieveMiddleware(), s.ShowHandler)
|
r.GET("/v1/models/:model", middleware.RetrieveMiddleware(), s.ShowHandler)
|
||||||
r.POST("/v1/responses", middleware.ResponsesMiddleware(), s.ChatHandler)
|
r.POST("/v1/responses", middleware.ResponsesMiddleware(), s.ChatHandler)
|
||||||
// OpenAI-compatible image generation endpoint
|
|
||||||
r.POST("/v1/images/generations", middleware.ImageGenerationsMiddleware(), s.GenerateHandler)
|
|
||||||
|
|
||||||
// Inference (Anthropic compatibility)
|
// Inference (Anthropic compatibility)
|
||||||
r.POST("/v1/messages", middleware.AnthropicMessagesMiddleware(), s.ChatHandler)
|
r.POST("/v1/messages", middleware.AnthropicMessagesMiddleware(), s.ChatHandler)
|
||||||
|
|
||||||
|
// Experimental image generation support
|
||||||
|
imagegenapi.RegisterRoutes(r, s)
|
||||||
|
|
||||||
if rc != nil {
|
if rc != nil {
|
||||||
// wrap old with new
|
// wrap old with new
|
||||||
rs := ®istry.Local{
|
rs := ®istry.Local{
|
||||||
@@ -2472,91 +2460,3 @@ func filterThinkTags(msgs []api.Message, m *Model) []api.Message {
|
|||||||
}
|
}
|
||||||
return msgs
|
return msgs
|
||||||
}
|
}
|
||||||
|
|
||||||
// handleImageGenerate handles image generation requests within GenerateHandler.
|
|
||||||
// This is called when the model has the Image capability.
|
|
||||||
func (s *Server) handleImageGenerate(c *gin.Context, req api.GenerateRequest, modelName string, checkpointStart time.Time) {
|
|
||||||
// Validate image dimensions
|
|
||||||
const maxDimension int32 = 4096
|
|
||||||
if req.Width > maxDimension || req.Height > maxDimension {
|
|
||||||
c.JSON(http.StatusBadRequest, gin.H{"error": fmt.Sprintf("width and height must be <= %d", maxDimension)})
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
// Schedule the runner for image generation
|
|
||||||
runner, _, _, err := s.scheduleRunner(c.Request.Context(), modelName, []model.Capability{model.CapabilityImage}, nil, req.KeepAlive)
|
|
||||||
if err != nil {
|
|
||||||
handleScheduleError(c, req.Model, err)
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
checkpointLoaded := time.Now()
|
|
||||||
|
|
||||||
// Handle load-only request (empty prompt)
|
|
||||||
if req.Prompt == "" {
|
|
||||||
c.JSON(http.StatusOK, api.GenerateResponse{
|
|
||||||
Model: req.Model,
|
|
||||||
CreatedAt: time.Now().UTC(),
|
|
||||||
Done: true,
|
|
||||||
DoneReason: "load",
|
|
||||||
})
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
// Set headers for streaming response
|
|
||||||
c.Header("Content-Type", "application/x-ndjson")
|
|
||||||
|
|
||||||
// Get seed from options if provided
|
|
||||||
var seed int64
|
|
||||||
if s, ok := req.Options["seed"]; ok {
|
|
||||||
switch v := s.(type) {
|
|
||||||
case int:
|
|
||||||
seed = int64(v)
|
|
||||||
case int64:
|
|
||||||
seed = v
|
|
||||||
case float64:
|
|
||||||
seed = int64(v)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
var streamStarted bool
|
|
||||||
if err := runner.Completion(c.Request.Context(), llm.CompletionRequest{
|
|
||||||
Prompt: req.Prompt,
|
|
||||||
Width: req.Width,
|
|
||||||
Height: req.Height,
|
|
||||||
Steps: req.Steps,
|
|
||||||
Seed: seed,
|
|
||||||
}, func(cr llm.CompletionResponse) {
|
|
||||||
streamStarted = true
|
|
||||||
res := api.GenerateResponse{
|
|
||||||
Model: req.Model,
|
|
||||||
CreatedAt: time.Now().UTC(),
|
|
||||||
Done: cr.Done,
|
|
||||||
}
|
|
||||||
|
|
||||||
if cr.TotalSteps > 0 {
|
|
||||||
res.Completed = int64(cr.Step)
|
|
||||||
res.Total = int64(cr.TotalSteps)
|
|
||||||
}
|
|
||||||
|
|
||||||
if cr.Image != "" {
|
|
||||||
res.Image = cr.Image
|
|
||||||
}
|
|
||||||
|
|
||||||
if cr.Done {
|
|
||||||
res.DoneReason = cr.DoneReason.String()
|
|
||||||
res.Metrics.TotalDuration = time.Since(checkpointStart)
|
|
||||||
res.Metrics.LoadDuration = checkpointLoaded.Sub(checkpointStart)
|
|
||||||
}
|
|
||||||
|
|
||||||
data, _ := json.Marshal(res)
|
|
||||||
c.Writer.Write(append(data, '\n'))
|
|
||||||
c.Writer.Flush()
|
|
||||||
}); err != nil {
|
|
||||||
// Only send JSON error if streaming hasn't started yet
|
|
||||||
// (once streaming starts, headers are committed and we can't change status code)
|
|
||||||
if !streamStarted {
|
|
||||||
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -571,10 +571,10 @@ func (s *Scheduler) loadImageGen(req *LlmRequest) bool {
|
|||||||
model: req.model,
|
model: req.model,
|
||||||
modelPath: req.model.ModelPath,
|
modelPath: req.model.ModelPath,
|
||||||
llama: server,
|
llama: server,
|
||||||
|
Options: &req.opts,
|
||||||
loading: false,
|
loading: false,
|
||||||
sessionDuration: sessionDuration,
|
sessionDuration: sessionDuration,
|
||||||
totalSize: server.TotalSize(),
|
refCount: 1,
|
||||||
vramSize: server.VRAMSize(),
|
|
||||||
}
|
}
|
||||||
|
|
||||||
s.loadedMu.Lock()
|
s.loadedMu.Lock()
|
||||||
|
|||||||
@@ -6,6 +6,7 @@ import (
|
|||||||
"errors"
|
"errors"
|
||||||
"log/slog"
|
"log/slog"
|
||||||
"os"
|
"os"
|
||||||
|
"slices"
|
||||||
"testing"
|
"testing"
|
||||||
"time"
|
"time"
|
||||||
|
|
||||||
@@ -16,6 +17,7 @@ import (
|
|||||||
"github.com/ollama/ollama/fs/ggml"
|
"github.com/ollama/ollama/fs/ggml"
|
||||||
"github.com/ollama/ollama/llm"
|
"github.com/ollama/ollama/llm"
|
||||||
"github.com/ollama/ollama/ml"
|
"github.com/ollama/ollama/ml"
|
||||||
|
"github.com/ollama/ollama/types/model"
|
||||||
)
|
)
|
||||||
|
|
||||||
func TestMain(m *testing.M) {
|
func TestMain(m *testing.M) {
|
||||||
@@ -805,8 +807,32 @@ func (s *mockLlm) GetDeviceInfos(ctx context.Context) []ml.DeviceInfo { return n
|
|||||||
func (s *mockLlm) HasExited() bool { return false }
|
func (s *mockLlm) HasExited() bool { return false }
|
||||||
func (s *mockLlm) GetActiveDeviceIDs() []ml.DeviceID { return nil }
|
func (s *mockLlm) GetActiveDeviceIDs() []ml.DeviceID { return nil }
|
||||||
|
|
||||||
|
// TestImageGenCapabilityDetection verifies that models with "image" capability
|
||||||
|
// are correctly identified and routed differently from language models.
|
||||||
|
func TestImageGenCapabilityDetection(t *testing.T) {
|
||||||
|
// Model with image capability should be detected
|
||||||
|
imageModel := &Model{
|
||||||
|
Config: model.ConfigV2{
|
||||||
|
Capabilities: []string{"image"},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
require.True(t, slices.Contains(imageModel.Config.Capabilities, "image"))
|
||||||
|
|
||||||
|
// Model without image capability should not be detected
|
||||||
|
langModel := &Model{
|
||||||
|
Config: model.ConfigV2{
|
||||||
|
Capabilities: []string{"completion"},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
require.False(t, slices.Contains(langModel.Config.Capabilities, "image"))
|
||||||
|
|
||||||
|
// Empty capabilities should not match
|
||||||
|
emptyModel := &Model{}
|
||||||
|
require.False(t, slices.Contains(emptyModel.Config.Capabilities, "image"))
|
||||||
|
}
|
||||||
|
|
||||||
// TestImageGenRunnerCanBeEvicted verifies that an image generation model
|
// TestImageGenRunnerCanBeEvicted verifies that an image generation model
|
||||||
// loaded in the scheduler can be evicted when idle.
|
// loaded in the scheduler can be evicted by a language model request.
|
||||||
func TestImageGenRunnerCanBeEvicted(t *testing.T) {
|
func TestImageGenRunnerCanBeEvicted(t *testing.T) {
|
||||||
ctx, done := context.WithTimeout(t.Context(), 500*time.Millisecond)
|
ctx, done := context.WithTimeout(t.Context(), 500*time.Millisecond)
|
||||||
defer done()
|
defer done()
|
||||||
@@ -838,59 +864,3 @@ func TestImageGenRunnerCanBeEvicted(t *testing.T) {
|
|||||||
require.NotNil(t, runner)
|
require.NotNil(t, runner)
|
||||||
require.Equal(t, "/fake/image/model", runner.modelPath)
|
require.Equal(t, "/fake/image/model", runner.modelPath)
|
||||||
}
|
}
|
||||||
|
|
||||||
// TestImageGenSchedulerCoexistence verifies that image generation models
|
|
||||||
// can coexist with language models in the scheduler and VRAM is tracked correctly.
|
|
||||||
func TestImageGenSchedulerCoexistence(t *testing.T) {
|
|
||||||
ctx, done := context.WithTimeout(t.Context(), 500*time.Millisecond)
|
|
||||||
defer done()
|
|
||||||
|
|
||||||
s := InitScheduler(ctx)
|
|
||||||
s.getGpuFn = getGpuFn
|
|
||||||
s.getSystemInfoFn = getSystemInfoFn
|
|
||||||
|
|
||||||
// Load both an imagegen runner and a language model runner
|
|
||||||
imageGenRunner := &runnerRef{
|
|
||||||
model: &Model{Name: "flux", ModelPath: "/fake/flux/model"},
|
|
||||||
modelPath: "/fake/flux/model",
|
|
||||||
llama: &mockLlm{vramSize: 8 * format.GigaByte, vramByGPU: map[ml.DeviceID]uint64{{Library: "Metal"}: 8 * format.GigaByte}},
|
|
||||||
sessionDuration: 10 * time.Millisecond,
|
|
||||||
numParallel: 1,
|
|
||||||
refCount: 0,
|
|
||||||
}
|
|
||||||
|
|
||||||
langModelRunner := &runnerRef{
|
|
||||||
model: &Model{Name: "llama3", ModelPath: "/fake/llama3/model"},
|
|
||||||
modelPath: "/fake/llama3/model",
|
|
||||||
llama: &mockLlm{vramSize: 4 * format.GigaByte, vramByGPU: map[ml.DeviceID]uint64{{Library: "Metal"}: 4 * format.GigaByte}},
|
|
||||||
sessionDuration: 10 * time.Millisecond,
|
|
||||||
numParallel: 1,
|
|
||||||
refCount: 0,
|
|
||||||
}
|
|
||||||
|
|
||||||
s.loadedMu.Lock()
|
|
||||||
s.loaded["/fake/flux/model"] = imageGenRunner
|
|
||||||
s.loaded["/fake/llama3/model"] = langModelRunner
|
|
||||||
s.loadedMu.Unlock()
|
|
||||||
|
|
||||||
// Verify both are loaded
|
|
||||||
s.loadedMu.Lock()
|
|
||||||
require.Len(t, s.loaded, 2)
|
|
||||||
require.NotNil(t, s.loaded["/fake/flux/model"])
|
|
||||||
require.NotNil(t, s.loaded["/fake/llama3/model"])
|
|
||||||
s.loadedMu.Unlock()
|
|
||||||
|
|
||||||
// Verify updateFreeSpace accounts for both
|
|
||||||
gpus := []ml.DeviceInfo{
|
|
||||||
{
|
|
||||||
DeviceID: ml.DeviceID{Library: "Metal"},
|
|
||||||
TotalMemory: 24 * format.GigaByte,
|
|
||||||
FreeMemory: 24 * format.GigaByte,
|
|
||||||
},
|
|
||||||
}
|
|
||||||
s.updateFreeSpace(gpus)
|
|
||||||
|
|
||||||
// Free memory should be reduced by both models
|
|
||||||
expectedFree := uint64(24*format.GigaByte) - uint64(8*format.GigaByte) - uint64(4*format.GigaByte)
|
|
||||||
require.Equal(t, expectedFree, gpus[0].FreeMemory)
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -279,7 +279,7 @@ func (b *blobUpload) uploadPart(ctx context.Context, method string, requestURL *
|
|||||||
case resp.StatusCode == http.StatusUnauthorized:
|
case resp.StatusCode == http.StatusUnauthorized:
|
||||||
w.Rollback()
|
w.Rollback()
|
||||||
challenge := parseRegistryChallenge(resp.Header.Get("www-authenticate"))
|
challenge := parseRegistryChallenge(resp.Header.Get("www-authenticate"))
|
||||||
token, err := getAuthorizationToken(ctx, challenge, requestURL.Host)
|
token, err := getAuthorizationToken(ctx, challenge)
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return err
|
return err
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -9,7 +9,7 @@ const (
|
|||||||
CapabilityVision = Capability("vision")
|
CapabilityVision = Capability("vision")
|
||||||
CapabilityEmbedding = Capability("embedding")
|
CapabilityEmbedding = Capability("embedding")
|
||||||
CapabilityThinking = Capability("thinking")
|
CapabilityThinking = Capability("thinking")
|
||||||
CapabilityImage = Capability("image")
|
CapabilityImageGeneration = Capability("image")
|
||||||
)
|
)
|
||||||
|
|
||||||
func (c Capability) String() string {
|
func (c Capability) String() string {
|
||||||
|
|||||||
50
x/README.md
Normal file
@@ -0,0 +1,50 @@
|
|||||||
|
# Experimental Features
|
||||||
|
|
||||||
|
## MLX Backend
|
||||||
|
|
||||||
|
We're working on a new experimental backend based on the [MLX project](https://github.com/ml-explore/mlx)
|
||||||
|
|
||||||
|
Support is currently limited to MacOS and Linux with CUDA GPUs. We're looking to add support for Windows CUDA soon, and other GPU vendors.
|
||||||
|
|
||||||
|
### Building ollama-mlx
|
||||||
|
|
||||||
|
The `ollama-mlx` binary is a separate build of Ollama with MLX support enabled. This enables experimental features like image generation.
|
||||||
|
|
||||||
|
#### macOS (Apple Silicon and Intel)
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Build MLX backend libraries
|
||||||
|
cmake --preset MLX
|
||||||
|
cmake --build --preset MLX --parallel
|
||||||
|
cmake --install build --component MLX
|
||||||
|
|
||||||
|
# Build ollama-mlx binary
|
||||||
|
go build -tags mlx -o ollama-mlx .
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Linux (CUDA)
|
||||||
|
|
||||||
|
On Linux, use the preset "MLX CUDA 13" or "MLX CUDA 12" to enable CUDA with the default Ollama NVIDIA GPU architectures enabled:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Build MLX backend libraries with CUDA support
|
||||||
|
cmake --preset 'MLX CUDA 13'
|
||||||
|
cmake --build --preset 'MLX CUDA 13' --parallel
|
||||||
|
cmake --install build --component MLX
|
||||||
|
|
||||||
|
# Build ollama-mlx binary
|
||||||
|
CGO_CFLAGS="-O3 -I$(pwd)/build/_deps/mlx-c-src" \
|
||||||
|
CGO_LDFLAGS="-L$(pwd)/build/lib/ollama -lmlxc -lmlx" \
|
||||||
|
go build -tags mlx -o ollama-mlx .
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Using build scripts
|
||||||
|
|
||||||
|
The build scripts automatically create the `ollama-mlx` binary:
|
||||||
|
|
||||||
|
- **macOS**: `./scripts/build_darwin.sh` produces `dist/darwin/ollama-mlx`
|
||||||
|
- **Linux**: `./scripts/build_linux.sh` produces `ollama-mlx` in the output archives
|
||||||
|
|
||||||
|
## Image Generation
|
||||||
|
|
||||||
|
Image generation is built into the `ollama-mlx` binary. Run `ollama-mlx serve` to start the server with image generation support enabled.
|
||||||
67
x/cmd/run.go
@@ -25,6 +25,14 @@ import (
|
|||||||
"github.com/ollama/ollama/x/tools"
|
"github.com/ollama/ollama/x/tools"
|
||||||
)
|
)
|
||||||
|
|
||||||
|
// MultilineState tracks the state of multiline input
|
||||||
|
type MultilineState int
|
||||||
|
|
||||||
|
const (
|
||||||
|
MultilineNone MultilineState = iota
|
||||||
|
MultilineSystem
|
||||||
|
)
|
||||||
|
|
||||||
// Tool output capping constants
|
// Tool output capping constants
|
||||||
const (
|
const (
|
||||||
// localModelTokenLimit is the token limit for local models (smaller context).
|
// localModelTokenLimit is the token limit for local models (smaller context).
|
||||||
@@ -648,7 +656,7 @@ func GenerateInteractive(cmd *cobra.Command, modelName string, wordWrap bool, op
|
|||||||
Prompt: ">>> ",
|
Prompt: ">>> ",
|
||||||
AltPrompt: "... ",
|
AltPrompt: "... ",
|
||||||
Placeholder: "Send a message (/? for help)",
|
Placeholder: "Send a message (/? for help)",
|
||||||
AltPlaceholder: "Press Enter to send",
|
AltPlaceholder: `Use """ to end multi-line input`,
|
||||||
})
|
})
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return err
|
return err
|
||||||
@@ -699,6 +707,7 @@ func GenerateInteractive(cmd *cobra.Command, modelName string, wordWrap bool, op
|
|||||||
var sb strings.Builder
|
var sb strings.Builder
|
||||||
var format string
|
var format string
|
||||||
var system string
|
var system string
|
||||||
|
var multiline MultilineState = MultilineNone
|
||||||
|
|
||||||
for {
|
for {
|
||||||
line, err := scanner.Readline()
|
line, err := scanner.Readline()
|
||||||
@@ -712,12 +721,37 @@ func GenerateInteractive(cmd *cobra.Command, modelName string, wordWrap bool, op
|
|||||||
}
|
}
|
||||||
scanner.Prompt.UseAlt = false
|
scanner.Prompt.UseAlt = false
|
||||||
sb.Reset()
|
sb.Reset()
|
||||||
|
multiline = MultilineNone
|
||||||
continue
|
continue
|
||||||
case err != nil:
|
case err != nil:
|
||||||
return err
|
return err
|
||||||
}
|
}
|
||||||
|
|
||||||
switch {
|
switch {
|
||||||
|
case multiline != MultilineNone:
|
||||||
|
// check if there's a multiline terminating string
|
||||||
|
before, ok := strings.CutSuffix(line, `"""`)
|
||||||
|
sb.WriteString(before)
|
||||||
|
if !ok {
|
||||||
|
fmt.Fprintln(&sb)
|
||||||
|
continue
|
||||||
|
}
|
||||||
|
|
||||||
|
switch multiline {
|
||||||
|
case MultilineSystem:
|
||||||
|
system = sb.String()
|
||||||
|
newMessage := api.Message{Role: "system", Content: system}
|
||||||
|
if len(messages) > 0 && messages[len(messages)-1].Role == "system" {
|
||||||
|
messages[len(messages)-1] = newMessage
|
||||||
|
} else {
|
||||||
|
messages = append(messages, newMessage)
|
||||||
|
}
|
||||||
|
fmt.Println("Set system message.")
|
||||||
|
sb.Reset()
|
||||||
|
}
|
||||||
|
|
||||||
|
multiline = MultilineNone
|
||||||
|
scanner.Prompt.UseAlt = false
|
||||||
case strings.HasPrefix(line, "/exit"), strings.HasPrefix(line, "/bye"):
|
case strings.HasPrefix(line, "/exit"), strings.HasPrefix(line, "/bye"):
|
||||||
return nil
|
return nil
|
||||||
case strings.HasPrefix(line, "/clear"):
|
case strings.HasPrefix(line, "/clear"):
|
||||||
@@ -826,18 +860,41 @@ func GenerateInteractive(cmd *cobra.Command, modelName string, wordWrap bool, op
|
|||||||
options[args[2]] = fp[args[2]]
|
options[args[2]] = fp[args[2]]
|
||||||
case "system":
|
case "system":
|
||||||
if len(args) < 3 {
|
if len(args) < 3 {
|
||||||
fmt.Println("Usage: /set system <message>")
|
fmt.Println("Usage: /set system <message> or /set system \"\"\"<multi-line message>\"\"\"")
|
||||||
continue
|
continue
|
||||||
}
|
}
|
||||||
|
|
||||||
system = strings.Join(args[2:], " ")
|
multiline = MultilineSystem
|
||||||
newMessage := api.Message{Role: "system", Content: system}
|
|
||||||
|
line := strings.Join(args[2:], " ")
|
||||||
|
line, ok := strings.CutPrefix(line, `"""`)
|
||||||
|
if !ok {
|
||||||
|
multiline = MultilineNone
|
||||||
|
} else {
|
||||||
|
// only cut suffix if the line is multiline
|
||||||
|
line, ok = strings.CutSuffix(line, `"""`)
|
||||||
|
if ok {
|
||||||
|
multiline = MultilineNone
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
sb.WriteString(line)
|
||||||
|
if multiline != MultilineNone {
|
||||||
|
scanner.Prompt.UseAlt = true
|
||||||
|
continue
|
||||||
|
}
|
||||||
|
|
||||||
|
system = sb.String()
|
||||||
|
newMessage := api.Message{Role: "system", Content: sb.String()}
|
||||||
|
// Check if the slice is not empty and the last message is from 'system'
|
||||||
if len(messages) > 0 && messages[len(messages)-1].Role == "system" {
|
if len(messages) > 0 && messages[len(messages)-1].Role == "system" {
|
||||||
|
// Replace the last message
|
||||||
messages[len(messages)-1] = newMessage
|
messages[len(messages)-1] = newMessage
|
||||||
} else {
|
} else {
|
||||||
messages = append(messages, newMessage)
|
messages = append(messages, newMessage)
|
||||||
}
|
}
|
||||||
fmt.Println("Set system message.")
|
fmt.Println("Set system message.")
|
||||||
|
sb.Reset()
|
||||||
continue
|
continue
|
||||||
default:
|
default:
|
||||||
fmt.Printf("Unknown command '/set %s'. Type /? for help\n", args[1])
|
fmt.Printf("Unknown command '/set %s'. Type /? for help\n", args[1])
|
||||||
@@ -1024,7 +1081,7 @@ func GenerateInteractive(cmd *cobra.Command, modelName string, wordWrap bool, op
|
|||||||
sb.WriteString(line)
|
sb.WriteString(line)
|
||||||
}
|
}
|
||||||
|
|
||||||
if sb.Len() > 0 {
|
if sb.Len() > 0 && multiline == MultilineNone {
|
||||||
newMessage := api.Message{Role: "user", Content: sb.String()}
|
newMessage := api.Message{Role: "user", Content: sb.String()}
|
||||||
messages = append(messages, newMessage)
|
messages = append(messages, newMessage)
|
||||||
|
|
||||||
|
|||||||
@@ -1,282 +0,0 @@
|
|||||||
// Package client provides client-side model creation for safetensors-based models.
|
|
||||||
//
|
|
||||||
// This package is in x/ because the safetensors model storage format is under development.
|
|
||||||
// It also exists to break an import cycle: server imports x/create, so x/create
|
|
||||||
// cannot import server. This sub-package can import server because server doesn't
|
|
||||||
// import it.
|
|
||||||
package client
|
|
||||||
|
|
||||||
import (
|
|
||||||
"bytes"
|
|
||||||
"encoding/json"
|
|
||||||
"fmt"
|
|
||||||
"io"
|
|
||||||
|
|
||||||
"github.com/ollama/ollama/progress"
|
|
||||||
"github.com/ollama/ollama/server"
|
|
||||||
"github.com/ollama/ollama/types/model"
|
|
||||||
"github.com/ollama/ollama/x/create"
|
|
||||||
)
|
|
||||||
|
|
||||||
// MinOllamaVersion is the minimum Ollama version required for safetensors models.
|
|
||||||
const MinOllamaVersion = "0.14.0"
|
|
||||||
|
|
||||||
// ModelfileConfig holds configuration extracted from a Modelfile.
|
|
||||||
type ModelfileConfig struct {
|
|
||||||
Template string
|
|
||||||
System string
|
|
||||||
License string
|
|
||||||
}
|
|
||||||
|
|
||||||
// CreateOptions holds all options for model creation.
|
|
||||||
type CreateOptions struct {
|
|
||||||
ModelName string
|
|
||||||
ModelDir string
|
|
||||||
Quantize string // "fp8" for quantization
|
|
||||||
Modelfile *ModelfileConfig // template/system/license from Modelfile
|
|
||||||
}
|
|
||||||
|
|
||||||
// CreateModel imports a model from a local directory.
|
|
||||||
// This creates blobs and manifest directly on disk, bypassing the HTTP API.
|
|
||||||
// Automatically detects model type (safetensors LLM vs image gen) and routes accordingly.
|
|
||||||
func CreateModel(opts CreateOptions, p *progress.Progress) error {
|
|
||||||
// Detect model type
|
|
||||||
isSafetensors := create.IsSafetensorsModelDir(opts.ModelDir)
|
|
||||||
isImageGen := create.IsTensorModelDir(opts.ModelDir)
|
|
||||||
|
|
||||||
if !isSafetensors && !isImageGen {
|
|
||||||
return fmt.Errorf("%s is not a supported model directory (needs config.json + *.safetensors or model_index.json)", opts.ModelDir)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Determine model type settings
|
|
||||||
var modelType, spinnerKey string
|
|
||||||
var capabilities []string
|
|
||||||
if isSafetensors {
|
|
||||||
modelType = "safetensors model"
|
|
||||||
spinnerKey = "create"
|
|
||||||
capabilities = []string{"completion"}
|
|
||||||
} else {
|
|
||||||
modelType = "image generation model"
|
|
||||||
spinnerKey = "imagegen"
|
|
||||||
capabilities = []string{"image"}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Set up progress spinner
|
|
||||||
statusMsg := "importing " + modelType
|
|
||||||
spinner := progress.NewSpinner(statusMsg)
|
|
||||||
p.Add(spinnerKey, spinner)
|
|
||||||
|
|
||||||
progressFn := func(msg string) {
|
|
||||||
spinner.Stop()
|
|
||||||
statusMsg = msg
|
|
||||||
spinner = progress.NewSpinner(statusMsg)
|
|
||||||
p.Add(spinnerKey, spinner)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create the model using shared callbacks
|
|
||||||
var err error
|
|
||||||
if isSafetensors {
|
|
||||||
err = create.CreateSafetensorsModel(
|
|
||||||
opts.ModelName, opts.ModelDir, opts.Quantize,
|
|
||||||
newLayerCreator(), newTensorLayerCreator(),
|
|
||||||
newManifestWriter(opts, capabilities),
|
|
||||||
progressFn,
|
|
||||||
)
|
|
||||||
} else {
|
|
||||||
err = create.CreateImageGenModel(
|
|
||||||
opts.ModelName, opts.ModelDir, opts.Quantize,
|
|
||||||
newLayerCreator(), newTensorLayerCreator(),
|
|
||||||
newManifestWriter(opts, capabilities),
|
|
||||||
progressFn,
|
|
||||||
)
|
|
||||||
}
|
|
||||||
|
|
||||||
spinner.Stop()
|
|
||||||
if err != nil {
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
|
|
||||||
fmt.Printf("Created %s '%s'\n", modelType, opts.ModelName)
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// newLayerCreator returns a LayerCreator callback for creating config/JSON layers.
|
|
||||||
func newLayerCreator() create.LayerCreator {
|
|
||||||
return func(r io.Reader, mediaType, name string) (create.LayerInfo, error) {
|
|
||||||
layer, err := server.NewLayer(r, mediaType)
|
|
||||||
if err != nil {
|
|
||||||
return create.LayerInfo{}, err
|
|
||||||
}
|
|
||||||
|
|
||||||
return create.LayerInfo{
|
|
||||||
Digest: layer.Digest,
|
|
||||||
Size: layer.Size,
|
|
||||||
MediaType: layer.MediaType,
|
|
||||||
Name: name,
|
|
||||||
}, nil
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// newTensorLayerCreator returns a QuantizingTensorLayerCreator callback for creating tensor layers.
|
|
||||||
// When quantize is non-empty, returns multiple layers (weight + scales + optional qbias).
|
|
||||||
func newTensorLayerCreator() create.QuantizingTensorLayerCreator {
|
|
||||||
return func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]create.LayerInfo, error) {
|
|
||||||
if quantize != "" {
|
|
||||||
return createQuantizedLayers(r, name, dtype, shape, quantize)
|
|
||||||
}
|
|
||||||
return createUnquantizedLayer(r, name)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// createQuantizedLayers quantizes a tensor and returns the resulting layers.
|
|
||||||
func createQuantizedLayers(r io.Reader, name, dtype string, shape []int32, quantize string) ([]create.LayerInfo, error) {
|
|
||||||
if !QuantizeSupported() {
|
|
||||||
return nil, fmt.Errorf("quantization requires MLX support")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Quantize the tensor
|
|
||||||
qweightData, scalesData, qbiasData, _, _, _, err := quantizeTensor(r, name, dtype, shape, quantize)
|
|
||||||
if err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to quantize %s: %w", name, err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create layer for quantized weight
|
|
||||||
weightLayer, err := server.NewLayer(bytes.NewReader(qweightData), server.MediaTypeImageTensor)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create layer for scales
|
|
||||||
scalesLayer, err := server.NewLayer(bytes.NewReader(scalesData), server.MediaTypeImageTensor)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
layers := []create.LayerInfo{
|
|
||||||
{
|
|
||||||
Digest: weightLayer.Digest,
|
|
||||||
Size: weightLayer.Size,
|
|
||||||
MediaType: weightLayer.MediaType,
|
|
||||||
Name: name,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
Digest: scalesLayer.Digest,
|
|
||||||
Size: scalesLayer.Size,
|
|
||||||
MediaType: scalesLayer.MediaType,
|
|
||||||
Name: name + "_scale",
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
// Add qbiases layer if present (affine mode)
|
|
||||||
if qbiasData != nil {
|
|
||||||
qbiasLayer, err := server.NewLayer(bytes.NewReader(qbiasData), server.MediaTypeImageTensor)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
layers = append(layers, create.LayerInfo{
|
|
||||||
Digest: qbiasLayer.Digest,
|
|
||||||
Size: qbiasLayer.Size,
|
|
||||||
MediaType: qbiasLayer.MediaType,
|
|
||||||
Name: name + "_qbias",
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
return layers, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// createUnquantizedLayer creates a single tensor layer without quantization.
|
|
||||||
func createUnquantizedLayer(r io.Reader, name string) ([]create.LayerInfo, error) {
|
|
||||||
layer, err := server.NewLayer(r, server.MediaTypeImageTensor)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
return []create.LayerInfo{
|
|
||||||
{
|
|
||||||
Digest: layer.Digest,
|
|
||||||
Size: layer.Size,
|
|
||||||
MediaType: layer.MediaType,
|
|
||||||
Name: name,
|
|
||||||
},
|
|
||||||
}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// newManifestWriter returns a ManifestWriter callback for writing the model manifest.
|
|
||||||
func newManifestWriter(opts CreateOptions, capabilities []string) create.ManifestWriter {
|
|
||||||
return func(modelName string, config create.LayerInfo, layers []create.LayerInfo) error {
|
|
||||||
name := model.ParseName(modelName)
|
|
||||||
if !name.IsValid() {
|
|
||||||
return fmt.Errorf("invalid model name: %s", modelName)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create config blob with version requirement
|
|
||||||
configData := model.ConfigV2{
|
|
||||||
ModelFormat: "safetensors",
|
|
||||||
Capabilities: capabilities,
|
|
||||||
Requires: MinOllamaVersion,
|
|
||||||
}
|
|
||||||
configJSON, err := json.Marshal(configData)
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("failed to marshal config: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create config layer blob
|
|
||||||
configLayer, err := server.NewLayer(bytes.NewReader(configJSON), "application/vnd.docker.container.image.v1+json")
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("failed to create config layer: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Convert LayerInfo to server.Layer
|
|
||||||
serverLayers := make([]server.Layer, 0, len(layers))
|
|
||||||
for _, l := range layers {
|
|
||||||
serverLayers = append(serverLayers, server.Layer{
|
|
||||||
MediaType: l.MediaType,
|
|
||||||
Digest: l.Digest,
|
|
||||||
Size: l.Size,
|
|
||||||
Name: l.Name,
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
// Add Modelfile layers if present
|
|
||||||
if opts.Modelfile != nil {
|
|
||||||
modelfileLayers, err := createModelfileLayers(opts.Modelfile)
|
|
||||||
if err != nil {
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
serverLayers = append(serverLayers, modelfileLayers...)
|
|
||||||
}
|
|
||||||
|
|
||||||
return server.WriteManifest(name, configLayer, serverLayers)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// createModelfileLayers creates layers for template, system, and license from Modelfile config.
|
|
||||||
func createModelfileLayers(mf *ModelfileConfig) ([]server.Layer, error) {
|
|
||||||
var layers []server.Layer
|
|
||||||
|
|
||||||
if mf.Template != "" {
|
|
||||||
layer, err := server.NewLayer(bytes.NewReader([]byte(mf.Template)), "application/vnd.ollama.image.template")
|
|
||||||
if err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to create template layer: %w", err)
|
|
||||||
}
|
|
||||||
layers = append(layers, layer)
|
|
||||||
}
|
|
||||||
|
|
||||||
if mf.System != "" {
|
|
||||||
layer, err := server.NewLayer(bytes.NewReader([]byte(mf.System)), "application/vnd.ollama.image.system")
|
|
||||||
if err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to create system layer: %w", err)
|
|
||||||
}
|
|
||||||
layers = append(layers, layer)
|
|
||||||
}
|
|
||||||
|
|
||||||
if mf.License != "" {
|
|
||||||
layer, err := server.NewLayer(bytes.NewReader([]byte(mf.License)), "application/vnd.ollama.image.license")
|
|
||||||
if err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to create license layer: %w", err)
|
|
||||||
}
|
|
||||||
layers = append(layers, layer)
|
|
||||||
}
|
|
||||||
|
|
||||||
return layers, nil
|
|
||||||
}
|
|
||||||
@@ -1,146 +0,0 @@
|
|||||||
package client
|
|
||||||
|
|
||||||
import (
|
|
||||||
"testing"
|
|
||||||
)
|
|
||||||
|
|
||||||
func TestModelfileConfig(t *testing.T) {
|
|
||||||
// Test that ModelfileConfig struct works as expected
|
|
||||||
config := &ModelfileConfig{
|
|
||||||
Template: "{{ .Prompt }}",
|
|
||||||
System: "You are a helpful assistant.",
|
|
||||||
License: "MIT",
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.Template != "{{ .Prompt }}" {
|
|
||||||
t.Errorf("Template = %q, want %q", config.Template, "{{ .Prompt }}")
|
|
||||||
}
|
|
||||||
if config.System != "You are a helpful assistant." {
|
|
||||||
t.Errorf("System = %q, want %q", config.System, "You are a helpful assistant.")
|
|
||||||
}
|
|
||||||
if config.License != "MIT" {
|
|
||||||
t.Errorf("License = %q, want %q", config.License, "MIT")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestModelfileConfig_Empty(t *testing.T) {
|
|
||||||
config := &ModelfileConfig{}
|
|
||||||
|
|
||||||
if config.Template != "" {
|
|
||||||
t.Errorf("Template should be empty, got %q", config.Template)
|
|
||||||
}
|
|
||||||
if config.System != "" {
|
|
||||||
t.Errorf("System should be empty, got %q", config.System)
|
|
||||||
}
|
|
||||||
if config.License != "" {
|
|
||||||
t.Errorf("License should be empty, got %q", config.License)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestModelfileConfig_PartialFields(t *testing.T) {
|
|
||||||
// Test config with only some fields set
|
|
||||||
config := &ModelfileConfig{
|
|
||||||
Template: "{{ .Prompt }}",
|
|
||||||
// System and License intentionally empty
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.Template == "" {
|
|
||||||
t.Error("Template should not be empty")
|
|
||||||
}
|
|
||||||
if config.System != "" {
|
|
||||||
t.Error("System should be empty")
|
|
||||||
}
|
|
||||||
if config.License != "" {
|
|
||||||
t.Error("License should be empty")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestMinOllamaVersion(t *testing.T) {
|
|
||||||
// Verify the minimum version constant is set
|
|
||||||
if MinOllamaVersion == "" {
|
|
||||||
t.Error("MinOllamaVersion should not be empty")
|
|
||||||
}
|
|
||||||
if MinOllamaVersion != "0.14.0" {
|
|
||||||
t.Errorf("MinOllamaVersion = %q, want %q", MinOllamaVersion, "0.14.0")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateModel_InvalidDir(t *testing.T) {
|
|
||||||
// Test that CreateModel returns error for invalid directory
|
|
||||||
err := CreateModel(CreateOptions{
|
|
||||||
ModelName: "test-model",
|
|
||||||
ModelDir: "/nonexistent/path",
|
|
||||||
}, nil)
|
|
||||||
if err == nil {
|
|
||||||
t.Error("expected error for nonexistent directory, got nil")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateModel_NotSafetensorsDir(t *testing.T) {
|
|
||||||
// Test that CreateModel returns error for directory without safetensors
|
|
||||||
dir := t.TempDir()
|
|
||||||
|
|
||||||
err := CreateModel(CreateOptions{
|
|
||||||
ModelName: "test-model",
|
|
||||||
ModelDir: dir,
|
|
||||||
}, nil)
|
|
||||||
if err == nil {
|
|
||||||
t.Error("expected error for empty directory, got nil")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateOptions(t *testing.T) {
|
|
||||||
opts := CreateOptions{
|
|
||||||
ModelName: "my-model",
|
|
||||||
ModelDir: "/path/to/model",
|
|
||||||
Quantize: "fp8",
|
|
||||||
Modelfile: &ModelfileConfig{
|
|
||||||
Template: "test",
|
|
||||||
System: "system",
|
|
||||||
License: "MIT",
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
if opts.ModelName != "my-model" {
|
|
||||||
t.Errorf("ModelName = %q, want %q", opts.ModelName, "my-model")
|
|
||||||
}
|
|
||||||
if opts.ModelDir != "/path/to/model" {
|
|
||||||
t.Errorf("ModelDir = %q, want %q", opts.ModelDir, "/path/to/model")
|
|
||||||
}
|
|
||||||
if opts.Quantize != "fp8" {
|
|
||||||
t.Errorf("Quantize = %q, want %q", opts.Quantize, "fp8")
|
|
||||||
}
|
|
||||||
if opts.Modelfile == nil {
|
|
||||||
t.Error("Modelfile should not be nil")
|
|
||||||
}
|
|
||||||
if opts.Modelfile.Template != "test" {
|
|
||||||
t.Errorf("Modelfile.Template = %q, want %q", opts.Modelfile.Template, "test")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateOptions_Defaults(t *testing.T) {
|
|
||||||
opts := CreateOptions{
|
|
||||||
ModelName: "test",
|
|
||||||
ModelDir: "/tmp",
|
|
||||||
}
|
|
||||||
|
|
||||||
// Quantize should default to empty
|
|
||||||
if opts.Quantize != "" {
|
|
||||||
t.Errorf("Quantize should be empty by default, got %q", opts.Quantize)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Modelfile should default to nil
|
|
||||||
if opts.Modelfile != nil {
|
|
||||||
t.Error("Modelfile should be nil by default")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestQuantizeSupported(t *testing.T) {
|
|
||||||
// This just verifies the function exists and returns a boolean
|
|
||||||
// The actual value depends on build tags (mlx vs non-mlx)
|
|
||||||
supported := QuantizeSupported()
|
|
||||||
|
|
||||||
// In non-mlx builds, this should be false
|
|
||||||
// We can't easily test both cases, so just verify it returns something
|
|
||||||
_ = supported
|
|
||||||
}
|
|
||||||
@@ -1,399 +0,0 @@
|
|||||||
package create
|
|
||||||
|
|
||||||
import (
|
|
||||||
"encoding/json"
|
|
||||||
"fmt"
|
|
||||||
"io"
|
|
||||||
"os"
|
|
||||||
"path/filepath"
|
|
||||||
"slices"
|
|
||||||
"strings"
|
|
||||||
|
|
||||||
"github.com/ollama/ollama/envconfig"
|
|
||||||
"github.com/ollama/ollama/x/imagegen/safetensors"
|
|
||||||
)
|
|
||||||
|
|
||||||
// ModelConfig represents the config blob stored with a model.
|
|
||||||
type ModelConfig struct {
|
|
||||||
ModelFormat string `json:"model_format"`
|
|
||||||
Capabilities []string `json:"capabilities"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// Manifest represents the manifest JSON structure.
|
|
||||||
type Manifest struct {
|
|
||||||
SchemaVersion int `json:"schemaVersion"`
|
|
||||||
MediaType string `json:"mediaType"`
|
|
||||||
Config ManifestLayer `json:"config"`
|
|
||||||
Layers []ManifestLayer `json:"layers"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// ManifestLayer represents a layer in the manifest.
|
|
||||||
type ManifestLayer struct {
|
|
||||||
MediaType string `json:"mediaType"`
|
|
||||||
Digest string `json:"digest"`
|
|
||||||
Size int64 `json:"size"`
|
|
||||||
Name string `json:"name,omitempty"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// defaultManifestDir returns the manifest storage directory.
|
|
||||||
func defaultManifestDir() string {
|
|
||||||
return filepath.Join(envconfig.Models(), "manifests")
|
|
||||||
}
|
|
||||||
|
|
||||||
// defaultBlobDir returns the blob storage directory.
|
|
||||||
func defaultBlobDir() string {
|
|
||||||
return filepath.Join(envconfig.Models(), "blobs")
|
|
||||||
}
|
|
||||||
|
|
||||||
// resolveManifestPath converts a model name to a manifest file path.
|
|
||||||
func resolveManifestPath(modelName string) string {
|
|
||||||
host := "registry.ollama.ai"
|
|
||||||
namespace := "library"
|
|
||||||
name := modelName
|
|
||||||
tag := "latest"
|
|
||||||
|
|
||||||
if idx := strings.LastIndex(name, ":"); idx != -1 {
|
|
||||||
tag = name[idx+1:]
|
|
||||||
name = name[:idx]
|
|
||||||
}
|
|
||||||
|
|
||||||
parts := strings.Split(name, "/")
|
|
||||||
switch len(parts) {
|
|
||||||
case 3:
|
|
||||||
host = parts[0]
|
|
||||||
namespace = parts[1]
|
|
||||||
name = parts[2]
|
|
||||||
case 2:
|
|
||||||
namespace = parts[0]
|
|
||||||
name = parts[1]
|
|
||||||
}
|
|
||||||
|
|
||||||
return filepath.Join(defaultManifestDir(), host, namespace, name, tag)
|
|
||||||
}
|
|
||||||
|
|
||||||
// loadManifest loads a manifest for the given model name.
|
|
||||||
func loadManifest(modelName string) (*Manifest, error) {
|
|
||||||
manifestPath := resolveManifestPath(modelName)
|
|
||||||
|
|
||||||
data, err := os.ReadFile(manifestPath)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
var manifest Manifest
|
|
||||||
if err := json.Unmarshal(data, &manifest); err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
return &manifest, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// loadModelConfig loads the config blob for a model.
|
|
||||||
func loadModelConfig(modelName string) (*ModelConfig, error) {
|
|
||||||
manifest, err := loadManifest(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
// Read the config blob
|
|
||||||
blobName := strings.Replace(manifest.Config.Digest, ":", "-", 1)
|
|
||||||
blobPath := filepath.Join(defaultBlobDir(), blobName)
|
|
||||||
|
|
||||||
data, err := os.ReadFile(blobPath)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
var config ModelConfig
|
|
||||||
if err := json.Unmarshal(data, &config); err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
|
|
||||||
return &config, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// IsSafetensorsModel checks if a model was created with the experimental
|
|
||||||
// safetensors builder by checking the model format in the config.
|
|
||||||
func IsSafetensorsModel(modelName string) bool {
|
|
||||||
config, err := loadModelConfig(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
return config.ModelFormat == "safetensors"
|
|
||||||
}
|
|
||||||
|
|
||||||
// IsSafetensorsLLMModel checks if a model is a safetensors LLM model
|
|
||||||
// (has completion capability, not image generation).
|
|
||||||
func IsSafetensorsLLMModel(modelName string) bool {
|
|
||||||
config, err := loadModelConfig(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
return config.ModelFormat == "safetensors" && slices.Contains(config.Capabilities, "completion")
|
|
||||||
}
|
|
||||||
|
|
||||||
// IsImageGenModel checks if a model is an image generation model
|
|
||||||
// (has image capability).
|
|
||||||
func IsImageGenModel(modelName string) bool {
|
|
||||||
config, err := loadModelConfig(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
return config.ModelFormat == "safetensors" && slices.Contains(config.Capabilities, "image")
|
|
||||||
}
|
|
||||||
|
|
||||||
// GetModelArchitecture returns the architecture from the model's config.json layer.
|
|
||||||
func GetModelArchitecture(modelName string) (string, error) {
|
|
||||||
manifest, err := loadManifest(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return "", err
|
|
||||||
}
|
|
||||||
|
|
||||||
// Find the config.json layer
|
|
||||||
for _, layer := range manifest.Layers {
|
|
||||||
if layer.Name == "config.json" && layer.MediaType == "application/vnd.ollama.image.json" {
|
|
||||||
blobName := strings.Replace(layer.Digest, ":", "-", 1)
|
|
||||||
blobPath := filepath.Join(defaultBlobDir(), blobName)
|
|
||||||
|
|
||||||
data, err := os.ReadFile(blobPath)
|
|
||||||
if err != nil {
|
|
||||||
return "", err
|
|
||||||
}
|
|
||||||
|
|
||||||
var cfg struct {
|
|
||||||
Architectures []string `json:"architectures"`
|
|
||||||
ModelType string `json:"model_type"`
|
|
||||||
}
|
|
||||||
if err := json.Unmarshal(data, &cfg); err != nil {
|
|
||||||
return "", err
|
|
||||||
}
|
|
||||||
|
|
||||||
// Prefer model_type, fall back to first architecture
|
|
||||||
if cfg.ModelType != "" {
|
|
||||||
return cfg.ModelType, nil
|
|
||||||
}
|
|
||||||
if len(cfg.Architectures) > 0 {
|
|
||||||
return cfg.Architectures[0], nil
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
return "", fmt.Errorf("architecture not found in model config")
|
|
||||||
}
|
|
||||||
|
|
||||||
// IsTensorModelDir checks if the directory contains a diffusers-style tensor model
|
|
||||||
// by looking for model_index.json, which is the standard diffusers pipeline config.
|
|
||||||
func IsTensorModelDir(dir string) bool {
|
|
||||||
_, err := os.Stat(filepath.Join(dir, "model_index.json"))
|
|
||||||
return err == nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// IsSafetensorsModelDir checks if the directory contains a standard safetensors model
|
|
||||||
// by looking for config.json and at least one .safetensors file.
|
|
||||||
func IsSafetensorsModelDir(dir string) bool {
|
|
||||||
// Must have config.json
|
|
||||||
if _, err := os.Stat(filepath.Join(dir, "config.json")); err != nil {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// Must have at least one .safetensors file
|
|
||||||
entries, err := os.ReadDir(dir)
|
|
||||||
if err != nil {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, entry := range entries {
|
|
||||||
if strings.HasSuffix(entry.Name(), ".safetensors") {
|
|
||||||
return true
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// LayerInfo holds metadata for a created layer.
|
|
||||||
type LayerInfo struct {
|
|
||||||
Digest string
|
|
||||||
Size int64
|
|
||||||
MediaType string
|
|
||||||
Name string // Path-style name: "component/tensor" or "path/to/config.json"
|
|
||||||
}
|
|
||||||
|
|
||||||
// LayerCreator is called to create a blob layer.
|
|
||||||
// name is the path-style name (e.g., "tokenizer/tokenizer.json")
|
|
||||||
type LayerCreator func(r io.Reader, mediaType, name string) (LayerInfo, error)
|
|
||||||
|
|
||||||
// TensorLayerCreator creates a tensor blob layer with metadata.
|
|
||||||
// name is the path-style name including component (e.g., "text_encoder/model.embed_tokens.weight")
|
|
||||||
type TensorLayerCreator func(r io.Reader, name, dtype string, shape []int32) (LayerInfo, error)
|
|
||||||
|
|
||||||
// QuantizingTensorLayerCreator creates tensor layers with optional quantization.
|
|
||||||
// When quantize is non-empty (e.g., "fp8"), returns multiple layers (weight + scales + biases).
|
|
||||||
type QuantizingTensorLayerCreator func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error)
|
|
||||||
|
|
||||||
// ManifestWriter writes the manifest file.
|
|
||||||
type ManifestWriter func(modelName string, config LayerInfo, layers []LayerInfo) error
|
|
||||||
|
|
||||||
// ShouldQuantize returns true if a tensor should be quantized.
|
|
||||||
// For image gen models (component non-empty): quantizes linear weights, skipping VAE, embeddings, norms.
|
|
||||||
// For LLM models (component empty): quantizes linear weights, skipping embeddings, norms, and small tensors.
|
|
||||||
func ShouldQuantize(name, component string) bool {
|
|
||||||
// Image gen specific: skip VAE entirely
|
|
||||||
if component == "vae" {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// Skip embeddings
|
|
||||||
if strings.Contains(name, "embed") {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// Skip layer norms and RMS norms
|
|
||||||
if strings.Contains(name, "norm") || strings.Contains(name, "ln_") || strings.Contains(name, "layernorm") {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// Skip biases
|
|
||||||
if strings.HasSuffix(name, ".bias") {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// Only quantize weights
|
|
||||||
return strings.HasSuffix(name, ".weight")
|
|
||||||
}
|
|
||||||
|
|
||||||
// ShouldQuantizeTensor returns true if a tensor should be quantized based on name and shape.
|
|
||||||
// This is a more detailed check that also considers tensor dimensions.
|
|
||||||
func ShouldQuantizeTensor(name string, shape []int32) bool {
|
|
||||||
// Use basic name-based check first
|
|
||||||
if !ShouldQuantize(name, "") {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// Only quantize 2D tensors (linear layers) - skip 1D (biases, norms) and higher-D (convolutions if any)
|
|
||||||
if len(shape) != 2 {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// Skip small tensors (less than 1024 elements) - not worth quantizing
|
|
||||||
if len(shape) >= 2 && int64(shape[0])*int64(shape[1]) < 1024 {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
// MLX quantization requires last dimension to be divisible by group size (32)
|
|
||||||
if shape[len(shape)-1]%32 != 0 {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
return true
|
|
||||||
}
|
|
||||||
|
|
||||||
// CreateSafetensorsModel imports a standard safetensors model from a directory.
|
|
||||||
// This handles Hugging Face style models with config.json and *.safetensors files.
|
|
||||||
// Stores each tensor as a separate blob for fine-grained deduplication.
|
|
||||||
// If quantize is non-empty (e.g., "fp8"), eligible tensors will be quantized.
|
|
||||||
func CreateSafetensorsModel(modelName, modelDir, quantize string, createLayer LayerCreator, createTensorLayer QuantizingTensorLayerCreator, writeManifest ManifestWriter, fn func(status string)) error {
|
|
||||||
var layers []LayerInfo
|
|
||||||
var configLayer LayerInfo
|
|
||||||
|
|
||||||
entries, err := os.ReadDir(modelDir)
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("failed to read directory: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Process all safetensors files
|
|
||||||
for _, entry := range entries {
|
|
||||||
if entry.IsDir() || !strings.HasSuffix(entry.Name(), ".safetensors") {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
stPath := filepath.Join(modelDir, entry.Name())
|
|
||||||
|
|
||||||
// Extract individual tensors from safetensors file
|
|
||||||
extractor, err := safetensors.OpenForExtraction(stPath)
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("failed to open %s: %w", stPath, err)
|
|
||||||
}
|
|
||||||
|
|
||||||
tensorNames := extractor.ListTensors()
|
|
||||||
quantizeMsg := ""
|
|
||||||
if quantize != "" {
|
|
||||||
quantizeMsg = fmt.Sprintf(", quantizing to %s", quantize)
|
|
||||||
}
|
|
||||||
fn(fmt.Sprintf("importing %s (%d tensors%s)", entry.Name(), len(tensorNames), quantizeMsg))
|
|
||||||
|
|
||||||
for _, tensorName := range tensorNames {
|
|
||||||
td, err := extractor.GetTensor(tensorName)
|
|
||||||
if err != nil {
|
|
||||||
extractor.Close()
|
|
||||||
return fmt.Errorf("failed to get tensor %s: %w", tensorName, err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Determine quantization type for this tensor (empty string if not quantizing)
|
|
||||||
quantizeType := ""
|
|
||||||
if quantize != "" && ShouldQuantizeTensor(tensorName, td.Shape) {
|
|
||||||
quantizeType = quantize
|
|
||||||
}
|
|
||||||
|
|
||||||
// Store as minimal safetensors format (88 bytes header overhead)
|
|
||||||
// This enables native mmap loading via mlx_load_safetensors
|
|
||||||
// createTensorLayer returns multiple layers if quantizing (weight + scales)
|
|
||||||
newLayers, err := createTensorLayer(td.SafetensorsReader(), tensorName, td.Dtype, td.Shape, quantizeType)
|
|
||||||
if err != nil {
|
|
||||||
extractor.Close()
|
|
||||||
return fmt.Errorf("failed to create layer for %s: %w", tensorName, err)
|
|
||||||
}
|
|
||||||
layers = append(layers, newLayers...)
|
|
||||||
}
|
|
||||||
|
|
||||||
extractor.Close()
|
|
||||||
}
|
|
||||||
|
|
||||||
// Process all JSON config files
|
|
||||||
for _, entry := range entries {
|
|
||||||
if entry.IsDir() || !strings.HasSuffix(entry.Name(), ".json") {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
// Skip the index file as we don't need it after extraction
|
|
||||||
if entry.Name() == "model.safetensors.index.json" {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
cfgPath := entry.Name()
|
|
||||||
fullPath := filepath.Join(modelDir, cfgPath)
|
|
||||||
|
|
||||||
fn(fmt.Sprintf("importing config %s", cfgPath))
|
|
||||||
|
|
||||||
f, err := os.Open(fullPath)
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("failed to open %s: %w", cfgPath, err)
|
|
||||||
}
|
|
||||||
|
|
||||||
layer, err := createLayer(f, "application/vnd.ollama.image.json", cfgPath)
|
|
||||||
f.Close()
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("failed to create layer for %s: %w", cfgPath, err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Use config.json as the config layer
|
|
||||||
if cfgPath == "config.json" {
|
|
||||||
configLayer = layer
|
|
||||||
}
|
|
||||||
|
|
||||||
layers = append(layers, layer)
|
|
||||||
}
|
|
||||||
|
|
||||||
if configLayer.Digest == "" {
|
|
||||||
return fmt.Errorf("config.json not found in %s", modelDir)
|
|
||||||
}
|
|
||||||
|
|
||||||
fn(fmt.Sprintf("writing manifest for %s", modelName))
|
|
||||||
|
|
||||||
if err := writeManifest(modelName, configLayer, layers); err != nil {
|
|
||||||
return fmt.Errorf("failed to write manifest: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
fn(fmt.Sprintf("successfully imported %s with %d layers", modelName, len(layers)))
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
@@ -1,752 +0,0 @@
|
|||||||
package create
|
|
||||||
|
|
||||||
import (
|
|
||||||
"bytes"
|
|
||||||
"encoding/binary"
|
|
||||||
"encoding/json"
|
|
||||||
"io"
|
|
||||||
"os"
|
|
||||||
"path/filepath"
|
|
||||||
"strings"
|
|
||||||
"testing"
|
|
||||||
)
|
|
||||||
|
|
||||||
func TestIsTensorModelDir(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
setup func(dir string) error
|
|
||||||
expected bool
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "valid diffusers model with model_index.json",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
return os.WriteFile(filepath.Join(dir, "model_index.json"), []byte(`{"_class_name": "FluxPipeline"}`), 0o644)
|
|
||||||
},
|
|
||||||
expected: true,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "empty directory",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
return nil
|
|
||||||
},
|
|
||||||
expected: false,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "directory with other files but no model_index.json",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
return os.WriteFile(filepath.Join(dir, "config.json"), []byte(`{}`), 0o644)
|
|
||||||
},
|
|
||||||
expected: false,
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
if err := tt.setup(dir); err != nil {
|
|
||||||
t.Fatalf("setup failed: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
got := IsTensorModelDir(dir)
|
|
||||||
if got != tt.expected {
|
|
||||||
t.Errorf("IsTensorModelDir() = %v, want %v", got, tt.expected)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestIsSafetensorsModelDir(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
setup func(dir string) error
|
|
||||||
expected bool
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "valid safetensors model with config.json and .safetensors file",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "config.json"), []byte(`{"model_type": "gemma3"}`), 0o644); err != nil {
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
return os.WriteFile(filepath.Join(dir, "model.safetensors"), []byte("dummy"), 0o644)
|
|
||||||
},
|
|
||||||
expected: true,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "config.json only, no safetensors files",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
return os.WriteFile(filepath.Join(dir, "config.json"), []byte(`{}`), 0o644)
|
|
||||||
},
|
|
||||||
expected: false,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "safetensors file only, no config.json",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
return os.WriteFile(filepath.Join(dir, "model.safetensors"), []byte("dummy"), 0o644)
|
|
||||||
},
|
|
||||||
expected: false,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "empty directory",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
return nil
|
|
||||||
},
|
|
||||||
expected: false,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "multiple safetensors files with config.json",
|
|
||||||
setup: func(dir string) error {
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "config.json"), []byte(`{}`), 0o644); err != nil {
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "model-00001-of-00002.safetensors"), []byte("dummy"), 0o644); err != nil {
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
return os.WriteFile(filepath.Join(dir, "model-00002-of-00002.safetensors"), []byte("dummy"), 0o644)
|
|
||||||
},
|
|
||||||
expected: true,
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
if err := tt.setup(dir); err != nil {
|
|
||||||
t.Fatalf("setup failed: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
got := IsSafetensorsModelDir(dir)
|
|
||||||
if got != tt.expected {
|
|
||||||
t.Errorf("IsSafetensorsModelDir() = %v, want %v", got, tt.expected)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestIsSafetensorsModelDir_NonexistentDir(t *testing.T) {
|
|
||||||
got := IsSafetensorsModelDir("/nonexistent/path/that/does/not/exist")
|
|
||||||
if got != false {
|
|
||||||
t.Errorf("IsSafetensorsModelDir() = %v for nonexistent dir, want false", got)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// createMinimalSafetensors creates a minimal valid safetensors file with one tensor
|
|
||||||
func createMinimalSafetensors(t *testing.T, path string) {
|
|
||||||
t.Helper()
|
|
||||||
|
|
||||||
// Create a minimal safetensors file with a single float32 tensor
|
|
||||||
header := map[string]interface{}{
|
|
||||||
"test_tensor": map[string]interface{}{
|
|
||||||
"dtype": "F32",
|
|
||||||
"shape": []int{2, 2},
|
|
||||||
"data_offsets": []int{0, 16}, // 4 float32 values = 16 bytes
|
|
||||||
},
|
|
||||||
}
|
|
||||||
headerJSON, err := json.Marshal(header)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("failed to marshal header: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Pad header to 8-byte alignment
|
|
||||||
padding := (8 - len(headerJSON)%8) % 8
|
|
||||||
headerJSON = append(headerJSON, bytes.Repeat([]byte(" "), padding)...)
|
|
||||||
|
|
||||||
// Write file
|
|
||||||
f, err := os.Create(path)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("failed to create file: %v", err)
|
|
||||||
}
|
|
||||||
defer f.Close()
|
|
||||||
|
|
||||||
// Write header size (8 bytes, little endian)
|
|
||||||
if err := binary.Write(f, binary.LittleEndian, uint64(len(headerJSON))); err != nil {
|
|
||||||
t.Fatalf("failed to write header size: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Write header
|
|
||||||
if _, err := f.Write(headerJSON); err != nil {
|
|
||||||
t.Fatalf("failed to write header: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Write tensor data (16 bytes of zeros for 4 float32 values)
|
|
||||||
if _, err := f.Write(make([]byte, 16)); err != nil {
|
|
||||||
t.Fatalf("failed to write tensor data: %v", err)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateSafetensorsModel(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
|
|
||||||
// Create config.json
|
|
||||||
configJSON := `{"model_type": "test", "architectures": ["TestModel"]}`
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "config.json"), []byte(configJSON), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write config.json: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create a minimal safetensors file
|
|
||||||
createMinimalSafetensors(t, filepath.Join(dir, "model.safetensors"))
|
|
||||||
|
|
||||||
// Track what was created
|
|
||||||
var createdLayers []LayerInfo
|
|
||||||
var manifestWritten bool
|
|
||||||
var manifestModelName string
|
|
||||||
var manifestConfigLayer LayerInfo
|
|
||||||
var manifestLayers []LayerInfo
|
|
||||||
var statusMessages []string
|
|
||||||
|
|
||||||
// Mock callbacks
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
data, err := io.ReadAll(r)
|
|
||||||
if err != nil {
|
|
||||||
return LayerInfo{}, err
|
|
||||||
}
|
|
||||||
layer := LayerInfo{
|
|
||||||
Digest: "sha256:test",
|
|
||||||
Size: int64(len(data)),
|
|
||||||
MediaType: mediaType,
|
|
||||||
Name: name,
|
|
||||||
}
|
|
||||||
createdLayers = append(createdLayers, layer)
|
|
||||||
return layer, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
data, err := io.ReadAll(r)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
layer := LayerInfo{
|
|
||||||
Digest: "sha256:tensor_" + name,
|
|
||||||
Size: int64(len(data)),
|
|
||||||
MediaType: "application/vnd.ollama.image.tensor",
|
|
||||||
Name: name,
|
|
||||||
}
|
|
||||||
createdLayers = append(createdLayers, layer)
|
|
||||||
return []LayerInfo{layer}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
manifestWritten = true
|
|
||||||
manifestModelName = modelName
|
|
||||||
manifestConfigLayer = config
|
|
||||||
manifestLayers = layers
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
|
|
||||||
progressFn := func(status string) {
|
|
||||||
statusMessages = append(statusMessages, status)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Run CreateSafetensorsModel
|
|
||||||
err := CreateSafetensorsModel("test-model", dir, "", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("CreateSafetensorsModel failed: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Verify manifest was written
|
|
||||||
if !manifestWritten {
|
|
||||||
t.Error("manifest was not written")
|
|
||||||
}
|
|
||||||
|
|
||||||
if manifestModelName != "test-model" {
|
|
||||||
t.Errorf("manifest model name = %q, want %q", manifestModelName, "test-model")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Verify config layer was set
|
|
||||||
if manifestConfigLayer.Name != "config.json" {
|
|
||||||
t.Errorf("config layer name = %q, want %q", manifestConfigLayer.Name, "config.json")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Verify we have at least one tensor and one config layer
|
|
||||||
hasTensor := false
|
|
||||||
hasConfig := false
|
|
||||||
for _, layer := range manifestLayers {
|
|
||||||
if layer.Name == "test_tensor" {
|
|
||||||
hasTensor = true
|
|
||||||
}
|
|
||||||
if layer.Name == "config.json" {
|
|
||||||
hasConfig = true
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
if !hasTensor {
|
|
||||||
t.Error("no tensor layer found in manifest")
|
|
||||||
}
|
|
||||||
if !hasConfig {
|
|
||||||
t.Error("no config layer found in manifest")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Verify status messages were sent
|
|
||||||
if len(statusMessages) == 0 {
|
|
||||||
t.Error("no status messages received")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateSafetensorsModel_NoConfigJson(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
|
|
||||||
// Create only a safetensors file, no config.json
|
|
||||||
createMinimalSafetensors(t, filepath.Join(dir, "model.safetensors"))
|
|
||||||
|
|
||||||
// Mock callbacks (minimal)
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return LayerInfo{Name: name}, nil
|
|
||||||
}
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return []LayerInfo{{Name: name}}, nil
|
|
||||||
}
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
progressFn := func(status string) {}
|
|
||||||
|
|
||||||
err := CreateSafetensorsModel("test-model", dir, "", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err == nil {
|
|
||||||
t.Error("expected error for missing config.json, got nil")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateSafetensorsModel_EmptyDir(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
|
|
||||||
// Mock callbacks
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
return LayerInfo{}, nil
|
|
||||||
}
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
return []LayerInfo{{}}, nil
|
|
||||||
}
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
progressFn := func(status string) {}
|
|
||||||
|
|
||||||
err := CreateSafetensorsModel("test-model", dir, "", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err == nil {
|
|
||||||
t.Error("expected error for empty directory, got nil")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateSafetensorsModel_SkipsIndexJson(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
|
|
||||||
// Create config.json
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "config.json"), []byte(`{}`), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write config.json: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create model.safetensors.index.json (should be skipped)
|
|
||||||
indexJSON := `{"metadata": {"total_size": 100}, "weight_map": {}}`
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "model.safetensors.index.json"), []byte(indexJSON), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write index.json: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create a minimal safetensors file
|
|
||||||
createMinimalSafetensors(t, filepath.Join(dir, "model.safetensors"))
|
|
||||||
|
|
||||||
var configNames []string
|
|
||||||
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
configNames = append(configNames, name)
|
|
||||||
return LayerInfo{Name: name, Digest: "sha256:test"}, nil
|
|
||||||
}
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return []LayerInfo{{Name: name}}, nil
|
|
||||||
}
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
progressFn := func(status string) {}
|
|
||||||
|
|
||||||
err := CreateSafetensorsModel("test-model", dir, "", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("CreateSafetensorsModel failed: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Verify model.safetensors.index.json was not included
|
|
||||||
for _, name := range configNames {
|
|
||||||
if name == "model.safetensors.index.json" {
|
|
||||||
t.Error("model.safetensors.index.json should have been skipped")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestResolveManifestPath(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
modelName string
|
|
||||||
wantParts []string // Parts that should appear in the path
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "simple model name",
|
|
||||||
modelName: "llama2",
|
|
||||||
wantParts: []string{"registry.ollama.ai", "library", "llama2", "latest"},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "model name with tag",
|
|
||||||
modelName: "llama2:7b",
|
|
||||||
wantParts: []string{"registry.ollama.ai", "library", "llama2", "7b"},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "model name with namespace",
|
|
||||||
modelName: "myuser/mymodel",
|
|
||||||
wantParts: []string{"registry.ollama.ai", "myuser", "mymodel", "latest"},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "model name with namespace and tag",
|
|
||||||
modelName: "myuser/mymodel:v1",
|
|
||||||
wantParts: []string{"registry.ollama.ai", "myuser", "mymodel", "v1"},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "fully qualified model name",
|
|
||||||
modelName: "registry.example.com/namespace/model:tag",
|
|
||||||
wantParts: []string{"registry.example.com", "namespace", "model", "tag"},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
got := resolveManifestPath(tt.modelName)
|
|
||||||
|
|
||||||
for _, part := range tt.wantParts {
|
|
||||||
if !strings.Contains(got, part) {
|
|
||||||
t.Errorf("resolveManifestPath(%q) = %q, missing part %q", tt.modelName, got, part)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestLayerInfo(t *testing.T) {
|
|
||||||
layer := LayerInfo{
|
|
||||||
Digest: "sha256:abc123",
|
|
||||||
Size: 1024,
|
|
||||||
MediaType: "application/vnd.ollama.image.tensor",
|
|
||||||
Name: "model.weight",
|
|
||||||
}
|
|
||||||
|
|
||||||
if layer.Digest != "sha256:abc123" {
|
|
||||||
t.Errorf("Digest = %q, want %q", layer.Digest, "sha256:abc123")
|
|
||||||
}
|
|
||||||
if layer.Size != 1024 {
|
|
||||||
t.Errorf("Size = %d, want %d", layer.Size, 1024)
|
|
||||||
}
|
|
||||||
if layer.MediaType != "application/vnd.ollama.image.tensor" {
|
|
||||||
t.Errorf("MediaType = %q, want %q", layer.MediaType, "application/vnd.ollama.image.tensor")
|
|
||||||
}
|
|
||||||
if layer.Name != "model.weight" {
|
|
||||||
t.Errorf("Name = %q, want %q", layer.Name, "model.weight")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestModelConfig(t *testing.T) {
|
|
||||||
config := ModelConfig{
|
|
||||||
ModelFormat: "safetensors",
|
|
||||||
Capabilities: []string{"completion", "chat"},
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.ModelFormat != "safetensors" {
|
|
||||||
t.Errorf("ModelFormat = %q, want %q", config.ModelFormat, "safetensors")
|
|
||||||
}
|
|
||||||
if len(config.Capabilities) != 2 {
|
|
||||||
t.Errorf("Capabilities length = %d, want %d", len(config.Capabilities), 2)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestManifest(t *testing.T) {
|
|
||||||
manifest := Manifest{
|
|
||||||
SchemaVersion: 2,
|
|
||||||
MediaType: "application/vnd.oci.image.manifest.v1+json",
|
|
||||||
Config: ManifestLayer{
|
|
||||||
MediaType: "application/vnd.docker.container.image.v1+json",
|
|
||||||
Digest: "sha256:config",
|
|
||||||
Size: 100,
|
|
||||||
},
|
|
||||||
Layers: []ManifestLayer{
|
|
||||||
{
|
|
||||||
MediaType: "application/vnd.ollama.image.tensor",
|
|
||||||
Digest: "sha256:layer1",
|
|
||||||
Size: 1000,
|
|
||||||
Name: "weight.bin",
|
|
||||||
},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
if manifest.SchemaVersion != 2 {
|
|
||||||
t.Errorf("SchemaVersion = %d, want %d", manifest.SchemaVersion, 2)
|
|
||||||
}
|
|
||||||
if manifest.Config.Digest != "sha256:config" {
|
|
||||||
t.Errorf("Config.Digest = %q, want %q", manifest.Config.Digest, "sha256:config")
|
|
||||||
}
|
|
||||||
if len(manifest.Layers) != 1 {
|
|
||||||
t.Errorf("Layers length = %d, want %d", len(manifest.Layers), 1)
|
|
||||||
}
|
|
||||||
if manifest.Layers[0].Name != "weight.bin" {
|
|
||||||
t.Errorf("Layers[0].Name = %q, want %q", manifest.Layers[0].Name, "weight.bin")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestShouldQuantize(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
tensor string
|
|
||||||
component string
|
|
||||||
want bool
|
|
||||||
}{
|
|
||||||
// VAE component should never be quantized
|
|
||||||
{"vae weight", "decoder.weight", "vae", false},
|
|
||||||
{"vae bias", "decoder.bias", "vae", false},
|
|
||||||
|
|
||||||
// Embeddings should not be quantized
|
|
||||||
{"embedding weight", "embed_tokens.weight", "", false},
|
|
||||||
{"embedding in name", "token_embedding.weight", "", false},
|
|
||||||
|
|
||||||
// Norms should not be quantized
|
|
||||||
{"layer norm", "layer_norm.weight", "", false},
|
|
||||||
{"rms norm", "rms_norm.weight", "", false},
|
|
||||||
{"ln prefix", "ln_1.weight", "", false},
|
|
||||||
{"layernorm in name", "input_layernorm.weight", "", false},
|
|
||||||
|
|
||||||
// Biases should not be quantized
|
|
||||||
{"bias tensor", "attention.bias", "", false},
|
|
||||||
{"proj bias", "o_proj.bias", "", false},
|
|
||||||
|
|
||||||
// Linear weights should be quantized
|
|
||||||
{"linear weight", "q_proj.weight", "", true},
|
|
||||||
{"attention weight", "self_attn.weight", "", true},
|
|
||||||
{"mlp weight", "mlp.gate_proj.weight", "", true},
|
|
||||||
|
|
||||||
// Transformer component weights should be quantized
|
|
||||||
{"transformer weight", "layers.0.weight", "transformer", true},
|
|
||||||
{"text_encoder weight", "encoder.weight", "text_encoder", true},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
got := ShouldQuantize(tt.tensor, tt.component)
|
|
||||||
if got != tt.want {
|
|
||||||
t.Errorf("ShouldQuantize(%q, %q) = %v, want %v", tt.tensor, tt.component, got, tt.want)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestShouldQuantizeTensor(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
tensor string
|
|
||||||
shape []int32
|
|
||||||
want bool
|
|
||||||
}{
|
|
||||||
// 2D tensors with sufficient size should be quantized
|
|
||||||
{"large 2D weight", "q_proj.weight", []int32{4096, 4096}, true},
|
|
||||||
{"medium 2D weight", "small_proj.weight", []int32{128, 128}, true},
|
|
||||||
|
|
||||||
// Small tensors should not be quantized (< 1024 elements)
|
|
||||||
{"tiny 2D weight", "tiny.weight", []int32{16, 16}, false},
|
|
||||||
{"small 2D weight", "small.weight", []int32{31, 31}, false},
|
|
||||||
|
|
||||||
// 1D tensors should not be quantized
|
|
||||||
{"1D tensor", "layer_norm.weight", []int32{4096}, false},
|
|
||||||
|
|
||||||
// 3D+ tensors should not be quantized
|
|
||||||
{"3D tensor", "conv.weight", []int32{64, 64, 3}, false},
|
|
||||||
{"4D tensor", "conv2d.weight", []int32{64, 64, 3, 3}, false},
|
|
||||||
|
|
||||||
// Embeddings should not be quantized regardless of shape
|
|
||||||
{"embedding 2D", "embed_tokens.weight", []int32{32000, 4096}, false},
|
|
||||||
|
|
||||||
// Norms should not be quantized regardless of shape
|
|
||||||
{"norm 2D", "layer_norm.weight", []int32{4096, 1}, false},
|
|
||||||
|
|
||||||
// Biases should not be quantized
|
|
||||||
{"bias 2D", "proj.bias", []int32{4096, 1}, false},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
got := ShouldQuantizeTensor(tt.tensor, tt.shape)
|
|
||||||
if got != tt.want {
|
|
||||||
t.Errorf("ShouldQuantizeTensor(%q, %v) = %v, want %v", tt.tensor, tt.shape, got, tt.want)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateSafetensorsModel_WithQuantize(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
|
|
||||||
// Create config.json
|
|
||||||
configJSON := `{"model_type": "test", "architectures": ["TestModel"]}`
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "config.json"), []byte(configJSON), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write config.json: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create a minimal safetensors file
|
|
||||||
createMinimalSafetensors(t, filepath.Join(dir, "model.safetensors"))
|
|
||||||
|
|
||||||
var quantizeRequested []string
|
|
||||||
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return LayerInfo{Name: name, Digest: "sha256:test"}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
quantizeRequested = append(quantizeRequested, quantize)
|
|
||||||
return []LayerInfo{{Name: name}}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
|
|
||||||
progressFn := func(status string) {}
|
|
||||||
|
|
||||||
// Run with quantize enabled
|
|
||||||
err := CreateSafetensorsModel("test-model", dir, "fp8", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("CreateSafetensorsModel failed: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Verify quantize was passed to callback (will be false for small test tensor)
|
|
||||||
if len(quantizeRequested) == 0 {
|
|
||||||
t.Error("no tensors processed")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// createMinimalImageGenModel creates a minimal diffusers-style model directory
|
|
||||||
func createMinimalImageGenModel(t *testing.T, dir string) {
|
|
||||||
t.Helper()
|
|
||||||
|
|
||||||
// Create model_index.json
|
|
||||||
modelIndex := `{"_class_name": "FluxPipeline", "_diffusers_version": "0.30.0"}`
|
|
||||||
if err := os.WriteFile(filepath.Join(dir, "model_index.json"), []byte(modelIndex), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write model_index.json: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create transformer directory with a safetensors file
|
|
||||||
transformerDir := filepath.Join(dir, "transformer")
|
|
||||||
if err := os.MkdirAll(transformerDir, 0o755); err != nil {
|
|
||||||
t.Fatalf("failed to create transformer dir: %v", err)
|
|
||||||
}
|
|
||||||
createMinimalSafetensors(t, filepath.Join(transformerDir, "model.safetensors"))
|
|
||||||
|
|
||||||
// Create transformer config
|
|
||||||
transformerConfig := `{"hidden_size": 3072}`
|
|
||||||
if err := os.WriteFile(filepath.Join(transformerDir, "config.json"), []byte(transformerConfig), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write transformer config: %v", err)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateImageGenModel(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
createMinimalImageGenModel(t, dir)
|
|
||||||
|
|
||||||
var manifestWritten bool
|
|
||||||
var manifestModelName string
|
|
||||||
var statusMessages []string
|
|
||||||
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return LayerInfo{Name: name, Digest: "sha256:test"}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return []LayerInfo{{Name: name, Digest: "sha256:tensor"}}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
manifestWritten = true
|
|
||||||
manifestModelName = modelName
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
|
|
||||||
progressFn := func(status string) {
|
|
||||||
statusMessages = append(statusMessages, status)
|
|
||||||
}
|
|
||||||
|
|
||||||
err := CreateImageGenModel("test-imagegen", dir, "", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("CreateImageGenModel failed: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
if !manifestWritten {
|
|
||||||
t.Error("manifest was not written")
|
|
||||||
}
|
|
||||||
|
|
||||||
if manifestModelName != "test-imagegen" {
|
|
||||||
t.Errorf("manifest model name = %q, want %q", manifestModelName, "test-imagegen")
|
|
||||||
}
|
|
||||||
|
|
||||||
if len(statusMessages) == 0 {
|
|
||||||
t.Error("no status messages received")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateImageGenModel_NoModelIndex(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
|
|
||||||
// Create only transformer without model_index.json
|
|
||||||
transformerDir := filepath.Join(dir, "transformer")
|
|
||||||
if err := os.MkdirAll(transformerDir, 0o755); err != nil {
|
|
||||||
t.Fatalf("failed to create transformer dir: %v", err)
|
|
||||||
}
|
|
||||||
createMinimalSafetensors(t, filepath.Join(transformerDir, "model.safetensors"))
|
|
||||||
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return LayerInfo{Name: name}, nil
|
|
||||||
}
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return []LayerInfo{{Name: name}}, nil
|
|
||||||
}
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
progressFn := func(status string) {}
|
|
||||||
|
|
||||||
err := CreateImageGenModel("test-imagegen", dir, "", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err == nil {
|
|
||||||
t.Error("expected error for missing model_index.json, got nil")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestCreateImageGenModel_WithQuantize(t *testing.T) {
|
|
||||||
dir := t.TempDir()
|
|
||||||
createMinimalImageGenModel(t, dir)
|
|
||||||
|
|
||||||
var quantizeRequested []string
|
|
||||||
|
|
||||||
createLayer := func(r io.Reader, mediaType, name string) (LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
return LayerInfo{Name: name, Digest: "sha256:test"}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, quantize string) ([]LayerInfo, error) {
|
|
||||||
io.ReadAll(r)
|
|
||||||
quantizeRequested = append(quantizeRequested, quantize)
|
|
||||||
return []LayerInfo{{Name: name}}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
writeManifest := func(modelName string, config LayerInfo, layers []LayerInfo) error {
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
|
|
||||||
progressFn := func(status string) {}
|
|
||||||
|
|
||||||
err := CreateImageGenModel("test-imagegen", dir, "fp8", createLayer, createTensorLayer, writeManifest, progressFn)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("CreateImageGenModel failed: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
if len(quantizeRequested) == 0 {
|
|
||||||
t.Error("no tensors processed")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
231
x/imagegen/api/handler.go
Normal file
@@ -0,0 +1,231 @@
|
|||||||
|
package api
|
||||||
|
|
||||||
|
import (
|
||||||
|
"fmt"
|
||||||
|
"net/http"
|
||||||
|
"strconv"
|
||||||
|
"strings"
|
||||||
|
"time"
|
||||||
|
|
||||||
|
"github.com/gin-gonic/gin"
|
||||||
|
|
||||||
|
"github.com/ollama/ollama/api"
|
||||||
|
"github.com/ollama/ollama/llm"
|
||||||
|
"github.com/ollama/ollama/x/imagegen"
|
||||||
|
)
|
||||||
|
|
||||||
|
// RunnerScheduler is the interface for scheduling a model runner.
|
||||||
|
// This is implemented by server.Server to avoid circular imports.
|
||||||
|
type RunnerScheduler interface {
|
||||||
|
ScheduleImageGenRunner(ctx *gin.Context, modelName string, opts api.Options, keepAlive *api.Duration) (llm.LlamaServer, error)
|
||||||
|
}
|
||||||
|
|
||||||
|
// RegisterRoutes registers the image generation API routes.
|
||||||
|
func RegisterRoutes(r gin.IRouter, scheduler RunnerScheduler) {
|
||||||
|
r.POST("/v1/images/generations", func(c *gin.Context) {
|
||||||
|
ImageGenerationHandler(c, scheduler)
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
// ImageGenerationHandler handles OpenAI-compatible image generation requests.
|
||||||
|
func ImageGenerationHandler(c *gin.Context, scheduler RunnerScheduler) {
|
||||||
|
var req ImageGenerationRequest
|
||||||
|
if err := c.BindJSON(&req); err != nil {
|
||||||
|
c.JSON(http.StatusBadRequest, gin.H{"error": gin.H{"message": err.Error()}})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
// Validate required fields
|
||||||
|
if req.Model == "" {
|
||||||
|
c.JSON(http.StatusBadRequest, gin.H{"error": gin.H{"message": "model is required"}})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
if req.Prompt == "" {
|
||||||
|
c.JSON(http.StatusBadRequest, gin.H{"error": gin.H{"message": "prompt is required"}})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
// Apply defaults
|
||||||
|
if req.N == 0 {
|
||||||
|
req.N = 1
|
||||||
|
}
|
||||||
|
if req.Size == "" {
|
||||||
|
req.Size = "1024x1024"
|
||||||
|
}
|
||||||
|
if req.ResponseFormat == "" {
|
||||||
|
req.ResponseFormat = "b64_json"
|
||||||
|
}
|
||||||
|
|
||||||
|
// Verify model exists
|
||||||
|
if imagegen.ResolveModelName(req.Model) == "" {
|
||||||
|
c.JSON(http.StatusNotFound, gin.H{"error": gin.H{"message": fmt.Sprintf("model %q not found", req.Model)}})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
// Parse size
|
||||||
|
width, height := parseSize(req.Size)
|
||||||
|
|
||||||
|
// Build options - we repurpose NumCtx/NumGPU for width/height
|
||||||
|
opts := api.Options{}
|
||||||
|
opts.NumCtx = int(width)
|
||||||
|
opts.NumGPU = int(height)
|
||||||
|
|
||||||
|
// Schedule runner
|
||||||
|
runner, err := scheduler.ScheduleImageGenRunner(c, req.Model, opts, nil)
|
||||||
|
if err != nil {
|
||||||
|
status := http.StatusInternalServerError
|
||||||
|
if strings.Contains(err.Error(), "not found") {
|
||||||
|
status = http.StatusNotFound
|
||||||
|
}
|
||||||
|
c.JSON(status, gin.H{"error": gin.H{"message": err.Error()}})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
// Build completion request
|
||||||
|
completionReq := llm.CompletionRequest{
|
||||||
|
Prompt: req.Prompt,
|
||||||
|
Options: &opts,
|
||||||
|
}
|
||||||
|
|
||||||
|
if req.Stream {
|
||||||
|
handleStreamingResponse(c, runner, completionReq, req.ResponseFormat)
|
||||||
|
} else {
|
||||||
|
handleNonStreamingResponse(c, runner, completionReq, req.ResponseFormat)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
func handleStreamingResponse(c *gin.Context, runner llm.LlamaServer, req llm.CompletionRequest, format string) {
|
||||||
|
c.Header("Content-Type", "text/event-stream")
|
||||||
|
c.Header("Cache-Control", "no-cache")
|
||||||
|
c.Header("Connection", "keep-alive")
|
||||||
|
|
||||||
|
var imageBase64 string
|
||||||
|
err := runner.Completion(c.Request.Context(), req, func(resp llm.CompletionResponse) {
|
||||||
|
if resp.Done {
|
||||||
|
imageBase64 = extractBase64(resp.Content)
|
||||||
|
} else {
|
||||||
|
progress := parseProgress(resp.Content)
|
||||||
|
if progress.Total > 0 {
|
||||||
|
c.SSEvent("progress", progress)
|
||||||
|
c.Writer.Flush()
|
||||||
|
}
|
||||||
|
}
|
||||||
|
})
|
||||||
|
if err != nil {
|
||||||
|
c.SSEvent("error", gin.H{"error": err.Error()})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
c.SSEvent("done", buildResponse(imageBase64, format))
|
||||||
|
}
|
||||||
|
|
||||||
|
func handleNonStreamingResponse(c *gin.Context, runner llm.LlamaServer, req llm.CompletionRequest, format string) {
|
||||||
|
var imageBase64 string
|
||||||
|
err := runner.Completion(c.Request.Context(), req, func(resp llm.CompletionResponse) {
|
||||||
|
if resp.Done {
|
||||||
|
imageBase64 = extractBase64(resp.Content)
|
||||||
|
}
|
||||||
|
})
|
||||||
|
if err != nil {
|
||||||
|
c.JSON(http.StatusInternalServerError, gin.H{"error": gin.H{"message": err.Error()}})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
c.JSON(http.StatusOK, buildResponse(imageBase64, format))
|
||||||
|
}
|
||||||
|
|
||||||
|
func parseSize(size string) (int32, int32) {
|
||||||
|
parts := strings.Split(size, "x")
|
||||||
|
if len(parts) != 2 {
|
||||||
|
return 1024, 1024
|
||||||
|
}
|
||||||
|
w, _ := strconv.Atoi(parts[0])
|
||||||
|
h, _ := strconv.Atoi(parts[1])
|
||||||
|
if w == 0 {
|
||||||
|
w = 1024
|
||||||
|
}
|
||||||
|
if h == 0 {
|
||||||
|
h = 1024
|
||||||
|
}
|
||||||
|
return int32(w), int32(h)
|
||||||
|
}
|
||||||
|
|
||||||
|
func extractBase64(content string) string {
|
||||||
|
if strings.HasPrefix(content, "IMAGE_BASE64:") {
|
||||||
|
return content[13:]
|
||||||
|
}
|
||||||
|
return ""
|
||||||
|
}
|
||||||
|
|
||||||
|
func parseProgress(content string) ImageProgressEvent {
|
||||||
|
var step, total int
|
||||||
|
fmt.Sscanf(content, "\rGenerating: step %d/%d", &step, &total)
|
||||||
|
return ImageProgressEvent{Step: step, Total: total}
|
||||||
|
}
|
||||||
|
|
||||||
|
func buildResponse(imageBase64, format string) ImageGenerationResponse {
|
||||||
|
resp := ImageGenerationResponse{
|
||||||
|
Created: time.Now().Unix(),
|
||||||
|
Data: make([]ImageData, 1),
|
||||||
|
}
|
||||||
|
|
||||||
|
if imageBase64 == "" {
|
||||||
|
return resp
|
||||||
|
}
|
||||||
|
|
||||||
|
if format == "url" {
|
||||||
|
// URL format not supported when using base64 transfer
|
||||||
|
resp.Data[0].B64JSON = imageBase64
|
||||||
|
} else {
|
||||||
|
resp.Data[0].B64JSON = imageBase64
|
||||||
|
}
|
||||||
|
|
||||||
|
return resp
|
||||||
|
}
|
||||||
|
|
||||||
|
// HandleGenerateRequest handles Ollama /api/generate requests for image gen models.
|
||||||
|
// This allows routes.go to delegate image generation with minimal code.
|
||||||
|
func HandleGenerateRequest(c *gin.Context, scheduler RunnerScheduler, modelName, prompt string, keepAlive *api.Duration, streamFn func(c *gin.Context, ch chan any)) {
|
||||||
|
opts := api.Options{}
|
||||||
|
|
||||||
|
// Schedule runner
|
||||||
|
runner, err := scheduler.ScheduleImageGenRunner(c, modelName, opts, keepAlive)
|
||||||
|
if err != nil {
|
||||||
|
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
// Build completion request
|
||||||
|
completionReq := llm.CompletionRequest{
|
||||||
|
Prompt: prompt,
|
||||||
|
Options: &opts,
|
||||||
|
}
|
||||||
|
|
||||||
|
// Stream responses via channel
|
||||||
|
ch := make(chan any)
|
||||||
|
go func() {
|
||||||
|
defer close(ch)
|
||||||
|
err := runner.Completion(c.Request.Context(), completionReq, func(resp llm.CompletionResponse) {
|
||||||
|
ch <- GenerateResponse{
|
||||||
|
Model: modelName,
|
||||||
|
CreatedAt: time.Now().UTC(),
|
||||||
|
Response: resp.Content,
|
||||||
|
Done: resp.Done,
|
||||||
|
}
|
||||||
|
})
|
||||||
|
if err != nil {
|
||||||
|
// Log error but don't block - channel is already being consumed
|
||||||
|
_ = err
|
||||||
|
}
|
||||||
|
}()
|
||||||
|
|
||||||
|
streamFn(c, ch)
|
||||||
|
}
|
||||||
|
|
||||||
|
// GenerateResponse matches api.GenerateResponse structure for streaming.
|
||||||
|
type GenerateResponse struct {
|
||||||
|
Model string `json:"model"`
|
||||||
|
CreatedAt time.Time `json:"created_at"`
|
||||||
|
Response string `json:"response"`
|
||||||
|
Done bool `json:"done"`
|
||||||
|
}
|
||||||
31
x/imagegen/api/types.go
Normal file
@@ -0,0 +1,31 @@
|
|||||||
|
// Package api provides OpenAI-compatible image generation API types.
|
||||||
|
package api
|
||||||
|
|
||||||
|
// ImageGenerationRequest is an OpenAI-compatible image generation request.
|
||||||
|
type ImageGenerationRequest struct {
|
||||||
|
Model string `json:"model"`
|
||||||
|
Prompt string `json:"prompt"`
|
||||||
|
N int `json:"n,omitempty"`
|
||||||
|
Size string `json:"size,omitempty"`
|
||||||
|
ResponseFormat string `json:"response_format,omitempty"`
|
||||||
|
Stream bool `json:"stream,omitempty"`
|
||||||
|
}
|
||||||
|
|
||||||
|
// ImageGenerationResponse is an OpenAI-compatible image generation response.
|
||||||
|
type ImageGenerationResponse struct {
|
||||||
|
Created int64 `json:"created"`
|
||||||
|
Data []ImageData `json:"data"`
|
||||||
|
}
|
||||||
|
|
||||||
|
// ImageData contains the generated image data.
|
||||||
|
type ImageData struct {
|
||||||
|
URL string `json:"url,omitempty"`
|
||||||
|
B64JSON string `json:"b64_json,omitempty"`
|
||||||
|
RevisedPrompt string `json:"revised_prompt,omitempty"`
|
||||||
|
}
|
||||||
|
|
||||||
|
// ImageProgressEvent is sent during streaming to indicate generation progress.
|
||||||
|
type ImageProgressEvent struct {
|
||||||
|
Step int `json:"step"`
|
||||||
|
Total int `json:"total"`
|
||||||
|
}
|
||||||
@@ -7,6 +7,7 @@ package imagegen
|
|||||||
|
|
||||||
import (
|
import (
|
||||||
"encoding/base64"
|
"encoding/base64"
|
||||||
|
"encoding/json"
|
||||||
"errors"
|
"errors"
|
||||||
"fmt"
|
"fmt"
|
||||||
"io"
|
"io"
|
||||||
@@ -38,20 +39,79 @@ func DefaultOptions() ImageGenOptions {
|
|||||||
return ImageGenOptions{
|
return ImageGenOptions{
|
||||||
Width: 1024,
|
Width: 1024,
|
||||||
Height: 1024,
|
Height: 1024,
|
||||||
Steps: 0, // 0 means model default
|
Steps: 9,
|
||||||
Seed: 0, // 0 means random
|
Seed: 0, // 0 means random
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// ModelInfo contains metadata about an image generation model.
|
||||||
|
type ModelInfo struct {
|
||||||
|
Architecture string
|
||||||
|
ParameterCount int64
|
||||||
|
Quantization string
|
||||||
|
}
|
||||||
|
|
||||||
|
// GetModelInfo returns metadata about an image generation model.
|
||||||
|
func GetModelInfo(modelName string) (*ModelInfo, error) {
|
||||||
|
manifest, err := LoadManifest(modelName)
|
||||||
|
if err != nil {
|
||||||
|
return nil, fmt.Errorf("failed to load manifest: %w", err)
|
||||||
|
}
|
||||||
|
|
||||||
|
info := &ModelInfo{}
|
||||||
|
|
||||||
|
// Read model_index.json for architecture, parameter count, and quantization
|
||||||
|
if data, err := manifest.ReadConfig("model_index.json"); err == nil {
|
||||||
|
var index struct {
|
||||||
|
Architecture string `json:"architecture"`
|
||||||
|
ParameterCount int64 `json:"parameter_count"`
|
||||||
|
Quantization string `json:"quantization"`
|
||||||
|
}
|
||||||
|
if json.Unmarshal(data, &index) == nil {
|
||||||
|
info.Architecture = index.Architecture
|
||||||
|
info.ParameterCount = index.ParameterCount
|
||||||
|
info.Quantization = index.Quantization
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Fallback: detect quantization from tensor names if not in config
|
||||||
|
if info.Quantization == "" {
|
||||||
|
for _, layer := range manifest.Manifest.Layers {
|
||||||
|
if strings.HasSuffix(layer.Name, ".weight_scale") {
|
||||||
|
info.Quantization = "FP8"
|
||||||
|
break
|
||||||
|
}
|
||||||
|
}
|
||||||
|
if info.Quantization == "" {
|
||||||
|
info.Quantization = "BF16"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Fallback: estimate parameter count if not in config
|
||||||
|
if info.ParameterCount == 0 {
|
||||||
|
var totalSize int64
|
||||||
|
for _, layer := range manifest.Manifest.Layers {
|
||||||
|
if layer.MediaType == "application/vnd.ollama.image.tensor" {
|
||||||
|
if !strings.HasSuffix(layer.Name, "_scale") && !strings.HasSuffix(layer.Name, "_qbias") {
|
||||||
|
totalSize += layer.Size
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
// Assume BF16 (2 bytes/param) as rough estimate
|
||||||
|
info.ParameterCount = totalSize / 2
|
||||||
|
}
|
||||||
|
|
||||||
|
return info, nil
|
||||||
|
}
|
||||||
|
|
||||||
// RegisterFlags adds image generation flags to the given command.
|
// RegisterFlags adds image generation flags to the given command.
|
||||||
// Flags are hidden since they only apply to image generation models.
|
// Flags are hidden since they only apply to image generation models.
|
||||||
func RegisterFlags(cmd *cobra.Command) {
|
func RegisterFlags(cmd *cobra.Command) {
|
||||||
cmd.Flags().Int("width", 1024, "Image width")
|
cmd.Flags().Int("width", 1024, "Image width")
|
||||||
cmd.Flags().Int("height", 1024, "Image height")
|
cmd.Flags().Int("height", 1024, "Image height")
|
||||||
cmd.Flags().Int("steps", 0, "Denoising steps (0 = model default)")
|
cmd.Flags().Int("steps", 9, "Denoising steps")
|
||||||
cmd.Flags().Int("seed", 0, "Random seed (0 for random)")
|
cmd.Flags().Int("seed", 0, "Random seed (0 for random)")
|
||||||
cmd.Flags().String("negative", "", "Negative prompt")
|
cmd.Flags().String("negative", "", "Negative prompt")
|
||||||
// Hide from main flags section - shown in separate section via AppendFlagsDocs
|
|
||||||
cmd.Flags().MarkHidden("width")
|
cmd.Flags().MarkHidden("width")
|
||||||
cmd.Flags().MarkHidden("height")
|
cmd.Flags().MarkHidden("height")
|
||||||
cmd.Flags().MarkHidden("steps")
|
cmd.Flags().MarkHidden("steps")
|
||||||
@@ -59,19 +119,6 @@ func RegisterFlags(cmd *cobra.Command) {
|
|||||||
cmd.Flags().MarkHidden("negative")
|
cmd.Flags().MarkHidden("negative")
|
||||||
}
|
}
|
||||||
|
|
||||||
// AppendFlagsDocs appends image generation flags documentation to the command's usage template.
|
|
||||||
func AppendFlagsDocs(cmd *cobra.Command) {
|
|
||||||
usage := `
|
|
||||||
Image Generation Flags (experimental):
|
|
||||||
--width int Image width
|
|
||||||
--height int Image height
|
|
||||||
--steps int Denoising steps
|
|
||||||
--seed int Random seed
|
|
||||||
--negative str Negative prompt
|
|
||||||
`
|
|
||||||
cmd.SetUsageTemplate(cmd.UsageTemplate() + usage)
|
|
||||||
}
|
|
||||||
|
|
||||||
// RunCLI handles the CLI for image generation models.
|
// RunCLI handles the CLI for image generation models.
|
||||||
// Returns true if it handled the request, false if the caller should continue with normal flow.
|
// Returns true if it handled the request, false if the caller should continue with normal flow.
|
||||||
// Supports flags: --width, --height, --steps, --seed, --negative
|
// Supports flags: --width, --height, --steps, --seed, --negative
|
||||||
@@ -111,15 +158,17 @@ func generateImageWithOptions(cmd *cobra.Command, modelName, prompt string, keep
|
|||||||
return err
|
return err
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Build request with image gen options encoded in Options fields
|
||||||
|
// NumCtx=width, NumGPU=height, NumPredict=steps, Seed=seed
|
||||||
req := &api.GenerateRequest{
|
req := &api.GenerateRequest{
|
||||||
Model: modelName,
|
Model: modelName,
|
||||||
Prompt: prompt,
|
Prompt: prompt,
|
||||||
Width: int32(opts.Width),
|
Options: map[string]any{
|
||||||
Height: int32(opts.Height),
|
"num_ctx": opts.Width,
|
||||||
Steps: int32(opts.Steps),
|
"num_gpu": opts.Height,
|
||||||
}
|
"num_predict": opts.Steps,
|
||||||
if opts.Seed != 0 {
|
"seed": opts.Seed,
|
||||||
req.Options = map[string]any{"seed": opts.Seed}
|
},
|
||||||
}
|
}
|
||||||
if keepAlive != nil {
|
if keepAlive != nil {
|
||||||
req.KeepAlive = keepAlive
|
req.KeepAlive = keepAlive
|
||||||
@@ -133,25 +182,32 @@ func generateImageWithOptions(cmd *cobra.Command, modelName, prompt string, keep
|
|||||||
var stepBar *progress.StepBar
|
var stepBar *progress.StepBar
|
||||||
var imageBase64 string
|
var imageBase64 string
|
||||||
err = client.Generate(cmd.Context(), req, func(resp api.GenerateResponse) error {
|
err = client.Generate(cmd.Context(), req, func(resp api.GenerateResponse) error {
|
||||||
// Handle progress updates using structured fields
|
content := resp.Response
|
||||||
if resp.Total > 0 {
|
|
||||||
if stepBar == nil {
|
// Handle progress updates - parse step info and switch to step bar
|
||||||
|
if strings.HasPrefix(content, "\rGenerating:") {
|
||||||
|
var step, total int
|
||||||
|
fmt.Sscanf(content, "\rGenerating: step %d/%d", &step, &total)
|
||||||
|
if stepBar == nil && total > 0 {
|
||||||
spinner.Stop()
|
spinner.Stop()
|
||||||
stepBar = progress.NewStepBar("Generating", int(resp.Total))
|
stepBar = progress.NewStepBar("Generating", total)
|
||||||
p.Add("", stepBar)
|
p.Add("", stepBar)
|
||||||
}
|
}
|
||||||
stepBar.Set(int(resp.Completed))
|
if stepBar != nil {
|
||||||
|
stepBar.Set(step)
|
||||||
|
}
|
||||||
|
return nil
|
||||||
}
|
}
|
||||||
|
|
||||||
// Handle final response with image data
|
// Handle final response with base64 image data
|
||||||
if resp.Done && resp.Image != "" {
|
if resp.Done && strings.HasPrefix(content, "IMAGE_BASE64:") {
|
||||||
imageBase64 = resp.Image
|
imageBase64 = content[13:]
|
||||||
}
|
}
|
||||||
|
|
||||||
return nil
|
return nil
|
||||||
})
|
})
|
||||||
|
|
||||||
p.StopAndClear()
|
p.Stop()
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return err
|
return err
|
||||||
}
|
}
|
||||||
@@ -189,23 +245,6 @@ func runInteractive(cmd *cobra.Command, modelName string, keepAlive *api.Duratio
|
|||||||
return err
|
return err
|
||||||
}
|
}
|
||||||
|
|
||||||
// Preload the model with the specified keepalive
|
|
||||||
p := progress.NewProgress(os.Stderr)
|
|
||||||
spinner := progress.NewSpinner("")
|
|
||||||
p.Add("", spinner)
|
|
||||||
|
|
||||||
preloadReq := &api.GenerateRequest{
|
|
||||||
Model: modelName,
|
|
||||||
KeepAlive: keepAlive,
|
|
||||||
}
|
|
||||||
if err := client.Generate(cmd.Context(), preloadReq, func(resp api.GenerateResponse) error {
|
|
||||||
return nil
|
|
||||||
}); err != nil {
|
|
||||||
p.StopAndClear()
|
|
||||||
return fmt.Errorf("failed to load model: %w", err)
|
|
||||||
}
|
|
||||||
p.StopAndClear()
|
|
||||||
|
|
||||||
scanner, err := readline.New(readline.Prompt{
|
scanner, err := readline.New(readline.Prompt{
|
||||||
Prompt: ">>> ",
|
Prompt: ">>> ",
|
||||||
Placeholder: "Describe an image to generate (/help for commands)",
|
Placeholder: "Describe an image to generate (/help for commands)",
|
||||||
@@ -243,7 +282,7 @@ func runInteractive(cmd *cobra.Command, modelName string, keepAlive *api.Duratio
|
|||||||
case strings.HasPrefix(line, "/bye"):
|
case strings.HasPrefix(line, "/bye"):
|
||||||
return nil
|
return nil
|
||||||
case strings.HasPrefix(line, "/?"), strings.HasPrefix(line, "/help"):
|
case strings.HasPrefix(line, "/?"), strings.HasPrefix(line, "/help"):
|
||||||
printInteractiveHelp()
|
printInteractiveHelp(opts)
|
||||||
continue
|
continue
|
||||||
case strings.HasPrefix(line, "/set "):
|
case strings.HasPrefix(line, "/set "):
|
||||||
if err := handleSetCommand(line[5:], &opts); err != nil {
|
if err := handleSetCommand(line[5:], &opts); err != nil {
|
||||||
@@ -262,12 +301,12 @@ func runInteractive(cmd *cobra.Command, modelName string, keepAlive *api.Duratio
|
|||||||
req := &api.GenerateRequest{
|
req := &api.GenerateRequest{
|
||||||
Model: modelName,
|
Model: modelName,
|
||||||
Prompt: line,
|
Prompt: line,
|
||||||
Width: int32(opts.Width),
|
Options: map[string]any{
|
||||||
Height: int32(opts.Height),
|
"num_ctx": opts.Width,
|
||||||
Steps: int32(opts.Steps),
|
"num_gpu": opts.Height,
|
||||||
}
|
"num_predict": opts.Steps,
|
||||||
if opts.Seed != 0 {
|
"seed": opts.Seed,
|
||||||
req.Options = map[string]any{"seed": opts.Seed}
|
},
|
||||||
}
|
}
|
||||||
if keepAlive != nil {
|
if keepAlive != nil {
|
||||||
req.KeepAlive = keepAlive
|
req.KeepAlive = keepAlive
|
||||||
@@ -282,25 +321,32 @@ func runInteractive(cmd *cobra.Command, modelName string, keepAlive *api.Duratio
|
|||||||
var imageBase64 string
|
var imageBase64 string
|
||||||
|
|
||||||
err = client.Generate(cmd.Context(), req, func(resp api.GenerateResponse) error {
|
err = client.Generate(cmd.Context(), req, func(resp api.GenerateResponse) error {
|
||||||
// Handle progress updates using structured fields
|
content := resp.Response
|
||||||
if resp.Total > 0 {
|
|
||||||
if stepBar == nil {
|
// Handle progress updates - parse step info and switch to step bar
|
||||||
|
if strings.HasPrefix(content, "\rGenerating:") {
|
||||||
|
var step, total int
|
||||||
|
fmt.Sscanf(content, "\rGenerating: step %d/%d", &step, &total)
|
||||||
|
if stepBar == nil && total > 0 {
|
||||||
spinner.Stop()
|
spinner.Stop()
|
||||||
stepBar = progress.NewStepBar("Generating", int(resp.Total))
|
stepBar = progress.NewStepBar("Generating", total)
|
||||||
p.Add("", stepBar)
|
p.Add("", stepBar)
|
||||||
}
|
}
|
||||||
stepBar.Set(int(resp.Completed))
|
if stepBar != nil {
|
||||||
|
stepBar.Set(step)
|
||||||
|
}
|
||||||
|
return nil
|
||||||
}
|
}
|
||||||
|
|
||||||
// Handle final response with image data
|
// Handle final response with base64 image data
|
||||||
if resp.Done && resp.Image != "" {
|
if resp.Done && strings.HasPrefix(content, "IMAGE_BASE64:") {
|
||||||
imageBase64 = resp.Image
|
imageBase64 = content[13:]
|
||||||
}
|
}
|
||||||
|
|
||||||
return nil
|
return nil
|
||||||
})
|
})
|
||||||
|
|
||||||
p.StopAndClear()
|
p.Stop()
|
||||||
if err != nil {
|
if err != nil {
|
||||||
fmt.Fprintf(os.Stderr, "Error: %v\n", err)
|
fmt.Fprintf(os.Stderr, "Error: %v\n", err)
|
||||||
continue
|
continue
|
||||||
@@ -351,13 +397,12 @@ func sanitizeFilename(s string) string {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// printInteractiveHelp prints help for interactive mode commands.
|
// printInteractiveHelp prints help for interactive mode commands.
|
||||||
// TODO: reconcile /set commands with /set parameter in text gen REPL (cmd/cmd.go)
|
func printInteractiveHelp(opts ImageGenOptions) {
|
||||||
func printInteractiveHelp() {
|
|
||||||
fmt.Fprintln(os.Stderr, "Commands:")
|
fmt.Fprintln(os.Stderr, "Commands:")
|
||||||
fmt.Fprintln(os.Stderr, " /set width <n> Set image width")
|
fmt.Fprintln(os.Stderr, " /set width <n> Set image width (current:", opts.Width, ")")
|
||||||
fmt.Fprintln(os.Stderr, " /set height <n> Set image height")
|
fmt.Fprintln(os.Stderr, " /set height <n> Set image height (current:", opts.Height, ")")
|
||||||
fmt.Fprintln(os.Stderr, " /set steps <n> Set denoising steps")
|
fmt.Fprintln(os.Stderr, " /set steps <n> Set denoising steps (current:", opts.Steps, ")")
|
||||||
fmt.Fprintln(os.Stderr, " /set seed <n> Set random seed")
|
fmt.Fprintln(os.Stderr, " /set seed <n> Set random seed (current:", opts.Seed, ", 0=random)")
|
||||||
fmt.Fprintln(os.Stderr, " /set negative <s> Set negative prompt")
|
fmt.Fprintln(os.Stderr, " /set negative <s> Set negative prompt")
|
||||||
fmt.Fprintln(os.Stderr, " /show Show current settings")
|
fmt.Fprintln(os.Stderr, " /show Show current settings")
|
||||||
fmt.Fprintln(os.Stderr, " /bye Exit")
|
fmt.Fprintln(os.Stderr, " /bye Exit")
|
||||||
|
|||||||
190
x/imagegen/client/create.go
Normal file
@@ -0,0 +1,190 @@
|
|||||||
|
// Package client provides client-side model creation for tensor-based models.
|
||||||
|
//
|
||||||
|
// This package is in x/ because the tensor model storage format is under development.
|
||||||
|
// It also exists to break an import cycle: server imports x/imagegen, so x/imagegen
|
||||||
|
// cannot import server. This sub-package can import server because server doesn't
|
||||||
|
// import it.
|
||||||
|
//
|
||||||
|
// TODO (jmorganca): This is temporary. When tensor models are promoted to production:
|
||||||
|
// 1. Add proper API endpoints for tensor model creation
|
||||||
|
// 2. Move tensor extraction to server-side
|
||||||
|
// 3. Remove this package
|
||||||
|
// 4. Follow the same client→server pattern as regular model creation
|
||||||
|
package client
|
||||||
|
|
||||||
|
import (
|
||||||
|
"bytes"
|
||||||
|
"encoding/json"
|
||||||
|
"fmt"
|
||||||
|
"io"
|
||||||
|
|
||||||
|
"github.com/ollama/ollama/progress"
|
||||||
|
"github.com/ollama/ollama/server"
|
||||||
|
"github.com/ollama/ollama/types/model"
|
||||||
|
"github.com/ollama/ollama/x/imagegen"
|
||||||
|
)
|
||||||
|
|
||||||
|
// MinOllamaVersion is the minimum Ollama version required for image generation models.
|
||||||
|
const MinOllamaVersion = "0.14.0"
|
||||||
|
|
||||||
|
// CreateModel imports a tensor-based model from a local directory.
|
||||||
|
// This creates blobs and manifest directly on disk, bypassing the HTTP API.
|
||||||
|
// If quantize is "fp8", weights will be quantized to mxfp8 format during import.
|
||||||
|
//
|
||||||
|
// TODO (jmorganca): Replace with API-based creation when promoted to production.
|
||||||
|
func CreateModel(modelName, modelDir, quantize string, p *progress.Progress) error {
|
||||||
|
if !imagegen.IsTensorModelDir(modelDir) {
|
||||||
|
return fmt.Errorf("%s is not an image generation model directory (model_index.json not found)", modelDir)
|
||||||
|
}
|
||||||
|
|
||||||
|
status := "importing image generation model"
|
||||||
|
spinner := progress.NewSpinner(status)
|
||||||
|
p.Add("imagegen", spinner)
|
||||||
|
|
||||||
|
// Create layer callback for config files
|
||||||
|
createLayer := func(r io.Reader, mediaType, name string) (imagegen.LayerInfo, error) {
|
||||||
|
layer, err := server.NewLayer(r, mediaType)
|
||||||
|
if err != nil {
|
||||||
|
return imagegen.LayerInfo{}, err
|
||||||
|
}
|
||||||
|
layer.Name = name
|
||||||
|
|
||||||
|
return imagegen.LayerInfo{
|
||||||
|
Digest: layer.Digest,
|
||||||
|
Size: layer.Size,
|
||||||
|
MediaType: layer.MediaType,
|
||||||
|
Name: name,
|
||||||
|
}, nil
|
||||||
|
}
|
||||||
|
|
||||||
|
// Create tensor layer callback for individual tensors
|
||||||
|
// name is path-style: "component/tensor_name"
|
||||||
|
// When quantize is true, returns multiple layers (weight + scales)
|
||||||
|
createTensorLayer := func(r io.Reader, name, dtype string, shape []int32, doQuantize bool) ([]imagegen.LayerInfo, error) {
|
||||||
|
if doQuantize {
|
||||||
|
// Check if quantization is supported
|
||||||
|
if !QuantizeSupported() {
|
||||||
|
return nil, fmt.Errorf("quantization requires MLX support")
|
||||||
|
}
|
||||||
|
|
||||||
|
// Quantize the tensor (affine mode returns weight, scales, qbiases)
|
||||||
|
qweightData, scalesData, qbiasData, _, _, _, err := quantizeTensor(r, name, dtype, shape)
|
||||||
|
if err != nil {
|
||||||
|
return nil, fmt.Errorf("failed to quantize %s: %w", name, err)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Create layer for quantized weight
|
||||||
|
weightLayer, err := server.NewLayer(bytes.NewReader(qweightData), server.MediaTypeImageTensor)
|
||||||
|
if err != nil {
|
||||||
|
return nil, err
|
||||||
|
}
|
||||||
|
|
||||||
|
// Create layer for scales (use _scale suffix convention)
|
||||||
|
scalesLayer, err := server.NewLayer(bytes.NewReader(scalesData), server.MediaTypeImageTensor)
|
||||||
|
if err != nil {
|
||||||
|
return nil, err
|
||||||
|
}
|
||||||
|
|
||||||
|
layers := []imagegen.LayerInfo{
|
||||||
|
{
|
||||||
|
Digest: weightLayer.Digest,
|
||||||
|
Size: weightLayer.Size,
|
||||||
|
MediaType: weightLayer.MediaType,
|
||||||
|
Name: name, // Keep original name for weight
|
||||||
|
},
|
||||||
|
{
|
||||||
|
Digest: scalesLayer.Digest,
|
||||||
|
Size: scalesLayer.Size,
|
||||||
|
MediaType: scalesLayer.MediaType,
|
||||||
|
Name: name + "_scale", // Add _scale suffix
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
// Add qbiases layer if present (affine mode)
|
||||||
|
if qbiasData != nil {
|
||||||
|
qbiasLayer, err := server.NewLayer(bytes.NewReader(qbiasData), server.MediaTypeImageTensor)
|
||||||
|
if err != nil {
|
||||||
|
return nil, err
|
||||||
|
}
|
||||||
|
layers = append(layers, imagegen.LayerInfo{
|
||||||
|
Digest: qbiasLayer.Digest,
|
||||||
|
Size: qbiasLayer.Size,
|
||||||
|
MediaType: qbiasLayer.MediaType,
|
||||||
|
Name: name + "_qbias", // Add _qbias suffix
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
return layers, nil
|
||||||
|
}
|
||||||
|
|
||||||
|
// Non-quantized path: just create a single layer
|
||||||
|
layer, err := server.NewLayer(r, server.MediaTypeImageTensor)
|
||||||
|
if err != nil {
|
||||||
|
return nil, err
|
||||||
|
}
|
||||||
|
|
||||||
|
return []imagegen.LayerInfo{
|
||||||
|
{
|
||||||
|
Digest: layer.Digest,
|
||||||
|
Size: layer.Size,
|
||||||
|
MediaType: layer.MediaType,
|
||||||
|
Name: name,
|
||||||
|
},
|
||||||
|
}, nil
|
||||||
|
}
|
||||||
|
|
||||||
|
// Create manifest writer callback
|
||||||
|
writeManifest := func(modelName string, config imagegen.LayerInfo, layers []imagegen.LayerInfo) error {
|
||||||
|
name := model.ParseName(modelName)
|
||||||
|
if !name.IsValid() {
|
||||||
|
return fmt.Errorf("invalid model name: %s", modelName)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Create a proper config blob with version requirement
|
||||||
|
configData := model.ConfigV2{
|
||||||
|
ModelFormat: "safetensors",
|
||||||
|
Capabilities: []string{"image"},
|
||||||
|
Requires: MinOllamaVersion,
|
||||||
|
}
|
||||||
|
configJSON, err := json.Marshal(configData)
|
||||||
|
if err != nil {
|
||||||
|
return fmt.Errorf("failed to marshal config: %w", err)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Create config layer blob
|
||||||
|
configLayer, err := server.NewLayer(bytes.NewReader(configJSON), "application/vnd.docker.container.image.v1+json")
|
||||||
|
if err != nil {
|
||||||
|
return fmt.Errorf("failed to create config layer: %w", err)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Convert LayerInfo to server.Layer (include the original model_index.json in layers)
|
||||||
|
serverLayers := make([]server.Layer, len(layers))
|
||||||
|
for i, l := range layers {
|
||||||
|
serverLayers[i] = server.Layer{
|
||||||
|
MediaType: l.MediaType,
|
||||||
|
Digest: l.Digest,
|
||||||
|
Size: l.Size,
|
||||||
|
Name: l.Name,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return server.WriteManifest(name, configLayer, serverLayers)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Progress callback
|
||||||
|
progressFn := func(msg string) {
|
||||||
|
spinner.Stop()
|
||||||
|
status = msg
|
||||||
|
spinner = progress.NewSpinner(status)
|
||||||
|
p.Add("imagegen", spinner)
|
||||||
|
}
|
||||||
|
|
||||||
|
err := imagegen.CreateModel(modelName, modelDir, quantize, createLayer, createTensorLayer, writeManifest, progressFn)
|
||||||
|
spinner.Stop()
|
||||||
|
if err != nil {
|
||||||
|
return err
|
||||||
|
}
|
||||||
|
|
||||||
|
fmt.Printf("Created image generation model '%s'\n", modelName)
|
||||||
|
return nil
|
||||||
|
}
|
||||||
@@ -11,16 +11,10 @@ import (
|
|||||||
"github.com/ollama/ollama/x/imagegen/mlx"
|
"github.com/ollama/ollama/x/imagegen/mlx"
|
||||||
)
|
)
|
||||||
|
|
||||||
// quantizeTensor loads a tensor from safetensors format, quantizes it,
|
// quantizeTensor loads a tensor from safetensors format, quantizes it to affine int8,
|
||||||
// and returns safetensors data for the quantized weights, scales, and biases.
|
// and returns safetensors data for the quantized weights, scales, and biases.
|
||||||
// Supported quantization types: "fp8" (affine 8-bit)
|
|
||||||
// Uses MLX's native SaveSafetensors to ensure correct dtype handling (especially uint32 for quantized weights).
|
// Uses MLX's native SaveSafetensors to ensure correct dtype handling (especially uint32 for quantized weights).
|
||||||
func quantizeTensor(r io.Reader, name, dtype string, shape []int32, quantize string) (qweightData, scalesData, qbiasData []byte, qweightShape, scalesShape, qbiasShape []int32, err error) {
|
func quantizeTensor(r io.Reader, name, dtype string, shape []int32) (qweightData, scalesData, qbiasData []byte, qweightShape, scalesShape, qbiasShape []int32, err error) {
|
||||||
// Lazy init MLX when needed for quantization
|
|
||||||
if err := mlx.InitMLX(); err != nil {
|
|
||||||
return nil, nil, nil, nil, nil, nil, fmt.Errorf("MLX initialization failed: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
tmpDir := ensureTempDir()
|
tmpDir := ensureTempDir()
|
||||||
|
|
||||||
// Read safetensors data to a temp file (LoadSafetensorsNative needs a path)
|
// Read safetensors data to a temp file (LoadSafetensorsNative needs a path)
|
||||||
@@ -56,15 +50,9 @@ func quantizeTensor(r io.Reader, name, dtype string, shape []int32, quantize str
|
|||||||
mlx.Eval(arr)
|
mlx.Eval(arr)
|
||||||
}
|
}
|
||||||
|
|
||||||
// Quantize based on quantization type
|
// Quantize with affine mode: group_size=32, bits=8
|
||||||
var qweight, scales, qbiases *mlx.Array
|
// Note: mxfp8 mode doesn't have matmul kernels in MLX, affine mode does
|
||||||
switch quantize {
|
qweight, scales, qbiases := mlx.Quantize(arr, 32, 8, "affine")
|
||||||
case "fp8":
|
|
||||||
// affine mode: group_size=32, bits=8
|
|
||||||
qweight, scales, qbiases = mlx.Quantize(arr, 32, 8, "affine")
|
|
||||||
default:
|
|
||||||
return nil, nil, nil, nil, nil, nil, fmt.Errorf("unsupported quantization type: %s", quantize)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Eval and make contiguous for data access
|
// Eval and make contiguous for data access
|
||||||
qweight = mlx.Contiguous(qweight)
|
qweight = mlx.Contiguous(qweight)
|
||||||
@@ -8,7 +8,7 @@ import (
|
|||||||
)
|
)
|
||||||
|
|
||||||
// quantizeTensor is not available without MLX
|
// quantizeTensor is not available without MLX
|
||||||
func quantizeTensor(r io.Reader, name, dtype string, shape []int32, quantize string) (qweightData, scalesData, qbiasData []byte, qweightShape, scalesShape, qbiasShape []int32, err error) {
|
func quantizeTensor(r io.Reader, name, dtype string, shape []int32) (qweightData, scalesData, qbiasData []byte, qweightShape, scalesShape, qbiasShape []int32, err error) {
|
||||||
return nil, nil, nil, nil, nil, nil, fmt.Errorf("quantization requires MLX support (build with mlx tag)")
|
return nil, nil, nil, nil, nil, nil, fmt.Errorf("quantization requires MLX support (build with mlx tag)")
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -65,12 +65,12 @@ func (s *utf8Streamer) Flush() string {
|
|||||||
return result
|
return result
|
||||||
}
|
}
|
||||||
|
|
||||||
|
func init() {
|
||||||
|
generationStream = mlx.NewStream()
|
||||||
|
}
|
||||||
|
|
||||||
// withStream runs fn with the generation stream as default
|
// withStream runs fn with the generation stream as default
|
||||||
func withStream(fn func()) {
|
func withStream(fn func()) {
|
||||||
// Lazy initialization of generationStream
|
|
||||||
if generationStream == nil {
|
|
||||||
generationStream = mlx.NewStream()
|
|
||||||
}
|
|
||||||
orig := mlx.GetDefaultStream()
|
orig := mlx.GetDefaultStream()
|
||||||
mlx.SetDefaultStream(generationStream)
|
mlx.SetDefaultStream(generationStream)
|
||||||
fn()
|
fn()
|
||||||
|
|||||||
@@ -48,7 +48,7 @@ func main() {
|
|||||||
// Image generation params
|
// Image generation params
|
||||||
width := flag.Int("width", 1024, "Image width")
|
width := flag.Int("width", 1024, "Image width")
|
||||||
height := flag.Int("height", 1024, "Image height")
|
height := flag.Int("height", 1024, "Image height")
|
||||||
steps := flag.Int("steps", 0, "Denoising steps (0 = model default)")
|
steps := flag.Int("steps", 9, "Denoising steps")
|
||||||
seed := flag.Int64("seed", 42, "Random seed")
|
seed := flag.Int64("seed", 42, "Random seed")
|
||||||
out := flag.String("output", "output.png", "Output path")
|
out := flag.String("output", "output.png", "Output path")
|
||||||
|
|
||||||
@@ -78,11 +78,6 @@ func main() {
|
|||||||
return
|
return
|
||||||
}
|
}
|
||||||
|
|
||||||
// Check if MLX initialized successfully
|
|
||||||
if !mlx.IsMLXAvailable() {
|
|
||||||
log.Fatalf("MLX initialization failed: %v", mlx.GetMLXInitError())
|
|
||||||
}
|
|
||||||
|
|
||||||
// CPU profiling
|
// CPU profiling
|
||||||
if *cpuProfile != "" {
|
if *cpuProfile != "" {
|
||||||
f, err := os.Create(*cpuProfile)
|
f, err := os.Create(*cpuProfile)
|
||||||
|
|||||||
@@ -1,4 +1,4 @@
|
|||||||
package create
|
package imagegen
|
||||||
|
|
||||||
import (
|
import (
|
||||||
"bytes"
|
"bytes"
|
||||||
@@ -12,24 +12,40 @@ import (
|
|||||||
"github.com/ollama/ollama/x/imagegen/safetensors"
|
"github.com/ollama/ollama/x/imagegen/safetensors"
|
||||||
)
|
)
|
||||||
|
|
||||||
// CreateImageGenModel imports an image generation model from a directory.
|
// IsTensorModelDir checks if the directory contains a tensor model
|
||||||
// Stores each tensor as a separate blob for fine-grained deduplication.
|
// by looking for model_index.json, which is the standard diffusers pipeline config.
|
||||||
// If quantize is specified, linear weights in transformer/text_encoder are quantized.
|
func IsTensorModelDir(dir string) bool {
|
||||||
// Supported quantization types: fp8 (or empty for no quantization).
|
_, err := os.Stat(filepath.Join(dir, "model_index.json"))
|
||||||
// Layer creation and manifest writing are done via callbacks to avoid import cycles.
|
return err == nil
|
||||||
func CreateImageGenModel(modelName, modelDir, quantize string, createLayer LayerCreator, createTensorLayer QuantizingTensorLayerCreator, writeManifest ManifestWriter, fn func(status string)) error {
|
}
|
||||||
// Validate quantization type
|
|
||||||
switch quantize {
|
|
||||||
case "", "fp8":
|
|
||||||
// valid
|
|
||||||
default:
|
|
||||||
return fmt.Errorf("unsupported quantization type %q: supported types are fp8", quantize)
|
|
||||||
}
|
|
||||||
|
|
||||||
|
// LayerInfo holds metadata for a created layer.
|
||||||
|
type LayerInfo struct {
|
||||||
|
Digest string
|
||||||
|
Size int64
|
||||||
|
MediaType string
|
||||||
|
Name string // Path-style name: "component/tensor" or "path/to/config.json"
|
||||||
|
}
|
||||||
|
|
||||||
|
// LayerCreator is called to create a blob layer.
|
||||||
|
// name is the path-style name (e.g., "tokenizer/tokenizer.json")
|
||||||
|
type LayerCreator func(r io.Reader, mediaType, name string) (LayerInfo, error)
|
||||||
|
|
||||||
|
// TensorLayerCreator creates a tensor blob layer with metadata.
|
||||||
|
// name is the path-style name including component (e.g., "text_encoder/model.embed_tokens.weight")
|
||||||
|
type TensorLayerCreator func(r io.Reader, name, dtype string, shape []int32) (LayerInfo, error)
|
||||||
|
|
||||||
|
// ManifestWriter writes the manifest file.
|
||||||
|
type ManifestWriter func(modelName string, config LayerInfo, layers []LayerInfo) error
|
||||||
|
|
||||||
|
// CreateModel imports an image generation model from a directory.
|
||||||
|
// Stores each tensor as a separate blob for fine-grained deduplication.
|
||||||
|
// If quantize is "fp8", linear weights in transformer/text_encoder are quantized to mxfp8 format.
|
||||||
|
// Layer creation and manifest writing are done via callbacks to avoid import cycles.
|
||||||
|
func CreateModel(modelName, modelDir, quantize string, createLayer LayerCreator, createTensorLayer QuantizingTensorLayerCreator, writeManifest ManifestWriter, fn func(status string)) error {
|
||||||
var layers []LayerInfo
|
var layers []LayerInfo
|
||||||
var configLayer LayerInfo
|
var configLayer LayerInfo
|
||||||
var totalParams int64 // Count parameters from original tensor shapes
|
var totalParams int64 // Count parameters from original tensor shapes
|
||||||
var torchDtype string // Read from component config for quantization display
|
|
||||||
|
|
||||||
// Components to process - extract individual tensors from each
|
// Components to process - extract individual tensors from each
|
||||||
components := []string{"text_encoder", "transformer", "vae"}
|
components := []string{"text_encoder", "transformer", "vae"}
|
||||||
@@ -61,8 +77,8 @@ func CreateImageGenModel(modelName, modelDir, quantize string, createLayer Layer
|
|||||||
|
|
||||||
tensorNames := extractor.ListTensors()
|
tensorNames := extractor.ListTensors()
|
||||||
quantizeMsg := ""
|
quantizeMsg := ""
|
||||||
if quantize != "" && component != "vae" {
|
if quantize == "fp8" && component != "vae" {
|
||||||
quantizeMsg = ", quantizing to " + quantize
|
quantizeMsg = ", quantizing to fp8"
|
||||||
}
|
}
|
||||||
fn(fmt.Sprintf("importing %s/%s (%d tensors%s)", component, entry.Name(), len(tensorNames), quantizeMsg))
|
fn(fmt.Sprintf("importing %s/%s (%d tensors%s)", component, entry.Name(), len(tensorNames), quantizeMsg))
|
||||||
|
|
||||||
@@ -87,14 +103,11 @@ func CreateImageGenModel(modelName, modelDir, quantize string, createLayer Layer
|
|||||||
// Use path-style name: "component/tensor_name"
|
// Use path-style name: "component/tensor_name"
|
||||||
fullName := component + "/" + tensorName
|
fullName := component + "/" + tensorName
|
||||||
|
|
||||||
// Determine quantization type for this tensor (empty string if not quantizing)
|
// Determine if this tensor should be quantized
|
||||||
quantizeType := ""
|
doQuantize := quantize == "fp8" && ShouldQuantize(tensorName, component)
|
||||||
if quantize != "" && ShouldQuantize(tensorName, component) && canQuantizeShape(td.Shape) {
|
|
||||||
quantizeType = quantize
|
|
||||||
}
|
|
||||||
|
|
||||||
// createTensorLayer returns multiple layers if quantizing (weight + scales)
|
// createTensorLayer returns multiple layers if quantizing (weight + scales)
|
||||||
newLayers, err := createTensorLayer(td.SafetensorsReader(), fullName, td.Dtype, td.Shape, quantizeType)
|
newLayers, err := createTensorLayer(td.SafetensorsReader(), fullName, td.Dtype, td.Shape, doQuantize)
|
||||||
if err != nil {
|
if err != nil {
|
||||||
extractor.Close()
|
extractor.Close()
|
||||||
return fmt.Errorf("failed to create layer for %s: %w", fullName, err)
|
return fmt.Errorf("failed to create layer for %s: %w", fullName, err)
|
||||||
@@ -106,19 +119,6 @@ func CreateImageGenModel(modelName, modelDir, quantize string, createLayer Layer
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// Read torch_dtype from text_encoder config for quantization display
|
|
||||||
if torchDtype == "" {
|
|
||||||
textEncoderConfig := filepath.Join(modelDir, "text_encoder/config.json")
|
|
||||||
if data, err := os.ReadFile(textEncoderConfig); err == nil {
|
|
||||||
var cfg struct {
|
|
||||||
TorchDtype string `json:"torch_dtype"`
|
|
||||||
}
|
|
||||||
if json.Unmarshal(data, &cfg) == nil && cfg.TorchDtype != "" {
|
|
||||||
torchDtype = cfg.TorchDtype
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Import config files
|
// Import config files
|
||||||
configFiles := []string{
|
configFiles := []string{
|
||||||
"model_index.json",
|
"model_index.json",
|
||||||
@@ -164,11 +164,11 @@ func CreateImageGenModel(modelName, modelDir, quantize string, createLayer Layer
|
|||||||
// Add parameter count (counted from tensor shapes during import)
|
// Add parameter count (counted from tensor shapes during import)
|
||||||
cfg["parameter_count"] = totalParams
|
cfg["parameter_count"] = totalParams
|
||||||
|
|
||||||
// Add quantization info - use quantize type if set, otherwise torch_dtype
|
// Add quantization info
|
||||||
if quantize != "" {
|
if quantize == "fp8" {
|
||||||
cfg["quantization"] = strings.ToUpper(quantize)
|
cfg["quantization"] = "FP8"
|
||||||
} else {
|
} else {
|
||||||
cfg["quantization"] = torchDtype
|
cfg["quantization"] = "BF16"
|
||||||
}
|
}
|
||||||
|
|
||||||
data, err = json.MarshalIndent(cfg, "", " ")
|
data, err = json.MarshalIndent(cfg, "", " ")
|
||||||
@@ -211,12 +211,3 @@ func CreateImageGenModel(modelName, modelDir, quantize string, createLayer Layer
|
|||||||
fn(fmt.Sprintf("successfully imported %s with %d layers", modelName, len(layers)))
|
fn(fmt.Sprintf("successfully imported %s with %d layers", modelName, len(layers)))
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
|
|
||||||
// canQuantizeShape returns true if a tensor shape is compatible with MLX quantization.
|
|
||||||
// MLX requires the last dimension to be divisible by the group size (32).
|
|
||||||
func canQuantizeShape(shape []int32) bool {
|
|
||||||
if len(shape) < 2 {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
return shape[len(shape)-1]%32 == 0
|
|
||||||
}
|
|
||||||
@@ -175,63 +175,3 @@ func (m *ModelManifest) HasTensorLayers() bool {
|
|||||||
}
|
}
|
||||||
return false
|
return false
|
||||||
}
|
}
|
||||||
|
|
||||||
// ModelInfo contains metadata about an image generation model.
|
|
||||||
type ModelInfo struct {
|
|
||||||
Architecture string
|
|
||||||
ParameterCount int64
|
|
||||||
Quantization string
|
|
||||||
}
|
|
||||||
|
|
||||||
// GetModelInfo returns metadata about an image generation model.
|
|
||||||
func GetModelInfo(modelName string) (*ModelInfo, error) {
|
|
||||||
manifest, err := LoadManifest(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to load manifest: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
info := &ModelInfo{}
|
|
||||||
|
|
||||||
// Read model_index.json for architecture, parameter count, and quantization
|
|
||||||
if data, err := manifest.ReadConfig("model_index.json"); err == nil {
|
|
||||||
var index struct {
|
|
||||||
Architecture string `json:"architecture"`
|
|
||||||
ParameterCount int64 `json:"parameter_count"`
|
|
||||||
Quantization string `json:"quantization"`
|
|
||||||
}
|
|
||||||
if json.Unmarshal(data, &index) == nil {
|
|
||||||
info.Architecture = index.Architecture
|
|
||||||
info.ParameterCount = index.ParameterCount
|
|
||||||
info.Quantization = index.Quantization
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Fallback: detect quantization from tensor names if not in config
|
|
||||||
if info.Quantization == "" {
|
|
||||||
for _, layer := range manifest.Manifest.Layers {
|
|
||||||
if strings.HasSuffix(layer.Name, ".weight_scale") {
|
|
||||||
info.Quantization = "FP8"
|
|
||||||
break
|
|
||||||
}
|
|
||||||
}
|
|
||||||
if info.Quantization == "" {
|
|
||||||
info.Quantization = "BF16"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Fallback: estimate parameter count if not in config
|
|
||||||
if info.ParameterCount == 0 {
|
|
||||||
var totalSize int64
|
|
||||||
for _, layer := range manifest.Manifest.Layers {
|
|
||||||
if layer.MediaType == "application/vnd.ollama.image.tensor" {
|
|
||||||
if !strings.HasSuffix(layer.Name, "_scale") && !strings.HasSuffix(layer.Name, "_qbias") {
|
|
||||||
totalSize += layer.Size
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
// Assume BF16 (2 bytes/param) as rough estimate
|
|
||||||
info.ParameterCount = totalSize / 2
|
|
||||||
}
|
|
||||||
|
|
||||||
return info, nil
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -95,3 +95,8 @@ func EstimateVRAM(modelName string) uint64 {
|
|||||||
}
|
}
|
||||||
return 21 * GB
|
return 21 * GB
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// HasTensorLayers checks if the given model has tensor layers.
|
||||||
|
func HasTensorLayers(modelName string) bool {
|
||||||
|
return ResolveModelName(modelName) != ""
|
||||||
|
}
|
||||||
|
|||||||
@@ -94,6 +94,13 @@ func TestEstimateVRAMDefault(t *testing.T) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
func TestHasTensorLayers(t *testing.T) {
|
||||||
|
// Non-existent model should return false
|
||||||
|
if HasTensorLayers("nonexistent-model") {
|
||||||
|
t.Error("HasTensorLayers() should return false for non-existent model")
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
func TestResolveModelName(t *testing.T) {
|
func TestResolveModelName(t *testing.T) {
|
||||||
// Non-existent model should return empty string
|
// Non-existent model should return empty string
|
||||||
result := ResolveModelName("nonexistent-model")
|
result := ResolveModelName("nonexistent-model")
|
||||||
|
|||||||
@@ -3,7 +3,7 @@
|
|||||||
package mlx
|
package mlx
|
||||||
|
|
||||||
/*
|
/*
|
||||||
#include "mlx.h"
|
#include "mlx/c/mlx.h"
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
|
|
||||||
// Forward declaration for Go callback
|
// Forward declaration for Go callback
|
||||||
|
|||||||
@@ -1,6 +0,0 @@
|
|||||||
//go:build mlx
|
|
||||||
|
|
||||||
// Package mlx provides Go bindings for the MLX-C library with dynamic loading support.
|
|
||||||
//
|
|
||||||
//go:generate go run generate_wrappers.go ../../../build/_deps/mlx-c-src/mlx/c mlx.h mlx.c
|
|
||||||
package mlx
|
|
||||||
@@ -1,439 +0,0 @@
|
|||||||
//go:build ignore
|
|
||||||
|
|
||||||
// This tool generates MLX-C dynamic loading wrappers.
|
|
||||||
// Usage: go run generate_wrappers.go <mlx-c-include-dir> <output-header> [output-impl]
|
|
||||||
package main
|
|
||||||
|
|
||||||
import (
|
|
||||||
"bytes"
|
|
||||||
"flag"
|
|
||||||
"fmt"
|
|
||||||
"io/fs"
|
|
||||||
"os"
|
|
||||||
"path/filepath"
|
|
||||||
"regexp"
|
|
||||||
"strings"
|
|
||||||
)
|
|
||||||
|
|
||||||
type Function struct {
|
|
||||||
Name string
|
|
||||||
ReturnType string
|
|
||||||
Params string
|
|
||||||
ParamNames []string
|
|
||||||
NeedsARM64Guard bool
|
|
||||||
}
|
|
||||||
|
|
||||||
func findHeaders(directory string) ([]string, error) {
|
|
||||||
var headers []string
|
|
||||||
err := filepath.WalkDir(directory, func(path string, d fs.DirEntry, err error) error {
|
|
||||||
if err != nil {
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
if !d.IsDir() && strings.HasSuffix(path, ".h") {
|
|
||||||
headers = append(headers, path)
|
|
||||||
}
|
|
||||||
return nil
|
|
||||||
})
|
|
||||||
return headers, err
|
|
||||||
}
|
|
||||||
|
|
||||||
func cleanContent(content string) string {
|
|
||||||
// Remove single-line comments
|
|
||||||
re := regexp.MustCompile(`//.*?\n`)
|
|
||||||
content = re.ReplaceAllString(content, "\n")
|
|
||||||
|
|
||||||
// Remove multi-line comments
|
|
||||||
re = regexp.MustCompile(`/\*.*?\*/`)
|
|
||||||
content = re.ReplaceAllString(content, "")
|
|
||||||
|
|
||||||
// Remove preprocessor directives (lines starting with #) - use multiline mode
|
|
||||||
re = regexp.MustCompile(`(?m)^\s*#.*?$`)
|
|
||||||
content = re.ReplaceAllString(content, "")
|
|
||||||
|
|
||||||
// Remove extern "C" { and } blocks more conservatively
|
|
||||||
// Only remove the extern "C" { line, not the content inside
|
|
||||||
re = regexp.MustCompile(`extern\s+"C"\s*\{\s*?\n`)
|
|
||||||
content = re.ReplaceAllString(content, "\n")
|
|
||||||
// Remove standalone closing braces that are not part of function declarations
|
|
||||||
re = regexp.MustCompile(`\n\s*\}\s*\n`)
|
|
||||||
content = re.ReplaceAllString(content, "\n")
|
|
||||||
|
|
||||||
// Collapse whitespace and newlines
|
|
||||||
re = regexp.MustCompile(`\s+`)
|
|
||||||
content = re.ReplaceAllString(content, " ")
|
|
||||||
|
|
||||||
return content
|
|
||||||
}
|
|
||||||
|
|
||||||
func extractParamNames(params string) []string {
|
|
||||||
if params == "" || strings.TrimSpace(params) == "void" {
|
|
||||||
return []string{}
|
|
||||||
}
|
|
||||||
|
|
||||||
var names []string
|
|
||||||
|
|
||||||
// Split by comma, but respect parentheses (for function pointers)
|
|
||||||
parts := splitParams(params)
|
|
||||||
|
|
||||||
// Remove array brackets
|
|
||||||
arrayBrackets := regexp.MustCompile(`\[.*?\]`)
|
|
||||||
|
|
||||||
// Function pointer pattern
|
|
||||||
funcPtrPattern := regexp.MustCompile(`\(\s*\*\s*(\w+)\s*\)`)
|
|
||||||
|
|
||||||
// Type keywords to skip
|
|
||||||
typeKeywords := map[string]bool{
|
|
||||||
"const": true,
|
|
||||||
"struct": true,
|
|
||||||
"unsigned": true,
|
|
||||||
"signed": true,
|
|
||||||
"long": true,
|
|
||||||
"short": true,
|
|
||||||
"int": true,
|
|
||||||
"char": true,
|
|
||||||
"float": true,
|
|
||||||
"double": true,
|
|
||||||
"void": true,
|
|
||||||
"size_t": true,
|
|
||||||
"uint8_t": true,
|
|
||||||
"uint16_t": true,
|
|
||||||
"uint32_t": true,
|
|
||||||
"uint64_t": true,
|
|
||||||
"int8_t": true,
|
|
||||||
"int16_t": true,
|
|
||||||
"int32_t": true,
|
|
||||||
"int64_t": true,
|
|
||||||
"intptr_t": true,
|
|
||||||
"uintptr_t": true,
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, part := range parts {
|
|
||||||
if part == "" {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
// Remove array brackets
|
|
||||||
part = arrayBrackets.ReplaceAllString(part, "")
|
|
||||||
|
|
||||||
// For function pointers like "void (*callback)(int)"
|
|
||||||
if matches := funcPtrPattern.FindStringSubmatch(part); len(matches) > 1 {
|
|
||||||
names = append(names, matches[1])
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
// Regular parameter: last identifier
|
|
||||||
tokens := regexp.MustCompile(`\w+`).FindAllString(part, -1)
|
|
||||||
if len(tokens) > 0 {
|
|
||||||
// The last token is usually the parameter name
|
|
||||||
// Skip type keywords
|
|
||||||
for i := len(tokens) - 1; i >= 0; i-- {
|
|
||||||
if !typeKeywords[tokens[i]] {
|
|
||||||
names = append(names, tokens[i])
|
|
||||||
break
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
return names
|
|
||||||
}
|
|
||||||
|
|
||||||
func splitParams(params string) []string {
|
|
||||||
var parts []string
|
|
||||||
var current bytes.Buffer
|
|
||||||
depth := 0
|
|
||||||
|
|
||||||
for _, char := range params + "," {
|
|
||||||
switch char {
|
|
||||||
case '(':
|
|
||||||
depth++
|
|
||||||
current.WriteRune(char)
|
|
||||||
case ')':
|
|
||||||
depth--
|
|
||||||
current.WriteRune(char)
|
|
||||||
case ',':
|
|
||||||
if depth == 0 {
|
|
||||||
parts = append(parts, strings.TrimSpace(current.String()))
|
|
||||||
current.Reset()
|
|
||||||
} else {
|
|
||||||
current.WriteRune(char)
|
|
||||||
}
|
|
||||||
default:
|
|
||||||
current.WriteRune(char)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
return parts
|
|
||||||
}
|
|
||||||
|
|
||||||
func parseFunctions(content string) []Function {
|
|
||||||
var functions []Function
|
|
||||||
|
|
||||||
// Match function declarations: return_type function_name(params);
|
|
||||||
// Matches both mlx_* and _mlx_* functions
|
|
||||||
pattern := regexp.MustCompile(`\b((?:const\s+)?(?:struct\s+)?[\w\s]+?[\*\s]*)\s+(_?mlx_\w+)\s*\(([^)]*(?:\([^)]*\)[^)]*)*)\)\s*;`)
|
|
||||||
|
|
||||||
matches := pattern.FindAllStringSubmatch(content, -1)
|
|
||||||
for _, match := range matches {
|
|
||||||
returnType := strings.TrimSpace(match[1])
|
|
||||||
funcName := strings.TrimSpace(match[2])
|
|
||||||
params := strings.TrimSpace(match[3])
|
|
||||||
|
|
||||||
// Skip if this looks like a variable declaration
|
|
||||||
if params == "" || strings.Contains(params, "{") {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
// Clean up return type
|
|
||||||
returnType = strings.Join(strings.Fields(returnType), " ")
|
|
||||||
|
|
||||||
// Extract parameter names
|
|
||||||
paramNames := extractParamNames(params)
|
|
||||||
|
|
||||||
// Check if ARM64 guard is needed
|
|
||||||
needsGuard := needsARM64Guard(funcName, returnType, params)
|
|
||||||
|
|
||||||
functions = append(functions, Function{
|
|
||||||
Name: funcName,
|
|
||||||
ReturnType: returnType,
|
|
||||||
Params: params,
|
|
||||||
ParamNames: paramNames,
|
|
||||||
NeedsARM64Guard: needsGuard,
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
return functions
|
|
||||||
}
|
|
||||||
|
|
||||||
func needsARM64Guard(name, retType, params string) bool {
|
|
||||||
return strings.Contains(name, "float16") ||
|
|
||||||
strings.Contains(name, "bfloat16") ||
|
|
||||||
strings.Contains(retType, "float16_t") ||
|
|
||||||
strings.Contains(retType, "bfloat16_t") ||
|
|
||||||
strings.Contains(params, "float16_t") ||
|
|
||||||
strings.Contains(params, "bfloat16_t")
|
|
||||||
}
|
|
||||||
|
|
||||||
func generateWrapperFiles(functions []Function, headerPath, implPath string) error {
|
|
||||||
// Generate header file
|
|
||||||
var headerBuf bytes.Buffer
|
|
||||||
|
|
||||||
headerBuf.WriteString("// AUTO-GENERATED by generate_wrappers.go - DO NOT EDIT\n")
|
|
||||||
headerBuf.WriteString("// This file provides wrapper declarations for MLX-C functions that use dlopen/dlsym\n")
|
|
||||||
headerBuf.WriteString("//\n")
|
|
||||||
headerBuf.WriteString("// Strategy: Include MLX-C headers for type definitions, then provide wrapper\n")
|
|
||||||
headerBuf.WriteString("// functions that shadow the originals, allowing Go code to call them directly (e.g., C.mlx_add).\n")
|
|
||||||
headerBuf.WriteString("// Function pointers are defined in mlx.c (single compilation unit).\n\n")
|
|
||||||
headerBuf.WriteString("#ifndef MLX_WRAPPERS_H\n")
|
|
||||||
headerBuf.WriteString("#define MLX_WRAPPERS_H\n\n")
|
|
||||||
|
|
||||||
headerBuf.WriteString("// Include MLX headers for type definitions and original declarations\n")
|
|
||||||
headerBuf.WriteString("#include \"mlx/c/mlx.h\"\n")
|
|
||||||
headerBuf.WriteString("#include \"mlx_dynamic.h\"\n")
|
|
||||||
headerBuf.WriteString("#include <stdio.h>\n\n")
|
|
||||||
|
|
||||||
// Undef all MLX functions to avoid conflicts
|
|
||||||
headerBuf.WriteString("// Undefine any existing MLX function macros\n")
|
|
||||||
for _, fn := range functions {
|
|
||||||
headerBuf.WriteString(fmt.Sprintf("#undef %s\n", fn.Name))
|
|
||||||
}
|
|
||||||
headerBuf.WriteString("\n")
|
|
||||||
|
|
||||||
// Function pointer extern declarations
|
|
||||||
headerBuf.WriteString("// Function pointer declarations (defined in mlx.c, loaded via dlsym)\n")
|
|
||||||
for _, fn := range functions {
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
headerBuf.WriteString("#if defined(__aarch64__) || defined(_M_ARM64)\n")
|
|
||||||
}
|
|
||||||
headerBuf.WriteString(fmt.Sprintf("extern %s (*%s_ptr)(%s);\n", fn.ReturnType, fn.Name, fn.Params))
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
headerBuf.WriteString("#endif\n")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
headerBuf.WriteString("\n")
|
|
||||||
|
|
||||||
// Initialization function declaration
|
|
||||||
headerBuf.WriteString("// Initialize all function pointers via dlsym (defined in mlx.c)\n")
|
|
||||||
headerBuf.WriteString("int mlx_load_functions(void* handle);\n\n")
|
|
||||||
|
|
||||||
// Wrapper function declarations
|
|
||||||
headerBuf.WriteString("// Wrapper function declarations that call through function pointers\n")
|
|
||||||
headerBuf.WriteString("// Go code calls these directly as C.mlx_* (no #define redirection needed)\n")
|
|
||||||
for _, fn := range functions {
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
headerBuf.WriteString("#if defined(__aarch64__) || defined(_M_ARM64)\n")
|
|
||||||
}
|
|
||||||
headerBuf.WriteString(fmt.Sprintf("%s %s(%s);\n", fn.ReturnType, fn.Name, fn.Params))
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
headerBuf.WriteString("#endif\n")
|
|
||||||
}
|
|
||||||
headerBuf.WriteString("\n")
|
|
||||||
}
|
|
||||||
|
|
||||||
headerBuf.WriteString("#endif // MLX_WRAPPERS_H\n")
|
|
||||||
|
|
||||||
// Write header file
|
|
||||||
if err := os.WriteFile(headerPath, headerBuf.Bytes(), 0644); err != nil {
|
|
||||||
return fmt.Errorf("failed to write header file: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Generate implementation file
|
|
||||||
var implBuf bytes.Buffer
|
|
||||||
|
|
||||||
implBuf.WriteString("// AUTO-GENERATED by generate_wrappers.go - DO NOT EDIT\n")
|
|
||||||
implBuf.WriteString("// This file contains the function pointer definitions and initialization\n")
|
|
||||||
implBuf.WriteString("// All function pointers are in a single compilation unit to avoid duplication\n\n")
|
|
||||||
|
|
||||||
implBuf.WriteString("#include \"mlx/c/mlx.h\"\n")
|
|
||||||
implBuf.WriteString("#include \"mlx_dynamic.h\"\n")
|
|
||||||
implBuf.WriteString("#include <stdio.h>\n")
|
|
||||||
implBuf.WriteString("#include <dlfcn.h>\n\n")
|
|
||||||
|
|
||||||
// Function pointer definitions
|
|
||||||
implBuf.WriteString("// Function pointer definitions\n")
|
|
||||||
for _, fn := range functions {
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
implBuf.WriteString("#if defined(__aarch64__) || defined(_M_ARM64)\n")
|
|
||||||
}
|
|
||||||
implBuf.WriteString(fmt.Sprintf("%s (*%s_ptr)(%s) = NULL;\n", fn.ReturnType, fn.Name, fn.Params))
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
implBuf.WriteString("#endif\n")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
implBuf.WriteString("\n")
|
|
||||||
|
|
||||||
// Initialization function
|
|
||||||
implBuf.WriteString("// Initialize all function pointers via dlsym\n")
|
|
||||||
implBuf.WriteString("int mlx_load_functions(void* handle) {\n")
|
|
||||||
implBuf.WriteString(" if (handle == NULL) {\n")
|
|
||||||
implBuf.WriteString(" fprintf(stderr, \"MLX: Invalid library handle\\n\");\n")
|
|
||||||
implBuf.WriteString(" return -1;\n")
|
|
||||||
implBuf.WriteString(" }\n\n")
|
|
||||||
|
|
||||||
for _, fn := range functions {
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
implBuf.WriteString("#if defined(__aarch64__) || defined(_M_ARM64)\n")
|
|
||||||
}
|
|
||||||
implBuf.WriteString(fmt.Sprintf(" %s_ptr = dlsym(handle, \"%s\");\n", fn.Name, fn.Name))
|
|
||||||
implBuf.WriteString(fmt.Sprintf(" if (%s_ptr == NULL) {\n", fn.Name))
|
|
||||||
implBuf.WriteString(fmt.Sprintf(" fprintf(stderr, \"MLX: Failed to load symbol: %s\\n\");\n", fn.Name))
|
|
||||||
implBuf.WriteString(" return -1;\n")
|
|
||||||
implBuf.WriteString(" }\n")
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
implBuf.WriteString("#endif\n")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
implBuf.WriteString(" return 0;\n")
|
|
||||||
implBuf.WriteString("}\n\n")
|
|
||||||
|
|
||||||
// Wrapper function implementations
|
|
||||||
implBuf.WriteString("// Wrapper function implementations that call through function pointers\n")
|
|
||||||
for _, fn := range functions {
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
implBuf.WriteString("#if defined(__aarch64__) || defined(_M_ARM64)\n")
|
|
||||||
}
|
|
||||||
implBuf.WriteString(fmt.Sprintf("%s %s(%s) {\n", fn.ReturnType, fn.Name, fn.Params))
|
|
||||||
|
|
||||||
// Call through function pointer
|
|
||||||
if fn.ReturnType != "void" {
|
|
||||||
implBuf.WriteString(fmt.Sprintf(" return %s_ptr(", fn.Name))
|
|
||||||
} else {
|
|
||||||
implBuf.WriteString(fmt.Sprintf(" %s_ptr(", fn.Name))
|
|
||||||
}
|
|
||||||
|
|
||||||
// Pass parameters
|
|
||||||
implBuf.WriteString(strings.Join(fn.ParamNames, ", "))
|
|
||||||
implBuf.WriteString(");\n")
|
|
||||||
implBuf.WriteString("}\n")
|
|
||||||
if fn.NeedsARM64Guard {
|
|
||||||
implBuf.WriteString("#endif\n")
|
|
||||||
}
|
|
||||||
implBuf.WriteString("\n")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Write implementation file
|
|
||||||
if err := os.WriteFile(implPath, implBuf.Bytes(), 0644); err != nil {
|
|
||||||
return fmt.Errorf("failed to write implementation file: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
|
|
||||||
func main() {
|
|
||||||
flag.Usage = func() {
|
|
||||||
fmt.Fprintf(flag.CommandLine.Output(), "Usage: go run generate_wrappers.go <mlx-c-include-dir> <output-header> [output-impl]\n")
|
|
||||||
fmt.Fprintf(flag.CommandLine.Output(), "Generate MLX-C dynamic loading wrappers.\n\n")
|
|
||||||
flag.PrintDefaults()
|
|
||||||
}
|
|
||||||
flag.Parse()
|
|
||||||
|
|
||||||
args := flag.Args()
|
|
||||||
if len(args) < 2 {
|
|
||||||
fmt.Fprintf(flag.CommandLine.Output(), "ERROR: Missing required arguments\n\n")
|
|
||||||
flag.Usage()
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
|
|
||||||
headerDir := args[0]
|
|
||||||
outputHeader := args[1]
|
|
||||||
// Default implementation file is same name with .c extension
|
|
||||||
outputImpl := outputHeader
|
|
||||||
if len(args) > 2 {
|
|
||||||
outputImpl = args[2]
|
|
||||||
} else if strings.HasSuffix(outputHeader, ".h") {
|
|
||||||
outputImpl = outputHeader[:len(outputHeader)-2] + ".c"
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check if header directory exists
|
|
||||||
if _, err := os.Stat(headerDir); os.IsNotExist(err) {
|
|
||||||
fmt.Fprintf(os.Stderr, "ERROR: MLX-C headers directory not found at: %s\n\n", headerDir)
|
|
||||||
fmt.Fprintf(os.Stderr, "Please run CMake first to download MLX-C dependencies:\n")
|
|
||||||
fmt.Fprintf(os.Stderr, " cmake -B build\n\n")
|
|
||||||
fmt.Fprintf(os.Stderr, "The CMake build will download and extract MLX-C headers needed for wrapper generation.\n")
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
|
|
||||||
fmt.Fprintf(os.Stderr, "Parsing MLX-C headers from: %s\n", headerDir)
|
|
||||||
|
|
||||||
// Find all headers
|
|
||||||
headers, err := findHeaders(headerDir)
|
|
||||||
if err != nil {
|
|
||||||
fmt.Fprintf(os.Stderr, "ERROR: Failed to find header files: %v\n", err)
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
fmt.Fprintf(os.Stderr, "Found %d header files\n", len(headers))
|
|
||||||
|
|
||||||
// Parse all headers
|
|
||||||
var allFunctions []Function
|
|
||||||
seen := make(map[string]bool)
|
|
||||||
|
|
||||||
for _, header := range headers {
|
|
||||||
content, err := os.ReadFile(header)
|
|
||||||
if err != nil {
|
|
||||||
fmt.Fprintf(os.Stderr, "Error reading %s: %v\n", header, err)
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
cleaned := cleanContent(string(content))
|
|
||||||
functions := parseFunctions(cleaned)
|
|
||||||
|
|
||||||
// Deduplicate
|
|
||||||
for _, fn := range functions {
|
|
||||||
if !seen[fn.Name] {
|
|
||||||
seen[fn.Name] = true
|
|
||||||
allFunctions = append(allFunctions, fn)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
fmt.Fprintf(os.Stderr, "Found %d unique function declarations\n", len(allFunctions))
|
|
||||||
|
|
||||||
// Generate wrapper files
|
|
||||||
if err := generateWrapperFiles(allFunctions, outputHeader, outputImpl); err != nil {
|
|
||||||
fmt.Fprintf(os.Stderr, "ERROR: Failed to generate wrapper files: %v\n", err)
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
|
|
||||||
fmt.Fprintf(os.Stderr, "Generated %s and %s successfully\n", outputHeader, outputImpl)
|
|
||||||
}
|
|
||||||
5786
x/imagegen/mlx/mlx.c
@@ -3,13 +3,12 @@
|
|||||||
package mlx
|
package mlx
|
||||||
|
|
||||||
/*
|
/*
|
||||||
#cgo CFLAGS: -O3 -I${SRCDIR}/../../../build/_deps/mlx-c-src -I${SRCDIR}
|
#cgo CFLAGS: -O3 -I${SRCDIR}/../../../build/_deps/mlx-c-src
|
||||||
|
#cgo LDFLAGS: -L${SRCDIR}/../../../build/lib/ollama/ -lmlxc -Wl,-rpath,${SRCDIR}/../../../build/lib/ollama/
|
||||||
#cgo darwin LDFLAGS: -lc++ -framework Metal -framework Foundation -framework Accelerate
|
#cgo darwin LDFLAGS: -lc++ -framework Metal -framework Foundation -framework Accelerate
|
||||||
#cgo linux LDFLAGS: -lstdc++ -ldl
|
#cgo linux LDFLAGS: -lstdc++ -lcuda -lcudart -lnvrtc
|
||||||
#cgo windows LDFLAGS: -lstdc++
|
|
||||||
|
|
||||||
// Use generated wrappers instead of direct MLX headers
|
#include "mlx/c/mlx.h"
|
||||||
#include "mlx.h"
|
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
#include <stdint.h>
|
#include <stdint.h>
|
||||||
#include <string.h>
|
#include <string.h>
|
||||||
@@ -43,6 +42,192 @@ static inline mlx_stream cpu_stream() {
|
|||||||
// CGO noescape/nocallback hints to reduce CGO overhead
|
// CGO noescape/nocallback hints to reduce CGO overhead
|
||||||
// noescape: pointers won't escape, no heap allocation needed
|
// noescape: pointers won't escape, no heap allocation needed
|
||||||
// nocallback: function won't call back into Go
|
// nocallback: function won't call back into Go
|
||||||
|
#cgo noescape mlx_add
|
||||||
|
#cgo nocallback mlx_add
|
||||||
|
#cgo noescape mlx_subtract
|
||||||
|
#cgo nocallback mlx_subtract
|
||||||
|
#cgo noescape mlx_multiply
|
||||||
|
#cgo nocallback mlx_multiply
|
||||||
|
#cgo noescape mlx_divide
|
||||||
|
#cgo nocallback mlx_divide
|
||||||
|
#cgo noescape mlx_negative
|
||||||
|
#cgo nocallback mlx_negative
|
||||||
|
#cgo noescape mlx_abs
|
||||||
|
#cgo nocallback mlx_abs
|
||||||
|
#cgo noescape mlx_exp
|
||||||
|
#cgo nocallback mlx_exp
|
||||||
|
#cgo noescape mlx_log
|
||||||
|
#cgo nocallback mlx_log
|
||||||
|
#cgo noescape mlx_sqrt
|
||||||
|
#cgo nocallback mlx_sqrt
|
||||||
|
#cgo noescape mlx_rsqrt
|
||||||
|
#cgo nocallback mlx_rsqrt
|
||||||
|
#cgo noescape mlx_square
|
||||||
|
#cgo nocallback mlx_square
|
||||||
|
#cgo noescape mlx_power
|
||||||
|
#cgo nocallback mlx_power
|
||||||
|
#cgo noescape mlx_erf
|
||||||
|
#cgo nocallback mlx_erf
|
||||||
|
#cgo noescape mlx_sigmoid
|
||||||
|
#cgo nocallback mlx_sigmoid
|
||||||
|
#cgo noescape mlx_tanh
|
||||||
|
#cgo nocallback mlx_tanh
|
||||||
|
#cgo noescape mlx_sin
|
||||||
|
#cgo nocallback mlx_sin
|
||||||
|
#cgo noescape mlx_cos
|
||||||
|
#cgo nocallback mlx_cos
|
||||||
|
#cgo noescape mlx_maximum
|
||||||
|
#cgo nocallback mlx_maximum
|
||||||
|
#cgo noescape mlx_minimum
|
||||||
|
#cgo nocallback mlx_minimum
|
||||||
|
#cgo noescape mlx_clip
|
||||||
|
#cgo nocallback mlx_clip
|
||||||
|
#cgo noescape mlx_sum
|
||||||
|
#cgo nocallback mlx_sum
|
||||||
|
#cgo noescape mlx_sum_axis
|
||||||
|
#cgo nocallback mlx_sum_axis
|
||||||
|
#cgo noescape mlx_mean
|
||||||
|
#cgo nocallback mlx_mean
|
||||||
|
#cgo noescape mlx_mean_axis
|
||||||
|
#cgo nocallback mlx_mean_axis
|
||||||
|
#cgo noescape mlx_var_axis
|
||||||
|
#cgo nocallback mlx_var_axis
|
||||||
|
#cgo noescape mlx_argmax
|
||||||
|
#cgo nocallback mlx_argmax
|
||||||
|
#cgo noescape mlx_argmax_axis
|
||||||
|
#cgo nocallback mlx_argmax_axis
|
||||||
|
#cgo noescape mlx_softmax_axis
|
||||||
|
#cgo nocallback mlx_softmax_axis
|
||||||
|
#cgo noescape mlx_cumsum
|
||||||
|
#cgo nocallback mlx_cumsum
|
||||||
|
#cgo noescape mlx_matmul
|
||||||
|
#cgo nocallback mlx_matmul
|
||||||
|
#cgo noescape mlx_addmm
|
||||||
|
#cgo nocallback mlx_addmm
|
||||||
|
#cgo noescape mlx_gather_mm
|
||||||
|
#cgo nocallback mlx_gather_mm
|
||||||
|
#cgo noescape mlx_gather_qmm
|
||||||
|
#cgo nocallback mlx_gather_qmm
|
||||||
|
#cgo noescape mlx_reshape
|
||||||
|
#cgo nocallback mlx_reshape
|
||||||
|
#cgo noescape mlx_transpose_axes
|
||||||
|
#cgo nocallback mlx_transpose_axes
|
||||||
|
#cgo noescape mlx_expand_dims
|
||||||
|
#cgo nocallback mlx_expand_dims
|
||||||
|
#cgo noescape mlx_squeeze_axis
|
||||||
|
#cgo nocallback mlx_squeeze_axis
|
||||||
|
#cgo noescape mlx_flatten
|
||||||
|
#cgo nocallback mlx_flatten
|
||||||
|
#cgo noescape mlx_concatenate_axis
|
||||||
|
#cgo nocallback mlx_concatenate_axis
|
||||||
|
#cgo noescape mlx_slice
|
||||||
|
#cgo nocallback mlx_slice
|
||||||
|
#cgo noescape mlx_slice_update
|
||||||
|
#cgo nocallback mlx_slice_update
|
||||||
|
#cgo noescape mlx_as_strided
|
||||||
|
#cgo nocallback mlx_as_strided
|
||||||
|
#cgo noescape mlx_view
|
||||||
|
#cgo nocallback mlx_view
|
||||||
|
#cgo noescape mlx_contiguous
|
||||||
|
#cgo nocallback mlx_contiguous
|
||||||
|
#cgo noescape mlx_pad
|
||||||
|
#cgo nocallback mlx_pad
|
||||||
|
#cgo noescape mlx_tile
|
||||||
|
#cgo nocallback mlx_tile
|
||||||
|
#cgo noescape mlx_take_axis
|
||||||
|
#cgo nocallback mlx_take_axis
|
||||||
|
#cgo noescape mlx_take_along_axis
|
||||||
|
#cgo nocallback mlx_take_along_axis
|
||||||
|
#cgo noescape mlx_put_along_axis
|
||||||
|
#cgo nocallback mlx_put_along_axis
|
||||||
|
#cgo noescape mlx_where
|
||||||
|
#cgo nocallback mlx_where
|
||||||
|
#cgo noescape mlx_argsort_axis
|
||||||
|
#cgo nocallback mlx_argsort_axis
|
||||||
|
#cgo noescape mlx_argpartition_axis
|
||||||
|
#cgo nocallback mlx_argpartition_axis
|
||||||
|
#cgo noescape mlx_topk_axis
|
||||||
|
#cgo nocallback mlx_topk_axis
|
||||||
|
#cgo noescape mlx_less
|
||||||
|
#cgo nocallback mlx_less
|
||||||
|
#cgo noescape mlx_greater_equal
|
||||||
|
#cgo nocallback mlx_greater_equal
|
||||||
|
#cgo noescape mlx_logical_and
|
||||||
|
#cgo nocallback mlx_logical_and
|
||||||
|
#cgo noescape mlx_zeros
|
||||||
|
#cgo nocallback mlx_zeros
|
||||||
|
#cgo noescape mlx_zeros_like
|
||||||
|
#cgo nocallback mlx_zeros_like
|
||||||
|
#cgo noescape mlx_ones
|
||||||
|
#cgo nocallback mlx_ones
|
||||||
|
#cgo noescape mlx_full
|
||||||
|
#cgo nocallback mlx_full
|
||||||
|
#cgo noescape mlx_arange
|
||||||
|
#cgo nocallback mlx_arange
|
||||||
|
#cgo noescape mlx_linspace
|
||||||
|
#cgo nocallback mlx_linspace
|
||||||
|
#cgo noescape mlx_tri
|
||||||
|
#cgo nocallback mlx_tri
|
||||||
|
#cgo noescape mlx_astype
|
||||||
|
#cgo nocallback mlx_astype
|
||||||
|
#cgo noescape mlx_fast_rms_norm
|
||||||
|
#cgo nocallback mlx_fast_rms_norm
|
||||||
|
#cgo noescape mlx_fast_rope
|
||||||
|
#cgo nocallback mlx_fast_rope
|
||||||
|
#cgo noescape mlx_fast_scaled_dot_product_attention
|
||||||
|
#cgo nocallback mlx_fast_scaled_dot_product_attention
|
||||||
|
#cgo noescape mlx_conv2d
|
||||||
|
#cgo nocallback mlx_conv2d
|
||||||
|
#cgo noescape mlx_conv3d
|
||||||
|
#cgo nocallback mlx_conv3d
|
||||||
|
#cgo noescape mlx_random_key
|
||||||
|
#cgo nocallback mlx_random_key
|
||||||
|
#cgo noescape mlx_random_split
|
||||||
|
#cgo nocallback mlx_random_split
|
||||||
|
#cgo noescape mlx_random_categorical_num_samples
|
||||||
|
#cgo nocallback mlx_random_categorical_num_samples
|
||||||
|
#cgo noescape mlx_random_normal
|
||||||
|
#cgo nocallback mlx_random_normal
|
||||||
|
#cgo noescape mlx_random_uniform
|
||||||
|
#cgo nocallback mlx_random_uniform
|
||||||
|
#cgo noescape mlx_array_eval
|
||||||
|
#cgo nocallback mlx_array_eval
|
||||||
|
#cgo noescape mlx_eval
|
||||||
|
#cgo nocallback mlx_eval
|
||||||
|
#cgo noescape mlx_async_eval
|
||||||
|
#cgo nocallback mlx_async_eval
|
||||||
|
#cgo noescape mlx_synchronize
|
||||||
|
#cgo nocallback mlx_synchronize
|
||||||
|
#cgo noescape mlx_array_new
|
||||||
|
#cgo nocallback mlx_array_new
|
||||||
|
#cgo noescape mlx_array_new_data
|
||||||
|
#cgo nocallback mlx_array_new_data
|
||||||
|
#cgo noescape mlx_array_new_float
|
||||||
|
#cgo nocallback mlx_array_new_float
|
||||||
|
#cgo noescape mlx_array_free
|
||||||
|
#cgo nocallback mlx_array_free
|
||||||
|
#cgo noescape mlx_array_size
|
||||||
|
#cgo nocallback mlx_array_size
|
||||||
|
#cgo noescape mlx_array_ndim
|
||||||
|
#cgo nocallback mlx_array_ndim
|
||||||
|
#cgo noescape mlx_array_dim
|
||||||
|
#cgo nocallback mlx_array_dim
|
||||||
|
#cgo noescape mlx_array_dtype
|
||||||
|
#cgo nocallback mlx_array_dtype
|
||||||
|
#cgo noescape mlx_array_item_int32
|
||||||
|
#cgo nocallback mlx_array_item_int32
|
||||||
|
#cgo noescape mlx_vector_array_new_data
|
||||||
|
#cgo nocallback mlx_vector_array_new_data
|
||||||
|
#cgo noescape mlx_vector_array_free
|
||||||
|
#cgo nocallback mlx_vector_array_free
|
||||||
|
#cgo noescape mlx_array_new_int
|
||||||
|
#cgo nocallback mlx_array_new_int
|
||||||
|
#cgo noescape mlx_stream_new_device
|
||||||
|
#cgo nocallback mlx_stream_new_device
|
||||||
|
#cgo noescape mlx_get_default_stream
|
||||||
|
#cgo nocallback mlx_get_default_stream
|
||||||
|
#cgo noescape mlx_set_default_stream
|
||||||
|
#cgo nocallback mlx_set_default_stream
|
||||||
*/
|
*/
|
||||||
import "C"
|
import "C"
|
||||||
import (
|
import (
|
||||||
@@ -1611,57 +1796,7 @@ func ArgmaxKeepArray(logits *Array) *Array {
|
|||||||
var RandomState = []*Array{nil}
|
var RandomState = []*Array{nil}
|
||||||
var randomStateMu sync.Mutex
|
var randomStateMu sync.Mutex
|
||||||
|
|
||||||
var mlxInitialized bool
|
|
||||||
var mlxInitError error
|
|
||||||
|
|
||||||
// InitMLX initializes the MLX library by dynamically loading libmlxc.
|
|
||||||
// This must be called before using any MLX functions.
|
|
||||||
// Returns an error if the library cannot be loaded.
|
|
||||||
func InitMLX() error {
|
|
||||||
if mlxInitialized {
|
|
||||||
return mlxInitError
|
|
||||||
}
|
|
||||||
|
|
||||||
// Try to load the MLX dynamic library
|
|
||||||
ret := C.mlx_dynamic_init()
|
|
||||||
if ret != 0 {
|
|
||||||
errMsg := C.GoString(C.mlx_dynamic_error())
|
|
||||||
mlxInitError = fmt.Errorf("failed to initialize MLX: %s", errMsg)
|
|
||||||
return mlxInitError
|
|
||||||
}
|
|
||||||
|
|
||||||
// Initialize all function pointers via dlsym
|
|
||||||
handle := C.mlx_get_handle()
|
|
||||||
ret = C.mlx_load_functions(handle)
|
|
||||||
if ret != 0 {
|
|
||||||
mlxInitError = fmt.Errorf("failed to load MLX function symbols")
|
|
||||||
return mlxInitError
|
|
||||||
}
|
|
||||||
|
|
||||||
mlxInitialized = true
|
|
||||||
mlxInitError = nil
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// IsMLXAvailable returns whether MLX was successfully initialized
|
|
||||||
func IsMLXAvailable() bool {
|
|
||||||
return mlxInitialized && mlxInitError == nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// GetMLXInitError returns any error that occurred during MLX initialization
|
|
||||||
func GetMLXInitError() error {
|
|
||||||
return mlxInitError
|
|
||||||
}
|
|
||||||
|
|
||||||
func init() {
|
func init() {
|
||||||
// Initialize MLX dynamic library first
|
|
||||||
if err := InitMLX(); err != nil {
|
|
||||||
// Don't panic in init - let the caller handle the error
|
|
||||||
// Store the error for later retrieval
|
|
||||||
mlxInitError = err
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
// Lock main goroutine to OS thread for CUDA context stability.
|
// Lock main goroutine to OS thread for CUDA context stability.
|
||||||
// CUDA contexts are bound to threads; Go can migrate goroutines between threads.
|
// CUDA contexts are bound to threads; Go can migrate goroutines between threads.
|
||||||
runtime.LockOSThread()
|
runtime.LockOSThread()
|
||||||
|
|||||||
2337
x/imagegen/mlx/mlx.h
@@ -1,144 +0,0 @@
|
|||||||
// mlx_dynamic.c - Dynamic loading wrapper for MLX-C library
|
|
||||||
// This file provides runtime dynamic loading of libmlxc instead of link-time binding
|
|
||||||
|
|
||||||
#include "mlx_dynamic.h"
|
|
||||||
#include <stdio.h>
|
|
||||||
#include <stdlib.h>
|
|
||||||
#include <string.h>
|
|
||||||
|
|
||||||
#ifdef _WIN32
|
|
||||||
#include <windows.h>
|
|
||||||
typedef HMODULE lib_handle_t;
|
|
||||||
#define LOAD_LIB(path) LoadLibraryA(path)
|
|
||||||
#define GET_SYMBOL(handle, name) GetProcAddress(handle, name)
|
|
||||||
#define CLOSE_LIB(handle) FreeLibrary(handle)
|
|
||||||
#define LIB_ERROR() "LoadLibrary failed"
|
|
||||||
#else
|
|
||||||
#include <dlfcn.h>
|
|
||||||
typedef void* lib_handle_t;
|
|
||||||
#define LOAD_LIB(path) dlopen(path, RTLD_LAZY | RTLD_GLOBAL)
|
|
||||||
#define GET_SYMBOL(handle, name) dlsym(handle, name)
|
|
||||||
#define CLOSE_LIB(handle) dlclose(handle)
|
|
||||||
#define LIB_ERROR() dlerror()
|
|
||||||
#ifdef __APPLE__
|
|
||||||
#include <mach-o/dyld.h>
|
|
||||||
#include <libgen.h>
|
|
||||||
#endif
|
|
||||||
#endif
|
|
||||||
|
|
||||||
static lib_handle_t mlx_handle = NULL;
|
|
||||||
static int mlx_initialized = 0;
|
|
||||||
static char mlx_error_buffer[512] = {0};
|
|
||||||
|
|
||||||
#ifdef __APPLE__
|
|
||||||
// Get path to library in same directory as executable
|
|
||||||
static char* get_exe_relative_path(const char* libname) {
|
|
||||||
static char path[1024];
|
|
||||||
uint32_t size = sizeof(path);
|
|
||||||
if (_NSGetExecutablePath(path, &size) != 0) {
|
|
||||||
return NULL;
|
|
||||||
}
|
|
||||||
// Get directory of executable
|
|
||||||
char* dir = dirname(path);
|
|
||||||
static char fullpath[1024];
|
|
||||||
snprintf(fullpath, sizeof(fullpath), "%s/%s", dir, libname);
|
|
||||||
return fullpath;
|
|
||||||
}
|
|
||||||
#endif
|
|
||||||
|
|
||||||
// Try to load library from a specific path
|
|
||||||
static int try_load_lib(const char* path) {
|
|
||||||
if (!path) return 0;
|
|
||||||
mlx_handle = LOAD_LIB(path);
|
|
||||||
return mlx_handle != NULL;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Initialize MLX dynamic library
|
|
||||||
// Returns 0 on success, -1 on failure
|
|
||||||
// On failure, call mlx_dynamic_error() to get error message
|
|
||||||
int mlx_dynamic_init(void) {
|
|
||||||
if (mlx_initialized) {
|
|
||||||
return 0; // Already initialized
|
|
||||||
}
|
|
||||||
|
|
||||||
const char* lib_path = NULL;
|
|
||||||
const char* tried_paths[8] = {0};
|
|
||||||
int num_tried = 0;
|
|
||||||
|
|
||||||
#ifdef _WIN32
|
|
||||||
// Windows: try same directory as executable
|
|
||||||
lib_path = "libmlxc.dll";
|
|
||||||
tried_paths[num_tried++] = lib_path;
|
|
||||||
if (try_load_lib(lib_path)) goto success;
|
|
||||||
#elif defined(__APPLE__)
|
|
||||||
// macOS: try executable directory first
|
|
||||||
lib_path = get_exe_relative_path("libmlxc.dylib");
|
|
||||||
if (lib_path) {
|
|
||||||
tried_paths[num_tried++] = lib_path;
|
|
||||||
if (try_load_lib(lib_path)) goto success;
|
|
||||||
}
|
|
||||||
// Try build directory (for tests run from repo root)
|
|
||||||
lib_path = "./build/lib/ollama/libmlxc.dylib";
|
|
||||||
tried_paths[num_tried++] = lib_path;
|
|
||||||
if (try_load_lib(lib_path)) goto success;
|
|
||||||
// Fallback to system paths
|
|
||||||
lib_path = "libmlxc.dylib";
|
|
||||||
tried_paths[num_tried++] = lib_path;
|
|
||||||
if (try_load_lib(lib_path)) goto success;
|
|
||||||
#else
|
|
||||||
// Linux: try build directory first (for tests)
|
|
||||||
lib_path = "./build/lib/ollama/libmlxc.so";
|
|
||||||
tried_paths[num_tried++] = lib_path;
|
|
||||||
if (try_load_lib(lib_path)) goto success;
|
|
||||||
// Fallback to system paths
|
|
||||||
lib_path = "libmlxc.so";
|
|
||||||
tried_paths[num_tried++] = lib_path;
|
|
||||||
if (try_load_lib(lib_path)) goto success;
|
|
||||||
#endif
|
|
||||||
|
|
||||||
// Failed to load library - build error message with all tried paths
|
|
||||||
{
|
|
||||||
const char* err = LIB_ERROR();
|
|
||||||
int offset = snprintf(mlx_error_buffer, sizeof(mlx_error_buffer),
|
|
||||||
"MLX: Failed to load libmlxc library. Tried: ");
|
|
||||||
for (int i = 0; i < num_tried && offset < (int)sizeof(mlx_error_buffer) - 50; i++) {
|
|
||||||
offset += snprintf(mlx_error_buffer + offset, sizeof(mlx_error_buffer) - offset,
|
|
||||||
"%s%s", i > 0 ? ", " : "", tried_paths[i]);
|
|
||||||
}
|
|
||||||
if (err) {
|
|
||||||
snprintf(mlx_error_buffer + offset, sizeof(mlx_error_buffer) - offset,
|
|
||||||
". Last error: %s", err);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return -1;
|
|
||||||
|
|
||||||
success:
|
|
||||||
mlx_initialized = 1;
|
|
||||||
snprintf(mlx_error_buffer, sizeof(mlx_error_buffer),
|
|
||||||
"MLX: Successfully loaded %s", lib_path ? lib_path : "library");
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Get the last error message
|
|
||||||
const char* mlx_dynamic_error(void) {
|
|
||||||
return mlx_error_buffer;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check if MLX is initialized
|
|
||||||
int mlx_dynamic_is_initialized(void) {
|
|
||||||
return mlx_initialized;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Get the library handle (for use by generated wrappers)
|
|
||||||
void* mlx_get_handle(void) {
|
|
||||||
return mlx_handle;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Cleanup (optional, called at program exit)
|
|
||||||
void mlx_dynamic_cleanup(void) {
|
|
||||||
if (mlx_handle != NULL) {
|
|
||||||
CLOSE_LIB(mlx_handle);
|
|
||||||
mlx_handle = NULL;
|
|
||||||
mlx_initialized = 0;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -1,29 +0,0 @@
|
|||||||
// mlx_dynamic.h - Dynamic loading interface for MLX-C library
|
|
||||||
#ifndef MLX_DYNAMIC_H
|
|
||||||
#define MLX_DYNAMIC_H
|
|
||||||
|
|
||||||
#ifdef __cplusplus
|
|
||||||
extern "C" {
|
|
||||||
#endif
|
|
||||||
|
|
||||||
// Initialize the MLX dynamic library
|
|
||||||
// Returns 0 on success, -1 on failure
|
|
||||||
int mlx_dynamic_init(void);
|
|
||||||
|
|
||||||
// Get the last error message from dynamic loading
|
|
||||||
const char* mlx_dynamic_error(void);
|
|
||||||
|
|
||||||
// Check if MLX is initialized
|
|
||||||
int mlx_dynamic_is_initialized(void);
|
|
||||||
|
|
||||||
// Get the library handle (for use by generated wrappers)
|
|
||||||
void* mlx_get_handle(void);
|
|
||||||
|
|
||||||
// Cleanup resources (optional, for clean shutdown)
|
|
||||||
void mlx_dynamic_cleanup(void);
|
|
||||||
|
|
||||||
#ifdef __cplusplus
|
|
||||||
}
|
|
||||||
#endif
|
|
||||||
|
|
||||||
#endif // MLX_DYNAMIC_H
|
|
||||||
@@ -4,30 +4,9 @@ package mlx
|
|||||||
|
|
||||||
import (
|
import (
|
||||||
"fmt"
|
"fmt"
|
||||||
"os"
|
|
||||||
"path/filepath"
|
|
||||||
"runtime"
|
|
||||||
"testing"
|
"testing"
|
||||||
)
|
)
|
||||||
|
|
||||||
// TestMain initializes MLX before running tests.
|
|
||||||
// If MLX libraries are not available, tests are skipped.
|
|
||||||
func TestMain(m *testing.M) {
|
|
||||||
// Change to repo root so ./build/lib/ollama/ path works
|
|
||||||
_, thisFile, _, _ := runtime.Caller(0)
|
|
||||||
repoRoot := filepath.Join(filepath.Dir(thisFile), "..", "..", "..")
|
|
||||||
if err := os.Chdir(repoRoot); err != nil {
|
|
||||||
fmt.Printf("Failed to change to repo root: %v\n", err)
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
|
|
||||||
if err := InitMLX(); err != nil {
|
|
||||||
fmt.Printf("Skipping MLX tests: %v\n", err)
|
|
||||||
os.Exit(0)
|
|
||||||
}
|
|
||||||
os.Exit(m.Run())
|
|
||||||
}
|
|
||||||
|
|
||||||
// TestBasicCleanup verifies non-kept arrays are freed and kept arrays survive.
|
// TestBasicCleanup verifies non-kept arrays are freed and kept arrays survive.
|
||||||
func TestBasicCleanup(t *testing.T) {
|
func TestBasicCleanup(t *testing.T) {
|
||||||
weight := NewArrayFloat32([]float32{1, 2, 3, 4}, []int32{2, 2})
|
weight := NewArrayFloat32([]float32{1, 2, 3, 4}, []int32{2, 2})
|
||||||
|
|||||||
@@ -3,33 +3,12 @@
|
|||||||
package qwen_image
|
package qwen_image
|
||||||
|
|
||||||
import (
|
import (
|
||||||
"fmt"
|
|
||||||
"os"
|
"os"
|
||||||
"path/filepath"
|
|
||||||
"runtime"
|
|
||||||
"testing"
|
"testing"
|
||||||
|
|
||||||
"github.com/ollama/ollama/x/imagegen/mlx"
|
"github.com/ollama/ollama/x/imagegen/mlx"
|
||||||
)
|
)
|
||||||
|
|
||||||
// TestMain initializes MLX before running tests.
|
|
||||||
// If MLX libraries are not available, tests are skipped.
|
|
||||||
func TestMain(m *testing.M) {
|
|
||||||
// Change to repo root so ./build/lib/ollama/ path works
|
|
||||||
_, thisFile, _, _ := runtime.Caller(0)
|
|
||||||
repoRoot := filepath.Join(filepath.Dir(thisFile), "..", "..", "..", "..")
|
|
||||||
if err := os.Chdir(repoRoot); err != nil {
|
|
||||||
fmt.Printf("Failed to change to repo root: %v\n", err)
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
|
|
||||||
if err := mlx.InitMLX(); err != nil {
|
|
||||||
fmt.Printf("Skipping qwen_image tests: %v\n", err)
|
|
||||||
os.Exit(0)
|
|
||||||
}
|
|
||||||
os.Exit(m.Run())
|
|
||||||
}
|
|
||||||
|
|
||||||
// TestPipelineOutput runs the full pipeline (integration test).
|
// TestPipelineOutput runs the full pipeline (integration test).
|
||||||
// Skips if model weights not found. Requires ~50GB VRAM.
|
// Skips if model weights not found. Requires ~50GB VRAM.
|
||||||
func TestPipelineOutput(t *testing.T) {
|
func TestPipelineOutput(t *testing.T) {
|
||||||
|
|||||||
@@ -172,7 +172,7 @@ func (m *Model) generate(cfg *GenerateConfig) (*mlx.Array, error) {
|
|||||||
cfg.Height = 1024
|
cfg.Height = 1024
|
||||||
}
|
}
|
||||||
if cfg.Steps <= 0 {
|
if cfg.Steps <= 0 {
|
||||||
cfg.Steps = 50
|
cfg.Steps = 30
|
||||||
}
|
}
|
||||||
if cfg.CFGScale <= 0 {
|
if cfg.CFGScale <= 0 {
|
||||||
cfg.CFGScale = 4.0
|
cfg.CFGScale = 4.0
|
||||||
|
|||||||
@@ -3,35 +3,13 @@
|
|||||||
package qwen_image_edit
|
package qwen_image_edit
|
||||||
|
|
||||||
import (
|
import (
|
||||||
"fmt"
|
|
||||||
"math"
|
"math"
|
||||||
"os"
|
|
||||||
"path/filepath"
|
|
||||||
"runtime"
|
|
||||||
"testing"
|
"testing"
|
||||||
|
|
||||||
"github.com/ollama/ollama/x/imagegen/mlx"
|
"github.com/ollama/ollama/x/imagegen/mlx"
|
||||||
"github.com/ollama/ollama/x/imagegen/models/qwen_image"
|
"github.com/ollama/ollama/x/imagegen/models/qwen_image"
|
||||||
)
|
)
|
||||||
|
|
||||||
// TestMain initializes MLX before running tests.
|
|
||||||
// If MLX libraries are not available, tests are skipped.
|
|
||||||
func TestMain(m *testing.M) {
|
|
||||||
// Change to repo root so ./build/lib/ollama/ path works
|
|
||||||
_, thisFile, _, _ := runtime.Caller(0)
|
|
||||||
repoRoot := filepath.Join(filepath.Dir(thisFile), "..", "..", "..", "..")
|
|
||||||
if err := os.Chdir(repoRoot); err != nil {
|
|
||||||
fmt.Printf("Failed to change to repo root: %v\n", err)
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
|
|
||||||
if err := mlx.InitMLX(); err != nil {
|
|
||||||
fmt.Printf("Skipping qwen_image_edit tests: %v\n", err)
|
|
||||||
os.Exit(0)
|
|
||||||
}
|
|
||||||
os.Exit(m.Run())
|
|
||||||
}
|
|
||||||
|
|
||||||
// TestComputeAxisFreqs verifies frequency computation matches Python reference
|
// TestComputeAxisFreqs verifies frequency computation matches Python reference
|
||||||
func TestComputeAxisFreqs(t *testing.T) {
|
func TestComputeAxisFreqs(t *testing.T) {
|
||||||
theta := float64(10000)
|
theta := float64(10000)
|
||||||
|
|||||||
@@ -194,7 +194,7 @@ func (m *Model) generate(ctx context.Context, cfg *GenerateConfig) (*mlx.Array,
|
|||||||
cfg.Height = 1024
|
cfg.Height = 1024
|
||||||
}
|
}
|
||||||
if cfg.Steps <= 0 {
|
if cfg.Steps <= 0 {
|
||||||
cfg.Steps = 9 // Z-Image turbo default
|
cfg.Steps = 9 // Turbo default
|
||||||
}
|
}
|
||||||
if cfg.CFGScale <= 0 {
|
if cfg.CFGScale <= 0 {
|
||||||
cfg.CFGScale = 4.0
|
cfg.CFGScale = 4.0
|
||||||
|
|||||||
@@ -3,34 +3,12 @@
|
|||||||
package nn
|
package nn
|
||||||
|
|
||||||
import (
|
import (
|
||||||
"fmt"
|
|
||||||
"math"
|
"math"
|
||||||
"os"
|
|
||||||
"path/filepath"
|
|
||||||
"runtime"
|
|
||||||
"testing"
|
"testing"
|
||||||
|
|
||||||
"github.com/ollama/ollama/x/imagegen/mlx"
|
"github.com/ollama/ollama/x/imagegen/mlx"
|
||||||
)
|
)
|
||||||
|
|
||||||
// TestMain initializes MLX before running tests.
|
|
||||||
// If MLX libraries are not available, tests are skipped.
|
|
||||||
func TestMain(m *testing.M) {
|
|
||||||
// Change to repo root so ./build/lib/ollama/ path works
|
|
||||||
_, thisFile, _, _ := runtime.Caller(0)
|
|
||||||
repoRoot := filepath.Join(filepath.Dir(thisFile), "..", "..", "..")
|
|
||||||
if err := os.Chdir(repoRoot); err != nil {
|
|
||||||
fmt.Printf("Failed to change to repo root: %v\n", err)
|
|
||||||
os.Exit(1)
|
|
||||||
}
|
|
||||||
|
|
||||||
if err := mlx.InitMLX(); err != nil {
|
|
||||||
fmt.Printf("Skipping nn tests: %v\n", err)
|
|
||||||
os.Exit(0)
|
|
||||||
}
|
|
||||||
os.Exit(m.Run())
|
|
||||||
}
|
|
||||||
|
|
||||||
// TestLinearNoBias verifies Linear without bias computes x @ w.T correctly.
|
// TestLinearNoBias verifies Linear without bias computes x @ w.T correctly.
|
||||||
func TestLinearNoBias(t *testing.T) {
|
func TestLinearNoBias(t *testing.T) {
|
||||||
// Weight: [out=2, in=3] -> transposed at forward time
|
// Weight: [out=2, in=3] -> transposed at forward time
|
||||||
|
|||||||
22
x/imagegen/quantize.go
Normal file
@@ -0,0 +1,22 @@
|
|||||||
|
package imagegen
|
||||||
|
|
||||||
|
import (
|
||||||
|
"io"
|
||||||
|
"strings"
|
||||||
|
)
|
||||||
|
|
||||||
|
// QuantizingTensorLayerCreator creates tensor layers with optional quantization.
|
||||||
|
// When quantize is true, returns multiple layers (weight + scales + biases).
|
||||||
|
type QuantizingTensorLayerCreator func(r io.Reader, name, dtype string, shape []int32, quantize bool) ([]LayerInfo, error)
|
||||||
|
|
||||||
|
// ShouldQuantize returns true if a tensor should be quantized.
|
||||||
|
// Quantizes linear weights only, skipping VAE, embeddings, norms, and biases.
|
||||||
|
func ShouldQuantize(name, component string) bool {
|
||||||
|
if component == "vae" {
|
||||||
|
return false
|
||||||
|
}
|
||||||
|
if strings.Contains(name, "embed") || strings.Contains(name, "norm") {
|
||||||
|
return false
|
||||||
|
}
|
||||||
|
return strings.HasSuffix(name, ".weight")
|
||||||
|
}
|
||||||
@@ -36,8 +36,6 @@ type Response struct {
|
|||||||
Content string `json:"content,omitempty"`
|
Content string `json:"content,omitempty"`
|
||||||
Image string `json:"image,omitempty"` // Base64-encoded PNG
|
Image string `json:"image,omitempty"` // Base64-encoded PNG
|
||||||
Done bool `json:"done"`
|
Done bool `json:"done"`
|
||||||
Step int `json:"step,omitempty"`
|
|
||||||
Total int `json:"total,omitempty"`
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// Server holds the model and handles requests
|
// Server holds the model and handles requests
|
||||||
@@ -64,12 +62,6 @@ func Execute(args []string) error {
|
|||||||
return fmt.Errorf("--port is required")
|
return fmt.Errorf("--port is required")
|
||||||
}
|
}
|
||||||
|
|
||||||
err := mlx.InitMLX()
|
|
||||||
if err != nil {
|
|
||||||
slog.Error("unable to initialize MLX", "error", err)
|
|
||||||
return err
|
|
||||||
}
|
|
||||||
slog.Info("MLX library initialized")
|
|
||||||
slog.Info("starting image runner", "model", *modelName, "port", *port)
|
slog.Info("starting image runner", "model", *modelName, "port", *port)
|
||||||
|
|
||||||
// Check memory requirements before loading
|
// Check memory requirements before loading
|
||||||
@@ -144,8 +136,16 @@ func (s *Server) completionHandler(w http.ResponseWriter, r *http.Request) {
|
|||||||
s.mu.Lock()
|
s.mu.Lock()
|
||||||
defer s.mu.Unlock()
|
defer s.mu.Unlock()
|
||||||
|
|
||||||
// Model applies its own defaults for width/height/steps
|
// Apply defaults
|
||||||
// Only seed needs to be set here if not provided
|
if req.Width <= 0 {
|
||||||
|
req.Width = 1024
|
||||||
|
}
|
||||||
|
if req.Height <= 0 {
|
||||||
|
req.Height = 1024
|
||||||
|
}
|
||||||
|
if req.Steps <= 0 {
|
||||||
|
req.Steps = 9
|
||||||
|
}
|
||||||
if req.Seed <= 0 {
|
if req.Seed <= 0 {
|
||||||
req.Seed = time.Now().UnixNano()
|
req.Seed = time.Now().UnixNano()
|
||||||
}
|
}
|
||||||
@@ -169,9 +169,8 @@ func (s *Server) completionHandler(w http.ResponseWriter, r *http.Request) {
|
|||||||
Seed: req.Seed,
|
Seed: req.Seed,
|
||||||
Progress: func(step, total int) {
|
Progress: func(step, total int) {
|
||||||
resp := Response{
|
resp := Response{
|
||||||
Step: step,
|
Content: fmt.Sprintf("\rGenerating: step %d/%d", step, total),
|
||||||
Total: total,
|
Done: false,
|
||||||
Done: false,
|
|
||||||
}
|
}
|
||||||
data, _ := json.Marshal(resp)
|
data, _ := json.Marshal(resp)
|
||||||
w.Write(data)
|
w.Write(data)
|
||||||
|
|||||||
@@ -25,11 +25,6 @@ import (
|
|||||||
)
|
)
|
||||||
|
|
||||||
// Server wraps an image generation subprocess to implement llm.LlamaServer.
|
// Server wraps an image generation subprocess to implement llm.LlamaServer.
|
||||||
//
|
|
||||||
// This implementation is compatible with Ollama's scheduler and can be loaded/unloaded
|
|
||||||
// like any other model. The plan is to eventually bring this into the llm/ package
|
|
||||||
// and evolve llm/ to support MLX and multimodal models. For now, keeping the code
|
|
||||||
// separate allows for independent iteration on image generation support.
|
|
||||||
type Server struct {
|
type Server struct {
|
||||||
mu sync.Mutex
|
mu sync.Mutex
|
||||||
cmd *exec.Cmd
|
cmd *exec.Cmd
|
||||||
@@ -42,6 +37,22 @@ type Server struct {
|
|||||||
lastErrLock sync.Mutex
|
lastErrLock sync.Mutex
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// completionRequest is sent to the subprocess
|
||||||
|
type completionRequest struct {
|
||||||
|
Prompt string `json:"prompt"`
|
||||||
|
Width int32 `json:"width,omitempty"`
|
||||||
|
Height int32 `json:"height,omitempty"`
|
||||||
|
Steps int `json:"steps,omitempty"`
|
||||||
|
Seed int64 `json:"seed,omitempty"`
|
||||||
|
}
|
||||||
|
|
||||||
|
// completionResponse is received from the subprocess
|
||||||
|
type completionResponse struct {
|
||||||
|
Content string `json:"content,omitempty"`
|
||||||
|
Image string `json:"image,omitempty"`
|
||||||
|
Done bool `json:"done"`
|
||||||
|
}
|
||||||
|
|
||||||
// NewServer spawns a new image generation subprocess and waits until it's ready.
|
// NewServer spawns a new image generation subprocess and waits until it's ready.
|
||||||
func NewServer(modelName string) (*Server, error) {
|
func NewServer(modelName string) (*Server, error) {
|
||||||
// Validate platform support before attempting to start
|
// Validate platform support before attempting to start
|
||||||
@@ -61,7 +72,7 @@ func NewServer(modelName string) (*Server, error) {
|
|||||||
port = rand.Intn(65535-49152) + 49152
|
port = rand.Intn(65535-49152) + 49152
|
||||||
}
|
}
|
||||||
|
|
||||||
// Get the current executable path (we use the same binary with runner subcommand)
|
// Get the ollama-mlx executable path (in same directory as current executable)
|
||||||
exe, err := os.Executable()
|
exe, err := os.Executable()
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return nil, fmt.Errorf("unable to lookup executable path: %w", err)
|
return nil, fmt.Errorf("unable to lookup executable path: %w", err)
|
||||||
@@ -69,9 +80,10 @@ func NewServer(modelName string) (*Server, error) {
|
|||||||
if eval, err := filepath.EvalSymlinks(exe); err == nil {
|
if eval, err := filepath.EvalSymlinks(exe); err == nil {
|
||||||
exe = eval
|
exe = eval
|
||||||
}
|
}
|
||||||
|
mlxExe := filepath.Join(filepath.Dir(exe), "ollama-mlx")
|
||||||
|
|
||||||
// Spawn subprocess: ollama runner --image-engine --model <path> --port <port>
|
// Spawn subprocess: ollama-mlx runner --image-engine --model <path> --port <port>
|
||||||
cmd := exec.Command(exe, "runner", "--image-engine", "--model", modelName, "--port", strconv.Itoa(port))
|
cmd := exec.Command(mlxExe, "runner", "--image-engine", "--model", modelName, "--port", strconv.Itoa(port))
|
||||||
cmd.Env = os.Environ()
|
cmd.Env = os.Environ()
|
||||||
|
|
||||||
// On Linux, set LD_LIBRARY_PATH to include MLX library directories
|
// On Linux, set LD_LIBRARY_PATH to include MLX library directories
|
||||||
@@ -127,13 +139,14 @@ func NewServer(modelName string) (*Server, error) {
|
|||||||
for scanner.Scan() {
|
for scanner.Scan() {
|
||||||
line := scanner.Text()
|
line := scanner.Text()
|
||||||
slog.Warn("image-runner", "msg", line)
|
slog.Warn("image-runner", "msg", line)
|
||||||
|
// Capture last error line for better error reporting
|
||||||
s.lastErrLock.Lock()
|
s.lastErrLock.Lock()
|
||||||
s.lastErr = line
|
s.lastErr = line
|
||||||
s.lastErrLock.Unlock()
|
s.lastErrLock.Unlock()
|
||||||
}
|
}
|
||||||
}()
|
}()
|
||||||
|
|
||||||
slog.Info("starting image runner subprocess", "exe", exe, "model", modelName, "port", port)
|
slog.Info("starting ollama-mlx image runner subprocess", "exe", mlxExe, "model", modelName, "port", port)
|
||||||
if err := cmd.Start(); err != nil {
|
if err := cmd.Start(); err != nil {
|
||||||
return nil, fmt.Errorf("failed to start image runner: %w", err)
|
return nil, fmt.Errorf("failed to start image runner: %w", err)
|
||||||
}
|
}
|
||||||
@@ -158,6 +171,7 @@ func (s *Server) ModelPath() string {
|
|||||||
return s.modelName
|
return s.modelName
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Load is called by the scheduler after the server is created.
|
||||||
func (s *Server) Load(ctx context.Context, systemInfo ml.SystemInfo, gpus []ml.DeviceInfo, requireFull bool) ([]ml.DeviceID, error) {
|
func (s *Server) Load(ctx context.Context, systemInfo ml.SystemInfo, gpus []ml.DeviceInfo, requireFull bool) ([]ml.DeviceID, error) {
|
||||||
return nil, nil
|
return nil, nil
|
||||||
}
|
}
|
||||||
@@ -190,16 +204,20 @@ func (s *Server) waitUntilRunning() error {
|
|||||||
for {
|
for {
|
||||||
select {
|
select {
|
||||||
case err := <-s.done:
|
case err := <-s.done:
|
||||||
// Include recent stderr lines for better error context
|
// Include last stderr line for better error context
|
||||||
errMsg := s.getLastErr()
|
s.lastErrLock.Lock()
|
||||||
if errMsg != "" {
|
lastErr := s.lastErr
|
||||||
return fmt.Errorf("image runner failed: %s (exit: %v)", errMsg, err)
|
s.lastErrLock.Unlock()
|
||||||
|
if lastErr != "" {
|
||||||
|
return fmt.Errorf("image runner failed: %s (exit: %v)", lastErr, err)
|
||||||
}
|
}
|
||||||
return fmt.Errorf("image runner exited unexpectedly: %w", err)
|
return fmt.Errorf("image runner exited unexpectedly: %w", err)
|
||||||
case <-timeout:
|
case <-timeout:
|
||||||
errMsg := s.getLastErr()
|
s.lastErrLock.Lock()
|
||||||
if errMsg != "" {
|
lastErr := s.lastErr
|
||||||
return fmt.Errorf("timeout waiting for image runner: %s", errMsg)
|
s.lastErrLock.Unlock()
|
||||||
|
if lastErr != "" {
|
||||||
|
return fmt.Errorf("timeout waiting for image runner: %s", lastErr)
|
||||||
}
|
}
|
||||||
return errors.New("timeout waiting for image runner to start")
|
return errors.New("timeout waiting for image runner to start")
|
||||||
case <-ticker.C:
|
case <-ticker.C:
|
||||||
@@ -211,41 +229,44 @@ func (s *Server) waitUntilRunning() error {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// getLastErr returns the last stderr line.
|
// WaitUntilRunning implements the LlamaServer interface (no-op since NewServer waits).
|
||||||
func (s *Server) getLastErr() string {
|
func (s *Server) WaitUntilRunning(ctx context.Context) error {
|
||||||
s.lastErrLock.Lock()
|
return nil
|
||||||
defer s.lastErrLock.Unlock()
|
|
||||||
return s.lastErr
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (s *Server) WaitUntilRunning(ctx context.Context) error { return nil }
|
// Completion generates an image from the prompt via the subprocess.
|
||||||
|
|
||||||
func (s *Server) Completion(ctx context.Context, req llm.CompletionRequest, fn func(llm.CompletionResponse)) error {
|
func (s *Server) Completion(ctx context.Context, req llm.CompletionRequest, fn func(llm.CompletionResponse)) error {
|
||||||
seed := req.Seed
|
// Build request
|
||||||
if seed == 0 {
|
creq := completionRequest{
|
||||||
seed = time.Now().UnixNano()
|
|
||||||
}
|
|
||||||
|
|
||||||
// Build request for subprocess
|
|
||||||
creq := struct {
|
|
||||||
Prompt string `json:"prompt"`
|
|
||||||
Width int32 `json:"width,omitempty"`
|
|
||||||
Height int32 `json:"height,omitempty"`
|
|
||||||
Steps int32 `json:"steps,omitempty"`
|
|
||||||
Seed int64 `json:"seed,omitempty"`
|
|
||||||
}{
|
|
||||||
Prompt: req.Prompt,
|
Prompt: req.Prompt,
|
||||||
Width: req.Width,
|
Width: 1024,
|
||||||
Height: req.Height,
|
Height: 1024,
|
||||||
Steps: req.Steps,
|
Steps: 9,
|
||||||
Seed: seed,
|
Seed: time.Now().UnixNano(),
|
||||||
}
|
}
|
||||||
|
|
||||||
|
if req.Options != nil {
|
||||||
|
if req.Options.NumCtx > 0 && req.Options.NumCtx <= 4096 {
|
||||||
|
creq.Width = int32(req.Options.NumCtx)
|
||||||
|
}
|
||||||
|
if req.Options.NumGPU > 0 && req.Options.NumGPU <= 4096 {
|
||||||
|
creq.Height = int32(req.Options.NumGPU)
|
||||||
|
}
|
||||||
|
if req.Options.NumPredict > 0 && req.Options.NumPredict <= 100 {
|
||||||
|
creq.Steps = req.Options.NumPredict
|
||||||
|
}
|
||||||
|
if req.Options.Seed > 0 {
|
||||||
|
creq.Seed = int64(req.Options.Seed)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Encode request body
|
||||||
body, err := json.Marshal(creq)
|
body, err := json.Marshal(creq)
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return err
|
return err
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Send request to subprocess
|
||||||
url := fmt.Sprintf("http://127.0.0.1:%d/completion", s.port)
|
url := fmt.Sprintf("http://127.0.0.1:%d/completion", s.port)
|
||||||
httpReq, err := http.NewRequestWithContext(ctx, "POST", url, bytes.NewReader(body))
|
httpReq, err := http.NewRequestWithContext(ctx, "POST", url, bytes.NewReader(body))
|
||||||
if err != nil {
|
if err != nil {
|
||||||
@@ -260,36 +281,30 @@ func (s *Server) Completion(ctx context.Context, req llm.CompletionRequest, fn f
|
|||||||
defer resp.Body.Close()
|
defer resp.Body.Close()
|
||||||
|
|
||||||
if resp.StatusCode != http.StatusOK {
|
if resp.StatusCode != http.StatusOK {
|
||||||
return fmt.Errorf("request failed: %d", resp.StatusCode)
|
return fmt.Errorf("completion request failed: %d", resp.StatusCode)
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Stream responses - use large buffer for base64 image data
|
||||||
scanner := bufio.NewScanner(resp.Body)
|
scanner := bufio.NewScanner(resp.Body)
|
||||||
scanner.Buffer(make([]byte, 1024*1024), 16*1024*1024) // 16MB max
|
scanner.Buffer(make([]byte, 1024*1024), 16*1024*1024) // 16MB max
|
||||||
for scanner.Scan() {
|
for scanner.Scan() {
|
||||||
// Parse subprocess response (has singular "image" field)
|
var cresp completionResponse
|
||||||
var raw struct {
|
if err := json.Unmarshal(scanner.Bytes(), &cresp); err != nil {
|
||||||
Image string `json:"image,omitempty"`
|
|
||||||
Content string `json:"content,omitempty"`
|
|
||||||
Done bool `json:"done"`
|
|
||||||
Step int `json:"step,omitempty"`
|
|
||||||
Total int `json:"total,omitempty"`
|
|
||||||
}
|
|
||||||
if err := json.Unmarshal(scanner.Bytes(), &raw); err != nil {
|
|
||||||
continue
|
continue
|
||||||
}
|
}
|
||||||
|
|
||||||
// Convert to llm.CompletionResponse
|
content := cresp.Content
|
||||||
cresp := llm.CompletionResponse{
|
// If this is the final response with an image, encode it in the content
|
||||||
Content: raw.Content,
|
if cresp.Done && cresp.Image != "" {
|
||||||
Done: raw.Done,
|
content = "IMAGE_BASE64:" + cresp.Image
|
||||||
Step: raw.Step,
|
|
||||||
TotalSteps: raw.Total,
|
|
||||||
Image: raw.Image,
|
|
||||||
}
|
}
|
||||||
|
|
||||||
fn(cresp)
|
fn(llm.CompletionResponse{
|
||||||
|
Content: content,
|
||||||
|
Done: cresp.Done,
|
||||||
|
})
|
||||||
if cresp.Done {
|
if cresp.Done {
|
||||||
return nil
|
break
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -331,18 +346,22 @@ func (s *Server) VRAMByGPU(id ml.DeviceID) uint64 {
|
|||||||
return s.vramSize
|
return s.vramSize
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Embedding is not supported for image generation models.
|
||||||
func (s *Server) Embedding(ctx context.Context, input string) ([]float32, int, error) {
|
func (s *Server) Embedding(ctx context.Context, input string) ([]float32, int, error) {
|
||||||
return nil, 0, errors.New("not supported")
|
return nil, 0, errors.New("embedding not supported for image generation models")
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Tokenize is not supported for image generation models.
|
||||||
func (s *Server) Tokenize(ctx context.Context, content string) ([]int, error) {
|
func (s *Server) Tokenize(ctx context.Context, content string) ([]int, error) {
|
||||||
return nil, errors.New("not supported")
|
return nil, errors.New("tokenize not supported for image generation models")
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Detokenize is not supported for image generation models.
|
||||||
func (s *Server) Detokenize(ctx context.Context, tokens []int) (string, error) {
|
func (s *Server) Detokenize(ctx context.Context, tokens []int) (string, error) {
|
||||||
return "", errors.New("not supported")
|
return "", errors.New("detokenize not supported for image generation models")
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Pid returns the subprocess PID.
|
||||||
func (s *Server) Pid() int {
|
func (s *Server) Pid() int {
|
||||||
s.mu.Lock()
|
s.mu.Lock()
|
||||||
defer s.mu.Unlock()
|
defer s.mu.Unlock()
|
||||||
@@ -352,9 +371,17 @@ func (s *Server) Pid() int {
|
|||||||
return -1
|
return -1
|
||||||
}
|
}
|
||||||
|
|
||||||
func (s *Server) GetPort() int { return s.port }
|
// GetPort returns the subprocess port.
|
||||||
func (s *Server) GetDeviceInfos(ctx context.Context) []ml.DeviceInfo { return nil }
|
func (s *Server) GetPort() int {
|
||||||
|
return s.port
|
||||||
|
}
|
||||||
|
|
||||||
|
// GetDeviceInfos returns nil since we don't track GPU info.
|
||||||
|
func (s *Server) GetDeviceInfos(ctx context.Context) []ml.DeviceInfo {
|
||||||
|
return nil
|
||||||
|
}
|
||||||
|
|
||||||
|
// HasExited returns true if the subprocess has exited.
|
||||||
func (s *Server) HasExited() bool {
|
func (s *Server) HasExited() bool {
|
||||||
select {
|
select {
|
||||||
case <-s.done:
|
case <-s.done:
|
||||||
|
|||||||
@@ -1,9 +1,5 @@
|
|||||||
include(FetchContent)
|
include(FetchContent)
|
||||||
|
|
||||||
# Read MLX version from top-level file (shared with Dockerfile)
|
|
||||||
file(READ "${CMAKE_SOURCE_DIR}/MLX_VERSION" MLX_C_GIT_TAG)
|
|
||||||
string(STRIP "${MLX_C_GIT_TAG}" MLX_C_GIT_TAG)
|
|
||||||
|
|
||||||
set(MLX_C_BUILD_EXAMPLES OFF)
|
set(MLX_C_BUILD_EXAMPLES OFF)
|
||||||
|
|
||||||
set(MLX_BUILD_GGUF OFF)
|
set(MLX_BUILD_GGUF OFF)
|
||||||
@@ -54,7 +50,7 @@ endif()
|
|||||||
FetchContent_Declare(
|
FetchContent_Declare(
|
||||||
mlx-c
|
mlx-c
|
||||||
GIT_REPOSITORY "https://github.com/ml-explore/mlx-c.git"
|
GIT_REPOSITORY "https://github.com/ml-explore/mlx-c.git"
|
||||||
GIT_TAG ${MLX_C_GIT_TAG})
|
GIT_TAG v0.4.1)
|
||||||
FetchContent_MakeAvailable(mlx-c)
|
FetchContent_MakeAvailable(mlx-c)
|
||||||
|
|
||||||
set_target_output_directory(mlx)
|
set_target_output_directory(mlx)
|
||||||
|
|||||||
@@ -1,92 +0,0 @@
|
|||||||
// mlx_dynamic.c - Dynamic loading wrapper for MLX-C library
|
|
||||||
// This file provides runtime dynamic loading of libmlxc instead of link-time binding
|
|
||||||
|
|
||||||
#include "mlx_dynamic.h"
|
|
||||||
#include <stdio.h>
|
|
||||||
#include <stdlib.h>
|
|
||||||
#include <string.h>
|
|
||||||
|
|
||||||
#ifdef _WIN32
|
|
||||||
#include <windows.h>
|
|
||||||
typedef HMODULE lib_handle_t;
|
|
||||||
#define LOAD_LIB(path) LoadLibraryA(path)
|
|
||||||
#define GET_SYMBOL(handle, name) GetProcAddress(handle, name)
|
|
||||||
#define CLOSE_LIB(handle) FreeLibrary(handle)
|
|
||||||
#define LIB_ERROR() "LoadLibrary failed"
|
|
||||||
static const char* LIB_NAMES[] = {"libmlxc.dll", NULL};
|
|
||||||
#else
|
|
||||||
#include <dlfcn.h>
|
|
||||||
typedef void* lib_handle_t;
|
|
||||||
#define LOAD_LIB(path) dlopen(path, RTLD_LAZY | RTLD_GLOBAL)
|
|
||||||
#define GET_SYMBOL(handle, name) dlsym(handle, name)
|
|
||||||
#define CLOSE_LIB(handle) dlclose(handle)
|
|
||||||
#define LIB_ERROR() dlerror()
|
|
||||||
#ifdef __APPLE__
|
|
||||||
static const char* LIB_NAMES[] = {
|
|
||||||
"libmlxc.dylib",
|
|
||||||
"@loader_path/../build/lib/ollama/libmlxc.dylib",
|
|
||||||
"@executable_path/../build/lib/ollama/libmlxc.dylib",
|
|
||||||
"build/lib/ollama/libmlxc.dylib",
|
|
||||||
"../build/lib/ollama/libmlxc.dylib",
|
|
||||||
NULL
|
|
||||||
};
|
|
||||||
#else
|
|
||||||
static const char* LIB_NAMES[] = {
|
|
||||||
"libmlxc.so",
|
|
||||||
"$ORIGIN/../build/lib/ollama/libmlxc.so",
|
|
||||||
"build/lib/ollama/libmlxc.so",
|
|
||||||
"../build/lib/ollama/libmlxc.so",
|
|
||||||
NULL
|
|
||||||
};
|
|
||||||
#endif
|
|
||||||
#endif
|
|
||||||
|
|
||||||
static lib_handle_t mlx_handle = NULL;
|
|
||||||
static int mlx_initialized = 0;
|
|
||||||
static char mlx_error_buffer[512] = {0};
|
|
||||||
|
|
||||||
// Initialize MLX dynamic library
|
|
||||||
// Returns 0 on success, -1 on failure
|
|
||||||
// On failure, call mlx_dynamic_error() to get error message
|
|
||||||
int mlx_dynamic_init(void) {
|
|
||||||
if (mlx_initialized) {
|
|
||||||
return 0; // Already initialized
|
|
||||||
}
|
|
||||||
|
|
||||||
// Try each possible library path
|
|
||||||
for (int i = 0; LIB_NAMES[i] != NULL; i++) {
|
|
||||||
mlx_handle = LOAD_LIB(LIB_NAMES[i]);
|
|
||||||
if (mlx_handle != NULL) {
|
|
||||||
mlx_initialized = 1;
|
|
||||||
snprintf(mlx_error_buffer, sizeof(mlx_error_buffer),
|
|
||||||
"MLX: Successfully loaded %s", LIB_NAMES[i]);
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Failed to load library
|
|
||||||
const char* err = LIB_ERROR();
|
|
||||||
snprintf(mlx_error_buffer, sizeof(mlx_error_buffer),
|
|
||||||
"MLX: Failed to load libmlxc library. %s",
|
|
||||||
err ? err : "Unknown error");
|
|
||||||
return -1;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Get the last error message
|
|
||||||
const char* mlx_dynamic_error(void) {
|
|
||||||
return mlx_error_buffer;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check if MLX is initialized
|
|
||||||
int mlx_dynamic_is_initialized(void) {
|
|
||||||
return mlx_initialized;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Cleanup (optional, called at program exit)
|
|
||||||
void mlx_dynamic_cleanup(void) {
|
|
||||||
if (mlx_handle != NULL) {
|
|
||||||
CLOSE_LIB(mlx_handle);
|
|
||||||
mlx_handle = NULL;
|
|
||||||
mlx_initialized = 0;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -1,26 +0,0 @@
|
|||||||
// mlx_dynamic.h - Dynamic loading interface for MLX-C library
|
|
||||||
#ifndef MLX_DYNAMIC_H
|
|
||||||
#define MLX_DYNAMIC_H
|
|
||||||
|
|
||||||
#ifdef __cplusplus
|
|
||||||
extern "C" {
|
|
||||||
#endif
|
|
||||||
|
|
||||||
// Initialize the MLX dynamic library
|
|
||||||
// Returns 0 on success, -1 on failure
|
|
||||||
int mlx_dynamic_init(void);
|
|
||||||
|
|
||||||
// Get the last error message from dynamic loading
|
|
||||||
const char* mlx_dynamic_error(void);
|
|
||||||
|
|
||||||
// Check if MLX is initialized
|
|
||||||
int mlx_dynamic_is_initialized(void);
|
|
||||||
|
|
||||||
// Cleanup resources (optional, for clean shutdown)
|
|
||||||
void mlx_dynamic_cleanup(void);
|
|
||||||
|
|
||||||
#ifdef __cplusplus
|
|
||||||
}
|
|
||||||
#endif
|
|
||||||
|
|
||||||
#endif // MLX_DYNAMIC_H
|
|
||||||
284
x/server/show.go
@@ -1,284 +0,0 @@
|
|||||||
package server
|
|
||||||
|
|
||||||
import (
|
|
||||||
"encoding/binary"
|
|
||||||
"encoding/json"
|
|
||||||
"fmt"
|
|
||||||
"io"
|
|
||||||
"os"
|
|
||||||
"strings"
|
|
||||||
|
|
||||||
"github.com/ollama/ollama/api"
|
|
||||||
"github.com/ollama/ollama/x/imagegen"
|
|
||||||
)
|
|
||||||
|
|
||||||
// modelConfig represents the HuggingFace config.json structure
|
|
||||||
type modelConfig struct {
|
|
||||||
Architectures []string `json:"architectures"`
|
|
||||||
ModelType string `json:"model_type"`
|
|
||||||
HiddenSize int `json:"hidden_size"`
|
|
||||||
NumHiddenLayers int `json:"num_hidden_layers"`
|
|
||||||
MaxPositionEmbeddings int `json:"max_position_embeddings"`
|
|
||||||
IntermediateSize int `json:"intermediate_size"`
|
|
||||||
NumAttentionHeads int `json:"num_attention_heads"`
|
|
||||||
NumKeyValueHeads int `json:"num_key_value_heads"`
|
|
||||||
VocabSize int `json:"vocab_size"`
|
|
||||||
RMSNormEps float64 `json:"rms_norm_eps"`
|
|
||||||
RopeTheta float64 `json:"rope_theta"`
|
|
||||||
TorchDtype string `json:"torch_dtype"`
|
|
||||||
TextConfig *struct {
|
|
||||||
HiddenSize int `json:"hidden_size"`
|
|
||||||
MaxPositionEmbeddings int `json:"max_position_embeddings"`
|
|
||||||
NumHiddenLayers int `json:"num_hidden_layers"`
|
|
||||||
} `json:"text_config"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// GetSafetensorsLLMInfo extracts model information from safetensors LLM models.
|
|
||||||
// It reads the config.json layer and returns a map compatible with GGML's KV format.
|
|
||||||
func GetSafetensorsLLMInfo(modelName string) (map[string]any, error) {
|
|
||||||
manifest, err := imagegen.LoadManifest(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to load manifest: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
var config modelConfig
|
|
||||||
if err := manifest.ReadConfigJSON("config.json", &config); err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to read config.json: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Calculate total tensor bytes from manifest layers
|
|
||||||
var totalBytes int64
|
|
||||||
var tensorCount int64
|
|
||||||
for _, layer := range manifest.Manifest.Layers {
|
|
||||||
if layer.MediaType == "application/vnd.ollama.image.tensor" {
|
|
||||||
totalBytes += layer.Size
|
|
||||||
tensorCount++
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
return buildModelInfo(config, totalBytes, tensorCount), nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// buildModelInfo constructs the model info map from config and tensor stats.
|
|
||||||
// This is separated for testability.
|
|
||||||
func buildModelInfo(config modelConfig, totalTensorBytes, tensorCount int64) map[string]any {
|
|
||||||
// Determine architecture
|
|
||||||
arch := config.ModelType
|
|
||||||
if arch == "" && len(config.Architectures) > 0 {
|
|
||||||
// Convert HuggingFace architecture name to Ollama format
|
|
||||||
// e.g., "Gemma3ForCausalLM" -> "gemma3"
|
|
||||||
hfArch := config.Architectures[0]
|
|
||||||
arch = strings.ToLower(hfArch)
|
|
||||||
arch = strings.TrimSuffix(arch, "forcausallm")
|
|
||||||
arch = strings.TrimSuffix(arch, "forconditionalgeneration")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Use text_config values if they exist (for multimodal models)
|
|
||||||
hiddenSize := config.HiddenSize
|
|
||||||
maxPosEmbed := config.MaxPositionEmbeddings
|
|
||||||
numLayers := config.NumHiddenLayers
|
|
||||||
|
|
||||||
if config.TextConfig != nil {
|
|
||||||
if config.TextConfig.HiddenSize > 0 {
|
|
||||||
hiddenSize = config.TextConfig.HiddenSize
|
|
||||||
}
|
|
||||||
if config.TextConfig.MaxPositionEmbeddings > 0 {
|
|
||||||
maxPosEmbed = config.TextConfig.MaxPositionEmbeddings
|
|
||||||
}
|
|
||||||
if config.TextConfig.NumHiddenLayers > 0 {
|
|
||||||
numLayers = config.TextConfig.NumHiddenLayers
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Get dtype to determine bytes per parameter for count calculation
|
|
||||||
dtype := config.TorchDtype
|
|
||||||
|
|
||||||
// Determine bytes per parameter based on dtype
|
|
||||||
var bytesPerParam int64 = 2 // default to float16/bfloat16
|
|
||||||
switch strings.ToLower(dtype) {
|
|
||||||
case "float32":
|
|
||||||
bytesPerParam = 4
|
|
||||||
case "float16", "bfloat16":
|
|
||||||
bytesPerParam = 2
|
|
||||||
case "int8", "uint8":
|
|
||||||
bytesPerParam = 1
|
|
||||||
}
|
|
||||||
|
|
||||||
// Subtract safetensors header overhead (88 bytes per tensor file)
|
|
||||||
// Each tensor is stored as a minimal safetensors file
|
|
||||||
totalBytes := totalTensorBytes - tensorCount*88
|
|
||||||
|
|
||||||
paramCount := totalBytes / bytesPerParam
|
|
||||||
|
|
||||||
info := map[string]any{
|
|
||||||
"general.architecture": arch,
|
|
||||||
}
|
|
||||||
|
|
||||||
if maxPosEmbed > 0 {
|
|
||||||
info[fmt.Sprintf("%s.context_length", arch)] = maxPosEmbed
|
|
||||||
}
|
|
||||||
|
|
||||||
if hiddenSize > 0 {
|
|
||||||
info[fmt.Sprintf("%s.embedding_length", arch)] = hiddenSize
|
|
||||||
}
|
|
||||||
|
|
||||||
if numLayers > 0 {
|
|
||||||
info[fmt.Sprintf("%s.block_count", arch)] = numLayers
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.NumAttentionHeads > 0 {
|
|
||||||
info[fmt.Sprintf("%s.attention.head_count", arch)] = config.NumAttentionHeads
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.NumKeyValueHeads > 0 {
|
|
||||||
info[fmt.Sprintf("%s.attention.head_count_kv", arch)] = config.NumKeyValueHeads
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.IntermediateSize > 0 {
|
|
||||||
info[fmt.Sprintf("%s.feed_forward_length", arch)] = config.IntermediateSize
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.VocabSize > 0 {
|
|
||||||
info[fmt.Sprintf("%s.vocab_size", arch)] = config.VocabSize
|
|
||||||
}
|
|
||||||
|
|
||||||
if paramCount > 0 {
|
|
||||||
info["general.parameter_count"] = paramCount
|
|
||||||
}
|
|
||||||
|
|
||||||
return info
|
|
||||||
}
|
|
||||||
|
|
||||||
// GetSafetensorsTensorInfo extracts tensor information from safetensors model layers.
|
|
||||||
// Each tensor is stored as a minimal safetensors file with an 88-byte header containing metadata.
|
|
||||||
func GetSafetensorsTensorInfo(modelName string) ([]api.Tensor, error) {
|
|
||||||
manifest, err := imagegen.LoadManifest(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to load manifest: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
return getTensorInfoFromManifest(manifest)
|
|
||||||
}
|
|
||||||
|
|
||||||
// getTensorInfoFromManifest extracts tensor info from a manifest.
|
|
||||||
// This is separated for testability.
|
|
||||||
func getTensorInfoFromManifest(manifest *imagegen.ModelManifest) ([]api.Tensor, error) {
|
|
||||||
var tensors []api.Tensor
|
|
||||||
|
|
||||||
for _, layer := range manifest.Manifest.Layers {
|
|
||||||
if layer.MediaType != "application/vnd.ollama.image.tensor" {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
// Read the safetensors header from the blob
|
|
||||||
blobPath := manifest.BlobPath(layer.Digest)
|
|
||||||
info, err := readSafetensorsHeader(blobPath)
|
|
||||||
if err != nil {
|
|
||||||
// Skip tensors we can't read
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
// Convert shape from int to uint64
|
|
||||||
shape := make([]uint64, len(info.Shape))
|
|
||||||
for i, s := range info.Shape {
|
|
||||||
shape[i] = uint64(s)
|
|
||||||
}
|
|
||||||
|
|
||||||
tensors = append(tensors, api.Tensor{
|
|
||||||
Name: layer.Name,
|
|
||||||
Type: info.Dtype,
|
|
||||||
Shape: shape,
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
return tensors, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// GetSafetensorsDtype returns the quantization type for a safetensors model.
|
|
||||||
// If the model is quantized (has _scale tensors), returns the quantization type (e.g., "FP8").
|
|
||||||
// Otherwise returns the torch_dtype from config.json.
|
|
||||||
func GetSafetensorsDtype(modelName string) (string, error) {
|
|
||||||
manifest, err := imagegen.LoadManifest(modelName)
|
|
||||||
if err != nil {
|
|
||||||
return "", fmt.Errorf("failed to load manifest: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check if model is quantized by looking for _scale tensors
|
|
||||||
for _, layer := range manifest.Manifest.Layers {
|
|
||||||
if layer.MediaType == "application/vnd.ollama.image.tensor" {
|
|
||||||
if strings.HasSuffix(layer.Name, "_scale") {
|
|
||||||
// Model is quantized - return FP8 (affine quantization)
|
|
||||||
return "FP8", nil
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Not quantized - return torch_dtype from config.json
|
|
||||||
var cfg struct {
|
|
||||||
TorchDtype string `json:"torch_dtype"`
|
|
||||||
}
|
|
||||||
if err := manifest.ReadConfigJSON("config.json", &cfg); err != nil {
|
|
||||||
return "", fmt.Errorf("failed to read config.json: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
return cfg.TorchDtype, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// safetensorsTensorInfo holds metadata about a tensor from a safetensors header
|
|
||||||
type safetensorsTensorInfo struct {
|
|
||||||
Dtype string `json:"dtype"`
|
|
||||||
Shape []int64 `json:"shape"`
|
|
||||||
}
|
|
||||||
|
|
||||||
// readSafetensorsHeader reads the JSON header from a safetensors file to get tensor metadata.
|
|
||||||
// Safetensors format: 8-byte header size (little endian) + JSON header + tensor data
|
|
||||||
func readSafetensorsHeader(path string) (*safetensorsTensorInfo, error) {
|
|
||||||
f, err := os.Open(path)
|
|
||||||
if err != nil {
|
|
||||||
return nil, err
|
|
||||||
}
|
|
||||||
defer f.Close()
|
|
||||||
|
|
||||||
return parseSafetensorsHeader(f)
|
|
||||||
}
|
|
||||||
|
|
||||||
// parseSafetensorsHeader parses a safetensors header from a reader.
|
|
||||||
// This is separated for testability.
|
|
||||||
func parseSafetensorsHeader(r io.Reader) (*safetensorsTensorInfo, error) {
|
|
||||||
// Read header size (8 bytes, little endian)
|
|
||||||
var headerSize uint64
|
|
||||||
if err := binary.Read(r, binary.LittleEndian, &headerSize); err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to read header size: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Sanity check - header shouldn't be too large
|
|
||||||
if headerSize > 1024*1024 {
|
|
||||||
return nil, fmt.Errorf("header size too large: %d", headerSize)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Read header JSON
|
|
||||||
headerBytes := make([]byte, headerSize)
|
|
||||||
if _, err := io.ReadFull(r, headerBytes); err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to read header: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Parse as map of tensor name -> info
|
|
||||||
var header map[string]json.RawMessage
|
|
||||||
if err := json.Unmarshal(headerBytes, &header); err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to parse header: %w", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Find the first (and should be only) tensor entry
|
|
||||||
for name, raw := range header {
|
|
||||||
if name == "__metadata__" {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
var info safetensorsTensorInfo
|
|
||||||
if err := json.Unmarshal(raw, &info); err != nil {
|
|
||||||
return nil, fmt.Errorf("failed to parse tensor info: %w", err)
|
|
||||||
}
|
|
||||||
return &info, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
return nil, fmt.Errorf("no tensor found in header")
|
|
||||||
}
|
|
||||||
@@ -1,597 +0,0 @@
|
|||||||
package server
|
|
||||||
|
|
||||||
import (
|
|
||||||
"bytes"
|
|
||||||
"encoding/binary"
|
|
||||||
"encoding/json"
|
|
||||||
"os"
|
|
||||||
"path/filepath"
|
|
||||||
"testing"
|
|
||||||
|
|
||||||
"github.com/ollama/ollama/x/imagegen"
|
|
||||||
)
|
|
||||||
|
|
||||||
func TestBuildModelInfo(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
config modelConfig
|
|
||||||
totalTensorBytes int64
|
|
||||||
tensorCount int64
|
|
||||||
wantArch string
|
|
||||||
wantContextLen int
|
|
||||||
wantEmbedLen int
|
|
||||||
wantBlockCount int
|
|
||||||
wantParamCount int64
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "gemma3 model with model_type",
|
|
||||||
config: modelConfig{
|
|
||||||
ModelType: "gemma3",
|
|
||||||
HiddenSize: 2560,
|
|
||||||
NumHiddenLayers: 34,
|
|
||||||
MaxPositionEmbeddings: 131072,
|
|
||||||
IntermediateSize: 10240,
|
|
||||||
NumAttentionHeads: 8,
|
|
||||||
NumKeyValueHeads: 4,
|
|
||||||
VocabSize: 262144,
|
|
||||||
TorchDtype: "bfloat16",
|
|
||||||
},
|
|
||||||
totalTensorBytes: 8_600_000_088, // ~4.3B params * 2 bytes + 88 bytes header
|
|
||||||
tensorCount: 1,
|
|
||||||
wantArch: "gemma3",
|
|
||||||
wantContextLen: 131072,
|
|
||||||
wantEmbedLen: 2560,
|
|
||||||
wantBlockCount: 34,
|
|
||||||
wantParamCount: 4_300_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "llama model with architectures array",
|
|
||||||
config: modelConfig{
|
|
||||||
Architectures: []string{"LlamaForCausalLM"},
|
|
||||||
HiddenSize: 4096,
|
|
||||||
NumHiddenLayers: 32,
|
|
||||||
MaxPositionEmbeddings: 4096,
|
|
||||||
IntermediateSize: 11008,
|
|
||||||
NumAttentionHeads: 32,
|
|
||||||
NumKeyValueHeads: 32,
|
|
||||||
VocabSize: 32000,
|
|
||||||
TorchDtype: "float16",
|
|
||||||
},
|
|
||||||
totalTensorBytes: 14_000_000_088, // ~7B params * 2 bytes + 88 bytes header
|
|
||||||
tensorCount: 1,
|
|
||||||
wantArch: "llama",
|
|
||||||
wantContextLen: 4096,
|
|
||||||
wantEmbedLen: 4096,
|
|
||||||
wantBlockCount: 32,
|
|
||||||
wantParamCount: 7_000_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "multimodal model with text_config",
|
|
||||||
config: modelConfig{
|
|
||||||
Architectures: []string{"Gemma3ForConditionalGeneration"},
|
|
||||||
HiddenSize: 1152, // vision hidden size
|
|
||||||
TextConfig: &struct {
|
|
||||||
HiddenSize int `json:"hidden_size"`
|
|
||||||
MaxPositionEmbeddings int `json:"max_position_embeddings"`
|
|
||||||
NumHiddenLayers int `json:"num_hidden_layers"`
|
|
||||||
}{
|
|
||||||
HiddenSize: 2560,
|
|
||||||
MaxPositionEmbeddings: 131072,
|
|
||||||
NumHiddenLayers: 34,
|
|
||||||
},
|
|
||||||
NumAttentionHeads: 8,
|
|
||||||
NumKeyValueHeads: 4,
|
|
||||||
VocabSize: 262144,
|
|
||||||
TorchDtype: "bfloat16",
|
|
||||||
},
|
|
||||||
totalTensorBytes: 8_600_000_088,
|
|
||||||
tensorCount: 1,
|
|
||||||
wantArch: "gemma3",
|
|
||||||
wantContextLen: 131072,
|
|
||||||
wantEmbedLen: 2560,
|
|
||||||
wantBlockCount: 34,
|
|
||||||
wantParamCount: 4_300_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "float32 model",
|
|
||||||
config: modelConfig{
|
|
||||||
ModelType: "test",
|
|
||||||
HiddenSize: 512,
|
|
||||||
NumHiddenLayers: 6,
|
|
||||||
MaxPositionEmbeddings: 2048,
|
|
||||||
TorchDtype: "float32",
|
|
||||||
},
|
|
||||||
totalTensorBytes: 400_000_088, // 100M params * 4 bytes + 88 bytes header
|
|
||||||
tensorCount: 1,
|
|
||||||
wantArch: "test",
|
|
||||||
wantContextLen: 2048,
|
|
||||||
wantEmbedLen: 512,
|
|
||||||
wantBlockCount: 6,
|
|
||||||
wantParamCount: 100_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "multiple tensors with header overhead",
|
|
||||||
config: modelConfig{
|
|
||||||
ModelType: "test",
|
|
||||||
HiddenSize: 256,
|
|
||||||
NumHiddenLayers: 4,
|
|
||||||
MaxPositionEmbeddings: 1024,
|
|
||||||
TorchDtype: "bfloat16",
|
|
||||||
},
|
|
||||||
totalTensorBytes: 2_000_880, // 1M params * 2 bytes + 10 tensors * 88 bytes
|
|
||||||
tensorCount: 10,
|
|
||||||
wantArch: "test",
|
|
||||||
wantContextLen: 1024,
|
|
||||||
wantEmbedLen: 256,
|
|
||||||
wantBlockCount: 4,
|
|
||||||
wantParamCount: 1_000_000,
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
info := buildModelInfo(tt.config, tt.totalTensorBytes, tt.tensorCount)
|
|
||||||
|
|
||||||
// Check architecture
|
|
||||||
if arch, ok := info["general.architecture"].(string); !ok || arch != tt.wantArch {
|
|
||||||
t.Errorf("architecture = %v, want %v", info["general.architecture"], tt.wantArch)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check context length
|
|
||||||
contextKey := tt.wantArch + ".context_length"
|
|
||||||
if contextLen, ok := info[contextKey].(int); !ok || contextLen != tt.wantContextLen {
|
|
||||||
t.Errorf("context_length = %v, want %v", info[contextKey], tt.wantContextLen)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check embedding length
|
|
||||||
embedKey := tt.wantArch + ".embedding_length"
|
|
||||||
if embedLen, ok := info[embedKey].(int); !ok || embedLen != tt.wantEmbedLen {
|
|
||||||
t.Errorf("embedding_length = %v, want %v", info[embedKey], tt.wantEmbedLen)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check block count
|
|
||||||
blockKey := tt.wantArch + ".block_count"
|
|
||||||
if blockCount, ok := info[blockKey].(int); !ok || blockCount != tt.wantBlockCount {
|
|
||||||
t.Errorf("block_count = %v, want %v", info[blockKey], tt.wantBlockCount)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Check parameter count
|
|
||||||
if paramCount, ok := info["general.parameter_count"].(int64); !ok || paramCount != tt.wantParamCount {
|
|
||||||
t.Errorf("parameter_count = %v, want %v", info["general.parameter_count"], tt.wantParamCount)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestBuildModelInfo_ArchitectureConversion(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
architectures []string
|
|
||||||
modelType string
|
|
||||||
wantArch string
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "LlamaForCausalLM",
|
|
||||||
architectures: []string{"LlamaForCausalLM"},
|
|
||||||
wantArch: "llama",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "Gemma3ForCausalLM",
|
|
||||||
architectures: []string{"Gemma3ForCausalLM"},
|
|
||||||
wantArch: "gemma3",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "Gemma3ForConditionalGeneration",
|
|
||||||
architectures: []string{"Gemma3ForConditionalGeneration"},
|
|
||||||
wantArch: "gemma3",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "Qwen2ForCausalLM",
|
|
||||||
architectures: []string{"Qwen2ForCausalLM"},
|
|
||||||
wantArch: "qwen2",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "model_type takes precedence",
|
|
||||||
architectures: []string{"LlamaForCausalLM"},
|
|
||||||
modelType: "custom",
|
|
||||||
wantArch: "custom",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "empty architectures with model_type",
|
|
||||||
architectures: nil,
|
|
||||||
modelType: "mymodel",
|
|
||||||
wantArch: "mymodel",
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
config := modelConfig{
|
|
||||||
Architectures: tt.architectures,
|
|
||||||
ModelType: tt.modelType,
|
|
||||||
}
|
|
||||||
info := buildModelInfo(config, 0, 0)
|
|
||||||
|
|
||||||
if arch, ok := info["general.architecture"].(string); !ok || arch != tt.wantArch {
|
|
||||||
t.Errorf("architecture = %v, want %v", info["general.architecture"], tt.wantArch)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestBuildModelInfo_BytesPerParam(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
dtype string
|
|
||||||
totalBytes int64
|
|
||||||
tensorCount int64
|
|
||||||
wantParamCount int64
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "bfloat16",
|
|
||||||
dtype: "bfloat16",
|
|
||||||
totalBytes: 2_000_088, // 1M * 2 + 88
|
|
||||||
tensorCount: 1,
|
|
||||||
wantParamCount: 1_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "float16",
|
|
||||||
dtype: "float16",
|
|
||||||
totalBytes: 2_000_088,
|
|
||||||
tensorCount: 1,
|
|
||||||
wantParamCount: 1_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "float32",
|
|
||||||
dtype: "float32",
|
|
||||||
totalBytes: 4_000_088, // 1M * 4 + 88
|
|
||||||
tensorCount: 1,
|
|
||||||
wantParamCount: 1_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "int8",
|
|
||||||
dtype: "int8",
|
|
||||||
totalBytes: 1_000_088, // 1M * 1 + 88
|
|
||||||
tensorCount: 1,
|
|
||||||
wantParamCount: 1_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "unknown dtype defaults to 2 bytes",
|
|
||||||
dtype: "unknown",
|
|
||||||
totalBytes: 2_000_088,
|
|
||||||
tensorCount: 1,
|
|
||||||
wantParamCount: 1_000_000,
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "empty dtype defaults to 2 bytes",
|
|
||||||
dtype: "",
|
|
||||||
totalBytes: 2_000_088,
|
|
||||||
tensorCount: 1,
|
|
||||||
wantParamCount: 1_000_000,
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
config := modelConfig{
|
|
||||||
ModelType: "test",
|
|
||||||
TorchDtype: tt.dtype,
|
|
||||||
}
|
|
||||||
info := buildModelInfo(config, tt.totalBytes, tt.tensorCount)
|
|
||||||
|
|
||||||
if paramCount, ok := info["general.parameter_count"].(int64); !ok || paramCount != tt.wantParamCount {
|
|
||||||
t.Errorf("parameter_count = %v, want %v", info["general.parameter_count"], tt.wantParamCount)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestParseSafetensorsHeader(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
header map[string]any
|
|
||||||
wantDtype string
|
|
||||||
wantShape []int64
|
|
||||||
wantErr bool
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "simple tensor",
|
|
||||||
header: map[string]any{
|
|
||||||
"weight": map[string]any{
|
|
||||||
"dtype": "BF16",
|
|
||||||
"shape": []int64{2560, 262144},
|
|
||||||
"data_offsets": []int64{0, 1342177280},
|
|
||||||
},
|
|
||||||
},
|
|
||||||
wantDtype: "BF16",
|
|
||||||
wantShape: []int64{2560, 262144},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "with metadata",
|
|
||||||
header: map[string]any{
|
|
||||||
"__metadata__": map[string]any{
|
|
||||||
"format": "pt",
|
|
||||||
},
|
|
||||||
"bias": map[string]any{
|
|
||||||
"dtype": "F32",
|
|
||||||
"shape": []int64{1024},
|
|
||||||
"data_offsets": []int64{0, 4096},
|
|
||||||
},
|
|
||||||
},
|
|
||||||
wantDtype: "F32",
|
|
||||||
wantShape: []int64{1024},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "float16 tensor",
|
|
||||||
header: map[string]any{
|
|
||||||
"layer.weight": map[string]any{
|
|
||||||
"dtype": "F16",
|
|
||||||
"shape": []int64{512, 512, 3, 3},
|
|
||||||
"data_offsets": []int64{0, 4718592},
|
|
||||||
},
|
|
||||||
},
|
|
||||||
wantDtype: "F16",
|
|
||||||
wantShape: []int64{512, 512, 3, 3},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
// Create safetensors format: 8-byte size + JSON header
|
|
||||||
headerJSON, err := json.Marshal(tt.header)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("failed to marshal header: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
var buf bytes.Buffer
|
|
||||||
if err := binary.Write(&buf, binary.LittleEndian, uint64(len(headerJSON))); err != nil {
|
|
||||||
t.Fatalf("failed to write header size: %v", err)
|
|
||||||
}
|
|
||||||
buf.Write(headerJSON)
|
|
||||||
|
|
||||||
info, err := parseSafetensorsHeader(&buf)
|
|
||||||
if (err != nil) != tt.wantErr {
|
|
||||||
t.Errorf("parseSafetensorsHeader() error = %v, wantErr %v", err, tt.wantErr)
|
|
||||||
return
|
|
||||||
}
|
|
||||||
if tt.wantErr {
|
|
||||||
return
|
|
||||||
}
|
|
||||||
|
|
||||||
if info.Dtype != tt.wantDtype {
|
|
||||||
t.Errorf("Dtype = %v, want %v", info.Dtype, tt.wantDtype)
|
|
||||||
}
|
|
||||||
|
|
||||||
if len(info.Shape) != len(tt.wantShape) {
|
|
||||||
t.Errorf("Shape length = %v, want %v", len(info.Shape), len(tt.wantShape))
|
|
||||||
} else {
|
|
||||||
for i, s := range info.Shape {
|
|
||||||
if s != tt.wantShape[i] {
|
|
||||||
t.Errorf("Shape[%d] = %v, want %v", i, s, tt.wantShape[i])
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestParseSafetensorsHeader_Errors(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
data []byte
|
|
||||||
wantErr string
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "empty data",
|
|
||||||
data: []byte{},
|
|
||||||
wantErr: "failed to read header size",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "truncated header size",
|
|
||||||
data: []byte{0x01, 0x02, 0x03},
|
|
||||||
wantErr: "failed to read header size",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "header size too large",
|
|
||||||
data: func() []byte {
|
|
||||||
var buf bytes.Buffer
|
|
||||||
binary.Write(&buf, binary.LittleEndian, uint64(2*1024*1024)) // 2MB
|
|
||||||
return buf.Bytes()
|
|
||||||
}(),
|
|
||||||
wantErr: "header size too large",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "truncated header",
|
|
||||||
data: func() []byte {
|
|
||||||
var buf bytes.Buffer
|
|
||||||
binary.Write(&buf, binary.LittleEndian, uint64(100))
|
|
||||||
buf.Write([]byte("short"))
|
|
||||||
return buf.Bytes()
|
|
||||||
}(),
|
|
||||||
wantErr: "failed to read header",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "invalid JSON",
|
|
||||||
data: func() []byte {
|
|
||||||
var buf bytes.Buffer
|
|
||||||
binary.Write(&buf, binary.LittleEndian, uint64(10))
|
|
||||||
buf.Write([]byte("not json!!"))
|
|
||||||
return buf.Bytes()
|
|
||||||
}(),
|
|
||||||
wantErr: "failed to parse header",
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "no tensors in header",
|
|
||||||
data: func() []byte {
|
|
||||||
header := map[string]any{
|
|
||||||
"__metadata__": map[string]any{"format": "pt"},
|
|
||||||
}
|
|
||||||
headerJSON, _ := json.Marshal(header)
|
|
||||||
var buf bytes.Buffer
|
|
||||||
binary.Write(&buf, binary.LittleEndian, uint64(len(headerJSON)))
|
|
||||||
buf.Write(headerJSON)
|
|
||||||
return buf.Bytes()
|
|
||||||
}(),
|
|
||||||
wantErr: "no tensor found in header",
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
_, err := parseSafetensorsHeader(bytes.NewReader(tt.data))
|
|
||||||
if err == nil {
|
|
||||||
t.Error("expected error, got nil")
|
|
||||||
return
|
|
||||||
}
|
|
||||||
if !bytes.Contains([]byte(err.Error()), []byte(tt.wantErr)) {
|
|
||||||
t.Errorf("error = %v, want error containing %v", err, tt.wantErr)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestGetTensorInfoFromManifest(t *testing.T) {
|
|
||||||
// Create a temp directory for blobs
|
|
||||||
tempDir := t.TempDir()
|
|
||||||
|
|
||||||
// Create test tensor blobs
|
|
||||||
tensors := []struct {
|
|
||||||
name string
|
|
||||||
digest string
|
|
||||||
dtype string
|
|
||||||
shape []int64
|
|
||||||
}{
|
|
||||||
{
|
|
||||||
name: "model.embed_tokens.weight",
|
|
||||||
digest: "sha256:abc123",
|
|
||||||
dtype: "BF16",
|
|
||||||
shape: []int64{262144, 2560},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "model.layers.0.self_attn.q_proj.weight",
|
|
||||||
digest: "sha256:def456",
|
|
||||||
dtype: "BF16",
|
|
||||||
shape: []int64{2560, 2560},
|
|
||||||
},
|
|
||||||
{
|
|
||||||
name: "model.norm.weight",
|
|
||||||
digest: "sha256:ghi789",
|
|
||||||
dtype: "F32",
|
|
||||||
shape: []int64{2560},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create blob files
|
|
||||||
var layers []imagegen.ManifestLayer
|
|
||||||
for _, tensor := range tensors {
|
|
||||||
// Create safetensors blob
|
|
||||||
header := map[string]any{
|
|
||||||
tensor.name: map[string]any{
|
|
||||||
"dtype": tensor.dtype,
|
|
||||||
"shape": tensor.shape,
|
|
||||||
"data_offsets": []int64{0, 1000},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
headerJSON, _ := json.Marshal(header)
|
|
||||||
|
|
||||||
var buf bytes.Buffer
|
|
||||||
binary.Write(&buf, binary.LittleEndian, uint64(len(headerJSON)))
|
|
||||||
buf.Write(headerJSON)
|
|
||||||
|
|
||||||
// Write blob file
|
|
||||||
blobName := "sha256-" + tensor.digest[7:]
|
|
||||||
blobPath := filepath.Join(tempDir, blobName)
|
|
||||||
if err := os.WriteFile(blobPath, buf.Bytes(), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write blob: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
layers = append(layers, imagegen.ManifestLayer{
|
|
||||||
MediaType: "application/vnd.ollama.image.tensor",
|
|
||||||
Digest: tensor.digest,
|
|
||||||
Size: int64(buf.Len() + 1000), // header + fake data
|
|
||||||
Name: tensor.name,
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
// Add a non-tensor layer (should be skipped)
|
|
||||||
layers = append(layers, imagegen.ManifestLayer{
|
|
||||||
MediaType: "application/vnd.ollama.image.json",
|
|
||||||
Digest: "sha256:config",
|
|
||||||
Size: 100,
|
|
||||||
Name: "config.json",
|
|
||||||
})
|
|
||||||
|
|
||||||
manifest := &imagegen.ModelManifest{
|
|
||||||
Manifest: &imagegen.Manifest{
|
|
||||||
Layers: layers,
|
|
||||||
},
|
|
||||||
BlobDir: tempDir,
|
|
||||||
}
|
|
||||||
|
|
||||||
result, err := getTensorInfoFromManifest(manifest)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("getTensorInfoFromManifest() error = %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
if len(result) != 3 {
|
|
||||||
t.Errorf("got %d tensors, want 3", len(result))
|
|
||||||
}
|
|
||||||
|
|
||||||
// Verify each tensor
|
|
||||||
for i, tensor := range tensors {
|
|
||||||
if i >= len(result) {
|
|
||||||
break
|
|
||||||
}
|
|
||||||
if result[i].Name != tensor.name {
|
|
||||||
t.Errorf("tensor[%d].Name = %v, want %v", i, result[i].Name, tensor.name)
|
|
||||||
}
|
|
||||||
if result[i].Type != tensor.dtype {
|
|
||||||
t.Errorf("tensor[%d].Type = %v, want %v", i, result[i].Type, tensor.dtype)
|
|
||||||
}
|
|
||||||
if len(result[i].Shape) != len(tensor.shape) {
|
|
||||||
t.Errorf("tensor[%d].Shape length = %v, want %v", i, len(result[i].Shape), len(tensor.shape))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestReadSafetensorsHeader(t *testing.T) {
|
|
||||||
// Create a temp file with a valid safetensors header
|
|
||||||
tempDir := t.TempDir()
|
|
||||||
|
|
||||||
header := map[string]any{
|
|
||||||
"test_tensor": map[string]any{
|
|
||||||
"dtype": "BF16",
|
|
||||||
"shape": []int64{1024, 768},
|
|
||||||
"data_offsets": []int64{0, 1572864},
|
|
||||||
},
|
|
||||||
}
|
|
||||||
headerJSON, _ := json.Marshal(header)
|
|
||||||
|
|
||||||
var buf bytes.Buffer
|
|
||||||
binary.Write(&buf, binary.LittleEndian, uint64(len(headerJSON)))
|
|
||||||
buf.Write(headerJSON)
|
|
||||||
|
|
||||||
filePath := filepath.Join(tempDir, "test.safetensors")
|
|
||||||
if err := os.WriteFile(filePath, buf.Bytes(), 0o644); err != nil {
|
|
||||||
t.Fatalf("failed to write test file: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
info, err := readSafetensorsHeader(filePath)
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("readSafetensorsHeader() error = %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
if info.Dtype != "BF16" {
|
|
||||||
t.Errorf("Dtype = %v, want BF16", info.Dtype)
|
|
||||||
}
|
|
||||||
if len(info.Shape) != 2 || info.Shape[0] != 1024 || info.Shape[1] != 768 {
|
|
||||||
t.Errorf("Shape = %v, want [1024, 768]", info.Shape)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestReadSafetensorsHeader_FileNotFound(t *testing.T) {
|
|
||||||
_, err := readSafetensorsHeader("/nonexistent/path/file.safetensors")
|
|
||||||
if err == nil {
|
|
||||||
t.Error("expected error for nonexistent file")
|
|
||||||
}
|
|
||||||
}
|
|
||||||