mirror of
https://github.com/mudler/LocalAI.git
synced 2026-02-03 03:02:38 -05:00
Compare commits
38 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
7e5fe35ae4 | ||
|
|
8c8cf38d4d | ||
|
|
75b25297fd | ||
|
|
009ee47fe2 | ||
|
|
ec2adc2c03 | ||
|
|
ad301e6ed7 | ||
|
|
d094381e5d | ||
|
|
3ff9bbd217 | ||
|
|
e62ee2bc06 | ||
|
|
b49721cdd1 | ||
|
|
64c0a7967f | ||
|
|
e96eadab40 | ||
|
|
e73283121b | ||
|
|
857d13e8d6 | ||
|
|
91db3d4d5c | ||
|
|
961cf29217 | ||
|
|
c839b334eb | ||
|
|
714bfcd45b | ||
|
|
77ce8b953e | ||
|
|
01ada95941 | ||
|
|
eabdc5042a | ||
|
|
96267d9437 | ||
|
|
9497a24127 | ||
|
|
fdf75c6d0e | ||
|
|
6352308882 | ||
|
|
a8172a0f4e | ||
|
|
ebcd10d66f | ||
|
|
885642915f | ||
|
|
2e424491c0 | ||
|
|
aa6faef8f7 | ||
|
|
b3254baf60 | ||
|
|
0a43d27f0e | ||
|
|
3fe11fe24d | ||
|
|
af18fdc749 | ||
|
|
32b5eddd7d | ||
|
|
07c3aa1869 | ||
|
|
e59bad89e7 | ||
|
|
b971807980 |
9
.github/bump_deps.sh
vendored
Executable file
9
.github/bump_deps.sh
vendored
Executable file
@@ -0,0 +1,9 @@
|
||||
#!/bin/bash
|
||||
set -xe
|
||||
REPO=$1
|
||||
BRANCH=$2
|
||||
VAR=$3
|
||||
|
||||
LAST_COMMIT=$(curl -s -H "Accept: application/vnd.github.VERSION.sha" "https://api.github.com/repos/$REPO/commits/$BRANCH")
|
||||
|
||||
sed -i Makefile -e "s/$VAR?=.*/$VAR?=$LAST_COMMIT/"
|
||||
42
.github/workflows/bump_deps.yaml
vendored
Normal file
42
.github/workflows/bump_deps.yaml
vendored
Normal file
@@ -0,0 +1,42 @@
|
||||
name: Bump dependencies
|
||||
on:
|
||||
schedule:
|
||||
- cron: 0 20 * * *
|
||||
workflow_dispatch:
|
||||
jobs:
|
||||
bump:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
include:
|
||||
- repository: "go-skynet/go-gpt4all-j.cpp"
|
||||
variable: "GOGPT4ALLJ_VERSION"
|
||||
branch: "master"
|
||||
- repository: "go-skynet/go-llama.cpp"
|
||||
variable: "GOLLAMA_VERSION"
|
||||
branch: "master"
|
||||
- repository: "go-skynet/go-gpt2.cpp"
|
||||
variable: "GOGPT2_VERSION"
|
||||
branch: "master"
|
||||
- repository: "donomii/go-rwkv.cpp"
|
||||
variable: "RWKV_VERSION"
|
||||
branch: "main"
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Bump dependencies 🔧
|
||||
run: |
|
||||
bash .github/bump_deps.sh ${{ matrix.repository }} ${{ matrix.branch }} ${{ matrix.variable }}
|
||||
- name: Create Pull Request
|
||||
uses: peter-evans/create-pull-request@v5
|
||||
with:
|
||||
token: ${{ secrets.UPDATE_BOT_TOKEN }}
|
||||
push-to-fork: ci-forks/LocalAI
|
||||
commit-message: ':arrow_up: Update ${{ matrix.repository }}'
|
||||
title: ':arrow_up: Update ${{ matrix.repository }}'
|
||||
branch: "update/${{ matrix.variable }}"
|
||||
body: Bump of ${{ matrix.repository }} version
|
||||
signoff: true
|
||||
|
||||
|
||||
|
||||
17
Makefile
17
Makefile
@@ -2,13 +2,10 @@ GOCMD=go
|
||||
GOTEST=$(GOCMD) test
|
||||
GOVET=$(GOCMD) vet
|
||||
BINARY_NAME=local-ai
|
||||
# renovate: datasource=github-tags depName=go-skynet/go-llama.cpp
|
||||
GOLLAMA_VERSION?=llama.cpp-f4cef87
|
||||
# renovate: datasource=git-refs packageNameTemplate=https://github.com/go-skynet/go-gpt4all-j.cpp currentValueTemplate=master depNameTemplate=go-gpt4all-j.cpp
|
||||
GOGPT4ALLJ_VERSION?=1f7bff57f66cb7062e40d0ac3abd2217815e5109
|
||||
# renovate: datasource=git-refs packageNameTemplate=https://github.com/go-skynet/go-gpt2.cpp currentValueTemplate=master depNameTemplate=go-gpt2.cpp
|
||||
GOGPT2_VERSION?=245a5bfe6708ab80dc5c733dcdbfbe3cfd2acdaa
|
||||
|
||||
GOLLAMA_VERSION?=67ff6a4db244b37e6efb4e6a5c5536d2bfae215b
|
||||
GOGPT4ALLJ_VERSION?=1f7bff57f66cb7062e40d0ac3abd2217815e5109
|
||||
GOGPT2_VERSION?=245a5bfe6708ab80dc5c733dcdbfbe3cfd2acdaa
|
||||
RWKV_REPO?=https://github.com/donomii/go-rwkv.cpp
|
||||
RWKV_VERSION?=af62fcc432be2847acb6e0688b2c2491d6588d58
|
||||
|
||||
@@ -54,6 +51,9 @@ go-gpt4all-j:
|
||||
go-rwkv:
|
||||
git clone --recurse-submodules $(RWKV_REPO) go-rwkv
|
||||
cd go-rwkv && git checkout -b build $(RWKV_VERSION) && git submodule update --init --recursive --depth 1
|
||||
@find ./go-rwkv -type f -name "*.c" -exec sed -i'' -e 's/ggml_/ggml_rwkv_/g' {} +
|
||||
@find ./go-rwkv -type f -name "*.cpp" -exec sed -i'' -e 's/ggml_/ggml_rwkv_/g' {} +
|
||||
@find ./go-rwkv -type f -name "*.h" -exec sed -i'' -e 's/ggml_/ggml_rwkv_/g' {} +
|
||||
|
||||
go-rwkv/librwkv.a: go-rwkv
|
||||
cd go-rwkv && cd rwkv.cpp && cmake . -DRWKV_BUILD_SHARED_LIBRARY=OFF && cmake --build . && cp librwkv.a .. && cp ggml/src/libggml.a ..
|
||||
@@ -77,7 +77,8 @@ go-gpt2/libgpt2.a: go-gpt2
|
||||
$(MAKE) -C go-gpt2 $(GENERIC_PREFIX)libgpt2.a
|
||||
|
||||
go-llama:
|
||||
git clone -b $(GOLLAMA_VERSION) --recurse-submodules https://github.com/go-skynet/go-llama.cpp go-llama
|
||||
git clone --recurse-submodules https://github.com/go-skynet/go-llama.cpp go-llama
|
||||
cd go-llama && git checkout -b build $(GOLLAMA_VERSION) && git submodule update --init --recursive --depth 1
|
||||
|
||||
go-llama/libbinding.a: go-llama
|
||||
$(MAKE) -C go-llama $(GENERIC_PREFIX)libbinding.a
|
||||
@@ -129,7 +130,7 @@ test-models/testmodel:
|
||||
|
||||
test: prepare test-models/testmodel
|
||||
cp tests/fixtures/* test-models
|
||||
@C_INCLUDE_PATH=${C_INCLUDE_PATH} LIBRARY_PATH=${LIBRARY_PATH} CONFIG_FILE=$(abspath ./)/test-models/config.yaml MODELS_PATH=$(abspath ./)/test-models $(GOCMD) test -v -timeout 30m ./...
|
||||
@C_INCLUDE_PATH=${C_INCLUDE_PATH} LIBRARY_PATH=${LIBRARY_PATH} CONFIG_FILE=$(abspath ./)/test-models/config.yaml MODELS_PATH=$(abspath ./)/test-models $(GOCMD) run github.com/onsi/ginkgo/v2/ginkgo -v -r ./...
|
||||
|
||||
## Help:
|
||||
help: ## Show this help.
|
||||
|
||||
31
README.md
31
README.md
@@ -19,6 +19,8 @@
|
||||
|
||||
LocalAI is a community-driven project, focused on making the AI accessible to anyone. Any contribution, feedback and PR is welcome! It was initially created by [mudler](https://github.com/mudler/) at the [SpectroCloud OSS Office](https://github.com/spectrocloud).
|
||||
|
||||
See [examples on how to integrate LocalAI](https://github.com/go-skynet/LocalAI/tree/master/examples/).
|
||||
|
||||
### News
|
||||
|
||||
- 02-05-2023: Support for `rwkv.cpp` models ( https://github.com/go-skynet/LocalAI/pull/158 ) and for `/edits` endpoint
|
||||
@@ -45,26 +47,45 @@ Tested with:
|
||||
- [GPT4ALL-J](https://gpt4all.io/models/ggml-gpt4all-j.bin)
|
||||
- Koala
|
||||
- [cerebras-GPT with ggml](https://huggingface.co/lxe/Cerebras-GPT-2.7B-Alpaca-SP-ggml)
|
||||
- WizardLM
|
||||
- [RWKV](https://github.com/BlinkDL/RWKV-LM) models with [rwkv.cpp](https://github.com/saharNooby/rwkv.cpp)
|
||||
|
||||
It should also be compatible with StableLM and GPTNeoX ggml models (untested)
|
||||
### Vicuna, Alpaca, LLaMa...
|
||||
|
||||
[llama.cpp](https://github.com/ggerganov/llama.cpp) based models are compatible
|
||||
|
||||
### GPT4ALL
|
||||
|
||||
Note: You might need to convert older models to the new format, see [here](https://github.com/ggerganov/llama.cpp#using-gpt4all) for instance to run `gpt4all`.
|
||||
|
||||
### GPT4ALL-J
|
||||
|
||||
No changes required to the model.
|
||||
|
||||
### RWKV
|
||||
|
||||
<details>
|
||||
|
||||
For `rwkv` models, you need to put also the associated tokenizer along with the ggml model:
|
||||
A full example on how to run a rwkv model is in the [examples](https://github.com/go-skynet/LocalAI/tree/master/examples/rwkv).
|
||||
|
||||
Note: rwkv models have an associated tokenizer along that needs to be provided with it:
|
||||
|
||||
```
|
||||
ls models
|
||||
36464540 -rw-r--r-- 1 mudler mudler 1.2G May 3 10:51 rwkv_small
|
||||
36464543 -rw-r--r-- 1 mudler mudler 2.4M May 3 10:51 rwkv_small.tokenizer.json
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Others
|
||||
|
||||
It should also be compatible with StableLM and GPTNeoX ggml models (untested).
|
||||
|
||||
### Hardware requirements
|
||||
|
||||
Depending on the model you are attempting to run might need more RAM or CPU resources. Check out also [here](https://github.com/ggerganov/llama.cpp#memorydisk-requirements) for `ggml` based backends. `rwkv` is less expensive on resources.
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
> `LocalAI` comes by default as a container image. You can check out all the available images with corresponding tags [here](https://quay.io/repository/go-skynet/local-ai?tab=tags&tag=latest).
|
||||
@@ -143,8 +164,6 @@ To build locally, run `make build` (see below).
|
||||
|
||||
### Other examples
|
||||
|
||||

|
||||
|
||||
To see other examples on how to integrate with other projects for instance chatbot-ui, see: [examples](https://github.com/go-skynet/LocalAI/tree/master/examples/).
|
||||
|
||||
|
||||
@@ -553,7 +572,7 @@ Not currently, as ggml doesn't support GPUs yet: https://github.com/ggerganov/ll
|
||||
### Where is the webUI?
|
||||
|
||||
<details>
|
||||
We are working on to have a good out of the box experience - however as LocalAI is an API you can already plug it into existing projects that provides are UI interfaces to OpenAI's APIs. There are several already on github, and should be compatible with LocalAI already (as it mimics the OpenAI API)
|
||||
There is the availability of localai-webui and chatbot-ui in the examples section and can be setup as per the instructions. However as LocalAI is an API you can already plug it into existing projects that provides are UI interfaces to OpenAI's APIs. There are several already on github, and should be compatible with LocalAI already (as it mimics the OpenAI API)
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
14
api/api.go
14
api/api.go
@@ -6,6 +6,7 @@ import (
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/gofiber/fiber/v2/middleware/cors"
|
||||
"github.com/gofiber/fiber/v2/middleware/logger"
|
||||
"github.com/gofiber/fiber/v2/middleware/recover"
|
||||
"github.com/rs/zerolog"
|
||||
"github.com/rs/zerolog/log"
|
||||
@@ -40,6 +41,12 @@ func App(configFile string, loader *model.ModelLoader, threads, ctxSize int, f16
|
||||
},
|
||||
})
|
||||
|
||||
if debug {
|
||||
app.Use(logger.New(logger.Config{
|
||||
Format: "[${ip}]:${port} ${status} - ${method} ${path}\n",
|
||||
}))
|
||||
}
|
||||
|
||||
cm := make(ConfigMerger)
|
||||
if err := cm.LoadConfigs(loader.ModelPath); err != nil {
|
||||
log.Error().Msgf("error loading config files: %s", err.Error())
|
||||
@@ -70,6 +77,13 @@ func App(configFile string, loader *model.ModelLoader, threads, ctxSize int, f16
|
||||
app.Post("/v1/completions", completionEndpoint(cm, debug, loader, threads, ctxSize, f16))
|
||||
app.Post("/completions", completionEndpoint(cm, debug, loader, threads, ctxSize, f16))
|
||||
|
||||
app.Post("/v1/embeddings", embeddingsEndpoint(cm, debug, loader, threads, ctxSize, f16))
|
||||
app.Post("/embeddings", embeddingsEndpoint(cm, debug, loader, threads, ctxSize, f16))
|
||||
|
||||
// /v1/engines/{engine_id}/embeddings
|
||||
|
||||
app.Post("/v1/engines/:model/embeddings", embeddingsEndpoint(cm, debug, loader, threads, ctxSize, f16))
|
||||
|
||||
app.Get("/v1/models", listModels(loader, cm))
|
||||
app.Get("/models", listModels(loader, cm))
|
||||
|
||||
|
||||
179
api/config.go
179
api/config.go
@@ -1,12 +1,16 @@
|
||||
package api
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
"gopkg.in/yaml.v3"
|
||||
)
|
||||
|
||||
@@ -21,8 +25,14 @@ type Config struct {
|
||||
Threads int `yaml:"threads"`
|
||||
Debug bool `yaml:"debug"`
|
||||
Roles map[string]string `yaml:"roles"`
|
||||
Embeddings bool `yaml:"embeddings"`
|
||||
Backend string `yaml:"backend"`
|
||||
TemplateConfig TemplateConfig `yaml:"template"`
|
||||
MirostatETA float64 `yaml:"mirostat_eta"`
|
||||
MirostatTAU float64 `yaml:"mirostat_tau"`
|
||||
Mirostat int `yaml:"mirostat"`
|
||||
|
||||
PromptStrings, InputStrings []string
|
||||
}
|
||||
|
||||
type TemplateConfig struct {
|
||||
@@ -100,3 +110,172 @@ func (cm ConfigMerger) LoadConfigs(path string) error {
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func updateConfig(config *Config, input *OpenAIRequest) {
|
||||
if input.Echo {
|
||||
config.Echo = input.Echo
|
||||
}
|
||||
if input.TopK != 0 {
|
||||
config.TopK = input.TopK
|
||||
}
|
||||
if input.TopP != 0 {
|
||||
config.TopP = input.TopP
|
||||
}
|
||||
|
||||
if input.Temperature != 0 {
|
||||
config.Temperature = input.Temperature
|
||||
}
|
||||
|
||||
if input.Maxtokens != 0 {
|
||||
config.Maxtokens = input.Maxtokens
|
||||
}
|
||||
|
||||
switch stop := input.Stop.(type) {
|
||||
case string:
|
||||
if stop != "" {
|
||||
config.StopWords = append(config.StopWords, stop)
|
||||
}
|
||||
case []interface{}:
|
||||
for _, pp := range stop {
|
||||
if s, ok := pp.(string); ok {
|
||||
config.StopWords = append(config.StopWords, s)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if input.RepeatPenalty != 0 {
|
||||
config.RepeatPenalty = input.RepeatPenalty
|
||||
}
|
||||
|
||||
if input.Keep != 0 {
|
||||
config.Keep = input.Keep
|
||||
}
|
||||
|
||||
if input.Batch != 0 {
|
||||
config.Batch = input.Batch
|
||||
}
|
||||
|
||||
if input.F16 {
|
||||
config.F16 = input.F16
|
||||
}
|
||||
|
||||
if input.IgnoreEOS {
|
||||
config.IgnoreEOS = input.IgnoreEOS
|
||||
}
|
||||
|
||||
if input.Seed != 0 {
|
||||
config.Seed = input.Seed
|
||||
}
|
||||
|
||||
if input.Mirostat != 0 {
|
||||
config.Mirostat = input.Mirostat
|
||||
}
|
||||
|
||||
if input.MirostatETA != 0 {
|
||||
config.MirostatETA = input.MirostatETA
|
||||
}
|
||||
|
||||
if input.MirostatTAU != 0 {
|
||||
config.MirostatTAU = input.MirostatTAU
|
||||
}
|
||||
|
||||
switch inputs := input.Input.(type) {
|
||||
case string:
|
||||
if inputs != "" {
|
||||
config.InputStrings = append(config.InputStrings, inputs)
|
||||
}
|
||||
case []interface{}:
|
||||
for _, pp := range inputs {
|
||||
if s, ok := pp.(string); ok {
|
||||
config.InputStrings = append(config.InputStrings, s)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
switch p := input.Prompt.(type) {
|
||||
case string:
|
||||
config.PromptStrings = append(config.PromptStrings, p)
|
||||
case []interface{}:
|
||||
for _, pp := range p {
|
||||
if s, ok := pp.(string); ok {
|
||||
config.PromptStrings = append(config.PromptStrings, s)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func readConfig(cm ConfigMerger, c *fiber.Ctx, loader *model.ModelLoader, debug bool, threads, ctx int, f16 bool) (*Config, *OpenAIRequest, error) {
|
||||
input := new(OpenAIRequest)
|
||||
// Get input data from the request body
|
||||
if err := c.BodyParser(input); err != nil {
|
||||
return nil, nil, err
|
||||
}
|
||||
|
||||
modelFile := input.Model
|
||||
|
||||
if c.Params("model") != "" {
|
||||
modelFile = c.Params("model")
|
||||
}
|
||||
|
||||
received, _ := json.Marshal(input)
|
||||
|
||||
log.Debug().Msgf("Request received: %s", string(received))
|
||||
|
||||
// Set model from bearer token, if available
|
||||
bearer := strings.TrimLeft(c.Get("authorization"), "Bearer ")
|
||||
bearerExists := bearer != "" && loader.ExistsInModelPath(bearer)
|
||||
|
||||
// If no model was specified, take the first available
|
||||
if modelFile == "" && !bearerExists {
|
||||
models, _ := loader.ListModels()
|
||||
if len(models) > 0 {
|
||||
modelFile = models[0]
|
||||
log.Debug().Msgf("No model specified, using: %s", modelFile)
|
||||
} else {
|
||||
log.Debug().Msgf("No model specified, returning error")
|
||||
return nil, nil, fmt.Errorf("no model specified")
|
||||
}
|
||||
}
|
||||
|
||||
// If a model is found in bearer token takes precedence
|
||||
if bearerExists {
|
||||
log.Debug().Msgf("Using model from bearer token: %s", bearer)
|
||||
modelFile = bearer
|
||||
}
|
||||
|
||||
// Load a config file if present after the model name
|
||||
modelConfig := filepath.Join(loader.ModelPath, modelFile+".yaml")
|
||||
if _, err := os.Stat(modelConfig); err == nil {
|
||||
if err := cm.LoadConfig(modelConfig); err != nil {
|
||||
return nil, nil, fmt.Errorf("failed loading model config (%s) %s", modelConfig, err.Error())
|
||||
}
|
||||
}
|
||||
|
||||
var config *Config
|
||||
cfg, exists := cm[modelFile]
|
||||
if !exists {
|
||||
config = &Config{
|
||||
OpenAIRequest: defaultRequest(modelFile),
|
||||
ContextSize: ctx,
|
||||
Threads: threads,
|
||||
F16: f16,
|
||||
Debug: debug,
|
||||
}
|
||||
} else {
|
||||
config = &cfg
|
||||
}
|
||||
|
||||
// Set the parameters for the language model prediction
|
||||
updateConfig(config, input)
|
||||
|
||||
// Don't allow 0 as setting
|
||||
if config.Threads == 0 {
|
||||
if threads != 0 {
|
||||
config.Threads = threads
|
||||
} else {
|
||||
config.Threads = 4
|
||||
}
|
||||
}
|
||||
|
||||
return config, input, nil
|
||||
}
|
||||
|
||||
279
api/openai.go
279
api/openai.go
@@ -5,8 +5,6 @@ import (
|
||||
"bytes"
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
@@ -33,13 +31,21 @@ type OpenAIUsage struct {
|
||||
TotalTokens int `json:"total_tokens"`
|
||||
}
|
||||
|
||||
type Item struct {
|
||||
Embedding []float32 `json:"embedding"`
|
||||
Index int `json:"index"`
|
||||
Object string `json:"object,omitempty"`
|
||||
}
|
||||
|
||||
type OpenAIResponse struct {
|
||||
Created int `json:"created,omitempty"`
|
||||
Object string `json:"object,omitempty"`
|
||||
ID string `json:"id,omitempty"`
|
||||
Model string `json:"model,omitempty"`
|
||||
Choices []Choice `json:"choices,omitempty"`
|
||||
Usage OpenAIUsage `json:"usage"`
|
||||
Created int `json:"created,omitempty"`
|
||||
Object string `json:"object,omitempty"`
|
||||
ID string `json:"id,omitempty"`
|
||||
Model string `json:"model,omitempty"`
|
||||
Choices []Choice `json:"choices,omitempty"`
|
||||
Data []Item `json:"data,omitempty"`
|
||||
|
||||
Usage OpenAIUsage `json:"usage"`
|
||||
}
|
||||
|
||||
type Choice struct {
|
||||
@@ -67,8 +73,8 @@ type OpenAIRequest struct {
|
||||
Prompt interface{} `json:"prompt" yaml:"prompt"`
|
||||
|
||||
// Edit endpoint
|
||||
Instruction string `json:"instruction" yaml:"instruction"`
|
||||
Input string `json:"input" yaml:"input"`
|
||||
Instruction string `json:"instruction" yaml:"instruction"`
|
||||
Input interface{} `json:"input" yaml:"input"`
|
||||
|
||||
Stop interface{} `json:"stop" yaml:"stop"`
|
||||
|
||||
@@ -92,6 +98,10 @@ type OpenAIRequest struct {
|
||||
RepeatPenalty float64 `json:"repeat_penalty" yaml:"repeat_penalty"`
|
||||
Keep int `json:"n_keep" yaml:"n_keep"`
|
||||
|
||||
MirostatETA float64 `json:"mirostat_eta" yaml:"mirostat_eta"`
|
||||
MirostatTAU float64 `json:"mirostat_tau" yaml:"mirostat_tau"`
|
||||
Mirostat int `json:"mirostat" yaml:"mirostat"`
|
||||
|
||||
Seed int `json:"seed" yaml:"seed"`
|
||||
}
|
||||
|
||||
@@ -105,135 +115,6 @@ func defaultRequest(modelFile string) OpenAIRequest {
|
||||
}
|
||||
}
|
||||
|
||||
func updateConfig(config *Config, input *OpenAIRequest) {
|
||||
if input.Echo {
|
||||
config.Echo = input.Echo
|
||||
}
|
||||
if input.TopK != 0 {
|
||||
config.TopK = input.TopK
|
||||
}
|
||||
if input.TopP != 0 {
|
||||
config.TopP = input.TopP
|
||||
}
|
||||
|
||||
if input.Temperature != 0 {
|
||||
config.Temperature = input.Temperature
|
||||
}
|
||||
|
||||
if input.Maxtokens != 0 {
|
||||
config.Maxtokens = input.Maxtokens
|
||||
}
|
||||
|
||||
switch stop := input.Stop.(type) {
|
||||
case string:
|
||||
if stop != "" {
|
||||
config.StopWords = append(config.StopWords, stop)
|
||||
}
|
||||
case []interface{}:
|
||||
for _, pp := range stop {
|
||||
if s, ok := pp.(string); ok {
|
||||
config.StopWords = append(config.StopWords, s)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if input.RepeatPenalty != 0 {
|
||||
config.RepeatPenalty = input.RepeatPenalty
|
||||
}
|
||||
|
||||
if input.Keep != 0 {
|
||||
config.Keep = input.Keep
|
||||
}
|
||||
|
||||
if input.Batch != 0 {
|
||||
config.Batch = input.Batch
|
||||
}
|
||||
|
||||
if input.F16 {
|
||||
config.F16 = input.F16
|
||||
}
|
||||
|
||||
if input.IgnoreEOS {
|
||||
config.IgnoreEOS = input.IgnoreEOS
|
||||
}
|
||||
|
||||
if input.Seed != 0 {
|
||||
config.Seed = input.Seed
|
||||
}
|
||||
}
|
||||
|
||||
func readConfig(cm ConfigMerger, c *fiber.Ctx, loader *model.ModelLoader, debug bool, threads, ctx int, f16 bool) (*Config, *OpenAIRequest, error) {
|
||||
input := new(OpenAIRequest)
|
||||
// Get input data from the request body
|
||||
if err := c.BodyParser(input); err != nil {
|
||||
return nil, nil, err
|
||||
}
|
||||
|
||||
modelFile := input.Model
|
||||
received, _ := json.Marshal(input)
|
||||
|
||||
log.Debug().Msgf("Request received: %s", string(received))
|
||||
|
||||
// Set model from bearer token, if available
|
||||
bearer := strings.TrimLeft(c.Get("authorization"), "Bearer ")
|
||||
bearerExists := bearer != "" && loader.ExistsInModelPath(bearer)
|
||||
|
||||
// If no model was specified, take the first available
|
||||
if modelFile == "" && !bearerExists {
|
||||
models, _ := loader.ListModels()
|
||||
if len(models) > 0 {
|
||||
modelFile = models[0]
|
||||
log.Debug().Msgf("No model specified, using: %s", modelFile)
|
||||
} else {
|
||||
log.Debug().Msgf("No model specified, returning error")
|
||||
return nil, nil, fmt.Errorf("no model specified")
|
||||
}
|
||||
}
|
||||
|
||||
// If a model is found in bearer token takes precedence
|
||||
if bearerExists {
|
||||
log.Debug().Msgf("Using model from bearer token: %s", bearer)
|
||||
modelFile = bearer
|
||||
}
|
||||
|
||||
// Load a config file if present after the model name
|
||||
modelConfig := filepath.Join(loader.ModelPath, modelFile+".yaml")
|
||||
if _, err := os.Stat(modelConfig); err == nil {
|
||||
if err := cm.LoadConfig(modelConfig); err != nil {
|
||||
return nil, nil, fmt.Errorf("failed loading model config (%s) %s", modelConfig, err.Error())
|
||||
}
|
||||
}
|
||||
|
||||
var config *Config
|
||||
cfg, exists := cm[modelFile]
|
||||
if !exists {
|
||||
config = &Config{
|
||||
OpenAIRequest: defaultRequest(modelFile),
|
||||
}
|
||||
} else {
|
||||
config = &cfg
|
||||
}
|
||||
|
||||
// Set the parameters for the language model prediction
|
||||
updateConfig(config, input)
|
||||
|
||||
if threads != 0 {
|
||||
config.Threads = threads
|
||||
}
|
||||
if ctx != 0 {
|
||||
config.ContextSize = ctx
|
||||
}
|
||||
if f16 {
|
||||
config.F16 = true
|
||||
}
|
||||
|
||||
if debug {
|
||||
config.Debug = true
|
||||
}
|
||||
|
||||
return config, input, nil
|
||||
}
|
||||
|
||||
// https://platform.openai.com/docs/api-reference/completions
|
||||
func completionEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader, threads, ctx int, f16 bool) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
@@ -244,19 +125,6 @@ func completionEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader,
|
||||
|
||||
log.Debug().Msgf("Parameter Config: %+v", config)
|
||||
|
||||
predInput := []string{}
|
||||
|
||||
switch p := input.Prompt.(type) {
|
||||
case string:
|
||||
predInput = append(predInput, p)
|
||||
case []interface{}:
|
||||
for _, pp := range p {
|
||||
if s, ok := pp.(string); ok {
|
||||
predInput = append(predInput, s)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
templateFile := config.Model
|
||||
|
||||
if config.TemplateConfig.Completion != "" {
|
||||
@@ -264,7 +132,7 @@ func completionEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader,
|
||||
}
|
||||
|
||||
var result []Choice
|
||||
for _, i := range predInput {
|
||||
for _, i := range config.PromptStrings {
|
||||
// A model can have a "file.bin.tmpl" file associated with a prompt template prefix
|
||||
templatedInput, err := loader.TemplatePrefix(templateFile, struct {
|
||||
Input string
|
||||
@@ -298,7 +166,62 @@ func completionEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader,
|
||||
}
|
||||
}
|
||||
|
||||
// https://platform.openai.com/docs/api-reference/completions
|
||||
func embeddingsEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader, threads, ctx int, f16 bool) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
config, input, err := readConfig(cm, c, loader, debug, threads, ctx, f16)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
log.Debug().Msgf("Parameter Config: %+v", config)
|
||||
items := []Item{}
|
||||
|
||||
for i, s := range config.InputStrings {
|
||||
|
||||
// get the model function to call for the result
|
||||
embedFn, err := ModelEmbedding(s, loader, *config)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
embeddings, err := embedFn()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
items = append(items, Item{Embedding: embeddings, Index: i, Object: "embedding"})
|
||||
}
|
||||
|
||||
resp := &OpenAIResponse{
|
||||
Model: input.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Data: items,
|
||||
Object: "list",
|
||||
}
|
||||
|
||||
jsonResult, _ := json.Marshal(resp)
|
||||
log.Debug().Msgf("Response: %s", jsonResult)
|
||||
|
||||
// Return the prediction in the response body
|
||||
return c.JSON(resp)
|
||||
}
|
||||
}
|
||||
|
||||
func chatEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader, threads, ctx int, f16 bool) func(c *fiber.Ctx) error {
|
||||
|
||||
process := func(s string, req *OpenAIRequest, config *Config, loader *model.ModelLoader, responses chan OpenAIResponse) {
|
||||
ComputeChoices(s, req, config, loader, func(s string, c *[]Choice) {}, func(s string) bool {
|
||||
resp := OpenAIResponse{
|
||||
Model: req.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: []Choice{{Delta: &Message{Role: "assistant", Content: s}}},
|
||||
Object: "chat.completion.chunk",
|
||||
}
|
||||
log.Debug().Msgf("Sending goroutine: %s", s)
|
||||
|
||||
responses <- resp
|
||||
return true
|
||||
})
|
||||
close(responses)
|
||||
}
|
||||
return func(c *fiber.Ctx) error {
|
||||
config, input, err := readConfig(cm, c, loader, debug, threads, ctx, f16)
|
||||
if err != nil {
|
||||
@@ -350,19 +273,7 @@ func chatEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader, thread
|
||||
if input.Stream {
|
||||
responses := make(chan OpenAIResponse)
|
||||
|
||||
go func() {
|
||||
ComputeChoices(predInput, input, config, loader, func(s string, c *[]Choice) {}, func(s string) bool {
|
||||
resp := OpenAIResponse{
|
||||
Model: input.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: []Choice{{Delta: &Message{Role: "assistant", Content: s}}},
|
||||
Object: "chat.completion.chunk",
|
||||
}
|
||||
|
||||
responses <- resp
|
||||
return true
|
||||
})
|
||||
close(responses)
|
||||
}()
|
||||
go process(predInput, input, config, loader, responses)
|
||||
|
||||
c.Context().SetBodyStreamWriter(fasthttp.StreamWriter(func(w *bufio.Writer) {
|
||||
|
||||
@@ -402,6 +313,8 @@ func chatEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader, thread
|
||||
Choices: result,
|
||||
Object: "chat.completion",
|
||||
}
|
||||
respData, _ := json.Marshal(resp)
|
||||
log.Debug().Msgf("Response: %s", respData)
|
||||
|
||||
// Return the prediction in the response body
|
||||
return c.JSON(resp)
|
||||
@@ -417,28 +330,32 @@ func editEndpoint(cm ConfigMerger, debug bool, loader *model.ModelLoader, thread
|
||||
|
||||
log.Debug().Msgf("Parameter Config: %+v", config)
|
||||
|
||||
predInput := input.Input
|
||||
templateFile := config.Model
|
||||
|
||||
if config.TemplateConfig.Edit != "" {
|
||||
templateFile = config.TemplateConfig.Edit
|
||||
}
|
||||
|
||||
// A model can have a "file.bin.tmpl" file associated with a prompt template prefix
|
||||
templatedInput, err := loader.TemplatePrefix(templateFile, struct {
|
||||
Input string
|
||||
Instruction string
|
||||
}{Input: predInput, Instruction: input.Instruction})
|
||||
if err == nil {
|
||||
predInput = templatedInput
|
||||
log.Debug().Msgf("Template found, input modified to: %s", predInput)
|
||||
}
|
||||
var result []Choice
|
||||
for _, i := range config.InputStrings {
|
||||
// A model can have a "file.bin.tmpl" file associated with a prompt template prefix
|
||||
templatedInput, err := loader.TemplatePrefix(templateFile, struct {
|
||||
Input string
|
||||
Instruction string
|
||||
}{Input: i})
|
||||
if err == nil {
|
||||
i = templatedInput
|
||||
log.Debug().Msgf("Template found, input modified to: %s", i)
|
||||
}
|
||||
|
||||
result, err := ComputeChoices(predInput, input, config, loader, func(s string, c *[]Choice) {
|
||||
*c = append(*c, Choice{Text: s})
|
||||
}, nil)
|
||||
if err != nil {
|
||||
return err
|
||||
r, err := ComputeChoices(i, input, config, loader, func(s string, c *[]Choice) {
|
||||
*c = append(*c, Choice{Text: s})
|
||||
}, nil)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
result = append(result, r...)
|
||||
}
|
||||
|
||||
resp := &OpenAIResponse{
|
||||
|
||||
@@ -11,98 +11,13 @@ import (
|
||||
gpt2 "github.com/go-skynet/go-gpt2.cpp"
|
||||
gptj "github.com/go-skynet/go-gpt4all-j.cpp"
|
||||
llama "github.com/go-skynet/go-llama.cpp"
|
||||
"github.com/hashicorp/go-multierror"
|
||||
)
|
||||
|
||||
const tokenizerSuffix = ".tokenizer.json"
|
||||
|
||||
// mutex still needed, see: https://github.com/ggerganov/llama.cpp/discussions/784
|
||||
var mutexMap sync.Mutex
|
||||
var mutexes map[string]*sync.Mutex = make(map[string]*sync.Mutex)
|
||||
|
||||
var loadedModels map[string]interface{} = map[string]interface{}{}
|
||||
var muModels sync.Mutex
|
||||
|
||||
func backendLoader(backendString string, loader *model.ModelLoader, modelFile string, llamaOpts []llama.ModelOption, threads uint32) (model interface{}, err error) {
|
||||
switch strings.ToLower(backendString) {
|
||||
case "llama":
|
||||
return loader.LoadLLaMAModel(modelFile, llamaOpts...)
|
||||
case "stablelm":
|
||||
return loader.LoadStableLMModel(modelFile)
|
||||
case "gpt2":
|
||||
return loader.LoadGPT2Model(modelFile)
|
||||
case "gptj":
|
||||
return loader.LoadGPTJModel(modelFile)
|
||||
case "rwkv":
|
||||
return loader.LoadRWKV(modelFile, modelFile+tokenizerSuffix, threads)
|
||||
default:
|
||||
return nil, fmt.Errorf("backend unsupported: %s", backendString)
|
||||
}
|
||||
}
|
||||
|
||||
func greedyLoader(loader *model.ModelLoader, modelFile string, llamaOpts []llama.ModelOption, threads uint32) (model interface{}, err error) {
|
||||
updateModels := func(model interface{}) {
|
||||
muModels.Lock()
|
||||
defer muModels.Unlock()
|
||||
loadedModels[modelFile] = model
|
||||
}
|
||||
|
||||
muModels.Lock()
|
||||
m, exists := loadedModels[modelFile]
|
||||
if exists {
|
||||
muModels.Unlock()
|
||||
return m, nil
|
||||
}
|
||||
muModels.Unlock()
|
||||
|
||||
model, modelerr := loader.LoadLLaMAModel(modelFile, llamaOpts...)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = loader.LoadGPTJModel(modelFile)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = loader.LoadGPT2Model(modelFile)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = loader.LoadStableLMModel(modelFile)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = loader.LoadRWKV(modelFile, modelFile+tokenizerSuffix, threads)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
return nil, fmt.Errorf("could not load model - all backends returned error: %s", err.Error())
|
||||
}
|
||||
|
||||
func ModelInference(s string, loader *model.ModelLoader, c Config, tokenCallback func(string) bool) (func() (string, error), error) {
|
||||
supportStreams := false
|
||||
modelFile := c.Model
|
||||
|
||||
// Try to load the model
|
||||
func defaultLLamaOpts(c Config) []llama.ModelOption {
|
||||
llamaOpts := []llama.ModelOption{}
|
||||
if c.ContextSize != 0 {
|
||||
llamaOpts = append(llamaOpts, llama.SetContext(c.ContextSize))
|
||||
@@ -110,13 +25,142 @@ func ModelInference(s string, loader *model.ModelLoader, c Config, tokenCallback
|
||||
if c.F16 {
|
||||
llamaOpts = append(llamaOpts, llama.EnableF16Memory)
|
||||
}
|
||||
if c.Embeddings {
|
||||
llamaOpts = append(llamaOpts, llama.EnableEmbeddings)
|
||||
}
|
||||
|
||||
return llamaOpts
|
||||
}
|
||||
|
||||
func ModelEmbedding(s string, loader *model.ModelLoader, c Config) (func() ([]float32, error), error) {
|
||||
if !c.Embeddings {
|
||||
return nil, fmt.Errorf("endpoint disabled for this model by API configuration")
|
||||
}
|
||||
|
||||
modelFile := c.Model
|
||||
|
||||
llamaOpts := defaultLLamaOpts(c)
|
||||
|
||||
var inferenceModel interface{}
|
||||
var err error
|
||||
if c.Backend == "" {
|
||||
inferenceModel, err = greedyLoader(loader, modelFile, llamaOpts, uint32(c.Threads))
|
||||
inferenceModel, err = loader.GreedyLoader(modelFile, llamaOpts, uint32(c.Threads))
|
||||
} else {
|
||||
inferenceModel, err = backendLoader(c.Backend, loader, modelFile, llamaOpts, uint32(c.Threads))
|
||||
inferenceModel, err = loader.BackendLoader(c.Backend, modelFile, llamaOpts, uint32(c.Threads))
|
||||
}
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
var fn func() ([]float32, error)
|
||||
switch model := inferenceModel.(type) {
|
||||
case *llama.LLama:
|
||||
fn = func() ([]float32, error) {
|
||||
predictOptions := buildLLamaPredictOptions(c)
|
||||
return model.Embeddings(s, predictOptions...)
|
||||
}
|
||||
default:
|
||||
fn = func() ([]float32, error) {
|
||||
return nil, fmt.Errorf("embeddings not supported by the backend")
|
||||
}
|
||||
}
|
||||
|
||||
return func() ([]float32, error) {
|
||||
// This is still needed, see: https://github.com/ggerganov/llama.cpp/discussions/784
|
||||
mutexMap.Lock()
|
||||
l, ok := mutexes[modelFile]
|
||||
if !ok {
|
||||
m := &sync.Mutex{}
|
||||
mutexes[modelFile] = m
|
||||
l = m
|
||||
}
|
||||
mutexMap.Unlock()
|
||||
l.Lock()
|
||||
defer l.Unlock()
|
||||
|
||||
embeds, err := fn()
|
||||
if err != nil {
|
||||
return embeds, err
|
||||
}
|
||||
// Remove trailing 0s
|
||||
for i := len(embeds) - 1; i >= 0; i-- {
|
||||
if embeds[i] == 0.0 {
|
||||
embeds = embeds[:i]
|
||||
} else {
|
||||
break
|
||||
}
|
||||
}
|
||||
return embeds, nil
|
||||
}, nil
|
||||
}
|
||||
|
||||
func buildLLamaPredictOptions(c Config) []llama.PredictOption {
|
||||
// Generate the prediction using the language model
|
||||
predictOptions := []llama.PredictOption{
|
||||
llama.SetTemperature(c.Temperature),
|
||||
llama.SetTopP(c.TopP),
|
||||
llama.SetTopK(c.TopK),
|
||||
llama.SetTokens(c.Maxtokens),
|
||||
llama.SetThreads(c.Threads),
|
||||
}
|
||||
|
||||
if c.Mirostat != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetMirostat(c.Mirostat))
|
||||
}
|
||||
|
||||
if c.MirostatETA != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetMirostatETA(c.MirostatETA))
|
||||
}
|
||||
|
||||
if c.MirostatTAU != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetMirostatTAU(c.MirostatTAU))
|
||||
}
|
||||
|
||||
if c.Debug {
|
||||
predictOptions = append(predictOptions, llama.Debug)
|
||||
}
|
||||
|
||||
predictOptions = append(predictOptions, llama.SetStopWords(c.StopWords...))
|
||||
|
||||
if c.RepeatPenalty != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetPenalty(c.RepeatPenalty))
|
||||
}
|
||||
|
||||
if c.Keep != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetNKeep(c.Keep))
|
||||
}
|
||||
|
||||
if c.Batch != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetBatch(c.Batch))
|
||||
}
|
||||
|
||||
if c.F16 {
|
||||
predictOptions = append(predictOptions, llama.EnableF16KV)
|
||||
}
|
||||
|
||||
if c.IgnoreEOS {
|
||||
predictOptions = append(predictOptions, llama.IgnoreEOS)
|
||||
}
|
||||
|
||||
if c.Seed != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetSeed(c.Seed))
|
||||
}
|
||||
|
||||
return predictOptions
|
||||
}
|
||||
|
||||
func ModelInference(s string, loader *model.ModelLoader, c Config, tokenCallback func(string) bool) (func() (string, error), error) {
|
||||
supportStreams := false
|
||||
modelFile := c.Model
|
||||
|
||||
llamaOpts := defaultLLamaOpts(c)
|
||||
|
||||
var inferenceModel interface{}
|
||||
var err error
|
||||
if c.Backend == "" {
|
||||
inferenceModel, err = loader.GreedyLoader(modelFile, llamaOpts, uint32(c.Threads))
|
||||
} else {
|
||||
inferenceModel, err = loader.BackendLoader(c.Backend, modelFile, llamaOpts, uint32(c.Threads))
|
||||
}
|
||||
if err != nil {
|
||||
return nil, err
|
||||
@@ -129,12 +173,15 @@ func ModelInference(s string, loader *model.ModelLoader, c Config, tokenCallback
|
||||
supportStreams = true
|
||||
|
||||
fn = func() (string, error) {
|
||||
//model.ProcessInput("You are a chatbot that is very good at chatting. blah blah blah")
|
||||
stopWord := "\n"
|
||||
if len(c.StopWords) > 0 {
|
||||
stopWord = c.StopWords[0]
|
||||
}
|
||||
|
||||
if err := model.ProcessInput(s); err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
response := model.GenerateResponse(c.Maxtokens, stopWord, float32(c.Temperature), float32(c.TopP), tokenCallback)
|
||||
|
||||
return response, nil
|
||||
@@ -219,49 +266,17 @@ func ModelInference(s string, loader *model.ModelLoader, c Config, tokenCallback
|
||||
model.SetTokenCallback(tokenCallback)
|
||||
}
|
||||
|
||||
// Generate the prediction using the language model
|
||||
predictOptions := []llama.PredictOption{
|
||||
llama.SetTemperature(c.Temperature),
|
||||
llama.SetTopP(c.TopP),
|
||||
llama.SetTopK(c.TopK),
|
||||
llama.SetTokens(c.Maxtokens),
|
||||
llama.SetThreads(c.Threads),
|
||||
}
|
||||
predictOptions := buildLLamaPredictOptions(c)
|
||||
|
||||
if c.Debug {
|
||||
predictOptions = append(predictOptions, llama.Debug)
|
||||
}
|
||||
|
||||
predictOptions = append(predictOptions, llama.SetStopWords(c.StopWords...))
|
||||
|
||||
if c.RepeatPenalty != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetPenalty(c.RepeatPenalty))
|
||||
}
|
||||
|
||||
if c.Keep != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetNKeep(c.Keep))
|
||||
}
|
||||
|
||||
if c.Batch != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetBatch(c.Batch))
|
||||
}
|
||||
|
||||
if c.F16 {
|
||||
predictOptions = append(predictOptions, llama.EnableF16KV)
|
||||
}
|
||||
|
||||
if c.IgnoreEOS {
|
||||
predictOptions = append(predictOptions, llama.IgnoreEOS)
|
||||
}
|
||||
|
||||
if c.Seed != 0 {
|
||||
predictOptions = append(predictOptions, llama.SetSeed(c.Seed))
|
||||
}
|
||||
|
||||
return model.Predict(
|
||||
str, er := model.Predict(
|
||||
s,
|
||||
predictOptions...,
|
||||
)
|
||||
// Seems that if we don't free the callback explicitly we leave functions registered (that might try to send on closed channels)
|
||||
// For instance otherwise the API returns: {"error":{"code":500,"message":"send on closed channel","type":""}}
|
||||
// after a stream event has occurred
|
||||
model.SetTokenCallback(nil)
|
||||
return str, er
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@@ -8,6 +8,8 @@ Here is a list of projects that can easily be integrated with the LocalAI backen
|
||||
- [discord-bot](https://github.com/go-skynet/LocalAI/tree/master/examples/discord-bot/) (by [@mudler](https://github.com/mudler))
|
||||
- [langchain](https://github.com/go-skynet/LocalAI/tree/master/examples/langchain/) (by [@dave-gray101](https://github.com/dave-gray101))
|
||||
- [langchain-python](https://github.com/go-skynet/LocalAI/tree/master/examples/langchain-python/) (by [@mudler](https://github.com/mudler))
|
||||
- [localai-webui](https://github.com/go-skynet/LocalAI/tree/master/examples/localai-webui/) (by [@dhruvgera](https://github.com/dhruvgera))
|
||||
- [rwkv](https://github.com/go-skynet/LocalAI/tree/master/examples/rwkv/) (by [@mudler](https://github.com/mudler))
|
||||
- [slack-bot](https://github.com/go-skynet/LocalAI/tree/master/examples/slack-bot/) (by [@mudler](https://github.com/mudler))
|
||||
|
||||
## Want to contribute?
|
||||
|
||||
5
examples/langchain/PY.Dockerfile
Normal file
5
examples/langchain/PY.Dockerfile
Normal file
@@ -0,0 +1,5 @@
|
||||
FROM python:3.10-bullseye
|
||||
COPY ./langchainpy-localai-example /app
|
||||
WORKDIR /app
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
ENTRYPOINT [ "python", "./simple_demo.py" ];
|
||||
@@ -1,10 +1,6 @@
|
||||
# langchain
|
||||
|
||||
Example of using langchain in TypeScript, with the standard OpenAI llm module, and LocalAI.
|
||||
|
||||
Example for python langchain to follow at a later date
|
||||
|
||||
Set up to make it easy to modify the `index.mts` file to look like any langchain example file.
|
||||
Example of using langchain, with the standard OpenAI llm module, and LocalAI. Has docker compose profiles for both the Typescript and Python versions.
|
||||
|
||||
**Please Note** - This is a tech demo example at this time. ggml-gpt4all-j has pretty terrible results for most langchain applications with the settings used in this example.
|
||||
|
||||
@@ -22,8 +18,11 @@ cd LocalAI/examples/langchain
|
||||
# Download gpt4all-j to models/
|
||||
wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up --build
|
||||
# start with docker-compose for typescript!
|
||||
docker-compose --profile ts up --build
|
||||
|
||||
# or start with docker-compose for python!
|
||||
docker-compose --profile py up --build
|
||||
```
|
||||
|
||||
## Copyright
|
||||
|
||||
@@ -15,11 +15,29 @@ services:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
|
||||
langchainjs:
|
||||
js:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: JS.Dockerfile
|
||||
profiles:
|
||||
- js
|
||||
- ts
|
||||
depends_on:
|
||||
- "api"
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_HOST=http://api:8080/v1'
|
||||
- 'OPENAI_API_BASE=http://api:8080/v1'
|
||||
- 'MODEL_NAME=gpt-3.5-turbo' #gpt-3.5-turbo' # ggml-gpt4all-j' # ggml-koala-13B-4bit-128g'
|
||||
|
||||
py:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: PY.Dockerfile
|
||||
profiles:
|
||||
- py
|
||||
depends_on:
|
||||
- "api"
|
||||
environment:
|
||||
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
|
||||
- 'OPENAI_API_BASE=http://api:8080/v1'
|
||||
- 'MODEL_NAME=gpt-3.5-turbo' #gpt-3.5-turbo' # ggml-gpt4all-j' # ggml-koala-13B-4bit-128g'
|
||||
@@ -4,7 +4,7 @@ import { Document } from "langchain/document";
|
||||
import { initializeAgentExecutorWithOptions } from "langchain/agents";
|
||||
import {Calculator} from "langchain/tools/calculator";
|
||||
|
||||
const pathToLocalAi = process.env['OPENAI_API_HOST'] || 'http://api:8080/v1';
|
||||
const pathToLocalAi = process.env['OPENAI_API_BASE'] || 'http://api:8080/v1';
|
||||
const fakeApiKey = process.env['OPENAI_API_KEY'] || '-';
|
||||
const modelName = process.env['MODEL_NAME'] || 'gpt-3.5-turbo';
|
||||
|
||||
|
||||
24
examples/langchain/langchainpy-localai-example/.vscode/launch.json
vendored
Normal file
24
examples/langchain/langchainpy-localai-example/.vscode/launch.json
vendored
Normal file
@@ -0,0 +1,24 @@
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Python: Current File",
|
||||
"type": "python",
|
||||
"request": "launch",
|
||||
"program": "${file}",
|
||||
"console": "integratedTerminal",
|
||||
"redirectOutput": true,
|
||||
"justMyCode": false
|
||||
},
|
||||
{
|
||||
"name": "Python: Attach to Port 5678",
|
||||
"type": "python",
|
||||
"request": "attach",
|
||||
"connect": {
|
||||
"host": "localhost",
|
||||
"port": 5678
|
||||
},
|
||||
"justMyCode": false
|
||||
}
|
||||
]
|
||||
}
|
||||
3
examples/langchain/langchainpy-localai-example/.vscode/settings.json
vendored
Normal file
3
examples/langchain/langchainpy-localai-example/.vscode/settings.json
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
{
|
||||
"python.defaultInterpreterPath": "${workspaceFolder}/.venv/Scripts/python"
|
||||
}
|
||||
39
examples/langchain/langchainpy-localai-example/full_demo.py
Normal file
39
examples/langchain/langchainpy-localai-example/full_demo.py
Normal file
@@ -0,0 +1,39 @@
|
||||
import os
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain import PromptTemplate, LLMChain
|
||||
from langchain.prompts.chat import (
|
||||
ChatPromptTemplate,
|
||||
SystemMessagePromptTemplate,
|
||||
AIMessagePromptTemplate,
|
||||
HumanMessagePromptTemplate,
|
||||
)
|
||||
from langchain.schema import (
|
||||
AIMessage,
|
||||
HumanMessage,
|
||||
SystemMessage
|
||||
)
|
||||
|
||||
print('Langchain + LocalAI PYTHON Tests')
|
||||
|
||||
base_path = os.environ.get('OPENAI_API_BASE', 'http://api:8080/v1')
|
||||
key = os.environ.get('OPENAI_API_KEY', '-')
|
||||
model_name = os.environ.get('MODEL_NAME', 'gpt-3.5-turbo')
|
||||
|
||||
|
||||
chat = ChatOpenAI(temperature=0, openai_api_base=base_path, openai_api_key=key, model_name=model_name, max_tokens=100)
|
||||
|
||||
print("Created ChatOpenAI for ", chat.model_name)
|
||||
|
||||
template = "You are a helpful assistant that translates {input_language} to {output_language}."
|
||||
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
|
||||
human_template = "{text}"
|
||||
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
|
||||
|
||||
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
|
||||
|
||||
print("ABOUT to execute")
|
||||
|
||||
# get a chat completion from the formatted messages
|
||||
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
|
||||
|
||||
print(".");
|
||||
@@ -0,0 +1,32 @@
|
||||
aiohttp==3.8.4
|
||||
aiosignal==1.3.1
|
||||
async-timeout==4.0.2
|
||||
attrs==23.1.0
|
||||
certifi==2022.12.7
|
||||
charset-normalizer==3.1.0
|
||||
colorama==0.4.6
|
||||
dataclasses-json==0.5.7
|
||||
debugpy==1.6.7
|
||||
frozenlist==1.3.3
|
||||
greenlet==2.0.2
|
||||
idna==3.4
|
||||
langchain==0.0.157
|
||||
marshmallow==3.19.0
|
||||
marshmallow-enum==1.5.1
|
||||
multidict==6.0.4
|
||||
mypy-extensions==1.0.0
|
||||
numexpr==2.8.4
|
||||
numpy==1.24.3
|
||||
openai==0.27.6
|
||||
openapi-schema-pydantic==1.2.4
|
||||
packaging==23.1
|
||||
pydantic==1.10.7
|
||||
PyYAML==6.0
|
||||
requests==2.29.0
|
||||
SQLAlchemy==2.0.12
|
||||
tenacity==8.2.2
|
||||
tqdm==4.65.0
|
||||
typing-inspect==0.8.0
|
||||
typing_extensions==4.5.0
|
||||
urllib3==1.26.15
|
||||
yarl==1.9.2
|
||||
@@ -0,0 +1,6 @@
|
||||
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
llm = OpenAI(temperature=0.9,model_name="gpt-3.5-turbo")
|
||||
text = "What would be a good company name for a company that makes colorful socks?"
|
||||
print(llm(text))
|
||||
@@ -12,6 +12,7 @@ stopwords:
|
||||
roles:
|
||||
user: " "
|
||||
system: " "
|
||||
backend: "gptj"
|
||||
template:
|
||||
completion: completion
|
||||
chat: completion # gpt4all
|
||||
26
examples/localai-webui/README.md
Normal file
26
examples/localai-webui/README.md
Normal file
@@ -0,0 +1,26 @@
|
||||
# localai-webui
|
||||
|
||||
Example of integration with [dhruvgera/localai-frontend](https://github.com/Dhruvgera/LocalAI-frontend).
|
||||
|
||||
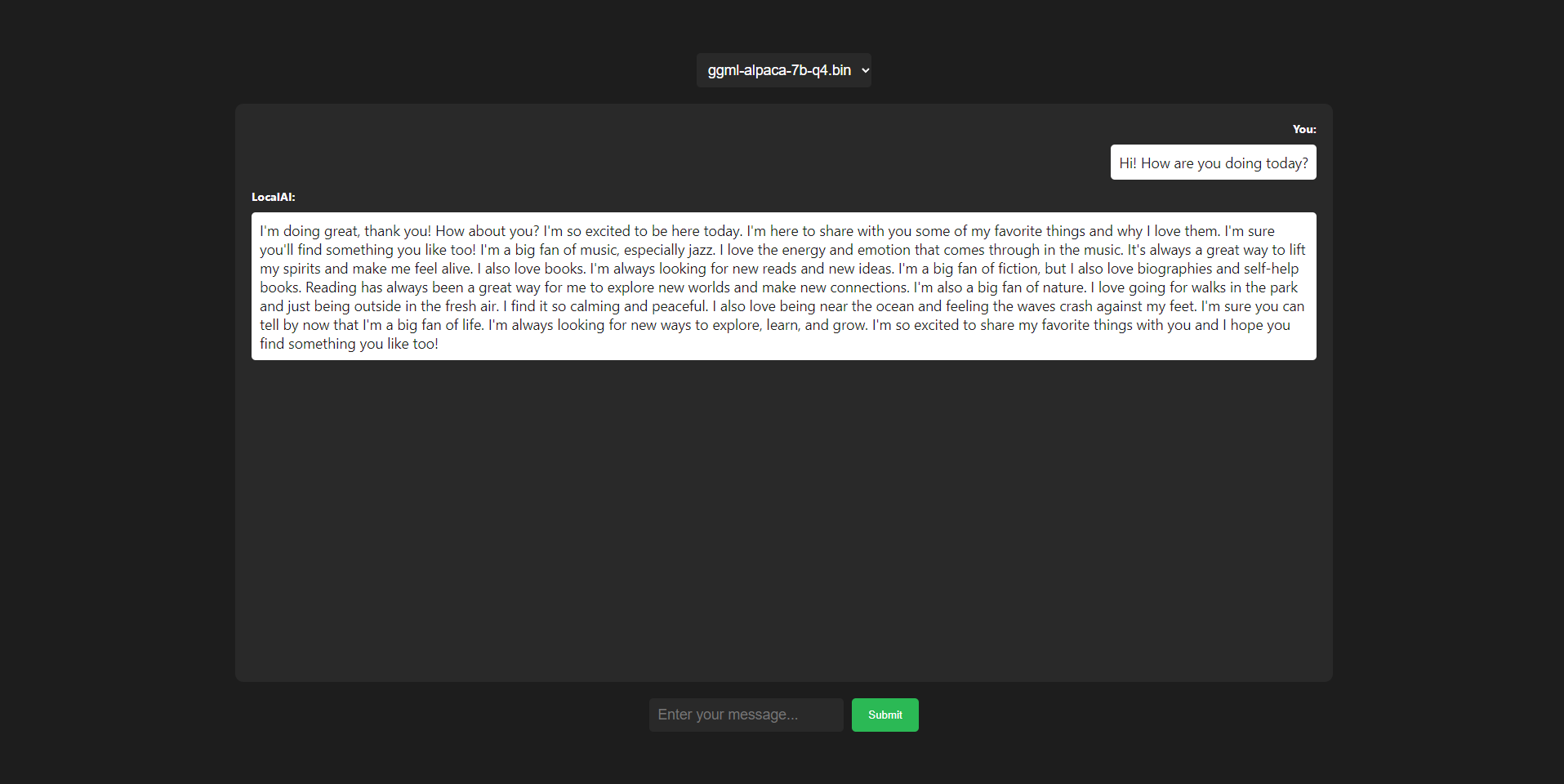
|
||||
|
||||
## Setup
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/localai-webui
|
||||
|
||||
# (optional) Checkout a specific LocalAI tag
|
||||
# git checkout -b build <TAG>
|
||||
|
||||
# Download any desired models to models/ in the parent LocalAI project dir
|
||||
# For example: wget https://gpt4all.io/models/ggml-gpt4all-j.bin
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up -d --build
|
||||
```
|
||||
|
||||
Open http://localhost:3000 for the Web UI.
|
||||
|
||||
20
examples/localai-webui/docker-compose.yml
Normal file
20
examples/localai-webui/docker-compose.yml
Normal file
@@ -0,0 +1,20 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- .env
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai"]
|
||||
|
||||
frontend:
|
||||
image: quay.io/go-skynet/localai-frontend:master
|
||||
ports:
|
||||
- 3000:3000
|
||||
1
examples/query_data/.gitignore
vendored
Normal file
1
examples/query_data/.gitignore
vendored
Normal file
@@ -0,0 +1 @@
|
||||
storage/
|
||||
49
examples/query_data/README.md
Normal file
49
examples/query_data/README.md
Normal file
@@ -0,0 +1,49 @@
|
||||
# Data query example
|
||||
|
||||
This example makes use of [Llama-Index](https://gpt-index.readthedocs.io/en/stable/getting_started/installation.html) to enable question answering on a set of documents.
|
||||
|
||||
It loosely follows [the quickstart](https://gpt-index.readthedocs.io/en/stable/guides/primer/usage_pattern.html).
|
||||
|
||||
## Requirements
|
||||
|
||||
For this in order to work, you will need a model compatible with the `llama.cpp` backend. This is will not work with gpt4all.
|
||||
|
||||
The example uses `WizardLM`. Edit the config files in `models/` accordingly to specify the model you use (change `HERE`).
|
||||
|
||||
You will also need a training data set. Copy that over `data`.
|
||||
|
||||
## Setup
|
||||
|
||||
Start the API:
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/query_data
|
||||
|
||||
# Copy your models, edit config files accordingly
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up -d --build
|
||||
```
|
||||
|
||||
### Create a storage:
|
||||
|
||||
```bash
|
||||
export OPENAI_API_BASE=http://localhost:8080/v1
|
||||
export OPENAI_API_KEY=sk-
|
||||
|
||||
python store.py
|
||||
```
|
||||
|
||||
After it finishes, a directory "storage" will be created with the vector index database.
|
||||
|
||||
## Query
|
||||
|
||||
```bash
|
||||
export OPENAI_API_BASE=http://localhost:8080/v1
|
||||
export OPENAI_API_KEY=sk-
|
||||
|
||||
python query.py
|
||||
```
|
||||
0
examples/query_data/data/.keep
Normal file
0
examples/query_data/data/.keep
Normal file
15
examples/query_data/docker-compose.yml
Normal file
15
examples/query_data/docker-compose.yml
Normal file
@@ -0,0 +1,15 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- .env
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai"]
|
||||
1
examples/query_data/models/completion.tmpl
Normal file
1
examples/query_data/models/completion.tmpl
Normal file
@@ -0,0 +1 @@
|
||||
{{.Input}}
|
||||
18
examples/query_data/models/embeddings.yaml
Normal file
18
examples/query_data/models/embeddings.yaml
Normal file
@@ -0,0 +1,18 @@
|
||||
name: text-embedding-ada-002
|
||||
parameters:
|
||||
model: HERE
|
||||
top_k: 80
|
||||
temperature: 0.2
|
||||
top_p: 0.7
|
||||
context_size: 1024
|
||||
threads: 14
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "GPT:"
|
||||
roles:
|
||||
user: " "
|
||||
system: " "
|
||||
embeddings: true
|
||||
template:
|
||||
completion: completion
|
||||
chat: gpt4all
|
||||
18
examples/query_data/models/gpt-3.5-turbo.yaml
Normal file
18
examples/query_data/models/gpt-3.5-turbo.yaml
Normal file
@@ -0,0 +1,18 @@
|
||||
name: gpt-3.5-turbo
|
||||
parameters:
|
||||
model: HERE
|
||||
top_k: 80
|
||||
temperature: 0.2
|
||||
top_p: 0.7
|
||||
context_size: 1024
|
||||
threads: 14
|
||||
embeddings: true
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "GPT:"
|
||||
roles:
|
||||
user: " "
|
||||
system: " "
|
||||
template:
|
||||
completion: completion
|
||||
chat: wizardlm
|
||||
3
examples/query_data/models/wizardlm.tmpl
Normal file
3
examples/query_data/models/wizardlm.tmpl
Normal file
@@ -0,0 +1,3 @@
|
||||
{{.Input}}
|
||||
|
||||
### Response:
|
||||
32
examples/query_data/query.py
Normal file
32
examples/query_data/query.py
Normal file
@@ -0,0 +1,32 @@
|
||||
import os
|
||||
|
||||
# Uncomment to specify your OpenAI API key here (local testing only, not in production!), or add corresponding environment variable (recommended)
|
||||
# os.environ['OPENAI_API_KEY']= ""
|
||||
|
||||
from llama_index import LLMPredictor, PromptHelper, ServiceContext
|
||||
from langchain.llms.openai import OpenAI
|
||||
from llama_index import StorageContext, load_index_from_storage
|
||||
|
||||
|
||||
# This example uses text-davinci-003 by default; feel free to change if desired
|
||||
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="gpt-3.5-turbo",openai_api_base="http://localhost:8080/v1"))
|
||||
|
||||
# Configure prompt parameters and initialise helper
|
||||
max_input_size = 1024
|
||||
num_output = 256
|
||||
max_chunk_overlap = 20
|
||||
|
||||
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
|
||||
|
||||
# Load documents from the 'data' directory
|
||||
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
|
||||
|
||||
# rebuild storage context
|
||||
storage_context = StorageContext.from_defaults(persist_dir='./storage')
|
||||
|
||||
# load index
|
||||
index = load_index_from_storage(storage_context, service_context=service_context, )
|
||||
|
||||
query_engine = index.as_query_engine()
|
||||
response = query_engine.query("XXXXXX your question here XXXXX")
|
||||
print(response)
|
||||
25
examples/query_data/store.py
Normal file
25
examples/query_data/store.py
Normal file
@@ -0,0 +1,25 @@
|
||||
import os
|
||||
|
||||
# Uncomment to specify your OpenAI API key here (local testing only, not in production!), or add corresponding environment variable (recommended)
|
||||
# os.environ['OPENAI_API_KEY']= ""
|
||||
|
||||
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader, LLMPredictor, PromptHelper, ServiceContext
|
||||
from langchain.llms.openai import OpenAI
|
||||
from llama_index import StorageContext, load_index_from_storage
|
||||
|
||||
# This example uses text-davinci-003 by default; feel free to change if desired
|
||||
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="gpt-3.5-turbo",openai_api_base="http://localhost:8080/v1"))
|
||||
|
||||
# Configure prompt parameters and initialise helper
|
||||
max_input_size = 256
|
||||
num_output = 256
|
||||
max_chunk_overlap = 10
|
||||
|
||||
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
|
||||
|
||||
# Load documents from the 'data' directory
|
||||
documents = SimpleDirectoryReader('data').load_data()
|
||||
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper, chunk_size_limit = 257)
|
||||
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
|
||||
index.storage_context.persist(persist_dir="./storage")
|
||||
|
||||
10
examples/rwkv/Dockerfile.build
Normal file
10
examples/rwkv/Dockerfile.build
Normal file
@@ -0,0 +1,10 @@
|
||||
FROM python
|
||||
|
||||
# convert the model (one-off)
|
||||
RUN pip3 install torch numpy
|
||||
|
||||
WORKDIR /build
|
||||
COPY ./scripts/ .
|
||||
|
||||
RUN git clone --recurse-submodules https://github.com/saharNooby/rwkv.cpp && cd rwkv.cpp && cmake . && cmake --build . --config Release
|
||||
ENTRYPOINT [ "/build/build.sh" ]
|
||||
59
examples/rwkv/README.md
Normal file
59
examples/rwkv/README.md
Normal file
@@ -0,0 +1,59 @@
|
||||
# rwkv
|
||||
|
||||
Example of how to run rwkv models.
|
||||
|
||||
## Run models
|
||||
|
||||
Setup:
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI/examples/rwkv
|
||||
|
||||
# (optional) Checkout a specific LocalAI tag
|
||||
# git checkout -b build <TAG>
|
||||
|
||||
# build the tooling image to convert an rwkv model locally:
|
||||
docker build -t rwkv-converter -f Dockerfile.build .
|
||||
|
||||
# download and convert a model (one-off) - it's going to be fast on CPU too!
|
||||
docker run -ti --name converter -v $PWD:/data rwkv-converter https://huggingface.co/BlinkDL/rwkv-4-raven/resolve/main/RWKV-4-Raven-1B5-v11-Eng99%25-Other1%25-20230425-ctx4096.pth /data/models/rwkv
|
||||
|
||||
# Get the tokenizer
|
||||
wget https://raw.githubusercontent.com/saharNooby/rwkv.cpp/5eb8f09c146ea8124633ab041d9ea0b1f1db4459/rwkv/20B_tokenizer.json -O models/rwkv.tokenizer.json
|
||||
|
||||
# start with docker-compose
|
||||
docker-compose up -d --build
|
||||
```
|
||||
|
||||
Test it out:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "gpt-3.5-turbo",
|
||||
"prompt": "A long time ago, in a galaxy far away",
|
||||
"max_tokens": 100,
|
||||
"temperature": 0.9, "top_p": 0.8, "top_k": 80
|
||||
}'
|
||||
|
||||
# {"object":"text_completion","model":"gpt-3.5-turbo","choices":[{"text":", there was a small group of five friends: Annie, Bryan, Charlie, Emily, and Jesse."}],"usage":{"prompt_tokens":0,"completion_tokens":0,"total_tokens":0}}
|
||||
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "gpt-3.5-turbo",
|
||||
"messages": [{"role": "user", "content": "How are you?"}],
|
||||
"temperature": 0.9, "top_p": 0.8, "top_k": 80
|
||||
}'
|
||||
|
||||
# {"object":"chat.completion","model":"gpt-3.5-turbo","choices":[{"message":{"role":"assistant","content":" Good, thanks. I am about to go to bed. I' ll talk to you later.Bye."}}],"usage":{"prompt_tokens":0,"completion_tokens":0,"total_tokens":0}}
|
||||
```
|
||||
|
||||
### Fine tuning
|
||||
|
||||
See [RWKV-LM](https://github.com/BlinkDL/RWKV-LM#training--fine-tuning). There is also a Google [colab](https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb).
|
||||
|
||||
## See also
|
||||
|
||||
- [RWKV-LM](https://github.com/BlinkDL/RWKV-LM)
|
||||
- [rwkv.cpp](https://github.com/saharNooby/rwkv.cpp)
|
||||
16
examples/rwkv/docker-compose.yaml
Normal file
16
examples/rwkv/docker-compose.yaml
Normal file
@@ -0,0 +1,16 @@
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:latest
|
||||
build:
|
||||
context: ../../
|
||||
dockerfile: Dockerfile.dev
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
- MODELS_PATH=/models
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
19
examples/rwkv/models/gpt-3.5-turbo.yaml
Normal file
19
examples/rwkv/models/gpt-3.5-turbo.yaml
Normal file
@@ -0,0 +1,19 @@
|
||||
name: gpt-3.5-turbo
|
||||
parameters:
|
||||
model: rwkv
|
||||
top_k: 80
|
||||
temperature: 0.9
|
||||
max_tokens: 100
|
||||
top_p: 0.8
|
||||
context_size: 1024
|
||||
threads: 14
|
||||
backend: "rwkv"
|
||||
cutwords:
|
||||
- "Bob:.*"
|
||||
roles:
|
||||
user: "Bob:"
|
||||
system: "Alice:"
|
||||
assistant: "Alice:"
|
||||
template:
|
||||
completion: rwkv_completion
|
||||
chat: rwkv_chat
|
||||
13
examples/rwkv/models/rwkv_chat.tmpl
Normal file
13
examples/rwkv/models/rwkv_chat.tmpl
Normal file
@@ -0,0 +1,13 @@
|
||||
The following is a verbose detailed conversation between Bob and a woman, Alice. Alice is intelligent, friendly and likeable. Alice is likely to agree with Bob.
|
||||
|
||||
Bob: Hello Alice, how are you doing?
|
||||
|
||||
Alice: Hi Bob! Thanks, I'm fine. What about you?
|
||||
|
||||
Bob: I am very good! It's nice to see you. Would you mind me chatting with you for a while?
|
||||
|
||||
Alice: Not at all! I'm listening.
|
||||
|
||||
{{.Input}}
|
||||
|
||||
Alice:
|
||||
1
examples/rwkv/models/rwkv_completion.tmpl
Normal file
1
examples/rwkv/models/rwkv_completion.tmpl
Normal file
@@ -0,0 +1 @@
|
||||
Complete the following sentence: {{.Input}}
|
||||
11
examples/rwkv/scripts/build.sh
Executable file
11
examples/rwkv/scripts/build.sh
Executable file
@@ -0,0 +1,11 @@
|
||||
#!/bin/bash
|
||||
set -ex
|
||||
|
||||
URL=$1
|
||||
OUT=$2
|
||||
FILENAME=$(basename $URL)
|
||||
|
||||
wget -nc $URL -O /build/$FILENAME
|
||||
|
||||
python3 /build/rwkv.cpp/rwkv/convert_pytorch_to_ggml.py /build/$FILENAME /build/float-model float16
|
||||
python3 /build/rwkv.cpp/rwkv/quantize.py /build/float-model $OUT Q4_2
|
||||
28
go.mod
28
go.mod
@@ -3,44 +3,46 @@ module github.com/go-skynet/LocalAI
|
||||
go 1.19
|
||||
|
||||
require (
|
||||
github.com/donomii/go-rwkv.cpp v0.0.0-20230503112711-af62fcc432be
|
||||
github.com/go-skynet/go-gpt2.cpp v0.0.0-20230422085954-245a5bfe6708
|
||||
github.com/go-skynet/go-gpt4all-j.cpp v0.0.0-20230422090028-1f7bff57f66c
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20230502121737-8ceb6167e405
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20230504223241-67ff6a4db244
|
||||
github.com/gofiber/fiber/v2 v2.44.0
|
||||
github.com/hashicorp/go-multierror v1.1.1
|
||||
github.com/jaypipes/ghw v0.10.0
|
||||
github.com/onsi/ginkgo/v2 v2.9.3
|
||||
github.com/onsi/ginkgo/v2 v2.9.4
|
||||
github.com/onsi/gomega v1.27.6
|
||||
github.com/otiai10/openaigo v1.1.0
|
||||
github.com/rs/zerolog v1.29.1
|
||||
github.com/sashabaranov/go-openai v1.9.1
|
||||
github.com/sashabaranov/go-openai v1.9.3
|
||||
github.com/swaggo/swag v1.16.1
|
||||
github.com/urfave/cli/v2 v2.25.3
|
||||
github.com/valyala/fasthttp v1.47.0
|
||||
gopkg.in/yaml.v3 v3.0.1
|
||||
)
|
||||
|
||||
require (
|
||||
github.com/StackExchange/wmi v1.2.1 // indirect
|
||||
github.com/KyleBanks/depth v1.2.1 // indirect
|
||||
github.com/PuerkitoBio/purell v1.1.1 // indirect
|
||||
github.com/PuerkitoBio/urlesc v0.0.0-20170810143723-de5bf2ad4578 // indirect
|
||||
github.com/andybalholm/brotli v1.0.5 // indirect
|
||||
github.com/cpuguy83/go-md2man/v2 v2.0.2 // indirect
|
||||
github.com/donomii/go-rwkv.cpp v0.0.0-20230502223004-0a3db3d72e7d // indirect
|
||||
github.com/ghodss/yaml v1.0.0 // indirect
|
||||
github.com/go-logr/logr v1.2.4 // indirect
|
||||
github.com/go-ole/go-ole v1.2.6 // indirect
|
||||
github.com/go-openapi/jsonpointer v0.19.5 // indirect
|
||||
github.com/go-openapi/jsonreference v0.19.6 // indirect
|
||||
github.com/go-openapi/spec v0.20.4 // indirect
|
||||
github.com/go-openapi/swag v0.19.15 // indirect
|
||||
github.com/go-task/slim-sprig v0.0.0-20230315185526-52ccab3ef572 // indirect
|
||||
github.com/google/go-cmp v0.5.9 // indirect
|
||||
github.com/google/pprof v0.0.0-20210407192527-94a9f03dee38 // indirect
|
||||
github.com/google/uuid v1.3.0 // indirect
|
||||
github.com/hashicorp/errwrap v1.0.0 // indirect
|
||||
github.com/jaypipes/pcidb v1.0.0 // indirect
|
||||
github.com/josharian/intern v1.0.0 // indirect
|
||||
github.com/klauspost/compress v1.16.3 // indirect
|
||||
github.com/kr/text v0.2.0 // indirect
|
||||
github.com/mailru/easyjson v0.7.6 // indirect
|
||||
github.com/mattn/go-colorable v0.1.13 // indirect
|
||||
github.com/mattn/go-isatty v0.0.18 // indirect
|
||||
github.com/mattn/go-runewidth v0.0.14 // indirect
|
||||
github.com/mitchellh/go-homedir v1.1.0 // indirect
|
||||
github.com/philhofer/fwd v1.1.2 // indirect
|
||||
github.com/pkg/errors v0.9.1 // indirect
|
||||
github.com/rivo/uniseg v0.2.0 // indirect
|
||||
github.com/russross/blackfriday/v2 v2.1.0 // indirect
|
||||
github.com/savsgio/dictpool v0.0.0-20221023140959-7bf2e61cea94 // indirect
|
||||
@@ -54,5 +56,5 @@ require (
|
||||
golang.org/x/text v0.9.0 // indirect
|
||||
golang.org/x/tools v0.8.0 // indirect
|
||||
gopkg.in/yaml.v2 v2.4.0 // indirect
|
||||
howett.net/plist v1.0.0 // indirect
|
||||
)
|
||||
|
||||
|
||||
90
go.sum
90
go.sum
@@ -1,5 +1,9 @@
|
||||
github.com/StackExchange/wmi v1.2.1 h1:VIkavFPXSjcnS+O8yTq7NI32k0R5Aj+v39y29VYDOSA=
|
||||
github.com/StackExchange/wmi v1.2.1/go.mod h1:rcmrprowKIVzvc+NUiLncP2uuArMWLCbu9SBzvHz7e8=
|
||||
github.com/KyleBanks/depth v1.2.1 h1:5h8fQADFrWtarTdtDudMmGsC7GPbOAu6RVB3ffsVFHc=
|
||||
github.com/KyleBanks/depth v1.2.1/go.mod h1:jzSb9d0L43HxTQfT+oSA1EEp2q+ne2uh6XgeJcm8brE=
|
||||
github.com/PuerkitoBio/purell v1.1.1 h1:WEQqlqaGbrPkxLJWfBwQmfEAE1Z7ONdDLqrN38tNFfI=
|
||||
github.com/PuerkitoBio/purell v1.1.1/go.mod h1:c11w/QuzBsJSee3cPx9rAFu61PvFxuPbtSwDGJws/X0=
|
||||
github.com/PuerkitoBio/urlesc v0.0.0-20170810143723-de5bf2ad4578 h1:d+Bc7a5rLufV/sSk/8dngufqelfh6jnri85riMAaF/M=
|
||||
github.com/PuerkitoBio/urlesc v0.0.0-20170810143723-de5bf2ad4578/go.mod h1:uGdkoq3SwY9Y+13GIhn11/XLaGBb4BfwItxLd5jeuXE=
|
||||
github.com/andybalholm/brotli v1.0.5 h1:8uQZIdzKmjc/iuPu7O2ioW48L81FgatrcpfFmiq/cCs=
|
||||
github.com/andybalholm/brotli v1.0.5/go.mod h1:fO7iG3H7G2nSZ7m0zPUDn85XEX2GTukHGRSepvi9Eig=
|
||||
github.com/chzyer/logex v1.1.10/go.mod h1:+Ywpsq7O8HXn0nuIou7OrIPyXbp3wmkHB+jjWRnGsAI=
|
||||
@@ -12,25 +16,22 @@ github.com/creack/pty v1.1.9/go.mod h1:oKZEueFk5CKHvIhNR5MUki03XCEU+Q6VDXinZuGJ3
|
||||
github.com/davecgh/go-spew v1.1.0/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
|
||||
github.com/davecgh/go-spew v1.1.1 h1:vj9j/u1bqnvCEfJOwUhtlOARqs3+rkHYY13jYWTU97c=
|
||||
github.com/davecgh/go-spew v1.1.1/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
|
||||
github.com/donomii/go-rwkv.cpp v0.0.0-20230502223004-0a3db3d72e7d h1:lSHwlYf1H4WAWYgf7rjEVTGen1qmigUq2Egpu8mnQiY=
|
||||
github.com/donomii/go-rwkv.cpp v0.0.0-20230502223004-0a3db3d72e7d/go.mod h1:H6QBF7/Tz6DAEBDXQged4H1BvsmqY/K5FG9wQRGa01g=
|
||||
github.com/ghodss/yaml v1.0.0 h1:wQHKEahhL6wmXdzwWG11gIVCkOv05bNOh+Rxn0yngAk=
|
||||
github.com/ghodss/yaml v1.0.0/go.mod h1:4dBDuWmgqj2HViK6kFavaiC9ZROes6MMH2rRYeMEF04=
|
||||
github.com/go-logr/logr v1.2.3 h1:2DntVwHkVopvECVRSlL5PSo9eG+cAkDCuckLubN+rq0=
|
||||
github.com/go-logr/logr v1.2.3/go.mod h1:jdQByPbusPIv2/zmleS9BjJVeZ6kBagPoEUsqbVz/1A=
|
||||
github.com/donomii/go-rwkv.cpp v0.0.0-20230503112711-af62fcc432be/go.mod h1:gWy7FIWioqYmYxkaoFyBnaKApeZVrUkHhv9EV9pz4dM=
|
||||
github.com/go-logr/logr v1.2.4 h1:g01GSCwiDw2xSZfjJ2/T9M+S6pFdcNtFYsp+Y43HYDQ=
|
||||
github.com/go-logr/logr v1.2.4/go.mod h1:jdQByPbusPIv2/zmleS9BjJVeZ6kBagPoEUsqbVz/1A=
|
||||
github.com/go-ole/go-ole v1.2.5/go.mod h1:pprOEPIfldk/42T2oK7lQ4v4JSDwmV0As9GaiUsvbm0=
|
||||
github.com/go-ole/go-ole v1.2.6 h1:/Fpf6oFPoeFik9ty7siob0G6Ke8QvQEuVcuChpwXzpY=
|
||||
github.com/go-ole/go-ole v1.2.6/go.mod h1:pprOEPIfldk/42T2oK7lQ4v4JSDwmV0As9GaiUsvbm0=
|
||||
github.com/go-skynet/go-gpt2.cpp v0.0.0-20230422085954-245a5bfe6708 h1:cfOi4TWvQ6JsAm9Q1A8I8j9YfNy10bmIfwOiyGyU5wQ=
|
||||
github.com/go-openapi/jsonpointer v0.19.3/go.mod h1:Pl9vOtqEWErmShwVjC8pYs9cog34VGT37dQOVbmoatg=
|
||||
github.com/go-openapi/jsonpointer v0.19.5 h1:gZr+CIYByUqjcgeLXnQu2gHYQC9o73G2XUeOFYEICuY=
|
||||
github.com/go-openapi/jsonpointer v0.19.5/go.mod h1:Pl9vOtqEWErmShwVjC8pYs9cog34VGT37dQOVbmoatg=
|
||||
github.com/go-openapi/jsonreference v0.19.6 h1:UBIxjkht+AWIgYzCDSv2GN+E/togfwXUJFRTWhl2Jjs=
|
||||
github.com/go-openapi/jsonreference v0.19.6/go.mod h1:diGHMEHg2IqXZGKxqyvWdfWU/aim5Dprw5bqpKkTvns=
|
||||
github.com/go-openapi/spec v0.20.4 h1:O8hJrt0UMnhHcluhIdUgCLRWyM2x7QkBXRvOs7m+O1M=
|
||||
github.com/go-openapi/spec v0.20.4/go.mod h1:faYFR1CvsJZ0mNsmsphTMSoRrNV3TEDoAM7FOEWeq8I=
|
||||
github.com/go-openapi/swag v0.19.5/go.mod h1:POnQmlKehdgb5mhVOsnJFsivZCEZ/vjK9gh66Z9tfKk=
|
||||
github.com/go-openapi/swag v0.19.15 h1:D2NRCBzS9/pEY3gP9Nl8aDqGUcPFrwG2p+CNFrLyrCM=
|
||||
github.com/go-openapi/swag v0.19.15/go.mod h1:QYRuS/SOXUCsnplDa677K7+DxSOj6IPNl/eQntq43wQ=
|
||||
github.com/go-skynet/go-gpt2.cpp v0.0.0-20230422085954-245a5bfe6708/go.mod h1:1Wj/xbkMfwQSOrhNYK178IzqQHstZbRfhx4s8p1M5VM=
|
||||
github.com/go-skynet/go-gpt4all-j.cpp v0.0.0-20230422090028-1f7bff57f66c h1:48I7jpLNGiQeBmF0SFVVbREh8vlG0zN13v9LH5ctXis=
|
||||
github.com/go-skynet/go-gpt4all-j.cpp v0.0.0-20230422090028-1f7bff57f66c/go.mod h1:5VZ9XbcINI0XcHhkcX8GPK8TplFGAzu1Hrg4tNiMCtI=
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20230430075552-377fd245eae2 h1:CYQRCbOfYtC77OxweAyrdxSVwoLIM/EdZ6Ij+xBzta8=
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20230430075552-377fd245eae2/go.mod h1:35AKIEMY+YTKCBJIa/8GZcNGJ2J+nQk1hQiWo/OnEWw=
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20230502121737-8ceb6167e405 h1:pbIxJ/eiL1Irdprxk/mquaxjR1XDGCE+7CT9BGJNRaY=
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20230502121737-8ceb6167e405/go.mod h1:35AKIEMY+YTKCBJIa/8GZcNGJ2J+nQk1hQiWo/OnEWw=
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20230504223241-67ff6a4db244/go.mod h1:LvSQx5QAYBAMpWkbyVFFDiM1Tzj8LP55DvmUM3hbRMY=
|
||||
github.com/go-task/slim-sprig v0.0.0-20230315185526-52ccab3ef572 h1:tfuBGBXKqDEevZMzYi5KSi8KkcZtzBcTgAUUtapy0OI=
|
||||
github.com/go-task/slim-sprig v0.0.0-20230315185526-52ccab3ef572/go.mod h1:9Pwr4B2jHnOSGXyyzV8ROjYa2ojvAY6HCGYYfMoC3Ls=
|
||||
github.com/godbus/dbus/v5 v5.0.4/go.mod h1:xhWf0FNVPg57R7Z0UbKHbJfkEywrmjJnf7w5xrFpKfA=
|
||||
@@ -48,16 +49,19 @@ github.com/hashicorp/errwrap v1.0.0/go.mod h1:YH+1FKiLXxHSkmPseP+kNlulaMuP3n2brv
|
||||
github.com/hashicorp/go-multierror v1.1.1 h1:H5DkEtf6CXdFp0N0Em5UCwQpXMWke8IA0+lD48awMYo=
|
||||
github.com/hashicorp/go-multierror v1.1.1/go.mod h1:iw975J/qwKPdAO1clOe2L8331t/9/fmwbPZ6JB6eMoM=
|
||||
github.com/ianlancetaylor/demangle v0.0.0-20200824232613-28f6c0f3b639/go.mod h1:aSSvb/t6k1mPoxDqO4vJh6VOCGPwU4O0C2/Eqndh1Sc=
|
||||
github.com/jaypipes/ghw v0.10.0 h1:UHu9UX08Py315iPojADFPOkmjTsNzHj4g4adsNKKteY=
|
||||
github.com/jaypipes/ghw v0.10.0/go.mod h1:jeJGbkRB2lL3/gxYzNYzEDETV1ZJ56OKr+CSeSEym+g=
|
||||
github.com/jaypipes/pcidb v1.0.0 h1:vtZIfkiCUE42oYbJS0TAq9XSfSmcsgo9IdxSm9qzYU8=
|
||||
github.com/jaypipes/pcidb v1.0.0/go.mod h1:TnYUvqhPBzCKnH34KrIX22kAeEbDCSRJ9cqLRCuNDfk=
|
||||
github.com/jessevdk/go-flags v1.4.0/go.mod h1:4FA24M0QyGHXBuZZK/XkWh8h0e1EYbRYJSGM75WSRxI=
|
||||
github.com/josharian/intern v1.0.0 h1:vlS4z54oSdjm0bgjRigI+G1HpF+tI+9rE5LLzOg8HmY=
|
||||
github.com/josharian/intern v1.0.0/go.mod h1:5DoeVV0s6jJacbCEi61lwdGj/aVlrQvzHFFd8Hwg//Y=
|
||||
github.com/klauspost/compress v1.16.3 h1:XuJt9zzcnaz6a16/OU53ZjWp/v7/42WcR5t2a0PcNQY=
|
||||
github.com/klauspost/compress v1.16.3/go.mod h1:ntbaceVETuRiXiv4DpjP66DpAtAGkEQskQzEyD//IeE=
|
||||
github.com/kr/pretty v0.1.0 h1:L/CwN0zerZDmRFUapSPitk6f+Q3+0za1rQkzVuMiMFI=
|
||||
github.com/kr/pretty v0.1.0/go.mod h1:dAy3ld7l9f0ibDNOQOHHMYYIIbhfbHSm3C4ZsoJORNo=
|
||||
github.com/kr/pty v1.1.1/go.mod h1:pFQYn66WHrOpPYNljwOMqo10TkYh1fy3cYio2l3bCsQ=
|
||||
github.com/kr/text v0.1.0/go.mod h1:4Jbv+DJW3UT/LiOwJeYQe1efqtUx/iVham/4vfdArNI=
|
||||
github.com/kr/text v0.2.0 h1:5Nx0Ya0ZqY2ygV366QzturHI13Jq95ApcVaJBhpS+AY=
|
||||
github.com/kr/text v0.2.0/go.mod h1:eLer722TekiGuMkidMxC/pM04lWEeraHUUmBw8l2grE=
|
||||
github.com/mailru/easyjson v0.0.0-20190614124828-94de47d64c63/go.mod h1:C1wdFJiN94OJF2b5HbByQZoLdCWB1Yqtg26g4irojpc=
|
||||
github.com/mailru/easyjson v0.0.0-20190626092158-b2ccc519800e/go.mod h1:C1wdFJiN94OJF2b5HbByQZoLdCWB1Yqtg26g4irojpc=
|
||||
github.com/mailru/easyjson v0.7.6 h1:8yTIVnZgCoiM1TgqoeTl+LfU5Jg6/xL3QhGQnimLYnA=
|
||||
github.com/mailru/easyjson v0.7.6/go.mod h1:xzfreul335JAWq5oZzymOObrkdz5UnU4kGfJJLY9Nlc=
|
||||
github.com/mattn/go-colorable v0.1.12/go.mod h1:u5H1YNBxpqRaxsYJYSkiCWKzEfiAb1Gb520KVy5xxl4=
|
||||
github.com/mattn/go-colorable v0.1.13 h1:fFA4WZxdEF4tXPZVKMLwD8oUnCTTo08duU7wxecdEvA=
|
||||
github.com/mattn/go-colorable v0.1.13/go.mod h1:7S9/ev0klgBDR4GtXTXX8a3vIGJpMovkB8vQcUbaXHg=
|
||||
@@ -67,12 +71,10 @@ github.com/mattn/go-isatty v0.0.18 h1:DOKFKCQ7FNG2L1rbrmstDN4QVRdS89Nkh85u68Uwp9
|
||||
github.com/mattn/go-isatty v0.0.18/go.mod h1:W+V8PltTTMOvKvAeJH7IuucS94S2C6jfK/D7dTCTo3Y=
|
||||
github.com/mattn/go-runewidth v0.0.14 h1:+xnbZSEeDbOIg5/mE6JF0w6n9duR1l3/WmbinWVwUuU=
|
||||
github.com/mattn/go-runewidth v0.0.14/go.mod h1:Jdepj2loyihRzMpdS35Xk/zdY8IAYHsh153qUoGf23w=
|
||||
github.com/mitchellh/go-homedir v1.1.0 h1:lukF9ziXFxDFPkA1vsr5zpc1XuPDn/wFntq5mG+4E0Y=
|
||||
github.com/mitchellh/go-homedir v1.1.0/go.mod h1:SfyaCUpYCn1Vlf4IUYiD9fPX4A5wJrkLzIz1N1q0pr0=
|
||||
github.com/onsi/ginkgo/v2 v2.9.2 h1:BA2GMJOtfGAfagzYtrAlufIP0lq6QERkFmHLMLPwFSU=
|
||||
github.com/onsi/ginkgo/v2 v2.9.2/go.mod h1:WHcJJG2dIlcCqVfBAwUCrJxSPFb6v4azBwgxeMeDuts=
|
||||
github.com/onsi/ginkgo/v2 v2.9.3 h1:5X2vl/isiKqkrOYjiaGgp3JQOcLV59g5o5SuTMqCcxU=
|
||||
github.com/onsi/ginkgo/v2 v2.9.3/go.mod h1:gCQYp2Q+kSoIj7ykSVb9nskRSsR6PUj4AiLywzIhbKM=
|
||||
github.com/niemeyer/pretty v0.0.0-20200227124842-a10e7caefd8e h1:fD57ERR4JtEqsWbfPhv4DMiApHyliiK5xCTNVSPiaAs=
|
||||
github.com/niemeyer/pretty v0.0.0-20200227124842-a10e7caefd8e/go.mod h1:zD1mROLANZcx1PVRCS0qkT7pwLkGfwJo4zjcN/Tysno=
|
||||
github.com/onsi/ginkgo/v2 v2.9.4 h1:xR7vG4IXt5RWx6FfIjyAtsoMAtnc3C/rFXBBd2AjZwE=
|
||||
github.com/onsi/ginkgo/v2 v2.9.4/go.mod h1:gCQYp2Q+kSoIj7ykSVb9nskRSsR6PUj4AiLywzIhbKM=
|
||||
github.com/onsi/gomega v1.27.6 h1:ENqfyGeS5AX/rlXDd/ETokDz93u0YufY1Pgxuy/PvWE=
|
||||
github.com/onsi/gomega v1.27.6/go.mod h1:PIQNjfQwkP3aQAH7lf7j87O/5FiNr+ZR8+ipb+qQlhg=
|
||||
github.com/otiai10/mint v1.4.1 h1:HOVBfKP1oXIc0wWo9hZ8JLdZtyCPWqjvmFDuVZ0yv2Y=
|
||||
@@ -81,7 +83,6 @@ github.com/otiai10/openaigo v1.1.0/go.mod h1:792bx6AWTS61weDi2EzKpHHnTF4eDMAlJ5G
|
||||
github.com/philhofer/fwd v1.1.1/go.mod h1:gk3iGcWd9+svBvR0sR+KPcfE+RNWozjowpeBVG3ZVNU=
|
||||
github.com/philhofer/fwd v1.1.2 h1:bnDivRJ1EWPjUIRXV5KfORO897HTbpFAQddBdE8t7Gw=
|
||||
github.com/philhofer/fwd v1.1.2/go.mod h1:qkPdfjR2SIEbspLqpe1tO4n5yICnr2DY7mqEx2tUTP0=
|
||||
github.com/pkg/errors v0.9.1 h1:FEBLx1zS214owpjy7qsBeixbURkuhQAwrK5UwLGTwt4=
|
||||
github.com/pkg/errors v0.9.1/go.mod h1:bwawxfHBFNV+L2hUp1rHADufV3IMtnDRdf1r5NINEl0=
|
||||
github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM=
|
||||
github.com/pmezard/go-difflib v1.0.0/go.mod h1:iKH77koFhYxTK1pcRnkKkqfTogsbg7gZNVY4sRDYZ/4=
|
||||
@@ -92,16 +93,19 @@ github.com/rs/zerolog v1.29.1 h1:cO+d60CHkknCbvzEWxP0S9K6KqyTjrCNUy1LdQLCGPc=
|
||||
github.com/rs/zerolog v1.29.1/go.mod h1:Le6ESbR7hc+DP6Lt1THiV8CQSdkkNrd3R0XbEgp3ZBU=
|
||||
github.com/russross/blackfriday/v2 v2.1.0 h1:JIOH55/0cWyOuilr9/qlrm0BSXldqnqwMsf35Ld67mk=
|
||||
github.com/russross/blackfriday/v2 v2.1.0/go.mod h1:+Rmxgy9KzJVeS9/2gXHxylqXiyQDYRxCVz55jmeOWTM=
|
||||
github.com/sashabaranov/go-openai v1.9.1 h1:3N52HkJKo9Zlo/oe1AVv5ZkCOny0ra58/ACvAxkN3MM=
|
||||
github.com/sashabaranov/go-openai v1.9.1/go.mod h1:lj5b/K+zjTSFxVLijLSTDZuP7adOgerWeFyZLUhAKRg=
|
||||
github.com/sashabaranov/go-openai v1.9.3 h1:uNak3Rn5pPsKRs9bdT7RqRZEyej/zdZOEI2/8wvrFtM=
|
||||
github.com/sashabaranov/go-openai v1.9.3/go.mod h1:lj5b/K+zjTSFxVLijLSTDZuP7adOgerWeFyZLUhAKRg=
|
||||
github.com/savsgio/dictpool v0.0.0-20221023140959-7bf2e61cea94 h1:rmMl4fXJhKMNWl+K+r/fq4FbbKI+Ia2m9hYBLm2h4G4=
|
||||
github.com/savsgio/dictpool v0.0.0-20221023140959-7bf2e61cea94/go.mod h1:90zrgN3D/WJsDd1iXHT96alCoN2KJo6/4x1DZC3wZs8=
|
||||
github.com/savsgio/gotils v0.0.0-20220530130905-52f3993e8d6d/go.mod h1:Gy+0tqhJvgGlqnTF8CVGP0AaGRjwBtXs/a5PA0Y3+A4=
|
||||
github.com/savsgio/gotils v0.0.0-20230208104028-c358bd845dee h1:8Iv5m6xEo1NR1AvpV+7XmhI4r39LGNzwUL4YpMuL5vk=
|
||||
github.com/savsgio/gotils v0.0.0-20230208104028-c358bd845dee/go.mod h1:qwtSXrKuJh/zsFQ12yEE89xfCrGKK63Rr7ctU/uCo4g=
|
||||
github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
|
||||
github.com/stretchr/testify v1.6.1 h1:hDPOHmpOpP40lSULcqw7IrRb/u7w6RpDC9399XyoNd0=
|
||||
github.com/stretchr/testify v1.3.0/go.mod h1:M5WIy9Dh21IEIfnGCwXGc5bZfKNJtfHm1UVUgZn+9EI=
|
||||
github.com/stretchr/testify v1.6.1/go.mod h1:6Fq8oRcR53rry900zMqJjRRixrwX3KX962/h/Wwjteg=
|
||||
github.com/stretchr/testify v1.7.0 h1:nwc3DEeHmmLAfoZucVR881uASk0Mfjw8xYJ99tb5CcY=
|
||||
github.com/swaggo/swag v1.16.1 h1:fTNRhKstPKxcnoKsytm4sahr8FaYzUcT7i1/3nd/fBg=
|
||||
github.com/swaggo/swag v1.16.1/go.mod h1:9/LMvHycG3NFHfR6LwvikHv5iFvmPADQ359cKikGxto=
|
||||
github.com/tinylib/msgp v1.1.6/go.mod h1:75BAfg2hauQhs3qedfdDZmWAPcFMAvJE5b9rGOMufyw=
|
||||
github.com/tinylib/msgp v1.1.8 h1:FCXC1xanKO4I8plpHGH2P7koL/RzZs12l/+r7vakfm0=
|
||||
github.com/tinylib/msgp v1.1.8/go.mod h1:qkpG+2ldGg4xRFmx+jfTvZPxfGFhi64BcnL9vkCm/Tw=
|
||||
@@ -124,14 +128,14 @@ golang.org/x/crypto v0.0.0-20210921155107-089bfa567519/go.mod h1:GvvjBRRGRdwPK5y
|
||||
golang.org/x/mod v0.3.0/go.mod h1:s0Qsj1ACt9ePp/hMypM3fl4fZqREWJwdYDEqhRiZZUA=
|
||||
golang.org/x/mod v0.6.0-dev.0.20220419223038-86c51ed26bb4/go.mod h1:jJ57K6gSWd91VN4djpZkiMVwK6gcyfeH4XE8wZrZaV4=
|
||||
golang.org/x/mod v0.7.0/go.mod h1:iBbtSCu2XBx23ZKBPSOrRkjjQPZFPuis4dIYUhu/chs=
|
||||
golang.org/x/mod v0.10.0 h1:lFO9qtOdlre5W1jxS3r/4szv2/6iXxScdzjoBMXNhYk=
|
||||
golang.org/x/net v0.0.0-20190404232315-eb5bcb51f2a3/go.mod h1:t9HGtf8HONx5eT2rtn7q6eTqICYqUVnKs3thJo3Qplg=
|
||||
golang.org/x/net v0.0.0-20190620200207-3b0461eec859/go.mod h1:z5CRVTTTmAJ677TzLLGU+0bjPO0LkuOLi4/5GtJWs/s=
|
||||
golang.org/x/net v0.0.0-20201021035429-f5854403a974/go.mod h1:sp8m0HH+o8qH0wwXwYZr8TS3Oi6o0r6Gce1SSxlDquU=
|
||||
golang.org/x/net v0.0.0-20210226172049-e18ecbb05110/go.mod h1:m0MpNAwzfU5UDzcl9v0D8zg8gWTRqZa9RBIspLL5mdg=
|
||||
golang.org/x/net v0.0.0-20210421230115-4e50805a0758/go.mod h1:72T/g9IO56b78aLF+1Kcs5dz7/ng1VjMUvfKvpfy+jM=
|
||||
golang.org/x/net v0.0.0-20220722155237-a158d28d115b/go.mod h1:XRhObCWvk6IyKnWLug+ECip1KBveYUHfp+8e9klMJ9c=
|
||||
golang.org/x/net v0.3.0/go.mod h1:MBQ8lrhLObU/6UmLb4fmbmk5OcyYmqtbGd/9yIeKjEE=
|
||||
golang.org/x/net v0.8.0 h1:Zrh2ngAOFYneWTAIAPethzeaQLuHwhuBkuV6ZiRnUaQ=
|
||||
golang.org/x/net v0.8.0/go.mod h1:QVkue5JL9kW//ek3r6jTKnTFis1tRmNAW2P1shuFdJc=
|
||||
golang.org/x/net v0.9.0 h1:aWJ/m6xSmxWBx+V0XRHTlrYrPG56jKsLdTFmsSsCzOM=
|
||||
golang.org/x/net v0.9.0/go.mod h1:d48xBJpPfHeWQsugry2m+kC02ZBRGRgulfHnEXEuWns=
|
||||
golang.org/x/sync v0.0.0-20190423024810-112230192c58/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
@@ -140,10 +144,10 @@ golang.org/x/sync v0.0.0-20220722155255-886fb9371eb4/go.mod h1:RxMgew5VJxzue5/jJ
|
||||
golang.org/x/sync v0.1.0/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sys v0.0.0-20190215142949-d0b11bdaac8a/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
|
||||
golang.org/x/sys v0.0.0-20190412213103-97732733099d/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20190916202348-b4ddaad3f8a3/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20191204072324-ce4227a45e2e/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20200930185726-fdedc70b468f/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20210420072515-93ed5bcd2bfe/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20210615035016-665e8c7367d1/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/sys v0.0.0-20210630005230-0f9fa26af87c/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/sys v0.0.0-20210927094055-39ccf1dd6fa6/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
@@ -159,10 +163,9 @@ golang.org/x/term v0.0.0-20210927222741-03fcf44c2211/go.mod h1:jbD1KX2456YbFQfuX
|
||||
golang.org/x/term v0.3.0/go.mod h1:q750SLmJuPmVoN1blW3UFBPREJfb1KmY3vwxfr+nFDA=
|
||||
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
||||
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||
golang.org/x/text v0.3.6/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||
golang.org/x/text v0.3.7/go.mod h1:u+2+/6zg+i71rQMx5EYifcz6MCKuco9NR6JIITiCfzQ=
|
||||
golang.org/x/text v0.5.0/go.mod h1:mrYo+phRRbMaCq/xk9113O4dZlRixOauAjOtrjsXDZ8=
|
||||
golang.org/x/text v0.8.0 h1:57P1ETyNKtuIjB4SRd15iJxuhj8Gc416Y78H3qgMh68=
|
||||
golang.org/x/text v0.8.0/go.mod h1:e1OnstbJyHTd6l/uOt8jFFHp6TRDWZR/bV3emEE/zU8=
|
||||
golang.org/x/text v0.9.0 h1:2sjJmO8cDvYveuX97RDLsxlyUxLl+GHoLxBiRdHllBE=
|
||||
golang.org/x/text v0.9.0/go.mod h1:e1OnstbJyHTd6l/uOt8jFFHp6TRDWZR/bV3emEE/zU8=
|
||||
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||
@@ -170,8 +173,6 @@ golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtn
|
||||
golang.org/x/tools v0.0.0-20201022035929-9cf592e881e9/go.mod h1:emZCQorbCU4vsT4fOWvOPXz4eW1wZW4PmDk9uLelYpA=
|
||||
golang.org/x/tools v0.1.12/go.mod h1:hNGJHUnrk76NpqgfD5Aqm5Crs+Hm0VOH/i9J2+nxYbc=
|
||||
golang.org/x/tools v0.4.0/go.mod h1:UE5sM2OK9E/d67R0ANs2xJizIymRP5gJU295PvKXxjQ=
|
||||
golang.org/x/tools v0.7.0 h1:W4OVu8VVOaIO0yzWMNdepAulS7YfoS3Zabrm8DOXXU4=
|
||||
golang.org/x/tools v0.7.0/go.mod h1:4pg6aUX35JBAogB10C9AtvVL+qowtN4pT3CGSQex14s=
|
||||
golang.org/x/tools v0.8.0 h1:vSDcovVPld282ceKgDimkRSC8kpaH1dgyc9UMzlt84Y=
|
||||
golang.org/x/tools v0.8.0/go.mod h1:JxBZ99ISMI5ViVkT1tr6tdNmXeTrcpVSD3vZ1RsRdN4=
|
||||
golang.org/x/xerrors v0.0.0-20190717185122-a985d3407aa7/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
|
||||
@@ -179,12 +180,13 @@ golang.org/x/xerrors v0.0.0-20191011141410-1b5146add898/go.mod h1:I/5z698sn9Ka8T
|
||||
golang.org/x/xerrors v0.0.0-20200804184101-5ec99f83aff1/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
|
||||
google.golang.org/protobuf v1.28.0 h1:w43yiav+6bVFTBQFZX0r7ipe9JQ1QsbMgHwbBziscLw=
|
||||
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127 h1:qIbj1fsPNlZgppZ+VLlY7N33q108Sa+fhmuc+sWQYwY=
|
||||
gopkg.in/yaml.v1 v1.0.0-20140924161607-9f9df34309c0/go.mod h1:WDnlLJ4WF5VGsH/HVa3CI79GS0ol3YnhVnKP89i0kNg=
|
||||
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||
gopkg.in/check.v1 v1.0.0-20200227125254-8fa46927fb4f h1:BLraFXnmrev5lT+xlilqcH8XK9/i0At2xKjWk4p6zsU=
|
||||
gopkg.in/check.v1 v1.0.0-20200227125254-8fa46927fb4f/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||
gopkg.in/yaml.v2 v2.2.2/go.mod h1:hI93XBmqTisBFMUTm0b8Fm+jr3Dg1NNxqwp+5A1VGuI=
|
||||
gopkg.in/yaml.v2 v2.4.0 h1:D8xgwECY7CYvx+Y2n4sBz93Jn9JRvxdiyyo8CTfuKaY=
|
||||
gopkg.in/yaml.v2 v2.4.0/go.mod h1:RDklbk79AGWmwhnvt/jBztapEOGDOx6ZbXqjP6csGnQ=
|
||||
gopkg.in/yaml.v3 v3.0.0-20200313102051-9f266ea9e77c/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM=
|
||||
gopkg.in/yaml.v3 v3.0.0-20200615113413-eeeca48fe776/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM=
|
||||
gopkg.in/yaml.v3 v3.0.1 h1:fxVm/GzAzEWqLHuvctI91KS9hhNmmWOoWu0XTYJS7CA=
|
||||
gopkg.in/yaml.v3 v3.0.1/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM=
|
||||
howett.net/plist v1.0.0 h1:7CrbWYbPPO/PyNy38b2EB/+gYbjCe2DXBxgtOOZbSQM=
|
||||
howett.net/plist v1.0.0/go.mod h1:lqaXoTrLY4hg8tnEzNru53gicrbv7rrk+2xJA/7hw9g=
|
||||
|
||||
14
main.go
14
main.go
@@ -1,11 +1,12 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"path/filepath"
|
||||
|
||||
api "github.com/go-skynet/LocalAI/api"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/jaypipes/ghw"
|
||||
"github.com/rs/zerolog"
|
||||
"github.com/rs/zerolog/log"
|
||||
"github.com/urfave/cli/v2"
|
||||
@@ -20,12 +21,6 @@ func main() {
|
||||
os.Exit(1)
|
||||
}
|
||||
|
||||
threads := 4
|
||||
cpu, err := ghw.CPU()
|
||||
if err == nil {
|
||||
threads = int(cpu.TotalCores)
|
||||
}
|
||||
|
||||
app := &cli.App{
|
||||
Name: "LocalAI",
|
||||
Usage: "OpenAI compatible API for running LLaMA/GPT models locally on CPU with consumer grade hardware.",
|
||||
@@ -42,13 +37,13 @@ func main() {
|
||||
Name: "threads",
|
||||
DefaultText: "Number of threads used for parallel computation. Usage of the number of physical cores in the system is suggested.",
|
||||
EnvVars: []string{"THREADS"},
|
||||
Value: threads,
|
||||
Value: 4,
|
||||
},
|
||||
&cli.StringFlag{
|
||||
Name: "models-path",
|
||||
DefaultText: "Path containing models used for inferencing",
|
||||
EnvVars: []string{"MODELS_PATH"},
|
||||
Value: path,
|
||||
Value: filepath.Join(path, "models"),
|
||||
},
|
||||
&cli.StringFlag{
|
||||
Name: "config-file",
|
||||
@@ -85,6 +80,7 @@ It uses llama.cpp, ggml and gpt4all as backend with golang c bindings.
|
||||
UsageText: `local-ai [options]`,
|
||||
Copyright: "go-skynet authors",
|
||||
Action: func(ctx *cli.Context) error {
|
||||
fmt.Printf("Starting LocalAI using %d threads, with models path: %s\n", ctx.Int("threads"), ctx.String("models-path"))
|
||||
return api.App(ctx.String("config-file"), model.NewModelLoader(ctx.String("models-path")), ctx.Int("threads"), ctx.Int("context-size"), ctx.Bool("f16"), ctx.Bool("debug"), false).Listen(ctx.String("address"))
|
||||
},
|
||||
}
|
||||
|
||||
@@ -10,6 +10,7 @@ import (
|
||||
"sync"
|
||||
"text/template"
|
||||
|
||||
"github.com/hashicorp/go-multierror"
|
||||
"github.com/rs/zerolog/log"
|
||||
|
||||
rwkv "github.com/donomii/go-rwkv.cpp"
|
||||
@@ -81,10 +82,9 @@ func (ml *ModelLoader) TemplatePrefix(modelName string, in interface{}) (string,
|
||||
if exists {
|
||||
m = t
|
||||
}
|
||||
|
||||
}
|
||||
if m == nil {
|
||||
return "", nil
|
||||
return "", fmt.Errorf("failed loading any template")
|
||||
}
|
||||
|
||||
var buf bytes.Buffer
|
||||
@@ -283,3 +283,83 @@ func (ml *ModelLoader) LoadLLaMAModel(modelName string, opts ...llama.ModelOptio
|
||||
ml.models[modelName] = model
|
||||
return model, err
|
||||
}
|
||||
|
||||
const tokenizerSuffix = ".tokenizer.json"
|
||||
|
||||
var loadedModels map[string]interface{} = map[string]interface{}{}
|
||||
var muModels sync.Mutex
|
||||
|
||||
func (ml *ModelLoader) BackendLoader(backendString string, modelFile string, llamaOpts []llama.ModelOption, threads uint32) (model interface{}, err error) {
|
||||
switch strings.ToLower(backendString) {
|
||||
case "llama":
|
||||
return ml.LoadLLaMAModel(modelFile, llamaOpts...)
|
||||
case "stablelm":
|
||||
return ml.LoadStableLMModel(modelFile)
|
||||
case "gpt2":
|
||||
return ml.LoadGPT2Model(modelFile)
|
||||
case "gptj":
|
||||
return ml.LoadGPTJModel(modelFile)
|
||||
case "rwkv":
|
||||
return ml.LoadRWKV(modelFile, modelFile+tokenizerSuffix, threads)
|
||||
default:
|
||||
return nil, fmt.Errorf("backend unsupported: %s", backendString)
|
||||
}
|
||||
}
|
||||
|
||||
func (ml *ModelLoader) GreedyLoader(modelFile string, llamaOpts []llama.ModelOption, threads uint32) (model interface{}, err error) {
|
||||
updateModels := func(model interface{}) {
|
||||
muModels.Lock()
|
||||
defer muModels.Unlock()
|
||||
loadedModels[modelFile] = model
|
||||
}
|
||||
|
||||
muModels.Lock()
|
||||
m, exists := loadedModels[modelFile]
|
||||
if exists {
|
||||
muModels.Unlock()
|
||||
return m, nil
|
||||
}
|
||||
muModels.Unlock()
|
||||
|
||||
model, modelerr := ml.LoadLLaMAModel(modelFile, llamaOpts...)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = ml.LoadGPTJModel(modelFile)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = ml.LoadGPT2Model(modelFile)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = ml.LoadStableLMModel(modelFile)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
model, modelerr = ml.LoadRWKV(modelFile, modelFile+tokenizerSuffix, threads)
|
||||
if modelerr == nil {
|
||||
updateModels(model)
|
||||
return model, nil
|
||||
} else {
|
||||
err = multierror.Append(err, modelerr)
|
||||
}
|
||||
|
||||
return nil, fmt.Errorf("could not load model - all backends returned error: %s", err.Error())
|
||||
}
|
||||
|
||||
@@ -1,17 +1,4 @@
|
||||
{
|
||||
"$schema": "https://docs.renovatebot.com/renovate-schema.json",
|
||||
"extends": [
|
||||
"config:base"
|
||||
],
|
||||
"regexManagers": [
|
||||
{
|
||||
"fileMatch": [
|
||||
"^Makefile$"
|
||||
],
|
||||
"matchStrings": [
|
||||
"#\\s*renovate:\\s*datasource=(?<datasource>.*?) depName=(?<depName>.*?)( datasourceTemplate=(?<datasourceTemplate>.*?))?( packageNameTemplate=(?<packageNameTemplate>.*?))?( depNameTemplate=(?<depNameTemplate>.*?))?( valueTemplate=(?<currentValueTemplate>.*?))?( versioning=(?<versioning>.*?))?\\s+.+_VERSION=(?<currentValue>.*?)\\s"
|
||||
],
|
||||
"versioningTemplate": "{{#if versioning}}{{versioning}}{{/if}}"
|
||||
}
|
||||
]
|
||||
"extends": ["config:base"]
|
||||
}
|
||||
|
||||
12
tests/fixtures/config.yaml
vendored
12
tests/fixtures/config.yaml
vendored
@@ -1,8 +1,10 @@
|
||||
- name: list1
|
||||
parameters:
|
||||
model: testmodel
|
||||
context_size: 512
|
||||
threads: 10
|
||||
top_p: 80
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
context_size: 10
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
@@ -14,9 +16,11 @@
|
||||
chat: ggml-gpt4all-j
|
||||
- name: list2
|
||||
parameters:
|
||||
top_p: 80
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
model: testmodel
|
||||
context_size: 512
|
||||
threads: 10
|
||||
context_size: 10
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
|
||||
6
tests/fixtures/gpt4.yaml
vendored
6
tests/fixtures/gpt4.yaml
vendored
@@ -1,8 +1,10 @@
|
||||
name: gpt4all
|
||||
parameters:
|
||||
model: testmodel
|
||||
context_size: 512
|
||||
threads: 10
|
||||
top_p: 80
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
context_size: 10
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
|
||||
6
tests/fixtures/gpt4_2.yaml
vendored
6
tests/fixtures/gpt4_2.yaml
vendored
@@ -1,8 +1,10 @@
|
||||
name: gpt4all-2
|
||||
parameters:
|
||||
model: testmodel
|
||||
context_size: 1024
|
||||
threads: 5
|
||||
top_p: 80
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
context_size: 10
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
|
||||
Reference in New Issue
Block a user