mirror of
https://github.com/mudler/LocalAI.git
synced 2026-02-03 11:13:31 -05:00
Compare commits
53 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
d5d82ba344 | ||
|
|
efe2883c5d | ||
|
|
47237c7c3c | ||
|
|
697c769b64 | ||
|
|
94261b1717 | ||
|
|
eaf85a30f9 | ||
|
|
6a88b030ea | ||
|
|
f538416fb3 | ||
|
|
06cd9ef98d | ||
|
|
f3d71f8819 | ||
|
|
b7127c2dc9 | ||
|
|
b2dc5fbd7e | ||
|
|
9e653d6abe | ||
|
|
52c9a7f45d | ||
|
|
ee42c9bfe6 | ||
|
|
e6c3e483a1 | ||
|
|
3a253c6cd7 | ||
|
|
e9c3bbc6d7 | ||
|
|
23d64ac53a | ||
|
|
34f9f20ff4 | ||
|
|
a4a72a79ae | ||
|
|
6ca4d38a01 | ||
|
|
b5c93f176a | ||
|
|
1aaf88098d | ||
|
|
6f447e613d | ||
|
|
dfb7c3b1aa | ||
|
|
b41eb5e1f3 | ||
|
|
9c2d264979 | ||
|
|
b996c3198c | ||
|
|
f879c07c86 | ||
|
|
441e2965ff | ||
|
|
cbe9a03e3c | ||
|
|
4ee7e73d00 | ||
|
|
1cca449726 | ||
|
|
faf7c1c325 | ||
|
|
58288494d6 | ||
|
|
72283dc744 | ||
|
|
b8240b4c18 | ||
|
|
5309da40b7 | ||
|
|
08b90b4720 | ||
|
|
2e890b3838 | ||
|
|
06656fc057 | ||
|
|
574fa67bdc | ||
|
|
e19d7226f8 | ||
|
|
0843fe6c65 | ||
|
|
62a02cd1fe | ||
|
|
949da7792d | ||
|
|
ce724a7e55 | ||
|
|
0a06c80801 | ||
|
|
edc55ade61 | ||
|
|
09e5d9007b | ||
|
|
db926896bd | ||
|
|
ab7b4d5ee9 |
4
.github/ISSUE_TEMPLATE/bug_report.md
vendored
4
.github/ISSUE_TEMPLATE/bug_report.md
vendored
@@ -2,9 +2,7 @@
|
||||
name: Bug report
|
||||
about: Create a report to help us improve
|
||||
title: ''
|
||||
labels: bug
|
||||
assignees: mudler
|
||||
|
||||
labels: bug, unconfirmed, up-for-grabs
|
||||
---
|
||||
|
||||
<!-- Thanks for helping us to improve LocalAI! We welcome all bug reports. Please fill out each area of the template so we can better help you. Comments like this will be hidden when you post but you can delete them if you wish. -->
|
||||
|
||||
4
.github/ISSUE_TEMPLATE/feature_request.md
vendored
4
.github/ISSUE_TEMPLATE/feature_request.md
vendored
@@ -2,9 +2,7 @@
|
||||
name: Feature request
|
||||
about: Suggest an idea for this project
|
||||
title: ''
|
||||
labels: enhancement
|
||||
assignees: mudler
|
||||
|
||||
labels: enhancement, up-for-grabs
|
||||
---
|
||||
|
||||
<!-- Thanks for helping us to improve LocalAI! We welcome all feature requests. Please fill out each area of the template so we can better help you. Comments like this will be hidden when you post but you can delete them if you wish. -->
|
||||
|
||||
86
.github/workflows/image-pr.yml
vendored
Normal file
86
.github/workflows/image-pr.yml
vendored
Normal file
@@ -0,0 +1,86 @@
|
||||
---
|
||||
name: 'build container images tests'
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
|
||||
concurrency:
|
||||
group: ci-${{ github.head_ref || github.ref }}-${{ github.repository }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
extras-image-build:
|
||||
uses: ./.github/workflows/image_build.yml
|
||||
with:
|
||||
tag-latest: ${{ matrix.tag-latest }}
|
||||
tag-suffix: ${{ matrix.tag-suffix }}
|
||||
ffmpeg: ${{ matrix.ffmpeg }}
|
||||
image-type: ${{ matrix.image-type }}
|
||||
build-type: ${{ matrix.build-type }}
|
||||
cuda-major-version: ${{ matrix.cuda-major-version }}
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
quayUsername: ${{ secrets.LOCALAI_REGISTRY_USERNAME }}
|
||||
quayPassword: ${{ secrets.LOCALAI_REGISTRY_PASSWORD }}
|
||||
strategy:
|
||||
# Pushing with all jobs in parallel
|
||||
# eats the bandwidth of all the nodes
|
||||
max-parallel: ${{ github.event_name != 'pull_request' && 2 || 4 }}
|
||||
matrix:
|
||||
include:
|
||||
- build-type: ''
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-ffmpeg'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-cublas-cuda12-ffmpeg'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
core-image-build:
|
||||
uses: ./.github/workflows/image_build.yml
|
||||
with:
|
||||
tag-latest: ${{ matrix.tag-latest }}
|
||||
tag-suffix: ${{ matrix.tag-suffix }}
|
||||
ffmpeg: ${{ matrix.ffmpeg }}
|
||||
image-type: ${{ matrix.image-type }}
|
||||
build-type: ${{ matrix.build-type }}
|
||||
cuda-major-version: ${{ matrix.cuda-major-version }}
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
quayUsername: ${{ secrets.LOCALAI_REGISTRY_USERNAME }}
|
||||
quayPassword: ${{ secrets.LOCALAI_REGISTRY_PASSWORD }}
|
||||
strategy:
|
||||
matrix:
|
||||
include:
|
||||
- build-type: ''
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-cublas-cuda12-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
1
.github/workflows/image.yml
vendored
1
.github/workflows/image.yml
vendored
@@ -2,7 +2,6 @@
|
||||
name: 'build container images'
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
push:
|
||||
branches:
|
||||
- master
|
||||
|
||||
18
.github/workflows/release.yaml
vendored
18
.github/workflows/release.yaml
vendored
@@ -34,10 +34,22 @@ jobs:
|
||||
sudo apt-get update
|
||||
sudo apt-get install build-essential ffmpeg
|
||||
|
||||
- name: Cache grpc
|
||||
id: cache-grpc
|
||||
uses: actions/cache@v3
|
||||
with:
|
||||
path: grpc
|
||||
key: ${{ runner.os }}-grpc
|
||||
- name: Build grpc
|
||||
if: steps.cache-grpc.outputs.cache-hit != 'true'
|
||||
run: |
|
||||
git clone --recurse-submodules -b v1.58.0 --depth 1 --shallow-submodules https://github.com/grpc/grpc && \
|
||||
cd grpc && mkdir -p cmake/build && cd cmake/build && cmake -DgRPC_INSTALL=ON \
|
||||
-DgRPC_BUILD_TESTS=OFF \
|
||||
../.. && sudo make -j12 install
|
||||
cd grpc && mkdir -p cmake/build && cd cmake/build && cmake -DgRPC_INSTALL=ON \
|
||||
-DgRPC_BUILD_TESTS=OFF \
|
||||
../.. && sudo make -j12
|
||||
- name: Install gRPC
|
||||
run: |
|
||||
cd grpc && cd cmake/build && sudo make -j12 install
|
||||
|
||||
- name: Build
|
||||
id: build
|
||||
|
||||
19
.github/workflows/test.yml
vendored
19
.github/workflows/test.yml
vendored
@@ -86,11 +86,22 @@ jobs:
|
||||
sudo cp -rfv sources/go-piper/piper-phonemize/pi/lib/. /usr/lib/ && \
|
||||
# Pre-build stable diffusion before we install a newer version of abseil (not compatible with stablediffusion-ncn)
|
||||
GO_TAGS="stablediffusion tts" GRPC_BACKENDS=backend-assets/grpc/stablediffusion make build
|
||||
|
||||
- name: Cache grpc
|
||||
id: cache-grpc
|
||||
uses: actions/cache@v3
|
||||
with:
|
||||
path: grpc
|
||||
key: ${{ runner.os }}-grpc
|
||||
- name: Build grpc
|
||||
if: steps.cache-grpc.outputs.cache-hit != 'true'
|
||||
run: |
|
||||
git clone --recurse-submodules -b v1.58.0 --depth 1 --shallow-submodules https://github.com/grpc/grpc && \
|
||||
cd grpc && mkdir -p cmake/build && cd cmake/build && cmake -DgRPC_INSTALL=ON \
|
||||
-DgRPC_BUILD_TESTS=OFF \
|
||||
../.. && sudo make -j12 install
|
||||
cd grpc && mkdir -p cmake/build && cd cmake/build && cmake -DgRPC_INSTALL=ON \
|
||||
-DgRPC_BUILD_TESTS=OFF \
|
||||
../.. && sudo make -j12
|
||||
- name: Install gRPC
|
||||
run: |
|
||||
cd grpc && cd cmake/build && sudo make -j12 install
|
||||
- name: Test
|
||||
run: |
|
||||
GO_TAGS="stablediffusion tts" make test
|
||||
|
||||
3
.gitmodules
vendored
3
.gitmodules
vendored
@@ -1,3 +1,6 @@
|
||||
[submodule "docs/themes/hugo-theme-relearn"]
|
||||
path = docs/themes/hugo-theme-relearn
|
||||
url = https://github.com/McShelby/hugo-theme-relearn.git
|
||||
[submodule "docs/themes/lotusdocs"]
|
||||
path = docs/themes/lotusdocs
|
||||
url = https://github.com/colinwilson/lotusdocs
|
||||
|
||||
16
Dockerfile
16
Dockerfile
@@ -13,9 +13,8 @@ ARG TARGETVARIANT
|
||||
|
||||
ENV BUILD_TYPE=${BUILD_TYPE}
|
||||
|
||||
ENV EXTERNAL_GRPC_BACKENDS="coqui:/build/backend/python/coqui/run.sh,huggingface-embeddings:/build/backend/python/sentencetransformers/run.sh,petals:/build/backend/python/petals/run.sh,transformers:/build/backend/python/transformers/run.sh,sentencetransformers:/build/backend/python/sentencetransformers/run.sh,autogptq:/build/backend/python/autogptq/run.sh,bark:/build/backend/python/bark/run.sh,diffusers:/build/backend/python/diffusers/run.sh,exllama:/build/backend/python/exllama/run.sh,vall-e-x:/build/backend/python/vall-e-x/run.sh,vllm:/build/backend/python/vllm/run.sh,exllama2:/build/backend/python/exllama2/run.sh,transformers-musicgen:/build/backend/python/transformers-musicgen/run.sh"
|
||||
ENV EXTERNAL_GRPC_BACKENDS="coqui:/build/backend/python/coqui/run.sh,huggingface-embeddings:/build/backend/python/sentencetransformers/run.sh,petals:/build/backend/python/petals/run.sh,transformers:/build/backend/python/transformers/run.sh,sentencetransformers:/build/backend/python/sentencetransformers/run.sh,autogptq:/build/backend/python/autogptq/run.sh,bark:/build/backend/python/bark/run.sh,diffusers:/build/backend/python/diffusers/run.sh,exllama:/build/backend/python/exllama/run.sh,vall-e-x:/build/backend/python/vall-e-x/run.sh,vllm:/build/backend/python/vllm/run.sh,mamba:/build/backend/python/mamba/run.sh,exllama2:/build/backend/python/exllama2/run.sh,transformers-musicgen:/build/backend/python/transformers-musicgen/run.sh"
|
||||
|
||||
ENV GALLERIES='[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.yaml"}, {"url": "github:go-skynet/model-gallery/huggingface.yaml","name":"huggingface"}]'
|
||||
ARG GO_TAGS="stablediffusion tinydream tts"
|
||||
|
||||
RUN apt-get update && \
|
||||
@@ -64,12 +63,12 @@ RUN curl https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc | gpg --dearmo
|
||||
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" > /etc/apt/sources.list.d/conda.list && \
|
||||
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" | tee -a /etc/apt/sources.list.d/conda.list && \
|
||||
apt-get update && \
|
||||
apt-get install -y conda
|
||||
apt-get install -y conda && apt-get clean
|
||||
|
||||
ENV PATH="/root/.cargo/bin:${PATH}"
|
||||
RUN pip install --upgrade pip
|
||||
RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
|
||||
RUN apt-get install -y espeak-ng espeak
|
||||
RUN apt-get install -y espeak-ng espeak && apt-get clean
|
||||
|
||||
###################################
|
||||
###################################
|
||||
@@ -127,10 +126,11 @@ ARG CUDA_MAJOR_VERSION=11
|
||||
ENV NVIDIA_DRIVER_CAPABILITIES=compute,utility
|
||||
ENV NVIDIA_REQUIRE_CUDA="cuda>=${CUDA_MAJOR_VERSION}.0"
|
||||
ENV NVIDIA_VISIBLE_DEVICES=all
|
||||
ENV PIP_CACHE_PURGE=true
|
||||
|
||||
# Add FFmpeg
|
||||
RUN if [ "${FFMPEG}" = "true" ]; then \
|
||||
apt-get install -y ffmpeg \
|
||||
apt-get install -y ffmpeg && apt-get clean \
|
||||
; fi
|
||||
|
||||
WORKDIR /build
|
||||
@@ -168,6 +168,9 @@ RUN if [ "${IMAGE_TYPE}" = "extras" ]; then \
|
||||
RUN if [ "${IMAGE_TYPE}" = "extras" ]; then \
|
||||
PATH=$PATH:/opt/conda/bin make -C backend/python/vllm \
|
||||
; fi
|
||||
RUN if [ "${IMAGE_TYPE}" = "extras" ]; then \
|
||||
PATH=$PATH:/opt/conda/bin make -C backend/python/mamba \
|
||||
; fi
|
||||
RUN if [ "${IMAGE_TYPE}" = "extras" ]; then \
|
||||
PATH=$PATH:/opt/conda/bin make -C backend/python/sentencetransformers \
|
||||
; fi
|
||||
@@ -193,6 +196,9 @@ RUN if [ "${IMAGE_TYPE}" = "extras" ]; then \
|
||||
PATH=$PATH:/opt/conda/bin make -C backend/python/coqui \
|
||||
; fi
|
||||
|
||||
# Make sure the models directory exists
|
||||
RUN mkdir -p /build/models
|
||||
|
||||
# Define the health check command
|
||||
HEALTHCHECK --interval=1m --timeout=10m --retries=10 \
|
||||
CMD curl -f $HEALTHCHECK_ENDPOINT || exit 1
|
||||
|
||||
2
LICENSE
2
LICENSE
@@ -1,6 +1,6 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 Ettore Di Giacinto
|
||||
Copyright (c) 2023-2024 Ettore Di Giacinto (mudler@localai.io)
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
|
||||
88
Makefile
88
Makefile
@@ -8,7 +8,7 @@ GOLLAMA_VERSION?=aeba71ee842819da681ea537e78846dc75949ac0
|
||||
|
||||
GOLLAMA_STABLE_VERSION?=50cee7712066d9e38306eccadcfbb44ea87df4b7
|
||||
|
||||
CPPLLAMA_VERSION?=cb1e2818e0e12ec99f7236ec5d4f3ffd8bcc2f4a
|
||||
CPPLLAMA_VERSION?=6f9939d119b2d004c264952eb510bd106455531e
|
||||
|
||||
# gpt4all version
|
||||
GPT4ALL_REPO?=https://github.com/nomic-ai/gpt4all
|
||||
@@ -140,8 +140,8 @@ endif
|
||||
ifeq ($(findstring tts,$(GO_TAGS)),tts)
|
||||
# OPTIONAL_TARGETS+=go-piper/libpiper_binding.a
|
||||
# OPTIONAL_TARGETS+=backend-assets/espeak-ng-data
|
||||
PIPER_CGO_CXXFLAGS+=-I$(shell pwd)/sources/go-piper/piper/src/cpp -I$(shell pwd)/sources/go-piper/piper/build/fi/include -I$(shell pwd)/sources/go-piper/piper/build/pi/include -I$(shell pwd)/sources/go-piper/piper/build/si/include
|
||||
PIPER_CGO_LDFLAGS+=-L$(shell pwd)/sources/go-piper/piper/build/fi/lib -L$(shell pwd)/sources/go-piper/piper/build/pi/lib -L$(shell pwd)/sources/go-piper/piper/build/si/lib -lfmt -lspdlog -lucd
|
||||
PIPER_CGO_CXXFLAGS+=-I$(CURDIR)/sources/go-piper/piper/src/cpp -I$(CURDIR)/sources/go-piper/piper/build/fi/include -I$(CURDIR)/sources/go-piper/piper/build/pi/include -I$(CURDIR)/sources/go-piper/piper/build/si/include
|
||||
PIPER_CGO_LDFLAGS+=-L$(CURDIR)/sources/go-piper/piper/build/fi/lib -L$(CURDIR)/sources/go-piper/piper/build/pi/lib -L$(CURDIR)/sources/go-piper/piper/build/si/lib -lfmt -lspdlog -lucd
|
||||
OPTIONAL_GRPC+=backend-assets/grpc/piper
|
||||
endif
|
||||
|
||||
@@ -153,6 +153,10 @@ ifeq ($(GRPC_BACKENDS),)
|
||||
GRPC_BACKENDS=$(ALL_GRPC_BACKENDS)
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_API_ONLY),true)
|
||||
GRPC_BACKENDS=
|
||||
endif
|
||||
|
||||
.PHONY: all test build vendor
|
||||
|
||||
all: help
|
||||
@@ -252,15 +256,15 @@ get-sources: backend/cpp/llama/llama.cpp sources/go-llama sources/go-llama-ggml
|
||||
touch $@
|
||||
|
||||
replace:
|
||||
$(GOCMD) mod edit -replace github.com/nomic-ai/gpt4all/gpt4all-bindings/golang=$(shell pwd)/sources/gpt4all/gpt4all-bindings/golang
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-ggml-transformers.cpp=$(shell pwd)/sources/go-ggml-transformers
|
||||
$(GOCMD) mod edit -replace github.com/donomii/go-rwkv.cpp=$(shell pwd)/sources/go-rwkv
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp=$(shell pwd)/sources/whisper.cpp
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp/bindings/go=$(shell pwd)/sources/whisper.cpp/bindings/go
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-bert.cpp=$(shell pwd)/sources/go-bert
|
||||
$(GOCMD) mod edit -replace github.com/mudler/go-stable-diffusion=$(shell pwd)/sources/go-stable-diffusion
|
||||
$(GOCMD) mod edit -replace github.com/M0Rf30/go-tiny-dream=$(shell pwd)/sources/go-tiny-dream
|
||||
$(GOCMD) mod edit -replace github.com/mudler/go-piper=$(shell pwd)/sources/go-piper
|
||||
$(GOCMD) mod edit -replace github.com/nomic-ai/gpt4all/gpt4all-bindings/golang=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-ggml-transformers.cpp=$(CURDIR)/sources/go-ggml-transformers
|
||||
$(GOCMD) mod edit -replace github.com/donomii/go-rwkv.cpp=$(CURDIR)/sources/go-rwkv
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp=$(CURDIR)/sources/whisper.cpp
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp/bindings/go=$(CURDIR)/sources/whisper.cpp/bindings/go
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-bert.cpp=$(CURDIR)/sources/go-bert
|
||||
$(GOCMD) mod edit -replace github.com/mudler/go-stable-diffusion=$(CURDIR)/sources/go-stable-diffusion
|
||||
$(GOCMD) mod edit -replace github.com/M0Rf30/go-tiny-dream=$(CURDIR)/sources/go-tiny-dream
|
||||
$(GOCMD) mod edit -replace github.com/mudler/go-piper=$(CURDIR)/sources/go-piper
|
||||
|
||||
prepare-sources: get-sources replace
|
||||
$(GOCMD) mod download
|
||||
@@ -290,19 +294,17 @@ clean: ## Remove build related file
|
||||
rm -rf ./sources
|
||||
rm -rf $(BINARY_NAME)
|
||||
rm -rf release/
|
||||
rm -rf ./backend/cpp/grpc/grpc_repo
|
||||
rm -rf ./backend/cpp/grpc/build
|
||||
rm -rf ./backend/cpp/grpc/installed_packages
|
||||
rm -rf backend-assets
|
||||
$(MAKE) -C backend/cpp/grpc clean
|
||||
$(MAKE) -C backend/cpp/llama clean
|
||||
|
||||
## Build:
|
||||
|
||||
build: grpcs prepare ## Build the project
|
||||
build: backend-assets grpcs prepare ## Build the project
|
||||
$(info ${GREEN}I local-ai build info:${RESET})
|
||||
$(info ${GREEN}I BUILD_TYPE: ${YELLOW}$(BUILD_TYPE)${RESET})
|
||||
$(info ${GREEN}I GO_TAGS: ${YELLOW}$(GO_TAGS)${RESET})
|
||||
$(info ${GREEN}I LD_FLAGS: ${YELLOW}$(LD_FLAGS)${RESET})
|
||||
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" $(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o $(BINARY_NAME) ./
|
||||
|
||||
dist: build
|
||||
@@ -417,6 +419,7 @@ protogen-python:
|
||||
python3 -m grpc_tools.protoc -Ibackend/ --python_out=backend/python/vall-e-x/ --grpc_python_out=backend/python/vall-e-x/ backend/backend.proto
|
||||
python3 -m grpc_tools.protoc -Ibackend/ --python_out=backend/python/vllm/ --grpc_python_out=backend/python/vllm/ backend/backend.proto
|
||||
python3 -m grpc_tools.protoc -Ibackend/ --python_out=backend/python/petals/ --grpc_python_out=backend/python/petals/ backend/backend.proto
|
||||
python3 -m grpc_tools.protoc -Ibackend/ --python_out=backend/python/mamba/ --grpc_python_out=backend/python/mamba/ backend/backend.proto
|
||||
python3 -m grpc_tools.protoc -Ibackend/ --python_out=backend/python/exllama2/ --grpc_python_out=backend/python/exllama2/ backend/backend.proto
|
||||
|
||||
## GRPC
|
||||
@@ -427,6 +430,7 @@ prepare-extra-conda-environments:
|
||||
$(MAKE) -C backend/python/coqui
|
||||
$(MAKE) -C backend/python/diffusers
|
||||
$(MAKE) -C backend/python/vllm
|
||||
$(MAKE) -C backend/python/mamba
|
||||
$(MAKE) -C backend/python/sentencetransformers
|
||||
$(MAKE) -C backend/python/transformers
|
||||
$(MAKE) -C backend/python/transformers-musicgen
|
||||
@@ -443,12 +447,18 @@ test-extra: prepare-test-extra
|
||||
$(MAKE) -C backend/python/transformers test
|
||||
$(MAKE) -C backend/python/diffusers test
|
||||
|
||||
backend-assets:
|
||||
mkdir -p backend-assets
|
||||
ifeq ($(BUILD_API_ONLY),true)
|
||||
touch backend-assets/keep
|
||||
endif
|
||||
|
||||
backend-assets/grpc:
|
||||
mkdir -p backend-assets/grpc
|
||||
|
||||
backend-assets/grpc/llama: backend-assets/grpc sources/go-llama/libbinding.a
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-llama.cpp=$(shell pwd)/sources/go-llama
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-llama LIBRARY_PATH=$(shell pwd)/sources/go-llama \
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-llama.cpp=$(CURDIR)/sources/go-llama
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-llama LIBRARY_PATH=$(CURDIR)/sources/go-llama \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/llama ./backend/go/llm/llama/
|
||||
# TODO: every binary should have its own folder instead, so can have different implementations
|
||||
ifeq ($(BUILD_TYPE),metal)
|
||||
@@ -467,17 +477,17 @@ ADDED_CMAKE_ARGS=-Dabsl_DIR=${INSTALLED_LIB_CMAKE}/absl \
|
||||
|
||||
backend/cpp/llama/grpc-server:
|
||||
ifdef BUILD_GRPC_FOR_BACKEND_LLAMA
|
||||
backend/cpp/grpc/script/build_grpc.sh ${INSTALLED_PACKAGES}
|
||||
$(MAKE) -C backend/cpp/grpc build
|
||||
export _PROTOBUF_PROTOC=${INSTALLED_PACKAGES}/bin/proto && \
|
||||
export _GRPC_CPP_PLUGIN_EXECUTABLE=${INSTALLED_PACKAGES}/bin/grpc_cpp_plugin && \
|
||||
export PATH=${PATH}:${INSTALLED_PACKAGES}/bin && \
|
||||
export PATH="${INSTALLED_PACKAGES}/bin:${PATH}" && \
|
||||
CMAKE_ARGS="${CMAKE_ARGS} ${ADDED_CMAKE_ARGS}" LLAMA_VERSION=$(CPPLLAMA_VERSION) $(MAKE) -C backend/cpp/llama grpc-server
|
||||
else
|
||||
echo "BUILD_GRPC_FOR_BACKEND_LLAMA is not defined."
|
||||
LLAMA_VERSION=$(CPPLLAMA_VERSION) $(MAKE) -C backend/cpp/llama grpc-server
|
||||
endif
|
||||
## BACKEND CPP LLAMA END
|
||||
|
||||
|
||||
##
|
||||
backend-assets/grpc/llama-cpp: backend-assets/grpc backend/cpp/llama/grpc-server
|
||||
cp -rfv backend/cpp/llama/grpc-server backend-assets/grpc/llama-cpp
|
||||
@@ -487,52 +497,52 @@ ifeq ($(BUILD_TYPE),metal)
|
||||
endif
|
||||
|
||||
backend-assets/grpc/llama-ggml: backend-assets/grpc sources/go-llama-ggml/libbinding.a
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-llama.cpp=$(shell pwd)/sources/go-llama-ggml
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-llama-ggml LIBRARY_PATH=$(shell pwd)/sources/go-llama-ggml \
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-llama.cpp=$(CURDIR)/sources/go-llama-ggml
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-llama-ggml LIBRARY_PATH=$(CURDIR)/sources/go-llama-ggml \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/llama-ggml ./backend/go/llm/llama-ggml/
|
||||
|
||||
backend-assets/grpc/gpt4all: backend-assets/grpc backend-assets/gpt4all sources/gpt4all/gpt4all-bindings/golang/libgpt4all.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/gpt4all/gpt4all-bindings/golang/ LIBRARY_PATH=$(shell pwd)/sources/gpt4all/gpt4all-bindings/golang/ \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang/ LIBRARY_PATH=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang/ \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gpt4all ./backend/go/llm/gpt4all/
|
||||
|
||||
backend-assets/grpc/dolly: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/dolly ./backend/go/llm/dolly/
|
||||
|
||||
backend-assets/grpc/gpt2: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gpt2 ./backend/go/llm/gpt2/
|
||||
|
||||
backend-assets/grpc/gptj: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gptj ./backend/go/llm/gptj/
|
||||
|
||||
backend-assets/grpc/gptneox: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gptneox ./backend/go/llm/gptneox/
|
||||
|
||||
backend-assets/grpc/mpt: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/mpt ./backend/go/llm/mpt/
|
||||
|
||||
backend-assets/grpc/replit: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/replit ./backend/go/llm/replit/
|
||||
|
||||
backend-assets/grpc/falcon-ggml: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/falcon-ggml ./backend/go/llm/falcon-ggml/
|
||||
|
||||
backend-assets/grpc/starcoder: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-ggml-transformers LIBRARY_PATH=$(shell pwd)/sources/go-ggml-transformers \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/starcoder ./backend/go/llm/starcoder/
|
||||
|
||||
backend-assets/grpc/rwkv: backend-assets/grpc sources/go-rwkv/librwkv.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-rwkv LIBRARY_PATH=$(shell pwd)/sources/go-rwkv \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-rwkv LIBRARY_PATH=$(CURDIR)/sources/go-rwkv \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/rwkv ./backend/go/llm/rwkv
|
||||
|
||||
backend-assets/grpc/bert-embeddings: backend-assets/grpc sources/go-bert/libgobert.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-bert LIBRARY_PATH=$(shell pwd)/sources/go-bert \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-bert LIBRARY_PATH=$(CURDIR)/sources/go-bert \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/bert-embeddings ./backend/go/llm/bert/
|
||||
|
||||
backend-assets/grpc/langchain-huggingface: backend-assets/grpc
|
||||
@@ -541,20 +551,20 @@ backend-assets/grpc/langchain-huggingface: backend-assets/grpc
|
||||
backend-assets/grpc/stablediffusion: backend-assets/grpc
|
||||
if [ ! -f backend-assets/grpc/stablediffusion ]; then \
|
||||
$(MAKE) sources/go-stable-diffusion/libstablediffusion.a; \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/go-stable-diffusion/ LIBRARY_PATH=$(shell pwd)/sources/go-stable-diffusion/ \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-stable-diffusion/ LIBRARY_PATH=$(CURDIR)/sources/go-stable-diffusion/ \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/stablediffusion ./backend/go/image/stablediffusion; \
|
||||
fi
|
||||
|
||||
backend-assets/grpc/tinydream: backend-assets/grpc sources/go-tiny-dream/libtinydream.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" LIBRARY_PATH=$(shell pwd)/go-tiny-dream \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" LIBRARY_PATH=$(CURDIR)/go-tiny-dream \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/tinydream ./backend/go/image/tinydream
|
||||
|
||||
backend-assets/grpc/piper: backend-assets/grpc backend-assets/espeak-ng-data sources/go-piper/libpiper_binding.a
|
||||
CGO_CXXFLAGS="$(PIPER_CGO_CXXFLAGS)" CGO_LDFLAGS="$(PIPER_CGO_LDFLAGS)" LIBRARY_PATH=$(shell pwd)/sources/go-piper \
|
||||
CGO_CXXFLAGS="$(PIPER_CGO_CXXFLAGS)" CGO_LDFLAGS="$(PIPER_CGO_LDFLAGS)" LIBRARY_PATH=$(CURDIR)/sources/go-piper \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/piper ./backend/go/tts/
|
||||
|
||||
backend-assets/grpc/whisper: backend-assets/grpc sources/whisper.cpp/libwhisper.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(shell pwd)/sources/whisper.cpp LIBRARY_PATH=$(shell pwd)/sources/whisper.cpp \
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/whisper.cpp LIBRARY_PATH=$(CURDIR)/sources/whisper.cpp \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/whisper ./backend/go/transcribe/
|
||||
|
||||
grpcs: prepare $(GRPC_BACKENDS)
|
||||
|
||||
16
README.md
16
README.md
@@ -20,6 +20,9 @@
|
||||
</a>
|
||||
</p>
|
||||
|
||||
[<img src="https://img.shields.io/badge/dockerhub-images-important.svg?logo=Docker">](https://hub.docker.com/r/localai/localai)
|
||||
[<img src="https://img.shields.io/badge/quay.io-images-important.svg?">](https://quay.io/repository/go-skynet/local-ai?tab=tags&tag=latest)
|
||||
|
||||
> :bulb: Get help - [❓FAQ](https://localai.io/faq/) [💭Discussions](https://github.com/go-skynet/LocalAI/discussions) [:speech_balloon: Discord](https://discord.gg/uJAeKSAGDy) [:book: Documentation website](https://localai.io/)
|
||||
>
|
||||
> [💻 Quickstart](https://localai.io/basics/getting_started/) [📣 News](https://localai.io/basics/news/) [ 🛫 Examples ](https://github.com/go-skynet/LocalAI/tree/master/examples/) [ 🖼️ Models ](https://localai.io/models/) [ 🚀 Roadmap ](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
@@ -40,6 +43,7 @@
|
||||
|
||||
[Roadmap](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
|
||||
- Mamba support: https://github.com/mudler/LocalAI/pull/1589
|
||||
- Start and share models with config file: https://github.com/mudler/LocalAI/pull/1522
|
||||
- 🐸 Coqui: https://github.com/mudler/LocalAI/pull/1489
|
||||
- Inline templates: https://github.com/mudler/LocalAI/pull/1452
|
||||
@@ -55,6 +59,12 @@ If you want to help and contribute, issues up for grabs: https://github.com/mudl
|
||||
|
||||
## 💻 [Getting started](https://localai.io/basics/getting_started/index.html)
|
||||
|
||||
For a detailed step-by-step introduction, refer to the [Getting Started](https://localai.io/basics/getting_started/index.html) guide. For those in a hurry, here's a straightforward one-liner to launch a LocalAI instance with [phi-2](https://huggingface.co/microsoft/phi-2) using `docker`:
|
||||
|
||||
```
|
||||
docker run -ti -p 8080:8080 localai/localai:v2.5.1-ffmpeg-core phi-2
|
||||
```
|
||||
|
||||
## 🚀 [Features](https://localai.io/features/)
|
||||
|
||||
- 📖 [Text generation with GPTs](https://localai.io/features/text-generation/) (`llama.cpp`, `gpt4all.cpp`, ... [:book: and more](https://localai.io/model-compatibility/index.html#model-compatibility-table))
|
||||
@@ -82,6 +92,10 @@ WebUIs:
|
||||
|
||||
Model galleries
|
||||
- https://github.com/go-skynet/model-gallery
|
||||
|
||||
Auto Docker / Model setup
|
||||
- https://io.midori-ai.xyz/howtos/easy-localai-installer/
|
||||
- https://io.midori-ai.xyz/howtos/easy-model-installer/
|
||||
|
||||
Other:
|
||||
- Helm chart https://github.com/go-skynet/helm-charts
|
||||
@@ -99,7 +113,7 @@ Other:
|
||||
- [How to build locally](https://localai.io/basics/build/index.html)
|
||||
- [How to install in Kubernetes](https://localai.io/basics/getting_started/index.html#run-localai-in-kubernetes)
|
||||
- [Projects integrating LocalAI](https://localai.io/integrations/)
|
||||
- [How tos section](https://localai.io/howtos/) (curated by our community)
|
||||
- [How tos section](https://io.midori-ai.xyz/howtos/) (curated by our community)
|
||||
|
||||
## :book: 🎥 [Media, Blogs, Social](https://localai.io/basics/news/#media-blogs-social)
|
||||
|
||||
|
||||
23
api/api.go
23
api/api.go
@@ -5,7 +5,6 @@ import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
@@ -17,7 +16,7 @@ import (
|
||||
"github.com/go-skynet/LocalAI/metrics"
|
||||
"github.com/go-skynet/LocalAI/pkg/assets"
|
||||
"github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/go-skynet/LocalAI/pkg/utils"
|
||||
"github.com/go-skynet/LocalAI/pkg/startup"
|
||||
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/gofiber/fiber/v2/middleware/cors"
|
||||
@@ -38,25 +37,7 @@ func Startup(opts ...options.AppOption) (*options.Option, *config.ConfigLoader,
|
||||
log.Info().Msgf("Starting LocalAI using %d threads, with models path: %s", options.Threads, options.Loader.ModelPath)
|
||||
log.Info().Msgf("LocalAI version: %s", internal.PrintableVersion())
|
||||
|
||||
modelPath := options.Loader.ModelPath
|
||||
if len(options.ModelsURL) > 0 {
|
||||
for _, url := range options.ModelsURL {
|
||||
if utils.LooksLikeURL(url) {
|
||||
// md5 of model name
|
||||
md5Name := utils.MD5(url)
|
||||
|
||||
// check if file exists
|
||||
if _, err := os.Stat(filepath.Join(modelPath, md5Name)); errors.Is(err, os.ErrNotExist) {
|
||||
err := utils.DownloadFile(url, filepath.Join(modelPath, md5Name)+".yaml", "", func(fileName, current, total string, percent float64) {
|
||||
utils.DisplayDownloadFunction(fileName, current, total, percent)
|
||||
})
|
||||
if err != nil {
|
||||
log.Error().Msgf("error loading model: %s", err.Error())
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
startup.PreloadModelsConfigurations(options.Loader.ModelPath, options.ModelsURL...)
|
||||
|
||||
cl := config.NewConfigLoader()
|
||||
if err := cl.LoadConfigs(options.Loader.ModelPath); err != nil {
|
||||
|
||||
@@ -16,9 +16,9 @@ import (
|
||||
. "github.com/go-skynet/LocalAI/api"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/metrics"
|
||||
"github.com/go-skynet/LocalAI/pkg/downloader"
|
||||
"github.com/go-skynet/LocalAI/pkg/gallery"
|
||||
"github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/go-skynet/LocalAI/pkg/utils"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
. "github.com/onsi/ginkgo/v2"
|
||||
. "github.com/onsi/gomega"
|
||||
@@ -61,7 +61,7 @@ func getModelStatus(url string) (response map[string]interface{}) {
|
||||
}
|
||||
|
||||
func getModels(url string) (response []gallery.GalleryModel) {
|
||||
utils.GetURI(url, func(url string, i []byte) error {
|
||||
downloader.GetURI(url, func(url string, i []byte) error {
|
||||
// Unmarshal YAML data into a struct
|
||||
return json.Unmarshal(i, &response)
|
||||
})
|
||||
|
||||
@@ -41,7 +41,7 @@ func ModelEmbedding(s string, tokens []int, loader *model.ModelLoader, c config.
|
||||
|
||||
var fn func() ([]float32, error)
|
||||
switch model := inferenceModel.(type) {
|
||||
case *grpc.Client:
|
||||
case grpc.Backend:
|
||||
fn = func() ([]float32, error) {
|
||||
predictOptions := gRPCPredictOpts(c, loader.ModelPath)
|
||||
if len(tokens) > 0 {
|
||||
|
||||
@@ -31,7 +31,7 @@ func ModelInference(ctx context.Context, s string, images []string, loader *mode
|
||||
|
||||
grpcOpts := gRPCModelOpts(c)
|
||||
|
||||
var inferenceModel *grpc.Client
|
||||
var inferenceModel grpc.Backend
|
||||
var err error
|
||||
|
||||
opts := modelOpts(c, o, []model.Option{
|
||||
|
||||
@@ -9,6 +9,7 @@ import (
|
||||
"strings"
|
||||
"sync"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/downloader"
|
||||
"github.com/go-skynet/LocalAI/pkg/utils"
|
||||
"github.com/rs/zerolog/log"
|
||||
"gopkg.in/yaml.v3"
|
||||
@@ -54,6 +55,9 @@ type Config struct {
|
||||
CUDA bool `yaml:"cuda"`
|
||||
|
||||
DownloadFiles []File `yaml:"download_files"`
|
||||
|
||||
Description string `yaml:"description"`
|
||||
Usage string `yaml:"usage"`
|
||||
}
|
||||
|
||||
type File struct {
|
||||
@@ -300,21 +304,21 @@ func (cm *ConfigLoader) Preload(modelPath string) error {
|
||||
// Create file path
|
||||
filePath := filepath.Join(modelPath, file.Filename)
|
||||
|
||||
if err := utils.DownloadFile(file.URI, filePath, file.SHA256, status); err != nil {
|
||||
if err := downloader.DownloadFile(file.URI, filePath, file.SHA256, status); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
|
||||
modelURL := config.PredictionOptions.Model
|
||||
modelURL = utils.ConvertURL(modelURL)
|
||||
modelURL = downloader.ConvertURL(modelURL)
|
||||
|
||||
if utils.LooksLikeURL(modelURL) {
|
||||
if downloader.LooksLikeURL(modelURL) {
|
||||
// md5 of model name
|
||||
md5Name := utils.MD5(modelURL)
|
||||
|
||||
// check if file exists
|
||||
if _, err := os.Stat(filepath.Join(modelPath, md5Name)); errors.Is(err, os.ErrNotExist) {
|
||||
err := utils.DownloadFile(modelURL, filepath.Join(modelPath, md5Name), "", status)
|
||||
err := downloader.DownloadFile(modelURL, filepath.Join(modelPath, md5Name), "", status)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
@@ -325,6 +329,15 @@ func (cm *ConfigLoader) Preload(modelPath string) error {
|
||||
c.PredictionOptions.Model = md5Name
|
||||
cm.configs[i] = *c
|
||||
}
|
||||
if cm.configs[i].Name != "" {
|
||||
log.Info().Msgf("Model name: %s", cm.configs[i].Name)
|
||||
}
|
||||
if cm.configs[i].Description != "" {
|
||||
log.Info().Msgf("Model description: %s", cm.configs[i].Description)
|
||||
}
|
||||
if cm.configs[i].Usage != "" {
|
||||
log.Info().Msgf("Model usage: \n%s", cm.configs[i].Usage)
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
@@ -112,7 +112,6 @@ message ModelOptions {
|
||||
int32 CLIPSkip = 33;
|
||||
string ControlNet = 48;
|
||||
|
||||
// RWKV
|
||||
string Tokenizer = 34;
|
||||
|
||||
// LLM (llama.cpp)
|
||||
|
||||
66
backend/cpp/grpc/Makefile
Normal file
66
backend/cpp/grpc/Makefile
Normal file
@@ -0,0 +1,66 @@
|
||||
# Basic platform detection
|
||||
HOST_SYSTEM = $(shell uname | cut -f 1 -d_)
|
||||
SYSTEM ?= $(HOST_SYSTEM)
|
||||
|
||||
TAG_LIB_GRPC?=v1.59.0
|
||||
GIT_REPO_LIB_GRPC?=https://github.com/grpc/grpc.git
|
||||
GIT_CLONE_DEPTH?=1
|
||||
NUM_BUILD_THREADS?=$(shell nproc --ignore=1)
|
||||
|
||||
INSTALLED_PACKAGES=installed_packages
|
||||
GRPC_REPO=grpc_repo
|
||||
GRPC_BUILD=grpc_build
|
||||
|
||||
export CMAKE_ARGS?=
|
||||
CMAKE_ARGS+=-DCMAKE_BUILD_TYPE=Release
|
||||
CMAKE_ARGS+=-DgRPC_INSTALL=ON
|
||||
CMAKE_ARGS+=-DEXECUTABLE_OUTPUT_PATH=../$(INSTALLED_PACKAGES)/grpc/bin
|
||||
CMAKE_ARGS+=-DLIBRARY_OUTPUT_PATH=../$(INSTALLED_PACKAGES)/grpc/lib
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_TESTS=OFF
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_CSHARP_EXT=OFF
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_GRPC_CPP_PLUGIN=ON
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_GRPC_CSHARP_PLUGIN=OFF
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_GRPC_NODE_PLUGIN=OFF
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_GRPC_OBJECTIVE_C_PLUGIN=OFF
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_GRPC_PHP_PLUGIN=OFF
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_GRPC_PYTHON_PLUGIN=ON
|
||||
CMAKE_ARGS+=-DgRPC_BUILD_GRPC_RUBY_PLUGIN=OFF
|
||||
CMAKE_ARGS+=-Dprotobuf_WITH_ZLIB=ON
|
||||
CMAKE_ARGS+=-DRE2_BUILD_TESTING=OFF
|
||||
CMAKE_ARGS+=-DCMAKE_INSTALL_PREFIX=../$(INSTALLED_PACKAGES)
|
||||
|
||||
# windows need to set OPENSSL_NO_ASM. Results in slower crypto performance but doesn't build otherwise.
|
||||
# May be resolvable, but for now its set. More info: https://stackoverflow.com/a/75240504/480673
|
||||
ifeq ($(SYSTEM),MSYS)
|
||||
CMAKE_ARGS+=-DOPENSSL_NO_ASM=ON
|
||||
endif
|
||||
ifeq ($(SYSTEM),MINGW64)
|
||||
CMAKE_ARGS+=-DOPENSSL_NO_ASM=ON
|
||||
endif
|
||||
ifeq ($(SYSTEM),MINGW32)
|
||||
CMAKE_ARGS+=-DOPENSSL_NO_ASM=ON
|
||||
endif
|
||||
ifeq ($(SYSTEM),CYGWIN)
|
||||
CMAKE_ARGS+=-DOPENSSL_NO_ASM=ON
|
||||
endif
|
||||
|
||||
$(INSTALLED_PACKAGES): grpc_build
|
||||
|
||||
$(GRPC_REPO):
|
||||
git clone --depth $(GIT_CLONE_DEPTH) -b $(TAG_LIB_GRPC) $(GIT_REPO_LIB_GRPC) $(GRPC_REPO)/grpc
|
||||
cd $(GRPC_REPO)/grpc && git submodule update --init --recursive --depth $(GIT_CLONE_DEPTH)
|
||||
|
||||
$(GRPC_BUILD): $(GRPC_REPO)
|
||||
mkdir -p $(GRPC_BUILD)
|
||||
cd $(GRPC_BUILD) && cmake $(CMAKE_ARGS) ../$(GRPC_REPO)/grpc && cmake --build . -- -j ${NUM_BUILD_THREADS} && cmake --build . --target install -- -j ${NUM_BUILD_THREADS}
|
||||
|
||||
build: $(INSTALLED_PACKAGES)
|
||||
|
||||
rebuild:
|
||||
rm -rf grpc_build
|
||||
$(MAKE) grpc_build
|
||||
|
||||
clean:
|
||||
rm -rf grpc_build
|
||||
rm -rf grpc_repo
|
||||
rm -rf installed_packages
|
||||
@@ -1,81 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
# Builds locally from sources the packages needed by the llama cpp backend.
|
||||
|
||||
# Makes sure a few base packages exist.
|
||||
# sudo apt-get --no-upgrade -y install g++ gcc binutils cmake git build-essential autoconf libtool pkg-config
|
||||
|
||||
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )"
|
||||
echo "Script directory: $SCRIPT_DIR"
|
||||
|
||||
CPP_INSTALLED_PACKAGES_DIR=$1
|
||||
if [ -z ${CPP_INSTALLED_PACKAGES_DIR} ]; then
|
||||
echo "CPP_INSTALLED_PACKAGES_DIR env variable not set. Don't know where to install: failed.";
|
||||
echo
|
||||
exit -1
|
||||
fi
|
||||
|
||||
if [ -d "${CPP_INSTALLED_PACKAGES_DIR}" ]; then
|
||||
echo "gRPC installation directory already exists. Nothing to do."
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# The depth when cloning a git repo. 1 speeds up the clone when the repo history is not needed.
|
||||
GIT_CLONE_DEPTH=1
|
||||
|
||||
NUM_BUILD_THREADS=$(nproc --ignore=1)
|
||||
|
||||
# Google gRPC --------------------------------------------------------------------------------------
|
||||
TAG_LIB_GRPC="v1.59.0"
|
||||
GIT_REPO_LIB_GRPC="https://github.com/grpc/grpc.git"
|
||||
GRPC_REPO_DIR="${SCRIPT_DIR}/../grpc_repo"
|
||||
GRPC_BUILD_DIR="${SCRIPT_DIR}/../grpc_build"
|
||||
SRC_DIR_LIB_GRPC="${GRPC_REPO_DIR}/grpc"
|
||||
|
||||
echo "SRC_DIR_LIB_GRPC: ${SRC_DIR_LIB_GRPC}"
|
||||
echo "GRPC_REPO_DIR: ${GRPC_REPO_DIR}"
|
||||
echo "GRPC_BUILD_DIR: ${GRPC_BUILD_DIR}"
|
||||
|
||||
mkdir -pv ${GRPC_REPO_DIR}
|
||||
|
||||
rm -rf ${GRPC_BUILD_DIR}
|
||||
mkdir -pv ${GRPC_BUILD_DIR}
|
||||
|
||||
mkdir -pv ${CPP_INSTALLED_PACKAGES_DIR}
|
||||
|
||||
if [ -d "${SRC_DIR_LIB_GRPC}" ]; then
|
||||
echo "gRPC source already exists locally. Not cloned again."
|
||||
else
|
||||
( cd ${GRPC_REPO_DIR} && \
|
||||
git clone --depth ${GIT_CLONE_DEPTH} -b ${TAG_LIB_GRPC} ${GIT_REPO_LIB_GRPC} && \
|
||||
cd ${SRC_DIR_LIB_GRPC} && \
|
||||
git submodule update --init --recursive --depth ${GIT_CLONE_DEPTH}
|
||||
)
|
||||
fi
|
||||
|
||||
( cd ${GRPC_BUILD_DIR} && \
|
||||
cmake -G "Unix Makefiles" \
|
||||
-DCMAKE_BUILD_TYPE=Release \
|
||||
-DgRPC_INSTALL=ON \
|
||||
-DEXECUTABLE_OUTPUT_PATH=${CPP_INSTALLED_PACKAGES_DIR}/grpc/bin \
|
||||
-DLIBRARY_OUTPUT_PATH=${CPP_INSTALLED_PACKAGES_DIR}/grpc/lib \
|
||||
-DgRPC_BUILD_TESTS=OFF \
|
||||
-DgRPC_BUILD_CSHARP_EXT=OFF \
|
||||
-DgRPC_BUILD_GRPC_CPP_PLUGIN=ON \
|
||||
-DgRPC_BUILD_GRPC_CSHARP_PLUGIN=OFF \
|
||||
-DgRPC_BUILD_GRPC_NODE_PLUGIN=OFF \
|
||||
-DgRPC_BUILD_GRPC_OBJECTIVE_C_PLUGIN=OFF \
|
||||
-DgRPC_BUILD_GRPC_PHP_PLUGIN=OFF \
|
||||
-DgRPC_BUILD_GRPC_PYTHON_PLUGIN=ON \
|
||||
-DgRPC_BUILD_GRPC_RUBY_PLUGIN=OFF \
|
||||
-Dprotobuf_WITH_ZLIB=ON \
|
||||
-DRE2_BUILD_TESTING=OFF \
|
||||
-DCMAKE_INSTALL_PREFIX=${CPP_INSTALLED_PACKAGES_DIR}/ \
|
||||
${SRC_DIR_LIB_GRPC} && \
|
||||
cmake --build . -- -j ${NUM_BUILD_THREADS} && \
|
||||
cmake --build . --target install -- -j ${NUM_BUILD_THREADS}
|
||||
)
|
||||
|
||||
rm -rf ${GRPC_BUILD_DIR}
|
||||
rm -rf ${GRPC_REPO_DIR}
|
||||
|
||||
@@ -158,8 +158,8 @@ static std::vector<uint8_t> base64_decode(const std::string & encoded_string)
|
||||
//
|
||||
|
||||
enum task_type {
|
||||
COMPLETION_TASK,
|
||||
CANCEL_TASK
|
||||
TASK_TYPE_COMPLETION,
|
||||
TASK_TYPE_CANCEL,
|
||||
};
|
||||
|
||||
struct task_server {
|
||||
@@ -458,8 +458,12 @@ struct llama_client_slot
|
||||
}
|
||||
|
||||
bool has_budget(gpt_params &global_params) {
|
||||
if (params.n_predict == -1 && global_params.n_predict == -1)
|
||||
{
|
||||
return true; // limitless
|
||||
}
|
||||
n_remaining = -1;
|
||||
if(params.n_predict != -1)
|
||||
if (params.n_predict != -1)
|
||||
{
|
||||
n_remaining = params.n_predict - n_decoded;
|
||||
}
|
||||
@@ -467,7 +471,7 @@ struct llama_client_slot
|
||||
{
|
||||
n_remaining = global_params.n_predict - n_decoded;
|
||||
}
|
||||
return n_remaining > 0 || n_remaining == -1; // no budget || limitless
|
||||
return n_remaining > 0; // no budget
|
||||
}
|
||||
|
||||
bool available() const {
|
||||
@@ -1113,7 +1117,7 @@ struct llama_server_context
|
||||
}
|
||||
|
||||
// check the limits
|
||||
if (slot.n_decoded > 2 && slot.has_next_token && !slot.has_budget(params))
|
||||
if (slot.n_decoded > 0 && slot.has_next_token && !slot.has_budget(params))
|
||||
{
|
||||
slot.stopped_limit = true;
|
||||
slot.has_next_token = false;
|
||||
@@ -1177,8 +1181,9 @@ struct llama_server_context
|
||||
return slot.images.size() > 0;
|
||||
}
|
||||
|
||||
void send_error(task_server& task, std::string error)
|
||||
void send_error(task_server& task, const std::string &error)
|
||||
{
|
||||
LOG_TEE("task %i - error: %s\n", task.id, error.c_str());
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
task_result res;
|
||||
res.id = task.id;
|
||||
@@ -1276,7 +1281,7 @@ struct llama_server_context
|
||||
{
|
||||
std::vector<completion_token_output> probs_output = {};
|
||||
const std::vector<llama_token> to_send_toks = llama_tokenize(ctx, tkn.text_to_send, false);
|
||||
size_t probs_pos = std::min(slot.sent_token_probs_index, slot.generated_token_probs.size());
|
||||
size_t probs_pos = std::min(slot.sent_token_probs_index, slot.generated_token_probs.size());
|
||||
size_t probs_stop_pos = std::min(slot.sent_token_probs_index + to_send_toks.size(), slot.generated_token_probs.size());
|
||||
if (probs_pos < probs_stop_pos)
|
||||
{
|
||||
@@ -1336,7 +1341,7 @@ struct llama_server_context
|
||||
{
|
||||
probs = std::vector<completion_token_output>(
|
||||
slot.generated_token_probs.begin(),
|
||||
slot.generated_token_probs.begin() + slot.sent_token_probs_index);
|
||||
slot.generated_token_probs.end());
|
||||
}
|
||||
res.result_json["completion_probabilities"] = probs_vector_to_json(ctx, probs);
|
||||
}
|
||||
@@ -1346,6 +1351,11 @@ struct llama_server_context
|
||||
res.result_json["oaicompat_token_ctr"] = slot.n_decoded;
|
||||
res.result_json["model"] = slot.oaicompat_model;
|
||||
}
|
||||
queue_results.push_back(res);
|
||||
condition_results.notify_all();
|
||||
|
||||
// done with results, unlock
|
||||
lock.unlock();
|
||||
|
||||
// parent multitask, if any, needs to be updated
|
||||
if (slot.multitask_id != -1)
|
||||
@@ -1353,8 +1363,6 @@ struct llama_server_context
|
||||
update_multi_task(slot.multitask_id, slot.task_id, res);
|
||||
}
|
||||
|
||||
queue_results.push_back(res);
|
||||
condition_results.notify_all();
|
||||
}
|
||||
|
||||
void send_embedding(llama_client_slot &slot)
|
||||
@@ -1399,11 +1407,11 @@ struct llama_server_context
|
||||
task.data = std::move(data);
|
||||
task.infill_mode = infill;
|
||||
task.embedding_mode = embedding;
|
||||
task.type = COMPLETION_TASK;
|
||||
task.type = TASK_TYPE_COMPLETION;
|
||||
task.multitask_id = multitask_id;
|
||||
|
||||
// when a completion task's prompt array is not a singleton, we split it into multiple requests
|
||||
if (task.data.at("prompt").size() > 1)
|
||||
if (task.data.count("prompt") && task.data.at("prompt").size() > 1)
|
||||
{
|
||||
lock.unlock(); // entering new func scope
|
||||
return split_multiprompt_task(task);
|
||||
@@ -1521,7 +1529,7 @@ struct llama_server_context
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
task_server task;
|
||||
task.id = id_gen++;
|
||||
task.type = CANCEL_TASK;
|
||||
task.type = TASK_TYPE_CANCEL;
|
||||
task.target_id = task_id;
|
||||
queue_tasks.push_back(task);
|
||||
condition_tasks.notify_one();
|
||||
@@ -1551,32 +1559,41 @@ struct llama_server_context
|
||||
void process_tasks()
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
std::vector<task_server> deferred_tasks;
|
||||
while (!queue_tasks.empty())
|
||||
{
|
||||
task_server task = queue_tasks.front();
|
||||
queue_tasks.erase(queue_tasks.begin());
|
||||
switch (task.type)
|
||||
{
|
||||
case COMPLETION_TASK: {
|
||||
case TASK_TYPE_COMPLETION: {
|
||||
llama_client_slot *slot = get_slot(json_value(task.data, "slot_id", -1));
|
||||
if (slot == nullptr)
|
||||
{
|
||||
LOG_TEE("slot unavailable\n");
|
||||
// send error result
|
||||
send_error(task, "slot unavailable");
|
||||
return;
|
||||
// if no slot is available, we defer this task for processing later
|
||||
deferred_tasks.push_back(task);
|
||||
break;
|
||||
}
|
||||
|
||||
if (task.data.contains("system_prompt"))
|
||||
{
|
||||
if (!all_slots_are_idle) {
|
||||
send_error(task, "system prompt can only be updated when all slots are idle");
|
||||
break;
|
||||
}
|
||||
process_system_prompt_data(task.data["system_prompt"]);
|
||||
// reset cache_tokens for all slots
|
||||
for (llama_client_slot &slot : slots)
|
||||
{
|
||||
slot.cache_tokens.clear();
|
||||
}
|
||||
}
|
||||
|
||||
slot->reset();
|
||||
|
||||
slot->infill = task.infill_mode;
|
||||
slot->embedding = task.embedding_mode;
|
||||
slot->task_id = task.id;
|
||||
slot->infill = task.infill_mode;
|
||||
slot->embedding = task.embedding_mode;
|
||||
slot->task_id = task.id;
|
||||
slot->multitask_id = task.multitask_id;
|
||||
|
||||
if (!launch_slot_with_data(slot, task.data))
|
||||
@@ -1586,7 +1603,7 @@ struct llama_server_context
|
||||
break;
|
||||
}
|
||||
} break;
|
||||
case CANCEL_TASK: { // release slot linked with the task id
|
||||
case TASK_TYPE_CANCEL: { // release slot linked with the task id
|
||||
for (auto & slot : slots)
|
||||
{
|
||||
if (slot.task_id == task.target_id)
|
||||
@@ -1599,7 +1616,14 @@ struct llama_server_context
|
||||
}
|
||||
}
|
||||
|
||||
// add all the deferred tasks back the the queue
|
||||
for (task_server &task : deferred_tasks)
|
||||
{
|
||||
queue_tasks.push_back(task);
|
||||
}
|
||||
|
||||
// remove finished multitasks from the queue of multitasks, and add the corresponding result to the result queue
|
||||
std::vector<task_result> agg_results;
|
||||
auto queue_iterator = queue_multitasks.begin();
|
||||
while (queue_iterator != queue_multitasks.end())
|
||||
{
|
||||
@@ -1620,8 +1644,7 @@ struct llama_server_context
|
||||
}
|
||||
aggregate_result.result_json = json{ "results", result_jsons };
|
||||
|
||||
std::lock_guard<std::mutex> lock(mutex_results);
|
||||
queue_results.push_back(aggregate_result);
|
||||
agg_results.push_back(aggregate_result);
|
||||
condition_results.notify_all();
|
||||
|
||||
queue_iterator = queue_multitasks.erase(queue_iterator);
|
||||
@@ -1631,14 +1654,19 @@ struct llama_server_context
|
||||
++queue_iterator;
|
||||
}
|
||||
}
|
||||
// done with tasks, unlock
|
||||
lock.unlock();
|
||||
|
||||
// copy aggregate results of complete multi-tasks to the results queue
|
||||
std::lock_guard<std::mutex> lock_results(mutex_results);
|
||||
queue_results.insert(queue_results.end(), agg_results.begin(), agg_results.end());
|
||||
}
|
||||
|
||||
bool update_slots() {
|
||||
// attend tasks
|
||||
process_tasks();
|
||||
|
||||
// update the system prompt wait until all slots are idle state
|
||||
if (system_need_update && all_slots_are_idle)
|
||||
if (system_need_update)
|
||||
{
|
||||
LOG_TEE("updating system prompt\n");
|
||||
update_system_prompt();
|
||||
@@ -1714,7 +1742,6 @@ struct llama_server_context
|
||||
|
||||
llama_batch_add(batch, slot.sampled, system_tokens.size() + slot.n_past, { slot.id }, true);
|
||||
|
||||
slot.n_decoded += 1;
|
||||
slot.n_past += 1;
|
||||
}
|
||||
|
||||
@@ -1729,7 +1756,8 @@ struct llama_server_context
|
||||
const bool has_prompt = slot.prompt.is_array() || (slot.prompt.is_string() && !slot.prompt.get<std::string>().empty()) || !slot.images.empty();
|
||||
|
||||
// empty prompt passed -> release the slot and send empty response
|
||||
if (slot.state == IDLE && slot.command == LOAD_PROMPT && !has_prompt)
|
||||
// note: infill mode allows empty prompt
|
||||
if (slot.state == IDLE && slot.command == LOAD_PROMPT && !has_prompt && !slot.infill)
|
||||
{
|
||||
slot.release();
|
||||
slot.print_timings();
|
||||
@@ -1832,7 +1860,7 @@ struct llama_server_context
|
||||
|
||||
slot.cache_tokens = prompt_tokens;
|
||||
|
||||
if (slot.n_past == slot.num_prompt_tokens)
|
||||
if (slot.n_past == slot.num_prompt_tokens && slot.n_past > 0)
|
||||
{
|
||||
// we have to evaluate at least 1 token to generate logits.
|
||||
LOG_TEE("slot %d : we have to evaluate at least 1 token to generate logits\n", slot.id);
|
||||
@@ -1932,6 +1960,7 @@ struct llama_server_context
|
||||
|
||||
llama_sampling_accept(slot.ctx_sampling, ctx, id, true);
|
||||
|
||||
slot.n_decoded += 1;
|
||||
if (slot.n_decoded == 1)
|
||||
{
|
||||
slot.t_start_genereration = ggml_time_us();
|
||||
@@ -2023,7 +2052,7 @@ json oaicompat_completion_params_parse(
|
||||
//
|
||||
// https://platform.openai.com/docs/api-reference/chat/create
|
||||
llama_sampling_params default_sparams;
|
||||
llama_params["model"] = json_value(body, "model", std::string("uknown"));
|
||||
llama_params["model"] = json_value(body, "model", std::string("unknown"));
|
||||
llama_params["prompt"] = format_chatml(body["messages"]); // OpenAI 'messages' to llama.cpp 'prompt'
|
||||
llama_params["cache_prompt"] = json_value(body, "cache_prompt", false);
|
||||
llama_params["temperature"] = json_value(body, "temperature", 0.0);
|
||||
@@ -2095,8 +2124,8 @@ static json format_final_response_oaicompat(const json &request, const task_resu
|
||||
{"object", streaming ? "chat.completion.chunk" : "chat.completion"},
|
||||
{"usage",
|
||||
json{{"completion_tokens", num_tokens_predicted},
|
||||
{"prompt_tokens", num_prompt_tokens},
|
||||
{"total_tokens", num_tokens_predicted + num_prompt_tokens}}},
|
||||
{"prompt_tokens", num_prompt_tokens},
|
||||
{"total_tokens", num_tokens_predicted + num_prompt_tokens}}},
|
||||
{"id", gen_chatcmplid()}};
|
||||
|
||||
if (server_verbose) {
|
||||
@@ -2436,10 +2465,10 @@ static void params_parse(const backend::ModelOptions* request,
|
||||
const char *env_parallel = std::getenv("LLAMACPP_PARALLEL");
|
||||
if (env_parallel != NULL) {
|
||||
params.n_parallel = std::stoi(env_parallel);
|
||||
params.cont_batching = true;
|
||||
} else {
|
||||
params.n_parallel = 1;
|
||||
}
|
||||
|
||||
// TODO: Add yarn
|
||||
|
||||
if (!request->tensorsplit().empty()) {
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
.PHONY: autogptq
|
||||
autogptq:
|
||||
@echo "Creating virtual environment..."
|
||||
@conda env create --name autogptq --file autogptq.yml
|
||||
@echo "Virtual environment created."
|
||||
$(MAKE) -C ../common-env/transformers
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate autogptq
|
||||
source activate transformers
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
@@ -13,3 +13,12 @@ if conda_env_exists "transformers" ; then
|
||||
else
|
||||
echo "Virtual environment already exists."
|
||||
fi
|
||||
|
||||
if [ "$PIP_CACHE_PURGE" = true ] ; then
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate transformers
|
||||
|
||||
pip cache purge
|
||||
fi
|
||||
@@ -45,7 +45,7 @@ dependencies:
|
||||
- fsspec==2023.6.0
|
||||
- funcy==2.0
|
||||
- grpcio==1.59.0
|
||||
- huggingface-hub==0.16.4
|
||||
- huggingface-hub
|
||||
- idna==3.4
|
||||
- jinja2==3.1.2
|
||||
- jmespath==1.0.1
|
||||
@@ -70,7 +70,6 @@ dependencies:
|
||||
- packaging==23.2
|
||||
- pandas
|
||||
- peft==0.5.0
|
||||
- git+https://github.com/bigscience-workshop/petals
|
||||
- protobuf==4.24.4
|
||||
- psutil==5.9.5
|
||||
- pyarrow==13.0.0
|
||||
@@ -85,17 +84,16 @@ dependencies:
|
||||
- scipy==1.11.3
|
||||
- six==1.16.0
|
||||
- sympy==1.12
|
||||
- tokenizers==0.14.0
|
||||
- torch==2.1.0
|
||||
- torchaudio==2.1.0
|
||||
- tokenizers
|
||||
- torch==2.1.2
|
||||
- torchaudio==2.1.2
|
||||
- tqdm==4.66.1
|
||||
- transformers==4.34.0
|
||||
- TTS==0.22.0
|
||||
- triton==2.1.0
|
||||
- typing-extensions==4.8.0
|
||||
- tzdata==2023.3
|
||||
- urllib3==1.26.17
|
||||
- xxhash==3.4.1
|
||||
- auto-gptq==0.6.0
|
||||
- yarl==1.9.2
|
||||
- soundfile
|
||||
- langid
|
||||
@@ -114,4 +112,7 @@ dependencies:
|
||||
- sudachipy
|
||||
- sudachidict_core
|
||||
- vocos
|
||||
- vllm==0.2.7
|
||||
- transformers>=4.36.0 # Required for Mixtral.
|
||||
- xformers==0.0.23.post1
|
||||
prefix: /opt/conda/envs/transformers
|
||||
|
||||
@@ -46,7 +46,7 @@ dependencies:
|
||||
- fsspec==2023.6.0
|
||||
- funcy==2.0
|
||||
- grpcio==1.59.0
|
||||
- huggingface-hub==0.16.4
|
||||
- huggingface-hub
|
||||
- idna==3.4
|
||||
- jinja2==3.1.2
|
||||
- jmespath==1.0.1
|
||||
@@ -59,7 +59,6 @@ dependencies:
|
||||
- packaging==23.2
|
||||
- pandas
|
||||
- peft==0.5.0
|
||||
- git+https://github.com/bigscience-workshop/petals
|
||||
- protobuf==4.24.4
|
||||
- psutil==5.9.5
|
||||
- pyarrow==13.0.0
|
||||
@@ -74,14 +73,14 @@ dependencies:
|
||||
- scipy==1.11.3
|
||||
- six==1.16.0
|
||||
- sympy==1.12
|
||||
- tokenizers==0.14.0
|
||||
- torch==2.1.0
|
||||
- torchaudio==2.1.0
|
||||
- tokenizers
|
||||
- torch==2.1.2
|
||||
- torchaudio==2.1.2
|
||||
- tqdm==4.66.1
|
||||
- transformers==4.34.0
|
||||
- triton==2.1.0
|
||||
- typing-extensions==4.8.0
|
||||
- tzdata==2023.3
|
||||
- auto-gptq==0.6.0
|
||||
- urllib3==1.26.17
|
||||
- xxhash==3.4.1
|
||||
- yarl==1.9.2
|
||||
@@ -102,4 +101,7 @@ dependencies:
|
||||
- sudachipy
|
||||
- sudachidict_core
|
||||
- vocos
|
||||
- vllm==0.2.7
|
||||
- transformers>=4.36.0 # Required for Mixtral.
|
||||
- xformers==0.0.23.post1
|
||||
prefix: /opt/conda/envs/transformers
|
||||
@@ -21,7 +21,7 @@ _ONE_DAY_IN_SECONDS = 60 * 60 * 24
|
||||
|
||||
# If MAX_WORKERS are specified in the environment use it, otherwise default to 1
|
||||
MAX_WORKERS = int(os.environ.get('PYTHON_GRPC_MAX_WORKERS', '1'))
|
||||
COQUI_LANGUAGE = os.environ.get('COQUI_LANGUAGE', 'en')
|
||||
COQUI_LANGUAGE = os.environ.get('COQUI_LANGUAGE', None)
|
||||
|
||||
# Implement the BackendServicer class with the service methods
|
||||
class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
@@ -33,11 +33,18 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
def LoadModel(self, request, context):
|
||||
|
||||
# Get device
|
||||
device = "cuda" if request.CUDA else "cpu"
|
||||
# device = "cuda" if request.CUDA else "cpu"
|
||||
if torch.cuda.is_available():
|
||||
print("CUDA is available", file=sys.stderr)
|
||||
device = "cuda"
|
||||
else:
|
||||
print("CUDA is not available", file=sys.stderr)
|
||||
device = "cpu"
|
||||
|
||||
if not torch.cuda.is_available() and request.CUDA:
|
||||
return backend_pb2.Result(success=False, message="CUDA is not available")
|
||||
|
||||
self.AudioPath = None
|
||||
# List available 🐸TTS models
|
||||
print(TTS().list_models())
|
||||
if os.path.isabs(request.AudioPath):
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
.PHONY: exllama
|
||||
exllama:
|
||||
@echo "Creating virtual environment..."
|
||||
@conda env create --name exllama --file exllama.yml
|
||||
@echo "Virtual environment created."
|
||||
$(MAKE) -C ../common-env/transformers
|
||||
bash install.sh
|
||||
|
||||
.PHONY: run
|
||||
|
||||
@@ -5,11 +5,15 @@
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate exllama
|
||||
source activate transformers
|
||||
|
||||
echo $CONDA_PREFIX
|
||||
|
||||
|
||||
git clone https://github.com/turboderp/exllama $CONDA_PREFIX/exllama && pushd $CONDA_PREFIX/exllama && pip install -r requirements.txt && popd
|
||||
|
||||
cp -rfv $CONDA_PREFIX/exllama/* ./
|
||||
cp -rfv $CONDA_PREFIX/exllama/* ./
|
||||
|
||||
if [ "$PIP_CACHE_PURGE" = true ] ; then
|
||||
pip cache purge
|
||||
fi
|
||||
@@ -6,7 +6,7 @@
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate exllama
|
||||
source activate transformers
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
.PHONY: exllama2
|
||||
exllama2:
|
||||
@echo "Creating virtual environment..."
|
||||
@conda env create --name exllama2 --file exllama2.yml
|
||||
@echo "Virtual environment created."
|
||||
$(MAKE) -C ../common-env/transformers
|
||||
bash install.sh
|
||||
|
||||
.PHONY: run
|
||||
|
||||
@@ -5,10 +5,14 @@
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate exllama2
|
||||
source activate transformers
|
||||
|
||||
echo $CONDA_PREFIX
|
||||
|
||||
git clone https://github.com/turboderp/exllamav2 $CONDA_PREFIX/exllamav2 && pushd $CONDA_PREFIX/exllamav2 && pip install -r requirements.txt && popd
|
||||
|
||||
cp -rfv $CONDA_PREFIX/exllamav2/* ./
|
||||
cp -rfv $CONDA_PREFIX/exllamav2/* ./
|
||||
|
||||
if [ "$PIP_CACHE_PURGE" = true ] ; then
|
||||
pip cache purge
|
||||
fi
|
||||
@@ -6,7 +6,7 @@
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate exllama2
|
||||
source activate transformers
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
16
backend/python/mamba/Makefile
Normal file
16
backend/python/mamba/Makefile
Normal file
@@ -0,0 +1,16 @@
|
||||
.PHONY: mamba
|
||||
mamba:
|
||||
$(MAKE) -C ../common-env/transformers
|
||||
bash install.sh
|
||||
|
||||
.PHONY: run
|
||||
run:
|
||||
@echo "Running mamba..."
|
||||
bash run.sh
|
||||
@echo "mamba run."
|
||||
|
||||
.PHONY: test
|
||||
test:
|
||||
@echo "Testing mamba..."
|
||||
bash test.sh
|
||||
@echo "mamba tested."
|
||||
5
backend/python/mamba/README.md
Normal file
5
backend/python/mamba/README.md
Normal file
@@ -0,0 +1,5 @@
|
||||
# Creating a separate environment for the mamba project
|
||||
|
||||
```
|
||||
make mamba
|
||||
```
|
||||
179
backend/python/mamba/backend_mamba.py
Normal file
179
backend/python/mamba/backend_mamba.py
Normal file
@@ -0,0 +1,179 @@
|
||||
#!/usr/bin/env python3
|
||||
from concurrent import futures
|
||||
import time
|
||||
import argparse
|
||||
import signal
|
||||
import sys
|
||||
import os
|
||||
|
||||
import backend_pb2
|
||||
import backend_pb2_grpc
|
||||
|
||||
import grpc
|
||||
|
||||
import torch
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
|
||||
|
||||
_ONE_DAY_IN_SECONDS = 60 * 60 * 24
|
||||
|
||||
# If MAX_WORKERS are specified in the environment use it, otherwise default to 1
|
||||
MAX_WORKERS = int(os.environ.get('PYTHON_GRPC_MAX_WORKERS', '1'))
|
||||
MAMBA_CHAT= os.environ.get('MAMBA_CHAT', '1') == '1'
|
||||
|
||||
# Implement the BackendServicer class with the service methods
|
||||
class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
"""
|
||||
A gRPC servicer that implements the Backend service defined in backend.proto.
|
||||
"""
|
||||
def generate(self,prompt, max_new_tokens):
|
||||
"""
|
||||
Generates text based on the given prompt and maximum number of new tokens.
|
||||
|
||||
Args:
|
||||
prompt (str): The prompt to generate text from.
|
||||
max_new_tokens (int): The maximum number of new tokens to generate.
|
||||
|
||||
Returns:
|
||||
str: The generated text.
|
||||
"""
|
||||
self.generator.end_beam_search()
|
||||
|
||||
# Tokenizing the input
|
||||
ids = self.generator.tokenizer.encode(prompt)
|
||||
|
||||
self.generator.gen_begin_reuse(ids)
|
||||
initial_len = self.generator.sequence[0].shape[0]
|
||||
has_leading_space = False
|
||||
decoded_text = ''
|
||||
for i in range(max_new_tokens):
|
||||
token = self.generator.gen_single_token()
|
||||
if i == 0 and self.generator.tokenizer.tokenizer.IdToPiece(int(token)).startswith('▁'):
|
||||
has_leading_space = True
|
||||
|
||||
decoded_text = self.generator.tokenizer.decode(self.generator.sequence[0][initial_len:])
|
||||
if has_leading_space:
|
||||
decoded_text = ' ' + decoded_text
|
||||
|
||||
if token.item() == self.generator.tokenizer.eos_token_id:
|
||||
break
|
||||
return decoded_text
|
||||
|
||||
def Health(self, request, context):
|
||||
"""
|
||||
Returns a health check message.
|
||||
|
||||
Args:
|
||||
request: The health check request.
|
||||
context: The gRPC context.
|
||||
|
||||
Returns:
|
||||
backend_pb2.Reply: The health check reply.
|
||||
"""
|
||||
return backend_pb2.Reply(message=bytes("OK", 'utf-8'))
|
||||
|
||||
def LoadModel(self, request, context):
|
||||
"""
|
||||
Loads a language model.
|
||||
|
||||
Args:
|
||||
request: The load model request.
|
||||
context: The gRPC context.
|
||||
|
||||
Returns:
|
||||
backend_pb2.Result: The load model result.
|
||||
"""
|
||||
try:
|
||||
tokenizerModel = request.Tokenizer
|
||||
if tokenizerModel == "":
|
||||
tokenizerModel = request.Model
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizerModel)
|
||||
if MAMBA_CHAT:
|
||||
tokenizer.eos_token = "<|endoftext|>"
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
self.tokenizer = tokenizer
|
||||
self.model = MambaLMHeadModel.from_pretrained(request.Model, device="cuda", dtype=torch.float16)
|
||||
except Exception as err:
|
||||
return backend_pb2.Result(success=False, message=f"Unexpected {err=}, {type(err)=}")
|
||||
return backend_pb2.Result(message="Model loaded successfully", success=True)
|
||||
|
||||
def Predict(self, request, context):
|
||||
"""
|
||||
Generates text based on the given prompt and sampling parameters.
|
||||
|
||||
Args:
|
||||
request: The predict request.
|
||||
context: The gRPC context.
|
||||
|
||||
Returns:
|
||||
backend_pb2.Result: The predict result.
|
||||
"""
|
||||
if request.TopP == 0:
|
||||
request.TopP = 0.9
|
||||
|
||||
max_tokens = request.Tokens
|
||||
|
||||
if request.Tokens == 0:
|
||||
max_tokens = 2000
|
||||
|
||||
# encoded_input = self.tokenizer(request.Prompt)
|
||||
tokens = self.tokenizer(request.Prompt, return_tensors="pt")
|
||||
input_ids = tokens.input_ids.to(device="cuda")
|
||||
out = self.model.generate(input_ids=input_ids, max_length=max_tokens, temperature=request.Temperature,
|
||||
top_p=request.TopP, eos_token_id=self.tokenizer.eos_token_id)
|
||||
|
||||
decoded = self.tokenizer.batch_decode(out)
|
||||
|
||||
generated_text = decoded[0]
|
||||
|
||||
# Remove prompt from response if present
|
||||
if request.Prompt in generated_text:
|
||||
generated_text = generated_text.replace(request.Prompt, "")
|
||||
|
||||
return backend_pb2.Reply(message=bytes(generated_text, encoding='utf-8'))
|
||||
|
||||
def PredictStream(self, request, context):
|
||||
"""
|
||||
Generates text based on the given prompt and sampling parameters, and streams the results.
|
||||
|
||||
Args:
|
||||
request: The predict stream request.
|
||||
context: The gRPC context.
|
||||
|
||||
Returns:
|
||||
backend_pb2.Result: The predict stream result.
|
||||
"""
|
||||
yield self.Predict(request, context)
|
||||
|
||||
def serve(address):
|
||||
server = grpc.server(futures.ThreadPoolExecutor(max_workers=MAX_WORKERS))
|
||||
backend_pb2_grpc.add_BackendServicer_to_server(BackendServicer(), server)
|
||||
server.add_insecure_port(address)
|
||||
server.start()
|
||||
print("Server started. Listening on: " + address, file=sys.stderr)
|
||||
|
||||
# Define the signal handler function
|
||||
def signal_handler(sig, frame):
|
||||
print("Received termination signal. Shutting down...")
|
||||
server.stop(0)
|
||||
sys.exit(0)
|
||||
|
||||
# Set the signal handlers for SIGINT and SIGTERM
|
||||
signal.signal(signal.SIGINT, signal_handler)
|
||||
signal.signal(signal.SIGTERM, signal_handler)
|
||||
|
||||
try:
|
||||
while True:
|
||||
time.sleep(_ONE_DAY_IN_SECONDS)
|
||||
except KeyboardInterrupt:
|
||||
server.stop(0)
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Run the gRPC server.")
|
||||
parser.add_argument(
|
||||
"--addr", default="localhost:50051", help="The address to bind the server to."
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
serve(args.addr)
|
||||
61
backend/python/mamba/backend_pb2.py
Normal file
61
backend/python/mamba/backend_pb2.py
Normal file
File diff suppressed because one or more lines are too long
363
backend/python/mamba/backend_pb2_grpc.py
Normal file
363
backend/python/mamba/backend_pb2_grpc.py
Normal file
@@ -0,0 +1,363 @@
|
||||
# Generated by the gRPC Python protocol compiler plugin. DO NOT EDIT!
|
||||
"""Client and server classes corresponding to protobuf-defined services."""
|
||||
import grpc
|
||||
|
||||
import backend_pb2 as backend__pb2
|
||||
|
||||
|
||||
class BackendStub(object):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
|
||||
def __init__(self, channel):
|
||||
"""Constructor.
|
||||
|
||||
Args:
|
||||
channel: A grpc.Channel.
|
||||
"""
|
||||
self.Health = channel.unary_unary(
|
||||
'/backend.Backend/Health',
|
||||
request_serializer=backend__pb2.HealthMessage.SerializeToString,
|
||||
response_deserializer=backend__pb2.Reply.FromString,
|
||||
)
|
||||
self.Predict = channel.unary_unary(
|
||||
'/backend.Backend/Predict',
|
||||
request_serializer=backend__pb2.PredictOptions.SerializeToString,
|
||||
response_deserializer=backend__pb2.Reply.FromString,
|
||||
)
|
||||
self.LoadModel = channel.unary_unary(
|
||||
'/backend.Backend/LoadModel',
|
||||
request_serializer=backend__pb2.ModelOptions.SerializeToString,
|
||||
response_deserializer=backend__pb2.Result.FromString,
|
||||
)
|
||||
self.PredictStream = channel.unary_stream(
|
||||
'/backend.Backend/PredictStream',
|
||||
request_serializer=backend__pb2.PredictOptions.SerializeToString,
|
||||
response_deserializer=backend__pb2.Reply.FromString,
|
||||
)
|
||||
self.Embedding = channel.unary_unary(
|
||||
'/backend.Backend/Embedding',
|
||||
request_serializer=backend__pb2.PredictOptions.SerializeToString,
|
||||
response_deserializer=backend__pb2.EmbeddingResult.FromString,
|
||||
)
|
||||
self.GenerateImage = channel.unary_unary(
|
||||
'/backend.Backend/GenerateImage',
|
||||
request_serializer=backend__pb2.GenerateImageRequest.SerializeToString,
|
||||
response_deserializer=backend__pb2.Result.FromString,
|
||||
)
|
||||
self.AudioTranscription = channel.unary_unary(
|
||||
'/backend.Backend/AudioTranscription',
|
||||
request_serializer=backend__pb2.TranscriptRequest.SerializeToString,
|
||||
response_deserializer=backend__pb2.TranscriptResult.FromString,
|
||||
)
|
||||
self.TTS = channel.unary_unary(
|
||||
'/backend.Backend/TTS',
|
||||
request_serializer=backend__pb2.TTSRequest.SerializeToString,
|
||||
response_deserializer=backend__pb2.Result.FromString,
|
||||
)
|
||||
self.TokenizeString = channel.unary_unary(
|
||||
'/backend.Backend/TokenizeString',
|
||||
request_serializer=backend__pb2.PredictOptions.SerializeToString,
|
||||
response_deserializer=backend__pb2.TokenizationResponse.FromString,
|
||||
)
|
||||
self.Status = channel.unary_unary(
|
||||
'/backend.Backend/Status',
|
||||
request_serializer=backend__pb2.HealthMessage.SerializeToString,
|
||||
response_deserializer=backend__pb2.StatusResponse.FromString,
|
||||
)
|
||||
|
||||
|
||||
class BackendServicer(object):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
|
||||
def Health(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def Predict(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def LoadModel(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def PredictStream(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def Embedding(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def GenerateImage(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def AudioTranscription(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def TTS(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def TokenizeString(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
def Status(self, request, context):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
|
||||
context.set_details('Method not implemented!')
|
||||
raise NotImplementedError('Method not implemented!')
|
||||
|
||||
|
||||
def add_BackendServicer_to_server(servicer, server):
|
||||
rpc_method_handlers = {
|
||||
'Health': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.Health,
|
||||
request_deserializer=backend__pb2.HealthMessage.FromString,
|
||||
response_serializer=backend__pb2.Reply.SerializeToString,
|
||||
),
|
||||
'Predict': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.Predict,
|
||||
request_deserializer=backend__pb2.PredictOptions.FromString,
|
||||
response_serializer=backend__pb2.Reply.SerializeToString,
|
||||
),
|
||||
'LoadModel': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.LoadModel,
|
||||
request_deserializer=backend__pb2.ModelOptions.FromString,
|
||||
response_serializer=backend__pb2.Result.SerializeToString,
|
||||
),
|
||||
'PredictStream': grpc.unary_stream_rpc_method_handler(
|
||||
servicer.PredictStream,
|
||||
request_deserializer=backend__pb2.PredictOptions.FromString,
|
||||
response_serializer=backend__pb2.Reply.SerializeToString,
|
||||
),
|
||||
'Embedding': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.Embedding,
|
||||
request_deserializer=backend__pb2.PredictOptions.FromString,
|
||||
response_serializer=backend__pb2.EmbeddingResult.SerializeToString,
|
||||
),
|
||||
'GenerateImage': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.GenerateImage,
|
||||
request_deserializer=backend__pb2.GenerateImageRequest.FromString,
|
||||
response_serializer=backend__pb2.Result.SerializeToString,
|
||||
),
|
||||
'AudioTranscription': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.AudioTranscription,
|
||||
request_deserializer=backend__pb2.TranscriptRequest.FromString,
|
||||
response_serializer=backend__pb2.TranscriptResult.SerializeToString,
|
||||
),
|
||||
'TTS': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.TTS,
|
||||
request_deserializer=backend__pb2.TTSRequest.FromString,
|
||||
response_serializer=backend__pb2.Result.SerializeToString,
|
||||
),
|
||||
'TokenizeString': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.TokenizeString,
|
||||
request_deserializer=backend__pb2.PredictOptions.FromString,
|
||||
response_serializer=backend__pb2.TokenizationResponse.SerializeToString,
|
||||
),
|
||||
'Status': grpc.unary_unary_rpc_method_handler(
|
||||
servicer.Status,
|
||||
request_deserializer=backend__pb2.HealthMessage.FromString,
|
||||
response_serializer=backend__pb2.StatusResponse.SerializeToString,
|
||||
),
|
||||
}
|
||||
generic_handler = grpc.method_handlers_generic_handler(
|
||||
'backend.Backend', rpc_method_handlers)
|
||||
server.add_generic_rpc_handlers((generic_handler,))
|
||||
|
||||
|
||||
# This class is part of an EXPERIMENTAL API.
|
||||
class Backend(object):
|
||||
"""Missing associated documentation comment in .proto file."""
|
||||
|
||||
@staticmethod
|
||||
def Health(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/Health',
|
||||
backend__pb2.HealthMessage.SerializeToString,
|
||||
backend__pb2.Reply.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def Predict(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/Predict',
|
||||
backend__pb2.PredictOptions.SerializeToString,
|
||||
backend__pb2.Reply.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def LoadModel(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/LoadModel',
|
||||
backend__pb2.ModelOptions.SerializeToString,
|
||||
backend__pb2.Result.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def PredictStream(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_stream(request, target, '/backend.Backend/PredictStream',
|
||||
backend__pb2.PredictOptions.SerializeToString,
|
||||
backend__pb2.Reply.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def Embedding(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/Embedding',
|
||||
backend__pb2.PredictOptions.SerializeToString,
|
||||
backend__pb2.EmbeddingResult.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def GenerateImage(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/GenerateImage',
|
||||
backend__pb2.GenerateImageRequest.SerializeToString,
|
||||
backend__pb2.Result.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def AudioTranscription(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/AudioTranscription',
|
||||
backend__pb2.TranscriptRequest.SerializeToString,
|
||||
backend__pb2.TranscriptResult.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def TTS(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/TTS',
|
||||
backend__pb2.TTSRequest.SerializeToString,
|
||||
backend__pb2.Result.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def TokenizeString(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/TokenizeString',
|
||||
backend__pb2.PredictOptions.SerializeToString,
|
||||
backend__pb2.TokenizationResponse.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
|
||||
@staticmethod
|
||||
def Status(request,
|
||||
target,
|
||||
options=(),
|
||||
channel_credentials=None,
|
||||
call_credentials=None,
|
||||
insecure=False,
|
||||
compression=None,
|
||||
wait_for_ready=None,
|
||||
timeout=None,
|
||||
metadata=None):
|
||||
return grpc.experimental.unary_unary(request, target, '/backend.Backend/Status',
|
||||
backend__pb2.HealthMessage.SerializeToString,
|
||||
backend__pb2.StatusResponse.FromString,
|
||||
options, channel_credentials,
|
||||
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
|
||||
21
backend/python/mamba/install.sh
Normal file
21
backend/python/mamba/install.sh
Normal file
@@ -0,0 +1,21 @@
|
||||
#!/bin/bash
|
||||
|
||||
##
|
||||
## A bash script installs the required dependencies of VALL-E-X and prepares the environment
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
if [ "$BUILD_TYPE" != "cublas" ]; then
|
||||
echo "[mamba] Attention!!! nvcc is required - skipping installation"
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Activate conda environment
|
||||
source activate transformers
|
||||
|
||||
echo $CONDA_PREFIX
|
||||
|
||||
pip install causal-conv1d==1.0.0 mamba-ssm==1.0.1
|
||||
|
||||
if [ "$PIP_CACHE_PURGE" = true ] ; then
|
||||
pip cache purge
|
||||
fi
|
||||
14
backend/python/mamba/run.sh
Executable file
14
backend/python/mamba/run.sh
Executable file
@@ -0,0 +1,14 @@
|
||||
#!/bin/bash
|
||||
|
||||
##
|
||||
## A bash script wrapper that runs the diffusers server with conda
|
||||
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate transformers
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
python $DIR/backend_mamba.py $@
|
||||
11
backend/python/mamba/test.sh
Normal file
11
backend/python/mamba/test.sh
Normal file
@@ -0,0 +1,11 @@
|
||||
#!/bin/bash
|
||||
##
|
||||
## A bash script wrapper that runs the transformers server with conda
|
||||
|
||||
# Activate conda environment
|
||||
source activate transformers
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
python -m unittest $DIR/test_backend_mamba.py
|
||||
76
backend/python/mamba/test_backend_mamba.py
Normal file
76
backend/python/mamba/test_backend_mamba.py
Normal file
@@ -0,0 +1,76 @@
|
||||
import unittest
|
||||
import subprocess
|
||||
import time
|
||||
import backend_pb2
|
||||
import backend_pb2_grpc
|
||||
|
||||
import grpc
|
||||
|
||||
import unittest
|
||||
import subprocess
|
||||
import time
|
||||
import grpc
|
||||
import backend_pb2_grpc
|
||||
import backend_pb2
|
||||
|
||||
class TestBackendServicer(unittest.TestCase):
|
||||
"""
|
||||
TestBackendServicer is the class that tests the gRPC service.
|
||||
|
||||
This class contains methods to test the startup and shutdown of the gRPC service.
|
||||
"""
|
||||
def setUp(self):
|
||||
self.service = subprocess.Popen(["python", "backend_vllm.py", "--addr", "localhost:50051"])
|
||||
time.sleep(10)
|
||||
|
||||
def tearDown(self) -> None:
|
||||
self.service.terminate()
|
||||
self.service.wait()
|
||||
|
||||
def test_server_startup(self):
|
||||
try:
|
||||
self.setUp()
|
||||
with grpc.insecure_channel("localhost:50051") as channel:
|
||||
stub = backend_pb2_grpc.BackendStub(channel)
|
||||
response = stub.Health(backend_pb2.HealthMessage())
|
||||
self.assertEqual(response.message, b'OK')
|
||||
except Exception as err:
|
||||
print(err)
|
||||
self.fail("Server failed to start")
|
||||
finally:
|
||||
self.tearDown()
|
||||
def test_load_model(self):
|
||||
"""
|
||||
This method tests if the model is loaded successfully
|
||||
"""
|
||||
try:
|
||||
self.setUp()
|
||||
with grpc.insecure_channel("localhost:50051") as channel:
|
||||
stub = backend_pb2_grpc.BackendStub(channel)
|
||||
response = stub.LoadModel(backend_pb2.ModelOptions(Model="facebook/opt-125m"))
|
||||
self.assertTrue(response.success)
|
||||
self.assertEqual(response.message, "Model loaded successfully")
|
||||
except Exception as err:
|
||||
print(err)
|
||||
self.fail("LoadModel service failed")
|
||||
finally:
|
||||
self.tearDown()
|
||||
|
||||
def test_text(self):
|
||||
"""
|
||||
This method tests if the embeddings are generated successfully
|
||||
"""
|
||||
try:
|
||||
self.setUp()
|
||||
with grpc.insecure_channel("localhost:50051") as channel:
|
||||
stub = backend_pb2_grpc.BackendStub(channel)
|
||||
response = stub.LoadModel(backend_pb2.ModelOptions(Model="facebook/opt-125m"))
|
||||
self.assertTrue(response.success)
|
||||
req = backend_pb2.PredictOptions(Prompt="The capital of France is")
|
||||
resp = stub.Predict(req)
|
||||
self.assertIsNotNone(resp.message)
|
||||
except Exception as err:
|
||||
print(err)
|
||||
self.fail("text service failed")
|
||||
finally:
|
||||
self.tearDown()
|
||||
@@ -1,6 +1,8 @@
|
||||
.PHONY: petals
|
||||
petals:
|
||||
$(MAKE) -C ../common-env/transformers
|
||||
@echo "Creating virtual environment..."
|
||||
@conda env create --name petals --file petals.yml
|
||||
@echo "Virtual environment created."
|
||||
|
||||
.PHONY: run
|
||||
run:
|
||||
|
||||
@@ -5,14 +5,16 @@
|
||||
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
CONDA_ENV=petals
|
||||
|
||||
# Activate conda environment
|
||||
# if source is available use it, or use conda
|
||||
#
|
||||
if [ -f /opt/conda/bin/activate ]; then
|
||||
source activate transformers
|
||||
source activate $CONDA_ENV
|
||||
else
|
||||
eval "$(conda shell.bash hook)"
|
||||
conda activate transformers
|
||||
conda activate $CONDA_ENV
|
||||
fi
|
||||
|
||||
# get the directory where the bash script is located
|
||||
|
||||
@@ -3,7 +3,16 @@
|
||||
## A bash script wrapper that runs the transformers server with conda
|
||||
|
||||
# Activate conda environment
|
||||
source activate transformers
|
||||
CONDA_ENV=petals
|
||||
# Activate conda environment
|
||||
# if source is available use it, or use conda
|
||||
#
|
||||
if [ -f /opt/conda/bin/activate ]; then
|
||||
source activate $CONDA_ENV
|
||||
else
|
||||
eval "$(conda shell.bash hook)"
|
||||
conda activate $CONDA_ENV
|
||||
fi
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
@@ -12,4 +12,8 @@ echo $CONDA_PREFIX
|
||||
|
||||
git clone https://github.com/Plachtaa/VALL-E-X.git $CONDA_PREFIX/vall-e-x && pushd $CONDA_PREFIX/vall-e-x && git checkout -b build $SHA && pip install -r requirements.txt && popd
|
||||
|
||||
cp -rfv $CONDA_PREFIX/vall-e-x/* ./
|
||||
cp -rfv $CONDA_PREFIX/vall-e-x/* ./
|
||||
|
||||
if [ "$PIP_CACHE_PURGE" = true ] ; then
|
||||
pip cache purge
|
||||
fi
|
||||
@@ -1,8 +1,6 @@
|
||||
.PHONY: vllm
|
||||
vllm:
|
||||
@echo "Creating virtual environment..."
|
||||
@conda env create --name vllm --file vllm.yml
|
||||
@echo "Virtual environment created."
|
||||
$(MAKE) -C ../common-env/transformers
|
||||
|
||||
.PHONY: run
|
||||
run:
|
||||
|
||||
@@ -97,12 +97,16 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
context: The gRPC context.
|
||||
|
||||
Returns:
|
||||
backend_pb2.Result: The predict result.
|
||||
backend_pb2.Reply: The predict result.
|
||||
"""
|
||||
if request.TopP == 0:
|
||||
request.TopP = 0.9
|
||||
|
||||
sampling_params = SamplingParams(temperature=request.Temperature, top_p=request.TopP)
|
||||
max_tokens = 200
|
||||
if request.Tokens > 0:
|
||||
max_tokens = request.Tokens
|
||||
|
||||
sampling_params = SamplingParams(max_tokens=max_tokens, temperature=request.Temperature, top_p=request.TopP)
|
||||
outputs = self.llm.generate([request.Prompt], sampling_params)
|
||||
|
||||
generated_text = outputs[0].outputs[0].text
|
||||
@@ -110,7 +114,7 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
if request.Prompt in generated_text:
|
||||
generated_text = generated_text.replace(request.Prompt, "")
|
||||
|
||||
return backend_pb2.Result(message=bytes(generated_text, encoding='utf-8'))
|
||||
return backend_pb2.Reply(message=bytes(generated_text, encoding='utf-8'))
|
||||
|
||||
def PredictStream(self, request, context):
|
||||
"""
|
||||
@@ -123,11 +127,7 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
Returns:
|
||||
backend_pb2.Result: The predict stream result.
|
||||
"""
|
||||
# Implement PredictStream RPC
|
||||
#for reply in some_data_generator():
|
||||
# yield reply
|
||||
# Not implemented yet
|
||||
return self.Predict(request, context)
|
||||
yield self.Predict(request, context)
|
||||
|
||||
def serve(address):
|
||||
server = grpc.server(futures.ThreadPoolExecutor(max_workers=MAX_WORKERS))
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate vllm
|
||||
source activate transformers
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
## A bash script wrapper that runs the transformers server with conda
|
||||
|
||||
# Activate conda environment
|
||||
source activate vllm
|
||||
source activate transformers
|
||||
|
||||
# get the directory where the bash script is located
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
|
||||
@@ -1,99 +0,0 @@
|
||||
name: vllm
|
||||
channels:
|
||||
- defaults
|
||||
dependencies:
|
||||
- _libgcc_mutex=0.1=main
|
||||
- _openmp_mutex=5.1=1_gnu
|
||||
- bzip2=1.0.8=h7b6447c_0
|
||||
- ca-certificates=2023.08.22=h06a4308_0
|
||||
- ld_impl_linux-64=2.38=h1181459_1
|
||||
- libffi=3.4.4=h6a678d5_0
|
||||
- libgcc-ng=11.2.0=h1234567_1
|
||||
- libgomp=11.2.0=h1234567_1
|
||||
- libstdcxx-ng=11.2.0=h1234567_1
|
||||
- libuuid=1.41.5=h5eee18b_0
|
||||
- ncurses=6.4=h6a678d5_0
|
||||
- openssl=3.0.11=h7f8727e_2
|
||||
- pip=23.2.1=py311h06a4308_0
|
||||
- python=3.11.5=h955ad1f_0
|
||||
- readline=8.2=h5eee18b_0
|
||||
- setuptools=68.0.0=py311h06a4308_0
|
||||
- sqlite=3.41.2=h5eee18b_0
|
||||
- tk=8.6.12=h1ccaba5_0
|
||||
- wheel=0.41.2=py311h06a4308_0
|
||||
- xz=5.4.2=h5eee18b_0
|
||||
- zlib=1.2.13=h5eee18b_0
|
||||
- pip:
|
||||
- aiosignal==1.3.1
|
||||
- anyio==3.7.1
|
||||
- attrs==23.1.0
|
||||
- certifi==2023.7.22
|
||||
- charset-normalizer==3.3.0
|
||||
- click==8.1.7
|
||||
- cmake==3.27.6
|
||||
- fastapi==0.103.2
|
||||
- filelock==3.12.4
|
||||
- frozenlist==1.4.0
|
||||
- fsspec==2023.9.2
|
||||
- grpcio==1.59.0
|
||||
- h11==0.14.0
|
||||
- httptools==0.6.0
|
||||
- huggingface-hub==0.17.3
|
||||
- idna==3.4
|
||||
- jinja2==3.1.2
|
||||
- jsonschema==4.19.1
|
||||
- jsonschema-specifications==2023.7.1
|
||||
- lit==17.0.2
|
||||
- markupsafe==2.1.3
|
||||
- mpmath==1.3.0
|
||||
- msgpack==1.0.7
|
||||
- networkx==3.1
|
||||
- ninja==1.11.1
|
||||
- numpy==1.26.0
|
||||
- nvidia-cublas-cu11==11.10.3.66
|
||||
- nvidia-cuda-cupti-cu11==11.7.101
|
||||
- nvidia-cuda-nvrtc-cu11==11.7.99
|
||||
- nvidia-cuda-runtime-cu11==11.7.99
|
||||
- nvidia-cudnn-cu11==8.5.0.96
|
||||
- nvidia-cufft-cu11==10.9.0.58
|
||||
- nvidia-curand-cu11==10.2.10.91
|
||||
- nvidia-cusolver-cu11==11.4.0.1
|
||||
- nvidia-cusparse-cu11==11.7.4.91
|
||||
- nvidia-nccl-cu11==2.14.3
|
||||
- nvidia-nvtx-cu11==11.7.91
|
||||
- packaging==23.2
|
||||
- pandas==2.1.1
|
||||
- protobuf==4.24.4
|
||||
- psutil==5.9.5
|
||||
- pyarrow==13.0.0
|
||||
- pydantic==1.10.13
|
||||
- python-dateutil==2.8.2
|
||||
- python-dotenv==1.0.0
|
||||
- pytz==2023.3.post1
|
||||
- pyyaml==6.0.1
|
||||
- ray==2.7.0
|
||||
- referencing==0.30.2
|
||||
- regex==2023.10.3
|
||||
- requests==2.31.0
|
||||
- rpds-py==0.10.4
|
||||
- safetensors==0.4.0
|
||||
- sentencepiece==0.1.99
|
||||
- six==1.16.0
|
||||
- sniffio==1.3.0
|
||||
- starlette==0.27.0
|
||||
- sympy==1.12
|
||||
- tokenizers==0.14.1
|
||||
- torch==2.0.1
|
||||
- tqdm==4.66.1
|
||||
- transformers==4.34.0
|
||||
- triton==2.0.0
|
||||
- typing-extensions==4.8.0
|
||||
- tzdata==2023.3
|
||||
- urllib3==2.0.6
|
||||
- uvicorn==0.23.2
|
||||
- uvloop==0.17.0
|
||||
- vllm==0.2.0
|
||||
- watchfiles==0.20.0
|
||||
- websockets==11.0.3
|
||||
- xformers==0.0.22
|
||||
prefix: /opt/conda/envs/vllm
|
||||
11
docs/assets/jsconfig.json
Normal file
11
docs/assets/jsconfig.json
Normal file
@@ -0,0 +1,11 @@
|
||||
{
|
||||
"compilerOptions": {
|
||||
"baseUrl": ".",
|
||||
"paths": {
|
||||
"*": [
|
||||
"../../../../.cache/hugo_cache/modules/filecache/modules/pkg/mod/github.com/gohugoio/hugo-mod-jslibs-dist/popperjs/v2@v2.21100.20000/package/dist/cjs/popper.js/*",
|
||||
"../../../../.cache/hugo_cache/modules/filecache/modules/pkg/mod/github.com/twbs/bootstrap@v5.3.2+incompatible/js/*"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
296
docs/config.toml
296
docs/config.toml
@@ -1,133 +1,178 @@
|
||||
# this is a required setting for this theme to appear on https://themes.gohugo.io/
|
||||
# change this to a value appropriate for you; if your site is served from a subdirectory
|
||||
# set it like "https://example.com/mysite/"
|
||||
baseURL = "https://localai.io/"
|
||||
languageCode = "en-GB"
|
||||
contentDir = "content"
|
||||
enableEmoji = true
|
||||
enableGitInfo = true # N.B. .GitInfo does not currently function with git submodule content directories
|
||||
|
||||
# canonicalization will only be used for the sitemap.xml and index.xml files;
|
||||
# if set to false, a site served from a subdirectory will generate wrong links
|
||||
# inside of the above mentioned files; if you serve the page from the servers root
|
||||
# you are free to set the value to false as recommended by the official Hugo documentation
|
||||
canonifyURLs = true # true -> all relative URLs would instead be canonicalized using baseURL
|
||||
# required value to serve this page from a webserver AND the file system;
|
||||
# if you don't want to serve your page from the file system, you can also set this value
|
||||
# to false
|
||||
relativeURLs = true # true -> rewrite all relative URLs to be relative to the current content
|
||||
# if you set uglyURLs to false, this theme will append 'index.html' to any branch bundle link
|
||||
# so your page can be also served from the file system; if you don't want that,
|
||||
# set disableExplicitIndexURLs=true in the [params] section
|
||||
uglyURLs = false # true -> basic/index.html -> basic.html
|
||||
defaultContentLanguage = 'en'
|
||||
|
||||
# the directory where Hugo reads the themes from; this is specific to your
|
||||
# installation and most certainly needs be deleted or changed
|
||||
#themesdir = "../.."
|
||||
# yeah, well, obviously a mandatory setting for your site, if you want to
|
||||
# use this theme ;-)
|
||||
theme = "hugo-theme-relearn"
|
||||
|
||||
# the main language of this site; also an automatic pirrrate translation is
|
||||
# available in this showcase
|
||||
languageCode = "en"
|
||||
|
||||
# make sure your defaultContentLanguage is the first one in the [languages]
|
||||
# array below, as the theme needs to make assumptions on it
|
||||
defaultContentLanguage = "en"
|
||||
|
||||
# the site's title of this showcase; you should change this ;-)
|
||||
title = "LocalAI Documentation"
|
||||
|
||||
# We disable this for testing the exampleSite; you must do so too
|
||||
# if you want to use the themes parameter disableGeneratorVersion=true;
|
||||
# otherwise Hugo will create a generator tag on your home page
|
||||
disableHugoGeneratorInject = true
|
||||
|
||||
[outputs]
|
||||
# add JSON to the home to support Lunr search; This is a mandatory setting
|
||||
# for the search functionality
|
||||
# add PRINT to home, section and page to activate the feature to print whole
|
||||
# chapters
|
||||
home = ["HTML", "RSS", "PRINT", "SEARCH", "SEARCHPAGE"]
|
||||
section = ["HTML", "RSS", "PRINT"]
|
||||
page = ["HTML", "RSS", "PRINT"]
|
||||
|
||||
[markup]
|
||||
[markup.highlight]
|
||||
# if `guessSyntax = true`, there will be no unstyled code even if no language
|
||||
# was given BUT Mermaid and Math codefences will not work anymore! So this is a
|
||||
# mandatory setting for your site if you want to use Mermaid or Math codefences
|
||||
guessSyntax = true
|
||||
defaultMarkdownHandler = "goldmark"
|
||||
[markup.tableOfContents]
|
||||
endLevel = 3
|
||||
startLevel = 1
|
||||
[markup.goldmark]
|
||||
[markup.goldmark.renderer]
|
||||
unsafe = true # https://jdhao.github.io/2019/12/29/hugo_html_not_shown/
|
||||
# [markup.highlight]
|
||||
# codeFences = false # disables Hugo's default syntax highlighting
|
||||
# [markup.goldmark.parser]
|
||||
# [markup.goldmark.parser.attribute]
|
||||
# block = true
|
||||
# title = true
|
||||
|
||||
# here in this showcase we use our own modified chroma syntax highlightning style
|
||||
# which is imported in theme-relearn-light.css / theme-relearn-dark.css;
|
||||
# if you want to use a predefined style instead:
|
||||
# - remove the following `noClasses`
|
||||
# - set the following `style` to a predefined style name
|
||||
# - remove the `@import` of the self-defined chroma stylesheet from your CSS files
|
||||
# (here eg.: theme-relearn-light.css / theme-relearn-dark.css)
|
||||
noClasses = false
|
||||
style = "tango"
|
||||
|
||||
[markup.goldmark.renderer]
|
||||
# activated for this showcase to use HTML and JavaScript; decide on your own needs;
|
||||
# if in doubt, remove this line
|
||||
unsafe = true
|
||||
|
||||
# allows `hugo server` to display this showcase in IE11; this is used for testing, as we
|
||||
# are still supporting IE11 - although with degraded experience; if you don't care about
|
||||
# `hugo server` or browsers of ancient times, fell free to remove this whole block
|
||||
[server]
|
||||
[[server.headers]]
|
||||
for = "**.html"
|
||||
[server.headers.values]
|
||||
X-UA-Compatible = "IE=edge"
|
||||
[params]
|
||||
|
||||
google_fonts = [
|
||||
["Inter", "300, 400, 600, 700"],
|
||||
["Fira Code", "500, 700"]
|
||||
]
|
||||
|
||||
sans_serif_font = "Inter" # Default is System font
|
||||
secondary_font = "Inter" # Default is System font
|
||||
mono_font = "Fira Code" # Default is System font
|
||||
|
||||
[params.footer]
|
||||
copyright = "© 2023-2024 <a href='https://mudler.pm' target=_blank>Ettore Di Giacinto</a>"
|
||||
version = true # includes git commit info
|
||||
|
||||
[params.social]
|
||||
github = "mudler/LocalAI" # YOUR_GITHUB_ID or YOUR_GITHUB_URL
|
||||
twitter = "LocalAI_API" # YOUR_TWITTER_ID
|
||||
dicord = "uJAeKSAGDy"
|
||||
# instagram = "colinwilson" # YOUR_INSTAGRAM_ID
|
||||
rss = true # show rss icon with link
|
||||
|
||||
[params.docs] # Parameters for the /docs 'template'
|
||||
|
||||
logo = "https://github.com/go-skynet/LocalAI/assets/2420543/0966aa2a-166e-4f99-a3e5-6c915fc997dd"
|
||||
logo_text = "LocalAI"
|
||||
title = "LocalAI documentation" # default html title for documentation pages/sections
|
||||
|
||||
pathName = "docs" # path name for documentation site | default "docs"
|
||||
|
||||
# themeColor = "cyan" # (optional) - Set theme accent colour. Options include: blue (default), green, red, yellow, emerald, cardinal, magenta, cyan
|
||||
|
||||
darkMode = true # enable dark mode option? default false
|
||||
|
||||
prism = true # enable syntax highlighting via Prism
|
||||
|
||||
prismTheme = "solarized-light" # (optional) - Set theme for PrismJS. Options include: lotusdocs (default), solarized-light, twilight, lucario
|
||||
|
||||
# gitinfo
|
||||
repoURL = "https://github.com/mudler/LocalAI" # Git repository URL for your site [support for GitHub, GitLab, and BitBucket]
|
||||
repoBranch = "master"
|
||||
editPage = true # enable 'Edit this page' feature - default false
|
||||
lastMod = true # enable 'Last modified' date on pages - default false
|
||||
lastModRelative = true # format 'Last modified' time as relative - default true
|
||||
|
||||
sidebarIcons = true # enable sidebar icons? default false
|
||||
breadcrumbs = true # default is true
|
||||
backToTop = true # enable back-to-top button? default true
|
||||
|
||||
# ToC
|
||||
toc = true # enable table of contents? default is true
|
||||
tocMobile = true # enable table of contents in mobile view? default is true
|
||||
scrollSpy = true # enable scrollspy on ToC? default is true
|
||||
|
||||
# front matter
|
||||
descriptions = true # enable front matter descriptions under content title?
|
||||
titleIcon = true # enable front matter icon title prefix? default is false
|
||||
|
||||
# content navigation
|
||||
navDesc = true # include front matter descriptions in Prev/Next navigation cards
|
||||
navDescTrunc = 30 # Number of characters by which to truncate the Prev/Next descriptions
|
||||
|
||||
listDescTrunc = 100 # Number of characters by which to truncate the list card description
|
||||
|
||||
# Link behaviour
|
||||
intLinkTooltip = true # Enable a tooltip for internal links that displays info about the destination? default false
|
||||
# extLinkNewTab = false # Open external links in a new Tab? default true
|
||||
# logoLinkURL = "" # Set a custom URL destination for the top header logo link.
|
||||
|
||||
[params.flexsearch] # Parameters for FlexSearch
|
||||
enabled = true
|
||||
# tokenize = "full"
|
||||
# optimize = true
|
||||
# cache = 100
|
||||
# minQueryChar = 3 # default is 0 (disabled)
|
||||
# maxResult = 5 # default is 5
|
||||
# searchSectionsIndex = []
|
||||
|
||||
[params.docsearch] # Parameters for DocSearch
|
||||
# appID = "" # Algolia Application ID
|
||||
# apiKey = "" # Algolia Search-Only API (Public) Key
|
||||
# indexName = "" # Index Name to perform search on (or set env variable HUGO_PARAM_DOCSEARCH_indexName)
|
||||
|
||||
[params.analytics] # Parameters for Analytics (Google, Plausible)
|
||||
# plausibleURL = "/docs/s" # (or set via env variable HUGO_PARAM_ANALYTICS_plausibleURL)
|
||||
# plausibleAPI = "/docs/s" # optional - (or set via env variable HUGO_PARAM_ANALYTICS_plausibleAPI)
|
||||
# plausibleDomain = "" # (or set via env variable HUGO_PARAM_ANALYTICS_plausibleDomain)
|
||||
|
||||
# [params.feedback]
|
||||
# enabled = true
|
||||
# emoticonTpl = true
|
||||
# eventDest = ["plausible","google"]
|
||||
# emoticonEventName = "Feedback"
|
||||
# positiveEventName = "Positive Feedback"
|
||||
# negativeEventName = "Negative Feedback"
|
||||
# positiveFormTitle = "What did you like?"
|
||||
# negativeFormTitle = "What went wrong?"
|
||||
# successMsg = "Thank you for helping to improve Lotus Docs' documentation!"
|
||||
# errorMsg = "Sorry! There was an error while attempting to submit your feedback!"
|
||||
# positiveForm = [
|
||||
# ["Accurate", "Accurately describes the feature or option."],
|
||||
# ["Solved my problem", "Helped me resolve an issue."],
|
||||
# ["Easy to understand", "Easy to follow and comprehend."],
|
||||
# ["Something else"]
|
||||
# ]
|
||||
# negativeForm = [
|
||||
# ["Inaccurate", "Doesn't accurately describe the feature or option."],
|
||||
# ["Couldn't find what I was looking for", "Missing important information."],
|
||||
# ["Hard to understand", "Too complicated or unclear."],
|
||||
# ["Code sample errors", "One or more code samples are incorrect."],
|
||||
# ["Something else"]
|
||||
# ]
|
||||
|
||||
[menu]
|
||||
[[menu.primary]]
|
||||
name = "Docs"
|
||||
url = "docs/"
|
||||
identifier = "docs"
|
||||
weight = 10
|
||||
[[menu.primary]]
|
||||
name = "Discord"
|
||||
url = "https://discord.gg/uJAeKSAGDy"
|
||||
identifier = "discord"
|
||||
weight = 20
|
||||
|
||||
# showcase of the menu shortcuts; you can use relative URLs linking
|
||||
# to your content or use fully-quallified URLs to link outside of
|
||||
# your project
|
||||
[languages]
|
||||
[languages.en]
|
||||
title = "LocalAI documentation"
|
||||
weight = 1
|
||||
languageName = "English"
|
||||
[languages.en.params]
|
||||
landingPageName = "<i class='fas fa-home'></i> Home"
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = "<i class='fas fa-home'></i> Home"
|
||||
url = "/"
|
||||
weight = 1
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = "<i class='fab fa-fw fa-github'></i> GitHub repo"
|
||||
identifier = "ds"
|
||||
url = "https://github.com/go-skynet/LocalAI"
|
||||
weight = 10
|
||||
# [languages.fr]
|
||||
# title = "LocalAI documentation"
|
||||
# languageName = "Français"
|
||||
# contentDir = "content/fr"
|
||||
# weight = 20
|
||||
# [languages.de]
|
||||
# title = "LocalAI documentation"
|
||||
# languageName = "Deutsch"
|
||||
# contentDir = "content/de"
|
||||
# weight = 30
|
||||
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = "<i class='fas fa-fw fa-camera'></i> Examples"
|
||||
url = "https://github.com/go-skynet/LocalAI/tree/master/examples/"
|
||||
weight = 11
|
||||
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = "<i class='fas fa-fw fa-images'></i> Model Gallery"
|
||||
url = "https://github.com/go-skynet/model-gallery"
|
||||
weight = 12
|
||||
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = "<i class='fas fa-fw fa-download'></i> Container images"
|
||||
url = "https://quay.io/repository/go-skynet/local-ai"
|
||||
weight = 20
|
||||
#[[languages.en.menu.shortcuts]]
|
||||
# name = "<i class='fas fa-fw fa-bullhorn'></i> Credits"
|
||||
# url = "more/credits/"
|
||||
# weight = 30
|
||||
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = "<i class='fas fa-fw fa-tags'></i> Releases"
|
||||
url = "https://github.com/go-skynet/LocalAI/releases"
|
||||
weight = 40
|
||||
|
||||
|
||||
# mounts are only needed in this showcase to access the publicly available screenshots;
|
||||
# remove this section if you don't need further mounts
|
||||
[module]
|
||||
replacements = "github.com/colinwilson/lotusdocs -> lotusdocs"
|
||||
[[module.mounts]]
|
||||
source = 'archetypes'
|
||||
target = 'archetypes'
|
||||
@@ -152,30 +197,11 @@ disableHugoGeneratorInject = true
|
||||
[[module.mounts]]
|
||||
source = 'static'
|
||||
target = 'static'
|
||||
|
||||
|
||||
# settings specific to this theme's features; choose to your likings and
|
||||
# consult this documentation for explaination
|
||||
[params]
|
||||
editURL = "https://github.com/mudler/LocalAI/edit/master/docs/content/"
|
||||
description = "Documentation for LocalAI"
|
||||
author = "Ettore Di Giacinto"
|
||||
showVisitedLinks = true
|
||||
collapsibleMenu = true
|
||||
disableBreadcrumb = false
|
||||
disableInlineCopyToClipBoard = true
|
||||
disableNextPrev = false
|
||||
disableLandingPageButton = true
|
||||
breadcrumbSeparator = ">"
|
||||
titleSeparator = "::"
|
||||
themeVariant = [ "auto", "relearn-bright", "relearn-light", "relearn-dark", "learn", "neon", "blue", "green", "red" ]
|
||||
themeVariantAuto = [ "relearn-light", "relearn-dark" ]
|
||||
disableSeoHiddenPages = true
|
||||
# this is to index search for your native language in other languages, too (eg.
|
||||
# pir in this showcase)
|
||||
additionalContentLanguage = [ "en" ]
|
||||
# this is for the stylesheet generator to allow for interactivity in Mermaid
|
||||
# graphs; you usually will not need it and you should remove this for
|
||||
# security reasons
|
||||
mermaidInitialize = "{ \"securityLevel\": \"loose\" }"
|
||||
mermaidZoom = true
|
||||
# uncomment line below for temporary local development of module
|
||||
# or when using a 'theme' as a git submodule
|
||||
[[module.imports]]
|
||||
path = "github.com/colinwilson/lotusdocs"
|
||||
disable = false
|
||||
[[module.imports]]
|
||||
path = "github.com/gohugoio/hugo-mod-bootstrap-scss/v5"
|
||||
disable = false
|
||||
|
||||
@@ -1,37 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Development documentation"
|
||||
weight = 7
|
||||
+++
|
||||
|
||||
{{% notice note %}}
|
||||
|
||||
This section is for developers and contributors. If you are looking for the user documentation, this is not the right place!
|
||||
|
||||
{{% /notice %}}
|
||||
|
||||
This section will collect how-to, notes and development documentation
|
||||
|
||||
## Contributing
|
||||
|
||||
We use conventional commits and semantic versioning. Please follow the [conventional commits](https://www.conventionalcommits.org/en/v1.0.0/) specification when writing commit messages.
|
||||
|
||||
## Creating a gRPC backend
|
||||
|
||||
LocalAI backends are `gRPC` servers.
|
||||
|
||||
In order to create a new backend you need:
|
||||
|
||||
- If there are changes required to the protobuf code, modify the [proto](https://github.com/go-skynet/LocalAI/blob/master/pkg/grpc/proto/backend.proto) file and re-generate the code with `make protogen`.
|
||||
- Modify the `Makefile` to add your new backend and re-generate the client code with `make protogen` if necessary.
|
||||
- Create a new `gRPC` server in `extra/grpc` if it's not written in go: [link](https://github.com/go-skynet/LocalAI/tree/master/extra/grpc), and create the specific implementation.
|
||||
- Golang `gRPC` servers should be added in the [pkg/backend](https://github.com/go-skynet/LocalAI/tree/master/pkg/backend) directory given their type. See [piper](https://github.com/go-skynet/LocalAI/blob/master/pkg/backend/tts/piper.go) as an example.
|
||||
- Golang servers needs a respective `cmd/grpc` binary that must be created too, see also [cmd/grpc/piper](https://github.com/go-skynet/LocalAI/tree/master/cmd/grpc/piper) as an example, update also the Makefile accordingly to build the binary during build time.
|
||||
- Update the Dockerfile: if the backend is written in another language, update the `Dockerfile` default *EXTERNAL_GRPC_BACKENDS* variable by listing the new binary [link](https://github.com/go-skynet/LocalAI/blob/c2233648164f67cdb74dd33b8d46244e14436ab3/Dockerfile#L14).
|
||||
|
||||
Once you are done, you can either re-build `LocalAI` with your backend or you can try it out by running the `gRPC` server manually and specifying the host and IP to LocalAI with `--external-grpc-backends` or using (`EXTERNAL_GRPC_BACKENDS` environment variable, comma separated list of `name:host:port` tuples, e.g. `my-awesome-backend:host:port`):
|
||||
|
||||
```bash
|
||||
./local-ai --debug --external-grpc-backends "my-awesome-backend:host:port" ...
|
||||
```
|
||||
11
docs/content/docs/advanced/_index.en.md
Normal file
11
docs/content/docs/advanced/_index.en.md
Normal file
@@ -0,0 +1,11 @@
|
||||
---
|
||||
weight: 20
|
||||
title: "Advanced"
|
||||
description: "Advanced usage"
|
||||
icon: science
|
||||
lead: ""
|
||||
date: 2020-10-06T08:49:15+00:00
|
||||
lastmod: 2020-10-06T08:49:15+00:00
|
||||
draft: false
|
||||
images: []
|
||||
---
|
||||
@@ -1,15 +1,16 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Advanced"
|
||||
weight = 6
|
||||
title = "Advanced usage"
|
||||
weight = 21
|
||||
url = '/advanced'
|
||||
+++
|
||||
|
||||
### Advanced configuration with YAML files
|
||||
|
||||
In order to define default prompts, model parameters (such as custom default `top_p` or `top_k`), LocalAI can be configured to serve user-defined models with a set of default parameters and templates.
|
||||
|
||||
You can create multiple `yaml` files in the models path or either specify a single YAML configuration file.
|
||||
In order to configure a model, you can create multiple `yaml` files in the models path or either specify a single YAML configuration file.
|
||||
Consider the following `models` folder in the `example/chatbot-ui`:
|
||||
|
||||
```
|
||||
@@ -96,6 +97,12 @@ Specifying a `config-file` via CLI allows to declare models in a single file as
|
||||
|
||||
See also [chatbot-ui](https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui) as an example on how to use config files.
|
||||
|
||||
It is possible to specify a full URL or a short-hand URL to a YAML model configuration file and use it on start with local-ai, for example to use phi-2:
|
||||
|
||||
```
|
||||
local-ai github://mudler/LocalAI/examples/configurations/phi-2.yaml@master
|
||||
```
|
||||
|
||||
### Full config model file reference
|
||||
|
||||
```yaml
|
||||
@@ -303,7 +310,7 @@ prompt_cache_all: true
|
||||
|
||||
By default LocalAI will try to autoload the model by trying all the backends. This might work for most of models, but some of the backends are NOT configured to autoload.
|
||||
|
||||
The available backends are listed in the [model compatibility table]({{%relref "model-compatibility" %}}).
|
||||
The available backends are listed in the [model compatibility table]({{%relref "docs/reference/compatibility-table" %}}).
|
||||
|
||||
In order to specify a backend for your models, create a model config file in your `models` directory specifying the backend:
|
||||
|
||||
@@ -337,6 +344,19 @@ Or a remote URI:
|
||||
./local-ai --debug --external-grpc-backends "my-awesome-backend:host:port"
|
||||
```
|
||||
|
||||
For example, to start vllm manually after compiling LocalAI (also assuming running the command from the root of the repository):
|
||||
|
||||
```bash
|
||||
./local-ai --external-grpc-backends "vllm:$PWD/backend/python/vllm/run.sh"
|
||||
```
|
||||
|
||||
Note that first is is necessary to create the conda environment with:
|
||||
|
||||
```bash
|
||||
make -C backend/python/vllm
|
||||
```
|
||||
|
||||
|
||||
### Environment variables
|
||||
|
||||
When LocalAI runs in a container,
|
||||
@@ -359,6 +379,36 @@ docker run --env REBUILD=true localai
|
||||
docker run --env-file .env localai
|
||||
```
|
||||
|
||||
### CLI parameters
|
||||
|
||||
You can control LocalAI with command line arguments, to specify a binding address, or the number of threads.
|
||||
|
||||
|
||||
| Parameter | Environmental Variable | Default Variable | Description |
|
||||
| ------------------------------ | ------------------------------- | -------------------------------------------------- | ------------------------------------------------------------------- |
|
||||
| --f16 | $F16 | false | Enable f16 mode |
|
||||
| --debug | $DEBUG | false | Enable debug mode |
|
||||
| --cors | $CORS | false | Enable CORS support |
|
||||
| --cors-allow-origins value | $CORS_ALLOW_ORIGINS | | Specify origins allowed for CORS |
|
||||
| --threads value | $THREADS | 4 | Number of threads to use for parallel computation |
|
||||
| --models-path value | $MODELS_PATH | ./models | Path to the directory containing models used for inferencing |
|
||||
| --preload-models value | $PRELOAD_MODELS | | List of models to preload in JSON format at startup |
|
||||
| --preload-models-config value | $PRELOAD_MODELS_CONFIG | | A config with a list of models to apply at startup. Specify the path to a YAML config file |
|
||||
| --config-file value | $CONFIG_FILE | | Path to the config file |
|
||||
| --address value | $ADDRESS | :8080 | Specify the bind address for the API server |
|
||||
| --image-path value | $IMAGE_PATH | | Path to the directory used to store generated images |
|
||||
| --context-size value | $CONTEXT_SIZE | 512 | Default context size of the model |
|
||||
| --upload-limit value | $UPLOAD_LIMIT | 15 | Default upload limit in megabytes (audio file upload) |
|
||||
| --galleries | $GALLERIES | | Allows to set galleries from command line |
|
||||
|--parallel-requests | $PARALLEL_REQUESTS | false | Enable backends to handle multiple requests in parallel. This is for backends that supports multiple requests in parallel, like llama.cpp or vllm |
|
||||
| --single-active-backend | $SINGLE_ACTIVE_BACKEND | false | Allow only one backend to be running |
|
||||
| --api-keys value | $API_KEY | empty | List of API Keys to enable API authentication. When this is set, all the requests must be authenticated with one of these API keys.
|
||||
| --enable-watchdog-idle | $WATCHDOG_IDLE | false | Enable watchdog for stopping idle backends. This will stop the backends if are in idle state for too long. (default: false) [$WATCHDOG_IDLE]
|
||||
| --enable-watchdog-busy | $WATCHDOG_BUSY | false | Enable watchdog for stopping busy backends that exceed a defined threshold.|
|
||||
| --watchdog-busy-timeout value | $WATCHDOG_BUSY_TIMEOUT | 5m | Watchdog timeout. This will restart the backend if it crashes. |
|
||||
| --watchdog-idle-timeout value | $WATCHDOG_IDLE_TIMEOUT | 15m | Watchdog idle timeout. This will restart the backend if it crashes. |
|
||||
| --preload-backend-only | $PRELOAD_BACKEND_ONLY | false | If set, the api is NOT launched, and only the preloaded models / backends are started. This is intended for multi-node setups. |
|
||||
| --external-grpc-backends | EXTERNAL_GRPC_BACKENDS | none | Comma separated list of external gRPC backends to use. Format: `name:host:port` or `name:/path/to/file` |
|
||||
|
||||
|
||||
### Extra backends
|
||||
@@ -383,11 +433,11 @@ RUN PATH=$PATH:/opt/conda/bin make -C backend/python/diffusers
|
||||
ENV EXTERNAL_GRPC_BACKENDS="diffusers:/build/backend/python/diffusers/run.sh"
|
||||
```
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
|
||||
You can specify remote external backends or path to local files. The syntax is `backend-name:/path/to/backend` or `backend-name:host:port`.
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
#### In runtime
|
||||
|
||||
@@ -2,12 +2,12 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Fine-tuning LLMs for text generation"
|
||||
weight = 3
|
||||
weight = 22
|
||||
+++
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
Section under construction
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
This section covers how to fine-tune a language model for text generation and consume it in LocalAI.
|
||||
|
||||
@@ -2,7 +2,9 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "FAQ"
|
||||
weight = 9
|
||||
weight = 24
|
||||
icon = "quiz"
|
||||
url = "/faq/"
|
||||
+++
|
||||
|
||||
## Frequently asked questions
|
||||
@@ -12,25 +14,13 @@ Here are answers to some of the most common questions.
|
||||
|
||||
### How do I get models?
|
||||
|
||||
<details>
|
||||
|
||||
Most gguf-based models should work, but newer models may require additions to the API. If a model doesn't work, please feel free to open up issues. However, be cautious about downloading models from the internet and directly onto your machine, as there may be security vulnerabilities in lama.cpp or ggml that could be maliciously exploited. Some models can be found on Hugging Face: https://huggingface.co/models?search=gguf, or models from gpt4all are compatible too: https://github.com/nomic-ai/gpt4all.
|
||||
|
||||
</details>
|
||||
|
||||
### What's the difference with Serge, or XXX?
|
||||
|
||||
|
||||
<details>
|
||||
|
||||
LocalAI is a multi-model solution that doesn't focus on a specific model type (e.g., llama.cpp or alpaca.cpp), and it handles all of these internally for faster inference, easy to set up locally and deploy to Kubernetes.
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
### Everything is slow, how come?
|
||||
|
||||
<details>
|
||||
### Everything is slow, how is it possible?
|
||||
|
||||
There are few situation why this could occur. Some tips are:
|
||||
- Don't use HDD to store your models. Prefer SSD over HDD. In case you are stuck with HDD, disable `mmap` in the model config file so it loads everything in memory.
|
||||
@@ -38,61 +28,31 @@ There are few situation why this could occur. Some tips are:
|
||||
- Run LocalAI with `DEBUG=true`. This gives more information, including stats on the token inference speed.
|
||||
- Check that you are actually getting an output: run a simple curl request with `"stream": true` to see how fast the model is responding.
|
||||
|
||||
</details>
|
||||
|
||||
### Can I use it with a Discord bot, or XXX?
|
||||
|
||||
<details>
|
||||
|
||||
Yes! If the client uses OpenAI and supports setting a different base URL to send requests to, you can use the LocalAI endpoint. This allows to use this with every application that was supposed to work with OpenAI, but without changing the application!
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
### Can this leverage GPUs?
|
||||
|
||||
<details>
|
||||
|
||||
There is partial GPU support, see build instructions above.
|
||||
|
||||
</details>
|
||||
There is GPU support, see {{%relref "docs/features/GPU-acceleration" %}}.
|
||||
|
||||
### Where is the webUI?
|
||||
|
||||
<details>
|
||||
There is the availability of localai-webui and chatbot-ui in the examples section and can be setup as per the instructions. However as LocalAI is an API you can already plug it into existing projects that provides are UI interfaces to OpenAI's APIs. There are several already on github, and should be compatible with LocalAI already (as it mimics the OpenAI API)
|
||||
|
||||
</details>
|
||||
There is the availability of localai-webui and chatbot-ui in the examples section and can be setup as per the instructions. However as LocalAI is an API you can already plug it into existing projects that provides are UI interfaces to OpenAI's APIs. There are several already on Github, and should be compatible with LocalAI already (as it mimics the OpenAI API)
|
||||
|
||||
### Does it work with AutoGPT?
|
||||
|
||||
<details>
|
||||
|
||||
Yes, see the [examples](https://github.com/go-skynet/LocalAI/tree/master/examples/)!
|
||||
|
||||
</details>
|
||||
|
||||
### How can I troubleshoot when something is wrong?
|
||||
|
||||
<details>
|
||||
|
||||
Enable the debug mode by setting `DEBUG=true` in the environment variables. This will give you more information on what's going on.
|
||||
You can also specify `--debug` in the command line.
|
||||
|
||||
</details>
|
||||
|
||||
### I'm getting 'invalid pitch' error when running with CUDA, what's wrong?
|
||||
|
||||
<details>
|
||||
|
||||
This typically happens when your prompt exceeds the context size. Try to reduce the prompt size, or increase the context size.
|
||||
|
||||
</details>
|
||||
|
||||
### I'm getting a 'SIGILL' error, what's wrong?
|
||||
|
||||
<details>
|
||||
|
||||
Your CPU probably does not have support for certain instructions that are compiled by default in the pre-built binaries. If you are running in a container, try setting `REBUILD=true` and disable the CPU instructions that are not compatible with your CPU. For instance: `CMAKE_ARGS="-DLLAMA_F16C=OFF -DLLAMA_AVX512=OFF -DLLAMA_AVX2=OFF -DLLAMA_FMA=OFF" make build`
|
||||
|
||||
</details>
|
||||
Your CPU probably does not have support for certain instructions that are compiled by default in the pre-built binaries. If you are running in a container, try setting `REBUILD=true` and disable the CPU instructions that are not compatible with your CPU. For instance: `CMAKE_ARGS="-DLLAMA_F16C=OFF -DLLAMA_AVX512=OFF -DLLAMA_AVX2=OFF -DLLAMA_FMA=OFF" make build`
|
||||
@@ -1,25 +1,35 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "⚡ GPU acceleration"
|
||||
weight = 2
|
||||
weight = 9
|
||||
url = "/features/gpu-acceleration/"
|
||||
+++
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert context="warning" %}}
|
||||
Section under construction
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
This section contains instruction on how to use LocalAI with GPU acceleration.
|
||||
|
||||
{{% notice note %}}
|
||||
For accelleration for AMD or Metal HW there are no specific container images, see the [build]({{%relref "build/#acceleration" %}})
|
||||
{{% /notice %}}
|
||||
{{% alert icon="⚡" context="warning" %}}
|
||||
For accelleration for AMD or Metal HW there are no specific container images, see the [build]({{%relref "docs/getting-started/build#Acceleration" %}})
|
||||
{{% /alert %}}
|
||||
|
||||
### CUDA
|
||||
### CUDA(NVIDIA) acceleration
|
||||
|
||||
#### Requirements
|
||||
|
||||
Requirement: nvidia-container-toolkit (installation instructions [1](https://www.server-world.info/en/note?os=Ubuntu_22.04&p=nvidia&f=2) [2](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html))
|
||||
|
||||
To use CUDA, use the images with the `cublas` tag.
|
||||
To check what CUDA version do you need, you can either run `nvidia-smi` or `nvcc --version`.
|
||||
|
||||
Alternatively, you can also check nvidia-smi with docker:
|
||||
|
||||
```
|
||||
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
|
||||
```
|
||||
|
||||
To use CUDA, use the images with the `cublas` tag, for example.
|
||||
|
||||
The image list is on [quay](https://quay.io/repository/go-skynet/local-ai?tab=tags):
|
||||
|
||||
8
docs/content/docs/features/_index.en.md
Normal file
8
docs/content/docs/features/_index.en.md
Normal file
@@ -0,0 +1,8 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Features"
|
||||
weight = 8
|
||||
icon = "feature_search"
|
||||
url = "/features/"
|
||||
+++
|
||||
@@ -1,10 +1,13 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🔈 Audio to text"
|
||||
weight = 2
|
||||
weight = 16
|
||||
url = "/features/audio-to-text/"
|
||||
+++
|
||||
|
||||
The transcription endpoint allows to convert audio files to text. The endpoint is based on [whisper.cpp](https://github.com/ggerganov/whisper.cpp), a C++ library for audio transcription. The endpoint supports the audio formats supported by `ffmpeg`.
|
||||
Audio to text models are models that can generate text from an audio file.
|
||||
|
||||
The transcription endpoint allows to convert audio files to text. The endpoint is based on [whisper.cpp](https://github.com/ggerganov/whisper.cpp), a C++ library for audio transcription. The endpoint input supports all the audio formats supported by `ffmpeg`.
|
||||
|
||||
## Usage
|
||||
|
||||
@@ -2,20 +2,21 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "✍️ Constrained grammars"
|
||||
weight = 6
|
||||
weight = 15
|
||||
url = "/features/constrained_grammars/"
|
||||
+++
|
||||
|
||||
The chat endpoint accepts an additional `grammar` parameter which takes a [BNF defined grammar](https://en.wikipedia.org/wiki/Backus%E2%80%93Naur_form).
|
||||
|
||||
This allows the LLM to constrain the output to a user-defined schema, allowing to generate `JSON`, `YAML`, and everything that can be defined with a BNF grammar.
|
||||
|
||||
{{% notice note %}}
|
||||
This feature works only with models compatible with the [llama.cpp](https://github.com/ggerganov/llama.cpp) backend (see also [Model compatibility]({{%relref "model-compatibility" %}})). For details on how it works, see the upstream PRs: https://github.com/ggerganov/llama.cpp/pull/1773, https://github.com/ggerganov/llama.cpp/pull/1887
|
||||
{{% /notice %}}
|
||||
{{% alert note %}}
|
||||
This feature works only with models compatible with the [llama.cpp](https://github.com/ggerganov/llama.cpp) backend (see also [Model compatibility]({{%relref "docs/reference/compatibility-table" %}})). For details on how it works, see the upstream PRs: https://github.com/ggerganov/llama.cpp/pull/1773, https://github.com/ggerganov/llama.cpp/pull/1887
|
||||
{{% /alert %}}
|
||||
|
||||
## Setup
|
||||
|
||||
Follow the setup instructions from the [LocalAI functions]({{%relref "features/openai-functions" %}}) page.
|
||||
Follow the setup instructions from the [LocalAI functions]({{%relref "docs/features/openai-functions" %}}) page.
|
||||
|
||||
## 💡 Usage example
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🧠 Embeddings"
|
||||
weight = 2
|
||||
weight = 13
|
||||
url = "/features/embeddings/"
|
||||
+++
|
||||
|
||||
LocalAI supports generating embeddings for text or list of tokens.
|
||||
@@ -73,7 +74,7 @@ parameters:
|
||||
|
||||
The `sentencetransformers` backend uses Python [sentence-transformers](https://github.com/UKPLab/sentence-transformers). For a list of all pre-trained models available see here: https://github.com/UKPLab/sentence-transformers#pre-trained-models
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
|
||||
- The `sentencetransformers` backend is an optional backend of LocalAI and uses Python. If you are running `LocalAI` from the containers you are good to go and should be already configured for use.
|
||||
- If you are running `LocalAI` manually you must install the python dependencies (`make prepare-extra-conda-environments`). This requires `conda` to be installed.
|
||||
@@ -82,7 +83,7 @@ The `sentencetransformers` backend uses Python [sentence-transformers](https://g
|
||||
- The `sentencetransformers` backend does support only embeddings of text, and not of tokens. If you need to embed tokens you can use the `bert` backend or `llama.cpp`.
|
||||
- No models are required to be downloaded before using the `sentencetransformers` backend. The models will be downloaded automatically the first time the API is used.
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
## Llama.cpp embeddings
|
||||
|
||||
@@ -2,13 +2,10 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🆕 GPT Vision"
|
||||
weight = 2
|
||||
weight = 14
|
||||
url = "/features/gpt-vision/"
|
||||
+++
|
||||
|
||||
{{% notice note %}}
|
||||
Available only on `master` builds
|
||||
{{% /notice %}}
|
||||
|
||||
LocalAI supports understanding images by using [LLaVA](https://llava.hliu.cc/), and implements the [GPT Vision API](https://platform.openai.com/docs/guides/vision) from OpenAI.
|
||||
|
||||

|
||||
@@ -27,4 +24,4 @@ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/jso
|
||||
|
||||
### Setup
|
||||
|
||||
To setup the LLaVa models, follow the full example in the [configuration examples](https://github.com/mudler/LocalAI/blob/master/examples/configurations/README.md#llava).
|
||||
To setup the LLaVa models, follow the full example in the [configuration examples](https://github.com/mudler/LocalAI/blob/master/examples/configurations/README.md#llava).
|
||||
@@ -2,13 +2,14 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🎨 Image generation"
|
||||
weight = 2
|
||||
weight = 12
|
||||
url = "/features/image-generation/"
|
||||
+++
|
||||
|
||||

|
||||
(Generated with [AnimagineXL](https://huggingface.co/Linaqruf/animagine-xl))
|
||||
|
||||
LocalAI supports generating images with Stable diffusion, running on CPU using a C++ implementation, [Stable-Diffusion-NCNN](https://github.com/EdVince/Stable-Diffusion-NCNN) ([binding](https://github.com/mudler/go-stable-diffusion)) and [🧨 Diffusers]({{%relref "model-compatibility/diffusers" %}}).
|
||||
LocalAI supports generating images with Stable diffusion, running on CPU using C++ and Python implementations.
|
||||
|
||||
## Usage
|
||||
|
||||
@@ -35,7 +36,9 @@ curl http://localhost:8080/v1/images/generations -H "Content-Type: application/j
|
||||
}'
|
||||
```
|
||||
|
||||
## stablediffusion-cpp
|
||||
## Backends
|
||||
|
||||
### stablediffusion-cpp
|
||||
|
||||
| mode=0 | mode=1 (winograd/sgemm) |
|
||||
|------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------|
|
||||
@@ -45,7 +48,7 @@ curl http://localhost:8080/v1/images/generations -H "Content-Type: application/j
|
||||
|
||||
Note: image generator supports images up to 512x512. You can use other tools however to upscale the image, for instance: https://github.com/upscayl/upscayl.
|
||||
|
||||
### Setup
|
||||
#### Setup
|
||||
|
||||
Note: In order to use the `images/generation` endpoint with the `stablediffusion` C++ backend, you need to build LocalAI with `GO_TAGS=stablediffusion`. If you are using the container images, it is already enabled.
|
||||
|
||||
@@ -128,11 +131,14 @@ models
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
## Diffusers
|
||||
### Diffusers
|
||||
|
||||
This is an extra backend - in the container is already available and there is nothing to do for the setup.
|
||||
[Diffusers](https://huggingface.co/docs/diffusers/index) is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. LocalAI has a diffusers backend which allows image generation using the `diffusers` library.
|
||||
|
||||
### Model setup
|
||||

|
||||
(Generated with [AnimagineXL](https://huggingface.co/Linaqruf/animagine-xl))
|
||||
|
||||
#### Model setup
|
||||
|
||||
The models will be downloaded the first time you use the backend from `huggingface` automatically.
|
||||
|
||||
@@ -150,3 +156,198 @@ diffusers:
|
||||
cuda: false # Enable for GPU usage (CUDA)
|
||||
scheduler_type: euler_a
|
||||
```
|
||||
|
||||
#### Dependencies
|
||||
|
||||
This is an extra backend - in the container is already available and there is nothing to do for the setup. Do not use *core* images (ending with `-core`). If you are building manually, see the [build instructions]({{%relref "docs/getting-started/build" %}}).
|
||||
|
||||
#### Model setup
|
||||
|
||||
The models will be downloaded the first time you use the backend from `huggingface` automatically.
|
||||
|
||||
Create a model configuration file in the `models` directory, for instance to use `Linaqruf/animagine-xl` with CPU:
|
||||
|
||||
```yaml
|
||||
name: animagine-xl
|
||||
parameters:
|
||||
model: Linaqruf/animagine-xl
|
||||
backend: diffusers
|
||||
cuda: true
|
||||
f16: true
|
||||
diffusers:
|
||||
scheduler_type: euler_a
|
||||
```
|
||||
|
||||
#### Local models
|
||||
|
||||
You can also use local models, or modify some parameters like `clip_skip`, `scheduler_type`, for instance:
|
||||
|
||||
```yaml
|
||||
name: stablediffusion
|
||||
parameters:
|
||||
model: toonyou_beta6.safetensors
|
||||
backend: diffusers
|
||||
step: 30
|
||||
f16: true
|
||||
cuda: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionPipeline
|
||||
enable_parameters: "negative_prompt,num_inference_steps,clip_skip"
|
||||
scheduler_type: "k_dpmpp_sde"
|
||||
cfg_scale: 8
|
||||
clip_skip: 11
|
||||
```
|
||||
|
||||
#### Configuration parameters
|
||||
|
||||
The following parameters are available in the configuration file:
|
||||
|
||||
| Parameter | Description | Default |
|
||||
| --- | --- | --- |
|
||||
| `f16` | Force the usage of `float16` instead of `float32` | `false` |
|
||||
| `step` | Number of steps to run the model for | `30` |
|
||||
| `cuda` | Enable CUDA acceleration | `false` |
|
||||
| `enable_parameters` | Parameters to enable for the model | `negative_prompt,num_inference_steps,clip_skip` |
|
||||
| `scheduler_type` | Scheduler type | `k_dpp_sde` |
|
||||
| `cfg_scale` | Configuration scale | `8` |
|
||||
| `clip_skip` | Clip skip | None |
|
||||
| `pipeline_type` | Pipeline type | `AutoPipelineForText2Image` |
|
||||
|
||||
There are available several types of schedulers:
|
||||
|
||||
| Scheduler | Description |
|
||||
| --- | --- |
|
||||
| `ddim` | DDIM |
|
||||
| `pndm` | PNDM |
|
||||
| `heun` | Heun |
|
||||
| `unipc` | UniPC |
|
||||
| `euler` | Euler |
|
||||
| `euler_a` | Euler a |
|
||||
| `lms` | LMS |
|
||||
| `k_lms` | LMS Karras |
|
||||
| `dpm_2` | DPM2 |
|
||||
| `k_dpm_2` | DPM2 Karras |
|
||||
| `dpm_2_a` | DPM2 a |
|
||||
| `k_dpm_2_a` | DPM2 a Karras |
|
||||
| `dpmpp_2m` | DPM++ 2M |
|
||||
| `k_dpmpp_2m` | DPM++ 2M Karras |
|
||||
| `dpmpp_sde` | DPM++ SDE |
|
||||
| `k_dpmpp_sde` | DPM++ SDE Karras |
|
||||
| `dpmpp_2m_sde` | DPM++ 2M SDE |
|
||||
| `k_dpmpp_2m_sde` | DPM++ 2M SDE Karras |
|
||||
|
||||
Pipelines types available:
|
||||
|
||||
| Pipeline type | Description |
|
||||
| --- | --- |
|
||||
| `StableDiffusionPipeline` | Stable diffusion pipeline |
|
||||
| `StableDiffusionImg2ImgPipeline` | Stable diffusion image to image pipeline |
|
||||
| `StableDiffusionDepth2ImgPipeline` | Stable diffusion depth to image pipeline |
|
||||
| `DiffusionPipeline` | Diffusion pipeline |
|
||||
| `StableDiffusionXLPipeline` | Stable diffusion XL pipeline |
|
||||
|
||||
#### Usage
|
||||
|
||||
#### Text to Image
|
||||
Use the `image` generation endpoint with the `model` name from the configuration file:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/images/generations \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"prompt": "<positive prompt>|<negative prompt>",
|
||||
"model": "animagine-xl",
|
||||
"step": 51,
|
||||
"size": "1024x1024"
|
||||
}'
|
||||
```
|
||||
|
||||
#### Image to Image
|
||||
|
||||
https://huggingface.co/docs/diffusers/using-diffusers/img2img
|
||||
|
||||
An example model (GPU):
|
||||
```yaml
|
||||
name: stablediffusion-edit
|
||||
parameters:
|
||||
model: nitrosocke/Ghibli-Diffusion
|
||||
backend: diffusers
|
||||
step: 25
|
||||
cuda: true
|
||||
f16: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionImg2ImgPipeline
|
||||
enable_parameters: "negative_prompt,num_inference_steps,image"
|
||||
```
|
||||
|
||||
```bash
|
||||
IMAGE_PATH=/path/to/your/image
|
||||
(echo -n '{"file": "'; base64 $IMAGE_PATH; echo '", "prompt": "a sky background","size": "512x512","model":"stablediffusion-edit"}') |
|
||||
curl -H "Content-Type: application/json" -d @- http://localhost:8080/v1/images/generations
|
||||
```
|
||||
|
||||
#### Depth to Image
|
||||
|
||||
https://huggingface.co/docs/diffusers/using-diffusers/depth2img
|
||||
|
||||
```yaml
|
||||
name: stablediffusion-depth
|
||||
parameters:
|
||||
model: stabilityai/stable-diffusion-2-depth
|
||||
backend: diffusers
|
||||
step: 50
|
||||
# Force CPU usage
|
||||
f16: true
|
||||
cuda: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionDepth2ImgPipeline
|
||||
enable_parameters: "negative_prompt,num_inference_steps,image"
|
||||
cfg_scale: 6
|
||||
```
|
||||
|
||||
```bash
|
||||
(echo -n '{"file": "'; base64 ~/path/to/image.jpeg; echo '", "prompt": "a sky background","size": "512x512","model":"stablediffusion-depth"}') |
|
||||
curl -H "Content-Type: application/json" -d @- http://localhost:8080/v1/images/generations
|
||||
```
|
||||
|
||||
#### img2vid
|
||||
|
||||
|
||||
```yaml
|
||||
name: img2vid
|
||||
parameters:
|
||||
model: stabilityai/stable-video-diffusion-img2vid
|
||||
backend: diffusers
|
||||
step: 25
|
||||
# Force CPU usage
|
||||
f16: true
|
||||
cuda: true
|
||||
diffusers:
|
||||
pipeline_type: StableVideoDiffusionPipeline
|
||||
```
|
||||
|
||||
```bash
|
||||
(echo -n '{"file": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png?download=true","size": "512x512","model":"img2vid"}') |
|
||||
curl -H "Content-Type: application/json" -X POST -d @- http://localhost:8080/v1/images/generations
|
||||
```
|
||||
|
||||
#### txt2vid
|
||||
|
||||
```yaml
|
||||
name: txt2vid
|
||||
parameters:
|
||||
model: damo-vilab/text-to-video-ms-1.7b
|
||||
backend: diffusers
|
||||
step: 25
|
||||
# Force CPU usage
|
||||
f16: true
|
||||
cuda: true
|
||||
diffusers:
|
||||
pipeline_type: VideoDiffusionPipeline
|
||||
cuda: true
|
||||
```
|
||||
|
||||
```bash
|
||||
(echo -n '{"prompt": "spiderman surfing","size": "512x512","model":"txt2vid"}') |
|
||||
curl -H "Content-Type: application/json" -X POST -d @- http://localhost:8080/v1/images/generations
|
||||
```
|
||||
@@ -2,7 +2,9 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🖼️ Model gallery"
|
||||
weight = 7
|
||||
|
||||
weight = 18
|
||||
url = '/models'
|
||||
+++
|
||||
|
||||
<h1 align="center">
|
||||
@@ -15,13 +17,13 @@ The model gallery is a (experimental!) collection of models configurations for [
|
||||
|
||||
LocalAI to ease out installations of models provide a way to preload models on start and downloading and installing them in runtime. You can install models manually by copying them over the `models` directory, or use the API to configure, download and verify the model assets for you. As the UI is still a work in progress, you will find here the documentation about the API Endpoints.
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
The models in this gallery are not directly maintained by LocalAI. If you find a model that is not working, please open an issue on the model gallery repository.
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
GPT and text generation models might have a license which is not permissive for commercial use or might be questionable or without any license at all. Please check the model license before using it. The official gallery contains only open licensed models.
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
## Useful Links and resources
|
||||
|
||||
@@ -48,7 +50,7 @@ GALLERIES=[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.
|
||||
|
||||
where `github:go-skynet/model-gallery/index.yaml` will be expanded automatically to `https://raw.githubusercontent.com/go-skynet/model-gallery/main/index.yaml`.
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
|
||||
As this feature is experimental, you need to run `local-ai` with a list of `GALLERIES`. Currently there are two galleries:
|
||||
|
||||
@@ -63,19 +65,19 @@ GALLERIES=[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.
|
||||
|
||||
If running with `docker-compose`, simply edit the `.env` file and uncomment the `GALLERIES` variable, and add the one you want to use.
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
You might not find all the models in this gallery. Automated CI updates the gallery automatically. You can find however most of the models on huggingface (https://huggingface.co/), generally it should be available `~24h` after upload.
|
||||
|
||||
By under any circumstances LocalAI and any developer is not responsible for the models in this gallery, as CI is just indexing them and providing a convenient way to install with an automatic configuration with a consistent API. Don't install models from authors you don't trust, and, check the appropriate license for your use case. Models are automatically indexed and hosted on huggingface (https://huggingface.co/). For any issue with the models, please open an issue on the model gallery repository if it's a LocalAI misconfiguration, otherwise refer to the huggingface repository. If you think a model should not be listed, please reach to us and we will remove it from the gallery.
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
|
||||
There is no documentation yet on how to build a gallery or a repository - but you can find an example in the [model-gallery](https://github.com/go-skynet/model-gallery) repository.
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
|
||||
### List Models
|
||||
@@ -117,7 +119,7 @@ where:
|
||||
- `bert-embeddings` is the model name in the gallery
|
||||
(read its [config here](https://github.com/go-skynet/model-gallery/blob/main/bert-embeddings.yaml)).
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
If the `huggingface` model gallery is enabled (it's enabled by default),
|
||||
and the model has an entry in the model gallery's associated YAML config
|
||||
(for `huggingface`, see [`model-gallery/huggingface.yaml`](https://github.com/go-skynet/model-gallery/blob/main/huggingface.yaml)),
|
||||
@@ -132,7 +134,7 @@ curl $LOCALAI/models/apply -H "Content-Type: application/json" -d '{
|
||||
```
|
||||
|
||||
Note that the `id` can be used similarly when pre-loading models at start.
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
|
||||
## How to install a model (without a gallery)
|
||||
@@ -217,7 +219,7 @@ YAML:
|
||||
|
||||
</details>
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
|
||||
You can find already some open licensed models in the [model gallery](https://github.com/go-skynet/model-gallery).
|
||||
|
||||
@@ -241,7 +243,7 @@ curl $LOCALAI/models/apply -H "Content-Type: application/json" -d '{
|
||||
|
||||
</details>
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
## Installing a model with a different name
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🔥 OpenAI functions"
|
||||
weight = 2
|
||||
weight = 17
|
||||
url = "/features/openai-functions/"
|
||||
+++
|
||||
|
||||
LocalAI supports running OpenAI functions with `llama.cpp` compatible models.
|
||||
@@ -67,13 +68,13 @@ response = openai.ChatCompletion.create(
|
||||
# ...
|
||||
```
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
When running the python script, be sure to:
|
||||
|
||||
- Set `OPENAI_API_KEY` environment variable to a random string (the OpenAI api key is NOT required!)
|
||||
- Set `OPENAI_API_BASE` to point to your LocalAI service, for example `OPENAI_API_BASE=http://localhost:8080`
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
## Advanced
|
||||
|
||||
264
docs/content/docs/features/text-generation.md
Normal file
264
docs/content/docs/features/text-generation.md
Normal file
@@ -0,0 +1,264 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "📖 Text generation (GPT)"
|
||||
weight = 10
|
||||
url = "/features/text-generation/"
|
||||
+++
|
||||
|
||||
LocalAI supports generating text with GPT with `llama.cpp` and other backends (such as `rwkv.cpp` as ) see also the [Model compatibility]({{%relref "docs/reference/compatibility-table" %}}) for an up-to-date list of the supported model families.
|
||||
|
||||
Note:
|
||||
|
||||
- You can also specify the model name as part of the OpenAI token.
|
||||
- If only one model is available, the API will use it for all the requests.
|
||||
|
||||
## API Reference
|
||||
|
||||
### Chat completions
|
||||
|
||||
https://platform.openai.com/docs/api-reference/chat
|
||||
|
||||
For example, to generate a chat completion, you can send a POST request to the `/v1/chat/completions` endpoint with the instruction as the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "ggml-koala-7b-model-q4_0-r2.bin",
|
||||
"messages": [{"role": "user", "content": "Say this is a test!"}],
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
Available additional parameters: `top_p`, `top_k`, `max_tokens`
|
||||
|
||||
### Edit completions
|
||||
|
||||
https://platform.openai.com/docs/api-reference/edits
|
||||
|
||||
To generate an edit completion you can send a POST request to the `/v1/edits` endpoint with the instruction as the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/edits -H "Content-Type: application/json" -d '{
|
||||
"model": "ggml-koala-7b-model-q4_0-r2.bin",
|
||||
"instruction": "rephrase",
|
||||
"input": "Black cat jumped out of the window",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
Available additional parameters: `top_p`, `top_k`, `max_tokens`.
|
||||
|
||||
### Completions
|
||||
|
||||
https://platform.openai.com/docs/api-reference/completions
|
||||
|
||||
To generate a completion, you can send a POST request to the `/v1/completions` endpoint with the instruction as per the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "ggml-koala-7b-model-q4_0-r2.bin",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
Available additional parameters: `top_p`, `top_k`, `max_tokens`
|
||||
|
||||
### List models
|
||||
|
||||
You can list all the models available with:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/models
|
||||
```
|
||||
|
||||
## Backends
|
||||
|
||||
### AutoGPTQ
|
||||
|
||||
[AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) is an easy-to-use LLMs quantization package with user-friendly apis, based on GPTQ algorithm.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
This is an extra backend - in the container images is already available and there is nothing to do for the setup.
|
||||
|
||||
If you are building LocalAI locally, you need to install [AutoGPTQ manually](https://github.com/PanQiWei/AutoGPTQ#quick-installation).
|
||||
|
||||
|
||||
#### Model setup
|
||||
|
||||
The models are automatically downloaded from `huggingface` if not present the first time. It is possible to define models via `YAML` config file, or just by querying the endpoint with the `huggingface` repository model name. For example, create a `YAML` config file in `models/`:
|
||||
|
||||
```
|
||||
name: orca
|
||||
backend: autogptq
|
||||
model_base_name: "orca_mini_v2_13b-GPTQ-4bit-128g.no-act.order"
|
||||
parameters:
|
||||
model: "TheBloke/orca_mini_v2_13b-GPTQ"
|
||||
# ...
|
||||
```
|
||||
|
||||
Test with:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "orca",
|
||||
"messages": [{"role": "user", "content": "How are you?"}],
|
||||
"temperature": 0.1
|
||||
}'
|
||||
```
|
||||
### RWKV
|
||||
|
||||
A full example on how to run a rwkv model is in the [examples](https://github.com/go-skynet/LocalAI/tree/master/examples/rwkv).
|
||||
|
||||
Note: rwkv models needs to specify the backend `rwkv` in the YAML config files and have an associated tokenizer along that needs to be provided with it:
|
||||
|
||||
```
|
||||
36464540 -rw-r--r-- 1 mudler mudler 1.2G May 3 10:51 rwkv_small
|
||||
36464543 -rw-r--r-- 1 mudler mudler 2.4M May 3 10:51 rwkv_small.tokenizer.json
|
||||
```
|
||||
|
||||
### llama.cpp
|
||||
|
||||
[llama.cpp](https://github.com/ggerganov/llama.cpp) is a popular port of Facebook's LLaMA model in C/C++.
|
||||
|
||||
{{% alert note %}}
|
||||
|
||||
The `ggml` file format has been deprecated. If you are using `ggml` models and you are configuring your model with a YAML file, specify, use the `llama-ggml` backend instead. If you are relying in automatic detection of the model, you should be fine. For `gguf` models, use the `llama` backend. The go backend is deprecated as well but still available as `go-llama`. The go backend supports still features not available in the mainline: speculative sampling and embeddings.
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
#### Features
|
||||
|
||||
The `llama.cpp` model supports the following features:
|
||||
- [📖 Text generation (GPT)]({{%relref "docs/features/text-generation" %}})
|
||||
- [🧠 Embeddings]({{%relref "docs/features/embeddings" %}})
|
||||
- [🔥 OpenAI functions]({{%relref "docs/features/openai-functions" %}})
|
||||
- [✍️ Constrained grammars]({{%relref "docs/features/constrained_grammars" %}})
|
||||
|
||||
#### Setup
|
||||
|
||||
LocalAI supports `llama.cpp` models out of the box. You can use the `llama.cpp` model in the same way as any other model.
|
||||
|
||||
##### Manual setup
|
||||
|
||||
It is sufficient to copy the `ggml` or `gguf` model files in the `models` folder. You can refer to the model in the `model` parameter in the API calls.
|
||||
|
||||
[You can optionally create an associated YAML]({{%relref "docs/advanced" %}}) model config file to tune the model's parameters or apply a template to the prompt.
|
||||
|
||||
Prompt templates are useful for models that are fine-tuned towards a specific prompt.
|
||||
|
||||
##### Automatic setup
|
||||
|
||||
LocalAI supports model galleries which are indexes of models. For instance, the huggingface gallery contains a large curated index of models from the huggingface model hub for `ggml` or `gguf` models.
|
||||
|
||||
For instance, if you have the galleries enabled and LocalAI already running, you can just start chatting with models in huggingface by running:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "TheBloke/WizardLM-13B-V1.2-GGML/wizardlm-13b-v1.2.ggmlv3.q2_K.bin",
|
||||
"messages": [{"role": "user", "content": "Say this is a test!"}],
|
||||
"temperature": 0.1
|
||||
}'
|
||||
```
|
||||
|
||||
LocalAI will automatically download and configure the model in the `model` directory.
|
||||
|
||||
Models can be also preloaded or downloaded on demand. To learn about model galleries, check out the [model gallery documentation]({{%relref "docs/features/model-gallery" %}}).
|
||||
|
||||
#### YAML configuration
|
||||
|
||||
To use the `llama.cpp` backend, specify `llama` as the backend in the YAML file:
|
||||
|
||||
```yaml
|
||||
name: llama
|
||||
backend: llama
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: file.gguf.bin
|
||||
```
|
||||
|
||||
In the example above we specify `llama` as the backend to restrict loading `gguf` models only.
|
||||
|
||||
For instance, to use the `llama-ggml` backend for `ggml` models:
|
||||
|
||||
```yaml
|
||||
name: llama
|
||||
backend: llama-ggml
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: file.ggml.bin
|
||||
```
|
||||
|
||||
#### Reference
|
||||
|
||||
- [llama](https://github.com/ggerganov/llama.cpp)
|
||||
- [binding](https://github.com/go-skynet/go-llama.cpp)
|
||||
|
||||
|
||||
### exllama/2
|
||||
|
||||
[Exllama](https://github.com/turboderp/exllama) is a "A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantized weights". Both `exllama` and `exllama2` are supported.
|
||||
|
||||
#### Model setup
|
||||
|
||||
Download the model as a folder inside the `model ` directory and create a YAML file specifying the `exllama` backend. For instance with the `TheBloke/WizardLM-7B-uncensored-GPTQ` model:
|
||||
|
||||
```
|
||||
$ git lfs install
|
||||
$ cd models && git clone https://huggingface.co/TheBloke/WizardLM-7B-uncensored-GPTQ
|
||||
$ ls models/
|
||||
.keep WizardLM-7B-uncensored-GPTQ/ exllama.yaml
|
||||
$ cat models/exllama.yaml
|
||||
name: exllama
|
||||
parameters:
|
||||
model: WizardLM-7B-uncensored-GPTQ
|
||||
backend: exllama
|
||||
# Note: you can also specify "exllama2" if it's an exllama2 model here
|
||||
# ...
|
||||
```
|
||||
|
||||
Test with:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "exllama",
|
||||
"messages": [{"role": "user", "content": "How are you?"}],
|
||||
"temperature": 0.1
|
||||
}'
|
||||
```
|
||||
|
||||
### vLLM
|
||||
|
||||
[vLLM](https://github.com/vllm-project/vllm) is a fast and easy-to-use library for LLM inference.
|
||||
|
||||
LocalAI has a built-in integration with vLLM, and it can be used to run models. You can check out `vllm` performance [here](https://github.com/vllm-project/vllm#performance).
|
||||
|
||||
#### Setup
|
||||
|
||||
Create a YAML file for the model you want to use with `vllm`.
|
||||
|
||||
To setup a model, you need to just specify the model name in the YAML config file:
|
||||
```yaml
|
||||
name: vllm
|
||||
backend: vllm
|
||||
parameters:
|
||||
model: "facebook/opt-125m"
|
||||
|
||||
# Decomment to specify a quantization method (optional)
|
||||
# quantization: "awq"
|
||||
```
|
||||
|
||||
The backend will automatically download the required files in order to run the model.
|
||||
|
||||
|
||||
#### Usage
|
||||
|
||||
Use the `completions` endpoint by specifying the `vllm` backend:
|
||||
```
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "vllm",
|
||||
"prompt": "Hello, my name is",
|
||||
"temperature": 0.1, "top_p": 0.1
|
||||
}'
|
||||
```
|
||||
159
docs/content/docs/features/text-to-audio.md
Normal file
159
docs/content/docs/features/text-to-audio.md
Normal file
@@ -0,0 +1,159 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🗣 Text to audio (TTS)"
|
||||
weight = 11
|
||||
url = "/features/text-to-audio/"
|
||||
+++
|
||||
|
||||
The `/tts` endpoint can be used to generate speech from text.
|
||||
|
||||
## Usage
|
||||
|
||||
Input: `input`, `model`
|
||||
|
||||
For example, to generate an audio file, you can send a POST request to the `/tts` endpoint with the instruction as the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"input": "Hello world",
|
||||
"model": "tts"
|
||||
}'
|
||||
```
|
||||
|
||||
Returns an `audio/wav` file.
|
||||
|
||||
|
||||
## Backends
|
||||
|
||||
### 🐸 Coqui
|
||||
|
||||
Required: Don't use `LocalAI` images ending with the `-core` tag,. Python dependencies are required in order to use this backend.
|
||||
|
||||
Coqui works without any configuration, to test it, you can run the following curl command:
|
||||
|
||||
```
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"backend": "coqui",
|
||||
"model": "tts_models/en/ljspeech/glow-tts",
|
||||
"input":"Hello, this is a test!"
|
||||
}'
|
||||
```
|
||||
|
||||
### Bark
|
||||
|
||||
[Bark](https://github.com/suno-ai/bark) allows to generate audio from text prompts.
|
||||
|
||||
This is an extra backend - in the container is already available and there is nothing to do for the setup.
|
||||
|
||||
#### Model setup
|
||||
|
||||
There is nothing to be done for the model setup. You can already start to use bark. The models will be downloaded the first time you use the backend.
|
||||
|
||||
#### Usage
|
||||
|
||||
Use the `tts` endpoint by specifying the `bark` backend:
|
||||
|
||||
```
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"backend": "bark",
|
||||
"input":"Hello!"
|
||||
}' | aplay
|
||||
```
|
||||
|
||||
To specify a voice from https://github.com/suno-ai/bark#-voice-presets ( https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c ), use the `model` parameter:
|
||||
|
||||
```
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"backend": "bark",
|
||||
"input":"Hello!",
|
||||
"model": "v2/en_speaker_4"
|
||||
}' | aplay
|
||||
```
|
||||
|
||||
### Piper
|
||||
|
||||
To install the `piper` audio models manually:
|
||||
|
||||
- Download Voices from https://github.com/rhasspy/piper/releases/tag/v0.0.2
|
||||
- Extract the `.tar.tgz` files (.onnx,.json) inside `models`
|
||||
- Run the following command to test the model is working
|
||||
|
||||
To use the tts endpoint, run the following command. You can specify a backend with the `backend` parameter. For example, to use the `piper` backend:
|
||||
```bash
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"model":"it-riccardo_fasol-x-low.onnx",
|
||||
"backend": "piper",
|
||||
"input": "Ciao, sono Ettore"
|
||||
}' | aplay
|
||||
```
|
||||
|
||||
Note:
|
||||
|
||||
- `aplay` is a Linux command. You can use other tools to play the audio file.
|
||||
- The model name is the filename with the extension.
|
||||
- The model name is case sensitive.
|
||||
- LocalAI must be compiled with the `GO_TAGS=tts` flag.
|
||||
|
||||
### Transformers-musicgen
|
||||
|
||||
LocalAI also has experimental support for `transformers-musicgen` for the generation of short musical compositions. Currently, this is implemented via the same requests used for text to speech:
|
||||
|
||||
```
|
||||
curl --request POST \
|
||||
--url http://localhost:8080/tts \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data '{
|
||||
"backend": "transformers-musicgen",
|
||||
"model": "facebook/musicgen-medium",
|
||||
"input": "Cello Rave"
|
||||
}' | aplay
|
||||
```
|
||||
|
||||
Future versions of LocalAI will expose additional control over audio generation beyond the text prompt.
|
||||
|
||||
### Vall-E-X
|
||||
|
||||
[VALL-E-X](https://github.com/Plachtaa/VALL-E-X) is an open source implementation of Microsoft's VALL-E X zero-shot TTS model.
|
||||
|
||||
#### Setup
|
||||
|
||||
The backend will automatically download the required files in order to run the model.
|
||||
|
||||
This is an extra backend - in the container is already available and there is nothing to do for the setup. If you are building manually, you need to install Vall-E-X manually first.
|
||||
|
||||
#### Usage
|
||||
|
||||
Use the tts endpoint by specifying the vall-e-x backend:
|
||||
|
||||
```
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"backend": "vall-e-x",
|
||||
"input":"Hello!"
|
||||
}' | aplay
|
||||
```
|
||||
|
||||
#### Voice cloning
|
||||
|
||||
In order to use voice cloning capabilities you must create a `YAML` configuration file to setup a model:
|
||||
|
||||
```yaml
|
||||
name: cloned-voice
|
||||
backend: vall-e-x
|
||||
parameters:
|
||||
model: "cloned-voice"
|
||||
vall-e:
|
||||
# The path to the audio file to be cloned
|
||||
# relative to the models directory
|
||||
audio_path: "path-to-wav-source.wav"
|
||||
```
|
||||
|
||||
Then you can specify the model name in the requests:
|
||||
|
||||
```
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"backend": "vall-e-x",
|
||||
"model": "cloned-voice",
|
||||
"input":"Hello!"
|
||||
}' | aplay
|
||||
```
|
||||
7
docs/content/docs/getting-started/_index.en.md
Normal file
7
docs/content/docs/getting-started/_index.en.md
Normal file
@@ -0,0 +1,7 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Getting started"
|
||||
weight = 2
|
||||
icon = "rocket_launch"
|
||||
+++
|
||||
@@ -1,14 +1,20 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Build"
|
||||
weight = 5
|
||||
title = "Build LocalAI from source"
|
||||
weight = 6
|
||||
url = '/basics/build/'
|
||||
|
||||
ico = "rocket_launch"
|
||||
+++
|
||||
|
||||
### Build
|
||||
|
||||
LocalAI can be built as a container image or as a single, portable binary. Note that the some model architectures might require Python libraries, which are not included in the binary. The binary contains only the core backends written in Go and C++.
|
||||
|
||||
LocalAI's extensible architecture allows you to add your own backends, which can be written in any language, and as such the container images contains also the Python dependencies to run all the available backends (for example, in order to run backends like __Diffusers__ that allows to generate images and videos from text).
|
||||
|
||||
In some cases you might want to re-build LocalAI from source (for instance to leverage Apple Silicon acceleration), or to build a custom container image with your own backends. This section contains instructions on how to build LocalAI from source.
|
||||
|
||||
#### Container image
|
||||
|
||||
Requirements:
|
||||
@@ -23,7 +29,9 @@ docker build -t localai .
|
||||
docker run localai
|
||||
```
|
||||
|
||||
#### Locally
|
||||
#### Build LocalAI locally
|
||||
|
||||
##### Requirements
|
||||
|
||||
In order to build LocalAI locally, you need the following requirements:
|
||||
|
||||
@@ -34,22 +42,22 @@ In order to build LocalAI locally, you need the following requirements:
|
||||
|
||||
To install the dependencies follow the instructions below:
|
||||
|
||||
{{< tabs >}}
|
||||
{{% tab name="Apple" %}}
|
||||
{{< tabs tabTotal="3" >}}
|
||||
{{% tab tabName="Apple" %}}
|
||||
|
||||
```bash
|
||||
brew install abseil cmake go grpc protobuf wget
|
||||
```
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab name="Debian" %}}
|
||||
{{% tab tabName="Debian" %}}
|
||||
|
||||
```bash
|
||||
apt install protobuf-compiler-grpc libgrpc-dev make cmake
|
||||
apt install golang protobuf-compiler-grpc libgrpc-dev make cmake
|
||||
```
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab name="From source" %}}
|
||||
{{% tab tabName="From source" %}}
|
||||
|
||||
Specify `BUILD_GRPC_FOR_BACKEND_LLAMA=true` to build automatically the gRPC dependencies
|
||||
|
||||
@@ -60,7 +68,7 @@ make ... BUILD_GRPC_FOR_BACKEND_LLAMA=true build
|
||||
{{% /tab %}}
|
||||
{{< /tabs >}}
|
||||
|
||||
|
||||
##### Build
|
||||
To build LocalAI with `make`:
|
||||
|
||||
```
|
||||
@@ -71,7 +79,17 @@ make build
|
||||
|
||||
This should produce the binary `local-ai`
|
||||
|
||||
{{% notice note %}}
|
||||
Here is the list of the variables available that can be used to customize the build:
|
||||
|
||||
| Variable | Default | Description |
|
||||
| ---------------------| ------- | ----------- |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas` |
|
||||
| `GO_TAGS` | `tts stablediffusion` | Go tags. Available: `stablediffusion`, `tts`, `tinydream` |
|
||||
| `CLBLAST_DIR` | | Specify a CLBlast directory |
|
||||
| `CUDA_LIBPATH` | | Specify a CUDA library path |
|
||||
| `BUILD_API_ONLY` | false | Set to true to build only the API (no backends will be built) |
|
||||
|
||||
{{% alert note %}}
|
||||
|
||||
#### CPU flagset compatibility
|
||||
|
||||
@@ -89,7 +107,7 @@ docker run quay.io/go-skynet/localai
|
||||
docker run --rm -ti -p 8080:8080 -e DEBUG=true -e MODELS_PATH=/models -e THREADS=1 -e REBUILD=true -e CMAKE_ARGS="-DLLAMA_F16C=OFF -DLLAMA_AVX512=OFF -DLLAMA_AVX2=OFF -DLLAMA_AVX=OFF -DLLAMA_FMA=OFF" -v $PWD/models:/models quay.io/go-skynet/local-ai:latest
|
||||
```
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
### Example: Build on mac
|
||||
|
||||
@@ -133,7 +151,7 @@ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/jso
|
||||
|
||||
**Requirements**: OpenCV, Gomp
|
||||
|
||||
Image generation is experimental and requires `GO_TAGS=stablediffusion` to be set during build:
|
||||
Image generation requires `GO_TAGS=stablediffusion` or `GO_TAGS=tinydream` to be set during build:
|
||||
|
||||
```
|
||||
make GO_TAGS=stablediffusion build
|
||||
@@ -151,15 +169,6 @@ make GO_TAGS=tts build
|
||||
|
||||
### Acceleration
|
||||
|
||||
List of the variables available to customize the build:
|
||||
|
||||
| Variable | Default | Description |
|
||||
| ---------------------| ------- | ----------- |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas` |
|
||||
| `GO_TAGS` | `tts stablediffusion` | Go tags. Available: `stablediffusion`, `tts` |
|
||||
| `CLBLAST_DIR` | | Specify a CLBlast directory |
|
||||
| `CUDA_LIBPATH` | | Specify a CUDA library path |
|
||||
|
||||
#### OpenBLAS
|
||||
|
||||
Software acceleration.
|
||||
@@ -216,7 +225,7 @@ make BUILD_TYPE=clblas build
|
||||
|
||||
To specify a clblast dir set: `CLBLAST_DIR`
|
||||
|
||||
### Metal (Apple Silicon)
|
||||
#### Metal (Apple Silicon)
|
||||
|
||||
```
|
||||
make BUILD_TYPE=metal build
|
||||
@@ -225,7 +234,16 @@ make BUILD_TYPE=metal build
|
||||
# Note: only models quantized with q4_0 are supported!
|
||||
```
|
||||
|
||||
### Build only a single backend
|
||||
|
||||
### Windows compatibility
|
||||
|
||||
Make sure to give enough resources to the running container. See https://github.com/go-skynet/LocalAI/issues/2
|
||||
|
||||
### Examples
|
||||
|
||||
More advanced build options are available, for instance to build only a single backend.
|
||||
|
||||
#### Build only a single backend
|
||||
|
||||
You can control the backends that are built by setting the `GRPC_BACKENDS` environment variable. For instance, to build only the `llama-cpp` backend only:
|
||||
|
||||
@@ -235,6 +253,10 @@ make GRPC_BACKENDS=backend-assets/grpc/llama-cpp build
|
||||
|
||||
By default, all the backends are built.
|
||||
|
||||
### Windows compatibility
|
||||
#### Specific llama.cpp version
|
||||
|
||||
Make sure to give enough resources to the running container. See https://github.com/go-skynet/LocalAI/issues/2
|
||||
To build with a specific version of llama.cpp, set `CPPLLAMA_VERSION` to the tag or wanted sha:
|
||||
|
||||
```
|
||||
CPPLLAMA_VERSION=<sha> make build
|
||||
```
|
||||
71
docs/content/docs/getting-started/customize-model.md
Normal file
71
docs/content/docs/getting-started/customize-model.md
Normal file
@@ -0,0 +1,71 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Customizing the Model"
|
||||
weight = 4
|
||||
icon = "rocket_launch"
|
||||
|
||||
+++
|
||||
|
||||
To customize the prompt template or the default settings of the model, a configuration file is utilized. This file must adhere to the LocalAI YAML configuration standards. For comprehensive syntax details, refer to the [advanced documentation]({{%relref "docs/advanced" %}}). The configuration file can be located either remotely (such as in a Github Gist) or within the local filesystem or a remote URL.
|
||||
|
||||
LocalAI can be initiated using either its container image or binary, with a command that includes URLs of model config files or utilizes a shorthand format (like `huggingface://` or `github://`), which is then expanded into complete URLs.
|
||||
|
||||
The configuration can also be set via an environment variable. For instance:
|
||||
|
||||
```
|
||||
# Command-Line Arguments
|
||||
local-ai github://owner/repo/file.yaml@branch
|
||||
|
||||
# Environment Variable
|
||||
MODELS="github://owner/repo/file.yaml@branch,github://owner/repo/file.yaml@branch" local-ai
|
||||
```
|
||||
|
||||
Here's an example to initiate the **phi-2** model:
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core https://gist.githubusercontent.com/mudler/ad601a0488b497b69ec549150d9edd18/raw/a8a8869ef1bb7e3830bf5c0bae29a0cce991ff8d/phi-2.yaml
|
||||
```
|
||||
|
||||
{{% alert icon="" %}}
|
||||
The model configurations used in the quickstart are accessible here: [https://github.com/mudler/LocalAI/tree/master/embedded/models](https://github.com/mudler/LocalAI/tree/master/embedded/models). Contributions are welcome; please feel free to submit a Pull Request.
|
||||
|
||||
The `phi-2` model configuration from the quickstart is expanded from [https://github.com/mudler/LocalAI/blob/master/examples/configurations/phi-2.yaml](https://github.com/mudler/LocalAI/blob/master/examples/configurations/phi-2.yaml).
|
||||
{{% /alert %}}
|
||||
|
||||
## Example: Customizing the Prompt Template
|
||||
|
||||
To modify the prompt template, create a Github gist or a Pastebin file, and copy the content from [https://github.com/mudler/LocalAI/blob/master/examples/configurations/phi-2.yaml](https://github.com/mudler/LocalAI/blob/master/examples/configurations/phi-2.yaml). Alter the fields as needed:
|
||||
|
||||
```yaml
|
||||
name: phi-2
|
||||
context_size: 2048
|
||||
f16: true
|
||||
threads: 11
|
||||
gpu_layers: 90
|
||||
mmap: true
|
||||
parameters:
|
||||
# Reference any HF model or a local file here
|
||||
model: huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
template:
|
||||
|
||||
chat: &template |
|
||||
Instruct: {{.Input}}
|
||||
Output:
|
||||
# Modify the prompt template here ^^^ as per your requirements
|
||||
completion: *template
|
||||
```
|
||||
|
||||
Then, launch LocalAI using your gist's URL:
|
||||
|
||||
```bash
|
||||
## Important! Substitute with your gist's URL!
|
||||
docker run -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core https://gist.githubusercontent.com/xxxx/phi-2.yaml
|
||||
```
|
||||
|
||||
## Next Steps
|
||||
|
||||
- Visit the [advanced section]({{%relref "docs/advanced" %}}) for more insights on prompt templates and configuration files.
|
||||
- To learn about fine-tuning an LLM model, check out the [fine-tuning section]({{%relref "docs/advanced/fine-tuning" %}}).
|
||||
166
docs/content/docs/getting-started/manual.md
Normal file
166
docs/content/docs/getting-started/manual.md
Normal file
@@ -0,0 +1,166 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Run models manually"
|
||||
weight = 5
|
||||
icon = "rocket_launch"
|
||||
|
||||
+++
|
||||
|
||||
|
||||
1. Ensure you have a model file, a configuration YAML file, or both. Customize model defaults and specific settings with a configuration file. For advanced configurations, refer to the [Advanced Documentation](docs/advanced).
|
||||
|
||||
2. For GPU Acceleration instructions, visit [GPU acceleration](docs/features/gpu-acceleration).
|
||||
|
||||
{{< tabs tabTotal="5" >}}
|
||||
{{% tab tabName="Docker" %}}
|
||||
|
||||
```bash
|
||||
# Prepare the models into the `model` directory
|
||||
mkdir models
|
||||
|
||||
# copy your models to it
|
||||
cp your-model.gguf models/
|
||||
|
||||
# run the LocalAI container
|
||||
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest --models-path /models --context-size 700 --threads 4
|
||||
# You should see:
|
||||
#
|
||||
# ┌───────────────────────────────────────────────────┐
|
||||
# │ Fiber v2.42.0 │
|
||||
# │ http://127.0.0.1:8080 │
|
||||
# │ (bound on host 0.0.0.0 and port 8080) │
|
||||
# │ │
|
||||
# │ Handlers ............. 1 Processes ........... 1 │
|
||||
# │ Prefork ....... Disabled PID ................. 1 │
|
||||
# └───────────────────────────────────────────────────┘
|
||||
|
||||
# Try the endpoint with curl
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "your-model.gguf",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
|
||||
**Other Docker Images**:
|
||||
|
||||
For other Docker images, please see the table in
|
||||
https://localai.io/basics/getting_started/#container-images.
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
Here is a more specific example:
|
||||
|
||||
```bash
|
||||
mkdir models
|
||||
|
||||
# Download luna-ai-llama2 to models/
|
||||
wget https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGUF/resolve/main/luna-ai-llama2-uncensored.Q4_0.gguf -O models/luna-ai-llama2
|
||||
|
||||
# Use a template from the examples
|
||||
cp -rf prompt-templates/getting_started.tmpl models/luna-ai-llama2.tmpl
|
||||
|
||||
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest --models-path /models --context-size 700 --threads 4
|
||||
|
||||
# Now API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
# {"object":"list","data":[{"id":"luna-ai-llama2","object":"model"}]}
|
||||
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "luna-ai-llama2",
|
||||
"messages": [{"role": "user", "content": "How are you?"}],
|
||||
"temperature": 0.9
|
||||
}'
|
||||
# {"model":"luna-ai-llama2","choices":[{"message":{"role":"assistant","content":"I'm doing well, thanks. How about you?"}}]}
|
||||
```
|
||||
|
||||
{{% alert note %}}
|
||||
- If running on Apple Silicon (ARM) it is **not** suggested to run on Docker due to emulation. Follow the [build instructions]({{%relref "docs/getting-started/build" %}}) to use Metal acceleration for full GPU support.
|
||||
- If you are running Apple x86_64 you can use `docker`, there is no additional gain into building it from source.
|
||||
{{% /alert %}}
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="Docker compose" %}}
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI
|
||||
|
||||
# (optional) Checkout a specific LocalAI tag
|
||||
# git checkout -b build <TAG>
|
||||
|
||||
# copy your models to models/
|
||||
cp your-model.gguf models/
|
||||
|
||||
# (optional) Edit the .env file to set things like context size and threads
|
||||
# vim .env
|
||||
|
||||
# start with docker compose
|
||||
docker compose up -d --pull always
|
||||
# or you can build the images with:
|
||||
# docker compose up -d --build
|
||||
|
||||
# Now API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
# {"object":"list","data":[{"id":"your-model.gguf","object":"model"}]}
|
||||
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "your-model.gguf",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
|
||||
**Other Docker Images**:
|
||||
|
||||
For other Docker images, please see the table in
|
||||
https://localai.io/basics/getting_started/#container-images.
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
Note: If you are on Windows, please make sure the project is on the Linux Filesystem, otherwise loading models might be slow. For more Info: [Microsoft Docs](https://learn.microsoft.com/en-us/windows/wsl/filesystems)
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="Kubernetes" %}}
|
||||
|
||||
For installing LocalAI in Kubernetes, you can use the following helm chart:
|
||||
|
||||
```bash
|
||||
# Install the helm repository
|
||||
helm repo add go-skynet https://go-skynet.github.io/helm-charts/
|
||||
# Update the repositories
|
||||
helm repo update
|
||||
# Get the values
|
||||
helm show values go-skynet/local-ai > values.yaml
|
||||
|
||||
# Edit the values value if needed
|
||||
# vim values.yaml ...
|
||||
|
||||
# Install the helm chart
|
||||
helm install local-ai go-skynet/local-ai -f values.yaml
|
||||
```
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="From binary" %}}
|
||||
|
||||
LocalAI binary releases are available in [Github](https://github.com/go-skynet/LocalAI/releases).
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="From source" %}}
|
||||
|
||||
See the [build section]({{%relref "docs/getting-started/build" %}}).
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
For more model configurations, visit the [Examples Section](https://github.com/mudler/LocalAI/tree/master/examples/configurations).
|
||||
188
docs/content/docs/getting-started/quickstart.md
Normal file
188
docs/content/docs/getting-started/quickstart.md
Normal file
@@ -0,0 +1,188 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Quickstart"
|
||||
weight = 3
|
||||
url = '/basics/getting_started/'
|
||||
icon = "rocket_launch"
|
||||
|
||||
+++
|
||||
|
||||
**LocalAI** is the free, Open Source OpenAI alternative. LocalAI act as a drop-in replacement REST API that's compatible with OpenAI API specifications for local inferencing. It allows you to run [LLMs]({{%relref "docs/features/text-generation" %}}), generate images, audio (and not only) locally or on-prem with consumer grade hardware, supporting multiple model families and architectures.
|
||||
|
||||
## Installation Methods
|
||||
|
||||
LocalAI is available as a container image and binary, compatible with various container engines like Docker, Podman, and Kubernetes. Container images are published on [quay.io](https://quay.io/repository/go-skynet/local-ai?tab=tags&tag=latest) and [Docker Hub](https://hub.docker.com/r/localai/localai). Binaries can be downloaded from [GitHub](https://github.com/mudler/LocalAI/releases).
|
||||
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
|
||||
**Hardware Requirements:** The hardware requirements for LocalAI vary based on the model size and quantization method used. For performance benchmarks with different backends, such as `llama.cpp`, visit [this link](https://github.com/ggerganov/llama.cpp#memorydisk-requirements). The `rwkv` backend is noted for its lower resource consumption.
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before you begin, ensure you have a container engine installed if you are not using the binaries. Suitable options include Docker or Podman. For installation instructions, refer to the following guides:
|
||||
|
||||
- [Install Docker Desktop (Mac, Windows, Linux)](https://docs.docker.com/get-docker/)
|
||||
- [Install Podman (Linux)](https://podman.io/getting-started/installation)
|
||||
- [Install Docker engine (Servers)](https://docs.docker.com/engine/install/#get-started)
|
||||
|
||||
|
||||
## Running Models
|
||||
|
||||
> _Do you have already a model file? Skip to [Run models manually]({{%relref "docs/getting-started/manual" %}})_.
|
||||
|
||||
LocalAI allows one-click runs with popular models. It downloads the model and starts the API with the model loaded.
|
||||
|
||||
There are different categories of models: [LLMs]({{%relref "docs/features/text-generation" %}}), [Multimodal LLM]({{%relref "docs/features/gpt-vision" %}}) , [Embeddings]({{%relref "docs/features/embeddings" %}}), [Audio to Text]({{%relref "docs/features/audio-to-text" %}}), and [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) depending on the backend being used and the model architecture.
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
|
||||
To customize the models, see [Model customization]({{%relref "docs/getting-started/customize-model" %}}). For more model configurations, visit the [Examples Section](https://github.com/mudler/LocalAI/tree/master/examples/configurations).
|
||||
{{% /alert %}}
|
||||
|
||||
{{< tabs tabTotal="3" >}}
|
||||
{{% tab tabName="CPU-only" %}}
|
||||
|
||||
> 💡Don't need GPU acceleration? use the CPU images which are lighter and do not have Nvidia dependencies
|
||||
|
||||
| Model | Category | Docker command |
|
||||
| --- | --- | --- |
|
||||
| [phi-2](https://huggingface.co/microsoft/phi-2) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core phi-2``` |
|
||||
| 🌋 [llava](https://github.com/SkunkworksAI/BakLLaVA) | [Multimodal LLM]({{%relref "docs/features/gpt-vision" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core llava``` |
|
||||
| [mistral-openorca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core mistral-openorca``` |
|
||||
| [bert-cpp](https://github.com/skeskinen/bert.cpp) | [Embeddings]({{%relref "docs/features/embeddings" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core bert-cpp``` |
|
||||
| [all-minilm-l6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | [Embeddings]({{%relref "docs/features/embeddings" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg all-minilm-l6-v2``` |
|
||||
| whisper-base | [Audio to Text]({{%relref "docs/features/audio-to-text" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core whisper-base``` |
|
||||
| rhasspy-voice-en-us-amy | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core rhasspy-voice-en-us-amy``` |
|
||||
| 🐸 [coqui](https://github.com/coqui-ai/TTS) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg coqui``` |
|
||||
| 🐶 [bark](https://github.com/suno-ai/bark) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg bark``` |
|
||||
| 🔊 [vall-e-x](https://github.com/Plachtaa/VALL-E-X) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg vall-e-x``` |
|
||||
| mixtral-instruct Mixtral-8x7B-Instruct-v0.1 | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core mixtral-instruct``` |
|
||||
| [tinyllama-chat](https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF) [original model](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v0.3) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core tinyllama-chat``` |
|
||||
| [dolphin-2.5-mixtral-8x7b](https://huggingface.co/TheBloke/dolphin-2.5-mixtral-8x7b-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core dolphin-2.5-mixtral-8x7b``` |
|
||||
| 🐍 [mamba](https://github.com/state-spaces/mamba) | [LLM]({{%relref "docs/features/text-generation" %}}) | GPU-only |
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="GPU (CUDA 11)" %}}
|
||||
|
||||
|
||||
> To know which version of CUDA do you have available, you can check with `nvidia-smi` or `nvcc --version` see also [GPU acceleration]({{%relref "docs/features/gpu-acceleration" %}}).
|
||||
|
||||
| Model | Category | Docker command |
|
||||
| --- | --- | --- |
|
||||
| [phi-2](https://huggingface.co/microsoft/phi-2) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core phi-2``` |
|
||||
| 🌋 [llava](https://github.com/SkunkworksAI/BakLLaVA) | [Multimodal LLM]({{%relref "docs/features/gpt-vision" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core llava``` |
|
||||
| [mistral-openorca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core mistral-openorca``` |
|
||||
| [bert-cpp](https://github.com/skeskinen/bert.cpp) | [Embeddings]({{%relref "docs/features/embeddings" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core bert-cpp``` |
|
||||
| [all-minilm-l6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | [Embeddings]({{%relref "docs/features/embeddings" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 all-minilm-l6-v2``` |
|
||||
| whisper-base | [Audio to Text]({{%relref "docs/features/audio-to-text" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core whisper-base``` |
|
||||
| rhasspy-voice-en-us-amy | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core rhasspy-voice-en-us-amy``` |
|
||||
| 🐸 [coqui](https://github.com/coqui-ai/TTS) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 coqui``` |
|
||||
| 🐶 [bark](https://github.com/suno-ai/bark) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 bark``` |
|
||||
| 🔊 [vall-e-x](https://github.com/Plachtaa/VALL-E-X) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 vall-e-x``` |
|
||||
| mixtral-instruct Mixtral-8x7B-Instruct-v0.1 | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core mixtral-instruct``` |
|
||||
| [tinyllama-chat](https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF) [original model](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v0.3) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core tinyllama-chat``` |
|
||||
| [dolphin-2.5-mixtral-8x7b](https://huggingface.co/TheBloke/dolphin-2.5-mixtral-8x7b-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core dolphin-2.5-mixtral-8x7b``` |
|
||||
| 🐍 [mamba](https://github.com/state-spaces/mamba) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 mamba-chat``` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
|
||||
{{% tab tabName="GPU (CUDA 12)" %}}
|
||||
|
||||
> To know which version of CUDA do you have available, you can check with `nvidia-smi` or `nvcc --version` see also [GPU acceleration]({{%relref "docs/features/gpu-acceleration" %}}).
|
||||
|
||||
| Model | Category | Docker command |
|
||||
| --- | --- | --- |
|
||||
| [phi-2](https://huggingface.co/microsoft/phi-2) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core phi-2``` |
|
||||
| 🌋 [llava](https://github.com/SkunkworksAI/BakLLaVA) | [Multimodal LLM]({{%relref "docs/features/gpt-vision" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core llava``` |
|
||||
| [mistral-openorca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core mistral-openorca``` |
|
||||
| [bert-cpp](https://github.com/skeskinen/bert.cpp) | [Embeddings]({{%relref "docs/features/embeddings" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core bert-cpp``` |
|
||||
| [all-minilm-l6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | [Embeddings]({{%relref "docs/features/embeddings" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 all-minilm-l6-v2``` |
|
||||
| whisper-base | [Audio to Text]({{%relref "docs/features/audio-to-text" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core whisper-base``` |
|
||||
| rhasspy-voice-en-us-amy | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core rhasspy-voice-en-us-amy``` |
|
||||
| 🐸 [coqui](https://github.com/coqui-ai/TTS) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 coqui``` |
|
||||
| 🐶 [bark](https://github.com/suno-ai/bark) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 bark``` |
|
||||
| 🔊 [vall-e-x](https://github.com/Plachtaa/VALL-E-X) | [Text to Audio]({{%relref "docs/features/text-to-audio" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 vall-e-x``` |
|
||||
| mixtral-instruct Mixtral-8x7B-Instruct-v0.1 | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core mixtral-instruct``` |
|
||||
| [tinyllama-chat](https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF) [original model](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v0.3) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core tinyllama-chat``` |
|
||||
| [dolphin-2.5-mixtral-8x7b](https://huggingface.co/TheBloke/dolphin-2.5-mixtral-8x7b-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core dolphin-2.5-mixtral-8x7b``` |
|
||||
| 🐍 [mamba](https://github.com/state-spaces/mamba) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 mamba-chat``` |
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
**Tip** You can actually specify multiple models to start an instance with the models loaded, for example to have both llava and phi-2 configured:
|
||||
|
||||
```bash
|
||||
docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core llava phi-2
|
||||
```
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
## Container images
|
||||
|
||||
LocalAI provides a variety of images to support different environments. These images are available on [quay.io](https://quay.io/repository/go-skynet/local-ai?tab=tags) and [Docker Hub](https://hub.docker.com/r/localai/localai).
|
||||
|
||||
For GPU Acceleration support for Nvidia video graphic cards, use the Nvidia/CUDA images, if you don't have a GPU, use the CPU images. If you have AMD or Mac Silicon, see the [build section]({{%relref "docs/getting-started/build" %}}).
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
|
||||
**Available Images Types**:
|
||||
|
||||
- Images ending with `-core` are smaller images without predownload python dependencies. Use these images if you plan to use `llama.cpp`, `stablediffusion-ncn`, `tinydream` or `rwkv` backends - if you are not sure which one to use, do **not** use these images.
|
||||
- FFMpeg is **not** included in the default images due to [its licensing](https://www.ffmpeg.org/legal.html). If you need FFMpeg, use the images ending with `-ffmpeg`. Note that `ffmpeg` is needed in case of using `audio-to-text` LocalAI's features.
|
||||
- If using old and outdated CPUs and no GPUs you might need to set `REBUILD` to `true` as environment variable along with options to disable the flags which your CPU does not support, however note that inference will perform poorly and slow. See also [flagset compatibility]({{%relref "docs/getting-started/build#cpu-flagset-compatibility" %}}).
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
{{< tabs tabTotal="3" >}}
|
||||
{{% tab tabName="Vanilla / CPU Images" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-----------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master` | `localai/localai:master` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest` | `localai/localai:latest` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}` | `localai/localai:{{< version >}}` |
|
||||
| Versioned image including FFMpeg| `quay.io/go-skynet/local-ai:{{< version >}}-ffmpeg` | `localai/localai:{{< version >}}-ffmpeg` |
|
||||
| Versioned image including FFMpeg, no python | `quay.io/go-skynet/local-ai:{{< version >}}-ffmpeg-core` | `localai/localai:{{< version >}}-ffmpeg-core` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="GPU Images CUDA 11" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-cublas-cuda11` | `localai/localai:master-cublas-cuda11` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-cublas-cuda11` | `localai/localai:latest-cublas-cuda11` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda11` | `localai/localai:{{< version >}}-cublas-cuda11` |
|
||||
| Versioned image including FFMpeg| `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda11-ffmpeg` | `localai/localai:{{< version >}}-cublas-cuda11-ffmpeg` |
|
||||
| Versioned image including FFMpeg, no python | `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda11-ffmpeg-core` | `localai/localai:{{< version >}}-cublas-cuda11-ffmpeg-core` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="GPU Images CUDA 12" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-cublas-cuda12` | `localai/localai:master-cublas-cuda12` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-cublas-cuda12` | `localai/localai:latest-cublas-cuda12` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda12` | `localai/localai:{{< version >}}-cublas-cuda12` |
|
||||
| Versioned image including FFMpeg| `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda12-ffmpeg` | `localai/localai:{{< version >}}-cublas-cuda12-ffmpeg` |
|
||||
| Versioned image including FFMpeg, no python | `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda12-ffmpeg-core` | `localai/localai:{{< version >}}-cublas-cuda12-ffmpeg-core` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
## What's next?
|
||||
|
||||
Explore further resources and community contributions:
|
||||
|
||||
- [Community How to's](https://io.midori-ai.xyz/howtos/)
|
||||
- [Examples](https://github.com/mudler/LocalAI/tree/master/examples#examples)
|
||||
|
||||
[](https://github.com/mudler/LocalAI/tree/master/examples#examples)
|
||||
28
docs/content/docs/integrations.md
Normal file
28
docs/content/docs/integrations.md
Normal file
@@ -0,0 +1,28 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Integrations"
|
||||
weight = 19
|
||||
icon = "rocket_launch"
|
||||
|
||||
+++
|
||||
|
||||
## Community integrations
|
||||
|
||||
List of projects that are using directly LocalAI behind the scenes can be found [here](https://github.com/mudler/LocalAI#-community-and-integrations).
|
||||
|
||||
The list below is a list of software that integrates with LocalAI.
|
||||
|
||||
- [AnythingLLM](https://github.com/Mintplex-Labs/anything-llm)
|
||||
- [Logseq GPT3 OpenAI plugin](https://github.com/briansunter/logseq-plugin-gpt3-openai) allows to set a base URL, and works with LocalAI.
|
||||
- https://github.com/longy2k/obsidian-bmo-chatbot
|
||||
- https://github.com/FlowiseAI/Flowise
|
||||
- https://github.com/k8sgpt-ai/k8sgpt
|
||||
- https://github.com/kairos-io/kairos
|
||||
- https://github.com/langchain4j/langchain4j
|
||||
- https://github.com/henomis/lingoose
|
||||
- https://github.com/trypromptly/LLMStack
|
||||
- https://github.com/mattermost/openops
|
||||
- https://github.com/charmbracelet/mods
|
||||
- https://github.com/cedriking/spark
|
||||
|
||||
Feel free to open up a Pull request (by clicking at the "Edit page" below) to get a page for your project made or if you see a error on one of the pages!
|
||||
@@ -1,8 +1,21 @@
|
||||
|
||||
+++
|
||||
archetype = "home"
|
||||
title = "LocalAI"
|
||||
title = "Overview"
|
||||
weight = 1
|
||||
toc = true
|
||||
description = "What is LocalAI?"
|
||||
tags = ["Beginners"]
|
||||
categories = [""]
|
||||
author = "Ettore Di Giacinto"
|
||||
# This allows to overwrite the landing page
|
||||
url = '/'
|
||||
icon = "info"
|
||||
+++
|
||||
|
||||
<p align="center">
|
||||
<a href="https://localai.io"><img width=512 src="https://github.com/go-skynet/LocalAI/assets/2420543/0966aa2a-166e-4f99-a3e5-6c915fc997dd"></a>
|
||||
</p >
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/go-skynet/LocalAI/fork" target="blank">
|
||||
<img src="https://img.shields.io/github/forks/go-skynet/LocalAI?style=for-the-badge" alt="LocalAI forks"/>
|
||||
@@ -18,11 +31,14 @@ title = "LocalAI"
|
||||
</a>
|
||||
</p>
|
||||
|
||||
> 💡 Get help - [❓FAQ](https://localai.io/faq/) [❓How tos](https://localai.io/howtos/) [💭Discussions](https://github.com/go-skynet/LocalAI/discussions) [💭Discord](https://discord.gg/uJAeKSAGDy)
|
||||
[<img src="https://img.shields.io/badge/dockerhub-images-important.svg?logo=Docker">](https://hub.docker.com/r/localai/localai)
|
||||
[<img src="https://img.shields.io/badge/quay.io-images-important.svg?">](https://quay.io/repository/go-skynet/local-ai?tab=tags&tag=latest)
|
||||
|
||||
> 💡 Get help - [❓FAQ](https://localai.io/faq/) [❓How tos](https://io.midori-ai.xyz/howtos/) [💭Discussions](https://github.com/go-skynet/LocalAI/discussions) [💭Discord](https://discord.gg/uJAeKSAGDy)
|
||||
>
|
||||
> [💻 Quickstart](https://localai.io/basics/getting_started/) [📣 News](https://localai.io/basics/news/) [ 🛫 Examples ](https://github.com/go-skynet/LocalAI/tree/master/examples/) [ 🖼️ Models ](https://localai.io/models/) [ 🚀 Roadmap ](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
|
||||
**LocalAI** is the free, Open Source OpenAI alternative. LocalAI act as a drop-in replacement REST API that's compatible with OpenAI API specifications for local inferencing. It allows you to run LLMs, generate images, audio (and not only) locally or on-prem with consumer grade hardware, supporting multiple model families that are compatible with the ggml format. Does not require GPU. It is maintained by [mudler](https://github.com/mudler).
|
||||
**LocalAI** is the free, Open Source OpenAI alternative. LocalAI act as a drop-in replacement REST API that's compatible with OpenAI API specifications for local inferencing. It allows you to run LLMs, generate images, audio (and not only) locally or on-prem with consumer grade hardware, supporting multiple model families and architectures. Does not require GPU. It is maintained by [mudler](https://github.com/mudler).
|
||||
|
||||
<p align="center">
|
||||
<a href="https://twitter.com/LocalAI_API" target="blank">
|
||||
@@ -62,7 +78,7 @@ Note that this started just as a fun weekend project by [mudler](https://github.
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "model-compatibility" %}}) to learn about all the components of LocalAI.
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||
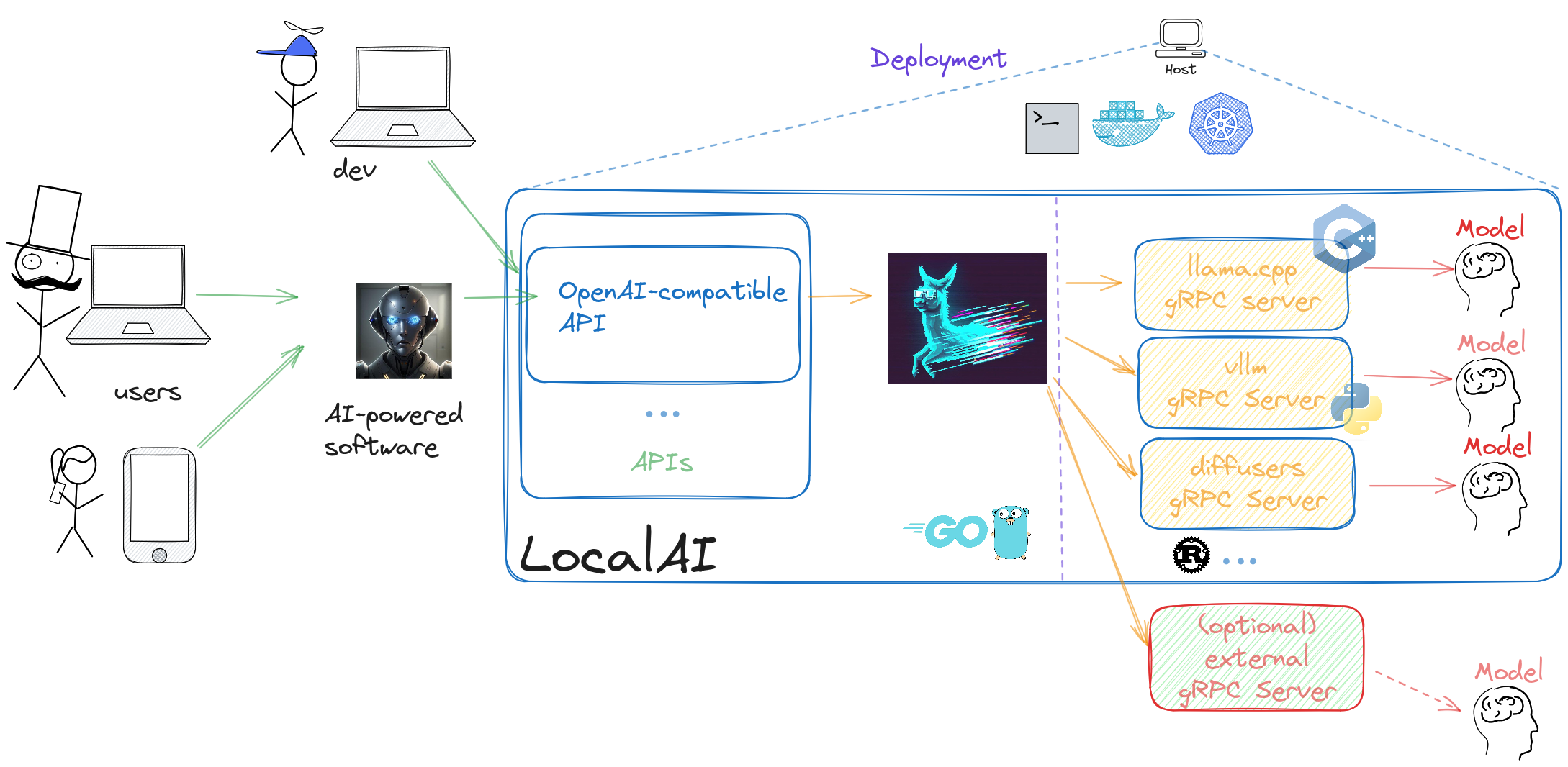
|
||||
|
||||
11
docs/content/docs/reference/_index.en.md
Normal file
11
docs/content/docs/reference/_index.en.md
Normal file
@@ -0,0 +1,11 @@
|
||||
---
|
||||
weight: 23
|
||||
title: "References"
|
||||
description: "Reference"
|
||||
icon: science
|
||||
lead: ""
|
||||
date: 2020-10-06T08:49:15+00:00
|
||||
lastmod: 2020-10-06T08:49:15+00:00
|
||||
draft: false
|
||||
images: []
|
||||
---
|
||||
@@ -1,29 +1,22 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Model compatibility"
|
||||
weight = 4
|
||||
title = "Model compatibility table"
|
||||
weight = 24
|
||||
url = "/model-compatibility/"
|
||||
+++
|
||||
|
||||
LocalAI is compatible with the models supported by [llama.cpp](https://github.com/ggerganov/llama.cpp) supports also [GPT4ALL-J](https://github.com/nomic-ai/gpt4all) and [cerebras-GPT with ggml](https://huggingface.co/lxe/Cerebras-GPT-2.7B-Alpaca-SP-ggml).
|
||||
|
||||
{{% notice note %}}
|
||||
|
||||
LocalAI will attempt to automatically load models which are not explicitly configured for a specific backend. You can specify the backend to use by configuring a model with a YAML file. See [the advanced section]({{%relref "advanced" %}}) for more details.
|
||||
|
||||
{{% /notice %}}
|
||||
|
||||
### Hardware requirements
|
||||
|
||||
Depending on the model you are attempting to run might need more RAM or CPU resources. Check out also [here](https://github.com/ggerganov/llama.cpp#memorydisk-requirements) for `gguf` based backends. `rwkv` is less expensive on resources.
|
||||
|
||||
### Model compatibility table
|
||||
|
||||
Besides llama based models, LocalAI is compatible also with other architectures. The table below lists all the compatible models families and the associated binding repository.
|
||||
|
||||
{{% alert note %}}
|
||||
|
||||
LocalAI will attempt to automatically load models which are not explicitly configured for a specific backend. You can specify the backend to use by configuring a model with a YAML file. See [the advanced section]({{%relref "docs/advanced" %}}) for more details.
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
| Backend and Bindings | Compatible models | Completion/Chat endpoint | Capability | Embeddings support | Token stream support | Acceleration |
|
||||
|----------------------------------------------------------------------------------|-----------------------|--------------------------|---------------------------|-----------------------------------|----------------------|--------------|
|
||||
| [llama.cpp]({{%relref "model-compatibility/llama-cpp" %}}) | Vicuna, Alpaca, LLaMa | yes | GPT and Functions | yes** | yes | CUDA, openCL, cuBLAS, Metal |
|
||||
| [llama.cpp]({{%relref "docs/features/text-generation#llama.cpp" %}}) | Vicuna, Alpaca, LLaMa | yes | GPT and Functions | yes** | yes | CUDA, openCL, cuBLAS, Metal |
|
||||
| [gpt4all-llama](https://github.com/nomic-ai/gpt4all) | Vicuna, Alpaca, LLaMa | yes | GPT | no | yes | N/A |
|
||||
| [gpt4all-mpt](https://github.com/nomic-ai/gpt4all) | MPT | yes | GPT | no | yes | N/A |
|
||||
| [gpt4all-j](https://github.com/nomic-ai/gpt4all) | GPT4ALL-J | yes | GPT | no | yes | N/A |
|
||||
@@ -43,40 +36,21 @@ Besides llama based models, LocalAI is compatible also with other architectures.
|
||||
| [langchain-huggingface](https://github.com/tmc/langchaingo) | Any text generators available on HuggingFace through API | yes | GPT | no | no | N/A |
|
||||
| [piper](https://github.com/rhasspy/piper) ([binding](https://github.com/mudler/go-piper)) | Any piper onnx model | no | Text to voice | no | no | N/A |
|
||||
| [falcon](https://github.com/cmp-nct/ggllm.cpp/tree/c12b2d65f732a0d8846db2244e070f0f3e73505c) ([binding](https://github.com/mudler/go-ggllm.cpp)) | Falcon *** | yes | GPT | no | yes | CUDA |
|
||||
| `huggingface-embeddings` [sentence-transformers](https://github.com/UKPLab/sentence-transformers) | BERT | no | Embeddings only | yes | no | N/A |
|
||||
| [sentencetransformers](https://github.com/UKPLab/sentence-transformers) | BERT | no | Embeddings only | yes | no | N/A |
|
||||
| `bark` | bark | no | Audio generation | no | no | yes |
|
||||
| `AutoGPTQ` | GPTQ | yes | GPT | yes | no | N/A |
|
||||
| `autogptq` | GPTQ | yes | GPT | yes | no | N/A |
|
||||
| `exllama` | GPTQ | yes | GPT only | no | no | N/A |
|
||||
| `diffusers` | SD,... | no | Image generation | no | no | N/A |
|
||||
| `vall-e-x` | Vall-E | no | Audio generation and Voice cloning | no | no | CPU/CUDA |
|
||||
| `vllm` | Various GPTs and quantization formats | yes | GPT | no | no | CPU/CUDA |
|
||||
| `exllama2` | GPTQ | yes | GPT only | no | no | N/A |
|
||||
| `transformers-musicgen` | | no | Audio generation | no | no | N/A |
|
||||
| [tinydream](https://github.com/symisc/tiny-dream#tiny-dreaman-embedded-header-only-stable-diffusion-inference-c-librarypixlabiotiny-dream) | stablediffusion | no | Image | no | no | N/A |
|
||||
| `coqui` | Coqui | no | Audio generation and Voice cloning | no | no | CPU/CUDA |
|
||||
| `petals` | Various GPTs and quantization formats | yes | GPT | no | no | CPU/CUDA |
|
||||
|
||||
Note: any backend name listed above can be used in the `backend` field of the model configuration file (See [the advanced section]({{%relref "advanced" %}})).
|
||||
Note: any backend name listed above can be used in the `backend` field of the model configuration file (See [the advanced section]({{%relref "docs/advanced" %}})).
|
||||
|
||||
- \* 7b ONLY
|
||||
- ** doesn't seem to be accurate
|
||||
- *** 7b and 40b with the `ggccv` format, for instance: https://huggingface.co/TheBloke/WizardLM-Uncensored-Falcon-40B-GGML
|
||||
|
||||
Tested with:
|
||||
|
||||
- [X] Automatically by CI with OpenLLAMA and GPT4ALL.
|
||||
- [X] LLaMA 🦙
|
||||
- [X] [Vicuna](https://github.com/ggerganov/llama.cpp/discussions/643#discussioncomment-5533894)
|
||||
- [Alpaca](https://github.com/ggerganov/llama.cpp#instruction-mode-with-alpaca)
|
||||
- [X] [GPT4ALL](https://gpt4all.io) (see also [using GPT4All](https://github.com/ggerganov/llama.cpp#using-gpt4all))
|
||||
- [X] [GPT4ALL-J](https://gpt4all.io/models/ggml-gpt4all-j.bin) (no changes required)
|
||||
- [X] [Koala](https://bair.berkeley.edu/blog/2023/04/03/koala/) 🐨
|
||||
- [X] Cerebras-GPT
|
||||
- [X] [WizardLM](https://github.com/nlpxucan/WizardLM)
|
||||
- [X] [RWKV](https://github.com/BlinkDL/RWKV-LM) models with [rwkv.cpp](https://github.com/saharNooby/rwkv.cpp)
|
||||
- [X] [bloom.cpp](https://github.com/NouamaneTazi/bloomz.cpp)
|
||||
- [X] [Chinese LLaMA / Alpaca](https://github.com/ymcui/Chinese-LLaMA-Alpaca)
|
||||
- [X] [Vigogne (French)](https://github.com/bofenghuang/vigogne)
|
||||
- [X] [OpenBuddy 🐶 (Multilingual)](https://github.com/OpenBuddy/OpenBuddy)
|
||||
- [X] [Pygmalion 7B / Metharme 7B](https://github.com/ggerganov/llama.cpp#using-pygmalion-7b--metharme-7b)
|
||||
- [X] [HuggingFace Inference](https://huggingface.co/inference-api) models available through API
|
||||
- [X] Falcon
|
||||
|
||||
Note: You might need to convert some models from older models to the new format, for indications, see [the README in llama.cpp](https://github.com/ggerganov/llama.cpp#using-gpt4all) for instance to run `gpt4all`.
|
||||
- *** 7b and 40b with the `ggccv` format, for instance: https://huggingface.co/TheBloke/WizardLM-Uncensored-Falcon-40B-GGML
|
||||
@@ -1,11 +1,17 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🆕 What's New"
|
||||
weight = 2
|
||||
title = "News"
|
||||
weight = 7
|
||||
url = '/basics/news/'
|
||||
|
||||
icon = "newspaper"
|
||||
+++
|
||||
|
||||
Release notes have been now moved completely over Github releases.
|
||||
|
||||
You can see the release notes [here](https://github.com/mudler/LocalAI/releases).
|
||||
|
||||
# Older release notes
|
||||
|
||||
## 04-12-2023: __v2.0.0__
|
||||
|
||||
This release brings a major overhaul in some backends.
|
||||
@@ -68,7 +74,7 @@ From this release the `llama` backend supports only `gguf` files (see {{< pr "94
|
||||
|
||||
### Image generation enhancements
|
||||
|
||||
The [Diffusers]({{%relref "model-compatibility/diffusers" %}}) backend got now various enhancements, including support to generate images from images, longer prompts, and support for more kernels schedulers. See the [Diffusers]({{%relref "model-compatibility/diffusers" %}}) documentation for more information.
|
||||
The [Diffusers]({{%relref "docs/features/image-generation" %}}) backend got now various enhancements, including support to generate images from images, longer prompts, and support for more kernels schedulers. See the [Diffusers]({{%relref "docs/features/image-generation" %}}) documentation for more information.
|
||||
|
||||
### Lora adapters
|
||||
|
||||
@@ -80,7 +86,7 @@ It is now possible for single-devices with one GPU to specify `--single-active-b
|
||||
|
||||
### Community spotlight
|
||||
|
||||

|
||||
|
||||
|
||||
#### Resources management
|
||||
|
||||
@@ -89,7 +95,7 @@ There is an ongoing effort in the community to better handling of resources. See
|
||||
|
||||
#### New how-to section
|
||||
|
||||
Thanks to the community efforts now we have a new [how-to section]({{%relref "howtos" %}}) with various examples on how to use LocalAI. This is a great starting point for new users! We are currently working on improving it, a huge shout out to {{< github "lunamidori5" >}} from the community for the impressive efforts on this!
|
||||
Thanks to the community efforts now we have a new [how-to website](https://io.midori-ai.xyz/howtos/) with various examples on how to use LocalAI. This is a great starting point for new users! We are currently working on improving it, a huge shout out to {{< github "lunamidori5" >}} from the community for the impressive efforts on this!
|
||||
|
||||
#### 💡 More examples!
|
||||
|
||||
@@ -131,7 +137,7 @@ The full changelog is available [here](https://github.com/go-skynet/LocalAI/rele
|
||||
|
||||
## 🔥🔥🔥🔥 12-08-2023: __v1.24.0__ 🔥🔥🔥🔥
|
||||
|
||||
This is release brings four(!) new additional backends to LocalAI: [🐶 Bark]({{%relref "model-compatibility/bark" %}}), 🦙 [AutoGPTQ]({{%relref "model-compatibility/autogptq" %}}), [🧨 Diffusers]({{%relref "model-compatibility/diffusers" %}}), 🦙 [exllama]({{%relref "model-compatibility/exllama" %}}) and a lot of improvements!
|
||||
This is release brings four(!) new additional backends to LocalAI: [🐶 Bark]({{%relref "docs/features/text-to-audio#bark" %}}), 🦙 [AutoGPTQ]({{%relref "docs/features/text-generation#autogptq" %}}), [🧨 Diffusers]({{%relref "docs/features/image-generation" %}}), 🦙 [exllama]({{%relref "docs/features/text-generation#exllama" %}}) and a lot of improvements!
|
||||
|
||||
### Major improvements:
|
||||
|
||||
@@ -143,23 +149,23 @@ This is release brings four(!) new additional backends to LocalAI: [🐶 Bark]({
|
||||
|
||||
### 🐶 Bark
|
||||
|
||||
[Bark]({{%relref "model-compatibility/bark" %}}) is a text-prompted generative audio model - it combines GPT techniques to generate Audio from text. It is a great addition to LocalAI, and it's available in the container images by default.
|
||||
[Bark]({{%relref "docs/features/text-to-audio#bark" %}}) is a text-prompted generative audio model - it combines GPT techniques to generate Audio from text. It is a great addition to LocalAI, and it's available in the container images by default.
|
||||
|
||||
It can also generate music, see the example: [lion.webm](https://user-images.githubusercontent.com/5068315/230684766-97f5ea23-ad99-473c-924b-66b6fab24289.webm)
|
||||
|
||||
### 🦙 AutoGPTQ
|
||||
|
||||
[AutoGPTQ]({{%relref "model-compatibility/autogptq" %}}) is an easy-to-use LLMs quantization package with user-friendly apis, based on GPTQ algorithm.
|
||||
[AutoGPTQ]({{%relref "docs/features/text-generation#autogptq" %}}) is an easy-to-use LLMs quantization package with user-friendly apis, based on GPTQ algorithm.
|
||||
|
||||
It is targeted mainly for GPU usage only. Check out the [AutoGPTQ documentation]({{%relref "model-compatibility/autogptq" %}}) for usage.
|
||||
It is targeted mainly for GPU usage only. Check out the [ documentation]({{%relref "docs/features/text-generation" %}}) for usage.
|
||||
|
||||
### 🦙 Exllama
|
||||
|
||||
[Exllama]({{%relref "model-compatibility/exllama" %}}) is a "A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantized weights". It is a faster alternative to run LLaMA models on GPU.Check out the [Exllama documentation]({{%relref "model-compatibility/exllama" %}}) for usage.
|
||||
[Exllama]({{%relref "docs/features/text-generation#exllama" %}}) is a "A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantized weights". It is a faster alternative to run LLaMA models on GPU.Check out the [Exllama documentation]({{%relref "docs/features/text-generation#exllama" %}}) for usage.
|
||||
|
||||
### 🧨 Diffusers
|
||||
|
||||
[Diffusers]({{%relref "model-compatibility/diffusers" %}}) is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Currently it is experimental, and supports generation only of images so you might encounter some issues on models which weren't tested yet. Check out the [Diffusers documentation]({{%relref "model-compatibility/diffusers" %}}) for usage.
|
||||
[Diffusers]({{%relref "docs/features/image-generation#diffusers" %}}) is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Currently it is experimental, and supports generation only of images so you might encounter some issues on models which weren't tested yet. Check out the [Diffusers documentation]({{%relref "docs/features/image-generation" %}}) for usage.
|
||||
|
||||
### 🔑 API Keys
|
||||
|
||||
@@ -195,11 +201,11 @@ Most notably, this release brings important fixes for CUDA (and not only):
|
||||
* fix: select function calls if 'name' is set in the request by {{< github "mudler" >}} in {{< pr "827" >}}
|
||||
* fix: symlink libphonemize in the container by {{< github "mudler" >}} in {{< pr "831" >}}
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
|
||||
From this release [OpenAI functions]({{%relref "features/openai-functions" %}}) are available in the `llama` backend. The `llama-grammar` has been deprecated. See also [OpenAI functions]({{%relref "features/openai-functions" %}}).
|
||||
From this release [OpenAI functions]({{%relref "docs/features/openai-functions" %}}) are available in the `llama` backend. The `llama-grammar` has been deprecated. See also [OpenAI functions]({{%relref "docs/features/openai-functions" %}}).
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
The full [changelog is available here](https://github.com/go-skynet/LocalAI/releases/tag/v1.23.0)
|
||||
|
||||
@@ -213,15 +219,15 @@ The full [changelog is available here](https://github.com/go-skynet/LocalAI/rele
|
||||
* feat: backends improvements by {{< github "mudler" >}} in {{< pr "778" >}}
|
||||
* feat(llama2): add template for chat messages by {{< github "dave-gray101" >}} in {{< pr "782" >}}
|
||||
|
||||
{{% notice note %}}
|
||||
{{% alert note %}}
|
||||
|
||||
From this release to use the OpenAI functions you need to use the `llama-grammar` backend. It has been added a `llama` backend for tracking `llama.cpp` master and `llama-grammar` for the grammar functionalities that have not been merged yet upstream. See also [OpenAI functions]({{%relref "features/openai-functions" %}}). Until the feature is merged we will have two llama backends.
|
||||
From this release to use the OpenAI functions you need to use the `llama-grammar` backend. It has been added a `llama` backend for tracking `llama.cpp` master and `llama-grammar` for the grammar functionalities that have not been merged yet upstream. See also [OpenAI functions]({{%relref "docs/features/openai-functions" %}}). Until the feature is merged we will have two llama backends.
|
||||
|
||||
{{% /notice %}}
|
||||
{{% /alert %}}
|
||||
|
||||
## Huggingface embeddings
|
||||
|
||||
In this release is now possible to specify to LocalAI external `gRPC` backends that can be used for inferencing {{< pr "778" >}}. It is now possible to write internal backends in any language, and a `huggingface-embeddings` backend is now available in the container image to be used with https://github.com/UKPLab/sentence-transformers. See also [Embeddings]({{%relref "features/embeddings" %}}).
|
||||
In this release is now possible to specify to LocalAI external `gRPC` backends that can be used for inferencing {{< pr "778" >}}. It is now possible to write internal backends in any language, and a `huggingface-embeddings` backend is now available in the container image to be used with https://github.com/UKPLab/sentence-transformers. See also [Embeddings]({{%relref "docs/features/embeddings" %}}).
|
||||
|
||||
## LLaMa 2 has been released!
|
||||
|
||||
@@ -266,7 +272,7 @@ The former, ggml-based backend has been renamed to `falcon-ggml`.
|
||||
|
||||
### Default pre-compiled binaries
|
||||
|
||||
From this release the default behavior of images has changed. Compilation is not triggered on start automatically, to recompile `local-ai` from scratch on start and switch back to the old behavior, you can set `REBUILD=true` in the environment variables. Rebuilding can be necessary if your CPU and/or architecture is old and the pre-compiled binaries are not compatible with your platform. See the [build section]({{%relref "build" %}}) for more information.
|
||||
From this release the default behavior of images has changed. Compilation is not triggered on start automatically, to recompile `local-ai` from scratch on start and switch back to the old behavior, you can set `REBUILD=true` in the environment variables. Rebuilding can be necessary if your CPU and/or architecture is old and the pre-compiled binaries are not compatible with your platform. See the [build section]({{%relref "docs/getting-started/build" %}}) for more information.
|
||||
|
||||
[Full release changelog](https://github.com/go-skynet/LocalAI/releases/tag/v1.21.0)
|
||||
|
||||
@@ -276,8 +282,8 @@ From this release the default behavior of images has changed. Compilation is not
|
||||
|
||||
### Exciting New Features 🎉
|
||||
|
||||
* Add Text-to-Audio generation with `go-piper` by {{< github "mudler" >}} in {{< pr "649" >}} See [API endpoints]({{%relref "features/text-to-audio" %}}) in our documentation.
|
||||
* Add gallery repository by {{< github "mudler" >}} in {{< pr "663" >}}. See [models]({{%relref "models" %}}) for documentation.
|
||||
* Add Text-to-Audio generation with `go-piper` by {{< github "mudler" >}} in {{< pr "649" >}} See [API endpoints]({{%relref "docs/features/text-to-audio" %}}) in our documentation.
|
||||
* Add gallery repository by {{< github "mudler" >}} in {{< pr "663" >}}. See [models]({{%relref "docs/features/model-gallery" %}}) for documentation.
|
||||
|
||||
### Container images
|
||||
- Standard (GPT + `stablediffusion`): `quay.io/go-skynet/local-ai:v1.20.0`
|
||||
@@ -289,7 +295,7 @@ From this release the default behavior of images has changed. Compilation is not
|
||||
|
||||
Updates to `llama.cpp`, `go-transformers`, `gpt4all.cpp` and `rwkv.cpp`.
|
||||
|
||||
The NUMA option was enabled by {{< github "mudler" >}} in {{< pr "684" >}}, along with many new parameters (`mmap`,`mmlock`, ..). See [advanced]({{%relref "advanced" %}}) for the full list of parameters.
|
||||
The NUMA option was enabled by {{< github "mudler" >}} in {{< pr "684" >}}, along with many new parameters (`mmap`,`mmlock`, ..). See [advanced]({{%relref "docs/advanced" %}}) for the full list of parameters.
|
||||
|
||||
### Gallery repositories
|
||||
|
||||
@@ -313,13 +319,13 @@ or a `tts` voice with:
|
||||
curl http://localhost:8080/models/apply -H "Content-Type: application/json" -d '{ "id": "model-gallery@voice-en-us-kathleen-low" }'
|
||||
```
|
||||
|
||||
See also [models]({{%relref "models" %}}) for a complete documentation.
|
||||
See also [models]({{%relref "docs/features/model-gallery" %}}) for a complete documentation.
|
||||
|
||||
### Text to Audio
|
||||
|
||||
Now `LocalAI` uses [piper](https://github.com/rhasspy/piper) and [go-piper](https://github.com/mudler/go-piper) to generate audio from text. This is an experimental feature, and it requires `GO_TAGS=tts` to be set during build. It is enabled by default in the pre-built container images.
|
||||
|
||||
To setup audio models, you can use the new galleries, or setup the models manually as described in [the API section of the documentation]({{%relref "features/text-to-audio" %}}).
|
||||
To setup audio models, you can use the new galleries, or setup the models manually as described in [the API section of the documentation]({{%relref "docs/features/text-to-audio" %}}).
|
||||
|
||||
You can check the full changelog in [Github](https://github.com/go-skynet/LocalAI/releases/tag/v1.20.0)
|
||||
|
||||
@@ -347,7 +353,7 @@ We now support a vast variety of models, while being backward compatible with pr
|
||||
### New features
|
||||
|
||||
- ✨ Added support for `falcon`-based model families (7b) ( [mudler](https://github.com/mudler) )
|
||||
- ✨ Experimental support for Metal Apple Silicon GPU - ( [mudler](https://github.com/mudler) and thanks to [Soleblaze](https://github.com/Soleblaze) for testing! ). See the [build section]({{%relref "build#Acceleration" %}}).
|
||||
- ✨ Experimental support for Metal Apple Silicon GPU - ( [mudler](https://github.com/mudler) and thanks to [Soleblaze](https://github.com/Soleblaze) for testing! ). See the [build section]({{%relref "docs/getting-started/build#Acceleration" %}}).
|
||||
- ✨ Support for token stream in the `/v1/completions` endpoint ( [samm81](https://github.com/samm81) )
|
||||
- ✨ Added huggingface backend ( [Evilfreelancer](https://github.com/EvilFreelancer) )
|
||||
- 📷 Stablediffusion now can output `2048x2048` images size with `esrgan`! ( [mudler](https://github.com/mudler) )
|
||||
@@ -388,7 +394,7 @@ Two new projects offer now direct integration with LocalAI!
|
||||
|
||||
Support for OpenCL has been added while building from sources.
|
||||
|
||||
You can now build LocalAI from source with `BUILD_TYPE=clblas` to have an OpenCL build. See also the [build section]({{%relref "build#Acceleration" %}}).
|
||||
You can now build LocalAI from source with `BUILD_TYPE=clblas` to have an OpenCL build. See also the [build section]({{%relref "docs/getting-started/build#Acceleration" %}}).
|
||||
|
||||
For instructions on how to install OpenCL/CLBlast see [here](https://github.com/ggerganov/llama.cpp#blas-build).
|
||||
|
||||
@@ -418,7 +424,7 @@ prompt_cache_path: "alpaca-cache"
|
||||
prompt_cache_all: true
|
||||
```
|
||||
|
||||
See also the [advanced section]({{%relref "advanced" %}}).
|
||||
See also the [advanced section]({{%relref "docs/advanced" %}}).
|
||||
|
||||
## Media, Blogs, Social
|
||||
|
||||
@@ -431,7 +437,7 @@ See also the [advanced section]({{%relref "advanced" %}}).
|
||||
|
||||
- 23-05-2023: __v1.15.0__ released. `go-gpt2.cpp` backend got renamed to `go-ggml-transformers.cpp` updated including https://github.com/ggerganov/llama.cpp/pull/1508 which breaks compatibility with older models. This impacts RedPajama, GptNeoX, MPT(not `gpt4all-mpt`), Dolly, GPT2 and Starcoder based models. [Binary releases available](https://github.com/go-skynet/LocalAI/releases), various fixes, including {{< pr "341" >}} .
|
||||
- 21-05-2023: __v1.14.0__ released. Minor updates to the `/models/apply` endpoint, `llama.cpp` backend updated including https://github.com/ggerganov/llama.cpp/pull/1508 which breaks compatibility with older models. `gpt4all` is still compatible with the old format.
|
||||
- 19-05-2023: __v1.13.0__ released! 🔥🔥 updates to the `gpt4all` and `llama` backend, consolidated CUDA support ( {{< pr "310" >}} thanks to @bubthegreat and @Thireus ), preliminar support for [installing models via API]({{%relref "advanced#" %}}).
|
||||
- 19-05-2023: __v1.13.0__ released! 🔥🔥 updates to the `gpt4all` and `llama` backend, consolidated CUDA support ( {{< pr "310" >}} thanks to @bubthegreat and @Thireus ), preliminar support for [installing models via API]({{%relref "docs/advanced#" %}}).
|
||||
- 17-05-2023: __v1.12.0__ released! 🔥🔥 Minor fixes, plus CUDA ({{< pr "258" >}}) support for `llama.cpp`-compatible models and image generation ({{< pr "272" >}}).
|
||||
- 16-05-2023: 🔥🔥🔥 Experimental support for CUDA ({{< pr "258" >}}) in the `llama.cpp` backend and Stable diffusion CPU image generation ({{< pr "272" >}}) in `master`.
|
||||
|
||||
@@ -1,17 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Features"
|
||||
weight = 3
|
||||
+++
|
||||
|
||||
This section contains the documentation for the features supported by LocalAI.
|
||||
|
||||
- [📖 Text generation (GPT)]({{%relref "features/text-generation" %}})
|
||||
- [🗣 Text to Audio]({{%relref "features/text-to-audio" %}})
|
||||
- [🔈 Audio to text]({{%relref "features/audio-to-text" %}})
|
||||
- [🎨 Image generation]({{%relref "features/image-generation" %}})
|
||||
- [🧠 Embeddings]({{%relref "features/embeddings" %}})
|
||||
- [🔥 OpenAI functions]({{%relref "features/openai-functions" %}})
|
||||
- [🆕 GPT Vision API]({{%relref "features/gpt-vision" %}})
|
||||
- [✍️ Constrained grammars]({{%relref "features/constrained_grammars" %}})
|
||||
@@ -1,70 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "📖 Text generation (GPT)"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
LocalAI supports generating text with GPT with `llama.cpp` and other backends (such as `rwkv.cpp` as ) see also the [Model compatibility]({{%relref "model-compatibility" %}}) for an up-to-date list of the supported model families.
|
||||
|
||||
Note:
|
||||
|
||||
- You can also specify the model name as part of the OpenAI token.
|
||||
- If only one model is available, the API will use it for all the requests.
|
||||
|
||||
### Chat completions
|
||||
|
||||
https://platform.openai.com/docs/api-reference/chat
|
||||
|
||||
For example, to generate a chat completion, you can send a POST request to the `/v1/chat/completions` endpoint with the instruction as the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "ggml-koala-7b-model-q4_0-r2.bin",
|
||||
"messages": [{"role": "user", "content": "Say this is a test!"}],
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
Available additional parameters: `top_p`, `top_k`, `max_tokens`
|
||||
|
||||
### Edit completions
|
||||
|
||||
https://platform.openai.com/docs/api-reference/edits
|
||||
|
||||
To generate an edit completion you can send a POST request to the `/v1/edits` endpoint with the instruction as the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/edits -H "Content-Type: application/json" -d '{
|
||||
"model": "ggml-koala-7b-model-q4_0-r2.bin",
|
||||
"instruction": "rephrase",
|
||||
"input": "Black cat jumped out of the window",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
Available additional parameters: `top_p`, `top_k`, `max_tokens`.
|
||||
|
||||
### Completions
|
||||
|
||||
https://platform.openai.com/docs/api-reference/completions
|
||||
|
||||
To generate a completion, you can send a POST request to the `/v1/completions` endpoint with the instruction as per the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "ggml-koala-7b-model-q4_0-r2.bin",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
Available additional parameters: `top_p`, `top_k`, `max_tokens`
|
||||
|
||||
### List models
|
||||
|
||||
You can list all the models available with:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/models
|
||||
```
|
||||
@@ -1,77 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🗣 Text to audio (TTS)"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
The `/tts` endpoint can be used to generate speech from text.
|
||||
|
||||
Input: `input`, `model`
|
||||
|
||||
For example, to generate an audio file, you can send a POST request to the `/tts` endpoint with the instruction as the request body:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"input": "Hello world",
|
||||
"model": "tts"
|
||||
}'
|
||||
```
|
||||
|
||||
Returns an `audio/wav` file.
|
||||
|
||||
#### Setup
|
||||
|
||||
LocalAI supports [bark]({{%relref "model-compatibility/bark" %}}) , `piper` and `vall-e-x`:
|
||||
|
||||
{{% notice note %}}
|
||||
|
||||
The `piper` backend is used for `onnx` models and requires the modules to be downloaded first.
|
||||
|
||||
To install the `piper` audio models manually:
|
||||
|
||||
- Download Voices from https://github.com/rhasspy/piper/releases/tag/v0.0.2
|
||||
- Extract the `.tar.tgz` files (.onnx,.json) inside `models`
|
||||
- Run the following command to test the model is working
|
||||
|
||||
{{% /notice %}}
|
||||
|
||||
To use the tts endpoint, run the following command. You can specify a backend with the `backend` parameter. For example, to use the `piper` backend:
|
||||
```bash
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"model":"it-riccardo_fasol-x-low.onnx",
|
||||
"backend": "piper",
|
||||
"input": "Ciao, sono Ettore"
|
||||
}' | aplay
|
||||
```
|
||||
|
||||
Note:
|
||||
|
||||
- `aplay` is a Linux command. You can use other tools to play the audio file.
|
||||
- The model name is the filename with the extension.
|
||||
- The model name is case sensitive.
|
||||
- LocalAI must be compiled with the `GO_TAGS=tts` flag.
|
||||
|
||||
LocalAI also has experimental support for `transformers-musicgen` for the generation of short musical compositions. Currently, this is implemented via the same requests used for text to speech:
|
||||
|
||||
```
|
||||
curl --request POST \
|
||||
--url http://localhost:8080/tts \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data '{
|
||||
"backend": "transformers-musicgen",
|
||||
"model": "facebook/musicgen-medium",
|
||||
"input": "Cello Rave"
|
||||
}' | aplay```
|
||||
|
||||
Future versions of LocalAI will expose additional control over audio generation beyond the text prompt.
|
||||
|
||||
#### Configuration
|
||||
|
||||
Audio models can be configured via `YAML` files. This allows to configure specific setting for each backend. For instance, backends might be specifying a voice or supports voice cloning which must be specified in the configuration file.
|
||||
|
||||
```yaml
|
||||
name: tts
|
||||
backend: vall-e-x
|
||||
parameters: ...
|
||||
```
|
||||
@@ -1,412 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Getting started"
|
||||
weight = 1
|
||||
url = '/basics/getting_started/'
|
||||
+++
|
||||
|
||||
`LocalAI` is available as a container image and binary. It can be used with docker, podman, kubernetes and any container engine. You can check out all the available images with corresponding tags [here](https://quay.io/repository/go-skynet/local-ai?tab=tags&tag=latest).
|
||||
|
||||
See also our [How to]({{%relref "howtos" %}}) section for end-to-end guided examples curated by the community.
|
||||
|
||||
### How to get started
|
||||
|
||||
The easiest way to run LocalAI is by using [`docker compose`](https://docs.docker.com/compose/install/) or with [Docker](https://docs.docker.com/engine/install/) (to build locally, see the [build section]({{%relref "build" %}})).
|
||||
|
||||
{{% notice note %}}
|
||||
To run with GPU Accelleration, see [GPU acceleration]({{%relref "features/gpu-acceleration" %}}).
|
||||
{{% /notice %}}
|
||||
|
||||
{{< tabs >}}
|
||||
{{% tab name="Docker" %}}
|
||||
|
||||
```bash
|
||||
# Prepare the models into the `model` directory
|
||||
mkdir models
|
||||
|
||||
# copy your models to it
|
||||
cp your-model.gguf models/
|
||||
|
||||
# run the LocalAI container
|
||||
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest --models-path /models --context-size 700 --threads 4
|
||||
# You should see:
|
||||
#
|
||||
# ┌───────────────────────────────────────────────────┐
|
||||
# │ Fiber v2.42.0 │
|
||||
# │ http://127.0.0.1:8080 │
|
||||
# │ (bound on host 0.0.0.0 and port 8080) │
|
||||
# │ │
|
||||
# │ Handlers ............. 1 Processes ........... 1 │
|
||||
# │ Prefork ....... Disabled PID ................. 1 │
|
||||
# └───────────────────────────────────────────────────┘
|
||||
|
||||
# Try the endpoint with curl
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "your-model.gguf",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
{{% notice note %}}
|
||||
- If running on Apple Silicon (ARM) it is **not** suggested to run on Docker due to emulation. Follow the [build instructions]({{%relref "build" %}}) to use Metal acceleration for full GPU support.
|
||||
- If you are running Apple x86_64 you can use `docker`, there is no additional gain into building it from source.
|
||||
{{% /notice %}}
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab name="Docker compose" %}}
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI
|
||||
|
||||
# (optional) Checkout a specific LocalAI tag
|
||||
# git checkout -b build <TAG>
|
||||
|
||||
# copy your models to models/
|
||||
cp your-model.gguf models/
|
||||
|
||||
# (optional) Edit the .env file to set things like context size and threads
|
||||
# vim .env
|
||||
|
||||
# start with docker compose
|
||||
docker compose up -d --pull always
|
||||
# or you can build the images with:
|
||||
# docker compose up -d --build
|
||||
|
||||
# Now API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
# {"object":"list","data":[{"id":"your-model.gguf","object":"model"}]}
|
||||
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "your-model.gguf",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
Note: If you are on Windows, please make sure the project is on the Linux Filesystem, otherwise loading models might be slow. For more Info: [Microsoft Docs](https://learn.microsoft.com/en-us/windows/wsl/filesystems)
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab name="Kubernetes" %}}
|
||||
|
||||
For installing LocalAI in Kubernetes, you can use the following helm chart:
|
||||
|
||||
```bash
|
||||
# Install the helm repository
|
||||
helm repo add go-skynet https://go-skynet.github.io/helm-charts/
|
||||
# Update the repositories
|
||||
helm repo update
|
||||
# Get the values
|
||||
helm show values go-skynet/local-ai > values.yaml
|
||||
|
||||
# Edit the values value if needed
|
||||
# vim values.yaml ...
|
||||
|
||||
# Install the helm chart
|
||||
helm install local-ai go-skynet/local-ai -f values.yaml
|
||||
```
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
### Container images
|
||||
|
||||
LocalAI has a set of images to support CUDA, ffmpeg and 'vanilla' (CPU-only). The image list is on [quay](https://quay.io/repository/go-skynet/local-ai?tab=tags):
|
||||
|
||||
{{< tabs >}}
|
||||
{{% tab name="Vanilla / CPU Images" %}}
|
||||
- `master`
|
||||
- `latest`
|
||||
- `{{< version >}}`
|
||||
- `{{< version >}}-ffmpeg`
|
||||
- `{{< version >}}-ffmpeg-core`
|
||||
|
||||
Core Images - Smaller images without predownload python dependencies
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab name="GPU Images CUDA 11" %}}
|
||||
- `master-cublas-cuda11`
|
||||
- `master-cublas-cuda11-core`
|
||||
- `{{< version >}}-cublas-cuda11`
|
||||
- `{{< version >}}-cublas-cuda11-core`
|
||||
- `{{< version >}}-cublas-cuda11-ffmpeg`
|
||||
- `{{< version >}}-cublas-cuda11-ffmpeg-core`
|
||||
|
||||
Core Images - Smaller images without predownload python dependencies
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab name="GPU Images CUDA 12" %}}
|
||||
- `master-cublas-cuda12`
|
||||
- `master-cublas-cuda12-core`
|
||||
- `{{< version >}}-cublas-cuda12`
|
||||
- `{{< version >}}-cublas-cuda12-core`
|
||||
- `{{< version >}}-cublas-cuda12-ffmpeg`
|
||||
- `{{< version >}}-cublas-cuda12-ffmpeg-core`
|
||||
|
||||
Core Images - Smaller images without predownload python dependencies
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
Example:
|
||||
|
||||
- Standard (GPT + `stablediffusion`): `quay.io/go-skynet/local-ai:latest`
|
||||
- FFmpeg: `quay.io/go-skynet/local-ai:{{< version >}}-ffmpeg`
|
||||
- CUDA 11+FFmpeg: `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda11-ffmpeg`
|
||||
- CUDA 12+FFmpeg: `quay.io/go-skynet/local-ai:{{< version >}}-cublas-cuda12-ffmpeg`
|
||||
|
||||
{{% notice note %}}
|
||||
Note: the binary inside the image is pre-compiled, and might not suite all CPUs.
|
||||
To enable CPU optimizations for the execution environment,
|
||||
the default behavior is to rebuild when starting the container.
|
||||
To disable this auto-rebuild behavior,
|
||||
set the environment variable `REBUILD` to `false`.
|
||||
|
||||
See [docs on all environment variables]({{%relref "advanced#environment-variables" %}})
|
||||
for more info.
|
||||
{{% /notice %}}
|
||||
|
||||
### Example: Use luna-ai-llama2 model with `docker`
|
||||
|
||||
```bash
|
||||
mkdir models
|
||||
|
||||
# Download luna-ai-llama2 to models/
|
||||
wget https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGUF/resolve/main/luna-ai-llama2-uncensored.Q4_0.gguf -O models/luna-ai-llama2
|
||||
|
||||
# Use a template from the examples
|
||||
cp -rf prompt-templates/getting_started.tmpl models/luna-ai-llama2.tmpl
|
||||
|
||||
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest --models-path /models --context-size 700 --threads 4
|
||||
|
||||
# Now API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
# {"object":"list","data":[{"id":"luna-ai-llama2","object":"model"}]}
|
||||
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "luna-ai-llama2",
|
||||
"messages": [{"role": "user", "content": "How are you?"}],
|
||||
"temperature": 0.9
|
||||
}'
|
||||
|
||||
# {"model":"luna-ai-llama2","choices":[{"message":{"role":"assistant","content":"I'm doing well, thanks. How about you?"}}]}
|
||||
```
|
||||
|
||||
To see other model configurations, see also the example section [here](https://github.com/mudler/LocalAI/tree/master/examples/configurations).
|
||||
|
||||
|
||||
### From binaries
|
||||
|
||||
LocalAI binary releases are available in [Github](https://github.com/go-skynet/LocalAI/releases).
|
||||
|
||||
You can control LocalAI with command line arguments, to specify a binding address, or the number of threads.
|
||||
|
||||
### CLI parameters
|
||||
|
||||
| Parameter | Environmental Variable | Default Variable | Description |
|
||||
| ------------------------------ | ------------------------------- | -------------------------------------------------- | ------------------------------------------------------------------- |
|
||||
| --f16 | $F16 | false | Enable f16 mode |
|
||||
| --debug | $DEBUG | false | Enable debug mode |
|
||||
| --cors | $CORS | false | Enable CORS support |
|
||||
| --cors-allow-origins value | $CORS_ALLOW_ORIGINS | | Specify origins allowed for CORS |
|
||||
| --threads value | $THREADS | 4 | Number of threads to use for parallel computation |
|
||||
| --models-path value | $MODELS_PATH | ./models | Path to the directory containing models used for inferencing |
|
||||
| --preload-models value | $PRELOAD_MODELS | | List of models to preload in JSON format at startup |
|
||||
| --preload-models-config value | $PRELOAD_MODELS_CONFIG | | A config with a list of models to apply at startup. Specify the path to a YAML config file |
|
||||
| --config-file value | $CONFIG_FILE | | Path to the config file |
|
||||
| --address value | $ADDRESS | :8080 | Specify the bind address for the API server |
|
||||
| --image-path value | $IMAGE_PATH | | Path to the directory used to store generated images |
|
||||
| --context-size value | $CONTEXT_SIZE | 512 | Default context size of the model |
|
||||
| --upload-limit value | $UPLOAD_LIMIT | 15 | Default upload limit in megabytes (audio file upload) |
|
||||
| --galleries | $GALLERIES | | Allows to set galleries from command line |
|
||||
|--parallel-requests | $PARALLEL_REQUESTS | false | Enable backends to handle multiple requests in parallel. This is for backends that supports multiple requests in parallel, like llama.cpp or vllm |
|
||||
| --single-active-backend | $SINGLE_ACTIVE_BACKEND | false | Allow only one backend to be running |
|
||||
| --api-keys value | $API_KEY | empty | List of API Keys to enable API authentication. When this is set, all the requests must be authenticated with one of these API keys.
|
||||
| --enable-watchdog-idle | $WATCHDOG_IDLE | false | Enable watchdog for stopping idle backends. This will stop the backends if are in idle state for too long. (default: false) [$WATCHDOG_IDLE]
|
||||
| --enable-watchdog-busy | $WATCHDOG_BUSY | false | Enable watchdog for stopping busy backends that exceed a defined threshold.|
|
||||
| --watchdog-busy-timeout value | $WATCHDOG_BUSY_TIMEOUT | 5m | Watchdog timeout. This will restart the backend if it crashes. |
|
||||
| --watchdog-idle-timeout value | $WATCHDOG_IDLE_TIMEOUT | 15m | Watchdog idle timeout. This will restart the backend if it crashes. |
|
||||
| --preload-backend-only | $PRELOAD_BACKEND_ONLY | false | If set, the api is NOT launched, and only the preloaded models / backends are started. This is intended for multi-node setups. |
|
||||
| --external-grpc-backends | EXTERNAL_GRPC_BACKENDS | none | Comma separated list of external gRPC backends to use. Format: `name:host:port` or `name:/path/to/file` |
|
||||
|
||||
### Run LocalAI in Kubernetes
|
||||
|
||||
LocalAI can be installed inside Kubernetes with helm.
|
||||
|
||||
Requirements:
|
||||
- SSD storage class, or disable `mmap` to load the whole model in memory
|
||||
|
||||
<details>
|
||||
By default, the helm chart will install LocalAI instance using the ggml-gpt4all-j model without persistent storage.
|
||||
|
||||
1. Add the helm repo
|
||||
```bash
|
||||
helm repo add go-skynet https://go-skynet.github.io/helm-charts/
|
||||
```
|
||||
2. Install the helm chart:
|
||||
```bash
|
||||
helm repo update
|
||||
helm install local-ai go-skynet/local-ai -f values.yaml
|
||||
```
|
||||
> **Note:** For further configuration options, see the [helm chart repository on GitHub](https://github.com/go-skynet/helm-charts).
|
||||
### Example values
|
||||
Deploy a single LocalAI pod with 6GB of persistent storage serving up a `ggml-gpt4all-j` model with custom prompt.
|
||||
```yaml
|
||||
### values.yaml
|
||||
|
||||
replicaCount: 1
|
||||
|
||||
deployment:
|
||||
image: quay.io/go-skynet/local-ai:latest ##(This is for CPU only, to use GPU change it to a image that supports GPU IE "v2.0.0-cublas-cuda12-core")
|
||||
env:
|
||||
threads: 4
|
||||
context_size: 512
|
||||
modelsPath: "/models"
|
||||
|
||||
resources:
|
||||
{}
|
||||
# We usually recommend not to specify default resources and to leave this as a conscious
|
||||
# choice for the user. This also increases chances charts run on environments with little
|
||||
# resources, such as Minikube. If you do want to specify resources, uncomment the following
|
||||
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
|
||||
# limits:
|
||||
# cpu: 100m
|
||||
# memory: 128Mi
|
||||
# requests:
|
||||
# cpu: 100m
|
||||
# memory: 128Mi
|
||||
|
||||
# Prompt templates to include
|
||||
# Note: the keys of this map will be the names of the prompt template files
|
||||
promptTemplates:
|
||||
{}
|
||||
# ggml-gpt4all-j.tmpl: |
|
||||
# The prompt below is a question to answer, a task to complete, or a conversation to respond to; decide which and write an appropriate response.
|
||||
# ### Prompt:
|
||||
# {{.Input}}
|
||||
# ### Response:
|
||||
|
||||
# Models to download at runtime
|
||||
models:
|
||||
# Whether to force download models even if they already exist
|
||||
forceDownload: false
|
||||
|
||||
# The list of URLs to download models from
|
||||
# Note: the name of the file will be the name of the loaded model
|
||||
list:
|
||||
- url: "https://gpt4all.io/models/ggml-gpt4all-j.bin"
|
||||
# basicAuth: base64EncodedCredentials
|
||||
|
||||
# Persistent storage for models and prompt templates.
|
||||
# PVC and HostPath are mutually exclusive. If both are enabled,
|
||||
# PVC configuration takes precedence. If neither are enabled, ephemeral
|
||||
# storage is used.
|
||||
persistence:
|
||||
pvc:
|
||||
enabled: false
|
||||
size: 6Gi
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
|
||||
annotations: {}
|
||||
|
||||
# Optional
|
||||
storageClass: ~
|
||||
|
||||
hostPath:
|
||||
enabled: false
|
||||
path: "/models"
|
||||
|
||||
service:
|
||||
type: ClusterIP
|
||||
port: 80
|
||||
annotations: {}
|
||||
# If using an AWS load balancer, you'll need to override the default 60s load balancer idle timeout
|
||||
# service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: "1200"
|
||||
|
||||
ingress:
|
||||
enabled: false
|
||||
className: ""
|
||||
annotations:
|
||||
{}
|
||||
# kubernetes.io/ingress.class: nginx
|
||||
# kubernetes.io/tls-acme: "true"
|
||||
hosts:
|
||||
- host: chart-example.local
|
||||
paths:
|
||||
- path: /
|
||||
pathType: ImplementationSpecific
|
||||
tls: []
|
||||
# - secretName: chart-example-tls
|
||||
# hosts:
|
||||
# - chart-example.local
|
||||
|
||||
nodeSelector: {}
|
||||
|
||||
tolerations: []
|
||||
|
||||
affinity: {}
|
||||
```
|
||||
</details>
|
||||
|
||||
|
||||
### Build from source
|
||||
|
||||
See the [build section]({{%relref "build" %}}).
|
||||
|
||||
### Other examples
|
||||
|
||||

|
||||
|
||||
To see other examples on how to integrate with other projects for instance for question answering or for using it with chatbot-ui, see: [examples](https://github.com/go-skynet/LocalAI/tree/master/examples/).
|
||||
|
||||
|
||||
### Clients
|
||||
|
||||
OpenAI clients are already compatible with LocalAI by overriding the basePath, or the target URL.
|
||||
|
||||
## Javascript
|
||||
|
||||
<details>
|
||||
|
||||
https://github.com/openai/openai-node/
|
||||
|
||||
```javascript
|
||||
import { Configuration, OpenAIApi } from 'openai';
|
||||
|
||||
const configuration = new Configuration({
|
||||
basePath: `http://localhost:8080/v1`
|
||||
});
|
||||
const openai = new OpenAIApi(configuration);
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
## Python
|
||||
|
||||
<details>
|
||||
|
||||
https://github.com/openai/openai-python
|
||||
|
||||
Set the `OPENAI_API_BASE` environment variable, or by code:
|
||||
|
||||
```python
|
||||
import openai
|
||||
|
||||
openai.api_base = "http://localhost:8080/v1"
|
||||
|
||||
# create a chat completion
|
||||
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Hello world"}])
|
||||
|
||||
# print the completion
|
||||
print(completion.choices[0].message.content)
|
||||
```
|
||||
|
||||
</details>
|
||||
@@ -1,19 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "How-tos"
|
||||
weight = 9
|
||||
+++
|
||||
|
||||
## How-tos
|
||||
|
||||
This section includes LocalAI end-to-end examples, tutorial and how-tos curated by the community and maintained by [lunamidori5](https://github.com/lunamidori5).
|
||||
|
||||
- [Setup LocalAI with Docker]({{%relref "howtos/easy-setup-docker" %}})
|
||||
- [Seting up a Model]({{%relref "howtos/easy-model" %}})
|
||||
- [Making Text / LLM requests to LocalAI]({{%relref "howtos/easy-request" %}})
|
||||
- [Making Photo / SD requests to LocalAI]({{%relref "howtos/easy-setup-sd" %}})
|
||||
|
||||
## Programs and Demos
|
||||
|
||||
This section includes other programs and how to setup, install, and use of LocalAI.
|
||||
- [Python LocalAI Demo]({{%relref "howtos/easy-setup-full" %}}) - [lunamidori5](https://github.com/lunamidori5)
|
||||
@@ -1,129 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Easy Model Setup"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
Lets learn how to setup a model, for this ``How To`` we are going to use the ``Dolphin 2.2.1 Mistral 7B`` model.
|
||||
|
||||
To download the model to your models folder, run this command in a commandline of your picking.
|
||||
```bash
|
||||
curl --location 'http://localhost:8080/models/apply' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{
|
||||
"id": "TheBloke/dolphin-2.2.1-mistral-7B-GGUF/dolphin-2.2.1-mistral-7b.Q4_0.gguf"
|
||||
}'
|
||||
```
|
||||
|
||||
Each model needs at least ``5`` files, with out these files, the model will run raw, what that means is you can not change settings of the model.
|
||||
```
|
||||
File 1 - The model's GGUF file
|
||||
File 2 - The model's .yaml file
|
||||
File 3 - The Chat API .tmpl file
|
||||
File 4 - The Chat API helper .tmpl file
|
||||
File 5 - The Completion API .tmpl file
|
||||
```
|
||||
So lets fix that! We are using ``lunademo`` name for this ``How To`` but you can name the files what ever you want! Lets make blank files to start with
|
||||
|
||||
```bash
|
||||
touch lunademo-chat.tmpl
|
||||
touch lunademo-chat-block.tmpl
|
||||
touch lunademo-completion.tmpl
|
||||
touch lunademo.yaml
|
||||
```
|
||||
Now lets edit the `"lunademo-chat.tmpl"`, This is the template that model "Chat" trained models use, but changed for LocalAI
|
||||
|
||||
```txt
|
||||
<|im_start|>{{if eq .RoleName "assistant"}}assistant{{else if eq .RoleName "system"}}system{{else if eq .RoleName "user"}}user{{end}}
|
||||
{{if .Content}}{{.Content}}{{end}}
|
||||
<|im_end|>
|
||||
```
|
||||
|
||||
For the `"lunademo-chat-block.tmpl"`, Looking at the huggingface repo, this model uses the ``<|im_start|>assistant`` tag for when the AI replys, so lets make sure to add that to this file. Do not add the user as we will be doing that in our yaml file!
|
||||
|
||||
```txt
|
||||
{{.Input}}
|
||||
<|im_start|>assistant
|
||||
```
|
||||
|
||||
Now in the `"lunademo-completion.tmpl"` file lets add this. (This is a hold over from OpenAI V0)
|
||||
|
||||
```txt
|
||||
{{.Input}}
|
||||
```
|
||||
|
||||
|
||||
For the `"lunademo.yaml"` file. Lets set it up for your computer or hardware. (If you want to see advanced yaml configs - [Link](https://localai.io/advanced/))
|
||||
|
||||
We are going to 1st setup the backend and context size.
|
||||
|
||||
```yaml
|
||||
backend: llama
|
||||
context_size: 2000
|
||||
```
|
||||
|
||||
What this does is tell ``LocalAI`` how to load the model. Then we are going to **add** our settings in after that. Lets add the models name and the models settings. The models ``name:`` is what you will put into your request when sending a ``OpenAI`` request to ``LocalAI``
|
||||
```yaml
|
||||
name: lunademo
|
||||
parameters:
|
||||
model: dolphin-2.2.1-mistral-7b.Q4_0.gguf
|
||||
```
|
||||
|
||||
Now that LocalAI knows what file to load with our request, lets add the template files to our models yaml file now.
|
||||
```yaml
|
||||
template:
|
||||
chat: lunademo-chat-block
|
||||
chat_message: lunademo-chat
|
||||
completion: lunademo-completion
|
||||
```
|
||||
|
||||
If you are running on ``GPU`` or want to tune the model, you can add settings like (higher the GPU Layers the more GPU used)
|
||||
```yaml
|
||||
f16: true
|
||||
gpu_layers: 4
|
||||
```
|
||||
|
||||
To fully tune the model to your like. But be warned, you **must** restart ``LocalAI`` after changing a yaml file
|
||||
|
||||
```bash
|
||||
docker compose restart
|
||||
```
|
||||
|
||||
If you want to check your models yaml, here is a full copy!
|
||||
```yaml
|
||||
backend: llama
|
||||
context_size: 2000
|
||||
##Put settings right here for tunning!! Before name but after Backend!
|
||||
name: lunademo
|
||||
parameters:
|
||||
model: dolphin-2.2.1-mistral-7b.Q4_0.gguf
|
||||
template:
|
||||
chat: lunademo-chat-block
|
||||
chat_message: lunademo-chat
|
||||
completion: lunademo-completion
|
||||
```
|
||||
|
||||
Now that we got that setup, lets test it out but sending a [request]({{%relref "easy-request" %}}) to Localai!
|
||||
|
||||
## ----- Adv Stuff -----
|
||||
|
||||
**(Please do not run these steps if you have already done the setup)**
|
||||
Alright now that we have learned how to set up our own models, here is how to use the gallery to do alot of this for us. This command will download and set up (mostly, we will **always** need to edit our yaml file to fit our computer / hardware)
|
||||
```bash
|
||||
curl http://localhost:8080/models/apply -H "Content-Type: application/json" -d '{
|
||||
"id": "model-gallery@lunademo"
|
||||
}'
|
||||
```
|
||||
|
||||
This will setup the model, models yaml, and both template files (you will see it only did one, as completions is out of date and not supported by ``OpenAI`` if you need one, just follow the steps from before to make one.
|
||||
If you would like to download a raw model using the gallery api, you can run this command. You will need to set up the 3 files needed to run the model tho!
|
||||
```bash
|
||||
curl --location 'http://localhost:8080/models/apply' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{
|
||||
"id": "NAME_OFF_HUGGINGFACE/REPO_NAME/MODENAME.gguf",
|
||||
"name": "REQUSTNAME"
|
||||
}'
|
||||
```
|
||||
|
||||
@@ -1,85 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Easy Request - All"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
## Curl Request
|
||||
|
||||
Curl Chat API -
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "lunademo",
|
||||
"messages": [{"role": "user", "content": "How are you?"}],
|
||||
"temperature": 0.9
|
||||
}'
|
||||
```
|
||||
|
||||
## Openai V1 - Recommended
|
||||
|
||||
This is for Python, ``OpenAI``=>``V1``
|
||||
|
||||
OpenAI Chat API Python -
|
||||
```python
|
||||
from openai import OpenAI
|
||||
|
||||
client = OpenAI(base_url="http://localhost:8080/v1", api_key="sk-xxx")
|
||||
|
||||
messages = [
|
||||
{"role": "system", "content": "You are LocalAI, a helpful, but really confused ai, you will only reply with confused emotes"},
|
||||
{"role": "user", "content": "Hello How are you today LocalAI"}
|
||||
]
|
||||
completion = client.chat.completions.create(
|
||||
model="lunademo",
|
||||
messages=messages,
|
||||
)
|
||||
|
||||
print(completion.choices[0].message)
|
||||
```
|
||||
See [OpenAI API](https://platform.openai.com/docs/api-reference) for more info!
|
||||
|
||||
## Openai V0 - Not Recommended
|
||||
|
||||
This is for Python, ``OpenAI``=``0.28.1``
|
||||
|
||||
OpenAI Chat API Python -
|
||||
|
||||
```python
|
||||
import os
|
||||
import openai
|
||||
openai.api_base = "http://localhost:8080/v1"
|
||||
openai.api_key = "sx-xxx"
|
||||
OPENAI_API_KEY = "sx-xxx"
|
||||
os.environ['OPENAI_API_KEY'] = OPENAI_API_KEY
|
||||
|
||||
completion = openai.ChatCompletion.create(
|
||||
model="lunademo",
|
||||
messages=[
|
||||
{"role": "system", "content": "You are LocalAI, a helpful, but really confused ai, you will only reply with confused emotes"},
|
||||
{"role": "user", "content": "How are you?"}
|
||||
]
|
||||
)
|
||||
|
||||
print(completion.choices[0].message.content)
|
||||
```
|
||||
|
||||
OpenAI Completion API Python -
|
||||
|
||||
```python
|
||||
import os
|
||||
import openai
|
||||
openai.api_base = "http://localhost:8080/v1"
|
||||
openai.api_key = "sx-xxx"
|
||||
OPENAI_API_KEY = "sx-xxx"
|
||||
os.environ['OPENAI_API_KEY'] = OPENAI_API_KEY
|
||||
|
||||
completion = openai.Completion.create(
|
||||
model="lunademo",
|
||||
prompt="function downloadFile(string url, string outputPath) ",
|
||||
max_tokens=256,
|
||||
temperature=0.5)
|
||||
|
||||
print(completion.choices[0].text)
|
||||
```
|
||||
@@ -1,184 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Easy Setup - Docker"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
{{% notice Note %}}
|
||||
- You will need about 10gb of RAM Free
|
||||
- You will need about 15gb of space free on C drive for ``Docker compose``
|
||||
{{% /notice %}}
|
||||
|
||||
We are going to run `LocalAI` with `docker compose` for this set up.
|
||||
|
||||
Lets setup our folders for ``LocalAI`` (run these to make the folders for you if you wish)
|
||||
```batch
|
||||
mkdir "LocalAI"
|
||||
cd LocalAI
|
||||
mkdir "models"
|
||||
mkdir "images"
|
||||
```
|
||||
|
||||
At this point we want to set up our `.env` file, here is a copy for you to use if you wish, Make sure this is in the ``LocalAI`` folder.
|
||||
|
||||
```bash
|
||||
## Set number of threads.
|
||||
## Note: prefer the number of physical cores. Overbooking the CPU degrades performance notably.
|
||||
THREADS=2
|
||||
|
||||
## Specify a different bind address (defaults to ":8080")
|
||||
# ADDRESS=127.0.0.1:8080
|
||||
|
||||
## Define galleries.
|
||||
## models will to install will be visible in `/models/available`
|
||||
GALLERIES=[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.yaml"}, {"url": "github:go-skynet/model-gallery/huggingface.yaml","name":"huggingface"}]
|
||||
|
||||
## Default path for models
|
||||
MODELS_PATH=/models
|
||||
|
||||
## Enable debug mode
|
||||
DEBUG=true
|
||||
|
||||
## Disables COMPEL (Lets Stable Diffuser work, uncomment if you plan on using it)
|
||||
# COMPEL=0
|
||||
|
||||
## Enable/Disable single backend (useful if only one GPU is available)
|
||||
# SINGLE_ACTIVE_BACKEND=true
|
||||
|
||||
## Specify a build type. Available: cublas, openblas, clblas.
|
||||
BUILD_TYPE=cublas
|
||||
|
||||
## Uncomment and set to true to enable rebuilding from source
|
||||
# REBUILD=true
|
||||
|
||||
## Enable go tags, available: stablediffusion, tts
|
||||
## stablediffusion: image generation with stablediffusion
|
||||
## tts: enables text-to-speech with go-piper
|
||||
## (requires REBUILD=true)
|
||||
#
|
||||
#GO_TAGS=tts
|
||||
|
||||
## Path where to store generated images
|
||||
# IMAGE_PATH=/tmp
|
||||
|
||||
## Specify a default upload limit in MB (whisper)
|
||||
# UPLOAD_LIMIT
|
||||
|
||||
# HUGGINGFACEHUB_API_TOKEN=Token here
|
||||
```
|
||||
|
||||
|
||||
Now that we have the `.env` set lets set up our `docker-compose` file.
|
||||
It will use a container from [quay.io](https://quay.io/repository/go-skynet/local-ai?tab=tags).
|
||||
|
||||
|
||||
{{< tabs >}}
|
||||
{{% tab name="CPU Only" %}}
|
||||
Also note this `docker-compose` file is for `CPU` only.
|
||||
|
||||
```docker
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
image: quay.io/go-skynet/local-ai:{{< version >}}
|
||||
tty: true # enable colorized logs
|
||||
restart: always # should this be on-failure ?
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- .env
|
||||
volumes:
|
||||
- ./models:/models
|
||||
- ./images/:/tmp/generated/images/
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
```
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab name="GPU and CPU" %}}
|
||||
Also note this `docker-compose` file is for `CUDA` only.
|
||||
|
||||
Please change the image to what you need.
|
||||
{{< tabs >}}
|
||||
{{% tab name="GPU Images CUDA 11" %}}
|
||||
- `master-cublas-cuda11`
|
||||
- `master-cublas-cuda11-core`
|
||||
- `{{< version >}}-cublas-cuda11`
|
||||
- `{{< version >}}-cublas-cuda11-core`
|
||||
- `{{< version >}}-cublas-cuda11-ffmpeg`
|
||||
- `{{< version >}}-cublas-cuda11-ffmpeg-core`
|
||||
|
||||
Core Images - Smaller images without predownload python dependencies
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab name="GPU Images CUDA 12" %}}
|
||||
- `master-cublas-cuda12`
|
||||
- `master-cublas-cuda12-core`
|
||||
- `{{< version >}}-cublas-cuda12`
|
||||
- `{{< version >}}-cublas-cuda12-core`
|
||||
- `{{< version >}}-cublas-cuda12-ffmpeg`
|
||||
- `{{< version >}}-cublas-cuda12-ffmpeg-core`
|
||||
|
||||
Core Images - Smaller images without predownload python dependencies
|
||||
{{% /tab %}}
|
||||
{{< /tabs >}}
|
||||
|
||||
```docker
|
||||
version: '3.6'
|
||||
|
||||
services:
|
||||
api:
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
count: 1
|
||||
capabilities: [gpu]
|
||||
image: quay.io/go-skynet/local-ai:[CHANGEMETOIMAGENEEDED]
|
||||
tty: true # enable colorized logs
|
||||
restart: always # should this be on-failure ?
|
||||
ports:
|
||||
- 8080:8080
|
||||
env_file:
|
||||
- .env
|
||||
volumes:
|
||||
- ./models:/models
|
||||
- ./images/:/tmp/generated/images/
|
||||
command: ["/usr/bin/local-ai" ]
|
||||
```
|
||||
{{% /tab %}}
|
||||
{{< /tabs >}}
|
||||
|
||||
|
||||
Make sure to save that in the root of the `LocalAI` folder. Then lets spin up the Docker run this in a `CMD` or `BASH`
|
||||
|
||||
```bash
|
||||
docker compose up -d --pull always
|
||||
```
|
||||
|
||||
|
||||
Now we are going to let that set up, once it is done, lets check to make sure our huggingface / localai galleries are working (wait until you see this screen to do this)
|
||||
|
||||
You should see:
|
||||
```
|
||||
┌───────────────────────────────────────────────────┐
|
||||
│ Fiber v2.42.0 │
|
||||
│ http://127.0.0.1:8080 │
|
||||
│ (bound on host 0.0.0.0 and port 8080) │
|
||||
│ │
|
||||
│ Handlers ............. 1 Processes ........... 1 │
|
||||
│ Prefork ....... Disabled PID ................. 1 │
|
||||
└───────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/models/available
|
||||
```
|
||||
|
||||
Output will look like this:
|
||||
|
||||

|
||||
|
||||
Now that we got that setup, lets go setup a [model]({{%relref "easy-model" %}})
|
||||
@@ -1,26 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Easy Setup - Embeddings"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
To install an embedding model, run the following command
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/models/apply -H "Content-Type: application/json" -d '{
|
||||
"id": "model-gallery@bert-embeddings"
|
||||
}'
|
||||
```
|
||||
|
||||
When you would like to request the model from CLI you can do
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/embeddings \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"input": "The food was delicious and the waiter...",
|
||||
"model": "bert-embeddings"
|
||||
}'
|
||||
```
|
||||
|
||||
See [OpenAI Embedding](https://platform.openai.com/docs/api-reference/embeddings/object) for more info!
|
||||
@@ -1,61 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Easy Demo - Full Chat Python AI"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
{{% notice Note %}}
|
||||
- You will need about 10gb of RAM Free
|
||||
- You will need about 15gb of space free on C drive for ``Docker-compose``
|
||||
{{% /notice %}}
|
||||
|
||||
This is for `Linux`, `Mac OS`, or `Windows` Hosts. - [Docker Desktop](https://docs.docker.com/engine/install/), [Python 3.11](https://www.python.org/downloads/release/python-3110/), [Git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git)
|
||||
|
||||
Linux Hosts:
|
||||
|
||||
There is a Full_Auto installer compatible with some types of Linux distributions, feel free to use them, but note that they may not fully work. If you need to install something, please use the links at the top.
|
||||
|
||||
```bash
|
||||
git clone https://github.com/lunamidori5/localai-lunademo.git
|
||||
|
||||
cd localai-lunademo
|
||||
|
||||
#Pick your type of linux for the Full Autos, if you already have python, docker, and docker-compose installed skip this chmod. But make sure you chmod the setup_linux file.
|
||||
|
||||
chmod +x Full_Auto_setup_Debian.sh or chmod +x Full_Auto_setup_Ubutnu.sh
|
||||
|
||||
chmod +x Setup_Linux.sh
|
||||
|
||||
#Make sure to install cuda to your host OS and to Docker if you plan on using GPU
|
||||
|
||||
./(the setupfile you wish to run)
|
||||
```
|
||||
|
||||
Windows Hosts:
|
||||
|
||||
```batch
|
||||
REM Make sure you have git, docker-desktop, and python 3.11 installed
|
||||
|
||||
git clone https://github.com/lunamidori5/localai-lunademo.git
|
||||
|
||||
cd localai-lunademo
|
||||
|
||||
call Setup.bat
|
||||
```
|
||||
|
||||
MacOS Hosts:
|
||||
- I need some help working on a MacOS Setup file, if you are willing to help out, please contact Luna Midori on [discord](https://discord.com/channels/1096914990004457512/1099364883755171890/1147591145057157200) or put in a PR on [Luna Midori's github](https://github.com/lunamidori5/localai-lunademo).
|
||||
|
||||
Video How Tos
|
||||
|
||||
- Ubuntu - ``COMING SOON``
|
||||
- Debian - ``COMING SOON``
|
||||
- Windows - ``COMING SOON``
|
||||
- MacOS - ``PLANED - NEED HELP``
|
||||
|
||||
Enjoy localai! (If you need help contact Luna Midori on [Discord](https://discord.com/channels/1096914990004457512/1099364883755171890/1147591145057157200))
|
||||
|
||||
{{% notice Issues %}}
|
||||
- Trying to run ``Setup.bat`` or ``Setup_Linux.sh`` from `Git Bash` on Windows is not working. (Somewhat fixed)
|
||||
- Running over `SSH` or other remote command line based apps may bug out, load slowly, or crash.
|
||||
{{% /notice %}}
|
||||
@@ -1,43 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Easy Setup - Stable Diffusion"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
To set up a Stable Diffusion model is super easy.
|
||||
In your ``models`` folder make a file called ``stablediffusion.yaml``, then edit that file with the following. (You can change ``Linaqruf/animagine-xl`` with what ever ``sd-lx`` model you would like.
|
||||
```yaml
|
||||
name: animagine-xl
|
||||
parameters:
|
||||
model: Linaqruf/animagine-xl
|
||||
backend: diffusers
|
||||
|
||||
# Force CPU usage - set to true for GPU
|
||||
f16: false
|
||||
diffusers:
|
||||
cuda: false # Enable for GPU usage (CUDA)
|
||||
scheduler_type: dpm_2_a
|
||||
```
|
||||
|
||||
If you are using docker, you will need to run in the localai folder with the ``docker-compose.yaml`` file in it
|
||||
```bash
|
||||
docker compose down
|
||||
```
|
||||
|
||||
Then in your ``.env`` file uncomment this line.
|
||||
```yaml
|
||||
COMPEL=0
|
||||
```
|
||||
|
||||
After that we can reinstall the LocalAI docker VM by running in the localai folder with the ``docker-compose.yaml`` file in it
|
||||
```bash
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
Then to download and setup the model, Just send in a normal ``OpenAI`` request! LocalAI will do the rest!
|
||||
```bash
|
||||
curl http://localhost:8080/v1/images/generations -H "Content-Type: application/json" -d '{
|
||||
"prompt": "Two Boxes, 1blue, 1red",
|
||||
"size": "1024x1024"
|
||||
}'
|
||||
```
|
||||
@@ -1,178 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "AIKit"
|
||||
description="AI + BuildKit = AIKit: Build and deploy large language models easily"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
GitHub Link - https://github.com/sozercan/aikit
|
||||
|
||||
[AIKit](https://github.com/sozercan/aikit) is a quick, easy, and local or cloud-agnostic way to get started to host and deploy large language models (LLMs) for inference. No GPU, internet access or additional tools are needed to get started except for [Docker](https://docs.docker.com/desktop/install/linux-install/)!
|
||||
|
||||
AIKit uses [LocalAI](https://localai.io/) under-the-hood to run inference. LocalAI provides a drop-in replacement REST API that is OpenAI API compatible, so you can use any OpenAI API compatible client, such as [Kubectl AI](https://github.com/sozercan/kubectl-ai), [Chatbot-UI](https://github.com/sozercan/chatbot-ui) and many more, to send requests to open-source LLMs powered by AIKit!
|
||||
|
||||
> At this time, AIKit is tested with LocalAI `llama` backend. Other backends may work but are not tested. Please open an issue if you'd like to see support for other backends.
|
||||
|
||||
## Features
|
||||
|
||||
- 🐳 No GPU, Internet access or additional tools needed except for [Docker](https://docs.docker.com/desktop/install/linux-install/)!
|
||||
- 🤏 Minimal image size, resulting in less vulnerabilities and smaller attack surface with a custom [distroless](https://github.com/GoogleContainerTools/distroless)-based image
|
||||
- 🚀 Easy to use declarative configuration
|
||||
- ✨ OpenAI API compatible to use with any OpenAI API compatible client
|
||||
- 🚢 Kubernetes deployment ready
|
||||
- 📦 Supports multiple models with a single image
|
||||
- 🖥️ Supports GPU-accelerated inferencing with NVIDIA GPUs
|
||||
- 🔐 Signed images for `aikit` and pre-made models
|
||||
|
||||
## Pre-made Models
|
||||
|
||||
AIKit comes with pre-made models that you can use out-of-the-box!
|
||||
|
||||
### CPU
|
||||
- 🦙 Llama 2 7B Chat: `ghcr.io/sozercan/llama2:7b`
|
||||
- 🦙 Llama 2 13B Chat: `ghcr.io/sozercan/llama2:13b`
|
||||
- 🐬 Orca 2 13B: `ghcr.io/sozercan/orca2:13b`
|
||||
|
||||
### NVIDIA CUDA
|
||||
|
||||
- 🦙 Llama 2 7B Chat (CUDA): `ghcr.io/sozercan/llama2:7b-cuda`
|
||||
- 🦙 Llama 2 13B Chat (CUDA): `ghcr.io/sozercan/llama2:13b-cuda`
|
||||
- 🐬 Orca 2 13B (CUDA): `ghcr.io/sozercan/orca2:13b-cuda`
|
||||
|
||||
> CUDA models includes CUDA v12. They are used with [NVIDIA GPU acceleration](#gpu-acceleration-support).
|
||||
|
||||
## Quick Start
|
||||
|
||||
### Creating an image
|
||||
|
||||
> This section shows how to create a custom image with models of your choosing. If you want to use one of the pre-made models, skip to [running models](#running-models).
|
||||
>
|
||||
> Please see [models folder](./models/) for pre-made model definitions. You can find more model examples at [go-skynet/model-gallery](https://github.com/go-skynet/model-gallery).
|
||||
|
||||
Create an `aikitfile.yaml` with the following structure:
|
||||
|
||||
```yaml
|
||||
#syntax=ghcr.io/sozercan/aikit:latest
|
||||
apiVersion: v1alpha1
|
||||
models:
|
||||
- name: llama-2-7b-chat
|
||||
source: https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/resolve/main/llama-2-7b-chat.Q4_K_M.gguf
|
||||
```
|
||||
|
||||
> This is the simplest way to get started to build an image. For full `aikitfile` specification, see [specs](docs/specs.md).
|
||||
|
||||
First, create a buildx buildkit instance. Alternatively, if you are using Docker v24 with [containerd image store](https://docs.docker.com/storage/containerd/) enabled, you can skip this step.
|
||||
|
||||
```bash
|
||||
docker buildx create --use --name aikit-builder
|
||||
```
|
||||
|
||||
Then build your image with:
|
||||
|
||||
```bash
|
||||
docker buildx build . -t my-model -f aikitfile.yaml --load
|
||||
```
|
||||
|
||||
This will build a local container image with your model(s). You can see the image with:
|
||||
|
||||
```bash
|
||||
docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
my-model latest e7b7c5a4a2cb About an hour ago 5.51GB
|
||||
```
|
||||
|
||||
### Running models
|
||||
|
||||
You can start the inferencing server for your models with:
|
||||
|
||||
```bash
|
||||
# for pre-made models, replace "my-model" with the image name
|
||||
docker run -d --rm -p 8080:8080 my-model
|
||||
```
|
||||
|
||||
You can then send requests to `localhost:8080` to run inference from your models. For example:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "llama-2-7b-chat",
|
||||
"messages": [{"role": "user", "content": "explain kubernetes in a sentence"}]
|
||||
}'
|
||||
{"created":1701236489,"object":"chat.completion","id":"dd1ff40b-31a7-4418-9e32-42151ab6875a","model":"llama-2-7b-chat","choices":[{"index":0,"finish_reason":"stop","message":{"role":"assistant","content":"\nKubernetes is a container orchestration system that automates the deployment, scaling, and management of containerized applications in a microservices architecture."}}],"usage":{"prompt_tokens":0,"completion_tokens":0,"total_tokens":0}}
|
||||
```
|
||||
|
||||
## Kubernetes Deployment
|
||||
|
||||
It is easy to get started to deploy your models to Kubernetes!
|
||||
|
||||
Make sure you have a Kubernetes cluster running and `kubectl` is configured to talk to it, and your model images are accessible from the cluster.
|
||||
|
||||
> You can use [kind](https://kind.sigs.k8s.io/) to create a local Kubernetes cluster for testing purposes.
|
||||
|
||||
```bash
|
||||
# create a deployment
|
||||
# for pre-made models, replace "my-model" with the image name
|
||||
kubectl create deployment my-llm-deployment --image=my-model
|
||||
|
||||
# expose it as a service
|
||||
kubectl expose deployment my-llm-deployment --port=8080 --target-port=8080 --name=my-llm-service
|
||||
|
||||
# easy to scale up and down as needed
|
||||
kubectl scale deployment my-llm-deployment --replicas=3
|
||||
|
||||
# port-forward for testing locally
|
||||
kubectl port-forward service/my-llm-service 8080:8080
|
||||
|
||||
# send requests to your model
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "llama-2-7b-chat",
|
||||
"messages": [{"role": "user", "content": "explain kubernetes in a sentence"}]
|
||||
}'
|
||||
{"created":1701236489,"object":"chat.completion","id":"dd1ff40b-31a7-4418-9e32-42151ab6875a","model":"llama-2-7b-chat","choices":[{"index":0,"finish_reason":"stop","message":{"role":"assistant","content":"\nKubernetes is a container orchestration system that automates the deployment, scaling, and management of containerized applications in a microservices architecture."}}],"usage":{"prompt_tokens":0,"completion_tokens":0,"total_tokens":0}}
|
||||
```
|
||||
|
||||
> For an example Kubernetes deployment and service YAML, see [kubernetes folder](./kubernetes/). Please note that these are examples, you may need to customize them (such as properly configured resource requests and limits) based on your needs.
|
||||
|
||||
## GPU Acceleration Support
|
||||
|
||||
> At this time, only NVIDIA GPU acceleration is supported. Please open an issue if you'd like to see support for other GPU vendors.
|
||||
|
||||
### NVIDIA
|
||||
|
||||
AIKit supports GPU accelerated inferencing with [NVIDIA Container Toolkit](https://github.com/NVIDIA/nvidia-container-toolkit). You must also have [NVIDIA Drivers](https://www.nvidia.com/en-us/drivers/unix/) installed on your host machine.
|
||||
|
||||
For Kubernetes, [NVIDIA GPU Operator](https://github.com/NVIDIA/gpu-operator) provides a streamlined way to install the NVIDIA drivers and container toolkit to configure your cluster to use GPUs.
|
||||
|
||||
To get started with GPU-accelerated inferencing, make sure to set the following in your `aikitfile` and build your model.
|
||||
|
||||
```yaml
|
||||
runtime: cuda # use NVIDIA CUDA runtime
|
||||
f16: true # use float16 precision
|
||||
gpu_layers: 35 # number of layers to offload to GPU
|
||||
low_vram: true # for devices with low VRAM
|
||||
```
|
||||
|
||||
> Make sure to customize these values based on your model and GPU specs.
|
||||
|
||||
After building the model, you can run it with [`--gpus all`](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/docker-specialized.html#gpu-enumeration) flag to enable GPU support:
|
||||
|
||||
```bash
|
||||
# for pre-made models, replace "my-model" with the image name
|
||||
docker run --rm --gpus all -p 8080:8080 my-model
|
||||
```
|
||||
|
||||
If GPU acceleration is working, you'll see output that is similar to following in the debug logs:
|
||||
|
||||
```bash
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr ggml_init_cublas: found 1 CUDA devices:
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr Device 0: Tesla T4, compute capability 7.5
|
||||
...
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: using CUDA for GPU acceleration
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: mem required = 70.41 MB (+ 2048.00 MB per state)
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: offloading 32 repeating layers to GPU
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: offloading non-repeating layers to GPU
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: offloading v cache to GPU
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: offloading k cache to GPU
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: offloaded 35/35 layers to GPU
|
||||
5:32AM DBG GRPC(llama-2-7b-chat.Q4_K_M.gguf-127.0.0.1:43735): stderr llm_load_tensors: VRAM used: 5869 MB
|
||||
```
|
||||
@@ -1,70 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "AnythingLLM"
|
||||
description="Integrate your LocalAI LLM and embedding models into AnythingLLM by Mintplex Labs"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
AnythingLLM is an open source ChatGPT equivalent tool for chatting with documents and more in a secure environment by [Mintplex Labs Inc](https://github.com/Mintplex-Labs).
|
||||
|
||||

|
||||
|
||||
⭐ Star on Github - https://github.com/Mintplex-Labs/anything-llm
|
||||
|
||||
* Chat with your LocalAI models (or hosted models like OpenAi, Anthropic, and Azure)
|
||||
* Embed documents (txt, pdf, json, and more) using your LocalAI Sentence Transformers
|
||||
* Select any vector database you want (Chroma, Pinecone, qDrant, Weaviate ) or use the embedded on-instance vector database (LanceDB)
|
||||
* Supports single or multi-user tenancy with built-in permissions
|
||||
* Full developer API
|
||||
* Locally running SQLite db for minimal setup.
|
||||
|
||||
AnythingLLM is a fully transparent tool to deliver a customized, white-label ChatGPT equivalent experience using only the models and services you or your organization are comfortable using.
|
||||
|
||||
### Why AnythingLLM?
|
||||
|
||||
AnythingLLM aims to enable you to quickly and comfortably get a ChatGPT equivalent experience using your proprietary documents for your organization with zero compromise on security or comfort.
|
||||
|
||||
### What does AnythingLLM include?
|
||||
- Full UI
|
||||
- Full admin console and panel for managing users, chats, model selection, vector db connection, and embedder selection
|
||||
- Multi-user support and logins
|
||||
- Supports both desktop and mobile view ports
|
||||
- Built in vector database where no data leaves your instance at all
|
||||
- Docker support
|
||||
|
||||
## Install
|
||||
|
||||
### Local via docker
|
||||
|
||||
Running via docker and integrating with your LocalAI instance is a breeze.
|
||||
|
||||
First, pull in the latest AnythingLLM Docker image
|
||||
`docker pull mintplexlabs/anythingllm:master`
|
||||
|
||||
Next, run the image on a container exposing port `3001`.
|
||||
`docker run -d -p 3001:3001 mintplexlabs/anythingllm:master`
|
||||
|
||||
Now open `http://localhost:3001` and you will start on-boarding for setting up your AnythingLLM instance to your comfort level
|
||||
|
||||
|
||||
## Integration with your LocalAI instance.
|
||||
|
||||
There are two areas where you can leverage your models loaded into LocalAI - LLM and Embedding. Any LLM models should be ready to run a chat completion.
|
||||
|
||||
### LLM model selection
|
||||
|
||||
During onboarding and from the sidebar setting you can select `LocalAI` as your LLM. Here you can set both the model and token limit of the specific model. The dropdown will automatically populate once your url is set.
|
||||
|
||||
The URL should look like `http://localhost:8000/v1` or wherever your LocalAI instance is being served from. Non-localhost URLs are permitted if hosting LocalAI on cloud services.
|
||||
|
||||

|
||||
|
||||
|
||||
### LLM embedding model selection
|
||||
|
||||
During onboarding and from the sidebar setting you can select `LocalAI` as your preferred embedding engine. This model will be the model used when you upload any kind of document via AnythingLLM. Here you can set the model from available models via the LocalAI API. The dropdown will automatically populate once your url is set.
|
||||
|
||||
The URL should look like `http://localhost:8000/v1` or wherever your LocalAI instance is being served from. Non-localhost URLs are permitted if hosting LocalAI on cloud services.
|
||||
|
||||

|
||||
@@ -1,58 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "BMO Chatbo"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
Generate and brainstorm ideas while creating your notes using Large Language Models (LLMs) such as OpenAI's "gpt-3.5-turbo" and "gpt-4" for Obsidian.
|
||||
|
||||

|
||||
|
||||
Github Link - https://github.com/longy2k/obsidian-bmo-chatbot
|
||||
|
||||
## Features
|
||||
- **Chat from anywhere in Obsidian:** Chat with your bot from anywhere within Obsidian.
|
||||
- **Chat with current note:** Use your chatbot to reference and engage within your current note.
|
||||
- **Chatbot responds in Markdown:** Receive formatted responses in Markdown for consistency.
|
||||
- **Customizable bot name:** Personalize the chatbot's name.
|
||||
- **System role prompt:** Configure the chatbot to prompt for user roles before responding to messages.
|
||||
- **Set Max Tokens and Temperature:** Customize the length and randomness of the chatbot's responses with Max Tokens and Temperature settings.
|
||||
- **System theme color accents:** Seamlessly matches the chatbot's interface with your system's color scheme.
|
||||
- **Interact with self-hosted Large Language Models (LLMs):** Use the REST API URL provided to interact with self-hosted Large Language Models (LLMs) using [LocalAI](https://localai.io/howtos/).
|
||||
|
||||
## Requirements
|
||||
To use this plugin, with [LocalAI](https://localai.io/howtos/), you will need to have the self-hosted API set up and running. You can follow the instructions provided by the self-hosted API provider to get it up and running.
|
||||
Once you have the REST API URL for your self-hosted API, you can use it with this plugin to interact with your models.
|
||||
Explore some ``GGUF`` models at [theBloke](https://huggingface.co/TheBloke).
|
||||
|
||||
## How to activate the plugin
|
||||
Two methods:
|
||||
|
||||
Obsidian Community plugins (**Recommended**):
|
||||
1. Search for "BMO Chatbot" in the Obsidian Community plugins.
|
||||
2. Enable "BMO Chatbot" in the settings.
|
||||
|
||||
To activate the plugin from this repo:
|
||||
1. Navigate to the plugin's folder in your terminal.
|
||||
2. Run `npm install` to install any necessary dependencies for the plugin.
|
||||
3. Once the dependencies have been installed, run `npm run build` to build the plugin.
|
||||
4. Once the plugin has been built, it should be ready to activate.
|
||||
|
||||
## Getting Started
|
||||
To start using the plugin, enable it in your settings menu and enter your OpenAPI key. After completing these steps, you can access the bot panel by clicking on the bot icon in the left sidebar.
|
||||
If you want to clear the chat history, simply click on the bot icon again in the left ribbon bar.
|
||||
|
||||
## Supported Models
|
||||
- OpenAI
|
||||
- gpt-3.5-turbo
|
||||
- gpt-3.5-turbo-16k
|
||||
- gpt-4
|
||||
- Anthropic
|
||||
- claude-instant-1.2
|
||||
- claude-2.0
|
||||
- Any self-hosted models using [LocalAI](https://localai.io/howtos/)
|
||||
|
||||
## Other Notes
|
||||
"BMO" is a tag name for this project, inspired by the character BMO from the animated TV show "Adventure Time."
|
||||
|
||||
@@ -1,103 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "BionicGPT"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
an on-premise replacement for ChatGPT, offering the advantages of Generative AI while maintaining strict data confidentiality, BionicGPT can run on your laptop or scale into the data center.
|
||||
|
||||

|
||||
|
||||
BionicGPT Homepage - https://bionic-gpt.com
|
||||
Github link - https://github.com/purton-tech/bionicgpt
|
||||
|
||||
<!-- Try it out -->
|
||||
## Try it out
|
||||
Cut and paste the following into a `docker-compose.yaml` file and run `docker-compose up -d` access the user interface on http://localhost:7800/auth/sign_up
|
||||
This has been tested on an AMD 2700x with 16GB of ram. The included `ggml-gpt4all-j` model runs on CPU only.
|
||||
**Warning** - The images in this `docker-compose` are large due to having the model weights pre-loaded for convenience.
|
||||
|
||||
```yaml
|
||||
services:
|
||||
|
||||
# LocalAI with pre-loaded ggml-gpt4all-j
|
||||
local-ai:
|
||||
image: ghcr.io/purton-tech/bionicgpt-model-api:llama-2-7b-chat
|
||||
|
||||
# Handles parsing of multiple documents types.
|
||||
unstructured:
|
||||
image: downloads.unstructured.io/unstructured-io/unstructured-api:db264d8
|
||||
ports:
|
||||
- "8000:8000"
|
||||
|
||||
# Handles routing between the application, barricade and the LLM API
|
||||
envoy:
|
||||
image: ghcr.io/purton-tech/bionicgpt-envoy:1.1.10
|
||||
ports:
|
||||
- "7800:7700"
|
||||
|
||||
# Postgres pre-loaded with pgVector
|
||||
db:
|
||||
image: ankane/pgvector
|
||||
environment:
|
||||
POSTGRES_PASSWORD: testpassword
|
||||
POSTGRES_USER: postgres
|
||||
POSTGRES_DB: finetuna
|
||||
healthcheck:
|
||||
test: ["CMD-SHELL", "pg_isready -U postgres"]
|
||||
interval: 10s
|
||||
timeout: 5s
|
||||
retries: 5
|
||||
|
||||
# Sets up our database tables
|
||||
migrations:
|
||||
image: ghcr.io/purton-tech/bionicgpt-db-migrations:1.1.10
|
||||
environment:
|
||||
DATABASE_URL: postgresql://postgres:testpassword@db:5432/postgres?sslmode=disable
|
||||
depends_on:
|
||||
db:
|
||||
condition: service_healthy
|
||||
|
||||
# Barricade handles all /auth routes for user sign up and sign in.
|
||||
barricade:
|
||||
image: purtontech/barricade
|
||||
environment:
|
||||
# This secret key is used to encrypt cookies.
|
||||
SECRET_KEY: 190a5bf4b3cbb6c0991967ab1c48ab30790af876720f1835cbbf3820f4f5d949
|
||||
DATABASE_URL: postgresql://postgres:testpassword@db:5432/postgres?sslmode=disable
|
||||
FORWARD_URL: app
|
||||
FORWARD_PORT: 7703
|
||||
REDIRECT_URL: /app/post_registration
|
||||
depends_on:
|
||||
db:
|
||||
condition: service_healthy
|
||||
migrations:
|
||||
condition: service_completed_successfully
|
||||
|
||||
# Our axum server delivering our user interface
|
||||
embeddings-job:
|
||||
image: ghcr.io/purton-tech/bionicgpt-embeddings-job:1.1.10
|
||||
environment:
|
||||
APP_DATABASE_URL: postgresql://ft_application:testpassword@db:5432/postgres?sslmode=disable
|
||||
depends_on:
|
||||
db:
|
||||
condition: service_healthy
|
||||
migrations:
|
||||
condition: service_completed_successfully
|
||||
|
||||
# Our axum server delivering our user interface
|
||||
app:
|
||||
image: ghcr.io/purton-tech/bionicgpt:1.1.10
|
||||
environment:
|
||||
APP_DATABASE_URL: postgresql://ft_application:testpassword@db:5432/postgres?sslmode=disable
|
||||
depends_on:
|
||||
db:
|
||||
condition: service_healthy
|
||||
migrations:
|
||||
condition: service_completed_successfully
|
||||
```
|
||||
|
||||
## Kubernetes Ready
|
||||
|
||||
BionicGPT is optimized to run on Kubernetes and implements the full pipeline of LLM fine tuning from data acquisition to user interface.
|
||||
@@ -1,54 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Flowise"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
Build LLM Apps Easily
|
||||
|
||||

|
||||
|
||||
Github Link - https://github.com/FlowiseAI/Flowise
|
||||
|
||||
## ⚡Local Install
|
||||
|
||||
Download and Install [NodeJS](https://nodejs.org/en/download) >= 18.15.0
|
||||
|
||||
1. Install Flowise
|
||||
```bash
|
||||
npm install -g flowise
|
||||
```
|
||||
2. Start Flowise
|
||||
|
||||
```bash
|
||||
npx flowise start
|
||||
```
|
||||
|
||||
3. Open [http://localhost:3000](http://localhost:3000)
|
||||
|
||||
## 🐳 Docker
|
||||
|
||||
### Docker Compose
|
||||
|
||||
1. Go to `docker` folder at the root of the project
|
||||
2. Copy `.env.example` file, paste it into the same location, and rename to `.env`
|
||||
3. `docker-compose up -d`
|
||||
4. Open [http://localhost:3000](http://localhost:3000)
|
||||
5. You can bring the containers down by `docker-compose stop --rmi all`
|
||||
|
||||
### Docker Compose (Flowise + LocalAI)
|
||||
|
||||
1. In a command line Run ``git clone https://github.com/go-skynet/LocalAI``
|
||||
2. Then run ``cd LocalAI/examples/flowise``
|
||||
3. Then run ``docker-compose up -d --pull always``
|
||||
4. Open [http://localhost:3000](http://localhost:3000)
|
||||
5. You can bring the containers down by `docker-compose stop --rmi all`
|
||||
|
||||
## 🌱 Env Variables
|
||||
|
||||
Flowise support different environment variables to configure your instance. You can specify the following variables in the `.env` file inside `packages/server` folder. Read [more](https://github.com/FlowiseAI/Flowise/blob/main/CONTRIBUTING.md#-env-variables)
|
||||
|
||||
## 📖 Documentation
|
||||
|
||||
[Flowise Docs](https://docs.flowiseai.com/)
|
||||
@@ -1,466 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "k8sgpt"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English.
|
||||
|
||||

|
||||
|
||||
It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
|
||||
|
||||
Github Link - https://github.com/k8sgpt-ai/k8sgpt
|
||||
|
||||
## CLI Installation
|
||||
|
||||
### Linux/Mac via brew
|
||||
|
||||
```
|
||||
brew tap k8sgpt-ai/k8sgpt
|
||||
brew install k8sgpt
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>RPM-based installation (RedHat/CentOS/Fedora)</summary>
|
||||
|
||||
**32 bit:**
|
||||
<!---x-release-please-start-version-->
|
||||
```
|
||||
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.18/k8sgpt_386.rpm
|
||||
sudo rpm -ivh k8sgpt_386.rpm
|
||||
```
|
||||
<!---x-release-please-end-->
|
||||
|
||||
**64 bit:**
|
||||
|
||||
<!---x-release-please-start-version-->
|
||||
```
|
||||
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.18/k8sgpt_amd64.rpm
|
||||
sudo rpm -ivh -i k8sgpt_amd64.rpm
|
||||
```
|
||||
<!---x-release-please-end-->
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>DEB-based installation (Ubuntu/Debian)</summary>
|
||||
|
||||
**32 bit:**
|
||||
<!---x-release-please-start-version-->
|
||||
```
|
||||
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.18/k8sgpt_386.deb
|
||||
sudo dpkg -i k8sgpt_386.deb
|
||||
```
|
||||
<!---x-release-please-end-->
|
||||
**64 bit:**
|
||||
|
||||
<!---x-release-please-start-version-->
|
||||
```
|
||||
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.18/k8sgpt_amd64.deb
|
||||
sudo dpkg -i k8sgpt_amd64.deb
|
||||
```
|
||||
<!---x-release-please-end-->
|
||||
</details>
|
||||
|
||||
<details>
|
||||
|
||||
<summary>APK-based installation (Alpine)</summary>
|
||||
|
||||
**32 bit:**
|
||||
<!---x-release-please-start-version-->
|
||||
```
|
||||
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.18/k8sgpt_386.apk
|
||||
apk add k8sgpt_386.apk
|
||||
```
|
||||
<!---x-release-please-end-->
|
||||
**64 bit:**
|
||||
<!---x-release-please-start-version-->
|
||||
```
|
||||
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.18/k8sgpt_amd64.apk
|
||||
apk add k8sgpt_amd64.apk
|
||||
```
|
||||
<!---x-release-please-end-->x
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Failing Installation on WSL or Linux (missing gcc)</summary>
|
||||
When installing Homebrew on WSL or Linux, you may encounter the following error:
|
||||
|
||||
```
|
||||
==> Installing k8sgpt from k8sgpt-ai/k8sgpt Error: The following formula cannot be installed from a bottle and must be
|
||||
built from the source. k8sgpt Install Clang or run brew install gcc.
|
||||
```
|
||||
|
||||
If you install gcc as suggested, the problem will persist. Therefore, you need to install the build-essential package.
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install build-essential
|
||||
```
|
||||
</details>
|
||||
|
||||
|
||||
### Windows
|
||||
|
||||
* Download the latest Windows binaries of **k8sgpt** from the [Release](https://github.com/k8sgpt-ai/k8sgpt/releases)
|
||||
tab based on your system architecture.
|
||||
* Extract the downloaded package to your desired location. Configure the system *path* variable with the binary location
|
||||
|
||||
## Operator Installation
|
||||
|
||||
To install within a Kubernetes cluster please use our `k8sgpt-operator` with installation instructions available [here](https://github.com/k8sgpt-ai/k8sgpt-operator)
|
||||
|
||||
_This mode of operation is ideal for continuous monitoring of your cluster and can integrate with your existing monitoring such as Prometheus and Alertmanager._
|
||||
|
||||
|
||||
## Quick Start
|
||||
|
||||
* Currently the default AI provider is OpenAI, you will need to generate an API key from [OpenAI](https://openai.com)
|
||||
* You can do this by running `k8sgpt generate` to open a browser link to generate it
|
||||
* Run `k8sgpt auth add` to set it in k8sgpt.
|
||||
* You can provide the password directly using the `--password` flag.
|
||||
* Run `k8sgpt filters` to manage the active filters used by the analyzer. By default, all filters are executed during analysis.
|
||||
* Run `k8sgpt analyze` to run a scan.
|
||||
* And use `k8sgpt analyze --explain` to get a more detailed explanation of the issues.
|
||||
* You also run `k8sgpt analyze --with-doc` (with or without the explain flag) to get the official documentation from kubernetes.
|
||||
|
||||
## Analyzers
|
||||
|
||||
K8sGPT uses analyzers to triage and diagnose issues in your cluster. It has a set of analyzers that are built in, but
|
||||
you will be able to write your own analyzers.
|
||||
|
||||
### Built in analyzers
|
||||
|
||||
#### Enabled by default
|
||||
|
||||
- [x] podAnalyzer
|
||||
- [x] pvcAnalyzer
|
||||
- [x] rsAnalyzer
|
||||
- [x] serviceAnalyzer
|
||||
- [x] eventAnalyzer
|
||||
- [x] ingressAnalyzer
|
||||
- [x] statefulSetAnalyzer
|
||||
- [x] deploymentAnalyzer
|
||||
- [x] cronJobAnalyzer
|
||||
- [x] nodeAnalyzer
|
||||
- [x] mutatingWebhookAnalyzer
|
||||
- [x] validatingWebhookAnalyzer
|
||||
|
||||
#### Optional
|
||||
|
||||
- [x] hpaAnalyzer
|
||||
- [x] pdbAnalyzer
|
||||
- [x] networkPolicyAnalyzer
|
||||
|
||||
## Examples
|
||||
|
||||
_Run a scan with the default analyzers_
|
||||
|
||||
```
|
||||
k8sgpt generate
|
||||
k8sgpt auth add
|
||||
k8sgpt analyze --explain
|
||||
k8sgpt analyze --explain --with-doc
|
||||
```
|
||||
|
||||
_Filter on resource_
|
||||
|
||||
```
|
||||
k8sgpt analyze --explain --filter=Service
|
||||
```
|
||||
|
||||
_Filter by namespace_
|
||||
```
|
||||
k8sgpt analyze --explain --filter=Pod --namespace=default
|
||||
```
|
||||
|
||||
_Output to JSON_
|
||||
|
||||
```
|
||||
k8sgpt analyze --explain --filter=Service --output=json
|
||||
```
|
||||
|
||||
_Anonymize during explain_
|
||||
|
||||
```
|
||||
k8sgpt analyze --explain --filter=Service --output=json --anonymize
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary> Using filters </summary>
|
||||
|
||||
_List filters_
|
||||
|
||||
```
|
||||
k8sgpt filters list
|
||||
```
|
||||
|
||||
_Add default filters_
|
||||
|
||||
```
|
||||
k8sgpt filters add [filter(s)]
|
||||
```
|
||||
|
||||
### Examples :
|
||||
|
||||
- Simple filter : `k8sgpt filters add Service`
|
||||
- Multiple filters : `k8sgpt filters add Ingress,Pod`
|
||||
|
||||
_Remove default filters_
|
||||
|
||||
```
|
||||
k8sgpt filters remove [filter(s)]
|
||||
```
|
||||
|
||||
### Examples :
|
||||
|
||||
- Simple filter : `k8sgpt filters remove Service`
|
||||
- Multiple filters : `k8sgpt filters remove Ingress,Pod`
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
|
||||
<summary> Additional commands </summary>
|
||||
|
||||
_List configured backends_
|
||||
|
||||
```
|
||||
k8sgpt auth list
|
||||
```
|
||||
|
||||
_Update configured backends_
|
||||
|
||||
```
|
||||
k8sgpt auth update $MY_BACKEND1,$MY_BACKEND2..
|
||||
```
|
||||
|
||||
_Remove configured backends_
|
||||
|
||||
```
|
||||
k8sgpt auth remove $MY_BACKEND1,$MY_BACKEND2..
|
||||
```
|
||||
|
||||
_List integrations_
|
||||
|
||||
```
|
||||
k8sgpt integrations list
|
||||
```
|
||||
|
||||
_Activate integrations_
|
||||
|
||||
```
|
||||
k8sgpt integrations activate [integration(s)]
|
||||
```
|
||||
|
||||
_Use integration_
|
||||
|
||||
```
|
||||
k8sgpt analyze --filter=[integration(s)]
|
||||
```
|
||||
|
||||
_Deactivate integrations_
|
||||
|
||||
```
|
||||
k8sgpt integrations deactivate [integration(s)]
|
||||
```
|
||||
|
||||
_Serve mode_
|
||||
|
||||
```
|
||||
k8sgpt serve
|
||||
```
|
||||
|
||||
_Analysis with serve mode_
|
||||
|
||||
```
|
||||
curl -X GET "http://localhost:8080/analyze?namespace=k8sgpt&explain=false"
|
||||
```
|
||||
</details>
|
||||
|
||||
|
||||
## Key Features
|
||||
|
||||
<details>
|
||||
<summary> LocalAI provider </summary>
|
||||
|
||||
To run local models, it is possible to use OpenAI compatible APIs, for instance [LocalAI](https://github.com/go-skynet/LocalAI) which uses [llama.cpp](https://github.com/ggerganov/llama.cpp) to run inference on consumer-grade hardware. Models supported by LocalAI for instance are Vicuna, Alpaca, LLaMA, Cerebras, GPT4ALL, GPT4ALL-J, Llama2 and koala.
|
||||
|
||||
|
||||
To run local inference, you need to download the models first, for instance you can find `gguf` compatible models in [huggingface.com](https://huggingface.co/models?search=gguf) (for example vicuna, alpaca and koala).
|
||||
|
||||
### Start the API server
|
||||
|
||||
To start the API server, follow the instruction in [LocalAI](https://localai.io/howtos/).
|
||||
|
||||
### Run k8sgpt
|
||||
|
||||
To run k8sgpt, run `k8sgpt auth add` with the `localai` backend:
|
||||
|
||||
```
|
||||
k8sgpt auth add --backend localai --model <model_name> --baseurl http://localhost:8080/v1 --temperature 0.7
|
||||
```
|
||||
|
||||
Now you can analyze with the `localai` backend:
|
||||
|
||||
```
|
||||
k8sgpt analyze --explain --backend localai
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Setting a new default AI provider</summary>
|
||||
|
||||
There may be scenarios where you wish to have K8sGPT plugged into several default AI providers. In this case you may wish to use one as a new default, other than OpenAI which is the project default.
|
||||
|
||||
_To view available providers_
|
||||
|
||||
```
|
||||
k8sgpt auth list
|
||||
Default:
|
||||
> openai
|
||||
Active:
|
||||
> openai
|
||||
> azureopenai
|
||||
Unused:
|
||||
> localai
|
||||
> noopai
|
||||
|
||||
```
|
||||
|
||||
|
||||
_To set a new default provider_
|
||||
|
||||
```
|
||||
k8sgpt auth default -p azureopenai
|
||||
Default provider set to azureopenai
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details>
|
||||
|
||||
With this option, the data is anonymized before being sent to the AI Backend. During the analysis execution, `k8sgpt` retrieves sensitive data (Kubernetes object names, labels, etc.). This data is masked when sent to the AI backend and replaced by a key that can be used to de-anonymize the data when the solution is returned to the user.
|
||||
|
||||
|
||||
<summary> Anonymization </summary>
|
||||
|
||||
1. Error reported during analysis:
|
||||
```bash
|
||||
Error: HorizontalPodAutoscaler uses StatefulSet/fake-deployment as ScaleTargetRef which does not exist.
|
||||
```
|
||||
|
||||
2. Payload sent to the AI backend:
|
||||
```bash
|
||||
Error: HorizontalPodAutoscaler uses StatefulSet/tGLcCRcHa1Ce5Rs as ScaleTargetRef which does not exist.
|
||||
```
|
||||
|
||||
3. Payload returned by the AI:
|
||||
```bash
|
||||
The Kubernetes system is trying to scale a StatefulSet named tGLcCRcHa1Ce5Rs using the HorizontalPodAutoscaler, but it cannot find the StatefulSet. The solution is to verify that the StatefulSet name is spelled correctly and exists in the same namespace as the HorizontalPodAutoscaler.
|
||||
```
|
||||
|
||||
4. Payload returned to the user:
|
||||
```bash
|
||||
The Kubernetes system is trying to scale a StatefulSet named fake-deployment using the HorizontalPodAutoscaler, but it cannot find the StatefulSet. The solution is to verify that the StatefulSet name is spelled correctly and exists in the same namespace as the HorizontalPodAutoscaler.
|
||||
```
|
||||
|
||||
Note: **Anonymization does not currently apply to events.**
|
||||
|
||||
### Further Details
|
||||
|
||||
**Anonymization does not currently apply to events.**
|
||||
|
||||
*In a few analysers like Pod, we feed to the AI backend the event messages which are not known beforehand thus we are not masking them for the **time being**.*
|
||||
|
||||
- The following is the list of analysers in which data is **being masked**:-
|
||||
|
||||
- Statefulset
|
||||
- Service
|
||||
- PodDisruptionBudget
|
||||
- Node
|
||||
- NetworkPolicy
|
||||
- Ingress
|
||||
- HPA
|
||||
- Deployment
|
||||
- Cronjob
|
||||
|
||||
- The following is the list of analysers in which data is **not being masked**:-
|
||||
|
||||
- RepicaSet
|
||||
- PersistentVolumeClaim
|
||||
- Pod
|
||||
- **_*Events_**
|
||||
|
||||
***Note**:
|
||||
- k8gpt will not mask the above analysers because they do not send any identifying information except **Events** analyser.
|
||||
- Masking for **Events** analyzer is scheduled in the near future as seen in this [issue](https://github.com/k8sgpt-ai/k8sgpt/issues/560). _Further research has to be made to understand the patterns and be able to mask the sensitive parts of an event like pod name, namespace etc._
|
||||
|
||||
- The following is the list of fields which are not **being masked**:-
|
||||
|
||||
- Describe
|
||||
- ObjectStatus
|
||||
- Replicas
|
||||
- ContainerStatus
|
||||
- **_*Event Message_**
|
||||
- ReplicaStatus
|
||||
- Count (Pod)
|
||||
|
||||
***Note**:
|
||||
- It is quite possible the payload of the event message might have something like "super-secret-project-pod-X crashed" which we don't currently redact _(scheduled in the near future as seen in this [issue](https://github.com/k8sgpt-ai/k8sgpt/issues/560))_.
|
||||
|
||||
### Proceed with care
|
||||
|
||||
- The K8gpt team recommends using an entirely different backend **(a local model) in critical production environments**. By using a local model, you can rest assured that everything stays within your DMZ, and nothing is leaked.
|
||||
- If there is any uncertainty about the possibility of sending data to a public LLM (open AI, Azure AI) and it poses a risk to business-critical operations, then, in such cases, the use of public LLM should be avoided based on personal assessment and the jurisdiction of risks involved.
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary> Configuration management</summary>
|
||||
|
||||
`k8sgpt` stores config data in the `$XDG_CONFIG_HOME/k8sgpt/k8sgpt.yaml` file. The data is stored in plain text, including your OpenAI key.
|
||||
|
||||
Config file locations:
|
||||
| OS | Path |
|
||||
| ------- | ------------------------------------------------ |
|
||||
| MacOS | ~/Library/Application Support/k8sgpt/k8sgpt.yaml |
|
||||
| Linux | ~/.config/k8sgpt/k8sgpt.yaml |
|
||||
| Windows | %LOCALAPPDATA%/k8sgpt/k8sgpt.yaml |
|
||||
</details>
|
||||
|
||||
<details>
|
||||
There may be scenarios where caching remotely is preferred.
|
||||
In these scenarios K8sGPT supports AWS S3 Integration.
|
||||
|
||||
<summary> Remote caching </summary>
|
||||
|
||||
_As a prerequisite `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` are required as environmental variables._
|
||||
|
||||
_Adding a remote cache_
|
||||
|
||||
Note: this will create the bucket if it does not exist
|
||||
```
|
||||
k8sgpt cache add --region <aws region> --bucket <name>
|
||||
```
|
||||
|
||||
_Listing cache items_
|
||||
```
|
||||
k8sgpt cache list
|
||||
```
|
||||
|
||||
_Removing the remote cache_
|
||||
Note: this will not delete the bucket
|
||||
```
|
||||
k8sgpt cache remove --bucket <name>
|
||||
```
|
||||
</details>
|
||||
|
||||
|
||||
## Documentation
|
||||
|
||||
Find our official documentation available [here](https://docs.k8sgpt.ai)
|
||||
@@ -1,39 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Kairos"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||

|
||||
|
||||
[Kairos](https://github.com/kairos-io/kairos) - Kubernetes-focused, Cloud Native Linux meta-distribution
|
||||
|
||||
The immutable Linux meta-distribution for edge Kubernetes.
|
||||
|
||||
Github Link - https://github.com/kairos-io/kairos
|
||||
|
||||
## Intro
|
||||
|
||||
With Kairos you can build immutable, bootable Kubernetes and OS images for your edge devices as easily as writing a Dockerfile. Optional P2P mesh with distributed ledger automates node bootstrapping and coordination. Updating nodes is as easy as CI/CD: push a new image to your container registry and let secure, risk-free A/B atomic upgrades do the rest. Kairos is part of the Secure Edge-Native Architecture (SENA) to securely run workloads at the Edge ([whitepaper](https://github.com/kairos-io/kairos/files/11250843/Secure-Edge-Native-Architecture-white-paper-20240417.3.pdf)).
|
||||
|
||||
Kairos (formerly `c3os`) is an open-source project which brings Edge, cloud, and bare metal lifecycle OS management into the same design principles with a unified Cloud Native API.
|
||||
|
||||
## At-a-glance:
|
||||
|
||||
- :bowtie: Community Driven
|
||||
- :octocat: Open Source
|
||||
- :lock: Linux immutable, meta-distribution
|
||||
- :key: Secure
|
||||
- :whale: Container-based
|
||||
- :penguin: Distribution agnostic
|
||||
|
||||
## Kairos can be used to:
|
||||
|
||||
- Easily spin-up a Kubernetes cluster, with the Linux distribution of your choice :penguin:
|
||||
- Create your Immutable infrastructure, no more infrastructure drift! :lock:
|
||||
- Manage the cluster lifecycle with Kubernetes—from building to provisioning, and upgrading :rocket:
|
||||
- Create a multiple—node, a single cluster that spans up across regions :earth_africa:
|
||||
|
||||
For comprehensive docs, tutorials, and examples see our [documentation](https://kairos.io/docs/getting-started/).
|
||||
|
||||
@@ -1,60 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "LLMStack"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||

|
||||
|
||||
[LLMStack](https://github.com/trypromptly/LLMStack) - LLMStack is a no-code platform for building generative AI applications, chatbots, agents and connecting them to your data and business processes.
|
||||
|
||||
Github Link - https://github.com/trypromptly/LLMStack
|
||||
|
||||
## Overview
|
||||
|
||||
Build tailor-made generative AI applications, chatbots and agents that cater to your unique needs by chaining multiple LLMs. Seamlessly integrate your own data and GPT-powered models without any coding experience using LLMStack's no-code builder. Trigger your AI chains from Slack or Discord. Deploy to the cloud or on-premise.
|
||||
|
||||
|
||||
|
||||
## Getting Started
|
||||
|
||||
LLMStack deployment comes with a default admin account whose credentials are `admin` and `promptly`. _Be sure to change the password from admin panel after logging in_.
|
||||
|
||||
## Features
|
||||
|
||||
**🔗 Chain multiple models**: LLMStack allows you to chain multiple LLMs together to build complex generative AI applications.
|
||||
|
||||
**📊 Use generative AI on your Data**: Import your data into your accounts and use it in AI chains. LLMStack allows importing various types (_CSV, TXT, PDF, DOCX, PPTX etc.,_) of data from a variety of sources (_gdrive, notion, websites, direct uploads etc.,_). Platform will take care of preprocessing and vectorization of your data and store it in the vector database that is provided out of the box.
|
||||
|
||||
**🛠️ No-code builder**: LLMStack comes with a no-code builder that allows you to build AI chains without any coding experience. You can chain multiple LLMs together and connect them to your data and business processes.
|
||||
|
||||
**☁️ Deploy to the cloud or on-premise**: LLMStack can be deployed to the cloud or on-premise. You can deploy it to your own infrastructure or use our cloud offering at [Promptly](https://trypromptly.com).
|
||||
|
||||
**🚀 API access**: Apps or chatbots built with LLMStack can be accessed via HTTP API. You can also trigger your AI chains from **_Slack_** or **_Discord_**.
|
||||
|
||||
**🏢 Multi-tenant**: LLMStack is multi-tenant. You can create multiple organizations and add users to them. Users can only access the data and AI chains that belong to their organization.
|
||||
|
||||
## What can you build with LLMStack?
|
||||
|
||||
Using LLMStack you can build a variety of generative AI applications, chatbots and agents. Here are some examples:
|
||||
|
||||
**📝 Text generation**: You can build apps that generate product descriptions, blog posts, news articles, tweets, emails, chat messages, etc., by using text generation models and optionally connecting your data. Check out this [marketing content generator](https://trypromptly.com/app/50ee8bae-712e-4b95-9254-74d7bcf3f0cb) for example
|
||||
|
||||
**🤖 Chatbots**: You can build chatbots trained on your data powered by ChatGPT like [Promptly Help](https://trypromptly.com/app/f4d7cb50-1805-4add-80c5-e30334bce53c) that is embedded on Promptly website
|
||||
|
||||
**🎨 Multimedia generation**: Build complex applications that can generate text, images, videos, audio, etc. from a prompt. This [story generator](https://trypromptly.com/app/9d6da897-67cf-4887-94ec-afd4b9362655) is an example
|
||||
|
||||
**🗣️ Conversational AI**: Build conversational AI systems that can have a conversation with a user. Check out this [Harry Potter character chatbot](https://trypromptly.com/app/bdeb9850-b32e-44cf-b2a8-e5d54dc5fba4)
|
||||
|
||||
**🔍 Search augmentation**: Build search augmentation systems that can augment search results with additional information using APIs. Sharebird uses LLMStack to augment search results with AI generated answer from their content similar to Bing's chatbot
|
||||
|
||||
**💬 Discord and Slack bots**: Apps built on LLMStack can be triggered from Slack or Discord. You can easily connect your AI chains to Slack or Discord from LLMStack's no-code app editor. Check out our [Discord server](https://discord.gg/3JsEzSXspJ) to interact with one such bot.
|
||||
|
||||
## Administration
|
||||
|
||||
Login to [http://localhost:3000/admin](http://localhost:3000/admin) using the admin account. You can add users and assign them to organizations in the admin panel.
|
||||
|
||||
## Documentation
|
||||
|
||||
Check out our documentation at [llmstack.ai/docs](https://llmstack.ai/docs/) to learn more about LLMStack.
|
||||
@@ -1,74 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "LinGoose"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
**LinGoose** (_Lingo + Go + Goose_ 🪿) aims to be a complete Go framework for creating LLM apps. 🤖 ⚙️
|
||||
|
||||

|
||||
|
||||
Github Link - https://github.com/henomis/lingoose
|
||||
|
||||
## Overview
|
||||
|
||||
**LinGoose** is a powerful Go framework for developing Large Language Model (LLM) based applications using pipelines. It is designed to be a complete solution and provides multiple components, including Prompts, Templates, Chat, Output Decoders, LLM, Pipelines, and Memory. With **LinGoose**, you can interact with LLM AI through prompts and generate complex templates. Additionally, it includes a chat feature, allowing you to create chatbots. The Output Decoders component enables you to extract specific information from the output of the LLM, while the LLM interface allows you to send prompts to various AI, such as the ones provided by OpenAI. You can chain multiple LLM steps together using Pipelines and store the output of each step in Memory for later retrieval. **LinGoose** also includes a Document component, which is used to store text, and a Loader component, which is used to load Documents from various sources. Finally, it includes TextSplitters, which are used to split text or Documents into multiple parts, Embedders, which are used to embed text or Documents into embeddings, and Indexes, which are used to store embeddings and documents and to perform searches.
|
||||
|
||||
## Components
|
||||
|
||||
**LinGoose** is composed of multiple components, each one with its own purpose.
|
||||
|
||||
| Component | Package | Description |
|
||||
| ----------------- | ----------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| **Prompt** | [prompt](prompt/) | Prompts are the way to interact with LLM AI. They can be simple text, or more complex templates. Supports **Prompt Templates** and **[Whisper](https://openai.com) prompt** |
|
||||
| **Chat Prompt** | [chat](chat/) | Chat is the way to interact with the chat LLM AI. It can be a simple text prompt, or a more complex chatbot. |
|
||||
| **Decoders** | [decoder](decoder/) | Output decoders are used to decode the output of the LLM. They can be used to extract specific information from the output. Supports **JSONDecoder** and **RegExDecoder** |
|
||||
| **LLMs** | [llm](llm/) | LLM is an interface to various AI such as the ones provided by OpenAI. It is responsible for sending the prompt to the AI and retrieving the output. Supports **[LocalAI](https://localai.io/howtos/)**, **[HuggingFace](https://huggingface.co)** and **[Llama.cpp](https://github.com/ggerganov/llama.cpp)**. |
|
||||
| **Pipelines** | [pipeline](pipeline/) | Pipelines are used to chain multiple LLM steps together. |
|
||||
| **Memory** | [memory](memory/) | Memory is used to store the output of each step. It can be used to retrieve the output of a previous step. Supports memory in **Ram** |
|
||||
| **Document** | [document](document/) | Document is used to store a text |
|
||||
| **Loaders** | [loader](loader/) | Loaders are used to load Documents from various sources. Supports **TextLoader**, **DirectoryLoader**, **PDFToTextLoader** and **PubMedLoader** . |
|
||||
| **TextSplitters** | [textsplitter](textsplitter/) | TextSplitters are used to split text or Documents into multiple parts. Supports **RecursiveTextSplitter**. |
|
||||
| **Embedders** | [embedder](embedder/) | Embedders are used to embed text or Documents into embeddings. Supports **[OpenAI](https://openai.com)** |
|
||||
| **Indexes** | [index](index/) | Indexes are used to store embeddings and documents and to perform searches. Supports **SimpleVectorIndex**, **[Pinecone](https://pinecone.io)** and **[Qdrant](https://qdrant.tech)** |
|
||||
|
||||
## Usage
|
||||
|
||||
Please refer to the documentation at [lingoose.io](https://lingoose.io/docs/) to understand how to use LinGoose. If you prefer the 👉 [examples directory](examples/) contains a lot of examples 🚀.
|
||||
However, here is a **powerful** example of what **LinGoose** is capable of:
|
||||
|
||||
_Talk is cheap. Show me the [code](examples/)._ - Linus Torvalds
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"context"
|
||||
|
||||
openaiembedder "github.com/henomis/lingoose/embedder/openai"
|
||||
"github.com/henomis/lingoose/index/option"
|
||||
simplevectorindex "github.com/henomis/lingoose/index/simpleVectorIndex"
|
||||
"github.com/henomis/lingoose/llm/openai"
|
||||
"github.com/henomis/lingoose/loader"
|
||||
qapipeline "github.com/henomis/lingoose/pipeline/qa"
|
||||
"github.com/henomis/lingoose/textsplitter"
|
||||
)
|
||||
|
||||
func main() {
|
||||
docs, _ := loader.NewPDFToTextLoader("./kb").WithPDFToTextPath("/opt/homebrew/bin/pdftotext").WithTextSplitter(textsplitter.NewRecursiveCharacterTextSplitter(2000, 200)).Load(context.Background())
|
||||
index := simplevectorindex.New("db", ".", openaiembedder.New(openaiembedder.AdaEmbeddingV2))
|
||||
index.LoadFromDocuments(context.Background(), docs)
|
||||
qapipeline.New(openai.NewChat().WithVerbose(true)).WithIndex(index).Query(context.Background(), "What is the NATO purpose?", option.WithTopK(1))
|
||||
}
|
||||
```
|
||||
|
||||
This is the _famous_ 4-lines **lingoose** knowledge base chatbot. 🤖
|
||||
|
||||
## Installation
|
||||
|
||||
Be sure to have a working Go environment, then run the following command:
|
||||
|
||||
```shell
|
||||
go get github.com/henomis/lingoose
|
||||
```
|
||||
@@ -1,174 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "LocalAGI"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
LocalAGI is a small 🤖 virtual assistant that you can run locally, made by the [LocalAI](https://github.com/go-skynet/LocalAI) author and powered by it.
|
||||
|
||||

|
||||
|
||||
[AutoGPT](https://github.com/Significant-Gravitas/Auto-GPT), [babyAGI](https://github.com/yoheinakajima/babyagi), ... and now LocalAGI!
|
||||
|
||||
Github Link - https://github.com/mudler/LocalAGI
|
||||
|
||||
## Info
|
||||
|
||||
The goal is:
|
||||
- Keep it simple, hackable and easy to understand
|
||||
- No API keys needed, No cloud services needed, 100% Local. Tailored for Local use, however still compatible with OpenAI.
|
||||
- Smart-agent/virtual assistant that can do tasks
|
||||
- Small set of dependencies
|
||||
- Run with Docker/Podman/Containers
|
||||
- Rather than trying to do everything, provide a good starting point for other projects
|
||||
|
||||
Note: Be warned! It was hacked in a weekend, and it's just an experiment to see what can be done with local LLMs.
|
||||
|
||||
|
||||
|
||||
## 🚀 Features
|
||||
|
||||
- 🧠 LLM for intent detection
|
||||
- 🧠 Uses functions for actions
|
||||
- 📝 Write to long-term memory
|
||||
- 📖 Read from long-term memory
|
||||
- 🌐 Internet access for search
|
||||
- :card_file_box: Write files
|
||||
- 🔌 Plan steps to achieve a goal
|
||||
- 🤖 Avatar creation with Stable Diffusion
|
||||
- 🗨️ Conversational
|
||||
- 🗣️ Voice synthesis with TTS
|
||||
|
||||
## :book: Quick start
|
||||
|
||||
No frills, just run docker-compose and start chatting with your virtual assistant:
|
||||
|
||||
```bash
|
||||
# Modify the configuration
|
||||
# nano .env
|
||||
docker-compose run -i --rm localagi
|
||||
```
|
||||
|
||||
## How to use it
|
||||
|
||||
By default localagi starts in interactive mode
|
||||
|
||||
### Examples
|
||||
|
||||
Road trip planner by limiting searching to internet to 3 results only:
|
||||
|
||||
```bash
|
||||
docker-compose run -i --rm localagi \
|
||||
--skip-avatar \
|
||||
--subtask-context \
|
||||
--postprocess \
|
||||
--search-results 3 \
|
||||
--prompt "prepare a plan for my roadtrip to san francisco"
|
||||
```
|
||||
|
||||
Limit results of planning to 3 steps:
|
||||
|
||||
```bash
|
||||
docker-compose run -i --rm localagi \
|
||||
--skip-avatar \
|
||||
--subtask-context \
|
||||
--postprocess \
|
||||
--search-results 1 \
|
||||
--prompt "do a plan for my roadtrip to san francisco" \
|
||||
--plan-message "The assistant replies with a plan of 3 steps to answer the request with a list of subtasks with logical steps. The reasoning includes a self-contained, detailed and descriptive instruction to fullfill the task."
|
||||
```
|
||||
|
||||
### Advanced
|
||||
|
||||
localagi has several options in the CLI to tweak the experience:
|
||||
|
||||
- `--system-prompt` is the system prompt to use. If not specified, it will use none.
|
||||
- `--prompt` is the prompt to use for batch mode. If not specified, it will default to interactive mode.
|
||||
- `--interactive` is the interactive mode. When used with `--prompt` will drop you in an interactive session after the first prompt is evaluated.
|
||||
- `--skip-avatar` will skip avatar creation. Useful if you want to run it in a headless environment.
|
||||
- `--re-evaluate` will re-evaluate if another action is needed or we have completed the user request.
|
||||
- `--postprocess` will postprocess the reasoning for analysis.
|
||||
- `--subtask-context` will include context in subtasks.
|
||||
- `--search-results` is the number of search results to use.
|
||||
- `--plan-message` is the message to use during planning. You can override the message for example to force a plan to have a different message.
|
||||
- `--tts-api-base` is the TTS API base. Defaults to `http://api:8080`.
|
||||
- `--localai-api-base` is the LocalAI API base. Defaults to `http://api:8080`.
|
||||
- `--images-api-base` is the Images API base. Defaults to `http://api:8080`.
|
||||
- `--embeddings-api-base` is the Embeddings API base. Defaults to `http://api:8080`.
|
||||
- `--functions-model` is the functions model to use. Defaults to `functions`.
|
||||
- `--embeddings-model` is the embeddings model to use. Defaults to `all-MiniLM-L6-v2`.
|
||||
- `--llm-model` is the LLM model to use. Defaults to `gpt-4`.
|
||||
- `--tts-model` is the TTS model to use. Defaults to `en-us-kathleen-low.onnx`.
|
||||
- `--stablediffusion-model` is the Stable Diffusion model to use. Defaults to `stablediffusion`.
|
||||
- `--stablediffusion-prompt` is the Stable Diffusion prompt to use. Defaults to `DEFAULT_PROMPT`.
|
||||
- `--force-action` will force a specific action.
|
||||
- `--debug` will enable debug mode.
|
||||
|
||||
### Customize
|
||||
|
||||
To use a different model, you can see the examples in the `config` folder.
|
||||
To select a model, modify the `.env` file and change the `PRELOAD_MODELS_CONFIG` variable to use a different configuration file.
|
||||
|
||||
### Caveats
|
||||
|
||||
The "goodness" of a model has a big impact on how LocalAGI works. Currently `13b` models are powerful enough to actually able to perform multi-step tasks or do more actions. However, it is quite slow when running on CPU (no big surprise here).
|
||||
|
||||
The context size is a limitation - you can find in the `config` examples to run with superhot 8k context size, but the quality is not good enough to perform complex tasks.
|
||||
|
||||
## What is LocalAGI?
|
||||
|
||||
It is a dead simple experiment to show how to tie the various LocalAI functionalities to create a virtual assistant that can do tasks. It is simple on purpose, trying to be minimalistic and easy to understand and customize for everyone.
|
||||
|
||||
It is different from babyAGI or AutoGPT as it uses [LocalAI functions](https://localai.io/features/openai-functions/) - it is a from scratch attempt built on purpose to run locally with [LocalAI](https://localai.io) (no API keys needed!) instead of expensive, cloud services. It sets apart from other projects as it strives to be small, and easy to fork on.
|
||||
|
||||
### How it works?
|
||||
|
||||
`LocalAGI` just does the minimal around LocalAI functions to create a virtual assistant that can do generic tasks. It works by an endless loop of `intent detection`, `function invocation`, `self-evaluation` and `reply generation` (if it decides to reply! :)). The agent is capable of planning complex tasks by invoking multiple functions, and remember things from the conversation.
|
||||
|
||||
In a nutshell, it goes like this:
|
||||
|
||||
- Decide based on the conversation history if it needs to take an action by using functions. It uses the LLM to detect the intent from the conversation.
|
||||
- if it need to take an action (e.g. "remember something from the conversation" ) or generate complex tasks ( executing a chain of functions to achieve a goal ) it invokes the functions
|
||||
- it re-evaluates if it needs to do any other action
|
||||
- return the result back to the LLM to generate a reply for the user
|
||||
|
||||
Under the hood LocalAI converts functions to llama.cpp BNF grammars. While OpenAI fine-tuned a model to reply to functions, LocalAI constrains the LLM to follow grammars. This is a much more efficient way to do it, and it is also more flexible as you can define your own functions and grammars. For learning more about this, check out the [LocalAI documentation](https://localai.io/docs/llm) and my tweet that explains how it works under the hoods: https://twitter.com/mudler_it/status/1675524071457533953.
|
||||
|
||||
### Agent functions
|
||||
|
||||
The intention of this project is to keep the agent minimal, so can be built on top of it or forked. The agent is capable of doing the following functions:
|
||||
- remember something from the conversation
|
||||
- recall something from the conversation
|
||||
- search something from the internet
|
||||
- plan a complex task by invoking multiple functions
|
||||
- write files to disk
|
||||
|
||||
## Roadmap
|
||||
|
||||
- [x] 100% Local, with Local AI. NO API KEYS NEEDED!
|
||||
- [x] Create a simple virtual assistant
|
||||
- [x] Make the virtual assistant do functions like store long-term memory and autonomously search between them when needed
|
||||
- [x] Create the assistant avatar with Stable Diffusion
|
||||
- [x] Give it a voice
|
||||
- [ ] Use weaviate instead of Chroma
|
||||
- [ ] Get voice input (push to talk or wakeword)
|
||||
- [ ] Make a REST API (OpenAI compliant?) so can be plugged by e.g. a third party service
|
||||
- [x] Take a system prompt so can act with a "character" (e.g. "answer in rick and morty style")
|
||||
|
||||
## Development
|
||||
|
||||
Run docker-compose with main.py checked-out:
|
||||
|
||||
```bash
|
||||
docker-compose run -v main.py:/app/main.py -i --rm localagi
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- a 13b model is enough for doing contextualized research and search/retrieve memory
|
||||
- a 30b model is enough to generate a roadmap trip plan ( so cool! )
|
||||
- With superhot models looses its magic, but maybe suitable for search
|
||||
- Context size is your enemy. `--postprocess` some times helps, but not always
|
||||
- It can be silly!
|
||||
- It is slow on CPU, don't expect `7b` models to perform good, and `13b` models perform better but on CPU are quite slow.
|
||||
@@ -1,84 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Mattermost-OpenOps"
|
||||
weight = 2
|
||||
+++
|
||||
|
||||
OpenOps is an open source platform for applying generative AI to workflows in secure environments.
|
||||
|
||||

|
||||
|
||||
Github Link - https://github.com/mattermost/openops
|
||||
|
||||
* Enables AI exploration with full data control in a multi-user pilot.
|
||||
* Supports broad ecosystem of AI models from OpenAI and Microsoft to open source LLMs from Hugging Face.
|
||||
* Speeds development of custom security, compliance and data custody policy from early evaluation to future scale.
|
||||
|
||||
Unliked closed source, vendor-controlled environments where data controls cannot be audited, OpenOps provides a transparent, open source, customer-controlled platform for developing, securing and auditing AI-accelerated workflows.
|
||||
|
||||
### Why Open Ops?
|
||||
|
||||
Everyone is in a race to deploy generative AI solutions, but need to do so in a responsible and safe way. OpenOps lets you run powerful models in a safe sandbox to establish the right safety protocols before rolling out to users. Here's an example of an evaluation, implementation, and iterative rollout process:
|
||||
|
||||
- **Phase 1:** Set up the OpenOps collaboration sandbox, a self-hosted service providing multi-user chat and integration with GenAI. *(this repository)*
|
||||
|
||||
- **Phase 2:** Evaluate different GenAI providers, whether from public SaaS services like OpenAI or local open source models, based on your security and privacy requirements.
|
||||
|
||||
- **Phase 3:** Invite select early adopters (especially colleagues focusing on trust and safety) to explore and evaluate the GenAI based on their workflows. Observe behavior, and record user feedback, and identify issues. Iterate on workflows and usage policies together in the sandbox. Consider issues such as data leakage, legal/copyright, privacy, response correctness and appropriateness as you apply AI at scale.
|
||||
|
||||
- **Phase 4:** Set and implement policies as availability is incrementally rolled out to your wider organization.
|
||||
|
||||
### What does OpenOps include?
|
||||
|
||||
Deploying the OpenOps sandbox includes the following components:
|
||||
- 🏰 **Mattermost Server** - Open source, self-hosted alternative to Discord and Slack for strict security environments with playbooks/workflow automation, tools integration, real time 1-1 and group messaging, audio calling and screenshare.
|
||||
- 📙 **PostgreSQL** - Database for storing private data from multi-user, chat collaboration discussions and audit history.
|
||||
- 🤖 [**Mattermost AI plugin**](https://github.com/mattermost/mattermost-plugin-ai) - Extension of Mattermost platform for AI bot and generative AI integration.
|
||||
- 🦙 **Open Source, Self-Hosted LLM models** - Models for evaluation and use case development from Hugging Face and other sources, including GPT4All (runs on a laptop in 4.2 GB) and Falcon LLM (example of leading scaled self-hosted models). Uses [LocalAI](https://github.com/go-skynet/LocalAI).
|
||||
- 🔌🧠 ***(Configurable)* Closed Source, Vendor-Hosted AI models** - SaaS-based GenAI models from Azure AI, OpenAI, & Anthropic.
|
||||
- 🔌📱 ***(Configurable)* Mattermost Mobile and Desktop Apps** - End-user apps for future production deployment.
|
||||
|
||||
## Install
|
||||
|
||||
### Local
|
||||
|
||||
***Rather watch a video?** 📽️ Check out our YouTube tutorial video for getting started with OpenOps: https://www.youtube.com/watch?v=20KSKBzZmik*
|
||||
|
||||
***Rather read a blog post?** 📝 Check out our Mattermost blog post for getting started with OpenOps: https://mattermost.com/blog/open-source-ai-framework/*
|
||||
|
||||
1. Clone the repository: `git clone https://github.com/mattermost/openops && cd openops`
|
||||
2. Start docker services and configure plugin
|
||||
- **If using OpenAI:**
|
||||
- Run `env backend=openai ./init.sh`
|
||||
- Run `./configure_openai.sh sk-<your openai key>` to add your API credentials *or* use the Mattermost system console to configure the plugin
|
||||
- **If using LocalAI:**
|
||||
- Run `env backend=localai ./init.sh`
|
||||
- Run `env backend=localai ./download_model.sh` to download one *or* supply your own gguf formatted model in the `models` directory.
|
||||
3. Access Mattermost and log in with the credentials provided in the terminal.
|
||||
|
||||
When you log in, you will start out in a direct message with your AI Assistant bot. Now you can start exploring AI [usages](#usage).
|
||||
|
||||
### Gitpod
|
||||
[](https://gitpod.io/#backend=openai/https://github.com/mattermost/openops)
|
||||
|
||||
1. Click the above badge and start your Gitpod workspace
|
||||
2. You will see VSCode interface and the workspace will configure itself automatically. Wait for the services to start and for your `root` login for Mattermost to be generated in the terminal
|
||||
3. Run `./configure_openai.sh sk-<your openai key>` to add your API credentials *or* use the Mattermost system console to configure the plugin
|
||||
4. Access Mattermost and log in with the credentials supplied in the terminal.
|
||||
|
||||
When you log in, you will start out in a direct message with your AI Assistant bot. Now you can start exploring AI [usages](#usage).
|
||||
|
||||
## Usage
|
||||
|
||||
There many ways to integrate generative AI into confidential, self-hosted workplace discussions. To help you get started, here are some examples provided in OpenOps:
|
||||
|
||||
| Title | Image | Description |
|
||||
| ---------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Streaming Conversation** |  | The OpenOps platform reproduces streamed replies from popular GenAI chatbots creating a sense of responsiveness and conversational engagement, while masking actual wait times. |
|
||||
| **Thread Summarization** |  | Use the "Summarize Thread" menu option or the `/summarize` command to get a summary of the thread in a Direct Message from an AI bot. AI-generated summaries can be created from private, chat-based discussions to speed information flows and decision-making while reducing the time and cost required for organizations to stay up-to-date. |
|
||||
| **Contextual Interrogation** |  | Users can ask follow-up questions to discussion summaries generated by AI bots to learn more about the underlying information without reviewing the raw input. |
|
||||
| **Meeting Summarization** |  | Create meeting summaries! Designed to work with the [Mattermost Calls plugin](https://github.com/mattermost/mattermost-plugin-calls) recording feature. |
|
||||
| **Chat with AI Bots** |  | End users can interact with the AI bot in any discussion thread by mentioning AI bot with an `@` prefix, as they would get the attention of a human user. The bot will receive the thread information as context for replying. |
|
||||
| **Sentiment Analysis** | [](https://github.com/mattermost/mattermost-plugin-ai/assets/3191642/5282b066-86b5-478d-ae10-57c3cb3ba038) | Use the "React for me" menu option to have the AI bot analyze the sentiment of messages use its conclusion to deliver an emoji reaction on the user’s behalf. |
|
||||
| **Reinforcement Learning from Human Feedback** |  | Bot posts are distinguished from human posts by having 👍 👎 icons available for human end users to signal whether the AI response was positive or problematic. The history of responses can be used in future to fine-tune the underlying AI models, as well as to potentially evaluate the responses of new models based on their correlation to positive and negative user ratings for past model responses. |
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user