mirror of
https://github.com/bentoml/OpenLLM.git
synced 2026-05-19 14:16:22 -04:00
docs: Add Llama 3.3 to readme (#1128)
This commit is contained in:
@@ -6,7 +6,7 @@
|
||||
[](https://twitter.com/bentomlai)
|
||||
[](https://l.bentoml.com/join-slack)
|
||||
|
||||
OpenLLM allows developers to run **any open-source LLMs** (Llama 3.2, Qwen2.5, Phi3 and [more](#supported-models)) or **custom models** as **OpenAI-compatible APIs** with a single command. It features a [built-in chat UI](#chat-ui), state-of-the-art inference backends, and a simplified workflow for creating enterprise-grade cloud deployment with Docker, Kubernetes, and [BentoCloud](#deploy-to-bentocloud).
|
||||
OpenLLM allows developers to run **any open-source LLMs** (Llama 3.3, Qwen2.5, Phi3 and [more](#supported-models)) or **custom models** as **OpenAI-compatible APIs** with a single command. It features a [built-in chat UI](#chat-ui), state-of-the-art inference backends, and a simplified workflow for creating enterprise-grade cloud deployment with Docker, Kubernetes, and [BentoCloud](#deploy-to-bentocloud).
|
||||
|
||||
Understand the [design philosophy of OpenLLM](https://www.bentoml.com/blog/from-ollama-to-openllm-running-llms-in-the-cloud).
|
||||
|
||||
@@ -19,8 +19,6 @@ pip install openllm # or pip3 install openllm
|
||||
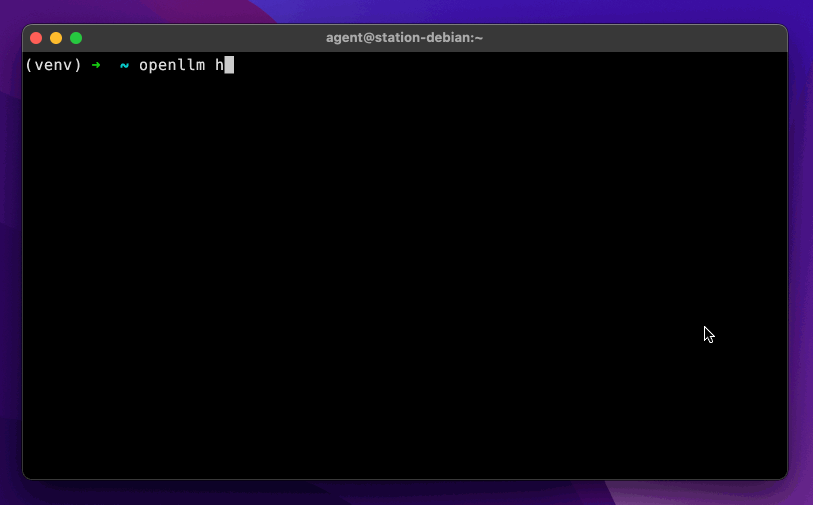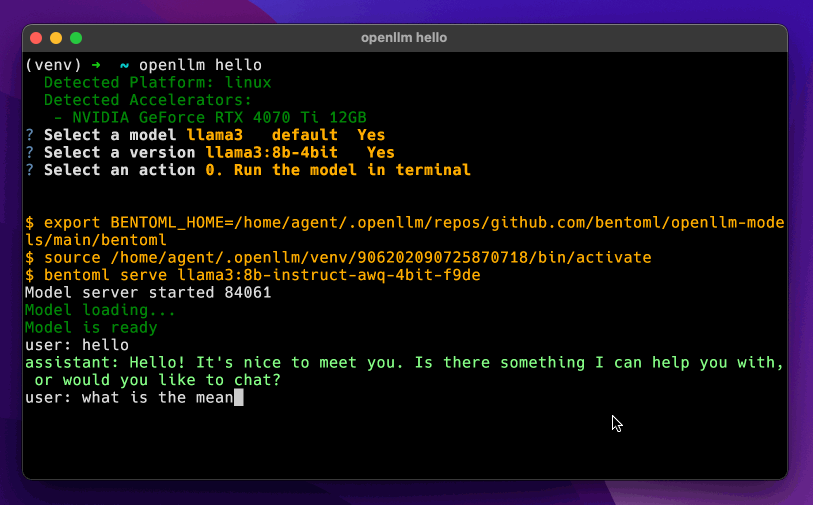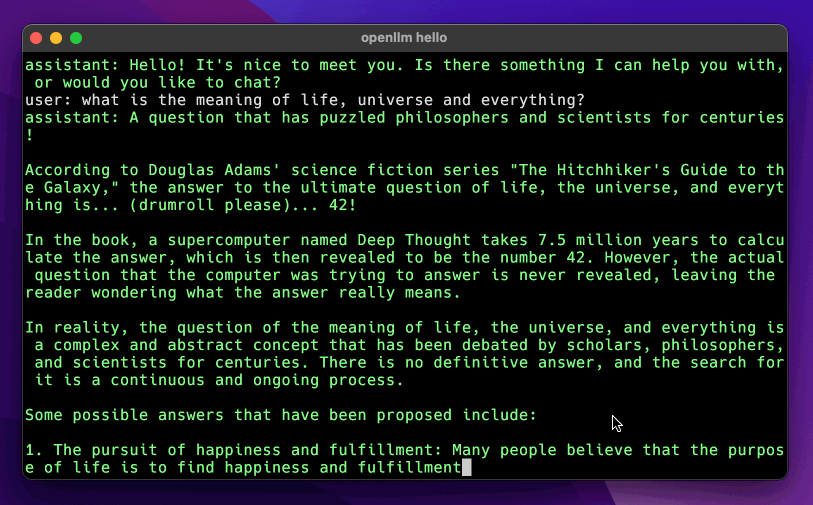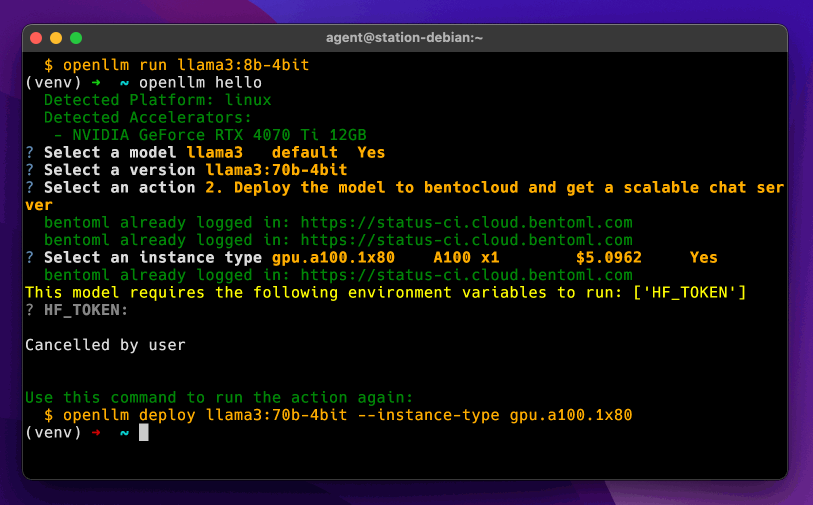
openllm hello
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Supported models
|
||||
@@ -29,11 +27,12 @@ OpenLLM supports a wide range of state-of-the-art open-source LLMs. You can also
|
||||
|
||||
| Model | Parameters | Quantization | Required GPU | Start a Server |
|
||||
| ---------------- | ---------- | ------------ | ------------- | ----------------------------------- |
|
||||
| Llama 3.2 | 1B | - | 12G | `openllm serve llama3.2:1b` |
|
||||
| Llama 3.3 | 70B | - | 80Gx2 | `openllm serve llama3.3:70b` |
|
||||
| Llama 3.2 | 3B | - | 12G | `openllm serve llama3.2:3b` |
|
||||
| Llama 3.2 Vision | 11B | - | 80G | `openllm serve llama3.2:11b-vision` |
|
||||
| Mistral | 7B | - | 24G | `openllm serve mistral:7b` |
|
||||
| Qwen 2.5 | 1.5B | - | 12G | `openllm serve qwen2.5:1.5b` |
|
||||
| Qwen 2.5 Coder | 7B | - | 24G | `openllm serve qwen2.5-coder:7b` |
|
||||
| Gemma 2 | 9B | - | 24G | `openllm serve gemma2:9b` |
|
||||
| Phi3 | 3.8B | - | 12G | `openllm serve phi3:3.8b` |
|
||||
|
||||
|
||||
Reference in New Issue
Block a user