diff --git a/.github/workflows/create-executables.yaml b/.github/workflows/create-executables.yaml
index b2090fc0..ab833f4c 100644
--- a/.github/workflows/create-executables.yaml
+++ b/.github/workflows/create-executables.yaml
@@ -19,7 +19,7 @@ jobs:
contents: write
steps:
- - uses: actions/checkout@v5
+ - uses: actions/checkout@v6
- name: Install uv
uses: astral-sh/setup-uv@v7
@@ -28,7 +28,7 @@ jobs:
uses: taiki-e/install-action@just
- name: Install the project
- run: uv sync --locked --all-extras --all-groups
+ run: just install
- name: Create executable
run: just create-executable
diff --git a/.github/workflows/deploy-docs.yaml b/.github/workflows/deploy-docs.yaml
index 70e99403..e02bb4c5 100644
--- a/.github/workflows/deploy-docs.yaml
+++ b/.github/workflows/deploy-docs.yaml
@@ -26,7 +26,7 @@ jobs:
name: Build
runs-on: ubuntu-latest
steps:
- - uses: actions/checkout@v5
+ - uses: actions/checkout@v6
- name: Install uv
uses: astral-sh/setup-uv@v7
@@ -35,7 +35,7 @@ jobs:
uses: taiki-e/install-action@just
- name: Install the project
- run: uv sync --locked --all-extras --all-groups
+ run: just install
- name: Build docs
run: just build-docs
diff --git a/.github/workflows/release.yaml b/.github/workflows/release.yaml
index 464b9a9c..432e36b5 100644
--- a/.github/workflows/release.yaml
+++ b/.github/workflows/release.yaml
@@ -22,7 +22,7 @@ jobs:
- update_files
runs-on: ubuntu-latest
steps:
- - uses: actions/checkout@v5
+ - uses: actions/checkout@v6
- name: Install uv
uses: astral-sh/setup-uv@v7
@@ -96,8 +96,8 @@ jobs:
- name: Upload package to PyPI
uses: pypa/gh-action-pypi-publish@release/v1
- publish_to_dockerhub_and_ghcr:
- name: Push Docker image to Docker Hub and GitHub Container Registry
+ publish_docker_to_ghcr:
+ name: Push Docker image to GitHub Container Registry
runs-on: ubuntu-latest
needs:
- publish_to_pypi
@@ -108,7 +108,7 @@ jobs:
id-token: write
steps:
- name: Check out the repo
- uses: actions/checkout@v5
+ uses: actions/checkout@v6
- name: Log in to the Container registry
uses: docker/login-action@v3
diff --git a/.github/workflows/test.yaml b/.github/workflows/test.yaml
index 119c6983..c770fb4a 100644
--- a/.github/workflows/test.yaml
+++ b/.github/workflows/test.yaml
@@ -20,25 +20,23 @@ jobs:
fail-fast: false
matrix:
os: [ubuntu, windows, macos]
- python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
+ python-version: ["3.12", "3.13", "3.14"]
runs-on: ${{ matrix.os }}-latest
steps:
- - uses: actions/checkout@v5
+ - uses: actions/checkout@v6
- name: Install uv
uses: astral-sh/setup-uv@v7
- with:
- python-version: "${{ matrix.python-version}}"
- name: Install just
uses: taiki-e/install-action@just
- name: Install the project
- run: uv sync --locked --all-extras --all-groups
+ run: just install
- name: Test
- run: just test-with-coverage
+ run: just test-coverage
- name: Rename the coverage file
run: mv .coverage .coverage.${{ matrix.python-version }}.${{ matrix.os }}
@@ -51,14 +49,12 @@ jobs:
path: .coverage.${{ matrix.python-version }}.${{ matrix.os }}
report-coverage:
- # Run only if the workflow was triggered by a push event
- if: github.event_name == 'push'
name: Generate the coverage report
needs: [test]
runs-on: ubuntu-latest
steps:
- - uses: actions/checkout@v5
+ - uses: actions/checkout@v6
- name: Download coverage files
uses: actions/download-artifact@v6
@@ -71,7 +67,7 @@ jobs:
uses: astral-sh/setup-uv@v7
- name: Install the project
- run: uv sync --locked --all-extras --all-groups
+ run: just install
- name: Install just
uses: taiki-e/install-action@just
@@ -86,6 +82,6 @@ jobs:
run: uv tool run smokeshow==0.4.0 upload ./htmlcov
env:
SMOKESHOW_GITHUB_STATUS_DESCRIPTION: Coverage {coverage-percentage}
- SMOKESHOW_GITHUB_COVERAGE_THRESHOLD: 20
+ SMOKESHOW_GITHUB_COVERAGE_THRESHOLD: 90
SMOKESHOW_GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
SMOKESHOW_GITHUB_PR_HEAD_SHA: ${{ github.event.pull_request.head.sha }}
diff --git a/.github/workflows/update-files.yaml b/.github/workflows/update-files.yaml
index a797908e..1ff25822 100644
--- a/.github/workflows/update-files.yaml
+++ b/.github/workflows/update-files.yaml
@@ -14,7 +14,7 @@ jobs:
contents: write
steps:
- - uses: actions/checkout@v5
+ - uses: actions/checkout@v6
- name: Install uv
uses: astral-sh/setup-uv@v7
@@ -23,7 +23,7 @@ jobs:
uses: taiki-e/install-action@just
- name: Install the project
- run: uv sync --locked --all-extras --all-groups
+ run: just install
- name: Set Git credentials
run: |
diff --git a/.gitignore b/.gitignore
index f493f687..33a1d59f 100644
--- a/.gitignore
+++ b/.gitignore
@@ -165,10 +165,7 @@ cython_debug/
# VSCode
.vscode/
-# Personal CVs
-*_CV.yaml
-*_cv.py
-*_CV.typ
+# RenderCV output
rendercv_output/
# Include reference files
@@ -189,4 +186,7 @@ rendercv_output/
render_command.prof
# Executables:
-bin/
\ No newline at end of file
+bin/
+
+# Coverage:
+coverage.md
\ No newline at end of file
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index c5dcd71d..48d29362 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -1,13 +1,16 @@
repos:
- repo: https://github.com/astral-sh/ruff-pre-commit
- rev: v0.11.2
+ rev: v0.14.8
hooks:
- id: ruff
+ - repo: https://github.com/RobertCraigie/pyright-python
+ rev: v1.1.407
+ hooks:
+ - id: pyright
- repo: https://github.com/codespell-project/codespell
rev: v2.4.1
hooks:
- id: codespell
- - repo: https://github.com/adrienverge/yamllint
- rev: v1.37.1
- hooks:
- - id: yamllint
+ args:
+ - --skip=src/rendercv/schema/models/locale/other_locales/*
+ - --exclude-file=schema.json
diff --git a/.yamllint.yaml b/.yamllint.yaml
deleted file mode 100644
index d1e02709..00000000
--- a/.yamllint.yaml
+++ /dev/null
@@ -1,3 +0,0 @@
-extends: default
-rules:
- line-length: disable
diff --git a/Dockerfile b/Dockerfile
index 4899d0e4..c46c97b7 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -1,31 +1,49 @@
-# syntax=docker/dockerfile:1.7
+# Use a Python image with uv pre-installed
+FROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim AS builder
-ARG UID=1000
-ARG GID=1000
+# Install the project into `/app`
+WORKDIR /app
-FROM python:3.13-slim AS builder
+# Enable bytecode compilation
+ENV UV_COMPILE_BYTECODE=1
-WORKDIR /build
+# Copy from the cache instead of linking since it's a mounted volume
+ENV UV_LINK_MODE=copy
-RUN python -m venv /opt/rendercv-venv \
- && /opt/rendercv-venv/bin/pip install --no-cache-dir --upgrade pip \
- && /opt/rendercv-venv/bin/pip install --no-cache-dir "rendercv[full]"
+# Install the project's dependencies using the lockfile and settings
+# This layer is cached separately from the project code for faster rebuilds
+RUN --mount=type=cache,target=/root/.cache/uv \
+ --mount=type=bind,source=uv.lock,target=uv.lock \
+ --mount=type=bind,source=pyproject.toml,target=pyproject.toml \
+ uv sync --locked --no-install-project --no-editable --extra full
-FROM python:3.13-slim
+# Then, add the rest of the project source code and install it
+# Installing separately from its dependencies allows optimal layer caching
+COPY . /app
+RUN --mount=type=cache,target=/root/.cache/uv \
+ uv sync --locked --no-editable --extra full
-ARG UID
-ARG GID
+# Final stage
+FROM python:3.12-slim-bookworm
-RUN groupadd --gid ${GID} rendercv \
- && useradd --uid ${UID} --gid ${GID} --create-home rendercv
+# Setup a non-root user
+RUN groupadd --system --gid 999 rendercv \
+ && useradd --system --gid 999 --uid 999 --create-home rendercv
-COPY --from=builder /opt/rendercv-venv /opt/rendercv-venv
+# Set working directory
+WORKDIR /app
-ENV PATH="/opt/rendercv-venv/bin:${PATH}"
+# Copy the virtual environment from the builder stage
+COPY --from=builder --chown=rendercv:rendercv /app/.venv /app/.venv
-WORKDIR /rendercv
+# Place executables in the environment at the front of the path
+ENV PATH="/app/.venv/bin:$PATH"
-USER rendercv:rendercv
+# Use the non-root user to run our application
+USER rendercv
-ENTRYPOINT ["/bin/bash"]
-
+# Set the entrypoint to the rendercv CLI (installed via pyproject.toml entry point)
+ENTRYPOINT ["rendercv"]
+
+# Default command shows help
+CMD ["--help"]
diff --git a/README.md b/README.md
index d6a63301..e43401f3 100644
--- a/README.md
+++ b/README.md
@@ -1,7 +1,7 @@
RenderCV
-_The engine of the [RenderCV App](https://rendercv.com)_
+_CV/resume generator for academics and engineers_
[](https://github.com/rendercv/rendercv/actions/workflows/test.yaml)
[](https://coverage-badge.samuelcolvin.workers.dev/redirect/rendercv/rendercv)
@@ -11,68 +11,149 @@ _The engine of the [RenderCV App](https://rendercv.com)_
-RenderCV engine is a Typst-based Python package with a command-line interface (CLI) that allows you to version-control your CV/resume as source code. It reads a CV written in a YAML file with Markdown syntax, converts it into a [Typst](https://typst.app) code, and generates a PDF.
+Write your CV or resume as YAML, then run RenderCV,
-RenderCV engine's focus is to provide these three features:
+```bash
+rendercv render John_Doe_CV.yaml
+```
-- **Content-first approach:** Users should be able to focus on the content instead of worrying about the formatting.
-- **A mechanism to version-control a CV's content and design separately:** The content and design of a CV are separate issues and they should be treated separately.
-- **Robustness:** A PDF should be delivered if there aren't any errors. If errors exist, they should be clearly explained along with solutions.
+and get a PDF with perfect typography. No template wrestling. No broken layouts. Consistent spacing, every time.
+With RenderCV, you can:
-It takes a YAML file that looks like this:
+- Version-control your CV — it's just text.
+- Focus on content — don't wory about the formatting.
+- Get perfect typography — kerning, spacing, hierarchy, all handled. No design skills required.
+
+A YAML file like this:
```yaml
cv:
name: John Doe
- location: Location
- email: john.doe@example.com
- phone: tel:+1-609-999-9995
+ location: San Francisco, CA
+ email: john.doe@email.com
+ website: https://rendercv.com/
social_networks:
- network: LinkedIn
- username: john.doe
+ username: rendercv
- network: GitHub
- username: john.doe
+ username: rendercv
sections:
- welcome_to_RenderCV!:
- - '[RenderCV](https://rendercv.com) is a Typst-based CV
- framework designed for academics and engineers, with Markdown
- syntax support.'
- - Each section title is arbitrary. Each section contains
- a list of entries, and there are 7 different entry types
- to choose from.
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
education:
- - institution: Stanford University
+ - institution: Princeton University
area: Computer Science
degree: PhD
- location: Stanford, CA, USA
- start_date: 2023-09
- end_date: present
+ date:
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
+ summary:
highlights:
- - Working on the optimization of autonomous vehicles
- in urban environments
+ - "Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment"
+ - "Advisor: Prof. Sanjeev Arora"
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
...
```
-Then, it produces one of these PDFs with its corresponding Typst file, Markdown file, HTML file, and images as PNGs. Click on the images below to preview PDF files.
+becomes one of these PDFs. Click on the images to preview.
-| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ClassicTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_Sb2novTheme_CV.pdf) |
-| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
-| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ModerncvTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringresumesTheme_CV.pdf) |
-| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringclassicTheme_CV.pdf) |  |
+| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ClassicTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringresumesTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_Sb2novTheme_CV.pdf) |
+| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
+| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ModerncvTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringclassicTheme_CV.pdf) |  |
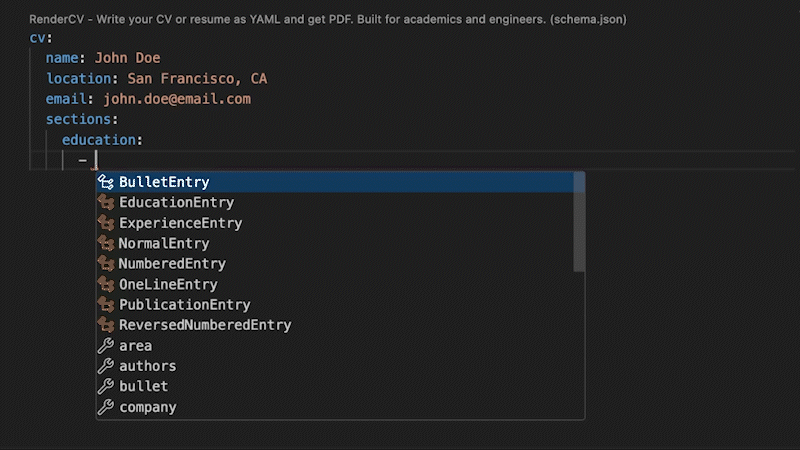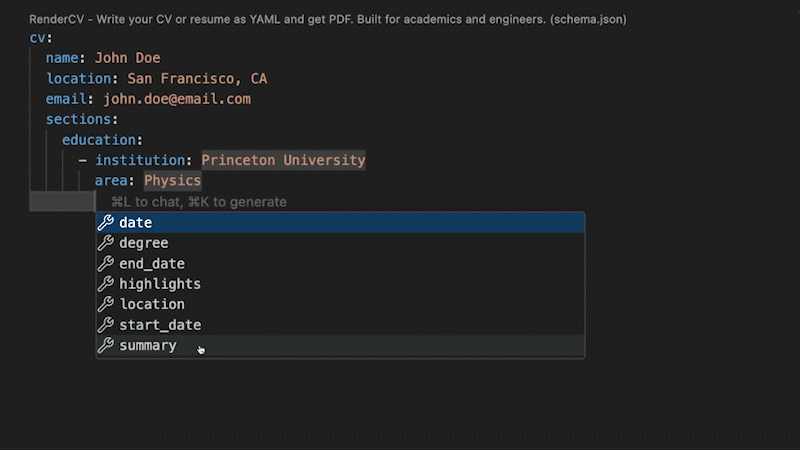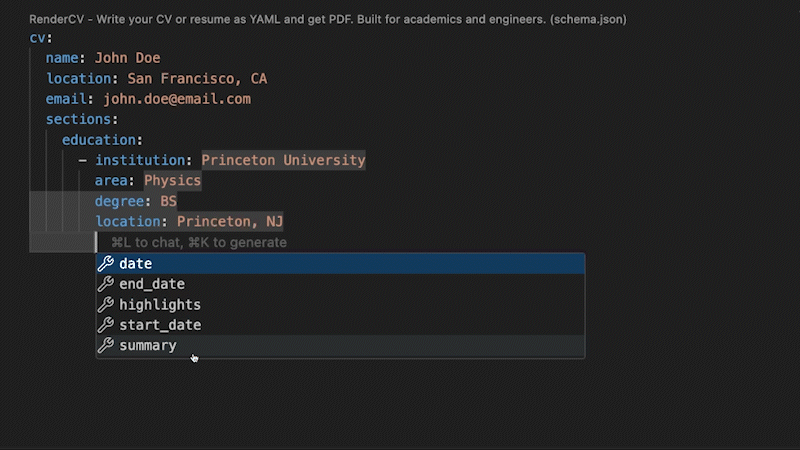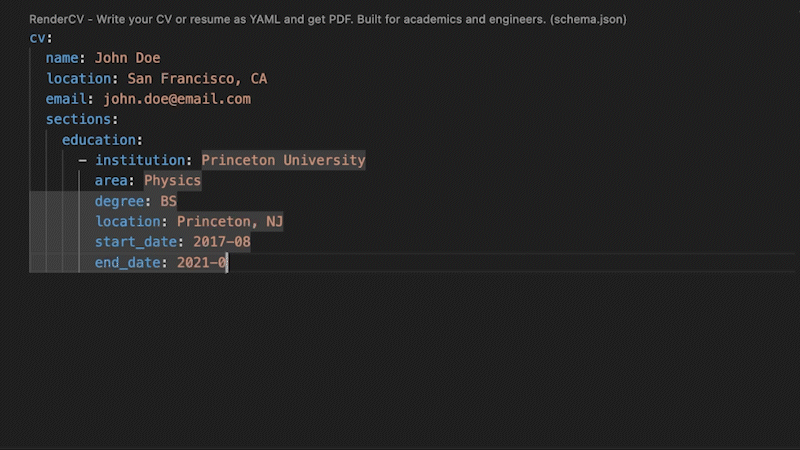
-RenderCV comes with a JSON Schema so that the YAML input file can be filled out interactively.
-
+## JSON Schema
-## Getting Started
+RenderCV's JSON Schema lets you fill out the YAML interactively, with autocompletion and inline documentation.
-RenderCV engine is very easy to install (`pip install "rendercv[full]"`) and easy to use (`rendercv new "John Doe"`). Follow the [user guide](https://docs.rendercv.com/user_guide) to get started.
+
-## Motivation
-We are developing a [purpose-built app](https://rendercv.com) for writing CVs and resumes that will be available on mobile and web. This Python project is the foundation of that app. Check out [our blog post](https://rendercv.com/introducing-rendercv/) to learn more about why one would use such an app.
+## Extensive Design Options
-## Contributing
+You have full control over every detail.
-All contributions to RenderCV are welcome! To get started, please read [the developer guide](https://docs.rendercv.com/developer_guide).
+```yaml
+design:
+ theme: classic
+ page:
+ size: us-letter
+ top_margin: 0.7in
+ bottom_margin: 0.7in
+ left_margin: 0.7in
+ right_margin: 0.7in
+ show_footer: true
+ show_top_note: true
+ colors:
+ body: rgb(0, 0, 0)
+ name: rgb(0, 79, 144)
+ headline: rgb(0, 79, 144)
+ connections: rgb(0, 79, 144)
+ section_titles: rgb(0, 79, 144)
+ links: rgb(0, 79, 144)
+ footer: rgb(128, 128, 128)
+ top_note: rgb(128, 128, 128)
+ typography:
+ line_spacing: 0.6em
+ alignment: justified
+ date_and_location_column_alignment: right
+ font_family: Source Sans 3
+ # ...and more
+```
+
+
+
+> [!TIP]
+> Want to set up a live preview environment like the one shown above? See [how to set up VS Code for RenderCV](https://docs.rendercv.com/user_guide/how_to/set_up_vs_code_for_rendercv.md).
+
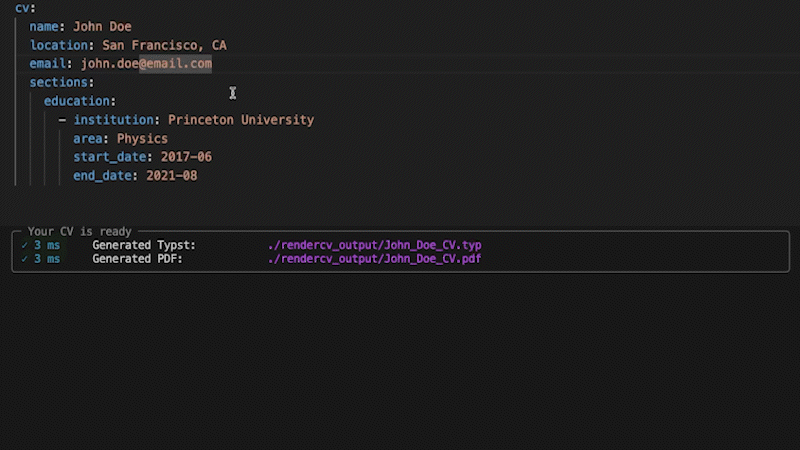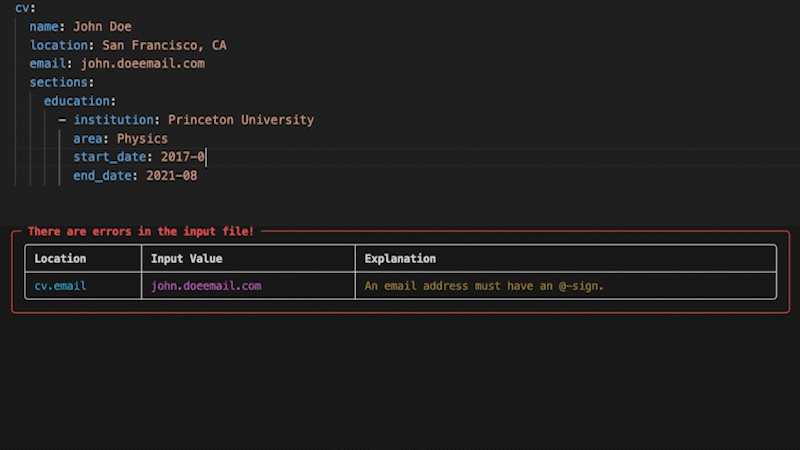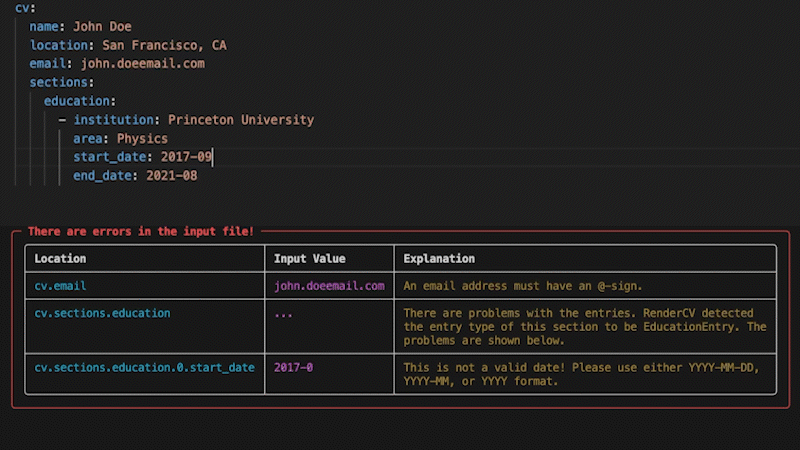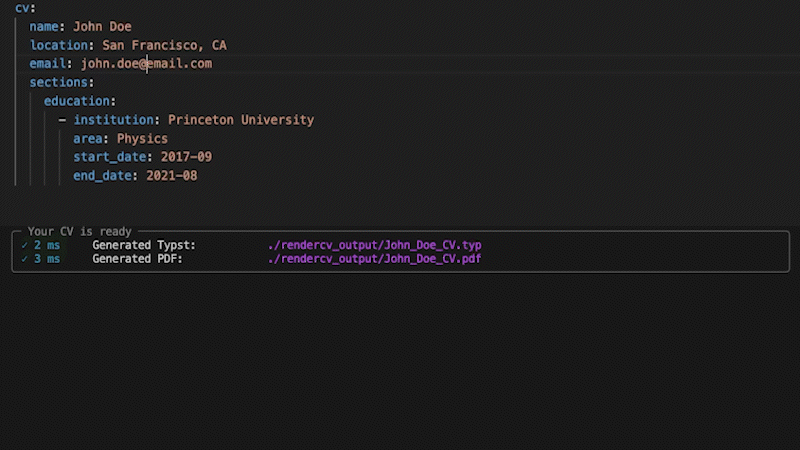
+## Strict Validation
+
+No surprises. If something's wrong, you'll know exactly what and where. If it's valid, you get a perfect PDF.
+
+
+
+
+## Any Language
+
+Fill out the locale field for your language.
+
+```yaml
+locale:
+ language: english
+ last_updated: Last updated in
+ month: month
+ months: months
+ year: year
+ years: years
+ present: present
+ month_abbreviations:
+ - Jan
+ - Feb
+ - Mar
+ ...
+```
+
+## Get Started
+
+Install RenderCV (Requires Python 3.12+):
+
+```
+pip install "rendercv[full]"
+```
+
+Create a new CV yaml file:
+
+```
+rendercv new "John Doe"
+```
+
+Edit the YAML, then render:
+
+```
+rendercv render "John_Doe_CV.yaml"
+```
+
+For more details, see the [user guide](https://docs.rendercv.com/user_guide/index.md).
diff --git a/docs/api_reference/api_reference.py b/docs/api_reference/api_reference.py
new file mode 100644
index 00000000..9a6d4af2
--- /dev/null
+++ b/docs/api_reference/api_reference.py
@@ -0,0 +1,37 @@
+from pathlib import Path
+
+import mkdocs_gen_files
+
+nav = mkdocs_gen_files.Nav()
+
+repository_root = Path(__file__).parent.parent.parent
+api_reference = repository_root / "docs" / "api_reference"
+src_rendercv = repository_root / "src" / "rendercv"
+nav[("src", "rendercv")] = "index.md"
+
+# Process each Python file in the objects directory
+for path in sorted(src_rendercv.rglob("*.py")):
+ # Skip __init__.py files and __main__.py files
+ if path.name in ("__init__.py", "__main__.py"):
+ continue
+
+ # Get the relative path from the objects directory
+ module_path = path.relative_to(src_rendercv).with_suffix("")
+ doc_path = module_path.with_suffix(".md")
+ parts = (f"rendercv.{module_path.parts[0]}", *module_path.parts[1:])
+
+ # Add to navigation
+ nav[("src", *parts)] = doc_path.as_posix()
+
+ # Generate the documentation page
+ with mkdocs_gen_files.open(f"api_reference/{doc_path}", "w") as fd:
+ module_ident = "rendercv." + ".".join(module_path.parts)
+ fd.write(f"::: {module_ident}\n")
+
+ # Set the edit path to the actual source file
+ # mkdocs_gen_files.set_edit_path(full_doc_path, full_doc_path.relative_to(docs_path))
+
+
+# Write the navigation file
+with mkdocs_gen_files.open("api_reference/SUMMARY.md", "w") as nav_file:
+ nav_file.writelines(nav.build_literate_nav())
diff --git a/docs/api_reference/index.md b/docs/api_reference/index.md
new file mode 100644
index 00000000..2c1f40bc
--- /dev/null
+++ b/docs/api_reference/index.md
@@ -0,0 +1,7 @@
+# API Reference
+
+RenderCV is a CLI application, not a library. Its internal API is not guaranteed to be stable and may change without notice. However, for those who wish to use RenderCV programmatically in Python scripts, the complete API reference is provided here.
+
+::: rendercv
+ options:
+ heading_level: 2
\ No newline at end of file
diff --git a/docs/assets/images/classic.png b/docs/assets/images/classic.png
index fcb97864..d83f13a0 100644
Binary files a/docs/assets/images/classic.png and b/docs/assets/images/classic.png differ
diff --git a/docs/assets/images/classic/bullet_entry.png b/docs/assets/images/classic/bullet_entry.png
index b84715e3..7d226ea4 100644
Binary files a/docs/assets/images/classic/bullet_entry.png and b/docs/assets/images/classic/bullet_entry.png differ
diff --git a/docs/assets/images/classic/classic.png b/docs/assets/images/classic/classic.png
new file mode 100644
index 00000000..5db5a3ad
Binary files /dev/null and b/docs/assets/images/classic/classic.png differ
diff --git a/docs/assets/images/classic/education_entry.png b/docs/assets/images/classic/education_entry.png
index 88ff4532..db884120 100644
Binary files a/docs/assets/images/classic/education_entry.png and b/docs/assets/images/classic/education_entry.png differ
diff --git a/docs/assets/images/classic/experience_entry.png b/docs/assets/images/classic/experience_entry.png
index 354dd13a..23f03ec1 100644
Binary files a/docs/assets/images/classic/experience_entry.png and b/docs/assets/images/classic/experience_entry.png differ
diff --git a/docs/assets/images/classic/normal_entry.png b/docs/assets/images/classic/normal_entry.png
index 987056c5..f3caa66d 100644
Binary files a/docs/assets/images/classic/normal_entry.png and b/docs/assets/images/classic/normal_entry.png differ
diff --git a/docs/assets/images/classic/numbered_entry.png b/docs/assets/images/classic/numbered_entry.png
index 20df24e8..f34fd5cf 100644
Binary files a/docs/assets/images/classic/numbered_entry.png and b/docs/assets/images/classic/numbered_entry.png differ
diff --git a/docs/assets/images/classic/one_line_entry.png b/docs/assets/images/classic/one_line_entry.png
index a519bdb1..de1edbcc 100644
Binary files a/docs/assets/images/classic/one_line_entry.png and b/docs/assets/images/classic/one_line_entry.png differ
diff --git a/docs/assets/images/classic/publication_entry.png b/docs/assets/images/classic/publication_entry.png
index 034458c0..872974eb 100644
Binary files a/docs/assets/images/classic/publication_entry.png and b/docs/assets/images/classic/publication_entry.png differ
diff --git a/docs/assets/images/classic/reversed_numbered_entry.png b/docs/assets/images/classic/reversed_numbered_entry.png
index 446b9e05..0071683d 100644
Binary files a/docs/assets/images/classic/reversed_numbered_entry.png and b/docs/assets/images/classic/reversed_numbered_entry.png differ
diff --git a/docs/assets/images/classic/text_entry.png b/docs/assets/images/classic/text_entry.png
index 3c06f92b..479be983 100644
Binary files a/docs/assets/images/classic/text_entry.png and b/docs/assets/images/classic/text_entry.png differ
diff --git a/docs/assets/images/design_options.gif b/docs/assets/images/design_options.gif
new file mode 100644
index 00000000..3feda754
Binary files /dev/null and b/docs/assets/images/design_options.gif differ
diff --git a/docs/assets/images/engineeringclassic.png b/docs/assets/images/engineeringclassic.png
index 5c4b9717..f987ba83 100644
Binary files a/docs/assets/images/engineeringclassic.png and b/docs/assets/images/engineeringclassic.png differ
diff --git a/docs/assets/images/engineeringclassic/bullet_entry.png b/docs/assets/images/engineeringclassic/bullet_entry.png
index 5bba50b3..49fc85a1 100644
Binary files a/docs/assets/images/engineeringclassic/bullet_entry.png and b/docs/assets/images/engineeringclassic/bullet_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/education_entry.png b/docs/assets/images/engineeringclassic/education_entry.png
index 71ecbd06..c93710b6 100644
Binary files a/docs/assets/images/engineeringclassic/education_entry.png and b/docs/assets/images/engineeringclassic/education_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/engineeringclassic.png b/docs/assets/images/engineeringclassic/engineeringclassic.png
new file mode 100644
index 00000000..7e834e97
Binary files /dev/null and b/docs/assets/images/engineeringclassic/engineeringclassic.png differ
diff --git a/docs/assets/images/engineeringclassic/experience_entry.png b/docs/assets/images/engineeringclassic/experience_entry.png
index 5dd43e25..1fce0cce 100644
Binary files a/docs/assets/images/engineeringclassic/experience_entry.png and b/docs/assets/images/engineeringclassic/experience_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/normal_entry.png b/docs/assets/images/engineeringclassic/normal_entry.png
index 7e868366..7c412d04 100644
Binary files a/docs/assets/images/engineeringclassic/normal_entry.png and b/docs/assets/images/engineeringclassic/normal_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/numbered_entry.png b/docs/assets/images/engineeringclassic/numbered_entry.png
index e833995b..571403eb 100644
Binary files a/docs/assets/images/engineeringclassic/numbered_entry.png and b/docs/assets/images/engineeringclassic/numbered_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/one_line_entry.png b/docs/assets/images/engineeringclassic/one_line_entry.png
index 750dda7b..a49cf102 100644
Binary files a/docs/assets/images/engineeringclassic/one_line_entry.png and b/docs/assets/images/engineeringclassic/one_line_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/publication_entry.png b/docs/assets/images/engineeringclassic/publication_entry.png
index ee64764e..c754fd3a 100644
Binary files a/docs/assets/images/engineeringclassic/publication_entry.png and b/docs/assets/images/engineeringclassic/publication_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/reversed_numbered_entry.png b/docs/assets/images/engineeringclassic/reversed_numbered_entry.png
index 1730fc0d..2d4e61bf 100644
Binary files a/docs/assets/images/engineeringclassic/reversed_numbered_entry.png and b/docs/assets/images/engineeringclassic/reversed_numbered_entry.png differ
diff --git a/docs/assets/images/engineeringclassic/text_entry.png b/docs/assets/images/engineeringclassic/text_entry.png
index 7d09aa17..dab40e24 100644
Binary files a/docs/assets/images/engineeringclassic/text_entry.png and b/docs/assets/images/engineeringclassic/text_entry.png differ
diff --git a/docs/assets/images/engineeringresumes.png b/docs/assets/images/engineeringresumes.png
index 75ba84f4..6b58ca2d 100644
Binary files a/docs/assets/images/engineeringresumes.png and b/docs/assets/images/engineeringresumes.png differ
diff --git a/docs/assets/images/engineeringresumes/bullet_entry.png b/docs/assets/images/engineeringresumes/bullet_entry.png
index 46a6fe0c..db38617f 100644
Binary files a/docs/assets/images/engineeringresumes/bullet_entry.png and b/docs/assets/images/engineeringresumes/bullet_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/education_entry.png b/docs/assets/images/engineeringresumes/education_entry.png
index 96fbb840..d5c80d76 100644
Binary files a/docs/assets/images/engineeringresumes/education_entry.png and b/docs/assets/images/engineeringresumes/education_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/engineeringresumes.png b/docs/assets/images/engineeringresumes/engineeringresumes.png
new file mode 100644
index 00000000..89d8ea5a
Binary files /dev/null and b/docs/assets/images/engineeringresumes/engineeringresumes.png differ
diff --git a/docs/assets/images/engineeringresumes/experience_entry.png b/docs/assets/images/engineeringresumes/experience_entry.png
index 5ed3ac49..be5ec42a 100644
Binary files a/docs/assets/images/engineeringresumes/experience_entry.png and b/docs/assets/images/engineeringresumes/experience_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/normal_entry.png b/docs/assets/images/engineeringresumes/normal_entry.png
index 950cd0f8..01331e9c 100644
Binary files a/docs/assets/images/engineeringresumes/normal_entry.png and b/docs/assets/images/engineeringresumes/normal_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/numbered_entry.png b/docs/assets/images/engineeringresumes/numbered_entry.png
index 370715a2..80744bad 100644
Binary files a/docs/assets/images/engineeringresumes/numbered_entry.png and b/docs/assets/images/engineeringresumes/numbered_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/one_line_entry.png b/docs/assets/images/engineeringresumes/one_line_entry.png
index 89699410..2c93503e 100644
Binary files a/docs/assets/images/engineeringresumes/one_line_entry.png and b/docs/assets/images/engineeringresumes/one_line_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/publication_entry.png b/docs/assets/images/engineeringresumes/publication_entry.png
index 4798eaa0..95b31905 100644
Binary files a/docs/assets/images/engineeringresumes/publication_entry.png and b/docs/assets/images/engineeringresumes/publication_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/reversed_numbered_entry.png b/docs/assets/images/engineeringresumes/reversed_numbered_entry.png
index da3cedbf..fcf6ed14 100644
Binary files a/docs/assets/images/engineeringresumes/reversed_numbered_entry.png and b/docs/assets/images/engineeringresumes/reversed_numbered_entry.png differ
diff --git a/docs/assets/images/engineeringresumes/text_entry.png b/docs/assets/images/engineeringresumes/text_entry.png
index 158d634d..fc3a3912 100644
Binary files a/docs/assets/images/engineeringresumes/text_entry.png and b/docs/assets/images/engineeringresumes/text_entry.png differ
diff --git a/docs/assets/images/json_schema.gif b/docs/assets/images/json_schema.gif
new file mode 100644
index 00000000..d9d15652
Binary files /dev/null and b/docs/assets/images/json_schema.gif differ
diff --git a/docs/assets/images/moderncv.png b/docs/assets/images/moderncv.png
index acfada44..bfc2c180 100644
Binary files a/docs/assets/images/moderncv.png and b/docs/assets/images/moderncv.png differ
diff --git a/docs/assets/images/moderncv/bullet_entry.png b/docs/assets/images/moderncv/bullet_entry.png
index 0f70e735..292495d2 100644
Binary files a/docs/assets/images/moderncv/bullet_entry.png and b/docs/assets/images/moderncv/bullet_entry.png differ
diff --git a/docs/assets/images/moderncv/education_entry.png b/docs/assets/images/moderncv/education_entry.png
index b1ed6c63..d52d2ecc 100644
Binary files a/docs/assets/images/moderncv/education_entry.png and b/docs/assets/images/moderncv/education_entry.png differ
diff --git a/docs/assets/images/moderncv/experience_entry.png b/docs/assets/images/moderncv/experience_entry.png
index 71c6b60c..2f29ad02 100644
Binary files a/docs/assets/images/moderncv/experience_entry.png and b/docs/assets/images/moderncv/experience_entry.png differ
diff --git a/docs/assets/images/moderncv/moderncv.png b/docs/assets/images/moderncv/moderncv.png
new file mode 100644
index 00000000..37c4ba40
Binary files /dev/null and b/docs/assets/images/moderncv/moderncv.png differ
diff --git a/docs/assets/images/moderncv/normal_entry.png b/docs/assets/images/moderncv/normal_entry.png
index 8bbc9f65..3aa73ce7 100644
Binary files a/docs/assets/images/moderncv/normal_entry.png and b/docs/assets/images/moderncv/normal_entry.png differ
diff --git a/docs/assets/images/moderncv/numbered_entry.png b/docs/assets/images/moderncv/numbered_entry.png
index 98acf9ab..bcea3233 100644
Binary files a/docs/assets/images/moderncv/numbered_entry.png and b/docs/assets/images/moderncv/numbered_entry.png differ
diff --git a/docs/assets/images/moderncv/one_line_entry.png b/docs/assets/images/moderncv/one_line_entry.png
index ba209b6d..291680d4 100644
Binary files a/docs/assets/images/moderncv/one_line_entry.png and b/docs/assets/images/moderncv/one_line_entry.png differ
diff --git a/docs/assets/images/moderncv/publication_entry.png b/docs/assets/images/moderncv/publication_entry.png
index 066ddc53..e95a80fc 100644
Binary files a/docs/assets/images/moderncv/publication_entry.png and b/docs/assets/images/moderncv/publication_entry.png differ
diff --git a/docs/assets/images/moderncv/reversed_numbered_entry.png b/docs/assets/images/moderncv/reversed_numbered_entry.png
index 5c684c94..6c83a38d 100644
Binary files a/docs/assets/images/moderncv/reversed_numbered_entry.png and b/docs/assets/images/moderncv/reversed_numbered_entry.png differ
diff --git a/docs/assets/images/moderncv/text_entry.png b/docs/assets/images/moderncv/text_entry.png
index 363ec68b..731b7cc4 100644
Binary files a/docs/assets/images/moderncv/text_entry.png and b/docs/assets/images/moderncv/text_entry.png differ
diff --git a/docs/assets/images/sb2nov.png b/docs/assets/images/sb2nov.png
index 052c595c..a9bc3829 100644
Binary files a/docs/assets/images/sb2nov.png and b/docs/assets/images/sb2nov.png differ
diff --git a/docs/assets/images/sb2nov/bullet_entry.png b/docs/assets/images/sb2nov/bullet_entry.png
index ed658462..44c87b92 100644
Binary files a/docs/assets/images/sb2nov/bullet_entry.png and b/docs/assets/images/sb2nov/bullet_entry.png differ
diff --git a/docs/assets/images/sb2nov/education_entry.png b/docs/assets/images/sb2nov/education_entry.png
index 958a44d4..c09f3227 100644
Binary files a/docs/assets/images/sb2nov/education_entry.png and b/docs/assets/images/sb2nov/education_entry.png differ
diff --git a/docs/assets/images/sb2nov/experience_entry.png b/docs/assets/images/sb2nov/experience_entry.png
index b1c8daef..cb0b1a4e 100644
Binary files a/docs/assets/images/sb2nov/experience_entry.png and b/docs/assets/images/sb2nov/experience_entry.png differ
diff --git a/docs/assets/images/sb2nov/normal_entry.png b/docs/assets/images/sb2nov/normal_entry.png
index 3602d77c..5cbab4cc 100644
Binary files a/docs/assets/images/sb2nov/normal_entry.png and b/docs/assets/images/sb2nov/normal_entry.png differ
diff --git a/docs/assets/images/sb2nov/numbered_entry.png b/docs/assets/images/sb2nov/numbered_entry.png
index bba99cec..33168ee3 100644
Binary files a/docs/assets/images/sb2nov/numbered_entry.png and b/docs/assets/images/sb2nov/numbered_entry.png differ
diff --git a/docs/assets/images/sb2nov/one_line_entry.png b/docs/assets/images/sb2nov/one_line_entry.png
index c4ad26b1..5163f0d3 100644
Binary files a/docs/assets/images/sb2nov/one_line_entry.png and b/docs/assets/images/sb2nov/one_line_entry.png differ
diff --git a/docs/assets/images/sb2nov/publication_entry.png b/docs/assets/images/sb2nov/publication_entry.png
index 2647e19b..a6c0c9dd 100644
Binary files a/docs/assets/images/sb2nov/publication_entry.png and b/docs/assets/images/sb2nov/publication_entry.png differ
diff --git a/docs/assets/images/sb2nov/reversed_numbered_entry.png b/docs/assets/images/sb2nov/reversed_numbered_entry.png
index 2310666c..a893ff1b 100644
Binary files a/docs/assets/images/sb2nov/reversed_numbered_entry.png and b/docs/assets/images/sb2nov/reversed_numbered_entry.png differ
diff --git a/docs/assets/images/sb2nov/sb2nov.png b/docs/assets/images/sb2nov/sb2nov.png
new file mode 100644
index 00000000..2b1ee35a
Binary files /dev/null and b/docs/assets/images/sb2nov/sb2nov.png differ
diff --git a/docs/assets/images/sb2nov/text_entry.png b/docs/assets/images/sb2nov/text_entry.png
index 82bda621..b9682d51 100644
Binary files a/docs/assets/images/sb2nov/text_entry.png and b/docs/assets/images/sb2nov/text_entry.png differ
diff --git a/docs/assets/images/schema.gif b/docs/assets/images/schema.gif
deleted file mode 100644
index a9c5c4cc..00000000
Binary files a/docs/assets/images/schema.gif and /dev/null differ
diff --git a/docs/assets/images/validation.gif b/docs/assets/images/validation.gif
new file mode 100644
index 00000000..ab0e05be
Binary files /dev/null and b/docs/assets/images/validation.gif differ
diff --git a/docs/changelog/index.md b/docs/changelog.md
similarity index 95%
rename from docs/changelog/index.md
rename to docs/changelog.md
index f9f64204..e6dab529 100644
--- a/docs/changelog/index.md
+++ b/docs/changelog.md
@@ -1,5 +1,7 @@
---
toc_depth: 1
+hide:
+ - navigation
---
# Changelog
@@ -92,8 +94,8 @@ RenderCV has transitioned from using $\LaTeX$ to Typst. RenderCV is now much fas
### Changed
- $\LaTeX$ has been replaced with Typst.
-- The `design` field has been changed completely. See the [documentation](https://docs.rendercv.com/user_guide/structure_of_the_yaml_input_file/#design-field) for details.
-- The `locale_catalog` field has been renamed to `locale`, and some fields have been moved from `design` to `locale`. See the [documentation](https://docs.rendercv.com/user_guide/structure_of_the_yaml_input_file/#locale-field) for details.
+- The `design` field has been changed completely.
+- The `locale_catalog` field has been renamed to `locale`, and some fields have been moved from `design` to `locale`.
- The `moderncv` theme's header has been changed.
@@ -167,7 +169,7 @@ RenderCV has transitioned from using $\LaTeX$ to Typst. RenderCV is now much fas
### Added
-- `rendercv_settings` field has been added to the YAML input file. For details, see [here](../user_guide/structure_of_the_yaml_input_file.md#rendercv_settings-field). It will be extended in the future.
+- `rendercv_settings` field has been added to the YAML input file. It will be extended in the future.
## [1.13] - July 23, 2024
@@ -176,8 +178,8 @@ RenderCV has transitioned from using $\LaTeX$ to Typst. RenderCV is now much fas
### Added
-- Arbitrary keys are now allowed in the `cv` field. For details, see [here](../user_guide/structure_of_the_yaml_input_file.md#using-arbitrary-keys).
-- Two new fields have been added to the `locale` field: `phone_number_format` and `date_style` ([#130](https://github.com/rendercv/rendercv/issues/130)). For details, see [here](../user_guide/structure_of_the_yaml_input_file.md#locale-field).
+- Arbitrary keys are now allowed in the `cv` field.
+- Two new fields have been added to the `locale` field: `phone_number_format` and `date_style` ([#130](https://github.com/rendercv/rendercv/issues/130)).
### Changed
@@ -195,7 +197,7 @@ RenderCV has transitioned from using $\LaTeX$ to Typst. RenderCV is now much fas
### Added
-- Arbitrary keys are now allowed in entry types. Users can use these keys in their templates. For details, see the [documentation](../user_guide/structure_of_the_yaml_input_file.md#using-arbitrary-keys).
+- Arbitrary keys are now allowed in entry types. Users can use these keys in their templates.
- The `locale.full_names_of_months` field has been added to the data model ([#111](https://github.com/rendercv/rendercv/issues/111)).
- The `TODAY` placeholder can be used in the `design.page_numbering_style` field now.
@@ -214,7 +216,7 @@ RenderCV has transitioned from using $\LaTeX$ to Typst. RenderCV is now much fas
### Added
-- CLI options now have short versions. See the [CLI documentation](https://docs.rendercv.com/user_guide/cli/) for more information.
+- CLI options now have short versions.
- CLI now notifies the user when a new version is available ([#89](https://github.com/rendercv/rendercv/issues/89)).
- `Google Scholar` has been added as a social network type ([#85](https://github.com/rendercv/rendercv/issues/85)).
- Two new design options have been added to the `classic`, `sb2nov`, and `engineeringresumes` themes: `separator_between_connections` and `use_icons_for_connections`.
@@ -259,7 +261,7 @@ RenderCV has transitioned from using $\LaTeX$ to Typst. RenderCV is now much fas
### Added
-- RenderCV is now a multilingual tool. English strings can be overridden with `locale` section in the YAML input file ([#26](https://github.com/rendercv/rendercv/issues/26), [#20](https://github.com/rendercv/rendercv/pull/20)). See the [documentation](../user_guide/structure_of_the_yaml_input_file.md#locale-field) for more information.
+- RenderCV is now a multilingual tool. English strings can be overridden with `locale` section in the YAML input file ([#26](https://github.com/rendercv/rendercv/issues/26), [#20](https://github.com/rendercv/rendercv/pull/20)).
- PNG files for each page can be generated now ([#57](https://github.com/rendercv/rendercv/issues/57)).
- `rendercv new` command now generates Markdown and $\LaTeX$ source files in addition to the YAML input file so that the default templates can be modified easily.
- A new CLI command has been added, `rendercv create-theme`, to allow users to create their own themes easily.
diff --git a/docs/developer_guide/code_guidelines/source_code.md b/docs/developer_guide/code_guidelines/source_code.md
new file mode 100644
index 00000000..d3feb231
--- /dev/null
+++ b/docs/developer_guide/code_guidelines/source_code.md
@@ -0,0 +1,57 @@
+# Guidelines for Writing Source Code
+
+## Type Annotations
+
+**Every function, variable, and class attribute must be strictly typed. No exceptions.**
+
+Use modern Python 3.12+ syntax:
+
+- Type aliases with `type` statement
+- PEP 695 type parameters (`[T]`, `[**P]`)
+- Pipe unions (`str | int`, not `Union[str, int]`)
+- Proper optional types (`str | None`, not `Optional[str]`)
+
+## Linting and Type Checking
+
+Always run `just check` and `just format` before committing. `just check` must show **zero errors**:
+
+```bash
+just format
+just check
+```
+
+If there's absolutely no alternative, use `# pyright: ignore[errorCode]` or `#NOQA: errorCode` to ignore typing or linting errors.
+
+## Docstrings
+
+Use [Google-style docstrings](https://google.github.io/styleguide/pyguide.html#38-comments-and-docstrings). Include a **"Why" section** and **"Example" section** when it adds value:
+
+```python
+def resolve_relative_path(
+ path: pathlib.Path, info: pydantic.ValidationInfo, must_exist: bool = True
+) -> pathlib.Path:
+ """Convert relative path to absolute path based on input file location.
+
+ Why:
+ Users reference files like `photo: profile.jpg` relative to their CV
+ YAML. This validator resolves such paths to absolute form and validates
+ existence, enabling file access during rendering.
+
+ Args:
+ path: Path to resolve (may be relative or absolute).
+ info: Validation context containing input file path.
+ must_exist: Whether to raise error if path doesn't exist.
+
+ Returns:
+ Absolute path.
+ """
+```
+
+Docstring order:
+
+1. Brief description (one line)
+2. Why section (when it adds value)
+3. Example section (when it adds value)
+4. Args section (mandatory)
+5. Returns section (mandatory)
+6. Raises section (mandatory if function raises exceptions)
diff --git a/docs/developer_guide/code_guidelines/tests.md b/docs/developer_guide/code_guidelines/tests.md
new file mode 100644
index 00000000..640cc041
--- /dev/null
+++ b/docs/developer_guide/code_guidelines/tests.md
@@ -0,0 +1,145 @@
+# Guidelines for Writing Tests
+
+## File Structure
+
+Each test file tests all classes and functions in its corresponding source file. The structure mirrors `src/rendercv/`:
+
+```
+src/rendercv/renderer/templater/date.py
+ → tests/renderer/templater/test_date.py
+ (tests all functions and classes in date.py)
+
+src/rendercv/schema/models/cv/section.py
+ → tests/schema/models/cv/test_section.py
+ (tests all functions and classes in section.py)
+```
+
+## Naming Conventions
+
+Test names must include the name of the function or class being tested.
+
+**When you need only one test**, use `test_` + the name:
+
+- Testing `clean_url()` → `test_clean_url`
+- Testing `Cv` → `test_cv`
+
+**When you need multiple tests**, wrap them in a class using `Test` + PascalCase name:
+
+- Testing `clean_url()` → `TestCleanUrl`
+- Testing `Cv` → `TestCv`
+
+Example with one test:
+
+```python
+@pytest.mark.parametrize(
+ ("url", "expected_clean_url"),
+ [
+ ("https://example.com", "example.com"),
+ ("https://example.com/", "example.com"),
+ ("https://example.com/test", "example.com/test"),
+ ],
+)
+def test_clean_url(url, expected_clean_url):
+ assert clean_url(url) == expected_clean_url
+```
+
+Example with multiple tests:
+
+```python
+class TestComputeDateString:
+ @pytest.mark.parametrize(...)
+ def test_date_parameter_takes_precedence(self, ...):
+ ...
+
+ @pytest.mark.parametrize(...)
+ def test_date_ranges(self, ...):
+ ...
+
+ @pytest.mark.parametrize(...)
+ def test_returns_none_for_incomplete_data(self, ...):
+ ...
+```
+
+## Use Parametrize for Variations
+
+Instead of writing multiple similar tests, use `@pytest.mark.parametrize`:
+
+```python
+@pytest.mark.parametrize(
+ ("input_a", "input_b", "expected"),
+ [
+ ("2020-01-01", "2021-01-01", "Jan 2020 – Jan 2021"),
+ ("2020-01", "2021-02-01", "Jan 2020 – Feb 2021"),
+ (2020, 2021, "2020 – 2021"),
+ ],
+)
+def test_date_ranges(self, input_a, input_b, expected):
+ result = compute_date_string(None, input_a, input_b, EnglishLocale())
+ assert result == expected
+```
+
+## Shared Fixtures with conftest.py
+
+Place shared fixtures in `conftest.py`. Use the closest one possible:
+
+- Fixtures for one folder → that folder's `conftest.py`
+- Fixtures for multiple folders → their closest common parent's `conftest.py`
+
+```
+tests/
+├── conftest.py # Used across all tests
+├── schema/
+│ ├── conftest.py # Used by schema tests only
+│ └── models/
+│ └── cv/
+│ ├── conftest.py # Used by CV model tests only
+│ ├── test_section.py
+│ └── test_cv.py
+└── renderer/
+ └── ...
+```
+
+## Testing Principles
+
+**Keep tests focused.** Test functions in isolation: input → output.
+
+**Don't create unnecessary fixtures.** If setup is one clear line, inline it:
+
+```python
+# Don't:
+@pytest.fixture
+def locale(self):
+ return EnglishLocale()
+
+def test_something(self, locale):
+ result = format_date(Date(2020, 1, 1), locale)
+
+# Do:
+def test_something(self):
+ result = format_date(Date(2020, 1, 1), EnglishLocale())
+```
+
+**Prefer real behavior over mocking.** Only mock when there's no practical alternative (external APIs, file system, etc.).
+
+**Name tests by expected behavior, not by input:**
+
+- Good: `test_returns_none_for_incomplete_data` - describes what should happen
+- Bad: `test_function_with_none_input` - describes input but not behavior
+
+**Keep tests simple:**
+
+```python
+def test_something(self, input, expected):
+ result = function_under_test(input)
+ assert result == expected
+```
+
+**What to test:**
+
+- Input → expected output
+- Input → expected error
+
+**What to avoid:**
+
+- Testing implementation details instead of behavior
+- Complex test setup when simple values work
diff --git a/docs/developer_guide/dockerfile.md b/docs/developer_guide/dockerfile.md
new file mode 100644
index 00000000..5b995223
--- /dev/null
+++ b/docs/developer_guide/dockerfile.md
@@ -0,0 +1,40 @@
+---
+toc_depth: 3
+---
+
+# Dockerfile
+
+## What is Docker?
+
+Docker lets software carry **its entire working environment** with it: the right language runtime, libraries, and configuration, all bundled into a single file called an *image*. Think of an image as a **frozen filesystem where everything is already installed and configured correctly**.
+
+When you run an image, Docker creates a **container**: a live, isolated instance of that environment running on your machine. When you're done, you can delete it without a trace. Your actual system stays untouched.
+
+## Why Docker Is Useful for RenderCV
+
+## Why Docker for RenderCV?
+
+RenderCV installs easily with `pip install rendercv` if you have Python. Most users don't need Docker.
+
+But Docker makes sense if you want:
+
+- **No installation at all** — no Python, no packages, nothing added to your system
+- **A reproducible environment** — the exact same setup on every machine, every time
+- **To bypass restrictions** — some systems block software installation but allow containers
+
+The RenderCV Docker image is a ready-made environment with Python and RenderCV pre-installed. Just run:
+```bash
+docker run -v "$PWD":/work -w /work ghcr.io/rendercv/rendercv render Your_CV.yaml
+```
+
+## How the Image Gets Published
+
+Docker images are stored in **registries**, which are servers that host images so anyone can download and run them. Docker Hub is the most popular, but GitHub has its own called GitHub Container Registry (GHCR).
+
+When you publish a GitHub release, the [`release.yaml` workflow](https://github.com/rendercv/rendercv/blob/main/.github/workflows/release.yaml) automatically builds and publishes the RenderCV image to GHCR at `ghcr.io/rendercv/rendercv`.
+
+When users run `docker run ghcr.io/rendercv/rendercv`, Docker automatically pulls the image from the registry if it's not already on their machine.
+
+## Learn More
+
+To learn more about writing `Dockerfile`, see the `uv`'s guide on [Docker](https://docs.astral.sh/uv/guides/integration/docker/).
diff --git a/docs/developer_guide/documentation.md b/docs/developer_guide/documentation.md
new file mode 100644
index 00000000..7030a0bc
--- /dev/null
+++ b/docs/developer_guide/documentation.md
@@ -0,0 +1,91 @@
+---
+toc_depth: 3
+---
+
+# Documentation
+
+## The Goal
+
+We want documentation at `docs.rendercv.com`, a proper website with navigation, search, theming, and interactive features.
+
+**What is a website?** A collection of HTML, CSS, and JavaScript files. Browsers download these files and render them as the pages you see. To have a website, you need:
+
+1. HTML/CSS/JavaScript files
+2. A server hosting those files
+3. A domain pointing to that server
+
+**The problem:** Writing HTML/CSS/JavaScript manually for documentation is impractical. You want to write content in Markdown and have it become a professional website automatically.
+
+**The solution:** [`mkdocs`](https://github.com/mkdocs/mkdocs) with [Material theme](https://github.com/squidfunk/mkdocs-material). You write Markdown in `docs/`, `mkdocs` generates HTML/CSS/JavaScript, and GitHub Pages hosts it at `docs.rendercv.com`.
+
+```mermaid
+flowchart LR
+ A[Markdown in docs/] --> B[MkDocs + Material]
+ B --> C[HTML/CSS/JS files]
+ C --> D[GitHub Pages hosting]
+ D --> E[docs.rendercv.com]
+```
+
+**This means:** Editing Markdown files in `docs/` updates the website at `docs.rendercv.com`.
+
+## Configuration: [`mkdocs.yaml`](https://github.com/rendercv/rendercv/blob/main/mkdocs.yaml)
+
+`mkdocs.yaml` controls how `mkdocs` builds the website:
+
+- **Site metadata:** name, description, repository
+- **Theme:** Material theme with colors and features
+- **Navigation:** sidebar structure
+- **Plugins:** see below
+
+## Plugins
+
+`mkdocs` plugins extend functionality beyond Markdown → HTML conversion.
+
+### [`mkdocstrings`](https://github.com/mkdocstrings/mkdocstrings): API Reference
+
+Generates API reference from Python docstrings. The entire [API Reference](../api_reference/index.md) section is auto-generated from `src/rendercv/`.
+
+### [`mkdocs-macros-plugin`](https://mkdocs-macros-plugin.readthedocs.io/): Dynamic Content
+
+Lets you inject code-generated values into Markdown. [`docs/docs_templating.py`](https://github.com/rendercv/rendercv/blob/main/docs/docs_templating.py) runs during build. It imports values directly from RenderCV's code and exposes them as variables. It's heavily used in [YAML Input Structure](../user_guide/yaml_input_structure.md) page.
+
+## Entry Type Figures
+
+The [YAML Input Structure](../user_guide/yaml_input_structure.md) page shows visual examples of each entry type rendered in each theme.
+
+These are auto-generated PNG images. Run `just update-entry-figures` to regenerate them from [`docs/user_guide/sample_entries.yaml`](https://github.com/rendercv/rendercv/blob/main/docs/user_guide/sample_entries.yaml).
+
+## Local Preview
+
+```bash
+just serve-docs
+```
+
+Starts a local server at `http://127.0.0.1:8000` with live reload. Edit Markdown files and see changes instantly.
+
+```bash
+just build-docs
+```
+
+Generates the final website in `site/` directory. Mainly used by GitHub workflows for final deployment (see [GitHub Workflows](github_workflows.md)).
+
+## Deployment
+
+Every push to `main` triggers automatic deployment.
+
+**The workflow** ([`.github/workflows/deploy-docs.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/deploy-docs.yaml)):
+
+1. **Trigger:** Runs on every push to `main`
+2. **Build step:**
+ - Installs dependencies (`uv`, `just`)
+ - Runs `just build-docs` to generate the website
+ - Uploads the `site/` directory as an artifact
+3. **Deploy step:**
+ - Takes the uploaded artifact
+ - Deploys it to GitHub Pages (a free static website hosting service)
+ - Makes it available at `docs.rendercv.com`
+
+## Learn More
+
+See the [MkDocs Material documentation](https://squidfunk.github.io/mkdocs-material/) for more information.
+
diff --git a/docs/developer_guide/faq.md b/docs/developer_guide/faq.md
deleted file mode 100644
index c191102a..00000000
--- a/docs/developer_guide/faq.md
+++ /dev/null
@@ -1,29 +0,0 @@
-
-# Frequently Asked Questions (FAQ)
-
-## How can I add a new social network to RenderCV?
-
-To add a new social network to RenderCV, go to the `rendercv/data/models/curriculum_vitae.py` file and follow these steps:
-
-1. Append the social network name (for example, "Facebook") to the `SocialNetworkName` type.
-2. If necessary, implement its username validation in the `SocialNetwork.check_username` method.
-3. Implement its URL generation using the `SocialNetwork.url` method. If the URL can be generated by appending the username to a hostname, only update `url_dictionary`.
-4. Finally, include the Typst icon of the social network to the `icon_dictionary` in the `CurriculumVitae.connections` method. RenderCV uses the [`fontawesome`](https://typst.app/universe/package/fontawesome/) package.
-
-Then, the tests should be implemented for the new social network with the following steps:
-
-1. Go to `tests/test_data.py` and update `test_social_network_url` accordingly, i.e., add a new `(network, username, expected_url)` tuple to the `pytest.mark.parametrize` decorator.
-2. Go to `tests/conftest.py` and add the new social network to `rendercv_filled_curriculum_vitae_data_model`.
-3. Set `update_testdata` to `True` in `conftest.py` and run the tests to update the `testdata` folder.
-4. Review the updated `testdata` folder manually to ensure everything works as expected. Then, set `update_testdata` to `False` and push the changes.
-
-## When should we consider adding a new entry type to RenderCV?
-
-We should add a new entry type if and only if the proposed design of the entry type cannot be achieved using any of the existing entry types. This is because RenderCV's entry types are not designed to function as data models. Their purpose is not to store specific data but rather to determine how a given set of strings will appear in the PDF.
-
-For example, JSON Resume follows a data-oriented approach. In JSON Resume, each entry type acts as a data model specifically designed to store structured information. RenderCV takes a design-oriented approach for two reasons:
-
-- There would be too many different data models that would ultimately look more or less the same in the PDF.
-- It would be impossible to provide all the different data models people might need.
-
-Therefore, we decided to create entry types solely for their design output.
diff --git a/docs/developer_guide/github_workflows.md b/docs/developer_guide/github_workflows.md
new file mode 100644
index 00000000..00b3f8e2
--- /dev/null
+++ b/docs/developer_guide/github_workflows.md
@@ -0,0 +1,123 @@
+---
+toc_depth: 3
+---
+
+# GitHub Actions
+
+## The Problem
+
+Every software project has repetitive tasks that must run consistently:
+
+- **On every update:** Run tests, redeploy documentation
+- **On every release:** Run tests, update `schema.json` and examples, build executables for 4 platforms, build package, upload to PyPI, push Docker image
+
+You could do these manually. But manual means:
+
+- Forgetting steps ("Did I update `schema.json`? Did I build the Windows executable?")
+- Wasted time ("Why am I doing the same 15 steps every release?")
+
+**What if you could write down these tasks once, and have them run automatically every time?**
+
+That's what **CI/CD (Continuous Integration/Continuous Deployment)** is. And **GitHub Actions** is GitHub's system for it.
+
+## What are GitHub Actions?
+
+GitHub actions are **automation scripts that run on GitHub's servers when certain events happen**.
+
+You define them in `.github/workflows/*.yaml` files. Each file describes:
+
+1. **When to run:** push to main? Pull request? New release?
+2. **What to do:** Run tests? Build docs? Publish package?
+3. **Where to run:** Linux? Windows? macOS? Multiple versions?
+
+GitHub reads these files and executes them automatically when the triggering events occur.
+
+**Why GitHub's servers?** Because you don't want to worry about it. Push your code, turn off your computer, you're done. GitHub handles the rest (running tests, deploying docs, building packages) without you having to keep your machine on or manually run anything.
+
+## RenderCV's Workflows
+
+RenderCV has 5 workflows. Each handles a specific automation task.
+
+**How workflows start:** Every workflow begins the same way: clone the repository, install `uv`, install `just`, then run some `just` commands. This recreates the same environment you'd have locally (see [Setup](index.md)).
+
+### 1. [`test.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/test.yaml): Run Tests
+
+**When it runs:**
+
+- Every push to `main` branch
+- Every pull request
+- Manually (via GitHub UI)
+- When called by other workflows
+
+**What it does:**
+
+1. Runs `just test-coverage` across **9 different environments** (3 operating systems × 3 Python versions: 3.12, 3.13, 3.14)
+2. Combines all coverage reports and uploads them to show the coverage report
+
+### 2. [`deploy-docs.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/deploy-docs.yaml): Deploy Documentation
+
+**When it runs:**
+
+- Every push to `main` branch
+- Manually (via GitHub UI)
+
+**What it does:**
+
+1. Builds the documentation website using `just build-docs`
+2. Uploads it to GitHub Pages
+3. Documentation is now live at https://docs.rendercv.com
+
+### 3. [`update-files.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/update-files.yaml): Update Generated Files
+
+**When it runs:**
+
+- Manually (via GitHub UI)
+- When called by the release workflow
+
+**What it does:**
+
+1. Regenerates files derived from code:
+ - `schema.json` using `just update-schema`
+ - Example YAML files and PDFs in `examples/` folder using `just update-examples`
+ - Entry figures using `just update-entry-figures`
+2. Commits and pushes these changes to the repository
+
+### 4. [`create-executables.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/create-executables.yaml): Create Executables
+
+**When it runs:**
+
+- Manually (via GitHub UI)
+- When called by the release workflow
+
+**What it does:**
+
+1. Builds standalone executables using `just create-executable` for 4 platforms:
+ - Linux (x86_64 and ARM64)
+ - macOS (ARM64)
+ - Windows (x86_64)
+2. Uploads executables as artifacts
+
+These are single-file executables that users can download and run without installing Python.
+
+### 5. [`release.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/release.yaml): Publish a Release
+
+**When it runs:**
+
+- When a new GitHub release is published
+
+**What it does:**
+
+This is the complete release pipeline. It orchestrates everything:
+
+1. **Run tests:** Calls `test.yaml` to ensure everything works
+2. **Update files:** Calls `update-files.yaml` to regenerate schema/examples
+3. **Build package:** Installs `uv`, builds Python wheel and source distribution using `uv build`
+4. **Create executables:** Calls `create-executables.yaml` for all platforms
+5. **Create GitHub release:** Downloads and uploads executables and wheel to the release
+6. **Publish to PyPI:** Downloads and uploads package so users can `pip install rendercv`
+7. **Publish Docker image:** Builds and pushes Docker image to GitHub Container Registry
+
+## Learn More
+
+- [GitHub Actions Documentation](https://docs.github.com/en/actions): Official docs
+- [`.github/workflows/`](https://github.com/rendercv/rendercv/tree/main/.github/workflows): RenderCV's workflow files
diff --git a/docs/developer_guide/how_to/add_locale.md b/docs/developer_guide/how_to/add_locale.md
new file mode 100644
index 00000000..57640ac2
--- /dev/null
+++ b/docs/developer_guide/how_to/add_locale.md
@@ -0,0 +1,65 @@
+# Add a New Locale
+
+1. Create a YAML file in `src/rendercv/schema/models/locale/other_locales/`
+
+ ```bash
+ touch src/rendercv/schema/models/locale/other_locales/mylanguage.yaml
+ ```
+
+2. Add the schema reference and provide translations
+
+ ```yaml
+ # yaml-language-server: $schema=../../../../../../schema.json
+ locale:
+ language: mylanguage
+ last_updated: "Your translation"
+ month: "Your translation"
+ months: "Your translation"
+ year: "Your translation"
+ years: "Your translation"
+ present: "Your translation"
+ month_abbreviations:
+ - Jan
+ - Feb
+ - Mar
+ - Apr
+ - May
+ - Jun
+ - Jul
+ - Aug
+ - Sep
+ - Oct
+ - Nov
+ - Dec
+ month_names:
+ - January
+ - February
+ - March
+ - April
+ - May
+ - June
+ - July
+ - August
+ - September
+ - October
+ - November
+ - December
+ ```
+
+3. Add ISO 639-1 language code to `english_locale.py`
+
+ Edit `src/rendercv/schema/models/locale/english_locale.py` line 95-108:
+
+ ```python
+ return {
+ "english": "en",
+ # ... existing languages
+ "mylanguage": "xx", # Add your two-letter ISO 639-1 code
+ }[self.language]
+ ```
+
+4. Done. Use it:
+
+ ```bash
+ rendercv new "John Doe" --locale mylanguage
+ ```
diff --git a/docs/developer_guide/how_to/add_social_network.md b/docs/developer_guide/how_to/add_social_network.md
new file mode 100644
index 00000000..a5e58b01
--- /dev/null
+++ b/docs/developer_guide/how_to/add_social_network.md
@@ -0,0 +1,114 @@
+# Add a New Social Network
+
+1. Add network name to `SocialNetworkName` type
+
+ Edit `src/rendercv/schema/models/cv/social_network.py`:
+
+ ```python
+ type SocialNetworkName = Literal[
+ "LinkedIn",
+ "GitHub",
+ # ... existing networks
+ "MyNetwork", # Add your network here
+ ]
+ ```
+
+2. Add URL pattern to `url_dictionary`
+
+ Edit `src/rendercv/schema/models/cv/social_network.py`:
+
+ ```python
+ url_dictionary: dict[SocialNetworkName, str] = {
+ "LinkedIn": "https://linkedin.com/in/",
+ # ... existing networks
+ "MyNetwork": "https://mynetwork.com/profile/", # Add URL base here
+ }
+ ```
+
+3. (Optional) Add username validation
+
+ If your network has special username format requirements, edit `src/rendercv/schema/models/cv/social_network.py`:
+
+ ```python
+ match network:
+ case "Mastodon":
+ # ... existing validations
+ case "MyNetwork":
+ # ... your custom validation logic
+ ```
+
+4. (Optional) Add custom URL generation
+
+ If URL generation requires special logic (not just base + username), edit `src/rendercv/schema/models/cv/social_network.py`:
+
+ ```python
+ @functools.cached_property
+ def url(self) -> str:
+ if self.network == "Mastodon":
+ # ... existing custom logic
+ elif self.network == "MyNetwork":
+ # ... your custom URL generation logic
+ else:
+ url = url_dictionary[self.network] + self.username
+ return url
+ ```
+
+5. Add Font Awesome icon
+
+ Edit `src/rendercv/renderer/templater/connections.py`:
+
+ ```python
+ typst_fa_icons = {
+ "LinkedIn": "linkedin",
+ # ... existing icons
+ "MyNetwork": "my-icon-name", # Add your icon name here
+ }
+ ```
+
+ See available icons at: [fontawesome.com/search](https://fontawesome.com/search)
+
+6. Add test for URL generation
+
+ Edit `tests/schema/models/cv/test_social_network.py`:
+
+ ```python
+ @pytest.mark.parametrize(
+ ("network", "username", "expected_url"),
+ [
+ # ... existing tests
+ (
+ "MyNetwork",
+ "myusername",
+ "https://mynetwork.com/profile/myusername",
+ ),
+ ],
+ )
+ def test_url(self, network, username, expected_url):
+ # test implementation
+ ```
+
+7. Add network to test fixtures
+
+ Edit `tests/renderer/conftest.py`, add your network to the `social_networks` list:
+
+ ```python
+ social_networks=[
+ SocialNetwork(network="LinkedIn", username="johndoe"),
+ # ... existing networks
+ SocialNetwork(network="MyNetwork", username="johndoe"),
+ ]
+ ```
+
+8. Update test data and verify visual output
+
+ ```bash
+ just update-testdata
+ ```
+
+ Check the generated PDFs in `tests/renderer/testdata/test_pdf_png/` to ensure your network appears correctly with the icon.
+
+9. Run tests to verify everything passes
+
+ ```bash
+ just test
+ ```
diff --git a/docs/developer_guide/how_to/add_theme.md b/docs/developer_guide/how_to/add_theme.md
new file mode 100644
index 00000000..2c71d4e9
--- /dev/null
+++ b/docs/developer_guide/how_to/add_theme.md
@@ -0,0 +1,27 @@
+# Add a New Theme
+
+1. Create a YAML file in `src/rendercv/schema/models/design/other_themes/`
+
+ ```bash
+ touch src/rendercv/schema/models/design/other_themes/mytheme.yaml
+ ```
+
+2. Add the schema reference and override Classic theme defaults
+
+ ```yaml
+ # yaml-language-server: $schema=../../../../../../schema.json
+ design:
+ theme: mytheme
+ # Override any defaults from classic_theme.py here
+ colors:
+ name: rgb(0,0,0)
+ typography:
+ font_family: New Computer Modern
+ # ... add any other overrides
+ ```
+
+3. Done. Use it:
+
+ ```bash
+ rendercv new "John Doe" --theme mytheme
+ ```
diff --git a/docs/developer_guide/index.md b/docs/developer_guide/index.md
index 1c1b014d..c64a31e7 100644
--- a/docs/developer_guide/index.md
+++ b/docs/developer_guide/index.md
@@ -1,114 +1,78 @@
-# Developer Guide
+---
+toc_depth: 1
+---
-All contributions to RenderCV are welcome!
+# Setup
-The source code is thoroughly documented and well-commented, making it an enjoyable read and easy to understand. A detailed documentation of the source code is available in the [API reference](../reference/index.md).
+## Prerequisites
+You need two tools to develop RenderCV:
-## Getting Started
+- **[`uv`](https://docs.astral.sh/uv/)**: Package and project manager. RenderCV uses `uv` to manage dependencies. It also handles Python installations, so you don't need to install Python separately.
+- **[`just`](https://github.com/casey/just)**: Command runner. Development commands are defined in the [`justfile`](https://github.com/rendercv/rendercv/blob/main/justfile), and you need `just` to run them.
-There are two ways of developing RenderCV: [locally](#develop-locally) or [with GitHub Codespaces](#develop-with-github-codespaces).
+Install them by following their official installation guides:
-### Develop Locally
+- [Install `uv`](https://docs.astral.sh/uv/getting-started/installation/)
+- [Install `just`](https://github.com/casey/just#installation)
-1. Install [Hatch](https://hatch.pypa.io/latest/). The installation guide for Hatch can be found [here](https://hatch.pypa.io/latest/install/#installation).
-
- Hatch is a Python project manager. It mainly allows you to define the virtual environments you need in [`pyproject.toml`](https://github.com/rendercv/rendercv/blob/main/pyproject.toml). Then, it takes care of the rest. Also, you don't need to install Python. Hatch will install it when you follow the steps below.
+## Setting Up the Development Environment
-2. Clone the repository.
- ```
+1. Clone the repository:
+
+ ```bash
git clone https://github.com/rendercv/rendercv.git
```
-3. Go to the `rendercv` directory.
- ```
+
+ and change to the repository directory:
+
+ ```bash
cd rendercv
```
-4. Start using one of the virtual environments by activating it in the terminal.
- Default development environment with Python 3.13:
+2. Set up the development environment (creates a virtual environment in `./.venv` with all dependencies):
+
```bash
- hatch shell default
+ just sync
```
- The same environment, but with Python 3.10 (or 3.11, 3.12, 3.13):
- ```bash
- hatch shell test.py3.10
- ```
+3. Run `just test` to verify all tests pass and everything is set up correctly.
-5. Finally, activate the virtual environment in your integrated development environment (IDE). In Visual Studio Code:
+4. Finally, activate the virtual environment in your integrated development environment (IDE). In Visual Studio Code:
- Press `Ctrl+Shift+P`.
- Type `Python: Select Interpreter`.
- - Select one of the virtual environments created by Hatch.
+ - Select the one in `./.venv`.
-### Develop with GitHub Codespaces
-
-1. [Fork](https://github.com/rendercv/rendercv/fork) the repository.
-2. Navigate to the forked repository.
-3. Click the <> **Code** button, then click the **Codespaces** tab, and then click **Create codespace on main**.
-
-Then, [Visual Studio Code for the Web](https://code.visualstudio.com/docs/editor/vscode-web) will be opened with a ready-to-use development environment.
-
-This is done with [Development containers](https://containers.dev/), and the environment is defined in the [`.devcontainer/devcontainer.json`](https://github.com/rendercv/rendercv/blob/main/.devcontainer/devcontainer.json) file. Dev containers can also be run locally using various [supporting tools and editors](https://containers.dev/supporting).
+That's it! You're now ready to start developing RenderCV.
## Available Commands
-These commands are defined in the [`pyproject.toml`](https://github.com/rendercv/rendercv/blob/main/pyproject.toml) file.
+### Development
-- Build the package
- ```bash
- hatch run build
- ```
-- Format the code with [Black](https://github.com/psf/black) and [Ruff](https://github.com/astral-sh/ruff)
- ```bash
- hatch run format
- ```
-- Lint the code with [Ruff](https://github.com/astral-sh/ruff)
- ```bash
- hatch run lint
- ```
-- Run [pre-commit](https://pre-commit.com/)
- ```bash
- hatch run precommit
- ```
-- Check the types with [Pyright](https://github.com/RobertCraigie/pyright-python)
- ```bash
- hatch run check-types
- ```
-- Run the tests with Python 3.13
- ```bash
- hatch run test
- ```
-- Run the tests with Python 3.13 and generate the coverage report
- ```bash
- hatch run test-and-report
- ```
-- Update [schema.json](https://github.com/rendercv/rendercv/blob/main/schema.json)
- ```bash
- hatch run update-schema
- ```
-- Update [`examples`](https://github.com/rendercv/rendercv/tree/main/examples) folder
- ```bash
- hatch run update-examples
- ```
-- Create an executable version of RenderCV with [PyInstaller](https://www.pyinstaller.org/)
- ```bash
- hatch run exe:create
- ```
-- Preview the documentation as you write it
- ```bash
- hatch run docs:serve
- ```
-- Build the documentation
- ```bash
- hatch run docs:build
- ```
-- Update figures of the entry types in the "[Structure of the YAML Input File](../user_guide/structure_of_the_yaml_input_file.md)"
- ```bash
- hatch run docs:update-entry-figures
- ```
+- `just sync`: Sync all dependencies (including extras and dev groups)
+- `just format`: Format code with black and ruff
+- `just check`: Run all checks (ruff, pyright, pre-commit)
-## About [`pyproject.toml`](https://github.com/rendercv/rendercv/blob/main/pyproject.toml)
+### Testing
-[`pyproject.toml`](https://github.com/rendercv/rendercv/blob/main/pyproject.toml) contains the metadata, dependencies, and tools required for the project. Please read through the file to understand the project's technical details.
+- `just test`: Run tests with pytest
+- `just test-coverage`: Run tests with coverage report
+- `just update-testdata`: Update test data files (see [Testing](testing.md) for more details)
+
+### Documentation
+
+- `just build-docs`: Build documentation
+- `just serve-docs`: Serve documentation locally with live reload
+
+### Scripts
+
+- `just update-schema`: Update JSON schema
+- `just update-entry-figures`: Update entry figures for documentation
+- `just update-examples`: Update example files
+- `just create-executable`: Create standalone executable
+
+### Utilities
+
+- `just count-lines`: Count lines of Python code in the `src/` directory
diff --git a/docs/developer_guide/json_schema.md b/docs/developer_guide/json_schema.md
new file mode 100644
index 00000000..d768b4ab
--- /dev/null
+++ b/docs/developer_guide/json_schema.md
@@ -0,0 +1,149 @@
+---
+toc_depth: 3
+---
+
+# JSON Schema
+
+## The Problem
+
+You've encountered this everywhere, even if you didn't realize it was the same problem:
+
+**VS Code settings** (`settings.json`):
+```json
+{
+ "editor.fontSize": 14,
+ "editor.tabSiz": 4 // ← Typo! VS Code highlights it red immediately
+}
+```
+
+**GitHub Actions workflows** (`.github/workflows/test.yaml`):
+```yaml
+on:
+ push:
+ branchs: # ← Typo! Your editor underlines it, suggests "branches"
+ - main
+```
+
+**These files are completely different (VS Code settings, GitHub workflows). But you get autocomplete and validation in both.** How?
+
+VS Code doesn't just "know" what's valid in `settings.json`. GitHub Actions workflows don't magically get autocomplete.
+
+**Someone had to tell your editor:** "Here are all the valid fields, their types, and what they mean."
+
+That "someone" is **JSON Schema**.
+
+## What is JSON Schema?
+
+JSON Schema is a **standard way to describe the structure of JSON/YAML documents**.
+
+Think of it as a specification, a formal description of what's valid:
+
+```json
+{
+ "type": "object",
+ "properties": {
+ "name": {
+ "type": "string",
+ "description": "Your full name"
+ },
+ "age": {
+ "type": "integer",
+ "minimum": 0,
+ "description": "Your age in years"
+ },
+ "email": {
+ "type": "string",
+ "format": "email"
+ }
+ },
+ "required": ["name"]
+}
+```
+
+This schema says:
+
+- A valid document is an object
+- It must have a `name` field (string, required)
+- It can have an `age` field (non-negative integer, optional)
+- It can have an `email` field (string matching email format, optional)
+
+**Why does JSON Schema exist?**
+
+Because JSON and YAML files are **everywhere**: configuration files, API requests/responses, CI/CD workflows, application settings, data files. They all share the same problem:
+
+**How do you communicate what's valid?**
+
+You could write documentation: "The `name` field is required and must be a string. The `age` field is optional and must be a non-negative integer." But **documentation is for humans to read, not machines**.
+
+JSON Schema is the **same information in machine-readable format** so editors can understand it.
+
+Once your editor has a schema, it can provide autocomplete, catch typos, and show inline documentation as you type.
+
+This is why:
+
+- **Microsoft publishes a JSON Schema for VS Code settings:** your editor fetches it and provides autocomplete
+- **GitHub publishes a JSON Schema for Actions workflows:** that's how you get field suggestions
+- **Thousands of tools do the same:** Kubernetes, Docker, Terraform, ESLint, package.json, tsconfig.json, the list goes on
+
+JSON Schema is **infrastructure for editor tooling**.
+
+## RenderCV's JSON Schema
+
+RenderCV has the same problem. Users write their CVs in YAML, and we want them to have a smooth editor experience with autocomplete, typo detection, and inline documentation.
+
+**Solution:** Publish a JSON Schema for RenderCV YAML files.
+
+
+
+That's why [`schema.json`](https://github.com/rendercv/rendercv/blob/main/schema.json) exists in the repository. Same universal problem, same universal solution.
+
+## How the Schema is Generated
+
+We don't write `schema.json` by hand. **It's automatically generated from Pydantic models.**
+
+RenderCV's entire data structure is defined using Pydantic models (see [Understanding RenderCV](understanding_rendercv.md) for details). Pydantic has a built-in feature: `model_json_schema()`, which generates JSON Schema from your models.
+
+That's what [`src/rendercv/schema/json_schema_generator.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/schema/json_schema_generator.py) does. It calls `model_json_schema()` on our top-level model and writes the result to `schema.json`.
+
+## How Editors Know to Use RenderCV's Schema
+
+There are two ways editors discover and use RenderCV's schema:
+
+### 1. Manual Declaration
+
+Add a special comment at the top of your YAML file:
+
+```yaml
+# yaml-language-server: $schema=https://raw.githubusercontent.com/rendercv/rendercv/refs/tags/v2.4/schema.json
+
+cv:
+ name: John Doe
+```
+
+This tells the editor: "Use RenderCV's schema for this file." Note the version tag in the URL, which ensures you get the schema matching your RenderCV version.
+
+**Requirements:** Your editor needs to support this. For VS Code, install the [YAML extension](https://marketplace.visualstudio.com/items?itemName=redhat.vscode-yaml).
+
+### 2. Schema Store (Automatic)
+
+RenderCV's schema is listed in [SchemaStore](https://github.com/SchemaStore/schemastore), a central registry of schemas that most IDEs use.
+
+In SchemaStore, RenderCV's schema is configured to automatically activate for files ending with `_CV.yaml`. This means:
+
+- If your file is named `John_Doe_CV.yaml`
+- And your editor uses SchemaStore (VS Code with YAML extension does)
+- You get autocomplete automatically, no comment needed
+
+## When is the Schema Generated?
+
+During development, whenever data models change, run:
+
+```bash
+just update-schema
+```
+
+This runs [`scripts/update_schema.py`](https://github.com/rendercv/rendercv/blob/main/scripts/update_schema.py), which regenerates `schema.json`.
+
+## Learn More
+
+- [Pydantic JSON Schema](https://docs.pydantic.dev/latest/concepts/json_schema/): How Pydantic generates schemas from models
diff --git a/docs/developer_guide/project_management.md b/docs/developer_guide/project_management.md
new file mode 100644
index 00000000..34ef0406
--- /dev/null
+++ b/docs/developer_guide/project_management.md
@@ -0,0 +1,138 @@
+---
+toc_depth: 3
+---
+
+# Project Management
+
+## What is "Project Management"?
+
+When you look at RenderCV's repository, you see:
+
+```
+.
+├── src/ ← The actual RenderCV code
+├── pyproject.toml ← Project configuration
+├── justfile ← Command shortcuts
+├── scripts/ ← Supplementary Python scripts
+├── .pre-commit-config.yaml ← Pre-commit configuration
+└── uv.lock ← Dependency lock file
+```
+
+**Project management is everything except `src/`.** It's all the infrastructure that lets us:
+
+- Share RenderCV with users (`pip install rendercv`)
+- Manage dependencies consistently
+- Automate testing, building, and releases
+- Ensure reproducibility across machines and time
+
+## Why Can't We Just Write Python Code?
+
+RenderCV is a Python project. The actual source code lives in `src/rendercv/`. Why do we need all these other files - `pyproject.toml`, `uv.lock`, `justfile`, `.github/workflows/`, etc.?
+
+**Because code alone doesn't solve two critical problems: distribution and development environment.**
+
+### Problem 1: Distribution
+
+**How do users get your code?**
+
+You could tell them "download these files, install dependencies with `pip install -r requirements.txt`, and run them with `python main.py`". But users want `pip install rendercv` and have it work instantly with `rendercv` command.
+
+**This requires:** Packaging your code and uploading to [PyPI](https://pypi.org) (Python Package Index).
+
+### Problem 2: Development Environment
+
+You have the source code. Two developers want to contribute.
+
+Developer A installs today with Python 3.11 and gets `pydantic==2.10`. Tests pass. Developer B installs one month later with Python 3.12 and gets `pydantic==2.11` which has breaking changes. Tests fail. "Works on A's machine" but not B's. B asks: "What formatter do you use? What settings? How do I run tests?"
+
+**What needs to happen:** Everyone gets the same Python version, same package versions (locked, not "latest"), same development tools with same settings. All in one command.
+
+**This requires:** Locking dependencies (Python version, every package, frozen in time), configuring all tools in one place, and automating setup so it's identical for everyone.
+
+### The Solution
+
+All those files you see in the repository (`pyproject.toml`, `uv.lock`, `justfile`, and more) work together to solve these problems. The result:
+
+**For users:**
+```bash
+pip install rendercv
+```
+
+Works instantly. Every time. Anywhere. All dependencies installed automatically.
+
+**For developers** ([Setup](index.md)):
+```bash
+just sync
+```
+
+One command. Identical environment for everyone: correct Python version, exact dependency versions, all dev tools ready. Works today, works in 2027. Bug from 6 months ago? Check out that commit, run `just sync`, exact environment recreated.
+
+The rest of this guide explains what each file does.
+
+## Files and Folders in the Root
+
+### [`pyproject.toml`](https://github.com/rendercv/rendercv/blob/main/pyproject.toml)
+
+The project definition file. This is the standard way to configure a Python project.
+
+This file defines:
+
+- Project metadata (name, version, description)
+- Dependencies (what packages RenderCV needs)
+- Entry points (makes `rendercv` a command)
+- Build configuration (how to package RenderCV)
+- Tool settings (ruff, pyright, pytest, etc.)
+
+Open the file to see the full configuration with detailed comments.
+
+### [`justfile`](https://github.com/rendercv/rendercv/blob/main/justfile)
+
+[just](https://github.com/casey/just) is a command runner, a tool that lets you define terminal commands in a file and run them easily.
+
+**Why do we need it?** During development, you constantly run commands like "run tests with coverage", "format all code", "build and serve docs". Without standardization:
+
+- Everyone types different commands with different options
+- You have to remember long command strings
+
+The `justfile` solves this: define each command once, and everyone runs the same thing:
+
+```bash
+just test # Runs pytest with the right options
+just format # Formats code with ruff
+just serve-docs # Builds and serves documentation locally
+just update-schema # Regenerates schema.json
+```
+
+This is why `just sync` works so elegantly. It's a standardized command that does exactly the same thing for everyone.
+
+### [`scripts/`](https://github.com/rendercv/rendercv/tree/main/scripts)
+
+Python scripts that automate some repetitive tasks.
+
+**Why do we need it?** Some tasks need to be done repeatedly but are too complex for simple shell commands:
+
+- `update_schema.py`: Generate `schema.json` from pydantic models
+- `update_examples.py`: Regenerate all example YAML files and PDFs in `examples/` folder
+- `create_executable.py`: Build standalone executable of RenderCV
+
+These scripts are called by `just` commands (`just update-schema`, `just update-examples`, etc.).
+
+### [`.pre-commit-config.yaml`](https://github.com/rendercv/rendercv/blob/main/.pre-commit-config.yaml)
+
+Configuration file for [`pre-commit`](https://pre-commit.com/), a tool that runs code quality checks.
+
+**Why do we need it?** Pre-commit's value is **fast CI/CD**. [pre-commit.ci](https://pre-commit.ci/) (free for open-source projects) automatically runs checks on every push and pull request. Forgot to format your code? The workflow fails, making it immediately obvious. Without pre-commit, we'd have to set up our own workflow to run these checks.
+
+Run `just check` locally to check your code before committing. We don't use pre-commit as git hooks (that run before every commit). We prefer manual checks when ready.
+
+### [`uv.lock`](https://github.com/rendercv/rendercv/blob/main/uv.lock)
+
+A dependency lock file. This is a record of the exact version of every package RenderCV uses (including dependencies of dependencies).
+
+**Why do we need it?** Remember development environment problem? This file solves it. When you run `just sync`, `uv` reads this file and installs the exact same versions everyone else has, not "the latest version", but "the exact version that's known to work". Without this file, developers would get different package versions and environments would drift apart.
+
+**Never edit this manually.** `uv` generates and updates it automatically. **Always commit it to git.** That's how everyone gets identical environments.
+
+## Learn More
+
+See the [`uv` documentation](https://docs.astral.sh/uv/) for more information on project management.
diff --git a/docs/developer_guide/testing.md b/docs/developer_guide/testing.md
index 835a1d93..b755cd1d 100644
--- a/docs/developer_guide/testing.md
+++ b/docs/developer_guide/testing.md
@@ -1,36 +1,79 @@
+---
+toc_depth: 2
+---
+
# Testing
-After implementing a new feature or fixing a bug, one can run all the tests to see if anything is broken.
+Tests check if your code does what it's supposed to do. Every time you change something, you need to verify it still works. Instead of manually checking everything, you write test code once and rerun it automatically.
-To run all the tests with each Python version (3.10, 3.11, 3.12, and 3.13), use the following command.
+Here's a simple example:
-```bash
-hatch run test:test
+```python
+def sum(a, b):
+ return a + b
+
+def test_sum():
+ assert sum(2, 3) == 5
+ assert sum(-1, 1) == 0
+ assert sum(0, 0) == 0
```
-To run the tests with a specific Python version, use the following command.
+If you change something in `sum`, you can run `test_sum` again to see if it's still working.
+
+All of the tests of RenderCV are written in [`tests/`](https://github.com/rendercv/rendercv/tree/main/tests) directory.
+
+## [`pytest`](https://github.com/pytest-dev/pytest): Testing Framework
+
+`pytest` is a Python library that provides utilities to write and run tests.
+
+**How does it work?** When you run `pytest`, it searches for files matching `test_*.py` in the `tests/` directory and executes all functions starting with `test_`.
+
+**Configuration:** `pytest` reads settings from `pyproject.toml` under `[tool.pytest.ini_options]`.
+
+## Running RenderCV Tests
+
+Whenever you make changes to RenderCV's source code, run the tests to ensure everything still works. If all tests pass, your changes didn't break anything.
```bash
-hatch run test.py3.10:test
+just test
```
-To run the tests with Python 3.13 and generate a coverage report, use the following command.
+## Reference File Comparison
+
+Some tests in [`tests/renderer/`](https://github.com/rendercv/rendercv/tree/main/tests/renderer) (specifically [`test_pdf_png.py`](https://github.com/rendercv/rendercv/blob/main/tests/renderer/test_pdf_png.py), [`test_typst.py`](https://github.com/rendercv/rendercv/blob/main/tests/renderer/test_typst.py), [`test_markdown.py`](https://github.com/rendercv/rendercv/blob/main/tests/renderer/test_markdown.py), and [`test_html.py`](https://github.com/rendercv/rendercv/blob/main/tests/renderer/test_html.py)) use reference file comparison:
+
+1. Tests generate output files by running RenderCV
+2. Generated files are compared against reference files in `tests/renderer/testdata/`
+3. If they match exactly, the test passes. Any difference fails the test.
+
+### Updating Reference Files
+
+You fix a bug that changes RenderCV's output. Tests fail because the new output doesn't match old reference files.
+
+**This is expected.** You intentionally changed the output. You need to update the reference files:
```bash
-hatch run test-and-report
+just update-testdata
```
-Once new commits are pushed to the `main` branch, the [`test.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/test.yaml) workflow will be automatically triggered, and the tests will run.
-
-## About [`testdata`](https://github.com/rendercv/rendercv/tree/main/tests/testdata) folder
-
-In some of the tests:
-
-- RenderCV generates an output with a sample input.
-- Then, the output is compared with a reference output, which has been manually generated and stored in `testdata`. If the files differ, the tests fail.
-
-
-When the `testdata` folder needs to be updated, it can be manually regenerated by setting `update_testdata` to `True` in `conftest.py` and running the tests.
!!! warning
- - Whenever the `testdata` folder is generated, the files should be reviewed manually to ensure everything works as expected.
- - `update_testdata` should be set to `False` before committing the changes.
+ **Manually verify new reference files before committing.** These become the source of truth. If you commit broken reference files, tests will pass even when RenderCV produces bad output. Always check generated PDFs and PNGs carefully.
+
+## [`pytest-cov`](https://github.com/pytest-dev/pytest-cov): Coverage Plugin for `pytest`
+
+Coverage is a measure of which code lines are executed when tests run. If tests execute a line, it's included in coverage. If tests execute all lines in `src/rendercv/`, coverage is 100%.
+
+**Why does it matter?** Coverage reports show you which parts of your code aren't tested yet, so you know where to write more tests.
+
+Run tests with coverage:
+
+```bash
+just test-coverage
+```
+
+This generates two outputs:
+
+- **Terminal:** Overall coverage percentage
+- **HTML report:** Open `htmlcov/index.html` to see exactly which lines are covered (green) and which aren't (red)
+
+**Configuration:** Coverage settings are in `pyproject.toml` under `[tool.coverage.run]` and `[tool.coverage.report]`.
diff --git a/docs/developer_guide/understanding_rendercv.md b/docs/developer_guide/understanding_rendercv.md
new file mode 100644
index 00000000..31c58529
--- /dev/null
+++ b/docs/developer_guide/understanding_rendercv.md
@@ -0,0 +1,311 @@
+---
+toc_depth: 3
+---
+
+# Understanding RenderCV
+
+This guide walks you through how RenderCV works, explaining each step and the tools we use.
+
+## The Core Workflow
+
+RenderCV does more than this (Markdown, HTML, PNG outputs, watching files, etc.), but at its core, what happens is:
+
+```mermaid
+flowchart LR
+ A[YAML file] --> B[Typst file]
+ B --> C[PDF]
+```
+
+Read a YAML file, generate a Typst file, compile it to PDF. Everything else is built on top of this foundation.
+
+Let's understand each step.
+
+## Step 1: Reading the YAML File
+
+When a user gives us a YAML file like this:
+
+```yaml
+cv:
+ name: John Doe
+ location: San Francisco, CA
+ sections:
+ education:
+ - institution: MIT
+ degree: PhD
+ start_date: 2020-09
+ end_date: 2024-05
+```
+
+We need to:
+
+1. Parse the YAML into Python dictionaries
+2. Validate the data (Does `start_date` come before `end_date`? Is `name` actually provided and is it a string?)
+
+### [`ruamel.yaml`](https://github.com/pycontribs/ruamel-yaml): YAML Parser
+
+First problem: reading YAML files.
+
+Python doesn't have a built-in YAML library. To read YAML files, you need a library. **We use `ruamel.yaml`**, one of the best YAML parsers available.
+
+What does it do? Simple: **converts YAML text into Python dictionaries.**
+
+**YAML file** (`cv.yaml`):
+```yaml
+cv:
+ name: John Doe
+ location: San Francisco, CA
+ sections:
+ education:
+ - institution: MIT
+ degree: PhD
+ start_date: 2020-09
+```
+
+**After parsing with `ruamel.yaml`:**
+```python
+from ruamel.yaml import YAML
+
+yaml = YAML()
+data = yaml.load(open("cv.yaml"))
+
+# Now data is a Python dictionary:
+{
+ "cv": {
+ "name": "John Doe",
+ "location": "San Francisco, CA",
+ "sections": {
+ "education": [
+ {
+ "institution": "MIT",
+ "degree": "PhD",
+ "start_date": "2020-09"
+ }
+ ]
+ }
+ }
+}
+
+# You can access it like any Python dict:
+data["cv"]["name"] # "John Doe"
+data["cv"]["sections"]["education"][0]["institution"] # "MIT"
+```
+
+That's it. YAML text becomes a Python dictionary we can work with.
+
+`ruamel.yaml` is being called in [`src/rendercv/schema/yaml_reader.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/schema/yaml_reader.py).
+
+### [`pydantic`](https://github.com/pydantic/pydantic): Python Dictionary Validator
+
+Now we have a dictionary. We need to validate it. Without a library, you'd write:
+
+```python
+if "name" not in data["cv"]:
+ raise ValueError("Missing 'name' field")
+
+if not isinstance(data["cv"]["name"], str):
+ raise ValueError("name must be a string")
+
+if "sections" in data["cv"]:
+ for section_name, entries in data["cv"]["sections"].items():
+ for entry in entries:
+ if "start_date" in entry and "end_date" in entry:
+ # Parse dates, compare them...
+ # This is already hundreds of lines and we're barely started
+```
+
+With `pydantic`, we can define the structure once:
+
+```python
+from pydantic import BaseModel
+from datetime import date as Date
+
+class Education(BaseModel):
+ institution: str
+ start_date: Date
+ end_date: Date
+
+ @pydantic.model_validator(mode="after")
+ def check_dates(self):
+ if self.start_date > self.end_date:
+ raise ValueError("start_date cannot be after end_date")
+ return self
+
+class Cv(BaseModel):
+ name: str
+ location: str | None = None
+ education: list[Education]
+```
+
+Then validate:
+
+```python
+# This dictionary (from ruamel.yaml):
+data = {
+ "name": "John Doe",
+ "location": "San Francisco",
+ "education": [
+ {
+ "institution": "MIT",
+ "start_date": "2020-09",
+ "end_date": "2024-05"
+ }
+ ]
+}
+
+# Becomes this validated object:
+cv = Cv.model_validate(data)
+
+# Now you have clean, validated objects:
+cv.name # "John Doe"
+cv.education[0].institution # "MIT"
+cv.education[0].start_date # "2020-09", guaranteed dates are valid
+```
+
+That's the power. Dictionary goes in, `pydantic` checks everything, clean Python object comes out.
+
+
+
+**RenderCV's entire data model is `pydantic` models all the way down:**
+
+```python
+class RenderCVModel(BaseModel):
+ cv: Cv # ← pydantic model
+ design: Design # ← pydantic model
+ locale: Locale # ← pydantic model
+ settings: Settings # ← pydantic model
+```
+
+Each field is another `pydantic` model. `Cv` contains more `pydantic` models like `EducationEntry`, `ExperienceEntry`, etc. It's nested validation: when you validate `RenderCVModel`, `pydantic` automatically validates every nested model too. One `model_validate()` call checks the entire structure.
+
+See [`src/rendercv/schema/models/rendercv_model.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/schema/models/rendercv_model.py) for the top-level model.
+
+## Step 2: Generating the Typst File
+
+Now we need to generate a Typst file:
+
+```typst
+= John Doe
+San Francisco, CA
+
+== Education
+#strong[MIT] #h(1fr) 2020 – 2024
+PhD in Computer Science
+```
+
+You could try string concatenation:
+
+```python
+typst = f"= {cv.name}\n"
+if cv.location:
+ typst += f"{cv.location}\n"
+typst += "\n"
+
+for section_title, entries in cv.sections.items():
+ typst += f"== {section_title}\n"
+ for entry in entries:
+ typst += f"#strong[{entry.institution}]"
+ # What about optional fields? Spacing? Line breaks?
+ # Multiple themes with different layouts?
+ # This is impossible to maintain!
+```
+
+This doesn't work. You're building hundreds of lines of string concatenation logic, handling conditionals, managing whitespace. It's unworkable.
+
+This is why **templating engines were invented**. When you need to programmatically generate complex text files, you need templates.
+
+### [`jinja2`](https://github.com/pallets/jinja): Templating Engine
+
+`jinja2` is the most famous templating engine for Python.
+
+**Template file** (`Header.j2.typ`):
+```jinja2
+= {{ cv.name }}
+{% if cv.location %}
+{{ cv.location }}
+{% endif %}
+
+{% if cv.email %}
+#link("mailto:{{ cv.email }}")
+{% endif %}
+```
+
+**Python code:**
+```python
+template = jinja2_env.get_template("Header.j2.typ")
+output = template.render(cv=cv)
+```
+
+**Result:**
+```typst
+= John Doe
+San Francisco, CA
+
+#link("mailto:john@example.com")
+```
+
+Clean separation: templates define layout, Python code provides data. Users can override templates to customize their CV without touching Python code.
+
+Typst templates live in [`src/rendercv/renderer/templater/templates/typst/`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/renderer/templater/templates/typst/).
+
+`jinja2` is being called in [`src/rendercv/renderer/templater/templater.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/renderer/templater/templater.py).
+
+### [`markdown`](https://github.com/Python-Markdown/markdown): Markdown to Typst
+
+Users want to write Markdown in their YAML:
+
+```yaml
+highlights:
+ - "**Published** [3 papers](https://example.com) on neural networks"
+ - "Collaborated with *Professor Smith*"
+```
+
+But Typst doesn't understand `**bold**` or `[links](url)`. We need Typst syntax: `#strong[bold]` and `#link("url")[text]`.
+
+**We use the `markdown` library.** It parses Markdown into an XML tree. Then we walk the tree and convert each element to Typst:
+
+```python
+match element.tag:
+ case "strong":
+ return f"#strong[{content}]"
+ case "em":
+ return f"#emph[{content}]"
+ case "a":
+ href = element.get("href")
+ return f'#link("{href}")[{content}]'
+```
+
+Result: `#strong[Published] #link("https://example.com")[3 papers]`
+
+See [`src/rendercv/renderer/templater/markdown_parser.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/renderer/templater/markdown_parser.py). The `markdown_to_typst()` function does this conversion.
+
+## Step 3: Compiling to PDF
+
+### [`typst`](https://github.com/messense/typst-py): Typst Compiler
+
+`typst` library is the Python bindings for the Typst compiler.
+
+```python
+from typst import compile
+compile("cv.typ", output="cv.pdf")
+```
+
+Done. Typst file has been compiled to PDF.
+
+`typst` is being called in [`src/rendercv/renderer/pdf_png.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/renderer/pdf_png.py).
+
+## The Complete Pipeline
+
+When you run `rendercv render cv.yaml`:
+
+1. **Parse** - `ruamel.yaml` reads YAML → Python dict
+2. **Validate** - `pydantic` validates dict → `RenderCVModel` object
+3. **Generate** - `jinja2` renders templates with data → Typst file
+4. **Compile** - `typst` compiles Typst → PDF
+
+Everything else (Markdown support, watch mode, PNG output, HTML export) builds on this core.
+
+## Learn More
+
+1. [`src/rendercv/cli/render_command/run_rendercv.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/cli/render_command/run_rendercv.py): The complete flow
+2. [`src/rendercv/schema/models/rendercv_model.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/schema/models/rendercv_model.py): The top-level Pydantic model
+3. [`src/rendercv/renderer/templater/templater.py`](https://github.com/rendercv/rendercv/blob/main/src/rendercv/renderer/templater/templater.py): Template rendering
diff --git a/docs/developer_guide/writing_documentation.md b/docs/developer_guide/writing_documentation.md
deleted file mode 100644
index 39da76ef..00000000
--- a/docs/developer_guide/writing_documentation.md
+++ /dev/null
@@ -1,52 +0,0 @@
-# Writing Documentation
-
-The documentation's source files are located in the [`docs`](https://github.com/rendercv/rendercv/tree/main/docs) directory and it is built using the [MkDocs](https://github.com/mkdocs/mkdocs) package. To work on the documentation and see the changes in real-time, run the following command.
-
-```bash
-hatch run docs:serve
-```
-
-Once the changes are pushed to the `main` branch, the [`deploy-docs.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/deploy-docs.yaml) workflow will be automatically triggered, and [docs.rendercv.com](https://docs.rendercv.com/) will be updated to the most recent version.
-
-
-## Updating the [`examples`](https://github.com/rendercv/rendercv/tree/main/examples) folder
-
-The `examples` folder includes example YAML files for all the built-in themes, along with their corresponding PDF outputs. Also, there are PNG files of the first pages of each theme in [`docs/assets/images`](https://github.com/rendercv/rendercv/tree/main/docs/assets/images). These examples are shown in [`README.md`](https://github.com/rendercv/rendercv/blob/main/README.md).
-
-These files are generated using [`scripts/update_examples.py`](https://github.com/rendercv/rendercv/blob/main/scripts/update_examples.py). The contents of the examples are taken from the [`create_a_sample_data_model`](https://docs.rendercv.com/reference/data/#rendercv.data.create_a_sample_data_model) function from [`rendercv.data`](https://docs.rendercv.com/reference/data/).
-
-Run the following command to update the `examples` folder.
-
-```bash
-hatch run update-examples
-```
-
-Once a new release is created on GitHub, the [`publish-to-pypi.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/publish-to-pypi.yaml) workflow will be automatically triggered, and the `examples` folder will be updated to the most recent version.
-
-## Updating figures of the entry types in the "[Structure of the YAML Input File](../user_guide/structure_of_the_yaml_input_file.md)"
-
-There are example figures for each entry type for each theme in the "[Structure of the YAML Input File](../user_guide/structure_of_the_yaml_input_file.md)" page.
-
-The figures are generated using [`scripts/update_entry_figures.py`](https://github.com/rendercv/rendercv/blob/main/scripts/update_entry_figures.py).
-
-Run the following command to update the figures.
-
-```bash
-hatch run docs:update-entry-figures
-```
-
-Once a new release is created on GitHub, the [`publish-to-pypi.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/publish-to-pypi.yaml) workflow will be automatically triggered, and the figures will be updated to the most recent version.
-
-## Updating the JSON Schema ([`schema.json`](https://github.com/rendercv/rendercv/blob/main/schema.json))
-
-The schema of RenderCV's input file is defined using [Pydantic](https://docs.pydantic.dev/latest/). Pydantic allows automatic creation and customization of JSON schemas from Pydantic models.
-
-The JSON Schema is also generated using [`scripts/update_schema.py`](https://github.com/rendercv/rendercv/blob/main/scripts/update_schema.py). It uses [`generate_json_schema`](https://docs.rendercv.com/reference/data/#rendercv.data.generate_json_schema) function from [`rendercv.data`](https://docs.rendercv.com/reference/data/).
-
-Run the following command to update the JSON Schema.
-
-```bash
-hatch run update-schema
-```
-
-Once a new release is created on GitHub, the [`publish-to-pypi.yaml`](https://github.com/rendercv/rendercv/blob/main/.github/workflows/publish-to-pypi.yaml) workflow will be automatically triggered, and `schema.json` will be updated to the most recent version.
diff --git a/docs/docs_templating.py b/docs/docs_templating.py
new file mode 100644
index 00000000..77784cf6
--- /dev/null
+++ b/docs/docs_templating.py
@@ -0,0 +1,142 @@
+"""This script generates the example entry figures and creates an environment for
+documentation templates using `mkdocs-macros-plugin`. For example, the content of the
+example entries found in
+"[Structure of the YAML Input File](https://docs.rendercv.com/user_guide/structure_of_the_yaml_input_file/)"
+are coming from this script.
+"""
+
+import io
+import pathlib
+from typing import get_args
+
+import pydantic
+import ruamel.yaml
+
+from rendercv.schema.models.cv.section import (
+ BulletEntry,
+ EducationEntry,
+ ExperienceEntry,
+ NormalEntry,
+ NumberedEntry,
+ OneLineEntry,
+ PublicationEntry,
+ ReversedNumberedEntry,
+)
+from rendercv.schema.models.cv.social_network import available_social_networks
+from rendercv.schema.models.design.built_in_design import available_themes
+from rendercv.schema.models.design.classic_theme import (
+ Alignment,
+ BodyAlignment,
+ Bullet,
+ PageSize,
+ PhoneNumberFormatType,
+ SectionTitleType,
+)
+from rendercv.schema.models.design.font_family import available_font_families
+from rendercv.schema.models.locale.locale import available_locales
+from rendercv.schema.yaml_reader import read_yaml
+
+repository_root = pathlib.Path(__file__).parent.parent
+rendercv_path = repository_root / "src" / "rendercv"
+image_assets_directory = pathlib.Path(__file__).parent / "assets" / "images"
+
+
+class SampleEntries(pydantic.BaseModel):
+ education_entry: EducationEntry
+ experience_entry: ExperienceEntry
+ normal_entry: NormalEntry
+ publication_entry: PublicationEntry
+ one_line_entry: OneLineEntry
+ bullet_entry: BulletEntry
+ numbered_entry: NumberedEntry
+ reversed_numbered_entry: ReversedNumberedEntry
+ text_entry: str
+
+
+def dictionary_to_yaml(dictionary: dict):
+ """Converts a dictionary to a YAML string.
+
+ Args:
+ dictionary: The dictionary to be converted to YAML.
+ Returns:
+ The YAML string.
+ """
+ yaml_object = ruamel.yaml.YAML()
+ yaml_object.width = 60
+ yaml_object.indent(mapping=2, sequence=4, offset=2)
+ with io.StringIO() as string_stream:
+ yaml_object.dump(dictionary, string_stream)
+ return string_stream.getvalue()
+
+
+def define_env(env):
+ # See https://mkdocs-macros-plugin.readthedocs.io/en/latest/macros/
+ sample_entries = read_yaml(
+ repository_root / "docs" / "user_guide" / "sample_entries.yaml"
+ )
+ # validate the parsed dictionary by creating an instance of SampleEntries:
+ sample_entries = SampleEntries(**sample_entries).model_dump()
+
+ entries_showcase = {}
+ for entry_name, entry in sample_entries.items():
+ proper_entry_name = entry_name.replace("_", " ").title().replace(" ", "")
+ entries_showcase[proper_entry_name] = {
+ "yaml": dictionary_to_yaml(entry),
+ "figures": [
+ {
+ "path": f"../assets/images/{theme}/{entry_name}.png",
+ "alt_text": f"{proper_entry_name} in {theme}",
+ "theme": theme,
+ }
+ for theme in available_themes
+ ],
+ }
+
+ env.variables["sample_entries"] = entries_showcase
+ env.variables["entry_count"] = len(sample_entries)
+ env.variables["entry_names"] = [
+ f"[{entry_name}](#{entry_name.lower()})" for entry_name in entries_showcase
+ ]
+
+ # Available themes strings (put available themes between ``)
+ themes = [f"`{theme}`" for theme in available_themes]
+ env.variables["available_themes"] = ", ".join(themes)
+
+ # Available locales string
+ locales = [f"`{locale}`" for locale in available_locales]
+ env.variables["available_locales"] = ", ".join(locales)
+
+ # Available social networks strings (put available social networks between ``)
+ social_networks = [
+ f"`{social_network}`" for social_network in available_social_networks
+ ]
+ env.variables["available_social_networks"] = ", ".join(social_networks)
+
+ # Others:
+ env.variables["available_page_sizes"] = ", ".join(
+ [f"`{page_size}`" for page_size in get_args(PageSize.__value__)]
+ )
+ env.variables["available_font_families"] = ", ".join(
+ [f"`{font_family}`" for font_family in available_font_families]
+ )
+ env.variables["available_body_alignments"] = ", ".join(
+ [f"`{text_alignment}`" for text_alignment in get_args(BodyAlignment.__value__)]
+ )
+ env.variables["available_phone_number_formats"] = ", ".join(
+ [
+ f"`{phone_number_format}`"
+ for phone_number_format in get_args(PhoneNumberFormatType.__value__)
+ ]
+ )
+ env.variables["available_alignments"] = ", ".join(
+ [f"`{alignment}`" for alignment in get_args(Alignment.__value__)]
+ )
+ env.variables["available_section_title_types"] = ", ".join(
+ [
+ f"`{section_title_type}`"
+ for section_title_type in get_args(SectionTitleType.__value__)
+ ]
+ )
+ env.variables["available_bullets"] = ", ".join(
+ [f"`{bullet}`" for bullet in get_args(Bullet.__value__)]
+ )
diff --git a/docs/dynamic_content_generation.py b/docs/dynamic_content_generation.py
deleted file mode 100644
index 1c8fa914..00000000
--- a/docs/dynamic_content_generation.py
+++ /dev/null
@@ -1,162 +0,0 @@
-"""This script generates the example entry figures and creates an environment for
-documentation templates using `mkdocs-macros-plugin`. For example, the content of the
-example entries found in
-"[Structure of the YAML Input File](https://docs.rendercv.com/user_guide/structure_of_the_yaml_input_file/)"
-are coming from this script.
-"""
-
-import io
-import pathlib
-from typing import get_args
-
-import pydantic
-import ruamel.yaml
-
-import rendercv.data as data
-import rendercv.themes.options as theme_options
-
-repository_root = pathlib.Path(__file__).parent.parent
-rendercv_path = repository_root / "src" / "rendercv"
-image_assets_directory = pathlib.Path(__file__).parent / "assets" / "images"
-
-
-class SampleEntries(pydantic.BaseModel):
- education_entry: data.EducationEntry
- experience_entry: data.ExperienceEntry
- normal_entry: data.NormalEntry
- publication_entry: data.PublicationEntry
- one_line_entry: data.OneLineEntry
- bullet_entry: data.BulletEntry
- numbered_entry: data.NumberedEntry
- reversed_numbered_entry: data.ReversedNumberedEntry
- text_entry: str
-
-
-def dictionary_to_yaml(dictionary: dict):
- """Converts a dictionary to a YAML string.
-
- Args:
- dictionary: The dictionary to be converted to YAML.
- Returns:
- The YAML string.
- """
- yaml_object = ruamel.yaml.YAML()
- yaml_object.width = 60
- yaml_object.indent(mapping=2, sequence=4, offset=2)
- with io.StringIO() as string_stream:
- yaml_object.dump(dictionary, string_stream)
- return string_stream.getvalue()
-
-
-def define_env(env):
- # See https://mkdocs-macros-plugin.readthedocs.io/en/latest/macros/
- sample_entries = data.read_a_yaml_file(
- repository_root / "docs" / "user_guide" / "sample_entries.yaml"
- )
- # validate the parsed dictionary by creating an instance of SampleEntries:
- SampleEntries(**sample_entries)
-
- entries_showcase = {}
- for entry_name, entry in sample_entries.items():
- proper_entry_name = entry_name.replace("_", " ").title().replace(" ", "")
- entries_showcase[proper_entry_name] = {
- "yaml": dictionary_to_yaml(entry),
- "figures": [
- {
- "path": f"../assets/images/{theme}/{entry_name}.png",
- "alt_text": f"{proper_entry_name} in {theme}",
- "theme": theme,
- }
- for theme in data.available_themes
- ],
- }
-
- env.variables["sample_entries"] = entries_showcase
-
- # For theme templates reference docs
- themes_path = rendercv_path / "themes"
- theme_templates = {}
- for theme in data.available_themes:
- theme_templates[theme] = {}
- for theme_file in themes_path.glob(f"{theme}/*.typ"):
- theme_templates[theme][theme_file.stem] = theme_file.read_text()
-
- # Update ordering of theme templates, if there are more files, add them to the
- # end
- order = [
- "Preamble.j2",
- "Header.j2",
- "SectionBeginning.j2",
- "SectionEnding.j2",
- "TextEntry.j2",
- "BulletEntry.j2",
- "NumberedEntry.j2",
- "ReversedNumberedEntry.j2",
- "OneLineEntry.j2",
- "EducationEntry.j2",
- "ExperienceEntry.j2",
- "NormalEntry.j2",
- "PublicationEntry.j2",
- ]
- remaining_files = set(theme_templates[theme].keys()) - set(order)
- order += list(remaining_files)
- theme_templates[theme] = {key: theme_templates[theme][key] for key in order}
-
- if theme != "markdown":
- theme_templates[theme] = {
- f"{key}.typ": value for key, value in theme_templates[theme].items()
- }
- else:
- theme_templates[theme] = {
- f"{key}.md": value for key, value in theme_templates[theme].items()
- }
-
- env.variables["theme_templates"] = theme_templates
-
- theme_components = {}
- for theme_file in themes_path.glob("components/*.typ"):
- theme_components[theme_file.stem] = theme_file.read_text()
- theme_components = {f"{key}.typ": value for key, value in theme_components.items()}
-
- env.variables["theme_components"] = theme_components
-
- # Available themes strings (put available themes between ``)
- themes = [f"`{theme}`" for theme in data.available_themes]
- env.variables["available_themes"] = ", ".join(themes)
-
- # Available social networks strings (put available social networks between ``)
- social_networks = [
- f"`{social_network}`" for social_network in data.available_social_networks
- ]
- env.variables["available_social_networks"] = ", ".join(social_networks)
-
- # Others:
- env.variables["available_page_sizes"] = ", ".join(
- [f"`{page_size}`" for page_size in get_args(theme_options.PageSize)]
- )
- env.variables["available_font_families"] = ", ".join(
- [f"`{font_family}`" for font_family in get_args(theme_options.FontFamily)]
- )
- env.variables["available_text_alignments"] = ", ".join(
- [
- f"`{text_alignment}`"
- for text_alignment in get_args(theme_options.TextAlignment)
- ]
- )
- env.variables["available_header_alignments"] = ", ".join(
- [
- f"`{header_alignment}`"
- for header_alignment in get_args(theme_options.Alignment)
- ]
- )
- env.variables["available_section_title_types"] = ", ".join(
- [
- f"`{section_title_type}`"
- for section_title_type in get_args(
- get_args(theme_options.SectionTitleType)[0]
- )
- ]
- )
- env.variables["available_bullets"] = ", ".join(
- [f"`{bullet}`" for bullet in get_args(theme_options.BulletPoint)]
- )
diff --git a/docs/index.md b/docs/index.md
index d0a241cf..ce7b3903 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -1,73 +1,158 @@
-# The engine of the [RenderCV App](https://rendercv.com)
+# RenderCV
+
+
+*CV/resume generator for academics and engineers*
[](https://github.com/rendercv/rendercv/actions/workflows/test.yaml)
[](https://coverage-badge.samuelcolvin.workers.dev/redirect/rendercv/rendercv)
[)](https://docs.rendercv.com)
[)](https://pypi.python.org/pypi/rendercv)
[)](https://pypistats.org/packages/rendercv)
+
-RenderCV engine is a Typst-based Python package with a command-line interface (CLI) that allows you to version-control your CV/resume as source code. It reads a CV written in a YAML file with Markdown syntax, converts it into a [Typst](https://typst.app) code, and generates a PDF.
+Write your CV or resume as YAML, then run RenderCV,
-RenderCV engine's focus is to provide these three features:
+```bash
+rendercv render John_Doe_CV.yaml
+```
-- **Content-first approach:** Users should be able to focus on the content instead of worrying about the formatting.
-- **A mechanism to version-control a CV's content and design separately:** The content and design of a CV are separate issues and they should be treated separately.
-- **Robustness:** A PDF should be delivered if there aren't any errors. If errors exist, they should be clearly explained along with solutions.
+and get a PDF with perfect typography. No template wrestling. No broken layouts. Consistent spacing, every time.
+With RenderCV, you can:
-It takes a YAML file that looks like this:
+- Version-control your CV — it's just text.
+- Focus on content — don't wory about the formatting.
+- Get perfect typography — kerning, spacing, hierarchy, all handled. No design skills required.
+
+A YAML file like this:
```yaml
cv:
name: John Doe
- location: Location
- email: john.doe@example.com
- phone: tel:+1-609-999-9995
+ location: San Francisco, CA
+ email: john.doe@email.com
+ website: https://rendercv.com/
social_networks:
- network: LinkedIn
- username: john.doe
+ username: rendercv
- network: GitHub
- username: john.doe
+ username: rendercv
sections:
- welcome_to_RenderCV!:
- - '[RenderCV](https://rendercv.com) is a Typst-based CV
- framework designed for academics and engineers, with Markdown
- syntax support.'
- - Each section title is arbitrary. Each section contains
- a list of entries, and there are 7 different entry types
- to choose from.
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
education:
- - institution: Stanford University
+ - institution: Princeton University
area: Computer Science
degree: PhD
- location: Stanford, CA, USA
- start_date: 2023-09
- end_date: present
+ date:
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
+ summary:
highlights:
- - Working on the optimization of autonomous vehicles
- in urban environments
+ - "Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment"
+ - "Advisor: Prof. Sanjeev Arora"
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
...
```
-Then, it produces one of these PDFs with its corresponding Typst file, Markdown file, HTML file, and images as PNGs. Click on the images below to preview PDF files.
+becomes one of these PDFs. Click on the images to preview.
-| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ClassicTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_Sb2novTheme_CV.pdf) |
-| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
-| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ModerncvTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringresumesTheme_CV.pdf) |
-| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringclassicTheme_CV.pdf) |  |
+| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ClassicTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringresumesTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_Sb2novTheme_CV.pdf) |
+| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
+| [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_ModerncvTheme_CV.pdf) | [](https://github.com/rendercv/rendercv/blob/main/examples/John_Doe_EngineeringclassicTheme_CV.pdf) |  |
-RenderCV comes with a JSON Schema so that the YAML input file can be filled out interactively.
-
+## JSON Schema
-## Getting Started
+RenderCV's JSON Schema lets you fill out the YAML interactively, with autocompletion and inline documentation.
-RenderCV engine is very easy to install (`pip install "rendercv[full]"`) and easy to use (`rendercv new "John Doe"`). Follow the [user guide](https://docs.rendercv.com/user_guide) to get started.
+
-## Motivation
-We are developing a [purpose-built app](https://rendercv.com) for writing CVs and resumes that will be available on mobile and web. This Python project is the foundation of that app. Check out [our blog post](https://rendercv.com/introducing-rendercv/) to learn more about why one would use such an app.
+## Extensive Design Options
-## Contributing
+You have full control over every detail.
-All contributions to RenderCV are welcome! To get started, please read [the developer guide](https://docs.rendercv.com/developer_guide).
+```yaml
+design:
+ theme: classic
+ page:
+ size: us-letter
+ top_margin: 0.7in
+ bottom_margin: 0.7in
+ left_margin: 0.7in
+ right_margin: 0.7in
+ show_footer: true
+ show_top_note: true
+ colors:
+ body: rgb(0, 0, 0)
+ name: rgb(0, 79, 144)
+ headline: rgb(0, 79, 144)
+ connections: rgb(0, 79, 144)
+ section_titles: rgb(0, 79, 144)
+ links: rgb(0, 79, 144)
+ footer: rgb(128, 128, 128)
+ top_note: rgb(128, 128, 128)
+ typography:
+ line_spacing: 0.6em
+ alignment: justified
+ date_and_location_column_alignment: right
+ font_family: Source Sans 3
+ # ...and more
+```
+
+
+
+> [!TIP]
+> Want to set up a live preview environment like the one shown above? See [how to set up VS Code for RenderCV](user_guide/how_to/set_up_vs_code_for_rendercv.md).
+
+## Strict Validation
+
+No surprises. If something's wrong, you'll know exactly what and where. If it's valid, you get a perfect PDF.
+
+
+
+
+## Any Language
+
+Fill out the locale field for your language.
+
+```yaml
+locale:
+ language: english
+ last_updated: Last updated in
+ month: month
+ months: months
+ year: year
+ years: years
+ present: present
+ month_abbreviations:
+ - Jan
+ - Feb
+ - Mar
+ ...
+```
+
+## Get Started
+
+Install RenderCV (Requires Python 3.12+):
+
+```
+pip install "rendercv[full]"
+```
+
+Create a new CV yaml file:
+
+```
+rendercv new "John Doe"
+```
+
+Edit the YAML, then render:
+
+```
+rendercv render "John_Doe_CV.yaml"
+```
+
+For more details, see the [user guide](user_guide/index.md).
diff --git a/docs/reference/api/functions.md b/docs/reference/api/functions.md
deleted file mode 100644
index 48d0213a..00000000
--- a/docs/reference/api/functions.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.api.functions`
-
-::: rendercv.api.functions
diff --git a/docs/reference/api/index.md b/docs/reference/api/index.md
deleted file mode 100644
index 7c6ca1fc..00000000
--- a/docs/reference/api/index.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.api`
-
-::: rendercv.api
diff --git a/docs/reference/cli/commands.md b/docs/reference/cli/commands.md
deleted file mode 100644
index fcc0e8de..00000000
--- a/docs/reference/cli/commands.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.cli.commands`
-
-::: rendercv.cli.commands
diff --git a/docs/reference/cli/index.md b/docs/reference/cli/index.md
deleted file mode 100644
index 96b10fde..00000000
--- a/docs/reference/cli/index.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.cli`
-
-::: rendercv.cli
diff --git a/docs/reference/cli/printer.md b/docs/reference/cli/printer.md
deleted file mode 100644
index 2aa1af94..00000000
--- a/docs/reference/cli/printer.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.cli.printer`
-
-::: rendercv.cli.printer
diff --git a/docs/reference/cli/utilities.md b/docs/reference/cli/utilities.md
deleted file mode 100644
index 4b4d50a4..00000000
--- a/docs/reference/cli/utilities.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.cli.utilities`
-
-::: rendercv.cli.utilities
diff --git a/docs/reference/data/generator.md b/docs/reference/data/generator.md
deleted file mode 100644
index 77438354..00000000
--- a/docs/reference/data/generator.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.generator`
-
-::: rendercv.data.generator
diff --git a/docs/reference/data/index.md b/docs/reference/data/index.md
deleted file mode 100644
index 166cf048..00000000
--- a/docs/reference/data/index.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data`
-
-::: rendercv.data
diff --git a/docs/reference/data/models/base.md b/docs/reference/data/models/base.md
deleted file mode 100644
index cdd6565e..00000000
--- a/docs/reference/data/models/base.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.base`
-
-::: rendercv.data.models.base
diff --git a/docs/reference/data/models/computers.md b/docs/reference/data/models/computers.md
deleted file mode 100644
index 3d407563..00000000
--- a/docs/reference/data/models/computers.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.computers`
-
-::: rendercv.data.models.computers
diff --git a/docs/reference/data/models/curriculum_vitae.md b/docs/reference/data/models/curriculum_vitae.md
deleted file mode 100644
index 332cd554..00000000
--- a/docs/reference/data/models/curriculum_vitae.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.curriculum_vitae`
-
-::: rendercv.data.models.curriculum_vitae
diff --git a/docs/reference/data/models/design.md b/docs/reference/data/models/design.md
deleted file mode 100644
index 118157d6..00000000
--- a/docs/reference/data/models/design.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.design`
-
-::: rendercv.data.models.design
diff --git a/docs/reference/data/models/entry_types.md b/docs/reference/data/models/entry_types.md
deleted file mode 100644
index 44e11462..00000000
--- a/docs/reference/data/models/entry_types.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.entry_types`
-
-::: rendercv.data.models.entry_types
diff --git a/docs/reference/data/models/index.md b/docs/reference/data/models/index.md
deleted file mode 100644
index 313fba01..00000000
--- a/docs/reference/data/models/index.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models`
-
-::: rendercv.data.models
diff --git a/docs/reference/data/models/locale.md b/docs/reference/data/models/locale.md
deleted file mode 100644
index cdf43d31..00000000
--- a/docs/reference/data/models/locale.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.locale`
-
-::: rendercv.data.models.locale
diff --git a/docs/reference/data/models/rendercv_data_model.md b/docs/reference/data/models/rendercv_data_model.md
deleted file mode 100644
index 6edd1cc3..00000000
--- a/docs/reference/data/models/rendercv_data_model.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.rendercv_data_model`
-
-::: rendercv.data.models.rendercv_data_model
diff --git a/docs/reference/data/models/rendercv_settings.md b/docs/reference/data/models/rendercv_settings.md
deleted file mode 100644
index bbce49c5..00000000
--- a/docs/reference/data/models/rendercv_settings.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.models.rendercv_settings`
-
-::: rendercv.data.models.rendercv_settings
\ No newline at end of file
diff --git a/docs/reference/data/reader.md b/docs/reference/data/reader.md
deleted file mode 100644
index 5264bb38..00000000
--- a/docs/reference/data/reader.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.data.reader`
-
-::: rendercv.data.reader
diff --git a/docs/reference/index.md b/docs/reference/index.md
deleted file mode 100644
index a35c4c5a..00000000
--- a/docs/reference/index.md
+++ /dev/null
@@ -1,57 +0,0 @@
----
-hide:
- - toc
----
-
-# API Reference
-
-RenderCV is a Typst-based Python package with a command-line interface (CLI) that allows
-you to version-control your CV/resume as source code.
-
-In this section, you can find how RenderCV's components are structured and how they interact with each other. The flowchart below illustrates the general operations of RenderCV.
-
-```mermaid
-flowchart TD
- subgraph rendercv.data
- A[YAML Input File] --parsing with ruamel.yaml package--> B(Python Dictionary)
- B --validation with pydantic package--> C((Pydantic Object))
- end
- subgraph rendercv.themes
- C --> AA[(Jinja2 Templates)]
- end
- AA --> D
- AA --> E
- subgraph rendercv.renderer
- E[Markdown File] --markdown package--> K[HTML FIle]
- D[Typst File] --typst package--> L[PDF File]
- D --typst package--> Z[PNG Files]
- end
-```
-
-- [`api`](api/index.md) package contains the functions to create a clean and simple API for RenderCV.
- - [`functions.py`](api/functions.md) module contains the basic functions that are used to interact with RenderCV.
-- [`cli`](cli/index.md) package contains the command-line interface (CLI) related code for RenderCV.
- - [`commands.py`](cli/commands.md) module contains the CLI commands.
- - [`printer.py`](cli/printer.md) module contains the functions and classes that are used to print nice-looking messages to the terminal.
- - [`utilities.py`](cli/utilities.md) module contains utility functions that are required by the CLI.
-- [`data`](data/index.md) package contains classes and functions to parse and validate a YAML input file.
- - [`models`](data/models/index.md) package contains the Pydantic data models, validators, and computed fields that are used in RenderCV.
- - [`computers.py`](data/models/computers.md) module contains functions that compute some properties based on the input data.
- - [`base.py`](data/models/base.md) module contains the base data model for the other data models.
- - [`entry_types.py`](data/models/entry_types.md) module contains the data models of the available entry types in RenderCV.
- - [`curriculum_vitae.py`](data/models/curriculum_vitae.md) module contains the data model of the `cv` field of the input file.
- - [`design.py`](data/models/design.md) module contains the data model of the `design` field of the input file.
- - [`locale.py`](data/models/locale.md) module contains the data model of the `locale` field of the input file.
- - [`rendercv_data_model.py`](data/models/rendercv_data_model.md) module contains the `RenderCVDataModel` data model, which is the main data model that defines the whole input file structure.
- - [`generator.py`](data/generator.md) module contains the functions for generating the JSON Schema of the input data format and a sample YAML input file.
- - [`reader.py`](data/reader.md) module contains the functions that are used to read the input files.
-- [`renderer`](renderer/index.md) package contains the necessary classes and functions for generating the output files from the `RenderCVDataModel` object.
- - [`renderer.py`](renderer/renderer.md) module contains the necessary functions for rendering Typst, PDF, Markdown, HTML, and PNG files from the data model.
- - [`templater.py`](renderer/templater.md) module contains the necessary classes and functions for templating the Typst and Markdown files from the data model.
-- [`themes`](themes/index.md) package contains the built-in themes of RenderCV.
- - [`options.py`](themes/options.md) module contains the standard data models for built-in Typst themes' design options
- - [`classic`](themes/classic.md) package contains the `classic` theme templates and data models for its design options.
- - [`engineeringresumes`](themes/engineeringresumes.md) package contains the `engineeringresumes` theme templates and data models for its design options.
- - [`sb2nov`](themes/sb2nov.md) package contains the `sb2nov` theme templates and data models for its design options.
- - [`moderncv`](themes/moderncv.md) package contains the `moderncv` theme templates and data models for its design options.
- - [`engineeringclassic`](themes/engineeringclassic.md) package contains the `engineeringclassic` theme templates and data models for its design options.
diff --git a/docs/reference/renderer/index.md b/docs/reference/renderer/index.md
deleted file mode 100644
index 51ca22d4..00000000
--- a/docs/reference/renderer/index.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.renderer`
-
-::: rendercv.renderer
diff --git a/docs/reference/renderer/renderer.md b/docs/reference/renderer/renderer.md
deleted file mode 100644
index 07beb194..00000000
--- a/docs/reference/renderer/renderer.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.renderer.renderer`
-
-::: rendercv.renderer.renderer
diff --git a/docs/reference/renderer/templater.md b/docs/reference/renderer/templater.md
deleted file mode 100644
index 0a249fa7..00000000
--- a/docs/reference/renderer/templater.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.renderer.templater`
-
-::: rendercv.renderer.templater
diff --git a/docs/reference/themes/classic.md b/docs/reference/themes/classic.md
deleted file mode 100644
index b0d174eb..00000000
--- a/docs/reference/themes/classic.md
+++ /dev/null
@@ -1,14 +0,0 @@
-# `rendercv.themes.classic`
-
-::: rendercv.themes.classic
-
-## Jinja Templates
-
-{% for template_name, template in theme_templates["classic"].items() %}
-### {{ template_name }}
-
-```typst
-{{ template }}
-```
-
-{% endfor %}
\ No newline at end of file
diff --git a/docs/reference/themes/components.md b/docs/reference/themes/components.md
deleted file mode 100644
index b42771ff..00000000
--- a/docs/reference/themes/components.md
+++ /dev/null
@@ -1,13 +0,0 @@
-# `rendercv.themes.components`
-
-## Jinja Templates
-
-{% for template_name, template in theme_components.items() %}
-
-### {{ template_name }}
-
-```typst
-{{ template }}
-```
-
-{% endfor %}
\ No newline at end of file
diff --git a/docs/reference/themes/engineeringclassic.md b/docs/reference/themes/engineeringclassic.md
deleted file mode 100644
index 77987bd8..00000000
--- a/docs/reference/themes/engineeringclassic.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# `rendercv.themes.engineeringclassic`
-
-::: rendercv.themes.engineeringclassic
-
-## Jinja Templates
-
-{% for template_name, template in theme_templates["engineeringclassic"].items() %}
-
-### {{ template_name }}
-
-```typst
-{{ template }}
-```
-
-{% endfor %}
\ No newline at end of file
diff --git a/docs/reference/themes/engineeringresumes.md b/docs/reference/themes/engineeringresumes.md
deleted file mode 100644
index bf68aad7..00000000
--- a/docs/reference/themes/engineeringresumes.md
+++ /dev/null
@@ -1,14 +0,0 @@
-# `rendercv.themes.engineeringresumes`
-
-::: rendercv.themes.engineeringresumes
-
-## Jinja Templates
-
-{% for template_name, template in theme_templates["engineeringresumes"].items() %}
-### {{ template_name }}
-
-```typst
-{{ template }}
-```
-
-{% endfor %}
\ No newline at end of file
diff --git a/docs/reference/themes/index.md b/docs/reference/themes/index.md
deleted file mode 100644
index a8e52c3e..00000000
--- a/docs/reference/themes/index.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.themes`
-
-::: rendercv.themes
diff --git a/docs/reference/themes/moderncv.md b/docs/reference/themes/moderncv.md
deleted file mode 100644
index 4af21a99..00000000
--- a/docs/reference/themes/moderncv.md
+++ /dev/null
@@ -1,14 +0,0 @@
-# `rendercv.themes.moderncv`
-
-::: rendercv.themes.moderncv
-
-## Jinja Templates
-
-{% for template_name, template in theme_templates["moderncv"].items() %}
-### {{ template_name }}
-
-```typst
-{{ template }}
-```
-
-{% endfor %}
\ No newline at end of file
diff --git a/docs/reference/themes/options.md b/docs/reference/themes/options.md
deleted file mode 100644
index 17947739..00000000
--- a/docs/reference/themes/options.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# `rendercv.themes.options`
-
-::: rendercv.themes.options
diff --git a/docs/reference/themes/sb2nov.md b/docs/reference/themes/sb2nov.md
deleted file mode 100644
index 8d07dd63..00000000
--- a/docs/reference/themes/sb2nov.md
+++ /dev/null
@@ -1,14 +0,0 @@
-# `rendercv.themes.sb2nov`
-
-::: rendercv.themes.sb2nov
-
-## Jinja Templates
-
-{% for template_name, template in theme_templates["sb2nov"].items() %}
-### {{ template_name }}
-
-```typst
-{{ template }}
-```
-
-{% endfor %}
\ No newline at end of file
diff --git a/docs/user_guide/cli.md b/docs/user_guide/cli.md
index 98907bd1..c38a5802 100644
--- a/docs/user_guide/cli.md
+++ b/docs/user_guide/cli.md
@@ -1,201 +1,91 @@
-# Command Line Interface (CLI)
+---
+toc_depth: 1
+---
-This page lists the available commands and options of the RenderCV CLI.
+# CLI Reference
-## `rendercv` command
+## `rendercv`
-- `#!bash --version` or `#!bash -v`
+Show version:
- Shows the version of RenderCV.
+```bash
+rendercv --version
+```
- ```bash
- rendercv --version
- ```
+Show help:
-- `#!bash --help` or `#!bash -h`
-
- Shows the help message.
+```bash
+rendercv --help
+```
- ```bash
- rendercv --help
- ```
+## `rendercv new`
-## `rendercv new` command
+Create a new CV YAML input file
-- `#!bash --theme "THEME_NAME"`
+```bash
+rendercv new "John Doe"
+```
- Generates files for a specific built-in theme, instead of the default `classic` theme. Currently, the available themes are: {{available_themes}}.
+### Options
- ```bash
- rendercv new "Full Name" --theme "THEME_NAME"
- ```
+| Option | Description |
+| ----------------------------- | ---------------------------------------------------------------- |
+| `--theme THEME` | Use a built-in theme: << available_themes >>. Default: `classic` |
+| `--locale LOCALE` | Use a locale: << available_locales >>. Default: `english` |
+| `--create-typst-templates` | Generate Typst template files for advanced customization |
+| `--create-markdown-templates` | Generate Markdown template files for advanced customization |
-- `#!bash --dont-create-theme-source-files` or `#!bash -notypst`
+## `rendercv render`
- Prevents the creation of the theme source files. By default, the theme source files are created.
+Render a CV from a YAML file.
- ```bash
- rendercv new "Full Name" --dont-create-theme-source-files
- ```
+```bash
+rendercv render John_Doe_CV.yaml
+```
-- `#!bash --dont-create-markdown-source-files` or `#!bash -nomd`
+### Options
- Prevents the creation of the Markdown source files. By default, the Markdown source files are created.
+All output paths are relative to the input file.
- ```bash
- rendercv new "Full Name" --dont-create-markdown-source-files
- ```
+| Option | Short | Description |
+| -------------------------- | --------- | -------------------------------------------------------- |
+| `--watch` | `-w` | Re-render automatically when the YAML file changes |
+| `--quiet` | `-q` | Suppress all output messages |
+| `--design FILE` | `-d` | Load `design` field from a separate YAML file |
+| `--locale-catalog FILE` | `-lc` | Load `locale` field from a separate YAML file |
+| `--settings FILE` | `-s` | Load `rendercv_settings` field from a separate YAML file |
+| `--pdf-path PATH` | `-pdf` | Custom path for PDF output |
+| `--typst-path PATH` | `-typ` | Custom path for Typst source output |
+| `--markdown-path PATH` | `-md` | Custom path for Markdown output |
+| `--html-path PATH` | `-html` | Custom path for HTML output |
+| `--png-path PATH` | `-png` | Custom path for PNG output |
+| `--dont-generate-pdf` | `-nopdf` | Skip PDF generation |
+| `--dont-generate-typst` | `-notyp` | Skip Typst generation (implies `-nopdf`, `-nopng`) |
+| `--dont-generate-markdown` | `-nomd` | Skip Markdown generation (implies `-nohtml`) |
+| `--dont-generate-html` | `-nohtml` | Skip HTML generation |
+| `--dont-generate-png` | `-nopng` | Skip PNG generation |
-- `#!bash --help` or `#!bash -h`
- Shows the help message.
+### Overriding YAML values
- ```bash
- rendercv new --help
- ```
+Override any field in the YAML file from the command line:
+```bash
+rendercv render John_Doe_CV.yaml --cv.phone "+1-555-555-5555"
+```
-## `rendercv render` command
+```bash
+rendercv render John_Doe_CV.yaml --cv.sections.education.0.institution "MIT"
+```
-- `#!bash --watch` or `#!bash -w`
+Useful for keeping sensitive information (phone, address) out of version control.
- Watches the input YAML file for changes and automatically renders if there is any change.
+## `rendercv create-theme`
- ```bash
- rendercv render "Full_Name_CV.yaml" --watch
- ```
+Create a custom theme with Typst templates you can modify.
-- `#!bash --output-folder-name "OUTPUT_FOLDER_NAME"` or `#!bash -o "OUTPUT_FOLDER_NAME"`
+```bash
+rendercv create-theme "mytheme"
+```
- Generates the output files in a folder with the given name. By default, the output folder name is `rendercv_output`. The output folder will be created in the current working directory.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --output-folder-name "OUTPUT_FOLDER_NAME"
- ```
-
-- `#!bash --typst-path "PATH"` or `#!bash -typst "PATH"`
-
- Copies the generated Typst source code from the output folder and pastes it to the specified path.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --typst-path "PATH"
- ```
-
-- `#!bash --pdf-path "PATH"` or `#!bash -pdf "PATH"`
-
- Copies the generated PDF file from the output folder and pastes it to the specified path.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --pdf-path "PATH"
- ```
-
-- `#!bash --markdown-path "PATH"` or `#!bash -md "PATH"`
-
- Copies the generated Markdown file from the output folder and pastes it to the specified path.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --markdown-path "PATH"
- ```
-
-- `#!bash --html-path "PATH"` or `#!bash -html "PATH"`
-
- Copies the generated HTML file from the output folder and pastes it to the specified path.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --html-path "PATH"
- ```
-
-- `#!bash --png-path "PATH"` or `#!bash -png "PATH"`
-
- Copies the generated PNG files from the output folder and pastes them to the specified path.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --png-path "PATH"
- ```
-
-- `#!bash --dont-generate-markdown` or `#!bash -nomd`
-
- Prevents the generation of the Markdown file.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --dont-generate-markdown
- ```
-
-- `#!bash --dont-generate-html` or `#!bash -nohtml`
-
- Prevents the generation of the HTML file.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --dont-generate-html
- ```
-
-- `#!bash --dont-generate-png` or `#!bash -nopng`
-
- Prevents the generation of the PNG files.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --dont-generate-png
- ```
-- `#!bash --design design.yaml`
-
- Uses the given design file for the `design` field of the input YAML file.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --design "design.yaml"
- ```
-
-- `#!bash --locale-catalog locale.yaml`
-
- Uses the given locale catalog file for the `locale` field of the input YAML file.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --locale-catalog "locale.yaml"
- ```
-
-- `#!bash --rendercv-settings rendercv_settings.yaml`
-
- Uses the given RenderCV settings file for the `rendercv_settings` field of the input YAML file.
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --rendercv-settings "rendercv_settings.yaml"
- ```
-
-- `#!bash --ANY.LOCATION.IN.THE.YAML.FILE "VALUE"`
-
- Overrides the value of `ANY.LOCATION.IN.THE.YAML.FILE` with `VALUE`. This option can be used to avoid storing sensitive information in the YAML file. Sensitive information, like phone numbers, can be passed as a command-line argument with environment variables. This method is also beneficial for creating multiple CVs using the same YAML file by changing only a few values. Here are a few examples:
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --cv.phone "+905555555555"
- ```
-
- ```bash
- rendercv render "Full_Name_CV.yaml" --cv.sections.education.1.institution "Your University"
- ```
-
- Multiple `#!bash --ANY.LOCATION.IN.THE.YAML.FILE "VALUE"` options can be used in the same command.
-
-- `#!bash --help` or `#!bash -h`
-
- Shows the help message.
-
- ```bash
- rendercv render --help
- ```
-
-## `rendercv create-theme` command
-
-- `#!bash --based-on "THEME_NAME"`
-
- Generates a custom theme based on the specified built-in theme, instead of the default `classic` theme. Currently, the available themes are: {{available_themes}}.
-
- ```bash
- rendercv create-theme "mycustomtheme" --based-on "THEME_NAME"
- ```
-
-- `#!bash --help` or `#!bash -h`
-
- Shows the help message.
-
- ```bash
- rendercv create-theme --help
- ```
+Creates a `mytheme/` directory in the current folder with all template files.
\ No newline at end of file
diff --git a/docs/user_guide/faq.md b/docs/user_guide/faq.md
deleted file mode 100644
index 11be0ff0..00000000
--- a/docs/user_guide/faq.md
+++ /dev/null
@@ -1,121 +0,0 @@
-# Frequently Asked Questions (FAQ)
-
-## How to use it with JSON Resume?
-
-You can use [jsonresume-to-rendercv](https://github.com/guruor/jsonresume-to-rendercv) to convert your JSON Resume file to a RenderCV input file.
-
-## How to use it with Docker?
-
-RenderCV's Docker image is available [on Docker Hub](https://hub.docker.com/r/rendercv/rendercv).
-
-If you have Docker installed, you can use RenderCV without installing anything else. Run the command below to open a Docker container with RenderCV installed.
-
-```bash
-docker run -it -v ./rendercv:/rendercv docker.io/rendercv/rendercv:latest
-```
-
-Then, you can use RenderCV CLI as if it were installed on your machine. The files will be saved in the `rendercv` directory.
-
-## How to create a custom theme?
-
-RenderCV is a general Typst-based CV framework. It allows you to use any Typst code to generate your CVs. To begin developing a custom theme, run the command below.
-
-```bash
-rendercv create-theme "mycustomtheme"
-```
-
-This command will create a directory called `mycustomtheme`, which contains the following files:
-
-``` { .sh .no-copy }
-├── mycustomtheme
-│ ├── __init__.py
-│ ├── Preamble.j2.typ
-│ ├── Header.j2.typ
-│ ├── EducationEntry.j2.typ
-│ ├── ExperienceEntry.j2.typ
-│ ├── NormalEntry.j2.typ
-│ ├── OneLineEntry.j2.typ
-│ ├── PublicationEntry.j2.typ
-│ ├── TextEntry.j2.typ
-│ ├── SectionBeginning.j2.typ
-│ └── SectionEnding.j2.typ
-└── Your_Full_Name_CV.yaml
-```
-
-The files are copied from the `classic` theme. You can update the contents of these files to create your custom theme.
-
-To use your custom theme, update the `design.theme` field in the YAML input file as shown below.
-
-```yaml
-cv:
- ...
-
-design:
- theme: mycustomtheme
-```
-
-Then, run the `render` command to render your CV with `mycustomtheme`.
-
-!!! note
- Since JSON Schema will not recognize the name of the custom theme, it may show a warning in your IDE. This warning can be ignored.
-
-Each of these `*.j2.typ` files is Typst code with some Python in it. These files allow RenderCV to create your CV out of the YAML input.
-
-The best way to understand how they work is to look at the templates of the built-in themes:
-
-- [templates of the `classic` theme](../reference/themes/classic.md#jinja-templates)
-
-For example, the content of `ExperienceEntry.j2.typ` for the `classic` theme is shown below:
-
-```typst
-\cventry{
- ((* if design.show_only_years *))
- <>
- ((* else *))
- <>
- ((* endif *))
-}{
- <>
-}{
- <>
-}{
- <>
-}{}{}
-((* for item in entry.highlights *))
-\cvline{}{\small <- >}
-((* endfor *))
-```
-
-The values between `<<` and `>>` are the names of Python variables, allowing you to write a Typst CV without writing any content. They will be replaced with the values found in the YAML input. The values between `((*` and `*))` are Python blocks, allowing you to use loops and conditional statements.
-
-The process of generating Typst files like this is called "templating," and it is achieved with a Python package called [Jinja](https://jinja.palletsprojects.com/en/3.1.x/).
-
-The `__init__.py` file found in the theme directory defines the design options of the custom theme. You can define your custom design options in this file.
-
-For example, an `__init__.py` file is shown below:
-
-```python
-from typing import Literal
-
-import pydantic
-
-class YourcustomthemeThemeOptions(pydantic.BaseModel):
- theme: Literal["yourcustomtheme"]
- option1: str
- option2: str
- option3: int
- option4: bool
-```
-
-RenderCV will then parse your custom design options from the YAML input. You can use these variables inside your `*.j2.typ` files as shown below:
-
-```typst
-<
>
-<>
-((* if design.option4 *))
- <>
-((* endif *))
-```
-
-!!! info
- Refer [here](cli.md#rendercv-create-theme-command) for the complete list of CLI options available for the `create-theme` command.
diff --git a/docs/user_guide/how_to/arbitrary_keys_in_entries.md b/docs/user_guide/how_to/arbitrary_keys_in_entries.md
new file mode 100644
index 00000000..820dc14b
--- /dev/null
+++ b/docs/user_guide/how_to/arbitrary_keys_in_entries.md
@@ -0,0 +1,30 @@
+# Arbitrary Keys in Entries
+
+The `design.templates` field controls how entry data is displayed. Add any custom field to your entries and reference it in templates using UPPERCASE placeholders.
+
+## How It Works
+
+Templates use **UPPERCASE PLACEHOLDERS** that map to entry keys.
+
+Given this entry:
+
+```yaml
+company: Google
+position: Software Engineer
+tech_stack: Python, Go, Kubernetes
+```
+
+And this template:
+
+```yaml
+design:
+ templates:
+ experience_entry:
+ main_column: |-
+ **COMPANY**, POSITION
+ *Tech stack:* TECH_STACK
+```
+
+RenderCV replaces `COMPANY` → "Google", `POSITION` → "Software Engineer", `TECH_STACK` → "Python, Go, Kubernetes".
+
+Any key you add to an entry becomes available as an uppercase placeholder.
diff --git a/docs/user_guide/how_to/custom_fonts.md b/docs/user_guide/how_to/custom_fonts.md
new file mode 100644
index 00000000..863953dc
--- /dev/null
+++ b/docs/user_guide/how_to/custom_fonts.md
@@ -0,0 +1,32 @@
+# Custom Fonts
+
+RenderCV automatically discovers custom fonts placed in a `fonts` directory next to your YAML input file.
+
+## How to Use Custom Fonts
+
+1. Create a `fonts` directory in the same location as your YAML file:
+
+ ```
+ Your_Name_CV.yaml
+ fonts/
+ CustomFont-Regular.ttf
+ CustomFont-Bold.ttf
+ AnotherFont.otf
+ ```
+
+2. In your YAML file, specify the font family name in the design section:
+
+ ```yaml
+ design:
+ typography:
+ font_family: CustomFont
+ ```
+
+## Supported Font Formats
+
+- `.ttf` (TrueType Font)
+- `.otf` (OpenType Font)
+
+## Font Family Names
+
+Use the font family name exactly as defined in the font file's metadata. For most fonts, this is the name you see when you install the font on your system.
diff --git a/docs/user_guide/how_to/override_default_templates.md b/docs/user_guide/how_to/override_default_templates.md
new file mode 100644
index 00000000..4b1431bb
--- /dev/null
+++ b/docs/user_guide/how_to/override_default_templates.md
@@ -0,0 +1,138 @@
+# Override Default Templates
+
+When design options don't provide enough control, you can override the default Typst templates to fully customize your CV's appearance.
+
+## When to Override Templates
+
+Use template overriding when you need to:
+
+- Change the fundamental layout structure
+- Add custom Typst functions or packages
+- Modify how entries are rendered beyond what `design.templates` allows
+- Create completely custom designs not achievable through design options
+
+For simpler customizations, try these first:
+
+- [`design`](../yaml_input_structure.md#design) for colors, fonts, spacing
+- [`design.templates`](arbitrary_keys_in_entries.md) for changing entry text layout
+
+## Two Methods
+
+### Method 1: Quick Template Customization
+
+Use this when you want to tweak an existing theme's templates without creating a full custom theme.
+
+1. Create templates alongside your CV:
+
+ ```bash
+ rendercv new "Your Name" --create-typst-templates
+ ```
+
+ This creates:
+ ```
+ Your_Name_CV.yaml
+ classic/
+ Preamble.j2.typ
+ Header.j2.typ
+ SectionBeginning.j2.typ
+ entries/
+ NormalEntry.j2.typ
+ ...
+ ```
+
+2. Modify any template file in the `classic/` folder.
+
+3. Render as usual:
+
+ ```bash
+ rendercv render Your_Name_CV.yaml
+ ```
+
+RenderCV automatically uses your local templates instead of the built-in ones.
+
+### Method 2: Create a Custom Theme
+
+Use this when building a reusable theme with its own design options.
+
+1. Create a custom theme:
+
+ ```bash
+ rendercv create-theme mytheme
+ ```
+
+ This creates:
+ ```
+ mytheme/
+ __init__.py
+ Preamble.j2.typ
+ Header.j2.typ
+ SectionBeginning.j2.typ
+ entries/
+ NormalEntry.j2.typ
+ ...
+ ```
+
+2. Modify template files and optionally add custom design options in `__init__.py`.
+
+3. Use your theme in the YAML file:
+
+ ```yaml
+ design:
+ theme: mytheme
+ # Your custom design options work here
+ ```
+
+4. Render:
+
+ ```bash
+ rendercv render Your_Name_CV.yaml
+ ```
+
+## Template Structure
+
+Templates use [Jinja2](https://jinja.palletsprojects.com/) syntax with Typst code:
+
+```typst
+// Example: entries/NormalEntry.j2.typ
+#regular-entry(
+ [
+{% for line in entry.main_column.splitlines() %}
+ {{ line }}
+{% endfor %}
+ ],
+ [
+{% for line in entry.date_and_location_column.splitlines() %}
+ {{ line }}
+{% endfor %}
+ ],
+)
+```
+
+### Variables Available in Templates
+
+- `cv`: All CV data (name, sections, etc.)
+- `design`: All design options
+- `locale`: Locale strings (month names, translations)
+- `entry`: Current entry data (in entry templates)
+
+Example accessing design options:
+
+```typst
+// In Preamble.j2.typ
+#show: rendercv.with(
+ page-size: "{{ design.page.size }}",
+ colors-body: {{ design.colors.body.as_rgb() }},
+ typography-font-family-body: "{{ design.typography.font_family.body }}",
+ // ...
+)
+```
+
+## Markdown Templates
+
+Both methods also support Markdown template customization with `--create-markdown-templates`. The process is identical to Typst templates.
+
+## Tips
+
+- Start by copying templates and making small changes
+- Templates are Jinja2 + Typst, not pure Typst
+- Delete template files you don't need to customize (RenderCV falls back to built-in versions)
diff --git a/docs/user_guide/how_to/set_up_vs_code_for_rendercv.md b/docs/user_guide/how_to/set_up_vs_code_for_rendercv.md
new file mode 100644
index 00000000..b3225708
--- /dev/null
+++ b/docs/user_guide/how_to/set_up_vs_code_for_rendercv.md
@@ -0,0 +1,80 @@
+# Set Up VS Code for RenderCV
+
+Visual Studio Code can be configured to provide a live preview environment for writing your CV with RenderCV. This setup enables you to see your changes reflected in the PDF instantly as you type, making the CV editing process smooth and interactive.
+
+## Required Extensions
+
+Install these two VS Code extensions:
+
+1. [**YAML Extension** by Red Hat](https://marketplace.visualstudio.com/items?itemName=redhat.vscode-yaml): Provides YAML language support with autocompletion and validation.
+
+2. [**PDF Viewer** by tomoki1207](https://marketplace.visualstudio.com/items?itemName=tomoki1207.pdf): Allows you to view PDF files directly within VS Code.
+
+## Configure Auto-Save
+
+To enable automatic rendering as you type, you need to configure VS Code to auto-save your files.
+
+1. Open the VS Code settings JSON file:
+
+ === "macOS"
+
+ Press `Cmd+Shift+P` to open the Command Palette, then type:
+
+ ```
+ Preferences: Open User Settings (JSON)
+ ```
+
+ === "Windows/Linux"
+
+ Press `Ctrl+Shift+P` to open the Command Palette, then type:
+
+ ```
+ Preferences: Open User Settings (JSON)
+ ```
+
+2. Add the following lines to your `settings.json` file:
+
+ ```json
+ {
+ "files.autoSave": "afterDelay",
+ "files.autoSaveDelay": 10
+ }
+ ```
+
+These settings will automatically save your YAML file 10 milliseconds after you stop typing.
+
+## Start Writing Your CV with Live Preview
+
+Once the extensions are installed and auto-save is configured, follow these steps to start the live preview:
+
+1. **Open your YAML input file** (e.g. `John_Doe_CV.yaml`) in VS Code
+
+2. **Run `rendercv render` with the watch mode**:
+
+ ```bash
+ rendercv render --watch John_Doe_CV.yaml
+ ```
+
+ The `--watch` flag tells RenderCV to monitor the YAML file for changes and automatically re-render the PDF whenever the file is saved.
+
+3. **Arrange your workspace**:
+
+ - Place your YAML file on the left side of the editor
+ - Open the generated PDF (from `rendercv_output/`) on the right side
+
+4. **Start editing**: As you make changes to the YAML file, they will be automatically saved, triggering RenderCV to regenerate the PDF. The PDF viewer will update to show your changes in real-time.
+
+
+
+!!! tip
+ You can split your editor vertically by right-clicking on the PDF file tab and selecting "Split Right" or using the keyboard shortcut `Cmd+\` (macOS) or `Ctrl+\` (Windows/Linux).
+
+## Troubleshooting
+
+If the live preview isn't working:
+
+- Make sure auto-save is enabled and the delay is set
+- Verify that `rendercv render --watch` is running in the terminal without errors
+- Try closing and reopening the PDF file in VS Code
+
+With this setup, you'll have a productive environment for creating and refining your CV with instant visual feedback.
diff --git a/docs/user_guide/index.md b/docs/user_guide/index.md
index 7d09d1d2..e913f2d0 100644
--- a/docs/user_guide/index.md
+++ b/docs/user_guide/index.md
@@ -1,79 +1,76 @@
-# User Guide
-
-This page provides everything you need to know about the usage of RenderCV.
+# Get Started
## Installation
-1. Install [Python](https://www.python.org/downloads/) (3.10 or newer).
+1. Install [Python](https://www.python.org/downloads/) (3.12 or newer).
2. Run the command below to install RenderCV.
-```bash
-pip install "rendercv[full]"
-```
+ === "pip"
-## Getting started
+ ```
+ pip install "rendercv[full]"
+ ```
-To get started, navigate to the directory where you want to create your CV and run the command below to create the input files.
+ === "pipx"
-```bash
-rendercv new "Your Full Name"
-```
-This command will create the following files:
+ ```
+ pipx install "rendercv[full]"
+ ```
-- A YAML input file called `Your_Name_CV.yaml`.
+ === "uv"
- This file contains the content and design options of your CV. A detailed explanation of the structure of the YAML input file is provided [here](structure_of_the_yaml_input_file.md).
+ ```
+ uv tool install "rendercv[full]"
+ ```
-- A directory called `classic`.
+ === "Docker"
+
+ Docker image is available at [ghcr.io/rendercv/rendercv](https://github.com/rendercv/rendercv/pkgs/container/rendercv).
- This directory contains the Typst templates of RenderCV's default built-in theme, `classic`. You can update its contents to tweak the appearance of the output PDF file.
+ ```bash
+ docker run -v "$PWD":/work -w /work ghcr.io/rendercv/rendercv new "Your Name"
+ ```
-- A directory called `markdown`.
+## Quick Start
- This directory contains the templates of RenderCV's default Markdown template. You can update its contents to tweak the Markdown and HTML output of the CV.
+1. Create a new CV YAML input file
-!!! note "A note about `classic` and `markdown` directories"
- It's optional to have the `classic` and `markdown` directories. If you don't have them, RenderCV will use the built-in theme and Markdown templates.
+ ```bash
+ rendercv new "Your Name"
+ ```
-!!! info
- Refer to the [here](cli.md#rendercv-new-command) for the complete list of CLI options available for the `new` command.
+ This creates a YAML input file called `Your_Name_CV.yaml`. This file contains the content, design options, translations and settings for RenderCV. See [YAML Input Structure](yaml_input_structure.md) for the full reference.
-Then, open the `Your_Name_CV.yaml` file in your favorite text editor and fill it with your information. See the [structure of the YAML input file](structure_of_the_yaml_input_file.md) for more information about the YAML input file.
+ See the [CLI Reference](cli.md#rendercv-new) for the complete list of options available for the `new` command.
+
+ !!! tip
+ To get started with another language or theme, you can use the `--locale` and `--theme` options:
-Finally, render the YAML input file to generate your CV.
+ ```bash
+ rendercv new "Your Name" --locale "turkish" --theme "engineeringresumes"
+ ```
-```bash
-rendercv render "Your_Name_CV.yaml"
-```
-This command will generate a directory called `rendercv_output`, which contains the following files:
+2. Render the YAML input file with
-- The CV in PDF format, `Your_Name_CV.pdf`.
-- Typst source code of the PDF file, `Your_Name_CV.typ`.
-- Images of each page of the PDF file in PNG format, `Your_Name_CV_1.png`, `Your_Name_CV_page_2.png`, etc.
-- The CV in Markdown format, `Your_Name_CV.md`.
-- The CV in HTML format, `Your_Name_CV.html`. You can open this file in a web browser and copy-paste the content to Grammarly for proofreading.
+ ```bash
+ rendercv render "Your_Name_CV.yaml"
+ ```
-To have RenderCV run automatically whenever the YAML input file is updated, use the `--watch` option.
+ This generates a `rendercv_output/` directory containing:
-```bash
-rendercv render --watch "Your_Name_CV.yaml"
-```
+ - `John_Doe_CV.pdf`: Your CV as PDF
+ - `John_Doe_CV.typ`: [Typst](https://typst.app) source code of the PDF
+ - `John_Doe_CV_1.png`, `..._2.png`, ...: PNG images of each page of the PDF
+ - `John_Doe_CV.md`: Your CV as Markdown
+ - `John_Doe_CV.html`: Your CV as HTML (generated from the Markdown)
-!!! info
- Refer to the [here](cli.md#rendercv-render-command) for the complete list of CLI options available for the `render` command.
+ See the [CLI Reference](cli.md#rendercv-render) for the complete list of options available for the `render` command.
-## Overriding built-in themes
+ !!! tip
+ To re-render automatically whenever you save changes, use the `--watch` option:
-If the theme and Markdown templates are found in the directory, they will override the default built-in theme and Markdown templates. You don't need to provide all the files; you can just provide the ones you want to override.
-
-For example, `ExperienceEntry` of the `classic` theme can be modified as shown below.
-
-``` { .sh .no-copy }
-├── classic
-│ └── ExperienceEntry.j2.typ # (1)!
-└── Your_Full_Name_CV.yaml
-```
-
-1. This file will override the built-in `ExperienceEntry.j2.typ` template of the `classic` theme.
+ ```bash
+ rendercv render --watch "Your_Name_CV.yaml"
+ ```
diff --git a/docs/user_guide/structure_of_the_yaml_input_file.md b/docs/user_guide/structure_of_the_yaml_input_file.md
deleted file mode 100644
index 39688c01..00000000
--- a/docs/user_guide/structure_of_the_yaml_input_file.md
+++ /dev/null
@@ -1,483 +0,0 @@
-# Structure of the YAML Input File
-
-RenderCV's input file consists of four parts: `cv`, `design`, `locale` and `rendercv_settings`.
-
-```yaml title="Your_Name_CV.yaml"
-cv:
- ...
- YOUR CONTENT
- ...
-design:
- ...
- YOUR DESIGN
- ...
-locale:
- ...
- TRANSLATIONS TO YOUR LANGUAGE
- ...
-rendercv_settings:
- ...
- RENDERCV SETTINGS
- ...
-```
-
-- The `cv` field is mandatory. It contains the **content of the CV**.
-- The `design` field is optional. It contains the **design options of the CV**. If you don't provide a `design` field, RenderCV will use the default design options with the `classic` theme.
-- The `locale` field is optional. It contains all the strings that define the CV's language (like month names, etc.). If you don't provide a `locale` field, the default English strings will be used.
-- The `rendercv_settings` field is optional. It contains the settings of RenderCV (output paths, keywords to make bold, etc.). If you don't provide a `rendercv_settings` field, the default settings will be used.
-
-!!! tip "Tip: JSON Schema"
- To maximize your productivity while editing the input YAML file, set up RenderCV's JSON Schema in your IDE. It will validate your inputs on the fly and give auto-complete suggestions.
-
- === "Visual Studio Code"
-
- 1. Install [YAML language support](https://marketplace.visualstudio.com/items?itemName=redhat.vscode-yaml) extension.
- 2. Then the Schema will be automatically set up because the file ends with `_CV.yaml`.
- 3. Press `Ctrl + Space` to see the auto-complete suggestions.
-
- === "Other"
-
- 4. Ensure your editor of choice has support for JSON Schema.
- 5. Add the following line at the top of `Your_Name_CV.yaml`:
-
- ``` yaml
- # yaml-language-server: $schema=https://github.com/rendercv/rendercv/blob/main/schema.json?raw=true
- ```
- 6. Press `Ctrl + Space` to see the auto-complete suggestions.
-
-## "`cv`" field
-
-The `cv` field of the YAML input starts with generic information, as shown below.
-
-```yaml
-cv:
- name: John Doe
- location: Your Location
- email: youremail@yourdomain.com
- phone: +905419999999 # (1)!
- website: https://example.com/
- social_networks:
- - network: LinkedIn # (2)!
- username: yourusername
- - network: GitHub
- username: yourusername
- ...
-```
-
-1. If you want to change the phone number formatting in the output, see the `locale` field's `phone_number_format` key.
-2. The available social networks are: {{available_social_networks}}.
-
-None of the values above are required. You can omit any or all of them, and RenderCV will adapt to your input. These generic fields are used in the header of the CV.
-
-The main content of your CV is stored in a field called `sections`.
-
-```yaml hl_lines="12 13 14 15"
-cv:
- name: John Doe
- location: Your Location
- email: youremail@yourdomain.com
- phone: +905419999999
- website: https://yourwebsite.com/
- social_networks:
- - network: LinkedIn
- username: yourusername
- - network: GitHub
- username: yourusername
- sections:
- ...
- YOUR CONTENT
- ...
-```
-
-### "`cv.sections`" field
-
-The `cv.sections` field is a dictionary where the keys are the section titles, and the values are lists. Each item of the list is an entry for that section.
-
-Here is an example:
-
-```yaml hl_lines="3 7"
-cv:
- sections:
- this_is_a_section_title: # (1)!
- - This is a TextEntry. # (2)!
- - This is another TextEntry under the same section.
- - This is another another TextEntry under the same section.
- this_is_another_section_title:
- - company: This time it's an ExperienceEntry. # (3)!
- position: Your position
- start_date: 2019-01-01
- end_date: 2020-01
- location: TX, USA
- highlights:
- - This is a highlight (a bullet point).
- - This is another highlight.
- - company: Another ExperienceEntry.
- position: Your position
- start_date: 2019-01-01
- end_date: 2020-01-10
- location: TX, USA
- highlights:
- - This is a highlight (a bullet point).
- - This is another highlight.
-```
-
-1. The section titles can be anything you want. They are the keys of the `sections` dictionary.
-2. Each section is a list of entries. This section has three `TextEntry`s.
-3. There are seven different entry types in RenderCV. Any of them can be used in the sections. This section has two `ExperienceEntry`s.
-
-There are seven different entry types in RenderCV. Different types of entries cannot be mixed under the same section, so for each section, you can only use one type of entry.
-
-The available entry types are: [`EducationEntry`](#educationentry), [`ExperienceEntry`](#experienceentry), [`PublicationEntry`](#publicationentry), [`NormalEntry`](#normalentry), [`OneLineEntry`](#onelineentry), [`BulletEntry`](#bulletentry), and [`TextEntry`](#textentry).
-
-Each entry type is a different object (a dictionary). Below, you can find all the entry types along with their optional/mandatory fields and how they appear in each built-in theme.
-
-{% for entry_name, entry in sample_entries.items() %}
-#### {{ entry_name }}
-
-{% if entry_name == "EducationEntry" %}
-
-**Mandatory Fields:**
-
-- `institution`: The name of the institution.
-- `area`: The area of study.
-
-**Optional Fields:**
-
-- `degree`: The type of degree (e.g., BS, MS, PhD)
-- `location`: The location
-- `start_date`: The start date in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format
-- `end_date`: The end date in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format or "present"
-- `date`: The date as a custom string or in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format. This will override `start_date` and `end_date`.
-- `summary`: The summary
-- `highlights`: The list of bullet points
-
-{% elif entry_name == "ExperienceEntry" %}
-
-**Mandatory Fields:**
-
-- `company`: The name of the company
-- `position`: The position
-
-**Optional Fields:**
-
-- `location`: The location
-- `start_date`: The start date in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format
-- `end_date`: The end date in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format or "present"
-- `date`: The date as a custom string or in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format. This will override `start_date` and `end_date`.
-- `summary`: The summary
-- `highlights`: The list of bullet points
-
-{% elif entry_name == "PublicationEntry" %}
-
-**Mandatory Fields:**
-
-- `title`: The title of the publication
-- `authors`: The authors of the publication
-
-**Optional Fields:**
-
-- `doi`: The DOI of the publication
-- `url`: The URL of the publication
-- `journal`: The journal of the publication
-- `date`: The date as a custom string or in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format
-
-{% elif entry_name == "NormalEntry" %}
-
-
-**Mandatory Fields:**
-
-- `name`: The name of the entry
-
-**Optional Fields:**
-
-- `location`: The location
-- `start_date`: The start date in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format
-- `end_date`: The end date in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format or "present"
-- `date`: The date as a custom string or in `YYYY-MM-DD`, `YYYY-MM`, or `YYYY` format. This will override `start_date` and `end_date`.
-- `summary`: The summary
-- `highlights`: The list of bullet points
-
-{% elif entry_name == "OneLineEntry" %}
-
-**Mandatory Fields:**
-
-- `label`: The label of the entry
-- `details`: The details of the entry
-
-{% elif entry_name == "BulletEntry" %}
-
-**Mandatory Fields:**
-
-- `bullet`: The bullet point
-
-{% elif entry_name == "NumberedEntry" %}
-
-**Mandatory Fields:**
-
-- `number`: The content of the numbered entry
-
-{% elif entry_name == "ReversedNumberedEntry" %}
-
-The `ReversedNumberedEntry` displays entries in descending numerical order.
-
-**Mandatory Fields:**
-
-- `reversed_number`: The content of the reversed numbered entry
-
-{% elif entry_name == "TextEntry" %}
-
-**Mandatory Fields:**
-
-- The text itself
-
-{% endif %}
-
-```yaml
-{{ entry["yaml"] }}
-```
- {% for figure in entry["figures"] %}
-=== "`{{ figure["theme"] }}` theme"
- ![figure["alt_text"]]({{ figure["path"] }})
- {% endfor %}
-{% endfor %}
-
-#### Markdown Syntax
-
-All the fields in the entries support Markdown syntax.
-
-You can make anything bold by surrounding it with `**`, italic with `*`, and links with `[]()`, as shown below.
-
-```yaml
-company: "**This will be bold**, *this will be italic*,
- and [this will be a link](https://example.com)."
-...
-```
-
-### Using arbitrary keys
-
-RenderCV allows the usage of any number of extra keys in the entries. For instance, the following is an `ExperienceEntry` containing an additional key, `an_arbitrary_key`.
-
-```yaml hl_lines="6"
-company: Some Company
-location: TX, USA
-position: Software Engineer
-start_date: 2020-07
-end_date: '2021-08-12'
-an_arbitrary_key: Developed an [IOS application](https://example.com).
-highlights:
- - Received more than **100,000 downloads**.
- - Managed a team of **5** engineers.
-```
-
-By default, the `an_arbitrary_key` key will not affect the output as the default design options do not use it. However, you can use the `an_arbitrary_key` key in your own design options (see `design.entry_types` field).
-
-## "`design`" field
-
-The `design` field contains your theme selection and its options. Currently, the available themes are: {{available_themes}}. The only difference between the themes are the `design` options. Their Typst templates are the same. Any theme can be obtained by playing with the `design` options. Custom themes can also be created (see [here](faq.md#how-to-create-a-custom-theme)).
-
-```yaml
-design:
- theme: classic
- ...
-```
-
-Use an IDE that supports JSON schema to avoid missing any available options for the theme (see [above](#structure-of-the-yaml-input-file)).
-
-An example `design` field for a `classic` theme is shown below:
-
-```yaml
-design:
- theme: classic # (1)!
- page:
- size: us-letter # (2)!
- top_margin: 2cm
- bottom_margin: 2cm
- left_margin: 2cm
- right_margin: 2cm
- show_page_numbering: true
- show_last_updated_date: true
- colors:
- text: black
- name: '#004f90'
- connections: '#004f90'
- section_titles: '#004f90'
- links: '#004f90'
- last_updated_date_and_page_numbering: grey
- text:
- font_family: Source Sans 3 # (3)!
- font_size: 10pt
- leading: 0.6em
- alignment: justified # (4)!
- date_and_location_column_alignment: right # (5)!
- links:
- underline: false
- use_external_link_icon: true
- header:
- name_font_family: Source Sans 3
- name_font_size: 30pt
- name_bold: true
- small_caps_for_name: false
- photo_width: 3.5cm
- vertical_space_between_name_and_connections: 0.7cm
- vertical_space_between_connections_and_first_section: 0.7cm
- horizontal_space_between_connections: 0.5cm
- connections_font_family: Source Sans 3
- separator_between_connections: ''
- use_icons_for_connections: true
- alignment: center # (6)!
- section_titles:
- type: with-partial-line # (7)!
- font_family: Source Sans 3
- font_size: 1.4em
- bold: true
- small_caps: false
- line_thickness: 0.5pt
- vertical_space_above: 0.5cm
- vertical_space_below: 0.3cm
- entries:
- date_and_location_width: 4.15cm
- left_and_right_margin: 0.2cm
- horizontal_space_between_columns: 0.1cm
- vertical_space_between_entries: 1.2em
- allow_page_break_in_sections: true
- allow_page_break_in_entries: true
- short_second_row: false
- show_time_spans_in: []
- highlights:
- bullet: • # (8)!
- top_margin: 0.25cm
- left_margin: 0.4cm
- vertical_space_between_highlights: 0.25cm
- horizontal_space_between_bullet_and_highlight: 0.5em
- summary_left_margin: 0cm
- entry_types:
- one_line_entry:
- template: '**LABEL:** DETAILS'
- education_entry:
- main_column_first_row_template: '**INSTITUTION**, AREA'
- degree_column_template: '**DEGREE**'
- degree_column_width: 1cm
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- LOCATION
- DATE
- normal_entry:
- main_column_first_row_template: '**NAME**'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- LOCATION
- DATE
- experience_entry:
- main_column_first_row_template: '**COMPANY**, POSITION'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- LOCATION
- DATE
- publication_entry:
- main_column_first_row_template: '**TITLE**'
- main_column_second_row_template: |-
- AUTHORS
- URL (JOURNAL)
- main_column_second_row_without_journal_template: |-
- AUTHORS
- URL
- main_column_second_row_without_url_template: |-
- AUTHORS
- JOURNAL
- date_and_location_column_template: DATE
-```
-
-1. The `design.theme` field only changes the default values of all the other fields in the `design` field. Therefore, if you don't change any of the other fields, the output will be the same for all the themes. You can remove all the other fields and just keep the `design.theme` field to use the default values of that theme.
-
- The available themes are: {{available_themes}}.
-
-2. The available page sizes are: {{available_page_sizes}}.
-3. The available font families are: {{available_font_families}}.
-4. The available text alignments are: {{available_text_alignments}}.
-5. The available date and location column alignments are: {{available_header_alignments}}.
-6. The available header alignments are: {{available_header_alignments}}.
-7. The available section title types are: {{available_section_title_types}}.
-8. The available bullet types are: {{available_bullets}}.
-
-## "`locale`" field
-
-This field is what makes RenderCV a multilingual tool. RenderCV uses some English strings to render PDFs. For example, it takes the dates in ISO format (`2020-01-01`) and converts them into human-friendly strings (`"Jan 2020"`). However, you can override these strings for your own language or needs with the `locale` field.
-
-Here is an example:
-
-```yaml
-locale:
- language: en
- phone_number_format: national # (1)!
- page_numbering_template: NAME - Page PAGE_NUMBER of TOTAL_PAGES # (4)!
- last_updated_date_template: Last updated in TODAY # (3)!
- date_template: MONTH_ABBREVIATION YEAR # (2)!
- month: month
- months: months
- year: year
- years: years
- present: present
- to: –
- abbreviations_for_months:
- - Jan
- - Feb
- - Mar
- - Apr
- - May
- - June
- - July
- - Aug
- - Sept
- - Oct
- - Nov
- - Dec
- full_names_of_months:
- - January
- - February
- - March
- - April
- - May
- - June
- - July
- - August
- - September
- - October
- - November
- - December
-```
-
-1. The available phone number formats are: `national`, `international`, and `E164`.
-2. The `MONTH_ABBREVIATION` and `YEAR` are placeholders. The available placeholders are: `FULL_MONTH_NAME`, `MONTH_ABBREVIATION`, `MONTH`, `MONTH_IN_TWO_DIGITS`, `YEAR`, and `YEAR_IN_TWO_DIGITS`.
-3. The available placeholders are: `TODAY`, which prints the today's date with `locale.date_template`.
-4. The available placeholders are: `NAME`, `PAGE_NUMBER`, `TOTAL_PAGES`, and `TODAY`.
-
-## "`rendercv_settings`" field
-
-The `rendercv_settings` field contains RenderCV settings.
-
-```yaml
-rendercv_settings:
- date: "2025-01-06" # (1)!
- bold_keywords:
- - Python # (2)!
- render_command:
- output_folder_name: rendercv_output
- pdf_path: NAME_IN_SNAKE_CASE_CV.pdf # (3)!
- typst_path: NAME_IN_LOWER_SNAKE_CASE_cv.typ
- html_path: NAME_IN_KEBAB_CASE_CV.html
- markdown_path: NAME.md
- dont_generate_html: false
- dont_generate_markdown: false
- dont_generate_pdf: false
- dont_generate_png: false
-```
-
-1. This field is used for time span calculations and last updated date text.
-2. The words in the list will be bolded in the output automatically.
-3. `NAME_IN_SNAKE_CASE` is a placeholder. The available placeholders are: `NAME_IN_SNAKE_CASE`, `NAME_IN_LOWER_SNAKE_CASE`, `NAME_IN_UPPER_SNAKE_CASE`, `NAME_IN_KEBAB_CASE`, `NAME_IN_LOWER_KEBAB_CASE`, `NAME_IN_UPPER_KEBAB_CASE`, `NAME`, `FULL_MONTH_NAME`, `MONTH_ABBREVIATION`, `MONTH`, `MONTH_IN_TWO_DIGITS`, `YEAR`, and `YEAR_IN_TWO_DIGITS`.
diff --git a/docs/user_guide/yaml_input_structure.md b/docs/user_guide/yaml_input_structure.md
new file mode 100644
index 00000000..ae4bbb5d
--- /dev/null
+++ b/docs/user_guide/yaml_input_structure.md
@@ -0,0 +1,543 @@
+# The YAML Input File
+
+RenderCV uses a single YAML file to generate your CV. This file has four top-level fields:
+
+```yaml title="Your_Name_CV.yaml"
+cv:
+ ...
+ # Your content (name, sections, entries)
+ ...
+design:
+ ...
+ # Visual styling (theme, colors, fonts, spacing)
+ ...
+locale:
+ ...
+ # Language strings (month names, "present", etc.)
+ ...
+settings:
+ ...
+ # RenderCV behavior (current date, bold keywords)
+ ...
+```
+
+Only `cv` is required. The others have sensible defaults.
+
+
+!!! Tip
+ To maximize your productivity while editing the input YAML file, set up RenderCV's JSON Schema in your IDE. It will validate your inputs on the fly and give auto-complete suggestions.
+
+ === "Visual Studio Code"
+
+ 1. Install the [YAML extension](https://marketplace.visualstudio.com/items?itemName=redhat.vscode-yaml).
+ 2. Name your file ending with `_CV.yaml`. The schema activates automatically.
+ 3. Press `Ctrl + Space` for suggestions.
+
+ === "Other Editors"
+
+ 1. Add this line at the top of your file:
+ ```yaml
+ # yaml-language-server: $schema=https://github.com/rendercv/rendercv/blob/main/schema.json?raw=true
+ ```
+ 2. Press `Ctrl + Space` for suggestions (if your editor supports JSON Schema).
+
+
+## The `cv` Field
+
+### Header Information
+
+The `cv` field begins with your personal information. All fields are optional. RenderCV adapts to whatever you provide.
+
+```yaml
+cv:
+ name: John Doe
+ headline: Machine Learning Engineer
+ location: San Francisco, CA
+ email: john@example.com # (1)!
+ phone: +14155551234 # (2)!
+ website: https://johndoe.dev # (3)!
+ photo: photo.jpg
+ social_networks:
+ - network: LinkedIn # (4)!
+ username: johndoe
+ - network: GitHub
+ username: johndoe
+ custom_connections:
+ - placeholder: Book a call # (5)!
+ url: https://cal.com/johndoe
+ fontawesome_icon: calendar-days
+```
+
+1. Multiple emails can be provided as a list.
+2. Multiple phone numbers can be provided as a list.
+3. Multiple websites can be provided as a list.
+4. << available_social_networks >>
+5. Custom connections let you add any extra link (or plain text if `url` is omitted) with your own display text (`placeholder`) and a Font Awesome icon name (e.g., `calendar-days`, `envelope`).
+
+### Sections
+
+The `sections` field holds the main content of your CV. It's a dictionary where:
+
+- **Keys** are section titles (displayed as headings). Section titles can be anything.
+- **Values** are lists of entries
+
+```yaml
+cv:
+ name: John Doe
+ sections:
+ summary:
+ - Software engineer with 10 years of experience in distributed systems.
+
+ experience:
+ - company: Acme Corp
+ position: Senior Engineer
+ start_date: 2020-01
+ end_date: present
+ highlights:
+ - Led migration to microservices architecture
+ - Reduced deployment time by 80%
+
+ education:
+ - institution: MIT
+ area: Computer Science
+ degree: BS
+ start_date: 2012-09
+ end_date: 2016-05
+
+ skills:
+ - label: Languages
+ details: Python, Go, Rust, TypeScript
+ - label: Infrastructure
+ details: Kubernetes, Terraform, AWS
+```
+
+
+!!! info "Section names don't dictate entry types"
+ **Any of the << entry_count >> entry types can be used in any section.** The section name is just a title. RenderCV doesn't enforce which entry type you use.
+
+ For example, an `experience` section could use `NormalEntry` instead of `ExperienceEntry`:
+
+ ```yaml
+ sections:
+ experience: # Using NormalEntry, not ExperienceEntry
+ - name: Acme Corp — Senior Engineer
+ start_date: 2020-01
+ end_date: present
+ highlights:
+ - Led migration to microservices architecture
+ ```
+
+ Or even `BulletEntry` for a minimal approach:
+
+ ```yaml
+ sections:
+ experience:
+ - bullet: "**Acme Corp** — Senior Engineer (2020–present)"
+ - bullet: "**StartupXYZ** — Founding Engineer (2018–2020)"
+ ```
+
+ Choose the entry type that best fits your content, not the section name.
+
+
+!!! warning "One entry type per section"
+ Each section must contain only one type of entry. You cannot mix `ExperienceEntry` and `EducationEntry` in the same section.
+
+## Entry Types
+
+RenderCV provides << entry_count >> entry types:
+{$ for entry_name in entry_names $}
+<< loop.index >>. << entry_name >>
+{$ endfor $}
+ each designed for different kinds of content.
+
+{$ for entry_name, entry in sample_entries.items() $}
+### << entry_name >>
+
+{$ if entry_name == "EducationEntry" $}
+For academic credentials.
+
+| Field | Required | Description |
+| ------------- | -------- | ---------------------------------------- |
+| `institution` | Yes | School or university name |
+| `area` | Yes | Field of study |
+| `degree` | No | Degree type (BS, MS, PhD, etc.) |
+| `date` | No | Custom date string (overrides start/end) |
+| `start_date` | No | Start date |
+| `end_date` | No | End date (or `present`) |
+| `location` | No | Institution location |
+| `summary` | No | Brief description |
+| `highlights` | No | List of bullet points |
+
+{$ elif entry_name == "ExperienceEntry" $}
+For work history and professional roles.
+
+| Field | Required | Description |
+| ------------ | -------- | ---------------------------------------- |
+| `company` | Yes | Employer name |
+| `position` | Yes | Job title |
+| `date` | No | Custom date string (overrides start/end) |
+| `start_date` | No | Start date |
+| `end_date` | No | End date (or `present`) |
+| `location` | No | Office location |
+| `summary` | No | Role description |
+| `highlights` | No | List of accomplishments |
+
+{$ elif entry_name == "PublicationEntry" $}
+For papers, articles, and other publications.
+
+| Field | Required | Description |
+| --------- | -------- | ------------------------------------------------ |
+| `title` | Yes | Publication title |
+| `authors` | Yes | List of author names (use `*Name*` for emphasis) |
+| `doi` | No | Digital Object Identifier |
+| `url` | No | Link to the publication |
+| `journal` | No | Journal, conference, or venue name |
+| `date` | No | Publication date |
+
+{$ elif entry_name == "NormalEntry" $}
+A flexible entry for projects, awards, certifications, or anything else.
+
+| Field | Required | Description |
+| ------------ | -------- | ---------------------------------------- |
+| `name` | Yes | Entry title |
+| `date` | No | Custom date string (overrides start/end) |
+| `start_date` | No | Start date |
+| `end_date` | No | End date (or `present`) |
+| `location` | No | Associated location |
+| `summary` | No | Brief description |
+| `highlights` | No | List of bullet points |
+
+{$ elif entry_name == "OneLineEntry" $}
+For compact key-value pairs, ideal for skills or technical proficiencies.
+
+| Field | Required | Description |
+| --------- | -------- | ------------------ |
+| `label` | Yes | Category name |
+| `details` | Yes | Associated details |
+
+{$ elif entry_name == "BulletEntry" $}
+A single bullet point. Use for simple lists.
+
+| Field | Required | Description |
+| -------- | -------- | --------------- |
+| `bullet` | Yes | The bullet text |
+
+{$ elif entry_name == "NumberedEntry" $}
+An automatically numbered entry.
+
+| Field | Required | Description |
+| -------- | -------- | ----------------- |
+| `number` | Yes | The entry content |
+
+{$ elif entry_name == "ReversedNumberedEntry" $}
+A numbered entry that counts down (useful for publication lists where recent items come first).
+
+| Field | Required | Description |
+| ----------------- | -------- | ----------------- |
+| `reversed_number` | Yes | The entry content |
+
+{$ elif entry_name == "TextEntry" $}
+Plain text without structure. Just write a string.
+
+{$ endif $}
+
+```yaml
+<< entry["yaml"] >>
+```
+
+{$ for figure in entry["figures"] $}
+=== "`<< figure["theme"] >>` theme"
+ ![<< figure["alt_text"] >>](<< figure["path"] >>)
+{$ endfor $}
+
+{$ endfor $}
+
+### Using Markdown
+
+All text fields support basic Markdown:
+
+```yaml
+highlights:
+ - Increased revenue by **$2M** annually
+ - Developed [open-source tool](https://github.com/example) with *500+ stars*
+```
+
+| Syntax | Result |
+| ------------- | --------- |
+| `**text**` | **bold** |
+| `*text*` | *italic* |
+| `[text](url)` | hyperlink |
+| `` `code` `` | `code` |
+
+### Using Typst
+
+All text fields support Typst math and commands.
+
+```yaml
+highlights:
+ - Showed that $$f(x) = x^2$$ is a parabola
+ - "This is an #emph[emphasized] text"
+```
+
+### Arbitrary Keys
+
+You can add arbitrary keys to any entry. By default, they're ignored, but you can reference them in custom templates (see `design.templates`). See [Arbitrary Keys in Entries](../user_guide/how_to/arbitrary_keys_in_entries.md) for more information.
+
+```yaml hl_lines="6"
+experience:
+ - company: Startup Inc
+ position: Founder
+ start_date: 2020-01
+ end_date: present
+ revenue: $5M ARR # Custom field
+ highlights:
+ - Built product from zero to profitability
+```
+
+## The `design` Field
+
+The `design` field controls the visual appearance of your CV. Start by choosing a theme:
+
+```yaml
+design:
+ theme: classic
+```
+
+Available themes: << available_themes >>
+
+Each theme has different default styling, but all options can be customized. The themes share the same underlying template. You can recreate any theme by adjusting the design options.
+
+!!! tip "Use the JSON Schema"
+ The design options are extensive. Use an editor with JSON Schema support to explore all available options with autocomplete.
+
+Below is a fully specified `design` field showing all available options:
+
+```yaml
+design:
+ theme: classic
+
+ page:
+ size: us-letter # (1)!
+ top_margin: 0.7in
+ bottom_margin: 0.7in
+ left_margin: 0.7in
+ right_margin: 0.7in
+ show_footer: true
+ show_top_note: true
+
+ colors:
+ body: rgb(0, 0, 0)
+ name: rgb(0, 79, 144)
+ headline: rgb(0, 79, 144)
+ connections: rgb(0, 79, 144)
+ section_titles: rgb(0, 79, 144)
+ links: rgb(0, 79, 144)
+ footer: rgb(128, 128, 128)
+ top_note: rgb(128, 128, 128)
+
+ typography:
+ line_spacing: 0.6em
+ alignment: justified # (2)!
+ date_and_location_column_alignment: right
+ font_family: # (11)!
+ body: Source Sans 3 # (9)!
+ name: Source Sans 3
+ headline: Source Sans 3
+ connections: Source Sans 3
+ section_titles: Source Sans 3
+ font_size:
+ body: 10pt
+ name: 30pt
+ headline: 10pt
+ connections: 10pt
+ section_titles: 1.4em
+ small_caps:
+ name: false
+ headline: false
+ connections: false
+ section_titles: false
+ bold:
+ name: true
+ headline: false
+ connections: false
+ section_titles: true
+
+ links:
+ underline: false
+ show_external_link_icon: false
+
+ header:
+ alignment: center # (3)!
+ photo_width: 3.5cm
+ photo_position: left # (8)!
+ photo_space_left: 0.4cm
+ photo_space_right: 0.4cm
+ space_below_name: 0.7cm
+ space_below_headline: 0.7cm
+ space_below_connections: 0.7cm
+ connections:
+ phone_number_format: national # (7)!
+ hyperlink: true
+ show_icons: true
+ display_urls_instead_of_usernames: false
+ separator: ''
+ space_between_connections: 0.5cm
+
+ section_titles:
+ type: with_partial_line # (4)!
+ line_thickness: 0.5pt
+ space_above: 0.5cm
+ space_below: 0.3cm
+
+ sections:
+ allow_page_break: true
+ space_between_regular_entries: 1.2em
+ space_between_text_based_entries: 0.3em
+ show_time_spans_in: # (5)!
+ - experience
+
+ entries:
+ date_and_location_width: 4.15cm
+ side_space: 0.2cm
+ space_between_columns: 0.1cm
+ allow_page_break: false
+ short_second_row: true
+ summary:
+ space_above: 0cm
+ space_left: 0cm
+ highlights:
+ bullet: • # (6)!
+ nested_bullet: •
+ space_left: 0.15cm
+ space_above: 0cm
+ space_between_items: 0cm
+ space_between_bullet_and_text: 0.5em
+
+ templates: # (10)!
+ footer: '*NAME -- PAGE_NUMBER/TOTAL_PAGES*'
+ top_note: '*LAST_UPDATED CURRENT_DATE*'
+ single_date: MONTH_ABBREVIATION YEAR
+ date_range: START_DATE – END_DATE
+ time_span: HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS
+ one_line_entry:
+ main_column: '**LABEL:** DETAILS'
+ education_entry:
+ main_column: |-
+ **INSTITUTION**, AREA
+ SUMMARY
+ HIGHLIGHTS
+ degree_column: '**DEGREE**'
+ date_and_location_column: |-
+ LOCATION
+ DATE
+ normal_entry:
+ main_column: |-
+ **NAME**
+ SUMMARY
+ HIGHLIGHTS
+ date_and_location_column: |-
+ LOCATION
+ DATE
+ experience_entry:
+ main_column: |-
+ **COMPANY**, POSITION
+ SUMMARY
+ HIGHLIGHTS
+ date_and_location_column: |-
+ LOCATION
+ DATE
+ publication_entry:
+ main_column: |-
+ **TITLE**
+ AUTHORS
+ URL (JOURNAL)
+ date_and_location_column: DATE
+```
+
+1. << available_page_sizes >>
+2. << available_body_alignments >>
+3. << available_alignments >>
+4. << available_section_title_types >>
+5. Sections that show duration (e.g., "2 years")
+6. << available_bullets >>
+7. << available_phone_number_formats >>
+8. `left`, `right`
+9. << available_font_families >>
+10. Advanced: customize entry rendering
+11. Font family can be directly specified as a string as well.
+
+## The `locale` Field
+
+The `locale` field lets you customize all language-specific strings. This is how you create a CV in any language.
+
+```yaml
+locale:
+ language: german
+ last_updated: Zuletzt aktualisiert am
+ month: Monat
+ months: Monate
+ year: Jahr
+ years: Jahre
+ present: heute
+ month_abbreviations:
+ - Jan
+ - Feb
+ - März
+ - Apr
+ - Mai
+ - Juni
+ - Juli
+ - Aug
+ - Sept
+ - Okt
+ - Nov
+ - Dez
+ month_names:
+ - Januar
+ - Februar
+ - März
+ - April
+ - Mai
+ - Juni
+ - Juli
+ - August
+ - September
+ - Oktober
+ - November
+ - Dezember
+```
+
+| Field | Description |
+| --------------------- | --------------------------------------- |
+| `language` | Language name (for your reference only) |
+| `last_updated` | Text before the date in the top note |
+| `month` / `months` | Singular/plural for duration display |
+| `year` / `years` | Singular/plural for duration display |
+| `present` | Text shown when `end_date` is `present` |
+| `month_abbreviations` | 12 abbreviated month names (Jan–Dec) |
+| `month_names` | 12 full month names |
+
+## The `settings` Field
+
+The `settings` field configures RenderCV's behavior.
+
+```yaml
+settings:
+ current_date: '2025-12-03'
+ render_command:
+ design:
+ locale:
+ typst_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.typ
+ pdf_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf
+ markdown_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.md
+ html_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.html
+ png_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.png
+ dont_generate_markdown: false
+ dont_generate_html: false
+ dont_generate_typst: false
+ dont_generate_pdf: false
+ dont_generate_png: false
+ bold_keywords:
+ - AWS
+ - Python
+```
diff --git a/examples/John_Doe_ClassicTheme_CV.pdf b/examples/John_Doe_ClassicTheme_CV.pdf
index 4e4fe1a0..629d2b6a 100644
Binary files a/examples/John_Doe_ClassicTheme_CV.pdf and b/examples/John_Doe_ClassicTheme_CV.pdf differ
diff --git a/examples/John_Doe_ClassicTheme_CV.yaml b/examples/John_Doe_ClassicTheme_CV.yaml
index 3e3055aa..5bada0f6 100644
--- a/examples/John_Doe_ClassicTheme_CV.yaml
+++ b/examples/John_Doe_ClassicTheme_CV.yaml
@@ -1,239 +1,330 @@
+# yaml-language-server: $schema=https://raw.githubusercontent.com/rendercv/rendercv/refs/tags/v2.4/schema.json
cv:
name: John Doe
- location: Location
- email: john.doe@example.com
- phone: +1-609-999-9995
- website:
+ headline:
+ location: San Francisco, CA
+ email: john.doe@email.com
+ photo:
+ phone:
+ website: https://rendercv.com/
social_networks:
- network: LinkedIn
- username: john.doe
+ username: rendercv
- network: GitHub
- username: john.doe
+ username: rendercv
+ custom_connections:
sections:
- welcome_to_RenderCV!:
- - '[RenderCV](https://rendercv.com) is a Typst-based CV framework designed for academics and engineers, with Markdown syntax support.'
- - Each section title is arbitrary. Each section contains a list of entries, and there are 7 different entry types to choose from.
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
education:
- - institution: Stanford University
+ - institution: Princeton University
area: Computer Science
degree: PhD
- grade:
date:
- start_date: 2023-09
- end_date: present
- location: Stanford, CA, USA
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
summary:
highlights:
- - Working on the optimization of autonomous vehicles in urban environments
+ - 'Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment'
+ - 'Advisor: Prof. Sanjeev Arora'
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
- institution: Boğaziçi University
area: Computer Engineering
degree: BS
- grade:
date:
- start_date: 2018-09
- end_date: 2022-06
+ start_date: 2014-09
+ end_date: 2018-06
location: Istanbul, Türkiye
summary:
highlights:
- - 'GPA: 3.9/4.0, ranked 1st out of 100 students'
- - 'Awards: Best Senior Project, High Honor'
+ - 'GPA: 3.97/4.00, Valedictorian'
+ - Fulbright Scholarship recipient for graduate studies
experience:
- - company: Company C
- position: Summer Intern
- date:
- start_date: 2024-06
- end_date: 2024-09
- location: Livingston, LA, USA
- summary:
- highlights:
- - Developed deep learning models for the detection of gravitational waves in LIGO data
- - Published [3 peer-reviewed research papers](https://example.com) about the project and results
- - company: Company B
- position: Summer Intern
+ - company: Nexus AI
+ position: Co-Founder & CTO
date:
start_date: 2023-06
- end_date: 2023-09
- location: Ankara, Türkiye
+ end_date: present
+ location: San Francisco, CA
summary:
highlights:
- - Optimized the production line by 15% by implementing a new scheduling algorithm
- - company: Company A
- position: Summer Intern
+ - Built foundation model infrastructure serving 2M+ monthly API requests with 99.97% uptime
+ - Raised $18M Series A led by Sequoia Capital, with participation from a16z and Founders Fund
+ - Scaled engineering team from 3 to 28 across ML research, platform, and applied AI divisions
+ - Developed proprietary inference optimization reducing latency by 73% compared to baseline
+ - company: NVIDIA Research
+ position: Research Intern
date:
- start_date: 2022-06
- end_date: 2022-09
- location: Istanbul, Türkiye
+ start_date: 2022-05
+ end_date: 2022-08
+ location: Santa Clara, CA
summary:
highlights:
- - Designed an inventory management web application for a warehouse
+ - Designed sparse attention mechanism reducing transformer memory footprint by 4.2x
+ - Co-authored paper accepted at NeurIPS 2022 (spotlight presentation, top 5% of submissions)
+ - company: Google DeepMind
+ position: Research Intern
+ date:
+ start_date: 2021-05
+ end_date: 2021-08
+ location: London, UK
+ summary:
+ highlights:
+ - Developed reinforcement learning algorithms for multi-agent coordination
+ - Published research at top-tier venues with significant academic impact
+ - ICML 2022 main conference paper, cited 340+ times within two years
+ - NeurIPS 2022 workshop paper on emergent communication protocols
+ - Invited journal extension in JMLR (2023)
+ - company: Apple ML Research
+ position: Research Intern
+ date:
+ start_date: 2020-05
+ end_date: 2020-08
+ location: Cupertino, CA
+ summary:
+ highlights:
+ - Created on-device neural network compression pipeline deployed across 50M+ devices
+ - Filed 2 patents on efficient model quantization techniques for edge inference
+ - company: Microsoft Research
+ position: Research Intern
+ date:
+ start_date: 2019-05
+ end_date: 2019-08
+ location: Redmond, WA
+ summary:
+ highlights:
+ - Implemented novel self-supervised learning framework for low-resource language modeling
+ - Research integrated into Azure Cognitive Services, reducing training data requirements by 60%
projects:
- - name: '[Example Project](https://example.com)'
+ - name: '[FlashInfer](https://github.com/)'
date:
- start_date: 2024-05
+ start_date: 2023-01
end_date: present
location:
- summary: A web application for writing essays
+ summary: Open-source library for high-performance LLM inference kernels
highlights:
- - Launched an [iOS app](https://example.com) in 09/2024 that currently has 10k+ monthly active users
- - The app is made open-source (3,000+ stars [on GitHub](https://github.com))
- - name: '[Teaching on Udemy](https://example.com)'
- date: Fall 2023
+ - Achieved 2.8x speedup over baseline attention implementations on A100 GPUs
+ - Adopted by 3 major AI labs, 8,500+ GitHub stars, 200+ contributors
+ - name: '[NeuralPrune](https://github.com/)'
+ date: '2021'
start_date:
end_date:
location:
- summary:
+ summary: Automated neural network pruning toolkit with differentiable masks
highlights:
- - Instructed the "Statistics" course on Udemy (60,000+ students, 200,000+ hours watched)
- skills:
- - label: Programming
- details: Proficient with Python, C++, and Git; good understanding of Web, app development, and DevOps
- - label: Mathematics
- details: Good understanding of differential equations, calculus, and linear algebra
- - label: Languages
- details: 'English (fluent, TOEFL: 118/120), Turkish (native)'
+ - Reduced model size by 90% with less than 1% accuracy degradation on ImageNet
+ - Featured in PyTorch ecosystem tools, 4,200+ GitHub stars
publications:
- - title: 3D Finite Element Analysis of No-Insulation Coils
+ - title: 'Sparse Mixture-of-Experts at Scale: Efficient Routing for Trillion-Parameter Models'
authors:
- - Frodo Baggins
- - '***John Doe***'
- - Samwise Gamgee
- doi: 10.1109/TASC.2023.3340648
+ - '*John Doe*'
+ - Sarah Williams
+ - David Park
+ summary:
+ doi: 10.1234/neurips.2023.1234
url:
- journal:
- date: 2004-01
- extracurricular_activities:
- - bullet: 'There are 7 unique entry types in RenderCV: *BulletEntry*, *TextEntry*, *EducationEntry*, *ExperienceEntry*, *NormalEntry*, *PublicationEntry*, and *OneLineEntry*.'
- - bullet: Each entry type has a different structure and layout. This document demonstrates all of them.
- numbered_entries:
- - number: This is a numbered entry.
- - number: This is another numbered entry.
- - number: This is the third numbered entry.
- reversed_numbered_entries:
- - reversed_number: This is a reversed numbered entry.
- - reversed_number: This is another reversed numbered entry.
- - reversed_number: This is the third reversed numbered entry.
- sort_entries: none
+ journal: NeurIPS 2023
+ date: 2023-07
+ - title: Neural Architecture Search via Differentiable Pruning
+ authors:
+ - James Liu
+ - '*John Doe*'
+ summary:
+ doi: 10.1234/neurips.2022.5678
+ url:
+ journal: NeurIPS 2022, Spotlight
+ date: 2022-12
+ - title: Multi-Agent Reinforcement Learning with Emergent Communication
+ authors:
+ - Maria Garcia
+ - '*John Doe*'
+ - Tom Anderson
+ summary:
+ doi: 10.1234/icml.2022.9012
+ url:
+ journal: ICML 2022
+ date: 2022-07
+ - title: On-Device Model Compression via Learned Quantization
+ authors:
+ - '*John Doe*'
+ - Kevin Wu
+ summary:
+ doi: 10.1234/iclr.2021.3456
+ url:
+ journal: ICLR 2021, Best Paper Award
+ date: 2021-05
+ selected_honors:
+ - bullet: MIT Technology Review 35 Under 35 Innovators (2024)
+ - bullet: Forbes 30 Under 30 in Enterprise Technology (2024)
+ - bullet: ACM Doctoral Dissertation Award Honorable Mention (2023)
+ - bullet: Google PhD Fellowship in Machine Learning (2020 – 2023)
+ - bullet: Fulbright Scholarship for Graduate Studies (2018)
+ skills:
+ - label: Languages
+ details: Python, C++, CUDA, Rust, Julia
+ - label: ML Frameworks
+ details: PyTorch, JAX, TensorFlow, Triton, ONNX
+ - label: Infrastructure
+ details: Kubernetes, Ray, distributed training, AWS, GCP
+ - label: Research Areas
+ details: Neural architecture search, model compression, efficient inference, multi-agent RL
+ patents:
+ - number: Adaptive Quantization for Neural Network Inference on Edge Devices (US Patent 11,234,567)
+ - number: Dynamic Sparsity Patterns for Efficient Transformer Attention (US Patent 11,345,678)
+ - number: Hardware-Aware Neural Architecture Search Method (US Patent 11,456,789)
+ invited_talks:
+ - reversed_number: Scaling Laws for Efficient Inference — Stanford HAI Symposium (2024)
+ - reversed_number: Building AI Infrastructure for the Next Decade — TechCrunch Disrupt (2024)
+ - reversed_number: 'From Research to Production: Lessons in ML Systems — NeurIPS Workshop (2023)'
+ - reversed_number: "Efficient Deep Learning: A Practitioner's Perspective — Google Tech Talk (2022)"
+ any_section_title:
+ - You can use any section title you want.
+ - 'You can choose any entry type for the section: `TextEntry`, `ExperienceEntry`, `EducationEntry`, `PublicationEntry`, `BulletEntry`, `NumberedEntry`, or `ReversedNumberedEntry`.'
+ - Markdown syntax is supported everywhere.
+ - The `design` field in YAML gives you control over almost any aspect of your CV design.
+ - See the [documentation](https://docs.rendercv.com) for more details.
design:
theme: classic
- page:
- size: us-letter
- top_margin: 2cm
- bottom_margin: 2cm
- left_margin: 2cm
- right_margin: 2cm
- show_page_numbering: true
- show_last_updated_date: true
- colors:
- text: rgb(0, 0, 0)
- name: rgb(0, 79, 144)
- connections: rgb(0, 79, 144)
- section_titles: rgb(0, 79, 144)
- links: rgb(0, 79, 144)
- last_updated_date_and_page_numbering: rgb(128, 128, 128)
- text:
- font_family: Source Sans 3
- font_size: 10pt
- leading: 0.6em
- alignment: justified
- date_and_location_column_alignment: right
- links:
- underline: false
- use_external_link_icon: true
- header:
- name_font_family: Source Sans 3
- name_font_size: 30pt
- name_bold: true
- small_caps_for_name: false
- photo_width: 3.5cm
- vertical_space_between_name_and_connections: 0.7cm
- vertical_space_between_connections_and_first_section: 0.7cm
- horizontal_space_between_connections: 0.5cm
- connections_font_family: Source Sans 3
- separator_between_connections: ''
- use_icons_for_connections: true
- use_urls_as_placeholders_for_connections: false
- make_connections_links: true
- alignment: center
- section_titles:
- type: with-partial-line
- font_family: Source Sans 3
- font_size: 1.4em
- bold: true
- small_caps: false
- line_thickness: 0.5pt
- vertical_space_above: 0.5cm
- vertical_space_below: 0.3cm
- entries:
- date_and_location_width: 4.15cm
- left_and_right_margin: 0.2cm
- horizontal_space_between_columns: 0.1cm
- vertical_space_between_entries: 1.2em
- allow_page_break_in_sections: true
- allow_page_break_in_entries: true
- short_second_row: false
- show_time_spans_in: []
- highlights:
- bullet: •
- nested_bullet: '-'
- top_margin: 0.25cm
- left_margin: 0.4cm
- vertical_space_between_highlights: 0.25cm
- horizontal_space_between_bullet_and_highlight: 0.5em
- summary_left_margin: 0cm
- entry_types:
- one_line_entry:
- template: '**LABEL:** DETAILS'
- education_entry:
- main_column_first_row_template: '**INSTITUTION**, AREA'
- degree_column_template: '**DEGREE**'
- degree_column_width: 1cm
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- LOCATION
- DATE
- normal_entry:
- main_column_first_row_template: '**NAME**'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- LOCATION
- DATE
- experience_entry:
- main_column_first_row_template: '**COMPANY**, POSITION'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- LOCATION
- DATE
- publication_entry:
- main_column_first_row_template: '**TITLE**'
- main_column_second_row_template: |-
- AUTHORS
- URL (JOURNAL)
- main_column_second_row_without_journal_template: |-
- AUTHORS
- URL
- main_column_second_row_without_url_template: |-
- AUTHORS
- JOURNAL
- date_and_location_column_template: DATE
+ # page:
+ # size: us-letter
+ # top_margin: 0.7in
+ # bottom_margin: 0.7in
+ # left_margin: 0.7in
+ # right_margin: 0.7in
+ # show_footer: true
+ # show_top_note: true
+ # colors:
+ # body: rgb(0, 0, 0)
+ # name: rgb(0, 79, 144)
+ # headline: rgb(0, 79, 144)
+ # connections: rgb(0, 79, 144)
+ # section_titles: rgb(0, 79, 144)
+ # links: rgb(0, 79, 144)
+ # footer: rgb(128, 128, 128)
+ # top_note: rgb(128, 128, 128)
+ # typography:
+ # line_spacing: 0.6em
+ # alignment: justified
+ # date_and_location_column_alignment: right
+ # font_family:
+ # body: Source Sans 3
+ # name: Source Sans 3
+ # headline: Source Sans 3
+ # connections: Source Sans 3
+ # section_titles: Source Sans 3
+ # font_size:
+ # body: 10pt
+ # name: 30pt
+ # headline: 10pt
+ # connections: 10pt
+ # section_titles: 1.4em
+ # small_caps:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: false
+ # bold:
+ # name: true
+ # headline: false
+ # connections: false
+ # section_titles: true
+ # links:
+ # underline: false
+ # show_external_link_icon: false
+ # header:
+ # alignment: center
+ # photo_width: 3.5cm
+ # photo_position: left
+ # photo_space_left: 0.4cm
+ # photo_space_right: 0.4cm
+ # space_below_name: 0.7cm
+ # space_below_headline: 0.7cm
+ # space_below_connections: 0.7cm
+ # connections:
+ # phone_number_format: national
+ # hyperlink: true
+ # show_icons: true
+ # display_urls_instead_of_usernames: false
+ # separator: ''
+ # space_between_connections: 0.5cm
+ # section_titles:
+ # type: with_partial_line
+ # line_thickness: 0.5pt
+ # space_above: 0.5cm
+ # space_below: 0.3cm
+ # sections:
+ # allow_page_break: true
+ # space_between_regular_entries: 1.2em
+ # space_between_text_based_entries: 0.3em
+ # show_time_spans_in:
+ # - experience
+ # entries:
+ # date_and_location_width: 4.15cm
+ # side_space: 0.2cm
+ # space_between_columns: 0.1cm
+ # allow_page_break: false
+ # short_second_row: true
+ # summary:
+ # space_above: 0cm
+ # space_left: 0cm
+ # highlights:
+ # bullet: •
+ # nested_bullet: •
+ # space_left: 0.15cm
+ # space_above: 0cm
+ # space_between_items: 0cm
+ # space_between_bullet_and_text: 0.5em
+ # templates:
+ # footer: '*NAME -- PAGE_NUMBER/TOTAL_PAGES*'
+ # top_note: '*LAST_UPDATED CURRENT_DATE*'
+ # single_date: MONTH_ABBREVIATION YEAR
+ # date_range: START_DATE – END_DATE
+ # time_span: HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS
+ # one_line_entry:
+ # main_column: '**LABEL:** DETAILS'
+ # education_entry:
+ # main_column: |-
+ # **INSTITUTION**, AREA
+ # SUMMARY
+ # HIGHLIGHTS
+ # degree_column: '**DEGREE**'
+ # date_and_location_column: |-
+ # LOCATION
+ # DATE
+ # normal_entry:
+ # main_column: |-
+ # **NAME**
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: |-
+ # LOCATION
+ # DATE
+ # experience_entry:
+ # main_column: |-
+ # **COMPANY**, POSITION
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: |-
+ # LOCATION
+ # DATE
+ # publication_entry:
+ # main_column: |-
+ # **TITLE**
+ # SUMMARY
+ # AUTHORS
+ # URL (JOURNAL)
+ # date_and_location_column: DATE
locale:
- language: en
- phone_number_format: national
- page_numbering_template: NAME - Page PAGE_NUMBER of TOTAL_PAGES
- last_updated_date_template: Last updated in TODAY
- date_template: MONTH_ABBREVIATION YEAR
+ language: english
+ last_updated: Last updated in
month: month
months: months
year: year
years: years
present: present
- to: –
- abbreviations_for_months:
+ month_abbreviations:
- Jan
- Feb
- Mar
@@ -246,7 +337,7 @@ locale:
- Oct
- Nov
- Dec
- full_names_of_months:
+ month_names:
- January
- February
- March
@@ -259,7 +350,19 @@ locale:
- October
- November
- December
-rendercv_settings:
- date: '2025-10-28'
+settings:
+ current_date: '2025-12-09'
+ render_command:
+ design:
+ locale:
+ typst_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.typ
+ pdf_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf
+ markdown_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.md
+ html_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.html
+ png_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.png
+ dont_generate_markdown: false
+ dont_generate_html: false
+ dont_generate_typst: false
+ dont_generate_pdf: false
+ dont_generate_png: false
bold_keywords: []
- sort_entries: none
diff --git a/examples/John_Doe_EngineeringclassicTheme_CV.pdf b/examples/John_Doe_EngineeringclassicTheme_CV.pdf
index 73c48a6a..de6b239b 100644
Binary files a/examples/John_Doe_EngineeringclassicTheme_CV.pdf and b/examples/John_Doe_EngineeringclassicTheme_CV.pdf differ
diff --git a/examples/John_Doe_EngineeringclassicTheme_CV.yaml b/examples/John_Doe_EngineeringclassicTheme_CV.yaml
index 051345eb..95af15a5 100644
--- a/examples/John_Doe_EngineeringclassicTheme_CV.yaml
+++ b/examples/John_Doe_EngineeringclassicTheme_CV.yaml
@@ -1,233 +1,323 @@
+# yaml-language-server: $schema=https://raw.githubusercontent.com/rendercv/rendercv/refs/tags/v2.4/schema.json
cv:
name: John Doe
- location: Location
- email: john.doe@example.com
- phone: +1-609-999-9995
- website:
+ headline:
+ location: San Francisco, CA
+ email: john.doe@email.com
+ photo:
+ phone:
+ website: https://rendercv.com/
social_networks:
- network: LinkedIn
- username: john.doe
+ username: rendercv
- network: GitHub
- username: john.doe
+ username: rendercv
+ custom_connections:
sections:
- welcome_to_RenderCV!:
- - '[RenderCV](https://rendercv.com) is a Typst-based CV framework designed for academics and engineers, with Markdown syntax support.'
- - Each section title is arbitrary. Each section contains a list of entries, and there are 7 different entry types to choose from.
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
education:
- - institution: Stanford University
+ - institution: Princeton University
area: Computer Science
degree: PhD
- grade:
date:
- start_date: 2023-09
- end_date: present
- location: Stanford, CA, USA
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
summary:
highlights:
- - Working on the optimization of autonomous vehicles in urban environments
+ - 'Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment'
+ - 'Advisor: Prof. Sanjeev Arora'
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
- institution: Boğaziçi University
area: Computer Engineering
degree: BS
- grade:
date:
- start_date: 2018-09
- end_date: 2022-06
+ start_date: 2014-09
+ end_date: 2018-06
location: Istanbul, Türkiye
summary:
highlights:
- - 'GPA: 3.9/4.0, ranked 1st out of 100 students'
- - 'Awards: Best Senior Project, High Honor'
+ - 'GPA: 3.97/4.00, Valedictorian'
+ - Fulbright Scholarship recipient for graduate studies
experience:
- - company: Company C
- position: Summer Intern
- date:
- start_date: 2024-06
- end_date: 2024-09
- location: Livingston, LA, USA
- summary:
- highlights:
- - Developed deep learning models for the detection of gravitational waves in LIGO data
- - Published [3 peer-reviewed research papers](https://example.com) about the project and results
- - company: Company B
- position: Summer Intern
+ - company: Nexus AI
+ position: Co-Founder & CTO
date:
start_date: 2023-06
- end_date: 2023-09
- location: Ankara, Türkiye
+ end_date: present
+ location: San Francisco, CA
summary:
highlights:
- - Optimized the production line by 15% by implementing a new scheduling algorithm
- - company: Company A
- position: Summer Intern
+ - Built foundation model infrastructure serving 2M+ monthly API requests with 99.97% uptime
+ - Raised $18M Series A led by Sequoia Capital, with participation from a16z and Founders Fund
+ - Scaled engineering team from 3 to 28 across ML research, platform, and applied AI divisions
+ - Developed proprietary inference optimization reducing latency by 73% compared to baseline
+ - company: NVIDIA Research
+ position: Research Intern
date:
- start_date: 2022-06
- end_date: 2022-09
- location: Istanbul, Türkiye
+ start_date: 2022-05
+ end_date: 2022-08
+ location: Santa Clara, CA
summary:
highlights:
- - Designed an inventory management web application for a warehouse
+ - Designed sparse attention mechanism reducing transformer memory footprint by 4.2x
+ - Co-authored paper accepted at NeurIPS 2022 (spotlight presentation, top 5% of submissions)
+ - company: Google DeepMind
+ position: Research Intern
+ date:
+ start_date: 2021-05
+ end_date: 2021-08
+ location: London, UK
+ summary:
+ highlights:
+ - Developed reinforcement learning algorithms for multi-agent coordination
+ - Published research at top-tier venues with significant academic impact
+ - ICML 2022 main conference paper, cited 340+ times within two years
+ - NeurIPS 2022 workshop paper on emergent communication protocols
+ - Invited journal extension in JMLR (2023)
+ - company: Apple ML Research
+ position: Research Intern
+ date:
+ start_date: 2020-05
+ end_date: 2020-08
+ location: Cupertino, CA
+ summary:
+ highlights:
+ - Created on-device neural network compression pipeline deployed across 50M+ devices
+ - Filed 2 patents on efficient model quantization techniques for edge inference
+ - company: Microsoft Research
+ position: Research Intern
+ date:
+ start_date: 2019-05
+ end_date: 2019-08
+ location: Redmond, WA
+ summary:
+ highlights:
+ - Implemented novel self-supervised learning framework for low-resource language modeling
+ - Research integrated into Azure Cognitive Services, reducing training data requirements by 60%
projects:
- - name: '[Example Project](https://example.com)'
+ - name: '[FlashInfer](https://github.com/)'
date:
- start_date: 2024-05
+ start_date: 2023-01
end_date: present
location:
- summary: A web application for writing essays
+ summary: Open-source library for high-performance LLM inference kernels
highlights:
- - Launched an [iOS app](https://example.com) in 09/2024 that currently has 10k+ monthly active users
- - The app is made open-source (3,000+ stars [on GitHub](https://github.com))
- - name: '[Teaching on Udemy](https://example.com)'
- date: Fall 2023
+ - Achieved 2.8x speedup over baseline attention implementations on A100 GPUs
+ - Adopted by 3 major AI labs, 8,500+ GitHub stars, 200+ contributors
+ - name: '[NeuralPrune](https://github.com/)'
+ date: '2021'
start_date:
end_date:
location:
- summary:
+ summary: Automated neural network pruning toolkit with differentiable masks
highlights:
- - Instructed the "Statistics" course on Udemy (60,000+ students, 200,000+ hours watched)
- skills:
- - label: Programming
- details: Proficient with Python, C++, and Git; good understanding of Web, app development, and DevOps
- - label: Mathematics
- details: Good understanding of differential equations, calculus, and linear algebra
- - label: Languages
- details: 'English (fluent, TOEFL: 118/120), Turkish (native)'
+ - Reduced model size by 90% with less than 1% accuracy degradation on ImageNet
+ - Featured in PyTorch ecosystem tools, 4,200+ GitHub stars
publications:
- - title: 3D Finite Element Analysis of No-Insulation Coils
+ - title: 'Sparse Mixture-of-Experts at Scale: Efficient Routing for Trillion-Parameter Models'
authors:
- - Frodo Baggins
- - '***John Doe***'
- - Samwise Gamgee
- doi: 10.1109/TASC.2023.3340648
+ - '*John Doe*'
+ - Sarah Williams
+ - David Park
+ summary:
+ doi: 10.1234/neurips.2023.1234
url:
- journal:
- date: 2004-01
- extracurricular_activities:
- - bullet: 'There are 7 unique entry types in RenderCV: *BulletEntry*, *TextEntry*, *EducationEntry*, *ExperienceEntry*, *NormalEntry*, *PublicationEntry*, and *OneLineEntry*.'
- - bullet: Each entry type has a different structure and layout. This document demonstrates all of them.
- numbered_entries:
- - number: This is a numbered entry.
- - number: This is another numbered entry.
- - number: This is the third numbered entry.
- reversed_numbered_entries:
- - reversed_number: This is a reversed numbered entry.
- - reversed_number: This is another reversed numbered entry.
- - reversed_number: This is the third reversed numbered entry.
- sort_entries: none
+ journal: NeurIPS 2023
+ date: 2023-07
+ - title: Neural Architecture Search via Differentiable Pruning
+ authors:
+ - James Liu
+ - '*John Doe*'
+ summary:
+ doi: 10.1234/neurips.2022.5678
+ url:
+ journal: NeurIPS 2022, Spotlight
+ date: 2022-12
+ - title: Multi-Agent Reinforcement Learning with Emergent Communication
+ authors:
+ - Maria Garcia
+ - '*John Doe*'
+ - Tom Anderson
+ summary:
+ doi: 10.1234/icml.2022.9012
+ url:
+ journal: ICML 2022
+ date: 2022-07
+ - title: On-Device Model Compression via Learned Quantization
+ authors:
+ - '*John Doe*'
+ - Kevin Wu
+ summary:
+ doi: 10.1234/iclr.2021.3456
+ url:
+ journal: ICLR 2021, Best Paper Award
+ date: 2021-05
+ selected_honors:
+ - bullet: MIT Technology Review 35 Under 35 Innovators (2024)
+ - bullet: Forbes 30 Under 30 in Enterprise Technology (2024)
+ - bullet: ACM Doctoral Dissertation Award Honorable Mention (2023)
+ - bullet: Google PhD Fellowship in Machine Learning (2020 – 2023)
+ - bullet: Fulbright Scholarship for Graduate Studies (2018)
+ skills:
+ - label: Languages
+ details: Python, C++, CUDA, Rust, Julia
+ - label: ML Frameworks
+ details: PyTorch, JAX, TensorFlow, Triton, ONNX
+ - label: Infrastructure
+ details: Kubernetes, Ray, distributed training, AWS, GCP
+ - label: Research Areas
+ details: Neural architecture search, model compression, efficient inference, multi-agent RL
+ patents:
+ - number: Adaptive Quantization for Neural Network Inference on Edge Devices (US Patent 11,234,567)
+ - number: Dynamic Sparsity Patterns for Efficient Transformer Attention (US Patent 11,345,678)
+ - number: Hardware-Aware Neural Architecture Search Method (US Patent 11,456,789)
+ invited_talks:
+ - reversed_number: Scaling Laws for Efficient Inference — Stanford HAI Symposium (2024)
+ - reversed_number: Building AI Infrastructure for the Next Decade — TechCrunch Disrupt (2024)
+ - reversed_number: 'From Research to Production: Lessons in ML Systems — NeurIPS Workshop (2023)'
+ - reversed_number: "Efficient Deep Learning: A Practitioner's Perspective — Google Tech Talk (2022)"
+ any_section_title:
+ - You can use any section title you want.
+ - 'You can choose any entry type for the section: `TextEntry`, `ExperienceEntry`, `EducationEntry`, `PublicationEntry`, `BulletEntry`, `NumberedEntry`, or `ReversedNumberedEntry`.'
+ - Markdown syntax is supported everywhere.
+ - The `design` field in YAML gives you control over almost any aspect of your CV design.
+ - See the [documentation](https://docs.rendercv.com) for more details.
design:
theme: engineeringclassic
- page:
- size: us-letter
- top_margin: 2cm
- bottom_margin: 2cm
- left_margin: 2cm
- right_margin: 2cm
- show_page_numbering: false
- show_last_updated_date: true
- colors:
- text: rgb(0, 0, 0)
- name: rgb(0, 79, 144)
- connections: rgb(0, 79, 144)
- section_titles: rgb(0, 79, 144)
- links: rgb(0, 79, 144)
- last_updated_date_and_page_numbering: rgb(128, 128, 128)
- text:
- font_family: Raleway
- font_size: 10pt
- leading: 0.6em
- alignment: justified
- date_and_location_column_alignment: right
- links:
- underline: false
- use_external_link_icon: false
- header:
- name_font_family: Raleway
- name_font_size: 30pt
- name_bold: false
- small_caps_for_name: false
- photo_width: 3.5cm
- vertical_space_between_name_and_connections: 0.7cm
- vertical_space_between_connections_and_first_section: 0.7cm
- horizontal_space_between_connections: 0.5cm
- connections_font_family: Raleway
- separator_between_connections: ''
- use_icons_for_connections: true
- use_urls_as_placeholders_for_connections: false
- make_connections_links: true
- alignment: left
- section_titles:
- type: with-partial-line
- font_family: Raleway
- font_size: 1.4em
- bold: false
- small_caps: false
- line_thickness: 0.5pt
- vertical_space_above: 0.5cm
- vertical_space_below: 0.3cm
- entries:
- date_and_location_width: 4.15cm
- left_and_right_margin: 0.2cm
- horizontal_space_between_columns: 0.1cm
- vertical_space_between_entries: 1.2em
- allow_page_break_in_sections: true
- allow_page_break_in_entries: true
- short_second_row: false
- show_time_spans_in: []
- highlights:
- bullet: •
- nested_bullet: '-'
- top_margin: 0.25cm
- left_margin: 0cm
- vertical_space_between_highlights: 0.25cm
- horizontal_space_between_bullet_and_highlight: 0.5em
- summary_left_margin: 0cm
- entry_types:
- one_line_entry:
- template: '**LABEL:** DETAILS'
- education_entry:
- main_column_first_row_template: '**INSTITUTION**, AREA -- LOCATION'
- degree_column_template: '**DEGREE**'
- degree_column_width: 1cm
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- normal_entry:
- main_column_first_row_template: '**NAME** -- **LOCATION**'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- experience_entry:
- main_column_first_row_template: '**POSITION**, COMPANY -- LOCATION'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- publication_entry:
- main_column_first_row_template: '**TITLE**'
- main_column_second_row_template: |-
- AUTHORS
- URL (JOURNAL)
- main_column_second_row_without_journal_template: |-
- AUTHORS
- URL
- main_column_second_row_without_url_template: |-
- AUTHORS
- JOURNAL
- date_and_location_column_template: DATE
+ # page:
+ # size: us-letter
+ # top_margin: 0.7in
+ # bottom_margin: 0.7in
+ # left_margin: 0.7in
+ # right_margin: 0.7in
+ # show_footer: true
+ # show_top_note: true
+ # colors:
+ # body: rgb(0, 0, 0)
+ # name: rgb(0, 79, 144)
+ # headline: rgb(0, 79, 144)
+ # connections: rgb(0, 79, 144)
+ # section_titles: rgb(0, 79, 144)
+ # links: rgb(0, 79, 144)
+ # footer: rgb(128, 128, 128)
+ # top_note: rgb(128, 128, 128)
+ # typography:
+ # line_spacing: 0.6em
+ # alignment: justified
+ # date_and_location_column_alignment: right
+ # font_family:
+ # body: Raleway
+ # name: Raleway
+ # headline: Raleway
+ # connections: Raleway
+ # section_titles: Raleway
+ # font_size:
+ # body: 10pt
+ # name: 30pt
+ # headline: 10pt
+ # connections: 10pt
+ # section_titles: 1.4em
+ # small_caps:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: false
+ # bold:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: false
+ # links:
+ # underline: false
+ # show_external_link_icon: false
+ # header:
+ # alignment: left
+ # photo_width: 3.5cm
+ # photo_position: left
+ # photo_space_left: 0.4cm
+ # photo_space_right: 0.4cm
+ # space_below_name: 0.7cm
+ # space_below_headline: 0.7cm
+ # space_below_connections: 0.7cm
+ # connections:
+ # phone_number_format: national
+ # hyperlink: true
+ # show_icons: true
+ # display_urls_instead_of_usernames: false
+ # separator: ''
+ # space_between_connections: 0.5cm
+ # section_titles:
+ # type: with_full_line
+ # line_thickness: 0.5pt
+ # space_above: 0.5cm
+ # space_below: 0.3cm
+ # sections:
+ # allow_page_break: true
+ # space_between_regular_entries: 1.2em
+ # space_between_text_based_entries: 0.3em
+ # show_time_spans_in: []
+ # entries:
+ # date_and_location_width: 4.15cm
+ # side_space: 0.2cm
+ # space_between_columns: 0.1cm
+ # allow_page_break: false
+ # short_second_row: false
+ # summary:
+ # space_above: 0.12cm
+ # space_left: 0cm
+ # highlights:
+ # bullet: •
+ # nested_bullet: •
+ # space_left: 0cm
+ # space_above: 0.12cm
+ # space_between_items: 0.12cm
+ # space_between_bullet_and_text: 0.5em
+ # templates:
+ # footer: '*NAME -- PAGE_NUMBER/TOTAL_PAGES*'
+ # top_note: '*LAST_UPDATED CURRENT_DATE*'
+ # single_date: MONTH_ABBREVIATION YEAR
+ # date_range: START_DATE – END_DATE
+ # time_span: HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS
+ # one_line_entry:
+ # main_column: '**LABEL:** DETAILS'
+ # education_entry:
+ # main_column: |-
+ # **INSTITUTION**, DEGREE in AREA -- LOCATION
+ # SUMMARY
+ # HIGHLIGHTS
+ # degree_column:
+ # date_and_location_column: DATE
+ # normal_entry:
+ # main_column: |-
+ # **NAME** -- **LOCATION**
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: DATE
+ # experience_entry:
+ # main_column: |-
+ # **POSITION**, COMPANY -- LOCATION
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: DATE
+ # publication_entry:
+ # main_column: |-
+ # **TITLE**
+ # SUMMARY
+ # AUTHORS
+ # URL (JOURNAL)
+ # date_and_location_column: DATE
locale:
- language: en
- phone_number_format: national
- page_numbering_template: NAME - Page PAGE_NUMBER of TOTAL_PAGES
- last_updated_date_template: Last updated in TODAY
- date_template: MONTH_ABBREVIATION YEAR
+ language: english
+ last_updated: Last updated in
month: month
months: months
year: year
years: years
present: present
- to: –
- abbreviations_for_months:
+ month_abbreviations:
- Jan
- Feb
- Mar
@@ -240,7 +330,7 @@ locale:
- Oct
- Nov
- Dec
- full_names_of_months:
+ month_names:
- January
- February
- March
@@ -253,7 +343,19 @@ locale:
- October
- November
- December
-rendercv_settings:
- date: '2025-10-28'
+settings:
+ current_date: '2025-12-09'
+ render_command:
+ design:
+ locale:
+ typst_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.typ
+ pdf_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf
+ markdown_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.md
+ html_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.html
+ png_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.png
+ dont_generate_markdown: false
+ dont_generate_html: false
+ dont_generate_typst: false
+ dont_generate_pdf: false
+ dont_generate_png: false
bold_keywords: []
- sort_entries: none
diff --git a/examples/John_Doe_EngineeringresumesTheme_CV.pdf b/examples/John_Doe_EngineeringresumesTheme_CV.pdf
index c1ad9975..05035f6e 100644
Binary files a/examples/John_Doe_EngineeringresumesTheme_CV.pdf and b/examples/John_Doe_EngineeringresumesTheme_CV.pdf differ
diff --git a/examples/John_Doe_EngineeringresumesTheme_CV.yaml b/examples/John_Doe_EngineeringresumesTheme_CV.yaml
index 1ecd559f..7459049b 100644
--- a/examples/John_Doe_EngineeringresumesTheme_CV.yaml
+++ b/examples/John_Doe_EngineeringresumesTheme_CV.yaml
@@ -1,233 +1,323 @@
+# yaml-language-server: $schema=https://raw.githubusercontent.com/rendercv/rendercv/refs/tags/v2.4/schema.json
cv:
name: John Doe
- location: Location
- email: john.doe@example.com
- phone: +1-609-999-9995
- website:
+ headline:
+ location: San Francisco, CA
+ email: john.doe@email.com
+ photo:
+ phone:
+ website: https://rendercv.com/
social_networks:
- network: LinkedIn
- username: john.doe
+ username: rendercv
- network: GitHub
- username: john.doe
+ username: rendercv
+ custom_connections:
sections:
- welcome_to_RenderCV!:
- - '[RenderCV](https://rendercv.com) is a Typst-based CV framework designed for academics and engineers, with Markdown syntax support.'
- - Each section title is arbitrary. Each section contains a list of entries, and there are 7 different entry types to choose from.
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
education:
- - institution: Stanford University
+ - institution: Princeton University
area: Computer Science
degree: PhD
- grade:
date:
- start_date: 2023-09
- end_date: present
- location: Stanford, CA, USA
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
summary:
highlights:
- - Working on the optimization of autonomous vehicles in urban environments
+ - 'Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment'
+ - 'Advisor: Prof. Sanjeev Arora'
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
- institution: Boğaziçi University
area: Computer Engineering
degree: BS
- grade:
date:
- start_date: 2018-09
- end_date: 2022-06
+ start_date: 2014-09
+ end_date: 2018-06
location: Istanbul, Türkiye
summary:
highlights:
- - 'GPA: 3.9/4.0, ranked 1st out of 100 students'
- - 'Awards: Best Senior Project, High Honor'
+ - 'GPA: 3.97/4.00, Valedictorian'
+ - Fulbright Scholarship recipient for graduate studies
experience:
- - company: Company C
- position: Summer Intern
- date:
- start_date: 2024-06
- end_date: 2024-09
- location: Livingston, LA, USA
- summary:
- highlights:
- - Developed deep learning models for the detection of gravitational waves in LIGO data
- - Published [3 peer-reviewed research papers](https://example.com) about the project and results
- - company: Company B
- position: Summer Intern
+ - company: Nexus AI
+ position: Co-Founder & CTO
date:
start_date: 2023-06
- end_date: 2023-09
- location: Ankara, Türkiye
+ end_date: present
+ location: San Francisco, CA
summary:
highlights:
- - Optimized the production line by 15% by implementing a new scheduling algorithm
- - company: Company A
- position: Summer Intern
+ - Built foundation model infrastructure serving 2M+ monthly API requests with 99.97% uptime
+ - Raised $18M Series A led by Sequoia Capital, with participation from a16z and Founders Fund
+ - Scaled engineering team from 3 to 28 across ML research, platform, and applied AI divisions
+ - Developed proprietary inference optimization reducing latency by 73% compared to baseline
+ - company: NVIDIA Research
+ position: Research Intern
date:
- start_date: 2022-06
- end_date: 2022-09
- location: Istanbul, Türkiye
+ start_date: 2022-05
+ end_date: 2022-08
+ location: Santa Clara, CA
summary:
highlights:
- - Designed an inventory management web application for a warehouse
+ - Designed sparse attention mechanism reducing transformer memory footprint by 4.2x
+ - Co-authored paper accepted at NeurIPS 2022 (spotlight presentation, top 5% of submissions)
+ - company: Google DeepMind
+ position: Research Intern
+ date:
+ start_date: 2021-05
+ end_date: 2021-08
+ location: London, UK
+ summary:
+ highlights:
+ - Developed reinforcement learning algorithms for multi-agent coordination
+ - Published research at top-tier venues with significant academic impact
+ - ICML 2022 main conference paper, cited 340+ times within two years
+ - NeurIPS 2022 workshop paper on emergent communication protocols
+ - Invited journal extension in JMLR (2023)
+ - company: Apple ML Research
+ position: Research Intern
+ date:
+ start_date: 2020-05
+ end_date: 2020-08
+ location: Cupertino, CA
+ summary:
+ highlights:
+ - Created on-device neural network compression pipeline deployed across 50M+ devices
+ - Filed 2 patents on efficient model quantization techniques for edge inference
+ - company: Microsoft Research
+ position: Research Intern
+ date:
+ start_date: 2019-05
+ end_date: 2019-08
+ location: Redmond, WA
+ summary:
+ highlights:
+ - Implemented novel self-supervised learning framework for low-resource language modeling
+ - Research integrated into Azure Cognitive Services, reducing training data requirements by 60%
projects:
- - name: '[Example Project](https://example.com)'
+ - name: '[FlashInfer](https://github.com/)'
date:
- start_date: 2024-05
+ start_date: 2023-01
end_date: present
location:
- summary: A web application for writing essays
+ summary: Open-source library for high-performance LLM inference kernels
highlights:
- - Launched an [iOS app](https://example.com) in 09/2024 that currently has 10k+ monthly active users
- - The app is made open-source (3,000+ stars [on GitHub](https://github.com))
- - name: '[Teaching on Udemy](https://example.com)'
- date: Fall 2023
+ - Achieved 2.8x speedup over baseline attention implementations on A100 GPUs
+ - Adopted by 3 major AI labs, 8,500+ GitHub stars, 200+ contributors
+ - name: '[NeuralPrune](https://github.com/)'
+ date: '2021'
start_date:
end_date:
location:
- summary:
+ summary: Automated neural network pruning toolkit with differentiable masks
highlights:
- - Instructed the "Statistics" course on Udemy (60,000+ students, 200,000+ hours watched)
- skills:
- - label: Programming
- details: Proficient with Python, C++, and Git; good understanding of Web, app development, and DevOps
- - label: Mathematics
- details: Good understanding of differential equations, calculus, and linear algebra
- - label: Languages
- details: 'English (fluent, TOEFL: 118/120), Turkish (native)'
+ - Reduced model size by 90% with less than 1% accuracy degradation on ImageNet
+ - Featured in PyTorch ecosystem tools, 4,200+ GitHub stars
publications:
- - title: 3D Finite Element Analysis of No-Insulation Coils
+ - title: 'Sparse Mixture-of-Experts at Scale: Efficient Routing for Trillion-Parameter Models'
authors:
- - Frodo Baggins
- - '***John Doe***'
- - Samwise Gamgee
- doi: 10.1109/TASC.2023.3340648
+ - '*John Doe*'
+ - Sarah Williams
+ - David Park
+ summary:
+ doi: 10.1234/neurips.2023.1234
url:
- journal:
- date: 2004-01
- extracurricular_activities:
- - bullet: 'There are 7 unique entry types in RenderCV: *BulletEntry*, *TextEntry*, *EducationEntry*, *ExperienceEntry*, *NormalEntry*, *PublicationEntry*, and *OneLineEntry*.'
- - bullet: Each entry type has a different structure and layout. This document demonstrates all of them.
- numbered_entries:
- - number: This is a numbered entry.
- - number: This is another numbered entry.
- - number: This is the third numbered entry.
- reversed_numbered_entries:
- - reversed_number: This is a reversed numbered entry.
- - reversed_number: This is another reversed numbered entry.
- - reversed_number: This is the third reversed numbered entry.
- sort_entries: none
+ journal: NeurIPS 2023
+ date: 2023-07
+ - title: Neural Architecture Search via Differentiable Pruning
+ authors:
+ - James Liu
+ - '*John Doe*'
+ summary:
+ doi: 10.1234/neurips.2022.5678
+ url:
+ journal: NeurIPS 2022, Spotlight
+ date: 2022-12
+ - title: Multi-Agent Reinforcement Learning with Emergent Communication
+ authors:
+ - Maria Garcia
+ - '*John Doe*'
+ - Tom Anderson
+ summary:
+ doi: 10.1234/icml.2022.9012
+ url:
+ journal: ICML 2022
+ date: 2022-07
+ - title: On-Device Model Compression via Learned Quantization
+ authors:
+ - '*John Doe*'
+ - Kevin Wu
+ summary:
+ doi: 10.1234/iclr.2021.3456
+ url:
+ journal: ICLR 2021, Best Paper Award
+ date: 2021-05
+ selected_honors:
+ - bullet: MIT Technology Review 35 Under 35 Innovators (2024)
+ - bullet: Forbes 30 Under 30 in Enterprise Technology (2024)
+ - bullet: ACM Doctoral Dissertation Award Honorable Mention (2023)
+ - bullet: Google PhD Fellowship in Machine Learning (2020 – 2023)
+ - bullet: Fulbright Scholarship for Graduate Studies (2018)
+ skills:
+ - label: Languages
+ details: Python, C++, CUDA, Rust, Julia
+ - label: ML Frameworks
+ details: PyTorch, JAX, TensorFlow, Triton, ONNX
+ - label: Infrastructure
+ details: Kubernetes, Ray, distributed training, AWS, GCP
+ - label: Research Areas
+ details: Neural architecture search, model compression, efficient inference, multi-agent RL
+ patents:
+ - number: Adaptive Quantization for Neural Network Inference on Edge Devices (US Patent 11,234,567)
+ - number: Dynamic Sparsity Patterns for Efficient Transformer Attention (US Patent 11,345,678)
+ - number: Hardware-Aware Neural Architecture Search Method (US Patent 11,456,789)
+ invited_talks:
+ - reversed_number: Scaling Laws for Efficient Inference — Stanford HAI Symposium (2024)
+ - reversed_number: Building AI Infrastructure for the Next Decade — TechCrunch Disrupt (2024)
+ - reversed_number: 'From Research to Production: Lessons in ML Systems — NeurIPS Workshop (2023)'
+ - reversed_number: "Efficient Deep Learning: A Practitioner's Perspective — Google Tech Talk (2022)"
+ any_section_title:
+ - You can use any section title you want.
+ - 'You can choose any entry type for the section: `TextEntry`, `ExperienceEntry`, `EducationEntry`, `PublicationEntry`, `BulletEntry`, `NumberedEntry`, or `ReversedNumberedEntry`.'
+ - Markdown syntax is supported everywhere.
+ - The `design` field in YAML gives you control over almost any aspect of your CV design.
+ - See the [documentation](https://docs.rendercv.com) for more details.
design:
theme: engineeringresumes
- page:
- size: us-letter
- top_margin: 2cm
- bottom_margin: 2cm
- left_margin: 2cm
- right_margin: 2cm
- show_page_numbering: false
- show_last_updated_date: true
- colors:
- text: rgb(0, 0, 0)
- name: rgb(0, 0, 0)
- connections: rgb(0, 0, 0)
- section_titles: rgb(0, 0, 0)
- links: rgb(0, 0, 0)
- last_updated_date_and_page_numbering: rgb(128, 128, 128)
- text:
- font_family: XCharter
- font_size: 10pt
- leading: 0.6em
- alignment: justified
- date_and_location_column_alignment: right
- links:
- underline: true
- use_external_link_icon: false
- header:
- name_font_family: XCharter
- name_font_size: 25pt
- name_bold: false
- small_caps_for_name: false
- photo_width: 3.5cm
- vertical_space_between_name_and_connections: 0.7cm
- vertical_space_between_connections_and_first_section: 0.7cm
- horizontal_space_between_connections: 0.5cm
- connections_font_family: XCharter
- separator_between_connections: '|'
- use_icons_for_connections: false
- use_urls_as_placeholders_for_connections: true
- make_connections_links: true
- alignment: center
- section_titles:
- type: with-full-line
- font_family: XCharter
- font_size: 1.2em
- bold: true
- small_caps: false
- line_thickness: 0.5pt
- vertical_space_above: 0.55cm
- vertical_space_below: 0.3cm
- entries:
- date_and_location_width: 4.15cm
- left_and_right_margin: 0cm
- horizontal_space_between_columns: 0.1cm
- vertical_space_between_entries: 0.4cm
- allow_page_break_in_sections: true
- allow_page_break_in_entries: true
- short_second_row: false
- show_time_spans_in: []
- highlights:
- bullet: •
- nested_bullet: '-'
- top_margin: 0.25cm
- left_margin: 0cm
- vertical_space_between_highlights: 0.19cm
- horizontal_space_between_bullet_and_highlight: 0.3em
- summary_left_margin: 0cm
- entry_types:
- one_line_entry:
- template: '**LABEL:** DETAILS'
- education_entry:
- main_column_first_row_template: '**INSTITUTION**, DEGREE in AREA -- LOCATION'
- degree_column_template:
- degree_column_width: 1cm
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- normal_entry:
- main_column_first_row_template: '**NAME** -- **LOCATION**'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- experience_entry:
- main_column_first_row_template: '**POSITION**, COMPANY -- LOCATION'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- publication_entry:
- main_column_first_row_template: '**TITLE**'
- main_column_second_row_template: |-
- AUTHORS
- URL (JOURNAL)
- main_column_second_row_without_journal_template: |-
- AUTHORS
- URL
- main_column_second_row_without_url_template: |-
- AUTHORS
- JOURNAL
- date_and_location_column_template: DATE
+ # page:
+ # size: us-letter
+ # top_margin: 0.7in
+ # bottom_margin: 0.7in
+ # left_margin: 0.7in
+ # right_margin: 0.7in
+ # show_footer: false
+ # show_top_note: true
+ # colors:
+ # body: rgb(0, 0, 0)
+ # name: rgb(0, 0, 0)
+ # headline: rgb(0, 0, 0)
+ # connections: rgb(0, 0, 0)
+ # section_titles: rgb(0, 0, 0)
+ # links: rgb(0, 0, 0)
+ # footer: rgb(128, 128, 128)
+ # top_note: rgb(128, 128, 128)
+ # typography:
+ # line_spacing: 0.6em
+ # alignment: justified
+ # date_and_location_column_alignment: right
+ # font_family:
+ # body: XCharter
+ # name: XCharter
+ # headline: XCharter
+ # connections: XCharter
+ # section_titles: XCharter
+ # font_size:
+ # body: 10pt
+ # name: 25pt
+ # headline: 10pt
+ # connections: 10pt
+ # section_titles: 1.2em
+ # small_caps:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: false
+ # bold:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: true
+ # links:
+ # underline: true
+ # show_external_link_icon: false
+ # header:
+ # alignment: center
+ # photo_width: 3.5cm
+ # photo_position: left
+ # photo_space_left: 0.4cm
+ # photo_space_right: 0.4cm
+ # space_below_name: 0.7cm
+ # space_below_headline: 0.7cm
+ # space_below_connections: 0.7cm
+ # connections:
+ # phone_number_format: national
+ # hyperlink: true
+ # show_icons: false
+ # display_urls_instead_of_usernames: true
+ # separator: '|'
+ # space_between_connections: 0.5cm
+ # section_titles:
+ # type: with_full_line
+ # line_thickness: 0.5pt
+ # space_above: 0.5cm
+ # space_below: 0.3cm
+ # sections:
+ # allow_page_break: true
+ # space_between_regular_entries: 0.42cm
+ # space_between_text_based_entries: 0.15cm
+ # show_time_spans_in: []
+ # entries:
+ # date_and_location_width: 4.15cm
+ # side_space: 0cm
+ # space_between_columns: 0.1cm
+ # allow_page_break: false
+ # short_second_row: false
+ # summary:
+ # space_above: 0.08cm
+ # space_left: 0cm
+ # highlights:
+ # bullet: ●
+ # nested_bullet: ●
+ # space_left: 0cm
+ # space_above: 0.08cm
+ # space_between_items: 0.08cm
+ # space_between_bullet_and_text: 0.3em
+ # templates:
+ # footer: '*NAME -- PAGE_NUMBER/TOTAL_PAGES*'
+ # top_note: '*LAST_UPDATED CURRENT_DATE*'
+ # single_date: MONTH_ABBREVIATION YEAR
+ # date_range: START_DATE – END_DATE
+ # time_span: HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS
+ # one_line_entry:
+ # main_column: '**LABEL:** DETAILS'
+ # education_entry:
+ # main_column: |-
+ # **INSTITUTION**, DEGREE in AREA -- LOCATION
+ # SUMMARY
+ # HIGHLIGHTS
+ # degree_column:
+ # date_and_location_column: DATE
+ # normal_entry:
+ # main_column: |-
+ # **NAME** -- **LOCATION**
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: DATE
+ # experience_entry:
+ # main_column: |-
+ # **POSITION**, COMPANY -- LOCATION
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: DATE
+ # publication_entry:
+ # main_column: |-
+ # **TITLE**
+ # SUMMARY
+ # AUTHORS
+ # URL (JOURNAL)
+ # date_and_location_column: DATE
locale:
- language: en
- phone_number_format: national
- page_numbering_template: NAME - Page PAGE_NUMBER of TOTAL_PAGES
- last_updated_date_template: Last updated in TODAY
- date_template: MONTH_ABBREVIATION YEAR
+ language: english
+ last_updated: Last updated in
month: month
months: months
year: year
years: years
present: present
- to: –
- abbreviations_for_months:
+ month_abbreviations:
- Jan
- Feb
- Mar
@@ -240,7 +330,7 @@ locale:
- Oct
- Nov
- Dec
- full_names_of_months:
+ month_names:
- January
- February
- March
@@ -253,7 +343,19 @@ locale:
- October
- November
- December
-rendercv_settings:
- date: '2025-10-28'
+settings:
+ current_date: '2025-12-09'
+ render_command:
+ design:
+ locale:
+ typst_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.typ
+ pdf_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf
+ markdown_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.md
+ html_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.html
+ png_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.png
+ dont_generate_markdown: false
+ dont_generate_html: false
+ dont_generate_typst: false
+ dont_generate_pdf: false
+ dont_generate_png: false
bold_keywords: []
- sort_entries: none
diff --git a/examples/John_Doe_ModerncvTheme_CV.pdf b/examples/John_Doe_ModerncvTheme_CV.pdf
index 398a59e2..cd621632 100644
Binary files a/examples/John_Doe_ModerncvTheme_CV.pdf and b/examples/John_Doe_ModerncvTheme_CV.pdf differ
diff --git a/examples/John_Doe_ModerncvTheme_CV.yaml b/examples/John_Doe_ModerncvTheme_CV.yaml
index 6be34637..a5b8c088 100644
--- a/examples/John_Doe_ModerncvTheme_CV.yaml
+++ b/examples/John_Doe_ModerncvTheme_CV.yaml
@@ -1,233 +1,323 @@
+# yaml-language-server: $schema=https://raw.githubusercontent.com/rendercv/rendercv/refs/tags/v2.4/schema.json
cv:
name: John Doe
- location: Location
- email: john.doe@example.com
- phone: +1-609-999-9995
- website:
+ headline:
+ location: San Francisco, CA
+ email: john.doe@email.com
+ photo:
+ phone:
+ website: https://rendercv.com/
social_networks:
- network: LinkedIn
- username: john.doe
+ username: rendercv
- network: GitHub
- username: john.doe
+ username: rendercv
+ custom_connections:
sections:
- welcome_to_RenderCV!:
- - '[RenderCV](https://rendercv.com) is a Typst-based CV framework designed for academics and engineers, with Markdown syntax support.'
- - Each section title is arbitrary. Each section contains a list of entries, and there are 7 different entry types to choose from.
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
education:
- - institution: Stanford University
+ - institution: Princeton University
area: Computer Science
degree: PhD
- grade:
date:
- start_date: 2023-09
- end_date: present
- location: Stanford, CA, USA
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
summary:
highlights:
- - Working on the optimization of autonomous vehicles in urban environments
+ - 'Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment'
+ - 'Advisor: Prof. Sanjeev Arora'
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
- institution: Boğaziçi University
area: Computer Engineering
degree: BS
- grade:
date:
- start_date: 2018-09
- end_date: 2022-06
+ start_date: 2014-09
+ end_date: 2018-06
location: Istanbul, Türkiye
summary:
highlights:
- - 'GPA: 3.9/4.0, ranked 1st out of 100 students'
- - 'Awards: Best Senior Project, High Honor'
+ - 'GPA: 3.97/4.00, Valedictorian'
+ - Fulbright Scholarship recipient for graduate studies
experience:
- - company: Company C
- position: Summer Intern
- date:
- start_date: 2024-06
- end_date: 2024-09
- location: Livingston, LA, USA
- summary:
- highlights:
- - Developed deep learning models for the detection of gravitational waves in LIGO data
- - Published [3 peer-reviewed research papers](https://example.com) about the project and results
- - company: Company B
- position: Summer Intern
+ - company: Nexus AI
+ position: Co-Founder & CTO
date:
start_date: 2023-06
- end_date: 2023-09
- location: Ankara, Türkiye
+ end_date: present
+ location: San Francisco, CA
summary:
highlights:
- - Optimized the production line by 15% by implementing a new scheduling algorithm
- - company: Company A
- position: Summer Intern
+ - Built foundation model infrastructure serving 2M+ monthly API requests with 99.97% uptime
+ - Raised $18M Series A led by Sequoia Capital, with participation from a16z and Founders Fund
+ - Scaled engineering team from 3 to 28 across ML research, platform, and applied AI divisions
+ - Developed proprietary inference optimization reducing latency by 73% compared to baseline
+ - company: NVIDIA Research
+ position: Research Intern
date:
- start_date: 2022-06
- end_date: 2022-09
- location: Istanbul, Türkiye
+ start_date: 2022-05
+ end_date: 2022-08
+ location: Santa Clara, CA
summary:
highlights:
- - Designed an inventory management web application for a warehouse
+ - Designed sparse attention mechanism reducing transformer memory footprint by 4.2x
+ - Co-authored paper accepted at NeurIPS 2022 (spotlight presentation, top 5% of submissions)
+ - company: Google DeepMind
+ position: Research Intern
+ date:
+ start_date: 2021-05
+ end_date: 2021-08
+ location: London, UK
+ summary:
+ highlights:
+ - Developed reinforcement learning algorithms for multi-agent coordination
+ - Published research at top-tier venues with significant academic impact
+ - ICML 2022 main conference paper, cited 340+ times within two years
+ - NeurIPS 2022 workshop paper on emergent communication protocols
+ - Invited journal extension in JMLR (2023)
+ - company: Apple ML Research
+ position: Research Intern
+ date:
+ start_date: 2020-05
+ end_date: 2020-08
+ location: Cupertino, CA
+ summary:
+ highlights:
+ - Created on-device neural network compression pipeline deployed across 50M+ devices
+ - Filed 2 patents on efficient model quantization techniques for edge inference
+ - company: Microsoft Research
+ position: Research Intern
+ date:
+ start_date: 2019-05
+ end_date: 2019-08
+ location: Redmond, WA
+ summary:
+ highlights:
+ - Implemented novel self-supervised learning framework for low-resource language modeling
+ - Research integrated into Azure Cognitive Services, reducing training data requirements by 60%
projects:
- - name: '[Example Project](https://example.com)'
+ - name: '[FlashInfer](https://github.com/)'
date:
- start_date: 2024-05
+ start_date: 2023-01
end_date: present
location:
- summary: A web application for writing essays
+ summary: Open-source library for high-performance LLM inference kernels
highlights:
- - Launched an [iOS app](https://example.com) in 09/2024 that currently has 10k+ monthly active users
- - The app is made open-source (3,000+ stars [on GitHub](https://github.com))
- - name: '[Teaching on Udemy](https://example.com)'
- date: Fall 2023
+ - Achieved 2.8x speedup over baseline attention implementations on A100 GPUs
+ - Adopted by 3 major AI labs, 8,500+ GitHub stars, 200+ contributors
+ - name: '[NeuralPrune](https://github.com/)'
+ date: '2021'
start_date:
end_date:
location:
- summary:
+ summary: Automated neural network pruning toolkit with differentiable masks
highlights:
- - Instructed the "Statistics" course on Udemy (60,000+ students, 200,000+ hours watched)
- skills:
- - label: Programming
- details: Proficient with Python, C++, and Git; good understanding of Web, app development, and DevOps
- - label: Mathematics
- details: Good understanding of differential equations, calculus, and linear algebra
- - label: Languages
- details: 'English (fluent, TOEFL: 118/120), Turkish (native)'
+ - Reduced model size by 90% with less than 1% accuracy degradation on ImageNet
+ - Featured in PyTorch ecosystem tools, 4,200+ GitHub stars
publications:
- - title: 3D Finite Element Analysis of No-Insulation Coils
+ - title: 'Sparse Mixture-of-Experts at Scale: Efficient Routing for Trillion-Parameter Models'
authors:
- - Frodo Baggins
- - '***John Doe***'
- - Samwise Gamgee
- doi: 10.1109/TASC.2023.3340648
+ - '*John Doe*'
+ - Sarah Williams
+ - David Park
+ summary:
+ doi: 10.1234/neurips.2023.1234
url:
- journal:
- date: 2004-01
- extracurricular_activities:
- - bullet: 'There are 7 unique entry types in RenderCV: *BulletEntry*, *TextEntry*, *EducationEntry*, *ExperienceEntry*, *NormalEntry*, *PublicationEntry*, and *OneLineEntry*.'
- - bullet: Each entry type has a different structure and layout. This document demonstrates all of them.
- numbered_entries:
- - number: This is a numbered entry.
- - number: This is another numbered entry.
- - number: This is the third numbered entry.
- reversed_numbered_entries:
- - reversed_number: This is a reversed numbered entry.
- - reversed_number: This is another reversed numbered entry.
- - reversed_number: This is the third reversed numbered entry.
- sort_entries: none
+ journal: NeurIPS 2023
+ date: 2023-07
+ - title: Neural Architecture Search via Differentiable Pruning
+ authors:
+ - James Liu
+ - '*John Doe*'
+ summary:
+ doi: 10.1234/neurips.2022.5678
+ url:
+ journal: NeurIPS 2022, Spotlight
+ date: 2022-12
+ - title: Multi-Agent Reinforcement Learning with Emergent Communication
+ authors:
+ - Maria Garcia
+ - '*John Doe*'
+ - Tom Anderson
+ summary:
+ doi: 10.1234/icml.2022.9012
+ url:
+ journal: ICML 2022
+ date: 2022-07
+ - title: On-Device Model Compression via Learned Quantization
+ authors:
+ - '*John Doe*'
+ - Kevin Wu
+ summary:
+ doi: 10.1234/iclr.2021.3456
+ url:
+ journal: ICLR 2021, Best Paper Award
+ date: 2021-05
+ selected_honors:
+ - bullet: MIT Technology Review 35 Under 35 Innovators (2024)
+ - bullet: Forbes 30 Under 30 in Enterprise Technology (2024)
+ - bullet: ACM Doctoral Dissertation Award Honorable Mention (2023)
+ - bullet: Google PhD Fellowship in Machine Learning (2020 – 2023)
+ - bullet: Fulbright Scholarship for Graduate Studies (2018)
+ skills:
+ - label: Languages
+ details: Python, C++, CUDA, Rust, Julia
+ - label: ML Frameworks
+ details: PyTorch, JAX, TensorFlow, Triton, ONNX
+ - label: Infrastructure
+ details: Kubernetes, Ray, distributed training, AWS, GCP
+ - label: Research Areas
+ details: Neural architecture search, model compression, efficient inference, multi-agent RL
+ patents:
+ - number: Adaptive Quantization for Neural Network Inference on Edge Devices (US Patent 11,234,567)
+ - number: Dynamic Sparsity Patterns for Efficient Transformer Attention (US Patent 11,345,678)
+ - number: Hardware-Aware Neural Architecture Search Method (US Patent 11,456,789)
+ invited_talks:
+ - reversed_number: Scaling Laws for Efficient Inference — Stanford HAI Symposium (2024)
+ - reversed_number: Building AI Infrastructure for the Next Decade — TechCrunch Disrupt (2024)
+ - reversed_number: 'From Research to Production: Lessons in ML Systems — NeurIPS Workshop (2023)'
+ - reversed_number: "Efficient Deep Learning: A Practitioner's Perspective — Google Tech Talk (2022)"
+ any_section_title:
+ - You can use any section title you want.
+ - 'You can choose any entry type for the section: `TextEntry`, `ExperienceEntry`, `EducationEntry`, `PublicationEntry`, `BulletEntry`, `NumberedEntry`, or `ReversedNumberedEntry`.'
+ - Markdown syntax is supported everywhere.
+ - The `design` field in YAML gives you control over almost any aspect of your CV design.
+ - See the [documentation](https://docs.rendercv.com) for more details.
design:
theme: moderncv
- page:
- size: us-letter
- top_margin: 2cm
- bottom_margin: 2cm
- left_margin: 2cm
- right_margin: 2cm
- show_page_numbering: true
- show_last_updated_date: true
- colors:
- text: rgb(0, 0, 0)
- name: rgb(0, 79, 144)
- connections: rgb(0, 79, 144)
- section_titles: rgb(0, 79, 144)
- links: rgb(0, 79, 144)
- last_updated_date_and_page_numbering: rgb(128, 128, 128)
- text:
- font_family: Fontin
- font_size: 10pt
- leading: 0.6em
- alignment: justified
- date_and_location_column_alignment: right
- links:
- underline: true
- use_external_link_icon: false
- header:
- name_font_family: Fontin
- name_font_size: 25pt
- name_bold: false
- small_caps_for_name: false
- photo_width: 3.5cm
- vertical_space_between_name_and_connections: 0.7cm
- vertical_space_between_connections_and_first_section: 0.7cm
- horizontal_space_between_connections: 0.5cm
- connections_font_family: Fontin
- separator_between_connections: ''
- use_icons_for_connections: true
- use_urls_as_placeholders_for_connections: false
- make_connections_links: true
- alignment: left
- section_titles:
- type: moderncv
- font_family: Fontin
- font_size: 1.4em
- bold: false
- small_caps: false
- line_thickness: 0.15cm
- vertical_space_above: 0.55cm
- vertical_space_below: 0.3cm
- entries:
- date_and_location_width: 4.15cm
- left_and_right_margin: 0cm
- horizontal_space_between_columns: 0.4cm
- vertical_space_between_entries: 0.4cm
- allow_page_break_in_sections: true
- allow_page_break_in_entries: true
- short_second_row: false
- show_time_spans_in: []
- highlights:
- bullet: •
- nested_bullet: '-'
- top_margin: 0.25cm
- left_margin: 0cm
- vertical_space_between_highlights: 0.19cm
- horizontal_space_between_bullet_and_highlight: 0.3em
- summary_left_margin: 0cm
- entry_types:
- one_line_entry:
- template: '**LABEL:** DETAILS'
- education_entry:
- main_column_first_row_template: '**INSTITUTION**, DEGREE in AREA -- LOCATION'
- degree_column_template:
- degree_column_width: 1cm
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- normal_entry:
- main_column_first_row_template: '**NAME** -- **LOCATION**'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- experience_entry:
- main_column_first_row_template: '**POSITION**, COMPANY -- LOCATION'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: DATE
- publication_entry:
- main_column_first_row_template: '**TITLE**'
- main_column_second_row_template: |-
- AUTHORS
- URL (JOURNAL)
- main_column_second_row_without_journal_template: |-
- AUTHORS
- URL
- main_column_second_row_without_url_template: |-
- AUTHORS
- JOURNAL
- date_and_location_column_template: DATE
+ # page:
+ # size: us-letter
+ # top_margin: 0.7in
+ # bottom_margin: 0.7in
+ # left_margin: 0.7in
+ # right_margin: 0.7in
+ # show_footer: true
+ # show_top_note: true
+ # colors:
+ # body: rgb(0, 0, 0)
+ # name: rgb(0, 79, 144)
+ # headline: rgb(0, 79, 144)
+ # connections: rgb(0, 79, 144)
+ # section_titles: rgb(0, 79, 144)
+ # links: rgb(0, 79, 144)
+ # footer: rgb(128, 128, 128)
+ # top_note: rgb(128, 128, 128)
+ # typography:
+ # line_spacing: 0.6em
+ # alignment: justified
+ # date_and_location_column_alignment: right
+ # font_family:
+ # body: Fontin
+ # name: Fontin
+ # headline: Fontin
+ # connections: Fontin
+ # section_titles: Fontin
+ # font_size:
+ # body: 10pt
+ # name: 25pt
+ # headline: 10pt
+ # connections: 10pt
+ # section_titles: 1.4em
+ # small_caps:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: false
+ # bold:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: false
+ # links:
+ # underline: true
+ # show_external_link_icon: false
+ # header:
+ # alignment: left
+ # photo_width: 4.15cm
+ # photo_position: left
+ # photo_space_left: 0cm
+ # photo_space_right: 0.3cm
+ # space_below_name: 0.7cm
+ # space_below_headline: 0.7cm
+ # space_below_connections: 0.7cm
+ # connections:
+ # phone_number_format: national
+ # hyperlink: true
+ # show_icons: true
+ # display_urls_instead_of_usernames: false
+ # separator: ''
+ # space_between_connections: 0.5cm
+ # section_titles:
+ # type: moderncv
+ # line_thickness: 0.15cm
+ # space_above: 0.55cm
+ # space_below: 0.3cm
+ # sections:
+ # allow_page_break: true
+ # space_between_regular_entries: 1.2em
+ # space_between_text_based_entries: 0.3em
+ # show_time_spans_in: []
+ # entries:
+ # date_and_location_width: 4.15cm
+ # side_space: 0cm
+ # space_between_columns: 0.3cm
+ # allow_page_break: false
+ # short_second_row: false
+ # summary:
+ # space_above: 0.1cm
+ # space_left: 0cm
+ # highlights:
+ # bullet: •
+ # nested_bullet: •
+ # space_left: 0cm
+ # space_above: 0.15cm
+ # space_between_items: 0.1cm
+ # space_between_bullet_and_text: 0.3em
+ # templates:
+ # footer: '*NAME -- PAGE_NUMBER/TOTAL_PAGES*'
+ # top_note: '*LAST_UPDATED CURRENT_DATE*'
+ # single_date: MONTH_ABBREVIATION YEAR
+ # date_range: START_DATE – END_DATE
+ # time_span: HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS
+ # one_line_entry:
+ # main_column: '**LABEL:** DETAILS'
+ # education_entry:
+ # main_column: |-
+ # **INSTITUTION**, DEGREE in AREA -- LOCATION
+ # SUMMARY
+ # HIGHLIGHTS
+ # degree_column:
+ # date_and_location_column: DATE
+ # normal_entry:
+ # main_column: |-
+ # **NAME** -- **LOCATION**
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: DATE
+ # experience_entry:
+ # main_column: |-
+ # **POSITION**, COMPANY -- LOCATION
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: DATE
+ # publication_entry:
+ # main_column: |-
+ # **TITLE**
+ # SUMMARY
+ # AUTHORS
+ # URL (JOURNAL)
+ # date_and_location_column: DATE
locale:
- language: en
- phone_number_format: national
- page_numbering_template: NAME - Page PAGE_NUMBER of TOTAL_PAGES
- last_updated_date_template: Last updated in TODAY
- date_template: MONTH_ABBREVIATION YEAR
+ language: english
+ last_updated: Last updated in
month: month
months: months
year: year
years: years
present: present
- to: –
- abbreviations_for_months:
+ month_abbreviations:
- Jan
- Feb
- Mar
@@ -240,7 +330,7 @@ locale:
- Oct
- Nov
- Dec
- full_names_of_months:
+ month_names:
- January
- February
- March
@@ -253,7 +343,19 @@ locale:
- October
- November
- December
-rendercv_settings:
- date: '2025-10-28'
+settings:
+ current_date: '2025-12-09'
+ render_command:
+ design:
+ locale:
+ typst_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.typ
+ pdf_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf
+ markdown_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.md
+ html_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.html
+ png_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.png
+ dont_generate_markdown: false
+ dont_generate_html: false
+ dont_generate_typst: false
+ dont_generate_pdf: false
+ dont_generate_png: false
bold_keywords: []
- sort_entries: none
diff --git a/examples/John_Doe_Sb2novTheme_CV.pdf b/examples/John_Doe_Sb2novTheme_CV.pdf
index 5276428b..b632a8aa 100644
Binary files a/examples/John_Doe_Sb2novTheme_CV.pdf and b/examples/John_Doe_Sb2novTheme_CV.pdf differ
diff --git a/examples/John_Doe_Sb2novTheme_CV.yaml b/examples/John_Doe_Sb2novTheme_CV.yaml
index f62a97af..b22e9311 100644
--- a/examples/John_Doe_Sb2novTheme_CV.yaml
+++ b/examples/John_Doe_Sb2novTheme_CV.yaml
@@ -1,243 +1,331 @@
+# yaml-language-server: $schema=https://raw.githubusercontent.com/rendercv/rendercv/refs/tags/v2.4/schema.json
cv:
name: John Doe
- location: Location
- email: john.doe@example.com
- phone: +1-609-999-9995
- website:
+ headline:
+ location: San Francisco, CA
+ email: john.doe@email.com
+ photo:
+ phone:
+ website: https://rendercv.com/
social_networks:
- network: LinkedIn
- username: john.doe
+ username: rendercv
- network: GitHub
- username: john.doe
+ username: rendercv
+ custom_connections:
sections:
- welcome_to_RenderCV!:
- - '[RenderCV](https://rendercv.com) is a Typst-based CV framework designed for academics and engineers, with Markdown syntax support.'
- - Each section title is arbitrary. Each section contains a list of entries, and there are 7 different entry types to choose from.
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
education:
- - institution: Stanford University
+ - institution: Princeton University
area: Computer Science
degree: PhD
- grade:
date:
- start_date: 2023-09
- end_date: present
- location: Stanford, CA, USA
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
summary:
highlights:
- - Working on the optimization of autonomous vehicles in urban environments
+ - 'Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment'
+ - 'Advisor: Prof. Sanjeev Arora'
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
- institution: Boğaziçi University
area: Computer Engineering
degree: BS
- grade:
date:
- start_date: 2018-09
- end_date: 2022-06
+ start_date: 2014-09
+ end_date: 2018-06
location: Istanbul, Türkiye
summary:
highlights:
- - 'GPA: 3.9/4.0, ranked 1st out of 100 students'
- - 'Awards: Best Senior Project, High Honor'
+ - 'GPA: 3.97/4.00, Valedictorian'
+ - Fulbright Scholarship recipient for graduate studies
experience:
- - company: Company C
- position: Summer Intern
- date:
- start_date: 2024-06
- end_date: 2024-09
- location: Livingston, LA, USA
- summary:
- highlights:
- - Developed deep learning models for the detection of gravitational waves in LIGO data
- - Published [3 peer-reviewed research papers](https://example.com) about the project and results
- - company: Company B
- position: Summer Intern
+ - company: Nexus AI
+ position: Co-Founder & CTO
date:
start_date: 2023-06
- end_date: 2023-09
- location: Ankara, Türkiye
+ end_date: present
+ location: San Francisco, CA
summary:
highlights:
- - Optimized the production line by 15% by implementing a new scheduling algorithm
- - company: Company A
- position: Summer Intern
+ - Built foundation model infrastructure serving 2M+ monthly API requests with 99.97% uptime
+ - Raised $18M Series A led by Sequoia Capital, with participation from a16z and Founders Fund
+ - Scaled engineering team from 3 to 28 across ML research, platform, and applied AI divisions
+ - Developed proprietary inference optimization reducing latency by 73% compared to baseline
+ - company: NVIDIA Research
+ position: Research Intern
date:
- start_date: 2022-06
- end_date: 2022-09
- location: Istanbul, Türkiye
+ start_date: 2022-05
+ end_date: 2022-08
+ location: Santa Clara, CA
summary:
highlights:
- - Designed an inventory management web application for a warehouse
+ - Designed sparse attention mechanism reducing transformer memory footprint by 4.2x
+ - Co-authored paper accepted at NeurIPS 2022 (spotlight presentation, top 5% of submissions)
+ - company: Google DeepMind
+ position: Research Intern
+ date:
+ start_date: 2021-05
+ end_date: 2021-08
+ location: London, UK
+ summary:
+ highlights:
+ - Developed reinforcement learning algorithms for multi-agent coordination
+ - Published research at top-tier venues with significant academic impact
+ - ICML 2022 main conference paper, cited 340+ times within two years
+ - NeurIPS 2022 workshop paper on emergent communication protocols
+ - Invited journal extension in JMLR (2023)
+ - company: Apple ML Research
+ position: Research Intern
+ date:
+ start_date: 2020-05
+ end_date: 2020-08
+ location: Cupertino, CA
+ summary:
+ highlights:
+ - Created on-device neural network compression pipeline deployed across 50M+ devices
+ - Filed 2 patents on efficient model quantization techniques for edge inference
+ - company: Microsoft Research
+ position: Research Intern
+ date:
+ start_date: 2019-05
+ end_date: 2019-08
+ location: Redmond, WA
+ summary:
+ highlights:
+ - Implemented novel self-supervised learning framework for low-resource language modeling
+ - Research integrated into Azure Cognitive Services, reducing training data requirements by 60%
projects:
- - name: '[Example Project](https://example.com)'
+ - name: '[FlashInfer](https://github.com/)'
date:
- start_date: 2024-05
+ start_date: 2023-01
end_date: present
location:
- summary: A web application for writing essays
+ summary: Open-source library for high-performance LLM inference kernels
highlights:
- - Launched an [iOS app](https://example.com) in 09/2024 that currently has 10k+ monthly active users
- - The app is made open-source (3,000+ stars [on GitHub](https://github.com))
- - name: '[Teaching on Udemy](https://example.com)'
- date: Fall 2023
+ - Achieved 2.8x speedup over baseline attention implementations on A100 GPUs
+ - Adopted by 3 major AI labs, 8,500+ GitHub stars, 200+ contributors
+ - name: '[NeuralPrune](https://github.com/)'
+ date: '2021'
start_date:
end_date:
location:
- summary:
+ summary: Automated neural network pruning toolkit with differentiable masks
highlights:
- - Instructed the "Statistics" course on Udemy (60,000+ students, 200,000+ hours watched)
- skills:
- - label: Programming
- details: Proficient with Python, C++, and Git; good understanding of Web, app development, and DevOps
- - label: Mathematics
- details: Good understanding of differential equations, calculus, and linear algebra
- - label: Languages
- details: 'English (fluent, TOEFL: 118/120), Turkish (native)'
+ - Reduced model size by 90% with less than 1% accuracy degradation on ImageNet
+ - Featured in PyTorch ecosystem tools, 4,200+ GitHub stars
publications:
- - title: 3D Finite Element Analysis of No-Insulation Coils
+ - title: 'Sparse Mixture-of-Experts at Scale: Efficient Routing for Trillion-Parameter Models'
authors:
- - Frodo Baggins
- - '***John Doe***'
- - Samwise Gamgee
- doi: 10.1109/TASC.2023.3340648
+ - '*John Doe*'
+ - Sarah Williams
+ - David Park
+ summary:
+ doi: 10.1234/neurips.2023.1234
url:
- journal:
- date: 2004-01
- extracurricular_activities:
- - bullet: 'There are 7 unique entry types in RenderCV: *BulletEntry*, *TextEntry*, *EducationEntry*, *ExperienceEntry*, *NormalEntry*, *PublicationEntry*, and *OneLineEntry*.'
- - bullet: Each entry type has a different structure and layout. This document demonstrates all of them.
- numbered_entries:
- - number: This is a numbered entry.
- - number: This is another numbered entry.
- - number: This is the third numbered entry.
- reversed_numbered_entries:
- - reversed_number: This is a reversed numbered entry.
- - reversed_number: This is another reversed numbered entry.
- - reversed_number: This is the third reversed numbered entry.
- sort_entries: none
+ journal: NeurIPS 2023
+ date: 2023-07
+ - title: Neural Architecture Search via Differentiable Pruning
+ authors:
+ - James Liu
+ - '*John Doe*'
+ summary:
+ doi: 10.1234/neurips.2022.5678
+ url:
+ journal: NeurIPS 2022, Spotlight
+ date: 2022-12
+ - title: Multi-Agent Reinforcement Learning with Emergent Communication
+ authors:
+ - Maria Garcia
+ - '*John Doe*'
+ - Tom Anderson
+ summary:
+ doi: 10.1234/icml.2022.9012
+ url:
+ journal: ICML 2022
+ date: 2022-07
+ - title: On-Device Model Compression via Learned Quantization
+ authors:
+ - '*John Doe*'
+ - Kevin Wu
+ summary:
+ doi: 10.1234/iclr.2021.3456
+ url:
+ journal: ICLR 2021, Best Paper Award
+ date: 2021-05
+ selected_honors:
+ - bullet: MIT Technology Review 35 Under 35 Innovators (2024)
+ - bullet: Forbes 30 Under 30 in Enterprise Technology (2024)
+ - bullet: ACM Doctoral Dissertation Award Honorable Mention (2023)
+ - bullet: Google PhD Fellowship in Machine Learning (2020 – 2023)
+ - bullet: Fulbright Scholarship for Graduate Studies (2018)
+ skills:
+ - label: Languages
+ details: Python, C++, CUDA, Rust, Julia
+ - label: ML Frameworks
+ details: PyTorch, JAX, TensorFlow, Triton, ONNX
+ - label: Infrastructure
+ details: Kubernetes, Ray, distributed training, AWS, GCP
+ - label: Research Areas
+ details: Neural architecture search, model compression, efficient inference, multi-agent RL
+ patents:
+ - number: Adaptive Quantization for Neural Network Inference on Edge Devices (US Patent 11,234,567)
+ - number: Dynamic Sparsity Patterns for Efficient Transformer Attention (US Patent 11,345,678)
+ - number: Hardware-Aware Neural Architecture Search Method (US Patent 11,456,789)
+ invited_talks:
+ - reversed_number: Scaling Laws for Efficient Inference — Stanford HAI Symposium (2024)
+ - reversed_number: Building AI Infrastructure for the Next Decade — TechCrunch Disrupt (2024)
+ - reversed_number: 'From Research to Production: Lessons in ML Systems — NeurIPS Workshop (2023)'
+ - reversed_number: "Efficient Deep Learning: A Practitioner's Perspective — Google Tech Talk (2022)"
+ any_section_title:
+ - You can use any section title you want.
+ - 'You can choose any entry type for the section: `TextEntry`, `ExperienceEntry`, `EducationEntry`, `PublicationEntry`, `BulletEntry`, `NumberedEntry`, or `ReversedNumberedEntry`.'
+ - Markdown syntax is supported everywhere.
+ - The `design` field in YAML gives you control over almost any aspect of your CV design.
+ - See the [documentation](https://docs.rendercv.com) for more details.
design:
theme: sb2nov
- page:
- size: us-letter
- top_margin: 2cm
- bottom_margin: 2cm
- left_margin: 2cm
- right_margin: 2cm
- show_page_numbering: true
- show_last_updated_date: true
- colors:
- text: rgb(0, 0, 0)
- name: rgb(0, 0, 0)
- connections: rgb(0, 0, 0)
- section_titles: rgb(0, 0, 0)
- links: rgb(0, 79, 144)
- last_updated_date_and_page_numbering: rgb(128, 128, 128)
- text:
- font_family: New Computer Modern
- font_size: 10pt
- leading: 0.6em
- alignment: justified
- date_and_location_column_alignment: right
- links:
- underline: true
- use_external_link_icon: false
- header:
- name_font_family: New Computer Modern
- name_font_size: 30pt
- name_bold: true
- small_caps_for_name: false
- photo_width: 3.5cm
- vertical_space_between_name_and_connections: 0.7cm
- vertical_space_between_connections_and_first_section: 0.7cm
- horizontal_space_between_connections: 0.5cm
- connections_font_family: New Computer Modern
- separator_between_connections: ''
- use_icons_for_connections: true
- use_urls_as_placeholders_for_connections: false
- make_connections_links: true
- alignment: center
- section_titles:
- type: with-full-line
- font_family: New Computer Modern
- font_size: 1.4em
- bold: true
- small_caps: false
- line_thickness: 0.5pt
- vertical_space_above: 0.5cm
- vertical_space_below: 0.3cm
- entries:
- date_and_location_width: 4.15cm
- left_and_right_margin: 0.2cm
- horizontal_space_between_columns: 0.1cm
- vertical_space_between_entries: 1.2em
- allow_page_break_in_sections: true
- allow_page_break_in_entries: true
- short_second_row: false
- show_time_spans_in: []
- highlights:
- bullet: ◦
- nested_bullet: '-'
- top_margin: 0.25cm
- left_margin: 0.4cm
- vertical_space_between_highlights: 0.25cm
- horizontal_space_between_bullet_and_highlight: 0.5em
- summary_left_margin: 0cm
- entry_types:
- one_line_entry:
- template: '**LABEL:** DETAILS'
- education_entry:
- main_column_first_row_template: |-
- **INSTITUTION**
- *DEGREE in AREA*
- degree_column_template:
- degree_column_width: 1cm
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- *LOCATION*
- *DATE*
- normal_entry:
- main_column_first_row_template: '**NAME**'
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- *LOCATION*
- *DATE*
- experience_entry:
- main_column_first_row_template: |-
- **POSITION**
- *COMPANY*
- main_column_second_row_template: |-
- SUMMARY
- HIGHLIGHTS
- date_and_location_column_template: |-
- *LOCATION*
- *DATE*
- publication_entry:
- main_column_first_row_template: '**TITLE**'
- main_column_second_row_template: |-
- AUTHORS
- URL (JOURNAL)
- main_column_second_row_without_journal_template: |-
- AUTHORS
- URL
- main_column_second_row_without_url_template: |-
- AUTHORS
- JOURNAL
- date_and_location_column_template: DATE
+ # page:
+ # size: us-letter
+ # top_margin: 0.7in
+ # bottom_margin: 0.7in
+ # left_margin: 0.7in
+ # right_margin: 0.7in
+ # show_footer: true
+ # show_top_note: true
+ # colors:
+ # body: rgb(0, 0, 0)
+ # name: rgb(0, 0, 0)
+ # headline: rgb(0, 0, 0)
+ # connections: rgb(0, 0, 0)
+ # section_titles: rgb(0, 0, 0)
+ # links: rgb(0, 0, 0)
+ # footer: rgb(128, 128, 128)
+ # top_note: rgb(128, 128, 128)
+ # typography:
+ # line_spacing: 0.6em
+ # alignment: justified
+ # date_and_location_column_alignment: right
+ # font_family:
+ # body: New Computer Modern
+ # name: New Computer Modern
+ # headline: New Computer Modern
+ # connections: New Computer Modern
+ # section_titles: New Computer Modern
+ # font_size:
+ # body: 10pt
+ # name: 30pt
+ # headline: 10pt
+ # connections: 10pt
+ # section_titles: 1.4em
+ # small_caps:
+ # name: false
+ # headline: false
+ # connections: false
+ # section_titles: false
+ # bold:
+ # name: true
+ # headline: false
+ # connections: false
+ # section_titles: true
+ # links:
+ # underline: true
+ # show_external_link_icon: false
+ # header:
+ # alignment: center
+ # photo_width: 3.5cm
+ # photo_position: left
+ # photo_space_left: 0.4cm
+ # photo_space_right: 0.4cm
+ # space_below_name: 0.7cm
+ # space_below_headline: 0.7cm
+ # space_below_connections: 0.7cm
+ # connections:
+ # phone_number_format: national
+ # hyperlink: true
+ # show_icons: false
+ # display_urls_instead_of_usernames: true
+ # separator: •
+ # space_between_connections: 0.5cm
+ # section_titles:
+ # type: with_full_line
+ # line_thickness: 0.5pt
+ # space_above: 0.5cm
+ # space_below: 0.3cm
+ # sections:
+ # allow_page_break: true
+ # space_between_regular_entries: 1.2em
+ # space_between_text_based_entries: 0.3em
+ # show_time_spans_in: []
+ # entries:
+ # date_and_location_width: 4.15cm
+ # side_space: 0.2cm
+ # space_between_columns: 0.1cm
+ # allow_page_break: false
+ # short_second_row: false
+ # summary:
+ # space_above: 0cm
+ # space_left: 0cm
+ # highlights:
+ # bullet: ◦
+ # nested_bullet: ◦
+ # space_left: 0.15cm
+ # space_above: 0cm
+ # space_between_items: 0cm
+ # space_between_bullet_and_text: 0.5em
+ # templates:
+ # footer: '*NAME -- PAGE_NUMBER/TOTAL_PAGES*'
+ # top_note: '*LAST_UPDATED CURRENT_DATE*'
+ # single_date: MONTH_ABBREVIATION YEAR
+ # date_range: START_DATE – END_DATE
+ # time_span: HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS
+ # one_line_entry:
+ # main_column: '**LABEL:** DETAILS'
+ # education_entry:
+ # main_column: |-
+ # **INSTITUTION**
+ # *DEGREE* *in* *AREA*
+ # SUMMARY
+ # HIGHLIGHTS
+ # degree_column:
+ # date_and_location_column: |-
+ # *LOCATION*
+ # *DATE*
+ # normal_entry:
+ # main_column: |-
+ # **NAME**
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: |-
+ # *LOCATION*
+ # *DATE*
+ # experience_entry:
+ # main_column: |-
+ # **POSITION**
+ # *COMPANY*
+ # SUMMARY
+ # HIGHLIGHTS
+ # date_and_location_column: |-
+ # *LOCATION*
+ # *DATE*
+ # publication_entry:
+ # main_column: |-
+ # **TITLE**
+ # SUMMARY
+ # AUTHORS
+ # URL (JOURNAL)
+ # date_and_location_column: DATE
locale:
- language: en
- phone_number_format: national
- page_numbering_template: NAME - Page PAGE_NUMBER of TOTAL_PAGES
- last_updated_date_template: Last updated in TODAY
- date_template: MONTH_ABBREVIATION YEAR
+ language: english
+ last_updated: Last updated in
month: month
months: months
year: year
years: years
present: present
- to: –
- abbreviations_for_months:
+ month_abbreviations:
- Jan
- Feb
- Mar
@@ -250,7 +338,7 @@ locale:
- Oct
- Nov
- Dec
- full_names_of_months:
+ month_names:
- January
- February
- March
@@ -263,7 +351,19 @@ locale:
- October
- November
- December
-rendercv_settings:
- date: '2025-10-28'
+settings:
+ current_date: '2025-12-09'
+ render_command:
+ design:
+ locale:
+ typst_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.typ
+ pdf_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf
+ markdown_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.md
+ html_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.html
+ png_path: rendercv_output/NAME_IN_SNAKE_CASE_CV.png
+ dont_generate_markdown: false
+ dont_generate_html: false
+ dont_generate_typst: false
+ dont_generate_pdf: false
+ dont_generate_png: false
bold_keywords: []
- sort_entries: none
diff --git a/justfile b/justfile
index aef0eb79..d9a091c5 100644
--- a/justfile
+++ b/justfile
@@ -1,59 +1,52 @@
+# Development:
+sync:
+ uv sync --all-extras --all-groups
+
format:
- uv run black src tests ; uv run ruff check --fix src tests ; uv run ruff format src tests
+ uv run --locked black src tests
+ uv run --locked ruff check --fix src tests
+ uv run --locked ruff format src tests
format-file target:
- uv run -- black {{target}}; uv run -- ruff check --fix {{target}}; uv run -- ruff format {{target}}
+ uv run --locked black {{target}}
+ uv run --locked ruff check --fix {{target}}
+ uv run --locked ruff format {{target}}
-lint:
- uv run -- ruff check src tests
+check:
+ uv run --locked ruff check src tests
+ uv run --locked pyright src tests
+ uv run --locked pre-commit run --all-files
-check-types:
- uv run -- pyright src tests
+# Testing:
+test:
+ uv run --locked pytest
-pre-commit:
- uv run -- pre-commit run --all-files
+update-testdata:
+ uv run --locked pytest --update-testdata
-count-lines:
- wc -l `find src -name '*.py'`
-
-update-schema:
- uv run scripts/update_schema.py
-
-update-entry-figures:
- uv run scripts/update_entry_figures.py
-
-update-examples:
- uv run scripts/update_examples.py
-
-create-executable:
- uv run scripts/create_executable.py
-
-profile-render-command:
- uv run -- python -m cProfile -o render_command.prof -m rendercv render examples/John_Doe_ClassicTheme_CV.yaml && snakeviz render_command.prof
-
-src-tree:
- tree src/rendercv --gitignore
+test-coverage:
+ uv run --locked pytest --cov=src/rendercv --cov-report=term --cov-report=html --cov-report=markdown
+# Docs:
build-docs:
- uv run mkdocs build --clean --strict
+ uv run --locked mkdocs build --clean --strict
serve-docs:
- uv run mkdocs serve
+ uv run --locked mkdocs serve --watch-theme
-test:
- uv run pytest
+# Scripts:
+update-schema:
+ uv run --locked scripts/update_schema.py
-test-with-coverage:
- uv run -- pytest --cov
+update-entry-figures:
+ uv run --locked scripts/update_entry_figures.py
-report-coverage:
- uv run -- pytest --cov --cov-report=html
+update-examples:
+ uv run --locked scripts/update_examples.py
-open video_path:
- uv run scripts/open.py {{video_path}}
+create-executable:
+ uv run --locked scripts/create_executable.py
-profile target:
- sudo -E uv run py-spy record -o profile.svg python {{target}}
-
-pull-data:
- uv run scripts/pull_data.py
+# Utilities:
+count-lines:
+ wc -l `find src -name '*.py'`
diff --git a/mkdocs.yaml b/mkdocs.yaml
index 54589db8..81c16ad4 100644
--- a/mkdocs.yaml
+++ b/mkdocs.yaml
@@ -1,8 +1,6 @@
site_name: RenderCV Engine
-site_description: A Python package with CLI tool to write and version-control CVs and resumes as source code
-site_author: RenderCV Team
-copyright: Copyright © 2023 - 2024 RenderCV
-site_url: https://docs.rendercv.com
+site_description: CV/resume generator for academics and engineers
+copyright: Copyright © 2023 - 2026 RenderCV
repo_url: https://github.com/rendercv/rendercv
repo_name: rendercv/rendercv
edit_uri: edit/main/docs/
@@ -37,7 +35,8 @@ theme:
- content.action.view # view source button for pages
- content.action.edit # view source button for pages
- navigation.footer # the previous and next buttons in the footer
- - navigation.indexes # allow mother pages to have their own index pages
+ - navigation.tabs # Top navbar
+ # - navigation.indexes # allow mother pages to have their own index pages
- navigation.instant # instant navigation for faster page loads
- navigation.instant.prefetch # prefetch pages for instant navigation
- navigation.instant.progress # show progress bar for instant navigation
@@ -51,58 +50,37 @@ theme:
- content.tabs.link # switch all the content tabs to the same label
nav:
- - Overview: index.md
- User Guide:
- - User Guide: user_guide/index.md
- - Structure of the YAML input file: user_guide/structure_of_the_yaml_input_file.md
+ - Welcome: index.md
+ - Get Started: user_guide/index.md
+ - YAML Input Structure: user_guide/yaml_input_structure.md
- CLI: user_guide/cli.md
- - FAQ: user_guide/faq.md
+ - How-To Guides:
+ - Set Up VS Code for RenderCV: user_guide/how_to/set_up_vs_code_for_rendercv.md
+ - Arbitrary Keys in Entries: user_guide/how_to/arbitrary_keys_in_entries.md
+ - Custom Fonts: user_guide/how_to/custom_fonts.md
+ - Override Default Templates: user_guide/how_to/override_default_templates.md
- Developer Guide:
- - Developer Guide: developer_guide/index.md
- - Writing Documentation: developer_guide/writing_documentation.md
+ - Setup: developer_guide/index.md
+ - Project Management: developer_guide/project_management.md
+ - Understanding RenderCV: developer_guide/understanding_rendercv.md
- Testing: developer_guide/testing.md
- - FAQ: developer_guide/faq.md
- - API Reference:
- - Reference: reference/index.md
- - api:
- - api: reference/api/index.md
- - functions.py: reference/api/functions.md
- - cli:
- - cli: reference/cli/index.md
- - commands.py: reference/cli/commands.md
- - printer.py: reference/cli/printer.md
- - utilities.py: reference/cli/utilities.md
- - data:
- - data: reference/data/index.md
- - models:
- - models: reference/data/models/index.md
- - base.py: reference/data/models/base.md
- - computers.py: reference/data/models/computers.md
- - entry_types.py: reference/data/models/entry_types.md
- - curriculum_vitae.py: reference/data/models/curriculum_vitae.md
- - design.py: reference/data/models/design.md
- - locale.py: reference/data/models/locale.md
- - rendercv_settings.py: reference/data/models/rendercv_settings.md
- - rendercv_data_model.py: reference/data/models/rendercv_data_model.md
- - generator.py: reference/data/generator.md
- - reader.py: reference/data/reader.md
- - renderer:
- - renderer: reference/renderer/index.md
- - renderer.py: reference/renderer/renderer.md
- - templater.py: reference/renderer/templater.md
- - themes:
- - themes: reference/themes/index.md
- - options.py: reference/themes/options.md
- - classic: reference/themes/classic.md
- - engineeringresumes: reference/themes/engineeringresumes.md
- - sb2nov: reference/themes/sb2nov.md
- - moderncv: reference/themes/moderncv.md
- - engineeringclassic: reference/themes/engineeringclassic.md
- - components: reference/themes/components.md
- - Changelog:
- - Changelog: changelog/index.md
+ - Documentation: developer_guide/documentation.md
+ - JSON Schema: developer_guide/json_schema.md
+ - GitHub Workflows: developer_guide/github_workflows.md
+ - Dockerfile: developer_guide/dockerfile.md
+ - Code Guidelines:
+ - Source Code: developer_guide/code_guidelines/source_code.md
+ - Tests: developer_guide/code_guidelines/tests.md
+ - How-To Guides:
+ - Add Theme: developer_guide/how_to/add_theme.md
+ - Add Locale: developer_guide/how_to/add_locale.md
+ - Add Social Network: developer_guide/how_to/add_social_network.md
+ - API Reference: api_reference/
+ - Changelog: changelog.md
markdown_extensions:
+ - github-callouts
# see https://facelessuser.github.io/pymdown-extensions/extensions/inlinehilite/ for more pymdownx info
- pymdownx.highlight:
anchor_linenums: true
@@ -124,19 +102,42 @@ markdown_extensions:
plugins:
- search
+ - literate-nav:
+ nav_file: SUMMARY.md
+ - gen-files:
+ scripts:
+ - docs/api_reference/api_reference.py
- macros: # mkdocs-macros-plugin
- module_name: docs/dynamic_content_generation
+ module_name: docs/docs_templating
+ j2_block_start_string: "{$"
+ j2_block_end_string: "$}"
+ j2_variable_start_string: "<<"
+ j2_variable_end_string: ">>"
- mkdocstrings:
handlers:
python:
- paths:
- - rendercv
options:
- members_order: source
+ members_order: alphabetical
show_bases: true
docstring_section_style: list
docstring_style: google
-
+ inherited_members: true
+ show_root_heading: true
+ heading_level: 1
+ show_symbol_type_heading: True
+ show_root_full_path: false
+ show_symbol_type_toc: true
+ signature_crossrefs: true
+ show_docstring_attributes: true
+ show_source: true
+ show_submodules: false
+ merge_init_into_class: true
+ annotations_path: brief
+ show_signature: true
+ show_docstring_examples: true
+ show_docstring_type_aliases: true
+ show_overloads: false
+ show_if_no_docstring: true
extra_javascript:
- assets/javascripts/katex.js
- https://unpkg.com/katex@0/dist/katex.min.js
diff --git a/pyproject.toml b/pyproject.toml
index 7c377d38..d4c7e2e6 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -43,16 +43,15 @@ description = 'Typst-based CV/resume generator'
authors = [{ name = 'Sina Atalay', email = 'dev@atalay.biz' }]
license = "MIT"
readme = "README.md"
-requires-python = '>=3.10'
+requires-python = '>=3.12'
# RenderCV depends on these packages. They are installed automatically when RenderCV is installed:
dependencies = [
'Jinja2>=3.1.6', # Generate Typst and Markdown files
- 'phonenumbers>=9.0.16', # Validate phone numbers
- 'email-validator>=2.3.0', # Validate email addresses
- 'pydantic>=2.12.3', # Validate and parse input files
- 'pycountry>=24.6.1', # ISO 639-3 validation
+ 'phonenumbers>=9.0.19', # Validate phone numbers
+ 'pydantic[email]>=2.10.6', # Validate and parse input files
'pydantic-extra-types>=2.10.6', # Validate extra types
- 'ruamel.yaml>=0.18.16', # Parse YAML files
+ 'ruamel.yaml>=0.18.10', # Parse YAML files
+ "packaging>=25.0", # For version checking
]
classifiers = [
"Intended Audience :: Science/Research",
@@ -71,12 +70,11 @@ classifiers = [
[project.optional-dependencies]
full = [
- 'typer>=0.20.0', # Command-line interface
- 'markdown>=3.9', # Convert Markdown to HTML
- 'watchdog>=6.0.0', # Monitor files for updates
- 'typst>=0.13.7', # Render PDF from Typst source files
- 'packaging>=25.0', # Validate version numbers
- 'rendercv-fonts', # Font files for RenderCV
+ 'typer>=0.20.0', # Command-line interface
+ 'markdown>=3.10', # Convert Markdown to HTML
+ 'watchdog>=6.0.0', # Monitor files for updates
+ 'typst>=0.14.4', # Render PDF from Typst source files
+ 'rendercv-fonts>=0.5.1', # Font files for RenderCV
]
[project.urls]
@@ -92,36 +90,32 @@ Changelog = 'https://docs.rendercv.com/changelog'
# See https://hatch.pypa.io/latest/config/metadata/#cli
# The key and value below mean: when someone installs RenderCV,
-# running `rendercv` in the terminal executes the function `app` in the module `cli`
-# inside the package `rendercv`.
-rendercv = 'rendercv.cli:app'
+# running `rendercv` in the terminal executes the function `entry_point` in
+# `src/rendercv/cli/entry_point.py`.
+rendercv = 'rendercv.cli.entry_point:entry_point'
# Virtual Environment Dependencies:
[dependency-groups]
dev = [
- 'ruff>=0.14.1', # Lint and format the code
- 'black>=25.9.0', # Format the code
- 'pyright>=1.1.406', # Type checking
- 'pre-commit>=4.3.0', # Run checks before committing
- 'pytest>=8.4.2', # Run tests
- 'pypdf>=6.1.3', # Read PDF files
- 'snakeviz>=2.2.2', # Profiling
- 'pyinstaller>=6.16.0', # Build executables
- "pytest-xdist>=3.8.0",
- "pytest-cov>=7.0.0",
- "coverage>=7.11.0",
- "pytest-rerunfailures>=16.1",
+ 'ruff>=0.14.8', # Lint and format the code
+ 'black>=25.12.0', # Format the code
+ 'pyright>=1.1.407', # Type checking
+ 'pre-commit>=4.5.0', # Run checks before committing
+ 'pytest>=9.0.2', # Run tests
+ 'pytest-cov>=7.0.0', # Coverage plugin for pytest with xdist support
+ 'pyinstaller>=6.17.0', # Build executables
+ "pytest-xdist>=3.8.0", # Run tests in parallel
]
docs = [
- 'mkdocs-material>=9.6.20',
- 'mkdocstrings[python]>=0.30.1', # Build reference docs from docstrings
- 'pdfCropMargins>=2.2.1', # Generate entry figures for documentation
- 'pillow>=10.4.0', # Lock dependency of pdfCropMargins
- 'mkdocs-macros-plugin>=1.4.0', # Enable dynamic content in docs
- 'PyMuPDF>=1.26.5', # Convert PDF files to images
-]
-exe = [
- 'pyinstaller>=6.16.0', # Build executables
+ 'mkdocs-material>=9.7.0',
+ 'mkdocs-gen-files>=0.6.0', # Dynamic page generation for API reference
+ 'mkdocs-literate-nav>=0.6.2', # Dynamic navigation for API reference
+ 'mkdocs-macros-plugin>=1.5.0', # Dynamic content in docs
+ 'mkdocstrings[python]>=1.0.0', # Build reference docs from docstrings
+ 'markdown-callouts>=0.4.0', # GitHub alert style admonitions
+ 'pdfCropMargins==2.2.1', # Generate entry figures for documentation
+ 'pillow==10.4.0', # Lock dependency of pdfCropMargins
+ 'PyMuPDF==1.26.5', # Convert PDF files to images
]
# Tools Settings:
@@ -165,6 +159,8 @@ ignore = [
'ISC001', # Conflicts with formatter
'UP007', # Allow Optional type
'PGH003', # Prefer not to ignore this
+ 'RUF001', # Allow other characters for locale
+ 'EM101', # Allow
]
flake8-unused-arguments.ignore-variadic-names = true
@@ -176,6 +172,8 @@ enable-unstable-feature = [
] # Break strings into multiple lines
[tool.pyright]
+venvPath = "."
+venv = ".venv"
typeCheckingMode = 'standard'
enableTypeIgnoreComments = false
reportUnnecessaryTypeIgnoreComment = true
@@ -183,10 +181,10 @@ reportIncompatibleVariableOverride = false
reportIncompatibleMethodOverride = false
reportMissingTypeStubs = false
reportPrivateUsage = false
-exclude = ['rendercv/themes/*']
+exclude = ['docs/**/*']
[tool.coverage.run]
-source = ['rendercv'] # Measure coverage in this source
+source = ['src/rendercv'] # Measure coverage in this source
concurrency = ['multiprocessing'] # For watcher tests
# Use relative paths for cross-platform coverage merging:
@@ -208,8 +206,6 @@ addopts = [
'--strict-markers', # Disallow unknown markers
'--strict-config', # Fail on unknown config options
'--numprocesses=auto', # Number of processes in parallel
- '--dist=loadfile', # Make sure specific jobs are grouped
- '--reruns=5', # Rerun flaky tests
]
testpaths = ['tests']
diff --git a/schema.json b/schema.json
index 0fcf6bfa..dd645e15 100644
--- a/schema.json
+++ b/schema.json
@@ -1,9 +1,75 @@
{
"$defs": {
+ "Alignment": {
+ "enum": [
+ "left",
+ "center",
+ "right"
+ ],
+ "type": "string"
+ },
+ "ArbitraryDate": {
+ "anyOf": [
+ {
+ "type": "integer"
+ },
+ {
+ "type": "string"
+ }
+ ]
+ },
+ "BuiltInDesign": {
+ "discriminator": {
+ "mapping": {
+ "classic": "#/$defs/ClassicTheme",
+ "engineeringclassic": "#/$defs/EngineeringclassicTheme",
+ "engineeringresumes": "#/$defs/EngineeringresumesTheme",
+ "moderncv": "#/$defs/ModerncvTheme",
+ "sb2nov": "#/$defs/Sb2novTheme"
+ },
+ "propertyName": "theme"
+ },
+ "oneOf": [
+ {
+ "$ref": "#/$defs/ClassicTheme"
+ },
+ {
+ "$ref": "#/$defs/EngineeringclassicTheme"
+ },
+ {
+ "$ref": "#/$defs/EngineeringresumesTheme"
+ },
+ {
+ "$ref": "#/$defs/ModerncvTheme"
+ },
+ {
+ "$ref": "#/$defs/Sb2novTheme"
+ }
+ ]
+ },
+ "Bullet": {
+ "enum": [
+ "●",
+ "•",
+ "◦",
+ "-",
+ "◆",
+ "★",
+ "■",
+ "—",
+ "○"
+ ],
+ "type": "string"
+ },
"BulletEntry": {
"additionalProperties": true,
+ "description": null,
"properties": {
"bullet": {
+ "examples": [
+ "Python, JavaScript, C++",
+ "Excellent communication skills"
+ ],
"title": "Bullet",
"type": "string"
}
@@ -11,10 +77,10 @@
"required": [
"bullet"
],
- "title": "Bullet Entry",
+ "title": "BulletEntry",
"type": "object"
},
- "ClassicThemeOptions": {
+ "ClassicTheme": {
"additionalProperties": false,
"properties": {
"theme": {
@@ -24,108 +90,49 @@
"type": "string"
},
"page": {
- "$ref": "#/$defs/rendercv__themes__options__Page"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Page__1"
},
"colors": {
- "$ref": "#/$defs/rendercv__themes__options__Colors"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Colors__1"
},
- "text": {
- "$ref": "#/$defs/rendercv__themes__options__Text"
+ "typography": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Typography__1"
},
"links": {
- "$ref": "#/$defs/rendercv__themes__options__Links"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Links__1"
},
"header": {
- "$ref": "#/$defs/rendercv__themes__options__Header"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Header__1"
},
"section_titles": {
- "$ref": "#/$defs/rendercv__themes__options__SectionTitles"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__SectionTitles__1"
+ },
+ "sections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Sections__1"
},
"entries": {
- "$ref": "#/$defs/rendercv__themes__options__Entries"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Entries__1"
},
- "highlights": {
- "$ref": "#/$defs/rendercv__themes__options__Highlights"
- },
- "entry_types": {
- "$ref": "#/$defs/EntryTypes"
+ "templates": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Templates__1"
}
},
- "title": "ClassicThemeOptions",
+ "title": "ClassicTheme",
"type": "object"
},
- "CurriculumVitae": {
- "additionalProperties": true,
+ "CustomConnection": {
+ "additionalProperties": false,
"properties": {
- "name": {
- "default": null,
- "title": "Name",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "fontawesome_icon": {
+ "title": "Fontawesome Icon",
+ "type": "string"
},
- "location": {
- "default": null,
- "title": "Location",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "placeholder": {
+ "title": "Placeholder",
+ "type": "string"
},
- "email": {
- "default": null,
- "title": "Email",
- "oneOf": [
- {
- "format": "email",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "photo": {
- "default": null,
- "description": "Path to the photo of the person, relative to the input file.",
- "title": "Photo",
- "oneOf": [
- {
- "format": "path",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "phone": {
- "default": null,
- "description": "Country code should be included. For example, +1 for the United States.",
- "title": "Phone",
- "oneOf": [
- {
- "format": "phone",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "website": {
- "default": null,
- "title": "Website",
- "oneOf": [
+ "url": {
+ "anyOf": [
{
"format": "uri",
"maxLength": 2083,
@@ -135,12 +142,125 @@
{
"type": "null"
}
+ ],
+ "title": "Url"
+ }
+ },
+ "required": [
+ "fontawesome_icon",
+ "placeholder",
+ "url"
+ ],
+ "title": "CustomConnection",
+ "type": "object"
+ },
+ "Cv": {
+ "additionalProperties": true,
+ "properties": {
+ "name": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "John Doe",
+ "Jane Smith"
+ ],
+ "title": "Name"
+ },
+ "headline": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "Software Engineer",
+ "Data Scientist",
+ "Product Manager"
+ ],
+ "title": "Headline"
+ },
+ "location": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "New York, NY",
+ "London, UK",
+ "Istanbul, Türkiye"
+ ],
+ "title": "Location"
+ },
+ "email": {
+ "default": null,
+ "description": "You can provide multiple emails as a list.",
+ "examples": [
+ "john.doe@example.com",
+ [
+ "john.doe.1@example.com",
+ "john.doe.2@example.com"
+ ]
+ ],
+ "title": "Email"
+ },
+ "photo": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ExistingPathRelativeToInput"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "Photo file path, relative to the YAML file.",
+ "examples": [
+ "photo.jpg",
+ "images/profile.png"
]
},
- "social_networks": {
+ "phone": {
"default": null,
- "title": "Social Networks",
- "oneOf": [
+ "description": "Your phone number with country code in international format (e.g., +1 for USA, +44 for UK). The display format in the output is controlled by `design.header.connections.phone_number_format`. You can provide multiple numbers as a list.",
+ "examples": [
+ "+1-234-567-8900",
+ [
+ "+1-234-567-8900",
+ "+44 20 1234 5678"
+ ]
+ ],
+ "title": "Phone"
+ },
+ "website": {
+ "default": null,
+ "description": "You can provide multiple URLs as a list.",
+ "examples": [
+ "https://johndoe.com",
+ [
+ "https://johndoe.com",
+ "https://www.janesmith.dev"
+ ]
+ ],
+ "title": "Website"
+ },
+ "social_networks": {
+ "anyOf": [
{
"items": {
"$ref": "#/$defs/SocialNetwork"
@@ -150,261 +270,54 @@
{
"type": "null"
}
- ]
- },
- "sections": {
- "default": null,
- "description": "The sections of the CV, like Education, Experience, etc.",
- "title": "Sections",
- "oneOf": [
- {
- "additionalProperties": {
- "anyOf": [
- {
- "items": {
- "$ref": "#/$defs/OneLineEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "$ref": "#/$defs/NormalEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "$ref": "#/$defs/ExperienceEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "$ref": "#/$defs/EducationEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "$ref": "#/$defs/PublicationEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "$ref": "#/$defs/BulletEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "$ref": "#/$defs/NumberedEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "$ref": "#/$defs/ReversedNumberedEntry"
- },
- "type": "array"
- },
- {
- "items": {
- "type": "string"
- },
- "type": "array"
- }
- ]
- },
- "type": "object"
- },
- {
- "type": "null"
- }
- ]
- },
- "sort_entries": {
- "default": "none",
- "enum": [
- "reverse-chronological",
- "chronological",
- "none"
],
- "title": "Sort Entries",
- "type": "string"
- }
- },
- "title": "CV",
- "type": "object"
- },
- "EducationEntry": {
- "additionalProperties": true,
- "properties": {
- "institution": {
- "title": "Institution",
- "type": "string"
- },
- "area": {
- "title": "Area",
- "type": "string"
- },
- "degree": {
"default": null,
- "description": "The type of the degree, such as BS, BA, PhD, MS.",
- "examples": [
- "BS",
- "BA",
- "PhD",
- "MS"
- ],
- "title": "Degree",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "title": "Social Networks"
},
- "grade": {
- "default": null,
- "examples": [
- "GPA: 3.00/4.00"
- ],
- "title": "Grade",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "date": {
- "default": null,
- "description": "The date can be written in the formats YYYY-MM-DD, YYYY-MM, or YYYY, or as an arbitrary string such as \"Fall 2023.\"",
- "examples": [
- "2020-09-24",
- "Fall 2023"
- ],
- "title": "Date",
- "oneOf": [
- {
- "type": "integer"
- },
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "start_date": {
- "default": null,
- "description": "The event's start date, written in YYYY-MM-DD, YYYY-MM, or YYYY format.",
- "examples": [
- "2020-09-24"
- ],
- "title": "Start Date",
- "oneOf": [
- {
- "type": "integer"
- },
- {
- "pattern": "\\d{4}-\\d{2}(-\\d{2})?",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "end_date": {
- "default": null,
- "description": "The event's end date, written in YYYY-MM-DD, YYYY-MM, or YYYY format. If the event is ongoing, type “present” or provide only the start date.",
- "examples": [
- "2020-09-24",
- "present"
- ],
- "title": "End Date",
- "oneOf": [
- {
- "const": "present",
- "type": "string"
- },
- {
- "type": "integer"
- },
- {
- "pattern": "\\d{4}-\\d{2}(-\\d{2})?",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "location": {
- "default": null,
- "examples": [
- "Istanbul, Türkiye"
- ],
- "title": "Location",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "summary": {
- "default": null,
- "examples": [
- "Did this and that."
- ],
- "title": "Summary",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "highlights": {
- "default": null,
- "examples": [
- "Did this.",
- "Did that."
- ],
- "title": "Highlights",
- "oneOf": [
+ "custom_connections": {
+ "anyOf": [
{
"items": {
- "type": "string"
+ "$ref": "#/$defs/CustomConnection"
},
"type": "array"
},
{
"type": "null"
}
- ]
+ ],
+ "default": null,
+ "title": "Custom Connections"
+ },
+ "sections": {
+ "anyOf": [
+ {
+ "additionalProperties": {
+ "$ref": "#/$defs/Section"
+ },
+ "type": "object"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The sections of your CV. Keys are section titles (e.g., Experience, Education), and values are lists of entries. Entry types are automatically detected based on their fields.",
+ "examples": [
+ {
+ "Education": "...",
+ "Experience": "...",
+ "Projects": "...",
+ "Skills": "..."
+ }
+ ],
+ "title": "Sections"
}
},
- "required": [
- "institution",
- "area"
- ],
- "title": "Education Entry",
+ "title": "Cv",
"type": "object"
},
- "EngineeringclassicThemeOptions": {
+ "EngineeringclassicTheme": {
"additionalProperties": false,
"properties": {
"theme": {
@@ -414,121 +327,37 @@
"type": "string"
},
"page": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__Page",
- "default": {
- "size": "us-letter",
- "top_margin": "2cm",
- "bottom_margin": "2cm",
- "left_margin": "2cm",
- "right_margin": "2cm",
- "show_page_numbering": false,
- "show_last_updated_date": true
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Page__1"
},
"colors": {
- "$ref": "#/$defs/rendercv__themes__options__Colors"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Colors__1"
},
- "text": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__Text",
- "default": {
- "font_family": "Raleway",
- "font_size": "10pt",
- "leading": "0.6em",
- "alignment": "justified",
- "date_and_location_column_alignment": "right"
- }
+ "typography": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Typography__2"
},
"links": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__Links",
- "default": {
- "underline": false,
- "use_external_link_icon": false
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Links__2"
},
"header": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__Header",
- "default": {
- "name_font_family": "Raleway",
- "name_font_size": "30pt",
- "name_bold": false,
- "small_caps_for_name": false,
- "photo_width": "3.5cm",
- "vertical_space_between_name_and_connections": "0.7cm",
- "vertical_space_between_connections_and_first_section": "0.7cm",
- "horizontal_space_between_connections": "0.5cm",
- "connections_font_family": "Raleway",
- "separator_between_connections": "",
- "use_icons_for_connections": true,
- "use_urls_as_placeholders_for_connections": false,
- "make_connections_links": true,
- "alignment": "left"
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Header__2"
},
"section_titles": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__SectionTitles",
- "default": {
- "type": "with-partial-line",
- "font_family": "Raleway",
- "font_size": "1.4em",
- "bold": false,
- "small_caps": false,
- "line_thickness": "0.5pt",
- "vertical_space_above": "0.5cm",
- "vertical_space_below": "0.3cm"
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__SectionTitles__2"
+ },
+ "sections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Sections__2"
},
"entries": {
- "$ref": "#/$defs/rendercv__themes__options__Entries"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Entries__2"
},
- "highlights": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__Highlights",
- "default": {
- "bullet": "•",
- "nested_bullet": "-",
- "top_margin": "0.25cm",
- "left_margin": "0cm",
- "vertical_space_between_highlights": "0.25cm",
- "horizontal_space_between_bullet_and_highlight": "0.5em",
- "summary_left_margin": "0cm"
- }
- },
- "entry_types": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__EntryOptionsTypes",
- "default": {
- "one_line_entry": {
- "template": "**LABEL:** DETAILS"
- },
- "education_entry": {
- "date_and_location_column_template": "DATE",
- "degree_column_template": "**DEGREE**",
- "degree_column_width": "1cm",
- "main_column_first_row_template": "**INSTITUTION**, AREA -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "normal_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**NAME** -- **LOCATION**",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "experience_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**POSITION**, COMPANY -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "publication_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**TITLE**",
- "main_column_second_row_template": "AUTHORS\nURL (JOURNAL)",
- "main_column_second_row_without_journal_template": "AUTHORS\nURL",
- "main_column_second_row_without_url_template": "AUTHORS\nJOURNAL"
- }
- }
+ "templates": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Templates__2"
}
},
- "title": "EngineeringclassicThemeOptions",
+ "title": "EngineeringclassicTheme",
"type": "object"
},
- "EngineeringresumesThemeOptions": {
+ "EngineeringresumesTheme": {
"additionalProperties": false,
"properties": {
"theme": {
@@ -538,425 +367,83 @@
"type": "string"
},
"page": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__Page",
- "default": {
- "size": "us-letter",
- "top_margin": "2cm",
- "bottom_margin": "2cm",
- "left_margin": "2cm",
- "right_margin": "2cm",
- "show_page_numbering": false,
- "show_last_updated_date": true
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Page__2"
},
"colors": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__Colors",
- "default": {
- "text": "rgb(0, 0, 0)",
- "name": "rgb(0, 0, 0)",
- "connections": "rgb(0, 0, 0)",
- "section_titles": "rgb(0, 0, 0)",
- "links": "rgb(0, 0, 0)",
- "last_updated_date_and_page_numbering": "rgb(128, 128, 128)"
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Colors__2"
},
- "text": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__Text",
- "default": {
- "font_family": "XCharter",
- "font_size": "10pt",
- "leading": "0.6em",
- "alignment": "justified",
- "date_and_location_column_alignment": "right"
- }
+ "typography": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Typography__3"
},
"links": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__Links",
- "default": {
- "underline": true,
- "use_external_link_icon": false
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Links__3"
},
"header": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__Header",
- "default": {
- "name_font_family": "XCharter",
- "name_font_size": "25pt",
- "name_bold": false,
- "small_caps_for_name": false,
- "photo_width": "3.5cm",
- "vertical_space_between_name_and_connections": "0.7cm",
- "vertical_space_between_connections_and_first_section": "0.7cm",
- "horizontal_space_between_connections": "0.5cm",
- "connections_font_family": "XCharter",
- "separator_between_connections": "|",
- "use_icons_for_connections": false,
- "use_urls_as_placeholders_for_connections": true,
- "make_connections_links": true,
- "alignment": "center"
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Header__3"
},
"section_titles": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__SectionTitles",
- "default": {
- "type": "with-full-line",
- "font_family": "XCharter",
- "font_size": "1.2em",
- "bold": true,
- "small_caps": false,
- "line_thickness": "0.5pt",
- "vertical_space_above": "0.55cm",
- "vertical_space_below": "0.3cm"
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__SectionTitles__3"
+ },
+ "sections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Sections__3"
},
"entries": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__Entries",
- "default": {
- "date_and_location_width": "4.15cm",
- "left_and_right_margin": "0cm",
- "horizontal_space_between_columns": "0.1cm",
- "vertical_space_between_entries": "0.4cm",
- "allow_page_break_in_sections": true,
- "allow_page_break_in_entries": true,
- "short_second_row": false,
- "show_time_spans_in": []
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Entries__3"
},
- "highlights": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__Highlights",
- "default": {
- "bullet": "•",
- "nested_bullet": "-",
- "top_margin": "0.25cm",
- "left_margin": "0cm",
- "vertical_space_between_highlights": "0.19cm",
- "horizontal_space_between_bullet_and_highlight": "0.3em",
- "summary_left_margin": "0cm"
- }
- },
- "entry_types": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__EntryOptionsTypes",
- "default": {
- "one_line_entry": {
- "template": "**LABEL:** DETAILS"
- },
- "education_entry": {
- "date_and_location_column_template": "DATE",
- "degree_column_template": null,
- "degree_column_width": "1cm",
- "main_column_first_row_template": "**INSTITUTION**, DEGREE in AREA -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "normal_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**NAME** -- **LOCATION**",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "experience_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**POSITION**, COMPANY -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "publication_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**TITLE**",
- "main_column_second_row_template": "AUTHORS\nURL (JOURNAL)",
- "main_column_second_row_without_journal_template": "AUTHORS\nURL",
- "main_column_second_row_without_url_template": "AUTHORS\nJOURNAL"
- }
- }
+ "templates": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Templates__3"
}
},
- "title": "EngineeringresumesThemeOptions",
+ "title": "EngineeringresumesTheme",
"type": "object"
},
- "EntryTypes": {
- "additionalProperties": false,
- "properties": {
- "one_line_entry": {
- "$ref": "#/$defs/OneLineEntryOptions"
- },
- "education_entry": {
- "$ref": "#/$defs/rendercv__themes__options__EducationEntryOptions"
- },
- "normal_entry": {
- "$ref": "#/$defs/rendercv__themes__options__NormalEntryOptions"
- },
- "experience_entry": {
- "$ref": "#/$defs/rendercv__themes__options__ExperienceEntryOptions"
- },
- "publication_entry": {
- "$ref": "#/$defs/PublicationEntryOptions"
- }
- },
- "title": "EntryTypes",
- "type": "object"
- },
- "ExperienceEntry": {
- "additionalProperties": true,
- "properties": {
- "company": {
- "title": "Company",
- "type": "string"
- },
- "position": {
- "title": "Position",
- "type": "string"
- },
- "date": {
- "default": null,
- "description": "The date can be written in the formats YYYY-MM-DD, YYYY-MM, or YYYY, or as an arbitrary string such as \"Fall 2023.\"",
- "examples": [
- "2020-09-24",
- "Fall 2023"
- ],
- "title": "Date",
- "oneOf": [
- {
- "type": "integer"
- },
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "start_date": {
- "default": null,
- "description": "The event's start date, written in YYYY-MM-DD, YYYY-MM, or YYYY format.",
- "examples": [
- "2020-09-24"
- ],
- "title": "Start Date",
- "oneOf": [
- {
- "type": "integer"
- },
- {
- "pattern": "\\d{4}-\\d{2}(-\\d{2})?",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "end_date": {
- "default": null,
- "description": "The event's end date, written in YYYY-MM-DD, YYYY-MM, or YYYY format. If the event is ongoing, type “present” or provide only the start date.",
- "examples": [
- "2020-09-24",
- "present"
- ],
- "title": "End Date",
- "oneOf": [
- {
- "const": "present",
- "type": "string"
- },
- {
- "type": "integer"
- },
- {
- "pattern": "\\d{4}-\\d{2}(-\\d{2})?",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "location": {
- "default": null,
- "examples": [
- "Istanbul, Türkiye"
- ],
- "title": "Location",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "summary": {
- "default": null,
- "examples": [
- "Did this and that."
- ],
- "title": "Summary",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "highlights": {
- "default": null,
- "examples": [
- "Did this.",
- "Did that."
- ],
- "title": "Highlights",
- "oneOf": [
- {
- "items": {
- "type": "string"
- },
- "type": "array"
- },
- {
- "type": "null"
- }
- ]
- }
- },
- "required": [
- "company",
- "position"
- ],
- "title": "Experience Entry",
- "type": "object"
- },
- "Locale": {
+ "EnglishLocale": {
"additionalProperties": false,
"properties": {
"language": {
- "default": "en",
- "description": "The language as an ISO 639 alpha-2 code. It is used for hyphenation patterns. The default value is 'en'.",
- "pattern": "^\\w{2}$",
+ "const": "english",
+ "default": "english",
+ "description": "The language for your CV. The default value is `english`.",
"title": "Language",
"type": "string"
},
- "phone_number_format": {
- "default": "national",
- "description": "If 'national', phone numbers are formatted without the country code. If 'international', phone numbers are formatted with the country code. The default value is 'national'.",
- "title": "Phone Number Format",
- "oneOf": [
- {
- "enum": [
- "national",
- "international",
- "E164"
- ],
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "page_numbering_template": {
- "default": "NAME - Page PAGE_NUMBER of TOTAL_PAGES",
- "description": "The template of the page numbering. The following placeholders can be used:\n- NAME: The name of the person\n- PAGE_NUMBER: The current page number\n- TOTAL_PAGES: The total number of pages\n- TODAY: Today's date with `locale.date_template`\nThe default value is \"NAME - Page PAGE_NUMBER of TOTAL_PAGES\".",
- "title": "Page Numbering Template",
+ "last_updated": {
+ "default": "Last updated in",
+ "description": "Translation of \"Last updated in\". The default value is `Last updated in`.",
+ "title": "Last Updated",
"type": "string"
},
- "last_updated_date_template": {
- "default": "Last updated in TODAY",
- "description": "The template of the last updated date. The following placeholders can be used:\n- TODAY: Today's date with `locale.date_template`\nThe default value is \"Last updated in TODAY\".",
- "title": "Last Updated Date Template",
- "type": "string"
- },
- "date_template": {
- "default": "MONTH_ABBREVIATION YEAR",
- "description": "The template of the date. The following placeholders can be used:\n-FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe default value is \"MONTH_ABBREVIATION YEAR\".",
- "title": "Date Template",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
"month": {
"default": "month",
- "description": "Translation of the word \"month\" in the locale.",
- "title": "Translation of \"month\"",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Translation of \"month\" (singular). The default value is `month`.",
+ "title": "Month",
+ "type": "string"
},
"months": {
"default": "months",
- "description": "Translation of the word \"months\" in the locale.",
- "title": "Translation of \"months\"",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Translation of \"months\" (plural). The default value is `months`.",
+ "title": "Months",
+ "type": "string"
},
"year": {
"default": "year",
- "description": "Translation of the word \"year\" in the locale.",
- "title": "Translation of \"year\"",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Translation of \"year\" (singular). The default value is `year`.",
+ "title": "Year",
+ "type": "string"
},
"years": {
"default": "years",
- "description": "Translation of the word \"years\" in the locale.",
- "title": "Translation of \"years\"",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Translation of \"years\" (plural). The default value is `years`.",
+ "title": "Years",
+ "type": "string"
},
"present": {
"default": "present",
- "description": "Translation of the word \"present\" in the locale.",
- "title": "Translation of \"present\"",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Translation of \"present\" for ongoing dates. The default value is `present`.",
+ "title": "Present",
+ "type": "string"
},
- "to": {
- "default": "–",
- "description": "The word or character used to indicate a range in the locale (e.g., \"2020 - 2021\").",
- "title": "Translation of \"to\"",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "abbreviations_for_months": {
+ "month_abbreviations": {
"default": [
"Jan",
"Feb",
@@ -971,23 +458,16 @@
"Nov",
"Dec"
],
- "description": "Abbreviations of the months in the locale.",
- "title": "Abbreviations of Months",
- "oneOf": [
- {
- "items": {
- "type": "string"
- },
- "maxItems": 12,
- "minItems": 12,
- "type": "array"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "maxItems": 12,
+ "minItems": 12,
+ "title": "Month Abbreviations",
+ "type": "array"
},
- "full_names_of_months": {
+ "month_names": {
"default": [
"January",
"February",
@@ -1002,27 +482,807 @@
"November",
"December"
],
- "description": "Full names of the months in the locale.",
- "title": "Full Names of Months",
- "oneOf": [
- {
- "items": {
- "type": "string"
- },
- "maxItems": 12,
- "minItems": 12,
- "type": "array"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "maxItems": 12,
+ "minItems": 12,
+ "title": "Month Names",
+ "type": "array"
}
},
- "title": "Locale",
+ "title": "EnglishLocale",
"type": "object"
},
- "ModerncvThemeOptions": {
+ "ExactDate": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "integer"
+ }
+ ]
+ },
+ "ExistingPathRelativeToInput": {
+ "format": "path",
+ "type": "string"
+ },
+ "FrenchLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "french",
+ "default": "french",
+ "description": "The language for your CV. The default value is `french`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "Dernière mise à jour",
+ "description": "Translation of \"Last updated in\". The default value is `Dernière mise à jour`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "mois",
+ "description": "Translation of \"month\" (singular). The default value is `mois`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "mois",
+ "description": "Translation of \"months\" (plural). The default value is `mois`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "an",
+ "description": "Translation of \"year\" (singular). The default value is `an`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "ans",
+ "description": "Translation of \"years\" (plural). The default value is `ans`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "présent",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `présent`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "Jan",
+ "Fév",
+ "Mar",
+ "Avr",
+ "Mai",
+ "Juin",
+ "Juil",
+ "Aoû",
+ "Sep",
+ "Oct",
+ "Nov",
+ "Déc"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "Janvier",
+ "Février",
+ "Mars",
+ "Avril",
+ "Mai",
+ "Juin",
+ "Juillet",
+ "Août",
+ "Septembre",
+ "Octobre",
+ "Novembre",
+ "Décembre"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "FrenchLocale",
+ "type": "object"
+ },
+ "GermanLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "german",
+ "default": "german",
+ "description": "The language for your CV. The default value is `german`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "Zuletzt aktualisiert",
+ "description": "Translation of \"Last updated in\". The default value is `Zuletzt aktualisiert`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "Monat",
+ "description": "Translation of \"month\" (singular). The default value is `Monat`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "Monate",
+ "description": "Translation of \"months\" (plural). The default value is `Monate`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "Jahr",
+ "description": "Translation of \"year\" (singular). The default value is `Jahr`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "Jahre",
+ "description": "Translation of \"years\" (plural). The default value is `Jahre`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "gegenwärtig",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `gegenwärtig`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "Jan",
+ "Feb",
+ "Mär",
+ "Apr",
+ "Mai",
+ "Jun",
+ "Jul",
+ "Aug",
+ "Sep",
+ "Okt",
+ "Nov",
+ "Dez"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "Januar",
+ "Februar",
+ "März",
+ "April",
+ "Mai",
+ "Juni",
+ "Juli",
+ "August",
+ "September",
+ "Oktober",
+ "November",
+ "Dezember"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "GermanLocale",
+ "type": "object"
+ },
+ "HindiLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "hindi",
+ "default": "hindi",
+ "description": "The language for your CV. The default value is `hindi`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "अंतिम अद्यतन",
+ "description": "Translation of \"Last updated in\". The default value is `अंतिम अद्यतन`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "महीना",
+ "description": "Translation of \"month\" (singular). The default value is `महीना`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "महीने",
+ "description": "Translation of \"months\" (plural). The default value is `महीने`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "वर्ष",
+ "description": "Translation of \"year\" (singular). The default value is `वर्ष`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "वर्ष",
+ "description": "Translation of \"years\" (plural). The default value is `वर्ष`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "वर्तमान",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `वर्तमान`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "जन",
+ "फर",
+ "मार",
+ "अप्र",
+ "मई",
+ "जून",
+ "जुल",
+ "अग",
+ "सित",
+ "अक्ट",
+ "नव",
+ "दिस"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "जनवरी",
+ "फरवरी",
+ "मार्च",
+ "अप्रैल",
+ "मई",
+ "जून",
+ "जुलाई",
+ "अगस्त",
+ "सितंबर",
+ "अक्टूबर",
+ "नवंबर",
+ "दिसंबर"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "HindiLocale",
+ "type": "object"
+ },
+ "ItalianLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "italian",
+ "default": "italian",
+ "description": "The language for your CV. The default value is `italian`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "Ultimo aggiornamento",
+ "description": "Translation of \"Last updated in\". The default value is `Ultimo aggiornamento`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "mese",
+ "description": "Translation of \"month\" (singular). The default value is `mese`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "mesi",
+ "description": "Translation of \"months\" (plural). The default value is `mesi`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "anno",
+ "description": "Translation of \"year\" (singular). The default value is `anno`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "anni",
+ "description": "Translation of \"years\" (plural). The default value is `anni`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "presente",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `presente`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "Gen",
+ "Feb",
+ "Mar",
+ "Apr",
+ "Mag",
+ "Giu",
+ "Lug",
+ "Ago",
+ "Set",
+ "Ott",
+ "Nov",
+ "Dic"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "Gennaio",
+ "Febbraio",
+ "Marzo",
+ "Aprile",
+ "Maggio",
+ "Giugno",
+ "Luglio",
+ "Agosto",
+ "Settembre",
+ "Ottobre",
+ "Novembre",
+ "Dicembre"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "ItalianLocale",
+ "type": "object"
+ },
+ "JapaneseLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "japanese",
+ "default": "japanese",
+ "description": "The language for your CV. The default value is `japanese`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "最終更新",
+ "description": "Translation of \"Last updated in\". The default value is `最終更新`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "月",
+ "description": "Translation of \"month\" (singular). The default value is `月`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "ヶ月",
+ "description": "Translation of \"months\" (plural). The default value is `ヶ月`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "年",
+ "description": "Translation of \"year\" (singular). The default value is `年`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "年",
+ "description": "Translation of \"years\" (plural). The default value is `年`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "現在",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `現在`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "1月",
+ "2月",
+ "3月",
+ "4月",
+ "5月",
+ "6月",
+ "7月",
+ "8月",
+ "9月",
+ "10月",
+ "11月",
+ "12月"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "1月",
+ "2月",
+ "3月",
+ "4月",
+ "5月",
+ "6月",
+ "7月",
+ "8月",
+ "9月",
+ "10月",
+ "11月",
+ "12月"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "JapaneseLocale",
+ "type": "object"
+ },
+ "KoreanLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "korean",
+ "default": "korean",
+ "description": "The language for your CV. The default value is `korean`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "마지막 업데이트",
+ "description": "Translation of \"Last updated in\". The default value is `마지막 업데이트`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "월",
+ "description": "Translation of \"month\" (singular). The default value is `월`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "개월",
+ "description": "Translation of \"months\" (plural). The default value is `개월`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "년",
+ "description": "Translation of \"year\" (singular). The default value is `년`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "년",
+ "description": "Translation of \"years\" (plural). The default value is `년`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "현재",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `현재`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "1월",
+ "2월",
+ "3월",
+ "4월",
+ "5월",
+ "6월",
+ "7월",
+ "8월",
+ "9월",
+ "10월",
+ "11월",
+ "12월"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "1월",
+ "2월",
+ "3월",
+ "4월",
+ "5월",
+ "6월",
+ "7월",
+ "8월",
+ "9월",
+ "10월",
+ "11월",
+ "12월"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "KoreanLocale",
+ "type": "object"
+ },
+ "ListOfEntries": {
+ "anyOf": [
+ {
+ "items": {
+ "type": "string"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/rendercv__schema__models__cv__entries__one_line__OneLineEntry"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/rendercv__schema__models__cv__entries__normal__NormalEntry"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/rendercv__schema__models__cv__entries__experience__ExperienceEntry"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/rendercv__schema__models__cv__entries__education__EducationEntry"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/rendercv__schema__models__cv__entries__publication__PublicationEntry"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/BulletEntry"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/NumberedEntry"
+ },
+ "type": "array"
+ },
+ {
+ "items": {
+ "$ref": "#/$defs/ReversedNumberedEntry"
+ },
+ "type": "array"
+ }
+ ]
+ },
+ "Locale": {
+ "discriminator": {
+ "mapping": {
+ "english": "#/$defs/EnglishLocale",
+ "french": "#/$defs/FrenchLocale",
+ "german": "#/$defs/GermanLocale",
+ "hindi": "#/$defs/HindiLocale",
+ "italian": "#/$defs/ItalianLocale",
+ "japanese": "#/$defs/JapaneseLocale",
+ "korean": "#/$defs/KoreanLocale",
+ "mandarin_chineese": "#/$defs/MandarinChineeseLocale",
+ "portuguese": "#/$defs/PortugueseLocale",
+ "russian": "#/$defs/RussianLocale",
+ "spanish": "#/$defs/SpanishLocale",
+ "turkish": "#/$defs/TurkishLocale"
+ },
+ "propertyName": "language"
+ },
+ "oneOf": [
+ {
+ "$ref": "#/$defs/EnglishLocale"
+ },
+ {
+ "$ref": "#/$defs/FrenchLocale"
+ },
+ {
+ "$ref": "#/$defs/GermanLocale"
+ },
+ {
+ "$ref": "#/$defs/HindiLocale"
+ },
+ {
+ "$ref": "#/$defs/ItalianLocale"
+ },
+ {
+ "$ref": "#/$defs/JapaneseLocale"
+ },
+ {
+ "$ref": "#/$defs/KoreanLocale"
+ },
+ {
+ "$ref": "#/$defs/MandarinChineeseLocale"
+ },
+ {
+ "$ref": "#/$defs/PortugueseLocale"
+ },
+ {
+ "$ref": "#/$defs/RussianLocale"
+ },
+ {
+ "$ref": "#/$defs/SpanishLocale"
+ },
+ {
+ "$ref": "#/$defs/TurkishLocale"
+ }
+ ]
+ },
+ "MandarinChineeseLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "mandarin_chineese",
+ "default": "mandarin_chineese",
+ "description": "The language for your CV. The default value is `mandarin_chineese`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "最后更新于",
+ "description": "Translation of \"Last updated in\". The default value is `最后更新于`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "个月",
+ "description": "Translation of \"month\" (singular). The default value is `个月`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "个月",
+ "description": "Translation of \"months\" (plural). The default value is `个月`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "年",
+ "description": "Translation of \"year\" (singular). The default value is `年`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "年",
+ "description": "Translation of \"years\" (plural). The default value is `年`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "至今",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `至今`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "1月",
+ "2月",
+ "3月",
+ "4月",
+ "5月",
+ "6月",
+ "7月",
+ "8月",
+ "9月",
+ "10月",
+ "11月",
+ "12月"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "一月",
+ "二月",
+ "三月",
+ "四月",
+ "五月",
+ "六月",
+ "七月",
+ "八月",
+ "九月",
+ "十月",
+ "十一月",
+ "十二月"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "MandarinChineeseLocale",
+ "type": "object"
+ },
+ "ModerncvTheme": {
"additionalProperties": false,
"properties": {
"theme": {
@@ -1032,253 +1292,45 @@
"type": "string"
},
"page": {
- "$ref": "#/$defs/rendercv__themes__options__Page"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Page__1"
},
"colors": {
- "$ref": "#/$defs/rendercv__themes__options__Colors"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Colors__1"
},
- "text": {
- "$ref": "#/$defs/rendercv__themes__moderncv__Text",
- "default": {
- "font_family": "Fontin",
- "font_size": "10pt",
- "leading": "0.6em",
- "alignment": "justified",
- "date_and_location_column_alignment": "right"
- }
+ "typography": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Typography__4"
},
"links": {
- "$ref": "#/$defs/rendercv__themes__moderncv__Links",
- "default": {
- "underline": true,
- "use_external_link_icon": false
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Links__4"
},
"header": {
- "$ref": "#/$defs/rendercv__themes__moderncv__Header",
- "default": {
- "name_font_family": "Fontin",
- "name_font_size": "25pt",
- "name_bold": false,
- "small_caps_for_name": false,
- "photo_width": "3.5cm",
- "vertical_space_between_name_and_connections": "0.7cm",
- "vertical_space_between_connections_and_first_section": "0.7cm",
- "horizontal_space_between_connections": "0.5cm",
- "connections_font_family": "Fontin",
- "separator_between_connections": "",
- "use_icons_for_connections": true,
- "use_urls_as_placeholders_for_connections": false,
- "make_connections_links": true,
- "alignment": "left"
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Header__4"
},
"section_titles": {
- "$ref": "#/$defs/rendercv__themes__moderncv__SectionTitles",
- "default": {
- "type": "moderncv",
- "font_family": "Fontin",
- "font_size": "1.4em",
- "bold": false,
- "small_caps": false,
- "line_thickness": "0.15cm",
- "vertical_space_above": "0.55cm",
- "vertical_space_below": "0.3cm"
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__SectionTitles__4"
+ },
+ "sections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Sections__4"
},
"entries": {
- "$ref": "#/$defs/rendercv__themes__moderncv__Entries",
- "default": {
- "date_and_location_width": "4.15cm",
- "left_and_right_margin": "0cm",
- "horizontal_space_between_columns": "0.4cm",
- "vertical_space_between_entries": "0.4cm",
- "allow_page_break_in_sections": true,
- "allow_page_break_in_entries": true,
- "short_second_row": false,
- "show_time_spans_in": []
- }
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Entries__4"
},
- "highlights": {
- "$ref": "#/$defs/rendercv__themes__moderncv__Highlights",
- "default": {
- "bullet": "•",
- "nested_bullet": "-",
- "top_margin": "0.25cm",
- "left_margin": "0cm",
- "vertical_space_between_highlights": "0.19cm",
- "horizontal_space_between_bullet_and_highlight": "0.3em",
- "summary_left_margin": "0cm"
- }
- },
- "entry_types": {
- "$ref": "#/$defs/rendercv__themes__moderncv__EntryOptionsTypes",
- "default": {
- "one_line_entry": {
- "template": "**LABEL:** DETAILS"
- },
- "education_entry": {
- "date_and_location_column_template": "DATE",
- "degree_column_template": null,
- "degree_column_width": "1cm",
- "main_column_first_row_template": "**INSTITUTION**, DEGREE in AREA -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "normal_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**NAME** -- **LOCATION**",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "experience_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**POSITION**, COMPANY -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "publication_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**TITLE**",
- "main_column_second_row_template": "AUTHORS\nURL (JOURNAL)",
- "main_column_second_row_without_journal_template": "AUTHORS\nURL",
- "main_column_second_row_without_url_template": "AUTHORS\nJOURNAL"
- }
- }
+ "templates": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Templates__4"
}
},
- "title": "ModerncvThemeOptions",
- "type": "object"
- },
- "NormalEntry": {
- "additionalProperties": true,
- "properties": {
- "name": {
- "title": "Name",
- "type": "string"
- },
- "date": {
- "default": null,
- "description": "The date can be written in the formats YYYY-MM-DD, YYYY-MM, or YYYY, or as an arbitrary string such as \"Fall 2023.\"",
- "examples": [
- "2020-09-24",
- "Fall 2023"
- ],
- "title": "Date",
- "oneOf": [
- {
- "type": "integer"
- },
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "start_date": {
- "default": null,
- "description": "The event's start date, written in YYYY-MM-DD, YYYY-MM, or YYYY format.",
- "examples": [
- "2020-09-24"
- ],
- "title": "Start Date",
- "oneOf": [
- {
- "type": "integer"
- },
- {
- "pattern": "\\d{4}-\\d{2}(-\\d{2})?",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "end_date": {
- "default": null,
- "description": "The event's end date, written in YYYY-MM-DD, YYYY-MM, or YYYY format. If the event is ongoing, type “present” or provide only the start date.",
- "examples": [
- "2020-09-24",
- "present"
- ],
- "title": "End Date",
- "oneOf": [
- {
- "const": "present",
- "type": "string"
- },
- {
- "type": "integer"
- },
- {
- "pattern": "\\d{4}-\\d{2}(-\\d{2})?",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "location": {
- "default": null,
- "examples": [
- "Istanbul, Türkiye"
- ],
- "title": "Location",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "summary": {
- "default": null,
- "examples": [
- "Did this and that."
- ],
- "title": "Summary",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "highlights": {
- "default": null,
- "examples": [
- "Did this.",
- "Did that."
- ],
- "title": "Highlights",
- "oneOf": [
- {
- "items": {
- "type": "string"
- },
- "type": "array"
- },
- {
- "type": "null"
- }
- ]
- }
- },
- "required": [
- "name"
- ],
- "title": "Normal Entry",
+ "title": "ModerncvTheme",
"type": "object"
},
"NumberedEntry": {
"additionalProperties": true,
+ "description": null,
"properties": {
"number": {
+ "examples": [
+ "First publication about XYZ",
+ "Patent for ABC technology"
+ ],
"title": "Number",
"type": "string"
}
@@ -1286,370 +1338,221 @@
"required": [
"number"
],
- "title": "Numbered Entry",
+ "title": "NumberedEntry",
"type": "object"
},
- "OneLineEntry": {
- "additionalProperties": true,
- "properties": {
- "label": {
- "title": "Label",
- "type": "string"
- },
- "details": {
- "title": "Details",
- "type": "string"
- }
- },
- "required": [
- "label",
- "details"
+ "PageSize": {
+ "enum": [
+ "a4",
+ "a5",
+ "us-letter",
+ "us-executive"
],
- "title": "One Line Entry",
- "type": "object"
+ "type": "string"
},
- "OneLineEntryOptions": {
+ "PhoneNumberFormatType": {
+ "enum": [
+ "national",
+ "international",
+ "E164"
+ ],
+ "type": "string"
+ },
+ "PlannedPathRelativeToInput": {
+ "format": "path",
+ "type": "string"
+ },
+ "PortugueseLocale": {
"additionalProperties": false,
"properties": {
- "template": {
- "default": "**LABEL:** DETAILS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Template",
- "type": "string"
- }
- },
- "title": "OneLineEntryOptions",
- "type": "object"
- },
- "PublicationEntry": {
- "additionalProperties": true,
- "properties": {
- "title": {
- "title": "Publication Title",
+ "language": {
+ "const": "portuguese",
+ "default": "portuguese",
+ "description": "The language for your CV. The default value is `portuguese`.",
+ "title": "Language",
"type": "string"
},
- "authors": {
+ "last_updated": {
+ "default": "Última atualização",
+ "description": "Translation of \"Last updated in\". The default value is `Última atualização`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "mês",
+ "description": "Translation of \"month\" (singular). The default value is `mês`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "meses",
+ "description": "Translation of \"months\" (plural). The default value is `meses`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "ano",
+ "description": "Translation of \"year\" (singular). The default value is `ano`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "anos",
+ "description": "Translation of \"years\" (plural). The default value is `anos`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "presente",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `presente`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "Jan",
+ "Fev",
+ "Mar",
+ "Abr",
+ "Mai",
+ "Jun",
+ "Jul",
+ "Ago",
+ "Set",
+ "Out",
+ "Nov",
+ "Dez"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
"items": {
"type": "string"
},
- "title": "Authors",
+ "title": "Month Abbreviations",
"type": "array"
},
- "doi": {
- "default": null,
- "examples": [
- "10.48550/arXiv.2310.03138"
+ "month_names": {
+ "default": [
+ "Janeiro",
+ "Fevereiro",
+ "Março",
+ "Abril",
+ "Maio",
+ "Junho",
+ "Julho",
+ "Agosto",
+ "Setembro",
+ "Outubro",
+ "Novembro",
+ "Dezembro"
],
- "title": "DOI",
- "oneOf": [
- {
- "pattern": "\\b10\\..*",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "url": {
- "default": null,
- "description": "If DOI is provided, it will be ignored.",
- "title": "URL",
- "oneOf": [
- {
- "format": "uri",
- "maxLength": 2083,
- "minLength": 1,
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "journal": {
- "default": null,
- "title": "Journal",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "date": {
- "default": null,
- "description": "The date can be written in the formats YYYY-MM-DD, YYYY-MM, or YYYY, or as an arbitrary string such as \"Fall 2023.\"",
- "examples": [
- "2020-09-24",
- "Fall 2023"
- ],
- "title": "Date",
- "oneOf": [
- {
- "type": "integer"
- },
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- }
- },
- "required": [
- "title",
- "authors"
- ],
- "title": "Publication Entry",
- "type": "object"
- },
- "PublicationEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**TITLE**",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "AUTHORS\nURL (JOURNAL)",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "main_column_second_row_without_journal_template": {
- "default": "AUTHORS\nURL",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Without Journal Template",
- "type": "string"
- },
- "main_column_second_row_without_url_template": {
- "default": "AUTHORS\nJOURNAL",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Without Url Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "PublicationEntryOptions",
- "type": "object"
- },
- "RenderCVSettings": {
- "additionalProperties": false,
- "properties": {
- "date": {
- "default": null,
- "description": "The date that will be used everywhere (e.g., in the output file names, last updated date, computation of time spans for the events that are currently happening, etc.). The default value is the current date.",
- "format": "date",
- "title": "Date",
- "type": "string"
- },
- "render_command": {
- "default": null,
- "description": "RenderCV's `render` command settings. They are the same as the command line arguments. CLI arguments have higher priority than the settings in the input file.",
- "title": "Render Command Settings",
- "oneOf": [
- {
- "$ref": "#/$defs/RenderCommandSettings"
- },
- {
- "type": "null"
- }
- ]
- },
- "bold_keywords": {
- "default": [],
- "description": "The keywords that will be bold in the output. The default value is an empty list.",
+ "description": "Full month names (January-December).",
"items": {
"type": "string"
},
- "title": "Bold Keywords",
+ "title": "Month Names",
"type": "array"
- },
- "sort_entries": {
- "default": "none",
- "description": "How the entries should be sorted based on their dates. The available options are 'reverse-chronological', 'chronological', and 'none'. The default value is 'none'.",
- "enum": [
- "reverse-chronological",
- "chronological",
- "none"
- ],
- "title": "Sort Entries",
- "type": "string"
}
},
- "title": "RenderCV Settings",
+ "title": "PortugueseLocale",
"type": "object"
},
- "RenderCommandSettings": {
+ "RenderCommand": {
"additionalProperties": false,
"properties": {
"design": {
- "default": null,
- "description": "The file path to the yaml file containing the `design` field separately.",
- "title": "`design` Field's YAML File",
- "oneOf": [
+ "anyOf": [
{
- "format": "path",
- "type": "string"
+ "$ref": "#/$defs/ExistingPathRelativeToInput"
},
{
"type": "null"
}
- ]
- },
- "rendercv_settings": {
+ ],
"default": null,
- "description": "The file path to the yaml file containing the `rendercv_settings` field separately.",
- "title": "`rendercv_settings` Field's YAML File",
- "oneOf": [
- {
- "format": "path",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Path to a YAML file containing the `design` field."
},
"locale": {
- "default": null,
- "description": "The file path to the yaml file containing the `locale` field separately.",
- "title": "`locale` Field's YAML File",
- "oneOf": [
+ "anyOf": [
{
- "format": "path",
- "type": "string"
+ "$ref": "#/$defs/ExistingPathRelativeToInput"
},
{
"type": "null"
}
- ]
- },
- "output_folder_name": {
- "default": "rendercv_output",
- "description": "The name of the folder where the output files will be saved. The following placeholders can be used:\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\n- NAME: The name of the CV owner\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe default value is \"MONTH_ABBREVIATION YEAR\".\nThe default value is \"rendercv_output\".",
- "title": "Output Folder Name",
- "type": "string"
- },
- "pdf_path": {
+ ],
"default": null,
- "description": "The path to copy the PDF file to. If it is not provided, the PDF file will not be copied. The following placeholders can be used:\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\n- NAME: The name of the CV owner\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe default value is \"MONTH_ABBREVIATION YEAR\".\nThe default value is null.",
- "title": "PDF Path",
- "oneOf": [
- {
- "format": "path",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "description": "Path to a YAML file containing the `locale` field."
},
"typst_path": {
- "default": null,
- "description": "The path to copy the Typst file to. If it is not provided, the Typst file will not be copied. The following placeholders can be used:\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\n- NAME: The name of the CV owner\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe default value is \"MONTH_ABBREVIATION YEAR\".\nThe default value is null.",
- "title": "Typst Path",
- "oneOf": [
- {
- "format": "path",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "$ref": "#/$defs/PlannedPathRelativeToInput",
+ "default": "rendercv_output/NAME_IN_SNAKE_CASE_CV.typ",
+ "description": "Output path for the Typst file, relative to the input YAML file. The default value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.typ`.\n\nThe following placeholders can be used:\n\n- MONTH_NAME: Full name of the month (e.g., January)\n- MONTH_ABBREVIATION: Abbreviation of the month (e.g., Jan)\n- MONTH: Month as a number (e.g., 1)\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits (e.g., 01)\n- YEAR: Year as a number (e.g., 2024)\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits (e.g., 24)\n- NAME: The name of the CV owner (e.g., John Doe)\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case (e.g., John_Doe)\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case (e.g., john_doe)\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case (e.g., JOHN_DOE)\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case (e.g., John-Doe)\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case (e.g., john-doe)\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case (e.g., JOHN-DOE)\n"
},
- "html_path": {
- "default": null,
- "description": "The path to copy the HTML file to. If it is not provided, the HTML file will not be copied. The following placeholders can be used:\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\n- NAME: The name of the CV owner\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe default value is \"MONTH_ABBREVIATION YEAR\".\nThe default value is null.",
- "title": "HTML Path",
- "oneOf": [
- {
- "format": "path",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "png_path": {
- "default": null,
- "description": "The path to copy the PNG file to. If it is not provided, the PNG file will not be copied. The following placeholders can be used:\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\n- NAME: The name of the CV owner\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe default value is \"MONTH_ABBREVIATION YEAR\".\nThe default value is null.",
- "title": "PNG Path",
- "oneOf": [
- {
- "format": "path",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "pdf_path": {
+ "$ref": "#/$defs/PlannedPathRelativeToInput",
+ "default": "rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf",
+ "description": "Output path for the PDF file, relative to the input YAML file. The default value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf`.\n\nThe following placeholders can be used:\n\n- MONTH_NAME: Full name of the month (e.g., January)\n- MONTH_ABBREVIATION: Abbreviation of the month (e.g., Jan)\n- MONTH: Month as a number (e.g., 1)\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits (e.g., 01)\n- YEAR: Year as a number (e.g., 2024)\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits (e.g., 24)\n- NAME: The name of the CV owner (e.g., John Doe)\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case (e.g., John_Doe)\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case (e.g., john_doe)\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case (e.g., JOHN_DOE)\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case (e.g., John-Doe)\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case (e.g., john-doe)\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case (e.g., JOHN-DOE)\n"
},
"markdown_path": {
- "default": null,
- "description": "The path to copy the Markdown file to. If it is not provided, the Markdown file will not be copied. The following placeholders can be used:\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\n- NAME: The name of the CV owner\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case\n- FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe default value is \"MONTH_ABBREVIATION YEAR\".\nThe default value is null.",
- "title": "Markdown Path",
- "oneOf": [
- {
- "format": "path",
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
+ "$ref": "#/$defs/PlannedPathRelativeToInput",
+ "default": "rendercv_output/NAME_IN_SNAKE_CASE_CV.md",
+ "description": "Output path for the Markdown file, relative to the input YAML file. The default value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.md`.\n\nThe following placeholders can be used:\n\n- MONTH_NAME: Full name of the month (e.g., January)\n- MONTH_ABBREVIATION: Abbreviation of the month (e.g., Jan)\n- MONTH: Month as a number (e.g., 1)\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits (e.g., 01)\n- YEAR: Year as a number (e.g., 2024)\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits (e.g., 24)\n- NAME: The name of the CV owner (e.g., John Doe)\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case (e.g., John_Doe)\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case (e.g., john_doe)\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case (e.g., JOHN_DOE)\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case (e.g., John-Doe)\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case (e.g., john-doe)\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case (e.g., JOHN-DOE)\n",
+ "title": "Markdown Path"
},
- "dont_generate_html": {
- "default": false,
- "description": "A boolean value to determine whether the HTML file will be generated. The default value is False.",
- "title": "Don't Generate HTML",
- "type": "boolean"
+ "html_path": {
+ "$ref": "#/$defs/PlannedPathRelativeToInput",
+ "default": "rendercv_output/NAME_IN_SNAKE_CASE_CV.html",
+ "description": "Output path for the HTML file, relative to the input YAML file. The default value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.html`.\n\nThe following placeholders can be used:\n\n- MONTH_NAME: Full name of the month (e.g., January)\n- MONTH_ABBREVIATION: Abbreviation of the month (e.g., Jan)\n- MONTH: Month as a number (e.g., 1)\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits (e.g., 01)\n- YEAR: Year as a number (e.g., 2024)\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits (e.g., 24)\n- NAME: The name of the CV owner (e.g., John Doe)\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case (e.g., John_Doe)\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case (e.g., john_doe)\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case (e.g., JOHN_DOE)\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case (e.g., John-Doe)\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case (e.g., john-doe)\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case (e.g., JOHN-DOE)\n"
+ },
+ "png_path": {
+ "$ref": "#/$defs/PlannedPathRelativeToInput",
+ "default": "rendercv_output/NAME_IN_SNAKE_CASE_CV.png",
+ "description": "Output path for PNG files, relative to the input YAML file. The default value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.png`.\n\nThe following placeholders can be used:\n\n- MONTH_NAME: Full name of the month (e.g., January)\n- MONTH_ABBREVIATION: Abbreviation of the month (e.g., Jan)\n- MONTH: Month as a number (e.g., 1)\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits (e.g., 01)\n- YEAR: Year as a number (e.g., 2024)\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits (e.g., 24)\n- NAME: The name of the CV owner (e.g., John Doe)\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case (e.g., John_Doe)\n- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case (e.g., john_doe)\n- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case (e.g., JOHN_DOE)\n- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case (e.g., John-Doe)\n- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case (e.g., john-doe)\n- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case (e.g., JOHN-DOE)\n"
},
"dont_generate_markdown": {
"default": false,
- "description": "A boolean value to determine whether the Markdown file will be generated. The default value is \"false\".",
+ "description": "Skip Markdown generation. This also disables HTML generation. The default value is `false`.",
"title": "Don't Generate Markdown",
"type": "boolean"
},
+ "dont_generate_html": {
+ "default": false,
+ "description": "Skip HTML generation. The default value is `false`.",
+ "title": "Don't Generate HTML",
+ "type": "boolean"
+ },
+ "dont_generate_typst": {
+ "default": false,
+ "description": "Skip Typst generation. This also disables PDF and PNG generation. The default value is `false`.",
+ "title": "Don't Generate Typst",
+ "type": "boolean"
+ },
"dont_generate_pdf": {
"default": false,
- "description": "A boolean value to determine whether the PDF file will be generated. The default value is False.",
+ "description": "Skip PDF generation. The default value is `false`.",
"title": "Don't Generate PDF",
"type": "boolean"
},
"dont_generate_png": {
"default": false,
- "description": "A boolean value to determine whether the PNG file will be generated. The default value is False.",
+ "description": "Skip PNG generation. The default value is `false`.",
"title": "Don't Generate PNG",
"type": "boolean"
- },
- "watch": {
- "default": false,
- "description": "A boolean value to determine whether to re-run RenderCV when the inputfile is updated. The default value is \"false\".",
- "title": "Re-run RenderCV When the Input File is Updated",
- "type": "boolean"
}
},
- "title": "RenderCommandSettings",
+ "title": "RenderCommand",
"type": "object"
},
"ReversedNumberedEntry": {
"additionalProperties": true,
+ "description": null,
"properties": {
"reversed_number": {
+ "description": "Reverse-numbered list item. Numbering goes in reverse (5, 4, 3, 2, 1), making recent items have higher numbers.",
+ "examples": [
+ "Latest research paper",
+ "Recent patent application"
+ ],
"title": "Reversed Number",
"type": "string"
}
@@ -1657,10 +1560,104 @@
"required": [
"reversed_number"
],
- "title": "Reversed Numbered Entry",
+ "title": "ReversedNumberedEntry",
"type": "object"
},
- "Sb2novThemeOptions": {
+ "RussianLocale": {
+ "additionalProperties": false,
+ "properties": {
+ "language": {
+ "const": "russian",
+ "default": "russian",
+ "description": "The language for your CV. The default value is `russian`.",
+ "title": "Language",
+ "type": "string"
+ },
+ "last_updated": {
+ "default": "Последнее обновление",
+ "description": "Translation of \"Last updated in\". The default value is `Последнее обновление`.",
+ "title": "Last Updated",
+ "type": "string"
+ },
+ "month": {
+ "default": "месяц",
+ "description": "Translation of \"month\" (singular). The default value is `месяц`.",
+ "title": "Month",
+ "type": "string"
+ },
+ "months": {
+ "default": "месяцы",
+ "description": "Translation of \"months\" (plural). The default value is `месяцы`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "год",
+ "description": "Translation of \"year\" (singular). The default value is `год`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "лет",
+ "description": "Translation of \"years\" (plural). The default value is `лет`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "настоящее время",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `настоящее время`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "Янв",
+ "Фев",
+ "Мар",
+ "Апр",
+ "Май",
+ "Июн",
+ "Июл",
+ "Авг",
+ "Сен",
+ "Окт",
+ "Ноя",
+ "Дек"
+ ],
+ "description": "Month abbreviations (Jan-Dec).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "Январь",
+ "Февраль",
+ "Март",
+ "Апрель",
+ "Май",
+ "Июнь",
+ "Июль",
+ "Август",
+ "Сентябрь",
+ "Октябрь",
+ "Ноябрь",
+ "Декабрь"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
+ "type": "array"
+ }
+ },
+ "title": "RussianLocale",
+ "type": "object"
+ },
+ "Sb2novTheme": {
"additionalProperties": false,
"properties": {
"theme": {
@@ -1670,61 +1667,119 @@
"type": "string"
},
"page": {
- "$ref": "#/$defs/rendercv__themes__options__Page"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Page__1"
},
"colors": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__Colors"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Colors__3"
},
- "text": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__Text"
+ "typography": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Typography__5"
},
"links": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__Links"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Links__5"
},
"header": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__Header"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Header__5"
},
"section_titles": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__SectionTitles"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__SectionTitles__5"
+ },
+ "sections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Sections__5"
},
"entries": {
- "$ref": "#/$defs/rendercv__themes__options__Entries"
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Entries__5"
},
- "highlights": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__Highlights"
- },
- "entry_types": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__EntryOptionsTypes"
+ "templates": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Templates__5"
}
},
- "title": "Sb2novThemeOptions",
+ "title": "Sb2novTheme",
+ "type": "object"
+ },
+ "Section": {
+ "$ref": "#/$defs/ListOfEntries"
+ },
+ "SectionTitleType": {
+ "enum": [
+ "with_partial_line",
+ "with_full_line",
+ "without_line",
+ "moderncv"
+ ],
+ "type": "string"
+ },
+ "Settings": {
+ "additionalProperties": false,
+ "properties": {
+ "current_date": {
+ "default": null,
+ "description": "The date to use as \"current date\" for filenames, the \"last updated\" label, and time span calculations. Defaults to the actual current date.",
+ "format": "date",
+ "title": "Date",
+ "type": "string"
+ },
+ "render_command": {
+ "$ref": "#/$defs/RenderCommand",
+ "description": "Settings for the `render` command. These correspond to command-line arguments. CLI arguments take precedence over these settings.",
+ "title": "Render Command Settings"
+ },
+ "bold_keywords": {
+ "default": [],
+ "description": "Keywords to automatically bold in the output.",
+ "items": {
+ "type": "string"
+ },
+ "title": "Bold Keywords",
+ "type": "array"
+ }
+ },
+ "title": "Settings",
+ "type": "object"
+ },
+ "SmallCaps": {
+ "additionalProperties": false,
+ "properties": {
+ "name": {
+ "default": false,
+ "description": "Whether to use small caps for the name. The default value is `false`.",
+ "title": "Name",
+ "type": "boolean"
+ },
+ "headline": {
+ "default": false,
+ "description": "Whether to use small caps for the headline. The default value is `false`.",
+ "title": "Headline",
+ "type": "boolean"
+ },
+ "connections": {
+ "default": false,
+ "description": "Whether to use small caps for connections. The default value is `false`.",
+ "title": "Connections",
+ "type": "boolean"
+ },
+ "section_titles": {
+ "default": false,
+ "description": "Whether to use small caps for section titles. The default value is `false`.",
+ "title": "Section Titles",
+ "type": "boolean"
+ }
+ },
+ "title": "SmallCaps",
"type": "object"
},
"SocialNetwork": {
"additionalProperties": false,
"properties": {
"network": {
- "enum": [
- "LinkedIn",
- "GitHub",
- "GitLab",
- "IMDB",
- "Instagram",
- "ORCID",
- "Mastodon",
- "StackOverflow",
- "ResearchGate",
- "YouTube",
- "Google Scholar",
- "Telegram",
- "Leetcode",
- "X"
- ],
- "title": "Social Network",
- "type": "string"
+ "$ref": "#/$defs/SocialNetworkName"
},
"username": {
- "description": "The username used in the social network. The link will be generated automatically.",
+ "examples": [
+ "john_doe",
+ "@johndoe@mastodon.social",
+ "12345/john-doe"
+ ],
"title": "Username",
"type": "string"
}
@@ -1733,3336 +1788,3685 @@
"network",
"username"
],
- "title": "Social Network",
+ "title": "SocialNetwork",
"type": "object"
},
- "rendercv__themes__engineeringclassic__EducationEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**INSTITUTION**, AREA -- LOCATION",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "degree_column_template": {
- "default": "**DEGREE**",
- "description": "If given, a degree column will be added to the education entry. If \"null\", no degree column will be shown. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Degree Column Template",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "degree_column_width": {
- "default": "1cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Degree Column Width",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "EducationEntryOptions",
- "type": "object"
+ "SocialNetworkName": {
+ "enum": [
+ "LinkedIn",
+ "GitHub",
+ "GitLab",
+ "IMDB",
+ "Instagram",
+ "ORCID",
+ "Mastodon",
+ "StackOverflow",
+ "ResearchGate",
+ "YouTube",
+ "Google Scholar",
+ "Telegram",
+ "WhatsApp",
+ "Leetcode",
+ "X"
+ ],
+ "type": "string"
},
- "rendercv__themes__engineeringclassic__EntryOptionsTypes": {
+ "SpanishLocale": {
"additionalProperties": false,
"properties": {
- "one_line_entry": {
- "$ref": "#/$defs/OneLineEntryOptions"
- },
- "education_entry": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__EducationEntryOptions",
- "default": {
- "main_column_first_row_template": "**INSTITUTION**, AREA -- LOCATION",
- "degree_column_template": "**DEGREE**",
- "degree_column_width": "1cm",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "normal_entry": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__NormalEntryOptions",
- "default": {
- "main_column_first_row_template": "**NAME** -- **LOCATION**",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "experience_entry": {
- "$ref": "#/$defs/rendercv__themes__engineeringclassic__ExperienceEntryOptions",
- "default": {
- "main_column_first_row_template": "**POSITION**, COMPANY -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "publication_entry": {
- "$ref": "#/$defs/PublicationEntryOptions"
- }
- },
- "title": "EntryOptionsTypes",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__ExperienceEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**POSITION**, COMPANY -- LOCATION",
- "title": "Main Column First Row Template",
+ "language": {
+ "const": "spanish",
+ "default": "spanish",
+ "description": "The language for your CV. The default value is `spanish`.",
+ "title": "Language",
"type": "string"
},
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
+ "last_updated": {
+ "default": "Última actualización",
+ "description": "Translation of \"Last updated in\". The default value is `Última actualización`.",
+ "title": "Last Updated",
"type": "string"
},
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
+ "month": {
+ "default": "mes",
+ "description": "Translation of \"month\" (singular). The default value is `mes`.",
+ "title": "Month",
"type": "string"
- }
- },
- "title": "ExperienceEntryOptions",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__Header": {
- "additionalProperties": false,
- "properties": {
- "name_font_family": {
- "default": "Raleway",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
+ },
+ "months": {
+ "default": "meses",
+ "description": "Translation of \"months\" (plural). The default value is `meses`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "año",
+ "description": "Translation of \"year\" (singular). The default value is `año`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "años",
+ "description": "Translation of \"years\" (plural). The default value is `años`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "presente",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `presente`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "Ene",
+ "Feb",
+ "Mar",
+ "Abr",
+ "May",
+ "Jun",
+ "Jul",
+ "Ago",
+ "Sep",
+ "Oct",
+ "Nov",
+ "Dic"
],
- "title": "Name Font Family",
- "type": "string"
- },
- "name_font_size": {
- "default": "30pt",
- "title": "Name Font Size",
- "type": "string"
- },
- "name_bold": {
- "default": false,
- "title": "Name Bold",
- "type": "boolean"
- },
- "small_caps_for_name": {
- "default": false,
- "title": "Small Caps For Name",
- "type": "boolean"
- },
- "photo_width": {
- "default": "3.5cm",
- "title": "Photo Width",
- "type": "string"
- },
- "vertical_space_between_name_and_connections": {
- "default": "0.7cm",
- "title": "Vertical Space Between Name And Connections",
- "type": "string"
- },
- "vertical_space_between_connections_and_first_section": {
- "default": "0.7cm",
- "title": "Vertical Space Between Connections And First Section",
- "type": "string"
- },
- "horizontal_space_between_connections": {
- "default": "0.5cm",
- "title": "Horizontal Space Between Connections",
- "type": "string"
- },
- "connections_font_family": {
- "default": "Raleway",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Connections Font Family",
- "type": "string"
- },
- "separator_between_connections": {
- "default": "",
- "title": "Separator Between Connections",
- "type": "string"
- },
- "use_icons_for_connections": {
- "default": true,
- "title": "Use Icons For Connections",
- "type": "boolean"
- },
- "use_urls_as_placeholders_for_connections": {
- "default": false,
- "title": "Use Urls As Placeholders For Connections",
- "type": "boolean"
- },
- "make_connections_links": {
- "default": true,
- "title": "Make Connections Links",
- "type": "boolean"
- },
- "alignment": {
- "default": "left",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Alignment",
- "type": "string"
- }
- },
- "title": "Header",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__Highlights": {
- "additionalProperties": false,
- "properties": {
- "bullet": {
- "default": "•",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Bullet",
- "type": "string"
- },
- "nested_bullet": {
- "default": "-",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Nested Bullet",
- "type": "string"
- },
- "top_margin": {
- "default": "0.25cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Top Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "0cm",
- "title": "Left Margin",
- "type": "string"
- },
- "vertical_space_between_highlights": {
- "default": "0.25cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Vertical Space Between Highlights",
- "type": "string"
- },
- "horizontal_space_between_bullet_and_highlight": {
- "default": "0.5em",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Horizontal Space Between Bullet And Highlight",
- "type": "string"
- },
- "summary_left_margin": {
- "default": "0cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Summary Left Margin",
- "type": "string"
- }
- },
- "title": "Highlights",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__Links": {
- "additionalProperties": false,
- "properties": {
- "underline": {
- "default": false,
- "title": "Underline",
- "type": "boolean"
- },
- "use_external_link_icon": {
- "default": false,
- "title": "Use External Link Icon",
- "type": "boolean"
- }
- },
- "title": "Links",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__NormalEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**NAME** -- **LOCATION**",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "NormalEntryOptions",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__Page": {
- "additionalProperties": false,
- "properties": {
- "size": {
- "default": "us-letter",
- "enum": [
- "a0",
- "a1",
- "a2",
- "a3",
- "a4",
- "a5",
- "a6",
- "a7",
- "a8",
- "us-letter",
- "us-legal",
- "us-executive",
- "us-gov-letter",
- "us-gov-legal",
- "us-business-card",
- "presentation-16-9",
- "presentation-4-3"
- ],
- "title": "Size",
- "type": "string"
- },
- "top_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Top Margin",
- "type": "string"
- },
- "bottom_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Bottom Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Left Margin",
- "type": "string"
- },
- "right_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Right Margin",
- "type": "string"
- },
- "show_page_numbering": {
- "default": false,
- "title": "Show Page Numbering",
- "type": "boolean"
- },
- "show_last_updated_date": {
- "default": true,
- "title": "Show Last Updated Date",
- "type": "boolean"
- }
- },
- "title": "Page",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__SectionTitles": {
- "additionalProperties": false,
- "properties": {
- "type": {
- "default": "with-partial-line",
- "enum": [
- "with-partial-line",
- "with-full-line",
- "without-line",
- "moderncv"
- ],
- "title": "Type",
- "type": "string"
- },
- "font_family": {
- "default": "Raleway",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "1.4em",
- "title": "Font Size",
- "type": "string"
- },
- "bold": {
- "default": false,
- "title": "Bold",
- "type": "boolean"
- },
- "small_caps": {
- "default": false,
- "title": "Small Caps",
- "type": "boolean"
- },
- "line_thickness": {
- "default": "0.5pt",
- "title": "Line Thickness",
- "type": "string"
- },
- "vertical_space_above": {
- "default": "0.5cm",
- "title": "Vertical Space Above",
- "type": "string"
- },
- "vertical_space_below": {
- "default": "0.3cm",
- "title": "Vertical Space Below",
- "type": "string"
- }
- },
- "title": "SectionTitles",
- "type": "object"
- },
- "rendercv__themes__engineeringclassic__Text": {
- "additionalProperties": false,
- "properties": {
- "font_family": {
- "default": "Raleway",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "10pt",
- "title": "Font Size",
- "type": "string"
- },
- "leading": {
- "default": "0.6em",
- "description": "The vertical space between adjacent lines of text.",
- "title": "Leading",
- "type": "string"
- },
- "alignment": {
- "default": "justified",
- "enum": [
- "left",
- "justified",
- "justified-with-no-hyphenation"
- ],
- "title": "Alignment",
- "type": "string"
- },
- "date_and_location_column_alignment": {
- "default": "right",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Date And Location Column Alignment",
- "type": "string"
- }
- },
- "title": "Text",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__Colors": {
- "additionalProperties": false,
- "properties": {
- "text": {
- "default": "black",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Text",
- "type": "string"
- },
- "name": {
- "default": "black",
- "format": "color",
- "title": "Name",
- "type": "string"
- },
- "connections": {
- "default": "black",
- "format": "color",
- "title": "Connections",
- "type": "string"
- },
- "section_titles": {
- "default": "black",
- "format": "color",
- "title": "Section Titles",
- "type": "string"
- },
- "links": {
- "default": "black",
- "format": "color",
- "title": "Links",
- "type": "string"
- },
- "last_updated_date_and_page_numbering": {
- "default": "grey",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Last Updated Date And Page Numbering",
- "type": "string"
- }
- },
- "title": "Colors",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__EducationEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**INSTITUTION**, DEGREE in AREA -- LOCATION",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "degree_column_template": {
- "default": null,
- "title": "Degree Column Template",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "degree_column_width": {
- "default": "1cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Degree Column Width",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "EducationEntryOptions",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__Entries": {
- "additionalProperties": false,
- "properties": {
- "date_and_location_width": {
- "default": "4.15cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Date And Location Width",
- "type": "string"
- },
- "left_and_right_margin": {
- "default": "0cm",
- "title": "Left And Right Margin",
- "type": "string"
- },
- "horizontal_space_between_columns": {
- "default": "0.1cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Horizontal Space Between Columns",
- "type": "string"
- },
- "vertical_space_between_entries": {
- "default": "0.4cm",
- "title": "Vertical Space Between Entries",
- "type": "string"
- },
- "allow_page_break_in_sections": {
- "default": true,
- "title": "Allow Page Break In Sections",
- "type": "boolean"
- },
- "allow_page_break_in_entries": {
- "default": true,
- "title": "Allow Page Break In Entries",
- "type": "boolean"
- },
- "short_second_row": {
- "default": false,
- "description": "If this option is \"true\", second row will be shortened to leave the bottom of the date empty.",
- "title": "Short Second Row",
- "type": "boolean"
- },
- "show_time_spans_in": {
- "description": "The list of section titles where the time spans will be shown in the entries.",
+ "description": "Month abbreviations (Jan-Dec).",
"items": {
"type": "string"
},
- "title": "Show Time Spans In",
+ "title": "Month Abbreviations",
"type": "array"
- }
- },
- "title": "Entries",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__EntryOptionsTypes": {
- "additionalProperties": false,
- "properties": {
- "one_line_entry": {
- "$ref": "#/$defs/OneLineEntryOptions"
},
- "education_entry": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__EducationEntryOptions",
- "default": {
- "main_column_first_row_template": "**INSTITUTION**, DEGREE in AREA -- LOCATION",
- "degree_column_template": null,
- "degree_column_width": "1cm",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "normal_entry": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__NormalEntryOptions",
- "default": {
- "main_column_first_row_template": "**NAME** -- **LOCATION**",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "experience_entry": {
- "$ref": "#/$defs/rendercv__themes__engineeringresumes__ExperienceEntryOptions",
- "default": {
- "main_column_first_row_template": "**POSITION**, COMPANY -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "publication_entry": {
- "$ref": "#/$defs/PublicationEntryOptions"
- }
- },
- "title": "EntryOptionsTypes",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__ExperienceEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**POSITION**, COMPANY -- LOCATION",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "ExperienceEntryOptions",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__Header": {
- "additionalProperties": false,
- "properties": {
- "name_font_family": {
- "default": "XCharter",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
+ "month_names": {
+ "default": [
+ "Enero",
+ "Febrero",
+ "Marzo",
+ "Abril",
+ "Mayo",
+ "Junio",
+ "Julio",
+ "Agosto",
+ "Septiembre",
+ "Octubre",
+ "Noviembre",
+ "Diciembre"
],
- "title": "Name Font Family",
- "type": "string"
- },
- "name_font_size": {
- "default": "25pt",
- "title": "Name Font Size",
- "type": "string"
- },
- "name_bold": {
- "default": false,
- "title": "Name Bold",
- "type": "boolean"
- },
- "small_caps_for_name": {
- "default": false,
- "title": "Small Caps For Name",
- "type": "boolean"
- },
- "photo_width": {
- "default": "3.5cm",
- "title": "Photo Width",
- "type": "string"
- },
- "vertical_space_between_name_and_connections": {
- "default": "0.7cm",
- "title": "Vertical Space Between Name And Connections",
- "type": "string"
- },
- "vertical_space_between_connections_and_first_section": {
- "default": "0.7cm",
- "title": "Vertical Space Between Connections And First Section",
- "type": "string"
- },
- "horizontal_space_between_connections": {
- "default": "0.5cm",
- "title": "Horizontal Space Between Connections",
- "type": "string"
- },
- "connections_font_family": {
- "default": "XCharter",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Connections Font Family",
- "type": "string"
- },
- "separator_between_connections": {
- "default": "|",
- "title": "Separator Between Connections",
- "type": "string"
- },
- "use_icons_for_connections": {
- "default": false,
- "title": "Use Icons For Connections",
- "type": "boolean"
- },
- "use_urls_as_placeholders_for_connections": {
- "default": true,
- "title": "Use Urls As Placeholders For Connections",
- "type": "boolean"
- },
- "make_connections_links": {
- "default": true,
- "title": "Make Connections Links",
- "type": "boolean"
- },
- "alignment": {
- "default": "center",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Alignment",
- "type": "string"
- }
- },
- "title": "Header",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__Highlights": {
- "additionalProperties": false,
- "properties": {
- "bullet": {
- "default": "•",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Bullet",
- "type": "string"
- },
- "nested_bullet": {
- "default": "-",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Nested Bullet",
- "type": "string"
- },
- "top_margin": {
- "default": "0.25cm",
- "title": "Top Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "0cm",
- "title": "Left Margin",
- "type": "string"
- },
- "vertical_space_between_highlights": {
- "default": "0.19cm",
- "title": "Vertical Space Between Highlights",
- "type": "string"
- },
- "horizontal_space_between_bullet_and_highlight": {
- "default": "0.3em",
- "title": "Horizontal Space Between Bullet And Highlight",
- "type": "string"
- },
- "summary_left_margin": {
- "default": "0cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Summary Left Margin",
- "type": "string"
- }
- },
- "title": "Highlights",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__Links": {
- "additionalProperties": false,
- "properties": {
- "underline": {
- "default": true,
- "title": "Underline",
- "type": "boolean"
- },
- "use_external_link_icon": {
- "default": false,
- "title": "Use External Link Icon",
- "type": "boolean"
- }
- },
- "title": "Links",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__NormalEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**NAME** -- **LOCATION**",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "NormalEntryOptions",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__Page": {
- "additionalProperties": false,
- "properties": {
- "size": {
- "default": "us-letter",
- "enum": [
- "a0",
- "a1",
- "a2",
- "a3",
- "a4",
- "a5",
- "a6",
- "a7",
- "a8",
- "us-letter",
- "us-legal",
- "us-executive",
- "us-gov-letter",
- "us-gov-legal",
- "us-business-card",
- "presentation-16-9",
- "presentation-4-3"
- ],
- "title": "Size",
- "type": "string"
- },
- "top_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Top Margin",
- "type": "string"
- },
- "bottom_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Bottom Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Left Margin",
- "type": "string"
- },
- "right_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Right Margin",
- "type": "string"
- },
- "show_page_numbering": {
- "default": false,
- "title": "Show Page Numbering",
- "type": "boolean"
- },
- "show_last_updated_date": {
- "default": true,
- "title": "Show Last Updated Date",
- "type": "boolean"
- }
- },
- "title": "Page",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__SectionTitles": {
- "additionalProperties": false,
- "properties": {
- "type": {
- "default": "with-full-line",
- "enum": [
- "with-partial-line",
- "with-full-line",
- "without-line",
- "moderncv"
- ],
- "title": "Type",
- "type": "string"
- },
- "font_family": {
- "default": "XCharter",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "1.2em",
- "title": "Font Size",
- "type": "string"
- },
- "bold": {
- "default": true,
- "title": "Bold",
- "type": "boolean"
- },
- "small_caps": {
- "default": false,
- "title": "Small Caps",
- "type": "boolean"
- },
- "line_thickness": {
- "default": "0.5pt",
- "title": "Line Thickness",
- "type": "string"
- },
- "vertical_space_above": {
- "default": "0.55cm",
- "title": "Vertical Space Above",
- "type": "string"
- },
- "vertical_space_below": {
- "default": "0.3cm",
- "title": "Vertical Space Below",
- "type": "string"
- }
- },
- "title": "SectionTitles",
- "type": "object"
- },
- "rendercv__themes__engineeringresumes__Text": {
- "additionalProperties": false,
- "properties": {
- "font_family": {
- "default": "XCharter",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "10pt",
- "title": "Font Size",
- "type": "string"
- },
- "leading": {
- "default": "0.6em",
- "title": "Leading",
- "type": "string"
- },
- "alignment": {
- "default": "justified",
- "enum": [
- "left",
- "justified",
- "justified-with-no-hyphenation"
- ],
- "title": "Alignment",
- "type": "string"
- },
- "date_and_location_column_alignment": {
- "default": "right",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Date And Location Column Alignment",
- "type": "string"
- }
- },
- "title": "Text",
- "type": "object"
- },
- "rendercv__themes__moderncv__EducationEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**INSTITUTION**, DEGREE in AREA -- LOCATION",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "degree_column_template": {
- "default": null,
- "title": "Degree Column Template",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "degree_column_width": {
- "default": "1cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Degree Column Width",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "EducationEntryOptions",
- "type": "object"
- },
- "rendercv__themes__moderncv__Entries": {
- "additionalProperties": false,
- "properties": {
- "date_and_location_width": {
- "default": "4.15cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Date And Location Width",
- "type": "string"
- },
- "left_and_right_margin": {
- "default": "0cm",
- "title": "Left And Right Margin",
- "type": "string"
- },
- "horizontal_space_between_columns": {
- "default": "0.4cm",
- "title": "Horizontal Space Between Columns",
- "type": "string"
- },
- "vertical_space_between_entries": {
- "default": "0.4cm",
- "title": "Vertical Space Between Entries",
- "type": "string"
- },
- "allow_page_break_in_sections": {
- "default": true,
- "title": "Allow Page Break In Sections",
- "type": "boolean"
- },
- "allow_page_break_in_entries": {
- "default": true,
- "title": "Allow Page Break In Entries",
- "type": "boolean"
- },
- "short_second_row": {
- "default": false,
- "description": "If this option is \"true\", second row will be shortened to leave the bottom of the date empty.",
- "title": "Short Second Row",
- "type": "boolean"
- },
- "show_time_spans_in": {
- "description": "The list of section titles where the time spans will be shown in the entries.",
+ "description": "Full month names (January-December).",
"items": {
"type": "string"
},
- "title": "Show Time Spans In",
+ "title": "Month Names",
"type": "array"
}
},
- "title": "Entries",
+ "title": "SpanishLocale",
"type": "object"
},
- "rendercv__themes__moderncv__EntryOptionsTypes": {
+ "TurkishLocale": {
"additionalProperties": false,
"properties": {
- "one_line_entry": {
- "$ref": "#/$defs/OneLineEntryOptions"
- },
- "education_entry": {
- "$ref": "#/$defs/rendercv__themes__moderncv__EducationEntryOptions",
- "default": {
- "main_column_first_row_template": "**INSTITUTION**, DEGREE in AREA -- LOCATION",
- "degree_column_template": null,
- "degree_column_width": "1cm",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "normal_entry": {
- "$ref": "#/$defs/rendercv__themes__moderncv__NormalEntryOptions",
- "default": {
- "main_column_first_row_template": "**NAME** -- **LOCATION**",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "experience_entry": {
- "$ref": "#/$defs/rendercv__themes__moderncv__ExperienceEntryOptions",
- "default": {
- "main_column_first_row_template": "**POSITION**, COMPANY -- LOCATION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS",
- "date_and_location_column_template": "DATE"
- }
- },
- "publication_entry": {
- "$ref": "#/$defs/PublicationEntryOptions"
- }
- },
- "title": "EntryOptionsTypes",
- "type": "object"
- },
- "rendercv__themes__moderncv__ExperienceEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**POSITION**, COMPANY -- LOCATION",
- "title": "Main Column First Row Template",
+ "language": {
+ "const": "turkish",
+ "default": "turkish",
+ "description": "The language for your CV. The default value is `turkish`.",
+ "title": "Language",
"type": "string"
},
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
+ "last_updated": {
+ "default": "Son güncelleme",
+ "description": "Translation of \"Last updated in\". The default value is `Son güncelleme`.",
+ "title": "Last Updated",
"type": "string"
},
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
+ "month": {
+ "default": "ay",
+ "description": "Translation of \"month\" (singular). The default value is `ay`.",
+ "title": "Month",
"type": "string"
- }
- },
- "title": "ExperienceEntryOptions",
- "type": "object"
- },
- "rendercv__themes__moderncv__Header": {
- "additionalProperties": false,
- "properties": {
- "name_font_family": {
- "default": "Fontin",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
+ },
+ "months": {
+ "default": "ay",
+ "description": "Translation of \"months\" (plural). The default value is `ay`.",
+ "title": "Months",
+ "type": "string"
+ },
+ "year": {
+ "default": "yıl",
+ "description": "Translation of \"year\" (singular). The default value is `yıl`.",
+ "title": "Year",
+ "type": "string"
+ },
+ "years": {
+ "default": "yıl",
+ "description": "Translation of \"years\" (plural). The default value is `yıl`.",
+ "title": "Years",
+ "type": "string"
+ },
+ "present": {
+ "default": "halen",
+ "description": "Translation of \"present\" for ongoing dates. The default value is `halen`.",
+ "title": "Present",
+ "type": "string"
+ },
+ "month_abbreviations": {
+ "default": [
+ "Oca",
+ "Şub",
+ "Mar",
+ "Nis",
+ "May",
+ "Haz",
+ "Tem",
+ "Ağu",
+ "Eyl",
+ "Eki",
+ "Kas",
+ "Ara"
],
- "title": "Name Font Family",
- "type": "string"
- },
- "name_font_size": {
- "default": "25pt",
- "title": "Name Font Size",
- "type": "string"
- },
- "name_bold": {
- "default": false,
- "title": "Name Bold",
- "type": "boolean"
- },
- "small_caps_for_name": {
- "default": false,
- "title": "Small Caps For Name",
- "type": "boolean"
- },
- "photo_width": {
- "default": "3.5cm",
- "title": "Photo Width",
- "type": "string"
- },
- "vertical_space_between_name_and_connections": {
- "default": "0.7cm",
- "title": "Vertical Space Between Name And Connections",
- "type": "string"
- },
- "vertical_space_between_connections_and_first_section": {
- "default": "0.7cm",
- "title": "Vertical Space Between Connections And First Section",
- "type": "string"
- },
- "horizontal_space_between_connections": {
- "default": "0.5cm",
- "title": "Horizontal Space Between Connections",
- "type": "string"
- },
- "connections_font_family": {
- "default": "Fontin",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Connections Font Family",
- "type": "string"
- },
- "separator_between_connections": {
- "default": "",
- "title": "Separator Between Connections",
- "type": "string"
- },
- "use_icons_for_connections": {
- "default": true,
- "title": "Use Icons For Connections",
- "type": "boolean"
- },
- "use_urls_as_placeholders_for_connections": {
- "default": false,
- "title": "Use Urls As Placeholders For Connections",
- "type": "boolean"
- },
- "make_connections_links": {
- "default": true,
- "title": "Make Connections Links",
- "type": "boolean"
- },
- "alignment": {
- "default": "left",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Alignment",
- "type": "string"
- }
- },
- "title": "Header",
- "type": "object"
- },
- "rendercv__themes__moderncv__Highlights": {
- "additionalProperties": false,
- "properties": {
- "bullet": {
- "default": "•",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Bullet",
- "type": "string"
- },
- "nested_bullet": {
- "default": "-",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Nested Bullet",
- "type": "string"
- },
- "top_margin": {
- "default": "0.25cm",
- "title": "Top Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "0cm",
- "title": "Left Margin",
- "type": "string"
- },
- "vertical_space_between_highlights": {
- "default": "0.19cm",
- "title": "Vertical Space Between Highlights",
- "type": "string"
- },
- "horizontal_space_between_bullet_and_highlight": {
- "default": "0.3em",
- "title": "Horizontal Space Between Bullet And Highlight",
- "type": "string"
- },
- "summary_left_margin": {
- "default": "0cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Summary Left Margin",
- "type": "string"
- }
- },
- "title": "Highlights",
- "type": "object"
- },
- "rendercv__themes__moderncv__Links": {
- "additionalProperties": false,
- "properties": {
- "underline": {
- "default": true,
- "title": "Underline",
- "type": "boolean"
- },
- "use_external_link_icon": {
- "default": false,
- "title": "Use External Link Icon",
- "type": "boolean"
- }
- },
- "title": "Links",
- "type": "object"
- },
- "rendercv__themes__moderncv__NormalEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**NAME** -- **LOCATION**",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "DATE",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "NormalEntryOptions",
- "type": "object"
- },
- "rendercv__themes__moderncv__SectionTitles": {
- "additionalProperties": false,
- "properties": {
- "type": {
- "default": "moderncv",
- "enum": [
- "with-partial-line",
- "with-full-line",
- "without-line",
- "moderncv"
- ],
- "title": "Type",
- "type": "string"
- },
- "font_family": {
- "default": "Fontin",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "1.4em",
- "title": "Font Size",
- "type": "string"
- },
- "bold": {
- "default": false,
- "title": "Bold",
- "type": "boolean"
- },
- "small_caps": {
- "default": false,
- "title": "Small Caps",
- "type": "boolean"
- },
- "line_thickness": {
- "default": "0.15cm",
- "title": "Line Thickness",
- "type": "string"
- },
- "vertical_space_above": {
- "default": "0.55cm",
- "title": "Vertical Space Above",
- "type": "string"
- },
- "vertical_space_below": {
- "default": "0.3cm",
- "title": "Vertical Space Below",
- "type": "string"
- }
- },
- "title": "SectionTitles",
- "type": "object"
- },
- "rendercv__themes__moderncv__Text": {
- "additionalProperties": false,
- "properties": {
- "font_family": {
- "default": "Fontin",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "10pt",
- "title": "Font Size",
- "type": "string"
- },
- "leading": {
- "default": "0.6em",
- "title": "Leading",
- "type": "string"
- },
- "alignment": {
- "default": "justified",
- "enum": [
- "left",
- "justified",
- "justified-with-no-hyphenation"
- ],
- "title": "Alignment",
- "type": "string"
- },
- "date_and_location_column_alignment": {
- "default": "right",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Date And Location Column Alignment",
- "type": "string"
- }
- },
- "title": "Text",
- "type": "object"
- },
- "rendercv__themes__options__Colors": {
- "additionalProperties": false,
- "properties": {
- "text": {
- "default": "black",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Text",
- "type": "string"
- },
- "name": {
- "default": "#004f90",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Name",
- "type": "string"
- },
- "connections": {
- "default": "#004f90",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Connections",
- "type": "string"
- },
- "section_titles": {
- "default": "#004f90",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Section Titles",
- "type": "string"
- },
- "links": {
- "default": "#004f90",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Links",
- "type": "string"
- },
- "last_updated_date_and_page_numbering": {
- "default": "grey",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Last Updated Date And Page Numbering",
- "type": "string"
- }
- },
- "title": "Colors",
- "type": "object"
- },
- "rendercv__themes__options__EducationEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**INSTITUTION**, AREA",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "degree_column_template": {
- "default": "**DEGREE**",
- "description": "If given, a degree column will be added to the education entry. If \"null\", no degree column will be shown. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Degree Column Template",
- "oneOf": [
- {
- "type": "string"
- },
- {
- "type": "null"
- }
- ]
- },
- "degree_column_width": {
- "default": "1cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Degree Column Width",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "LOCATION\nDATE",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "EducationEntryOptions",
- "type": "object"
- },
- "rendercv__themes__options__Entries": {
- "additionalProperties": false,
- "properties": {
- "date_and_location_width": {
- "default": "4.15cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Date And Location Width",
- "type": "string"
- },
- "left_and_right_margin": {
- "default": "0.2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Left And Right Margin",
- "type": "string"
- },
- "horizontal_space_between_columns": {
- "default": "0.1cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Horizontal Space Between Columns",
- "type": "string"
- },
- "vertical_space_between_entries": {
- "default": "1.2em",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Vertical Space Between Entries",
- "type": "string"
- },
- "allow_page_break_in_sections": {
- "default": true,
- "title": "Allow Page Break In Sections",
- "type": "boolean"
- },
- "allow_page_break_in_entries": {
- "default": true,
- "title": "Allow Page Break In Entries",
- "type": "boolean"
- },
- "short_second_row": {
- "default": false,
- "description": "If this option is \"true\", second row will be shortened to leave the bottom of the date empty.",
- "title": "Short Second Row",
- "type": "boolean"
- },
- "show_time_spans_in": {
- "description": "The list of section titles where the time spans will be shown in the entries.",
+ "description": "Month abbreviations (Jan-Dec).",
"items": {
"type": "string"
},
- "title": "Show Time Spans In",
+ "title": "Month Abbreviations",
+ "type": "array"
+ },
+ "month_names": {
+ "default": [
+ "Ocak",
+ "Şubat",
+ "Mart",
+ "Nisan",
+ "Mayıs",
+ "Haziran",
+ "Temmuz",
+ "Ağustos",
+ "Eylül",
+ "Ekim",
+ "Kasım",
+ "Aralık"
+ ],
+ "description": "Full month names (January-December).",
+ "items": {
+ "type": "string"
+ },
+ "title": "Month Names",
"type": "array"
}
},
- "title": "Entries",
+ "title": "TurkishLocale",
"type": "object"
},
- "rendercv__themes__options__ExperienceEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**COMPANY**, POSITION",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "LOCATION\nDATE",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "ExperienceEntryOptions",
- "type": "object"
+ "TypstDimension": {
+ "type": "string"
},
- "rendercv__themes__options__Header": {
- "additionalProperties": false,
+ "rendercv__schema__models__cv__entries__education__EducationEntry": {
+ "additionalProperties": true,
+ "description": null,
"properties": {
- "name_font_family": {
- "default": "Source Sans 3",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Name Font Family",
- "type": "string"
- },
- "name_font_size": {
- "default": "30pt",
- "title": "Name Font Size",
- "type": "string"
- },
- "name_bold": {
- "default": true,
- "title": "Name Bold",
- "type": "boolean"
- },
- "small_caps_for_name": {
- "default": false,
- "title": "Small Caps For Name",
- "type": "boolean"
- },
- "photo_width": {
- "default": "3.5cm",
- "title": "Photo Width",
- "type": "string"
- },
- "vertical_space_between_name_and_connections": {
- "default": "0.7cm",
- "title": "Vertical Space Between Name And Connections",
- "type": "string"
- },
- "vertical_space_between_connections_and_first_section": {
- "default": "0.7cm",
- "title": "Vertical Space Between Connections And First Section",
- "type": "string"
- },
- "horizontal_space_between_connections": {
- "default": "0.5cm",
- "title": "Horizontal Space Between Connections",
- "type": "string"
- },
- "connections_font_family": {
- "default": "Source Sans 3",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Connections Font Family",
- "type": "string"
- },
- "separator_between_connections": {
- "default": "",
- "title": "Separator Between Connections",
- "type": "string"
- },
- "use_icons_for_connections": {
- "default": true,
- "title": "Use Icons For Connections",
- "type": "boolean"
- },
- "use_urls_as_placeholders_for_connections": {
- "default": false,
- "title": "Use Urls As Placeholders For Connections",
- "type": "boolean"
- },
- "make_connections_links": {
- "default": true,
- "title": "Make Connections Links",
- "type": "boolean"
- },
- "alignment": {
- "default": "center",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Alignment",
- "type": "string"
- }
- },
- "title": "Header",
- "type": "object"
- },
- "rendercv__themes__options__Highlights": {
- "additionalProperties": false,
- "properties": {
- "bullet": {
- "default": "•",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Bullet",
- "type": "string"
- },
- "nested_bullet": {
- "default": "-",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
- ],
- "title": "Nested Bullet",
- "type": "string"
- },
- "top_margin": {
- "default": "0.25cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Top Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "0.4cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Left Margin",
- "type": "string"
- },
- "vertical_space_between_highlights": {
- "default": "0.25cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Vertical Space Between Highlights",
- "type": "string"
- },
- "horizontal_space_between_bullet_and_highlight": {
- "default": "0.5em",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Horizontal Space Between Bullet And Highlight",
- "type": "string"
- },
- "summary_left_margin": {
- "default": "0cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Summary Left Margin",
- "type": "string"
- }
- },
- "title": "Highlights",
- "type": "object"
- },
- "rendercv__themes__options__Links": {
- "additionalProperties": false,
- "properties": {
- "underline": {
- "default": false,
- "title": "Underline",
- "type": "boolean"
- },
- "use_external_link_icon": {
- "default": true,
- "title": "Use External Link Icon",
- "type": "boolean"
- }
- },
- "title": "Links",
- "type": "object"
- },
- "rendercv__themes__options__NormalEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**NAME**",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "LOCATION\nDATE",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "NormalEntryOptions",
- "type": "object"
- },
- "rendercv__themes__options__Page": {
- "additionalProperties": false,
- "properties": {
- "size": {
- "default": "us-letter",
- "enum": [
- "a0",
- "a1",
- "a2",
- "a3",
- "a4",
- "a5",
- "a6",
- "a7",
- "a8",
- "us-letter",
- "us-legal",
- "us-executive",
- "us-gov-letter",
- "us-gov-legal",
- "us-business-card",
- "presentation-16-9",
- "presentation-4-3"
- ],
- "title": "Size",
- "type": "string"
- },
- "top_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Top Margin",
- "type": "string"
- },
- "bottom_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Bottom Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Left Margin",
- "type": "string"
- },
- "right_margin": {
- "default": "2cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Right Margin",
- "type": "string"
- },
- "show_page_numbering": {
- "default": true,
- "title": "Show Page Numbering",
- "type": "boolean"
- },
- "show_last_updated_date": {
- "default": true,
- "title": "Show Last Updated Date",
- "type": "boolean"
- }
- },
- "title": "Page",
- "type": "object"
- },
- "rendercv__themes__options__SectionTitles": {
- "additionalProperties": false,
- "properties": {
- "type": {
- "default": "with-partial-line",
- "enum": [
- "with-partial-line",
- "with-full-line",
- "without-line",
- "moderncv"
- ],
- "title": "Type",
- "type": "string"
- },
- "font_family": {
- "default": "Source Sans 3",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "1.4em",
- "title": "Font Size",
- "type": "string"
- },
- "bold": {
- "default": true,
- "title": "Bold",
- "type": "boolean"
- },
- "small_caps": {
- "default": false,
- "title": "Small Caps",
- "type": "boolean"
- },
- "line_thickness": {
- "default": "0.5pt",
- "title": "Line Thickness",
- "type": "string"
- },
- "vertical_space_above": {
- "default": "0.5cm",
- "title": "Vertical Space Above",
- "type": "string"
- },
- "vertical_space_below": {
- "default": "0.3cm",
- "title": "Vertical Space Below",
- "type": "string"
- }
- },
- "title": "SectionTitles",
- "type": "object"
- },
- "rendercv__themes__options__Text": {
- "additionalProperties": false,
- "properties": {
- "font_family": {
- "default": "Source Sans 3",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "10pt",
- "title": "Font Size",
- "type": "string"
- },
- "leading": {
- "default": "0.6em",
- "description": "The vertical space between adjacent lines of text.",
- "title": "Leading",
- "type": "string"
- },
- "alignment": {
- "default": "justified",
- "enum": [
- "left",
- "justified",
- "justified-with-no-hyphenation"
- ],
- "title": "Alignment",
- "type": "string"
- },
- "date_and_location_column_alignment": {
- "default": "right",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Date And Location Column Alignment",
- "type": "string"
- }
- },
- "title": "Text",
- "type": "object"
- },
- "rendercv__themes__sb2nov__Colors": {
- "additionalProperties": false,
- "properties": {
- "text": {
- "default": "black",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
+ "institution": {
"examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
+ "Boğaziçi University",
+ "MIT",
+ "Harvard University"
],
- "format": "color",
- "title": "Text",
+ "title": "Institution",
"type": "string"
},
- "name": {
- "default": "black",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
+ "area": {
+ "description": "Field of study or major.",
"examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
+ "Mechanical Engineering",
+ "Computer Science",
+ "Electrical Engineering"
],
- "format": "color",
- "title": "Name",
+ "title": "Area",
"type": "string"
},
- "connections": {
- "default": "black",
- "format": "color",
- "title": "Connections",
- "type": "string"
- },
- "section_titles": {
- "default": "black",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Section Titles",
- "type": "string"
- },
- "links": {
- "default": "#004f90",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Links",
- "type": "string"
- },
- "last_updated_date_and_page_numbering": {
- "default": "grey",
- "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value.",
- "examples": [
- "Black",
- "7fffd4",
- "rgb(0,79,144)",
- "hsl(270, 60%, 70%)"
- ],
- "format": "color",
- "title": "Last Updated Date And Page Numbering",
- "type": "string"
- }
- },
- "title": "Colors",
- "type": "object"
- },
- "rendercv__themes__sb2nov__EducationEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**INSTITUTION**\n*DEGREE in AREA*",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "degree_column_template": {
- "default": null,
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Degree Column Template",
- "oneOf": [
+ "degree": {
+ "anyOf": [
{
"type": "string"
},
{
"type": "null"
}
+ ],
+ "default": null,
+ "examples": [
+ "BS",
+ "BA",
+ "PhD",
+ "MS"
+ ],
+ "title": "Degree"
+ },
+ "date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ArbitraryDate"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The date of this event in YYYY-MM-DD, YYYY-MM, or YYYY format, or any custom text like 'Fall 2023'. Use this for single-day or imprecise dates. For date ranges, use `start_date` and `end_date` instead.",
+ "examples": [
+ "2020-09-24",
+ "2020-09",
+ "2020",
+ "Fall 2023",
+ "Summer 2020"
]
},
- "degree_column_width": {
- "default": "1cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Degree Column Width",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "*LOCATION*\n*DATE*",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "EducationEntryOptions",
- "type": "object"
- },
- "rendercv__themes__sb2nov__EntryOptionsTypes": {
- "additionalProperties": false,
- "properties": {
- "one_line_entry": {
- "$ref": "#/$defs/OneLineEntryOptions"
- },
- "education_entry": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__EducationEntryOptions"
- },
- "normal_entry": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__NormalEntryOptions"
- },
- "experience_entry": {
- "$ref": "#/$defs/rendercv__themes__sb2nov__ExperienceEntryOptions"
- },
- "publication_entry": {
- "$ref": "#/$defs/PublicationEntryOptions"
- }
- },
- "title": "EntryOptionsTypes",
- "type": "object"
- },
- "rendercv__themes__sb2nov__ExperienceEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**POSITION**\n*COMPANY*",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "*LOCATION*\n*DATE*",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "ExperienceEntryOptions",
- "type": "object"
- },
- "rendercv__themes__sb2nov__Header": {
- "additionalProperties": false,
- "properties": {
- "name_font_family": {
- "default": "New Computer Modern",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
+ "start_date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ExactDate"
+ },
+ {
+ "type": "null"
+ }
],
- "title": "Name Font Family",
- "type": "string"
+ "default": null,
+ "description": "The start date in YYYY-MM-DD, YYYY-MM, or YYYY format.",
+ "examples": [
+ "2020-09-24",
+ "2020-09",
+ "2020"
+ ]
},
- "name_font_size": {
- "default": "30pt",
- "title": "Name Font Size",
- "type": "string"
- },
- "name_bold": {
- "default": true,
- "title": "Name Bold",
- "type": "boolean"
- },
- "small_caps_for_name": {
- "default": false,
- "title": "Small Caps For Name",
- "type": "boolean"
- },
- "photo_width": {
- "default": "3.5cm",
- "title": "Photo Width",
- "type": "string"
- },
- "vertical_space_between_name_and_connections": {
- "default": "0.7cm",
- "title": "Vertical Space Between Name And Connections",
- "type": "string"
- },
- "vertical_space_between_connections_and_first_section": {
- "default": "0.7cm",
- "title": "Vertical Space Between Connections And First Section",
- "type": "string"
- },
- "horizontal_space_between_connections": {
- "default": "0.5cm",
- "title": "Horizontal Space Between Connections",
- "type": "string"
- },
- "connections_font_family": {
- "default": "New Computer Modern",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
+ "end_date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ExactDate"
+ },
+ {
+ "const": "present",
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
],
- "title": "Connections Font Family",
- "type": "string"
- },
- "separator_between_connections": {
- "default": "",
- "title": "Separator Between Connections",
- "type": "string"
- },
- "use_icons_for_connections": {
- "default": true,
- "title": "Use Icons For Connections",
- "type": "boolean"
- },
- "use_urls_as_placeholders_for_connections": {
- "default": false,
- "title": "Use Urls As Placeholders For Connections",
- "type": "boolean"
- },
- "make_connections_links": {
- "default": true,
- "title": "Make Connections Links",
- "type": "boolean"
- },
- "alignment": {
- "default": "center",
- "enum": [
- "left",
- "center",
- "right"
+ "default": null,
+ "description": "The end date in YYYY-MM-DD, YYYY-MM, or YYYY format. Use \"present\" for ongoing events, or omit it to indicate the event is ongoing.",
+ "examples": [
+ "2024-05-20",
+ "2024-05",
+ "2024",
+ "present"
],
- "title": "Alignment",
- "type": "string"
- }
- },
- "title": "Header",
- "type": "object"
- },
- "rendercv__themes__sb2nov__Highlights": {
- "additionalProperties": false,
- "properties": {
- "bullet": {
- "default": "◦",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
+ "title": "End Date"
+ },
+ "location": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
],
- "title": "Bullet",
- "type": "string"
- },
- "nested_bullet": {
- "default": "-",
- "enum": [
- "•",
- "◦",
- "-",
- "◆",
- "★",
- "■",
- "—",
- "○"
+ "default": null,
+ "examples": [
+ "Istanbul, Türkiye",
+ "New York, NY",
+ "Remote"
],
- "title": "Nested Bullet",
- "type": "string"
+ "title": "Location"
},
- "top_margin": {
- "default": "0.25cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Top Margin",
- "type": "string"
- },
- "left_margin": {
- "default": "0.4cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Left Margin",
- "type": "string"
- },
- "vertical_space_between_highlights": {
- "default": "0.25cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Vertical Space Between Highlights",
- "type": "string"
- },
- "horizontal_space_between_bullet_and_highlight": {
- "default": "0.5em",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Horizontal Space Between Bullet And Highlight",
- "type": "string"
- },
- "summary_left_margin": {
- "default": "0cm",
- "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, 0.1cm.",
- "title": "Summary Left Margin",
- "type": "string"
- }
- },
- "title": "Highlights",
- "type": "object"
- },
- "rendercv__themes__sb2nov__Links": {
- "additionalProperties": false,
- "properties": {
- "underline": {
- "default": true,
- "title": "Underline",
- "type": "boolean"
- },
- "use_external_link_icon": {
- "default": false,
- "title": "Use External Link Icon",
- "type": "boolean"
- }
- },
- "title": "Links",
- "type": "object"
- },
- "rendercv__themes__sb2nov__NormalEntryOptions": {
- "additionalProperties": false,
- "properties": {
- "main_column_first_row_template": {
- "default": "**NAME**",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column First Row Template",
- "type": "string"
- },
- "main_column_second_row_template": {
- "default": "SUMMARY\nHIGHLIGHTS",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Main Column Second Row Template",
- "type": "string"
- },
- "date_and_location_column_template": {
- "default": "*LOCATION*\n*DATE*",
- "description": "The content of the template. The available placeholders are all the keys used in the entries (in uppercase).",
- "title": "Date And Location Column Template",
- "type": "string"
- }
- },
- "title": "NormalEntryOptions",
- "type": "object"
- },
- "rendercv__themes__sb2nov__SectionTitles": {
- "additionalProperties": false,
- "properties": {
- "type": {
- "default": "with-full-line",
- "enum": [
- "with-partial-line",
- "with-full-line",
- "without-line",
- "moderncv"
+ "summary": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
],
- "title": "Type",
- "type": "string"
- },
- "font_family": {
- "default": "New Computer Modern",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
+ "default": null,
+ "examples": [
+ "Led a team of 5 engineers to develop innovative solutions.",
+ "Completed advanced coursework in machine learning and artificial intelligence."
],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "1.4em",
- "title": "Font Size",
- "type": "string"
- },
- "bold": {
- "default": true,
- "title": "Bold",
- "type": "boolean"
- },
- "small_caps": {
- "default": false,
- "title": "Small Caps",
- "type": "boolean"
- },
- "line_thickness": {
- "default": "0.5pt",
- "title": "Line Thickness",
- "type": "string"
- },
- "vertical_space_above": {
- "default": "0.5cm",
- "title": "Vertical Space Above",
- "type": "string"
- },
- "vertical_space_below": {
- "default": "0.3cm",
- "title": "Vertical Space Below",
- "type": "string"
- }
- },
- "title": "SectionTitles",
- "type": "object"
- },
- "rendercv__themes__sb2nov__Text": {
- "additionalProperties": false,
- "properties": {
- "font_family": {
- "default": "New Computer Modern",
- "enum": [
- "Aptos",
- "Arial",
- "Calibri",
- "Cambria",
- "Candara",
- "DejaVu Sans Mono",
- "Didot",
- "EB Garamond",
- "Fontin",
- "Garamond",
- "Gentium Book Plus",
- "Georgia",
- "Gill Sans",
- "Helvetica",
- "Inter",
- "Lato",
- "Libertinus Serif",
- "Montserrat",
- "Mukta",
- "New Computer Modern",
- "Noto Sans",
- "Open Sans",
- "Open Sauce Sans",
- "Playfair Display",
- "Poppins",
- "Raleway",
- "Roboto",
- "Source Sans 3",
- "Tahoma",
- "Times New Roman",
- "Ubuntu",
- "Verdana",
- "XCharter"
- ],
- "title": "Font Family",
- "type": "string"
- },
- "font_size": {
- "default": "10pt",
- "title": "Font Size",
- "type": "string"
- },
- "leading": {
- "default": "0.6em",
- "description": "The vertical space between adjacent lines of text.",
- "title": "Leading",
- "type": "string"
- },
- "alignment": {
- "default": "justified",
- "enum": [
- "left",
- "justified",
- "justified-with-no-hyphenation"
- ],
- "title": "Alignment",
- "type": "string"
- },
- "date_and_location_column_alignment": {
- "default": "right",
- "enum": [
- "left",
- "center",
- "right"
- ],
- "title": "Date And Location Column Alignment",
- "type": "string"
- }
- },
- "title": "Text",
- "type": "object"
- }
- },
- "additionalProperties": false,
- "description": "RenderCV data model.",
- "properties": {
- "cv": {
- "$ref": "#/$defs/CurriculumVitae",
- "description": "The content of the CV."
- },
- "design": {
- "default": {
- "theme": "classic",
- "page": {
- "bottom_margin": "2cm",
- "left_margin": "2cm",
- "right_margin": "2cm",
- "show_last_updated_date": true,
- "show_page_numbering": true,
- "size": "us-letter",
- "top_margin": "2cm"
- },
- "colors": {
- "connections": "rgb(0, 79, 144)",
- "last_updated_date_and_page_numbering": "rgb(128, 128, 128)",
- "links": "rgb(0, 79, 144)",
- "name": "rgb(0, 79, 144)",
- "section_titles": "rgb(0, 79, 144)",
- "text": "rgb(0, 0, 0)"
- },
- "text": {
- "alignment": "justified",
- "date_and_location_column_alignment": "right",
- "font_family": "Source Sans 3",
- "font_size": "10pt",
- "leading": "0.6em"
- },
- "links": {
- "underline": false,
- "use_external_link_icon": true
- },
- "header": {
- "alignment": "center",
- "connections_font_family": "Source Sans 3",
- "horizontal_space_between_connections": "0.5cm",
- "make_connections_links": true,
- "name_bold": true,
- "name_font_family": "Source Sans 3",
- "name_font_size": "30pt",
- "photo_width": "3.5cm",
- "separator_between_connections": "",
- "small_caps_for_name": false,
- "use_icons_for_connections": true,
- "use_urls_as_placeholders_for_connections": false,
- "vertical_space_between_connections_and_first_section": "0.7cm",
- "vertical_space_between_name_and_connections": "0.7cm"
- },
- "section_titles": {
- "bold": true,
- "font_family": "Source Sans 3",
- "font_size": "1.4em",
- "line_thickness": "0.5pt",
- "small_caps": false,
- "type": "with-partial-line",
- "vertical_space_above": "0.5cm",
- "vertical_space_below": "0.3cm"
- },
- "entries": {
- "allow_page_break_in_entries": true,
- "allow_page_break_in_sections": true,
- "date_and_location_width": "4.15cm",
- "horizontal_space_between_columns": "0.1cm",
- "left_and_right_margin": "0.2cm",
- "short_second_row": false,
- "show_time_spans_in": [],
- "vertical_space_between_entries": "1.2em"
+ "title": "Summary"
},
"highlights": {
- "bullet": "•",
- "horizontal_space_between_bullet_and_highlight": "0.5em",
- "left_margin": "0.4cm",
- "nested_bullet": "-",
- "summary_left_margin": "0cm",
- "top_margin": "0.25cm",
- "vertical_space_between_highlights": "0.25cm"
- },
- "entry_types": {
- "education_entry": {
- "date_and_location_column_template": "LOCATION\nDATE",
- "degree_column_template": "**DEGREE**",
- "degree_column_width": "1cm",
- "main_column_first_row_template": "**INSTITUTION**, AREA",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "experience_entry": {
- "date_and_location_column_template": "LOCATION\nDATE",
- "main_column_first_row_template": "**COMPANY**, POSITION",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "normal_entry": {
- "date_and_location_column_template": "LOCATION\nDATE",
- "main_column_first_row_template": "**NAME**",
- "main_column_second_row_template": "SUMMARY\nHIGHLIGHTS"
- },
- "one_line_entry": {
- "template": "**LABEL:** DETAILS"
- },
- "publication_entry": {
- "date_and_location_column_template": "DATE",
- "main_column_first_row_template": "**TITLE**",
- "main_column_second_row_template": "AUTHORS\nURL (JOURNAL)",
- "main_column_second_row_without_journal_template": "AUTHORS\nURL",
- "main_column_second_row_without_url_template": "AUTHORS\nJOURNAL"
- }
+ "anyOf": [
+ {
+ "items": {
+ "type": "string"
+ },
+ "type": "array"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "Bullet points for key achievements, responsibilities, or contributions.",
+ "examples": [
+ [
+ "Increased system performance by 40% through optimization.",
+ "Mentored 3 junior developers and conducted code reviews.",
+ "Implemented CI/CD pipeline reducing deployment time by 60%."
+ ]
+ ],
+ "title": "Highlights"
}
},
- "description": "The design information of the CV. The default is the `classic` theme.",
- "discriminator": {
- "mapping": {
- "classic": "#/$defs/ClassicThemeOptions",
- "engineeringclassic": "#/$defs/EngineeringclassicThemeOptions",
- "engineeringresumes": "#/$defs/EngineeringresumesThemeOptions",
- "moderncv": "#/$defs/ModerncvThemeOptions",
- "sb2nov": "#/$defs/Sb2novThemeOptions"
- },
- "propertyName": "theme"
- },
- "oneOf": [
- {
- "$ref": "#/$defs/ClassicThemeOptions"
- },
- {
- "$ref": "#/$defs/Sb2novThemeOptions"
- },
- {
- "$ref": "#/$defs/EngineeringresumesThemeOptions"
- },
- {
- "$ref": "#/$defs/EngineeringclassicThemeOptions"
- },
- {
- "$ref": "#/$defs/ModerncvThemeOptions"
- }
+ "required": [
+ "institution",
+ "area"
],
+ "title": "EducationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__cv__entries__experience__ExperienceEntry": {
+ "additionalProperties": true,
+ "description": null,
+ "properties": {
+ "company": {
+ "examples": [
+ "Microsoft",
+ "Google",
+ "Princeton Plasma Physics Laboratory"
+ ],
+ "title": "Company",
+ "type": "string"
+ },
+ "position": {
+ "examples": [
+ "Software Engineer",
+ "Research Assistant",
+ "Project Manager"
+ ],
+ "title": "Position",
+ "type": "string"
+ },
+ "date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ArbitraryDate"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The date of this event in YYYY-MM-DD, YYYY-MM, or YYYY format, or any custom text like 'Fall 2023'. Use this for single-day or imprecise dates. For date ranges, use `start_date` and `end_date` instead.",
+ "examples": [
+ "2020-09-24",
+ "2020-09",
+ "2020",
+ "Fall 2023",
+ "Summer 2020"
+ ]
+ },
+ "start_date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ExactDate"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The start date in YYYY-MM-DD, YYYY-MM, or YYYY format.",
+ "examples": [
+ "2020-09-24",
+ "2020-09",
+ "2020"
+ ]
+ },
+ "end_date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ExactDate"
+ },
+ {
+ "const": "present",
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The end date in YYYY-MM-DD, YYYY-MM, or YYYY format. Use \"present\" for ongoing events, or omit it to indicate the event is ongoing.",
+ "examples": [
+ "2024-05-20",
+ "2024-05",
+ "2024",
+ "present"
+ ],
+ "title": "End Date"
+ },
+ "location": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "Istanbul, Türkiye",
+ "New York, NY",
+ "Remote"
+ ],
+ "title": "Location"
+ },
+ "summary": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "Led a team of 5 engineers to develop innovative solutions.",
+ "Completed advanced coursework in machine learning and artificial intelligence."
+ ],
+ "title": "Summary"
+ },
+ "highlights": {
+ "anyOf": [
+ {
+ "items": {
+ "type": "string"
+ },
+ "type": "array"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "Bullet points for key achievements, responsibilities, or contributions.",
+ "examples": [
+ [
+ "Increased system performance by 40% through optimization.",
+ "Mentored 3 junior developers and conducted code reviews.",
+ "Implemented CI/CD pipeline reducing deployment time by 60%."
+ ]
+ ],
+ "title": "Highlights"
+ }
+ },
+ "required": [
+ "company",
+ "position"
+ ],
+ "title": "ExperienceEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__cv__entries__normal__NormalEntry": {
+ "additionalProperties": true,
+ "description": null,
+ "properties": {
+ "name": {
+ "examples": [
+ "Some Project",
+ "Some Event",
+ "Some Award"
+ ],
+ "title": "Name",
+ "type": "string"
+ },
+ "date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ArbitraryDate"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The date of this event in YYYY-MM-DD, YYYY-MM, or YYYY format, or any custom text like 'Fall 2023'. Use this for single-day or imprecise dates. For date ranges, use `start_date` and `end_date` instead.",
+ "examples": [
+ "2020-09-24",
+ "2020-09",
+ "2020",
+ "Fall 2023",
+ "Summer 2020"
+ ]
+ },
+ "start_date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ExactDate"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The start date in YYYY-MM-DD, YYYY-MM, or YYYY format.",
+ "examples": [
+ "2020-09-24",
+ "2020-09",
+ "2020"
+ ]
+ },
+ "end_date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ExactDate"
+ },
+ {
+ "const": "present",
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The end date in YYYY-MM-DD, YYYY-MM, or YYYY format. Use \"present\" for ongoing events, or omit it to indicate the event is ongoing.",
+ "examples": [
+ "2024-05-20",
+ "2024-05",
+ "2024",
+ "present"
+ ],
+ "title": "End Date"
+ },
+ "location": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "Istanbul, Türkiye",
+ "New York, NY",
+ "Remote"
+ ],
+ "title": "Location"
+ },
+ "summary": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "Led a team of 5 engineers to develop innovative solutions.",
+ "Completed advanced coursework in machine learning and artificial intelligence."
+ ],
+ "title": "Summary"
+ },
+ "highlights": {
+ "anyOf": [
+ {
+ "items": {
+ "type": "string"
+ },
+ "type": "array"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "Bullet points for key achievements, responsibilities, or contributions.",
+ "examples": [
+ [
+ "Increased system performance by 40% through optimization.",
+ "Mentored 3 junior developers and conducted code reviews.",
+ "Implemented CI/CD pipeline reducing deployment time by 60%."
+ ]
+ ],
+ "title": "Highlights"
+ }
+ },
+ "required": [
+ "name"
+ ],
+ "title": "NormalEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__cv__entries__one_line__OneLineEntry": {
+ "additionalProperties": true,
+ "description": null,
+ "properties": {
+ "label": {
+ "examples": [
+ "Languages",
+ "Citizenship",
+ "Security Clearance"
+ ],
+ "title": "Label",
+ "type": "string"
+ },
+ "details": {
+ "examples": [
+ "English (native), Spanish (fluent)",
+ "US Citizen",
+ "Top Secret"
+ ],
+ "title": "Details",
+ "type": "string"
+ }
+ },
+ "required": [
+ "label",
+ "details"
+ ],
+ "title": "OneLineEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__cv__entries__publication__PublicationEntry": {
+ "additionalProperties": true,
+ "description": null,
+ "properties": {
+ "title": {
+ "examples": [
+ "Deep Learning for Computer Vision",
+ "Advances in Quantum Computing"
+ ],
+ "title": "Title",
+ "type": "string"
+ },
+ "authors": {
+ "description": "You can bold your name with **double asterisks**.",
+ "examples": [
+ [
+ "John Doe",
+ "**Jane Smith**",
+ "Bob Johnson"
+ ]
+ ],
+ "items": {
+ "type": "string"
+ },
+ "title": "Authors",
+ "type": "array"
+ },
+ "summary": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "examples": [
+ "This paper presents a new method for computer vision."
+ ],
+ "title": "Summary"
+ },
+ "doi": {
+ "anyOf": [
+ {
+ "pattern": "\\b10\\..*",
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The DOI (Digital Object Identifier). If provided, it will be used as the link instead of the URL.",
+ "examples": [
+ "10.48550/arXiv.2310.03138"
+ ],
+ "title": "Doi"
+ },
+ "url": {
+ "anyOf": [
+ {
+ "format": "uri",
+ "maxLength": 2083,
+ "minLength": 1,
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "A URL link to the publication. Ignored if DOI is provided.",
+ "title": "Url"
+ },
+ "journal": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The journal, conference, or venue where it was published.",
+ "examples": [
+ "Nature",
+ "IEEE Conference on Computer Vision",
+ "arXiv preprint"
+ ],
+ "title": "Journal"
+ },
+ "date": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/ArbitraryDate"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "The date of this event in YYYY-MM-DD, YYYY-MM, or YYYY format, or any custom text like 'Fall 2023'. Use this for single-day or imprecise dates. For date ranges, use `start_date` and `end_date` instead.",
+ "examples": [
+ "2020-09-24",
+ "2020-09",
+ "2020",
+ "Fall 2023",
+ "Summer 2020"
+ ]
+ }
+ },
+ "required": [
+ "title",
+ "authors"
+ ],
+ "title": "PublicationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Bold__1": {
+ "additionalProperties": false,
+ "properties": {
+ "name": {
+ "default": true,
+ "description": "Whether to make the name bold. The default value is `true`.",
+ "title": "Name",
+ "type": "boolean"
+ },
+ "headline": {
+ "default": false,
+ "description": "Whether to make the headline bold. The default value is `false`.",
+ "title": "Headline",
+ "type": "boolean"
+ },
+ "connections": {
+ "default": false,
+ "description": "Whether to make connections bold. The default value is `false`.",
+ "title": "Connections",
+ "type": "boolean"
+ },
+ "section_titles": {
+ "default": true,
+ "description": "Whether to make section titles bold. The default value is `true`.",
+ "title": "Section Titles",
+ "type": "boolean"
+ }
+ },
+ "title": "Bold",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Bold__2": {
+ "additionalProperties": false,
+ "properties": {
+ "name": {
+ "default": false,
+ "description": "Whether to make the name bold. The default value is `true`.",
+ "title": "Name",
+ "type": "boolean"
+ },
+ "headline": {
+ "default": false,
+ "description": "Whether to make the headline bold. The default value is `false`.",
+ "title": "Headline",
+ "type": "boolean"
+ },
+ "connections": {
+ "default": false,
+ "description": "Whether to make connections bold. The default value is `false`.",
+ "title": "Connections",
+ "type": "boolean"
+ },
+ "section_titles": {
+ "default": false,
+ "description": "Whether to make section titles bold. The default value is `true`.",
+ "title": "Section Titles",
+ "type": "boolean"
+ }
+ },
+ "title": "Bold",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Bold__3": {
+ "additionalProperties": false,
+ "properties": {
+ "name": {
+ "default": false,
+ "description": "Whether to make the name bold. The default value is `true`.",
+ "title": "Name",
+ "type": "boolean"
+ },
+ "headline": {
+ "default": false,
+ "description": "Whether to make the headline bold. The default value is `false`.",
+ "title": "Headline",
+ "type": "boolean"
+ },
+ "connections": {
+ "default": false,
+ "description": "Whether to make connections bold. The default value is `false`.",
+ "title": "Connections",
+ "type": "boolean"
+ },
+ "section_titles": {
+ "default": true,
+ "description": "Whether to make section titles bold. The default value is `true`.",
+ "title": "Section Titles",
+ "type": "boolean"
+ }
+ },
+ "title": "Bold",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Bold__4": {
+ "additionalProperties": false,
+ "properties": {
+ "name": {
+ "default": false,
+ "description": "Whether to make the name bold. The default value is `true`.",
+ "title": "Name",
+ "type": "boolean"
+ },
+ "headline": {
+ "default": false,
+ "description": "Whether to make the headline bold. The default value is `false`.",
+ "title": "Headline",
+ "type": "boolean"
+ },
+ "connections": {
+ "default": false,
+ "description": "Whether to make connections bold. The default value is `false`.",
+ "title": "Connections",
+ "type": "boolean"
+ },
+ "section_titles": {
+ "default": false,
+ "description": "Whether to make section titles bold. The default value is `true`.",
+ "title": "Section Titles",
+ "type": "boolean"
+ }
+ },
+ "title": "Bold",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Colors__1": {
+ "additionalProperties": false,
+ "properties": {
+ "body": {
+ "default": "rgb(0, 0, 0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 0, 0)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Body",
+ "type": "string"
+ },
+ "name": {
+ "default": "rgb(0, 79, 144)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 79, 144)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Name",
+ "type": "string"
+ },
+ "headline": {
+ "default": "rgb(0, 79, 144)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 79, 144)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Headline",
+ "type": "string"
+ },
+ "connections": {
+ "default": "rgb(0, 79, 144)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 79, 144)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Connections",
+ "type": "string"
+ },
+ "section_titles": {
+ "default": "rgb(0, 79, 144)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 79, 144)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Section Titles",
+ "type": "string"
+ },
+ "links": {
+ "default": "rgb(0, 79, 144)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 79, 144)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Links",
+ "type": "string"
+ },
+ "footer": {
+ "default": "rgb(128, 128, 128)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(128, 128, 128)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "rgb(128, 128, 128)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(128, 128, 128)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Top Note",
+ "type": "string"
+ }
+ },
+ "title": "Colors",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Colors__2": {
+ "additionalProperties": false,
+ "properties": {
+ "body": {
+ "default": "rgb(0, 0, 0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 0, 0)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Body",
+ "type": "string"
+ },
+ "name": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Name",
+ "type": "string"
+ },
+ "headline": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Headline",
+ "type": "string"
+ },
+ "connections": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Connections",
+ "type": "string"
+ },
+ "section_titles": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Section Titles",
+ "type": "string"
+ },
+ "links": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Links",
+ "type": "string"
+ },
+ "footer": {
+ "default": "rgb(128, 128, 128)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(128, 128, 128)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "rgb(128, 128, 128)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(128, 128, 128)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Top Note",
+ "type": "string"
+ }
+ },
+ "title": "Colors",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Colors__3": {
+ "additionalProperties": false,
+ "properties": {
+ "body": {
+ "default": "rgb(0, 0, 0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0, 0, 0)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Body",
+ "type": "string"
+ },
+ "name": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Name",
+ "type": "string"
+ },
+ "headline": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Headline",
+ "type": "string"
+ },
+ "connections": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Connections",
+ "type": "string"
+ },
+ "section_titles": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Section Titles",
+ "type": "string"
+ },
+ "links": {
+ "default": "rgb(0,0,0)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(0,0,0)`.",
+ "format": "color",
+ "title": "Links",
+ "type": "string"
+ },
+ "footer": {
+ "default": "rgb(128, 128, 128)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(128, 128, 128)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "rgb(128, 128, 128)",
+ "description": "The color can be specified either with their name (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB value, or HSL value. The default value is `rgb(128, 128, 128)`.",
+ "examples": [
+ "Black",
+ "7fffd4",
+ "rgb(0,79,144)",
+ "hsl(270, 60%, 70%)"
+ ],
+ "format": "color",
+ "title": "Top Note",
+ "type": "string"
+ }
+ },
+ "title": "Colors",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Connections__1": {
+ "additionalProperties": false,
+ "properties": {
+ "phone_number_format": {
+ "$ref": "#/$defs/PhoneNumberFormatType",
+ "default": "national",
+ "description": "Phone number format. The default value is `national`."
+ },
+ "hyperlink": {
+ "default": true,
+ "description": "Make contact information clickable in the PDF. The default value is `true`.",
+ "title": "Hyperlink",
+ "type": "boolean"
+ },
+ "show_icons": {
+ "default": true,
+ "description": "Show icons next to contact information. The default value is `true`.",
+ "title": "Show Icons",
+ "type": "boolean"
+ },
+ "display_urls_instead_of_usernames": {
+ "default": false,
+ "description": "Display full URLs instead of labels. The default value is `false`.",
+ "title": "Display Urls Instead Of Usernames",
+ "type": "boolean"
+ },
+ "separator": {
+ "default": "",
+ "description": "Character(s) to separate contact items (e.g., '|' or '•'). Leave empty for no separator. The default value is `''`.",
+ "title": "Separator",
+ "type": "string"
+ },
+ "space_between_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5cm",
+ "description": "Horizontal space between contact items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5cm`."
+ }
+ },
+ "title": "Connections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Connections__2": {
+ "additionalProperties": false,
+ "properties": {
+ "phone_number_format": {
+ "$ref": "#/$defs/PhoneNumberFormatType",
+ "default": "national",
+ "description": "Phone number format. The default value is `national`."
+ },
+ "hyperlink": {
+ "default": true,
+ "description": "Make contact information clickable in the PDF. The default value is `true`.",
+ "title": "Hyperlink",
+ "type": "boolean"
+ },
+ "show_icons": {
+ "default": false,
+ "description": "Show icons next to contact information. The default value is `true`.",
+ "title": "Show Icons",
+ "type": "boolean"
+ },
+ "display_urls_instead_of_usernames": {
+ "default": true,
+ "description": "Display full URLs instead of labels. The default value is `false`.",
+ "title": "Display Urls Instead Of Usernames",
+ "type": "boolean"
+ },
+ "separator": {
+ "default": "|",
+ "description": "Character(s) to separate contact items (e.g., '|' or '•'). Leave empty for no separator. The default value is `''`.",
+ "title": "Separator",
+ "type": "string"
+ },
+ "space_between_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5cm",
+ "description": "Horizontal space between contact items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5cm`."
+ }
+ },
+ "title": "Connections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Connections__3": {
+ "additionalProperties": false,
+ "properties": {
+ "phone_number_format": {
+ "$ref": "#/$defs/PhoneNumberFormatType",
+ "default": "national",
+ "description": "Phone number format. The default value is `national`."
+ },
+ "hyperlink": {
+ "default": true,
+ "description": "Make contact information clickable in the PDF. The default value is `true`.",
+ "title": "Hyperlink",
+ "type": "boolean"
+ },
+ "show_icons": {
+ "default": false,
+ "description": "Show icons next to contact information. The default value is `true`.",
+ "title": "Show Icons",
+ "type": "boolean"
+ },
+ "display_urls_instead_of_usernames": {
+ "default": true,
+ "description": "Display full URLs instead of labels. The default value is `false`.",
+ "title": "Display Urls Instead Of Usernames",
+ "type": "boolean"
+ },
+ "separator": {
+ "default": "•",
+ "description": "Character(s) to separate contact items (e.g., '|' or '•'). Leave empty for no separator. The default value is `''`.",
+ "title": "Separator",
+ "type": "string"
+ },
+ "space_between_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5cm",
+ "description": "Horizontal space between contact items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5cm`."
+ }
+ },
+ "title": "Connections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__EducationEntry__1": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**INSTITUTION**, AREA\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**INSTITUTION**, AREA\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "degree_column": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": "**DEGREE**",
+ "description": "If given, a degree column will be added to the education entry. If \"null\", no degree column will be shown. The available placeholders are all the keys used in the entries (in uppercase). The default value is `**DEGREE**`.",
+ "title": "Degree Column"
+ },
+ "date_and_location_column": {
+ "default": "LOCATION\nDATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "EducationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__EducationEntry__2": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**INSTITUTION**, DEGREE in AREA -- LOCATION\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**INSTITUTION**, AREA\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "degree_column": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "If given, a degree column will be added to the education entry. If \"null\", no degree column will be shown. The available placeholders are all the keys used in the entries (in uppercase). The default value is `None`.",
+ "title": "Degree Column"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "EducationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__EducationEntry__3": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**INSTITUTION**, DEGREE in AREA -- LOCATION\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**INSTITUTION**, AREA\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "degree_column": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "If given, a degree column will be added to the education entry. If \"null\", no degree column will be shown. The available placeholders are all the keys used in the entries (in uppercase). The default value is `None`.",
+ "title": "Degree Column"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "EducationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__EducationEntry__4": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**INSTITUTION**, DEGREE in AREA -- LOCATION\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**INSTITUTION**, AREA\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "degree_column": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "If given, a degree column will be added to the education entry. If \"null\", no degree column will be shown. The available placeholders are all the keys used in the entries (in uppercase). The default value is `None`.",
+ "title": "Degree Column"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "EducationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__EducationEntry__5": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**INSTITUTION**\n*DEGREE* *in* *AREA*\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**INSTITUTION**, AREA\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "degree_column": {
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "null"
+ }
+ ],
+ "default": null,
+ "description": "If given, a degree column will be added to the education entry. If \"null\", no degree column will be shown. The available placeholders are all the keys used in the entries (in uppercase). The default value is `None`.",
+ "title": "Degree Column"
+ },
+ "date_and_location_column": {
+ "default": "*LOCATION*\n*DATE*",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "EducationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Entries__1": {
+ "additionalProperties": false,
+ "properties": {
+ "date_and_location_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "4.15cm",
+ "description": "Width of the date/location column. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `4.15cm`."
+ },
+ "side_space": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.2cm",
+ "description": "Left and right margins. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.2cm`."
+ },
+ "space_between_columns": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.1cm",
+ "description": "Space between main content and date/location columns. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.1cm`."
+ },
+ "allow_page_break": {
+ "default": false,
+ "description": "Allow page breaks within entries. If false, entries that don't fit will move to a new page. The default value is `false`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "short_second_row": {
+ "default": true,
+ "description": "Shorten the second row to align with the date/location column. The default value is `true`.",
+ "title": "Short Second Row",
+ "type": "boolean"
+ },
+ "summary": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Summary__1",
+ "description": "Summary text settings."
+ },
+ "highlights": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Highlights__1",
+ "description": "Highlights settings."
+ }
+ },
+ "title": "Entries",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Entries__2": {
+ "additionalProperties": false,
+ "properties": {
+ "date_and_location_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "4.15cm",
+ "description": "Width of the date/location column. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `4.15cm`."
+ },
+ "side_space": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.2cm",
+ "description": "Left and right margins. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.2cm`."
+ },
+ "space_between_columns": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.1cm",
+ "description": "Space between main content and date/location columns. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.1cm`."
+ },
+ "allow_page_break": {
+ "default": false,
+ "description": "Allow page breaks within entries. If false, entries that don't fit will move to a new page. The default value is `false`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "short_second_row": {
+ "default": false,
+ "description": "Shorten the second row to align with the date/location column. The default value is `true`.",
+ "title": "Short Second Row",
+ "type": "boolean"
+ },
+ "summary": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Summary__2",
+ "description": "Summary text settings."
+ },
+ "highlights": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Highlights__2",
+ "description": "Highlights settings."
+ }
+ },
+ "title": "Entries",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Entries__3": {
+ "additionalProperties": false,
+ "properties": {
+ "date_and_location_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "4.15cm",
+ "description": "Width of the date/location column. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `4.15cm`."
+ },
+ "side_space": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left and right margins. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_between_columns": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.1cm",
+ "description": "Space between main content and date/location columns. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.1cm`."
+ },
+ "allow_page_break": {
+ "default": false,
+ "description": "Allow page breaks within entries. If false, entries that don't fit will move to a new page. The default value is `false`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "short_second_row": {
+ "default": false,
+ "description": "Shorten the second row to align with the date/location column. The default value is `true`.",
+ "title": "Short Second Row",
+ "type": "boolean"
+ },
+ "summary": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Summary__3",
+ "description": "Summary text settings."
+ },
+ "highlights": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Highlights__3",
+ "description": "Highlights settings."
+ }
+ },
+ "title": "Entries",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Entries__4": {
+ "additionalProperties": false,
+ "properties": {
+ "date_and_location_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "4.15cm",
+ "description": "Width of the date/location column. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `4.15cm`."
+ },
+ "side_space": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left and right margins. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_between_columns": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3cm",
+ "description": "Space between main content and date/location columns. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.3cm`. The default value is `0.3cm`."
+ },
+ "allow_page_break": {
+ "default": false,
+ "description": "Allow page breaks within entries. If false, entries that don't fit will move to a new page. The default value is `false`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "short_second_row": {
+ "default": false,
+ "description": "Shorten the second row to align with the date/location column. The default value is `true`.",
+ "title": "Short Second Row",
+ "type": "boolean"
+ },
+ "summary": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Summary__4",
+ "description": "Summary text settings."
+ },
+ "highlights": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Highlights__4",
+ "description": "Highlights settings."
+ }
+ },
+ "title": "Entries",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Entries__5": {
+ "additionalProperties": false,
+ "properties": {
+ "date_and_location_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "4.15cm",
+ "description": "Width of the date/location column. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `4.15cm`."
+ },
+ "side_space": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.2cm",
+ "description": "Left and right margins. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.2cm`."
+ },
+ "space_between_columns": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.1cm",
+ "description": "Space between main content and date/location columns. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.1cm`."
+ },
+ "allow_page_break": {
+ "default": false,
+ "description": "Allow page breaks within entries. If false, entries that don't fit will move to a new page. The default value is `false`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "short_second_row": {
+ "default": false,
+ "description": "Shorten the second row to align with the date/location column. The default value is `true`.",
+ "title": "Short Second Row",
+ "type": "boolean"
+ },
+ "summary": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Summary__1",
+ "description": "Summary text settings."
+ },
+ "highlights": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Highlights__5",
+ "description": "Highlights settings."
+ }
+ },
+ "title": "Entries",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__ExperienceEntry__1": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**COMPANY**, POSITION\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**COMPANY**, POSITION\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "LOCATION\nDATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "ExperienceEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__ExperienceEntry__2": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**POSITION**, COMPANY -- LOCATION\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**COMPANY**, POSITION\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "ExperienceEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__ExperienceEntry__3": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**POSITION**, COMPANY -- LOCATION\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**COMPANY**, POSITION\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "ExperienceEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__ExperienceEntry__4": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**POSITION**, COMPANY -- LOCATION\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**COMPANY**, POSITION\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "ExperienceEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__ExperienceEntry__5": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**POSITION**\n*COMPANY*\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**COMPANY**, POSITION\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "*LOCATION*\n*DATE*",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "ExperienceEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__FontFamily": {
+ "additionalProperties": false,
+ "properties": {
+ "body": {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily",
+ "default": "Source Sans 3",
+ "description": "The font family for body text. The default value is `Source Sans 3`."
+ },
+ "name": {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily",
+ "default": "Source Sans 3",
+ "description": "The font family for the name. The default value is `Source Sans 3`."
+ },
+ "headline": {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily",
+ "default": "Source Sans 3",
+ "description": "The font family for the headline. The default value is `Source Sans 3`."
+ },
+ "connections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily",
+ "default": "Source Sans 3",
+ "description": "The font family for connections. The default value is `Source Sans 3`."
+ },
+ "section_titles": {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily",
+ "default": "Source Sans 3",
+ "description": "The font family for section titles. The default value is `Source Sans 3`."
+ }
+ },
+ "title": "FontFamily",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__FontSize__1": {
+ "additionalProperties": false,
+ "properties": {
+ "body": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for body text. The default value is `10pt`."
+ },
+ "name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "30pt",
+ "description": "The font size for the name. The default value is `30pt`."
+ },
+ "headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for the headline. The default value is `10pt`."
+ },
+ "connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for connections. The default value is `10pt`."
+ },
+ "section_titles": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "1.4em",
+ "description": "The font size for section titles. The default value is `1.4em`."
+ }
+ },
+ "title": "FontSize",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__FontSize__2": {
+ "additionalProperties": false,
+ "properties": {
+ "body": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for body text. The default value is `10pt`."
+ },
+ "name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "25pt",
+ "description": "The font size for the name. The default value is `25pt`."
+ },
+ "headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for the headline. The default value is `10pt`."
+ },
+ "connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for connections. The default value is `10pt`."
+ },
+ "section_titles": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "1.2em",
+ "description": "The font size for section titles. The default value is `1.2em`."
+ }
+ },
+ "title": "FontSize",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__FontSize__3": {
+ "additionalProperties": false,
+ "properties": {
+ "body": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for body text. The default value is `10pt`."
+ },
+ "name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "25pt",
+ "description": "The font size for the name. The default value is `25pt`."
+ },
+ "headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for the headline. The default value is `10pt`."
+ },
+ "connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "10pt",
+ "description": "The font size for connections. The default value is `10pt`."
+ },
+ "section_titles": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "1.4em",
+ "description": "The font size for section titles. The default value is `1.4em`."
+ }
+ },
+ "title": "FontSize",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Header__1": {
+ "additionalProperties": false,
+ "properties": {
+ "alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "center",
+ "description": "Header alignment. Options: 'left', 'center', 'right'. The default value is `center`."
+ },
+ "photo_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "3.5cm",
+ "description": "Photo width. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `3.5cm`."
+ },
+ "photo_position": {
+ "default": "left",
+ "description": "Photo position (left or right). The default value is `left`.",
+ "enum": [
+ "left",
+ "right"
+ ],
+ "title": "Photo Position",
+ "type": "string"
+ },
+ "photo_space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the left of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "photo_space_right": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the right of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "space_below_name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below your name. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below the headline. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below contact information. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "connections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Connections__1",
+ "description": "Contact information settings."
+ }
+ },
+ "title": "Header",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Header__2": {
+ "additionalProperties": false,
+ "properties": {
+ "alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "left",
+ "description": "Header alignment. Options: 'left', 'center', 'right'. The default value is `left`."
+ },
+ "photo_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "3.5cm",
+ "description": "Photo width. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `3.5cm`."
+ },
+ "photo_position": {
+ "default": "left",
+ "description": "Photo position (left or right). The default value is `left`.",
+ "enum": [
+ "left",
+ "right"
+ ],
+ "title": "Photo Position",
+ "type": "string"
+ },
+ "photo_space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the left of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "photo_space_right": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the right of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "space_below_name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below your name. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below the headline. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below contact information. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "connections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Connections__1",
+ "description": "Contact information settings."
+ }
+ },
+ "title": "Header",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Header__3": {
+ "additionalProperties": false,
+ "properties": {
+ "alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "center",
+ "description": "Header alignment. Options: 'left', 'center', 'right'. The default value is `center`."
+ },
+ "photo_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "3.5cm",
+ "description": "Photo width. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `3.5cm`."
+ },
+ "photo_position": {
+ "default": "left",
+ "description": "Photo position (left or right). The default value is `left`.",
+ "enum": [
+ "left",
+ "right"
+ ],
+ "title": "Photo Position",
+ "type": "string"
+ },
+ "photo_space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the left of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "photo_space_right": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the right of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "space_below_name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below your name. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below the headline. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below contact information. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "connections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Connections__2",
+ "description": "Contact information settings."
+ }
+ },
+ "title": "Header",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Header__4": {
+ "additionalProperties": false,
+ "properties": {
+ "alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "left",
+ "description": "Header alignment. Options: 'left', 'center', 'right'. The default value is `left`."
+ },
+ "photo_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "4.15cm",
+ "description": "Photo width. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `4.15cm`."
+ },
+ "photo_position": {
+ "default": "left",
+ "description": "Photo position (left or right). The default value is `left`.",
+ "enum": [
+ "left",
+ "right"
+ ],
+ "title": "Photo Position",
+ "type": "string"
+ },
+ "photo_space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Space to the left of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "photo_space_right": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3cm",
+ "description": "Space to the right of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3cm`."
+ },
+ "space_below_name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below your name. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below the headline. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below contact information. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "connections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Connections__1",
+ "description": "Contact information settings."
+ }
+ },
+ "title": "Header",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Header__5": {
+ "additionalProperties": false,
+ "properties": {
+ "alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "center",
+ "description": "Header alignment. Options: 'left', 'center', 'right'. The default value is `center`."
+ },
+ "photo_width": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "3.5cm",
+ "description": "Photo width. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `3.5cm`."
+ },
+ "photo_position": {
+ "default": "left",
+ "description": "Photo position (left or right). The default value is `left`.",
+ "enum": [
+ "left",
+ "right"
+ ],
+ "title": "Photo Position",
+ "type": "string"
+ },
+ "photo_space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the left of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "photo_space_right": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.4cm",
+ "description": "Space to the right of the photo. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.4cm`."
+ },
+ "space_below_name": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below your name. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_headline": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below the headline. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "space_below_connections": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7cm",
+ "description": "Space below contact information. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7cm`."
+ },
+ "connections": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Connections__3",
+ "description": "Contact information settings."
+ }
+ },
+ "title": "Header",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Highlights__1": {
+ "additionalProperties": false,
+ "properties": {
+ "bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "•",
+ "description": "Bullet character for highlights. The default value is `•`."
+ },
+ "nested_bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "•",
+ "description": "Bullet character for nested highlights. The default value is `•`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.15cm",
+ "description": "Left indentation. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.15cm`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Space above highlights. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_between_items": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Space between highlight items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_between_bullet_and_text": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5em",
+ "description": "Space between bullet and text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5em`."
+ }
+ },
+ "title": "Highlights",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Highlights__2": {
+ "additionalProperties": false,
+ "properties": {
+ "bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "•",
+ "description": "Bullet character for highlights. The default value is `•`."
+ },
+ "nested_bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "•",
+ "description": "Bullet character for nested highlights. The default value is `•`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left indentation. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.12cm",
+ "description": "Space above highlights. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.12cm`."
+ },
+ "space_between_items": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.12cm",
+ "description": "Space between highlight items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.12cm`."
+ },
+ "space_between_bullet_and_text": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5em",
+ "description": "Space between bullet and text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5em`."
+ }
+ },
+ "title": "Highlights",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Highlights__3": {
+ "additionalProperties": false,
+ "properties": {
+ "bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "●",
+ "description": "Bullet character for highlights. The default value is `●`."
+ },
+ "nested_bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "●",
+ "description": "Bullet character for nested highlights. The default value is `●`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left indentation. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.08cm",
+ "description": "Space above highlights. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.08cm`."
+ },
+ "space_between_items": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.08cm",
+ "description": "Space between highlight items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.08cm`."
+ },
+ "space_between_bullet_and_text": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3em",
+ "description": "Space between bullet and text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3em`."
+ }
+ },
+ "title": "Highlights",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Highlights__4": {
+ "additionalProperties": false,
+ "properties": {
+ "bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "•",
+ "description": "Bullet character for highlights. The default value is `•`."
+ },
+ "nested_bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "•",
+ "description": "Bullet character for nested highlights. The default value is `•`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left indentation. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.15cm",
+ "description": "Space above highlights. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.15cm`."
+ },
+ "space_between_items": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.1cm",
+ "description": "Space between highlight items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.1cm`."
+ },
+ "space_between_bullet_and_text": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3em",
+ "description": "Space between bullet and text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3em`."
+ }
+ },
+ "title": "Highlights",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Highlights__5": {
+ "additionalProperties": false,
+ "properties": {
+ "bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "◦",
+ "description": "Bullet character for highlights. The default value is `◦`."
+ },
+ "nested_bullet": {
+ "$ref": "#/$defs/Bullet",
+ "default": "◦",
+ "description": "Bullet character for nested highlights. The default value is `◦`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.15cm",
+ "description": "Left indentation. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.15cm`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Space above highlights. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_between_items": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Space between highlight items. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_between_bullet_and_text": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5em",
+ "description": "Space between bullet and text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5em`."
+ }
+ },
+ "title": "Highlights",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Links__1": {
+ "additionalProperties": false,
+ "properties": {
+ "underline": {
+ "default": false,
+ "description": "Underline hyperlinks. The default value is `false`.",
+ "title": "Underline",
+ "type": "boolean"
+ },
+ "show_external_link_icon": {
+ "default": false,
+ "description": "Show an external link icon next to URLs. The default value is `false`.",
+ "title": "Show External Link Icon",
+ "type": "boolean"
+ }
+ },
+ "title": "Links",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Links__2": {
+ "additionalProperties": false,
+ "properties": {
+ "underline": {
+ "default": false,
+ "description": "Underline hyperlinks. The default value is `false`.",
+ "title": "Underline",
+ "type": "boolean"
+ },
+ "show_external_link_icon": {
+ "default": false,
+ "description": "Show an external link icon next to URLs. The default value is `false`.",
+ "title": "Show External Link Icon",
+ "type": "boolean"
+ }
+ },
+ "title": "Links",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Links__3": {
+ "additionalProperties": false,
+ "properties": {
+ "underline": {
+ "default": true,
+ "description": "Underline hyperlinks. The default value is `false`.",
+ "title": "Underline",
+ "type": "boolean"
+ },
+ "show_external_link_icon": {
+ "default": false,
+ "description": "Show an external link icon next to URLs. The default value is `false`.",
+ "title": "Show External Link Icon",
+ "type": "boolean"
+ }
+ },
+ "title": "Links",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Links__4": {
+ "additionalProperties": false,
+ "properties": {
+ "underline": {
+ "default": true,
+ "description": "Underline hyperlinks. The default value is `false`.",
+ "title": "Underline",
+ "type": "boolean"
+ },
+ "show_external_link_icon": {
+ "default": false,
+ "description": "Show an external link icon next to URLs. The default value is `false`.",
+ "title": "Show External Link Icon",
+ "type": "boolean"
+ }
+ },
+ "title": "Links",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Links__5": {
+ "additionalProperties": false,
+ "properties": {
+ "underline": {
+ "default": true,
+ "description": "Underline hyperlinks. The default value is `false`.",
+ "title": "Underline",
+ "type": "boolean"
+ },
+ "show_external_link_icon": {
+ "default": false,
+ "description": "Show an external link icon next to URLs. The default value is `false`.",
+ "title": "Show External Link Icon",
+ "type": "boolean"
+ }
+ },
+ "title": "Links",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__NormalEntry__1": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**NAME**\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**NAME**\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "LOCATION\nDATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "NormalEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__NormalEntry__2": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**NAME** -- **LOCATION**\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**NAME**\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "NormalEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__NormalEntry__3": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**NAME** -- **LOCATION**\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**NAME**\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "NormalEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__NormalEntry__4": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**NAME** -- **LOCATION**\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**NAME**\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "NormalEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__NormalEntry__5": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**NAME**\nSUMMARY\nHIGHLIGHTS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**NAME**\\nSUMMARY\\nHIGHLIGHTS`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "*LOCATION*\n*DATE*",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `LOCATION\\nDATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "NormalEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__OneLineEntry": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**LABEL:** DETAILS",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**LABEL:** DETAILS`.",
+ "title": "Main Column",
+ "type": "string"
+ }
+ },
+ "title": "OneLineEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Page__1": {
+ "additionalProperties": false,
+ "properties": {
+ "size": {
+ "$ref": "#/$defs/PageSize",
+ "default": "us-letter",
+ "description": "The page size. Use 'a4' (international standard) or 'us-letter' (US standard). The default value is `us-letter`."
+ },
+ "top_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "bottom_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "left_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "right_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "show_footer": {
+ "default": true,
+ "description": "Show the footer at the bottom of pages. The default value is `true`.",
+ "title": "Show Footer",
+ "type": "boolean"
+ },
+ "show_top_note": {
+ "default": true,
+ "description": "Show the top note at the top of the first page. The default value is `true`.",
+ "title": "Show Top Note",
+ "type": "boolean"
+ }
+ },
+ "title": "Page",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Page__2": {
+ "additionalProperties": false,
+ "properties": {
+ "size": {
+ "$ref": "#/$defs/PageSize",
+ "default": "us-letter",
+ "description": "The page size. Use 'a4' (international standard) or 'us-letter' (US standard). The default value is `us-letter`."
+ },
+ "top_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "bottom_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "left_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "right_margin": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.7in",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.7in`."
+ },
+ "show_footer": {
+ "default": false,
+ "description": "Show the footer at the bottom of pages. The default value is `true`.",
+ "title": "Show Footer",
+ "type": "boolean"
+ },
+ "show_top_note": {
+ "default": true,
+ "description": "Show the top note at the top of the first page. The default value is `true`.",
+ "title": "Show Top Note",
+ "type": "boolean"
+ }
+ },
+ "title": "Page",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__PublicationEntry": {
+ "additionalProperties": false,
+ "properties": {
+ "main_column": {
+ "default": "**TITLE**\nSUMMARY\nAUTHORS\nURL (JOURNAL)",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `**TITLE**\\nSUMMARY\\nAUTHORS\\nURL (JOURNAL)`.",
+ "title": "Main Column",
+ "type": "string"
+ },
+ "date_and_location_column": {
+ "default": "DATE",
+ "description": "The content of the template. The available placeholders are all the keys used in the entries in uppercase. For example, **TITLE**. The default value is `DATE`.",
+ "title": "Date And Location Column",
+ "type": "string"
+ }
+ },
+ "title": "PublicationEntry",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__SectionTitles__1": {
+ "additionalProperties": false,
+ "properties": {
+ "type": {
+ "$ref": "#/$defs/SectionTitleType",
+ "default": "with_partial_line",
+ "description": "Section title visual style. Use 'with_partial_line' for a line next to the title, 'with_full_line' for a line across the page, 'without_line' for no line, or 'moderncv' for the ModernCV style. The default value is `with_partial_line`."
+ },
+ "line_thickness": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5pt",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5pt`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5cm`."
+ },
+ "space_below": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3cm`."
+ }
+ },
+ "title": "SectionTitles",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__SectionTitles__2": {
+ "additionalProperties": false,
+ "properties": {
+ "type": {
+ "$ref": "#/$defs/SectionTitleType",
+ "default": "with_full_line",
+ "description": "Section title visual style. Use 'with_partial_line' for a line next to the title, 'with_full_line' for a line across the page, 'without_line' for no line, or 'moderncv' for the ModernCV style. The default value is `with_full_line`."
+ },
+ "line_thickness": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5pt",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5pt`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5cm`."
+ },
+ "space_below": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3cm`."
+ }
+ },
+ "title": "SectionTitles",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__SectionTitles__3": {
+ "additionalProperties": false,
+ "properties": {
+ "type": {
+ "$ref": "#/$defs/SectionTitleType",
+ "default": "with_full_line",
+ "description": "Section title visual style. Use 'with_partial_line' for a line next to the title, 'with_full_line' for a line across the page, 'without_line' for no line, or 'moderncv' for the ModernCV style. The default value is `with_full_line`."
+ },
+ "line_thickness": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5pt",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5pt`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5cm`."
+ },
+ "space_below": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3cm`."
+ }
+ },
+ "title": "SectionTitles",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__SectionTitles__4": {
+ "additionalProperties": false,
+ "properties": {
+ "type": {
+ "$ref": "#/$defs/SectionTitleType",
+ "default": "moderncv",
+ "description": "Section title visual style. Use 'with_partial_line' for a line next to the title, 'with_full_line' for a line across the page, 'without_line' for no line, or 'moderncv' for the ModernCV style. The default value is `moderncv`."
+ },
+ "line_thickness": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.15cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.15cm`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.55cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.55cm`."
+ },
+ "space_below": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3cm`."
+ }
+ },
+ "title": "SectionTitles",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__SectionTitles__5": {
+ "additionalProperties": false,
+ "properties": {
+ "type": {
+ "$ref": "#/$defs/SectionTitleType",
+ "default": "with_full_line",
+ "description": "Section title visual style. Use 'with_partial_line' for a line next to the title, 'with_full_line' for a line across the page, 'without_line' for no line, or 'moderncv' for the ModernCV style. The default value is `with_full_line`."
+ },
+ "line_thickness": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5pt",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5pt`."
+ },
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.5cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.5cm`."
+ },
+ "space_below": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3cm",
+ "description": "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3cm`."
+ }
+ },
+ "title": "SectionTitles",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Sections__1": {
+ "additionalProperties": false,
+ "properties": {
+ "allow_page_break": {
+ "default": true,
+ "description": "Allow page breaks within sections. If false, sections that don't fit will start on a new page. The default value is `true`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "space_between_regular_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "1.2em",
+ "description": "Vertical space between entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `1.2em`."
+ },
+ "space_between_text_based_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3em",
+ "description": "Vertical space between text-based entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3em`."
+ },
+ "show_time_spans_in": {
+ "default": [
+ "experience"
+ ],
+ "description": "Section titles where time spans (e.g., '2 years 3 months') should be displayed. The default value is `['experience']`.",
+ "examples": [
+ [
+ "Experience"
+ ],
+ [
+ "Experience",
+ "Education"
+ ]
+ ],
+ "items": {
+ "type": "string"
+ },
+ "title": "Show Time Spans In",
+ "type": "array"
+ }
+ },
+ "title": "Sections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Sections__2": {
+ "additionalProperties": false,
+ "properties": {
+ "allow_page_break": {
+ "default": true,
+ "description": "Allow page breaks within sections. If false, sections that don't fit will start on a new page. The default value is `true`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "space_between_regular_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "1.2em",
+ "description": "Vertical space between entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `1.2em`."
+ },
+ "space_between_text_based_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3em",
+ "description": "Vertical space between text-based entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3em`."
+ },
+ "show_time_spans_in": {
+ "description": "Section titles where time spans (e.g., '2 years 3 months') should be displayed. The default value is `[]`.",
+ "items": {
+ "type": "string"
+ },
+ "title": "Show Time Spans In",
+ "type": "array"
+ }
+ },
+ "title": "Sections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Sections__3": {
+ "additionalProperties": false,
+ "properties": {
+ "allow_page_break": {
+ "default": true,
+ "description": "Allow page breaks within sections. If false, sections that don't fit will start on a new page. The default value is `true`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "space_between_regular_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.42cm",
+ "description": "Vertical space between entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.42cm`."
+ },
+ "space_between_text_based_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.15cm",
+ "description": "Vertical space between text-based entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.15cm`."
+ },
+ "show_time_spans_in": {
+ "description": "Section titles where time spans (e.g., '2 years 3 months') should be displayed. The default value is `[]`.",
+ "items": {
+ "type": "string"
+ },
+ "title": "Show Time Spans In",
+ "type": "array"
+ }
+ },
+ "title": "Sections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Sections__4": {
+ "additionalProperties": false,
+ "properties": {
+ "allow_page_break": {
+ "default": true,
+ "description": "Allow page breaks within sections. If false, sections that don't fit will start on a new page. The default value is `true`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "space_between_regular_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "1.2em",
+ "description": "Vertical space between entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `1.2em`."
+ },
+ "space_between_text_based_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3em",
+ "description": "Vertical space between text-based entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3em`."
+ },
+ "show_time_spans_in": {
+ "description": "Section titles where time spans (e.g., '2 years 3 months') should be displayed. The default value is `[]`.",
+ "items": {
+ "type": "string"
+ },
+ "title": "Show Time Spans In",
+ "type": "array"
+ }
+ },
+ "title": "Sections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Sections__5": {
+ "additionalProperties": false,
+ "properties": {
+ "allow_page_break": {
+ "default": true,
+ "description": "Allow page breaks within sections. If false, sections that don't fit will start on a new page. The default value is `true`.",
+ "title": "Allow Page Break",
+ "type": "boolean"
+ },
+ "space_between_regular_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "1.2em",
+ "description": "Vertical space between entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `1.2em`."
+ },
+ "space_between_text_based_entries": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.3em",
+ "description": "Vertical space between text-based entries. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.3em`."
+ },
+ "show_time_spans_in": {
+ "description": "Section titles where time spans (e.g., '2 years 3 months') should be displayed. The default value is `[]`.",
+ "items": {
+ "type": "string"
+ },
+ "title": "Show Time Spans In",
+ "type": "array"
+ }
+ },
+ "title": "Sections",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Summary__1": {
+ "additionalProperties": false,
+ "properties": {
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Space above summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left margin for summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ }
+ },
+ "title": "Summary",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Summary__2": {
+ "additionalProperties": false,
+ "properties": {
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.12cm",
+ "description": "Space above summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.12cm`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left margin for summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ }
+ },
+ "title": "Summary",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Summary__3": {
+ "additionalProperties": false,
+ "properties": {
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.08cm",
+ "description": "Space above summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.08cm`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left margin for summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ }
+ },
+ "title": "Summary",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Summary__4": {
+ "additionalProperties": false,
+ "properties": {
+ "space_above": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.1cm",
+ "description": "Space above summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0.1cm`."
+ },
+ "space_left": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0cm",
+ "description": "Left margin for summary text. It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`. The default value is `0cm`."
+ }
+ },
+ "title": "Summary",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Templates__1": {
+ "additionalProperties": false,
+ "properties": {
+ "footer": {
+ "default": "*NAME -- PAGE_NUMBER/TOTAL_PAGES*",
+ "description": "Template for the footer. Available placeholders: NAME, PAGE_NUMBER, TOTAL_PAGES. The default value is `*NAME -- PAGE_NUMBER/TOTAL_PAGES*`.",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "*LAST_UPDATED CURRENT_DATE*",
+ "description": "Template for the top note. Available placeholders: LAST_UPDATED, CURRENT_DATE. The default value is `*LAST_UPDATED CURRENT_DATE*`.",
+ "title": "Top Note",
+ "type": "string"
+ },
+ "single_date": {
+ "default": "MONTH_ABBREVIATION YEAR",
+ "description": "Template for single dates. Available placeholders: MONTH_ABBREVIATION, YEAR. The default value is `MONTH_ABBREVIATION YEAR`.",
+ "title": "Single Date",
+ "type": "string"
+ },
+ "date_range": {
+ "default": "START_DATE – END_DATE",
+ "description": "Template for date ranges. Available placeholders: START_DATE, END_DATE. The default value is `START_DATE – END_DATE`.",
+ "title": "Date Range",
+ "type": "string"
+ },
+ "time_span": {
+ "default": "HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS",
+ "description": "Template for time spans. Available placeholders: HOW_MANY_YEARS, YEARS, HOW_MANY_MONTHS, MONTHS. The default value is `HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS`.",
+ "title": "Time Span",
+ "type": "string"
+ },
+ "one_line_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__OneLineEntry",
+ "description": "Template for one-line entries."
+ },
+ "education_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__EducationEntry__1",
+ "description": "Template for education entries."
+ },
+ "normal_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__NormalEntry__1",
+ "description": "Template for normal entries."
+ },
+ "experience_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__ExperienceEntry__1",
+ "description": "Template for experience entries."
+ },
+ "publication_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__PublicationEntry",
+ "description": "Template for publication entries."
+ }
+ },
+ "title": "Templates",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Templates__2": {
+ "additionalProperties": false,
+ "properties": {
+ "footer": {
+ "default": "*NAME -- PAGE_NUMBER/TOTAL_PAGES*",
+ "description": "Template for the footer. Available placeholders: NAME, PAGE_NUMBER, TOTAL_PAGES. The default value is `*NAME -- PAGE_NUMBER/TOTAL_PAGES*`.",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "*LAST_UPDATED CURRENT_DATE*",
+ "description": "Template for the top note. Available placeholders: LAST_UPDATED, CURRENT_DATE. The default value is `*LAST_UPDATED CURRENT_DATE*`.",
+ "title": "Top Note",
+ "type": "string"
+ },
+ "single_date": {
+ "default": "MONTH_ABBREVIATION YEAR",
+ "description": "Template for single dates. Available placeholders: MONTH_ABBREVIATION, YEAR. The default value is `MONTH_ABBREVIATION YEAR`.",
+ "title": "Single Date",
+ "type": "string"
+ },
+ "date_range": {
+ "default": "START_DATE – END_DATE",
+ "description": "Template for date ranges. Available placeholders: START_DATE, END_DATE. The default value is `START_DATE – END_DATE`.",
+ "title": "Date Range",
+ "type": "string"
+ },
+ "time_span": {
+ "default": "HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS",
+ "description": "Template for time spans. Available placeholders: HOW_MANY_YEARS, YEARS, HOW_MANY_MONTHS, MONTHS. The default value is `HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS`.",
+ "title": "Time Span",
+ "type": "string"
+ },
+ "one_line_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__OneLineEntry",
+ "description": "Template for one-line entries."
+ },
+ "education_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__EducationEntry__2",
+ "description": "Template for education entries."
+ },
+ "normal_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__NormalEntry__2",
+ "description": "Template for normal entries."
+ },
+ "experience_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__ExperienceEntry__2",
+ "description": "Template for experience entries."
+ },
+ "publication_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__PublicationEntry",
+ "description": "Template for publication entries."
+ }
+ },
+ "title": "Templates",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Templates__3": {
+ "additionalProperties": false,
+ "properties": {
+ "footer": {
+ "default": "*NAME -- PAGE_NUMBER/TOTAL_PAGES*",
+ "description": "Template for the footer. Available placeholders: NAME, PAGE_NUMBER, TOTAL_PAGES. The default value is `*NAME -- PAGE_NUMBER/TOTAL_PAGES*`.",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "*LAST_UPDATED CURRENT_DATE*",
+ "description": "Template for the top note. Available placeholders: LAST_UPDATED, CURRENT_DATE. The default value is `*LAST_UPDATED CURRENT_DATE*`.",
+ "title": "Top Note",
+ "type": "string"
+ },
+ "single_date": {
+ "default": "MONTH_ABBREVIATION YEAR",
+ "description": "Template for single dates. Available placeholders: MONTH_ABBREVIATION, YEAR. The default value is `MONTH_ABBREVIATION YEAR`.",
+ "title": "Single Date",
+ "type": "string"
+ },
+ "date_range": {
+ "default": "START_DATE – END_DATE",
+ "description": "Template for date ranges. Available placeholders: START_DATE, END_DATE. The default value is `START_DATE – END_DATE`.",
+ "title": "Date Range",
+ "type": "string"
+ },
+ "time_span": {
+ "default": "HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS",
+ "description": "Template for time spans. Available placeholders: HOW_MANY_YEARS, YEARS, HOW_MANY_MONTHS, MONTHS. The default value is `HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS`.",
+ "title": "Time Span",
+ "type": "string"
+ },
+ "one_line_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__OneLineEntry",
+ "description": "Template for one-line entries."
+ },
+ "education_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__EducationEntry__3",
+ "description": "Template for education entries."
+ },
+ "normal_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__NormalEntry__3",
+ "description": "Template for normal entries."
+ },
+ "experience_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__ExperienceEntry__3",
+ "description": "Template for experience entries."
+ },
+ "publication_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__PublicationEntry",
+ "description": "Template for publication entries."
+ }
+ },
+ "title": "Templates",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Templates__4": {
+ "additionalProperties": false,
+ "properties": {
+ "footer": {
+ "default": "*NAME -- PAGE_NUMBER/TOTAL_PAGES*",
+ "description": "Template for the footer. Available placeholders: NAME, PAGE_NUMBER, TOTAL_PAGES. The default value is `*NAME -- PAGE_NUMBER/TOTAL_PAGES*`.",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "*LAST_UPDATED CURRENT_DATE*",
+ "description": "Template for the top note. Available placeholders: LAST_UPDATED, CURRENT_DATE. The default value is `*LAST_UPDATED CURRENT_DATE*`.",
+ "title": "Top Note",
+ "type": "string"
+ },
+ "single_date": {
+ "default": "MONTH_ABBREVIATION YEAR",
+ "description": "Template for single dates. Available placeholders: MONTH_ABBREVIATION, YEAR. The default value is `MONTH_ABBREVIATION YEAR`.",
+ "title": "Single Date",
+ "type": "string"
+ },
+ "date_range": {
+ "default": "START_DATE – END_DATE",
+ "description": "Template for date ranges. Available placeholders: START_DATE, END_DATE. The default value is `START_DATE – END_DATE`.",
+ "title": "Date Range",
+ "type": "string"
+ },
+ "time_span": {
+ "default": "HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS",
+ "description": "Template for time spans. Available placeholders: HOW_MANY_YEARS, YEARS, HOW_MANY_MONTHS, MONTHS. The default value is `HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS`.",
+ "title": "Time Span",
+ "type": "string"
+ },
+ "one_line_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__OneLineEntry",
+ "description": "Template for one-line entries."
+ },
+ "education_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__EducationEntry__4",
+ "description": "Template for education entries."
+ },
+ "normal_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__NormalEntry__4",
+ "description": "Template for normal entries."
+ },
+ "experience_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__ExperienceEntry__4",
+ "description": "Template for experience entries."
+ },
+ "publication_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__PublicationEntry",
+ "description": "Template for publication entries."
+ }
+ },
+ "title": "Templates",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Templates__5": {
+ "additionalProperties": false,
+ "properties": {
+ "footer": {
+ "default": "*NAME -- PAGE_NUMBER/TOTAL_PAGES*",
+ "description": "Template for the footer. Available placeholders: NAME, PAGE_NUMBER, TOTAL_PAGES. The default value is `*NAME -- PAGE_NUMBER/TOTAL_PAGES*`.",
+ "title": "Footer",
+ "type": "string"
+ },
+ "top_note": {
+ "default": "*LAST_UPDATED CURRENT_DATE*",
+ "description": "Template for the top note. Available placeholders: LAST_UPDATED, CURRENT_DATE. The default value is `*LAST_UPDATED CURRENT_DATE*`.",
+ "title": "Top Note",
+ "type": "string"
+ },
+ "single_date": {
+ "default": "MONTH_ABBREVIATION YEAR",
+ "description": "Template for single dates. Available placeholders: MONTH_ABBREVIATION, YEAR. The default value is `MONTH_ABBREVIATION YEAR`.",
+ "title": "Single Date",
+ "type": "string"
+ },
+ "date_range": {
+ "default": "START_DATE – END_DATE",
+ "description": "Template for date ranges. Available placeholders: START_DATE, END_DATE. The default value is `START_DATE – END_DATE`.",
+ "title": "Date Range",
+ "type": "string"
+ },
+ "time_span": {
+ "default": "HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS",
+ "description": "Template for time spans. Available placeholders: HOW_MANY_YEARS, YEARS, HOW_MANY_MONTHS, MONTHS. The default value is `HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS`.",
+ "title": "Time Span",
+ "type": "string"
+ },
+ "one_line_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__OneLineEntry",
+ "description": "Template for one-line entries."
+ },
+ "education_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__EducationEntry__5",
+ "description": "Template for education entries."
+ },
+ "normal_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__NormalEntry__5",
+ "description": "Template for normal entries."
+ },
+ "experience_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__ExperienceEntry__5",
+ "description": "Template for experience entries."
+ },
+ "publication_entry": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__PublicationEntry",
+ "description": "Template for publication entries."
+ }
+ },
+ "title": "Templates",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Typography__1": {
+ "additionalProperties": false,
+ "properties": {
+ "line_spacing": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.6em",
+ "description": "Space between lines of text. Larger values create more vertical space. The default value is `0.6em`."
+ },
+ "alignment": {
+ "default": "justified",
+ "description": "Text alignment. Options: 'left', 'justified' (spreads text across full width), 'justified-with-no-hyphenation' (justified without word breaks). The default value is `justified`.",
+ "enum": [
+ "left",
+ "justified",
+ "justified-with-no-hyphenation"
+ ],
+ "title": "Alignment",
+ "type": "string"
+ },
+ "date_and_location_column_alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "right",
+ "description": "Alignment for dates and locations in entries. Options: 'left', 'center', 'right'. The default value is `right`."
+ },
+ "font_family": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontFamily"
+ },
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily"
+ }
+ ],
+ "description": "The font family. You can provide a single font name as a string (applies to all elements), or a dictionary with keys 'body', 'name', 'headline', 'connections', and 'section_titles' to customize each element. Any system font can be used.",
+ "title": "Font Family"
+ },
+ "font_size": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontSize__1",
+ "description": "Font sizes for different elements."
+ },
+ "small_caps": {
+ "$ref": "#/$defs/SmallCaps",
+ "description": "Small caps styling for different elements."
+ },
+ "bold": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Bold__1",
+ "description": "Bold styling for different elements."
+ }
+ },
+ "title": "Typography",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Typography__2": {
+ "additionalProperties": false,
+ "properties": {
+ "line_spacing": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.6em",
+ "description": "Space between lines of text. Larger values create more vertical space. The default value is `0.6em`."
+ },
+ "alignment": {
+ "default": "justified",
+ "description": "Text alignment. Options: 'left', 'justified' (spreads text across full width), 'justified-with-no-hyphenation' (justified without word breaks). The default value is `justified`.",
+ "enum": [
+ "left",
+ "justified",
+ "justified-with-no-hyphenation"
+ ],
+ "title": "Alignment",
+ "type": "string"
+ },
+ "date_and_location_column_alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "right",
+ "description": "Alignment for dates and locations in entries. Options: 'left', 'center', 'right'. The default value is `right`."
+ },
+ "font_family": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontFamily"
+ },
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily"
+ }
+ ],
+ "description": "The font family. You can provide a single font name as a string (applies to all elements), or a dictionary with keys 'body', 'name', 'headline', 'connections', and 'section_titles' to customize each element. Any system font can be used.",
+ "title": "Font Family"
+ },
+ "font_size": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontSize__1",
+ "description": "Font sizes for different elements."
+ },
+ "small_caps": {
+ "$ref": "#/$defs/SmallCaps",
+ "description": "Small caps styling for different elements."
+ },
+ "bold": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Bold__2",
+ "description": "Bold styling for different elements."
+ }
+ },
+ "title": "Typography",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Typography__3": {
+ "additionalProperties": false,
+ "properties": {
+ "line_spacing": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.6em",
+ "description": "Space between lines of text. Larger values create more vertical space. The default value is `0.6em`."
+ },
+ "alignment": {
+ "default": "justified",
+ "description": "Text alignment. Options: 'left', 'justified' (spreads text across full width), 'justified-with-no-hyphenation' (justified without word breaks). The default value is `justified`.",
+ "enum": [
+ "left",
+ "justified",
+ "justified-with-no-hyphenation"
+ ],
+ "title": "Alignment",
+ "type": "string"
+ },
+ "date_and_location_column_alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "right",
+ "description": "Alignment for dates and locations in entries. Options: 'left', 'center', 'right'. The default value is `right`."
+ },
+ "font_family": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontFamily"
+ },
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily"
+ }
+ ],
+ "description": "The font family. You can provide a single font name as a string (applies to all elements), or a dictionary with keys 'body', 'name', 'headline', 'connections', and 'section_titles' to customize each element. Any system font can be used.",
+ "title": "Font Family"
+ },
+ "font_size": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontSize__2",
+ "description": "Font sizes for different elements."
+ },
+ "small_caps": {
+ "$ref": "#/$defs/SmallCaps",
+ "description": "Small caps styling for different elements."
+ },
+ "bold": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Bold__3",
+ "description": "Bold styling for different elements."
+ }
+ },
+ "title": "Typography",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Typography__4": {
+ "additionalProperties": false,
+ "properties": {
+ "line_spacing": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.6em",
+ "description": "Space between lines of text. Larger values create more vertical space. The default value is `0.6em`."
+ },
+ "alignment": {
+ "default": "justified",
+ "description": "Text alignment. Options: 'left', 'justified' (spreads text across full width), 'justified-with-no-hyphenation' (justified without word breaks). The default value is `justified`.",
+ "enum": [
+ "left",
+ "justified",
+ "justified-with-no-hyphenation"
+ ],
+ "title": "Alignment",
+ "type": "string"
+ },
+ "date_and_location_column_alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "right",
+ "description": "Alignment for dates and locations in entries. Options: 'left', 'center', 'right'. The default value is `right`."
+ },
+ "font_family": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontFamily"
+ },
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily"
+ }
+ ],
+ "description": "The font family. You can provide a single font name as a string (applies to all elements), or a dictionary with keys 'body', 'name', 'headline', 'connections', and 'section_titles' to customize each element. Any system font can be used.",
+ "title": "Font Family"
+ },
+ "font_size": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontSize__3",
+ "description": "Font sizes for different elements."
+ },
+ "small_caps": {
+ "$ref": "#/$defs/SmallCaps",
+ "description": "Small caps styling for different elements."
+ },
+ "bold": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Bold__4",
+ "description": "Bold styling for different elements."
+ }
+ },
+ "title": "Typography",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__classic_theme__Typography__5": {
+ "additionalProperties": false,
+ "properties": {
+ "line_spacing": {
+ "$ref": "#/$defs/TypstDimension",
+ "default": "0.6em",
+ "description": "Space between lines of text. Larger values create more vertical space. The default value is `0.6em`."
+ },
+ "alignment": {
+ "default": "justified",
+ "description": "Text alignment. Options: 'left', 'justified' (spreads text across full width), 'justified-with-no-hyphenation' (justified without word breaks). The default value is `justified`.",
+ "enum": [
+ "left",
+ "justified",
+ "justified-with-no-hyphenation"
+ ],
+ "title": "Alignment",
+ "type": "string"
+ },
+ "date_and_location_column_alignment": {
+ "$ref": "#/$defs/Alignment",
+ "default": "right",
+ "description": "Alignment for dates and locations in entries. Options: 'left', 'center', 'right'. The default value is `right`."
+ },
+ "font_family": {
+ "anyOf": [
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontFamily"
+ },
+ {
+ "$ref": "#/$defs/rendercv__schema__models__design__font_family__FontFamily"
+ }
+ ],
+ "description": "The font family. You can provide a single font name as a string (applies to all elements), or a dictionary with keys 'body', 'name', 'headline', 'connections', and 'section_titles' to customize each element. Any system font can be used.",
+ "title": "Font Family"
+ },
+ "font_size": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__FontSize__1",
+ "description": "Font sizes for different elements."
+ },
+ "small_caps": {
+ "$ref": "#/$defs/SmallCaps",
+ "description": "Small caps styling for different elements."
+ },
+ "bold": {
+ "$ref": "#/$defs/rendercv__schema__models__design__classic_theme__Bold__1",
+ "description": "Bold styling for different elements."
+ }
+ },
+ "title": "Typography",
+ "type": "object"
+ },
+ "rendercv__schema__models__design__font_family__FontFamily": {
+ "enum": [
+ "Aptos",
+ "Arial",
+ "Arial Rounded MT",
+ "Arial Unicode MS",
+ "Comic Sans MS",
+ "Courier New",
+ "DejaVu Sans Mono",
+ "Didot",
+ "EB Garamond",
+ "Fontin",
+ "Garamond",
+ "Gentium Book Plus",
+ "Georgia",
+ "Gill Sans",
+ "Helvetica",
+ "Impact",
+ "Inter",
+ "Lato",
+ "Libertinus Serif",
+ "Lucida Sans Unicode",
+ "Mukta",
+ "New Computer Modern",
+ "Noto Sans",
+ "Open Sans",
+ "Open Sauce Sans",
+ "Poppins",
+ "Raleway",
+ "Roboto",
+ "Source Sans 3",
+ "Tahoma",
+ "Times New Roman",
+ "Trebuchet MS",
+ "Ubuntu",
+ "Verdana",
+ "XCharter"
+ ],
+ "type": "string"
+ }
+ },
+ "additionalProperties": true,
+ "properties": {
+ "cv": {
+ "$ref": "#/$defs/Cv",
+ "description": "The content of the CV.",
+ "title": "CV"
+ },
+ "design": {
+ "$ref": "#/$defs/BuiltInDesign",
+ "description": "The design information of the CV. The default is the `classic` theme.",
"title": "Design"
},
"locale": {
"$ref": "#/$defs/Locale",
- "default": null,
"description": "The locale catalog of the CV to allow the support of multiple languages.",
"title": "Locale Catalog"
},
- "rendercv_settings": {
- "$ref": "#/$defs/RenderCVSettings",
- "default": {
- "date": "2025-10-28",
- "render_command": null,
- "bold_keywords": [],
- "sort_entries": "none"
- },
- "description": "The settings of the RenderCV."
+ "settings": {
+ "$ref": "#/$defs/Settings",
+ "description": "The settings of the RenderCV.",
+ "title": "RenderCV Settings"
}
},
"required": [],
"title": "RenderCV",
"type": "object",
+ "description": "Write your CV or resume as YAML and get PDF. Built for academics and engineers.",
"$id": "https://raw.githubusercontent.com/rendercv/rendercv/main/schema.json",
"$schema": "http://json-schema.org/draft-07/schema#"
}
\ No newline at end of file
diff --git a/scripts/create_executable.py b/scripts/create_executable.py
index 8bcf2fce..b628d7bb 100644
--- a/scripts/create_executable.py
+++ b/scripts/create_executable.py
@@ -5,83 +5,73 @@ import subprocess
import sys
import tempfile
import zipfile
-from typing import Final
+root_path = pathlib.Path(__file__).parent.parent
-def create_executable() -> None:
- """Create a standalone executable for the current platform and zip it with preserved permissions."""
+platform_names = {
+ "linux": "linux",
+ "darwin": "macos",
+ "win32": "windows",
+}
- # Constants
- root_path: Final[pathlib.Path] = pathlib.Path(__file__).parent.parent
+machine_names = {
+ "AMD64": "x86_64",
+ "x86_64": "x86_64",
+ "aarch64": "ARM64",
+ "arm64": "ARM64",
+}
- platform_names: Final[dict[str, str]] = {
- "linux": "linux",
- "darwin": "macos",
- "win32": "windows",
- }
+with tempfile.TemporaryDirectory() as temp_dir:
+ temp_path = pathlib.Path(temp_dir)
- machine_names: Final[dict[str, str]] = {
- "AMD64": "x86_64",
- "x86_64": "x86_64",
- "aarch64": "ARM64",
- "arm64": "ARM64",
- }
+ # Copy rendercv to temp directory
+ shutil.copytree(root_path / "src" / "rendercv", temp_path / "rendercv")
- with tempfile.TemporaryDirectory() as temp_dir:
- temp_path = pathlib.Path(temp_dir)
+ # Create entry point script
+ rendercv_file = temp_path / "rendercv.py"
+ rendercv_file.write_text("import rendercv.cli.app as app; app.app()")
- # Copy rendercv to temp directory
- shutil.copytree(root_path / "src" / "rendercv", temp_path / "rendercv")
+ # Run PyInstaller
+ subprocess.run(
+ [
+ sys.executable,
+ "-m",
+ "PyInstaller",
+ "--onefile",
+ "--clean",
+ "--collect-all",
+ "rendercv",
+ "--collect-all",
+ "rendercv_fonts",
+ "--distpath",
+ "bin",
+ str(rendercv_file),
+ ],
+ check=True,
+ )
- # Create entry point script
- rendercv_file = temp_path / "rendercv.py"
- rendercv_file.write_text("import rendercv.cli as cli; cli.app()")
+ # Determine executable name based on platform
+ platform_name = platform_names[sys.platform]
+ machine_name = machine_names[platform.machine()]
- # Run PyInstaller
- subprocess.run(
- [
- sys.executable,
- "-m",
- "PyInstaller",
- "--onefile",
- "--clean",
- "--collect-all",
- "rendercv",
- "--collect-all",
- "rendercv_fonts",
- "--distpath",
- "bin",
- str(rendercv_file),
- ],
- check=True,
- )
+ # Get original and new executable paths
+ match sys.platform:
+ case "win32":
+ original_name = "rendercv.exe"
+ new_name = f"rendercv-{platform_name}-{machine_name}.exe"
+ case _:
+ original_name = "rendercv"
+ new_name = f"rendercv-{platform_name}-{machine_name}"
- # Determine executable name based on platform
- platform_name = platform_names[sys.platform]
- machine_name = machine_names[platform.machine()]
+ original_path = root_path / "bin" / original_name
+ executable_path = root_path / "bin" / new_name
+ original_path.rename(executable_path)
- # Get original and new executable paths
- match sys.platform:
- case "win32":
- original_name = "rendercv.exe"
- new_name = f"rendercv-{platform_name}-{machine_name}.exe"
- case _:
- original_name = "rendercv"
- new_name = f"rendercv-{platform_name}-{machine_name}"
+# Create zip archive with preserved executable permissions
+zip_path = executable_path.with_suffix(".zip")
- original_path = root_path / "bin" / original_name
- executable_path = root_path / "bin" / new_name
- original_path.rename(executable_path)
-
- # Create zip archive with preserved executable permissions
- zip_path = executable_path.with_suffix(".zip")
-
- with zipfile.ZipFile(zip_path, "w", zipfile.ZIP_DEFLATED) as zipf:
- zipinfo = zipfile.ZipInfo(executable_path.name)
- # Set Unix executable permissions (rwxr-xr-x) - 0o755 shifted to external_attr position
- zipinfo.external_attr = 0o755 << 16
- zipf.writestr(zipinfo, executable_path.read_bytes())
-
-
-if __name__ == "__main__":
- create_executable()
+with zipfile.ZipFile(zip_path, "w", zipfile.ZIP_DEFLATED) as zipf:
+ zipinfo = zipfile.ZipInfo(executable_path.name)
+ # Set Unix executable permissions (rwxr-xr-x) - 0o755 shifted to external_attr position
+ zipinfo.external_attr = 0o755 << 16
+ zipf.writestr(zipinfo, executable_path.read_bytes())
diff --git a/scripts/update_entry_figures.py b/scripts/update_entry_figures.py
index ff115326..993e1c1b 100644
--- a/scripts/update_entry_figures.py
+++ b/scripts/update_entry_figures.py
@@ -1,47 +1,23 @@
-"""This script generates the example entry figures and creates an environment for
-documentation templates using `mkdocs-macros-plugin`. For example, the content of the
-example entries found in
-"[Structure of the YAML Input File](https://docs.rendercv.com/user_guide/structure_of_the_yaml_input_file/)"
-are coming from this script.
-"""
-
import pathlib
-import shutil
import tempfile
import fitz
import pdfCropMargins
-import pydantic
-import rendercv.data as data
-import rendercv.renderer as renderer
+from rendercv.renderer.pdf_png import generate_pdf
+from rendercv.renderer.typst import generate_typst
+from rendercv.schema.models.cv.cv import Cv
+from rendercv.schema.models.design.built_in_design import available_themes
+from rendercv.schema.models.rendercv_model import RenderCVModel
+from rendercv.schema.rendercv_model_builder import build_rendercv_dictionary_and_model
+from rendercv.schema.yaml_reader import read_yaml
repository_root = pathlib.Path(__file__).parent.parent
rendercv_path = repository_root / "rendercv"
image_assets_directory = repository_root / "docs" / "assets" / "images"
-class SampleEntries(pydantic.BaseModel):
- education_entry: data.EducationEntry
- experience_entry: data.ExperienceEntry
- normal_entry: data.NormalEntry
- publication_entry: data.PublicationEntry
- one_line_entry: data.OneLineEntry
- bullet_entry: data.BulletEntry
- numbered_entry: data.NumberedEntry
- reversed_numbered_entry: data.ReversedNumberedEntry
- text_entry: str
-
-
-def render_pngs_from_pdf(pdf_file_path: pathlib.Path) -> list[pathlib.Path]:
- """Render a PNG file for each page of the given PDF file.
-
- Args:
- pdf_file_path: The path to the PDF file.
-
- Returns:
- The paths to the rendered PNG files.
- """
+def pdf_to_png(pdf_file_path: pathlib.Path) -> list[pathlib.Path]:
# check if the file exists:
if not pdf_file_path.is_file():
message = f"The file {pdf_file_path} doesn't exist!"
@@ -54,100 +30,86 @@ def render_pngs_from_pdf(pdf_file_path: pathlib.Path) -> list[pathlib.Path]:
pdf = fitz.open(pdf_file_path) # open the PDF file
for page in pdf: # iterate the pages
image = page.get_pixmap(dpi=300) # type: ignore
- png_file_path = png_directory / f"{png_file_name}_{page.number + 1}.png" # type: ignore
+ assert page.number is not None
+ png_file_path = png_directory / f"{png_file_name}_{page.number + 1}.png"
image.save(png_file_path)
png_files.append(png_file_path)
return png_files
-def generate_entry_figures():
- """Generate an image for each entry type and theme."""
- # Generate PDF figures for each entry type and theme
- entries = data.read_a_yaml_file(
- repository_root / "docs" / "user_guide" / "sample_entries.yaml"
- )
- entry_types = entries.keys()
- entries = SampleEntries(**entries)
- themes = data.available_themes
+entries = read_yaml(repository_root / "docs" / "user_guide" / "sample_entries.yaml")
+entry_types = entries.keys()
+themes = available_themes
- with tempfile.TemporaryDirectory() as temporary_directory:
- # Create temporary directory
- temporary_directory_path = pathlib.Path(temporary_directory)
- for theme in themes:
- design_dictionary = {
- "theme": theme,
- "page": {
- "show_page_numbering": False,
- "show_last_updated_date": False,
+with tempfile.TemporaryDirectory() as temporary_directory:
+ # Create temporary directory
+ temporary_directory_path = pathlib.Path(temporary_directory)
+ for theme in themes:
+ design_dictionary = {
+ "theme": theme,
+ "page": {
+ "show_page_numbering": False,
+ "show_last_updated_date": False,
+ },
+ }
+
+ for entry_type in entry_types:
+ # Create data model with only one section and one entry
+ typst_path = temporary_directory_path / "typst.typ"
+ pdf_path = temporary_directory_path / "pdf.pdf"
+ _, model = build_rendercv_dictionary_and_model(
+ RenderCVModel(
+ cv=Cv(sections={entry_type: [entries[entry_type]]}),
+ ).model_dump_json(),
+ typst_path=typst_path,
+ pdf_path=pdf_path,
+ overrides={
+ "design": { # pyright: ignore[reportArgumentType]
+ "theme": theme,
+ "page": {"show_footer": False, "show_top_note": False},
+ }
},
- }
+ )
- for entry_type in entry_types:
- # Create data model with only one section and one entry
- data_model = data.RenderCVDataModel(
- cv=data.CurriculumVitae(
- sections={entry_type: [getattr(entries, entry_type)]}
- ),
- design=design_dictionary,
- )
+ # Render
+ generate_typst(model)
+ generate_pdf(model, typst_path)
- # Render
- typst_file_path = renderer.create_a_typst_file_and_copy_theme_files(
- data_model, temporary_directory_path
- )
- pdf_file_path = renderer.render_a_pdf_from_typst(typst_file_path)
+ # Prepare output directory and file path
+ output_directory = image_assets_directory / theme
+ output_directory.mkdir(parents=True, exist_ok=True)
- # Prepare output directory and file path
- output_directory = image_assets_directory / theme
- output_directory.mkdir(parents=True, exist_ok=True)
- output_pdf_file_path = output_directory / f"{entry_type}.pdf"
+ output_pdf_file_path = temporary_directory_path / f"{entry_type}.pdf"
+ # Crop margins
+ pdfCropMargins.crop(
+ argv_list=[
+ "-p4",
+ "100",
+ "0",
+ "100",
+ "0",
+ "-a4",
+ "0",
+ "-30",
+ "0",
+ "-30",
+ "-o",
+ str(output_pdf_file_path.absolute()),
+ str(pdf_path.absolute()),
+ ]
+ )
- # Remove file if it exists
- if output_pdf_file_path.exists():
- output_pdf_file_path.unlink()
+ # Convert PDF to image
+ png_file_path = pdf_to_png(output_pdf_file_path)[0]
+ desired_png_file_path = image_assets_directory / theme / f"{entry_type}.png"
- # Crop margins
- pdfCropMargins.crop(
- argv_list=[
- "-p4",
- "100",
- "0",
- "100",
- "0",
- "-a4",
- "0",
- "-30",
- "0",
- "-30",
- "-o",
- str(output_pdf_file_path.absolute()),
- str(pdf_file_path.absolute()),
- ]
- )
+ # If image exists, remove it
+ if desired_png_file_path.exists():
+ desired_png_file_path.unlink()
- # Convert PDF to image
- png_file_path = render_pngs_from_pdf(output_pdf_file_path)[0]
- desired_png_file_path = output_pdf_file_path.with_suffix(".png")
-
- # If image exists, remove it
- if desired_png_file_path.exists():
- desired_png_file_path.unlink()
-
- # Move image to desired location
- png_file_path.rename(desired_png_file_path)
-
- # Remove PDF file
- output_pdf_file_path.unlink()
+ # Move image to desired location
+ png_file_path.rename(desired_png_file_path)
-def update_index():
- """Update index.md file by copying README.md file."""
- index_file_path = repository_root / "docs" / "index.md"
- readme_file_path = repository_root / "README.md"
- shutil.copy(readme_file_path, index_file_path)
-
-
-if __name__ == "__main__":
- generate_entry_figures()
- print("Entry figures generated successfully.") # NOQA: T201
+print("Entry figures generated successfully.") # NOQA: T201
diff --git a/scripts/update_examples.py b/scripts/update_examples.py
index 319d8fda..a231b99f 100644
--- a/scripts/update_examples.py
+++ b/scripts/update_examples.py
@@ -1,89 +1,51 @@
-"""This script generates the `examples` folder in the repository root."""
-
-import os
import pathlib
import shutil
+import tempfile
-import rendercv.cli as cli
-import rendercv.data as data
-import rendercv.renderer as renderer
+from rendercv.cli.render_command.progress_panel import ProgressPanel
+from rendercv.cli.render_command.run_rendercv import run_rendercv
+from rendercv.schema.models.design.built_in_design import available_themes
+from rendercv.schema.sample_generator import create_sample_yaml_input_file
repository_root = pathlib.Path(__file__).parent.parent
rendercv_path = repository_root / "rendercv"
image_assets_directory = repository_root / "docs" / "assets" / "images"
-def generate_examples():
- """Generate example YAML and PDF files."""
- examples_directory_path = pathlib.Path(__file__).parent.parent / "examples"
+examples_directory_path = pathlib.Path(__file__).parent.parent / "examples"
- # Check if examples directory exists. If not, create it
- if not examples_directory_path.exists():
- examples_directory_path.mkdir()
+# Check if examples directory exists. If not, create it
+if not examples_directory_path.exists():
+ examples_directory_path.mkdir()
- os.chdir(examples_directory_path)
- themes = data.available_themes
- for theme in themes:
- cli.cli_command_new(
- "John Doe",
- theme,
- dont_create_theme_source_files=True,
- dont_create_markdown_source_files=True,
- )
- yaml_file_path = examples_directory_path / "John_Doe_CV.yaml"
+for theme in available_themes:
+ yaml_file_path = (
+ examples_directory_path / f"John_Doe_{theme.capitalize()}Theme_CV.yaml"
+ )
+ create_sample_yaml_input_file(
+ file_path=yaml_file_path,
+ name="John Doe",
+ theme=theme,
+ locale="english",
+ )
- # Remove the first line from the YAML file (Json Schema):
- yaml_file_path.write_text(yaml_file_path.read_text().split("\n", 1)[1])
-
- # Rename John_Doe_CV.yaml
- proper_theme_name = theme.capitalize() + "Theme"
- new_yaml_file_path = (
- examples_directory_path / f"John_Doe_{proper_theme_name}_CV.yaml"
- )
- if new_yaml_file_path.exists():
- new_yaml_file_path.unlink()
- yaml_file_path.rename(new_yaml_file_path)
- yaml_file_path = new_yaml_file_path
-
- # Generate PDF file
- cli.cli_command_render(yaml_file_path)
-
- output_pdf_file = (
- examples_directory_path / "rendercv_output" / "John_Doe_CV.pdf"
- )
- output_typst_file = (
- examples_directory_path / "rendercv_output" / "John_Doe_CV.typ"
+ with tempfile.TemporaryDirectory() as temp_directory:
+ temp_directory_path = pathlib.Path(temp_directory)
+ run_rendercv(
+ yaml_file_path,
+ progress=ProgressPanel(),
+ typst_path=temp_directory_path / f"{yaml_file_path.stem}.typ",
+ pdf_path=examples_directory_path / f"{yaml_file_path.stem}.pdf",
+ png_path=temp_directory_path / f"{yaml_file_path.stem}.png",
+ dont_generate_html=True,
+ dont_generate_markdown=True,
)
- # Move PDF file to examples directory
- new_pdf_file_path = examples_directory_path / f"{yaml_file_path.stem}.pdf"
- if new_pdf_file_path.exists():
- new_pdf_file_path.unlink()
- output_pdf_file.rename(new_pdf_file_path)
-
- # Convert first page of PDF to image
- png_file_paths = renderer.render_pngs_from_typst(output_typst_file)
- first_page_png_file_path = png_file_paths[0]
- if len(png_file_paths) > 1:
- # Remove other pages
- for png_file_path in png_file_paths[1:]:
- png_file_path.unlink()
-
- desired_png_file_path = image_assets_directory / f"{theme}.png"
-
- # If image exists, remove it
- if desired_png_file_path.exists():
- desired_png_file_path.unlink()
-
- # Move image to desired location
- first_page_png_file_path.rename(desired_png_file_path)
-
- # Remove rendercv_output directory
- rendercv_output_directory = examples_directory_path / "rendercv_output"
-
- shutil.rmtree(rendercv_output_directory)
+ image_assets_directory.mkdir(parents=True, exist_ok=True)
+ shutil.copy(
+ temp_directory_path / f"{yaml_file_path.stem}_1.png",
+ image_assets_directory / f"{theme}.png",
+ )
-if __name__ == "__main__":
- generate_examples()
- print("Examples generated successfully.") # NOQA: T201
+print("Examples generated successfully.") # NOQA: T201
diff --git a/scripts/update_schema.py b/scripts/update_schema.py
index ccb9cbd3..d8f54f0f 100644
--- a/scripts/update_schema.py
+++ b/scripts/update_schema.py
@@ -1,18 +1,7 @@
-"""This script generates the JSON schema (schema.json) in the repository root."""
-
import pathlib
-import rendercv.data as data
+from rendercv.schema.json_schema_generator import generate_json_schema_file
-repository_root = pathlib.Path(__file__).parent.parent
-
-
-def generate_schema():
- """Generate the schema."""
- json_schema_file_path = repository_root / "schema.json"
- data.generate_json_schema_file(json_schema_file_path)
-
-
-if __name__ == "__main__":
- generate_schema()
- print("Schema generated successfully.") # NOQA: T201
+json_schema_file_path = pathlib.Path(__file__).parent.parent / "schema.json"
+generate_json_schema_file(json_schema_file_path)
+print("Schema generated successfully.") # NOQA: T201
diff --git a/src/rendercv/__init__.py b/src/rendercv/__init__.py
index 9584af57..9b32110a 100644
--- a/src/rendercv/__init__.py
+++ b/src/rendercv/__init__.py
@@ -1,48 +1,9 @@
-"""
-RenderCV is a Typst-based Python package with a command-line interface (CLI) that allows
-you to version-control your CV/resume as source code.
-"""
+import warnings
-__version__ = "2.3"
-
-from .api import (
- create_a_markdown_file_from_a_python_dictionary,
- create_a_markdown_file_from_a_yaml_string,
- create_a_pdf_from_a_python_dictionary,
- create_a_pdf_from_a_yaml_string,
- create_a_typst_file_from_a_python_dictionary,
- create_a_typst_file_from_a_yaml_string,
- create_an_html_file_from_a_python_dictionary,
- create_an_html_file_from_a_yaml_string,
- create_contents_of_a_markdown_file_from_a_python_dictionary,
- create_contents_of_a_markdown_file_from_a_yaml_string,
- create_contents_of_a_typst_file_from_a_python_dictionary,
- create_contents_of_a_typst_file_from_a_yaml_string,
- read_a_python_dictionary_and_return_a_data_model,
- read_a_yaml_string_and_return_a_data_model,
+__version__ = "2.4"
+__description__ = (
+ "Write your CV or resume as YAML and get PDF. Built for academics and engineers."
)
-__all__ = [
- "create_a_markdown_file_from_a_python_dictionary",
- "create_a_markdown_file_from_a_python_dictionary",
- "create_a_markdown_file_from_a_yaml_string",
- "create_a_pdf_from_a_python_dictionary",
- "create_a_pdf_from_a_yaml_string",
- "create_a_typst_file_from_a_python_dictionary",
- "create_a_typst_file_from_a_yaml_string",
- "create_an_html_file_from_a_python_dictionary",
- "create_an_html_file_from_a_yaml_string",
- "create_contents_of_a_markdown_file_from_a_python_dictionary",
- "create_contents_of_a_markdown_file_from_a_yaml_string",
- "create_contents_of_a_typst_file_from_a_python_dictionary",
- "create_contents_of_a_typst_file_from_a_python_dictionary",
- "create_contents_of_a_typst_file_from_a_yaml_string",
- "read_a_python_dictionary_and_return_a_data_model",
- "read_a_yaml_string_and_return_a_data_model",
-]
-_partial_install_error_message = (
- "It seems you have a partial installation of RenderCV, so this feature is"
- " unavailable. To enable full functionality, run:\n\npip install"
- ' "rendercv[full]"`'
-)
+warnings.filterwarnings("ignore") # Ignore Pydantic warnings
diff --git a/src/rendercv/__main__.py b/src/rendercv/__main__.py
index 995e85d9..1be28e81 100644
--- a/src/rendercv/__main__.py
+++ b/src/rendercv/__main__.py
@@ -4,8 +4,7 @@ invoked directly from the command line with `python -m rendercv`. That's why we
here so that we can invoke the CLI from the command line with `python -m rendercv`.
"""
-from . import cli
+from .cli.entry_point import entry_point
if __name__ == "__main__":
- if hasattr(cli, "app"):
- cli.app()
+ entry_point()
diff --git a/src/rendercv/api/__init__.py b/src/rendercv/api/__init__.py
deleted file mode 100644
index f4b98fad..00000000
--- a/src/rendercv/api/__init__.py
+++ /dev/null
@@ -1,38 +0,0 @@
-"""
-The `rendercv.api` package contains the functions to create a clean and simple API for
-RenderCV.
-"""
-
-from .functions import (
- create_a_markdown_file_from_a_python_dictionary,
- create_a_markdown_file_from_a_yaml_string,
- create_a_pdf_from_a_python_dictionary,
- create_a_pdf_from_a_yaml_string,
- create_a_typst_file_from_a_python_dictionary,
- create_a_typst_file_from_a_yaml_string,
- create_an_html_file_from_a_python_dictionary,
- create_an_html_file_from_a_yaml_string,
- create_contents_of_a_markdown_file_from_a_python_dictionary,
- create_contents_of_a_markdown_file_from_a_yaml_string,
- create_contents_of_a_typst_file_from_a_python_dictionary,
- create_contents_of_a_typst_file_from_a_yaml_string,
- read_a_python_dictionary_and_return_a_data_model,
- read_a_yaml_string_and_return_a_data_model,
-)
-
-__all__ = [
- "create_a_markdown_file_from_a_python_dictionary",
- "create_a_markdown_file_from_a_yaml_string",
- "create_a_pdf_from_a_python_dictionary",
- "create_a_pdf_from_a_yaml_string",
- "create_a_typst_file_from_a_python_dictionary",
- "create_a_typst_file_from_a_yaml_string",
- "create_an_html_file_from_a_python_dictionary",
- "create_an_html_file_from_a_yaml_string",
- "create_contents_of_a_markdown_file_from_a_python_dictionary",
- "create_contents_of_a_markdown_file_from_a_yaml_string",
- "create_contents_of_a_typst_file_from_a_python_dictionary",
- "create_contents_of_a_typst_file_from_a_yaml_string",
- "read_a_python_dictionary_and_return_a_data_model",
- "read_a_yaml_string_and_return_a_data_model",
-]
diff --git a/src/rendercv/api/functions.py b/src/rendercv/api/functions.py
deleted file mode 100644
index a57a8ab6..00000000
--- a/src/rendercv/api/functions.py
+++ /dev/null
@@ -1,381 +0,0 @@
-"""
-The `rendercv.api.functions` package contains the basic functions that are used to
-interact with the RenderCV.
-"""
-
-import pathlib
-import shutil
-import tempfile
-from collections.abc import Callable
-
-import pydantic
-
-from .. import data, renderer
-
-
-def _create_contents_of_a_something_from_something(
- input: dict | str, parser: Callable, renderer: Callable
-) -> str | list[dict]:
- """
- Validate the input, generate a file and return it as a string. If there are any
- validation errors, return them as a list of dictionaries.
-
- Args:
- input: The input file as a dictionary or a string.
- parser: The parser function.
- renderer: The renderer function.
-
- Returns:
- The file as a string or a list of dictionaries that contain the error messages,
- locations, and the input values.
- """
- try:
- data_model = parser(input)
- except pydantic.ValidationError as e:
- if isinstance(input, str):
- return data.parse_validation_errors(e, input)
- return data.parse_validation_errors(e)
-
- return renderer(data_model)
-
-
-def _create_a_file_from_something(
- input: dict | str,
- parser: Callable,
- renderer: Callable,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input, generate a file and save it to the output file path.
-
- Args:
- input: The input file as a dictionary or a string.
- parser: The parser function.
- renderer: The renderer function.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- try:
- data_model = parser(input)
- except pydantic.ValidationError as e:
- return data.parse_validation_errors(e)
-
- with tempfile.TemporaryDirectory() as temp_dir:
- temporary_output_path = pathlib.Path(temp_dir)
- file = renderer(data_model, temporary_output_path)
- shutil.move(file, output_file_path)
-
- return None
-
-
-def read_a_python_dictionary_and_return_a_data_model(
- input_file_as_a_dict: dict,
-) -> data.RenderCVDataModel:
- """
- Validate the input dictionary and return the data model.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
-
- Returns:
- The data model.
- """
- return data.validate_input_dictionary_and_return_the_data_model(
- input_file_as_a_dict,
- )
-
-
-def read_a_yaml_string_and_return_a_data_model(
- yaml_file_as_string: str,
-) -> data.RenderCVDataModel:
- """
- Validate the YAML input file given as a string and return the data model.
-
- Args:
- yaml_file_as_string: The input file as a string.
-
- Returns:
- The data model.
- """
- input_file_as_a_dict = data.read_a_yaml_file(yaml_file_as_string)
- return read_a_python_dictionary_and_return_a_data_model(input_file_as_a_dict)
-
-
-def create_contents_of_a_typst_file_from_a_python_dictionary(
- input_file_as_a_dict: dict,
-) -> str | list[dict]:
- """
- Validate the input dictionary, generate a Typst file and return it as a string. If
- there are any validation errors, return them as a list of dictionaries.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
-
- Returns:
- The Typst file as a string or a list of dictionaries that contain the error
- messages, locations, and the input values.
- """
- return _create_contents_of_a_something_from_something(
- input_file_as_a_dict,
- read_a_python_dictionary_and_return_a_data_model,
- renderer.create_contents_of_a_typst_file,
- )
-
-
-def create_contents_of_a_typst_file_from_a_yaml_string(
- yaml_file_as_string: str,
-) -> str | list[dict]:
- """
- Validate the YAML input file given as a string, generate a Typst file and return it
- as a string. If there are any validation errors, return them as a list of
- dictionaries.
-
- Args:
- yaml_file_as_string: The input file as a string.
-
- Returns:
- The Typst file as a string or a list of dictionaries that contain the error
- messages, locations, and the input values.
- """
- return _create_contents_of_a_something_from_something(
- yaml_file_as_string,
- read_a_yaml_string_and_return_a_data_model,
- renderer.create_contents_of_a_typst_file,
- )
-
-
-def create_contents_of_a_markdown_file_from_a_python_dictionary(
- input_file_as_a_dict: dict,
-) -> str | list[dict]:
- """
- Validate the input dictionary, generate a Markdown file and return it as a string.
- If there are any validation errors, return them as a list of dictionaries.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
-
- Returns:
- The Markdown file as a string or a list of dictionaries that contain the error
- messages, locations, and the input values.
- """
- return _create_contents_of_a_something_from_something(
- input_file_as_a_dict,
- read_a_python_dictionary_and_return_a_data_model,
- renderer.create_contents_of_a_markdown_file,
- )
-
-
-def create_contents_of_a_markdown_file_from_a_yaml_string(
- yaml_file_as_string: str,
-) -> str | list[dict]:
- """
- Validate the input file given as a string, generate a Markdown file and return it as
- a string. If there are any validation errors, return them as a list of dictionaries.
-
- Args:
- yaml_file_as_string: The input file as a string.
-
- Returns:
- The Markdown file as a string or a list of dictionaries that contain the error
- messages, locations, and the input values.
- """
- return _create_contents_of_a_something_from_something(
- yaml_file_as_string,
- read_a_yaml_string_and_return_a_data_model,
- renderer.create_contents_of_a_markdown_file,
- )
-
-
-def create_a_typst_file_from_a_yaml_string(
- yaml_file_as_string: str,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input file given as a string, generate a Typst file and save it to the
- output file path.
-
- Args:
- yaml_file_as_string: The input file as a string.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
-
- return _create_a_file_from_something(
- yaml_file_as_string,
- read_a_yaml_string_and_return_a_data_model,
- renderer.create_a_typst_file,
- output_file_path,
- )
-
-
-def create_a_typst_file_from_a_python_dictionary(
- input_file_as_a_dict: dict,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input dictionary, generate a Typst file and save it to the output file
- path.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- return _create_a_file_from_something(
- input_file_as_a_dict,
- read_a_python_dictionary_and_return_a_data_model,
- renderer.create_a_typst_file,
- output_file_path,
- )
-
-
-def create_a_markdown_file_from_a_python_dictionary(
- input_file_as_a_dict: dict,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input dictionary, generate a Markdown file and save it to the output
- file path.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- return _create_a_file_from_something(
- input_file_as_a_dict,
- read_a_python_dictionary_and_return_a_data_model,
- renderer.create_a_markdown_file,
- output_file_path,
- )
-
-
-def create_a_markdown_file_from_a_yaml_string(
- yaml_file_as_string: str,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input file given as a string, generate a Markdown file and save it to
- the output file path.
-
- Args:
- yaml_file_as_string: The input file as a string.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- return _create_a_file_from_something(
- yaml_file_as_string,
- read_a_yaml_string_and_return_a_data_model,
- renderer.create_a_markdown_file,
- output_file_path,
- )
-
-
-def create_an_html_file_from_a_python_dictionary(
- input_file_as_a_dict: dict,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input dictionary, generate an HTML file and save it to the output file
- path.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- return _create_a_file_from_something(
- input_file_as_a_dict,
- read_a_python_dictionary_and_return_a_data_model,
- lambda x, y: renderer.render_an_html_from_markdown(
- renderer.create_a_markdown_file(x, y),
- ),
- output_file_path,
- )
-
-
-def create_an_html_file_from_a_yaml_string(
- yaml_file_as_string: str,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input file given as a string, generate an HTML file and save it to the
- output file path.
-
- Args:
- yaml_file_as_string: The input file as a string.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- return _create_a_file_from_something(
- yaml_file_as_string,
- read_a_yaml_string_and_return_a_data_model,
- lambda x, y: renderer.render_an_html_from_markdown(
- renderer.create_a_markdown_file(x, y),
- ),
- output_file_path,
- )
-
-
-def create_a_pdf_from_a_yaml_string(
- yaml_file_as_string: str,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input file given as a string, generate a PDF file and save it to the
- output file path.
-
- Args:
- yaml_file_as_string: The input file as a string.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- return _create_a_file_from_something(
- yaml_file_as_string,
- read_a_yaml_string_and_return_a_data_model,
- lambda x, y: renderer.render_a_pdf_from_typst(
- renderer.create_a_typst_file(x, y)
- ),
- output_file_path,
- )
-
-
-def create_a_pdf_from_a_python_dictionary(
- input_file_as_a_dict: dict,
- output_file_path: pathlib.Path,
-) -> list[dict] | None:
- """
- Validate the input dictionary, generate a PDF file and save it to the output file
- path.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
- output_file_path: The output file path.
-
- Returns:
- The output file path.
- """
- return _create_a_file_from_something(
- input_file_as_a_dict,
- read_a_python_dictionary_and_return_a_data_model,
- lambda x, y: renderer.render_a_pdf_from_typst(
- renderer.create_a_typst_file(x, y),
- ),
- output_file_path,
- )
diff --git a/src/rendercv/cli/__init__.py b/src/rendercv/cli/__init__.py
index f268ad28..e69de29b 100644
--- a/src/rendercv/cli/__init__.py
+++ b/src/rendercv/cli/__init__.py
@@ -1,27 +0,0 @@
-"""
-The `rendercv.cli` package contains the functions and classes that handle RenderCV's
-command-line interface (CLI). It uses [Typer](https://typer.tiangolo.com/) to create the
-CLI and [Rich](https://rich.readthedocs.io/en/latest/) to provide a nice-looking
-interface.
-"""
-
-try:
- from .commands import (
- app,
- cli_command_create_theme,
- cli_command_new,
- cli_command_no_args,
- cli_command_render,
- )
-
- __all__ = [
- "app",
- "cli_command_create_theme",
- "cli_command_new",
- "cli_command_no_args",
- "cli_command_render",
- ]
-except ImportError:
- from .. import _partial_install_error_message
-
- print(_partial_install_error_message) # noqa: T201
diff --git a/src/rendercv/cli/app.py b/src/rendercv/cli/app.py
new file mode 100644
index 00000000..22f8a7b9
--- /dev/null
+++ b/src/rendercv/cli/app.py
@@ -0,0 +1,79 @@
+import importlib
+import json
+import pathlib
+import ssl
+import urllib.request
+from typing import Annotated
+
+import packaging.version
+import typer
+from rich import print
+
+from rendercv import __version__
+
+app = typer.Typer(
+ rich_markup_mode="rich",
+ # to make `rendercv --version` work:
+ invoke_without_command=True,
+ no_args_is_help=True,
+ context_settings={"help_option_names": ["-h", "--help"]},
+)
+
+
+@app.callback()
+def cli_command_no_args(
+ version_requested: Annotated[
+ bool | None, typer.Option("--version", "-v", help="Show the version")
+ ] = None,
+):
+ """RenderCV is a command-line tool for rendering CVs from YAML input files. For more
+ information, see https://docs.rendercv.com.
+ """
+ warn_if_new_version_is_available()
+
+ if version_requested:
+ print(f"RenderCV v{__version__}")
+
+
+def warn_if_new_version_is_available() -> None:
+ """Check PyPI for newer RenderCV version and display update notice.
+
+ Why:
+ Users should be notified of updates for bug fixes and features.
+ Non-blocking check on startup ensures users stay informed without
+ interrupting workflow if check fails.
+ """
+ url = "https://pypi.org/pypi/rendercv/json"
+ try:
+ with urllib.request.urlopen(
+ url, context=ssl._create_unverified_context()
+ ) as response:
+ data = response.read()
+ encoding = response.info().get_content_charset("utf-8")
+ json_data = json.loads(data.decode(encoding))
+ version_string = json_data["info"]["version"]
+ latest_version = packaging.version.Version(version_string)
+ except Exception:
+ latest_version = None
+
+ if latest_version is not None:
+ version = packaging.version.Version(__version__)
+ if version < latest_version:
+ print(
+ "\n[bold yellow]A new version of RenderCV is available! You are using"
+ f" v{__version__}, and the latest version is v{latest_version}.[/bold"
+ " yellow]\n"
+ )
+
+
+# Auto import all commands so that they are registered with the app:
+cli_folder_path = pathlib.Path(__file__).parent
+for file in cli_folder_path.rglob("*_command.py"):
+ # Enforce folder structure: ./name_command/name_command.py
+ folder_name = file.parent.name # e.g. "foo_command"
+ py_file_name = file.stem # e.g. "foo_command"
+
+ # Build full module path: .foo_command.foo_command
+ full_module = f"{__package__}.{folder_name}.{py_file_name}"
+
+ module = importlib.import_module(full_module)
diff --git a/src/rendercv/cli/commands.py b/src/rendercv/cli/commands.py
deleted file mode 100644
index 4bc69b0c..00000000
--- a/src/rendercv/cli/commands.py
+++ /dev/null
@@ -1,402 +0,0 @@
-"""
-The `rendercv.cli.commands` module contains all the command-line interface (CLI)
-commands of RenderCV.
-"""
-
-import copy
-import inspect # NEW: for signature inspection
-import pathlib
-from typing import Annotated
-
-import typer
-from click.core import Parameter # NEW: needed for monkey-patch
-from rich import print
-
-from .. import __version__, data
-from . import printer, utilities
-
-_orig_make_metavar = Parameter.make_metavar # preserve original implementation
-_orig_sig = inspect.signature(_orig_make_metavar)
-_orig_param_count = len(_orig_sig.parameters) # includes ``self``
-
-
-def _adapt_make_metavar(self, *args, **kwargs): # type: ignore[override]
- """Adapter to call *make_metavar* regardless of Click version.
-
- It normalises the positional arguments emitted by Typer to match the
- signature expected by the underlying Click version:
-
- • Click < 8.1 → make_metavar(self, param_hint=None)
- • Click ≥ 8.1 → make_metavar(self, ctx, param_hint=None)
- """
-
- # Determine expected arg layout (excluding *self*).
- expects_ctx = _orig_param_count == 3 # self + ctx + param_hint
-
- ctx = None
- param_hint = None
-
- if expects_ctx:
- if len(args) == 1:
- # We only got ``param_hint``; fabricate ctx=None.
- param_hint = args[0]
- elif len(args) >= 2:
- ctx, param_hint = args[:2]
- else:
- # Original expects only param_hint.
- if len(args) >= 1:
- param_hint = args[0]
-
- # Delegate to the original function with correct positional arguments.
- if expects_ctx:
- return _orig_make_metavar(self, ctx, param_hint, **kwargs) # type: ignore[arg-type]
- return _orig_make_metavar(self, param_hint, **kwargs) # type: ignore[arg-type]
-
-
-# Apply the monkey-patch once.
-Parameter.make_metavar = _adapt_make_metavar # type: ignore[assignment]
-
-app = typer.Typer(
- rich_markup_mode="rich",
- add_completion=False,
- # to make `rendercv --version` work:
- invoke_without_command=True,
- no_args_is_help=True,
- context_settings={"help_option_names": ["-h", "--help"]},
- # don't show local variables in unhandled exceptions:
- pretty_exceptions_show_locals=False,
-)
-
-
-@app.command(
- name="render",
- help=(
- "Render a YAML input file. Example: [yellow]rendercv render"
- " John_Doe_CV.yaml[/yellow]. Details: [cyan]rendercv render --help[/cyan]"
- ),
- # allow extra arguments for updating the data model (for overriding the values of
- # the input file):
- context_settings={"allow_extra_args": True, "ignore_unknown_options": True},
-)
-@printer.handle_and_print_raised_exceptions
-def cli_command_render(
- input_file_name: Annotated[str, typer.Argument(help="The YAML input file.")],
- design: Annotated[
- str | None,
- typer.Option(
- "--design",
- "-d",
- help='The "design" field\'s YAML input file.',
- ),
- ] = None,
- locale: Annotated[
- str | None,
- typer.Option(
- "--locale-catalog",
- "-lc",
- help='The "locale" field\'s YAML input file.',
- ),
- ] = None,
- rendercv_settings: Annotated[
- str | None,
- typer.Option(
- "--rendercv-settings",
- "-rs",
- help='The "rendercv_settings" field\'s YAML input file.',
- ),
- ] = None,
- output_folder_name: Annotated[
- str,
- typer.Option(
- "--output-folder-name",
- "-o",
- help="Name of the output folder",
- ),
- ] = "rendercv_output",
- typst_path: Annotated[
- str | None,
- typer.Option(
- "--typst-path",
- "-typst",
- help="Copy the Typst file to the given path",
- ),
- ] = None,
- pdf_path: Annotated[
- str | None,
- typer.Option(
- "--pdf-path",
- "-pdf",
- help="Copy the PDF file to the given path",
- ),
- ] = None,
- markdown_path: Annotated[
- str | None,
- typer.Option(
- "--markdown-path",
- "-md",
- help="Copy the Markdown file to the given path",
- ),
- ] = None,
- html_path: Annotated[
- str | None,
- typer.Option(
- "--html-path",
- "-html",
- help="Copy the HTML file to the given path",
- ),
- ] = None,
- png_path: Annotated[
- str | None,
- typer.Option(
- "--png-path",
- "-png",
- help="Copy the PNG file to the given path",
- ),
- ] = None,
- dont_generate_markdown: Annotated[
- bool,
- typer.Option(
- "--dont-generate-markdown",
- "-nomd",
- help="Don't generate the Markdown and HTML file",
- ),
- ] = False,
- dont_generate_html: Annotated[
- bool,
- typer.Option(
- "--dont-generate-html",
- "-nohtml",
- help="Don't generate the HTML file",
- ),
- ] = False,
- dont_generate_pdf: Annotated[
- bool,
- typer.Option(
- "--dont-generate-pdf",
- "-nopdf",
- help="Don't generate the PDF file",
- ),
- ] = False,
- dont_generate_png: Annotated[
- bool,
- typer.Option(
- "--dont-generate-png",
- "-nopng",
- help="Don't generate the PNG file",
- ),
- ] = False,
- watch: Annotated[
- bool,
- typer.Option(
- "--watch",
- "-w",
- help="Automatically re-run RenderCV when the input file is updated",
- ),
- ] = False,
- # This is a dummy argument for the help message for
- # extra_data_model_override_argumets:
- _: Annotated[
- str | None,
- typer.Option(
- "--YAMLLOCATION",
- help="Overrides the value of YAMLLOCATION. For example,"
- ' [cyan bold]--cv.phone "123-456-7890"[/cyan bold].',
- ),
- ] = None,
- extra_data_model_override_arguments: typer.Context = None, # type: ignore
-):
- """Render a CV from a YAML input file."""
- printer.welcome()
- original_working_directory = pathlib.Path.cwd()
- input_file_path = pathlib.Path(input_file_name).absolute()
-
- # from . import utilities as u # removed redundant alias import
- argument_names = list(utilities.get_default_render_command_cli_arguments().keys())
- argument_names.remove("_")
- argument_names.remove("extra_data_model_override_arguments")
- # This is where the user input is accessed and stored:
- variables = copy.copy(locals())
- cli_render_arguments = {name: variables[name] for name in argument_names}
-
- input_file_as_a_dict = utilities.read_and_construct_the_input(
- input_file_path, cli_render_arguments, extra_data_model_override_arguments
- )
-
- watch = input_file_as_a_dict["rendercv_settings"]["render_command"]["watch"]
-
- if watch:
-
- @printer.handle_and_print_raised_exceptions_without_exit
- def run_rendercv():
- input_file_as_a_dict = (
- utilities.update_render_command_settings_of_the_input_file(
- data.read_a_yaml_file(input_file_path), cli_render_arguments
- )
- )
- utilities.run_rendercv_with_printer(
- input_file_as_a_dict, original_working_directory, input_file_path
- )
-
- utilities.run_a_function_if_a_file_changes(input_file_path, run_rendercv)
- else:
- utilities.run_rendercv_with_printer(
- input_file_as_a_dict, original_working_directory, input_file_path
- )
-
-
-@app.command(
- name="new",
- help=(
- "Generate a YAML input file to get started. Example: [yellow]rendercv new"
- ' "John Doe"[/yellow]. Details: [cyan]rendercv new --help[/cyan]'
- ),
-)
-def cli_command_new(
- full_name: Annotated[str, typer.Argument(help="Your full name")],
- theme: Annotated[
- str,
- typer.Option(
- help=(
- "The name of the theme (available themes are:"
- f" {', '.join(data.available_themes)})"
- )
- ),
- ] = "classic",
- dont_create_theme_source_files: Annotated[
- bool,
- typer.Option(
- "--dont-create-theme-source-files",
- "-notypst",
- help="Don't create theme source files",
- ),
- ] = False,
- dont_create_markdown_source_files: Annotated[
- bool,
- typer.Option(
- "--dont-create-markdown-source-files",
- "-nomd",
- help="Don't create the Markdown source files",
- ),
- ] = False,
-):
- """Generate a YAML input file and the Typst and Markdown source files"""
- created_files_and_folders = []
-
- input_file_name = f"{full_name.replace(' ', '_')}_CV.yaml"
- input_file_path = pathlib.Path(input_file_name)
-
- if input_file_path.exists():
- printer.warning(
- f'The input file "{input_file_name}" already exists! A new input file is'
- " not created"
- )
- else:
- try:
- data.create_a_sample_yaml_input_file(
- input_file_path, name=full_name, theme=theme
- )
- created_files_and_folders.append(input_file_path.name)
- except ValueError as e:
- # if the theme is not in the available themes, then raise an error
- printer.error(exception=e)
-
- if not dont_create_theme_source_files:
- # copy the package's theme files to the current directory
- theme_folder = utilities.copy_templates(theme, pathlib.Path.cwd())
- if theme_folder is not None:
- created_files_and_folders.append(theme_folder.name)
- else:
- printer.warning(
- f'The theme folder "{theme}" already exists! The theme files are not'
- " created"
- )
-
- if not dont_create_markdown_source_files:
- # copy the package's markdown files to the current directory
- markdown_folder = utilities.copy_templates("markdown", pathlib.Path.cwd())
- if markdown_folder is not None:
- created_files_and_folders.append(markdown_folder.name)
- else:
- printer.warning(
- 'The "markdown" folder already exists! The Markdown files are not'
- " created"
- )
-
- if len(created_files_and_folders) > 0:
- created_files_and_folders_string = ",\n".join(created_files_and_folders)
- printer.information(
- "The following RenderCV input file and folders have been"
- f" created:\n{created_files_and_folders_string}"
- )
-
-
-@app.command(
- name="create-theme",
- help=(
- "Create a custom theme folder based on an existing theme. Example:"
- " [yellow]rendercv create-theme customtheme[/yellow]. Details: [cyan]rendercv"
- " create-theme --help[/cyan]"
- ),
-)
-def cli_command_create_theme(
- theme_name: Annotated[
- str,
- typer.Argument(help="The name of the new theme"),
- ],
- based_on: Annotated[
- str,
- typer.Option(
- help=(
- "The name of the existing theme to base the new theme on (available"
- f" themes are: {', '.join(data.available_themes)})"
- )
- ),
- ] = "classic",
-):
- """Create a custom theme based on an existing theme"""
- if based_on not in data.available_themes:
- printer.error(
- f'The theme "{based_on}" is not in the list of available themes:'
- f" {', '.join(data.available_themes)}"
- )
-
- theme_folder = utilities.copy_templates(
- based_on, pathlib.Path.cwd(), new_folder_name=theme_name
- )
-
- if theme_folder is None:
- printer.warning(
- f'The theme folder "{theme_name}" already exists! The theme files are not'
- " created"
- )
- return
-
- based_on_theme_directory = (
- pathlib.Path(__file__).parent.parent / "themes" / based_on
- )
- based_on_theme_init_file = based_on_theme_directory / "__init__.py"
- based_on_theme_init_file_contents = based_on_theme_init_file.read_text()
-
- # generate the new init file:
- class_name = f"{theme_name.capitalize()}ThemeOptions"
- literal_name = f'Literal["{theme_name}"]'
- new_init_file_contents = based_on_theme_init_file_contents.replace(
- f'Literal["{based_on}"]', literal_name
- ).replace(f"{based_on.capitalize()}ThemeOptions", class_name)
-
- # create the new __init__.py file:
- (theme_folder / "__init__.py").write_text(new_init_file_contents)
-
- printer.information(f'The theme folder "{theme_folder.name}" has been created.')
-
-
-@app.callback()
-def cli_command_no_args(
- version_requested: Annotated[
- bool | None, typer.Option("--version", "-v", help="Show the version")
- ] = None,
-):
- if version_requested:
- there_is_a_new_version = printer.warn_if_new_version_is_available()
- if not there_is_a_new_version:
- print(f"RenderCV v{__version__}")
diff --git a/src/rendercv/cli/copy_templates.py b/src/rendercv/cli/copy_templates.py
new file mode 100644
index 00000000..92b9ed56
--- /dev/null
+++ b/src/rendercv/cli/copy_templates.py
@@ -0,0 +1,31 @@
+import pathlib
+import shutil
+from typing import Literal
+
+
+def copy_templates(
+ template_type: Literal["markdown", "typst"], copy_templates_to: pathlib.Path
+) -> None:
+ """Copy built-in template directory to user location for customization.
+
+ Why:
+ Users creating custom themes need starting templates to modify.
+
+ Args:
+ template_type: Which template set to copy.
+ copy_templates_to: Destination directory path.
+ """
+ # copy the package's theme files to the current directory
+ template_directory = (
+ pathlib.Path(__file__).parent.parent
+ / "renderer"
+ / "templater"
+ / "templates"
+ / template_type
+ )
+ # copy the folder but don't include __init__.py:
+ shutil.copytree(
+ template_directory,
+ copy_templates_to,
+ ignore=shutil.ignore_patterns("__init__.py", "__pycache__"),
+ )
diff --git a/tests/__init__.py b/src/rendercv/cli/create_theme_command/__init__.py
similarity index 100%
rename from tests/__init__.py
rename to src/rendercv/cli/create_theme_command/__init__.py
diff --git a/src/rendercv/cli/create_theme_command/create_init_file_for_theme.py b/src/rendercv/cli/create_theme_command/create_init_file_for_theme.py
new file mode 100644
index 00000000..9f3cde90
--- /dev/null
+++ b/src/rendercv/cli/create_theme_command/create_init_file_for_theme.py
@@ -0,0 +1,43 @@
+import pathlib
+
+from rendercv.exception import RenderCVUserError
+from rendercv.schema.models.design.design import custom_theme_name_pattern
+
+
+def create_init_file_for_theme(theme_name: str, init_file_path: pathlib.Path) -> None:
+ """Generate `__init__.py` for custom theme by templating from ClassicTheme.
+
+ Why:
+ Custom themes need Pydantic models defining design options. Generating
+ from ClassicTheme provides working example with all standard fields
+ users can modify or extend.
+
+ Args:
+ theme_name: Snake_case theme identifier.
+ init_file_path: Destination path for __init__.py.
+ """
+ if not custom_theme_name_pattern.match(theme_name):
+ message = (
+ "The custom theme name should only contain lowercase letters and digits."
+ f" The provided value is `{theme_name}`."
+ )
+ raise RenderCVUserError(message)
+
+ classic_theme_file = (
+ pathlib.Path(__file__).parent.parent.parent
+ / "schema"
+ / "models"
+ / "design"
+ / "classic_theme.py"
+ )
+ new_init_file_contents = classic_theme_file.read_text()
+
+ new_init_file_contents = new_init_file_contents.replace(
+ "class ClassicTheme(BaseModelWithoutExtraKeys):",
+ f"class {theme_name.capitalize()}Theme(BaseModelWithoutExtraKeys):",
+ )
+ new_init_file_contents = new_init_file_contents.replace(
+ 'theme: Literal["classic"] = "classic"',
+ f'theme: Literal["{theme_name}"] = "{theme_name}"',
+ )
+ init_file_path.write_text(new_init_file_contents)
diff --git a/src/rendercv/cli/create_theme_command/create_theme_command.py b/src/rendercv/cli/create_theme_command/create_theme_command.py
new file mode 100644
index 00000000..3812d5b4
--- /dev/null
+++ b/src/rendercv/cli/create_theme_command/create_theme_command.py
@@ -0,0 +1,64 @@
+import pathlib
+import textwrap
+from typing import Annotated
+
+import rich.panel
+import typer
+from rich import print
+
+from rendercv.exception import RenderCVUserError
+
+from ..app import app
+from ..copy_templates import copy_templates
+from .create_init_file_for_theme import create_init_file_for_theme
+
+
+@app.command(
+ name="create-theme",
+ help=(
+ "Create a custom theme folder with Typst templates to customize. Example:"
+ " [yellow]rendercv create-theme customtheme[/yellow]. Details: [cyan]rendercv"
+ " create-theme --help[/cyan]"
+ ),
+)
+def cli_command_create_theme(
+ theme_name: Annotated[
+ str,
+ typer.Argument(help="The name of the new theme"),
+ ],
+):
+ new_theme_folder = pathlib.Path.cwd() / theme_name
+
+ if new_theme_folder.exists():
+ message = f'The theme folder "{theme_name}" already exists!'
+ raise RenderCVUserError(message)
+
+ copy_templates("typst", new_theme_folder)
+
+ # Create the __init__.py file for the new theme:
+ create_init_file_for_theme(theme_name, new_theme_folder / "__init__.py")
+
+ # Build the panel
+ message = textwrap.dedent(f"""
+ [green]✓[/green] Created your custom theme: [purple]./{theme_name}[/purple]
+
+ What you can do with this theme:
+ 1. Modify the Typst templates in [purple]./{theme_name}/
+ 2. Edit [purple]./{theme_name}/__init__.py[/purple] to:
+ - Add your own design options to use in the YAML input file
+ - Change the default values of existing options
+ - Or simply delete it if you only want to customize templates
+
+ To use your theme, set in your YAML input file:
+ [cyan] design:
+ [cyan] theme: {theme_name}
+ """).strip("\n")
+
+ print(
+ rich.panel.Panel(
+ message,
+ title="Theme created",
+ title_align="left",
+ border_style="bright_black",
+ )
+ )
diff --git a/src/rendercv/cli/entry_point.py b/src/rendercv/cli/entry_point.py
new file mode 100644
index 00000000..9a7aa0bf
--- /dev/null
+++ b/src/rendercv/cli/entry_point.py
@@ -0,0 +1,31 @@
+"""Entry point for the RenderCV CLI.
+
+Why:
+ Users might install RenderCV with `pip install rendercv` instead of
+ `pip install rendercv[full]`. This module catches that case and shows a helpful
+ error message instead of a confusing `ImportError`.
+"""
+
+import sys
+
+
+def entry_point() -> None:
+ """Entry point for the RenderCV CLI."""
+ try:
+ from .app import app as cli_app # NOQA: PLC0415
+ except ImportError:
+ error_message = """
+It looks like you installed RenderCV with:
+
+ pip install rendercv
+
+But RenderCV needs to be installed with:
+
+ pip install "rendercv[full]"
+
+Please reinstall with the correct command above.
+"""
+ sys.stderr.write(error_message)
+ raise SystemExit(1) from None
+
+ cli_app()
diff --git a/src/rendercv/cli/error_handler.py b/src/rendercv/cli/error_handler.py
new file mode 100644
index 00000000..30ea46ab
--- /dev/null
+++ b/src/rendercv/cli/error_handler.py
@@ -0,0 +1,51 @@
+import functools
+from collections.abc import Callable
+
+import rich.panel
+import typer
+from rich import print
+
+from rendercv.exception import RenderCVUserError
+
+
+def handle_user_errors[T, **P](function: Callable[P, None]) -> Callable[P, None]:
+ """Decorator that catches user errors and displays friendly messages without stack traces.
+
+ Why:
+ CLI commands should show clean error messages for expected user errors
+ (invalid YAML, missing files) while preserving stack traces for
+ unexpected errors. This decorator wraps all command functions.
+
+ Example:
+ ```py
+ @app.command()
+ @handle_user_errors
+ def my_command():
+ # Any RenderCVUserError gets caught and displayed cleanly
+ pass
+ ```
+
+ Args:
+ function: CLI command function to wrap.
+
+ Returns:
+ Wrapped function with error handling.
+ """
+
+ @functools.wraps(function)
+ def wrapper(*args: P.args, **kwargs: P.kwargs) -> None:
+ try:
+ return function(*args, **kwargs)
+ except RenderCVUserError as e:
+ if e.message:
+ print(
+ rich.panel.Panel(
+ e.message,
+ title="[bold red]Error[/bold red]",
+ title_align="left",
+ border_style="bold red",
+ )
+ )
+ raise typer.Exit(code=1) from e
+
+ return wrapper
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/BulletEntry.j2.typ b/src/rendercv/cli/new_command/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/BulletEntry.j2.typ
rename to src/rendercv/cli/new_command/__init__.py
diff --git a/src/rendercv/cli/new_command/new_command.py b/src/rendercv/cli/new_command/new_command.py
new file mode 100644
index 00000000..e2504626
--- /dev/null
+++ b/src/rendercv/cli/new_command/new_command.py
@@ -0,0 +1,178 @@
+import pathlib
+from collections.abc import Callable
+from typing import Annotated
+
+import rich.panel
+import typer
+from rich import print
+
+from rendercv.exception import RenderCVUserError
+from rendercv.schema.models.design.built_in_design import available_themes
+from rendercv.schema.models.locale.locale import available_locales
+from rendercv.schema.sample_generator import create_sample_yaml_input_file
+
+from ..app import app
+from ..copy_templates import copy_templates
+from ..error_handler import handle_user_errors
+from .print_welcome import print_welcome
+
+
+@app.command(
+ name="new",
+ help=(
+ "Generate a YAML input file to get started. Example: [yellow]rendercv new"
+ ' "John Doe"[/yellow]. Details: [cyan]rendercv new --help[/cyan]'
+ ),
+)
+@handle_user_errors
+def cli_command_new(
+ full_name: Annotated[str, typer.Argument(help="Your full name")],
+ theme: Annotated[
+ str,
+ typer.Option(
+ help=(
+ "The name of the theme (available themes are:"
+ f" {', '.join(available_themes)})"
+ )
+ ),
+ ] = "classic",
+ locale: Annotated[
+ str,
+ typer.Option(
+ help=(
+ "The name of the locale (available locales are:"
+ f" {', '.join(available_locales)}). You can also continue with"
+ " `English`, and then write your own `locale` field for your own"
+ " language."
+ )
+ ),
+ ] = "english",
+ create_typst_templates: Annotated[
+ bool,
+ typer.Option(
+ "--create-typst-templates",
+ help="Create Typst templates",
+ ),
+ ] = False,
+ create_markdown_templates: Annotated[
+ bool,
+ typer.Option(
+ "--create-markdown-templates",
+ help="Create Markdown templates",
+ ),
+ ] = False,
+):
+ if theme not in available_themes:
+ message = (
+ f"Theme {theme} is not available. Available themes are:"
+ f" {', '.join(available_themes)}"
+ )
+ raise RenderCVUserError(message)
+
+ if locale not in available_locales:
+ message = (
+ f"Locale {locale} is not available. Available locales are:"
+ f" {', '.join(available_locales)}"
+ )
+ raise RenderCVUserError(message)
+
+ print_welcome()
+
+ input_file_path = pathlib.Path(f"{full_name.replace(' ', '_')}_CV.yaml")
+ typst_templates_folder = pathlib.Path(theme)
+ markdown_folder = pathlib.Path("markdown")
+
+ # Define all items to create: (description, path, creator, skip)
+ items_to_create: list[tuple[str, pathlib.Path, Callable[[], object], bool]] = [
+ (
+ "Your YAML input file",
+ input_file_path,
+ lambda: create_sample_yaml_input_file(
+ file_path=input_file_path, name=full_name, theme=theme, locale=locale
+ ),
+ True, # never skip the input file
+ ),
+ (
+ "Typst templates",
+ typst_templates_folder,
+ lambda: copy_templates("typst", typst_templates_folder),
+ create_typst_templates,
+ ),
+ (
+ "Markdown templates",
+ markdown_folder,
+ lambda: copy_templates("markdown", markdown_folder),
+ create_markdown_templates,
+ ),
+ ]
+
+ # Process items
+ created_items: list[tuple[str, pathlib.Path]] = []
+ existing_items: list[tuple[str, pathlib.Path]] = []
+ for description, path, creator, create in items_to_create:
+ if not create:
+ continue
+ if path.exists():
+ existing_items.append((description, path))
+ else:
+ creator()
+ created_items.append((description, path))
+
+ # Build the panel
+ lines: list[str] = []
+
+ # Input file status (always first)
+ input_file_created = any(
+ desc == "Your YAML input file" for desc, _ in created_items
+ )
+ if input_file_created:
+ lines.append(
+ "[green]✓[/green] Created your YAML input file: "
+ f"[purple]./{input_file_path}[/purple]"
+ )
+ else:
+ lines.append(
+ f"Your YAML input file already exists: [purple]./{input_file_path}[/purple]"
+ )
+
+ # Next steps (always visible)
+ lines.append("")
+ lines.append("Next steps:")
+ lines.append(" 1. Edit the YAML input file with your information")
+ lines.append(f" 2. Run: [cyan]rendercv render {input_file_path}[/cyan]")
+
+ # Templates (exclude input file from these lists)
+ created_templates = [
+ (d, p) for d, p in created_items if d != "Your YAML input file"
+ ]
+ existing_templates = [
+ (d, p) for d, p in existing_items if d != "Your YAML input file"
+ ]
+
+ if created_templates:
+ lines.append("")
+ lines.append("Also created:")
+ for desc, path in created_templates:
+ lines.append(f" ○ {desc}: ./{path}")
+
+ if existing_templates:
+ lines.append("")
+ lines.append("Not modified (already exist):")
+ for desc, path in existing_templates:
+ lines.append(f" - {desc}: ./{path}")
+
+ if created_templates or existing_templates:
+ lines.append("")
+ lines.append(
+ "Templates are for advanced design customization. You can ignore or"
+ " delete them."
+ )
+
+ print(
+ rich.panel.Panel(
+ "\n".join(lines),
+ title="Get started",
+ title_align="left",
+ border_style="bright_black",
+ )
+ )
diff --git a/src/rendercv/cli/new_command/print_welcome.py b/src/rendercv/cli/new_command/print_welcome.py
new file mode 100644
index 00000000..e25091b3
--- /dev/null
+++ b/src/rendercv/cli/new_command/print_welcome.py
@@ -0,0 +1,32 @@
+import rich
+import rich.panel
+from rich import print
+
+from rendercv import __version__
+
+
+def print_welcome():
+ """Display welcome banner with version and useful links.
+
+ Why:
+ New users need guidance on where to find documentation and support.
+ """
+ print(f"\nWelcome to [dodger_blue3]RenderCV v{__version__}[/dodger_blue3]!\n")
+ links = {
+ "RenderCV App": "https://rendercv.com",
+ "Documentation": "https://docs.rendercv.com",
+ "Source code": "https://github.com/rendercv/rendercv/",
+ "Bug reports": "https://github.com/rendercv/rendercv/issues/",
+ }
+ link_strings = [
+ f"[bold cyan]{title + ':':<15}[/bold cyan] [link={link}]{link}[/link]"
+ for title, link in links.items()
+ ]
+ link_panel = rich.panel.Panel(
+ "\n".join(link_strings),
+ title="Useful Links",
+ title_align="left",
+ border_style="bright_black",
+ )
+
+ print(link_panel)
diff --git a/src/rendercv/cli/printer.py b/src/rendercv/cli/printer.py
deleted file mode 100644
index 7d75d495..00000000
--- a/src/rendercv/cli/printer.py
+++ /dev/null
@@ -1,350 +0,0 @@
-"""
-The `rendercv.cli.printer` module contains all the functions and classes that are used
-to print nice-looking messages to the terminal.
-"""
-
-import functools
-from collections.abc import Callable
-
-import jinja2
-import packaging.version
-import pydantic
-import rich
-import rich.live
-import rich.panel
-import rich.progress
-import rich.table
-import rich.text
-import ruamel.yaml
-import typer
-from rich import print
-
-from .. import __version__, data
-from . import utilities
-
-
-class LiveProgressReporter(rich.live.Live):
- """This class is a wrapper around `rich.live.Live` that provides the live progress
- reporting functionality.
-
- Args:
- number_of_steps: The number of steps to be finished.
- end_message: The message to be printed when the progress is finished. Defaults
- to "Your CV is rendered!".
- """
-
- def __init__(self, number_of_steps: int, end_message: str = "Your CV is rendered!"):
- class TimeElapsedColumn(rich.progress.ProgressColumn):
- def render(self, task: "rich.progress.Task") -> rich.text.Text:
- elapsed = task.finished_time if task.finished else task.elapsed
- assert elapsed is not None
- elapsed = elapsed * 1000 # Convert to milliseconds
- delta = f"{elapsed:.0f} ms"
- return rich.text.Text(str(delta), style="progress.elapsed")
-
- self.step_progress = rich.progress.Progress(
- TimeElapsedColumn(), rich.progress.TextColumn("{task.description}")
- )
-
- self.overall_progress = rich.progress.Progress(
- TimeElapsedColumn(),
- rich.progress.BarColumn(),
- rich.progress.TextColumn("{task.description}"),
- )
-
- self.group = rich.console.Group(
- rich.panel.Panel(rich.console.Group(self.step_progress)),
- self.overall_progress,
- )
-
- self.overall_task_id = self.overall_progress.add_task("", total=number_of_steps)
- self.number_of_steps = number_of_steps
- self.end_message = end_message
- self.current_step = 0
- self.overall_progress.update(
- self.overall_task_id,
- description=(
- f"[bold #AAAAAA]({self.current_step} out of"
- f" {self.number_of_steps} steps finished)"
- ),
- )
- super().__init__(self.group)
-
- def __enter__(self) -> "LiveProgressReporter":
- """Overwrite the `__enter__` method for the correct return type."""
- self.start(refresh=self._renderable is not None)
- return self
-
- def start_a_step(self, step_name: str):
- """Start a step and update the progress bars.
-
- Args:
- step_name: The name of the step.
- """
- self.current_step_name = step_name
- self.current_step_id = self.step_progress.add_task(
- f"{self.current_step_name} has started."
- )
-
- def finish_the_current_step(self):
- """Finish the current step and update the progress bars."""
- self.step_progress.stop_task(self.current_step_id)
- self.step_progress.update(
- self.current_step_id, description=f"{self.current_step_name} has finished."
- )
- self.current_step += 1
- self.overall_progress.update(
- self.overall_task_id,
- description=(
- f"[bold #AAAAAA]({self.current_step} out of"
- f" {self.number_of_steps} steps finished)"
- ),
- advance=1,
- )
- if self.current_step == self.number_of_steps:
- self.end()
-
- def end(self):
- """End the live progress reporting."""
- self.overall_progress.update(
- self.overall_task_id,
- description=f"[yellow]{self.end_message}",
- )
-
-
-def warn_if_new_version_is_available() -> bool:
- """Check if a new version of RenderCV is available and print a warning message if
- there is a new version. Also, return True if there is a new version, and False
- otherwise.
-
- Returns:
- True if there is a new version, and False otherwise.
- """
- latest_version = utilities.get_latest_version_number_from_pypi()
- version = packaging.version.Version(__version__)
- if latest_version is not None and version < latest_version:
- warning(
- f"A new version of RenderCV is available! You are using v{__version__},"
- f" and the latest version is v{latest_version}."
- )
- return True
- return False
-
-
-def welcome():
- """Print a welcome message to the terminal."""
- warn_if_new_version_is_available()
-
- table = rich.table.Table(
- title=(
- "\nWelcome to [bold]Render[dodger_blue3]CV[/dodger_blue3][/bold]! Some"
- " useful links:"
- ),
- title_justify="left",
- )
-
- table.add_column("Title", style="magenta", justify="left")
- table.add_column("Link", style="cyan", justify="right", no_wrap=True)
-
- table.add_row("[bold]RenderCV App", "https://rendercv.com")
- table.add_row("Documentation", "https://docs.rendercv.com")
- table.add_row("Source code", "https://github.com/rendercv/rendercv/")
- table.add_row("Bug reports", "https://github.com/rendercv/rendercv/issues/")
- table.add_row("Feature requests", "https://github.com/rendercv/rendercv/issues/")
- table.add_row("Discussions", "https://github.com/rendercv/rendercv/discussions/")
- table.add_row("RenderCV Pipeline", "https://github.com/rendercv/rendercv-pipeline/")
-
- print(table)
-
-
-def warning(text: str):
- """Print a warning message to the terminal.
-
- Args:
- text: The text of the warning message.
- """
- print(f"[bold yellow]{text}")
-
-
-def error(text: str | None = None, exception: Exception | None = None):
- """Print an error message to the terminal and exit the program. If an exception is
- given, then print the exception's message as well. If neither text nor exception is
- given, then print an empty line and exit the program.
-
- Args:
- text: The text of the error message.
- exception: An exception object. Defaults to None.
- """
- if exception is not None:
- exception_messages = [str(arg) for arg in exception.args]
- exception_message = "\n\n".join(exception_messages)
- if text is None:
- text = "An error occurred:"
-
- print(
- f"\n[bold red]{text}[/bold red]\n\n[orange4]{exception_message}[/orange4]\n"
- )
- elif text is not None:
- print(f"\n[bold red]{text}\n")
- else:
- print()
-
-
-def information(text: str):
- """Print an information message to the terminal.
-
- Args:
- text: The text of the information message.
- """
- print(f"[green]{text}")
-
-
-def print_validation_errors(exception: pydantic.ValidationError):
- """Take a Pydantic validation error and print the error messages in a nice table.
-
- Pydantic's `ValidationError` object is a complex object that contains a lot of
- information about the error. This function takes a `ValidationError` object and
- extracts the error messages, locations, and the input values. Then, it prints them
- in a nice table with [Rich](https://rich.readthedocs.io/en/latest/).
-
- Args:
- exception: The Pydantic validation error object.
- """
- errors = data.parse_validation_errors(exception)
-
- # Print the errors in a nice table:
- table = rich.table.Table(
- title="[bold red]\nThere are some errors in the data model!\n",
- title_justify="left",
- show_lines=True,
- )
- table.add_column("Location", style="cyan", no_wrap=True)
- table.add_column("Input Value", style="magenta")
- table.add_column("Error Message", style="orange4")
-
- for error_object in errors:
- table.add_row(
- ".".join(error_object["loc"]),
- error_object["input"],
- error_object["msg"],
- )
-
- print(table)
-
-
-def handle_and_print_raised_exceptions_without_exit(function: Callable) -> Callable:
- """Return a wrapper function that handles exceptions. It does not exit the program
- after an exception is raised. It just prints the error message and continues the
- execution.
-
- A decorator in Python is a syntactic convenience that allows a Python to interpret
- the code below:
-
- ```python
- @handle_exceptions
- def my_function():
- pass
- ```
-
- as
-
- ```python
- my_function = handle_exceptions(my_function)
- ```
-
- which means that the function `my_function` is modified by the `handle_exceptions`.
-
- Args:
- function: The function to be wrapped.
-
- Returns:
- The wrapped function.
- """
-
- @functools.wraps(function)
- def wrapper(*args, **kwargs):
- code = 4
- try:
- function(*args, **kwargs)
- except pydantic.ValidationError as e:
- print_validation_errors(e)
- except ruamel.yaml.YAMLError as e:
- error(
- "There is a YAML error in the input file!\n\nTry to use quotation marks"
- " to make sure the YAML parser understands the field is a string.",
- e,
- )
- except FileNotFoundError as e:
- error(exception=e)
- except UnicodeDecodeError as e:
- # find the problematic character that cannot be decoded with utf-8
- bad_character = str(e.object[e.start : e.end])
- try:
- bad_character_context = str(e.object[e.start - 16 : e.end + 16])
- except IndexError:
- bad_character_context = ""
-
- error(
- "The input file contains a character that cannot be decoded with"
- f" UTF-8 ({bad_character}):\n {bad_character_context}",
- )
- except ValueError as e:
- error(exception=e)
- except typer.Exit:
- pass
- except jinja2.exceptions.TemplateSyntaxError as e:
- error(
- f"There is a problem with the template ({e.filename}) at line"
- f" {e.lineno}!",
- e,
- )
- except RuntimeError as e:
- error(exception=e)
- except Exception as e:
- raise e
- else:
- code = 0
-
- return code
-
- return wrapper
-
-
-def handle_and_print_raised_exceptions(function: Callable) -> Callable:
- """Return a wrapper function that handles exceptions. It exits the program after an
- exception is raised.
-
- A decorator in Python is a syntactic convenience that allows a Python to interpret
- the code below:
-
- ```python
- @handle_exceptions
- def my_function():
- pass
- ```
-
- as
-
- ```python
- my_function = handle_exceptions(my_function)
- ```
-
- which means that the function `my_function` is modified by the `handle_exceptions`.
-
- Args:
- function: The function to be wrapped.
-
- Returns:
- The wrapped function.
- """
-
- @functools.wraps(function)
- def wrapper(*args, **kwargs):
- without_exit_wrapper = handle_and_print_raised_exceptions_without_exit(function)
-
- code = without_exit_wrapper(*args, **kwargs)
-
- if code != 0:
- raise typer.Exit(code)
-
- return wrapper
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/EducationEntry.j2.typ b/src/rendercv/cli/render_command/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/EducationEntry.j2.typ
rename to src/rendercv/cli/render_command/__init__.py
diff --git a/src/rendercv/cli/render_command/parse_override_arguments.py b/src/rendercv/cli/render_command/parse_override_arguments.py
new file mode 100644
index 00000000..74353ef6
--- /dev/null
+++ b/src/rendercv/cli/render_command/parse_override_arguments.py
@@ -0,0 +1,55 @@
+import typer
+
+from rendercv.exception import RenderCVUserError
+
+
+def parse_override_arguments(extra_arguments: typer.Context) -> dict[str, str]:
+ """Parse CLI override arguments into dotted-path dictionary.
+
+ Why:
+ Users need quick field overrides without editing YAML. We need to parse
+ `--cv.phone "123"` style arguments.
+
+ Example:
+ ```py
+ # From: rendercv render cv.yaml --cv.name "Jane" --cv.phone "456"
+ args = parse_override_arguments(ctx)
+ # Returns: {"cv.name": "Jane", "cv.phone": "456"}
+ ```
+
+ Args:
+ extra_arguments: Typer context containing unparsed arguments.
+
+ Returns:
+ Map of dotted paths to override values.
+ """
+ key_and_values: dict[str, str] = {}
+
+ # `extra_arguments.args` is a list of arbitrary arguments that haven't been
+ # specified in `cli_render_command` function's definition. They are used to allow
+ # users to edit their data model in CLI. The elements with even indexes in this list
+ # are keys that start with double dashed, such as
+ # `--cv.sections.education.0.institution`. The following elements are the
+ # corresponding values of the key, such as `"Bogazici University"`. The for loop
+ # below parses `ctx.args` accordingly.
+
+ if len(extra_arguments.args) % 2 != 0:
+ message = (
+ "There is a problem with the extra arguments"
+ f" ({','.join(extra_arguments.args)})! Each key should have a corresponding"
+ " value."
+ )
+ raise RenderCVUserError(message)
+
+ for i in range(0, len(extra_arguments.args), 2):
+ key = extra_arguments.args[i]
+ value = extra_arguments.args[i + 1]
+ if not key.startswith("--"):
+ message = f"The key ({key}) should start with double dashes!"
+ raise RenderCVUserError(message)
+
+ key = key.replace("--", "")
+
+ key_and_values[key] = value
+
+ return key_and_values
diff --git a/src/rendercv/cli/render_command/progress_panel.py b/src/rendercv/cli/render_command/progress_panel.py
new file mode 100644
index 00000000..746874e1
--- /dev/null
+++ b/src/rendercv/cli/render_command/progress_panel.py
@@ -0,0 +1,157 @@
+import contextlib
+import pathlib
+from dataclasses import dataclass
+
+import rich.box
+import rich.live
+import rich.panel
+import rich.table
+import typer
+
+from rendercv.exception import RenderCVUserError, RenderCVValidationError
+
+
+class ProgressPanel(rich.live.Live):
+ """Live-updating terminal panel showing CV generation progress with timing.
+
+ Example:
+ ```py
+ with ProgressPanel(quiet=False) as progress:
+ progress.update_progress("50", "Generated PDF", [Path("cv.pdf")])
+ progress.finish_progress()
+ # Displays: ✓ 50 ms Generated PDF: ./cv.pdf
+ ```
+
+ Args:
+ quiet: Suppress all terminal output.
+ """
+
+ def __init__(self, quiet: bool = False):
+ self.quiet = quiet
+ self.completed_steps: list[CompletedStep] = []
+ super().__init__(
+ rich.panel.Panel(
+ "...",
+ title="Rendering your CV...",
+ title_align="left",
+ border_style="bright_black",
+ ),
+ refresh_per_second=4,
+ )
+
+ def update_progress(
+ self, time_took: str, message: str, paths: list[pathlib.Path]
+ ) -> None:
+ """Add completed step to progress display.
+
+ Args:
+ time_took: Execution time in milliseconds as string.
+ message: Step description.
+ paths: Generated file paths to display.
+ """
+ self.completed_steps.append(CompletedStep(time_took, message, paths))
+ self.print_progress_panel(title="Rendering your CV...")
+
+ def finish_progress(self) -> None:
+ """Display final success panel and clear state."""
+ self.print_progress_panel(title="Your CV is ready")
+ self.completed_steps.clear()
+
+ def print_progress_panel(self, title: str) -> None:
+ """Render progress panel with all completed steps.
+
+ Args:
+ title: Panel title text.
+ """
+ if self.quiet:
+ return
+
+ lines: list[str] = []
+ for step in self.completed_steps:
+ paths_str = ""
+ if step.paths:
+ with contextlib.suppress(ValueError):
+ step.paths = [
+ path.relative_to(pathlib.Path.cwd()) for path in step.paths
+ ]
+ paths_as_strings = [f"./{path}" for path in step.paths]
+ paths_str = "; ".join(paths_as_strings)
+
+ timing = f"[bold green]{step.timing_ms + ' ms':<8}[/bold green]"
+ message = step.message + (": " if paths_str else ".")
+ paths_display = f"[purple]{paths_str}[/purple]" if paths_str else ""
+ lines.append(f"[green]✓[/green] {timing} {message:<26} {paths_display}")
+
+ content = "\n".join(lines) if lines else "Rendering..."
+
+ self.update(
+ rich.panel.Panel(
+ content,
+ title=title,
+ title_align="left",
+ border_style="bright_black",
+ )
+ )
+
+ def print_user_error(self, user_error: RenderCVUserError) -> None:
+ """Display error panel and exit with error code.
+
+ Args:
+ user_error: User-facing error to display.
+ """
+ self.clear()
+ self.update(
+ rich.panel.Panel(
+ user_error.message or "An unknown error occurred.",
+ title="[bold red]Error[/bold red]",
+ title_align="left",
+ border_style="bold red",
+ )
+ )
+ raise typer.Exit(code=1)
+
+ def print_validation_errors(self, errors: list[RenderCVValidationError]) -> None:
+ """Display validation errors in table format and exit.
+
+ Why:
+ Pydantic validation errors are parsed into user-friendly messages with
+ YAML locations. Table shows exactly which field failed and why.
+
+ Args:
+ errors: List of validation errors with location, input, and message.
+ """
+ self.completed_steps.clear()
+ table = rich.table.Table(expand=True, show_lines=True, box=rich.box.ROUNDED)
+ table.add_column("Location", style="cyan", no_wrap=True)
+ table.add_column("Input Value", style="magenta", no_wrap=True)
+ table.add_column("Explanation", style="orange4")
+
+ for error_object in errors:
+ table.add_row(
+ ".".join(error_object.location),
+ error_object.input,
+ error_object.message,
+ )
+
+ self.update(
+ rich.panel.Panel(
+ table,
+ title="[bold red]There are errors in the input file![/bold red]",
+ title_align="left",
+ border_style="bold red",
+ )
+ )
+
+ raise typer.Exit(code=1)
+
+ def clear(self) -> None:
+ """Clear all completed steps and panel display."""
+ self.completed_steps.clear()
+ self.update("")
+
+
+@dataclass
+class CompletedStep:
+ timing_ms: str
+ message: str
+ paths: list[pathlib.Path]
diff --git a/src/rendercv/cli/render_command/render_command.py b/src/rendercv/cli/render_command/render_command.py
new file mode 100644
index 00000000..ad2d4b9f
--- /dev/null
+++ b/src/rendercv/cli/render_command/render_command.py
@@ -0,0 +1,212 @@
+import pathlib
+from typing import Annotated
+
+import typer
+
+from rendercv.schema.rendercv_model_builder import (
+ BuildRendercvModelArguments,
+)
+
+from ..app import app
+from ..error_handler import handle_user_errors
+from .parse_override_arguments import parse_override_arguments
+from .progress_panel import ProgressPanel
+from .run_rendercv import run_rendercv
+from .watcher import run_function_if_file_changes
+
+
+@app.command(
+ name="render",
+ help=(
+ "Render a YAML input file. Example: [yellow]rendercv render"
+ " John_Doe_CV.yaml[/yellow]. Details: [cyan]rendercv render --help[/cyan]"
+ ),
+ # allow extra arguments for updating the old_data model (for overriding the values of
+ # the input file):
+ context_settings={"allow_extra_args": True, "ignore_unknown_options": True},
+)
+@handle_user_errors
+def cli_command_render(
+ input_file_name: Annotated[str, typer.Argument(help="The YAML input file.")],
+ design: Annotated[
+ str | None,
+ typer.Option(
+ "--design",
+ "-d",
+ help='The "design" field\'s YAML input file.',
+ ),
+ ] = None,
+ locale: Annotated[
+ str | None,
+ typer.Option(
+ "--locale-catalog",
+ "-lc",
+ help='The "locale" field\'s YAML input file.',
+ ),
+ ] = None,
+ settings: Annotated[
+ str | None,
+ typer.Option(
+ "--settings",
+ "-s",
+ help='The "settings" field\'s YAML input file.',
+ ),
+ ] = None,
+ typst_path: Annotated[
+ str | None,
+ typer.Option(
+ "--typst-path",
+ "-typ",
+ help=(
+ "Save the generated Typst file to the specified path, relative to the"
+ " input file."
+ ),
+ ),
+ ] = None,
+ pdf_path: Annotated[
+ str | None,
+ typer.Option(
+ "--pdf-path",
+ "-pdf",
+ help=(
+ "Save the generated PDF file to the specified path, relative to the"
+ " input file."
+ ),
+ ),
+ ] = None,
+ markdown_path: Annotated[
+ str | None,
+ typer.Option(
+ "--markdown-path",
+ "-md",
+ help=(
+ "Save the generated Markdown file to the specified path, relative to"
+ " the input file."
+ ),
+ ),
+ ] = None,
+ html_path: Annotated[
+ str | None,
+ typer.Option(
+ "--html-path",
+ "-html",
+ help=(
+ "Save the generated HTML file to the specified path, relative to the"
+ " input file."
+ ),
+ ),
+ ] = None,
+ png_path: Annotated[
+ str | None,
+ typer.Option(
+ "--png-path",
+ "-png",
+ help=(
+ "Save the generated PNG files to the specified path, relative to the"
+ " input file."
+ ),
+ ),
+ ] = None,
+ dont_generate_markdown: Annotated[
+ bool,
+ typer.Option(
+ "--dont-generate-markdown",
+ "-nomd",
+ help=(
+ "If provided, the Markdown file will not be generated. Disabling"
+ " Markdown generation implicitly disables HTML."
+ ),
+ ),
+ ] = False,
+ dont_generate_html: Annotated[
+ bool,
+ typer.Option(
+ "--dont-generate-html",
+ "-nohtml",
+ help="If provided, the HTML file will not be generated.",
+ ),
+ ] = False,
+ dont_generate_typst: Annotated[
+ bool,
+ typer.Option(
+ "--dont-generate-typst",
+ "-notyp",
+ help=(
+ "If provided, the Typst file will not be generated. Disabling Typst"
+ " generation implicitly disables PDF and PNG."
+ ),
+ ),
+ ] = False,
+ dont_generate_pdf: Annotated[
+ bool,
+ typer.Option(
+ "--dont-generate-pdf",
+ "-nopdf",
+ help="If provided, the PDF file will not be generated.",
+ ),
+ ] = False,
+ dont_generate_png: Annotated[
+ bool,
+ typer.Option(
+ "--dont-generate-png",
+ "-nopng",
+ help="If provided, the PNG file will not be generated.",
+ ),
+ ] = False,
+ watch: Annotated[
+ bool,
+ typer.Option(
+ "--watch",
+ "-w",
+ help=(
+ "If provided, RenderCV will automatically re-run when the input file is"
+ " updated."
+ ),
+ ),
+ ] = False,
+ quiet: Annotated[
+ bool,
+ typer.Option(
+ "--quiet",
+ "-q",
+ help="If provided, RenderCV will not print any messages.",
+ ),
+ ] = False,
+ # This is a dummy argument for the help message for
+ # extra_data_model_override_argumets:
+ _: Annotated[
+ str | None,
+ typer.Option(
+ "--YAMLLOCATION",
+ help="Overrides the value of YAMLLOCATION. For example,"
+ ' [cyan bold]--cv.phone "123-456-7890"[/cyan bold].',
+ ),
+ ] = None,
+ extra_data_model_override_arguments: typer.Context = None, # pyright: ignore[reportArgumentType]
+):
+ arguments: BuildRendercvModelArguments = {
+ "design_file_path_or_contents": design,
+ "locale_file_path_or_contents": locale,
+ "settings_file_path_or_contents": settings,
+ "typst_path": typst_path,
+ "pdf_path": pdf_path,
+ "markdown_path": markdown_path,
+ "html_path": html_path,
+ "png_path": png_path,
+ "dont_generate_typst": dont_generate_typst,
+ "dont_generate_html": dont_generate_html,
+ "dont_generate_markdown": dont_generate_markdown,
+ "dont_generate_pdf": dont_generate_pdf,
+ "dont_generate_png": dont_generate_png,
+ "overrides": parse_override_arguments(extra_data_model_override_arguments),
+ }
+ input_file_path = pathlib.Path(input_file_name).absolute()
+
+ with ProgressPanel(quiet=quiet) as progress_panel:
+ if watch:
+ run_function_if_file_changes(
+ input_file_path,
+ lambda: run_rendercv(input_file_path, progress_panel, **arguments),
+ )
+ else:
+ run_rendercv(input_file_path, progress_panel, **arguments)
diff --git a/src/rendercv/cli/render_command/run_rendercv.py b/src/rendercv/cli/render_command/run_rendercv.py
new file mode 100644
index 00000000..d0cb971b
--- /dev/null
+++ b/src/rendercv/cli/render_command/run_rendercv.py
@@ -0,0 +1,158 @@
+import pathlib
+import time
+from collections.abc import Callable
+from typing import Unpack
+
+import jinja2
+import ruamel.yaml
+
+from rendercv.exception import RenderCVUserError, RenderCVUserValidationError
+from rendercv.renderer.html import generate_html
+from rendercv.renderer.markdown import generate_markdown
+from rendercv.renderer.pdf_png import generate_pdf, generate_png
+from rendercv.renderer.typst import generate_typst
+from rendercv.schema.rendercv_model_builder import (
+ BuildRendercvModelArguments,
+ build_rendercv_dictionary_and_model,
+)
+
+from .progress_panel import ProgressPanel
+
+
+def timed_step[T, **P](
+ message: str,
+ progress_panel: ProgressPanel,
+ func: Callable[P, T],
+ *args: P.args,
+ **kwargs: P.kwargs,
+) -> T:
+ """Execute function, measure timing, and update progress panel with result.
+
+ Why:
+ Each generation step (Typst, PDF, PNG) returns file paths. This wrapper
+ times execution and automatically displays results in progress panel.
+
+ Example:
+ ```py
+ pdf_path = timed_step(
+ "Generated PDF", progress, generate_pdf, rendercv_model, typst_path
+ )
+ # Progress shows: ✓ 150 ms Generated PDF: ./cv.pdf
+ ```
+
+ Args:
+ message: Step description for progress display.
+ progress_panel: Progress panel to update.
+ func: Function to execute and time.
+ args: Positional arguments for func.
+ kwargs: Keyword arguments for func.
+
+ Returns:
+ Function result.
+ """
+ start = time.perf_counter()
+ result = func(*args, **kwargs)
+ end = time.perf_counter()
+ timing_ms = f"{(end - start) * 1000:.0f}"
+
+ paths: list[pathlib.Path] = []
+ if isinstance(result, pathlib.Path):
+ paths = [result]
+ elif isinstance(result, list) and result:
+ if len(result) > 1:
+ message = f"{message}s"
+ paths = result
+
+ if paths:
+ progress_panel.update_progress(
+ time_took=timing_ms, message=message, paths=paths
+ )
+
+ return result
+
+
+def run_rendercv(
+ main_input_file_path_or_contents: pathlib.Path | str,
+ progress: ProgressPanel,
+ **kwargs: Unpack[BuildRendercvModelArguments],
+):
+ """Execute complete CV generation pipeline with progress tracking and error handling.
+
+ Why:
+ Orchestrates the full flow: YAML → Pydantic validation → Typst generation →
+ PDF/PNG/HTML/Markdown outputs. Catches all error types and displays them
+ through progress panel for clean CLI experience.
+
+ Example:
+ ```py
+ with ProgressPanel() as progress:
+ run_rendercv(
+ Path("cv.yaml"), progress, pdf_path="output.pdf", dont_generate_png=True
+ )
+ # Generates PDF, skips PNG, shows progress for each step
+ ```
+
+ Args:
+ main_input_file_path_or_contents: YAML file path or raw content string.
+ progress: Progress panel for output display.
+ kwargs: Optional overrides for design/locale files, output paths, and generation flags.
+ """
+ try:
+ _, rendercv_model = timed_step(
+ "Validated the input file",
+ progress,
+ build_rendercv_dictionary_and_model,
+ main_input_file_path_or_contents,
+ **kwargs,
+ )
+ typst_path = timed_step(
+ "Generated Typst",
+ progress,
+ generate_typst,
+ rendercv_model,
+ )
+ timed_step(
+ "Generated PDF",
+ progress,
+ generate_pdf,
+ rendercv_model,
+ typst_path,
+ )
+ timed_step(
+ "Generated PNG",
+ progress,
+ generate_png,
+ rendercv_model,
+ typst_path,
+ )
+ md_path = timed_step(
+ "Generated Markdown",
+ progress,
+ generate_markdown,
+ rendercv_model,
+ )
+ timed_step(
+ "Generated HTML",
+ progress,
+ generate_html,
+ rendercv_model,
+ md_path,
+ )
+ progress.finish_progress()
+ except RenderCVUserError as e:
+ progress.print_user_error(e)
+ except ruamel.yaml.YAMLError as e:
+ progress.print_user_error(
+ RenderCVUserError(message=f"This is not a valid YAML file!\n\n{e}")
+ )
+ except jinja2.exceptions.TemplateSyntaxError as e:
+ progress.print_user_error(
+ RenderCVUserError(
+ message=(
+ f"There is a problem with the template ({e.filename}) at line"
+ f" {e.lineno}!\n\n{e}"
+ )
+ )
+ )
+ except RenderCVUserValidationError as e:
+ progress.print_validation_errors(e.validation_errors)
diff --git a/src/rendercv/cli/render_command/watcher.py b/src/rendercv/cli/render_command/watcher.py
new file mode 100644
index 00000000..abe305b5
--- /dev/null
+++ b/src/rendercv/cli/render_command/watcher.py
@@ -0,0 +1,51 @@
+import contextlib
+import pathlib
+import sys
+import time
+from collections.abc import Callable
+
+import typer
+import watchdog.events
+import watchdog.observers
+
+
+def run_function_if_file_changes(file_path: pathlib.Path, function: Callable):
+ """Watch the file located at `file_path` and call the `function` when the file is
+ modified. The function should not take any arguments.
+
+ Args:
+ file_path (pathlib.Path): The path of the file to watch for.
+ function (Callable): The function to be called on file modification.
+ """
+ path_to_watch = str(file_path.absolute())
+ if sys.platform == "win32":
+ # Windows does not support single file watching, so we watch the directory
+ path_to_watch = str(file_path.parent.absolute())
+
+ class EventHandler(watchdog.events.FileSystemEventHandler):
+ def __init__(self, function: Callable):
+ super().__init__()
+ self.function = function
+
+ def on_modified(self, event: watchdog.events.FileModifiedEvent) -> None:
+ if event.src_path != str(file_path.absolute()):
+ return
+
+ with contextlib.suppress(typer.Exit):
+ self.function()
+
+ event_handler = EventHandler(function)
+
+ observer = watchdog.observers.Observer()
+ observer.schedule(event_handler, path_to_watch, recursive=True)
+ observer.start()
+ # Run the function immediately for the first time:
+ event_handler.on_modified(
+ watchdog.events.FileModifiedEvent(str(file_path.absolute()))
+ )
+ try:
+ while True:
+ time.sleep(1)
+ except KeyboardInterrupt:
+ observer.stop()
+ observer.join()
diff --git a/src/rendercv/cli/utilities.py b/src/rendercv/cli/utilities.py
deleted file mode 100644
index c4918076..00000000
--- a/src/rendercv/cli/utilities.py
+++ /dev/null
@@ -1,519 +0,0 @@
-"""
-The `rendercv.cli.utilities` module contains utility functions that are required by CLI.
-"""
-
-import contextlib
-import inspect
-import json
-import os
-import pathlib
-import shutil
-import ssl
-import sys
-import time
-import urllib.request
-from collections.abc import Callable
-from typing import Any
-
-import packaging.version
-import typer
-import watchdog.events
-import watchdog.observers
-
-from .. import __version__, data, renderer
-from . import commands, printer
-
-
-def set_or_update_a_value(
- dictionary: dict,
- key: str,
- value: str,
- sub_dictionary: dict | list | None = None,
-) -> dict: # type: ignore
- """Set or update a value in a dictionary for the given key. For example, a key can
- be `cv.sections.education.3.institution` and the value can be "Bogazici University".
-
- Args:
- dictionary: The dictionary to set or update the value.
- key: The key to set or update the value.
- value: The value to set or update.
- sub_dictionary: The sub dictionary to set or update the value. This is used for
- recursive calls. Defaults to None.
- """
- # Recursively call this function until the last key is reached:
-
- keys = key.split(".")
-
- updated_dict = sub_dictionary if sub_dictionary is not None else dictionary
-
- if len(keys) == 1:
- # Set the value:
- if value.startswith("{") and value.endswith("}"):
- # Allow users to assign dictionaries:
- value = eval(value)
- elif value.startswith("[") and value.endswith("]"):
- # Allow users to assign lists:
- value = eval(value)
-
- if isinstance(updated_dict, list):
- key = int(key) # type: ignore
-
- updated_dict[key] = value # type: ignore
-
- else:
- # get the first key and call the function with remaining keys:
- first_key = keys[0]
- key = ".".join(keys[1:])
-
- if isinstance(updated_dict, list):
- first_key = int(first_key)
-
- if isinstance(first_key, int) or first_key in updated_dict:
- # Key exists, get the sub dictionary:
- sub_dictionary = updated_dict[first_key] # type: ignore
- else:
- # Key does not exist, create a new sub dictionary:
- sub_dictionary = {}
-
- updated_sub_dict = set_or_update_a_value(dictionary, key, value, sub_dictionary)
- updated_dict[first_key] = updated_sub_dict # type: ignore
-
- return updated_dict # type: ignore
-
-
-def set_or_update_values(
- dictionary: dict,
- key_and_values: dict[str, str],
-) -> dict:
- """Set or update values in a dictionary for the given keys. It uses the
- `set_or_update_a_value` function to set or update the values.
-
- Args:
- dictionary: The dictionary to set or update the values.
- key_and_values: The key and value pairs to set or update.
- """
- for key, value in key_and_values.items():
- dictionary = set_or_update_a_value(dictionary, key, value) # type: ignore
-
- return dictionary
-
-
-def copy_files(paths: list[pathlib.Path] | pathlib.Path, new_path: pathlib.Path):
- """Copy files to the given path. If there are multiple files, then rename the new
- path by adding a number to the end of the path.
-
- Args:
- paths: The paths of the files to be copied.
- new_path: The path to copy the files to.
- """
- if isinstance(paths, pathlib.Path):
- paths = [paths]
-
- if len(paths) == 1:
- shutil.copy2(paths[0], new_path)
- else:
- for i, file_path in enumerate(paths):
- # append a number to the end of the path:
- number = i + 1
- png_path_with_page_number = (
- pathlib.Path(new_path).parent
- / f"{pathlib.Path(new_path).stem}_{number}.png"
- )
- shutil.copy2(file_path, png_path_with_page_number)
-
-
-def get_latest_version_number_from_pypi() -> packaging.version.Version | None:
- """Get the latest version number of RenderCV from PyPI.
-
- Example:
- ```python
- get_latest_version_number_from_pypi()
- ```
- returns
- `"1.1"`
-
- Returns:
- The latest version number of RenderCV from PyPI. Returns None if the version
- number cannot be fetched.
- """
- version: packaging.version.Version | None = None
- url = "https://pypi.org/pypi/rendercv/json"
- try:
- with urllib.request.urlopen(
- url, context=ssl._create_unverified_context()
- ) as response:
- data = response.read()
- encoding = response.info().get_content_charset("utf-8")
- json_data = json.loads(data.decode(encoding))
- version_string = json_data["info"]["version"]
- version = packaging.version.Version(version_string)
- except Exception:
- pass
-
- if version is None:
- return packaging.version.Version(__version__)
-
- return version
-
-
-def copy_templates(
- folder_name: str,
- copy_to: pathlib.Path,
- new_folder_name: str | None = None,
-) -> pathlib.Path | None:
- """Copy one of the folders found in `rendercv.templates` to `copy_to`.
-
- Args:
- folder_name: The name of the folder to be copied.
- copy_to: The path to copy the folder to.
-
- Returns:
- The path to the copied folder.
- """
- # copy the package's theme files to the current directory
- template_directory = pathlib.Path(__file__).parent.parent / "themes" / folder_name
- if new_folder_name:
- destination = copy_to / new_folder_name
- else:
- destination = copy_to / folder_name
-
- if destination.exists():
- return None
- # copy the folder but don't include __init__.py:
- shutil.copytree(
- template_directory,
- destination,
- ignore=shutil.ignore_patterns("__init__.py", "__pycache__"),
- )
-
- return destination
-
-
-def parse_render_command_override_arguments(
- extra_arguments: typer.Context,
-) -> dict["str", "str"]:
- """Parse extra arguments given to the `render` command as data model key and value
- pairs and return them as a dictionary.
-
- Args:
- extra_arguments: The extra arguments context.
-
- Returns:
- The key and value pairs.
- """
- key_and_values: dict[str, str] = {}
-
- # `extra_arguments.args` is a list of arbitrary arguments that haven't been
- # specified in `cli_render_command` function's definition. They are used to allow
- # users to edit their data model in CLI. The elements with even indexes in this list
- # are keys that start with double dashed, such as
- # `--cv.sections.education.0.institution`. The following elements are the
- # corresponding values of the key, such as `"Bogazici University"`. The for loop
- # below parses `ctx.args` accordingly.
-
- if len(extra_arguments.args) % 2 != 0:
- message = (
- "There is a problem with the extra arguments"
- f" ({','.join(extra_arguments.args)})! Each key should have a corresponding"
- " value."
- )
- raise ValueError(message)
-
- for i in range(0, len(extra_arguments.args), 2):
- key = extra_arguments.args[i]
- value = extra_arguments.args[i + 1]
- if not key.startswith("--"):
- message = f"The key ({key}) should start with double dashes!"
- raise ValueError(message)
-
- key = key.replace("--", "")
-
- key_and_values[key] = value
-
- return key_and_values
-
-
-def get_default_render_command_cli_arguments() -> dict:
- """Get the default values of the `render` command's CLI arguments.
-
- Returns:
- The default values of the `render` command's CLI arguments.
- """
- sig = inspect.signature(commands.cli_command_render)
- return {
- k: v.default
- for k, v in sig.parameters.items()
- if v.default is not inspect.Parameter.empty
- }
-
-
-def update_render_command_settings_of_the_input_file(
- input_file_as_a_dict: dict,
- render_command_cli_arguments: dict,
-) -> dict:
- """Update the input file's `rendercv_settings.render_command` field with the given
- values (only the non-default ones) of the `render` command's CLI arguments.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
- render_command_cli_arguments: The command line arguments of the `render`
- command.
-
- Returns:
- The updated input file as a dictionary.
- """
- default_render_command_cli_arguments = get_default_render_command_cli_arguments()
-
- # Loop through `render_command_cli_arguments` and if the value is not the default
- # value, overwrite the value in the input file's `rendercv_settings.render_command`
- # field. If the field is the default value, check if it exists in the input file.
- # If it doesn't exist, add it to the input file. If it exists, don't do anything.
- if "rendercv_settings" not in input_file_as_a_dict:
- input_file_as_a_dict["rendercv_settings"] = {}
-
- if (
- "render_command" not in input_file_as_a_dict["rendercv_settings"]
- or input_file_as_a_dict["rendercv_settings"]["render_command"] is None
- ):
- input_file_as_a_dict["rendercv_settings"]["render_command"] = {}
-
- render_command_field = input_file_as_a_dict["rendercv_settings"]["render_command"]
- for key, value in render_command_cli_arguments.items():
- if (
- value != default_render_command_cli_arguments[key]
- or key not in render_command_field
- ):
- render_command_field[key] = value
-
- input_file_as_a_dict["rendercv_settings"]["render_command"] = render_command_field
-
- return input_file_as_a_dict
-
-
-def run_rendercv_with_printer(
- input_file_as_a_dict: dict,
- working_directory: pathlib.Path,
- input_file_path: pathlib.Path,
-):
- """Run RenderCV with a live progress reporter. Working dictionary is where the
- output files will be saved. Input file path is required for accessing the template
- overrides.
-
- Args:
- input_file_as_a_dict: The input file as a dictionary.
- working_directory: The working directory where the output files will be saved.
- input_file_path: The path of the input file.
- """
- render_command_settings_dict = input_file_as_a_dict["rendercv_settings"][
- "render_command"
- ]
-
- # Compute the number of steps
- # 1. Validate the input file.
- # 2. Create the Typst file.
- # 3. Render PDF from Typst.
- # 4. Render PNGs from PDF.
- # 5. Create the Markdown file.
- # 6. Render HTML from Markdown.
- number_of_steps = 6
- if render_command_settings_dict["dont_generate_pdf"]:
- number_of_steps -= 1
-
- if render_command_settings_dict["dont_generate_png"]:
- number_of_steps -= 1
-
- if render_command_settings_dict["dont_generate_markdown"]:
- number_of_steps -= 2
- else:
- if render_command_settings_dict["dont_generate_html"]:
- number_of_steps -= 1
-
- with printer.LiveProgressReporter(number_of_steps=number_of_steps) as progress:
- progress.start_a_step("Validating the input file")
-
- data_model = data.validate_input_dictionary_and_return_the_data_model(
- input_file_as_a_dict,
- context={"input_file_directory": input_file_path.parent},
- )
-
- # Change the current working directory to the input file's directory (because
- # the template overrides are looked up in the current working directory). The
- # output files will be in the original working directory. It should be done
- # after the input file is validated (because of the rendercv_settings).
- os.chdir(input_file_path.parent)
-
- render_command_settings: data.models.RenderCommandSettings = (
- data_model.rendercv_settings.render_command # type: ignore
- )
- output_directory = (
- working_directory / render_command_settings.output_folder_name
- )
-
- progress.finish_the_current_step()
-
- progress.start_a_step("Generating the Typst file")
-
- typst_file_path_in_output_folder = (
- renderer.create_a_typst_file_and_copy_theme_files(
- data_model, output_directory
- )
- )
- if render_command_settings.typst_path:
- copy_files(
- typst_file_path_in_output_folder,
- render_command_settings.typst_path,
- )
-
- progress.finish_the_current_step()
-
- if not render_command_settings.dont_generate_pdf:
- progress.start_a_step("Rendering the Typst file to a PDF")
-
- pdf_file_path_in_output_folder = renderer.render_a_pdf_from_typst(
- typst_file_path_in_output_folder,
- )
- if render_command_settings.pdf_path:
- copy_files(
- pdf_file_path_in_output_folder,
- render_command_settings.pdf_path,
- )
-
- progress.finish_the_current_step()
-
- if not render_command_settings.dont_generate_png:
- progress.start_a_step("Rendering PNG files from the PDF")
-
- png_file_paths_in_output_folder = renderer.render_pngs_from_typst(
- typst_file_path_in_output_folder
- )
- if render_command_settings.png_path:
- copy_files(
- png_file_paths_in_output_folder,
- render_command_settings.png_path,
- )
-
- progress.finish_the_current_step()
-
- if not render_command_settings.dont_generate_markdown:
- progress.start_a_step("Generating the Markdown file")
-
- markdown_file_path_in_output_folder = renderer.create_a_markdown_file(
- data_model, output_directory
- )
- if render_command_settings.markdown_path:
- copy_files(
- markdown_file_path_in_output_folder,
- render_command_settings.markdown_path,
- )
-
- progress.finish_the_current_step()
-
- if not render_command_settings.dont_generate_html:
- progress.start_a_step(
- "Rendering the Markdown file to a HTML (for Grammarly)"
- )
-
- html_file_path_in_output_folder = renderer.render_an_html_from_markdown(
- markdown_file_path_in_output_folder
- )
- if render_command_settings.html_path:
- copy_files(
- html_file_path_in_output_folder,
- render_command_settings.html_path,
- )
-
- progress.finish_the_current_step()
-
-
-def run_a_function_if_a_file_changes(file_path: pathlib.Path, function: Callable):
- """Watch the file located at `file_path` and call the `function` when the file is
- modified. The function should not take any arguments.
-
- Args:
- file_path (pathlib.Path): The path of the file to watch for.
- function (Callable): The function to be called on file modification.
- """
- # Run the function immediately for the first time
- function()
-
- path_to_watch = str(file_path.absolute())
- if sys.platform == "win32":
- # Windows does not support single file watching, so we watch the directory
- path_to_watch = str(file_path.parent.absolute())
-
- class EventHandler(watchdog.events.FileSystemEventHandler):
- def __init__(self, function: Callable):
- super().__init__()
- self.function_to_call = function
-
- def on_modified(self, event: watchdog.events.FileModifiedEvent) -> None:
- if event.src_path != str(file_path.absolute()):
- return
-
- printer.information(
- "\n\nThe input file has been updated. Re-running RenderCV..."
- )
- with contextlib.suppress(Exception):
- # Exceptions in the watchdog event handler thread should not
- # crash the application. They are already handled by the
- # decorated function, but we add this defensive check to ensure
- # the watcher continues running even if an unexpected exception
- # occurs in a background thread.
- self.function_to_call()
-
- event_handler = EventHandler(function)
-
- observer = watchdog.observers.Observer()
- observer.schedule(event_handler, path_to_watch, recursive=True)
- observer.start()
- try:
- while True:
- time.sleep(1)
- except KeyboardInterrupt:
- observer.stop()
- observer.join()
-
-
-def read_and_construct_the_input(
- input_file_path: pathlib.Path,
- cli_render_arguments: dict[str, Any],
- extra_data_model_override_arguments: typer.Context | None = None,
-) -> dict:
- """Read RenderCV YAML files and CLI to construct the user's input as a dictionary.
- Input file is read, CLI arguments override the input file, and individual design,
- locale catalog, etc. files are read if they are provided.
-
- Args:
- input_file_path: The path of the input file.
- cli_render_arguments: The command line arguments of the `render` command.
- extra_data_model_override_arguments: The extra arguments context. Defaults to
- None.
-
- Returns:
- The input of the user as a dictionary.
- """
- input_file_as_a_dict = data.read_a_yaml_file(input_file_path)
-
- # Read individual `design`, `locale`, etc. files if they are provided in the
- # input file:
- for field in data.rendercv_data_model_fields:
- if field in cli_render_arguments and cli_render_arguments[field] is not None:
- yaml_path = pathlib.Path(cli_render_arguments[field]).absolute()
- yaml_file_as_a_dict = data.read_a_yaml_file(yaml_path)
- input_file_as_a_dict[field] = yaml_file_as_a_dict[field]
-
- # Update the input file if there are extra override arguments (for example,
- # --cv.phone "123-456-7890"):
- if extra_data_model_override_arguments:
- key_and_values = parse_render_command_override_arguments(
- extra_data_model_override_arguments
- )
- input_file_as_a_dict = set_or_update_values(
- input_file_as_a_dict, key_and_values
- )
-
- # If non-default CLI arguments are provided, override the
- # `rendercv_settings.render_command`:
- return update_render_command_settings_of_the_input_file(
- input_file_as_a_dict, cli_render_arguments
- )
diff --git a/src/rendercv/data/__init__.py b/src/rendercv/data/__init__.py
deleted file mode 100644
index 9fd82cca..00000000
--- a/src/rendercv/data/__init__.py
+++ /dev/null
@@ -1,92 +0,0 @@
-"""
-The `rendercv.data` package contains the necessary classes and functions for
-
-- Parsing and validating a YAML input file
-- Computing some properties based on a YAML input file (like converting ISO dates to
- plain English, URLs of social networks, etc.)
-- Generating a JSON Schema for RenderCV's data format
-- Generating a sample YAML input file
-
-The validators and data format of RenderCV are written using
-[Pydantic](https://github.com/pydantic/pydantic).
-"""
-
-from .generator import (
- create_a_sample_data_model,
- create_a_sample_yaml_input_file,
- generate_json_schema,
- generate_json_schema_file,
-)
-from .models import (
- BulletEntry,
- CurriculumVitae,
- EducationEntry,
- Entry,
- ExperienceEntry,
- Locale,
- NormalEntry,
- NumberedEntry,
- OneLineEntry,
- PublicationEntry,
- RenderCommandSettings,
- RenderCVDataModel,
- RenderCVSettings,
- ReversedNumberedEntry,
- SectionContents,
- SocialNetwork,
- available_entry_models,
- available_entry_type_names,
- available_social_networks,
- available_theme_options,
- available_themes,
- format_date,
- get_date_input,
- make_a_url_clean,
- make_keywords_bold_in_a_string,
- rendercv_data_model_fields,
-)
-from .reader import (
- get_error_message_and_location_and_value_from_a_custom_error,
- parse_validation_errors,
- read_a_yaml_file,
- read_input_file,
- validate_input_dictionary_and_return_the_data_model,
-)
-
-__all__ = [
- "BulletEntry",
- "CurriculumVitae",
- "EducationEntry",
- "Entry",
- "ExperienceEntry",
- "Locale",
- "NormalEntry",
- "NumberedEntry",
- "OneLineEntry",
- "PublicationEntry",
- "RenderCVDataModel",
- "RenderCVSettings",
- "RenderCommandSettings",
- "ReversedNumberedEntry",
- "SectionContents",
- "SocialNetwork",
- "available_entry_models",
- "available_entry_type_names",
- "available_social_networks",
- "available_theme_options",
- "available_themes",
- "create_a_sample_data_model",
- "create_a_sample_yaml_input_file",
- "format_date",
- "generate_json_schema",
- "generate_json_schema_file",
- "get_date_input",
- "get_error_message_and_location_and_value_from_a_custom_error",
- "make_a_url_clean",
- "make_keywords_bold_in_a_string",
- "parse_validation_errors",
- "read_a_yaml_file",
- "read_input_file",
- "rendercv_data_model_fields",
- "validate_input_dictionary_and_return_the_data_model",
-]
diff --git a/src/rendercv/data/generator.py b/src/rendercv/data/generator.py
deleted file mode 100644
index 7f56a611..00000000
--- a/src/rendercv/data/generator.py
+++ /dev/null
@@ -1,185 +0,0 @@
-"""
-The `rendercv.data.generator` module contains all the functions for generating the JSON
-Schema of the input data format and a sample YAML input file.
-"""
-
-import io
-import json
-import pathlib
-
-import pydantic
-import ruamel.yaml
-
-from .. import __version__
-from . import models, reader
-
-
-def dictionary_to_yaml(dictionary: dict) -> str:
- """Converts a dictionary to a YAML string.
-
- Args:
- dictionary: The dictionary to be converted to YAML.
-
- Returns:
- The YAML string.
- """
-
- # Source: https://gist.github.com/alertedsnake/c521bc485b3805aa3839aef29e39f376
- def str_representer(dumper, data):
- if len(data.splitlines()) > 1: # check for multiline string
- return dumper.represent_scalar("tag:yaml.org,2002:str", data, style="|")
- return dumper.represent_scalar("tag:yaml.org,2002:str", data)
-
- yaml_object = ruamel.yaml.YAML()
- yaml_object.encoding = "utf-8"
- yaml_object.width = 9999
- yaml_object.indent(mapping=2, sequence=4, offset=2)
- yaml_object.representer.add_representer(str, str_representer)
-
- with io.StringIO() as string_stream:
- yaml_object.dump(dictionary, string_stream)
- return string_stream.getvalue()
-
-
-def create_a_sample_data_model(
- name: str = "John Doe", theme: str = "classic"
-) -> models.RenderCVDataModel:
- """Return a sample data model for new users to start with.
-
- Args:
- name: The name of the person. Defaults to "John Doe".
-
- Returns:
- A sample data model.
- """
- # Check if the theme is valid:
- if theme not in models.available_theme_options:
- available_themes_string = ", ".join(models.available_theme_options.keys())
- message = (
- f"The theme should be one of the following: {available_themes_string}!"
- f' The provided theme is "{theme}".'
- )
- raise ValueError(message)
-
- # read the sample_content.yaml file
- sample_content = pathlib.Path(__file__).parent / "sample_content.yaml"
- sample_content_dictionary = reader.read_a_yaml_file(sample_content)
- cv = models.CurriculumVitae(**sample_content_dictionary)
-
- # Update the name:
- name = name.encode().decode("unicode-escape")
- cv.name = name
-
- design = models.available_theme_options[theme](theme=theme)
-
- return models.RenderCVDataModel(cv=cv, design=design)
-
-
-def create_a_sample_yaml_input_file(
- input_file_path: pathlib.Path | None = None,
- name: str = "John Doe",
- theme: str = "classic",
-) -> str:
- """Create a sample YAML input file and return it as a string. If the input file path
- is provided, then also save the contents to the file.
-
- Args:
- input_file_path: The path to save the input file. Defaults to None.
- name: The name of the person. Defaults to "John Doe".
- theme: The theme of the CV. Defaults to "classic".
-
- Returns:
- The sample YAML input file as a string.
- """
- data_model = create_a_sample_data_model(name=name, theme=theme)
-
- # Instead of getting the dictionary with data_model.model_dump() directly, we
- # convert it to JSON and then to a dictionary. Because the YAML library we are
- # using sometimes has problems with the dictionary returned by model_dump().
-
- # We exclude "cv.sections" because the data model automatically generates them.
- # The user's "cv.sections" input is actually "cv.sections_input" in the data
- # model. It is shown as "cv.sections" in the YAML file because an alias is being
- # used. If"cv.sections" were not excluded, the automatically generated
- # "cv.sections" would overwrite the "cv.sections_input". "cv.sections" are
- # automatically generated from "cv.sections_input" to make the templating
- # process easier. "cv.sections_input" exists for the convenience of the user.
- # Also, we don't want to show the cv.photo field in the Web app.
- data_model_as_json = data_model.model_dump_json(
- exclude_none=False,
- by_alias=True,
- exclude={
- "cv": {"sections", "photo"},
- "rendercv_settings": {"render_command"},
- },
- )
- data_model_as_dictionary = json.loads(data_model_as_json)
-
- yaml_string = dictionary_to_yaml(data_model_as_dictionary)
-
- # Add a comment to the first line, for JSON Schema:
- comment_to_add = (
- "# yaml-language-server:"
- f" $schema=https://raw.githubusercontent.com/rendercv/rendercv/refs/tags/v{__version__}/schema.json\n"
- )
- yaml_string = comment_to_add + yaml_string
-
- if input_file_path is not None:
- input_file_path.write_text(yaml_string, encoding="utf-8")
-
- return yaml_string
-
-
-def generate_json_schema() -> dict:
- """Generate the JSON schema of RenderCV.
-
- JSON schema is generated for the users to make it easier for them to write the input
- file. The JSON Schema of RenderCV is saved in the root directory of the repository
- and distributed to the users with the
- [JSON Schema Store](https://www.schemastore.org/).
-
- Returns:
- The JSON schema of RenderCV.
- """
-
- class RenderCVSchemaGenerator(pydantic.json_schema.GenerateJsonSchema):
- def generate(self, schema, mode="validation"): # type: ignore
- json_schema = super().generate(schema, mode=mode)
-
- # Basic information about the schema:
- json_schema["title"] = "RenderCV"
- json_schema["description"] = "RenderCV data model."
- json_schema["$id"] = (
- "https://raw.githubusercontent.com/rendercv/rendercv/main/schema.json"
- )
- json_schema["$schema"] = "http://json-schema.org/draft-07/schema#"
-
- # Loop through $defs and remove docstring descriptions and fix optional
- # fields
- for _, value in json_schema["$defs"].items():
- for _, field in value["properties"].items():
- if "anyOf" in field:
- field["oneOf"] = field["anyOf"]
- del field["anyOf"]
-
- if "description" in value and value["description"].startswith(
- "This class is"
- ):
- del value["description"]
-
- return json_schema
-
- return models.RenderCVDataModel.model_json_schema(
- schema_generator=RenderCVSchemaGenerator
- )
-
-
-def generate_json_schema_file(json_schema_path: pathlib.Path):
- """Generate the JSON schema of RenderCV and save it to a file.
-
- Args:
- json_schema_path: The path to save the JSON schema.
- """
- schema = generate_json_schema()
- schema_json = json.dumps(schema, indent=2, ensure_ascii=False)
- json_schema_path.write_text(schema_json, encoding="utf-8")
diff --git a/src/rendercv/data/models/__init__.py b/src/rendercv/data/models/__init__.py
deleted file mode 100644
index fae6724f..00000000
--- a/src/rendercv/data/models/__init__.py
+++ /dev/null
@@ -1,87 +0,0 @@
-"""
-The `rendercv.data.models` package contains all the Pydantic data models, validators,
-and computed fields that are used in RenderCV. The package is divided into several
-modules, each containing a different group of data models.
-
-- `base.py`: Contains `RenderCVBaseModel`, which is the parent class of all the data
- models in RenderCV.
-- `computers.py`: Contains all the functions that are used to compute some values of
- the fields in the data models. For example, converting ISO dates to human-readable
- dates.
-- `entry_types.py`: Contains all the data models that are used to represent the entries
- in the CV.
-- `curriculum_vitae.py`: Contains the `CurriculumVitae` data model, which is the main
- data model that contains all the content of the CV.
-- `design.py`: Contains the data model that is used to represent the design options of
- the CV.
-- `locale.py`: Contains the data model that is used to represent the locale
- catalog of the CV.
-- `rendercv_settings.py`: Contains the data model that is used to represent the settings
- of the RenderCV.
-- `rendercv_data_model.py`: Contains the `RenderCVDataModel` data model, which is the
- main data model that defines the whole input file structure.
-"""
-
-import warnings
-
-from .computers import format_date, get_date_input, make_a_url_clean
-from .curriculum_vitae import (
- CurriculumVitae,
- SectionContents,
- Sections,
- SocialNetwork,
- available_social_networks,
-)
-from .design import (
- available_theme_options,
- available_themes,
-)
-from .entry_types import (
- BulletEntry,
- EducationEntry,
- Entry,
- ExperienceEntry,
- NormalEntry,
- NumberedEntry,
- OneLineEntry,
- PublicationEntry,
- ReversedNumberedEntry,
- available_entry_models,
- available_entry_type_names,
- make_keywords_bold_in_a_string,
-)
-from .locale import Locale
-from .rendercv_data_model import RenderCVDataModel, rendercv_data_model_fields
-from .rendercv_settings import RenderCommandSettings, RenderCVSettings
-
-warnings.filterwarnings("ignore")
-
-__all__ = [
- "BulletEntry",
- "CurriculumVitae",
- "EducationEntry",
- "Entry",
- "ExperienceEntry",
- "Locale",
- "NormalEntry",
- "NumberedEntry",
- "OneLineEntry",
- "PublicationEntry",
- "RenderCVDataModel",
- "RenderCVSettings",
- "RenderCommandSettings",
- "ReversedNumberedEntry",
- "SectionContents",
- "Sections",
- "SocialNetwork",
- "available_entry_models",
- "available_entry_type_names",
- "available_social_networks",
- "available_theme_options",
- "available_themes",
- "format_date",
- "get_date_input",
- "make_a_url_clean",
- "make_keywords_bold_in_a_string",
- "rendercv_data_model_fields",
-]
diff --git a/src/rendercv/data/models/base.py b/src/rendercv/data/models/base.py
deleted file mode 100644
index f6043f5c..00000000
--- a/src/rendercv/data/models/base.py
+++ /dev/null
@@ -1,24 +0,0 @@
-"""
-The `rendercv.data.models.base` module contains the parent classes of all the data
-models in RenderCV.
-"""
-
-import pydantic
-
-
-class RenderCVBaseModelWithoutExtraKeys(pydantic.BaseModel):
- """This class is the parent class of the data models that do not allow extra keys.
- It has only one difference from the default `pydantic.BaseModel`: It raises an error
- if an unknown key is provided in the input file.
- """
-
- model_config = pydantic.ConfigDict(extra="forbid", validate_default=True)
-
-
-class RenderCVBaseModelWithExtraKeys(pydantic.BaseModel):
- """This class is the parent class of the data models that allow extra keys. It has
- only one difference from the default `pydantic.BaseModel`: It allows extra keys in
- the input file.
- """
-
- model_config = pydantic.ConfigDict(extra="allow", validate_default=True)
diff --git a/src/rendercv/data/models/computers.py b/src/rendercv/data/models/computers.py
deleted file mode 100644
index f9576411..00000000
--- a/src/rendercv/data/models/computers.py
+++ /dev/null
@@ -1,439 +0,0 @@
-"""
-The `rendercv.data.models.computers` module contains functions that compute some
-properties based on the input data. For example, it includes functions that calculate
-the time span between two dates, the date string, the URL of a social network, etc.
-"""
-
-import importlib
-import pathlib
-import re
-from datetime import date as Date
-
-import phonenumbers
-
-from .curriculum_vitae import curriculum_vitae
-from .locale import locale
-
-
-def format_phone_number(phone_number: str) -> str:
- """Format a phone number to the format specified in the `locale` dictionary.
-
- Example:
- ```python
- format_phone_number("+17034800500")
- ```
- returns
- ```python
- "(703) 480-0500"
- ```
-
- Args:
- phone_number: The phone number to format.
-
- Returns:
- The formatted phone number.
- """
-
- format = locale["phone_number_format"].upper() # type: ignore
-
- parsed_number = phonenumbers.parse(phone_number, None)
- return phonenumbers.format_number(
- parsed_number, getattr(phonenumbers.PhoneNumberFormat, format)
- )
-
-
-def get_date_input() -> Date:
- """Return the date input.
-
- Returns:
- The date input.
- """
- module = importlib.import_module(".rendercv_settings", __package__)
- return module.DATE_INPUT
-
-
-def format_date(date: Date, date_template: str | None = None) -> str:
- """Formats a `Date` object to a string in the following format: "Jan 2021". The
- month names are taken from the `locale` dictionary from the
- `rendercv.data_models.models` module.
-
- Example:
- ```python
- format_date(Date(2024, 5, 1))
- ```
- will return
-
- `"May 2024"`
-
- Args:
- date: The date to format.
- date_template: The template of the date string. If not provided, the default date
- style from the `locale` dictionary will be used.
-
- Returns:
- The formatted date.
- """
- full_month_names = locale["full_names_of_months"]
- short_month_names = locale["abbreviations_for_months"]
-
- month = int(date.strftime("%m"))
- year = date.strftime(format="%Y")
-
- placeholders = {
- "FULL_MONTH_NAME": full_month_names[month - 1],
- "MONTH_ABBREVIATION": short_month_names[month - 1],
- "MONTH_IN_TWO_DIGITS": f"{month:02d}",
- "YEAR_IN_TWO_DIGITS": str(year[-2:]),
- "MONTH": str(month),
- "YEAR": str(year),
- }
- if date_template is None:
- date_template = locale["date_template"] # type: ignore
-
- assert isinstance(date_template, str)
-
- for placeholder, value in placeholders.items():
- date_template = date_template.replace(placeholder, value) # type: ignore
-
- return date_template
-
-
-def replace_placeholders(value: str) -> str:
- """Replaces the placeholders in a string with the corresponding values."""
- name = curriculum_vitae.get("name", "None")
- full_month_names = locale["full_names_of_months"]
- short_month_names = locale["abbreviations_for_months"]
-
- date_input = get_date_input()
- month = date_input.month
- year = str(date_input.year)
-
- name_snake_case = name.replace(" ", "_")
- name_kebab_case = name.replace(" ", "-")
-
- placeholders = (
- ("NAME_IN_SNAKE_CASE", name_snake_case),
- ("NAME_IN_LOWER_SNAKE_CASE", name_snake_case.lower()),
- ("NAME_IN_UPPER_SNAKE_CASE", name_snake_case.upper()),
- ("NAME_IN_KEBAB_CASE", name_kebab_case),
- ("NAME_IN_LOWER_KEBAB_CASE", name_kebab_case.lower()),
- ("NAME_IN_UPPER_KEBAB_CASE", name_kebab_case.upper()),
- ("FULL_MONTH_NAME", full_month_names[month - 1]),
- ("MONTH_ABBREVIATION", short_month_names[month - 1]),
- ("MONTH_IN_TWO_DIGITS", f"{month:02d}"),
- ("YEAR_IN_TWO_DIGITS", year[-2:]),
- ("NAME", name),
- ("YEAR", year),
- ("MONTH", str(month)),
- )
-
- for placeholder, placeholder_value in placeholders:
- value = value.replace(placeholder, placeholder_value)
-
- return value
-
-
-def convert_string_to_path(value: str) -> pathlib.Path:
- """Converts a string to a `pathlib.Path` object by replacing the placeholders
- with the corresponding values. If the path is not an absolute path, it is
- converted to an absolute path by prepending the current working directory.
- """
- value = replace_placeholders(value)
-
- return pathlib.Path(value).absolute()
-
-
-def compute_time_span_string(
- start_date: str | int | None,
- end_date: str | int | None,
- date: str | int | None,
-) -> str:
- """
- Return a time span string based on the provided dates.
-
- Example:
- ```python
- get_time_span_string("2020-01-01", "2020-05-01", None)
- ```
-
- returns
-
- `"4 months"`
-
- Args:
- start_date: A start date in YYYY-MM-DD, YYYY-MM, or YYYY format.
- end_date: An end date in YYYY-MM-DD, YYYY-MM, or YYYY format or "present".
- date: A date in YYYY-MM-DD, YYYY-MM, or YYYY format or a custom string. If
- provided, start_date and end_date will be ignored.
-
- Returns:
- The computed time span string.
- """
- date_is_provided = date is not None
- start_date_is_provided = start_date is not None
- end_date_is_provided = end_date is not None
-
- if date_is_provided:
- # If only the date is provided, the time span is irrelevant. So, return an
- # empty string.
- return ""
-
- if not start_date_is_provided and not end_date_is_provided:
- # If neither start_date nor end_date is provided, return an empty string.
- return ""
-
- if isinstance(start_date, int) or isinstance(end_date, int):
- # Then it means one of the dates is year, so time span cannot be more
- # specific than years.
- start_year = get_date_object(start_date).year # type: ignore
- end_year = get_date_object(end_date).year # type: ignore
-
- time_span_in_years = end_year - start_year
-
- if time_span_in_years < 2:
- time_span_string = "1 year"
- else:
- time_span_string = f"{time_span_in_years} years"
-
- return time_span_string
-
- # Then it means both start_date and end_date are in YYYY-MM-DD or YYYY-MM
- # format.
- end_date = get_date_object(end_date) # type: ignore
- start_date = get_date_object(start_date) # type: ignore
-
- # Calculate the number of days between start_date and end_date:
- timespan_in_days = (end_date - start_date).days # type: ignore
-
- # Calculate the number of years and months between start_date and end_date:
- how_many_years = timespan_in_days // 365
- how_many_months = (timespan_in_days % 365) // 30 + 1
- # Deal with overflow (prevent rounding to 1 year 12 months, etc.)
- how_many_years += how_many_months // 12
- how_many_months %= 12
-
- # Format the number of years and months between start_date and end_date:
- if how_many_years == 0:
- how_many_years_string = None
- elif how_many_years == 1:
- how_many_years_string = f"1 {locale['year']}"
- else:
- how_many_years_string = f"{how_many_years} {locale['years']}"
-
- # Format the number of months between start_date and end_date:
- if how_many_months == 1 or (how_many_years_string is None and how_many_months == 0):
- how_many_months_string = f"1 {locale['month']}"
- elif how_many_months == 0:
- how_many_months_string = None
- else:
- how_many_months_string = f"{how_many_months} {locale['months']}"
-
- # Combine howManyYearsString and howManyMonthsString:
- if how_many_years_string is None and how_many_months_string is not None:
- time_span_string = how_many_months_string
- elif how_many_months_string is None and how_many_years_string is not None:
- time_span_string = how_many_years_string
- elif how_many_years_string is not None and how_many_months_string is not None:
- time_span_string = f"{how_many_years_string} {how_many_months_string}"
- else:
- message = "The time span is not valid!"
- raise ValueError(message)
-
- return time_span_string.strip()
-
-
-def compute_date_string(
- start_date: str | int | None,
- end_date: str | int | None,
- date: str | int | None,
- show_only_years: bool = False,
-) -> str:
- """Return a date string based on the provided dates.
-
- Example:
- ```python
- get_date_string("2020-01-01", "2021-01-01", None)
- ```
- returns
- ```
- "Jan 2020 to Jan 2021"
- ```
-
- Args:
- start_date: A start date in YYYY-MM-DD, YYYY-MM, or YYYY format.
- end_date: An end date in YYYY-MM-DD, YYYY-MM, or YYYY format or "present".
- date: A date in YYYY-MM-DD, YYYY-MM, or YYYY format or a custom string. If
- provided, start_date and end_date will be ignored.
- show_only_years: If True, only the years will be shown in the date string.
-
- Returns:
- The computed date string.
- """
- date_is_provided = date is not None
- start_date_is_provided = start_date is not None
- end_date_is_provided = end_date is not None
-
- if date_is_provided:
- if isinstance(date, int):
- # Then it means only the year is provided
- date_string = str(date)
- else:
- try:
- date_object = get_date_object(date)
- if show_only_years:
- date_string = str(date_object.year)
- else:
- date_string = format_date(date_object)
- except ValueError:
- # Then it is a custom date string (e.g., "My Custom Date")
- date_string = str(date)
- elif start_date_is_provided and end_date_is_provided:
- if isinstance(start_date, int):
- # Then it means only the year is provided
- start_date = str(start_date)
- else:
- # Then it means start_date is either in YYYY-MM-DD or YYYY-MM format
- date_object = get_date_object(start_date)
- if show_only_years:
- start_date = date_object.year
- else:
- start_date = format_date(date_object)
-
- if end_date == "present":
- end_date = locale["present"] # type: ignore
- elif isinstance(end_date, int):
- # Then it means only the year is provided
- end_date = str(end_date)
- else:
- # Then it means end_date is either in YYYY-MM-DD or YYYY-MM format
- date_object = get_date_object(end_date)
- end_date = date_object.year if show_only_years else format_date(date_object)
-
- date_string = f"{start_date} {locale['to']} {end_date}"
-
- else:
- # Neither date, start_date, nor end_date are provided, so return an empty
- # string:
- date_string = ""
-
- return date_string
-
-
-def make_a_url_clean(url: str) -> str:
- """Make a URL clean by removing the protocol, www, and trailing slashes.
-
- Example:
- ```python
- make_a_url_clean("https://www.example.com/")
- ```
- returns
- `"example.com"`
-
- Args:
- url: The URL to make clean.
-
- Returns:
- The clean URL.
- """
- url = url.replace("https://", "").replace("http://", "")
- if url.endswith("/"):
- url = url[:-1]
-
- return url
-
-
-def get_date_object(date: str | int) -> Date:
- """Parse a date string in YYYY-MM-DD, YYYY-MM, or YYYY format and return a
- `datetime.date` object. This function is used throughout the validation process of
- the data models.
-
- Args:
- date: The date string to parse.
-
- Returns:
- The parsed date.
- """
- if isinstance(date, int):
- date_object = Date.fromisoformat(f"{date}-01-01")
- elif re.fullmatch(r"\d{4}-\d{2}-\d{2}", date):
- # Then it is in YYYY-MM-DD format
- date_object = Date.fromisoformat(date)
- elif re.fullmatch(r"\d{4}-\d{2}", date):
- # Then it is in YYYY-MM format
- date_object = Date.fromisoformat(f"{date}-01")
- elif re.fullmatch(r"\d{4}", date):
- # Then it is in YYYY format
- date_object = Date.fromisoformat(f"{date}-01-01")
- elif date == "present":
- date_object = get_date_input()
- else:
- message = (
- "This is not a valid date! Please use either YYYY-MM-DD, YYYY-MM, or"
- " YYYY format."
- )
- raise ValueError(message)
-
- return date_object
-
-
-def dictionary_key_to_proper_section_title(key: str) -> str:
- """Convert a dictionary key to a proper section title.
-
- Example:
- ```python
- dictionary_key_to_proper_section_title("section_title")
- ```
- returns
- `"Section Title"`
-
- Args:
- key: The key to convert to a proper section title.
-
- Returns:
- The proper section title.
- """
- title = key.replace("_", " ")
- words = title.split(" ")
-
- words_not_capitalized_in_a_title = [
- "a",
- "and",
- "as",
- "at",
- "but",
- "by",
- "for",
- "from",
- "if",
- "in",
- "into",
- "like",
- "near",
- "nor",
- "of",
- "off",
- "on",
- "onto",
- "or",
- "over",
- "so",
- "than",
- "that",
- "to",
- "upon",
- "when",
- "with",
- "yet",
- ]
-
- # loop through the words and if the word doesn't contain any uppercase letters,
- # capitalize the first letter of the word. If the word contains uppercase letters,
- # don't change the word.
- return " ".join(
- (
- word.capitalize()
- if (word.islower() and word not in words_not_capitalized_in_a_title)
- else word
- )
- for word in words
- )
diff --git a/src/rendercv/data/models/curriculum_vitae.py b/src/rendercv/data/models/curriculum_vitae.py
deleted file mode 100644
index 91514043..00000000
--- a/src/rendercv/data/models/curriculum_vitae.py
+++ /dev/null
@@ -1,699 +0,0 @@
-"""
-The `rendercv.data.models.curriculum_vitae` module contains the data model of the `cv`
-field of the input file.
-"""
-
-import functools
-import importlib
-import pathlib
-import re
-from typing import Annotated, Any, Literal, get_args
-
-import pydantic
-import pydantic_extra_types.phone_numbers as pydantic_phone_numbers
-
-from . import computers, entry_types
-from .base import RenderCVBaseModelWithExtraKeys, RenderCVBaseModelWithoutExtraKeys
-
-# ======================================================================================
-# Create validator functions: ==========================================================
-# ======================================================================================
-
-
-class SectionBase(RenderCVBaseModelWithoutExtraKeys):
- """This class is the parent class of all the section types. It is being used
- in RenderCV internally, and it is not meant to be used directly by the users.
- It is used by `rendercv.data_models.utilities.create_a_section_model` function to
- create a section model based on any entry type.
- """
-
- title: str
- entry_type: str
- entries: list[Any]
-
-
-# Create a URL validator:
-url_validator = pydantic.TypeAdapter(pydantic.HttpUrl)
-
-
-def validate_url(url: str) -> str:
- """Validate a URL.
-
- Args:
- url: The URL to validate.
-
- Returns:
- The validated URL.
- """
- url_validator.validate_strings(url)
- return url
-
-
-def create_a_section_validator(entry_type: type) -> type[SectionBase]:
- """Create a section model based on the entry type. See [Pydantic's documentation
- about dynamic model
- creation](https://pydantic-docs.helpmanual.io/usage/models/#dynamic-model-creation)
- for more information.
-
- The section model is used to validate a section.
-
- Args:
- entry_type: The entry type to create the section model. It's not an instance of
- the entry type, but the entry type itself.
-
- Returns:
- The section validator (a Pydantic model).
- """
- if entry_type is str:
- model_name = "SectionWithTextEntries"
- entry_type_name = "TextEntry"
- else:
- model_name = "SectionWith" + entry_type.__name__.replace("Entry", "Entries")
- entry_type_name = entry_type.__name__
-
- return pydantic.create_model(
- model_name,
- entry_type=(Literal[entry_type_name], ...), # type: ignore
- entries=(list[entry_type], ...),
- __base__=SectionBase,
- )
-
-
-def get_characteristic_entry_attributes(
- entry_types: tuple[type],
-) -> dict[type, set[str]]:
- """Get the characteristic attributes of the entry types.
-
- Args:
- entry_types: The entry types to get their characteristic attributes. These are
- not instances of the entry types, but the entry types themselves. `str` type
- should not be included in this list.
-
- Returns:
- The characteristic attributes of the entry types.
- """
- # Look at all the entry types, collect their attributes with
- # EntryType.model_fields.keys() and find the common ones.
- all_attributes = []
- for EntryType in entry_types:
- all_attributes.extend(EntryType.model_fields.keys())
-
- common_attributes = {
- attribute for attribute in all_attributes if all_attributes.count(attribute) > 1
- }
-
- # Store each entry type's characteristic attributes in a dictionary:
- characteristic_entry_attributes = {}
- for EntryType in entry_types:
- characteristic_entry_attributes[EntryType] = (
- set(EntryType.model_fields.keys()) - common_attributes
- )
-
- return characteristic_entry_attributes
-
-
-def get_entry_type_name_and_section_validator(
- entry: dict[str, str | list[str]] | str | type | None, entry_types: tuple[type]
-) -> tuple[str, type[SectionBase]]:
- """Get the entry type name and the section validator based on the entry.
-
- It takes an entry (as a dictionary or a string) and a list of entry types. Then
- it determines the entry type and creates a section validator based on the entry
- type.
-
- Args:
- entry: The entry to determine its type.
- entry_types: The entry types to determine the entry type. These are not
- instances of the entry types, but the entry types themselves. `str` type
- should not be included in this list.
-
- Returns:
- The entry type name and the section validator.
- """
-
- if isinstance(entry, dict):
- entry_type_name = None # the entry type is not determined yet
- characteristic_entry_attributes = get_characteristic_entry_attributes(
- entry_types
- )
-
- for (
- EntryType,
- characteristic_attributes,
- ) in characteristic_entry_attributes.items():
- # If at least one of the characteristic_entry_attributes is in the entry,
- # then it means the entry is of this type:
- if characteristic_attributes & set(entry.keys()):
- entry_type_name = EntryType.__name__
- section_type = create_a_section_validator(EntryType)
- break
-
- if entry_type_name is None:
- message = "The entry is not provided correctly."
- raise ValueError(message)
-
- elif isinstance(entry, str):
- # Then it is a TextEntry
- entry_type_name = "TextEntry"
- section_type = create_a_section_validator(str)
-
- elif entry is None:
- message = "The entry cannot be a null value."
- raise ValueError(message)
-
- else:
- # Then the entry is already initialized with a data model:
- entry_type_name = entry.__class__.__name__
- section_type = create_a_section_validator(entry.__class__)
-
- return entry_type_name, section_type # type: ignore
-
-
-def validate_a_section(
- sections_input: list[Any], entry_types: tuple[type]
-) -> list[entry_types.Entry]:
- """Validate a list of entries (a section) based on the entry types.
-
- Sections input is a list of entries. Since there are multiple entry types, it is not
- possible to validate it directly. Firstly, the entry type is determined with the
- `get_entry_type_name_and_section_validator` function. If the entry type cannot be
- determined, an error is raised. If the entry type is determined, the rest of the
- list is validated with the section validator.
-
- Args:
- sections_input: The sections input to validate.
- entry_types: The entry types to determine the entry type. These are not
- instances of the entry types, but the entry types themselves. `str` type
- should not be included in this list.
-
- Returns:
- The validated sections input.
- """
- if isinstance(sections_input, list):
- # Find the entry type based on the first identifiable entry:
- entry_type_name = None
- section_type = None
- for entry in sections_input:
- try:
- entry_type_name, section_type = (
- get_entry_type_name_and_section_validator(entry, entry_types)
- )
- break
- except ValueError:
- # If the entry type cannot be determined, try the next entry:
- pass
-
- if entry_type_name is None or section_type is None:
- message = (
- "RenderCV couldn't match this section with any entry types! Please"
- " check the entries and make sure they are provided correctly."
- )
- raise ValueError(
- message,
- "", # This is the location of the error
- "", # This is value of the error
- )
-
- section = {
- "title": "Test Section",
- "entry_type": entry_type_name,
- "entries": sections_input,
- }
-
- try:
- section_object = section_type.model_validate(
- section,
- )
- sections_input = section_object.entries
- except pydantic.ValidationError as e:
- new_error = ValueError(
- "There are problems with the entries. RenderCV detected the entry type"
- f" of this section to be {entry_type_name}! The problems are shown"
- " below.",
- "", # This is the location of the error
- "", # This is value of the error
- )
- raise new_error from e
-
- else:
- message = (
- "Each section should be a list of entries! Please see the documentation for"
- " more information about the sections."
- )
- raise ValueError(message)
- return sections_input
-
-
-def validate_a_social_network_username(username: str, network: str) -> str:
- """Check if the `username` field in the `SocialNetwork` model is provided correctly.
-
- Args:
- username: The username to validate.
-
- Returns:
- The validated username.
- """
- if network == "Mastodon":
- mastodon_username_pattern = r"@[^@]+@[^@]+"
- if not re.fullmatch(mastodon_username_pattern, username):
- message = 'Mastodon username should be in the format "@username@domain"!'
- raise ValueError(message)
- elif network == "StackOverflow":
- stackoverflow_username_pattern = r"\d+\/[^\/]+"
- if not re.fullmatch(stackoverflow_username_pattern, username):
- message = (
- 'StackOverflow username should be in the format "user_id/username"!'
- )
- raise ValueError(message)
- elif network == "YouTube":
- if username.startswith("@"):
- message = (
- 'YouTube username should not start with "@"! Remove "@" from the'
- " beginning of the username."
- )
- raise ValueError(message)
- elif network == "ORCID":
- orcid_username_pattern = r"\d{4}-\d{4}-\d{4}-\d{3}[\dX]"
- if not re.fullmatch(orcid_username_pattern, username):
- message = "ORCID username should be in the format 'XXXX-XXXX-XXXX-XXX'!"
- raise ValueError(message)
- elif network == "IMDB":
- imdb_username_pattern = r"nm\d{7}"
- if not re.fullmatch(imdb_username_pattern, username):
- message = "IMDB name should be in the format 'nmXXXXXXX'!"
- raise ValueError(message)
-
- return username
-
-
-# ======================================================================================
-# Create custom types: =================================================================
-# ======================================================================================
-
-# Create a custom type named SectionContents, which is a list of entries. The entries
-# can be any of the available entry types. The section is validated with the
-# `validate_a_section` function.
-SectionContents = Annotated[
- pydantic.json_schema.SkipJsonSchema[Any] | entry_types.ListOfEntries,
- pydantic.BeforeValidator(
- lambda entries: validate_a_section(
- entries, entry_types=entry_types.available_entry_models
- )
- ),
-]
-
-# Create a custom type named SectionInput, which is a dictionary where the keys are the
-# section titles and the values are the list of entries in that section.
-Sections = dict[str, SectionContents] | None
-
-# Create a custom type named SocialNetworkName, which is a literal type of the available
-# social networks.
-SocialNetworkName = Literal[
- "LinkedIn",
- "GitHub",
- "GitLab",
- "IMDB",
- "Instagram",
- "ORCID",
- "Mastodon",
- "StackOverflow",
- "ResearchGate",
- "YouTube",
- "Google Scholar",
- "Telegram",
- "Leetcode",
- "X",
-]
-
-available_social_networks = get_args(SocialNetworkName)
-
-# ======================================================================================
-# Create the models: ===================================================================
-# ======================================================================================
-
-
-class SocialNetwork(RenderCVBaseModelWithoutExtraKeys):
- """This class is the data model of a social network."""
-
- model_config = pydantic.ConfigDict(
- title="Social Network",
- )
- network: SocialNetworkName = pydantic.Field(
- title="Social Network",
- )
- username: str = pydantic.Field(
- title="Username",
- description=(
- "The username used in the social network. The link will be generated"
- " automatically."
- ),
- )
-
- @pydantic.field_validator("username")
- @classmethod
- def check_username(cls, username: str, info: pydantic.ValidationInfo) -> str:
- """Check if the username is provided correctly."""
- if "network" not in info.data:
- # the network is either not provided or not one of the available social
- # networks. In this case, don't check the username, since Pydantic will
- # raise an error for the network.
- return username
-
- network = info.data["network"]
-
- return validate_a_social_network_username(username, network)
-
- @pydantic.model_validator(mode="after") # type: ignore
- def check_url(self) -> "SocialNetwork":
- """Validate the URL of the social network."""
- if self.network == "Mastodon":
- # All the other social networks have valid URLs. Mastodon URLs contain both
- # the username and the domain. So, we need to validate if the url is valid.
- validate_url(self.url)
-
- return self
-
- @functools.cached_property
- def url(self) -> str:
- """Return the URL of the social network and cache `url` as an attribute of the
- instance.
- """
- if self.network == "Mastodon":
- # Split domain and username
- _, username, domain = self.username.split("@")
- url = f"https://{domain}/@{username}"
- else:
- url_dictionary = {
- "LinkedIn": "https://linkedin.com/in/",
- "GitHub": "https://github.com/",
- "GitLab": "https://gitlab.com/",
- "IMDB": "https://imdb.com/name/",
- "Instagram": "https://instagram.com/",
- "ORCID": "https://orcid.org/",
- "StackOverflow": "https://stackoverflow.com/users/",
- "ResearchGate": "https://researchgate.net/profile/",
- "YouTube": "https://youtube.com/@",
- "Google Scholar": "https://scholar.google.com/citations?user=",
- "Telegram": "https://t.me/",
- "Leetcode": "https://leetcode.com/u/",
- "X": "https://x.com/",
- }
- url = url_dictionary[self.network] + self.username
-
- return url
-
-
-class CurriculumVitae(RenderCVBaseModelWithExtraKeys):
- """This class is the data model of the `cv` field."""
-
- # ---------------------------------------------------------------------
- # Private attributes
- # ---------------------------------------------------------------------
-
- # Store the order of the keys in the YAML `cv` mapping so that the header
- # connections can be rendered in the same order that the user defines.
- _yaml_key_order: list[str] = pydantic.PrivateAttr(default_factory=list)
-
- # ---------------------------------------------------------------------
- # Model Validators
- # ---------------------------------------------------------------------
-
- @pydantic.model_validator(mode="before")
- @classmethod
- def _capture_yaml_key_order(cls, data: dict[str, Any]): # type: ignore[override]
- """Capture the order of the keys in the YAML *before* validation.
-
- Pydantic gives us the raw input mapping during the *before* validation
- stage. At this point the order of the keys is still exactly how the
- user wrote them in the YAML file (ruamel keeps the insertion order).
- We copy that order into a dedicated key so that it becomes available
- after validation. The copied list is then assigned to a private
- attribute in an *after* validator.
- """
-
- # The input can be a `CommentedMap` which keeps insertion order. We
- # convert to `dict` just in case but still preserve the order.
- if isinstance(data, dict):
- data["__yaml_key_order__"] = list(data.keys())
-
- return data
-
- @pydantic.model_validator(mode="after") # type: ignore[override]
- def _populate_yaml_key_order(self):
- """Populate the private attribute that stores the YAML key order."""
-
- # `__yaml_key_order__` lives in the *extra* values (`__pydantic_extra__`)
- # because it is not a declared field. Pop it if present.
- extra: dict[str, Any] | None = getattr(self, "__pydantic_extra__", None)
-
- if extra and "__yaml_key_order__" in extra:
- self._yaml_key_order = extra.pop("__yaml_key_order__") # type: ignore[assignment]
-
- return self
-
- model_config = pydantic.ConfigDict(
- title="CV",
- )
- name: str | None = pydantic.Field(
- default=None,
- title="Name",
- )
- location: str | None = pydantic.Field(
- default=None,
- title="Location",
- )
- email: pydantic.EmailStr | None = pydantic.Field(
- default=None,
- title="Email",
- )
- photo: pathlib.Path | None = pydantic.Field(
- default=None,
- title="Photo",
- description="Path to the photo of the person, relative to the input file.",
- )
- phone: pydantic_phone_numbers.PhoneNumber | None = pydantic.Field(
- default=None,
- title="Phone",
- description=(
- "Country code should be included. For example, +1 for the United States."
- ),
- )
- website: pydantic.HttpUrl | None = pydantic.Field(
- default=None,
- title="Website",
- )
- social_networks: list[SocialNetwork] | None = pydantic.Field(
- default=None,
- title="Social Networks",
- )
- sections_input: Sections = pydantic.Field(
- default=None,
- title="Sections",
- description="The sections of the CV, like Education, Experience, etc.",
- # This is an alias to allow users to use `sections` in the YAML file:
- # `sections` key is preserved for RenderCV's internal use.
- alias="sections",
- )
- sort_entries: Literal["reverse-chronological", "chronological", "none"] = "none"
-
- @pydantic.field_validator("photo")
- @classmethod
- def update_photo_path(cls, value: pathlib.Path | None) -> pathlib.Path | None:
- """Cast `photo` to Path and make the path absolute"""
- if value:
- module = importlib.import_module(".rendercv_data_model", __package__)
- INPUT_FILE_DIRECTORY = module.INPUT_FILE_DIRECTORY
-
- if INPUT_FILE_DIRECTORY is not None:
- profile_picture_parent_folder = INPUT_FILE_DIRECTORY
- else:
- profile_picture_parent_folder = pathlib.Path.cwd()
-
- return profile_picture_parent_folder / str(value)
-
- return value
-
- @pydantic.field_validator("name")
- @classmethod
- def update_curriculum_vitae(cls, value: str, info: pydantic.ValidationInfo) -> str:
- """Update the `curriculum_vitae` dictionary."""
- if value:
- curriculum_vitae[info.field_name] = value # type: ignore
-
- return value
-
- @functools.cached_property
- def connections(self) -> list[dict[str, str | None]]:
- """Return all the connections of the person as a list of dictionaries and cache
- `connections` as an attribute of the instance. The connections are used in the
- header of the CV.
-
- Returns:
- The connections of the person.
- """
- # Helper functions to create each connection dictionary -----------------
-
- def _location_connection():
- return {
- "typst_icon": "location-dot",
- "url": None,
- "clean_url": None,
- "placeholder": self.location,
- }
-
- def _email_connection():
- return {
- "typst_icon": "envelope",
- "url": f"mailto:{self.email}",
- "clean_url": self.email,
- "placeholder": self.email,
- }
-
- def _phone_connection():
- phone_placeholder = computers.format_phone_number(self.phone) # type: ignore
- return {
- "typst_icon": "phone",
- "url": self.phone,
- "clean_url": phone_placeholder,
- "placeholder": phone_placeholder,
- }
-
- def _website_connection():
- website_placeholder = computers.make_a_url_clean(str(self.website))
- return {
- "typst_icon": "link",
- "url": str(self.website),
- "clean_url": website_placeholder,
- "placeholder": website_placeholder,
- }
-
- def _social_networks_connections():
- icon_dictionary = {
- "LinkedIn": "linkedin",
- "GitHub": "github",
- "GitLab": "gitlab",
- "IMDB": "imdb",
- "Instagram": "instagram",
- "Mastodon": "mastodon",
- "ORCID": "orcid",
- "StackOverflow": "stack-overflow",
- "ResearchGate": "researchgate",
- "YouTube": "youtube",
- "Google Scholar": "graduation-cap",
- "Telegram": "telegram",
- "Leetcode": "code",
- "X": "x-twitter",
- }
-
- connections_list: list[dict[str, str | None]] = []
- if self.social_networks is None:
- return connections_list
-
- for social_network in self.social_networks:
- clean_url = computers.make_a_url_clean(social_network.url)
- connection = {
- "typst_icon": icon_dictionary[social_network.network],
- "url": social_network.url,
- "clean_url": clean_url,
- "placeholder": social_network.username,
- }
-
- if social_network.network == "StackOverflow":
- username = social_network.username.split("/")[1]
- connection["placeholder"] = username
- if social_network.network == "Google Scholar":
- connection["placeholder"] = "Google Scholar"
- if social_network.network == "IMDB":
- connection["placeholder"] = "IMDB Profile"
-
- connections_list.append(connection) # type: ignore[arg-type]
-
- return connections_list
-
- # ------------------------------------------------------------------
- # Build the connections list in the exact order of the YAML keys
- # ------------------------------------------------------------------
-
- key_to_handler = {
- "location": (self.location is not None, _location_connection),
- "email": (self.email is not None, _email_connection),
- "phone": (self.phone is not None, _phone_connection),
- "website": (self.website is not None, _website_connection),
- "social_networks": (self.social_networks is not None, _social_networks_connections),
- }
-
- connections: list[dict[str, str | None]] = []
-
- # Prefer the order captured from the YAML file. If, for any reason, it was
- # not captured, fall back to the traditional fixed ordering used before so
- # that existing behaviour remains unchanged.
- if self._yaml_key_order:
- ordered_keys = [key for key in self._yaml_key_order if key in key_to_handler]
- else:
- ordered_keys = list(key_to_handler.keys())
-
- for key in ordered_keys:
- present, handler = key_to_handler[key]
- if not present:
- continue
- if key == "social_networks":
- connections.extend(handler()) # type: ignore
- else:
- connections.append(handler())
-
- return connections
-
- @functools.cached_property
- def sections(self) -> list[SectionBase]:
- """Compute the sections of the CV based on the input sections.
-
- The original `sections` input is a dictionary where the keys are the section titles
- and the values are the list of entries in that section. This function converts the
- input sections to a list of `SectionBase` objects. This makes it easier to work with
- the sections in the rest of the code.
-
- Returns:
- The computed sections.
- """
- sections: list[SectionBase] = []
-
- if self.sections_input is not None:
- for title, entries in self.sections_input.items():
- formatted_title = computers.dictionary_key_to_proper_section_title(
- title
- )
-
- # The first entry can be used because all the entries in the section are
- # already validated with the `validate_a_section` function:
- entry_type_name, _ = get_entry_type_name_and_section_validator(
- entries[0], # type: ignore
- entry_types=entry_types.available_entry_models,
- )
-
- sort_order = self.sort_entries
- sorted_entries = entry_types.sort_entries_by_date(entries, sort_order)
-
- # SectionBase is used so that entries are not validated again:
- section = SectionBase(
- title=formatted_title,
- entry_type=entry_type_name,
- entries=sorted_entries,
- )
- sections.append(section)
-
- return sections
-
- @pydantic.field_serializer("phone")
- def serialize_phone(
- self, phone: pydantic_phone_numbers.PhoneNumber | None
- ) -> str | None:
- """Serialize the phone number."""
- if phone is not None:
- return phone.replace("tel:", "")
-
- return phone
-
-
-# The dictionary below will be overwritten by CurriculumVitae class, which will contain
-# some important data for the CV.
-curriculum_vitae: dict[str, str] = {}
diff --git a/src/rendercv/data/models/design.py b/src/rendercv/data/models/design.py
deleted file mode 100644
index 58a6983b..00000000
--- a/src/rendercv/data/models/design.py
+++ /dev/null
@@ -1,212 +0,0 @@
-"""
-The `rendercv.data.models.design` module contains the data model of the `design` field
-of the input file.
-"""
-
-import importlib
-import importlib.util
-import os
-import pathlib
-from typing import Annotated, Any
-
-import pydantic
-
-from ...themes import (
- ClassicThemeOptions,
- EngineeringclassicThemeOptions,
- EngineeringresumesThemeOptions,
- ModerncvThemeOptions,
- Sb2novThemeOptions,
-)
-from . import entry_types
-from .base import RenderCVBaseModelWithoutExtraKeys
-
-# ======================================================================================
-# Create validator functions: ==========================================================
-# ======================================================================================
-
-
-def validate_design_options(
- design: Any,
- available_theme_options: dict[str, type],
- available_entry_type_names: list[str],
-) -> Any:
- """Check if the design options are for a built-in theme or a custom theme. If it is
- a built-in theme, validate it with the corresponding data model. If it is a custom
- theme, check if the necessary files are provided and validate it with the custom
- theme data model, found in the `__init__.py` file of the custom theme folder.
-
- Args:
- design: The design options to validate.
- available_theme_options: The available theme options. The keys are the theme
- names and the values are the corresponding data models.
- available_entry_type_names: The available entry type names. These are used to
- validate if all the templates are provided in the custom theme folder.
-
- Returns:
- The validated design as a Pydantic data model.
- """
- module = importlib.import_module(".rendercv_data_model", __package__)
- INPUT_FILE_DIRECTORY = module.INPUT_FILE_DIRECTORY
-
- original_working_directory = pathlib.Path.cwd()
-
- # Change the working directory to the input file directory:
-
- if isinstance(design, tuple(available_theme_options.values())):
- # Then it means it is an already validated built-in theme. Return it as it is:
- return design
- if design["theme"] in available_theme_options:
- # Then it is a built-in theme, but it is not validated yet. Validate it and
- # return it:
- ThemeDataModel = available_theme_options[design["theme"]]
- return ThemeDataModel(**design)
- # It is a custom theme. Validate it:
- theme_name: str = str(design["theme"])
-
- # Custom theme should only contain letters and digits:
- if not theme_name.isalnum():
- message = "The custom theme name should only contain letters and digits."
- raise ValueError(
- message,
- "theme", # this is the location of the error
- theme_name, # this is value of the error
- )
-
- if INPUT_FILE_DIRECTORY is None:
- theme_parent_folder = pathlib.Path.cwd()
- else:
- theme_parent_folder = INPUT_FILE_DIRECTORY
-
- custom_theme_folder = theme_parent_folder / theme_name
-
- # Check if the custom theme folder exists:
- if not custom_theme_folder.exists():
- message = (
- (
- f"The custom theme folder `{custom_theme_folder}` does not exist."
- " It should be in the working directory as the input file."
- ),
- )
- raise ValueError(
- message,
- "", # this is the location of the error
- theme_name, # this is value of the error
- )
-
- # check if all the necessary files are provided in the custom theme folder:
- required_entry_files = [
- custom_theme_folder / (entry_type_name + ".j2.typ")
- for entry_type_name in available_entry_type_names
- ]
- required_files = [
- custom_theme_folder / "SectionBeginning.j2.typ", # section beginning template
- custom_theme_folder / "SectionEnding.j2.typ", # section ending template
- custom_theme_folder / "Preamble.j2.typ", # preamble template
- custom_theme_folder / "Header.j2.typ", # header template
- *required_entry_files,
- ]
-
- for file in required_files:
- if not file.exists():
- message = (
- f"You provided a custom theme, but the file `{file}` is not"
- f" found in the folder `{custom_theme_folder}`."
- )
- raise ValueError(
- message,
- "", # This is the location of the error
- theme_name, # This is value of the error
- )
-
- # Import __init__.py file from the custom theme folder if it exists:
- path_to_init_file = custom_theme_folder / "__init__.py"
-
- if path_to_init_file.exists():
- spec = importlib.util.spec_from_file_location(
- "theme",
- path_to_init_file,
- )
-
- theme_module = importlib.util.module_from_spec(spec) # type: ignore
- try:
- spec.loader.exec_module(theme_module) # type: ignore
- except SyntaxError as e:
- message = (
- f"The custom theme {theme_name}'s __init__.py file has a syntax"
- " error. Please fix it."
- )
- raise ValueError(message) from e
- except ImportError as e:
- message = (
- (
- f"The custom theme {theme_name}'s __init__.py file has an"
- " import error. If you have copy-pasted RenderCV's built-in"
- " themes, make sure to update the import statements (e.g.,"
- ' "from . import" to "from rendercv.themes import").'
- ),
- )
-
- raise ValueError(message) from e
-
- ThemeDataModel = getattr(
- theme_module,
- f"{theme_name.capitalize()}ThemeOptions", # type: ignore
- )
-
- # Initialize and validate the custom theme data model:
- theme_data_model = ThemeDataModel(**design)
- else:
- # Then it means there is no __init__.py file in the custom theme folder.
- # Create a dummy data model and use that instead.
- class ThemeOptionsAreNotProvided(RenderCVBaseModelWithoutExtraKeys):
- theme: str = theme_name
-
- theme_data_model = ThemeOptionsAreNotProvided(theme=theme_name)
-
- os.chdir(original_working_directory)
-
- return theme_data_model
-
-
-# ======================================================================================
-# Create custom types: =================================================================
-# ======================================================================================
-
-available_theme_options = {
- "classic": ClassicThemeOptions,
- "sb2nov": Sb2novThemeOptions,
- "engineeringresumes": EngineeringresumesThemeOptions,
- "engineeringclassic": EngineeringclassicThemeOptions,
- "moderncv": ModerncvThemeOptions,
-}
-
-available_themes = list(available_theme_options.keys())
-
-# Create a custom type named RenderCVBuiltinDesign:
-# It is a union of all the design options and the correct design option is determined by
-# the theme field, thanks to Pydantic's discriminator feature.
-# See https://docs.pydantic.dev/2.7/concepts/fields/#discriminator for more information
-RenderCVBuiltinDesign = Annotated[
- ClassicThemeOptions
- | Sb2novThemeOptions
- | EngineeringresumesThemeOptions
- | EngineeringclassicThemeOptions
- | ModerncvThemeOptions,
- pydantic.Field(discriminator="theme"),
-]
-
-# Create a custom type named RenderCVDesign:
-# RenderCV supports custom themes as well. Therefore, `Any` type is used to allow custom
-# themes. However, the JSON Schema generation is skipped, otherwise, the JSON Schema
-# would accept any `design` field in the YAML input file.
-RenderCVDesign = Annotated[
- pydantic.json_schema.SkipJsonSchema[Any] | RenderCVBuiltinDesign,
- pydantic.BeforeValidator(
- lambda design: validate_design_options(
- design,
- available_theme_options=available_theme_options,
- available_entry_type_names=entry_types.available_entry_type_names, # type: ignore
- )
- ),
-]
diff --git a/src/rendercv/data/models/entry_types.py b/src/rendercv/data/models/entry_types.py
deleted file mode 100644
index f56f3b67..00000000
--- a/src/rendercv/data/models/entry_types.py
+++ /dev/null
@@ -1,710 +0,0 @@
-"""
-The `rendercv.models.data.entry_types` module contains the data models of all the available
-entry types in RenderCV.
-"""
-
-import abc
-import functools
-import re
-from datetime import date as Date
-from typing import Annotated, Literal
-
-import pydantic
-
-from . import computers
-from .base import RenderCVBaseModelWithExtraKeys
-
-# ======================================================================================
-# Create validator functions: ==========================================================
-# ======================================================================================
-
-
-def validate_date_field(date: int | str | None) -> int | str | None:
- """Check if the `date` field is provided correctly.
-
- Args:
- date: The date to validate.
-
- Returns:
- The validated date.
- """
- date_is_provided = date is not None
-
- if date_is_provided:
- if isinstance(date, str):
- if re.fullmatch(r"\d{4}-\d{2}(-\d{2})?", date):
- # Then it is in YYYY-MM-DD or YYYY-MMY format
- # Check if it is a valid date:
- computers.get_date_object(date)
- elif re.fullmatch(r"\d{4}", date):
- # Then it is in YYYY format, so, convert it to an integer:
-
- # This is not required for start_date and end_date because they
- # can't be casted into a general string. For date, this needs to
- # be done manually, because it can be a general string.
- date = int(date)
-
- elif isinstance(date, Date):
- # Pydantic parses YYYY-MM-DD dates as datetime.date objects. We need to
- # convert them to strings because that is how RenderCV uses them.
- date = date.isoformat()
-
- return date
-
-
-def validate_start_and_end_date_fields(
- date: str | Date,
-) -> str:
- """Check if the `start_date` and `end_date` fields are provided correctly.
-
- Args:
- date: The date to validate.
-
- Returns:
- The validated date.
- """
- date_is_provided = date is not None
-
- if date_is_provided:
- if isinstance(date, Date):
- # Pydantic parses YYYY-MM-DD dates as datetime.date objects. We need to
- # convert them to strings because that is how RenderCV uses them.
- date = date.isoformat()
-
- elif date != "present":
- # Validate the date:
- computers.get_date_object(date)
-
- return date
-
-
-# See https://peps.python.org/pep-0484/#forward-references for more information about
-# the quotes around the type hints.
-def validate_and_adjust_dates_for_an_entry(
- start_date: "StartDate",
- end_date: "EndDate",
- date: "ArbitraryDate",
-) -> tuple["StartDate", "EndDate", "ArbitraryDate"]:
- """Check if the dates are provided correctly and make the necessary adjustments.
-
- Args:
- start_date: The start date of the event.
- end_date: The end date of the event.
- date: The date of the event.
-
- Returns:
- The validated and adjusted `start_date`, `end_date`, and `date`.
- """
- date_is_provided = date is not None
- start_date_is_provided = start_date is not None
- end_date_is_provided = end_date is not None
-
- if date_is_provided:
- # If only date is provided, ignore start_date and end_date:
- start_date = None
- end_date = None
- elif not start_date_is_provided and end_date_is_provided:
- # If only end_date is provided, assume it is a one-day event and act like
- # only the date is provided:
- date = end_date
- start_date = None
- end_date = None
- elif start_date_is_provided:
- start_date_object = computers.get_date_object(start_date)
- if not end_date_is_provided:
- # If only start_date is provided, assume it is an ongoing event, i.e.,
- # the end_date is present:
- end_date = "present"
-
- if end_date != "present":
- end_date_object = computers.get_date_object(end_date)
-
- if start_date_object > end_date_object:
- message = '"start_date" can not be after "end_date"!'
-
- raise ValueError(
- message,
- "start_date", # This is the location of the error
- str(start_date), # This is value of the error
- )
-
- return start_date, end_date, date
-
-
-# ======================================================================================
-# Create custom types: =================================================================
-# ======================================================================================
-
-
-# See https://docs.pydantic.dev/2.7/concepts/types/#custom-types and
-# https://docs.pydantic.dev/2.7/concepts/validators/#annotated-validators
-# for more information about custom types.
-
-# ExactDate that accepts only strings in YYYY-MM-DD or YYYY-MM format:
-ExactDate = Annotated[
- str,
- pydantic.Field(
- pattern=r"\d{4}-\d{2}(-\d{2})?",
- ),
-]
-
-# ArbitraryDate that accepts either an integer or a string, but it is validated with
-# `validate_date_field` function:
-ArbitraryDate = Annotated[
- int | str | None,
- pydantic.BeforeValidator(validate_date_field),
-]
-
-# StartDate that accepts either an integer or an ExactDate, but it is validated with
-# `validate_start_and_end_date_fields` function:
-StartDate = Annotated[
- int | ExactDate | None,
- pydantic.BeforeValidator(validate_start_and_end_date_fields),
-]
-
-# EndDate that accepts either an integer, the string "present", or an ExactDate, but it
-# is validated with `validate_start_and_end_date_fields` function:
-EndDate = Annotated[
- Literal["present"] | int | ExactDate | None,
- pydantic.BeforeValidator(validate_start_and_end_date_fields),
-]
-
-# ======================================================================================
-# Create the entry models: =============================================================
-# ======================================================================================
-
-
-class EntryType(abc.ABC):
- """This class is an abstract class that defines all the methods an entry type should
- have."""
-
- @abc.abstractmethod
- def make_keywords_bold(self, keywords: list[str]) -> "EntryType": ...
-
-
-def make_keywords_bold_in_a_string(string: str, keywords: list[str]) -> str:
- """Make the given keywords bold in the given string, handling capitalization and substring issues.
-
- Examples:
- >>> make_keywords_bold_in_a_string("I know java and javascript", ["java"])
- 'I know **java** and javascript'
-
- >>> make_keywords_bold_in_a_string("Experience with aws, Aws and AWS", ["aws"])
- 'Experience with **aws**, **Aws** and **AWS**'
- """
-
- def bold_match(match):
- return f"**{match.group(0)}**"
-
- for keyword in keywords:
- # Use re.escape to ensure special characters in keywords are handled
- pattern = r"\b" + re.escape(keyword) + r"\b"
- string = re.sub(pattern, bold_match, string, flags=re.IGNORECASE)
-
- return string
-
-
-class OneLineEntry(RenderCVBaseModelWithExtraKeys, EntryType):
- """This class is the data model of `OneLineEntry`."""
-
- model_config = pydantic.ConfigDict(title="One Line Entry")
- label: str = pydantic.Field(
- title="Label",
- )
- details: str = pydantic.Field(
- title="Details",
- )
-
- def make_keywords_bold(self, keywords: list[str]) -> "OneLineEntry":
- """Make the given keywords bold in the `details` field.
-
- Args:
- keywords: The keywords to make bold.
-
- Returns:
- A OneLineEntry with the keywords made bold in the `details` field.
- """
- self.details = make_keywords_bold_in_a_string(self.details, keywords)
- return self
-
-
-class BulletEntry(RenderCVBaseModelWithExtraKeys, EntryType):
- """This class is the data model of `BulletEntry`."""
-
- model_config = pydantic.ConfigDict(title="Bullet Entry")
- bullet: str = pydantic.Field(
- title="Bullet",
- )
-
- def make_keywords_bold(self, keywords: list[str]) -> "BulletEntry":
- """Make the given keywords bold in the `bullet` field.
-
- Args:
- keywords: The keywords to make bold.
-
- Returns:
- A BulletEntry with the keywords made bold in the `bullet` field.
- """
- self.bullet = make_keywords_bold_in_a_string(self.bullet, keywords)
- return self
-
-
-class NumberedEntry(RenderCVBaseModelWithExtraKeys, EntryType):
- """This class is the data model of `NumberedEntry`."""
-
- model_config = pydantic.ConfigDict(title="Numbered Entry")
-
- number: str = pydantic.Field(
- title="Number",
- )
-
- def make_keywords_bold(self, keywords: list[str]) -> "NumberedEntry":
- """Make the given keywords bold in the `number` field.
-
- Args:
- keywords: The keywords to make bold.
-
- Returns:
- A NumberedEntry with the keywords made bold in the `number` field.
- """
- self.number = make_keywords_bold_in_a_string(str(self.number), keywords)
- return self
-
-
-class ReversedNumberedEntry(RenderCVBaseModelWithExtraKeys, EntryType):
- """This class is the data model of `ReversedNumberedEntry`."""
-
- model_config = pydantic.ConfigDict(title="Reversed Numbered Entry")
- reversed_number: str = pydantic.Field(
- title="Reversed Number",
- )
-
- def make_keywords_bold(self, keywords: list[str]) -> "ReversedNumberedEntry":
- """Make the given keywords bold in the `reversed_number` field.
-
- Args:
- keywords: The keywords to make bold.
-
- Returns:
- A ReversedNumberedEntry with the keywords made bold in the `reversed_number` field.
- """
- self.reversed_number = make_keywords_bold_in_a_string(
- str(self.reversed_number), keywords
- )
- return self
-
-
-class EntryWithDate(RenderCVBaseModelWithExtraKeys):
- """This class is the parent class of some of the entry types that have date
- fields.
- """
-
- date: ArbitraryDate = pydantic.Field(
- default=None,
- title="Date",
- description=(
- "The date can be written in the formats YYYY-MM-DD, YYYY-MM, or YYYY, or as"
- ' an arbitrary string such as "Fall 2023."'
- ),
- examples=["2020-09-24", "Fall 2023"],
- )
-
- @functools.cached_property
- def date_string(self) -> str:
- """Return a date string based on the `date` field and cache `date_string` as
- an attribute of the instance.
- """
- return computers.compute_date_string(
- start_date=None, end_date=None, date=self.date
- )
-
-
-class PublicationEntryBase(RenderCVBaseModelWithExtraKeys):
- """This class is the parent class of the `PublicationEntry` class."""
-
- title: str = pydantic.Field(
- title="Publication Title",
- )
- authors: list[str] = pydantic.Field(
- title="Authors",
- )
- doi: Annotated[str, pydantic.Field(pattern=r"\b10\..*")] | None = pydantic.Field(
- default=None,
- title="DOI",
- examples=["10.48550/arXiv.2310.03138"],
- )
- url: pydantic.HttpUrl | None = pydantic.Field(
- default=None,
- title="URL",
- description="If DOI is provided, it will be ignored.",
- )
- journal: str | None = pydantic.Field(
- default=None,
- title="Journal",
- )
-
- @pydantic.model_validator(mode="after") # type: ignore
- def ignore_url_if_doi_is_given(self) -> "PublicationEntryBase":
- """Check if DOI is provided and ignore the URL if it is provided."""
- doi_is_provided = self.doi is not None
-
- if doi_is_provided:
- self.url = None
-
- return self
-
- @functools.cached_property
- def doi_url(self) -> str:
- """Return the URL of the DOI and cache `doi_url` as an attribute of the
- instance.
- """
- doi_is_provided = self.doi is not None
-
- if doi_is_provided:
- return f"https://doi.org/{self.doi}"
- return ""
-
- @functools.cached_property
- def clean_url(self) -> str:
- """Return the clean URL of the publication and cache `clean_url` as an attribute
- of the instance.
- """
- url_is_provided = self.url is not None
-
- if url_is_provided:
- return computers.make_a_url_clean(str(self.url)) # type: ignore
- return ""
-
- def make_keywords_bold(
- self,
- keywords: list[str], # NOQA: ARG002
- ) -> "PublicationEntryBase":
- return self
-
-
-# The following class is to ensure PublicationEntryBase keys come first,
-# then the keys of the EntryWithDate class. The only way to achieve this in Pydantic is
-# to do this. The same thing is done for the other classes as well.
-class PublicationEntry(EntryWithDate, PublicationEntryBase, EntryType):
- """This class is the data model of `PublicationEntry`. `PublicationEntry` class is
- created by combining the `EntryWithDate` and `PublicationEntryBase` classes to have
- the fields in the correct order.
- """
-
- model_config = pydantic.ConfigDict(title="Publication Entry")
-
-
-class EntryBase(EntryWithDate):
- """This class is the parent class of some of the entry types. It is being used
- because some of the entry types have common fields like dates, highlights, location,
- etc.
- """
-
- start_date: StartDate = pydantic.Field(
- default=None,
- title="Start Date",
- description=(
- "The event's start date, written in YYYY-MM-DD, YYYY-MM, or YYYY format."
- ),
- examples=["2020-09-24"],
- )
- end_date: EndDate = pydantic.Field(
- default=None,
- title="End Date",
- description=(
- "The event's end date, written in YYYY-MM-DD, YYYY-MM, or YYYY format. If"
- " the event is ongoing, type “present” or provide only the start date."
- ),
- examples=["2020-09-24", "present"],
- )
- location: str | None = pydantic.Field(
- default=None,
- title="Location",
- examples=["Istanbul, Türkiye"],
- )
- summary: str | None = pydantic.Field(
- default=None,
- title="Summary",
- examples=["Did this and that."],
- )
- highlights: list[str] | None = pydantic.Field(
- default=None,
- title="Highlights",
- examples=["Did this.", "Did that."],
- )
-
- @pydantic.field_validator("highlights", mode="after")
- @classmethod
- def handle_nested_bullets_in_highlights(
- cls, highlights: list[str] | None
- ) -> list[str] | None:
- """Handle nested bullets in the `highlights` field."""
- if highlights:
- return [highlight.replace(" - ", "\n - ") for highlight in highlights]
-
- return highlights
-
- @pydantic.model_validator(mode="after") # type: ignore
- def check_and_adjust_dates(self) -> "EntryBase":
- """Call the `validate_adjust_dates_of_an_entry` function to validate the
- dates.
- """
- self.start_date, self.end_date, self.date = (
- validate_and_adjust_dates_for_an_entry(
- start_date=self.start_date, end_date=self.end_date, date=self.date
- )
- )
- return self
-
- @functools.cached_property
- def date_string(self) -> str:
- """Return a date string based on the `date`, `start_date`, and `end_date` fields
- and cache `date_string` as an attribute of the instance.
-
- Example:
- ```python
- entry = dm.EntryBase(
- start_date="2020-10-11", end_date="2021-04-04"
- ).date_string
- ```
- returns
- `"Nov 2020 to Apr 2021"`
- """
- return computers.compute_date_string(
- start_date=self.start_date, end_date=self.end_date, date=self.date
- )
-
- @functools.cached_property
- def date_string_only_years(self) -> str:
- """Return a date string that only contains years based on the `date`,
- `start_date`, and `end_date` fields and cache `date_string_only_years` as an
- attribute of the instance.
-
- Example:
- ```python
- entry = dm.EntryBase(
- start_date="2020-10-11", end_date="2021-04-04"
- ).date_string_only_years
- ```
- returns
- `"2020 to 2021"`
- """
- return computers.compute_date_string(
- start_date=self.start_date,
- end_date=self.end_date,
- date=self.date,
- show_only_years=True,
- )
-
- @functools.cached_property
- def time_span_string(self) -> str:
- """Return a time span string based on the `date`, `start_date`, and `end_date`
- fields and cache `time_span_string` as an attribute of the instance.
- """
- return computers.compute_time_span_string(
- start_date=self.start_date, end_date=self.end_date, date=self.date
- )
-
- def make_keywords_bold(self, keywords: list[str]) -> "EntryBase":
- """Make the given keywords bold in the `summary` and `highlights` fields.
-
- Args:
- keywords: The keywords to make bold.
-
- Returns:
- An EntryBase with the keywords made bold in the `summary` and `highlights`
- fields.
- """
- if self.summary:
- self.summary = make_keywords_bold_in_a_string(self.summary, keywords)
-
- if self.highlights:
- self.highlights = [
- make_keywords_bold_in_a_string(highlight, keywords)
- for highlight in self.highlights
- ]
-
- return self
-
-
-class NormalEntryBase(RenderCVBaseModelWithExtraKeys):
- """This class is the parent class of the `NormalEntry` class."""
-
- name: str = pydantic.Field(
- title="Name",
- )
-
-
-class NormalEntry(EntryBase, NormalEntryBase, EntryType):
- """This class is the data model of `NormalEntry`. `NormalEntry` class is created by
- combining the `EntryBase` and `NormalEntryBase` classes to have the fields in the
- correct order.
- """
-
- model_config = pydantic.ConfigDict(title="Normal Entry")
-
-
-class ExperienceEntryBase(RenderCVBaseModelWithExtraKeys):
- """This class is the parent class of the `ExperienceEntry` class."""
-
- company: str = pydantic.Field(
- title="Company",
- )
- position: str = pydantic.Field(
- title="Position",
- )
-
-
-class ExperienceEntry(EntryBase, ExperienceEntryBase, EntryType):
- """This class is the data model of `ExperienceEntry`. `ExperienceEntry` class is
- created by combining the `EntryBase` and `ExperienceEntryBase` classes to have the
- fields in the correct order.
- """
-
- model_config = pydantic.ConfigDict(title="Experience Entry")
-
-
-class EducationEntryBase(RenderCVBaseModelWithExtraKeys):
- """This class is the parent class of the `EducationEntry` class."""
-
- institution: str = pydantic.Field(
- title="Institution",
- )
- area: str = pydantic.Field(
- title="Area",
- )
- degree: str | None = pydantic.Field(
- default=None,
- title="Degree",
- description="The type of the degree, such as BS, BA, PhD, MS.",
- examples=["BS", "BA", "PhD", "MS"],
- )
- grade: str | None = pydantic.Field(
- default=None,
- title="Grade",
- examples=["GPA: 3.00/4.00"],
- )
-
-
-class EducationEntry(EntryBase, EducationEntryBase, EntryType):
- """This class is the data model of `EducationEntry`. `EducationEntry` class is
- created by combining the `EntryBase` and `EducationEntryBase` classes to have the
- fields in the correct order.
- """
-
- model_config = pydantic.ConfigDict(title="Education Entry")
-
-
-# ======================================================================================
-# Create custom types based on the entry models: =======================================
-# ======================================================================================
-# Create a custom type named Entry:
-Entry = (
- OneLineEntry
- | NormalEntry
- | ExperienceEntry
- | EducationEntry
- | PublicationEntry
- | BulletEntry
- | NumberedEntry
- | ReversedNumberedEntry
- | str
-)
-
-# Create a custom type named ListOfEntries:
-ListOfEntries = (
- list[OneLineEntry]
- | list[NormalEntry]
- | list[ExperienceEntry]
- | list[EducationEntry]
- | list[PublicationEntry]
- | list[BulletEntry]
- | list[NumberedEntry]
- | list[ReversedNumberedEntry]
- | list[str]
-)
-
-# ======================================================================================
-# Store the available entry types: =====================================================
-# ======================================================================================
-# Entry.__args__[:-1] is a tuple of all the entry types except `str``:
-# `str` (TextEntry) is not included because it's validation handled differently. It is
-# not a Pydantic model, but a string.
-available_entry_models: tuple[type[Entry]] = tuple(Entry.__args__[:-1])
-
-available_entry_type_names = tuple(
- [entry_type.__name__ for entry_type in available_entry_models] + ["TextEntry"]
-)
-
-
-def compute_dates_for_sorting(
- start_date: StartDate,
- end_date: EndDate,
- date: ArbitraryDate,
-) -> tuple[Date | None, Date | None]:
- """Return end and start dates for sorting based on entry date fields."""
-
- start_date, end_date, date = validate_and_adjust_dates_for_an_entry(
- start_date=start_date, end_date=end_date, date=date
- )
-
- # If only ``date`` is provided, use it for both end and start dates
- if date is not None:
- try:
- date_obj = computers.get_date_object(date)
- return date_obj, date_obj
- except ValueError:
- return None, None
-
- end_date_obj: Date | None = None
- if end_date is not None:
- try:
- end_date_obj = computers.get_date_object(end_date)
- except ValueError:
- end_date_obj = None
-
- start_date_obj: Date | None = None
- if start_date is not None:
- try:
- start_date_obj = computers.get_date_object(start_date)
- except ValueError:
- start_date_obj = None
-
- return end_date_obj, start_date_obj
-
-
-def sort_entries_by_date(entries: list[Entry], order: str) -> list[Entry]:
- """Sort the given entries based on the provided order."""
-
- if order not in {"reverse-chronological", "chronological"}:
- return entries
-
- processed: list[tuple[Entry, Date | None, Date | None]] = []
- for entry in entries:
- if isinstance(entry, str):
- processed.append((entry, None, None))
- else:
- start = getattr(entry, "start_date", None)
- end = getattr(entry, "end_date", None)
- d = getattr(entry, "date", None)
- end_obj, start_obj = compute_dates_for_sorting(
- start_date=start,
- end_date=end,
- date=d,
- )
- processed.append((entry, end_obj, start_obj))
-
- reverse = order == "reverse-chronological"
- default_end = Date.min if reverse else Date.max
- default_start = Date.min if reverse else Date.max
-
- def key(item: tuple[Entry, Date | None, Date | None]):
- _entry, end_obj, start_obj = item
- return (
- end_obj or default_end,
- start_obj or default_start,
- )
-
- processed.sort(key=key, reverse=reverse)
-
- return [item[0] for item in processed]
diff --git a/src/rendercv/data/models/locale.py b/src/rendercv/data/models/locale.py
deleted file mode 100644
index ba6b1f0e..00000000
--- a/src/rendercv/data/models/locale.py
+++ /dev/null
@@ -1,176 +0,0 @@
-"""
-The `rendercv.models.locale` module contains the data model of the
-`locale` field of the input file.
-"""
-
-from typing import Annotated, Literal
-
-import annotated_types as at
-import pydantic
-import pydantic_extra_types.language_code
-
-from .base import RenderCVBaseModelWithoutExtraKeys
-
-
-class Locale(RenderCVBaseModelWithoutExtraKeys):
- """This class is the data model of the locale catalog. The values of each field
- updates the `locale` dictionary.
- """
-
- model_config = pydantic.ConfigDict(title="Locale")
-
- language: pydantic_extra_types.language_code.LanguageAlpha2 = pydantic.Field(
- default="en", # type: ignore
- title="Language",
- description=(
- "The language as an ISO 639 alpha-2 code. It is used for hyphenation"
- " patterns. The default value is 'en'."
- ),
- )
- phone_number_format: Literal["national", "international", "E164"] | None = (
- pydantic.Field(
- default="national",
- title="Phone Number Format",
- description=(
- "If 'national', phone numbers are formatted without the country code."
- " If 'international', phone numbers are formatted with the country"
- " code. The default value is 'national'."
- ),
- )
- )
- page_numbering_template: str = pydantic.Field(
- default="NAME - Page PAGE_NUMBER of TOTAL_PAGES",
- title="Page Numbering Template",
- description=(
- "The template of the page numbering. The following placeholders can be"
- " used:\n- NAME: The name of the person\n- PAGE_NUMBER: The current page"
- " number\n- TOTAL_PAGES: The total number of pages\n- TODAY: Today's date"
- ' with `locale.date_template`\nThe default value is "NAME -'
- ' Page PAGE_NUMBER of TOTAL_PAGES".'
- ),
- )
- last_updated_date_template: str = pydantic.Field(
- default="Last updated in TODAY",
- title="Last Updated Date Template",
- description=(
- "The template of the last updated date. The following placeholders can be"
- " used:\n- TODAY: Today's date with `locale.date_template`\nThe"
- ' default value is "Last updated in TODAY".'
- ),
- )
- date_template: str | None = pydantic.Field(
- default="MONTH_ABBREVIATION YEAR",
- title="Date Template",
- description=(
- "The template of the date. The following placeholders can be"
- " used:\n-FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION:"
- " Abbreviation of the month\n- MONTH: Month as a number\n-"
- " MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a"
- " number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\nThe"
- ' default value is "MONTH_ABBREVIATION YEAR".'
- ),
- )
- month: str | None = pydantic.Field(
- default="month",
- title='Translation of "month"',
- description='Translation of the word "month" in the locale.',
- )
- months: str | None = pydantic.Field(
- default="months",
- title='Translation of "months"',
- description='Translation of the word "months" in the locale.',
- )
- year: str | None = pydantic.Field(
- default="year",
- title='Translation of "year"',
- description='Translation of the word "year" in the locale.',
- )
- years: str | None = pydantic.Field(
- default="years",
- title='Translation of "years"',
- description='Translation of the word "years" in the locale.',
- )
- present: str | None = pydantic.Field(
- default="present",
- title='Translation of "present"',
- description='Translation of the word "present" in the locale.',
- )
- to: str | None = pydantic.Field(
- default="–", # NOQA: RUF001
- title='Translation of "to"',
- description=(
- "The word or character used to indicate a range in the locale (e.g.,"
- ' "2020 - 2021").'
- ),
- )
- abbreviations_for_months: (
- Annotated[list[str], at.Len(min_length=12, max_length=12)] | None
- ) = pydantic.Field(
- # Month abbreviations are taken from
- # https://web.library.yale.edu/cataloging/months:
- default=[
- "Jan",
- "Feb",
- "Mar",
- "Apr",
- "May",
- "June",
- "July",
- "Aug",
- "Sept",
- "Oct",
- "Nov",
- "Dec",
- ],
- title="Abbreviations of Months",
- description="Abbreviations of the months in the locale.",
- )
- full_names_of_months: (
- Annotated[list[str], at.Len(min_length=12, max_length=12)] | None
- ) = pydantic.Field(
- default=[
- "January",
- "February",
- "March",
- "April",
- "May",
- "June",
- "July",
- "August",
- "September",
- "October",
- "November",
- "December",
- ],
- title="Full Names of Months",
- description="Full names of the months in the locale.",
- )
-
- @pydantic.field_validator(
- "month",
- "months",
- "year",
- "years",
- "present",
- "abbreviations_for_months",
- "to",
- "full_names_of_months",
- "phone_number_format",
- "date_template",
- )
- @classmethod
- def update_locale(cls, value: str, info: pydantic.ValidationInfo) -> str:
- """Update the `locale` dictionary."""
- if value:
- locale[info.field_name] = value # type: ignore
-
- return value
-
-
-# The dictionary below will be overwritten by Locale class, which will contain
-# month names, month abbreviations, and other locale-specific strings.
-locale: dict[str, str | list[str]] = {}
-
-# Initialize even if the RenderCVDataModel is not called (to make `format_date` function
-# work on its own):
-Locale()
diff --git a/src/rendercv/data/models/rendercv_data_model.py b/src/rendercv/data/models/rendercv_data_model.py
deleted file mode 100644
index 75f56443..00000000
--- a/src/rendercv/data/models/rendercv_data_model.py
+++ /dev/null
@@ -1,86 +0,0 @@
-"""
-The `rendercv.data.models.rendercv_data_model` module contains the `RenderCVDataModel`
-data model, which is the main data model that defines the whole input file structure.
-"""
-
-import pathlib
-
-import pydantic
-
-from ...themes import ClassicThemeOptions
-from .base import RenderCVBaseModelWithoutExtraKeys
-from .curriculum_vitae import CurriculumVitae
-from .design import RenderCVDesign
-from .locale import Locale
-from .rendercv_settings import RenderCVSettings
-
-INPUT_FILE_DIRECTORY: pathlib.Path | None = None
-
-
-class RenderCVDataModel(RenderCVBaseModelWithoutExtraKeys):
- """This class binds both the CV and the design information together."""
-
- # `cv` is normally required, but don't enforce it in JSON Schema to allow
- # `design` or `locale` fields to have individual YAML files.
- model_config = pydantic.ConfigDict(json_schema_extra={"required": []})
- cv: CurriculumVitae = pydantic.Field(
- title="CV",
- description="The content of the CV.",
- )
- design: RenderCVDesign = pydantic.Field(
- default=ClassicThemeOptions(theme="classic"),
- title="Design",
- description=(
- "The design information of the CV. The default is the `classic` theme."
- ),
- )
- locale: Locale = pydantic.Field(
- default=None, # type: ignore
- title="Locale Catalog",
- description=(
- "The locale catalog of the CV to allow the support of multiple languages."
- ),
- )
- rendercv_settings: RenderCVSettings = pydantic.Field(
- default=RenderCVSettings(),
- title="RenderCV Settings",
- description="The settings of the RenderCV.",
- )
-
- @pydantic.model_validator(mode="before")
- @classmethod
- def update_paths(
- cls, model, info: pydantic.ValidationInfo
- ) -> RenderCVSettings | None:
- """Update the paths in the RenderCV settings."""
- global INPUT_FILE_DIRECTORY # NOQA: PLW0603
-
- context = info.context
- if context:
- input_file_directory = context.get("input_file_directory", None)
- INPUT_FILE_DIRECTORY = input_file_directory
- else:
- INPUT_FILE_DIRECTORY = None
-
- return model
-
- @pydantic.field_validator("locale", mode="before")
- @classmethod
- def update_locale(cls, value) -> Locale:
- """Update the output folder name in the RenderCV settings."""
- # Somehow, we need this for `test_if_local_catalog_resets` to pass.
- if value is None:
- return Locale()
-
- return value
-
- @pydantic.model_validator(mode="after") # type: ignore
- def apply_sort_entries(self) -> "RenderCVDataModel":
- """Propagate sort order from settings to the CV."""
-
- self.cv.sort_entries = self.rendercv_settings.sort_entries
-
- return self
-
-
-rendercv_data_model_fields = tuple(RenderCVDataModel.model_fields.keys())
diff --git a/src/rendercv/data/models/rendercv_settings.py b/src/rendercv/data/models/rendercv_settings.py
deleted file mode 100644
index 89ed7c6c..00000000
--- a/src/rendercv/data/models/rendercv_settings.py
+++ /dev/null
@@ -1,255 +0,0 @@
-"""
-The `rendercv.models.rendercv_settings` module contains the data model of the
-`rendercv_settings` field of the input file.
-"""
-
-import datetime
-import pathlib
-from typing import Literal
-
-import pydantic
-
-from . import computers
-from .base import RenderCVBaseModelWithoutExtraKeys
-
-file_path_placeholder_description = (
- "The following placeholders can be used:\n- FULL_MONTH_NAME: Full name of the"
- " month\n- MONTH_ABBREVIATION: Abbreviation of the month\n- MONTH: Month as a"
- " number\n- MONTH_IN_TWO_DIGITS: Month as a number in two digits\n- YEAR: Year as a"
- " number\n- YEAR_IN_TWO_DIGITS: Year as a number in two digits\n- NAME: The name of"
- " the CV owner\n- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case\n-"
- " NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case\n-"
- " NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case\n-"
- " NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case\n-"
- " NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case\n-"
- " NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case\n-"
- " FULL_MONTH_NAME: Full name of the month\n- MONTH_ABBREVIATION: Abbreviation of"
- " the month\n- MONTH: Month as a number\n- MONTH_IN_TWO_DIGITS: Month as a number"
- " in two digits\n- YEAR: Year as a number\n- YEAR_IN_TWO_DIGITS: Year as a number"
- ' in two digits\nThe default value is "MONTH_ABBREVIATION YEAR".\nThe default value'
- " is null."
-)
-
-file_path_placeholder_description_without_default = (
- file_path_placeholder_description.replace("\nThe default value is null.", "")
-)
-
-DATE_INPUT = datetime.date.today()
-
-
-class RenderCommandSettings(RenderCVBaseModelWithoutExtraKeys):
- """This class is the data model of the `render` command's settings."""
-
- design: pathlib.Path | None = pydantic.Field(
- default=None,
- title="`design` Field's YAML File",
- description=(
- "The file path to the yaml file containing the `design` field separately."
- ),
- )
-
- rendercv_settings: pathlib.Path | None = pydantic.Field(
- default=None,
- title="`rendercv_settings` Field's YAML File",
- description=(
- "The file path to the yaml file containing the `rendercv_settings` field"
- " separately."
- ),
- )
-
- locale: pathlib.Path | None = pydantic.Field(
- default=None,
- title="`locale` Field's YAML File",
- description=(
- "The file path to the yaml file containing the `locale` field separately."
- ),
- )
-
- output_folder_name: str = pydantic.Field(
- default="rendercv_output",
- title="Output Folder Name",
- description=(
- "The name of the folder where the output files will be saved."
- f" {file_path_placeholder_description_without_default}\nThe default value"
- ' is "rendercv_output".'
- ),
- )
-
- pdf_path: pathlib.Path | None = pydantic.Field(
- default=None,
- title="PDF Path",
- description=(
- "The path to copy the PDF file to. If it is not provided, the PDF file will"
- f" not be copied. {file_path_placeholder_description}"
- ),
- )
-
- typst_path: pathlib.Path | None = pydantic.Field(
- default=None,
- title="Typst Path",
- description=(
- "The path to copy the Typst file to. If it is not provided, the Typst file"
- f" will not be copied. {file_path_placeholder_description}"
- ),
- )
-
- html_path: pathlib.Path | None = pydantic.Field(
- default=None,
- title="HTML Path",
- description=(
- "The path to copy the HTML file to. If it is not provided, the HTML file"
- f" will not be copied. {file_path_placeholder_description}"
- ),
- )
-
- png_path: pathlib.Path | None = pydantic.Field(
- default=None,
- title="PNG Path",
- description=(
- "The path to copy the PNG file to. If it is not provided, the PNG file will"
- f" not be copied. {file_path_placeholder_description}"
- ),
- )
-
- markdown_path: pathlib.Path | None = pydantic.Field(
- default=None,
- title="Markdown Path",
- description=(
- "The path to copy the Markdown file to. If it is not provided, the Markdown"
- f" file will not be copied. {file_path_placeholder_description}"
- ),
- )
-
- dont_generate_html: bool = pydantic.Field(
- default=False,
- title="Don't Generate HTML",
- description=(
- "A boolean value to determine whether the HTML file will be generated. The"
- " default value is False."
- ),
- )
-
- dont_generate_markdown: bool = pydantic.Field(
- default=False,
- title="Don't Generate Markdown",
- description=(
- "A boolean value to determine whether the Markdown file will be generated."
- ' The default value is "false".'
- ),
- )
-
- dont_generate_pdf: bool = pydantic.Field(
- default=False,
- title="Don't Generate PDF",
- description=(
- "A boolean value to determine whether the PDF file will be generated. The"
- " default value is False."
- ),
- )
-
- dont_generate_png: bool = pydantic.Field(
- default=False,
- title="Don't Generate PNG",
- description=(
- "A boolean value to determine whether the PNG file will be generated. The"
- " default value is False."
- ),
- )
-
- watch: bool = pydantic.Field(
- default=False,
- title="Re-run RenderCV When the Input File is Updated",
- description=(
- "A boolean value to determine whether to re-run RenderCV when the input"
- 'file is updated. The default value is "false".'
- ),
- )
-
- @pydantic.field_validator(
- "output_folder_name",
- mode="before",
- )
- @classmethod
- def replace_placeholders(cls, value: str) -> str:
- """Replaces the placeholders in a string with the corresponding values."""
- return computers.replace_placeholders(value)
-
- @pydantic.field_validator(
- "design",
- "locale",
- "rendercv_settings",
- "pdf_path",
- "typst_path",
- "html_path",
- "png_path",
- "markdown_path",
- mode="before",
- )
- @classmethod
- def convert_string_to_path(cls, value: str | None) -> pathlib.Path | None:
- """Converts a string to a `pathlib.Path` object by replacing the placeholders
- with the corresponding values. If the path is not an absolute path, it is
- converted to an absolute path by prepending the current working directory.
- """
- if value is None:
- return None
-
- return computers.convert_string_to_path(value)
-
-
-class RenderCVSettings(RenderCVBaseModelWithoutExtraKeys):
- """This class is the data model of the RenderCV settings."""
-
- model_config = pydantic.ConfigDict(title="RenderCV Settings")
-
- date: datetime.date = pydantic.Field(
- default=datetime.date.today(),
- title="Date",
- description=(
- "The date that will be used everywhere (e.g., in the output file names,"
- " last updated date, computation of time spans for the events that are"
- " currently happening, etc.). The default value is the current date."
- ),
- json_schema_extra={
- "default": None,
- },
- )
- render_command: RenderCommandSettings | None = pydantic.Field(
- default=None,
- title="Render Command Settings",
- description=(
- "RenderCV's `render` command settings. They are the same as the command"
- " line arguments. CLI arguments have higher priority than the settings in"
- " the input file."
- ),
- )
- bold_keywords: list[str] = pydantic.Field(
- default=[],
- title="Bold Keywords",
- description=(
- "The keywords that will be bold in the output. The default value is an"
- " empty list."
- ),
- )
- sort_entries: Literal["reverse-chronological", "chronological", "none"] = (
- pydantic.Field(
- default="none",
- title="Sort Entries",
- description=(
- "How the entries should be sorted based on their dates. The available"
- " options are 'reverse-chronological', 'chronological', and 'none'. The"
- " default value is 'none'."
- ),
- )
- )
-
- @pydantic.field_validator("date")
- @classmethod
- def mock_today(cls, value: datetime.date) -> datetime.date:
- """Mocks the current date for testing."""
-
- global DATE_INPUT # NOQA: PLW0603
-
- DATE_INPUT = value
-
- return value
diff --git a/src/rendercv/data/reader.py b/src/rendercv/data/reader.py
deleted file mode 100644
index 94b90dc6..00000000
--- a/src/rendercv/data/reader.py
+++ /dev/null
@@ -1,409 +0,0 @@
-"""
-The `rendercv.data.reader` module contains the functions that are used to read the input
-file (YAML or JSON) and return them as an instance of `RenderCVDataModel`, which is a
-Pydantic data model of RenderCV's data format.
-"""
-
-import pathlib
-import re
-
-import pydantic
-import ruamel.yaml
-from ruamel.yaml.comments import CommentedMap
-
-from . import models
-from .models import entry_types
-
-
-def make_given_keywords_bold_in_sections(
- sections_input: models.Sections, keywords: list[str]
-) -> models.Sections:
- """Iterate over the dictionary recursively and make the given keywords bold.
-
- Args:
- sections_input: The sections input as a Pydantic model.
- keywords: The keywords to make bold.
-
- Returns:
- The dictionary with the given keywords bold.
- """
- if sections_input is None:
- return None
-
- for entries in sections_input.values():
- for i, entry in enumerate(entries):
- if isinstance(entry, str):
- entries[i] = entry_types.make_keywords_bold_in_a_string( # type: ignore
- entry, keywords
- )
- elif callable(getattr(entry, "make_keywords_bold", None)):
- entries[i] = entry.make_keywords_bold(keywords) # type: ignore
-
- return sections_input
-
-
-def get_error_message_and_location_and_value_from_a_custom_error(
- error_string: str,
-) -> tuple[str | None, str | None, str | None]:
- """Look at a string and figure out if it's a custom error message that has been
- sent from `rendercv.data.reader.read_input_file`. If it is, then return the custom
- message, location, and the input value.
-
- This is done because sometimes we raise an error about a specific field in the model
- validation level, but Pydantic doesn't give us the exact location of the error
- because it's a model-level error. So, we raise a custom error with three string
- arguments: message, location, and input value. Those arguments then combined into a
- string by Python. This function is used to parse that custom error message and
- return the three values.
-
- Args:
- error_string: The error message.
-
- Returns:
- The custom message, location, and the input value.
- """
- pattern = r"""\(['"](.*)['"], '(.*)', '(.*)'\)"""
- match = re.search(pattern, error_string)
- if match:
- return match.group(1), match.group(2), match.group(3)
- return None, None, None
-
-
-def get_coordinates_of_a_key_in_a_yaml_object(
- yaml_object: ruamel.yaml.YAML, location: list[str]
-) -> tuple[tuple[int, int], tuple[int, int]]:
- """Find the coordinates of a key in a YAML object.
-
- Args:
- yaml_object: The YAML object.
- location: The location of the key in the YAML object. For example,
- `['cv', 'sections', 'education', '0', 'degree']`.
-
- Returns:
- The coordinates of the key in the YAML object in the format
- ((start_line, start_column), (end_line, end_column)).
- (Line and column numbers are 0-indexed.)
- """
-
- def get_inner_yaml_object_from_its_key(
- yaml_object: CommentedMap, location_key: str
- ) -> tuple[CommentedMap, tuple[tuple[int, int], tuple[int, int]]]:
- # If the part is numeric, interpret it as a list index:
- try:
- index = int(location_key)
- try:
- inner_yaml_object = yaml_object[index]
- # Get the coordinates from the list's lc.data (which is a list of tuples).
- start_line, start_col = yaml_object.lc.data[index]
- end_line, end_col = start_line, start_col
- coordinates = ((start_line + 1, start_col - 1), (end_line + 1, end_col))
- except IndexError as e:
- message = f"Index {index} is out of range in the YAML file."
- raise KeyError(message) from e
- except ValueError as e:
- # Otherwise, the part is a key in a mapping.
- if location_key not in yaml_object:
- message = f"Key '{location_key}' not found in the YAML file."
- raise KeyError(message) from e
-
- inner_yaml_object = yaml_object[location_key]
- start_line, start_col, end_line, end_col = yaml_object.lc.data[location_key]
- coordinates = ((start_line + 1, start_col + 1), (end_line + 1, end_col))
-
- return inner_yaml_object, coordinates
-
- current_yaml_object: ruamel.yaml.YAML = yaml_object
- coordinates = ((0, 0), (0, 0))
- # start from the first key and move forward:
- for location_key in location:
- current_yaml_object, coordinates = get_inner_yaml_object_from_its_key(
- current_yaml_object, location_key
- )
-
- return coordinates
-
-
-def parse_validation_errors(
- exception: pydantic.ValidationError, yaml_file_as_string: str | None = None
-) -> list[dict[str, str]]:
- """Take a Pydantic validation error, parse it, and return a list of error
- dictionaries that contain the error messages, locations, and the input values.
-
- Pydantic's `ValidationError` object is a complex object that contains a lot of
- information about the error. This function takes a `ValidationError` object and
- extracts the error messages, locations, and the input values.
-
- Args:
- exception: The Pydantic validation error object.
- yaml_file_as_string: The YAML file as a string.
-
- Returns:
- A list of error dictionaries that contain the error messages, locations, and the
- input values.
- """
- # This dictionary is used to convert the error messages that Pydantic returns to
- # more user-friendly messages.
- error_dictionary: dict[str, str] = {
- "Input should be 'present'": (
- "This is not a valid date! Please use either YYYY-MM-DD, YYYY-MM, or YYYY"
- ' format or "present"!'
- ),
- "Input should be a valid integer, unable to parse string as an integer": (
- "This is not a valid date! Please use either YYYY-MM-DD, YYYY-MM, or YYYY"
- " format!"
- ),
- "String should match pattern '\\d{4}-\\d{2}(-\\d{2})?'": (
- "This is not a valid date! Please use either YYYY-MM-DD, YYYY-MM, or YYYY"
- " format!"
- ),
- "String should match pattern '\\b10\\..*'": (
- 'A DOI prefix should always start with "10.". For example,'
- ' "10.1109/TASC.2023.3340648".'
- ),
- "URL scheme should be 'http' or 'https'": "This is not a valid URL!",
- "Field required": "This field is required!",
- "value is not a valid phone number": "This is not a valid phone number!",
- "month must be in 1..12": "The month must be between 1 and 12!",
- "day is out of range for month": "The day is out of range for the month!",
- "Extra inputs are not permitted": (
- "This field is unknown for this object! Please remove it."
- ),
- "Input should be a valid string": (
- "This field should be provided or removed to use the default value!"
- ),
- "Input should be a valid list": (
- "This field should contain a list of items but it doesn't!"
- ),
- "value is not a valid color: value must be tuple, list or string": (
- "This is not a valid color! Here are some examples of valid colors:"
- ' "red", "#ff0000", "rgb(255, 0, 0)", "hsl(0, 100%, 50%)"'
- ),
- "value is not a valid color: string not recognised as a valid color": (
- "This is not a valid color! Here are some examples of valid colors:"
- ' "red", "#ff0000", "rgb(255, 0, 0)", "hsl(0, 100%, 50%)"'
- ),
- }
-
- unwanted_texts = ["value is not a valid email address: ", "Value error, "]
-
- # Check if this is a section error. If it is, we need to handle it differently.
- # This is needed because how dm.validate_section_input function raises an exception.
- # This is done to tell the user which which EntryType RenderCV excepts to see.
- errors = exception.errors()
- for error_object in errors.copy():
- if (
- "There are problems with the entries." in error_object["msg"]
- and "ctx" in error_object
- ):
- location = error_object["loc"]
- ctx_object = error_object["ctx"]
- if "error" in ctx_object:
- inner_error_object = ctx_object["error"]
- if hasattr(inner_error_object, "__cause__"):
- cause_object = inner_error_object.__cause__
- cause_object_errors = cause_object.errors()
- for cause_error_object in cause_object_errors:
- # we use [1:] to avoid `entries` location. It is a location for
- # RenderCV's own data model, not the user's data model.
- cause_error_object["loc"] = tuple(
- list(location) + list(cause_error_object["loc"][1:])
- )
- errors.extend(cause_object_errors)
-
- # some locations are not really the locations in the input file, but some
- # information about the model coming from Pydantic. We need to remove them.
- # (e.g. avoid stuff like .end_date.literal['present'])
- unwanted_locations = ["tagged-union", "list", "literal", "int", "constrained-str"]
- for error_object in errors:
- location = [str(location_element) for location_element in error_object["loc"]]
- new_location = [str(location_element) for location_element in location]
- for location_element in location:
- for unwanted_location in unwanted_locations:
- if unwanted_location in location_element:
- new_location.remove(location_element)
- error_object["loc"] = new_location # type: ignore
-
- # Parse all the errors and create a new list of errors.
- new_errors: list[dict[str, str]] = []
- for error_object in errors:
- message = error_object["msg"]
- location = ".".join(error_object["loc"]) # type: ignore
- input = error_object["input"]
-
- # Check if this is a custom error message:
- custom_message, custom_location, custom_input_value = (
- get_error_message_and_location_and_value_from_a_custom_error(message)
- )
- if custom_message is not None:
- message = custom_message
- if custom_location:
- # If the custom location is not empty, then add it to the location.
- location = f"{location}.{custom_location}"
- input = custom_input_value
-
- # Don't show unwanted texts in the error message:
- for unwanted_text in unwanted_texts:
- message = message.replace(unwanted_text, "")
-
- # Convert the error message to a more user-friendly message if it's in the
- # error_dictionary:
- if message in error_dictionary:
- message = error_dictionary[message]
-
- # Special case for end_date because Pydantic returns multiple end_date errors
- # since it has multiple valid formats:
- if "end_date" in location:
- message = (
- "This is not a valid end date! Please use either YYYY-MM-DD, YYYY-MM,"
- ' or YYYY format or "present"!'
- )
-
- # If the input is a dictionary or a list (the model itself fails to validate),
- # then don't show the input. It looks confusing and it is not helpful.
- if isinstance(input, dict | list):
- input = ""
-
- new_error = {
- "loc": tuple(location.split(".")),
- "msg": message,
- "input": str(input),
- }
-
- if yaml_file_as_string:
- yaml_object = read_a_yaml_file_with_coordinates(yaml_file_as_string)
- coordinates = get_coordinates_of_a_key_in_a_yaml_object(
- yaml_object,
- list(new_error["loc"]), # type: ignore
- )
- new_error["yaml_loc"] = coordinates
-
- # if new_error is not in new_errors, then add it to new_errors
- if new_error not in new_errors:
- new_errors.append(new_error)
-
- return new_errors
-
-
-def read_a_yaml_file(file_path_or_contents: pathlib.Path | str) -> dict:
- """Read a YAML file and return its content as a dictionary. The YAML file can be
- given as a path to the file or as the contents of the file as a string.
-
- Args:
- file_path_or_contents: The path to the YAML file or the contents of the YAML
- file as a string.
-
- Returns:
- The content of the YAML file as a dictionary.
- """
-
- if isinstance(file_path_or_contents, pathlib.Path):
- # Check if the file exists:
- if not file_path_or_contents.exists():
- message = f"The input file {file_path_or_contents} doesn't exist!"
- raise FileNotFoundError(message)
-
- # Check the file extension:
- accepted_extensions = [".yaml", ".yml", ".json", ".json5"]
- if file_path_or_contents.suffix not in accepted_extensions:
- user_friendly_accepted_extensions = [
- f"[green]{ext}[/green]" for ext in accepted_extensions
- ]
- user_friendly_accepted_extensions = ", ".join(
- user_friendly_accepted_extensions
- )
- message = (
- "The input file should have one of the following extensions:"
- f" {user_friendly_accepted_extensions}. The input file is"
- f" {file_path_or_contents}."
- )
- raise ValueError(message)
-
- file_content = file_path_or_contents.read_text(encoding="utf-8")
- else:
- file_content = file_path_or_contents
-
- yaml_as_a_dictionary: dict = ruamel.yaml.YAML().load(file_content)
-
- if yaml_as_a_dictionary is None:
- message = "The input file is empty!"
- raise ValueError(message)
-
- return yaml_as_a_dictionary
-
-
-def read_a_yaml_file_with_coordinates(
- file_path_or_contents: pathlib.Path | str,
-) -> CommentedMap:
- """Read a YAML file and return its content as a CommentedMap with location information.
-
- Args:
- file_path_or_contents: The path to the YAML file or the contents of the YAML
- file as a string.
-
- Returns:
- The content of the YAML file as a CommentedMap with location information.
- """
-
- if isinstance(file_path_or_contents, pathlib.Path):
- file_content = file_path_or_contents.read_text(encoding="utf-8")
- else:
- file_content = file_path_or_contents
-
- yaml = ruamel.yaml.YAML()
- yaml_as_commented_map: CommentedMap = yaml.load(file_content)
-
- if yaml_as_commented_map is None:
- message = "The input file is empty!"
- raise ValueError(message)
-
- return yaml_as_commented_map
-
-
-def validate_input_dictionary_and_return_the_data_model(
- input_dictionary: dict,
- context: dict | None = None,
-) -> models.RenderCVDataModel:
- """Validate the input dictionary by creating an instance of `RenderCVDataModel`,
- which is a Pydantic data model of RenderCV's data format.
-
- Args:
- input_dictionary: The input dictionary.
- context: The context dictionary that is used to validate the input dictionary.
- It's used to send the input file path with the context object, but it's not
- required.
-
- Returns:
- The data model.
- """
- # Validate the parsed dictionary by creating an instance of RenderCVDataModel:
- data_model = models.RenderCVDataModel.model_validate(
- input_dictionary, context=context
- )
-
- # If the `bold_keywords` field is provided in the `rendercv_settings`, make the
- # given keywords bold in the `cv.sections` field:
- if data_model.rendercv_settings and data_model.rendercv_settings.bold_keywords:
- data_model.cv.sections_input = make_given_keywords_bold_in_sections(
- data_model.cv.sections_input,
- data_model.rendercv_settings.bold_keywords,
- )
-
- return data_model
-
-
-def read_input_file(
- file_path_or_contents: pathlib.Path | str,
-) -> models.RenderCVDataModel:
- """Read the input file (YAML or JSON) and return them as an instance of
- `RenderCVDataModel`, which is a Pydantic data model of RenderCV's data format.
-
- Args:
- file_path_or_contents: The path to the input file or the contents of the input
- file as a string.
-
- Returns:
- The data model.
- """
- input_as_dictionary = read_a_yaml_file(file_path_or_contents)
-
- return validate_input_dictionary_and_return_the_data_model(input_as_dictionary)
diff --git a/src/rendercv/data/sample_content.yaml b/src/rendercv/data/sample_content.yaml
deleted file mode 100644
index f1e30302..00000000
--- a/src/rendercv/data/sample_content.yaml
+++ /dev/null
@@ -1,95 +0,0 @@
----
-name: John Doe
-location: Location
-email: john.doe@example.com
-phone: +1-609-999-9995
-social_networks:
- - network: LinkedIn
- username: john.doe
- - network: GitHub
- username: john.doe
-sections:
- welcome_to_RenderCV!:
- - "[RenderCV](https://rendercv.com) is a Typst-based CV framework designed for academics and engineers, with Markdown syntax support."
- - "Each section title is arbitrary. Each section contains a list of entries, and there are 7 different entry types to choose from."
- education:
- - institution: Stanford University
- location: Stanford, CA, USA
- area: Computer Science
- degree: PhD
- start_date: 2023-09
- end_date: present
- highlights:
- - Working on the optimization of autonomous vehicles in urban environments
- - institution: Boğaziçi University
- location: Istanbul, Türkiye
- area: Computer Engineering
- degree: BS
- start_date: 2018-09
- end_date: 2022-06
- highlights:
- - "GPA: 3.9/4.0, ranked 1st out of 100 students"
- - "Awards: Best Senior Project, High Honor"
- experience:
- - company: Company C
- position: Summer Intern
- location: Livingston, LA, USA
- start_date: 2024-06
- end_date: 2024-09
- highlights:
- - Developed deep learning models for the detection of gravitational waves in LIGO data
- - Published [3 peer-reviewed research papers](https://example.com) about the project and results
- - company: Company B
- position: Summer Intern
- location: Ankara, Türkiye
- start_date: 2023-06
- end_date: 2023-09
- highlights:
- - Optimized the production line by 15% by implementing a new scheduling algorithm
- - company: Company A
- position: Summer Intern
- location: Istanbul, Türkiye
- start_date: 2022-06
- end_date: 2022-09
- highlights:
- - Designed an inventory management web application for a warehouse
- projects:
- - name: "[Example Project](https://example.com)"
- start_date: 2024-05
- end_date: present
- summary: "A web application for writing essays"
- highlights:
- - "Launched an [iOS app](https://example.com) in 09/2024 that currently has 10k+ monthly active users"
- - "The app is made open-source (3,000+ stars [on GitHub](https://github.com))"
- - name: "[Teaching on Udemy](https://example.com)"
- date: Fall 2023
- highlights:
- - 'Instructed the "Statistics" course on Udemy (60,000+ students, 200,000+ hours watched)'
- skills:
- - label: Programming
- details: Proficient with Python, C++, and Git; good understanding of Web, app development, and DevOps
- - label: Mathematics
- details: Good understanding of differential equations, calculus, and linear algebra
- - label: Languages
- details: "English (fluent, TOEFL: 118/120), Turkish (native)"
- publications:
- - title: 3D Finite Element Analysis of No-Insulation Coils
- authors:
- - Frodo Baggins
- - "***John Doe***"
- - Samwise Gamgee
- doi: 10.1109/TASC.2023.3340648
- date: 2004-01
- extracurricular_activities:
- - bullet:
- "There are 7 unique entry types in RenderCV: *BulletEntry*, *TextEntry*, *EducationEntry*,
- *ExperienceEntry*, *NormalEntry*, *PublicationEntry*, and *OneLineEntry*."
- - bullet: "Each entry type has a different structure and layout. This document demonstrates all of them."
- numbered_entries:
- - number: "This is a numbered entry."
- - number: "This is another numbered entry."
- - number: "This is the third numbered entry."
- reversed_numbered_entries:
- - reversed_number: "This is a reversed numbered entry."
- - reversed_number: "This is another reversed numbered entry."
- - reversed_number: "This is the third reversed numbered entry."
diff --git a/src/rendercv/exception.py b/src/rendercv/exception.py
new file mode 100644
index 00000000..8dd9cbdb
--- /dev/null
+++ b/src/rendercv/exception.py
@@ -0,0 +1,24 @@
+from dataclasses import dataclass, field
+
+
+@dataclass
+class RenderCVValidationError:
+ location: tuple[str, ...]
+ yaml_location: tuple[tuple[int, int], tuple[int, int]]
+ message: str
+ input: str
+
+
+@dataclass
+class RenderCVUserError(ValueError):
+ message: str | None = field(default=None)
+
+
+@dataclass
+class RenderCVUserValidationError(ValueError):
+ validation_errors: list[RenderCVValidationError]
+
+
+@dataclass
+class RenderCVInternalError(RuntimeError):
+ message: str
diff --git a/src/rendercv/renderer/__init__.py b/src/rendercv/renderer/__init__.py
index 23bb16e7..e69de29b 100644
--- a/src/rendercv/renderer/__init__.py
+++ b/src/rendercv/renderer/__init__.py
@@ -1,34 +0,0 @@
-"""
-The `rendercv.renderer` package contains the necessary classes and functions for
-generating Typst, PDF, Markdown, HTML, and PNG files from the `RenderCVDataModel`
-object.
-
-The Typst and Markdown files are generated with
-[Jinja2](https://jinja.palletsprojects.com/en/3.1.x/) templates. Then, the Typst
-file is rendered into a PDF and PNGs with
-[`typst` package](https://github.com/messense/typst-py). The Markdown file is rendered
-into an HTML file with
-[`markdown` package](https://github.com/Python-Markdown/markdown).
-"""
-
-from .renderer import (
- create_a_markdown_file,
- create_a_typst_file,
- create_a_typst_file_and_copy_theme_files,
- create_contents_of_a_markdown_file,
- create_contents_of_a_typst_file,
- render_a_pdf_from_typst,
- render_an_html_from_markdown,
- render_pngs_from_typst,
-)
-
-__all__ = [
- "create_a_markdown_file",
- "create_a_typst_file",
- "create_a_typst_file_and_copy_theme_files",
- "create_contents_of_a_markdown_file",
- "create_contents_of_a_typst_file",
- "render_a_pdf_from_typst",
- "render_an_html_from_markdown",
- "render_pngs_from_typst",
-]
diff --git a/src/rendercv/renderer/html.py b/src/rendercv/renderer/html.py
new file mode 100644
index 00000000..dd438c69
--- /dev/null
+++ b/src/rendercv/renderer/html.py
@@ -0,0 +1,35 @@
+import pathlib
+
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .path_resolver import resolve_rendercv_file_path
+from .templater.templater import render_html
+
+
+def generate_html(
+ rendercv_model: RenderCVModel, markdown_path: pathlib.Path | None
+) -> pathlib.Path | None:
+ """Generate HTML file from Markdown source with styling.
+
+ Why:
+ HTML format enables web hosting and sharing CVs online. Converts
+ Markdown to HTML body and wraps with CSS styling and metadata.
+
+ Args:
+ rendercv_model: CV model for path resolution and rendering context.
+ markdown_path: Path to Markdown source file.
+
+ Returns:
+ Path to generated HTML file, or None if generation disabled.
+ """
+ if (
+ rendercv_model.settings.render_command.dont_generate_html
+ or markdown_path is None
+ ):
+ return None
+ html_path = resolve_rendercv_file_path(
+ rendercv_model, rendercv_model.settings.render_command.html_path
+ )
+ html_contents = render_html(rendercv_model, markdown_path.read_text())
+ html_path.write_text(html_contents)
+ return html_path
diff --git a/src/rendercv/renderer/markdown.py b/src/rendercv/renderer/markdown.py
new file mode 100644
index 00000000..329379ff
--- /dev/null
+++ b/src/rendercv/renderer/markdown.py
@@ -0,0 +1,29 @@
+import pathlib
+
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .path_resolver import resolve_rendercv_file_path
+from .templater.templater import render_full_template
+
+
+def generate_markdown(rendercv_model: RenderCVModel) -> pathlib.Path | None:
+ """Generate Markdown file from CV model via Jinja2 templates.
+
+ Why:
+ Markdown provides human-readable CV format for version control and
+ web platforms. Acts as intermediate format for HTML generation.
+
+ Args:
+ rendercv_model: Validated CV model with content.
+
+ Returns:
+ Path to generated Markdown file, or None if generation disabled.
+ """
+ if rendercv_model.settings.render_command.dont_generate_markdown:
+ return None
+ markdown_path = resolve_rendercv_file_path(
+ rendercv_model, rendercv_model.settings.render_command.markdown_path
+ )
+ markdown_contents = render_full_template(rendercv_model, "markdown")
+ markdown_path.write_text(markdown_contents)
+ return markdown_path
diff --git a/src/rendercv/renderer/path_resolver.py b/src/rendercv/renderer/path_resolver.py
new file mode 100644
index 00000000..abe754c9
--- /dev/null
+++ b/src/rendercv/renderer/path_resolver.py
@@ -0,0 +1,76 @@
+import pathlib
+
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .templater.string_processor import substitute_placeholders
+
+
+def resolve_rendercv_file_path(
+ rendercv_model: RenderCVModel, file_path: pathlib.Path
+) -> pathlib.Path:
+ """Resolve output file path with placeholder substitution and directory creation.
+
+ Why:
+ Users specify output paths like `NAME_CV_YEAR.pdf` with placeholders
+ for dynamic naming. Substitution uses current date and CV name to
+ generate actual file names, creating parent directories if needed.
+
+ Example:
+ ```py
+ # Given model with name="John Doe" and year=2025
+ path = resolve_rendercv_file_path(
+ model, pathlib.Path("output/NAME_IN_LOWER_SNAKE_CASE_CV_YEAR.pdf")
+ )
+ # Returns: pathlib.Path("output/john_doe_CV_2025.pdf")
+ ```
+
+ Args:
+ rendercv_model: CV model containing name and date for substitution.
+ file_path: Template path with placeholders.
+
+ Returns:
+ Resolved absolute path with substituted filename.
+ """
+ current_date = rendercv_model.settings.current_date
+ current_date_month_index = current_date.month - 1
+ file_path_placeholders = {
+ "MONTH_NAME": rendercv_model.locale.month_names[current_date_month_index],
+ "MONTH_ABBREVIATION": rendercv_model.locale.month_abbreviations[
+ current_date_month_index
+ ],
+ "MONTH": str(current_date.month),
+ "MONTH_IN_TWO_DIGITS": f"{current_date.month:02d}",
+ "YEAR": str(current_date.year),
+ "YEAR_IN_TWO_DIGITS": str(current_date.year)[-2:],
+ "NAME": rendercv_model.cv.name,
+ "NAME_IN_SNAKE_CASE": (
+ rendercv_model.cv.name.replace(" ", "_") if rendercv_model.cv.name else None
+ ),
+ "NAME_IN_LOWER_SNAKE_CASE": (
+ rendercv_model.cv.name.replace(" ", "_").lower()
+ if rendercv_model.cv.name
+ else None
+ ),
+ "NAME_IN_UPPER_SNAKE_CASE": (
+ rendercv_model.cv.name.replace(" ", "_").upper()
+ if rendercv_model.cv.name
+ else None
+ ),
+ "NAME_IN_KEBAB_CASE": (
+ rendercv_model.cv.name.replace(" ", "-") if rendercv_model.cv.name else None
+ ),
+ "NAME_IN_LOWER_KEBAB_CASE": (
+ rendercv_model.cv.name.replace(" ", "-").lower()
+ if rendercv_model.cv.name
+ else None
+ ),
+ "NAME_IN_UPPER_KEBAB_CASE": (
+ rendercv_model.cv.name.replace(" ", "-").upper()
+ if rendercv_model.cv.name
+ else None
+ ),
+ }
+ file_name = substitute_placeholders(file_path.name, file_path_placeholders)
+ resolved_file_path = file_path.parent / file_name
+ resolved_file_path.parent.mkdir(parents=True, exist_ok=True)
+ return resolved_file_path
diff --git a/src/rendercv/renderer/pdf_png.py b/src/rendercv/renderer/pdf_png.py
new file mode 100644
index 00000000..5864f4af
--- /dev/null
+++ b/src/rendercv/renderer/pdf_png.py
@@ -0,0 +1,133 @@
+import functools
+import pathlib
+import shutil
+
+import rendercv_fonts
+import typst
+
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .path_resolver import resolve_rendercv_file_path
+
+
+def generate_pdf(
+ rendercv_model: RenderCVModel, typst_path: pathlib.Path | None
+) -> pathlib.Path | None:
+ """Compile Typst source to PDF using typst-py compiler.
+
+ Why:
+ PDF is the primary output format for CVs. Typst compilation produces
+ high-quality PDFs with proper fonts, layout, and typography from the
+ intermediate Typst markup.
+
+ Args:
+ rendercv_model: CV model for path resolution and photo handling.
+ typst_path: Path to Typst source file to compile.
+
+ Returns:
+ Path to generated PDF file, or None if generation disabled.
+ """
+ if rendercv_model.settings.render_command.dont_generate_pdf or typst_path is None:
+ return None
+ pdf_path = resolve_rendercv_file_path(
+ rendercv_model, rendercv_model.settings.render_command.pdf_path
+ )
+ typst_compiler = get_typst_compiler(typst_path, rendercv_model._input_file_path)
+ copy_photo_next_to_typst_file(rendercv_model, typst_path)
+ typst_compiler.compile(format="pdf", output=pdf_path)
+
+ return pdf_path
+
+
+def generate_png(
+ rendercv_model: RenderCVModel, typst_path: pathlib.Path | None
+) -> list[pathlib.Path] | None:
+ """Compile Typst source to PNG images using typst-py compiler.
+
+ Why:
+ PNG format enables CV preview in web applications and README files.
+ Multi-page CVs produce multiple PNG files with sequential numbering.
+
+ Args:
+ rendercv_model: CV model for path resolution and photo handling.
+ typst_path: Path to Typst source file to compile.
+
+ Returns:
+ List of paths to generated PNG files, or None if generation disabled.
+ """
+ if rendercv_model.settings.render_command.dont_generate_png or typst_path is None:
+ return None
+ png_path = resolve_rendercv_file_path(
+ rendercv_model, rendercv_model.settings.render_command.png_path
+ )
+ typst_compiler = get_typst_compiler(typst_path, rendercv_model._input_file_path)
+ copy_photo_next_to_typst_file(rendercv_model, typst_path)
+ png_files_bytes = typst_compiler.compile(format="png")
+
+ if not isinstance(png_files_bytes, list):
+ png_files_bytes = [png_files_bytes]
+
+ png_files = []
+ for i, png_file_bytes in enumerate(png_files_bytes):
+ assert png_file_bytes is not None
+ png_file = png_path.parent / (png_path.stem + f"_{i + 1}.png")
+ png_file.write_bytes(png_file_bytes)
+ png_files.append(png_file)
+
+ return png_files if png_files else None
+
+
+def copy_photo_next_to_typst_file(
+ rendercv_model: RenderCVModel, typst_path: pathlib.Path
+) -> None:
+ """Copy CV photo to Typst file directory for compilation.
+
+ Why:
+ Typst compiler resolves image paths relative to source file location.
+ Copying photo ensures compilation succeeds regardless of original
+ photo location.
+
+ Args:
+ rendercv_model: CV model containing photo path.
+ typst_path: Path to Typst source file.
+ """
+ if rendercv_model.cv.photo:
+ photo_path = rendercv_model.cv.photo
+ copy_to = typst_path.parent / photo_path.name
+ if photo_path != copy_to:
+ shutil.copy(
+ rendercv_model.cv.photo,
+ typst_path.parent / rendercv_model.cv.photo.name,
+ )
+
+
+@functools.lru_cache(maxsize=1)
+def get_typst_compiler(
+ file_path: pathlib.Path,
+ input_file_path: pathlib.Path | None,
+) -> typst.Compiler:
+ """Create cached Typst compiler with font paths configured.
+
+ Why:
+ Compiler initialization is expensive. Caching enables reuse for both
+ PDF and PNG generation. Font paths include package fonts and optional
+ user fonts from input file directory.
+
+ Args:
+ file_path: Typst source file to compile.
+ input_file_path: Original input file path for relative font resolution.
+
+ Returns:
+ Configured Typst compiler instance.
+ """
+ return typst.Compiler(
+ file_path,
+ font_paths=[
+ *rendercv_fonts.paths_to_font_folders,
+ (
+ input_file_path.parent / "fonts"
+ if input_file_path
+ else pathlib.Path.cwd() / "fonts"
+ ),
+ ],
+ )
diff --git a/src/rendercv/renderer/renderer.py b/src/rendercv/renderer/renderer.py
deleted file mode 100644
index f2f12afd..00000000
--- a/src/rendercv/renderer/renderer.py
+++ /dev/null
@@ -1,385 +0,0 @@
-"""
-The `rendercv.renderer.renderer` module contains the necessary functions for rendering
-Typst, PDF, Markdown, HTML, and PNG files from the `RenderCVDataModel` object.
-"""
-
-import importlib
-import importlib.resources
-import pathlib
-import re
-import shutil
-import sys
-from typing import Any, Literal
-
-from .. import data
-from . import templater
-
-
-def create_a_file_name_without_extension_from_name(name: str | None) -> str:
- """Create a file name from the given name by replacing the spaces with underscores
- and removing typst commands.
-
- Args:
- name: The name to be converted.
-
- Returns:
- The converted name (without the extension).
- """
- name_without_typst_commands = templater.remove_typst_commands(str(name))
- return f"{name_without_typst_commands.replace(' ', '_')}_CV"
-
-
-def create_a_file_and_write_contents_to_it(
- contents: str, file_name: str, output_directory: pathlib.Path
-) -> pathlib.Path:
- """Create a file with the given contents in the output directory.
-
- Args:
- contents: The contents of the file.
- file_name: The name of the file.
- output_directory: Path to the output directory.
-
- Returns:
- The path to the created file.
- """
- # Create output directory if it doesn't exist:
- if not output_directory.is_dir():
- output_directory.mkdir(parents=True)
-
- file_path = output_directory / file_name
- file_path.write_text(contents, encoding="utf-8")
-
- return file_path
-
-
-def copy_theme_files_to_output_directory(
- theme_name: str,
- output_directory_path: pathlib.Path,
-):
- """Copy the auxiliary files (all the files that don't end with `.j2.typ` and `.py`)
- of the theme to the output directory.
-
- Args:
- theme_name: The name of the theme.
- output_directory_path: Path to the output directory.
- """
- if theme_name in data.available_themes:
- theme_directory_path = importlib.resources.files(
- f"rendercv.themes.{theme_name}"
- )
- else:
- # Then it means the theme is a custom theme. If theme_directory is not given
- # as an argument, then look for the theme in the current working directory.
- theme_directory_path = pathlib.Path.cwd() / theme_name
-
- if not theme_directory_path.is_dir():
- message = (
- f"The theme {theme_name} doesn't exist in the available themes and"
- " the current working directory!"
- )
- raise FileNotFoundError(message)
-
- dont_copy_files_with_these_extensions = [".py", ".j2.typ"]
- for theme_file in theme_directory_path.iterdir():
- # theme_file.suffix returns the latest part of the file name after the last dot.
- # But we need the latest part of the file name after the first dot:
- try:
- suffix = re.search(r"\..*", theme_file.name)[0] # type: ignore
- except TypeError:
- suffix = ""
-
- if suffix not in dont_copy_files_with_these_extensions and theme_file.name != "__pycache__":
- if theme_file.is_dir():
- shutil.copytree(
- str(theme_file),
- output_directory_path / theme_file.name,
- dirs_exist_ok=True,
- )
- else:
- shutil.copyfile(
- str(theme_file), output_directory_path / theme_file.name
- )
-
-
-def create_contents_of_a_typst_file(
- rendercv_data_model: data.RenderCVDataModel,
-) -> str:
- """Create a Typst file with the given data model and return it as a string.
-
- Args:
- rendercv_data_model: The data model.
-
- Returns:
- The path to the generated Typst file.
- """
- jinja2_environment = templater.Jinja2Environment().environment
-
- file_object = templater.TypstFile(
- rendercv_data_model,
- jinja2_environment,
- )
-
- return file_object.get_full_code()
-
-
-def create_a_typst_file(
- rendercv_data_model: data.RenderCVDataModel,
- output_directory: pathlib.Path,
-) -> pathlib.Path:
- """Create a Typst file (depending on the theme) with the given data model and write
- it to the output directory.
-
- Args:
- rendercv_data_model: The data model.
- output_directory: Path to the output directory. If not given, the Typst file
- will be returned as a string.
-
- Returns:
- The path to the generated Typst file.
- """
-
- typst_contents = create_contents_of_a_typst_file(rendercv_data_model)
-
- file_name_without_extension = create_a_file_name_without_extension_from_name(
- rendercv_data_model.cv.name
- )
- file_name = f"{file_name_without_extension}.typ"
-
- return create_a_file_and_write_contents_to_it(
- typst_contents,
- file_name,
- output_directory,
- )
-
-
-def create_contents_of_a_markdown_file(
- rendercv_data_model: data.RenderCVDataModel,
-) -> str:
- """Create a Markdown file with the given data model and return it as a string.
-
- Args:
- rendercv_data_model: The data model.
-
- Returns:
- The path to the generated Markdown file.
- """
- jinja2_environment = templater.Jinja2Environment().environment
-
- markdown_file_object = templater.MarkdownFile(
- rendercv_data_model,
- jinja2_environment,
- )
-
- return markdown_file_object.get_full_code()
-
-
-def create_a_markdown_file(
- rendercv_data_model: data.RenderCVDataModel, output_directory: pathlib.Path
-) -> pathlib.Path:
- """Render the Markdown file with the given data model and write it to the output
- directory.
-
- Args:
- rendercv_data_model: The data model.
- output_directory: Path to the output directory.
-
- Returns:
- The path to the rendered Markdown file.
- """
- markdown_contents = create_contents_of_a_markdown_file(rendercv_data_model)
-
- file_name_without_extension = create_a_file_name_without_extension_from_name(
- rendercv_data_model.cv.name
- )
- file_name = f"{file_name_without_extension}.md"
-
- return create_a_file_and_write_contents_to_it(
- markdown_contents,
- file_name,
- output_directory,
- )
-
-
-def create_a_typst_file_and_copy_theme_files(
- rendercv_data_model: data.RenderCVDataModel, output_directory: pathlib.Path
-) -> pathlib.Path:
- """Render the Typst file with the given data model in the output directory and
- copy the auxiliary theme files to the output directory.
-
- Args:
- rendercv_data_model: The data model.
- output_directory: Path to the output directory.
-
- Returns:
- The path to the rendered Typst file.
- """
- file_path = create_a_typst_file(rendercv_data_model, output_directory)
- copy_theme_files_to_output_directory(
- rendercv_data_model.design.theme, output_directory
- )
-
- # Copy the profile picture to the output directory, if it exists:
- if rendercv_data_model.cv.photo:
- shutil.copyfile(
- rendercv_data_model.cv.photo,
- output_directory / rendercv_data_model.cv.photo.name,
- )
-
- return file_path
-
-
-class TypstCompiler:
- """A singleton class for the Typst compiler."""
-
- instance: "TypstCompiler"
- compiler: Any
- file_path: pathlib.Path
-
- def __new__(cls, file_path: pathlib.Path):
- if not hasattr(cls, "instance") or cls.instance.file_path != file_path:
- try:
- rendercv_fonts = importlib.import_module("rendercv_fonts")
- typst = importlib.import_module("typst")
- except Exception as e:
- parent = importlib.import_module("..", __package__)
- raise ImportError(parent._parial_install_error_message) from e
-
- cls.instance = super().__new__(cls)
- cls.instance.file_path = file_path
- cls.instance.compiler = typst.Compiler(
- file_path,
- font_paths=[
- *rendercv_fonts.paths_to_font_folders,
- pathlib.Path.cwd() / "fonts",
- ],
- )
-
- return cls.instance
-
- def run(
- self,
- output: pathlib.Path,
- format: Literal["png", "pdf"],
- ppi: float | None = None,
- ) -> pathlib.Path | list[pathlib.Path]:
- return self.instance.compiler.compile(format=format, output=output, ppi=ppi)
-
-
-def render_a_pdf_from_typst(file_path: pathlib.Path) -> pathlib.Path:
- """Run TinyTeX with the given Typst file to render the PDF.
-
- Args:
- file_path: The path to the Typst file.
-
- Returns:
- The path to the rendered PDF file.
- """
- # Pre-process the Typst source to avoid unwanted spacing that may be
- # introduced by inline formatting (e.g. `Pro#strong[gram]ming`).
- # When bold / italic markup is used **inside** a single word, recent Typst
- # versions treat the word parts as separate, causing additional spacing
- # when extracting text with pypdf. To stay backward-compatible with the
- # reference files shipped in the test-suite we strip such intra-word
- # formatting before the compilation step. This has no visual impact on the
- # extracted plain text but guarantees deterministic test output.
- if file_path.is_file():
- source = file_path.read_text(encoding="utf-8")
- # Collapse *inline* bold / italic markup that appears **inside** a word,
- # e.g. `Pro#strong[gram]ming` -> `Programming`. Such patterns cause the
- # new Typst engine to insert extra spacing inside the original word.
- # We repeatedly apply the substitution to handle nesting like
- # `#strong[Pro#strong[gram]ming]`.
-
- inline_pattern = re.compile(
- r"([A-Za-z])([A-Za-z]*)#(?:strong|emph)\[([A-Za-z]+)\]([A-Za-z]+)"
- )
- previous = None
- while previous != source:
- previous = source
- source = inline_pattern.sub(lambda m: "".join(m.groups()), source)
- _ = file_path.write_text(source, encoding="utf-8")
-
- # Create the compiler *after* the preprocessing so that it reads the updated
- # source file.
- typst_compiler = TypstCompiler(file_path)
-
- # Before running Typst, make sure the PDF file is not open in another program,
- # that wouldn't allow Typst to write to it. Remove the PDF file if it exists,
- # if it's not removable, then raise an error:
- pdf_output_path = file_path.with_suffix(".pdf")
-
- if sys.platform == "win32":
- if pdf_output_path.is_file():
- try:
- pdf_output_path.unlink()
- except PermissionError as e:
- message = (
- f"The PDF file {pdf_output_path} is open in another program and"
- " doesn't allow RenderCV to rewrite it. Please close the PDF file."
- )
- raise RuntimeError(message) from e
-
- typst_compiler.run(output=pdf_output_path, format="pdf")
-
- return pdf_output_path
-
-
-def render_pngs_from_typst(
- file_path: pathlib.Path, ppi: float = 150
-) -> list[pathlib.Path]:
- """Run Typst with the given Typst file to render the PNG files.
-
- Args:
- file_path: The path to the Typst file.
- ppi: Pixels per inch for PNG output, defaults to 150.
-
- Returns:
- Paths to the rendered PNG files.
- """
- typst_compiler = TypstCompiler(file_path)
- output_path = file_path.parent / (file_path.stem + "_{p}.png")
- typst_compiler.run(format="png", ppi=ppi, output=output_path)
-
- # Look at the outtput folder and find the PNG files:
- png_files = list(output_path.parent.glob(f"{file_path.stem}_*.png"))
- return sorted(png_files, key=lambda x: int(x.stem.split("_")[-1]))
-
-
-def render_an_html_from_markdown(markdown_file_path: pathlib.Path) -> pathlib.Path:
- """Render an HTML file from a Markdown file with the same name and in the same
- directory. It uses `rendercv/themes/main.j2.html` as the Jinja2 template.
-
- Args:
- markdown_file_path: The path to the Markdown file.
-
- Returns:
- The path to the rendered HTML file.
- """
- try:
- markdown = importlib.import_module("markdown")
- except Exception as e:
- parent = importlib.import_module("..", __package__)
- raise ImportError(parent._parial_install_error_message) from e
-
- # check if the file exists:
- if not markdown_file_path.is_file():
- message = f"The file {markdown_file_path} doesn't exist!"
- raise FileNotFoundError(message)
-
- # Convert the markdown file to HTML:
- markdown_text = markdown_file_path.read_text(encoding="utf-8")
- html_body = markdown.markdown(markdown_text)
-
- # Get the title of the markdown content:
- title = re.search(r"# (.*)\n", markdown_text)
- title = title.group(1) if title else None
-
- jinja2_environment = templater.Jinja2Environment().environment
- html_template = jinja2_environment.get_template("main.j2.html")
- html = html_template.render(html_body=html_body, title=title)
-
- # Write html into a file:
- html_file_path = markdown_file_path.parent / f"{markdown_file_path.stem}.html"
- html_file_path.write_text(html, encoding="utf-8")
-
- return html_file_path
diff --git a/src/rendercv/renderer/templater.py b/src/rendercv/renderer/templater.py
deleted file mode 100644
index 07d5b6ee..00000000
--- a/src/rendercv/renderer/templater.py
+++ /dev/null
@@ -1,843 +0,0 @@
-"""
-The `rendercv.renderer.templater` module contains all the necessary classes and
-functions for templating the Typst and Markdown files from the `RenderCVDataModel`
-object.
-"""
-
-import copy
-import pathlib
-import re
-from collections.abc import Callable
-from typing import get_args, get_origin, overload
-
-import jinja2
-import pydantic
-
-from .. import data
-
-
-class TemplatedFile:
- """This class is a base class for `TypstFile`, and `MarkdownFile` classes. It
- contains the common methods and attributes for both classes. These classes are used
- to generate the Typst and Markdown files with the data model and Jinja2
- templates.
-
- Args:
- data_model: The data model.
- environment: The Jinja2 environment.
- """
-
- def __init__(
- self,
- data_model: data.RenderCVDataModel,
- environment: jinja2.Environment,
- ):
- self.cv = data_model.cv
- self.design = data_model.design
- self.locale = data_model.locale
- self.environment = environment
-
- def template(
- self,
- theme_name: str,
- template_name: str,
- extension: str,
- entry: data.Entry | None = None,
- **kwargs,
- ) -> str:
- """Template one of the files in the `themes` directory.
-
- Args:
- template_name: The name of the template file.
- entry: The title of the section.
-
- Returns:
- The templated file.
- """
- template = self.environment.get_template(
- f"{theme_name}/{template_name}.j2.{extension}"
- )
-
- # Loop through the entry attributes and make them "" if they are None:
- # This is necessary because otherwise they will be templated as "None" since
- # it's the string representation of None.
-
- # Only don't touch the date fields, because only date_string is called and
- # setting dates to "" will cause problems.
- fields_to_ignore = ["start_date", "end_date", "date"]
-
- if entry is not None and not isinstance(entry, str):
- # Iterate over the model fields themselves (not the serialised dict) so
- # we *never* coerce complex objects like `HttpUrl` into plain strings.
- for key, model_field in entry.__class__.model_fields.items():
- if key in fields_to_ignore:
- continue
-
- value = getattr(entry, key)
- if value is not None:
- continue
-
- field_type = model_field.annotation
- origin = get_origin(field_type)
-
- # 1) Identify list-like annotations (e.g., list[str] | None)
- is_list_field = (
- origin is list
- or field_type is list
- or any(
- get_origin(arg) is list or arg is list
- for arg in get_args(field_type)
- )
- )
-
- # 2) Identify *plain* string annotations (str | None)
- is_string_field = field_type is str or (
- origin is not None
- and all(arg in {str, type(None)} for arg in get_args(field_type))
- and any(arg is str for arg in get_args(field_type))
- )
-
- if is_list_field:
- entry.__setattr__(key, [])
- elif is_string_field:
- entry.__setattr__(key, "")
-
- # The arguments of the template can be used in the template file:
- return template.render(
- cv=self.cv,
- design=self.design,
- locale=self.locale,
- entry=entry,
- today=data.format_date(data.get_date_input()),
- **kwargs,
- )
-
- def get_full_code(self, main_template_name: str, **kwargs) -> str:
- """Combine all the templates to get the full code of the file."""
- main_template = self.environment.get_template(main_template_name)
- return main_template.render(
- **kwargs,
- )
-
-
-class TypstFile(TemplatedFile):
- """This class represents a Typst file. It generates the Typst code with the
- data model and Jinja2 templates.
- """
-
- def __init__(
- self,
- data_model: data.RenderCVDataModel,
- environment: jinja2.Environment,
- ):
- typst_file_data_model = copy.deepcopy(data_model)
-
- if typst_file_data_model.cv.sections_input is not None:
- transformed_sections = transform_markdown_sections_to_typst_sections(
- typst_file_data_model.cv.sections_input
- )
- typst_file_data_model.cv.sections_input = transformed_sections
-
- super().__init__(typst_file_data_model, environment)
-
- def render_templates(
- self,
- ) -> tuple[str, str, list[tuple[str, list[str], str, str]]]:
- """Render and return all the templates for the Typst file.
-
- Returns:
- The preamble, header, and sections of the Typst file.
- """
- # All the template field names:
- all_template_names = [
- "main_column_first_row_template",
- "main_column_second_row_template",
- "main_column_second_row_without_url_template",
- "main_column_second_row_without_journal_template",
- "date_and_location_column_template",
- "template",
- "degree_column_template",
- ]
-
- # All the placeholders used in the templates:
- sections_input: dict[str, list[pydantic.BaseModel]] = self.cv.sections_input # type: ignore
- # Loop through the sections and entries to find all the field names:
- placeholder_keys: set[str] = set()
- if sections_input:
- for section in sections_input.values():
- for entry in section:
- if isinstance(entry, str):
- break
- for key in entry.__class__.model_fields:
- placeholder_keys.add(key.upper())
-
- pattern = re.compile(r"(? str:
- return pattern.sub("_", name).lower()
-
- # Template the preamble, header, and sections:
- preamble = self.template("Preamble")
- header = self.template("Header")
- sections: list[tuple[str, list[str], str, str]] = []
- for section in self.cv.sections:
- section_beginning = self.template(
- "SectionBeginning",
- section_title=escape_typst_characters(section.title),
- entry_type=section.entry_type,
- )
-
- templates = {
- template_name: getattr(
- getattr(
- getattr(self.design, "entry_types", None),
- camel_to_snake(section.entry_type),
- None,
- ),
- template_name,
- None,
- )
- for template_name in all_template_names
- }
-
- entries: list[str] = []
- for i, entry in enumerate(section.entries):
- # Prepare placeholders:
- placeholders = {}
- for placeholder_key in placeholder_keys:
- components_path = (
- pathlib.Path(__file__).parent.parent / "themes" / "components"
- )
- lowercase_placeholder_key = placeholder_key.lower()
- if (
- components_path / f"{lowercase_placeholder_key}.j2.typ"
- ).exists():
- placeholder_value = super().template(
- "components",
- lowercase_placeholder_key,
- "typ",
- entry,
- section_title=section.title,
- )
- else:
- arbitrary_keys = getattr(entry, "model_extra", None)
- placeholder_value = arbitrary_keys.get(lowercase_placeholder_key, None) if isinstance(arbitrary_keys, dict) else None
-
- placeholders[placeholder_key] = (
- placeholder_value if placeholder_value != "None" else None
- )
-
- # Substitute the placeholders in the templates:
- templates_with_substitutions = {
- template_name: (
- input_template_to_typst(
- templates[template_name],
- placeholders, # type: ignore
- )
- if templates.get(template_name)
- else None
- )
- for template_name in all_template_names
- }
-
- entries.append(
- self.template(
- section.entry_type,
- entry=entry,
- section_title=section.title,
- entry_type=section.entry_type,
- is_first_entry=i == 0,
- **templates_with_substitutions, # all the templates
- )
- )
- section_ending = self.template(
- "SectionEnding",
- section_title=section.title,
- entry_type=section.entry_type,
- )
- sections.append(
- (section_beginning, entries, section_ending, section.entry_type)
- )
-
- return preamble, header, sections
-
- def template(
- self,
- template_name: str,
- entry: data.Entry | None = None,
- **kwargs,
- ) -> str:
- """Template one of the files in the `themes` directory.
-
- Args:
- template_name: The name of the template file.
- entry: The data model of the entry.
-
- Returns:
- The templated file.
- """
- return super().template(
- self.design.theme,
- template_name,
- "typ",
- entry,
- **kwargs,
- )
-
- def get_full_code(self) -> str:
- """Get the Typst code of the file.
-
- Returns:
- The Typst code.
- """
- preamble, header, sections = self.render_templates()
- code: str = super().get_full_code(
- "main.j2.typ",
- preamble=preamble,
- header=header,
- sections=sections,
- )
- return code
-
- def create_file(self, file_path: pathlib.Path):
- """Write the Typst code to a file."""
- file_path.write_text(self.get_full_code(), encoding="utf-8")
-
-
-class MarkdownFile(TemplatedFile):
- """This class represents a Markdown file. It generates the Markdown code with the
- data model and Jinja2 templates. Markdown files are generated to produce an HTML
- which can be copy-pasted to [Grammarly](https://app.grammarly.com/) for
- proofreading.
- """
-
- def render_templates(self) -> tuple[str, list[tuple[str, list[str]]]]:
- """Render and return all the templates for the Markdown file.
-
- Returns:
- The header and sections of the Markdown file.
- """
- # Template the header and sections:
- header = self.template("Header")
- sections: list[tuple[str, list[str]]] = []
- for section in self.cv.sections:
- section_beginning = self.template(
- "SectionBeginning",
- section_title=section.title,
- entry_type=section.entry_type,
- )
- entries: list[str] = []
- for i, entry in enumerate(section.entries):
- is_first_entry = bool(i == 0)
- entries.append(
- self.template(
- section.entry_type,
- entry=entry,
- section_title=section.title,
- entry_type=section.entry_type,
- is_first_entry=is_first_entry,
- )
- )
- sections.append((section_beginning, entries))
-
- result: tuple[str, list[tuple[str, list[str]]]] = (header, sections)
- return result
-
- def template(
- self,
- template_name: str,
- entry: data.Entry | None = None,
- **kwargs,
- ) -> str:
- """Template one of the files in the `themes` directory.
-
- Args:
- template_name: The name of the template file.
- entry: The data model of the entry.
-
- Returns:
- The templated file.
- """
- return super().template(
- "markdown",
- template_name,
- "md",
- entry,
- **kwargs,
- )
-
- def get_full_code(self) -> str:
- """Get the Markdown code of the file.
-
- Returns:
- The Markdown code.
- """
- header, sections = self.render_templates()
- code: str = super().get_full_code(
- "main.j2.md",
- header=header,
- sections=sections,
- )
- return code
-
- def create_file(self, file_path: pathlib.Path):
- """Write the Markdown code to a file."""
- file_path.write_text(self.get_full_code(), encoding="utf-8")
-
-
-def input_template_to_typst(
- input_template: str | None, placeholders: dict[str, str | None]
-) -> str:
- """Convert an input template to Typst.
-
- Args:
- input_template: The input template.
- placeholders: The placeholders and their values.
-
- Returns:
- Typst string.
- """
- if input_template is None:
- return ""
-
- output = replace_placeholders_with_actual_values(
- markdown_to_typst(input_template),
- placeholders,
- )
-
- # If \n is escaped, revert:
- output = output.replace("\\n", "\n")
-
- # If there are blank italics and bolds, remove them:
- output = output.replace("#emph[]", "")
- output = output.replace("#strong[]", "")
-
- # Check if there are any letters in the input template. If not, return an empty
- if not re.search(r"[a-zA-Z]", input_template):
- return ""
-
- # Find italic and bold links and fix them:
- # For example:
- # Convert `#emph[#link("https://google.com")[italic link]]` to
- # `#link("https://google.com")[#emph[italic link]]`
- output = re.sub(
- r"#emph\[#link\(\"(.*?)\"\)\[(.*?)\]\]",
- r'#link("\1")[#emph[\2]]',
- output,
- )
- output = re.sub(
- r"#strong\[#link\(\"(.*?)\"\)\[(.*?)\]\]",
- r'#link("\1")[#strong[\2]]',
- output,
- )
- output = re.sub(
- r"#strong\[#emph\[#link\(\"(.*?)\"\)\[(.*?)\]\]\]",
- r'#link("\1")[#strong[#emph[\2]]]',
- output,
- )
-
- # Replace all multiple \n with a double \n:
- output = re.sub(r"\n+", r"\n\n", output)
-
- # Strip whitespace
- output = output.strip()
-
- # Strip non-alphanumeric, non-typst characters from the beginning and end of the
- # string. For example, when location is not given in a template like this:
- # "NAME -- LOCATION", "NAME -- " should become "NAME".
- output = re.sub(r"^[^\w\s#\[\]\n\(\)]*", "", output)
- output = re.sub(r"[^\w\s#\[\]\n\(\)]*$", "", output)
-
- return output # noqa: RET504
-
-
-@overload
-def remove_typst_commands(string: None) -> None: ...
-
-
-@overload
-def remove_typst_commands(string: str) -> str: ...
-
-
-def remove_typst_commands(string: str | None) -> str | None:
- """Remove Typst commands from a string.
-
- Args:
- string: The string to remove Typst commands from.
-
- Returns:
- The string without Typst commands.
- """
- if string:
- commands = re.findall(r"\#.*?\[.*?\]", string)
- for command in commands:
- string = string.replace(command, "")
-
- return string
-
- return None
-
-
-def escape_characters(string: str, escape_dictionary: dict[str, str]) -> str:
- """Escape characters in a string by using `escape_dictionary`, where keys are
- characters to escape and values are their escaped versions.
-
- Example:
- ```python
- escape_characters("This is a # string.", {"#": "\\#"})
- ```
- returns
- `"This is a \\# string."`
-
- Args:
- string: The string to escape.
- escape_dictionary: The dictionary of escape characters.
-
- Returns:
- The escaped string.
- """
-
- translation_map = str.maketrans(escape_dictionary)
-
- # Don't escape urls as hyperref package will do it automatically:
- # Find all the links in the sentence:
- links = re.findall(r"\[(.*?)\]\((.*?)\)", string)
-
- # Replace the links with a dummy string and save links with escaped characters:
- new_links = []
- for i, link in enumerate(links):
- placeholder = link[0]
- escaped_placeholder = placeholder.translate(translation_map)
- url = link[1]
-
- original_link = f"[{placeholder}]({url})"
- string = string.replace(original_link, f"!!-link{i}-!!")
-
- new_link = f"[{escaped_placeholder}]({url})"
- new_links.append(new_link)
-
- # If there are equations in the sentence, don't escape the special characters:
- # Find all the equations in the sentence:
- equations = re.findall(r"(\$\$.*?\$\$)", string)
- new_equations = []
- for i, equation in enumerate(equations):
- string = string.replace(equation, f"!!-equation{i}-!!")
-
- # Keep only one dollar sign for inline equations:
- new_equation = equation.replace("$$", "$")
- new_equations.append(new_equation)
-
- # If there are Typst commands, don't escape the special characters:
- commands = re.findall(r"(\#.*?\[.*?\])", string)
- for i, command in enumerate(commands):
- string = string.replace(command, f"!!-command{i}-!!")
-
- # Loop through the letters of the sentence and if you find an escape character,
- # replace it with their equivalent:
- string = string.translate(translation_map)
-
- # Replace !!-link{i}-!!" with the original urls:
- for i, new_link in enumerate(new_links):
- string = string.replace(f"!!-link{i}-!!", new_link)
-
- # Replace !!-equation{i}-!!" with the original equations:
- for i, new_equation in enumerate(new_equations):
- string = string.replace(f"!!-equation{i}-!!", new_equation)
-
- # Replace !!-command{i}-!!" with the original commands:
- for i, command in enumerate(commands):
- string = string.replace(f"!!-command{i}-!!", command)
-
- return string
-
-
-@overload
-def escape_typst_characters(string: None) -> None: ...
-
-
-@overload
-def escape_typst_characters(string: str) -> str: ...
-
-
-def escape_typst_characters(string: str | None) -> str | None:
- """Escape Typst characters in a string by adding a backslash before them.
-
- Example:
- ```python
- escape_typst_characters("This is a # string.")
- ```
- returns
- `"This is a \\# string."`
-
- Args:
- string: The string to escape.
-
- Returns:
- The escaped string.
- """
- if string is None:
- return None
-
- escape_dictionary = {
- "[": "\\[",
- "]": "\\]",
- "(": "\\(",
- ")": "\\)",
- "\\": "\\\\",
- '"': '\\"',
- "#": "\\#",
- "$": "\\$",
- "@": "\\@",
- "%": "\\%",
- "~": "\\~",
- "_": "\\_",
- "/": "\\/",
- }
-
- return escape_characters(string, escape_dictionary)
-
-
-def markdown_to_typst(markdown_string: str) -> str:
- """Convert a Markdown string to Typst.
-
- Example:
- ```python
- markdown_to_typst(
- "This is a **bold** text with an [*italic link*](https://google.com)."
- )
- ```
-
- returns
-
- `"This is a *bold* text with an #link("https://google.com")[_italic link_]."`
-
- Args:
- markdown_string: The Markdown string to convert.
-
- Returns:
- The Typst string.
- """
- # convert links
- links = re.findall(r"\[([^\]\[]*)\]\((.*?)\)", markdown_string)
- if links is not None:
- for link in links:
- link_text = link[0]
- link_url = link[1]
-
- old_link_string = f"[{link_text}]({link_url})"
- new_link_string = f'#link("{link_url}")[{link_text}]'
-
- markdown_string = markdown_string.replace(old_link_string, new_link_string)
-
- # Process escaped asterisks in the yaml (such that they are actual asterisks,
- # and not markers for bold/italics). We need to temporarily replace them with
- # a dummy string.
-
- ONE_STAR = "ONE_STAR"
-
- # NOTE: We get a mix of escape levels depending on whether the star is in a quoted
- # or unquoted yaml entry. This is a bit of a mess but below seems to work
- # as i would instinctively expect.
- markdown_string = markdown_string.replace("\\\\*", ONE_STAR)
- markdown_string = markdown_string.replace("\\*", ONE_STAR)
-
- # convert bold and italic:
- bold_and_italics = re.findall(r"\*\*\*(.+?)\*\*\*", markdown_string)
- if bold_and_italics is not None:
- for bold_and_italic_text in bold_and_italics:
- old_bold_and_italic_text = f"***{bold_and_italic_text}***"
- new_bold_and_italic_text = f"#strong[#emph[{bold_and_italic_text}]]"
-
- markdown_string = markdown_string.replace(
- old_bold_and_italic_text, new_bold_and_italic_text
- )
-
- # convert bold
- bolds = re.findall(r"\*\*(.+?)\*\*", markdown_string)
- if bolds is not None:
- for bold_text in bolds:
- old_bold_text = f"**{bold_text}**"
- new_bold_text = f"#strong[{bold_text}]"
- markdown_string = markdown_string.replace(old_bold_text, new_bold_text)
-
- # convert italic
- italics = re.findall(r"\*(.+?)\*", markdown_string)
- if italics is not None:
- for italic_text in italics:
- old_italic_text = f"*{italic_text}*"
- new_italic_text = f"#emph[{italic_text}]"
-
- markdown_string = markdown_string.replace(old_italic_text, new_italic_text)
-
- # Revert normal asterisks then convert them to Typst's asterisks
- markdown_string = markdown_string.replace(ONE_STAR, "*")
-
- # convert any remaining asterisks to Typst's asterisk
- # - Asterisk with a space can just be replaced.
- # - Asterisk without a space needs a zero-width box to delimit it.
- typst_asterisk = "#sym.ast.basic"
- zero_box = "#h(0pt, weak: true) "
- markdown_string = markdown_string.replace("* ", typst_asterisk + " ")
- markdown_string = markdown_string.replace("*", typst_asterisk + zero_box)
-
- # At this point, the document ought to have absolutely no '*' characters left!
- # NOTE: The final typst file might still have some asterisks when specifying a
- # size, for example `#v(design-text-font-size * 0.4)`
- # XXX: Maybe put this behind some kind of debug flag? -MK
- # assert "*" not in markdown_string
-
- return markdown_string # noqa: RET504
-
-
-def transform_markdown_sections_to_something_else_sections(
- sections: dict[str, data.SectionContents],
- functions_to_apply: list[Callable],
-) -> dict[str, data.SectionContents] | None:
- """
- Recursively loop through sections and update all the strings by applying the
- `functions_to_apply` functions, given as an argument.
-
- Args:
- sections: Sections with Markdown strings.
- functions_to_apply: Functions to apply to the strings.
-
- Returns:
- Sections with updated strings.
- """
-
- def apply_functions_to_string(string: str):
- for function in functions_to_apply:
- string = function(string)
- return string
-
- for key, value in sections.items():
- transformed_list = []
- for entry in value:
- if isinstance(entry, str):
- # Then it means it's a TextEntry.
- result = apply_functions_to_string(entry)
- transformed_list.append(result)
- else:
- # Then it means it's one of the other entries.
- # Fields whose *value* should never be string-processed / overwritten
- # because they are stored as specialised objects (e.g. pydantic HttpUrl).
- fields_to_skip = {"doi", "url", "website"}
-
- for entry_key, _model_field in entry.__class__.model_fields.items():
- if entry_key in fields_to_skip:
- continue
-
- inner_value = getattr(entry, entry_key)
-
- # Process str
- if isinstance(inner_value, str):
- setattr(
- entry, entry_key, apply_functions_to_string(inner_value)
- )
-
- # Process list[str]
- elif isinstance(inner_value, list):
- new_list: list = []
- changed = False
- for item in inner_value:
- if isinstance(item, str):
- new_list.append(apply_functions_to_string(item))
- changed = True
- else:
- new_list.append(item)
- if changed:
- setattr(entry, entry_key, new_list)
- transformed_list.append(entry)
-
- sections[key] = transformed_list
-
- return sections
-
-
-def transform_markdown_sections_to_typst_sections(
- sections: dict[str, data.SectionContents],
-) -> dict[str, data.SectionContents] | None:
- """
- Recursively loop through sections and convert all the Markdown strings (user input
- is in Markdown format) to Typst strings.
-
- Args:
- sections: Sections with Markdown strings.
-
- Returns:
- Sections with Typst strings.
- """
- return transform_markdown_sections_to_something_else_sections(
- sections,
- [escape_typst_characters, markdown_to_typst],
- )
-
-
-def replace_placeholders_with_actual_values(
- text: str,
- placeholders: dict[str, str | None],
-) -> str:
- """Replace the placeholders in a string with actual values.
-
- This function can be used as a Jinja2 filter in templates.
-
- Args:
- text: The text with placeholders.
- placeholders: The placeholders and their values.
-
- Returns:
- The string with actual values.
- """
- for placeholder, value in placeholders.items():
- # Use regex only for whole-word placeholders like DATE, NAME, etc.
- if re.fullmatch(r"\w+", placeholder): # e.g., "DATE", "NAME"
- pattern = rf"\b{placeholder}\b"
- text = re.sub(pattern, str(value or ""), text)
- else:
- # Fall back to literal replacement if placeholder is not a word (e.g., "{name}")
- text = text.replace(placeholder, str(value or ""))
- return text
-
-
-class Jinja2Environment:
- instance: "Jinja2Environment"
- environment: jinja2.Environment
- current_working_directory: pathlib.Path | None = None
-
- def __new__(cls):
- if (
- not hasattr(cls, "instance")
- or cls.current_working_directory != pathlib.Path.cwd()
- ):
- cls.instance = super().__new__(cls)
-
- themes_directory = pathlib.Path(__file__).parent.parent / "themes"
-
- # create a Jinja2 environment:
- # we need to add the current working directory because custom themes might be used.
- environment = jinja2.Environment(
- loader=jinja2.FileSystemLoader([pathlib.Path.cwd(), themes_directory]),
- trim_blocks=True,
- lstrip_blocks=True,
- )
-
- # set custom delimiters:
- environment.block_start_string = "((*"
- environment.block_end_string = "*))"
- environment.variable_start_string = "<<"
- environment.variable_end_string = ">>"
- environment.comment_start_string = "((#"
- environment.comment_end_string = "#))"
-
- # add custom Jinja2 filters:
- environment.filters["replace_placeholders_with_actual_values"] = (
- replace_placeholders_with_actual_values
- )
- environment.filters["escape_typst_characters"] = escape_typst_characters
- environment.filters["markdown_to_typst"] = markdown_to_typst
- environment.filters["make_a_url_clean"] = data.make_a_url_clean
- environment.filters["remove_typst_commands"] = remove_typst_commands
-
- cls.environment = environment
-
- return cls.instance
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/ExperienceEntry.j2.typ b/src/rendercv/renderer/templater/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/ExperienceEntry.j2.typ
rename to src/rendercv/renderer/templater/__init__.py
diff --git a/src/rendercv/renderer/templater/connections.py b/src/rendercv/renderer/templater/connections.py
new file mode 100644
index 00000000..60558851
--- /dev/null
+++ b/src/rendercv/renderer/templater/connections.py
@@ -0,0 +1,233 @@
+from dataclasses import dataclass
+from typing import Literal
+
+import phonenumbers
+
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .markdown_parser import markdown_to_typst
+from .string_processor import clean_url
+
+fontawesome_icons = {
+ "LinkedIn": "linkedin",
+ "GitHub": "github",
+ "GitLab": "gitlab",
+ "IMDB": "imdb",
+ "Instagram": "instagram",
+ "Mastodon": "mastodon",
+ "ORCID": "orcid",
+ "StackOverflow": "stack-overflow",
+ "ResearchGate": "researchgate",
+ "YouTube": "youtube",
+ "Google Scholar": "graduation-cap",
+ "Telegram": "telegram",
+ "WhatsApp": "whatsapp",
+ "Leetcode": "code",
+ "X": "x-twitter",
+ "location": "location-dot",
+ "email": "envelope",
+ "phone": "phone",
+ "website": "link",
+}
+
+
+def compute_connections(
+ rendercv_model: RenderCVModel, file_type: Literal["typst", "markdown"]
+) -> list[str]:
+ """Route to format-specific connection generator.
+
+ Args:
+ rendercv_model: CV model with contact information.
+ file_type: Target format for connections.
+
+ Returns:
+ List of formatted connection strings.
+ """
+ return {
+ "typst": compute_connections_for_typst,
+ "markdown": compute_connections_for_markdown,
+ }[file_type](rendercv_model)
+
+
+@dataclass
+class Connection:
+ fontawesome_icon: str
+ url: str | None
+ body: str
+
+
+def parse_connections(rendercv_model: RenderCVModel) -> list[Connection]:
+ """Extract contact information from CV model into normalized connection format.
+
+ Why:
+ CV header displays various contact methods in user-defined order. This
+ extracts emails, phones, websites, location, and social networks from
+ the model, preserving the order specified in the input file.
+
+ Args:
+ rendercv_model: CV model with contact information.
+
+ Returns:
+ List of connections with icon specifiers, URLs, and display text.
+ """
+ connections: list[Connection] = []
+ for key in rendercv_model.cv._key_order:
+ match key:
+ case "email":
+ emails = rendercv_model.cv.email
+ if not isinstance(emails, list):
+ emails = [emails]
+
+ for email in emails:
+ url = f"mailto:{email}"
+ body = str(email)
+ connections.append(
+ Connection(
+ fontawesome_icon=fontawesome_icons[key], url=url, body=body
+ )
+ )
+
+ case "phone":
+ phones = rendercv_model.cv.phone
+ assert phones is not None
+ if not isinstance(phones, list):
+ phones = [phones]
+
+ for phone in phones:
+ url = str(phone)
+ body = phonenumbers.format_number(
+ phonenumbers.parse(phone, None),
+ getattr(
+ phonenumbers.PhoneNumberFormat,
+ rendercv_model.design.header.connections.phone_number_format.upper(),
+ ),
+ )
+ connections.append(
+ Connection(
+ fontawesome_icon=fontawesome_icons[key], url=url, body=body
+ )
+ )
+
+ case "website":
+ websites = rendercv_model.cv.website
+ assert websites
+ if not isinstance(websites, list):
+ websites = [websites]
+
+ for website in websites:
+ url = str(website)
+ body = clean_url(website)
+ connections.append(
+ Connection(
+ fontawesome_icon=fontawesome_icons[key], url=url, body=body
+ )
+ )
+
+ case "location":
+ url = None
+ body = str(rendercv_model.cv.location)
+ connections.append(
+ Connection(
+ fontawesome_icon=fontawesome_icons[key], url=None, body=body
+ )
+ )
+
+ case "social_networks":
+ assert rendercv_model.cv.social_networks is not None
+ for social_network in rendercv_model.cv.social_networks:
+ url = social_network.url
+ if rendercv_model.design.header.connections.display_urls_instead_of_usernames:
+ body = clean_url(url)
+ else:
+ match social_network.network:
+ case "Google Scholar":
+ body = "Google Scholar"
+ case _:
+ body = social_network.username
+ connections.append(
+ Connection(
+ fontawesome_icon=fontawesome_icons[social_network.network],
+ url=url,
+ body=body,
+ )
+ )
+
+ case "custom_connections":
+ assert rendercv_model.cv.custom_connections is not None
+ for custom_connection in rendercv_model.cv.custom_connections:
+ url = (
+ str(custom_connection.url)
+ if custom_connection.url is not None
+ else None
+ )
+ body = custom_connection.placeholder
+ connections.append(
+ Connection(
+ fontawesome_icon=custom_connection.fontawesome_icon,
+ url=url,
+ body=body,
+ )
+ )
+
+ return connections
+
+
+def compute_connections_for_typst(rendercv_model: RenderCVModel) -> list[str]:
+ """Format connections with Typst markup, Font Awesome icons, and conditional hyperlinks.
+
+ Why:
+ Typst templates need connection strings with icon syntax and link markup.
+ Icon visibility and hyperlink behavior are user-configurable through
+ design settings, requiring conditional formatting at render time.
+
+ Args:
+ rendercv_model: CV model with contact information and design settings.
+
+ Returns:
+ List of Typst-formatted connection strings ready for template insertion.
+ """
+ connections = parse_connections(rendercv_model)
+
+ show_icon = rendercv_model.design.header.connections.show_icons
+ hyperlink = rendercv_model.design.header.connections.hyperlink
+
+ placeholders = [
+ (
+ f'#connection-with-icon("{connection.fontawesome_icon}")'
+ f"[{markdown_to_typst(connection.body)}]"
+ if show_icon
+ else markdown_to_typst(connection.body)
+ )
+ for connection in connections
+ ]
+
+ return [
+ (
+ f'#link("{connection.url}", icon: false, if-underline: false, if-color:'
+ f" false)[{placeholder}]"
+ if connection.url and hyperlink
+ else placeholder
+ )
+ for connection, placeholder in zip(connections, placeholders, strict=True)
+ ]
+
+
+def compute_connections_for_markdown(rendercv_model: RenderCVModel) -> list[str]:
+ """Format connections as Markdown links without icons.
+
+ Args:
+ rendercv_model: CV model with contact information.
+
+ Returns:
+ List of Markdown-formatted connection strings.
+ """
+ connections = parse_connections(rendercv_model)
+
+ return [
+ (
+ f"[{connection.body}]({connection.url})"
+ if connection.url
+ else connection.body
+ )
+ for connection in connections
+ ]
diff --git a/src/rendercv/renderer/templater/date.py b/src/rendercv/renderer/templater/date.py
new file mode 100644
index 00000000..2b951e66
--- /dev/null
+++ b/src/rendercv/renderer/templater/date.py
@@ -0,0 +1,280 @@
+from datetime import date as Date
+
+from rendercv.exception import RenderCVInternalError
+from rendercv.schema.models.cv.entries.bases.entry_with_complex_fields import (
+ get_date_object,
+)
+from rendercv.schema.models.locale.locale import Locale
+
+from .string_processor import substitute_placeholders
+
+
+def date_object_to_string(
+ date: Date, *, locale: Locale, single_date_template: str
+) -> str:
+ """Convert date object to localized string using template placeholders.
+
+ Why:
+ Date display varies by locale and user preference. Template-based
+ formatting allows MONTH_ABBREVIATION YEAR or MONTH_NAME, YEAR without
+ hardcoding formats for each language.
+
+ Example:
+ ```py
+ result = date_object_to_string(
+ Date(2025, 3, 15),
+ locale=english_locale,
+ single_date_template="MONTH_ABBREVIATION YEAR",
+ )
+ # Returns: "Mar 2025"
+ ```
+
+ Args:
+ date: Date to format.
+ locale: Locale providing month names and abbreviations.
+ single_date_template: Template with date placeholders.
+
+ Returns:
+ Formatted date string with placeholders substituted.
+ """
+ month_names = locale.month_names
+ month_abbreviations = locale.month_abbreviations
+
+ month = int(date.strftime("%m"))
+ year = int(date.strftime(format="%Y"))
+
+ placeholders: dict[str, str] = {
+ "MONTH_NAME": month_names[month - 1],
+ "MONTH_ABBREVIATION": month_abbreviations[month - 1],
+ "MONTH": str(month),
+ "MONTH_IN_TWO_DIGITS": f"{month:02d}",
+ "YEAR": str(year),
+ "YEAR_IN_TWO_DIGITS": str(year)[-2:],
+ }
+
+ return substitute_placeholders(single_date_template, placeholders)
+
+
+def format_date_range(
+ start_date: str | int,
+ end_date: str | int,
+ *,
+ locale: Locale,
+ single_date_template: str,
+ date_range_template: str,
+) -> str:
+ """Format date range with localized start and end dates.
+
+ Why:
+ CV entries use date ranges for employment and education. Users provide
+ dates as year-only integers, YYYY-MM strings, YYYY-MM-DD strings, or
+ "present". Unified formatting handles all input types consistently.
+
+ Example:
+ ```py
+ result = format_date_range(
+ "2020-06",
+ "present",
+ locale=english_locale,
+ single_date_template="MONTH_ABBREVIATION YEAR",
+ date_range_template="START_DATE to END_DATE",
+ )
+ # Returns: "Jun 2020 to present"
+ ```
+
+ Args:
+ start_date: Start date as integer year or ISO date string.
+ end_date: End date as integer year, ISO date string, or "present".
+ locale: Locale providing month names and present translation.
+ single_date_template: Template for formatting individual dates.
+ date_range_template: Template combining start and end dates.
+
+ Returns:
+ Formatted date range string.
+ """
+ if isinstance(start_date, int):
+ # Then it means only the year is provided
+ start_date = str(start_date)
+ else:
+ # Then it means start_date is either in YYYY-MM-DD or YYYY-MM format
+ date_object = get_date_object(start_date)
+ start_date = date_object_to_string(
+ date_object, locale=locale, single_date_template=single_date_template
+ )
+
+ if end_date == "present":
+ end_date = locale.present
+ elif isinstance(end_date, int):
+ # Then it means only the year is provided
+ end_date = str(end_date)
+ else:
+ # Then it means end_date is either in YYYY-MM-DD or YYYY-MM format
+ date_object = get_date_object(end_date)
+ end_date = date_object_to_string(
+ date_object, locale=locale, single_date_template=single_date_template
+ )
+
+ placeholders: dict[str, str] = {
+ "START_DATE": start_date,
+ "END_DATE": end_date,
+ }
+
+ return substitute_placeholders(date_range_template, placeholders)
+
+
+def format_single_date(
+ date: str | int, *, locale: Locale, single_date_template: str
+) -> str:
+ """Format single date with locale-aware template or pass through custom strings.
+
+ Why:
+ Publications and certifications use single dates rather than ranges.
+ Custom date strings like "Spring 2024" need preservation while standard
+ dates require localized formatting.
+
+ Example:
+ ```py
+ # Standard date formatting
+ result = format_single_date(
+ "2024-03", locale=english_locale, single_date_template="MONTH_NAME YEAR"
+ )
+ # Returns: "March 2024"
+
+ # Custom string pass-through
+ result = format_single_date(
+ "Spring 2024", locale=english_locale, single_date_template="MONTH_NAME YEAR"
+ )
+ # Returns: "Spring 2024"
+ ```
+
+ Args:
+ date: Date as integer year, ISO date string, "present", or custom text.
+ locale: Locale providing present translation.
+ single_date_template: Template for formatting standard dates.
+
+ Returns:
+ Formatted date string or original custom text.
+ """
+ if isinstance(date, int):
+ # Only year is provided
+ date_string = str(date)
+ elif date == "present":
+ date_string = locale.present
+ else:
+ try:
+ date_object = get_date_object(date)
+ date_string = date_object_to_string(
+ date_object, locale=locale, single_date_template=single_date_template
+ )
+ except RenderCVInternalError:
+ # Then it is a custom date string (e.g., "My Custom Date")
+ date_string = str(date)
+
+ return date_string
+
+
+def compute_time_span_string(
+ start_date: str | int,
+ end_date: str | int,
+ *,
+ locale: Locale,
+ current_date: Date,
+ time_span_template: str,
+) -> str:
+ """Calculate and format duration between dates with localized units.
+
+ Why:
+ CV readers need quick understanding of experience length. Automatic
+ calculation shows "2 years 3 months" or "1 year" based on date
+ precision, with proper singular/plural forms per locale.
+
+ Example:
+ ```py
+ result = compute_time_span_string(
+ "2020-06",
+ "2023-09",
+ locale=english_locale,
+ current_date=Date(2025, 1, 1),
+ time_span_template="HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS",
+ )
+ # Returns: "3 years 4 months"
+ ```
+
+ Args:
+ start_date: Start date as integer year or ISO date string.
+ end_date: End date as integer year, ISO date string, or "present".
+ locale: Locale providing year/month singular/plural forms.
+ current_date: Reference date for "present" calculation.
+ time_span_template: Template for formatting duration output.
+
+ Returns:
+ Formatted time span string with years and months.
+ """
+ if isinstance(start_date, int) or isinstance(end_date, int):
+ # Then it means one of the dates is year, so time span cannot be more
+ # specific than years.
+ start_year = get_date_object(start_date, current_date).year
+ end_year = get_date_object(end_date, current_date).year
+
+ time_span_in_years = end_year - start_year
+
+ if time_span_in_years < 2:
+ how_many_years = "1"
+ locale_years = locale.year
+ else:
+ how_many_years = str(time_span_in_years)
+ locale_years = locale.years
+
+ placeholders: dict[str, str] = {
+ "HOW_MANY_YEARS": how_many_years,
+ "YEARS": locale_years,
+ "HOW_MANY_MONTHS": "",
+ "MONTHS": "",
+ }
+
+ return substitute_placeholders(time_span_template, placeholders)
+
+ # Then it means both start_date and end_date are in YYYY-MM-DD or YYYY-MM
+ # format.
+ end_date_object = get_date_object(end_date, current_date)
+ start_date_object = get_date_object(start_date, current_date)
+
+ # Calculate the number of days between start_date and end_date:
+ timespan_in_days = (end_date_object - start_date_object).days
+
+ # Calculate the number of years and months between start_date and end_date:
+ how_many_years = timespan_in_days // 365
+ how_many_months = (timespan_in_days % 365) // 30 + 1
+ # Deal with overflow (prevent rounding to 1 year 12 months, etc.)
+ how_many_years += how_many_months // 12
+ how_many_months %= 12
+
+ # Format the number of years and months between start_date and end_date:
+ if how_many_years == 0:
+ how_many_years = ""
+ locale_years = ""
+ elif how_many_years == 1:
+ how_many_years = "1"
+ locale_years = locale.year
+ else:
+ how_many_years = str(how_many_years)
+ locale_years = locale.years
+
+ # Format the number of months between start_date and end_date:
+ if how_many_months == 0:
+ how_many_months = ""
+ locale_months = ""
+ elif how_many_months == 1:
+ how_many_months = "1"
+ locale_months = locale.month
+ else:
+ how_many_months = str(how_many_months)
+ locale_months = locale.months
+
+ placeholders = {
+ "HOW_MANY_YEARS": how_many_years,
+ "YEARS": locale_years,
+ "HOW_MANY_MONTHS": how_many_months,
+ "MONTHS": locale_months,
+ }
+ return substitute_placeholders(time_span_template, placeholders)
diff --git a/src/rendercv/renderer/templater/entry_templates_from_input.py b/src/rendercv/renderer/templater/entry_templates_from_input.py
new file mode 100644
index 00000000..7815d784
--- /dev/null
+++ b/src/rendercv/renderer/templater/entry_templates_from_input.py
@@ -0,0 +1,394 @@
+import re
+import textwrap
+from datetime import date as Date
+
+from rendercv.exception import RenderCVInternalError
+from rendercv.schema.models.cv.entries.publication import PublicationEntry
+from rendercv.schema.models.cv.section import Entry
+from rendercv.schema.models.design.classic_theme import Templates
+from rendercv.schema.models.locale.locale import Locale
+
+from .date import compute_time_span_string, format_date_range, format_single_date
+from .string_processor import clean_url, substitute_placeholders
+
+uppercase_word_pattern = re.compile(r"\b[A-Z_]+\b")
+
+
+def render_entry_templates[EntryType: Entry](
+ entry: EntryType,
+ *,
+ templates: Templates,
+ locale: Locale,
+ show_time_span: bool,
+ current_date: Date,
+) -> EntryType:
+ """Expand entry templates by substituting field placeholders with processed values.
+
+ Why:
+ Entry display is user-customizable through YAML templates. This applies
+ templates to entries, processing special fields (dates, highlights, URLs)
+ and removing placeholders for missing optional fields.
+
+ Args:
+ entry: Entry to process with templates.
+ templates: Template collection for entry types and dates.
+ locale: Locale for date and text formatting.
+ show_time_span: Whether to include duration calculation in dates.
+ current_date: Reference date for "present" and time span calculations.
+
+ Returns:
+ Entry with template-generated display fields.
+ """
+ if isinstance(entry, str) or not hasattr(templates, entry.entry_type_in_snake_case):
+ # It's a TextEntry, or an entry type without templates. Return it as is:
+ return entry
+
+ entry_templates: dict[str, str] = getattr(
+ templates, entry.entry_type_in_snake_case
+ ).model_dump(exclude_none=True)
+
+ entry_fields: dict[str, str | str] = {
+ key.upper(): value for key, value in entry.model_dump(exclude_none=True).items()
+ }
+
+ # Handle special placeholders:
+ if "HIGHLIGHTS" in entry_fields:
+ highlights = getattr(entry, "highlights", None)
+ assert highlights is not None
+ entry_fields["HIGHLIGHTS"] = process_highlights(highlights)
+
+ if "AUTHORS" in entry_fields:
+ authors = getattr(entry, "authors", None)
+ assert authors is not None
+ entry_fields["AUTHORS"] = process_authors(authors)
+
+ if (
+ "DATE" in entry_fields
+ or "START_DATE" in entry_fields
+ or "END_DATE" in entry_fields
+ ):
+ entry_fields["DATE"] = process_date(
+ date=getattr(entry, "date", None),
+ start_date=getattr(entry, "start_date", None),
+ end_date=getattr(entry, "end_date", None),
+ locale=locale,
+ show_time_span=show_time_span,
+ current_date=current_date,
+ single_date_template=templates.single_date,
+ date_range_template=templates.date_range,
+ time_span_template=templates.time_span,
+ )
+
+ if "START_DATE" in entry_fields:
+ start_date = getattr(entry, "start_date", None)
+ assert start_date is not None
+ entry_fields["START_DATE"] = format_single_date(
+ start_date,
+ locale=locale,
+ single_date_template=templates.single_date,
+ )
+
+ if "END_DATE" in entry_fields:
+ end_date = getattr(entry, "end_date", None)
+ assert end_date is not None
+ entry_fields["END_DATE"] = format_single_date(
+ end_date,
+ locale=locale,
+ single_date_template=templates.single_date,
+ )
+
+ if "URL" in entry_fields:
+ entry_fields["URL"] = process_url(entry)
+
+ if "DOI" in entry_fields:
+ entry_fields["URL"] = process_url(entry)
+ entry_fields["DOI"] = process_doi(entry)
+
+ if "SUMMARY" in entry_fields:
+ entry_fields["SUMMARY"] = process_summary(entry_fields["SUMMARY"])
+
+ entry_templates = remove_not_provided_placeholders(entry_templates, entry_fields)
+
+ for template_name, template in (entry_templates | entry_fields).items():
+ setattr(
+ entry,
+ template_name,
+ substitute_placeholders(template, entry_fields),
+ )
+
+ return entry
+
+
+def process_highlights(highlights: list[str]) -> str:
+ """Convert highlight list to Markdown unordered list with nested items.
+
+ Example:
+ ```py
+ result = process_highlights(
+ [
+ "Led team of 5 engineers",
+ "Reduced costs - Server optimization - Database indexing",
+ ]
+ )
+ # Returns:
+ # - Led team of 5 engineers
+ # - Reduced costs
+ # - Server optimization
+ # - Database indexing
+ ```
+
+ Args:
+ highlights: Highlight strings with optional " - " for sub-bullets.
+
+ Returns:
+ Markdown list string with nested indentation.
+ """
+ highlights = ["- " + highlight.replace(" - ", "\n - ") for highlight in highlights]
+ return "\n".join(highlights)
+
+
+def process_authors(authors: list[str]) -> str:
+ """Join author names with comma separation.
+
+ Args:
+ authors: Author names for publication entry.
+
+ Returns:
+ Comma-separated author string.
+ """
+ return ", ".join(authors)
+
+
+def process_date(
+ *,
+ date: str | int | None,
+ start_date: str | int | None,
+ end_date: str | int | None,
+ locale: Locale,
+ current_date: Date,
+ show_time_span: bool,
+ single_date_template: str,
+ date_range_template: str,
+ time_span_template: str,
+) -> str:
+ """Format date field as single date or range with optional time span.
+
+ Why:
+ Entry date fields vary by type: publications use single dates, experience
+ uses ranges. This routes to appropriate formatter and optionally appends
+ duration calculation for employment sections.
+
+ Example:
+ ```py
+ # Single date for publication
+ result = process_date(
+ date="2024-03",
+ start_date=None,
+ end_date=None,
+ locale=english_locale,
+ current_date=Date(2025, 1, 1),
+ show_time_span=False,
+ single_date_template="MONTH_NAME YEAR",
+ date_range_template="",
+ time_span_template="",
+ )
+ # Returns: "March 2024"
+
+ # Date range with time span for employment
+ result = process_date(
+ date=None,
+ start_date="2020-06",
+ end_date="present",
+ locale=english_locale,
+ current_date=Date(2025, 1, 1),
+ show_time_span=True,
+ single_date_template="MONTH_ABBREVIATION YEAR",
+ date_range_template="START_DATE to END_DATE",
+ time_span_template="HOW_MANY_YEARS YEARS",
+ )
+ # Returns: "Jun 2020 to present\n\n4 years"
+ ```
+
+ Args:
+ date: Single date for publications and certifications.
+ start_date: Range start for employment and education.
+ end_date: Range end for employment and education.
+ locale: Locale for date formatting.
+ current_date: Reference date for "present" calculation.
+ show_time_span: Whether to append duration to date range.
+ single_date_template: Template for single date formatting.
+ date_range_template: Template for date range formatting.
+ time_span_template: Template for duration formatting.
+
+ Returns:
+ Formatted date string, optionally with time span on new lines.
+ """
+ if date and not (start_date or end_date):
+ return format_single_date(
+ date, locale=locale, single_date_template=single_date_template
+ )
+ if start_date and end_date:
+ date_range = format_date_range(
+ start_date,
+ end_date,
+ locale=locale,
+ single_date_template=single_date_template,
+ date_range_template=date_range_template,
+ )
+ if show_time_span:
+ time_span = compute_time_span_string(
+ start_date,
+ end_date,
+ locale=locale,
+ current_date=current_date,
+ time_span_template=time_span_template,
+ )
+ return f"{date_range}\n\n{time_span}"
+
+ return date_range
+
+ raise RenderCVInternalError("Date is not provided for this entry.")
+
+
+def process_url(entry: Entry) -> str:
+ """Format entry URL as Markdown link with cleaned display text.
+
+ Example:
+ ```py
+ # Entry with url="https://www.example.com/project"
+ result = process_url(entry)
+ # Returns: "[example.com/project](https://www.example.com/project)"
+ ```
+
+ Args:
+ entry: Entry with url or doi field.
+
+ Returns:
+ Markdown link with cleaned URL as display text.
+ """
+ if isinstance(entry, PublicationEntry) and entry.doi:
+ return process_doi(entry)
+ if hasattr(entry, "url") and entry.url: # pyright: ignore[reportAttributeAccessIssue]
+ url = entry.url # pyright: ignore[reportAttributeAccessIssue]
+ return f"[{clean_url(url)}]({url})"
+ raise RenderCVInternalError("URL is not provided for this entry.")
+
+
+def process_doi(entry: Entry) -> str:
+ """Format publication DOI as Markdown link to DOI URL.
+
+ Example:
+ ```py
+ # Entry with doi="10.1000/xyz123"
+ result = process_doi(entry)
+ # Returns: "[10.1000/xyz123](https://doi.org/10.1000/xyz123)"
+ ```
+
+ Args:
+ entry: Publication entry with DOI.
+
+ Returns:
+ Markdown link with DOI as display text and DOI URL as target.
+ """
+ if isinstance(entry, PublicationEntry) and entry.doi:
+ return f"[{entry.doi}]({entry.doi_url})"
+ raise RenderCVInternalError("DOI is not provided for this entry.")
+
+
+def process_summary(summary: str) -> str:
+ """Wrap summary text in Markdown admonition syntax for special rendering in Typst.
+
+ Example:
+ ```py
+ result = process_summary("Key project achievements\\nand outcomes")
+ # Returns:
+ # !!! note
+ # Key project achievements
+ # and outcomes
+ ```
+
+ Args:
+ summary: Summary text to wrap.
+
+ Returns:
+ Markdown admonition block with indented summary.
+ """
+ return f"!!! note\n{textwrap.indent(summary, ' ')}"
+
+
+def remove_not_provided_placeholders(
+ entry_templates: dict[str, str], entry_fields: dict[str, str]
+) -> dict[str, str]:
+ """Remove template placeholders for missing optional fields and surrounding punctuation.
+
+ Why:
+ Optional entry fields like location or URL should disappear cleanly from
+ templates when not provided. Regex removal eliminates placeholders plus
+ adjacent punctuation to prevent "Position at " or trailing commas.
+
+ Example:
+ ```py
+ templates = {"title": "POSITION at COMPANY, LOCATION"}
+ fields = {"POSITION": "Engineer", "COMPANY": "Acme"} # LOCATION missing
+ result = remove_not_provided_placeholders(templates, fields)
+ # Returns: {"title": "POSITION at COMPANY"}
+ ```
+
+ Args:
+ entry_templates: Template strings with uppercase placeholders.
+ entry_fields: Available field values with uppercase keys.
+
+ Returns:
+ Templates with missing placeholders and surrounding characters removed.
+ """
+ # Remove the not provided placeholders from the templates, including characters
+ # around them:
+ used_placeholders_in_templates = set(
+ uppercase_word_pattern.findall(" ".join(entry_templates.values()))
+ )
+ not_provided_placeholders = used_placeholders_in_templates - set(
+ entry_fields.keys()
+ )
+ if not_provided_placeholders:
+ not_provided_placeholders_pattern = re.compile(
+ r"\S*(?:" + "|".join(not_provided_placeholders) + r")\S*"
+ )
+ entry_templates = {
+ key: clean_trailing_parts(not_provided_placeholders_pattern.sub("", value))
+ for key, value in entry_templates.items()
+ }
+
+ return entry_templates
+
+
+unwanted_trailing_parts_pattern = re.compile(r"[^A-Za-z0-9.!?\[\]\(\)\*_%]+$")
+
+
+def clean_trailing_parts(text: str) -> str:
+ """Remove trailing characters except alphanumeric and markdown formatting chars.
+
+ Why:
+ Placeholder removal can leave trailing separators like commas, colons,
+ or dashes. Regex preserves markdown formatting (brackets, asterisks)
+ while removing unwanted trailing characters.
+
+ Example:
+ ```py
+ result = clean_trailing_parts("Position at Company, \\nLink: ")
+ # Returns: "Position at Company\\nLink"
+ # Removes ", " and ": "
+ ```
+
+ Args:
+ text: Text with potential trailing characters.
+
+ Returns:
+ Text with only allowed trailing characters (A-Z, a-z, 0-9, .!?[]())*_%).
+ """
+ new_lines = []
+ for line in text.splitlines():
+ new_line = line.rstrip()
+ if new_line == "":
+ continue
+ new_lines.append(unwanted_trailing_parts_pattern.sub("", new_line).rstrip())
+ return "\n".join(new_lines)
diff --git a/src/rendercv/renderer/templater/footer_and_top_note.py b/src/rendercv/renderer/templater/footer_and_top_note.py
new file mode 100644
index 00000000..1ec2817a
--- /dev/null
+++ b/src/rendercv/renderer/templater/footer_and_top_note.py
@@ -0,0 +1,121 @@
+from collections.abc import Callable
+from datetime import date as Date
+
+from rendercv.schema.models.locale.locale import Locale
+
+from .date import date_object_to_string
+from .string_processor import apply_string_processors, substitute_placeholders
+
+
+def render_top_note_template(
+ top_note_template: str,
+ *,
+ locale: Locale,
+ current_date: Date,
+ name: str | None,
+ single_date_template: str,
+ string_processors: list[Callable[[str], str]] | None = None,
+) -> str:
+ """Render top note by substituting placeholders and applying string processors.
+
+ Why:
+ Top notes display generation metadata like "Last Updated: Jan 2025" at
+ document top. Template-based generation allows localization and custom
+ formatting per user preference.
+
+ Example:
+ ```py
+ result = render_top_note_template(
+ "LAST_UPDATED: CURRENT_DATE",
+ locale=english_locale,
+ current_date=date(2025, 1, 15),
+ name="John Doe",
+ single_date_template="MONTH_ABBREVIATION YEAR",
+ )
+ # Returns: "Last Updated: Jan 2025"
+ ```
+
+ Args:
+ top_note_template: Template with CURRENT_DATE, LAST_UPDATED, NAME placeholders.
+ locale: Locale providing last_updated translation.
+ current_date: Date for timestamp.
+ name: CV owner name for placeholder substitution.
+ single_date_template: Template for date formatting.
+ string_processors: Optional processors for markdown parsing and formatting.
+
+ Returns:
+ Rendered top note with substituted placeholders.
+ """
+ if string_processors is None:
+ string_processors = []
+
+ placeholders: dict[str, str] = {
+ "CURRENT_DATE": date_object_to_string(
+ current_date,
+ locale=locale,
+ single_date_template=single_date_template,
+ ),
+ "LAST_UPDATED": locale.last_updated,
+ "NAME": name or "",
+ }
+ return apply_string_processors(
+ substitute_placeholders(top_note_template, placeholders), string_processors
+ )
+
+
+def render_footer_template(
+ footer_template: str,
+ *,
+ locale: Locale,
+ current_date: Date,
+ name: str | None,
+ single_date_template: str,
+ string_processors: list[Callable[[str], str]] | None = None,
+) -> str:
+ """Render footer by substituting placeholders and wrapping in Typst context block.
+
+ Why:
+ Footers show page numbers and metadata on each page. Typst context blocks
+ enable dynamic page number access. Template substitution handles localized
+ dates and names before wrapping in required Typst syntax.
+
+ Example:
+ ```py
+ result = render_footer_template(
+ "NAME - Page PAGE_NUMBER of TOTAL_PAGES",
+ locale=english_locale,
+ current_date=date(2025, 1, 15),
+ name="John Doe",
+ single_date_template="MONTH_ABBREVIATION YEAR",
+ )
+ # Returns: "context { [John Doe - Page #str(here().page()) of #str(counter(page).final().first())] }"
+ ```
+
+ Args:
+ footer_template: Template with NAME, PAGE_NUMBER, TOTAL_PAGES, CURRENT_DATE placeholders.
+ locale: Locale for date formatting.
+ current_date: Date for timestamp.
+ name: CV owner name for placeholder substitution.
+ single_date_template: Template for date formatting.
+ string_processors: Optional processors for markdown parsing and formatting.
+
+ Returns:
+ Typst context block with rendered footer content.
+ """
+ if string_processors is None:
+ string_processors = []
+
+ placeholders: dict[str, str] = {
+ "CURRENT_DATE": date_object_to_string(
+ current_date,
+ locale=locale,
+ single_date_template=single_date_template,
+ ),
+ "NAME": name or "",
+ "PAGE_NUMBER": "#str(here().page())",
+ "TOTAL_PAGES": "#str(counter(page).final().first())",
+ }
+ return (
+ "context {"
+ f" [{apply_string_processors(substitute_placeholders(footer_template, placeholders), string_processors)}] }}"
+ )
diff --git a/src/rendercv/renderer/templater/markdown_parser.py b/src/rendercv/renderer/templater/markdown_parser.py
new file mode 100644
index 00000000..65624077
--- /dev/null
+++ b/src/rendercv/renderer/templater/markdown_parser.py
@@ -0,0 +1,180 @@
+import itertools
+import re
+from xml.etree.ElementTree import Element
+
+import markdown
+import markdown.core
+
+
+def to_typst_string(elem: Element) -> str:
+ """Recursively convert XML Element tree to Typst markup string.
+
+ Why:
+ Python Markdown library outputs XML Element tree. Typst requires its
+ own markup syntax for bold, italic, links, etc. Recursive traversal
+ converts entire element tree including nested formatting.
+
+ Args:
+ elem: XML Element from Markdown parser.
+
+ Returns:
+ Typst-formatted string.
+ """
+ result = []
+
+ # Handle the element's text content
+ if elem.text:
+ result.append(escape_typst_characters(elem.text))
+
+ # Process child elements
+ for child in elem:
+ match child.tag:
+ case "strong":
+ # Bold: **text** -> #strong[text]
+ inner = to_typst_string(child)
+ child_content = f"#strong[{inner}]"
+
+ case "em":
+ # Italic: *text* -> #emph[text]
+ inner = to_typst_string(child)
+ child_content = f"#emph[{inner}]"
+
+ case "code":
+ # Inline code: `text` -> `text`
+ # Code content is already escaped by the parser
+ child_content = f"`{child.text}`"
+
+ case "a":
+ # Link: [text](url) -> #link("url")[text]
+ href = child.get("href", "")
+ inner = to_typst_string(child)
+ child_content = f'#link("{href}")[{inner}]'
+
+ case "div":
+ child_content = "#summary[" + to_typst_string(child).strip("\n") + "]"
+
+ case _:
+ if getattr(child, "attrib", {}).get("class") == "admonition-title":
+ continue
+ child_content = to_typst_string(child)
+
+ result.append(child_content)
+
+ # Handle tail text (text after the closing tag of child)
+ if child.tail:
+ result.append(escape_typst_characters(child.tail))
+
+ return "".join(result)
+
+
+typst_command_pattern = re.compile(r"#([A-Za-z][^\s()\[]*)(\([^)]*\))?(\[[^\]]*\])?")
+math_pattern = re.compile(r"(\$\$.*?\$\$)")
+
+
+def escape_typst_characters(string: str) -> str:
+ """Escape Typst special characters while preserving Typst commands and math.
+
+ Why:
+ User content may contain Typst special characters like `#`, `$`, `[` that
+ would break compilation. Escaping prevents interpretation as commands.
+ Existing Typst commands and math must remain unescaped.
+
+ Args:
+ string: Text to escape.
+
+ Returns:
+ Escaped string safe for Typst.
+ """
+ if string == "\n":
+ return string
+
+ # Find all the Typst commands, and keep them separate so that nothing is escaped
+ # inside the commands.
+ typst_command_mapping = {}
+ for i, match in enumerate(
+ itertools.chain(
+ math_pattern.finditer(string),
+ typst_command_pattern.finditer(string),
+ )
+ ):
+ dummy_name = f"RENDERCVTYPSTCOMMANDORMATH{i}"
+ typst_command_mapping[dummy_name] = match.group(0)
+ string = string.replace(typst_command_mapping[dummy_name], dummy_name)
+ typst_command_mapping[dummy_name] = typst_command_mapping[dummy_name].replace(
+ "$$", "$"
+ )
+
+ # Add the tail after the last match
+ escape_dictionary = {
+ "[": "\\[",
+ "]": "\\]",
+ "\\": "\\\\",
+ '"': '\\"',
+ "#": "\\#",
+ "$": "\\$",
+ "@": "\\@",
+ "%": "\\%",
+ "~": "\\~",
+ "_": "\\_",
+ "/": "\\/",
+ ">": "\\>",
+ "<": "\\<",
+ }
+
+ string = string.translate(str.maketrans(escape_dictionary))
+
+ # string.translate() only supports single-character replacements, so we need to
+ # handle the longer replacements separately.
+ longer_escape_dictionary = {
+ "* ": "#sym.ast.basic ",
+ "*": "#sym.ast.basic#h(0pt, weak: true) ",
+ }
+ for key, value in longer_escape_dictionary.items():
+ string = string.replace(key, value)
+
+ # Replace the dummy names with the full Typst commands
+ for dummy_name, full_command in typst_command_mapping.items():
+ string = string.replace(dummy_name, full_command)
+
+ return string
+
+
+# Create a Markdown instance
+md = markdown.core.Markdown(extensions=["admonition"])
+md.output_formats["typst"] = to_typst_string # pyright: ignore[reportArgumentType]
+md.set_output_format("typst") # pyright: ignore[reportArgumentType]
+md.parser.blockprocessors.deregister("hashheader")
+md.parser.blockprocessors.deregister("setextheader")
+md.parser.blockprocessors.deregister("olist")
+md.parser.blockprocessors.deregister("ulist")
+md.parser.blockprocessors.deregister("quote")
+md.stripTopLevelTags = False
+
+
+def markdown_to_typst(markdown_string: str) -> str:
+ """Convert Markdown string to Typst markup.
+
+ Why:
+ Users write content in Markdown for readability. Typst compilation
+ requires Typst markup. Custom Markdown parser with Typst output
+ format bridges this gap.
+
+ Args:
+ markdown_string: Markdown content.
+
+ Returns:
+ Typst-formatted string.
+ """
+ return md.convert(markdown_string)
+
+
+def markdown_to_html(markdown_string: str) -> str:
+ """Convert Markdown string to HTML using python-markdown library.
+
+ Args:
+ markdown_string: Markdown content.
+
+ Returns:
+ HTML-formatted string.
+ """
+ return markdown.markdown(markdown_string)
diff --git a/src/rendercv/renderer/templater/model_processor.py b/src/rendercv/renderer/templater/model_processor.py
new file mode 100644
index 00000000..5c6ad022
--- /dev/null
+++ b/src/rendercv/renderer/templater/model_processor.py
@@ -0,0 +1,124 @@
+from collections.abc import Callable
+from typing import Literal
+
+from rendercv.schema.models.cv.section import Entry
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .connections import compute_connections
+from .entry_templates_from_input import render_entry_templates
+from .footer_and_top_note import render_footer_template, render_top_note_template
+from .markdown_parser import markdown_to_typst
+from .string_processor import apply_string_processors, make_keywords_bold
+
+
+def process_model(
+ rendercv_model: RenderCVModel, file_type: Literal["typst", "markdown"]
+) -> RenderCVModel:
+ """Pre-process CV model for template rendering with format-specific transformations.
+
+ Why:
+ Templates need processed data, not raw model. This applies markdown
+ parsing, keyword bolding, connection formatting, date rendering, and
+ entry template expansion before templates execute.
+
+ Args:
+ rendercv_model: Validated CV model.
+ file_type: Target format for format-specific processors.
+
+ Returns:
+ Processed model ready for templates.
+ """
+ string_processors: list[Callable[[str], str]] = [
+ lambda string: make_keywords_bold(string, rendercv_model.settings.bold_keywords)
+ ]
+ if file_type == "typst":
+ string_processors.extend([markdown_to_typst])
+
+ rendercv_model.cv.plain_name = rendercv_model.cv.name # pyright: ignore[reportAttributeAccessIssue]
+ rendercv_model.cv.name = apply_string_processors(
+ rendercv_model.cv.name, string_processors
+ )
+ rendercv_model.cv.headline = apply_string_processors(
+ rendercv_model.cv.headline, string_processors
+ )
+ rendercv_model.cv.connections = compute_connections(rendercv_model, file_type) # pyright: ignore[reportAttributeAccessIssue]
+ rendercv_model.cv.top_note = render_top_note_template( # pyright: ignore[reportAttributeAccessIssue]
+ rendercv_model.design.templates.top_note,
+ locale=rendercv_model.locale,
+ current_date=rendercv_model.settings.current_date,
+ name=rendercv_model.cv.name,
+ single_date_template=rendercv_model.design.templates.single_date,
+ string_processors=string_processors,
+ )
+
+ rendercv_model.cv.footer = render_footer_template( # pyright: ignore[reportAttributeAccessIssue]
+ rendercv_model.design.templates.footer,
+ locale=rendercv_model.locale,
+ current_date=rendercv_model.settings.current_date,
+ name=rendercv_model.cv.name,
+ single_date_template=rendercv_model.design.templates.single_date,
+ string_processors=string_processors,
+ )
+ if rendercv_model.cv.sections is None:
+ return rendercv_model
+
+ for section in rendercv_model.cv.rendercv_sections:
+ section.title = apply_string_processors(section.title, string_processors)
+ show_time_span = (
+ section.snake_case_title
+ in rendercv_model.design.sections.show_time_spans_in
+ )
+ for i, entry in enumerate(section.entries):
+ entry = render_entry_templates( # NOQA: PLW2901
+ entry,
+ templates=rendercv_model.design.templates,
+ locale=rendercv_model.locale,
+ show_time_span=show_time_span,
+ current_date=rendercv_model.settings.current_date,
+ )
+ section.entries[i] = process_fields(entry, string_processors)
+
+ return rendercv_model
+
+
+def process_fields(
+ entry: Entry, string_processors: list[Callable[[str], str]]
+) -> Entry:
+ """Apply string processors to all entry fields except skipped technical fields.
+
+ Why:
+ Entry fields need markdown parsing and formatting, but dates, DOIs, and
+ URLs must remain unprocessed for correct linking and formatting. Field-
+ level processing enables selective transformation.
+
+ Args:
+ entry: Entry to process (model or string).
+ string_processors: Transformation functions to apply.
+
+ Returns:
+ Entry with processed fields.
+ """
+ skipped = {"start_date", "end_date", "doi", "url"}
+
+ if isinstance(entry, str):
+ return apply_string_processors(entry, string_processors)
+
+ data = entry.model_dump(exclude_none=True)
+ for field, value in data.items():
+ if field in skipped or field.startswith("_"):
+ continue
+
+ if isinstance(value, str):
+ setattr(entry, field, apply_string_processors(value, string_processors))
+ elif isinstance(value, list):
+ setattr(
+ entry,
+ field,
+ [apply_string_processors(v, string_processors) for v in value],
+ )
+ else:
+ setattr(
+ entry, field, apply_string_processors(str(value), string_processors)
+ )
+
+ return entry
diff --git a/src/rendercv/renderer/templater/string_processor.py b/src/rendercv/renderer/templater/string_processor.py
new file mode 100644
index 00000000..c784b3a6
--- /dev/null
+++ b/src/rendercv/renderer/templater/string_processor.py
@@ -0,0 +1,147 @@
+import functools
+import re
+from collections.abc import Callable
+from typing import overload
+
+import pydantic
+
+from rendercv.exception import RenderCVInternalError
+
+
+@overload
+def apply_string_processors(
+ string: None, string_processors: list[Callable[[str], str]]
+) -> None: ...
+@overload
+def apply_string_processors(
+ string: str, string_processors: list[Callable[[str], str]]
+) -> str: ...
+def apply_string_processors(
+ string: str | None, string_processors: list[Callable[[str], str]]
+) -> str | None:
+ """Apply sequence of string transformation functions via reduce.
+
+ Why:
+ Multiple transformations (markdown parsing, keyword bolding, escaping)
+ need sequential application. Functional reduce pattern chains processors
+ cleanly without intermediate variables.
+
+ Args:
+ string: Input string or None.
+ string_processors: Functions to apply in order.
+
+ Returns:
+ Transformed string, or None if input was None.
+ """
+ if string is None:
+ return string
+ return functools.reduce(lambda v, f: f(v), string_processors, string)
+
+
+@functools.lru_cache(maxsize=64)
+def build_keyword_matcher_pattern(keywords: frozenset[str]) -> re.Pattern:
+ """Build cached regex pattern for matching keywords with longest-first priority.
+
+ Why:
+ Keyword matching happens repeatedly during rendering. Cached patterns
+ avoid recompilation. Longest-first sorting prevents "Python" from matching
+ before "Python 3" in same text.
+
+ Args:
+ keywords: Set of keywords to match.
+
+ Returns:
+ Compiled regex pattern.
+ """
+ if not keywords:
+ message = "Keywords cannot be empty"
+ raise RenderCVInternalError(message)
+
+ pattern = (
+ "(" + "|".join(sorted(map(re.escape, keywords), key=len, reverse=True)) + ")"
+ )
+ return re.compile(pattern)
+
+
+def make_keywords_bold(string: str, keywords: list[str]) -> str:
+ """Wrap all keyword occurrences in Markdown bold syntax.
+
+ Why:
+ Users configure keywords like "Python" or "Machine Learning" to highlight
+ in their CV. Automatic bolding applies consistent emphasis across all
+ content without manual markup.
+
+ Example:
+ ```py
+ result = make_keywords_bold("Expert in Python and Java", ["Python"])
+ # Returns: "Expert in **Python** and Java"
+ ```
+
+ Args:
+ string: Text to process.
+ keywords: Keywords to make bold.
+
+ Returns:
+ String with keywords wrapped in ** markers.
+ """
+ if not keywords:
+ return string
+
+ pattern = build_keyword_matcher_pattern(frozenset(keywords))
+ return pattern.sub(lambda m: f"**{m.group(0)}**", string)
+
+
+def substitute_placeholders(string: str, placeholders: dict[str, str]) -> str:
+ """Replace all placeholder occurrences with their values.
+
+ Why:
+ Output file names use placeholders like NAME and YEAR for dynamic naming.
+ Pattern matching with longest-first ensures "YEAR_IN_TWO_DIGITS" matches
+ before "YEAR" in same string.
+
+ Example:
+ ```py
+ result = substitute_placeholders(
+ "NAME_CV_YEAR.pdf", {"NAME": "John_Doe", "YEAR": "2025"}
+ )
+ # Returns: "John_Doe_CV_2025.pdf"
+ ```
+
+ Args:
+ string: Template string with placeholders.
+ placeholders: Map of placeholder names to replacement values.
+
+ Returns:
+ String with all placeholders replaced.
+ """
+ if not placeholders:
+ return string
+
+ pattern = build_keyword_matcher_pattern(frozenset(placeholders.keys()))
+ return pattern.sub(lambda m: placeholders[m.group(0)], string).strip()
+
+
+def clean_url(url: str | pydantic.HttpUrl) -> str:
+ """Remove protocol, www, and trailing slashes from URL.
+
+ Why:
+ CV formatting displays cleaner URLs without https:// prefix. Used as
+ Jinja2 filter in templates for consistent URL presentation.
+
+ Example:
+ ```py
+ result = clean_url("https://www.example.com/")
+ # Returns: "example.com"
+ ```
+
+ Args:
+ url: URL to clean.
+
+ Returns:
+ Clean URL string.
+ """
+ url = str(url).replace("https://", "").replace("http://", "")
+ if url.endswith("/"):
+ url = url[:-1]
+
+ return url
diff --git a/src/rendercv/renderer/templater/templater.py b/src/rendercv/renderer/templater/templater.py
new file mode 100644
index 00000000..b4a4c200
--- /dev/null
+++ b/src/rendercv/renderer/templater/templater.py
@@ -0,0 +1,214 @@
+import contextlib
+import functools
+import pathlib
+from typing import Literal
+
+import jinja2
+
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .markdown_parser import markdown_to_html
+from .model_processor import process_model
+from .string_processor import clean_url
+
+templates_directory = pathlib.Path(__file__).parent / "templates"
+
+
+@functools.lru_cache(maxsize=1)
+def get_jinja2_environment(
+ input_file_path: pathlib.Path | None = None,
+) -> jinja2.Environment:
+ """Create cached Jinja2 environment with custom filters and template loaders.
+
+ Why:
+ Template rendering is called multiple times per render. Caching environment
+ prevents repeated filesystem scans. Loader hierarchy enables user template
+ overrides by checking input file directory before built-in templates.
+
+ Args:
+ input_file_path: Path to input file for user template override resolution.
+
+ Returns:
+ Configured Jinja2 environment with filters and loaders.
+ """
+ env = jinja2.Environment(
+ loader=jinja2.FileSystemLoader(
+ [
+ ( # To allow users to override the templates:
+ input_file_path.parent if input_file_path else pathlib.Path.cwd()
+ ),
+ templates_directory,
+ ]
+ ),
+ trim_blocks=True,
+ lstrip_blocks=True,
+ )
+ env.filters["clean_url"] = clean_url
+ env.filters["strip"] = lambda string: string.strip()
+ return env
+
+
+def render_full_template(
+ rendercv_model: RenderCVModel, file_type: Literal["typst", "markdown"]
+) -> str:
+ """Render complete CV document by assembling preamble, header, and sections.
+
+ Why:
+ CV generation requires consistent structure across formats. This orchestrates
+ model processing, template rendering for each component, and assembly into
+ final document following proper order.
+
+ Example:
+ ```py
+ typst_document = render_full_template(rendercv_model, "typst")
+ # Returns complete .typ file with preamble, header, and all sections
+
+ markdown_document = render_full_template(rendercv_model, "markdown")
+ # Returns complete .md file with header and all sections
+ ```
+
+ Args:
+ rendercv_model: CV model to render.
+ file_type: Output format for template selection and processing.
+
+ Returns:
+ Complete rendered document as string.
+ """
+ extension = {
+ "typst": "typ",
+ "markdown": "md",
+ }[file_type]
+
+ rendercv_model = process_model(rendercv_model, file_type)
+
+ header = render_single_template(
+ file_type,
+ f"Header.j2.{extension}",
+ rendercv_model,
+ )
+ if file_type == "typst":
+ preamble = render_single_template(
+ file_type,
+ f"Preamble.j2.{extension}",
+ rendercv_model,
+ )
+ code = f"{preamble}\n\n{header}\n"
+ else:
+ code = f"{header}\n"
+
+ for rendercv_section in rendercv_model.cv.rendercv_sections:
+ section_beginning = render_single_template(
+ file_type,
+ f"SectionBeginning.j2.{extension}",
+ rendercv_model,
+ section_title=rendercv_section.title,
+ snake_case_section_title=rendercv_section.snake_case_title,
+ entry_type=rendercv_section.entry_type,
+ )
+ section_ending = render_single_template(
+ file_type,
+ f"SectionEnding.j2.{extension}",
+ rendercv_model,
+ entry_type=rendercv_section.entry_type,
+ )
+ entry_codes = []
+ for entry in rendercv_section.entries:
+ entry_code = render_single_template(
+ file_type,
+ f"entries/{rendercv_section.entry_type}.j2.{extension}",
+ rendercv_model,
+ entry=entry,
+ )
+ entry_codes.append(entry_code)
+ entries_code = "\n\n".join(entry_codes)
+ section_code = f"{section_beginning}\n{entries_code}\n{section_ending}"
+ code += f"\n{section_code}"
+
+ return code
+
+
+def render_html(rendercv_model: RenderCVModel, markdown: str) -> str:
+ """Convert Markdown to HTML and wrap with full HTML template.
+
+ Why:
+ HTML output requires both content conversion (Markdown to HTML body) and
+ document structure (head, CSS, metadata). Separate function handles HTML-
+ specific workflow distinct from Typst/Markdown direct generation.
+
+ Example:
+ ```py
+ markdown_content = render_full_template(rendercv_model, "markdown")
+ html_document = render_html(rendercv_model, markdown_content)
+ # Returns complete HTML with , CSS, and converted Markdown body
+ ```
+
+ Args:
+ rendercv_model: CV model for template context.
+ markdown: Markdown content to convert.
+
+ Returns:
+ Complete HTML document.
+ """
+ html_body = markdown_to_html(markdown)
+ return render_single_template(
+ "html", "Full.html", rendercv_model, html_body=html_body
+ )
+
+
+def render_single_template(
+ file_type: Literal["markdown", "typst", "html"],
+ relative_template_path: str,
+ rendercv_model: RenderCVModel,
+ **kwargs,
+) -> str:
+ """Render single Jinja2 template with user override support. Arbitrary keyword
+ arguments may be passed to the template as additional template variables.
+
+ Why:
+ Users can override built-in templates by placing custom templates in
+ theme folder alongside input file. Typst templates check theme-specific
+ location first, falling back to built-in templates if not found.
+
+ Example:
+ ```py
+ header = render_single_template("typst", "Header.j2.typ", rendercv_model)
+ # First checks for classic/Header.j2.typ in input file directory
+ # Falls back to built-in typst/Header.j2.typ if not found
+
+ section = render_single_template(
+ "typst",
+ "SectionBeginning.j2.typ",
+ rendercv_model,
+ section_title="Experience",
+ )
+ ```
+
+ Args:
+ file_type: Format for template directory selection.
+ relative_template_path: Template file path relative to format directory.
+ rendercv_model: CV model providing template context.
+
+ Returns:
+ Rendered template as string.
+ """
+ jinja2_environment = get_jinja2_environment(rendercv_model._input_file_path)
+ template = None
+ if file_type == "typst":
+ # Try user's own Typst templates first:
+ with contextlib.suppress(jinja2.TemplateNotFound):
+ template = jinja2_environment.get_template(
+ f"{rendercv_model.design.theme}/{relative_template_path}"
+ )
+
+ if template is None:
+ template = jinja2_environment.get_template(
+ f"{file_type}/{relative_template_path}"
+ )
+
+ return template.render(
+ cv=rendercv_model.cv,
+ design=rendercv_model.design,
+ locale=rendercv_model.locale,
+ settings=rendercv_model.settings,
+ **kwargs,
+ )
diff --git a/src/rendercv/themes/main.j2.html b/src/rendercv/renderer/templater/templates/html/Full.html
similarity index 94%
rename from src/rendercv/themes/main.j2.html
rename to src/rendercv/renderer/templater/templates/html/Full.html
index 5ee86ac1..65bfd38a 100644
--- a/src/rendercv/themes/main.j2.html
+++ b/src/rendercv/renderer/templater/templates/html/Full.html
@@ -1,12 +1,12 @@
-
+
- <<title>>
+ {{ title }}
- <>
+ {{ html_body|indent(8) }}
diff --git a/src/rendercv/renderer/templater/templates/markdown/Header.j2.md b/src/rendercv/renderer/templater/templates/markdown/Header.j2.md
new file mode 100644
index 00000000..e3f4df99
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/Header.j2.md
@@ -0,0 +1,21 @@
+{% if cv.name %}
+# {{ cv.name }}'s CV
+{% endif %}
+
+{% if cv.phone %}
+- Phone: {{cv.phone|replace("tel:", "")|replace("-"," ")}}
+{% endif %}
+{% if cv.email %}
+- Email: [{{cv.email}}](mailto:{{cv.email}})
+{% endif %}
+{% if cv.location %}
+- Location: {{cv.location}}
+{% endif %}
+{% if cv.website %}
+- Website: [{{cv.website|replace("https://","")|replace("/","")}}]({{cv.website}})
+{% endif %}
+{% if cv.social_networks %}
+ {% for network in cv.social_networks %}
+- {{network.network}}: [{{network.username}}]({{network.url}})
+ {% endfor %}
+{% endif %}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/markdown/SectionBeginning.j2.md b/src/rendercv/renderer/templater/templates/markdown/SectionBeginning.j2.md
new file mode 100644
index 00000000..3135445a
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/SectionBeginning.j2.md
@@ -0,0 +1,2 @@
+# {{section_title}}
+
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/Header.j2.typ b/src/rendercv/renderer/templater/templates/markdown/SectionEnding.j2.md
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/Header.j2.typ
rename to src/rendercv/renderer/templater/templates/markdown/SectionEnding.j2.md
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/BulletEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/BulletEntry.j2.md
new file mode 100644
index 00000000..57fe6663
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/BulletEntry.j2.md
@@ -0,0 +1 @@
+- {{entry.bullet}}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/EducationEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/EducationEntry.j2.md
new file mode 100644
index 00000000..c129e2a4
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/EducationEntry.j2.md
@@ -0,0 +1,16 @@
+## {{ entry.main_column.splitlines()[0] }}
+{%- if design.templates.education_entry.degree_column %}
+
+
+{{ entry.degree_column }}
+
+{% endif -%}
+{% for line in entry.date_and_location_column.splitlines() %}
+{{ line }}
+
+{% endfor %}
+{% for line in entry.main_column.splitlines()[1:] %}
+{%- if line != "!!! note" -%}{{ line|replace(" ", "") }}
+
+{% endif -%}
+{% endfor %}
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/ExperienceEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/ExperienceEntry.j2.md
new file mode 100644
index 00000000..38d2a013
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/ExperienceEntry.j2.md
@@ -0,0 +1,11 @@
+## {{ entry.main_column.splitlines()[0] }}
+
+{% for line in entry.date_and_location_column.splitlines() %}
+{{ line }}
+
+{% endfor %}
+{% for line in entry.main_column.splitlines()[1:] %}
+{%- if line != "!!! note" -%}{{ line|replace(" ", "") }}
+
+{% endif -%}
+{% endfor %}
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/NormalEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/NormalEntry.j2.md
new file mode 100644
index 00000000..38d2a013
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/NormalEntry.j2.md
@@ -0,0 +1,11 @@
+## {{ entry.main_column.splitlines()[0] }}
+
+{% for line in entry.date_and_location_column.splitlines() %}
+{{ line }}
+
+{% endfor %}
+{% for line in entry.main_column.splitlines()[1:] %}
+{%- if line != "!!! note" -%}{{ line|replace(" ", "") }}
+
+{% endif -%}
+{% endfor %}
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/NumberedEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/NumberedEntry.j2.md
new file mode 100644
index 00000000..472a3fc4
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/NumberedEntry.j2.md
@@ -0,0 +1 @@
+- {{entry.number}}
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/OneLineEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/OneLineEntry.j2.md
new file mode 100644
index 00000000..ba527f0b
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/OneLineEntry.j2.md
@@ -0,0 +1 @@
+- {{entry.label}}: {{entry.details}}
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/PublicationEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/PublicationEntry.j2.md
new file mode 100644
index 00000000..38d2a013
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/PublicationEntry.j2.md
@@ -0,0 +1,11 @@
+## {{ entry.main_column.splitlines()[0] }}
+
+{% for line in entry.date_and_location_column.splitlines() %}
+{{ line }}
+
+{% endfor %}
+{% for line in entry.main_column.splitlines()[1:] %}
+{%- if line != "!!! note" -%}{{ line|replace(" ", "") }}
+
+{% endif -%}
+{% endfor %}
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/ReversedNumberedEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/ReversedNumberedEntry.j2.md
new file mode 100644
index 00000000..8e3d5f92
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/ReversedNumberedEntry.j2.md
@@ -0,0 +1 @@
+- {{entry.reversed_number}}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/markdown/entries/TextEntry.j2.md b/src/rendercv/renderer/templater/templates/markdown/entries/TextEntry.j2.md
new file mode 100644
index 00000000..22300e9f
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/markdown/entries/TextEntry.j2.md
@@ -0,0 +1 @@
+{{entry}}
diff --git a/src/rendercv/renderer/templater/templates/typst/Header.j2.typ b/src/rendercv/renderer/templater/templates/typst/Header.j2.typ
new file mode 100644
index 00000000..345b89bf
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/Header.j2.typ
@@ -0,0 +1,44 @@
+{% macro image() %}
+#pad(left: {{ design.header.photo_space_left }}, right: {{ design.header.photo_space_right }}, image("{{ cv.photo.name }}", width: {{ design.header.photo_width }}))
+{% endmacro %}
+
+{% if cv.photo %}
+{% set photo = "image(\"" + cv.photo|string + "\", width: "+ design.header.photo_width + ")" %}
+#grid(
+{% if design.header.photo_position == "left" %}
+ columns: (auto, 1fr),
+{% else %}
+ columns: (1fr, auto),
+{% endif %}
+ column-gutter: 0cm,
+ align: horizon + left,
+{% if design.header.photo_position == "left" %}
+ [{{ image() }}],
+ [
+{% else %}
+ [
+{% endif %}
+{% endif %}
+{% if cv.name %}
+= {{ cv.name }}
+{% endif %}
+
+{% if cv.headline %}
+ #headline([{{ cv.headline }}])
+
+{% endif %}
+#connections(
+{% for connection in cv.connections %}
+ [{{ connection }}],
+{% endfor %}
+)
+{% if cv.photo %}
+{% if design.header.photo_position == "left" %}
+ ]
+)
+{% else %}
+ ],
+ [{{ image() }}],
+)
+{% endif %}
+{% endif %}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/typst/Preamble.j2.typ b/src/rendercv/renderer/templater/templates/typst/Preamble.j2.typ
new file mode 100644
index 00000000..e476c71a
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/Preamble.j2.typ
@@ -0,0 +1,83 @@
+// Import the rendercv function and all the refactored components
+#import "@preview/rendercv:0.1.0": *
+
+// Apply the rendercv template with custom configuration
+#show: rendercv.with(
+ name: "{{ cv.name }}",
+ footer: {{ cv.footer }},
+ top-note: [ {{ cv.top_note }} ],
+ locale-catalog-language: "{{ locale.language_iso_639_1 }}",
+ page-size: "{{ design.page.size }}",
+ page-top-margin: {{ design.page.top_margin }},
+ page-bottom-margin: {{ design.page.bottom_margin }},
+ page-left-margin: {{ design.page.left_margin }},
+ page-right-margin: {{ design.page.right_margin }},
+ page-show-footer: {{ design.page.show_footer|lower }},
+ page-show-top-note: {{ design.page.show_top_note|lower }},
+ colors-body: {{ design.colors.body.as_rgb() }},
+ colors-name: {{ design.colors.name.as_rgb() }},
+ colors-headline: {{ design.colors.headline.as_rgb() }},
+ colors-connections: {{ design.colors.connections.as_rgb() }},
+ colors-section-titles: {{ design.colors.section_titles.as_rgb() }},
+ colors-links: {{ design.colors.links.as_rgb() }},
+ colors-footer: {{ design.colors.footer.as_rgb() }},
+ colors-top-note: {{ design.colors.top_note.as_rgb() }},
+ typography-line-spacing: {{ design.typography.line_spacing }},
+ typography-alignment: "{{ design.typography.alignment }}",
+ typography-date-and-location-column-alignment: {{ design.typography.date_and_location_column_alignment }},
+ typography-font-family-body: "{{ design.typography.font_family.body }}",
+ typography-font-family-name: "{{ design.typography.font_family.name }}",
+ typography-font-family-headline: "{{ design.typography.font_family.headline }}",
+ typography-font-family-connections: "{{ design.typography.font_family.connections }}",
+ typography-font-family-section-titles: "{{ design.typography.font_family.section_titles }}",
+ typography-font-size-body: {{ design.typography.font_size.body }},
+ typography-font-size-name: {{ design.typography.font_size.name }},
+ typography-font-size-headline: {{ design.typography.font_size.headline }},
+ typography-font-size-connections: {{ design.typography.font_size.connections }},
+ typography-font-size-section-titles: {{ design.typography.font_size.section_titles }},
+ typography-small-caps-name: {{ design.typography.small_caps.name|lower }},
+ typography-small-caps-headline: {{ design.typography.small_caps.headline|lower }},
+ typography-small-caps-connections: {{ design.typography.small_caps.connections|lower }},
+ typography-small-caps-section-titles: {{ design.typography.small_caps.section_titles|lower }},
+ typography-bold-name: {{ design.typography.bold.name|lower }},
+ typography-bold-headline: {{ design.typography.bold.headline|lower }},
+ typography-bold-connections: {{ design.typography.bold.connections|lower }},
+ typography-bold-section-titles: {{ design.typography.bold.section_titles|lower }},
+ links-underline: {{ design.links.underline|lower }},
+ links-show-external-link-icon: {{ design.links.show_external_link_icon|lower }},
+ header-alignment: {{ design.header.alignment }},
+ header-photo-width: {{ design.header.photo_width }},
+ header-space-below-name: {{ design.header.space_below_name }},
+ header-space-below-headline: {{ design.header.space_below_headline }},
+ header-space-below-connections: {{ design.header.space_below_connections }},
+ header-connections-hyperlink: {{ design.header.connections.hyperlink|lower }},
+ header-connections-show-icons: {{ design.header.connections.show_icons|lower }},
+ header-connections-display-urls-instead-of-usernames: {{ design.header.connections.display_urls_instead_of_usernames|lower }},
+ header-connections-separator: "{{ design.header.connections.separator }}",
+ header-connections-space-between-connections: {{ design.header.connections.space_between_connections }},
+ section-titles-type: "{{ design.section_titles.type }}",
+ section-titles-line-thickness: {{ design.section_titles.line_thickness }},
+ section-titles-space-above: {{ design.section_titles.space_above }},
+ section-titles-space-below: {{ design.section_titles.space_below }},
+ sections-allow-page-break: {{ design.sections.allow_page_break|lower }},
+ sections-space-between-text-based-entries: {{ design.sections.space_between_text_based_entries }},
+ sections-space-between-regular-entries: {{ design.sections.space_between_regular_entries }},
+ entries-date-and-location-width: {{ design.entries.date_and_location_width }},
+ entries-side-space: {{ design.entries.side_space }},
+ entries-space-between-columns: {{ design.entries.space_between_columns }},
+ entries-allow-page-break: {{ design.entries.allow_page_break|lower }},
+ entries-short-second-row: {{ design.entries.short_second_row|lower }},
+ entries-summary-space-left: {{ design.entries.summary.space_left }},
+ entries-summary-space-above: {{ design.entries.summary.space_above }},
+ entries-highlights-bullet: {% if design.entries.highlights.bullet == "●" %} text(13pt, [•], baseline: -0.6pt) {% else %} "{{ design.entries.highlights.bullet }}" {% endif %},
+ entries-highlights-nested-bullet: {% if design.entries.highlights.nested_bullet == "●" %} text(13pt, [•], baseline: -0.6pt) {% else %} "{{ design.entries.highlights.nested_bullet }}" {% endif %},
+ entries-highlights-space-left: {{ design.entries.highlights.space_left }},
+ entries-highlights-space-above: {{ design.entries.highlights.space_above }},
+ entries-highlights-space-between-items: {{ design.entries.highlights.space_between_items }},
+ entries-highlights-space-between-bullet-and-text: {{ design.entries.highlights.space_between_bullet_and_text }},
+ date: datetime(
+ year: {{ settings.current_date.year }},
+ month: {{ settings.current_date.month }},
+ day: {{ settings.current_date.day }},
+ ),
+)
diff --git a/src/rendercv/renderer/templater/templates/typst/SectionBeginning.j2.typ b/src/rendercv/renderer/templater/templates/typst/SectionBeginning.j2.typ
new file mode 100644
index 00000000..ba90be88
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/SectionBeginning.j2.typ
@@ -0,0 +1,6 @@
+== {{section_title}}
+{% if entry_type in ["ReversedNumberedEntry"] %}
+
+#reversed-numbered-entries(
+ [
+{% endif %}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/typst/SectionEnding.j2.typ b/src/rendercv/renderer/templater/templates/typst/SectionEnding.j2.typ
new file mode 100644
index 00000000..b26c6b27
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/SectionEnding.j2.typ
@@ -0,0 +1,4 @@
+{% if entry_type in ["ReversedNumberedEntry"] %}
+ ],
+)
+{% endif %}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/BulletEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/BulletEntry.j2.typ
new file mode 100644
index 00000000..a23cdf1f
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/BulletEntry.j2.typ
@@ -0,0 +1 @@
+- {{entry.bullet}}
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/EducationEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/EducationEntry.j2.typ
new file mode 100644
index 00000000..661d9c7b
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/EducationEntry.j2.typ
@@ -0,0 +1,33 @@
+{% if not design.entries.short_second_row %}
+{% set first_row_lines = entry.date_and_location_column.splitlines()|length %}
+{% if first_row_lines == 0 %} {% set first_row_lines = 1 %} {% endif %}
+{% else %}
+{% set first_row_lines = entry.main_column.splitlines()|length %}
+{% endif %}
+#education-entry(
+ [
+{% for line in entry.main_column.splitlines()[:first_row_lines] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+ [
+{% for line in entry.date_and_location_column.splitlines() %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% if design.templates.education_entry.degree_column %}
+ degree-column: [
+ {{ entry.degree_column|indent(4) }}
+ ],
+{% endif %}
+{% if not design.entries.short_second_row %}
+ main-column-second-row: [
+{% for line in entry.main_column.splitlines()[first_row_lines:] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% endif %}
+)
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/ExperienceEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/ExperienceEntry.j2.typ
new file mode 100644
index 00000000..dce549c5
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/ExperienceEntry.j2.typ
@@ -0,0 +1,28 @@
+{% if not design.entries.short_second_row %}
+{% set first_row_lines = entry.date_and_location_column.splitlines()|length %}
+{% if first_row_lines == 0 %} {% set first_row_lines = 1 %} {% endif %}
+{% else %}
+{% set first_row_lines = entry.main_column.splitlines()|length %}
+{% endif %}
+#regular-entry(
+ [
+{% for line in entry.main_column.splitlines()[:first_row_lines] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+ [
+{% for line in entry.date_and_location_column.splitlines() %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% if not design.entries.short_second_row %}
+ main-column-second-row: [
+{% for line in entry.main_column.splitlines()[first_row_lines:] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% endif %}
+)
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/NormalEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/NormalEntry.j2.typ
new file mode 100644
index 00000000..dce549c5
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/NormalEntry.j2.typ
@@ -0,0 +1,28 @@
+{% if not design.entries.short_second_row %}
+{% set first_row_lines = entry.date_and_location_column.splitlines()|length %}
+{% if first_row_lines == 0 %} {% set first_row_lines = 1 %} {% endif %}
+{% else %}
+{% set first_row_lines = entry.main_column.splitlines()|length %}
+{% endif %}
+#regular-entry(
+ [
+{% for line in entry.main_column.splitlines()[:first_row_lines] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+ [
+{% for line in entry.date_and_location_column.splitlines() %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% if not design.entries.short_second_row %}
+ main-column-second-row: [
+{% for line in entry.main_column.splitlines()[first_row_lines:] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% endif %}
+)
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/NumberedEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/NumberedEntry.j2.typ
new file mode 100644
index 00000000..158945bf
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/NumberedEntry.j2.typ
@@ -0,0 +1 @@
++ {{entry.number}}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/OneLineEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/OneLineEntry.j2.typ
new file mode 100644
index 00000000..e2c6608d
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/OneLineEntry.j2.typ
@@ -0,0 +1 @@
+{{entry.main_column}}
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/PublicationEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/PublicationEntry.j2.typ
new file mode 100644
index 00000000..dce549c5
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/PublicationEntry.j2.typ
@@ -0,0 +1,28 @@
+{% if not design.entries.short_second_row %}
+{% set first_row_lines = entry.date_and_location_column.splitlines()|length %}
+{% if first_row_lines == 0 %} {% set first_row_lines = 1 %} {% endif %}
+{% else %}
+{% set first_row_lines = entry.main_column.splitlines()|length %}
+{% endif %}
+#regular-entry(
+ [
+{% for line in entry.main_column.splitlines()[:first_row_lines] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+ [
+{% for line in entry.date_and_location_column.splitlines() %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% if not design.entries.short_second_row %}
+ main-column-second-row: [
+{% for line in entry.main_column.splitlines()[first_row_lines:] %}
+ {{ line|indent(4) }}
+
+{% endfor %}
+ ],
+{% endif %}
+)
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/ReversedNumberedEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/ReversedNumberedEntry.j2.typ
new file mode 100644
index 00000000..471528a1
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/ReversedNumberedEntry.j2.typ
@@ -0,0 +1 @@
++ {{entry.reversed_number}}
\ No newline at end of file
diff --git a/src/rendercv/renderer/templater/templates/typst/entries/TextEntry.j2.typ b/src/rendercv/renderer/templater/templates/typst/entries/TextEntry.j2.typ
new file mode 100644
index 00000000..22300e9f
--- /dev/null
+++ b/src/rendercv/renderer/templater/templates/typst/entries/TextEntry.j2.typ
@@ -0,0 +1 @@
+{{entry}}
diff --git a/src/rendercv/renderer/typst.py b/src/rendercv/renderer/typst.py
new file mode 100644
index 00000000..ec9e890a
--- /dev/null
+++ b/src/rendercv/renderer/typst.py
@@ -0,0 +1,30 @@
+import pathlib
+
+from rendercv.schema.models.rendercv_model import RenderCVModel
+
+from .path_resolver import resolve_rendercv_file_path
+from .templater.templater import render_full_template
+
+
+def generate_typst(rendercv_model: RenderCVModel) -> pathlib.Path | None:
+ """Generate Typst source file from CV model via Jinja2 templates.
+
+ Why:
+ Typst is the intermediate format before PDF/PNG compilation. Templates
+ convert validated model data to Typst markup with proper formatting,
+ fonts, and styling from design options.
+
+ Args:
+ rendercv_model: Validated CV model with content and design.
+
+ Returns:
+ Path to generated Typst file, or None if generation disabled.
+ """
+ if rendercv_model.settings.render_command.dont_generate_typst:
+ return None
+ typst_path = resolve_rendercv_file_path(
+ rendercv_model, rendercv_model.settings.render_command.typst_path
+ )
+ typst_contents = render_full_template(rendercv_model, "typst")
+ typst_path.write_text(typst_contents)
+ return typst_path
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/NormalEntry.j2.typ b/src/rendercv/schema/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/NormalEntry.j2.typ
rename to src/rendercv/schema/__init__.py
diff --git a/src/rendercv/schema/error_dictionary.yaml b/src/rendercv/schema/error_dictionary.yaml
new file mode 100644
index 00000000..ece1cf29
--- /dev/null
+++ b/src/rendercv/schema/error_dictionary.yaml
@@ -0,0 +1,15 @@
+# Keys are Pydantic's error messages. The values are what we want to show to the user.
+Input should be 'present': This is not a valid `end_date`. Please use either YYYY-MM-DD, YYYY-MM, or YYYY format or 'present'.
+Input should be a valid integer, unable to parse string as an integer: This is not a valid date. Please use either YYYY-MM-DD, YYYY-MM, or YYYY format.
+String should match pattern '\\d{4}-\\d{2}(-\\d{2})?': This is not a valid date. Please use either YYYY-MM-DD, YYYY-MM, or YYYY format.
+String should match pattern '\\b10\\..*': A DOI prefix should always start with "10.". For example, "10.1109/TASC.2023.3340648".
+URL scheme should be 'http' or 'https': This is not a valid URL.
+Field required: This field is required.
+value is not a valid phone number: This is not a valid phone number.
+month must be in 1..12: The month must be between 1 and 12.
+day is out of range for month: The day is out of range for the month.
+Extra inputs are not permitted: This field is unknown for this object. Please remove it.
+Input should be a valid string: This field should be provided or removed to use the default value.
+Input should be a valid list: This field should contain a list of items but it doesn't.
+"value is not a valid color: value must be tuple, list or string": 'This is not a valid color. Here are some examples of valid colors: "red", "#ff0000", "rgb(255, 0, 0)", "hsl(0, 100%, 50%)"'
+"value is not a valid color: string not recognised as a valid color": 'This is not a valid color. Here are some examples of valid colors: "red", "#ff0000", "rgb(255, 0, 0)", "hsl(0, 100%, 50%)"'
diff --git a/src/rendercv/schema/json_schema_generator.py b/src/rendercv/schema/json_schema_generator.py
new file mode 100644
index 00000000..a79979e3
--- /dev/null
+++ b/src/rendercv/schema/json_schema_generator.py
@@ -0,0 +1,45 @@
+import json
+import pathlib
+
+import pydantic
+
+from rendercv import __description__
+
+from .models.rendercv_model import RenderCVModel
+
+
+def generate_json_schema() -> dict:
+ """Generate JSON Schema (Draft-07) from RenderCV Pydantic models.
+
+ Why:
+ IDEs and validators need machine-readable schema for autocompletion
+ and real-time validation. Custom generator adds RenderCV-specific
+ metadata like title, description, and canonical schema URL.
+
+ Returns:
+ Draft-07 JSON Schema dictionary.
+ """
+
+ class RenderCVSchemaGenerator(pydantic.json_schema.GenerateJsonSchema):
+ def generate(self, schema, mode="validation"):
+ json_schema = super().generate(schema, mode=mode)
+ json_schema["title"] = "RenderCV"
+ json_schema["description"] = __description__
+ json_schema["$id"] = (
+ "https://raw.githubusercontent.com/rendercv/rendercv/main/schema.json"
+ )
+ json_schema["$schema"] = "http://json-schema.org/draft-07/schema#"
+ return json_schema
+
+ return RenderCVModel.model_json_schema(schema_generator=RenderCVSchemaGenerator)
+
+
+def generate_json_schema_file(json_schema_path: pathlib.Path) -> None:
+ """Generate and save JSON Schema to file.
+
+ Args:
+ json_schema_path: Target file path for schema output.
+ """
+ schema = generate_json_schema()
+ schema_json = json.dumps(schema, indent=2, ensure_ascii=False)
+ json_schema_path.write_text(schema_json, encoding="utf-8")
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/NumberedEntry.j2.typ b/src/rendercv/schema/models/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/NumberedEntry.j2.typ
rename to src/rendercv/schema/models/__init__.py
diff --git a/src/rendercv/schema/models/base.py b/src/rendercv/schema/models/base.py
new file mode 100644
index 00000000..04af9844
--- /dev/null
+++ b/src/rendercv/schema/models/base.py
@@ -0,0 +1,9 @@
+import pydantic
+
+
+class BaseModelWithoutExtraKeys(pydantic.BaseModel):
+ model_config = pydantic.ConfigDict(extra="forbid", validate_default=True)
+
+
+class BaseModelWithExtraKeys(pydantic.BaseModel):
+ model_config = pydantic.ConfigDict(extra="allow", validate_default=True)
diff --git a/src/rendercv/schema/models/custom_error_types.py b/src/rendercv/schema/models/custom_error_types.py
new file mode 100644
index 00000000..37c6d5d2
--- /dev/null
+++ b/src/rendercv/schema/models/custom_error_types.py
@@ -0,0 +1,6 @@
+from enum import Enum
+
+
+class CustomPydanticErrorTypes(str, Enum):
+ entry_validation = "rendercv_entry_validation_error"
+ other = "rendercv_other_error"
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/OneLineEntry.j2.typ b/src/rendercv/schema/models/cv/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/OneLineEntry.j2.typ
rename to src/rendercv/schema/models/cv/__init__.py
diff --git a/src/rendercv/schema/models/cv/custom_connection.py b/src/rendercv/schema/models/cv/custom_connection.py
new file mode 100644
index 00000000..b62f219e
--- /dev/null
+++ b/src/rendercv/schema/models/cv/custom_connection.py
@@ -0,0 +1,9 @@
+import pydantic
+
+from ..base import BaseModelWithoutExtraKeys
+
+
+class CustomConnection(BaseModelWithoutExtraKeys):
+ fontawesome_icon: str
+ placeholder: str
+ url: pydantic.HttpUrl | None
diff --git a/src/rendercv/schema/models/cv/cv.py b/src/rendercv/schema/models/cv/cv.py
new file mode 100644
index 00000000..7e729f9c
--- /dev/null
+++ b/src/rendercv/schema/models/cv/cv.py
@@ -0,0 +1,220 @@
+import functools
+from typing import Any, Self
+
+import pydantic
+import pydantic_extra_types.phone_numbers as pydantic_phone_numbers
+
+from ..base import BaseModelWithExtraKeys
+from ..path import ExistingPathRelativeToInput
+from .custom_connection import CustomConnection
+from .section import BaseRenderCVSection, Section, get_rendercv_sections
+from .social_network import SocialNetwork
+
+email_validator = pydantic.TypeAdapter(pydantic.EmailStr)
+emails_validator = pydantic.TypeAdapter(list[pydantic.EmailStr])
+website_validator = pydantic.TypeAdapter(pydantic.HttpUrl)
+websites_validator = pydantic.TypeAdapter(list[pydantic.HttpUrl])
+phone_validator = pydantic.TypeAdapter(pydantic_phone_numbers.PhoneNumber)
+phones_validator = pydantic.TypeAdapter(list[pydantic_phone_numbers.PhoneNumber])
+
+
+class Cv(BaseModelWithExtraKeys):
+ name: str | None = pydantic.Field(
+ default=None,
+ examples=["John Doe", "Jane Smith"],
+ )
+ headline: str | None = pydantic.Field(
+ default=None,
+ examples=["Software Engineer", "Data Scientist", "Product Manager"],
+ )
+ location: str | None = pydantic.Field(
+ default=None,
+ examples=["New York, NY", "London, UK", "Istanbul, Türkiye"],
+ )
+ email: pydantic.EmailStr | list[pydantic.EmailStr] | None = pydantic.Field(
+ default=None,
+ description="You can provide multiple emails as a list.",
+ examples=[
+ "john.doe@example.com",
+ ["john.doe.1@example.com", "john.doe.2@example.com"],
+ ],
+ )
+ photo: ExistingPathRelativeToInput | None = pydantic.Field(
+ default=None,
+ description="Photo file path, relative to the YAML file.",
+ examples=["photo.jpg", "images/profile.png"],
+ )
+ phone: (
+ pydantic_phone_numbers.PhoneNumber
+ | list[pydantic_phone_numbers.PhoneNumber]
+ | None
+ ) = pydantic.Field(
+ default=None,
+ description=(
+ "Your phone number with country code in international format (e.g., +1 for"
+ " USA, +44 for UK). The display format in the output is controlled by"
+ " `design.header.connections.phone_number_format`. You can provide multiple"
+ " numbers as a list."
+ ),
+ examples=[
+ "+1-234-567-8900",
+ ["+1-234-567-8900", "+44 20 1234 5678"],
+ ],
+ )
+ website: pydantic.HttpUrl | list[pydantic.HttpUrl] | None = pydantic.Field(
+ default=None,
+ description="You can provide multiple URLs as a list.",
+ examples=[
+ "https://johndoe.com",
+ ["https://johndoe.com", "https://www.janesmith.dev"],
+ ],
+ )
+ social_networks: list[SocialNetwork] | None = pydantic.Field(
+ default=None,
+ )
+ custom_connections: list[CustomConnection] | None = pydantic.Field(
+ default=None,
+ )
+ sections: dict[str, Section] | None = pydantic.Field(
+ default=None,
+ description=(
+ "The sections of your CV. Keys are section titles (e.g., Experience,"
+ " Education), and values are lists of entries. Entry types are"
+ " automatically detected based on their fields."
+ ),
+ examples=[
+ {
+ "Experience": "...",
+ "Education": "...",
+ "Projects": "...",
+ "Skills": "...",
+ }
+ ],
+ )
+
+ # Store the order of the keys so that the header can be rendered in the same order
+ # that the user defines.
+ _key_order: list[str] = pydantic.PrivateAttr(default_factory=list)
+
+ @functools.cached_property
+ def rendercv_sections(self) -> list[BaseRenderCVSection]:
+ """Transform user's section dict to list of typed section objects.
+
+ Why:
+ Templates need sections as list with title/entry_type metadata.
+ Cached property computes once after validation, enabling repeated
+ template access without recomputation.
+
+ Returns:
+ List of section objects for template rendering.
+ """
+ return get_rendercv_sections(self.sections)
+
+ @pydantic.model_validator(mode="wrap")
+ @classmethod
+ def capture_input_order(
+ cls, data: Any, handler: pydantic.ModelWrapValidatorHandler[Self]
+ ) -> "Cv":
+ """Preserve YAML field order for header rendering.
+
+ Why:
+ Header fields (name, label, location, etc.) must render in user-defined
+ order, not alphabetical. Wrap validator captures dict key order before
+ Pydantic reorders fields.
+
+ Args:
+ data: Raw input data before validation.
+ handler: Pydantic's validation handler.
+
+ Returns:
+ Validated CV instance with _key_order preserved.
+ """
+ # If data is already a Cv instance, preserve its _key_order
+ if isinstance(data, cls):
+ return data
+
+ # Capture the input order before validation
+ key_order = list(data.keys()) if isinstance(data, dict) else []
+
+ # Let Pydantic do its validation
+ instance = handler(data)
+
+ # Set the private attribute on the instance:
+ # If the values of those keys are None, remove the key from the key_order
+ instance._key_order = [key for key in key_order if data.get(key) is not None]
+
+ return instance
+
+ @pydantic.field_validator("website", "email", "phone", mode="plain")
+ @classmethod
+ def validate_list_or_scalar_fields(
+ cls, value: Any, info: pydantic.ValidationInfo
+ ) -> (
+ pydantic.EmailStr
+ | pydantic.HttpUrl
+ | pydantic_phone_numbers.PhoneNumber
+ | list[pydantic.EmailStr]
+ | list[pydantic.HttpUrl]
+ | list[pydantic_phone_numbers.PhoneNumber]
+ | None
+ ):
+ """Validate fields that accept single value or list with type-specific errors.
+
+ Why:
+ Users provide either `email: "x@y.com"` or `email: ["x@y.com", "a@b.com"]`.
+ Plain mode validator detects list vs scalar first, enabling specific error
+ messages like "invalid email in list" instead of generic validation errors.
+
+ Args:
+ value: Single value or list to validate.
+ info: Validation context containing field name.
+
+ Returns:
+ Validated single value or list.
+ """
+ # Allow None values since these fields are optional
+ if value is None:
+ return None
+
+ assert info.field_name is not None
+
+ validators: tuple[
+ pydantic.TypeAdapter[pydantic.EmailStr]
+ | pydantic.TypeAdapter[pydantic.HttpUrl]
+ | pydantic.TypeAdapter[pydantic_phone_numbers.PhoneNumber],
+ (
+ pydantic.TypeAdapter[list[pydantic.EmailStr]]
+ | pydantic.TypeAdapter[list[pydantic.HttpUrl]]
+ | pydantic.TypeAdapter[list[pydantic_phone_numbers.PhoneNumber]]
+ ),
+ ] = {
+ "website": (website_validator, websites_validator),
+ "email": (email_validator, emails_validator),
+ "phone": (phone_validator, phones_validator),
+ }[info.field_name]
+
+ if isinstance(value, list):
+ return validators[1].validate_python(value)
+
+ return validators[0].validate_python(value)
+
+ @pydantic.field_serializer("phone")
+ def serialize_phone(
+ self, phone: pydantic_phone_numbers.PhoneNumber | None
+ ) -> str | None:
+ """Remove tel: prefix from phone number for clean serialization.
+
+ Why:
+ phone number library adds "tel:" URI scheme for validation.
+ Serialization strips prefix so templates render plain numbers.
+
+ Args:
+ phone: Validated phone number with tel: prefix.
+
+ Returns:
+ Phone string without tel: prefix, or None.
+ """
+ if phone is not None:
+ return phone.replace("tel:", "")
+
+ return phone
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/Preamble.j2.typ b/src/rendercv/schema/models/cv/entries/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/Preamble.j2.typ
rename to src/rendercv/schema/models/cv/entries/__init__.py
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/PublicationEntry.j2.typ b/src/rendercv/schema/models/cv/entries/bases/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/PublicationEntry.j2.typ
rename to src/rendercv/schema/models/cv/entries/bases/__init__.py
diff --git a/src/rendercv/schema/models/cv/entries/bases/entry.py b/src/rendercv/schema/models/cv/entries/bases/entry.py
new file mode 100644
index 00000000..964b0672
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/bases/entry.py
@@ -0,0 +1,18 @@
+import functools
+import re
+
+import pydantic
+
+from ....base import BaseModelWithExtraKeys
+
+entry_type_to_snake_case_pattern = re.compile(r"(? str:
+ return entry_type_to_snake_case_pattern.sub(
+ "_", self.__class__.__name__
+ ).lower()
diff --git a/src/rendercv/schema/models/cv/entries/bases/entry_with_complex_fields.py b/src/rendercv/schema/models/cv/entries/bases/entry_with_complex_fields.py
new file mode 100644
index 00000000..ce1ab093
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/bases/entry_with_complex_fields.py
@@ -0,0 +1,168 @@
+import re
+from datetime import date as Date
+from typing import Annotated, Literal, Self
+
+import pydantic
+import pydantic_core
+
+from rendercv.exception import RenderCVInternalError
+
+from .....pydantic_error_handling import CustomPydanticErrorTypes
+from ....validation_context import get_current_date
+from .entry_with_date import BaseEntryWithDate
+
+
+def validate_exact_date(date: str | int) -> str | int:
+ """Validate date conforms to strict format requirements.
+
+ Why:
+ start_date/end_date need strict formats for date arithmetic (calculating
+ duration). Unlike arbitrary dates, these must parse to actual Date objects
+ for comparison and duration rendering.
+
+ Args:
+ date: Date value to validate.
+
+ Returns:
+ Original date if valid.
+ """
+ try:
+ get_date_object(date)
+ except RenderCVInternalError as e:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "This is not a valid date! Please use either YYYY-MM-DD, YYYY-MM, or YYYY"
+ " format.",
+ ) from e
+ return date
+
+
+type ExactDate = Annotated[str | int, pydantic.AfterValidator(validate_exact_date)]
+
+
+def get_date_object(date: str | int, current_date: Date | None = None) -> Date:
+ """Convert date string/int to Python Date object.
+
+ Why:
+ Date arithmetic (start/end comparison, duration calculation) requires
+ Python Date objects. This parser handles multiple formats including
+ "present" keyword for ongoing positions.
+
+ Example:
+ ```py
+ date_obj = get_date_object("2023-05", Date(2025, 1, 1))
+ # Returns Date(2023, 5, 1)
+
+ present_obj = get_date_object("present", Date(2025, 1, 1))
+ # Returns Date(2025, 1, 1)
+ ```
+
+ Args:
+ date: Date in YYYY-MM-DD, YYYY-MM, YYYY format, or "present".
+ current_date: Reference date for "present" keyword.
+
+ Returns:
+ Python Date object.
+ """
+ if isinstance(date, int):
+ date_object = Date.fromisoformat(f"{date}-01-01")
+ elif re.fullmatch(r"\d{4}-\d{2}-\d{2}", date):
+ # Then it is in YYYY-MM-DD format
+ date_object = Date.fromisoformat(date)
+ elif re.fullmatch(r"\d{4}-\d{2}", date):
+ # Then it is in YYYY-MM format
+ date_object = Date.fromisoformat(f"{date}-01")
+ elif re.fullmatch(r"\d{4}", date):
+ # Then it is in YYYY format
+ date_object = Date.fromisoformat(f"{date}-01-01")
+ elif date == "present":
+ assert current_date is not None
+ date_object = current_date
+ else:
+ raise RenderCVInternalError("This is not a valid date!")
+
+ return date_object
+
+
+class BaseEntryWithComplexFields(BaseEntryWithDate):
+ model_config = pydantic.ConfigDict(json_schema_extra={"description": None})
+
+ start_date: ExactDate | None = pydantic.Field(
+ default=None,
+ description="The start date in YYYY-MM-DD, YYYY-MM, or YYYY format.",
+ examples=["2020-09-24", "2020-09", "2020"],
+ )
+ end_date: ExactDate | Literal["present"] | None = pydantic.Field(
+ default=None,
+ description=(
+ 'The end date in YYYY-MM-DD, YYYY-MM, or YYYY format. Use "present" for'
+ " ongoing events, or omit it to indicate the event is ongoing."
+ ),
+ examples=["2024-05-20", "2024-05", "2024", "present"],
+ )
+ location: str | None = pydantic.Field(
+ default=None,
+ examples=["Istanbul, Türkiye", "New York, NY", "Remote"],
+ )
+ summary: str | None = pydantic.Field(
+ default=None,
+ examples=[
+ "Led a team of 5 engineers to develop innovative solutions.",
+ (
+ "Completed advanced coursework in machine learning and artificial"
+ " intelligence."
+ ),
+ ],
+ )
+ highlights: list[str] | None = pydantic.Field(
+ default=None,
+ description=(
+ "Bullet points for key achievements, responsibilities, or contributions."
+ ),
+ examples=[
+ [
+ "Increased system performance by 40% through optimization.",
+ "Mentored 3 junior developers and conducted code reviews.",
+ "Implemented CI/CD pipeline reducing deployment time by 60%.",
+ ]
+ ],
+ )
+
+ @pydantic.model_validator(mode="after")
+ def check_and_adjust_dates(self, info: pydantic.ValidationInfo) -> Self:
+ date_is_provided = self.date is not None
+ start_date_is_provided = self.start_date is not None
+ end_date_is_provided = self.end_date is not None
+
+ if date_is_provided:
+ # If only date is provided, ignore start_date and end_date:
+ self.start_date = None
+ self.end_date = None
+ elif not start_date_is_provided and end_date_is_provided:
+ # If only end_date is provided, assume it is a one-day event and act like
+ # only the date is provided:
+ self.date = self.end_date
+ self.start_date = None
+ self.end_date = None
+ elif start_date_is_provided and not end_date_is_provided:
+ # If only start_date is provided, assume it is an ongoing event, i.e., the
+ # end_date is present:
+ self.end_date = "present"
+
+ if self.start_date and self.end_date:
+ # Check if the start_date is before the end_date:
+ current_date = get_current_date(info)
+ start_date_object = get_date_object(self.start_date, current_date)
+ end_date_object = get_date_object(self.end_date, current_date)
+ if start_date_object > end_date_object:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "`start_date` cannot be after `end_date`. The `start_date` is"
+ " {start_date} and the `end_date` is {end_date}.",
+ {
+ "start_date": self.start_date,
+ "end_date": self.end_date,
+ },
+ )
+
+ return self
diff --git a/src/rendercv/schema/models/cv/entries/bases/entry_with_date.py b/src/rendercv/schema/models/cv/entries/bases/entry_with_date.py
new file mode 100644
index 00000000..b653ea54
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/bases/entry_with_date.py
@@ -0,0 +1,50 @@
+import re
+from datetime import date as Date
+from typing import Annotated
+
+import pydantic
+
+from .entry import BaseEntry
+
+
+def validate_arbitrary_date(date: int | str) -> int | str:
+ """Validate date format while allowing flexible user input.
+
+ Why:
+ Users enter dates like "Fall 2023" or "2020-09" for events. Strict
+ dates (YYYY-MM-DD/YYYY-MM/YYYY) get validated via ISO parsing, while
+ custom text passes through for template rendering.
+
+ Args:
+ date: Date value to validate.
+
+ Returns:
+ Original date if valid.
+ """
+ date_str = str(date)
+
+ if re.fullmatch(r"\d{4}-\d{2}-\d{2}", date_str):
+ Date.fromisoformat(date_str)
+ elif re.fullmatch(r"\d{4}-\d{2}", date_str):
+ Date.fromisoformat(f"{date_str}-01")
+
+ return date
+
+
+type ArbitraryDate = Annotated[
+ int | str, pydantic.AfterValidator(validate_arbitrary_date)
+]
+
+
+class BaseEntryWithDate(BaseEntry):
+ model_config = pydantic.ConfigDict(json_schema_extra={"description": None})
+
+ date: ArbitraryDate | None = pydantic.Field(
+ default=None,
+ description=(
+ "The date of this event in YYYY-MM-DD, YYYY-MM, or YYYY format, or any"
+ " custom text like 'Fall 2023'. Use this for single-day or imprecise dates."
+ " For date ranges, use `start_date` and `end_date` instead."
+ ),
+ examples=["2020-09-24", "2020-09", "2020", "Fall 2023", "Summer 2020"],
+ )
diff --git a/src/rendercv/schema/models/cv/entries/bullet.py b/src/rendercv/schema/models/cv/entries/bullet.py
new file mode 100644
index 00000000..18ac86ee
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/bullet.py
@@ -0,0 +1,9 @@
+import pydantic
+
+from .bases.entry import BaseEntry
+
+
+class BulletEntry(BaseEntry):
+ bullet: str = pydantic.Field(
+ examples=["Python, JavaScript, C++", "Excellent communication skills"],
+ )
diff --git a/src/rendercv/schema/models/cv/entries/education.py b/src/rendercv/schema/models/cv/entries/education.py
new file mode 100644
index 00000000..724cc456
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/education.py
@@ -0,0 +1,27 @@
+import pydantic
+
+from .bases.entry import BaseEntry
+from .bases.entry_with_complex_fields import BaseEntryWithComplexFields
+
+
+class BaseEducationEntry(BaseEntry):
+ institution: str = pydantic.Field(
+ examples=["Boğaziçi University", "MIT", "Harvard University"],
+ )
+ area: str = pydantic.Field(
+ description="Field of study or major.",
+ examples=[
+ "Mechanical Engineering",
+ "Computer Science",
+ "Electrical Engineering",
+ ],
+ )
+ degree: str | None = pydantic.Field(
+ default=None,
+ examples=["BS", "BA", "PhD", "MS"],
+ )
+
+
+# This approach ensures EducationEntryBase keys appear first in the key order:
+class EducationEntry(BaseEntryWithComplexFields, BaseEducationEntry):
+ pass
diff --git a/src/rendercv/schema/models/cv/entries/experience.py b/src/rendercv/schema/models/cv/entries/experience.py
new file mode 100644
index 00000000..deaf1bb6
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/experience.py
@@ -0,0 +1,18 @@
+import pydantic
+
+from .bases.entry import BaseEntry
+from .bases.entry_with_complex_fields import BaseEntryWithComplexFields
+
+
+class BaseExperienceEntry(BaseEntry):
+ company: str = pydantic.Field(
+ examples=["Microsoft", "Google", "Princeton Plasma Physics Laboratory"],
+ )
+ position: str = pydantic.Field(
+ examples=["Software Engineer", "Research Assistant", "Project Manager"],
+ )
+
+
+# This approach ensures ExperienceEntryBase keys appear first in the key order:
+class ExperienceEntry(BaseEntryWithComplexFields, BaseExperienceEntry):
+ pass
diff --git a/src/rendercv/schema/models/cv/entries/normal.py b/src/rendercv/schema/models/cv/entries/normal.py
new file mode 100644
index 00000000..c8c66e42
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/normal.py
@@ -0,0 +1,15 @@
+import pydantic
+
+from .bases.entry import BaseEntry
+from .bases.entry_with_complex_fields import BaseEntryWithComplexFields
+
+
+class BaseNormalEntry(BaseEntry):
+ name: str = pydantic.Field(
+ examples=["Some Project", "Some Event", "Some Award"],
+ )
+
+
+# This approach ensures NormalEntryBase keys appear first in the key order:
+class NormalEntry(BaseEntryWithComplexFields, BaseNormalEntry):
+ pass
diff --git a/src/rendercv/schema/models/cv/entries/numbered.py b/src/rendercv/schema/models/cv/entries/numbered.py
new file mode 100644
index 00000000..dbfcdb95
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/numbered.py
@@ -0,0 +1,9 @@
+import pydantic
+
+from .bases.entry import BaseEntry
+
+
+class NumberedEntry(BaseEntry):
+ number: str = pydantic.Field(
+ examples=["First publication about XYZ", "Patent for ABC technology"],
+ )
diff --git a/src/rendercv/schema/models/cv/entries/one_line.py b/src/rendercv/schema/models/cv/entries/one_line.py
new file mode 100644
index 00000000..648e12c2
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/one_line.py
@@ -0,0 +1,12 @@
+import pydantic
+
+from .bases.entry import BaseEntry
+
+
+class OneLineEntry(BaseEntry):
+ label: str = pydantic.Field(
+ examples=["Languages", "Citizenship", "Security Clearance"],
+ )
+ details: str = pydantic.Field(
+ examples=["English (native), Spanish (fluent)", "US Citizen", "Top Secret"],
+ )
diff --git a/src/rendercv/schema/models/cv/entries/publication.py b/src/rendercv/schema/models/cv/entries/publication.py
new file mode 100644
index 00000000..efd3c7f9
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/publication.py
@@ -0,0 +1,101 @@
+import functools
+from typing import Self
+
+import pydantic
+
+from .bases.entry import BaseEntry
+from .bases.entry_with_date import BaseEntryWithDate
+
+url_validator = pydantic.TypeAdapter(pydantic.HttpUrl)
+
+
+class BasePublicationEntry(BaseEntry):
+ title: str = pydantic.Field(
+ examples=[
+ "Deep Learning for Computer Vision",
+ "Advances in Quantum Computing",
+ ],
+ )
+ authors: list[str] = pydantic.Field(
+ description="You can bold your name with **double asterisks**.",
+ examples=[["John Doe", "**Jane Smith**", "Bob Johnson"]],
+ )
+ summary: str | None = pydantic.Field(
+ default=None,
+ examples=["This paper presents a new method for computer vision."],
+ )
+ doi: str | None = pydantic.Field(
+ default=None,
+ description=(
+ "The DOI (Digital Object Identifier). If provided, it will be used as the"
+ " link instead of the URL."
+ ),
+ examples=["10.48550/arXiv.2310.03138"],
+ pattern=r"\b10\..*",
+ )
+ url: pydantic.HttpUrl | None = pydantic.Field(
+ default=None,
+ description="A URL link to the publication. Ignored if DOI is provided.",
+ )
+ journal: str | None = pydantic.Field(
+ default=None,
+ description="The journal, conference, or venue where it was published.",
+ examples=["Nature", "IEEE Conference on Computer Vision", "arXiv preprint"],
+ )
+
+ @pydantic.model_validator(mode="after")
+ def ignore_url_if_doi_is_given(self) -> Self:
+ """Prioritize DOI over custom URL when both provided.
+
+ Why:
+ DOI is canonical, stable identifier for publications. When provided,
+ ignore user's URL to ensure templates use official DOI link.
+
+ Returns:
+ Publication instance with url cleared if DOI exists.
+ """
+ doi_is_provided = self.doi is not None
+
+ if doi_is_provided:
+ self.url = None
+
+ return self
+
+ @pydantic.model_validator(mode="after")
+ def validate_doi_url(self) -> Self:
+ """Validate generated DOI URL is well-formed.
+
+ Why:
+ DOI URL generation from DOI string might produce invalid URLs.
+ Post-validation ensures generated URLs are valid.
+
+ Returns:
+ Validated publication instance.
+ """
+ if self.doi_url:
+ url_validator.validate_strings(self.doi_url)
+
+ return self
+
+ @functools.cached_property
+ def doi_url(self) -> str | None:
+ """Generate DOI URL from DOI identifier.
+
+ Why:
+ DOI identifiers need https://doi.org/ prefix for linking.
+ Property generates complete URL from DOI string.
+
+ Returns:
+ Complete DOI URL, or None if no DOI provided.
+ """
+ doi_is_provided = self.doi is not None
+
+ if doi_is_provided:
+ return f"https://doi.org/{self.doi}"
+
+ return None
+
+
+# This approach ensures PublicationEntryBase keys appear first in the key order:
+class PublicationEntry(BaseEntryWithDate, BasePublicationEntry):
+ pass
diff --git a/src/rendercv/schema/models/cv/entries/reversed_numbered.py b/src/rendercv/schema/models/cv/entries/reversed_numbered.py
new file mode 100644
index 00000000..7a4805ed
--- /dev/null
+++ b/src/rendercv/schema/models/cv/entries/reversed_numbered.py
@@ -0,0 +1,13 @@
+import pydantic
+
+from .bases.entry import BaseEntry
+
+
+class ReversedNumberedEntry(BaseEntry):
+ reversed_number: str = pydantic.Field(
+ description=(
+ "Reverse-numbered list item. Numbering goes in reverse (5, 4, 3, 2, 1),"
+ " making recent items have higher numbers."
+ ),
+ examples=["Latest research paper", "Recent patent application"],
+ )
diff --git a/src/rendercv/schema/models/cv/section.py b/src/rendercv/schema/models/cv/section.py
new file mode 100644
index 00000000..fe43a431
--- /dev/null
+++ b/src/rendercv/schema/models/cv/section.py
@@ -0,0 +1,353 @@
+from collections import Counter
+from functools import reduce
+from operator import or_
+from typing import Annotated, Any, Literal, get_args
+
+import pydantic
+import pydantic_core
+
+from ...pydantic_error_handling import CustomPydanticErrorTypes
+from ..base import BaseModelWithoutExtraKeys
+from .entries.bullet import BulletEntry
+from .entries.education import EducationEntry
+from .entries.experience import ExperienceEntry
+from .entries.normal import NormalEntry
+from .entries.numbered import NumberedEntry
+from .entries.one_line import OneLineEntry
+from .entries.publication import PublicationEntry
+from .entries.reversed_numbered import ReversedNumberedEntry
+
+########################################################################################
+# Below needs to be updated when new entry types are added.
+
+# str is an entry type (TextEntry) but not a model, so it's not included in EntryModel.
+type EntryModel = (
+ OneLineEntry
+ | NormalEntry
+ | ExperienceEntry
+ | EducationEntry
+ | PublicationEntry
+ | BulletEntry
+ | NumberedEntry
+ | ReversedNumberedEntry
+)
+type Entry = EntryModel | str
+########################################################################################
+available_entry_models: tuple[type[EntryModel], ...] = get_args(EntryModel.__value__)
+available_entry_type_names: tuple[str, ...] = tuple(
+ [entry_type.__name__ for entry_type in available_entry_models] + ["TextEntry"]
+)
+type ListOfEntries = list[str] | reduce( # pyright: ignore[reportInvalidTypeForm]
+ or_, [list[entry_type] for entry_type in available_entry_models]
+)
+
+
+def get_characteristic_entry_fields(
+ entry_types: tuple[type[EntryModel], ...],
+) -> dict[type[EntryModel], set[str]]:
+ """Calculate unique fields per entry type for automatic type detection.
+
+ Why:
+ Users provide entries without explicit type declarations. Detecting
+ entry type by unique fields (e.g., `degree` for EducationEntry)
+ enables automatic routing to correct validators.
+
+ Args:
+ entry_types: Entry type classes to analyze.
+
+ Returns:
+ Map of entry types to their unique field names.
+ """
+ all_attributes: list[str] = []
+ for EntryType in entry_types:
+ all_attributes.extend(EntryType.model_fields.keys())
+
+ attribute_counts = Counter(all_attributes)
+ common_attributes = {attr for attr, count in attribute_counts.items() if count > 1}
+
+ characteristic_entry_fields: dict[type[EntryModel], set[str]] = {}
+ for EntryType in entry_types:
+ characteristic_entry_fields[EntryType] = (
+ set(EntryType.model_fields.keys()) - common_attributes
+ )
+
+ return characteristic_entry_fields
+
+
+characteristic_entry_fields = get_characteristic_entry_fields(available_entry_models)
+
+
+class BaseRenderCVSection(BaseModelWithoutExtraKeys):
+ title: str
+ entry_type: str
+ entries: list[Any]
+
+ @property
+ def snake_case_title(self) -> str:
+ return self.title.lower().replace(" ", "_")
+
+
+def create_section_models(
+ entry_type: type[EntryModel] | type[str],
+) -> type[BaseRenderCVSection]:
+ """Generate Pydantic model for section containing specific entry type.
+
+ Why:
+ Each section validates that all entries match a single type. Dynamic
+ model generation creates type-safe section models with proper validation
+ constraints for each entry type.
+
+ Args:
+ entry_type: Entry class or str for TextEntry.
+
+ Returns:
+ Pydantic section model class.
+ """
+ if entry_type is str:
+ model_name = "SectionWithTextEntries"
+ entry_type_name = "TextEntry"
+ else:
+ model_name = "SectionWith" + entry_type.__name__.replace("Entry", "Entries")
+ entry_type_name = entry_type.__name__
+
+ return pydantic.create_model(
+ model_name,
+ entry_type=(Literal[entry_type_name], ...),
+ entries=(list[entry_type], ...),
+ __base__=BaseRenderCVSection,
+ )
+
+
+section_models: dict[type[EntryModel] | type[str], type[BaseRenderCVSection]] = {
+ entry_type: create_section_models(entry_type)
+ for entry_type in available_entry_models
+}
+section_models[str] = create_section_models(str)
+
+
+def get_entry_type_name_and_section_model(
+ entry: dict[str, str | list[str]] | str | EntryModel | None,
+) -> tuple[str, type[BaseRenderCVSection]]:
+ """Infer entry type from entry data and return corresponding section model.
+
+ Why:
+ Sections contain mixed raw entry data (dicts/strings) before validation.
+ Type inference via characteristic fields enables routing each entry to
+ its correct validator model.
+
+ Args:
+ entry: Raw or validated entry data.
+
+ Returns:
+ Tuple of entry type name and section model class.
+ """
+
+ if isinstance(entry, dict):
+ entry_type_name = None
+ section_model = None
+ for EntryType, characteristic_fields in characteristic_entry_fields.items():
+ # If at least one of the characteristic_fields is in the entry,
+ # then it means the entry is of this type:
+ if characteristic_fields & set(entry.keys()):
+ entry_type_name = EntryType.__name__
+ section_model = section_models[EntryType]
+ break
+
+ if section_model is None or entry_type_name is None:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The entry does not match any entry type.",
+ )
+
+ elif isinstance(entry, str):
+ # Then it is a TextEntry
+ entry_type_name = "TextEntry"
+ section_model = section_models[str]
+
+ elif entry is None:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The entry cannot be None.",
+ )
+
+ else:
+ # Then the entry is already initialized with a data model:
+ entry_type_name = entry.__class__.__name__
+ section_model = section_models[entry.__class__]
+
+ return entry_type_name, section_model
+
+
+def validate_section(sections_input: Any) -> Any:
+ """Validate section entries with automatic type detection and error reporting.
+
+ Why:
+ Section validation must infer entry type from first valid entry,
+ then validate all entries against that type. Custom error messages
+ identify detected type and aggregate nested validation errors.
+
+ Args:
+ sections_input: Raw section data (list of entries).
+
+ Returns:
+ Validated list of entry instances.
+ """
+ if isinstance(sections_input, list):
+ # Find the entry type based on the first identifiable entry:
+ entry_type_name = None
+ section_type = None
+ for entry in sections_input:
+ try:
+ entry_type_name, section_type = get_entry_type_name_and_section_model(
+ entry
+ )
+ break
+ except pydantic_core.PydanticCustomError:
+ # If the entry type cannot be determined, try the next entry:
+ continue
+
+ if entry_type_name is None or section_type is None:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "RenderCV couldn't match this section with any entry types. Please"
+ " check the entries and make sure they are provided correctly.",
+ )
+
+ section = {
+ "title": "Dummy Section for Validation",
+ "entry_type": entry_type_name,
+ "entries": sections_input,
+ }
+
+ try:
+ section_object = section_type.model_validate(section)
+ sections_input = section_object.entries
+ except pydantic.ValidationError as e:
+ new_error = pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.entry_validation.value,
+ "There are problems with the entries. RenderCV detected the entry type"
+ " of this section to be {entry_type_name}. The problems are shown"
+ " below.",
+ {"entry_type_name": entry_type_name, "caused_by": e.errors()},
+ )
+ raise new_error from e
+
+ else:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "Each section should be a list of entries! This is not a list.",
+ )
+
+ return sections_input
+
+
+# Create a custom type named Section, which is a list of entries. The entries can be any
+# of the available entry types. The section is validated with the `validate_section`
+# function.
+type Section = Annotated[
+ pydantic.json_schema.SkipJsonSchema[Any] | ListOfEntries,
+ pydantic.BeforeValidator(lambda entries: validate_section(entries)),
+]
+
+
+def dictionary_key_to_proper_section_title(key: str) -> str:
+ """Convert snake_case section key to title case with proper capitalization.
+
+ Why:
+ Users write `education_and_training` in YAML for readability. Rendering
+ requires "Education and Training" with proper title case rules (lowercase
+ articles/prepositions).
+
+ Example:
+ ```py
+ title = dictionary_key_to_proper_section_title("education_and_training")
+ # Returns "Education and Training"
+ ```
+
+ Args:
+ key: Section key from YAML.
+
+ Returns:
+ Properly capitalized section title.
+ """
+ # If there is either a space or an uppercase letter in the key, return it as is.
+ if " " in key or any(letter.isupper() for letter in key):
+ return key
+
+ title = key.replace("_", " ")
+ words = title.split(" ")
+
+ words_not_capitalized_in_a_title = [
+ "a",
+ "and",
+ "as",
+ "at",
+ "but",
+ "by",
+ "for",
+ "from",
+ "if",
+ "in",
+ "into",
+ "like",
+ "near",
+ "nor",
+ "of",
+ "off",
+ "on",
+ "onto",
+ "or",
+ "over",
+ "so",
+ "than",
+ "that",
+ "to",
+ "upon",
+ "when",
+ "with",
+ "yet",
+ ]
+
+ return " ".join(
+ (word.capitalize() if (word not in words_not_capitalized_in_a_title) else word)
+ for word in words
+ )
+
+
+def get_rendercv_sections(
+ sections: dict[str, list[Any]] | None,
+) -> list[BaseRenderCVSection]:
+ """Transform user's section dictionary into list of typed section objects.
+
+ Why:
+ YAML sections are dicts for user convenience (e.g., `{education: [...]}`).
+ Template rendering requires list of section objects with title and
+ entry_type fields. This conversion happens after validation.
+
+ Args:
+ sections: User's section dictionary with titles as keys.
+
+ Returns:
+ List of section objects ready for template rendering.
+ """
+ sections_rendercv: list[BaseRenderCVSection] = []
+
+ if sections is not None:
+ for title, entries in sections.items():
+ formatted_title = dictionary_key_to_proper_section_title(title)
+
+ # The first entry can be used because all the entries in the section are
+ # already validated with the `validate_a_section` function:
+ entry_type_name, _ = get_entry_type_name_and_section_model(
+ entries[0],
+ )
+
+ # SectionBase is used so that entries are not validated again:
+ section = BaseRenderCVSection(
+ title=formatted_title,
+ entry_type=entry_type_name,
+ entries=entries,
+ )
+ sections_rendercv.append(section)
+
+ return sections_rendercv
diff --git a/src/rendercv/schema/models/cv/social_network.py b/src/rendercv/schema/models/cv/social_network.py
new file mode 100644
index 00000000..44799ee7
--- /dev/null
+++ b/src/rendercv/schema/models/cv/social_network.py
@@ -0,0 +1,164 @@
+import functools
+import re
+from typing import Literal, get_args
+
+import pydantic
+import pydantic_core
+import pydantic_extra_types.phone_numbers as pydantic_phone_numbers
+
+from ...pydantic_error_handling import CustomPydanticErrorTypes
+from ..base import BaseModelWithoutExtraKeys
+
+url_validator = pydantic.TypeAdapter(pydantic.HttpUrl)
+type SocialNetworkName = Literal[
+ "LinkedIn",
+ "GitHub",
+ "GitLab",
+ "IMDB",
+ "Instagram",
+ "ORCID",
+ "Mastodon",
+ "StackOverflow",
+ "ResearchGate",
+ "YouTube",
+ "Google Scholar",
+ "Telegram",
+ "WhatsApp",
+ "Leetcode",
+ "X",
+]
+available_social_networks = get_args(SocialNetworkName.__value__)
+url_dictionary: dict[SocialNetworkName, str] = {
+ "LinkedIn": "https://linkedin.com/in/",
+ "GitHub": "https://github.com/",
+ "GitLab": "https://gitlab.com/",
+ "IMDB": "https://imdb.com/name/",
+ "Instagram": "https://instagram.com/",
+ "ORCID": "https://orcid.org/",
+ "StackOverflow": "https://stackoverflow.com/users/",
+ "ResearchGate": "https://researchgate.net/profile/",
+ "YouTube": "https://youtube.com/@",
+ "Google Scholar": "https://scholar.google.com/citations?user=",
+ "Telegram": "https://t.me/",
+ "WhatsApp": "https://wa.me/",
+ "Leetcode": "https://leetcode.com/u/",
+ "X": "https://x.com/",
+}
+
+
+class SocialNetwork(BaseModelWithoutExtraKeys):
+ network: SocialNetworkName = pydantic.Field()
+ username: str = pydantic.Field(
+ examples=["john_doe", "@johndoe@mastodon.social", "12345/john-doe"],
+ )
+
+ @pydantic.field_validator("username")
+ @classmethod
+ def check_username(cls, username: str, info: pydantic.ValidationInfo) -> str:
+ """Validate username format per network's requirements.
+
+ Why:
+ Different platforms have specific username formats (e.g., Mastodon needs
+ @user@domain, StackOverflow needs id/name). Early validation prevents
+ broken URL generation.
+
+ Args:
+ username: Username to validate.
+ info: Validation context containing network field.
+
+ Returns:
+ Validated username.
+ """
+ if "network" not in info.data:
+ # the network is either not provided or not one of the available social
+ # networks. In this case, don't check the username, since Pydantic will
+ # raise an error for the network.
+ return username
+
+ network = info.data["network"]
+
+ match network:
+ case "Mastodon":
+ mastodon_username_pattern = r"@[^@]+@[^@]+"
+ if not re.fullmatch(mastodon_username_pattern, username):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ 'Mastodon username should be in the format "@username@domain".',
+ )
+ case "StackOverflow":
+ stackoverflow_username_pattern = r"\d+\/[^\/]+"
+ if not re.fullmatch(stackoverflow_username_pattern, username):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "StackOverflow username should be in the format"
+ ' "user_id/username".',
+ )
+ case "YouTube":
+ if username.startswith("@"):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ 'YouTube username should not start with "@". Remove "@" from'
+ ' the beginning of the username."',
+ )
+ case "ORCID":
+ orcid_username_pattern = r"\d{4}-\d{4}-\d{4}-\d{3}[\dX]"
+ if not re.fullmatch(orcid_username_pattern, username):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "ORCID username should be in the format 'XXXX-XXXX-XXXX-XXX'.",
+ )
+ case "IMDB":
+ imdb_username_pattern = r"nm\d{7}"
+ if not re.fullmatch(imdb_username_pattern, username):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "IMDB name should be in the format 'nmXXXXXXX'.",
+ )
+
+ case "WhatsApp":
+ phone_validator = pydantic.TypeAdapter(
+ pydantic_phone_numbers.PhoneNumber
+ )
+ try:
+ phone_validator.validate_python(username)
+ except pydantic.ValidationError as e:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "WhatsApp username should be your phone number with country"
+ " code in international format (e.g., +1 for USA, +44 for UK).",
+ ) from e
+
+ return username
+
+ @pydantic.model_validator(mode="after")
+ def validate_generated_url(self) -> "SocialNetwork":
+ """Validate generated URL is well-formed.
+
+ Why:
+ URL generation from username might produce invalid URLs if username
+ format is wrong. Post-validation check catches edge cases.
+
+ Returns:
+ Validated social network instance.
+ """
+ url_validator.validate_strings(self.url)
+ return self
+
+ @functools.cached_property
+ def url(self) -> str:
+ """Generate profile URL from network and username.
+
+ Why:
+ Users provide network+username for brevity. Property generates full
+ URLs with platform-specific logic (e.g., Mastodon domain extraction).
+
+ Returns:
+ Complete profile URL.
+ """
+ if self.network == "Mastodon":
+ _, username, domain = self.username.split("@")
+ url = f"https://{domain}/@{username}"
+ else:
+ url = url_dictionary[self.network] + self.username
+
+ return url
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/ReversedNumberedEntry.j2.typ b/src/rendercv/schema/models/design/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/ReversedNumberedEntry.j2.typ
rename to src/rendercv/schema/models/design/__init__.py
diff --git a/src/rendercv/schema/models/design/built_in_design.py b/src/rendercv/schema/models/design/built_in_design.py
new file mode 100644
index 00000000..c3cfa254
--- /dev/null
+++ b/src/rendercv/schema/models/design/built_in_design.py
@@ -0,0 +1,50 @@
+from functools import reduce
+from operator import or_
+from pathlib import Path
+from typing import Annotated, get_args
+
+import pydantic
+
+from ...variant_pydantic_model_generator import create_variant_pydantic_model
+from ...yaml_reader import read_yaml
+from .classic_theme import ClassicTheme
+
+
+def discover_other_themes() -> list[type[ClassicTheme]]:
+ """Auto-discover and load theme variant classes from other_themes/ directory.
+
+ Why:
+ Built-in themes beyond classic are defined as YAML files with field
+ overrides. Dynamic discovery and variant generation keeps theme
+ system extensible without code changes for each theme.
+
+ Returns:
+ List of dynamically generated theme variant classes.
+ """
+ other_themes_dir = Path(__file__).parent / "other_themes"
+ discovered: list[type[ClassicTheme]] = []
+
+ for yaml_file in sorted(other_themes_dir.glob("*.yaml")):
+ theme_class = create_variant_pydantic_model(
+ variant_name=yaml_file.stem,
+ defaults=read_yaml(yaml_file)["design"],
+ base_class=ClassicTheme,
+ discriminator_field="theme",
+ class_name_suffix="Theme",
+ module_name="rendercv.schema.models.design",
+ )
+ discovered.append(theme_class)
+
+ return discovered
+
+
+# Build discriminated union dynamically
+type BuiltInDesign = Annotated[
+ ClassicTheme | reduce(or_, discover_other_themes()), # pyright: ignore[reportInvalidTypeForm]
+ pydantic.Field(discriminator="theme"),
+]
+available_themes: list[str] = [
+ ThemeClass.model_fields["theme"].default
+ for ThemeClass in get_args(get_args(BuiltInDesign.__value__)[0])
+]
+built_in_design_adapter = pydantic.TypeAdapter(BuiltInDesign)
diff --git a/src/rendercv/schema/models/design/classic_theme.py b/src/rendercv/schema/models/design/classic_theme.py
new file mode 100644
index 00000000..cb08c69a
--- /dev/null
+++ b/src/rendercv/schema/models/design/classic_theme.py
@@ -0,0 +1,746 @@
+from typing import Literal
+
+import pydantic
+
+from rendercv.schema.models.base import BaseModelWithoutExtraKeys
+from rendercv.schema.models.design.color import Color
+from rendercv.schema.models.design.font_family import FontFamily as FontFamilyType
+from rendercv.schema.models.design.typst_dimension import TypstDimension
+
+type Bullet = Literal["●", "•", "◦", "-", "◆", "★", "■", "—", "○"]
+type BodyAlignment = Literal["left", "justified", "justified-with-no-hyphenation"]
+type Alignment = Literal["left", "center", "right"]
+type SectionTitleType = Literal[
+ "with_partial_line", "with_full_line", "without_line", "moderncv"
+]
+type PhoneNumberFormatType = Literal["national", "international", "E164"]
+type PageSize = Literal["a4", "a5", "us-letter", "us-executive"]
+
+length_common_description = (
+ "It can be specified with units (cm, in, pt, mm, ex, em). For example, `0.1cm`."
+)
+
+
+class Page(BaseModelWithoutExtraKeys):
+ size: PageSize = pydantic.Field(
+ default="us-letter",
+ description=(
+ "The page size. Use 'a4' (international standard) or 'us-letter' (US"
+ " standard). The default value is `us-letter`."
+ ),
+ )
+ top_margin: TypstDimension = pydantic.Field(
+ default="0.7in",
+ description=length_common_description + " The default value is `0.7in`.",
+ )
+ bottom_margin: TypstDimension = pydantic.Field(
+ default="0.7in",
+ description=length_common_description + " The default value is `0.7in`.",
+ )
+ left_margin: TypstDimension = pydantic.Field(
+ default="0.7in",
+ description=length_common_description + " The default value is `0.7in`.",
+ )
+ right_margin: TypstDimension = pydantic.Field(
+ default="0.7in",
+ description=length_common_description + " The default value is `0.7in`.",
+ )
+ show_footer: bool = pydantic.Field(
+ default=True,
+ description=(
+ "Show the footer at the bottom of pages. The default value is `true`."
+ ),
+ )
+ show_top_note: bool = pydantic.Field(
+ default=True,
+ description=(
+ "Show the top note at the top of the first page. The default value is"
+ " `true`."
+ ),
+ )
+
+
+color_common_description = (
+ "The color can be specified either with their name"
+ " (https://www.w3.org/TR/SVG11/types.html#ColorKeywords), hexadecimal value, RGB"
+ " value, or HSL value."
+)
+color_common_examples = ["Black", "7fffd4", "rgb(0,79,144)", "hsl(270, 60%, 70%)"]
+
+
+class Colors(BaseModelWithoutExtraKeys):
+ body: Color = pydantic.Field(
+ default=Color("rgb(0, 0, 0)"),
+ description=(
+ color_common_description + " The default value is `rgb(0, 0, 0)`."
+ ),
+ examples=color_common_examples,
+ )
+ name: Color = pydantic.Field(
+ default=Color("rgb(0, 79, 144)"),
+ description=color_common_description
+ + " The default value is `rgb(0, 79, 144)`.",
+ examples=color_common_examples,
+ )
+ headline: Color = pydantic.Field(
+ default=Color("rgb(0, 79, 144)"),
+ description=color_common_description
+ + " The default value is `rgb(0, 79, 144)`.",
+ examples=color_common_examples,
+ )
+ connections: Color = pydantic.Field(
+ default=Color("rgb(0, 79, 144)"),
+ description=color_common_description
+ + " The default value is `rgb(0, 79, 144)`.",
+ examples=color_common_examples,
+ )
+ section_titles: Color = pydantic.Field(
+ default=Color("rgb(0, 79, 144)"),
+ description=color_common_description
+ + " The default value is `rgb(0, 79, 144)`.",
+ examples=color_common_examples,
+ )
+ links: Color = pydantic.Field(
+ default=Color("rgb(0, 79, 144)"),
+ description=color_common_description
+ + " The default value is `rgb(0, 79, 144)`.",
+ examples=color_common_examples,
+ )
+ footer: Color = pydantic.Field(
+ default=Color("rgb(128, 128, 128)"),
+ description=color_common_description
+ + " The default value is `rgb(128, 128, 128)`.",
+ examples=color_common_examples,
+ )
+ top_note: Color = pydantic.Field(
+ default=Color("rgb(128, 128, 128)"),
+ description=color_common_description
+ + " The default value is `rgb(128, 128, 128)`.",
+ examples=color_common_examples,
+ )
+
+
+class FontFamily(BaseModelWithoutExtraKeys):
+ body: FontFamilyType = pydantic.Field(
+ default="Source Sans 3",
+ description=(
+ "The font family for body text. The default value is `Source Sans 3`."
+ ),
+ )
+ name: FontFamilyType = pydantic.Field(
+ default="Source Sans 3",
+ description=(
+ "The font family for the name. The default value is `Source Sans 3`."
+ ),
+ )
+ headline: FontFamilyType = pydantic.Field(
+ default="Source Sans 3",
+ description=(
+ "The font family for the headline. The default value is `Source Sans 3`."
+ ),
+ )
+ connections: FontFamilyType = pydantic.Field(
+ default="Source Sans 3",
+ description=(
+ "The font family for connections. The default value is `Source Sans 3`."
+ ),
+ )
+ section_titles: FontFamilyType = pydantic.Field(
+ default="Source Sans 3",
+ description=(
+ "The font family for section titles. The default value is `Source Sans 3`."
+ ),
+ )
+
+
+class FontSize(BaseModelWithoutExtraKeys):
+ body: TypstDimension = pydantic.Field(
+ default="10pt",
+ description="The font size for body text. The default value is `10pt`.",
+ )
+ name: TypstDimension = pydantic.Field(
+ default="30pt",
+ description="The font size for the name. The default value is `30pt`.",
+ )
+ headline: TypstDimension = pydantic.Field(
+ default="10pt",
+ description="The font size for the headline. The default value is `10pt`.",
+ )
+ connections: TypstDimension = pydantic.Field(
+ default="10pt",
+ description="The font size for connections. The default value is `10pt`.",
+ )
+ section_titles: TypstDimension = pydantic.Field(
+ default="1.4em",
+ description="The font size for section titles. The default value is `1.4em`.",
+ )
+
+
+class SmallCaps(BaseModelWithoutExtraKeys):
+ name: bool = pydantic.Field(
+ default=False,
+ description=(
+ "Whether to use small caps for the name. The default value is `false`."
+ ),
+ )
+ headline: bool = pydantic.Field(
+ default=False,
+ description=(
+ "Whether to use small caps for the headline. The default value is `false`."
+ ),
+ )
+ connections: bool = pydantic.Field(
+ default=False,
+ description=(
+ "Whether to use small caps for connections. The default value is `false`."
+ ),
+ )
+ section_titles: bool = pydantic.Field(
+ default=False,
+ description=(
+ "Whether to use small caps for section titles. The default value is"
+ " `false`."
+ ),
+ )
+
+
+class Bold(BaseModelWithoutExtraKeys):
+ name: bool = pydantic.Field(
+ default=True,
+ description="Whether to make the name bold. The default value is `true`.",
+ )
+ headline: bool = pydantic.Field(
+ default=False,
+ description="Whether to make the headline bold. The default value is `false`.",
+ )
+ connections: bool = pydantic.Field(
+ default=False,
+ description="Whether to make connections bold. The default value is `false`.",
+ )
+ section_titles: bool = pydantic.Field(
+ default=True,
+ description="Whether to make section titles bold. The default value is `true`.",
+ )
+
+
+class Typography(BaseModelWithoutExtraKeys):
+ line_spacing: TypstDimension = pydantic.Field(
+ default="0.6em",
+ description=(
+ "Space between lines of text. Larger values create more vertical space. The"
+ " default value is `0.6em`."
+ ),
+ )
+ alignment: Literal["left", "justified", "justified-with-no-hyphenation"] = (
+ pydantic.Field(
+ default="justified",
+ description=(
+ "Text alignment. Options: 'left', 'justified' (spreads text across full"
+ " width), 'justified-with-no-hyphenation' (justified without word"
+ " breaks). The default value is `justified`."
+ ),
+ )
+ )
+ date_and_location_column_alignment: Alignment = pydantic.Field(
+ default="right",
+ description=(
+ "Alignment for dates and locations in entries. Options: 'left', 'center',"
+ " 'right'. The default value is `right`."
+ ),
+ )
+ font_family: FontFamily | FontFamilyType = pydantic.Field(
+ default_factory=FontFamily,
+ description=(
+ "The font family. You can provide a single font name as a string (applies"
+ " to all elements), or a dictionary with keys 'body', 'name', 'headline',"
+ " 'connections', and 'section_titles' to customize each element. Any system"
+ " font can be used."
+ ),
+ )
+ font_size: FontSize = pydantic.Field(
+ default_factory=FontSize,
+ description="Font sizes for different elements.",
+ )
+ small_caps: SmallCaps = pydantic.Field(
+ default_factory=SmallCaps,
+ description="Small caps styling for different elements.",
+ )
+ bold: Bold = pydantic.Field(
+ default_factory=Bold,
+ description="Bold styling for different elements.",
+ )
+
+ @pydantic.field_validator(
+ "font_family", mode="plain", json_schema_input_type=FontFamily | FontFamilyType
+ )
+ @classmethod
+ def validate_font_family(
+ cls, font_family: FontFamily | FontFamilyType
+ ) -> FontFamily:
+ """Convert string font to FontFamily object with uniform styling.
+
+ Why:
+ Users can provide simple string "Latin Modern Roman" for all text,
+ or specify per-element fonts via FontFamily dict. Validator accepts
+ both, expanding strings to full FontFamily objects.
+
+ Args:
+ font_family: String font name or FontFamily object.
+
+ Returns:
+ FontFamily object with all fields populated.
+ """
+ if isinstance(font_family, str):
+ return FontFamily(
+ body=font_family,
+ name=font_family,
+ headline=font_family,
+ connections=font_family,
+ section_titles=font_family,
+ )
+
+ return FontFamily.model_validate(font_family)
+
+
+class Links(BaseModelWithoutExtraKeys):
+ underline: bool = pydantic.Field(
+ default=False,
+ description="Underline hyperlinks. The default value is `false`.",
+ )
+ show_external_link_icon: bool = pydantic.Field(
+ default=False,
+ description=(
+ "Show an external link icon next to URLs. The default value is `false`."
+ ),
+ )
+
+
+class Connections(BaseModelWithoutExtraKeys):
+ phone_number_format: PhoneNumberFormatType = pydantic.Field(
+ default="national",
+ description="Phone number format. The default value is `national`.",
+ )
+ hyperlink: bool = pydantic.Field(
+ default=True,
+ description=(
+ "Make contact information clickable in the PDF. The default value is"
+ " `true`."
+ ),
+ )
+ show_icons: bool = pydantic.Field(
+ default=True,
+ description=(
+ "Show icons next to contact information. The default value is `true`."
+ ),
+ )
+ display_urls_instead_of_usernames: bool = pydantic.Field(
+ default=False,
+ description=(
+ "Display full URLs instead of labels. The default value is `false`."
+ ),
+ )
+ separator: str = pydantic.Field(
+ default="",
+ description=(
+ "Character(s) to separate contact items (e.g., '|' or '•'). Leave empty for"
+ " no separator. The default value is `''`."
+ ),
+ )
+ space_between_connections: TypstDimension = pydantic.Field(
+ default="0.5cm",
+ description=(
+ "Horizontal space between contact items. "
+ + length_common_description
+ + " The default value is `0.5cm`."
+ ),
+ )
+
+
+class Header(BaseModelWithoutExtraKeys):
+ alignment: Alignment = pydantic.Field(
+ default="center",
+ description=(
+ "Header alignment. Options: 'left', 'center', 'right'. The default value is"
+ " `center`."
+ ),
+ )
+ photo_width: TypstDimension = pydantic.Field(
+ default="3.5cm",
+ description="Photo width. "
+ + length_common_description
+ + " The default value is `3.5cm`.",
+ )
+ photo_position: Literal["left", "right"] = pydantic.Field(
+ default="left",
+ description="Photo position (left or right). The default value is `left`.",
+ )
+ photo_space_left: TypstDimension = pydantic.Field(
+ default="0.4cm",
+ description=(
+ "Space to the left of the photo. "
+ + length_common_description
+ + " The default value is `0.4cm`."
+ ),
+ )
+ photo_space_right: TypstDimension = pydantic.Field(
+ default="0.4cm",
+ description=(
+ "Space to the right of the photo. "
+ + length_common_description
+ + " The default value is `0.4cm`."
+ ),
+ )
+ space_below_name: TypstDimension = pydantic.Field(
+ default="0.7cm",
+ description="Space below your name. "
+ + length_common_description
+ + " The default value is `0.7cm`.",
+ )
+ space_below_headline: TypstDimension = pydantic.Field(
+ default="0.7cm",
+ description="Space below the headline. "
+ + length_common_description
+ + " The default value is `0.7cm`.",
+ )
+ space_below_connections: TypstDimension = pydantic.Field(
+ default="0.7cm",
+ description="Space below contact information. "
+ + length_common_description
+ + " The default value is `0.7cm`.",
+ )
+ connections: Connections = pydantic.Field(
+ default_factory=Connections,
+ description="Contact information settings.",
+ )
+
+
+class SectionTitles(BaseModelWithoutExtraKeys):
+ type: SectionTitleType = pydantic.Field(
+ default="with_partial_line",
+ description=(
+ "Section title visual style. Use 'with_partial_line' for a line next to the"
+ " title, 'with_full_line' for a line across the page, 'without_line' for no"
+ " line, or 'moderncv' for the ModernCV style. The default value is"
+ " `with_partial_line`."
+ ),
+ )
+ line_thickness: TypstDimension = pydantic.Field(
+ default="0.5pt",
+ description=length_common_description + " The default value is `0.5pt`.",
+ )
+ space_above: TypstDimension = pydantic.Field(
+ default="0.5cm",
+ description=length_common_description + " The default value is `0.5cm`.",
+ )
+ space_below: TypstDimension = pydantic.Field(
+ default="0.3cm",
+ description=length_common_description + " The default value is `0.3cm`.",
+ )
+
+
+class Sections(BaseModelWithoutExtraKeys):
+ allow_page_break: bool = pydantic.Field(
+ default=True,
+ description=(
+ "Allow page breaks within sections. If false, sections that don't fit will"
+ " start on a new page. The default value is `true`."
+ ),
+ )
+ space_between_regular_entries: TypstDimension = pydantic.Field(
+ default="1.2em",
+ description=(
+ "Vertical space between entries. "
+ + length_common_description
+ + " The default value is `1.2em`."
+ ),
+ )
+ space_between_text_based_entries: TypstDimension = pydantic.Field(
+ default="0.3em",
+ description=(
+ "Vertical space between text-based entries. "
+ + length_common_description
+ + " The default value is `0.3em`."
+ ),
+ )
+ # page_break_before: list[str] = pydantic.Field(
+ # default=[],
+ # description=(
+ # "Section titles before which a page break should be inserted. The default"
+ # " value is `[]`."
+ # ),
+ # examples=[["Experience"], ["Education"]],
+ # )
+ show_time_spans_in: list[str] = pydantic.Field(
+ default=["experience"],
+ description=(
+ "Section titles where time spans (e.g., '2 years 3 months') should be"
+ " displayed. The default value is `['experience']`."
+ ),
+ examples=[["Experience"], ["Experience", "Education"]],
+ )
+
+ @pydantic.field_validator(
+ # "page_break_before",
+ "show_time_spans_in",
+ mode="after",
+ )
+ @classmethod
+ def convert_section_titles_to_snake_case(cls, value: list[str]) -> list[str]:
+ return [section_title.lower().replace(" ", "_") for section_title in value]
+
+
+class Summary(BaseModelWithoutExtraKeys):
+ space_above: TypstDimension = pydantic.Field(
+ default="0cm",
+ description=(
+ "Space above summary text. "
+ + length_common_description
+ + " The default value is `0cm`."
+ ),
+ )
+ space_left: TypstDimension = pydantic.Field(
+ default="0cm",
+ description=(
+ "Left margin for summary text. "
+ + length_common_description
+ + " The default value is `0cm`."
+ ),
+ )
+
+
+class Highlights(BaseModelWithoutExtraKeys):
+ bullet: Bullet = pydantic.Field(
+ default="•",
+ description="Bullet character for highlights. The default value is `•`.",
+ )
+ nested_bullet: Bullet = pydantic.Field(
+ default="•",
+ description="Bullet character for nested highlights. The default value is `•`.",
+ )
+ space_left: TypstDimension = pydantic.Field(
+ default="0.15cm",
+ description=(
+ "Left indentation. "
+ + length_common_description
+ + " The default value is `0.15cm`."
+ ),
+ )
+ space_above: TypstDimension = pydantic.Field(
+ default="0cm",
+ description=(
+ "Space above highlights. "
+ + length_common_description
+ + " The default value is `0cm`."
+ ),
+ )
+ space_between_items: TypstDimension = pydantic.Field(
+ default="0cm",
+ description=(
+ "Space between highlight items. "
+ + length_common_description
+ + " The default value is `0cm`."
+ ),
+ )
+ space_between_bullet_and_text: TypstDimension = pydantic.Field(
+ default="0.5em",
+ description=(
+ "Space between bullet and text. "
+ + length_common_description
+ + " The default value is `0.5em`."
+ ),
+ )
+
+
+class Entries(BaseModelWithoutExtraKeys):
+ date_and_location_width: TypstDimension = pydantic.Field(
+ default="4.15cm",
+ description=(
+ "Width of the date/location column. "
+ + length_common_description
+ + " The default value is `4.15cm`."
+ ),
+ )
+ side_space: TypstDimension = pydantic.Field(
+ default="0.2cm",
+ description=(
+ "Left and right margins. "
+ + length_common_description
+ + " The default value is `0.2cm`."
+ ),
+ )
+ space_between_columns: TypstDimension = pydantic.Field(
+ default="0.1cm",
+ description=(
+ "Space between main content and date/location columns. "
+ + length_common_description
+ + " The default value is `0.1cm`."
+ ),
+ )
+ allow_page_break: bool = pydantic.Field(
+ default=False,
+ description=(
+ "Allow page breaks within entries. If false, entries that don't fit will"
+ " move to a new page. The default value is `false`."
+ ),
+ )
+ short_second_row: bool = pydantic.Field(
+ default=True,
+ description=(
+ "Shorten the second row to align with the date/location column. The default"
+ " value is `true`."
+ ),
+ )
+ summary: Summary = pydantic.Field(
+ default_factory=Summary,
+ description="Summary text settings.",
+ )
+ highlights: Highlights = pydantic.Field(
+ default_factory=Highlights,
+ description="Highlights settings.",
+ )
+
+
+template_common_description = (
+ "The content of the template. The available placeholders are all the keys used in"
+ " the entries in uppercase. For example, **TITLE**."
+)
+
+
+class OneLineEntry(BaseModelWithoutExtraKeys):
+ main_column: str = pydantic.Field(
+ default="**LABEL:** DETAILS",
+ description=template_common_description
+ + " The default value is `**LABEL:** DETAILS`.",
+ )
+
+
+class EducationEntry(BaseModelWithoutExtraKeys):
+ main_column: str = pydantic.Field(
+ default="**INSTITUTION**, AREA\nSUMMARY\nHIGHLIGHTS",
+ description=template_common_description
+ + " The default value is `**INSTITUTION**, AREA\\nSUMMARY\\nHIGHLIGHTS`.",
+ )
+ degree_column: str | None = pydantic.Field(
+ default="**DEGREE**",
+ description=(
+ 'If given, a degree column will be added to the education entry. If "null",'
+ " no degree column will be shown. The available placeholders are all the"
+ " keys used in the entries (in uppercase). The default value is"
+ " `**DEGREE**`."
+ ),
+ )
+ date_and_location_column: str = pydantic.Field(
+ default="LOCATION\nDATE",
+ description=template_common_description
+ + " The default value is `LOCATION\\nDATE`.",
+ )
+
+
+class NormalEntry(BaseModelWithoutExtraKeys):
+ main_column: str = pydantic.Field(
+ default="**NAME**\nSUMMARY\nHIGHLIGHTS",
+ description=template_common_description
+ + " The default value is `**NAME**\\nSUMMARY\\nHIGHLIGHTS`.",
+ )
+ date_and_location_column: str = pydantic.Field(
+ default="LOCATION\nDATE",
+ description=template_common_description
+ + " The default value is `LOCATION\\nDATE`.",
+ )
+
+
+class ExperienceEntry(BaseModelWithoutExtraKeys):
+ main_column: str = pydantic.Field(
+ default="**COMPANY**, POSITION\nSUMMARY\nHIGHLIGHTS",
+ description=template_common_description
+ + " The default value is `**COMPANY**, POSITION\\nSUMMARY\\nHIGHLIGHTS`.",
+ )
+ date_and_location_column: str = pydantic.Field(
+ default="LOCATION\nDATE",
+ description=template_common_description
+ + " The default value is `LOCATION\\nDATE`.",
+ )
+
+
+class PublicationEntry(BaseModelWithoutExtraKeys):
+ main_column: str = pydantic.Field(
+ default="**TITLE**\nSUMMARY\nAUTHORS\nURL (JOURNAL)",
+ description=template_common_description
+ + " The default value is `**TITLE**\\nSUMMARY\\nAUTHORS\\nURL (JOURNAL)`.",
+ )
+ date_and_location_column: str = pydantic.Field(
+ default="DATE",
+ description=template_common_description + " The default value is `DATE`.",
+ )
+
+
+class Templates(BaseModelWithoutExtraKeys):
+ footer: str = pydantic.Field(
+ default="*NAME -- PAGE_NUMBER/TOTAL_PAGES*",
+ description=(
+ "Template for the footer. Available placeholders: NAME, PAGE_NUMBER,"
+ " TOTAL_PAGES. The default value is `*NAME -- PAGE_NUMBER/TOTAL_PAGES*`."
+ ),
+ )
+ top_note: str = pydantic.Field(
+ default="*LAST_UPDATED CURRENT_DATE*",
+ description=(
+ "Template for the top note. Available placeholders: LAST_UPDATED,"
+ " CURRENT_DATE. The default value is `*LAST_UPDATED CURRENT_DATE*`."
+ ),
+ )
+ single_date: str = pydantic.Field(
+ default="MONTH_ABBREVIATION YEAR",
+ description=(
+ "Template for single dates. Available placeholders: MONTH_ABBREVIATION,"
+ " YEAR. The default value is `MONTH_ABBREVIATION YEAR`."
+ ),
+ )
+ date_range: str = pydantic.Field(
+ default="START_DATE – END_DATE",
+ description=(
+ "Template for date ranges. Available placeholders: START_DATE, END_DATE."
+ " The default value is `START_DATE – END_DATE`."
+ ),
+ )
+ time_span: str = pydantic.Field(
+ default="HOW_MANY_YEARS YEARS HOW_MANY_MONTHS MONTHS",
+ description=(
+ "Template for time spans. Available placeholders: HOW_MANY_YEARS, YEARS,"
+ " HOW_MANY_MONTHS, MONTHS. The default value is `HOW_MANY_YEARS YEARS"
+ " HOW_MANY_MONTHS MONTHS`."
+ ),
+ )
+ one_line_entry: OneLineEntry = pydantic.Field(
+ default_factory=OneLineEntry,
+ description="Template for one-line entries.",
+ )
+ education_entry: EducationEntry = pydantic.Field(
+ default_factory=EducationEntry,
+ description="Template for education entries.",
+ )
+ normal_entry: NormalEntry = pydantic.Field(
+ default_factory=NormalEntry,
+ description="Template for normal entries.",
+ )
+ experience_entry: ExperienceEntry = pydantic.Field(
+ default_factory=ExperienceEntry,
+ description="Template for experience entries.",
+ )
+ publication_entry: PublicationEntry = pydantic.Field(
+ default_factory=PublicationEntry,
+ description="Template for publication entries.",
+ )
+
+
+class ClassicTheme(BaseModelWithoutExtraKeys):
+ theme: Literal["classic"] = "classic"
+ page: Page = pydantic.Field(default_factory=Page)
+ colors: Colors = pydantic.Field(default_factory=Colors)
+ typography: Typography = pydantic.Field(default_factory=Typography)
+ links: Links = pydantic.Field(default_factory=Links)
+ header: Header = pydantic.Field(default_factory=Header)
+ section_titles: SectionTitles = pydantic.Field(default_factory=SectionTitles)
+ sections: Sections = pydantic.Field(default_factory=Sections)
+ entries: Entries = pydantic.Field(default_factory=Entries)
+ templates: Templates = pydantic.Field(default_factory=Templates)
diff --git a/src/rendercv/schema/models/design/color.py b/src/rendercv/schema/models/design/color.py
new file mode 100644
index 00000000..935d68dd
--- /dev/null
+++ b/src/rendercv/schema/models/design/color.py
@@ -0,0 +1,15 @@
+from pydantic_extra_types.color import Color as PydanticColor
+
+
+class Color(PydanticColor):
+ def __str__(self) -> str:
+ """Convert color to RGB string for Typst rendering.
+
+ Why:
+ Typst templates need colors as rgb(r,g,b) strings. Override ensures
+ Color objects serialize correctly in Jinja2 templates.
+
+ Returns:
+ RGB string like "rgb(255, 0, 0)".
+ """
+ return self.as_rgb()
diff --git a/src/rendercv/schema/models/design/design.py b/src/rendercv/schema/models/design/design.py
new file mode 100644
index 00000000..7b8804a2
--- /dev/null
+++ b/src/rendercv/schema/models/design/design.py
@@ -0,0 +1,146 @@
+import importlib
+import importlib.util
+import pathlib
+import re
+from typing import Annotated, Any
+
+import pydantic
+import pydantic_core
+
+from ...pydantic_error_handling import CustomPydanticErrorTypes
+from ..validation_context import get_input_file_path
+from .built_in_design import BuiltInDesign, built_in_design_adapter
+from .classic_theme import ClassicTheme
+
+custom_theme_name_pattern = re.compile(r"^[a-z0-9]+$")
+
+
+def validate_design(design: Any, info: pydantic.ValidationInfo) -> Any:
+ """Validate design options for built-in or custom themes with dynamic loading.
+
+ Why:
+ Users can use built-in themes or create custom themes in local folders.
+ Validation attempts built-in first, then falls back to dynamic import
+ of custom theme classes from theme folder's __init__.py.
+
+ Args:
+ design: Design dictionary to validate.
+ info: Validation context containing input file path.
+
+ Returns:
+ Validated design model (built-in or custom theme class).
+ """
+ try:
+ return built_in_design_adapter.validate_python(design)
+ except pydantic.ValidationError as e:
+ errors = e.errors()
+ custom_theme = False
+ for error in errors:
+ if (
+ "ctx" in error
+ and "discriminator" in error["ctx"]
+ and error["ctx"]["discriminator"] == "'theme'"
+ ):
+ custom_theme = True
+ break
+
+ if custom_theme:
+ pass
+ else:
+ raise e
+
+ # Then it's a custom theme:
+ input_file_path = get_input_file_path(info)
+ relative_to = input_file_path.parent if input_file_path else pathlib.Path.cwd()
+ theme_name = str(design["theme"])
+
+ # Custom theme should only contain letters and digits:
+ if not custom_theme_name_pattern.match(theme_name):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The custom theme name should only contain lowercase letters and digits."
+ " The provided value is `{theme_name}`.",
+ {
+ "theme_name": theme_name,
+ "loc": ("design", "theme"),
+ "input": theme_name,
+ },
+ )
+
+ custom_theme_folder = relative_to / theme_name
+ # Check if the custom theme folder exists:
+ if not custom_theme_folder.exists():
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The custom theme folder `{custom_theme_folder}` does not exist. It should"
+ " be in the same directory as the input file.",
+ {"custom_theme_folder": custom_theme_folder.absolute()},
+ )
+ # Check if at least there is one *.j2.typ file in the custom theme folder:
+ if not any(custom_theme_folder.rglob("*.j2.typ")):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The custom theme folder `{custom_theme_folder}` does not contain any"
+ " *.j2.typ files. It should contain at least one *.j2.typ file.",
+ {"custom_theme_folder": custom_theme_folder.absolute()},
+ )
+
+ # Import __init__.py file from the custom theme folder if it exists:
+ path_to_init_file = custom_theme_folder / "__init__.py"
+ if path_to_init_file.exists():
+ spec = importlib.util.spec_from_file_location(
+ "theme",
+ path_to_init_file,
+ )
+ assert spec is not None
+
+ theme_module = importlib.util.module_from_spec(spec)
+ try:
+ assert spec.loader is not None
+ spec.loader.exec_module(theme_module)
+ except SyntaxError as e:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The custom theme {theme_name}'s __init__.py file has a syntax"
+ " error. Please fix it.",
+ {"theme_name": theme_name},
+ ) from e
+ except ImportError as e:
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The custom theme {theme_name}'s __init__.py file has an import error!"
+ " Check the import statements.",
+ {"theme_name": theme_name},
+ ) from e
+
+ model_name = f"{theme_name.capitalize()}Theme"
+ try:
+ theme_data_model_class = getattr(
+ theme_module,
+ model_name,
+ )
+ except AttributeError as e:
+ message = (
+ f"The custom theme {theme_name} does not have a {model_name} class."
+ )
+ raise ValueError(message) from e
+
+ # Initialize and validate the custom theme data model:
+ theme_data_model = theme_data_model_class(**design)
+ else:
+ # Then it means there is no __init__.py file in the custom theme folder.
+ # Create a dummy data model and use that instead.
+ class ThemeOptionsAreNotProvided(ClassicTheme):
+ theme: str = theme_name
+
+ theme_data_model = ThemeOptionsAreNotProvided(theme=theme_name)
+
+ return theme_data_model
+
+
+# RenderCV supports custom themes as well. For JSON schema, expose only BuiltInDesign.
+# The validator runs after the built-in validation to support custom themes.
+Design = Annotated[
+ BuiltInDesign,
+ pydantic.WrapValidator(lambda v, _, info: validate_design(v, info)),
+]
diff --git a/src/rendercv/schema/models/design/font_family.py b/src/rendercv/schema/models/design/font_family.py
new file mode 100644
index 00000000..5ba60858
--- /dev/null
+++ b/src/rendercv/schema/models/design/font_family.py
@@ -0,0 +1,53 @@
+from typing import Literal
+
+from pydantic.json_schema import SkipJsonSchema
+
+available_font_families = sorted(
+ [
+ # Typst built-ins
+ "Libertinus Serif",
+ "New Computer Modern",
+ "DejaVu Sans Mono",
+ # RenderCV bundled
+ "Mukta",
+ "Open Sans",
+ "Gentium Book Plus",
+ "Noto Sans",
+ "Lato",
+ "Source Sans 3",
+ "EB Garamond",
+ "Open Sauce Sans",
+ "Fontin",
+ "Roboto",
+ "Ubuntu",
+ "Poppins",
+ "Raleway",
+ "XCharter",
+ # Common system fonts
+ "Arial",
+ "Arial Rounded MT",
+ "Arial Unicode MS",
+ "Courier New",
+ "Times New Roman",
+ "Trebuchet MS",
+ "Verdana",
+ "Georgia",
+ "Tahoma",
+ "Impact",
+ "Comic Sans MS",
+ "Lucida Sans Unicode",
+ "Helvetica",
+ "Tahoma",
+ "Times New Roman",
+ "Verdana",
+ "Georgia",
+ "Aptos",
+ "Inter",
+ "Garamond",
+ "Gill Sans",
+ "Didot",
+ ]
+)
+
+
+type FontFamily = SkipJsonSchema[str] | Literal[*tuple(available_font_families)] # pyright: ignore[reportInvalidTypeForm]
diff --git a/src/rendercv/schema/models/design/other_themes/engineeringclassic.yaml b/src/rendercv/schema/models/design/other_themes/engineeringclassic.yaml
new file mode 100644
index 00000000..e00451f3
--- /dev/null
+++ b/src/rendercv/schema/models/design/other_themes/engineeringclassic.yaml
@@ -0,0 +1,40 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+design:
+ theme: engineeringclassic
+ typography:
+ font_family:
+ body: Raleway
+ name: Raleway
+ headline: Raleway
+ connections: Raleway
+ section_titles: Raleway
+ bold:
+ name: false
+ section_titles: false
+ header:
+ alignment: left
+ links:
+ show_external_link_icon: false
+ section_titles:
+ type: with_full_line
+ sections:
+ show_time_spans_in: []
+ entries:
+ short_second_row: false
+ summary:
+ space_above: 0.12cm
+ highlights:
+ space_left: "0cm"
+ space_above: 0.12cm
+ space_between_items: "0.12cm"
+ templates:
+ education_entry:
+ main_column: "**INSTITUTION**, DEGREE in AREA -- LOCATION\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
+ degree_column: null
+ normal_entry:
+ main_column: "**NAME** -- **LOCATION**\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
+ experience_entry:
+ main_column: "**POSITION**, COMPANY -- LOCATION\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
diff --git a/src/rendercv/schema/models/design/other_themes/engineeringresumes.yaml b/src/rendercv/schema/models/design/other_themes/engineeringresumes.yaml
new file mode 100644
index 00000000..9bb9cb8b
--- /dev/null
+++ b/src/rendercv/schema/models/design/other_themes/engineeringresumes.yaml
@@ -0,0 +1,62 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+design:
+ theme: engineeringresumes
+ page:
+ show_footer: false
+ typography:
+ font_family:
+ body: XCharter
+ name: XCharter
+ headline: XCharter
+ connections: XCharter
+ section_titles: XCharter
+ font_size:
+ name: "25pt"
+ section_titles: "1.2em"
+ bold:
+ name: false
+ header:
+ connections:
+ separator: "|"
+ show_icons: false
+ display_urls_instead_of_usernames: true
+ colors:
+ name: rgb(0,0,0)
+ connections: rgb(0,0,0)
+ headline: rgb(0,0,0)
+ section_titles: rgb(0,0,0)
+ links: rgb(0,0,0)
+ links:
+ underline: true
+ show_external_link_icon: false
+ section_titles:
+ type: with_full_line
+ space_above: "0.5cm"
+ space_below: "0.3cm"
+ sections:
+ space_between_regular_entries: "0.42cm"
+ space_between_text_based_entries: "0.15cm"
+ show_time_spans_in: []
+ entries:
+ short_second_row: false
+ summary:
+ space_above: 0.08cm
+ side_space: "0cm"
+ highlights:
+ bullet: ●
+ nested_bullet: ●
+ space_left: "0cm"
+ space_above: 0.08cm
+ space_between_items: 0.08cm
+ space_between_bullet_and_text: 0.3em
+ templates:
+ education_entry:
+ main_column: "**INSTITUTION**, DEGREE in AREA -- LOCATION\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
+ degree_column: null
+ normal_entry:
+ main_column: "**NAME** -- **LOCATION**\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
+ experience_entry:
+ main_column: "**POSITION**, COMPANY -- LOCATION\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
diff --git a/src/rendercv/schema/models/design/other_themes/moderncv.yaml b/src/rendercv/schema/models/design/other_themes/moderncv.yaml
new file mode 100644
index 00000000..f23636b7
--- /dev/null
+++ b/src/rendercv/schema/models/design/other_themes/moderncv.yaml
@@ -0,0 +1,54 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+design:
+ theme: moderncv
+ typography:
+ line_spacing: 0.6em
+ font_family:
+ body: Fontin
+ name: Fontin
+ headline: Fontin
+ connections: Fontin
+ section_titles: Fontin
+ font_size:
+ name: 25pt
+ section_titles: 1.4em
+ bold:
+ name: false
+ section_titles: false
+ header:
+ alignment: left
+ photo_width: 4.15cm
+ photo_space_left: 0cm
+ photo_space_right: 0.3cm
+ links:
+ underline: true
+ show_external_link_icon: false
+ section_titles:
+ type: moderncv
+ space_above: 0.55cm
+ space_below: 0.3cm
+ line_thickness: 0.15cm
+ sections:
+ show_time_spans_in: []
+ entries:
+ short_second_row: false
+ side_space: 0cm
+ space_between_columns: 0.3cm
+ summary:
+ space_above: 0.1cm
+ highlights:
+ space_left: 0cm
+ space_above: 0.15cm
+ space_between_items: 0.1cm
+ space_between_bullet_and_text: 0.3em
+ templates:
+ education_entry:
+ main_column: "**INSTITUTION**, DEGREE in AREA -- LOCATION\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
+ degree_column: null
+ normal_entry:
+ main_column: "**NAME** -- **LOCATION**\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
+ experience_entry:
+ main_column: "**POSITION**, COMPANY -- LOCATION\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: DATE
diff --git a/src/rendercv/schema/models/design/other_themes/sb2nov.yaml b/src/rendercv/schema/models/design/other_themes/sb2nov.yaml
new file mode 100644
index 00000000..f2b83402
--- /dev/null
+++ b/src/rendercv/schema/models/design/other_themes/sb2nov.yaml
@@ -0,0 +1,44 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+design:
+ theme: sb2nov
+ typography:
+ font_family:
+ body: New Computer Modern
+ name: New Computer Modern
+ headline: New Computer Modern
+ connections: New Computer Modern
+ section_titles: New Computer Modern
+ colors:
+ name: rgb(0,0,0)
+ connections: rgb(0,0,0)
+ section_titles: rgb(0,0,0)
+ headline: rgb(0,0,0)
+ links: rgb(0,0,0)
+ links:
+ underline: true
+ show_external_link_icon: false
+ section_titles:
+ type: with_full_line
+ sections:
+ show_time_spans_in: []
+ header:
+ connections:
+ hyperlink: true
+ show_icons: false
+ display_urls_instead_of_usernames: true
+ separator: "•"
+ entries:
+ short_second_row: false
+ highlights:
+ bullet: "◦"
+ nested_bullet: "◦"
+ templates:
+ education_entry:
+ main_column: "**INSTITUTION**\n*DEGREE* *in* *AREA*\nSUMMARY\nHIGHLIGHTS"
+ degree_column: null
+ date_and_location_column: "*LOCATION*\n*DATE*"
+ normal_entry:
+ date_and_location_column: "*LOCATION*\n*DATE*"
+ experience_entry:
+ main_column: "**POSITION**\n*COMPANY*\nSUMMARY\nHIGHLIGHTS"
+ date_and_location_column: "*LOCATION*\n*DATE*"
diff --git a/src/rendercv/schema/models/design/typst_dimension.py b/src/rendercv/schema/models/design/typst_dimension.py
new file mode 100644
index 00000000..ab5a07a1
--- /dev/null
+++ b/src/rendercv/schema/models/design/typst_dimension.py
@@ -0,0 +1,32 @@
+import re
+from typing import Annotated
+
+import pydantic
+import pydantic_core
+
+from ...pydantic_error_handling import CustomPydanticErrorTypes
+
+
+def validate_typst_dimension(dimension: str) -> str:
+ """Validate Typst dimension format with unit.
+
+ Why:
+ Typst requires dimensions with explicit units (e.g., 1cm, 0.5in).
+ Validation prevents compilation errors from missing or invalid units.
+
+ Args:
+ dimension: Dimension string to validate.
+
+ Returns:
+ Original dimension if valid.
+ """
+ if not re.fullmatch(r"-?\d+(?:\.\d+)?(cm|in|pt|mm|ex|em)", dimension):
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The value must be a number followed by a unit (cm, in, pt, mm, ex, em)."
+ " For example, 0.1cm.",
+ )
+ return dimension
+
+
+type TypstDimension = Annotated[str, pydantic.AfterValidator(validate_typst_dimension)]
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/SectionBeginning.j2.typ b/src/rendercv/schema/models/locale/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/SectionBeginning.j2.typ
rename to src/rendercv/schema/models/locale/__init__.py
diff --git a/src/rendercv/schema/models/locale/english_locale.py b/src/rendercv/schema/models/locale/english_locale.py
new file mode 100644
index 00000000..484b4e36
--- /dev/null
+++ b/src/rendercv/schema/models/locale/english_locale.py
@@ -0,0 +1,110 @@
+import functools
+from typing import Annotated, Literal
+
+import annotated_types as at
+import pydantic
+
+from ..base import BaseModelWithoutExtraKeys
+
+
+class EnglishLocale(BaseModelWithoutExtraKeys):
+ language: Literal["english"] = pydantic.Field(
+ default="english",
+ description="The language for your CV. The default value is `english`.",
+ )
+ last_updated: str = pydantic.Field(
+ default="Last updated in",
+ description=(
+ 'Translation of "Last updated in". The default value is `Last updated in`.'
+ ),
+ )
+ month: str = pydantic.Field(
+ default="month",
+ description='Translation of "month" (singular). The default value is `month`.',
+ )
+ months: str = pydantic.Field(
+ default="months",
+ description='Translation of "months" (plural). The default value is `months`.',
+ )
+ year: str = pydantic.Field(
+ default="year",
+ description='Translation of "year" (singular). The default value is `year`.',
+ )
+ years: str = pydantic.Field(
+ default="years",
+ description='Translation of "years" (plural). The default value is `years`.',
+ )
+ present: str = pydantic.Field(
+ default="present",
+ description=(
+ 'Translation of "present" for ongoing dates. The default value is'
+ " `present`."
+ ),
+ )
+ # From https://web.library.yale.edu/cataloging/months
+ month_abbreviations: Annotated[list[str], at.Len(min_length=12, max_length=12)] = (
+ pydantic.Field(
+ default=[
+ "Jan",
+ "Feb",
+ "Mar",
+ "Apr",
+ "May",
+ "June",
+ "July",
+ "Aug",
+ "Sept",
+ "Oct",
+ "Nov",
+ "Dec",
+ ],
+ description="Month abbreviations (Jan-Dec).",
+ )
+ )
+ month_names: Annotated[list[str], at.Len(min_length=12, max_length=12)] = (
+ pydantic.Field(
+ default=[
+ "January",
+ "February",
+ "March",
+ "April",
+ "May",
+ "June",
+ "July",
+ "August",
+ "September",
+ "October",
+ "November",
+ "December",
+ ],
+ description="Full month names (January-December).",
+ )
+ )
+
+ @functools.cached_property
+ def language_iso_639_1(self) -> str:
+ """Get ISO 639-1 two-letter language code for locale.
+
+ Why:
+ Typst's text element requires ISO 639-1/2/3 language codes for the
+ lang parameter. This enables proper hyphenation, smart quotes, and
+ accessibility (screen readers use it for voice selection). HTML export
+ also uses it for lang attribute.
+
+ Returns:
+ Two-letter ISO 639-1 language code for Typst and HTML.
+ """
+ return {
+ "english": "en",
+ "mandarin_chineese": "zh",
+ "hindi": "hi",
+ "spanish": "es",
+ "french": "fr",
+ "portuguese": "pt",
+ "german": "de",
+ "turkish": "tr",
+ "italian": "it",
+ "russian": "ru",
+ "japanese": "ja",
+ "korean": "ko",
+ }[self.language]
diff --git a/src/rendercv/schema/models/locale/locale.py b/src/rendercv/schema/models/locale/locale.py
new file mode 100644
index 00000000..23c0d928
--- /dev/null
+++ b/src/rendercv/schema/models/locale/locale.py
@@ -0,0 +1,50 @@
+from functools import reduce
+from operator import or_
+from pathlib import Path
+from typing import Annotated, get_args
+
+import pydantic
+
+from ...variant_pydantic_model_generator import create_variant_pydantic_model
+from ...yaml_reader import read_yaml
+from .english_locale import EnglishLocale
+
+
+def discover_other_locales() -> list[type[EnglishLocale]]:
+ """Auto-discover and load locale variant classes from other_locales/ directory.
+
+ Why:
+ Locales beyond English are defined as YAML files with translations
+ and format overrides. Dynamic discovery enables community-contributed
+ locales without core code changes.
+
+ Returns:
+ List of dynamically generated locale variant classes.
+ """
+ other_locales_dir = Path(__file__).parent / "other_locales"
+ discovered: list[type[EnglishLocale]] = []
+
+ for yaml_file in sorted(other_locales_dir.glob("*.yaml")):
+ locale_model = create_variant_pydantic_model(
+ variant_name=yaml_file.stem,
+ defaults=read_yaml(yaml_file, read_type="safe")["locale"],
+ base_class=EnglishLocale,
+ discriminator_field="language",
+ class_name_suffix="Locale",
+ module_name="rendercv.schema.models.locale",
+ )
+ discovered.append(locale_model)
+
+ return discovered
+
+
+# Build discriminated union dynamically
+type Locale = Annotated[
+ EnglishLocale | reduce(or_, discover_other_locales()), # pyright: ignore[reportInvalidTypeForm]
+ pydantic.Field(discriminator="language"),
+]
+available_locales = [
+ LocaleModel.model_fields["language"].default
+ for LocaleModel in get_args(get_args(Locale.__value__)[0])
+]
+locale_adapter = pydantic.TypeAdapter(Locale)
diff --git a/src/rendercv/schema/models/locale/other_locales/french.yaml b/src/rendercv/schema/models/locale/other_locales/french.yaml
new file mode 100644
index 00000000..c7cad0ca
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/french.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: french
+ last_updated: Dernière mise à jour
+ month: mois
+ months: mois
+ year: an
+ years: ans
+ present: présent
+ month_abbreviations:
+ - Jan
+ - Fév
+ - Mar
+ - Avr
+ - Mai
+ - Juin
+ - Juil
+ - Aoû
+ - Sep
+ - Oct
+ - Nov
+ - Déc
+ month_names:
+ - Janvier
+ - Février
+ - Mars
+ - Avril
+ - Mai
+ - Juin
+ - Juillet
+ - Août
+ - Septembre
+ - Octobre
+ - Novembre
+ - Décembre
diff --git a/src/rendercv/schema/models/locale/other_locales/german.yaml b/src/rendercv/schema/models/locale/other_locales/german.yaml
new file mode 100644
index 00000000..8957628d
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/german.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: german
+ last_updated: Zuletzt aktualisiert
+ month: Monat
+ months: Monate
+ year: Jahr
+ years: Jahre
+ present: gegenwärtig
+ month_abbreviations:
+ - Jan
+ - Feb
+ - Mär
+ - Apr
+ - Mai
+ - Jun
+ - Jul
+ - Aug
+ - Sep
+ - Okt
+ - Nov
+ - Dez
+ month_names:
+ - Januar
+ - Februar
+ - März
+ - April
+ - Mai
+ - Juni
+ - Juli
+ - August
+ - September
+ - Oktober
+ - November
+ - Dezember
diff --git a/src/rendercv/schema/models/locale/other_locales/hindi.yaml b/src/rendercv/schema/models/locale/other_locales/hindi.yaml
new file mode 100644
index 00000000..12c2005e
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/hindi.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: hindi
+ last_updated: अंतिम अद्यतन
+ month: महीना
+ months: महीने
+ year: वर्ष
+ years: वर्ष
+ present: वर्तमान
+ month_abbreviations:
+ - जन
+ - फर
+ - मार
+ - अप्र
+ - मई
+ - जून
+ - जुल
+ - अग
+ - सित
+ - अक्ट
+ - नव
+ - दिस
+ month_names:
+ - जनवरी
+ - फरवरी
+ - मार्च
+ - अप्रैल
+ - मई
+ - जून
+ - जुलाई
+ - अगस्त
+ - सितंबर
+ - अक्टूबर
+ - नवंबर
+ - दिसंबर
diff --git a/src/rendercv/schema/models/locale/other_locales/italian.yaml b/src/rendercv/schema/models/locale/other_locales/italian.yaml
new file mode 100644
index 00000000..31230c4c
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/italian.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: italian
+ last_updated: Ultimo aggiornamento
+ month: mese
+ months: mesi
+ year: anno
+ years: anni
+ present: presente
+ month_abbreviations:
+ - Gen
+ - Feb
+ - Mar
+ - Apr
+ - Mag
+ - Giu
+ - Lug
+ - Ago
+ - Set
+ - Ott
+ - Nov
+ - Dic
+ month_names:
+ - Gennaio
+ - Febbraio
+ - Marzo
+ - Aprile
+ - Maggio
+ - Giugno
+ - Luglio
+ - Agosto
+ - Settembre
+ - Ottobre
+ - Novembre
+ - Dicembre
diff --git a/src/rendercv/schema/models/locale/other_locales/japanese.yaml b/src/rendercv/schema/models/locale/other_locales/japanese.yaml
new file mode 100644
index 00000000..3f5de53b
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/japanese.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: japanese
+ last_updated: 最終更新
+ month: 月
+ months: ヶ月
+ year: 年
+ years: 年
+ present: 現在
+ month_abbreviations:
+ - 1月
+ - 2月
+ - 3月
+ - 4月
+ - 5月
+ - 6月
+ - 7月
+ - 8月
+ - 9月
+ - 10月
+ - 11月
+ - 12月
+ month_names:
+ - 1月
+ - 2月
+ - 3月
+ - 4月
+ - 5月
+ - 6月
+ - 7月
+ - 8月
+ - 9月
+ - 10月
+ - 11月
+ - 12月
diff --git a/src/rendercv/schema/models/locale/other_locales/korean.yaml b/src/rendercv/schema/models/locale/other_locales/korean.yaml
new file mode 100644
index 00000000..9b11b7d2
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/korean.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: korean
+ last_updated: 마지막 업데이트
+ month: 월
+ months: 개월
+ year: 년
+ years: 년
+ present: 현재
+ month_abbreviations:
+ - 1월
+ - 2월
+ - 3월
+ - 4월
+ - 5월
+ - 6월
+ - 7월
+ - 8월
+ - 9월
+ - 10월
+ - 11월
+ - 12월
+ month_names:
+ - 1월
+ - 2월
+ - 3월
+ - 4월
+ - 5월
+ - 6월
+ - 7월
+ - 8월
+ - 9월
+ - 10월
+ - 11월
+ - 12월
diff --git a/src/rendercv/schema/models/locale/other_locales/mandarin_chineese.yaml b/src/rendercv/schema/models/locale/other_locales/mandarin_chineese.yaml
new file mode 100644
index 00000000..a0d040ed
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/mandarin_chineese.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: mandarin_chineese
+ last_updated: 最后更新于
+ month: 个月
+ months: 个月
+ year: 年
+ years: 年
+ present: 至今
+ month_abbreviations:
+ - 1月
+ - 2月
+ - 3月
+ - 4月
+ - 5月
+ - 6月
+ - 7月
+ - 8月
+ - 9月
+ - 10月
+ - 11月
+ - 12月
+ month_names:
+ - 一月
+ - 二月
+ - 三月
+ - 四月
+ - 五月
+ - 六月
+ - 七月
+ - 八月
+ - 九月
+ - 十月
+ - 十一月
+ - 十二月
diff --git a/src/rendercv/schema/models/locale/other_locales/portuguese.yaml b/src/rendercv/schema/models/locale/other_locales/portuguese.yaml
new file mode 100644
index 00000000..4000d4c0
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/portuguese.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: portuguese
+ last_updated: Última atualização
+ month: mês
+ months: meses
+ year: ano
+ years: anos
+ present: presente
+ month_abbreviations:
+ - Jan
+ - Fev
+ - Mar
+ - Abr
+ - Mai
+ - Jun
+ - Jul
+ - Ago
+ - Set
+ - Out
+ - Nov
+ - Dez
+ month_names:
+ - Janeiro
+ - Fevereiro
+ - Março
+ - Abril
+ - Maio
+ - Junho
+ - Julho
+ - Agosto
+ - Setembro
+ - Outubro
+ - Novembro
+ - Dezembro
diff --git a/src/rendercv/schema/models/locale/other_locales/russian.yaml b/src/rendercv/schema/models/locale/other_locales/russian.yaml
new file mode 100644
index 00000000..8645adba
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/russian.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: russian
+ last_updated: Последнее обновление
+ month: месяц
+ months: месяцы
+ year: год
+ years: лет
+ present: настоящее время
+ month_abbreviations:
+ - Янв
+ - Фев
+ - Мар
+ - Апр
+ - Май
+ - Июн
+ - Июл
+ - Авг
+ - Сен
+ - Окт
+ - Ноя
+ - Дек
+ month_names:
+ - Январь
+ - Февраль
+ - Март
+ - Апрель
+ - Май
+ - Июнь
+ - Июль
+ - Август
+ - Сентябрь
+ - Октябрь
+ - Ноябрь
+ - Декабрь
diff --git a/src/rendercv/schema/models/locale/other_locales/spanish.yaml b/src/rendercv/schema/models/locale/other_locales/spanish.yaml
new file mode 100644
index 00000000..51da8f7d
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/spanish.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: spanish
+ last_updated: Última actualización
+ month: mes
+ months: meses
+ year: año
+ years: años
+ present: presente
+ month_abbreviations:
+ - Ene
+ - Feb
+ - Mar
+ - Abr
+ - May
+ - Jun
+ - Jul
+ - Ago
+ - Sep
+ - Oct
+ - Nov
+ - Dic
+ month_names:
+ - Enero
+ - Febrero
+ - Marzo
+ - Abril
+ - Mayo
+ - Junio
+ - Julio
+ - Agosto
+ - Septiembre
+ - Octubre
+ - Noviembre
+ - Diciembre
diff --git a/src/rendercv/schema/models/locale/other_locales/turkish.yaml b/src/rendercv/schema/models/locale/other_locales/turkish.yaml
new file mode 100644
index 00000000..a48cad14
--- /dev/null
+++ b/src/rendercv/schema/models/locale/other_locales/turkish.yaml
@@ -0,0 +1,35 @@
+# yaml-language-server: $schema=../../../../../../schema.json
+locale:
+ language: turkish
+ last_updated: Son güncelleme
+ month: ay
+ months: ay
+ year: yıl
+ years: yıl
+ present: halen
+ month_abbreviations:
+ - Oca
+ - Şub
+ - Mar
+ - Nis
+ - May
+ - Haz
+ - Tem
+ - Ağu
+ - Eyl
+ - Eki
+ - Kas
+ - Ara
+ month_names:
+ - Ocak
+ - Şubat
+ - Mart
+ - Nisan
+ - Mayıs
+ - Haziran
+ - Temmuz
+ - Ağustos
+ - Eylül
+ - Ekim
+ - Kasım
+ - Aralık
diff --git a/src/rendercv/schema/models/path.py b/src/rendercv/schema/models/path.py
new file mode 100644
index 00000000..b2da439e
--- /dev/null
+++ b/src/rendercv/schema/models/path.py
@@ -0,0 +1,76 @@
+import pathlib
+from typing import Annotated
+
+import pydantic
+import pydantic_core
+
+from ..pydantic_error_handling import CustomPydanticErrorTypes
+from .validation_context import get_input_file_path
+
+
+def resolve_relative_path(
+ path: pathlib.Path, info: pydantic.ValidationInfo, *, must_exist: bool = True
+) -> pathlib.Path:
+ """Convert relative path to absolute path based on input file location.
+
+ Why:
+ Users reference files like `photo: profile.jpg` relative to their CV
+ YAML. This validator resolves such paths to absolute form and validates
+ existence, enabling file access during rendering.
+
+ Example:
+ ```py
+ # In validators: photo_path = resolve_relative_path(photo, info)
+ # Input: "photo.jpg" in /home/user/cv.yaml
+ # Output: /home/user/photo.jpg (absolute, validated to exist)
+ ```
+
+ Args:
+ path: Path to resolve (may be relative or absolute).
+ info: Validation context containing input file path.
+ must_exist: Whether to raise error if path doesn't exist.
+
+ Returns:
+ Absolute path.
+ """
+ if path:
+ input_file_path = get_input_file_path(info)
+ relative_to = input_file_path.parent if input_file_path else pathlib.Path.cwd()
+ if not path.is_absolute():
+ path = relative_to / path
+
+ if must_exist:
+ if not path.exists():
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The file `{file_path}` does not exist.",
+ {"file_path": path.relative_to(relative_to)},
+ )
+ if not path.is_file():
+ raise pydantic_core.PydanticCustomError(
+ CustomPydanticErrorTypes.other.value,
+ "The path `{path}` is not a file.",
+ {"path": path.relative_to(relative_to)},
+ )
+
+ return path
+
+
+def serialize_path(path: pathlib.Path) -> str:
+ return str(path.relative_to(pathlib.Path.cwd()))
+
+
+type ExistingPathRelativeToInput = Annotated[
+ pathlib.Path,
+ pydantic.AfterValidator(
+ lambda path, info: resolve_relative_path(path, info, must_exist=True)
+ ),
+]
+
+type PlannedPathRelativeToInput = Annotated[
+ pathlib.Path,
+ pydantic.AfterValidator(
+ lambda path, info: resolve_relative_path(path, info, must_exist=False)
+ ),
+ pydantic.PlainSerializer(serialize_path),
+]
diff --git a/src/rendercv/schema/models/rendercv_model.py b/src/rendercv/schema/models/rendercv_model.py
new file mode 100644
index 00000000..5d6f4021
--- /dev/null
+++ b/src/rendercv/schema/models/rendercv_model.py
@@ -0,0 +1,61 @@
+import pathlib
+
+import pydantic
+
+from .base import BaseModelWithExtraKeys
+from .cv.cv import Cv
+from .design.classic_theme import ClassicTheme
+from .design.design import Design
+from .locale.locale import EnglishLocale, Locale
+from .settings.settings import Settings
+from .validation_context import get_input_file_path
+
+
+class RenderCVModel(BaseModelWithExtraKeys):
+ # Technically, `cv` is a required field, but we don't pass it to the JSON Schema
+ # so that the same schema can be used for standalone design, locale, and settings
+ # files.
+ model_config = pydantic.ConfigDict(json_schema_extra={"required": []})
+ cv: Cv = pydantic.Field(
+ title="CV",
+ description="The content of the CV.",
+ )
+ design: Design = pydantic.Field(
+ default_factory=ClassicTheme,
+ title="Design",
+ description=(
+ "The design information of the CV. The default is the `classic` theme."
+ ),
+ )
+ locale: Locale = pydantic.Field(
+ default_factory=EnglishLocale,
+ title="Locale Catalog",
+ description=(
+ "The locale catalog of the CV to allow the support of multiple languages."
+ ),
+ )
+ settings: Settings = pydantic.Field(
+ default_factory=Settings,
+ title="RenderCV Settings",
+ description="The settings of the RenderCV.",
+ )
+
+ _input_file_path: pathlib.Path | None = pydantic.PrivateAttr(default=None)
+
+ @pydantic.model_validator(mode="after")
+ def set_input_file_path(self, info: pydantic.ValidationInfo) -> "RenderCVModel":
+ """Store input file path in private attribute for path resolution.
+
+ Why:
+ Photo paths and other relative references need input file location
+ for resolution. Private attribute stores this after validation for
+ downstream processing.
+
+ Args:
+ info: Validation context containing input file path.
+
+ Returns:
+ Model instance with _input_file_path set.
+ """
+ self._input_file_path = get_input_file_path(info)
+ return self
diff --git a/tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/SectionEnding.j2.typ b/src/rendercv/schema/models/settings/__init__.py
similarity index 100%
rename from tests/testdata/test_copy_theme_files_to_output_directory_custom_theme/dummytheme/SectionEnding.j2.typ
rename to src/rendercv/schema/models/settings/__init__.py
diff --git a/src/rendercv/schema/models/settings/render_command.py b/src/rendercv/schema/models/settings/render_command.py
new file mode 100644
index 00000000..d8618415
--- /dev/null
+++ b/src/rendercv/schema/models/settings/render_command.py
@@ -0,0 +1,109 @@
+import pathlib
+
+import pydantic
+
+from ..base import BaseModelWithoutExtraKeys
+from ..path import ExistingPathRelativeToInput, PlannedPathRelativeToInput
+
+file_path_placeholders_description = """The following placeholders can be used:
+
+- MONTH_NAME: Full name of the month (e.g., January)
+- MONTH_ABBREVIATION: Abbreviation of the month (e.g., Jan)
+- MONTH: Month as a number (e.g., 1)
+- MONTH_IN_TWO_DIGITS: Month as a number in two digits (e.g., 01)
+- YEAR: Year as a number (e.g., 2024)
+- YEAR_IN_TWO_DIGITS: Year as a number in two digits (e.g., 24)
+- NAME: The name of the CV owner (e.g., John Doe)
+- NAME_IN_SNAKE_CASE: The name of the CV owner in snake case (e.g., John_Doe)
+- NAME_IN_LOWER_SNAKE_CASE: The name of the CV owner in lower snake case (e.g., john_doe)
+- NAME_IN_UPPER_SNAKE_CASE: The name of the CV owner in upper snake case (e.g., JOHN_DOE)
+- NAME_IN_KEBAB_CASE: The name of the CV owner in kebab case (e.g., John-Doe)
+- NAME_IN_LOWER_KEBAB_CASE: The name of the CV owner in lower kebab case (e.g., john-doe)
+- NAME_IN_UPPER_KEBAB_CASE: The name of the CV owner in upper kebab case (e.g., JOHN-DOE)
+"""
+
+
+class RenderCommand(BaseModelWithoutExtraKeys):
+ design: ExistingPathRelativeToInput | None = pydantic.Field(
+ default=None,
+ description="Path to a YAML file containing the `design` field.",
+ )
+ locale: ExistingPathRelativeToInput | None = pydantic.Field(
+ default=None,
+ description="Path to a YAML file containing the `locale` field.",
+ )
+ typst_path: PlannedPathRelativeToInput = pydantic.Field(
+ default=pathlib.Path("rendercv_output/NAME_IN_SNAKE_CASE_CV.typ"),
+ description=(
+ "Output path for the Typst file, relative to the input YAML file. The"
+ " default"
+ " value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.typ`.\n\n"
+ f"{file_path_placeholders_description}"
+ ),
+ )
+ pdf_path: PlannedPathRelativeToInput = pydantic.Field(
+ default=pathlib.Path("rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf"),
+ description=(
+ "Output path for the PDF file, relative to the input YAML file. The default"
+ " value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.pdf`.\n\n"
+ f"{file_path_placeholders_description}"
+ ),
+ )
+ markdown_path: PlannedPathRelativeToInput = pydantic.Field(
+ default=pathlib.Path("rendercv_output/NAME_IN_SNAKE_CASE_CV.md"),
+ title="Markdown Path",
+ description=(
+ "Output path for the Markdown file, relative to the input YAML file. The"
+ " default value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.md`.\n\n"
+ f"{file_path_placeholders_description}"
+ ),
+ )
+ html_path: PlannedPathRelativeToInput = pydantic.Field(
+ default=pathlib.Path("rendercv_output/NAME_IN_SNAKE_CASE_CV.html"),
+ description=(
+ "Output path for the HTML file, relative to the input YAML file. The"
+ " default"
+ " value is `rendercv_output/NAME_IN_SNAKE_CASE_CV.html`.\n\n"
+ f"{file_path_placeholders_description}"
+ ),
+ )
+ png_path: PlannedPathRelativeToInput = pydantic.Field(
+ default=pathlib.Path("rendercv_output/NAME_IN_SNAKE_CASE_CV.png"),
+ description=(
+ "Output path for PNG files, relative to the input YAML file. The default"
+ " value"
+ " is `rendercv_output/NAME_IN_SNAKE_CASE_CV.png`.\n\n"
+ f"{file_path_placeholders_description}"
+ ),
+ )
+ dont_generate_markdown: bool = pydantic.Field(
+ default=False,
+ title="Don't Generate Markdown",
+ description=(
+ "Skip Markdown generation. This also disables HTML generation. The default"
+ " value is `false`."
+ ),
+ )
+ dont_generate_html: bool = pydantic.Field(
+ default=False,
+ title="Don't Generate HTML",
+ description="Skip HTML generation. The default value is `false`.",
+ )
+ dont_generate_typst: bool = pydantic.Field(
+ default=False,
+ title="Don't Generate Typst",
+ description=(
+ "Skip Typst generation. This also disables PDF and PNG generation. The"
+ " default value is `false`."
+ ),
+ )
+ dont_generate_pdf: bool = pydantic.Field(
+ default=False,
+ title="Don't Generate PDF",
+ description="Skip PDF generation. The default value is `false`.",
+ )
+ dont_generate_png: bool = pydantic.Field(
+ default=False,
+ title="Don't Generate PNG",
+ description="Skip PNG generation. The default value is `false`.",
+ )
diff --git a/src/rendercv/schema/models/settings/settings.py b/src/rendercv/schema/models/settings/settings.py
new file mode 100644
index 00000000..37045e2f
--- /dev/null
+++ b/src/rendercv/schema/models/settings/settings.py
@@ -0,0 +1,50 @@
+import datetime
+
+import pydantic
+
+from ..base import BaseModelWithoutExtraKeys
+from .render_command import RenderCommand
+
+
+class Settings(BaseModelWithoutExtraKeys):
+ current_date: datetime.date = pydantic.Field(
+ default_factory=datetime.date.today,
+ title="Date",
+ description=(
+ 'The date to use as "current date" for filenames, the "last updated" label,'
+ " and time span calculations. Defaults to the actual current date."
+ ),
+ json_schema_extra={
+ "default": None,
+ },
+ )
+ render_command: RenderCommand = pydantic.Field(
+ default_factory=RenderCommand,
+ title="Render Command Settings",
+ description=(
+ "Settings for the `render` command. These correspond to command-line"
+ " arguments. CLI arguments take precedence over these settings."
+ ),
+ )
+ bold_keywords: list[str] = pydantic.Field(
+ default=[],
+ title="Bold Keywords",
+ description="Keywords to automatically bold in the output.",
+ )
+
+ @pydantic.field_validator("bold_keywords")
+ @classmethod
+ def keep_unique_keywords(cls, value: list[str]) -> list[str]:
+ """Remove duplicate keywords from bold list.
+
+ Why:
+ Users might accidentally list same keyword multiple times. Deduplication
+ prevents redundant bold highlighting operations during rendering.
+
+ Args:
+ value: List of keywords potentially with duplicates.
+
+ Returns:
+ List with unique keywords only.
+ """
+ return list(set(value))
diff --git a/src/rendercv/schema/models/validation_context.py b/src/rendercv/schema/models/validation_context.py
new file mode 100644
index 00000000..99c8704e
--- /dev/null
+++ b/src/rendercv/schema/models/validation_context.py
@@ -0,0 +1,51 @@
+import pathlib
+from datetime import date as Date
+from typing import cast
+
+import pydantic
+
+
+class ValidationContext(pydantic.BaseModel):
+ input_file_path: pathlib.Path | None = None
+ current_date: Date | None = None
+
+
+def get_input_file_path(info: pydantic.ValidationInfo) -> pathlib.Path | None:
+ """Extract input file path from validation context.
+
+ Why:
+ Relative paths in YAML (like photo references) must resolve relative
+ to the input file's directory. Validators access this path via context
+ to compute absolute paths during validation.
+
+ Args:
+ info: Pydantic validation info containing context.
+
+ Returns:
+ Input file path if available, otherwise None.
+ """
+ if isinstance(info.context, dict):
+ context = cast(ValidationContext, info.context["context"])
+ if context.input_file_path:
+ return context.input_file_path
+ return None
+
+
+def get_current_date(info: pydantic.ValidationInfo) -> Date:
+ """Extract current date from validation context or default to today.
+
+ Why:
+ Date calculations (like months of experience) must use consistent
+ reference dates. Users can override via settings.current_date for
+ reproducible builds, otherwise defaults to today.
+
+ Args:
+ info: Pydantic validation info containing context.
+
+ Returns:
+ Current date from context or Date.today().
+ """
+ if isinstance(info.context, dict):
+ context = cast(ValidationContext, info.context["context"])
+ return context.current_date or Date.today()
+ return Date.today()
diff --git a/src/rendercv/schema/override_dictionary.py b/src/rendercv/schema/override_dictionary.py
new file mode 100644
index 00000000..a32c5329
--- /dev/null
+++ b/src/rendercv/schema/override_dictionary.py
@@ -0,0 +1,133 @@
+import copy
+from typing import overload
+
+from rendercv.exception import RenderCVUserError
+
+
+@overload
+def update_value_by_location(
+ dict_or_list: dict,
+ key: str,
+ value: str,
+ full_key: str,
+) -> dict: ...
+@overload
+def update_value_by_location(
+ dict_or_list: list,
+ key: str,
+ value: str,
+ full_key: str,
+) -> list: ...
+def update_value_by_location(
+ dict_or_list: dict | list,
+ key: str,
+ value: str,
+ full_key: str,
+) -> dict | list:
+ """Navigate nested structure via dotted path and update value.
+
+ Why:
+ CLI overrides like `--cv.sections.education.0.institution MIT`
+ must modify deeply nested YAML values without requiring users
+ to edit files. Recursive traversal handles arbitrary nesting
+ with proper index validation and error context.
+
+ Example:
+ ```py
+ data = {"cv": {"sections": {"education": [{"institution": "A"}]}}}
+ result = update_value_by_location(
+ data,
+ "cv.sections.education.0.institution",
+ "MIT",
+ "cv.sections.education.0.institution",
+ )
+ assert result["cv"]["sections"]["education"][0]["institution"] == "MIT"
+ ```
+
+ Args:
+ dict_or_list: Target structure to modify.
+ key: Remaining path segments to traverse.
+ value: Replacement value.
+ full_key: Original full path for error messages.
+
+ Returns:
+ Modified structure.
+ """
+ keys = key.split(".")
+ first_key: str | int = keys[0]
+ remaining_key = ".".join(keys[1:])
+
+ # Calculate the parent path for error messages
+ processed_count = len(full_key.split(".")) - len(key.split("."))
+ previous_key = (
+ ".".join(full_key.split(".")[:processed_count]) if processed_count > 0 else ""
+ )
+
+ if isinstance(dict_or_list, list):
+ try:
+ first_key = int(first_key)
+ except ValueError as e:
+ message = (
+ f"`{previous_key}` corresponds to a list, but `{keys[0]}` is not an"
+ " integer."
+ )
+ raise RenderCVUserError(message) from e
+
+ if first_key >= len(dict_or_list):
+ message = (
+ f"Index {first_key} is out of range for the list `{previous_key}`."
+ )
+ raise RenderCVUserError(message)
+ elif not isinstance(dict_or_list, dict):
+ message = (
+ f"It seems like there's something wrong with `{full_key}`, but we don't"
+ " know what it is."
+ )
+ raise RenderCVUserError(message)
+
+ if len(keys) == 1:
+ new_value = value
+ else:
+ new_value = update_value_by_location(
+ dict_or_list[first_key], # pyright: ignore[reportArgumentType, reportCallIssue]
+ remaining_key,
+ value,
+ full_key=full_key,
+ )
+
+ dict_or_list[first_key] = new_value # pyright: ignore[reportArgumentType, reportCallIssue]
+
+ return dict_or_list
+
+
+def apply_overrides_to_dictionary(
+ dictionary: dict,
+ overrides: dict[str, str],
+) -> dict:
+ """Apply multiple CLI overrides to dictionary.
+
+ Why:
+ Users need to test configuration changes without editing YAML files.
+ Batching overrides ensures all modifications happen before validation,
+ preventing partial invalid states.
+
+ Example:
+ ```py
+ data = {"cv": {"name": "John", "phone": "123"}}
+ overrides = {"cv.name": "Jane", "cv.phone": "456"}
+ result = apply_overrides_to_dictionary(data, overrides)
+ assert result["cv"]["name"] == "Jane"
+ ```
+
+ Args:
+ dictionary: Source dictionary to modify.
+ overrides: Map of dotted paths to new values.
+
+ Returns:
+ Deep copy with all overrides applied.
+ """
+ new_dictionary = copy.deepcopy(dictionary)
+ for key, value in overrides.items():
+ new_dictionary = update_value_by_location(new_dictionary, key, value, key)
+
+ return new_dictionary
diff --git a/src/rendercv/schema/pydantic_error_handling.py b/src/rendercv/schema/pydantic_error_handling.py
new file mode 100644
index 00000000..76691a56
--- /dev/null
+++ b/src/rendercv/schema/pydantic_error_handling.py
@@ -0,0 +1,222 @@
+import pathlib
+from typing import cast
+
+import pydantic
+import pydantic_core
+import ruamel.yaml
+from ruamel.yaml.comments import CommentedMap
+
+from rendercv.exception import RenderCVInternalError, RenderCVValidationError
+
+from .models.custom_error_types import CustomPydanticErrorTypes
+from .yaml_reader import read_yaml
+
+error_dictionary = cast(
+ dict[str, str],
+ read_yaml(pathlib.Path(__file__).parent / "error_dictionary.yaml"),
+)
+unwanted_texts = ("value is not a valid email address: ", "Value error, ")
+unwanted_locations = (
+ "tagged-union",
+ "list",
+ "literal",
+ "int",
+ "constrained-str",
+ "function-after",
+)
+
+
+def parse_plain_pydantic_error(
+ plain_error: pydantic_core.ErrorDetails, user_input_as_commented_map: CommentedMap
+) -> RenderCVValidationError:
+ """Transform raw Pydantic error into user-friendly validation error with YAML coordinates.
+
+ Why:
+ Pydantic errors contain technical jargon and generic locations unsuitable
+ for end users. This converts them to plain English messages with exact
+ YAML line numbers, mapped via error_dictionary.yaml.
+
+ Args:
+ plain_error: Raw Pydantic validation error.
+ user_input_as_commented_map: YAML dict with line/column metadata.
+
+ Returns:
+ Structured error with location tuple, friendly message, and YAML coordinates.
+ """
+ for unwanted_text in unwanted_texts:
+ plain_error["msg"] = plain_error["msg"].replace(unwanted_text, "")
+
+ if plain_error["loc"][0] in ["design", "locale"]:
+ # Skip the second key because it's the discriminator value.
+ plain_error["loc"] = plain_error["loc"][:1] + plain_error["loc"][2:]
+
+ if "ctx" in plain_error:
+ if "input" in plain_error["ctx"]:
+ plain_error["input"] = plain_error["ctx"]["input"]
+
+ if "loc" in plain_error["ctx"]:
+ plain_error["loc"] = plain_error["ctx"]["loc"]
+
+ location = tuple(
+ str(location_element)
+ for location_element in plain_error["loc"]
+ if not any(item in str(location_element) for item in unwanted_locations)
+ )
+ # Special case for end_date because Pydantic returns multiple end_date errors
+ # since it has multiple valid formats:
+ if "end_date" in location[-1]:
+ plain_error["msg"] = (
+ "This is not a valid `end_date`! Please use either YYYY-MM-DD, YYYY-MM,"
+ ' or YYYY format or "present"!'
+ )
+
+ error_message = error_dictionary.get(plain_error["msg"], plain_error["msg"])
+ if not error_message.endswith("."):
+ error_message += "."
+
+ return RenderCVValidationError(
+ location=location,
+ message=error_message,
+ input=(
+ str(plain_error["input"])
+ if not isinstance(plain_error["input"], dict | list)
+ else "..."
+ ),
+ yaml_location=get_coordinates_of_a_key_in_a_yaml_object(
+ user_input_as_commented_map,
+ location if plain_error["type"] != "missing" else location[:-1],
+ ),
+ )
+
+
+def parse_validation_errors(
+ exception: pydantic.ValidationError,
+ rendercv_dictionary_as_commented_map: CommentedMap,
+) -> list[RenderCVValidationError]:
+ """Extract all validation errors from Pydantic exception with deduplication.
+
+ Why:
+ Single Pydantic ValidationError contains multiple sub-errors. Entry
+ validation errors include nested causes that must be flattened and
+ deduplicated before display. This aggregates all errors into a single
+ list for table rendering.
+
+ Args:
+ exception: Pydantic validation exception.
+ rendercv_dictionary_as_commented_map: YAML dict with location metadata.
+
+ Returns:
+ Deduplicated list of user-friendly validation errors.
+ """
+ all_plain_errors = exception.errors()
+ all_final_errors: list[RenderCVValidationError] = []
+
+ for plain_error in all_plain_errors:
+ all_final_errors.append(
+ parse_plain_pydantic_error(
+ plain_error, rendercv_dictionary_as_commented_map
+ )
+ )
+
+ if plain_error["type"] == CustomPydanticErrorTypes.entry_validation.value:
+ assert "ctx" in plain_error
+ assert "caused_by" in plain_error["ctx"]
+ for plain_cause_error in plain_error["ctx"]["caused_by"]:
+ loc = plain_cause_error["loc"][1:] # Omit `entries` location
+ plain_cause_error["loc"] = plain_error["loc"] + loc
+ all_final_errors.append(
+ parse_plain_pydantic_error(
+ plain_cause_error, rendercv_dictionary_as_commented_map
+ )
+ )
+
+ # Remove duplicates from all_final_errors:
+ error_locations = set()
+ errors_without_duplicates = []
+ for error in all_final_errors:
+ location = error.location
+ if location not in error_locations:
+ error_locations.add(location)
+ errors_without_duplicates.append(error)
+
+ return errors_without_duplicates
+
+
+def get_inner_yaml_object_from_its_key(
+ yaml_object: CommentedMap, location_key: str
+) -> tuple[CommentedMap, tuple[tuple[int, int], tuple[int, int]]]:
+ """Navigate one level into YAML structure and extract coordinates.
+
+ Why:
+ Error locations are dotted paths like `cv.sections.education.0.degree`.
+ Each traversal step must extract both the nested object and its exact
+ source coordinates for error highlighting.
+
+ Args:
+ yaml_object: Current YAML object being traversed.
+ location_key: Single key or list index as string.
+
+ Returns:
+ Tuple of nested object and ((start_line, start_col), (end_line, end_col)).
+ """
+ # If the part is numeric, interpret it as a list index:
+ try:
+ index = int(location_key)
+ try:
+ inner_yaml_object = yaml_object[index]
+ # Get the coordinates from the list's lc.data (which is a list of tuples).
+ start_line, start_col = yaml_object.lc.data[index]
+ end_line, end_col = start_line, start_col
+ coordinates = ((start_line + 1, start_col - 1), (end_line + 1, end_col))
+ except IndexError as e:
+ message = f"Index {index} is out of range in the YAML file."
+ raise RenderCVInternalError(message) from e
+ except ValueError as e:
+ # Otherwise, the part is a key in a mapping.
+ if location_key not in yaml_object:
+ message = f"Key '{location_key}' not found in the YAML file."
+ raise RenderCVInternalError(message) from e
+
+ inner_yaml_object = yaml_object[location_key]
+ start_line, start_col, end_line, end_col = yaml_object.lc.data[location_key]
+ coordinates = ((start_line + 1, start_col + 1), (end_line + 1, end_col))
+
+ return inner_yaml_object, coordinates
+
+
+def get_coordinates_of_a_key_in_a_yaml_object(
+ yaml_object: ruamel.yaml.YAML, location: tuple[str, ...]
+) -> tuple[tuple[int, int], tuple[int, int]]:
+ """Resolve dotted location path to exact YAML source coordinates.
+
+ Why:
+ Error tables must show users exactly which line/column contains
+ the invalid value. Recursive traversal through CommentedMap's
+ lc.data preserves coordinates at every nesting level.
+
+ Example:
+ ```py
+ data = read_yaml(pathlib.Path("cv.yaml"))
+ coords = get_coordinates_of_a_key_in_a_yaml_object(
+ data, ("cv", "sections", "education", "0", "degree")
+ )
+ # coords = ((12, 4), (12, 10)) for line 12, columns 4-10
+ ```
+
+ Args:
+ yaml_object: Root YAML object with location metadata.
+ location: Path segments from root to target key.
+
+ Returns:
+ ((start_line, start_col), (end_line, end_col)) in 1-indexed coordinates.
+ """
+
+ current_yaml_object: ruamel.yaml.YAML = yaml_object
+ coordinates = ((0, 0), (0, 0))
+ # start from the first key and move forward:
+ for location_key in location:
+ current_yaml_object, coordinates = get_inner_yaml_object_from_its_key(
+ current_yaml_object, location_key
+ )
+
+ return coordinates
diff --git a/src/rendercv/schema/rendercv_model_builder.py b/src/rendercv/schema/rendercv_model_builder.py
new file mode 100644
index 00000000..b59c57a3
--- /dev/null
+++ b/src/rendercv/schema/rendercv_model_builder.py
@@ -0,0 +1,171 @@
+import pathlib
+from typing import TypedDict, Unpack
+
+import pydantic
+from ruamel.yaml.comments import CommentedMap
+
+from rendercv.exception import RenderCVUserValidationError
+
+from .models.rendercv_model import RenderCVModel
+from .models.validation_context import ValidationContext
+from .override_dictionary import apply_overrides_to_dictionary
+from .pydantic_error_handling import parse_validation_errors
+from .yaml_reader import read_yaml
+
+
+class BuildRendercvModelArguments(TypedDict, total=False):
+ design_file_path_or_contents: pathlib.Path | str | None
+ locale_file_path_or_contents: pathlib.Path | str | None
+ settings_file_path_or_contents: pathlib.Path | str | None
+ typst_path: pathlib.Path | str | None
+ pdf_path: pathlib.Path | str | None
+ markdown_path: pathlib.Path | str | None
+ html_path: pathlib.Path | str | None
+ png_path: pathlib.Path | str | None
+ dont_generate_typst: bool | None
+ dont_generate_html: bool | None
+ dont_generate_markdown: bool | None
+ dont_generate_pdf: bool | None
+ dont_generate_png: bool | None
+ overrides: dict[str, str] | None
+
+
+def build_rendercv_dictionary(
+ main_input_file_path_or_contents: pathlib.Path | str,
+ **kwargs: Unpack[BuildRendercvModelArguments],
+) -> CommentedMap:
+ """Merge main YAML with overlays and CLI overrides into final dictionary.
+
+ Why:
+ Users need modular configuration (separate design/locale files) and
+ quick testing (CLI overrides). This pipeline applies all modifications
+ before validation, ensuring users see complete configuration errors.
+
+ Example:
+ ```py
+ data = build_rendercv_dictionary(
+ pathlib.Path("cv.yaml"),
+ design_file_path_or_contents=pathlib.Path("classic.yaml"),
+ overrides={"cv.phone": "+1234567890"},
+ )
+ # data contains merged cv + design + overrides
+ ```
+
+ Args:
+ main_input_file_path_or_contents: Primary CV YAML file or string.
+ kwargs: Optional YAML overlay paths, output paths, generation flags, and CLI overrides.
+
+ Returns:
+ Merged dictionary ready for validation.
+ """
+ input_dict = read_yaml(main_input_file_path_or_contents)
+
+ # Optional YAML overlays
+ yaml_overlays: dict[str, pathlib.Path | str | None] = {
+ "design": kwargs.get("design_file_path_or_contents"),
+ "locale": kwargs.get("locale_file_path_or_contents"),
+ "settings": kwargs.get("settings_file_path_or_contents"),
+ }
+
+ for key, path in yaml_overlays.items():
+ if path:
+ input_dict[key] = read_yaml(path)[key]
+
+ # Optional render-command overrides
+ render_overrides: dict[str, pathlib.Path | str | bool | None] = {
+ "typst_path": kwargs.get("typst_path"),
+ "pdf_path": kwargs.get("pdf_path"),
+ "markdown_path": kwargs.get("markdown_path"),
+ "html_path": kwargs.get("html_path"),
+ "png_path": kwargs.get("png_path"),
+ "dont_generate_typst": kwargs.get("dont_generate_typst"),
+ "dont_generate_html": kwargs.get("dont_generate_html"),
+ "dont_generate_markdown": kwargs.get("dont_generate_markdown"),
+ "dont_generate_pdf": kwargs.get("dont_generate_pdf"),
+ "dont_generate_png": kwargs.get("dont_generate_png"),
+ }
+
+ input_dict.setdefault("settings", {}).setdefault("render_command", {})
+
+ for key, value in render_overrides.items():
+ if value:
+ input_dict["settings"]["render_command"][key] = value
+
+ overrides = kwargs.get("overrides")
+ if overrides:
+ input_dict = apply_overrides_to_dictionary(input_dict, overrides)
+
+ return input_dict
+
+
+def build_rendercv_model_from_commented_map(
+ commented_map: CommentedMap,
+ input_file_path: pathlib.Path | None = None,
+) -> RenderCVModel:
+ """Validate merged dictionary and build Pydantic model with error mapping.
+
+ Why:
+ Validation transforms raw YAML into type-safe objects. When validation
+ fails, CommentedMap metadata enables precise error location reporting
+ instead of generic Pydantic messages.
+
+ Args:
+ commented_map: Merged dictionary with line/column metadata.
+ input_file_path: Source file path for context and photo resolution.
+
+ Returns:
+ Validated RenderCVModel instance.
+ """
+ try:
+ model = RenderCVModel.model_validate(
+ commented_map,
+ context={
+ "context": ValidationContext(
+ input_file_path=input_file_path,
+ current_date=commented_map.get("settings", {}).get(
+ "current_date", None
+ ),
+ )
+ },
+ )
+ except pydantic.ValidationError as e:
+ validation_errors = parse_validation_errors(e, commented_map)
+ raise RenderCVUserValidationError(validation_errors) from e
+
+ return model
+
+
+def build_rendercv_dictionary_and_model(
+ main_input_file_path_or_contents: pathlib.Path | str,
+ **kwargs: Unpack[BuildRendercvModelArguments],
+) -> tuple[CommentedMap, RenderCVModel]:
+ """Complete pipeline from raw input to validated model.
+
+ Why:
+ Main entry point for render command combines merging and validation
+ in one call. Returns both dictionary and model because error handlers
+ need dictionary metadata for location mapping.
+
+ Example:
+ ```py
+ data, model = build_rendercv_dictionary_and_model(
+ pathlib.Path("cv.yaml"), pdf_path="output.pdf"
+ )
+ # model.cv.name is validated, data preserves YAML line numbers
+ ```
+
+ Args:
+ main_input_file_path_or_contents: Primary CV YAML file or string.
+ kwargs: Optional YAML overlay paths, output paths, generation flags, and CLI overrides.
+
+ Returns:
+ Tuple of merged dictionary and validated model.
+ """
+ d = build_rendercv_dictionary(main_input_file_path_or_contents, **kwargs)
+ input_file_path = (
+ main_input_file_path_or_contents
+ if isinstance(main_input_file_path_or_contents, pathlib.Path)
+ else None
+ )
+ m = build_rendercv_model_from_commented_map(d, input_file_path)
+ return d, m
diff --git a/src/rendercv/schema/sample_content.yaml b/src/rendercv/schema/sample_content.yaml
new file mode 100644
index 00000000..ff94917e
--- /dev/null
+++ b/src/rendercv/schema/sample_content.yaml
@@ -0,0 +1,182 @@
+# yaml-language-server: $schema=../../../schema.json
+cv:
+ name: John Doe
+ headline:
+ location: San Francisco, CA
+ email: john.doe@email.com
+ photo:
+ phone:
+ website: https://rendercv.com/
+ social_networks:
+ - network: LinkedIn
+ username: rendercv
+ - network: GitHub
+ username: rendercv
+ sections:
+ Welcome to RenderCV:
+ - RenderCV reads a CV written in a YAML file, and generates a PDF with professional typography.
+ - See the [documentation](https://docs.rendercv.com) for more details.
+ education:
+ - institution: Princeton University
+ area: Computer Science
+ degree: PhD
+ date:
+ start_date: 2018-09
+ end_date: 2023-05
+ location: Princeton, NJ
+ summary:
+ highlights:
+ - "Thesis: Efficient Neural Architecture Search for Resource-Constrained Deployment"
+ - "Advisor: Prof. Sanjeev Arora"
+ - NSF Graduate Research Fellowship, Siebel Scholar (Class of 2022)
+ - date:
+ start_date: 2014-09
+ end_date: 2018-06
+ location: Istanbul, Türkiye
+ summary:
+ highlights:
+ - "GPA: 3.97/4.00, Valedictorian"
+ - Fulbright Scholarship recipient for graduate studies
+ institution: Boğaziçi University
+ area: Computer Engineering
+ degree: BS
+ experience:
+ - date:
+ start_date: 2023-06
+ end_date: present
+ location: San Francisco, CA
+ summary:
+ highlights:
+ - Built foundation model infrastructure serving 2M+ monthly API requests with 99.97% uptime
+ - Raised $18M Series A led by Sequoia Capital, with participation from a16z and Founders Fund
+ - Scaled engineering team from 3 to 28 across ML research, platform, and applied AI divisions
+ - Developed proprietary inference optimization reducing latency by 73% compared to baseline
+ company: Nexus AI
+ position: Co-Founder & CTO
+ - date:
+ start_date: 2022-05
+ end_date: 2022-08
+ location: Santa Clara, CA
+ summary:
+ highlights:
+ - Designed sparse attention mechanism reducing transformer memory footprint by 4.2x
+ - Co-authored paper accepted at NeurIPS 2022 (spotlight presentation, top 5% of submissions)
+ company: NVIDIA Research
+ position: Research Intern
+ - date:
+ start_date: 2021-05
+ end_date: 2021-08
+ location: London, UK
+ summary:
+ highlights:
+ - Developed reinforcement learning algorithms for multi-agent coordination
+ - Published research at top-tier venues with significant academic impact
+ - ICML 2022 main conference paper, cited 340+ times within two years
+ - NeurIPS 2022 workshop paper on emergent communication protocols
+ - Invited journal extension in JMLR (2023)
+ company: Google DeepMind
+ position: Research Intern
+ - date:
+ start_date: 2020-05
+ end_date: 2020-08
+ location: Cupertino, CA
+ summary:
+ highlights:
+ - Created on-device neural network compression pipeline deployed across 50M+ devices
+ - Filed 2 patents on efficient model quantization techniques for edge inference
+ company: Apple ML Research
+ position: Research Intern
+ - date:
+ start_date: 2019-05
+ end_date: 2019-08
+ location: Redmond, WA
+ summary:
+ highlights:
+ - Implemented novel self-supervised learning framework for low-resource language modeling
+ - Research integrated into Azure Cognitive Services, reducing training data requirements by 60%
+ company: Microsoft Research
+ position: Research Intern
+ projects:
+ - date:
+ start_date: 2023-01
+ end_date: present
+ location:
+ summary: Open-source library for high-performance LLM inference kernels
+ highlights:
+ - Achieved 2.8x speedup over baseline attention implementations on A100 GPUs
+ - Adopted by 3 major AI labs, 8,500+ GitHub stars, 200+ contributors
+ name: "[FlashInfer](https://github.com/)"
+ - date: "2021"
+ start_date:
+ end_date:
+ location:
+ summary: Automated neural network pruning toolkit with differentiable masks
+ highlights:
+ - Reduced model size by 90% with less than 1% accuracy degradation on ImageNet
+ - Featured in PyTorch ecosystem tools, 4,200+ GitHub stars
+ name: "[NeuralPrune](https://github.com/)"
+ publications:
+ - date: 2023-07
+ title: "Sparse Mixture-of-Experts at Scale: Efficient Routing for Trillion-Parameter Models"
+ authors:
+ - "*John Doe*"
+ - Sarah Williams
+ - David Park
+ doi: 10.1234/neurips.2023.1234
+ url:
+ journal: NeurIPS 2023
+ - date: 2022-12
+ title: Neural Architecture Search via Differentiable Pruning
+ authors:
+ - James Liu
+ - "*John Doe*"
+ doi: 10.1234/neurips.2022.5678
+ url:
+ journal: NeurIPS 2022, Spotlight
+ - date: 2022-07
+ title: Multi-Agent Reinforcement Learning with Emergent Communication
+ authors:
+ - Maria Garcia
+ - "*John Doe*"
+ - Tom Anderson
+ doi: 10.1234/icml.2022.9012
+ url:
+ journal: ICML 2022
+ - date: 2021-05
+ title: On-Device Model Compression via Learned Quantization
+ authors:
+ - "*John Doe*"
+ - Kevin Wu
+ doi: 10.1234/iclr.2021.3456
+ url:
+ journal: ICLR 2021, Best Paper Award
+ selected_honors:
+ - bullet: MIT Technology Review 35 Under 35 Innovators (2024)
+ - bullet: Forbes 30 Under 30 in Enterprise Technology (2024)
+ - bullet: ACM Doctoral Dissertation Award Honorable Mention (2023)
+ - bullet: Google PhD Fellowship in Machine Learning (2020 – 2023)
+ - bullet: Fulbright Scholarship for Graduate Studies (2018)
+ skills:
+ - label: Languages
+ details: Python, C++, CUDA, Rust, Julia
+ - label: ML Frameworks
+ details: PyTorch, JAX, TensorFlow, Triton, ONNX
+ - label: Infrastructure
+ details: Kubernetes, Ray, distributed training, AWS, GCP
+ - label: Research Areas
+ details: Neural architecture search, model compression, efficient inference, multi-agent RL
+ patents:
+ - number: Adaptive Quantization for Neural Network Inference on Edge Devices (US Patent 11,234,567)
+ - number: Dynamic Sparsity Patterns for Efficient Transformer Attention (US Patent 11,345,678)
+ - number: Hardware-Aware Neural Architecture Search Method (US Patent 11,456,789)
+ invited_talks:
+ - reversed_number: Scaling Laws for Efficient Inference — Stanford HAI Symposium (2024)
+ - reversed_number: Building AI Infrastructure for the Next Decade — TechCrunch Disrupt (2024)
+ - reversed_number: "From Research to Production: Lessons in ML Systems — NeurIPS Workshop (2023)"
+ - reversed_number: "Efficient Deep Learning: A Practitioner's Perspective — Google Tech Talk (2022)"
+ any_section_title:
+ - You can use any section title you want.
+ - "You can choose any entry type for the section: `TextEntry`, `ExperienceEntry`, `EducationEntry`, `PublicationEntry`, `BulletEntry`, `NumberedEntry`, or `ReversedNumberedEntry`."
+ - Markdown syntax is supported everywhere.
+ - The `design` field in YAML gives you control over almost any aspect of your CV design.
+ - "See the [documentation](https://docs.rendercv.com) for more details."
diff --git a/src/rendercv/schema/sample_generator.py b/src/rendercv/schema/sample_generator.py
new file mode 100644
index 00000000..a6ecf398
--- /dev/null
+++ b/src/rendercv/schema/sample_generator.py
@@ -0,0 +1,197 @@
+import io
+import json
+import pathlib
+import re
+from typing import overload
+
+import ruamel.yaml
+
+from rendercv import __version__
+from rendercv.exception import RenderCVUserError
+
+from .models.cv.cv import Cv
+from .models.design.built_in_design import available_themes, built_in_design_adapter
+from .models.locale.locale import available_locales, locale_adapter
+from .models.rendercv_model import RenderCVModel
+from .rendercv_model_builder import read_yaml
+
+
+def dictionary_to_yaml(dictionary: dict) -> str:
+ """Convert dictionary to formatted YAML string with multiline preservation.
+
+ Why:
+ Sample YAML generation must produce readable output with proper
+ formatting for multiline strings. Custom representer ensures
+ bullet points and descriptions use pipe syntax.
+
+ Args:
+ dictionary: Data structure to convert.
+
+ Returns:
+ Formatted YAML string.
+ """
+
+ # Source: https://gist.github.com/alertedsnake/c521bc485b3805aa3839aef29e39f376
+ def str_representer(dumper, data):
+ if len(data.splitlines()) > 1: # check for multiline string
+ return dumper.represent_scalar("tag:yaml.org,2002:str", data, style="|")
+ return dumper.represent_scalar("tag:yaml.org,2002:str", data)
+
+ yaml_object = ruamel.yaml.YAML()
+ yaml_object.encoding = "utf-8"
+ yaml_object.width = 9999
+ yaml_object.indent(mapping=2, sequence=4, offset=2)
+ yaml_object.representer.add_representer(str, str_representer)
+
+ with io.StringIO() as string_stream:
+ yaml_object.dump(dictionary, string_stream)
+ return string_stream.getvalue()
+
+
+def create_sample_rendercv_pydantic_model(
+ *, name: str = "John Doe", theme: str = "classic", locale: str = "english"
+) -> RenderCVModel:
+ """Build sample CV model from sample content.
+
+ Why:
+ New users need working examples to understand structure. Sample content
+ provides realistic content that validates successfully and renders
+ to all output formats without errors.
+
+ Args:
+ name: Person's full name.
+ theme: Design theme identifier.
+ locale: Locale language identifier.
+
+ Returns:
+ Validated model with sample content.
+ """
+ sample_content = pathlib.Path(__file__).parent / "sample_content.yaml"
+ sample_content_dictionary = read_yaml(sample_content)["cv"]
+ cv = Cv(**sample_content_dictionary)
+
+ name = name.encode().decode("unicode-escape")
+ cv.name = name
+
+ design = built_in_design_adapter.validate_python({"theme": theme})
+ locale = locale_adapter.validate_python({"language": locale})
+
+ return RenderCVModel(cv=cv, design=design, locale=locale)
+
+
+@overload
+def create_sample_yaml_input_file(
+ *,
+ file_path: None,
+ name: str = "John Doe",
+ theme: str = "classic",
+ locale: str = "english",
+) -> str: ...
+@overload
+def create_sample_yaml_input_file(
+ *,
+ file_path: pathlib.Path,
+ name: str = "John Doe",
+ theme: str = "classic",
+ locale: str = "english",
+) -> None: ...
+def create_sample_yaml_input_file(
+ *,
+ file_path: pathlib.Path | None = None,
+ name: str = "John Doe",
+ theme: str = "classic",
+ locale: str = "english",
+) -> str | None:
+ """Generate formatted sample YAML with schema hint and commented design options.
+
+ Why:
+ New command provides users with immediately usable CV templates.
+ JSON schema hint enables IDE autocompletion, commented design
+ fields show customization options without overwhelming beginners.
+
+ Example:
+ ```py
+ yaml_content = create_sample_yaml_input_file(
+ file_path=pathlib.Path("John_Doe_CV.yaml"), name="John Doe", theme="classic"
+ )
+ # File written with schema hint, cv content, and commented design
+ ```
+
+ Args:
+ file_path: Optional path to write file.
+ name: Person's full name.
+ theme: Design theme identifier.
+ locale: Language/date format identifier.
+
+ Returns:
+ YAML string if file_path is None, otherwise None after writing file.
+ """
+ if theme not in available_themes:
+ message = (
+ f"The theme {theme} is not available. The available themes are:"
+ f" {available_themes}"
+ )
+ raise RenderCVUserError(message)
+
+ if locale not in available_locales:
+ message = (
+ f"The locale {locale} is not available. The available locales are:"
+ f" {available_locales}. \n\nBut you can continue with `English`, and then"
+ " write your own `locale` field in the input file."
+ )
+ raise RenderCVUserError(message)
+
+ data_model = create_sample_rendercv_pydantic_model(
+ name=name, theme=theme, locale=locale
+ )
+
+ # Instead of getting the dictionary with data_model.model_dump() directly, we
+ # convert it to JSON and then to a dictionary. Because the YAML library we are
+ # using sometimes has problems with the dictionary returned by model_dump().
+
+ # We exclude "cv.sections" because the data model automatically generates them.
+ # The user's "cv.sections" input is actually "cv.sections_input" in the data
+ # model. It is shown as "cv.sections" in the YAML file because an alias is being
+ # used. If"cv.sections" were not excluded, the automatically generated
+ # "cv.sections" would overwrite the "cv.sections_input". "cv.sections" are
+ # automatically generated from "cv.sections_input" to make the templating
+ # process easier. "cv.sections_input" exists for the convenience of the user.
+ # Also, we don't want to show the cv.photo field in the Web app.
+ data_model_as_json = data_model.model_dump_json(
+ exclude_none=False,
+ by_alias=True,
+ )
+ data_model_as_dictionary = json.loads(data_model_as_json)
+
+ yaml_string = dictionary_to_yaml(data_model_as_dictionary)
+
+ # Process for nested bullets:
+ yaml_string = re.sub(r"(? type[T]:
+ """Create Pydantic model variant with customized defaults.
+
+ Why:
+ Themes share common structure but differ in default colors, fonts,
+ and spacing. Variant generation creates theme-specific classes that
+ inherit validation logic while exposing different defaults in JSON schema.
+
+ Example:
+ ```py
+ ModernTheme = create_variant_pydantic_model(
+ variant_name="modern",
+ defaults={"theme": "modern", "colors": {"primary": "#000"}},
+ base_class=BaseTheme,
+ discriminator_field="theme",
+ class_name_suffix="Theme",
+ module_name="rendercv.themes",
+ )
+ # Creates class "ModernTheme" with theme="modern" as Literal type
+ ```
+
+ Args:
+ variant_name: Snake_case name for PascalCase conversion.
+ defaults: Field overrides with nested dict support.
+ base_class: Base model to inherit from.
+ discriminator_field: Field to constrain as Literal for tagged unions.
+ class_name_suffix: Appended to generated class name.
+ module_name: Module path for the generated class.
+
+ Returns:
+ New model class with overrides applied.
+ """
+ validate_defaults_against_base(defaults, base_class, variant_name)
+
+ field_specs: dict[str, Any] = {}
+ base_fields = base_class.model_fields
+
+ for field_name, default_value in defaults.items():
+ base_field_info = base_fields[field_name]
+
+ if field_name == discriminator_field:
+ field_specs[field_name] = create_discriminator_field_spec(
+ default_value, base_field_info
+ )
+ elif isinstance(default_value, dict):
+ field_specs[field_name] = create_nested_field_spec(
+ default_value, base_field_info
+ )
+ else:
+ field_specs[field_name] = create_simple_field_spec(
+ default_value, base_field_info
+ )
+
+ class_name = generate_model_name(variant_name, class_name_suffix)
+
+ return pydantic.create_model(
+ class_name,
+ __base__=base_class,
+ __module__=module_name,
+ **field_specs,
+ )
+
+
+def validate_defaults_against_base(
+ defaults: dict[str, Any],
+ base_class: type[pydantic.BaseModel],
+ variant_name: str,
+) -> None:
+ """Validate that all fields in defaults exist in the base model.
+
+ Why:
+ Typos in theme definitions cause silent failures. Early validation
+ prevents variants with undefined fields from being created.
+
+ Args:
+ defaults: Field overrides to validate.
+ base_class: Base model defining valid fields.
+ variant_name: Variant identifier for error messages.
+ """
+ base_fields = base_class.model_fields
+
+ for field_name in defaults:
+ if field_name not in base_fields:
+ message = (
+ f"Field '{field_name}' in defaults for '{variant_name}' "
+ f"is not defined in {base_class.__name__}"
+ )
+ raise RenderCVInternalError(message)
+
+
+def generate_model_name(variant_name: str, class_name_suffix: str) -> str:
+ """Convert snake_case variant name to PascalCase class name with suffix.
+
+ Args:
+ variant_name: Snake_case name.
+ class_name_suffix: Suffix to append.
+
+ Returns:
+ PascalCase class name with suffix.
+ """
+ # Convert snake_case to PascalCase: my_variant_name -> MyVariantName
+ # Instead of title(), just capitalize first letter of each word
+ pascal_case = "".join(word.capitalize() for word in variant_name.split("_"))
+ return f"{pascal_case}{class_name_suffix}"
+
+
+def update_description_with_new_default(
+ original_description: str | None,
+ old_default: Any,
+ new_default: Any,
+) -> str | None:
+ """Update field description to reflect new default value.
+
+ Why:
+ JSON schema descriptions must show current defaults. When variants
+ override defaults, descriptions need updating so IDE tooltips display
+ accurate information.
+
+ Args:
+ original_description: Original field description.
+ old_default: Old default value.
+ new_default: New default value to replace with.
+
+ Returns:
+ Updated description or None if no description exists.
+ """
+ if original_description is None:
+ return None
+
+ # Simple string replacement of old default with new default
+ old_default_str = str(old_default)
+ new_default_str = str(new_default)
+
+ return original_description.replace(f"`{old_default_str}`", f"`{new_default_str}`")
+
+
+def create_discriminator_field_spec(
+ discriminator_value: Any,
+ base_field_info: FieldInfo,
+) -> FieldSpec:
+ """Create field spec for discriminator field with Literal type constraint.
+
+ Why:
+ Pydantic discriminated unions require Literal types for routing.
+ Converting theme="classic" to Literal["classic"] enables automatic
+ theme class selection during validation.
+
+ Args:
+ discriminator_value: Value for the discriminator.
+ base_field_info: Base model's field info.
+
+ Returns:
+ Tuple of Literal type annotation and Field with default value.
+ """
+ field_annotation = Literal[discriminator_value]
+
+ # Update description with new default value
+ updated_description = update_description_with_new_default(
+ base_field_info.description,
+ base_field_info.default,
+ discriminator_value,
+ )
+
+ new_field = cast(
+ FieldInfo,
+ pydantic.Field(
+ default=discriminator_value,
+ description=updated_description,
+ title=base_field_info.title,
+ ),
+ )
+ return (cast(type[Any], field_annotation), new_field)
+
+
+def deep_merge_nested_object[T: pydantic.BaseModel](
+ base_nested_obj: T,
+ updates: dict[str, Any],
+) -> T:
+ """Recursively merge nested dictionary updates into Pydantic model instance.
+
+ Why:
+ Theme variants often override only specific nested fields like
+ `colors.primary` while keeping other color defaults. Deep merge
+ enables partial updates without requiring full object replacement.
+
+ Args:
+ base_nested_obj: Base model instance to merge into.
+ updates: Dictionary updates with arbitrary nesting depth.
+
+ Returns:
+ New model instance with updates applied.
+ """
+ # Build the final update dict by recursively merging nested objects
+ merged_updates: dict[str, Any] = {}
+
+ for key, value in updates.items():
+ # Check if this is a nested dict that should be recursively merged
+ if isinstance(value, dict):
+ # Get the current value of this field from base_nested_obj
+ current_value = getattr(base_nested_obj, key, None)
+
+ # If the current value is a Pydantic model, recursively merge
+ if isinstance(current_value, pydantic.BaseModel):
+ merged_updates[key] = deep_merge_nested_object(current_value, value)
+ else:
+ # Not a Pydantic model, just use the dict as-is
+ merged_updates[key] = value
+ else:
+ # Simple value, use directly
+ merged_updates[key] = value
+
+ return base_nested_obj.model_copy(update=merged_updates)
+
+
+def create_nested_model_variant_model(
+ base_model_class: type[pydantic.BaseModel],
+ updates: dict[str, Any],
+) -> type[pydantic.BaseModel]:
+ """Create variant class for nested model with updated field descriptions.
+
+ Why:
+ Nested field defaults must reflect in JSON schema for accurate IDE
+ tooltips. Creating variant classes ensures descriptions update at all
+ nesting levels, not just the top level.
+
+ Args:
+ base_model_class: Base nested model class.
+ updates: Field updates with potential nested dicts.
+
+ Returns:
+ New model class with updated descriptions and defaults.
+ """
+ field_specs: dict[str, Any] = {}
+ base_fields = base_model_class.model_fields
+
+ for field_name, new_value in updates.items():
+ if field_name not in base_fields:
+ # Skip fields that don't exist in the base model
+ continue
+
+ base_field_info = base_fields[field_name]
+
+ if isinstance(new_value, dict):
+ # Check if this field is a nested Pydantic model
+ nested_obj = None
+ if base_field_info.default_factory is not None:
+ factory = cast(Callable[[], Any], base_field_info.default_factory)
+ nested_obj = factory()
+ elif isinstance(base_field_info.default, pydantic.BaseModel):
+ nested_obj = base_field_info.default
+
+ if nested_obj is not None and isinstance(nested_obj, pydantic.BaseModel):
+ # Recursively create nested field spec
+ field_specs[field_name] = create_nested_field_spec(
+ new_value, base_field_info
+ )
+ else:
+ # Not a nested model, just a dict field - treat as simple value
+ field_specs[field_name] = create_simple_field_spec(
+ new_value, base_field_info
+ )
+ else:
+ # Simple value - update description
+ field_specs[field_name] = create_simple_field_spec(
+ new_value, base_field_info
+ )
+
+ # Create variant class inheriting from base
+ return pydantic.create_model(
+ base_model_class.__name__,
+ __base__=base_model_class,
+ __module__=base_model_class.__module__,
+ **field_specs,
+ )
+
+
+def create_nested_field_spec(
+ default_value: dict[str, Any],
+ base_field_info: FieldInfo,
+) -> FieldSpec:
+ """Create field spec for nested Pydantic model with partial overrides.
+
+ Why:
+ Nested model fields require variant classes to preserve accurate JSON
+ schema metadata. This ensures nested defaults appear correctly in IDE
+ autocompletion and documentation.
+
+ Args:
+ default_value: Dictionary updates to apply to nested model.
+ base_field_info: Base model's field info.
+
+ Returns:
+ Tuple of variant class annotation and Field with default_factory.
+ """
+ # Get the base nested object - could be from default or default_factory
+ base_nested_obj: pydantic.BaseModel | None = None
+
+ if base_field_info.default_factory is not None:
+ # Create an instance using the factory
+ # Cast to proper callable type to satisfy type checker
+ factory = cast(Callable[[], Any], base_field_info.default_factory)
+ base_nested_obj = cast(pydantic.BaseModel, factory())
+ elif isinstance(base_field_info.default, pydantic.BaseModel):
+ # The default is already a Pydantic model instance
+ base_nested_obj = base_field_info.default
+
+ if base_nested_obj is not None:
+ # Create a variant class with updated field specs and descriptions
+ base_model_class = type(base_nested_obj)
+ variant_class = create_nested_model_variant_model(
+ base_model_class, default_value
+ )
+
+ new_field = cast(
+ FieldInfo,
+ pydantic.Field(
+ default_factory=variant_class,
+ description=base_field_info.description,
+ title=base_field_info.title,
+ ),
+ )
+
+ return (variant_class, new_field)
+ # No Pydantic model found, just use the dict directly
+ # (This should be rare - it means the field type is just dict)
+ new_field = cast(
+ FieldInfo,
+ pydantic.Field(
+ default=default_value,
+ description=base_field_info.description,
+ title=base_field_info.title,
+ ),
+ )
+
+ return (
+ cast(type[Any], base_field_info.annotation),
+ new_field,
+ )
+
+
+def create_simple_field_spec(
+ default_value: Any,
+ base_field_info: FieldInfo,
+) -> FieldSpec:
+ """Create field spec for simple field with updated default.
+
+ Args:
+ default_value: New default value for field.
+ base_field_info: Base model's field info.
+
+ Returns:
+ Tuple of field annotation and Field with default value.
+ """
+ # Update description with new default value
+ updated_description = update_description_with_new_default(
+ base_field_info.description,
+ base_field_info.default,
+ default_value,
+ )
+
+ new_field = cast(
+ FieldInfo,
+ pydantic.Field(
+ default=default_value,
+ description=updated_description,
+ title=base_field_info.title,
+ ),
+ )
+ return (cast(type[Any], base_field_info.annotation), new_field)
diff --git a/src/rendercv/schema/yaml_reader.py b/src/rendercv/schema/yaml_reader.py
new file mode 100644
index 00000000..a0f4d462
--- /dev/null
+++ b/src/rendercv/schema/yaml_reader.py
@@ -0,0 +1,77 @@
+import pathlib
+from typing import Literal
+
+import ruamel.yaml
+from ruamel.yaml.comments import CommentedMap
+
+from rendercv.exception import RenderCVInternalError, RenderCVUserError
+
+
+def read_yaml(
+ file_path_or_contents: pathlib.Path | str,
+ read_type: Literal["safe"] | None = None,
+) -> CommentedMap:
+ """Parse YAML/JSON content from file path or string.
+
+ Why:
+ Validation errors must point to exact YAML locations. CommentedMap
+ preserves source coordinates that map Pydantic errors back to input
+ lines, enabling user-friendly error tables showing exactly where
+ mistakes occur in the input file.
+
+ Example:
+ ```py
+ data = read_yaml(pathlib.Path("cv.yaml"))
+ name = data["cv"]["name"] # Regular dict access
+ # Line info also available: data.lc.data["cv"][0] = (line, col)
+ ```
+
+ Args:
+ file_path_or_contents: File path or raw YAML string.
+ read_type: Parsing mode passed to ruamel.yaml.
+
+ Returns:
+ Dictionary with line/column metadata for error reporting.
+ """
+ if isinstance(file_path_or_contents, pathlib.Path):
+ # Check if the file exists:
+ if not file_path_or_contents.exists():
+ message = f"The input file `{file_path_or_contents}` doesn't exist!"
+ raise RenderCVUserError(message)
+
+ # Check the file extension:
+ accepted_extensions = [".yaml", ".yml", ".json", ".json5"]
+ if file_path_or_contents.suffix not in accepted_extensions:
+ message = (
+ "The input file should have one of the following extensions:"
+ f" {', '.join(accepted_extensions)}. The input file is"
+ f" {file_path_or_contents.name}."
+ )
+ raise RenderCVUserError(message)
+
+ file_content = file_path_or_contents.read_text(encoding="utf-8")
+ else:
+ file_content = file_path_or_contents
+
+ yaml = ruamel.yaml.YAML(typ=read_type)
+
+ # Disable ISO date parsing, keep it as a string:
+ yaml.constructor.yaml_constructors["tag:yaml.org,2002:timestamp"] = (
+ lambda loader, node: loader.construct_scalar(node)
+ )
+
+ yaml_as_dictionary: CommentedMap = yaml.load(file_content)
+
+ if yaml_as_dictionary is None:
+ message = "The input file is empty!"
+ raise RenderCVUserError(message)
+
+ if isinstance(yaml_as_dictionary, str):
+ message = (
+ "You probably meant to pass a path to the YAML file, but you passed as a"
+ " string and RenderCV interpreted it as the contents of the YAML file."
+ f" Pass the path using `pathlib.Path({file_path_or_contents})`."
+ )
+ raise RenderCVInternalError(message)
+
+ return yaml_as_dictionary
diff --git a/src/rendercv/themes/__init__.py b/src/rendercv/themes/__init__.py
deleted file mode 100644
index 799c8138..00000000
--- a/src/rendercv/themes/__init__.py
+++ /dev/null
@@ -1,18 +0,0 @@
-"""
-The `rendercv.themes` package contains all the built-in templates and the design data
-models for the themes.
-"""
-
-from .classic import ClassicThemeOptions
-from .engineeringclassic import EngineeringclassicThemeOptions
-from .engineeringresumes import EngineeringresumesThemeOptions
-from .moderncv import ModerncvThemeOptions
-from .sb2nov import Sb2novThemeOptions
-
-__all__ = [
- "ClassicThemeOptions",
- "EngineeringclassicThemeOptions",
- "EngineeringresumesThemeOptions",
- "ModerncvThemeOptions",
- "Sb2novThemeOptions",
-]
diff --git a/src/rendercv/themes/classic/BulletEntry.j2.typ b/src/rendercv/themes/classic/BulletEntry.j2.typ
deleted file mode 100644
index addd8c5a..00000000
--- a/src/rendercv/themes/classic/BulletEntry.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-#one-col-entry(content: [#bullet-entry[<>]])
diff --git a/src/rendercv/themes/classic/EducationEntry.j2.typ b/src/rendercv/themes/classic/EducationEntry.j2.typ
deleted file mode 100644
index 6c4eb9d3..00000000
--- a/src/rendercv/themes/classic/EducationEntry.j2.typ
+++ /dev/null
@@ -1,106 +0,0 @@
-((* if date_and_location_column_template and design.entry_types.education_entry.degree_column_template *))
-// YES DATE, YES DEGREE
-#three-col-entry(
- left-column-width: <>,
- left-content: [<>],
- middle-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
-((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n")) and main_column_second_row_template *))
-#block(
- [
- #set par(spacing: 0pt)
- <>
- ],
- inset: (
- left: design-entry-types-education-entry-degree-column-width + design-entries-horizontal-space-between-columns + design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
-)
-((* endif *))
-((* elif date_and_location_column_template and not design.entry_types.education_entry.degree_column_template *))
-// YES DATE, NO DEGREE
-#two-col-entry(
- left-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#block(
- [
- #set par(spacing: 0pt)
- <>
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
-)
-((* endif *))
-((* elif not date_and_location_column_template and design.entry_types.education_entry.degree_column_template *))
-// NO DATE, YES DEGREE
-#two-col-entry(
- left-column-width: <>,
- right-column-width: 1fr,
- alignments: (left, left),
- left-content: [
- <>
- ],
- right-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
-)
-((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n")) and main_column_second_row_template *))
-#block(
- [
- #set par(spacing: 0pt)
- <>
- ],
- inset: (
- left: design-entry-types-education-entry-degree-column-width + design-entries-horizontal-space-between-columns + design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
-)
-((* endif *))
-((* else *))
-// NO DATE, NO DEGREE
-
-#one-col-entry(
- content: [
- <>
-
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
- <>
- ],
-)
-((* endif *))
\ No newline at end of file
diff --git a/src/rendercv/themes/classic/ExperienceEntry.j2.typ b/src/rendercv/themes/classic/ExperienceEntry.j2.typ
deleted file mode 100644
index 163487f7..00000000
--- a/src/rendercv/themes/classic/ExperienceEntry.j2.typ
+++ /dev/null
@@ -1,36 +0,0 @@
-((* if date_and_location_column_template *))
-#two-col-entry(
- left-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#one-col-entry(
- content: [
- <>
- ],
-)
-((* endif *))
-((* else *))
-
-#one-col-entry(
- content: [
- <>
-
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
- <>
- ],
-)
-((* endif *))
diff --git a/src/rendercv/themes/classic/Header.j2.typ b/src/rendercv/themes/classic/Header.j2.typ
deleted file mode 100644
index 4a2614ec..00000000
--- a/src/rendercv/themes/classic/Header.j2.typ
+++ /dev/null
@@ -1,42 +0,0 @@
-((* if cv.photo *))
-#two-col(
- left-column-width: design-header-photo-width * 1.1,
- right-column-width: 1fr,
- left-content: [
- #align(
- left + horizon,
- image("profile_picture.jpg", width: design-header-photo-width),
- )
- ],
- column-gutter: 0cm,
- right-content: [
-((* endif *))
-((* if cv.name *))
-= <>
-((* endif *))
-
-// Print connections:
-#let connections-list = (
-((* for connection in cv.connections *))
- [((*- if connection["url"] and design.header.make_connections_links -*))
- #box(original-link("<>")[
- ((*- endif -*))
- ((*- if design.header.use_icons_for_connections -*))
- #fa-icon("<>", size: 0.9em) #h(0.05cm)
- ((*- endif -*))
- ((*- if not design.header.use_urls_as_placeholders_for_connections or not connection["url"] -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
- ((*- if connection["url"] and design.header.make_connections_links -*))
- ])
- ((*- endif -*))],
-((* endfor *))
-)
-#connections(connections-list)
-
-((* if cv.photo *))
- ],
-)
-((* endif *))
diff --git a/src/rendercv/themes/classic/NormalEntry.j2.typ b/src/rendercv/themes/classic/NormalEntry.j2.typ
deleted file mode 100644
index 163487f7..00000000
--- a/src/rendercv/themes/classic/NormalEntry.j2.typ
+++ /dev/null
@@ -1,36 +0,0 @@
-((* if date_and_location_column_template *))
-#two-col-entry(
- left-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#one-col-entry(
- content: [
- <>
- ],
-)
-((* endif *))
-((* else *))
-
-#one-col-entry(
- content: [
- <>
-
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
- <>
- ],
-)
-((* endif *))
diff --git a/src/rendercv/themes/classic/NumberedEntry.j2.typ b/src/rendercv/themes/classic/NumberedEntry.j2.typ
deleted file mode 100644
index b8ec33ee..00000000
--- a/src/rendercv/themes/classic/NumberedEntry.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-+ <>
\ No newline at end of file
diff --git a/src/rendercv/themes/classic/OneLineEntry.j2.typ b/src/rendercv/themes/classic/OneLineEntry.j2.typ
deleted file mode 100644
index f48dd411..00000000
--- a/src/rendercv/themes/classic/OneLineEntry.j2.typ
+++ /dev/null
@@ -1,3 +0,0 @@
-#one-col-entry(
- content: [<>]
-)
diff --git a/src/rendercv/themes/classic/Preamble.j2.typ b/src/rendercv/themes/classic/Preamble.j2.typ
deleted file mode 100644
index ced8f257..00000000
--- a/src/rendercv/themes/classic/Preamble.j2.typ
+++ /dev/null
@@ -1,475 +0,0 @@
-
-((* set page_numbering_template_placeholders = {
- "NAME": cv.name,
- "PAGE_NUMBER": "\" + str(here().page()) + \"",
- "TOTAL_PAGES": "\" + str(counter(page).final().first()) + \"",
- "TODAY": today
-} *))
-((* set last_updated_date_template_placeholders = {
- "TODAY": today,
-} *))
-#import "@preview/fontawesome:0.5.0": fa-icon
-
-#let name = "<>"
-#let locale-catalog-page-numbering-style = context { "<>" }
-#let locale-catalog-last-updated-date-style = "<>"
-#let locale-catalog-language = "<>"
-#let design-page-size = "<>"
-#let design-colors-text = <>
-#let design-colors-section-titles = <>
-#let design-colors-last-updated-date-and-page-numbering = <>
-#let design-colors-name = <>
-#let design-colors-connections = <>
-#let design-colors-links = <>
-#let design-section-titles-font-family = "<>"
-#let design-section-titles-bold = <>
-#let design-section-titles-line-thickness = <>
-#let design-section-titles-font-size = <>
-#let design-section-titles-type = "<>"
-#let design-section-titles-vertical-space-above = <>
-#let design-section-titles-vertical-space-below = <>
-#let design-section-titles-small-caps = <>
-#let design-links-use-external-link-icon = <>
-#let design-text-font-size = <>
-#let design-text-leading = <>
-#let design-text-font-family = "<>"
-#let design-text-alignment = "<>"
-#let design-text-date-and-location-column-alignment = <>
-#let design-header-photo-width = <>
-#let design-header-use-icons-for-connections = <>
-#let design-header-name-font-family = "<>"
-#let design-header-name-font-size = <>
-#let design-header-name-bold = <>
-#let design-header-small-caps-for-name = <>
-#let design-header-connections-font-family = "<>"
-#let design-header-vertical-space-between-name-and-connections = <>
-#let design-header-vertical-space-between-connections-and-first-section = <>
-#let design-header-use-icons-for-connections = <>
-#let design-header-horizontal-space-between-connections = <>
-#let design-header-separator-between-connections = "<>"
-#let design-header-alignment = <>
-#let design-highlights-summary-left-margin = <>
-#let design-highlights-bullet = "<>"
-#let design-highlights-nested-bullet = "<>"
-#let design-highlights-top-margin = <>
-#let design-highlights-left-margin = <>
-#let design-highlights-vertical-space-between-highlights = <>
-#let design-highlights-horizontal-space-between-bullet-and-highlights = <>
-#let design-entries-vertical-space-between-entries = <>
-#let design-entries-date-and-location-width = <>
-#let design-entries-allow-page-break-in-entries = <>
-#let design-entries-horizontal-space-between-columns = <>
-#let design-entries-left-and-right-margin = <>
-#let design-page-top-margin = <>
-#let design-page-bottom-margin = <>
-#let design-page-left-margin = <>
-#let design-page-right-margin = <>
-#let design-page-show-last-updated-date = <>
-#let design-page-show-page-numbering = <>
-#let design-links-underline = <>
-#let design-entry-types-education-entry-degree-column-width = <>
-#let date = datetime.today()
-
-// Metadata:
-#set document(author: name, title: name + "'s CV", date: date)
-
-// Page settings:
-#set page(
- margin: (
- top: design-page-top-margin,
- bottom: design-page-bottom-margin,
- left: design-page-left-margin,
- right: design-page-right-margin,
- ),
- paper: design-page-size,
- footer: if design-page-show-page-numbering {
- text(
- fill: design-colors-last-updated-date-and-page-numbering,
- align(center, [_#locale-catalog-page-numbering-style _]),
- size: 0.9em,
- )
- } else {
- none
- },
- footer-descent: 0% - 0.3em + design-page-bottom-margin / 2,
-)
-// Text settings:
-#let justify
-#let hyphenate
-#if design-text-alignment == "justified" {
- justify = true
- hyphenate = true
-} else if design-text-alignment == "left" {
- justify = false
- hyphenate = false
-} else if design-text-alignment == "justified-with-no-hyphenation" {
- justify = true
- hyphenate = false
-}
-#set text(
- font: design-text-font-family,
- size: design-text-font-size,
- lang: locale-catalog-language,
- hyphenate: hyphenate,
- fill: design-colors-text,
- // Disable ligatures for better ATS compatibility:
- ligatures: true,
-)
-#set par(
- spacing: 0pt,
- leading: design-text-leading,
- justify: justify,
-)
-#set enum(
- spacing: design-entries-vertical-space-between-entries,
-)
-
-// Highlights settings:
-#let highlights(..content) = {
- list(
- ..content,
- marker: design-highlights-bullet,
- spacing: design-highlights-vertical-space-between-highlights,
- indent: design-highlights-left-margin,
- body-indent: design-highlights-horizontal-space-between-bullet-and-highlights,
- )
-}
-#show list: set list(
- marker: design-highlights-nested-bullet,
- spacing: design-highlights-vertical-space-between-highlights,
- indent: 0pt,
- body-indent: design-highlights-horizontal-space-between-bullet-and-highlights,
-)
-
-// Entry utilities:
-#let bullet-entry(..content) = {
- list(
- ..content,
- marker: design-highlights-bullet,
- spacing: 0pt,
- indent: 0pt,
- body-indent: design-highlights-horizontal-space-between-bullet-and-highlights,
- )
-}
-#let three-col(
- left-column-width: 1fr,
- middle-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- middle-content: "",
- right-content: "",
- alignments: (auto, auto, auto),
-) = [
- #block(
- grid(
- columns: (left-column-width, middle-column-width, right-column-width),
- column-gutter: design-entries-horizontal-space-between-columns,
- align: alignments,
- ([#set par(spacing: design-text-leading); #left-content]),
- ([#set par(spacing: design-text-leading); #middle-content]),
- ([#set par(spacing: design-text-leading); #right-content]),
- ),
- breakable: true,
- width: 100%,
- )
-]
-
-#let two-col(
- left-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- right-content: "",
- alignments: (auto, auto),
- column-gutter: design-entries-horizontal-space-between-columns,
-) = [
- #block(
- grid(
- columns: (left-column-width, right-column-width),
- column-gutter: column-gutter,
- align: alignments,
- ([#set par(spacing: design-text-leading); #left-content]),
- ([#set par(spacing: design-text-leading); #right-content]),
- ),
- breakable: true,
- width: 100%,
- )
-]
-
-// Main heading settings:
-#let header-font-weight
-#if design-header-name-bold {
- header-font-weight = 700
-} else {
- header-font-weight = 400
-}
-#show heading.where(level: 1): it => [
- #set par(spacing: 0pt)
- #set align(design-header-alignment)
- #set text(
- font: design-header-name-font-family,
- weight: header-font-weight,
- size: design-header-name-font-size,
- fill: design-colors-name,
- )
- #if design-header-small-caps-for-name [
- #smallcaps(it.body)
- ] else [
- #it.body
- ]
- // Vertical space after the name
- #v(design-header-vertical-space-between-name-and-connections)
-]
-
-#let section-title-font-weight
-#if design-section-titles-bold {
- section-title-font-weight = 700
-} else {
- section-title-font-weight = 400
-}
-
-#show heading.where(level: 2): it => [
- #set align(left)
- #set text(size: (1em / 1.2)) // reset
- #set text(
- font: design-section-titles-font-family,
- size: (design-section-titles-font-size),
- weight: section-title-font-weight,
- fill: design-colors-section-titles,
- )
- #let section-title = (
- if design-section-titles-small-caps [
- #smallcaps(it.body)
- ] else [
- #it.body
- ]
- )
- // Vertical space above the section title
- #v(design-section-titles-vertical-space-above, weak: true)
- #block(
- breakable: false,
- width: 100%,
- [
- #if design-section-titles-type == "moderncv" [
- #two-col(
- alignments: (right, left),
- left-column-width: design-entries-date-and-location-width,
- right-column-width: 1fr,
- left-content: [
- #align(horizon, box(width: 1fr, height: design-section-titles-line-thickness, fill: design-colors-section-titles))
- ],
- right-content: [
- #section-title
- ]
- )
-
- ] else [
- #box(
- [
- #section-title
- #if design-section-titles-type == "with-partial-line" [
- #box(width: 1fr, height: design-section-titles-line-thickness, fill: design-colors-section-titles)
- ] else if design-section-titles-type == "with-full-line" [
-
- #v(design-text-font-size * 0.4)
- #box(width: 1fr, height: design-section-titles-line-thickness, fill: design-colors-section-titles)
- ]
- ]
- )
- ]
- ] + v(1em),
- )
- #v(-1em)
- // Vertical space after the section title
- #v(design-section-titles-vertical-space-below - 0.5em)
-]
-
-// Links:
-#let original-link = link
-#let link(url, body) = {
- body = [#if design-links-underline [#underline(body)] else [#body]]
- body = [#if design-links-use-external-link-icon [#body#h(design-text-font-size/4)#box(
- fa-icon("external-link", size: 0.7em),
- baseline: -10%,
- )] else [#body]]
- body = [#set text(fill: design-colors-links);#body]
- original-link(url, body)
-}
-
-// Last updated date text:
-#if design-page-show-last-updated-date {
- let dx
- if design-section-titles-type == "moderncv" {
- dx = 0cm
- } else {
- dx = -design-entries-left-and-right-margin
- }
- place(
- top + right,
- dy: -design-page-top-margin / 2,
- dx: dx,
- text(
- [_#locale-catalog-last-updated-date-style _],
- fill: design-colors-last-updated-date-and-page-numbering,
- size: 0.9em,
- ),
- )
-}
-
-#let connections(connections-list) = context {
- set text(fill: design-colors-connections, font: design-header-connections-font-family)
- set par(leading: design-text-leading*1.7, justify: false)
- let list-of-connections = ()
- let separator = (
- h(design-header-horizontal-space-between-connections / 2, weak: true)
- + design-header-separator-between-connections
- + h(design-header-horizontal-space-between-connections / 2, weak: true)
- )
- let starting-index = 0
- while (starting-index < connections-list.len()) {
- let left-sum-right-margin
- if type(page.margin) == "dictionary" {
- left-sum-right-margin = page.margin.left + page.margin.right
- } else {
- left-sum-right-margin = page.margin * 4
- }
-
- let ending-index = starting-index + 1
- while (
- measure(connections-list.slice(starting-index, ending-index).join(separator)).width
- ((* if cv.photo *))
- < page.width - left-sum-right-margin - design-header-photo-width * 1.1
- ((* else *))
- < page.width - left-sum-right-margin
- ((* endif *))
- ) {
- ending-index = ending-index + 1
- if ending-index > connections-list.len() {
- break
- }
- }
- if ending-index > connections-list.len() {
- ending-index = connections-list.len()
- }
- list-of-connections.push(connections-list.slice(starting-index, ending-index).join(separator))
- starting-index = ending-index
- }
- align(list-of-connections.join(linebreak()), design-header-alignment)
- v(design-header-vertical-space-between-connections-and-first-section - design-section-titles-vertical-space-above)
-}
-
-#let three-col-entry(
- left-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- middle-content: "",
- right-content: "",
- alignments: (left, auto, right),
-) = (
- if design-section-titles-type == "moderncv" [
- #three-col(
- left-column-width: right-column-width,
- middle-column-width: left-column-width,
- right-column-width: 1fr,
- left-content: right-content,
- middle-content: [
- #block(
- [
- #left-content
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ],
- right-content: middle-content,
- alignments: (design-text-date-and-location-column-alignment, left, auto),
- )
- ] else [
- #block(
- [
- #three-col(
- left-column-width: left-column-width,
- right-column-width: right-column-width,
- left-content: left-content,
- middle-content: middle-content,
- right-content: right-content,
- alignments: alignments,
- )
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ]
-)
-
-#let two-col-entry(
- left-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- right-content: "",
- alignments: (auto, design-text-date-and-location-column-alignment),
- column-gutter: design-entries-horizontal-space-between-columns,
-) = (
- if design-section-titles-type == "moderncv" [
- #two-col(
- left-column-width: right-column-width,
- right-column-width: left-column-width,
- left-content: right-content,
- right-content: [
- #block(
- [
- #left-content
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ],
- alignments: (design-text-date-and-location-column-alignment, auto),
- )
- ] else [
- #block(
- [
- #two-col(
- left-column-width: left-column-width,
- right-column-width: right-column-width,
- left-content: left-content,
- right-content: right-content,
- alignments: alignments,
- )
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ]
-)
-
-#let one-col-entry(content: "") = [
- #let left-space = design-entries-left-and-right-margin
- #if design-section-titles-type == "moderncv" [
- #(left-space = left-space + design-entries-date-and-location-width + design-entries-horizontal-space-between-columns)
- ]
- #block(
- [#set par(spacing: design-text-leading); #content],
- breakable: design-entries-allow-page-break-in-entries,
- inset: (
- left: left-space,
- right: design-entries-left-and-right-margin,
- ),
- width: 100%,
- )
-]
diff --git a/src/rendercv/themes/classic/PublicationEntry.j2.typ b/src/rendercv/themes/classic/PublicationEntry.j2.typ
deleted file mode 100644
index d4b12b8c..00000000
--- a/src/rendercv/themes/classic/PublicationEntry.j2.typ
+++ /dev/null
@@ -1,45 +0,0 @@
-((* if date_and_location_column_template *))
-#two-col-entry(
- left-content: [
- <>
-
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- #v(-design-text-leading)
- ((* if not (entry.doi or entry.url)*))
- <>
- ((*- elif not entry.journal -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#one-col-entry(content:[
- ((* if not (entry.doi or entry.url)*))
- <>
- ((*- elif not entry.journal -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
-])
- ((* endif *))
-((* else *))
-#one-col-entry(content:[
- <>
-
- #v(-design-text-leading)
- ((* if not (entry.doi or entry.url)*))
- <>
- ((*- elif not entry.journal -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
-])
-((* endif *))
\ No newline at end of file
diff --git a/src/rendercv/themes/classic/ReversedNumberedEntry.j2.typ b/src/rendercv/themes/classic/ReversedNumberedEntry.j2.typ
deleted file mode 100644
index 8f267333..00000000
--- a/src/rendercv/themes/classic/ReversedNumberedEntry.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-[<>],
\ No newline at end of file
diff --git a/src/rendercv/themes/classic/SectionBeginning.j2.typ b/src/rendercv/themes/classic/SectionBeginning.j2.typ
deleted file mode 100644
index 2029508e..00000000
--- a/src/rendercv/themes/classic/SectionBeginning.j2.typ
+++ /dev/null
@@ -1,12 +0,0 @@
-== <>
-((* if not design.entries.allow_page_break_in_sections *))
-#block(
- [
-((* endif *))
-((* if entry_type in ["NumberedEntry", "ReversedNumberedEntry"] *))
-#one-col-entry(
- content: [
- ((* if entry_type == "ReversedNumberedEntry" *))
- #let rev-enum-items = (
- ((* endif *))
-((* endif *))
diff --git a/src/rendercv/themes/classic/SectionEnding.j2.typ b/src/rendercv/themes/classic/SectionEnding.j2.typ
deleted file mode 100644
index 8dd8a3ce..00000000
--- a/src/rendercv/themes/classic/SectionEnding.j2.typ
+++ /dev/null
@@ -1,21 +0,0 @@
-((* if entry_type in ["NumberedEntry", "ReversedNumberedEntry"] *))
- ((* if entry_type == "ReversedNumberedEntry" *))
- )
- #enum(
- numbering: n => [#{rev-enum-items.len() + 1 - n}.],
- ..rev-enum-items,
- )
- ((* endif *))
- ],
-)
-((* endif *))
-((* if not design.entries.allow_page_break_in_sections *))
- ],
- breakable: false,
- inset: (
- left: 0cm,
- right: 0cm,
- ),
- width: 100%,
-)
-((* endif *))
\ No newline at end of file
diff --git a/src/rendercv/themes/classic/TextEntry.j2.typ b/src/rendercv/themes/classic/TextEntry.j2.typ
deleted file mode 100644
index 66434f9c..00000000
--- a/src/rendercv/themes/classic/TextEntry.j2.typ
+++ /dev/null
@@ -1,3 +0,0 @@
-#one-col-entry(
- content: [<>]
-)
\ No newline at end of file
diff --git a/src/rendercv/themes/classic/__init__.py b/src/rendercv/themes/classic/__init__.py
deleted file mode 100644
index b8de6458..00000000
--- a/src/rendercv/themes/classic/__init__.py
+++ /dev/null
@@ -1,7 +0,0 @@
-from typing import Literal
-
-from rendercv.themes.options import ThemeOptions
-
-
-class ClassicThemeOptions(ThemeOptions):
- theme: Literal["classic"] = "classic"
diff --git a/src/rendercv/themes/components/area.j2.typ b/src/rendercv/themes/components/area.j2.typ
deleted file mode 100644
index db3bbe29..00000000
--- a/src/rendercv/themes/components/area.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/authors.j2.typ b/src/rendercv/themes/components/authors.j2.typ
deleted file mode 100644
index f1812d48..00000000
--- a/src/rendercv/themes/components/authors.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-#v(design-highlights-top-margin);<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/company.j2.typ b/src/rendercv/themes/components/company.j2.typ
deleted file mode 100644
index 5a87cff2..00000000
--- a/src/rendercv/themes/components/company.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/date.j2.typ b/src/rendercv/themes/components/date.j2.typ
deleted file mode 100644
index 278a8003..00000000
--- a/src/rendercv/themes/components/date.j2.typ
+++ /dev/null
@@ -1,5 +0,0 @@
-<>
-((*- if section_title in design.entries.show_time_spans_in *))
-
-<>
-((* endif -*))
\ No newline at end of file
diff --git a/src/rendercv/themes/components/degree.j2.typ b/src/rendercv/themes/components/degree.j2.typ
deleted file mode 100644
index d6c83722..00000000
--- a/src/rendercv/themes/components/degree.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/details.j2.typ b/src/rendercv/themes/components/details.j2.typ
deleted file mode 100644
index 0dcae931..00000000
--- a/src/rendercv/themes/components/details.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/grade.j2.typ b/src/rendercv/themes/components/grade.j2.typ
deleted file mode 100644
index 57418ca4..00000000
--- a/src/rendercv/themes/components/grade.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
diff --git a/src/rendercv/themes/components/highlights.j2.typ b/src/rendercv/themes/components/highlights.j2.typ
deleted file mode 100644
index 7405a43d..00000000
--- a/src/rendercv/themes/components/highlights.j2.typ
+++ /dev/null
@@ -1,9 +0,0 @@
-((* for item in entry.highlights *))
- ((* if loop.first *))
- #v(design-highlights-top-margin);#highlights(
- ((*- endif -*))
- [<>],
- ((*- if loop.last -*))
- )
- ((* endif *))
-((* endfor *))
\ No newline at end of file
diff --git a/src/rendercv/themes/components/institution.j2.typ b/src/rendercv/themes/components/institution.j2.typ
deleted file mode 100644
index 1d1ee319..00000000
--- a/src/rendercv/themes/components/institution.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/journal.j2.typ b/src/rendercv/themes/components/journal.j2.typ
deleted file mode 100644
index 8c4f0ffe..00000000
--- a/src/rendercv/themes/components/journal.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/label.j2.typ b/src/rendercv/themes/components/label.j2.typ
deleted file mode 100644
index c7c2574d..00000000
--- a/src/rendercv/themes/components/label.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/location.j2.typ b/src/rendercv/themes/components/location.j2.typ
deleted file mode 100644
index a7d01597..00000000
--- a/src/rendercv/themes/components/location.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/name.j2.typ b/src/rendercv/themes/components/name.j2.typ
deleted file mode 100644
index f69f7f35..00000000
--- a/src/rendercv/themes/components/name.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/position.j2.typ b/src/rendercv/themes/components/position.j2.typ
deleted file mode 100644
index 33ccf844..00000000
--- a/src/rendercv/themes/components/position.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/summary.j2.typ b/src/rendercv/themes/components/summary.j2.typ
deleted file mode 100644
index 4b32667f..00000000
--- a/src/rendercv/themes/components/summary.j2.typ
+++ /dev/null
@@ -1,3 +0,0 @@
-((*- if entry.summary -*))
-#two-col(left-column-width: design-highlights-summary-left-margin, right-column-width: 1fr, left-content: [], right-content: [#v(design-highlights-top-margin);#align(left, [<>])], column-gutter: 0cm)
-((*- endif -*))
diff --git a/src/rendercv/themes/components/title.j2.typ b/src/rendercv/themes/components/title.j2.typ
deleted file mode 100644
index d7691034..00000000
--- a/src/rendercv/themes/components/title.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-<>
\ No newline at end of file
diff --git a/src/rendercv/themes/components/url.j2.typ b/src/rendercv/themes/components/url.j2.typ
deleted file mode 100644
index f527e03b..00000000
--- a/src/rendercv/themes/components/url.j2.typ
+++ /dev/null
@@ -1,7 +0,0 @@
-((*- if entry.doi -*))
-#link("<>")[<>]
-((*- elif entry.url and entry.clean_url -*))
-#link("<>")[<>]
-((*- elif entry.url -*))
-#link("<>")[<>]
-((*- endif -*))
\ No newline at end of file
diff --git a/src/rendercv/themes/engineeringclassic/BulletEntry.j2.typ b/src/rendercv/themes/engineeringclassic/BulletEntry.j2.typ
deleted file mode 100644
index addd8c5a..00000000
--- a/src/rendercv/themes/engineeringclassic/BulletEntry.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-#one-col-entry(content: [#bullet-entry[<>]])
diff --git a/src/rendercv/themes/engineeringclassic/EducationEntry.j2.typ b/src/rendercv/themes/engineeringclassic/EducationEntry.j2.typ
deleted file mode 100644
index 6c4eb9d3..00000000
--- a/src/rendercv/themes/engineeringclassic/EducationEntry.j2.typ
+++ /dev/null
@@ -1,106 +0,0 @@
-((* if date_and_location_column_template and design.entry_types.education_entry.degree_column_template *))
-// YES DATE, YES DEGREE
-#three-col-entry(
- left-column-width: <>,
- left-content: [<>],
- middle-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
-((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n")) and main_column_second_row_template *))
-#block(
- [
- #set par(spacing: 0pt)
- <>
- ],
- inset: (
- left: design-entry-types-education-entry-degree-column-width + design-entries-horizontal-space-between-columns + design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
-)
-((* endif *))
-((* elif date_and_location_column_template and not design.entry_types.education_entry.degree_column_template *))
-// YES DATE, NO DEGREE
-#two-col-entry(
- left-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#block(
- [
- #set par(spacing: 0pt)
- <>
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
-)
-((* endif *))
-((* elif not date_and_location_column_template and design.entry_types.education_entry.degree_column_template *))
-// NO DATE, YES DEGREE
-#two-col-entry(
- left-column-width: <>,
- right-column-width: 1fr,
- alignments: (left, left),
- left-content: [
- <>
- ],
- right-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
-)
-((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n")) and main_column_second_row_template *))
-#block(
- [
- #set par(spacing: 0pt)
- <>
- ],
- inset: (
- left: design-entry-types-education-entry-degree-column-width + design-entries-horizontal-space-between-columns + design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
-)
-((* endif *))
-((* else *))
-// NO DATE, NO DEGREE
-
-#one-col-entry(
- content: [
- <>
-
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
- <>
- ],
-)
-((* endif *))
\ No newline at end of file
diff --git a/src/rendercv/themes/engineeringclassic/ExperienceEntry.j2.typ b/src/rendercv/themes/engineeringclassic/ExperienceEntry.j2.typ
deleted file mode 100644
index 163487f7..00000000
--- a/src/rendercv/themes/engineeringclassic/ExperienceEntry.j2.typ
+++ /dev/null
@@ -1,36 +0,0 @@
-((* if date_and_location_column_template *))
-#two-col-entry(
- left-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#one-col-entry(
- content: [
- <>
- ],
-)
-((* endif *))
-((* else *))
-
-#one-col-entry(
- content: [
- <>
-
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
- <>
- ],
-)
-((* endif *))
diff --git a/src/rendercv/themes/engineeringclassic/Header.j2.typ b/src/rendercv/themes/engineeringclassic/Header.j2.typ
deleted file mode 100644
index 4a2614ec..00000000
--- a/src/rendercv/themes/engineeringclassic/Header.j2.typ
+++ /dev/null
@@ -1,42 +0,0 @@
-((* if cv.photo *))
-#two-col(
- left-column-width: design-header-photo-width * 1.1,
- right-column-width: 1fr,
- left-content: [
- #align(
- left + horizon,
- image("profile_picture.jpg", width: design-header-photo-width),
- )
- ],
- column-gutter: 0cm,
- right-content: [
-((* endif *))
-((* if cv.name *))
-= <>
-((* endif *))
-
-// Print connections:
-#let connections-list = (
-((* for connection in cv.connections *))
- [((*- if connection["url"] and design.header.make_connections_links -*))
- #box(original-link("<>")[
- ((*- endif -*))
- ((*- if design.header.use_icons_for_connections -*))
- #fa-icon("<>", size: 0.9em) #h(0.05cm)
- ((*- endif -*))
- ((*- if not design.header.use_urls_as_placeholders_for_connections or not connection["url"] -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
- ((*- if connection["url"] and design.header.make_connections_links -*))
- ])
- ((*- endif -*))],
-((* endfor *))
-)
-#connections(connections-list)
-
-((* if cv.photo *))
- ],
-)
-((* endif *))
diff --git a/src/rendercv/themes/engineeringclassic/NormalEntry.j2.typ b/src/rendercv/themes/engineeringclassic/NormalEntry.j2.typ
deleted file mode 100644
index 163487f7..00000000
--- a/src/rendercv/themes/engineeringclassic/NormalEntry.j2.typ
+++ /dev/null
@@ -1,36 +0,0 @@
-((* if date_and_location_column_template *))
-#two-col-entry(
- left-content: [
- <>
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
-
- <>
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#one-col-entry(
- content: [
- <>
- ],
-)
-((* endif *))
-((* else *))
-
-#one-col-entry(
- content: [
- <>
-
- ((* if main_column_second_row_template *))
- #v(-design-text-leading)
- ((* endif *))
- <>
- ],
-)
-((* endif *))
diff --git a/src/rendercv/themes/engineeringclassic/NumberedEntry.j2.typ b/src/rendercv/themes/engineeringclassic/NumberedEntry.j2.typ
deleted file mode 100644
index b8ec33ee..00000000
--- a/src/rendercv/themes/engineeringclassic/NumberedEntry.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-+ <>
\ No newline at end of file
diff --git a/src/rendercv/themes/engineeringclassic/OneLineEntry.j2.typ b/src/rendercv/themes/engineeringclassic/OneLineEntry.j2.typ
deleted file mode 100644
index f48dd411..00000000
--- a/src/rendercv/themes/engineeringclassic/OneLineEntry.j2.typ
+++ /dev/null
@@ -1,3 +0,0 @@
-#one-col-entry(
- content: [<>]
-)
diff --git a/src/rendercv/themes/engineeringclassic/Preamble.j2.typ b/src/rendercv/themes/engineeringclassic/Preamble.j2.typ
deleted file mode 100644
index ced8f257..00000000
--- a/src/rendercv/themes/engineeringclassic/Preamble.j2.typ
+++ /dev/null
@@ -1,475 +0,0 @@
-
-((* set page_numbering_template_placeholders = {
- "NAME": cv.name,
- "PAGE_NUMBER": "\" + str(here().page()) + \"",
- "TOTAL_PAGES": "\" + str(counter(page).final().first()) + \"",
- "TODAY": today
-} *))
-((* set last_updated_date_template_placeholders = {
- "TODAY": today,
-} *))
-#import "@preview/fontawesome:0.5.0": fa-icon
-
-#let name = "<>"
-#let locale-catalog-page-numbering-style = context { "<>" }
-#let locale-catalog-last-updated-date-style = "<>"
-#let locale-catalog-language = "<>"
-#let design-page-size = "<>"
-#let design-colors-text = <>
-#let design-colors-section-titles = <>
-#let design-colors-last-updated-date-and-page-numbering = <>
-#let design-colors-name = <>
-#let design-colors-connections = <>
-#let design-colors-links = <>
-#let design-section-titles-font-family = "<>"
-#let design-section-titles-bold = <>
-#let design-section-titles-line-thickness = <>
-#let design-section-titles-font-size = <>
-#let design-section-titles-type = "<>"
-#let design-section-titles-vertical-space-above = <>
-#let design-section-titles-vertical-space-below = <>
-#let design-section-titles-small-caps = <>
-#let design-links-use-external-link-icon = <>
-#let design-text-font-size = <>
-#let design-text-leading = <>
-#let design-text-font-family = "<>"
-#let design-text-alignment = "<>"
-#let design-text-date-and-location-column-alignment = <>
-#let design-header-photo-width = <>
-#let design-header-use-icons-for-connections = <>
-#let design-header-name-font-family = "<>"
-#let design-header-name-font-size = <>
-#let design-header-name-bold = <>
-#let design-header-small-caps-for-name = <>
-#let design-header-connections-font-family = "<>"
-#let design-header-vertical-space-between-name-and-connections = <>
-#let design-header-vertical-space-between-connections-and-first-section = <>
-#let design-header-use-icons-for-connections = <>
-#let design-header-horizontal-space-between-connections = <>
-#let design-header-separator-between-connections = "<>"
-#let design-header-alignment = <>
-#let design-highlights-summary-left-margin = <>
-#let design-highlights-bullet = "<>"
-#let design-highlights-nested-bullet = "<>"
-#let design-highlights-top-margin = <>
-#let design-highlights-left-margin = <>
-#let design-highlights-vertical-space-between-highlights = <>
-#let design-highlights-horizontal-space-between-bullet-and-highlights = <>
-#let design-entries-vertical-space-between-entries = <>
-#let design-entries-date-and-location-width = <>
-#let design-entries-allow-page-break-in-entries = <>
-#let design-entries-horizontal-space-between-columns = <>
-#let design-entries-left-and-right-margin = <>
-#let design-page-top-margin = <>
-#let design-page-bottom-margin = <>
-#let design-page-left-margin = <>
-#let design-page-right-margin = <>
-#let design-page-show-last-updated-date = <>
-#let design-page-show-page-numbering = <>
-#let design-links-underline = <>
-#let design-entry-types-education-entry-degree-column-width = <>
-#let date = datetime.today()
-
-// Metadata:
-#set document(author: name, title: name + "'s CV", date: date)
-
-// Page settings:
-#set page(
- margin: (
- top: design-page-top-margin,
- bottom: design-page-bottom-margin,
- left: design-page-left-margin,
- right: design-page-right-margin,
- ),
- paper: design-page-size,
- footer: if design-page-show-page-numbering {
- text(
- fill: design-colors-last-updated-date-and-page-numbering,
- align(center, [_#locale-catalog-page-numbering-style _]),
- size: 0.9em,
- )
- } else {
- none
- },
- footer-descent: 0% - 0.3em + design-page-bottom-margin / 2,
-)
-// Text settings:
-#let justify
-#let hyphenate
-#if design-text-alignment == "justified" {
- justify = true
- hyphenate = true
-} else if design-text-alignment == "left" {
- justify = false
- hyphenate = false
-} else if design-text-alignment == "justified-with-no-hyphenation" {
- justify = true
- hyphenate = false
-}
-#set text(
- font: design-text-font-family,
- size: design-text-font-size,
- lang: locale-catalog-language,
- hyphenate: hyphenate,
- fill: design-colors-text,
- // Disable ligatures for better ATS compatibility:
- ligatures: true,
-)
-#set par(
- spacing: 0pt,
- leading: design-text-leading,
- justify: justify,
-)
-#set enum(
- spacing: design-entries-vertical-space-between-entries,
-)
-
-// Highlights settings:
-#let highlights(..content) = {
- list(
- ..content,
- marker: design-highlights-bullet,
- spacing: design-highlights-vertical-space-between-highlights,
- indent: design-highlights-left-margin,
- body-indent: design-highlights-horizontal-space-between-bullet-and-highlights,
- )
-}
-#show list: set list(
- marker: design-highlights-nested-bullet,
- spacing: design-highlights-vertical-space-between-highlights,
- indent: 0pt,
- body-indent: design-highlights-horizontal-space-between-bullet-and-highlights,
-)
-
-// Entry utilities:
-#let bullet-entry(..content) = {
- list(
- ..content,
- marker: design-highlights-bullet,
- spacing: 0pt,
- indent: 0pt,
- body-indent: design-highlights-horizontal-space-between-bullet-and-highlights,
- )
-}
-#let three-col(
- left-column-width: 1fr,
- middle-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- middle-content: "",
- right-content: "",
- alignments: (auto, auto, auto),
-) = [
- #block(
- grid(
- columns: (left-column-width, middle-column-width, right-column-width),
- column-gutter: design-entries-horizontal-space-between-columns,
- align: alignments,
- ([#set par(spacing: design-text-leading); #left-content]),
- ([#set par(spacing: design-text-leading); #middle-content]),
- ([#set par(spacing: design-text-leading); #right-content]),
- ),
- breakable: true,
- width: 100%,
- )
-]
-
-#let two-col(
- left-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- right-content: "",
- alignments: (auto, auto),
- column-gutter: design-entries-horizontal-space-between-columns,
-) = [
- #block(
- grid(
- columns: (left-column-width, right-column-width),
- column-gutter: column-gutter,
- align: alignments,
- ([#set par(spacing: design-text-leading); #left-content]),
- ([#set par(spacing: design-text-leading); #right-content]),
- ),
- breakable: true,
- width: 100%,
- )
-]
-
-// Main heading settings:
-#let header-font-weight
-#if design-header-name-bold {
- header-font-weight = 700
-} else {
- header-font-weight = 400
-}
-#show heading.where(level: 1): it => [
- #set par(spacing: 0pt)
- #set align(design-header-alignment)
- #set text(
- font: design-header-name-font-family,
- weight: header-font-weight,
- size: design-header-name-font-size,
- fill: design-colors-name,
- )
- #if design-header-small-caps-for-name [
- #smallcaps(it.body)
- ] else [
- #it.body
- ]
- // Vertical space after the name
- #v(design-header-vertical-space-between-name-and-connections)
-]
-
-#let section-title-font-weight
-#if design-section-titles-bold {
- section-title-font-weight = 700
-} else {
- section-title-font-weight = 400
-}
-
-#show heading.where(level: 2): it => [
- #set align(left)
- #set text(size: (1em / 1.2)) // reset
- #set text(
- font: design-section-titles-font-family,
- size: (design-section-titles-font-size),
- weight: section-title-font-weight,
- fill: design-colors-section-titles,
- )
- #let section-title = (
- if design-section-titles-small-caps [
- #smallcaps(it.body)
- ] else [
- #it.body
- ]
- )
- // Vertical space above the section title
- #v(design-section-titles-vertical-space-above, weak: true)
- #block(
- breakable: false,
- width: 100%,
- [
- #if design-section-titles-type == "moderncv" [
- #two-col(
- alignments: (right, left),
- left-column-width: design-entries-date-and-location-width,
- right-column-width: 1fr,
- left-content: [
- #align(horizon, box(width: 1fr, height: design-section-titles-line-thickness, fill: design-colors-section-titles))
- ],
- right-content: [
- #section-title
- ]
- )
-
- ] else [
- #box(
- [
- #section-title
- #if design-section-titles-type == "with-partial-line" [
- #box(width: 1fr, height: design-section-titles-line-thickness, fill: design-colors-section-titles)
- ] else if design-section-titles-type == "with-full-line" [
-
- #v(design-text-font-size * 0.4)
- #box(width: 1fr, height: design-section-titles-line-thickness, fill: design-colors-section-titles)
- ]
- ]
- )
- ]
- ] + v(1em),
- )
- #v(-1em)
- // Vertical space after the section title
- #v(design-section-titles-vertical-space-below - 0.5em)
-]
-
-// Links:
-#let original-link = link
-#let link(url, body) = {
- body = [#if design-links-underline [#underline(body)] else [#body]]
- body = [#if design-links-use-external-link-icon [#body#h(design-text-font-size/4)#box(
- fa-icon("external-link", size: 0.7em),
- baseline: -10%,
- )] else [#body]]
- body = [#set text(fill: design-colors-links);#body]
- original-link(url, body)
-}
-
-// Last updated date text:
-#if design-page-show-last-updated-date {
- let dx
- if design-section-titles-type == "moderncv" {
- dx = 0cm
- } else {
- dx = -design-entries-left-and-right-margin
- }
- place(
- top + right,
- dy: -design-page-top-margin / 2,
- dx: dx,
- text(
- [_#locale-catalog-last-updated-date-style _],
- fill: design-colors-last-updated-date-and-page-numbering,
- size: 0.9em,
- ),
- )
-}
-
-#let connections(connections-list) = context {
- set text(fill: design-colors-connections, font: design-header-connections-font-family)
- set par(leading: design-text-leading*1.7, justify: false)
- let list-of-connections = ()
- let separator = (
- h(design-header-horizontal-space-between-connections / 2, weak: true)
- + design-header-separator-between-connections
- + h(design-header-horizontal-space-between-connections / 2, weak: true)
- )
- let starting-index = 0
- while (starting-index < connections-list.len()) {
- let left-sum-right-margin
- if type(page.margin) == "dictionary" {
- left-sum-right-margin = page.margin.left + page.margin.right
- } else {
- left-sum-right-margin = page.margin * 4
- }
-
- let ending-index = starting-index + 1
- while (
- measure(connections-list.slice(starting-index, ending-index).join(separator)).width
- ((* if cv.photo *))
- < page.width - left-sum-right-margin - design-header-photo-width * 1.1
- ((* else *))
- < page.width - left-sum-right-margin
- ((* endif *))
- ) {
- ending-index = ending-index + 1
- if ending-index > connections-list.len() {
- break
- }
- }
- if ending-index > connections-list.len() {
- ending-index = connections-list.len()
- }
- list-of-connections.push(connections-list.slice(starting-index, ending-index).join(separator))
- starting-index = ending-index
- }
- align(list-of-connections.join(linebreak()), design-header-alignment)
- v(design-header-vertical-space-between-connections-and-first-section - design-section-titles-vertical-space-above)
-}
-
-#let three-col-entry(
- left-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- middle-content: "",
- right-content: "",
- alignments: (left, auto, right),
-) = (
- if design-section-titles-type == "moderncv" [
- #three-col(
- left-column-width: right-column-width,
- middle-column-width: left-column-width,
- right-column-width: 1fr,
- left-content: right-content,
- middle-content: [
- #block(
- [
- #left-content
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ],
- right-content: middle-content,
- alignments: (design-text-date-and-location-column-alignment, left, auto),
- )
- ] else [
- #block(
- [
- #three-col(
- left-column-width: left-column-width,
- right-column-width: right-column-width,
- left-content: left-content,
- middle-content: middle-content,
- right-content: right-content,
- alignments: alignments,
- )
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ]
-)
-
-#let two-col-entry(
- left-column-width: 1fr,
- right-column-width: design-entries-date-and-location-width,
- left-content: "",
- right-content: "",
- alignments: (auto, design-text-date-and-location-column-alignment),
- column-gutter: design-entries-horizontal-space-between-columns,
-) = (
- if design-section-titles-type == "moderncv" [
- #two-col(
- left-column-width: right-column-width,
- right-column-width: left-column-width,
- left-content: right-content,
- right-content: [
- #block(
- [
- #left-content
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ],
- alignments: (design-text-date-and-location-column-alignment, auto),
- )
- ] else [
- #block(
- [
- #two-col(
- left-column-width: left-column-width,
- right-column-width: right-column-width,
- left-content: left-content,
- right-content: right-content,
- alignments: alignments,
- )
- ],
- inset: (
- left: design-entries-left-and-right-margin,
- right: design-entries-left-and-right-margin,
- ),
- breakable: design-entries-allow-page-break-in-entries,
- width: 100%,
- )
- ]
-)
-
-#let one-col-entry(content: "") = [
- #let left-space = design-entries-left-and-right-margin
- #if design-section-titles-type == "moderncv" [
- #(left-space = left-space + design-entries-date-and-location-width + design-entries-horizontal-space-between-columns)
- ]
- #block(
- [#set par(spacing: design-text-leading); #content],
- breakable: design-entries-allow-page-break-in-entries,
- inset: (
- left: left-space,
- right: design-entries-left-and-right-margin,
- ),
- width: 100%,
- )
-]
diff --git a/src/rendercv/themes/engineeringclassic/PublicationEntry.j2.typ b/src/rendercv/themes/engineeringclassic/PublicationEntry.j2.typ
deleted file mode 100644
index d4b12b8c..00000000
--- a/src/rendercv/themes/engineeringclassic/PublicationEntry.j2.typ
+++ /dev/null
@@ -1,45 +0,0 @@
-((* if date_and_location_column_template *))
-#two-col-entry(
- left-content: [
- <>
-
- ((* if design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv" *))
- #v(-design-text-leading)
- ((* if not (entry.doi or entry.url)*))
- <>
- ((*- elif not entry.journal -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
- ((* endif *))
- ],
- right-content: [
- <>
- ],
-)
- ((* if not (design.entries.short_second_row or date_and_location_column_template.count("\n\n") > main_column_first_row_template.count("\n\n") or design.section_titles.type=="moderncv") *))
-#one-col-entry(content:[
- ((* if not (entry.doi or entry.url)*))
- <>
- ((*- elif not entry.journal -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
-])
- ((* endif *))
-((* else *))
-#one-col-entry(content:[
- <>
-
- #v(-design-text-leading)
- ((* if not (entry.doi or entry.url)*))
- <>
- ((*- elif not entry.journal -*))
- <>
- ((*- else -*))
- <>
- ((*- endif -*))
-])
-((* endif *))
\ No newline at end of file
diff --git a/src/rendercv/themes/engineeringclassic/ReversedNumberedEntry.j2.typ b/src/rendercv/themes/engineeringclassic/ReversedNumberedEntry.j2.typ
deleted file mode 100644
index 8f267333..00000000
--- a/src/rendercv/themes/engineeringclassic/ReversedNumberedEntry.j2.typ
+++ /dev/null
@@ -1 +0,0 @@
-[<>],
\ No newline at end of file
diff --git a/src/rendercv/themes/engineeringclassic/SectionBeginning.j2.typ b/src/rendercv/themes/engineeringclassic/SectionBeginning.j2.typ
deleted file mode 100644
index 2029508e..00000000
--- a/src/rendercv/themes/engineeringclassic/SectionBeginning.j2.typ
+++ /dev/null
@@ -1,12 +0,0 @@
-== <>
-((* if not design.entries.allow_page_break_in_sections *))
-#block(
- [
-((* endif *))
-((* if entry_type in ["NumberedEntry", "ReversedNumberedEntry"] *))
-#one-col-entry(
- content: [
- ((* if entry_type == "ReversedNumberedEntry" *))
- #let rev-enum-items = (
- ((* endif *))
-((* endif *))
diff --git a/src/rendercv/themes/engineeringclassic/SectionEnding.j2.typ b/src/rendercv/themes/engineeringclassic/SectionEnding.j2.typ
deleted file mode 100644
index 8dd8a3ce..00000000
--- a/src/rendercv/themes/engineeringclassic/SectionEnding.j2.typ
+++ /dev/null
@@ -1,21 +0,0 @@
-((* if entry_type in ["NumberedEntry", "ReversedNumberedEntry"] *))
- ((* if entry_type == "ReversedNumberedEntry" *))
- )
- #enum(
- numbering: n => [#{rev-enum-items.len() + 1 - n}.],
- ..rev-enum-items,
- )
- ((* endif *))
- ],
-)
-((* endif *))
-((* if not design.entries.allow_page_break_in_sections *))
- ],
- breakable: false,
- inset: (
- left: 0cm,
- right: 0cm,
- ),
- width: 100%,
-)
-((* endif *))
\ No newline at end of file
diff --git a/src/rendercv/themes/engineeringclassic/TextEntry.j2.typ b/src/rendercv/themes/engineeringclassic/TextEntry.j2.typ
deleted file mode 100644
index 66434f9c..00000000
--- a/src/rendercv/themes/engineeringclassic/TextEntry.j2.typ
+++ /dev/null
@@ -1,3 +0,0 @@
-#one-col-entry(
- content: [<