mirror of
https://github.com/fastapi/fastapi.git
synced 2026-01-14 00:47:59 -05:00
Compare commits
21 Commits
translatio
...
fr-llm-pro
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
273d21c722 | ||
|
|
154ce03ff0 | ||
|
|
49653aa295 | ||
|
|
2c8c164956 | ||
|
|
f03a1502a0 | ||
|
|
a2912ffa26 | ||
|
|
8183e748ee | ||
|
|
cefd50702a | ||
|
|
3d1f9268fc | ||
|
|
7eac6e3169 | ||
|
|
21d2c5cea0 | ||
|
|
c75ae058e4 | ||
|
|
961b2e844a | ||
|
|
b4ba7f4652 | ||
|
|
c35e1fd4b4 | ||
|
|
d1c67c0055 | ||
|
|
18762e38a9 | ||
|
|
b1db1395b6 | ||
|
|
17ff8aa9f9 | ||
|
|
77038711cf | ||
|
|
f73d79ac9d |
2
.github/dependabot.yml
vendored
2
.github/dependabot.yml
vendored
@@ -8,7 +8,7 @@ updates:
|
||||
commit-message:
|
||||
prefix: ⬆
|
||||
# Python
|
||||
- package-ecosystem: "pip"
|
||||
- package-ecosystem: "uv"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "monthly"
|
||||
|
||||
25
.github/workflows/build-docs.yml
vendored
25
.github/workflows/build-docs.yml
vendored
@@ -8,9 +8,6 @@ on:
|
||||
- opened
|
||||
- synchronize
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
changes:
|
||||
runs-on: ubuntu-latest
|
||||
@@ -31,8 +28,8 @@ jobs:
|
||||
- README.md
|
||||
- docs/**
|
||||
- docs_src/**
|
||||
- requirements-docs.txt
|
||||
- pyproject.toml
|
||||
- uv.lock
|
||||
- mkdocs.yml
|
||||
- mkdocs.env.yml
|
||||
- .github/workflows/build-docs.yml
|
||||
@@ -49,21 +46,20 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install docs extras
|
||||
run: uv pip install -r requirements-docs.txt
|
||||
run: uv sync --locked --no-dev --group docs
|
||||
- name: Export Language Codes
|
||||
id: show-langs
|
||||
run: |
|
||||
echo "langs=$(python ./scripts/docs.py langs-json)" >> $GITHUB_OUTPUT
|
||||
echo "langs=$(uv run ./scripts/docs.py langs-json)" >> $GITHUB_OUTPUT
|
||||
|
||||
build-docs:
|
||||
needs:
|
||||
@@ -83,25 +79,24 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install docs extras
|
||||
run: uv pip install -r requirements-docs.txt
|
||||
run: uv sync --locked --no-dev --group docs
|
||||
- name: Update Languages
|
||||
run: python ./scripts/docs.py update-languages
|
||||
run: uv run ./scripts/docs.py update-languages
|
||||
- uses: actions/cache@v4
|
||||
with:
|
||||
key: mkdocs-cards-${{ matrix.lang }}-${{ github.ref }}
|
||||
path: docs/${{ matrix.lang }}/.cache
|
||||
- name: Build Docs
|
||||
run: python ./scripts/docs.py build-lang ${{ matrix.lang }}
|
||||
run: uv run ./scripts/docs.py build-lang ${{ matrix.lang }}
|
||||
- uses: actions/upload-artifact@v5
|
||||
with:
|
||||
name: docs-site-${{ matrix.lang }}
|
||||
|
||||
12
.github/workflows/contributors.yml
vendored
12
.github/workflows/contributors.yml
vendored
@@ -10,9 +10,6 @@ on:
|
||||
required: false
|
||||
default: "false"
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
job:
|
||||
if: github.repository_owner == 'fastapi'
|
||||
@@ -28,17 +25,16 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt
|
||||
run: uv sync --locked --no-dev --group github-actions
|
||||
# Allow debugging with tmate
|
||||
- name: Setup tmate session
|
||||
uses: mxschmitt/action-tmate@v3
|
||||
@@ -48,6 +44,6 @@ jobs:
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.FASTAPI_PR_TOKEN }}
|
||||
- name: FastAPI People Contributors
|
||||
run: python ./scripts/contributors.py
|
||||
run: uv run ./scripts/contributors.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.FASTAPI_PR_TOKEN }}
|
||||
|
||||
16
.github/workflows/deploy-docs.yml
vendored
16
.github/workflows/deploy-docs.yml
vendored
@@ -12,9 +12,6 @@ permissions:
|
||||
pull-requests: write
|
||||
statuses: write
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
deploy-docs:
|
||||
runs-on: ubuntu-latest
|
||||
@@ -27,19 +24,18 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install GitHub Actions dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt
|
||||
run: uv sync --locked --no-dev --group github-actions
|
||||
- name: Deploy Docs Status Pending
|
||||
run: python ./scripts/deploy_docs_status.py
|
||||
run: uv run ./scripts/deploy_docs_status.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
COMMIT_SHA: ${{ github.event.workflow_run.head_sha }}
|
||||
@@ -70,14 +66,14 @@ jobs:
|
||||
command: pages deploy ./site --project-name=${{ env.PROJECT_NAME }} --branch=${{ env.BRANCH }}
|
||||
- name: Deploy Docs Status Error
|
||||
if: failure()
|
||||
run: python ./scripts/deploy_docs_status.py
|
||||
run: uv run ./scripts/deploy_docs_status.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
COMMIT_SHA: ${{ github.event.workflow_run.head_sha }}
|
||||
RUN_ID: ${{ github.run_id }}
|
||||
STATE: "error"
|
||||
- name: Comment Deploy
|
||||
run: python ./scripts/deploy_docs_status.py
|
||||
run: uv run ./scripts/deploy_docs_status.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
DEPLOY_URL: ${{ steps.deploy.outputs.deployment-url }}
|
||||
|
||||
12
.github/workflows/label-approved.yml
vendored
12
.github/workflows/label-approved.yml
vendored
@@ -8,9 +8,6 @@ on:
|
||||
permissions:
|
||||
pull-requests: write
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
label-approved:
|
||||
if: github.repository_owner == 'fastapi'
|
||||
@@ -24,19 +21,18 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install GitHub Actions dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt
|
||||
run: uv sync --locked --no-dev --group github-actions
|
||||
- name: Label Approved
|
||||
run: python ./scripts/label_approved.py
|
||||
run: uv run ./scripts/label_approved.py
|
||||
env:
|
||||
TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
CONFIG: >
|
||||
|
||||
12
.github/workflows/notify-translations.yml
vendored
12
.github/workflows/notify-translations.yml
vendored
@@ -15,9 +15,6 @@ on:
|
||||
required: false
|
||||
default: 'false'
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
job:
|
||||
runs-on: ubuntu-latest
|
||||
@@ -32,17 +29,16 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt
|
||||
run: uv sync --locked --no-dev --group github-actions
|
||||
# Allow debugging with tmate
|
||||
- name: Setup tmate session
|
||||
uses: mxschmitt/action-tmate@v3
|
||||
@@ -52,7 +48,7 @@ jobs:
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Notify Translations
|
||||
run: python ./scripts/notify_translations.py
|
||||
run: uv run ./scripts/notify_translations.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
NUMBER: ${{ github.event.inputs.number || null }}
|
||||
|
||||
12
.github/workflows/people.yml
vendored
12
.github/workflows/people.yml
vendored
@@ -10,9 +10,6 @@ on:
|
||||
required: false
|
||||
default: "false"
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
job:
|
||||
if: github.repository_owner == 'fastapi'
|
||||
@@ -28,17 +25,16 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt
|
||||
run: uv sync --locked --no-dev --group github-actions
|
||||
# Allow debugging with tmate
|
||||
- name: Setup tmate session
|
||||
uses: mxschmitt/action-tmate@v3
|
||||
@@ -48,7 +44,7 @@ jobs:
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.FASTAPI_PEOPLE }}
|
||||
- name: FastAPI People Experts
|
||||
run: python ./scripts/people.py
|
||||
run: uv run ./scripts/people.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.FASTAPI_PEOPLE }}
|
||||
SLEEP_INTERVAL: ${{ vars.PEOPLE_SLEEP_INTERVAL }}
|
||||
|
||||
7
.github/workflows/pre-commit.yml
vendored
7
.github/workflows/pre-commit.yml
vendored
@@ -40,18 +40,15 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.14"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: |
|
||||
uv venv
|
||||
uv pip install -r requirements.txt
|
||||
run: uv sync --locked --extra all
|
||||
- name: Run prek - pre-commit
|
||||
id: precommit
|
||||
run: uvx prek run --from-ref origin/${GITHUB_BASE_REF} --to-ref HEAD --show-diff-on-failure
|
||||
|
||||
15
.github/workflows/publish.yml
vendored
15
.github/workflows/publish.yml
vendored
@@ -15,6 +15,7 @@ jobs:
|
||||
- fastapi-slim
|
||||
permissions:
|
||||
id-token: write
|
||||
contents: read
|
||||
steps:
|
||||
- name: Dump GitHub context
|
||||
env:
|
||||
@@ -24,19 +25,15 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.10"
|
||||
python-version-file: ".python-version"
|
||||
# Issue ref: https://github.com/actions/setup-python/issues/436
|
||||
# cache: "pip"
|
||||
# cache-dependency-path: pyproject.toml
|
||||
- name: Install build dependencies
|
||||
run: pip install build
|
||||
- name: Install uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
- name: Build distribution
|
||||
run: uv build
|
||||
env:
|
||||
TIANGOLO_BUILD_PACKAGE: ${{ matrix.package }}
|
||||
run: python -m build
|
||||
- name: Publish
|
||||
uses: pypa/gh-action-pypi-publish@v1.13.0
|
||||
- name: Dump GitHub context
|
||||
env:
|
||||
GITHUB_CONTEXT: ${{ toJson(github) }}
|
||||
run: echo "$GITHUB_CONTEXT"
|
||||
run: uv publish
|
||||
|
||||
11
.github/workflows/smokeshow.yml
vendored
11
.github/workflows/smokeshow.yml
vendored
@@ -8,9 +8,6 @@ on:
|
||||
permissions:
|
||||
statuses: write
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
smokeshow:
|
||||
runs-on: ubuntu-latest
|
||||
@@ -23,14 +20,14 @@ jobs:
|
||||
- uses: actions/checkout@v6
|
||||
- uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: '3.13'
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
- run: uv pip install -r requirements-github-actions.txt
|
||||
uv.lock
|
||||
- run: uv sync --locked --no-dev --group github-actions
|
||||
- uses: actions/download-artifact@v6
|
||||
with:
|
||||
name: coverage-html
|
||||
@@ -41,7 +38,7 @@ jobs:
|
||||
- name: Upload coverage to Smokeshow
|
||||
run: |
|
||||
for i in 1 2 3 4 5; do
|
||||
if smokeshow upload htmlcov; then
|
||||
if uv run smokeshow upload htmlcov; then
|
||||
echo "Smokeshow upload success!"
|
||||
break
|
||||
fi
|
||||
|
||||
12
.github/workflows/sponsors.yml
vendored
12
.github/workflows/sponsors.yml
vendored
@@ -10,9 +10,6 @@ on:
|
||||
required: false
|
||||
default: "false"
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
job:
|
||||
if: github.repository_owner == 'fastapi'
|
||||
@@ -28,17 +25,16 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt
|
||||
run: uv sync --locked --no-dev --group github-actions
|
||||
# Allow debugging with tmate
|
||||
- name: Setup tmate session
|
||||
uses: mxschmitt/action-tmate@v3
|
||||
@@ -46,7 +42,7 @@ jobs:
|
||||
with:
|
||||
limit-access-to-actor: true
|
||||
- name: FastAPI People Sponsors
|
||||
run: python ./scripts/sponsors.py
|
||||
run: uv run ./scripts/sponsors.py
|
||||
env:
|
||||
SPONSORS_TOKEN: ${{ secrets.SPONSORS_TOKEN }}
|
||||
PR_TOKEN: ${{ secrets.FASTAPI_PR_TOKEN }}
|
||||
|
||||
4
.github/workflows/test-redistribute.yml
vendored
4
.github/workflows/test-redistribute.yml
vendored
@@ -26,7 +26,7 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.10"
|
||||
python-version-file: ".python-version"
|
||||
- name: Install build dependencies
|
||||
run: pip install build
|
||||
- name: Build source distribution
|
||||
@@ -40,7 +40,7 @@ jobs:
|
||||
- name: Install test dependencies
|
||||
run: |
|
||||
cd dist/fastapi*/
|
||||
pip install -r requirements-tests.txt
|
||||
pip install --group tests --editable .[all]
|
||||
env:
|
||||
TIANGOLO_BUILD_PACKAGE: ${{ matrix.package }}
|
||||
- name: Run source distribution tests
|
||||
|
||||
26
.github/workflows/test.yml
vendored
26
.github/workflows/test.yml
vendored
@@ -13,7 +13,7 @@ on:
|
||||
- cron: "0 0 * * 1"
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
UV_NO_SYNC: true
|
||||
|
||||
jobs:
|
||||
test:
|
||||
@@ -44,6 +44,8 @@ jobs:
|
||||
coverage: coverage
|
||||
fail-fast: false
|
||||
runs-on: ${{ matrix.os }}
|
||||
env:
|
||||
UV_PYTHON: ${{ matrix.python-version }}
|
||||
steps:
|
||||
- name: Dump GitHub context
|
||||
env:
|
||||
@@ -57,17 +59,16 @@ jobs:
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-tests.txt
|
||||
run: uv sync --locked --no-dev --group tests --extra all
|
||||
- run: mkdir coverage
|
||||
- name: Test
|
||||
if: matrix.codspeed != 'codspeed'
|
||||
run: bash scripts/test.sh
|
||||
run: uv run bash scripts/test.sh
|
||||
env:
|
||||
COVERAGE_FILE: coverage/.coverage.${{ runner.os }}-py${{ matrix.python-version }}
|
||||
CONTEXT: ${{ runner.os }}-py${{ matrix.python-version }}
|
||||
@@ -79,7 +80,7 @@ jobs:
|
||||
CONTEXT: ${{ runner.os }}-py${{ matrix.python-version }}
|
||||
with:
|
||||
mode: simulation
|
||||
run: coverage run -m pytest tests/ --codspeed
|
||||
run: uv run coverage run -m pytest tests/ --codspeed
|
||||
# Do not store coverage for all possible combinations to avoid file size max errors in Smokeshow
|
||||
- name: Store coverage files
|
||||
if: matrix.coverage == 'coverage'
|
||||
@@ -100,17 +101,16 @@ jobs:
|
||||
- uses: actions/checkout@v6
|
||||
- uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: '3.11'
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-tests.txt
|
||||
run: uv sync --locked --no-dev --group tests --extra all
|
||||
- name: Get coverage files
|
||||
uses: actions/download-artifact@v6
|
||||
with:
|
||||
@@ -118,15 +118,15 @@ jobs:
|
||||
path: coverage
|
||||
merge-multiple: true
|
||||
- run: ls -la coverage
|
||||
- run: coverage combine coverage
|
||||
- run: coverage html --title "Coverage for ${{ github.sha }}"
|
||||
- run: uv run coverage combine coverage
|
||||
- run: uv run coverage html --title "Coverage for ${{ github.sha }}"
|
||||
- name: Store coverage HTML
|
||||
uses: actions/upload-artifact@v5
|
||||
with:
|
||||
name: coverage-html
|
||||
path: htmlcov
|
||||
include-hidden-files: true
|
||||
- run: coverage report --fail-under=100
|
||||
- run: uv run coverage report --fail-under=100
|
||||
|
||||
# https://github.com/marketplace/actions/alls-green#why
|
||||
check: # This job does nothing and is only used for the branch protection
|
||||
|
||||
12
.github/workflows/topic-repos.yml
vendored
12
.github/workflows/topic-repos.yml
vendored
@@ -5,9 +5,6 @@ on:
|
||||
- cron: "0 12 1 * *"
|
||||
workflow_dispatch:
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
|
||||
jobs:
|
||||
topic-repos:
|
||||
if: github.repository_owner == 'fastapi'
|
||||
@@ -23,18 +20,17 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
version: "0.4.15"
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install GitHub Actions dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt
|
||||
run: uv sync --locked --no-dev --group github-actions
|
||||
- name: Update Topic Repos
|
||||
run: python ./scripts/topic_repos.py
|
||||
run: uv run ./scripts/topic_repos.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.FASTAPI_PR_TOKEN }}
|
||||
|
||||
29
.github/workflows/translate.yml
vendored
29
.github/workflows/translate.yml
vendored
@@ -30,9 +30,11 @@ on:
|
||||
type: string
|
||||
required: false
|
||||
default: ""
|
||||
|
||||
env:
|
||||
UV_SYSTEM_PYTHON: 1
|
||||
commit_in_place:
|
||||
description: Whether to commit changes directly instead of making a PR
|
||||
type: boolean
|
||||
required: false
|
||||
default: false
|
||||
|
||||
jobs:
|
||||
langs:
|
||||
@@ -45,20 +47,20 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt -r requirements-translations.txt
|
||||
run: uv sync --locked --no-dev --group github-actions --group translations
|
||||
- name: Export Language Codes
|
||||
id: show-langs
|
||||
run: |
|
||||
echo "langs=$(python ./scripts/translate.py llm-translatable-json)" >> $GITHUB_OUTPUT
|
||||
echo "commands=$(python ./scripts/translate.py commands-json)" >> $GITHUB_OUTPUT
|
||||
echo "langs=$(uv run ./scripts/translate.py llm-translatable-json)" >> $GITHUB_OUTPUT
|
||||
echo "commands=$(uv run ./scripts/translate.py commands-json)" >> $GITHUB_OUTPUT
|
||||
env:
|
||||
LANGUAGE: ${{ github.event.inputs.language }}
|
||||
COMMAND: ${{ github.event.inputs.command }}
|
||||
@@ -84,15 +86,15 @@ jobs:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.11"
|
||||
python-version-file: ".python-version"
|
||||
- name: Setup uv
|
||||
uses: astral-sh/setup-uv@v7
|
||||
with:
|
||||
cache-dependency-glob: |
|
||||
requirements**.txt
|
||||
pyproject.toml
|
||||
uv.lock
|
||||
- name: Install Dependencies
|
||||
run: uv pip install -r requirements-github-actions.txt -r requirements-translations.txt
|
||||
run: uv sync --locked --no-dev --group github-actions --group translations
|
||||
# Allow debugging with tmate
|
||||
- name: Setup tmate session
|
||||
uses: mxschmitt/action-tmate@v3
|
||||
@@ -104,11 +106,12 @@ jobs:
|
||||
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
||||
- name: FastAPI Translate
|
||||
run: |
|
||||
python ./scripts/translate.py ${{ matrix.command }}
|
||||
python ./scripts/translate.py make-pr
|
||||
uv run ./scripts/translate.py ${{ matrix.command }}
|
||||
uv run ./scripts/translate.py make-pr
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.FASTAPI_TRANSLATIONS }}
|
||||
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
||||
LANGUAGE: ${{ matrix.lang }}
|
||||
EN_PATH: ${{ github.event.inputs.en_path }}
|
||||
COMMAND: ${{ matrix.command }}
|
||||
COMMIT_IN_PLACE: ${{ github.event.inputs.commit_in_place }}
|
||||
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -29,7 +29,4 @@ archive.zip
|
||||
# macOS
|
||||
.DS_Store
|
||||
|
||||
# Ignore while the setup still depends on requirements.txt files
|
||||
uv.lock
|
||||
|
||||
.codspeed
|
||||
|
||||
@@ -6,6 +6,7 @@ repos:
|
||||
hooks:
|
||||
- id: check-added-large-files
|
||||
args: ['--maxkb=750']
|
||||
exclude: ^uv.lock$
|
||||
- id: check-toml
|
||||
- id: check-yaml
|
||||
args:
|
||||
@@ -57,3 +58,9 @@ repos:
|
||||
entry: uv run ./scripts/docs.py ensure-non-translated
|
||||
files: ^docs/(?!en/).*|^scripts/docs\.py$
|
||||
pass_filenames: false
|
||||
|
||||
- id: fix-translations
|
||||
language: unsupported
|
||||
name: fix translations
|
||||
entry: uv run ./scripts/translation_fixer.py fix-pages
|
||||
files: ^docs/(?!en/).*/docs/.*\.md$
|
||||
|
||||
1
.python-version
Normal file
1
.python-version
Normal file
@@ -0,0 +1 @@
|
||||
3.11
|
||||
@@ -6,44 +6,20 @@ First, you might want to see the basic ways to [help FastAPI and get help](help-
|
||||
|
||||
If you already cloned the <a href="https://github.com/fastapi/fastapi" class="external-link" target="_blank">fastapi repository</a> and you want to deep dive in the code, here are some guidelines to set up your environment.
|
||||
|
||||
### Virtual environment
|
||||
|
||||
Follow the instructions to create and activate a [virtual environment](virtual-environments.md){.internal-link target=_blank} for the internal code of `fastapi`.
|
||||
|
||||
### Install requirements
|
||||
|
||||
After activating the environment, install the required packages:
|
||||
|
||||
//// tab | `pip`
|
||||
Create a virtual environment and install the required packages with <a href="https://github.com/astral-sh/uv" class="external-link" target="_blank">`uv`</a>:
|
||||
|
||||
<div class="termy">
|
||||
|
||||
```console
|
||||
$ pip install -r requirements.txt
|
||||
$ uv sync
|
||||
|
||||
---> 100%
|
||||
```
|
||||
|
||||
</div>
|
||||
|
||||
////
|
||||
|
||||
//// tab | `uv`
|
||||
|
||||
If you have <a href="https://github.com/astral-sh/uv" class="external-link" target="_blank">`uv`</a>:
|
||||
|
||||
<div class="termy">
|
||||
|
||||
```console
|
||||
$ uv pip install -r requirements.txt
|
||||
|
||||
---> 100%
|
||||
```
|
||||
|
||||
</div>
|
||||
|
||||
////
|
||||
|
||||
It will install all the dependencies and your local FastAPI in your local environment.
|
||||
|
||||
### Using your local FastAPI
|
||||
@@ -56,9 +32,9 @@ That way, you don't have to "install" your local version to be able to test ever
|
||||
|
||||
/// note | Technical Details
|
||||
|
||||
This only happens when you install using this included `requirements.txt` instead of running `pip install fastapi` directly.
|
||||
This only happens when you install using `uv sync` instead of running `pip install fastapi` directly.
|
||||
|
||||
That is because inside the `requirements.txt` file, the local version of FastAPI is marked to be installed in "editable" mode, with the `-e` option.
|
||||
That is because `uv sync` will install the local version of FastAPI in "editable" mode by default.
|
||||
|
||||
///
|
||||
|
||||
|
||||
@@ -7,14 +7,25 @@ hide:
|
||||
|
||||
## Latest Changes
|
||||
|
||||
### Docs
|
||||
|
||||
* 📝 Specify language code for code block. PR [#14656](https://github.com/fastapi/fastapi/pull/14656) by [@YuriiMotov](https://github.com/YuriiMotov).
|
||||
|
||||
### Translations
|
||||
|
||||
* 🌐 Update translations for es (update-outdated). PR [#14686](https://github.com/fastapi/fastapi/pull/14686) by [@tiangolo](https://github.com/tiangolo).
|
||||
* 🔧 Add LLM prompt file for Turkish, generated from the existing translations. PR [#14547](https://github.com/fastapi/fastapi/pull/14547) by [@tiangolo](https://github.com/tiangolo).
|
||||
* 🔧 Add LLM prompt file for Traditional Chinese, generated from the existing translations. PR [#14550](https://github.com/fastapi/fastapi/pull/14550) by [@tiangolo](https://github.com/tiangolo).
|
||||
* 🔧 Add LLM prompt file for Simplified Chinese, generated from the existing translations. PR [#14549](https://github.com/fastapi/fastapi/pull/14549) by [@tiangolo](https://github.com/tiangolo).
|
||||
|
||||
### Internal
|
||||
|
||||
* 🔨 Refactor translation script to allow committing in place. PR [#14687](https://github.com/fastapi/fastapi/pull/14687) by [@tiangolo](https://github.com/tiangolo).
|
||||
* 🐛 Fix translation script path. PR [#14685](https://github.com/fastapi/fastapi/pull/14685) by [@tiangolo](https://github.com/tiangolo).
|
||||
* ✅ Enable tests in CI for scripts. PR [#14684](https://github.com/fastapi/fastapi/pull/14684) by [@tiangolo](https://github.com/tiangolo).
|
||||
* 🔧 Add pre-commit local script to fix language translations. PR [#14683](https://github.com/fastapi/fastapi/pull/14683) by [@tiangolo](https://github.com/tiangolo).
|
||||
* ⬆️ Migrate to uv. PR [#14676](https://github.com/fastapi/fastapi/pull/14676) by [@DoctorJohn](https://github.com/DoctorJohn).
|
||||
* 🔨 Add LLM translations tool fixer. PR [#14652](https://github.com/fastapi/fastapi/pull/14652) by [@YuriiMotov](https://github.com/YuriiMotov).
|
||||
* 👥 Update FastAPI People - Sponsors. PR [#14626](https://github.com/fastapi/fastapi/pull/14626) by [@tiangolo](https://github.com/tiangolo).
|
||||
* 👥 Update FastAPI GitHub topic repositories. PR [#14630](https://github.com/fastapi/fastapi/pull/14630) by [@tiangolo](https://github.com/tiangolo).
|
||||
* 👥 Update FastAPI People - Contributors and Translators. PR [#14625](https://github.com/fastapi/fastapi/pull/14625) by [@tiangolo](https://github.com/tiangolo).
|
||||
|
||||
@@ -56,7 +56,7 @@ from app.routers import items
|
||||
|
||||
The same file structure with comments:
|
||||
|
||||
```
|
||||
```bash
|
||||
.
|
||||
├── app # "app" is a Python package
|
||||
│ ├── __init__.py # this file makes "app" a "Python package"
|
||||
|
||||
@@ -1,17 +1,17 @@
|
||||
# Archivo de prueba de LLM { #llm-test-file }
|
||||
|
||||
Este documento prueba si el <abbr title="Large Language Model – Modelo de lenguaje grande">LLM</abbr>, que traduce la documentación, entiende el `general_prompt` en `scripts/translate.py` y el prompt específico del idioma en `docs/{language code}/llm-prompt.md`. El prompt específico del idioma se agrega al final de `general_prompt`.
|
||||
Este documento prueba si el <abbr title="Large Language Model - Modelo de lenguaje grande">LLM</abbr>, que traduce la documentación, entiende el `general_prompt` en `scripts/translate.py` y el prompt específico del idioma en `docs/{language code}/llm-prompt.md`. El prompt específico del idioma se agrega al final de `general_prompt`.
|
||||
|
||||
Las pruebas añadidas aquí serán vistas por todas las personas que diseñan prompts específicos del idioma.
|
||||
|
||||
Úsalo de la siguiente manera:
|
||||
|
||||
* Ten un prompt específico del idioma – `docs/{language code}/llm-prompt.md`.
|
||||
* Ten un prompt específico del idioma - `docs/{language code}/llm-prompt.md`.
|
||||
* Haz una traducción fresca de este documento a tu idioma destino (mira, por ejemplo, el comando `translate-page` de `translate.py`). Esto creará la traducción en `docs/{language code}/docs/_llm-test.md`.
|
||||
* Comprueba si todo está bien en la traducción.
|
||||
* Revisa si las cosas están bien en la traducción.
|
||||
* Si es necesario, mejora tu prompt específico del idioma, el prompt general, o el documento en inglés.
|
||||
* Luego corrige manualmente los problemas restantes en la traducción para que sea una buena traducción.
|
||||
* Vuelve a traducir, teniendo la buena traducción en su lugar. El resultado ideal sería que el LLM ya no hiciera cambios a la traducción. Eso significa que el prompt general y tu prompt específico del idioma están tan bien como pueden estar (a veces hará algunos cambios aparentemente aleatorios; la razón es que <a href="https://doublespeak.chat/#/handbook#deterministic-output" class="external-link" target="_blank">los LLMs no son algoritmos deterministas</a>).
|
||||
* Vuelve a traducir, teniendo la buena traducción en su lugar. El resultado ideal sería que el LLM ya no hiciera cambios a la traducción. Eso significa que el prompt general y tu prompt específico del idioma están tan bien como pueden estar (A veces hará algunos cambios aparentemente aleatorios; la razón es que <a href="https://doublespeak.chat/#/handbook#deterministic-output" class="external-link" target="_blank">los LLMs no son algoritmos deterministas</a>).
|
||||
|
||||
Las pruebas:
|
||||
|
||||
@@ -23,7 +23,7 @@ Este es un fragmento de código: `foo`. Y este es otro fragmento de código: `ba
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
El contenido de los fragmentos de código debe dejarse tal cual.
|
||||
|
||||
@@ -45,7 +45,7 @@ El LLM probablemente traducirá esto mal. Lo interesante es si mantiene la tradu
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
La persona que diseña el prompt puede elegir si quiere convertir comillas neutras a comillas tipográficas. También está bien dejarlas como están.
|
||||
|
||||
@@ -67,7 +67,7 @@ Hardcore: `Yesterday, my friend wrote: "If you spell incorrectly correctly, you
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
... Sin embargo, las comillas dentro de fragmentos de código deben quedarse tal cual.
|
||||
|
||||
@@ -112,7 +112,7 @@ works(foo="bar") # Esto funciona 🎉
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
El código en bloques de código no debe modificarse, con la excepción de los comentarios.
|
||||
|
||||
@@ -154,7 +154,7 @@ Algo de texto
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
Las pestañas y los bloques `Info`/`Note`/`Warning`/etc. deben tener la traducción de su título añadida después de una barra vertical (`|`).
|
||||
|
||||
@@ -181,7 +181,7 @@ El texto del enlace debe traducirse, la dirección del enlace debe apuntar a la
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
Los enlaces deben traducirse, pero su dirección debe permanecer sin cambios. Una excepción son los enlaces absolutos a páginas de la documentación de FastAPI. En ese caso deben enlazar a la traducción.
|
||||
|
||||
@@ -197,10 +197,10 @@ Aquí algunas cosas envueltas en elementos HTML "abbr" (algunas son inventadas):
|
||||
|
||||
### El abbr da una frase completa { #the-abbr-gives-a-full-phrase }
|
||||
|
||||
* <abbr title="Getting Things Done – Hacer las cosas">GTD</abbr>
|
||||
* <abbr title="less than – menor que"><code>lt</code></abbr>
|
||||
* <abbr title="XML Web Token – Token web XML">XWT</abbr>
|
||||
* <abbr title="Parallel Server Gateway Interface – Interfaz de pasarela de servidor paralela">PSGI</abbr>
|
||||
* <abbr title="Getting Things Done - Hacer las cosas">GTD</abbr>
|
||||
* <abbr title="less than - menor que"><code>lt</code></abbr>
|
||||
* <abbr title="XML Web Token - Token web XML">XWT</abbr>
|
||||
* <abbr title="Parallel Server Gateway Interface - Interfaz de pasarela de servidor paralela">PSGI</abbr>
|
||||
|
||||
### El abbr da una explicación { #the-abbr-gives-an-explanation }
|
||||
|
||||
@@ -209,12 +209,12 @@ Aquí algunas cosas envueltas en elementos HTML "abbr" (algunas son inventadas):
|
||||
|
||||
### El abbr da una frase completa y una explicación { #the-abbr-gives-a-full-phrase-and-an-explanation }
|
||||
|
||||
* <abbr title="Mozilla Developer Network – Red de Desarrolladores de Mozilla: documentación para desarrolladores, escrita por la gente de Firefox">MDN</abbr>
|
||||
* <abbr title="Input/Output – Entrada/Salida: lectura o escritura de disco, comunicaciones de red.">I/O</abbr>.
|
||||
* <abbr title="Mozilla Developer Network - Red de Desarrolladores de Mozilla: documentación para desarrolladores, escrita por la gente de Firefox">MDN</abbr>
|
||||
* <abbr title="Input/Output: lectura o escritura de disco, comunicaciones de red.">I/O</abbr>.
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
Los atributos "title" de los elementos "abbr" se traducen siguiendo instrucciones específicas.
|
||||
|
||||
@@ -242,7 +242,7 @@ Hola de nuevo.
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
La única regla estricta para los encabezados es que el LLM deje la parte del hash dentro de llaves sin cambios, lo que asegura que los enlaces no se rompan.
|
||||
|
||||
@@ -355,7 +355,7 @@ Para instrucciones específicas del idioma, mira p. ej. la sección `### Heading
|
||||
* los headers
|
||||
* el header de autorización
|
||||
* el header `Authorization`
|
||||
* el header Forwarded
|
||||
* el header forwarded
|
||||
|
||||
* el sistema de inyección de dependencias
|
||||
* la dependencia
|
||||
@@ -368,7 +368,7 @@ Para instrucciones específicas del idioma, mira p. ej. la sección `### Heading
|
||||
* paralelismo
|
||||
* multiprocesamiento
|
||||
|
||||
* la variable de entorno
|
||||
* la env var
|
||||
* la variable de entorno
|
||||
* el `PATH`
|
||||
* la variable `PATH`
|
||||
@@ -433,7 +433,7 @@ Para instrucciones específicas del idioma, mira p. ej. la sección `### Heading
|
||||
* el motor de plantillas
|
||||
|
||||
* la anotación de tipos
|
||||
* la anotación de tipos
|
||||
* las anotaciones de tipos
|
||||
|
||||
* el worker del servidor
|
||||
* el worker de Uvicorn
|
||||
@@ -468,7 +468,7 @@ Para instrucciones específicas del idioma, mira p. ej. la sección `### Heading
|
||||
* el ítem
|
||||
* el paquete
|
||||
* el lifespan
|
||||
* el bloqueo
|
||||
* el lock
|
||||
* el middleware
|
||||
* la aplicación móvil
|
||||
* el módulo
|
||||
@@ -494,7 +494,7 @@ Para instrucciones específicas del idioma, mira p. ej. la sección `### Heading
|
||||
|
||||
////
|
||||
|
||||
//// tab | Información
|
||||
//// tab | Info
|
||||
|
||||
Esta es una lista no completa y no normativa de términos (mayormente) técnicos vistos en la documentación. Puede ayudar a la persona que diseña el prompt a identificar para qué términos el LLM necesita una mano. Por ejemplo cuando sigue revirtiendo una buena traducción a una traducción subóptima. O cuando tiene problemas conjugando/declinando un término en tu idioma.
|
||||
|
||||
|
||||
@@ -10,7 +10,7 @@ Si no eres un "experto" en OpenAPI, probablemente no necesites esto.
|
||||
|
||||
Puedes establecer el `operationId` de OpenAPI para ser usado en tu *path operation* con el parámetro `operation_id`.
|
||||
|
||||
Tienes que asegurarte de que sea único para cada operación.
|
||||
Tendrías que asegurarte de que sea único para cada operación.
|
||||
|
||||
{* ../../docs_src/path_operation_advanced_configuration/tutorial001_py39.py hl[6] *}
|
||||
|
||||
@@ -46,7 +46,7 @@ Para excluir una *path operation* del esquema OpenAPI generado (y por lo tanto,
|
||||
|
||||
Puedes limitar las líneas usadas del docstring de una *path operation function* para OpenAPI.
|
||||
|
||||
Añadir un `\f` (un carácter de separación de página escapado) hace que **FastAPI** trunque la salida usada para OpenAPI en este punto.
|
||||
Añadir un `\f` (un carácter "form feed" escapado) hace que **FastAPI** trunque la salida usada para OpenAPI en este punto.
|
||||
|
||||
No aparecerá en la documentación, pero otras herramientas (como Sphinx) podrán usar el resto.
|
||||
|
||||
@@ -141,9 +141,9 @@ Podrías hacer eso con `openapi_extra`:
|
||||
|
||||
{* ../../docs_src/path_operation_advanced_configuration/tutorial006_py39.py hl[19:36, 39:40] *}
|
||||
|
||||
En este ejemplo, no declaramos ningún modelo Pydantic. De hecho, el cuerpo del request ni siquiera se <abbr title="convertido de algún formato plano, como bytes, a objetos de Python">parse</abbr> como JSON, se lee directamente como `bytes`, y la función `magic_data_reader()` sería la encargada de parsearlo de alguna manera.
|
||||
En este ejemplo, no declaramos ningún modelo Pydantic. De hecho, el request body ni siquiera se <abbr title="converted from some plain format, like bytes, into Python objects - convertido de algún formato plano, como bytes, a objetos de Python">parse</abbr> como JSON, se lee directamente como `bytes`, y la función `magic_data_reader()` sería la encargada de parsearlo de alguna manera.
|
||||
|
||||
Sin embargo, podemos declarar el esquema esperado para el cuerpo del request.
|
||||
Sin embargo, podemos declarar el esquema esperado para el request body.
|
||||
|
||||
### Tipo de contenido personalizado de OpenAPI { #custom-openapi-content-type }
|
||||
|
||||
@@ -153,48 +153,16 @@ Y podrías hacer esto incluso si el tipo de datos en el request no es JSON.
|
||||
|
||||
Por ejemplo, en esta aplicación no usamos la funcionalidad integrada de FastAPI para extraer el JSON Schema de los modelos Pydantic ni la validación automática para JSON. De hecho, estamos declarando el tipo de contenido del request como YAML, no JSON:
|
||||
|
||||
//// tab | Pydantic v2
|
||||
|
||||
{* ../../docs_src/path_operation_advanced_configuration/tutorial007_py39.py hl[15:20, 22] *}
|
||||
|
||||
////
|
||||
|
||||
//// tab | Pydantic v1
|
||||
|
||||
{* ../../docs_src/path_operation_advanced_configuration/tutorial007_pv1_py39.py hl[15:20, 22] *}
|
||||
|
||||
////
|
||||
|
||||
/// info | Información
|
||||
|
||||
En la versión 1 de Pydantic el método para obtener el JSON Schema para un modelo se llamaba `Item.schema()`, en la versión 2 de Pydantic, el método se llama `Item.model_json_schema()`.
|
||||
|
||||
///
|
||||
|
||||
Sin embargo, aunque no estamos usando la funcionalidad integrada por defecto, aún estamos usando un modelo Pydantic para generar manualmente el JSON Schema para los datos que queremos recibir en YAML.
|
||||
|
||||
Luego usamos el request directamente, y extraemos el cuerpo como `bytes`. Esto significa que FastAPI ni siquiera intentará parsear la carga útil del request como JSON.
|
||||
|
||||
Y luego en nuestro código, parseamos ese contenido YAML directamente, y nuevamente estamos usando el mismo modelo Pydantic para validar el contenido YAML:
|
||||
|
||||
//// tab | Pydantic v2
|
||||
|
||||
{* ../../docs_src/path_operation_advanced_configuration/tutorial007_py39.py hl[24:31] *}
|
||||
|
||||
////
|
||||
|
||||
//// tab | Pydantic v1
|
||||
|
||||
{* ../../docs_src/path_operation_advanced_configuration/tutorial007_pv1_py39.py hl[24:31] *}
|
||||
|
||||
////
|
||||
|
||||
/// info | Información
|
||||
|
||||
En la versión 1 de Pydantic el método para parsear y validar un objeto era `Item.parse_obj()`, en la versión 2 de Pydantic, el método se llama `Item.model_validate()`.
|
||||
|
||||
///
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
Aquí reutilizamos el mismo modelo Pydantic.
|
||||
|
||||
@@ -46,12 +46,6 @@ $ pip install "fastapi[all]"
|
||||
|
||||
</div>
|
||||
|
||||
/// info | Información
|
||||
|
||||
En Pydantic v1 venía incluido con el paquete principal. Ahora se distribuye como este paquete independiente para que puedas elegir si instalarlo o no si no necesitas esa funcionalidad.
|
||||
|
||||
///
|
||||
|
||||
### Crear el objeto `Settings` { #create-the-settings-object }
|
||||
|
||||
Importa `BaseSettings` de Pydantic y crea una sub-clase, muy similar a un modelo de Pydantic.
|
||||
@@ -60,31 +54,15 @@ De la misma forma que con los modelos de Pydantic, declaras atributos de clase c
|
||||
|
||||
Puedes usar todas las mismas funcionalidades de validación y herramientas que usas para los modelos de Pydantic, como diferentes tipos de datos y validaciones adicionales con `Field()`.
|
||||
|
||||
//// tab | Pydantic v2
|
||||
|
||||
{* ../../docs_src/settings/tutorial001_py39.py hl[2,5:8,11] *}
|
||||
|
||||
////
|
||||
|
||||
//// tab | Pydantic v1
|
||||
|
||||
/// info | Información
|
||||
|
||||
En Pydantic v1 importarías `BaseSettings` directamente desde `pydantic` en lugar de desde `pydantic_settings`.
|
||||
|
||||
///
|
||||
|
||||
{* ../../docs_src/settings/tutorial001_pv1_py39.py hl[2,5:8,11] *}
|
||||
|
||||
////
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
Si quieres algo rápido para copiar y pegar, no uses este ejemplo, usa el último más abajo.
|
||||
|
||||
///
|
||||
|
||||
Luego, cuando creas una instance de esa clase `Settings` (en este caso, en el objeto `settings`), Pydantic leerá las variables de entorno de una manera indiferente a mayúsculas y minúsculas, por lo que una variable en mayúsculas `APP_NAME` aún será leída para el atributo `app_name`.
|
||||
Luego, cuando creas un instance de esa clase `Settings` (en este caso, en el objeto `settings`), Pydantic leerá las variables de entorno de una manera indiferente a mayúsculas y minúsculas, por lo que una variable en mayúsculas `APP_NAME` aún será leída para el atributo `app_name`.
|
||||
|
||||
Luego convertirá y validará los datos. Así que, cuando uses ese objeto `settings`, tendrás datos de los tipos que declaraste (por ejemplo, `items_per_user` será un `int`).
|
||||
|
||||
@@ -110,7 +88,7 @@ $ ADMIN_EMAIL="deadpool@example.com" APP_NAME="ChimichangApp" fastapi run main.p
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
Para establecer múltiples variables de entorno para un solo comando, simplemente sepáralas con un espacio y ponlas todas antes del comando.
|
||||
Para establecer múltiples env vars para un solo comando, simplemente sepáralas con un espacio y ponlas todas antes del comando.
|
||||
|
||||
///
|
||||
|
||||
@@ -150,7 +128,7 @@ Proveniente del ejemplo anterior, tu archivo `config.py` podría verse como:
|
||||
|
||||
{* ../../docs_src/settings/app02_an_py39/config.py hl[10] *}
|
||||
|
||||
Nota que ahora no creamos una instance por defecto `settings = Settings()`.
|
||||
Nota que ahora no creamos un instance por defecto `settings = Settings()`.
|
||||
|
||||
### El archivo principal de la app { #the-main-app-file }
|
||||
|
||||
@@ -172,11 +150,11 @@ Y luego podemos requerirlo desde la *path operation function* como una dependenc
|
||||
|
||||
### Configuraciones y pruebas { #settings-and-testing }
|
||||
|
||||
Luego sería muy fácil proporcionar un objeto de configuraciones diferente durante las pruebas al sobrescribir una dependencia para `get_settings`:
|
||||
Luego sería muy fácil proporcionar un objeto de configuraciones diferente durante las pruebas al crear una sobrescritura de dependencia para `get_settings`:
|
||||
|
||||
{* ../../docs_src/settings/app02_an_py39/test_main.py hl[9:10,13,21] *}
|
||||
|
||||
En la dependencia sobreescrita establecemos un nuevo valor para el `admin_email` al crear el nuevo objeto `Settings`, y luego devolvemos ese nuevo objeto.
|
||||
En la sobrescritura de dependencia establecemos un nuevo valor para el `admin_email` al crear el nuevo objeto `Settings`, y luego devolvemos ese nuevo objeto.
|
||||
|
||||
Luego podemos probar que se está usando.
|
||||
|
||||
@@ -215,8 +193,6 @@ APP_NAME="ChimichangApp"
|
||||
|
||||
Y luego actualizar tu `config.py` con:
|
||||
|
||||
//// tab | Pydantic v2
|
||||
|
||||
{* ../../docs_src/settings/app03_an_py39/config.py hl[9] *}
|
||||
|
||||
/// tip | Consejo
|
||||
@@ -225,26 +201,6 @@ El atributo `model_config` se usa solo para configuración de Pydantic. Puedes l
|
||||
|
||||
///
|
||||
|
||||
////
|
||||
|
||||
//// tab | Pydantic v1
|
||||
|
||||
{* ../../docs_src/settings/app03_an_py39/config_pv1.py hl[9:10] *}
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
La clase `Config` se usa solo para configuración de Pydantic. Puedes leer más en <a href="https://docs.pydantic.dev/1.10/usage/model_config/" class="external-link" target="_blank">Pydantic Model Config</a>.
|
||||
|
||||
///
|
||||
|
||||
////
|
||||
|
||||
/// info | Información
|
||||
|
||||
En la versión 1 de Pydantic la configuración se hacía en una clase interna `Config`, en la versión 2 de Pydantic se hace en un atributo `model_config`. Este atributo toma un `dict`, y para obtener autocompletado y errores en línea, puedes importar y usar `SettingsConfigDict` para definir ese `dict`.
|
||||
|
||||
///
|
||||
|
||||
Aquí definimos la configuración `env_file` dentro de tu clase Pydantic `Settings`, y establecemos el valor en el nombre del archivo con el archivo dotenv que queremos usar.
|
||||
|
||||
### Creando el `Settings` solo una vez con `lru_cache` { #creating-the-settings-only-once-with-lru-cache }
|
||||
@@ -331,7 +287,7 @@ participant execute as Ejecutar función
|
||||
end
|
||||
```
|
||||
|
||||
En el caso de nuestra dependencia `get_settings()`, la función ni siquiera toma argumentos, por lo que siempre devolverá el mismo valor.
|
||||
En el caso de nuestra dependencia `get_settings()`, la función ni siquiera toma argumentos, por lo que siempre devuelve el mismo valor.
|
||||
|
||||
De esa manera, se comporta casi como si fuera solo una variable global. Pero como usa una función de dependencia, entonces podemos sobrescribirla fácilmente para las pruebas.
|
||||
|
||||
|
||||
@@ -2,21 +2,23 @@
|
||||
|
||||
Si tienes una app de FastAPI antigua, podrías estar usando Pydantic versión 1.
|
||||
|
||||
FastAPI ha tenido compatibilidad con Pydantic v1 o v2 desde la versión 0.100.0.
|
||||
FastAPI versión 0.100.0 tenía compatibilidad con Pydantic v1 o v2. Usaba la que tuvieras instalada.
|
||||
|
||||
Si tenías instalado Pydantic v2, lo usaba. Si en cambio tenías Pydantic v1, usaba ese.
|
||||
FastAPI versión 0.119.0 introdujo compatibilidad parcial con Pydantic v1 desde dentro de Pydantic v2 (como `pydantic.v1`), para facilitar la migración a v2.
|
||||
|
||||
Pydantic v1 está deprecado y su soporte se eliminará en las próximas versiones de FastAPI, deberías migrar a Pydantic v2. Así obtendrás las funcionalidades, mejoras y correcciones más recientes.
|
||||
FastAPI 0.126.0 eliminó la compatibilidad con Pydantic v1, aunque siguió soportando `pydantic.v1` por un poquito más de tiempo.
|
||||
|
||||
/// warning | Advertencia
|
||||
|
||||
Además, el equipo de Pydantic dejó de dar soporte a Pydantic v1 para las versiones más recientes de Python, comenzando con Python 3.14.
|
||||
El equipo de Pydantic dejó de dar soporte a Pydantic v1 para las versiones más recientes de Python, comenzando con **Python 3.14**.
|
||||
|
||||
Esto incluye `pydantic.v1`, que ya no está soportado en Python 3.14 y superiores.
|
||||
|
||||
Si quieres usar las funcionalidades más recientes de Python, tendrás que asegurarte de usar Pydantic v2.
|
||||
|
||||
///
|
||||
|
||||
Si tienes una app de FastAPI antigua con Pydantic v1, aquí te muestro cómo migrarla a Pydantic v2 y las nuevas funcionalidades en FastAPI 0.119.0 para ayudarte con una migración gradual.
|
||||
Si tienes una app de FastAPI antigua con Pydantic v1, aquí te muestro cómo migrarla a Pydantic v2, y las **funcionalidades en FastAPI 0.119.0** para ayudarte con una migración gradual.
|
||||
|
||||
## Guía oficial { #official-guide }
|
||||
|
||||
@@ -44,9 +46,9 @@ Después de esto, puedes ejecutar los tests y revisa si todo funciona. Si es as
|
||||
|
||||
## Pydantic v1 en v2 { #pydantic-v1-in-v2 }
|
||||
|
||||
Pydantic v2 incluye todo lo de Pydantic v1 como un submódulo `pydantic.v1`.
|
||||
Pydantic v2 incluye todo lo de Pydantic v1 como un submódulo `pydantic.v1`. Pero esto ya no está soportado en versiones por encima de Python 3.13.
|
||||
|
||||
Esto significa que puedes instalar la versión más reciente de Pydantic v2 e importar y usar los componentes viejos de Pydantic v1 desde ese submódulo, como si tuvieras instalado el Pydantic v1 antiguo.
|
||||
Esto significa que puedes instalar la versión más reciente de Pydantic v2 e importar y usar los componentes viejos de Pydantic v1 desde este submódulo, como si tuvieras instalado el Pydantic v1 antiguo.
|
||||
|
||||
{* ../../docs_src/pydantic_v1_in_v2/tutorial001_an_py310.py hl[1,4] *}
|
||||
|
||||
@@ -66,7 +68,7 @@ Ten en cuenta que, como el equipo de Pydantic ya no da soporte a Pydantic v1 en
|
||||
|
||||
### Pydantic v1 y v2 en la misma app { #pydantic-v1-and-v2-on-the-same-app }
|
||||
|
||||
No está soportado por Pydantic tener un modelo de Pydantic v2 con sus propios campos definidos como modelos de Pydantic v1 o viceversa.
|
||||
**No está soportado** por Pydantic tener un modelo de Pydantic v2 con sus propios campos definidos como modelos de Pydantic v1 o viceversa.
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
@@ -106,7 +108,7 @@ graph TB
|
||||
style V2Field fill:#f9fff3
|
||||
```
|
||||
|
||||
En algunos casos, incluso es posible tener modelos de Pydantic v1 y v2 en la misma path operation de tu app de FastAPI:
|
||||
En algunos casos, incluso es posible tener modelos de Pydantic v1 y v2 en la misma **path operation** de tu app de FastAPI:
|
||||
|
||||
{* ../../docs_src/pydantic_v1_in_v2/tutorial003_an_py310.py hl[2:3,6,12,21:22] *}
|
||||
|
||||
@@ -122,12 +124,12 @@ Si necesitas usar algunas de las herramientas específicas de FastAPI para pará
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
Primero prueba con `bump-pydantic`; si tus tests pasan y eso funciona, entonces terminaste con un solo comando. ✨
|
||||
Primero prueba con `bump-pydantic`, si tus tests pasan y eso funciona, entonces terminaste con un solo comando. ✨
|
||||
|
||||
///
|
||||
|
||||
Si `bump-pydantic` no funciona para tu caso, puedes usar la compatibilidad de modelos Pydantic v1 y v2 en la misma app para hacer la migración a Pydantic v2 de forma gradual.
|
||||
Si `bump-pydantic` no funciona para tu caso de uso, puedes usar la compatibilidad de modelos Pydantic v1 y v2 en la misma app para hacer la migración a Pydantic v2 de forma gradual.
|
||||
|
||||
Podrías primero actualizar Pydantic para usar la última versión 2 y cambiar los imports para usar `pydantic.v1` para todos tus modelos.
|
||||
Podrías primero actualizar Pydantic para usar la última versión 2, y cambiar los imports para usar `pydantic.v1` para todos tus modelos.
|
||||
|
||||
Luego puedes empezar a migrar tus modelos de Pydantic v1 a v2 por grupos, en pasos graduales. 🚶
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Separación de Esquemas OpenAPI para Entrada y Salida o No { #separate-openapi-schemas-for-input-and-output-or-not }
|
||||
|
||||
Al usar **Pydantic v2**, el OpenAPI generado es un poco más exacto y **correcto** que antes. 😎
|
||||
Desde que se lanzó **Pydantic v2**, el OpenAPI generado es un poco más exacto y **correcto** que antes. 😎
|
||||
|
||||
De hecho, en algunos casos, incluso tendrá **dos JSON Schemas** en OpenAPI para el mismo modelo Pydantic, para entrada y salida, dependiendo de si tienen **valores por defecto**.
|
||||
|
||||
@@ -85,7 +85,7 @@ Probablemente el caso principal para esto es si ya tienes algún código cliente
|
||||
|
||||
En ese caso, puedes desactivar esta funcionalidad en **FastAPI**, con el parámetro `separate_input_output_schemas=False`.
|
||||
|
||||
/// info | Información
|
||||
/// info
|
||||
|
||||
El soporte para `separate_input_output_schemas` fue agregado en FastAPI `0.102.0`. 🤓
|
||||
|
||||
@@ -100,5 +100,3 @@ Y ahora habrá un único esquema para entrada y salida para el modelo, solo `Ite
|
||||
<div class="screenshot">
|
||||
<img src="/img/tutorial/separate-openapi-schemas/image05.png">
|
||||
</div>
|
||||
|
||||
Este es el mismo comportamiento que en Pydantic v1. 🤓
|
||||
|
||||
@@ -93,13 +93,13 @@ Las funcionalidades clave son:
|
||||
|
||||
"_Estoy súper emocionado con **FastAPI**. ¡Es tan divertido!_"
|
||||
|
||||
<div style="text-align: right; margin-right: 10%;">Brian Okken - <strong><a href="https://pythonbytes.fm/episodes/show/123/time-to-right-the-py-wrongs?time_in_sec=855" target="_blank">host del podcast Python Bytes</a></strong> <a href="https://x.com/brianokken/status/1112220079972728832" target="_blank"><small>(ref)</small></a></div>
|
||||
<div style="text-align: right; margin-right: 10%;">Brian Okken - <strong><a href="https://pythonbytes.fm/episodes/show/123/time-to-right-the-py-wrongs?time_in_sec=855" target="_blank">Python Bytes</a> host del podcast</strong> <a href="https://x.com/brianokken/status/1112220079972728832" target="_blank"><small>(ref)</small></a></div>
|
||||
|
||||
---
|
||||
|
||||
"_Honestamente, lo que has construido parece súper sólido y pulido. En muchos aspectos, es lo que quería que **Hug** fuera; es realmente inspirador ver a alguien construir eso._"
|
||||
|
||||
<div style="text-align: right; margin-right: 10%;">Timothy Crosley - <strong><a href="https://github.com/hugapi/hug" target="_blank">creador de Hug</a></strong> <a href="https://news.ycombinator.com/item?id=19455465" target="_blank"><small>(ref)</small></a></div>
|
||||
<div style="text-align: right; margin-right: 10%;">Timothy Crosley - <strong><a href="https://github.com/hugapi/hug" target="_blank">Hug</a> creador</strong> <a href="https://news.ycombinator.com/item?id=19455465" target="_blank"><small>(ref)</small></a></div>
|
||||
|
||||
---
|
||||
|
||||
@@ -117,6 +117,12 @@ Las funcionalidades clave son:
|
||||
|
||||
---
|
||||
|
||||
## Mini documental de FastAPI { #fastapi-mini-documentary }
|
||||
|
||||
Hay un <a href="https://www.youtube.com/watch?v=mpR8ngthqiE" class="external-link" target="_blank">mini documental de FastAPI</a> lanzado a finales de 2025, puedes verlo online:
|
||||
|
||||
<a href="https://www.youtube.com/watch?v=mpR8ngthqiE" target="_blank"><img src="https://fastapi.tiangolo.com/img/fastapi-documentary.jpg" alt="FastAPI Mini Documentary"></a>
|
||||
|
||||
## **Typer**, el FastAPI de las CLIs { #typer-the-fastapi-of-clis }
|
||||
|
||||
<a href="https://typer.tiangolo.com" target="_blank"><img src="https://typer.tiangolo.com/img/logo-margin/logo-margin-vector.svg" style="width: 20%;"></a>
|
||||
@@ -268,7 +274,7 @@ Verás la documentación interactiva automática de la API (proporcionada por <a
|
||||
|
||||
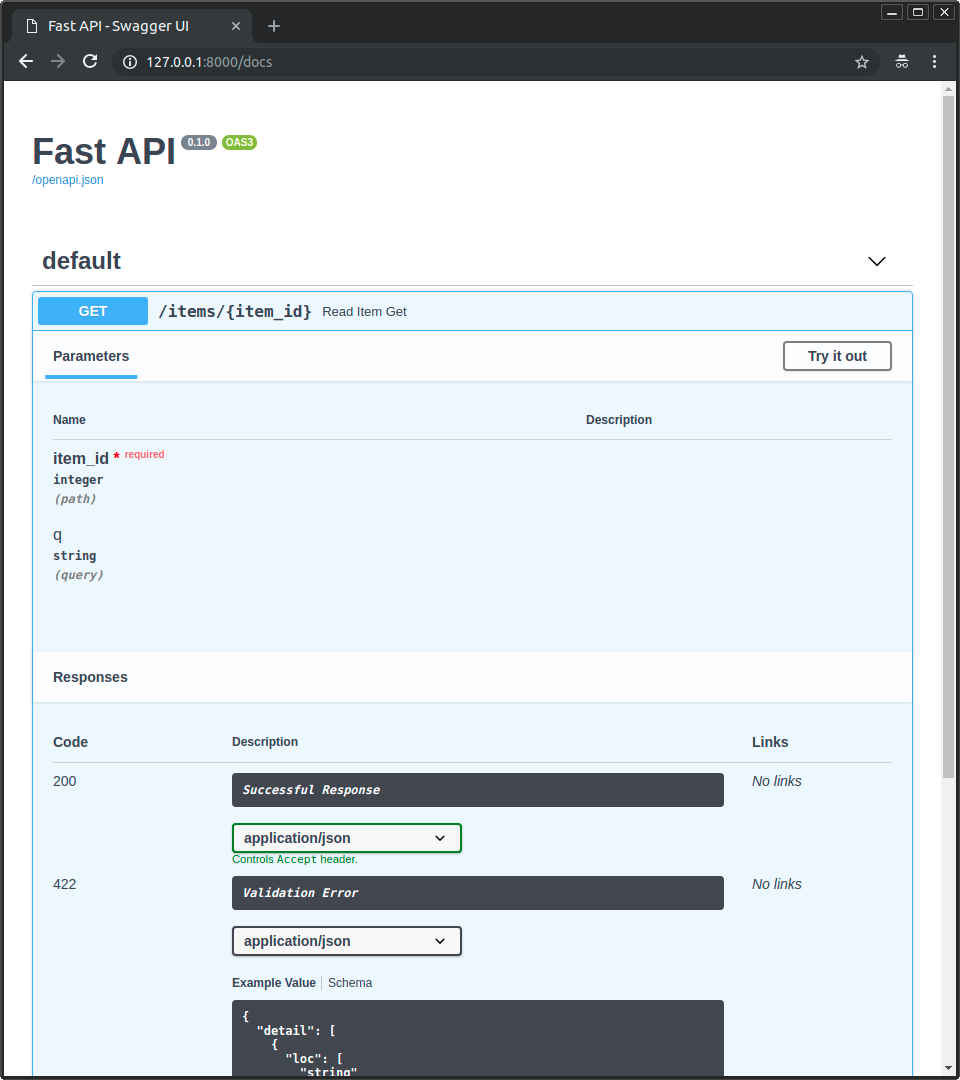
|
||||
|
||||
### Documentación de API Alternativa { #alternative-api-docs }
|
||||
### Documentación alternativa de la API { #alternative-api-docs }
|
||||
|
||||
Y ahora, ve a <a href="http://127.0.0.1:8000/redoc" class="external-link" target="_blank">http://127.0.0.1:8000/redoc</a>.
|
||||
|
||||
@@ -276,7 +282,7 @@ Verás la documentación alternativa automática (proporcionada por <a href="htt
|
||||
|
||||
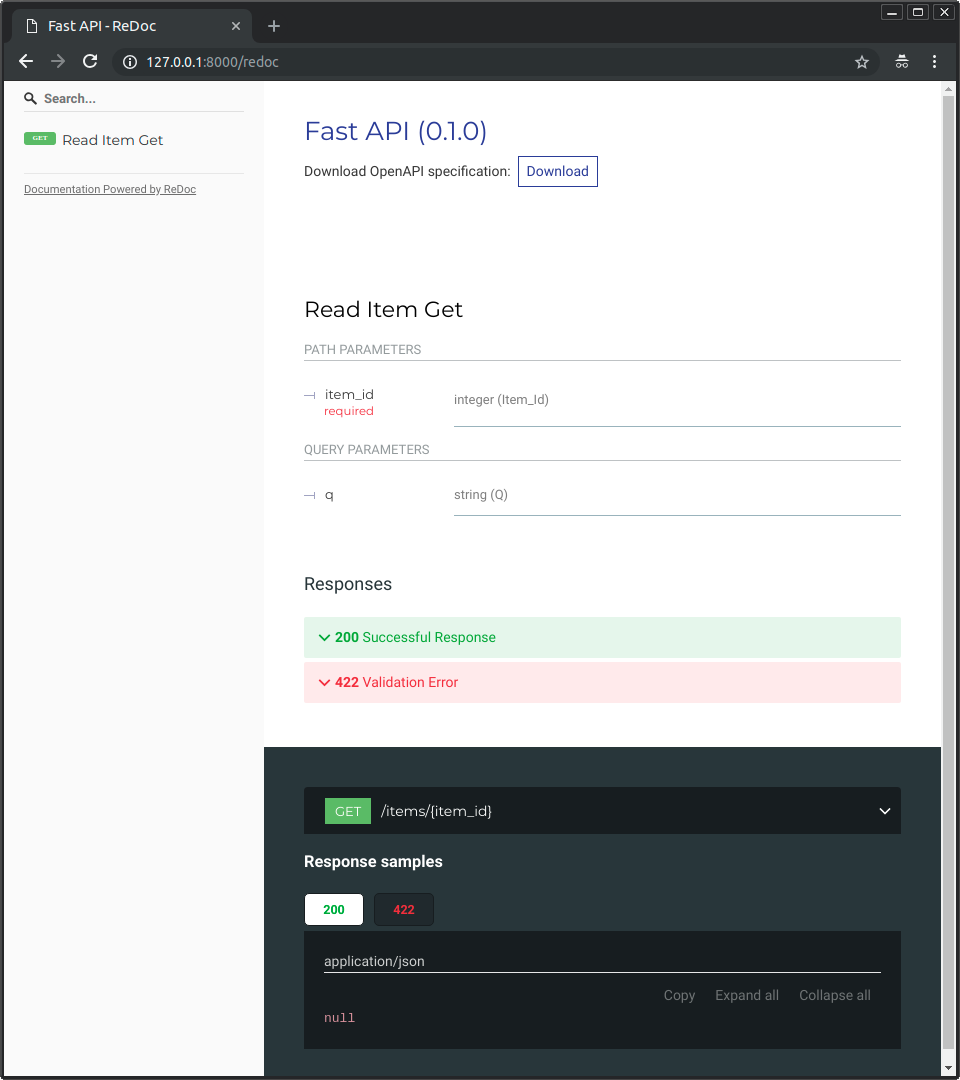
|
||||
|
||||
## Actualización del Ejemplo { #example-upgrade }
|
||||
## Actualización del ejemplo { #example-upgrade }
|
||||
|
||||
Ahora modifica el archivo `main.py` para recibir un body desde un request `PUT`.
|
||||
|
||||
@@ -314,7 +320,7 @@ def update_item(item_id: int, item: Item):
|
||||
|
||||
El servidor `fastapi dev` debería recargarse automáticamente.
|
||||
|
||||
### Actualización de la Documentación Interactiva de la API { #interactive-api-docs-upgrade }
|
||||
### Actualización de la documentación interactiva de la API { #interactive-api-docs-upgrade }
|
||||
|
||||
Ahora ve a <a href="http://127.0.0.1:8000/docs" class="external-link" target="_blank">http://127.0.0.1:8000/docs</a>.
|
||||
|
||||
@@ -330,7 +336,7 @@ Ahora ve a <a href="http://127.0.0.1:8000/docs" class="external-link" target="_b
|
||||
|
||||
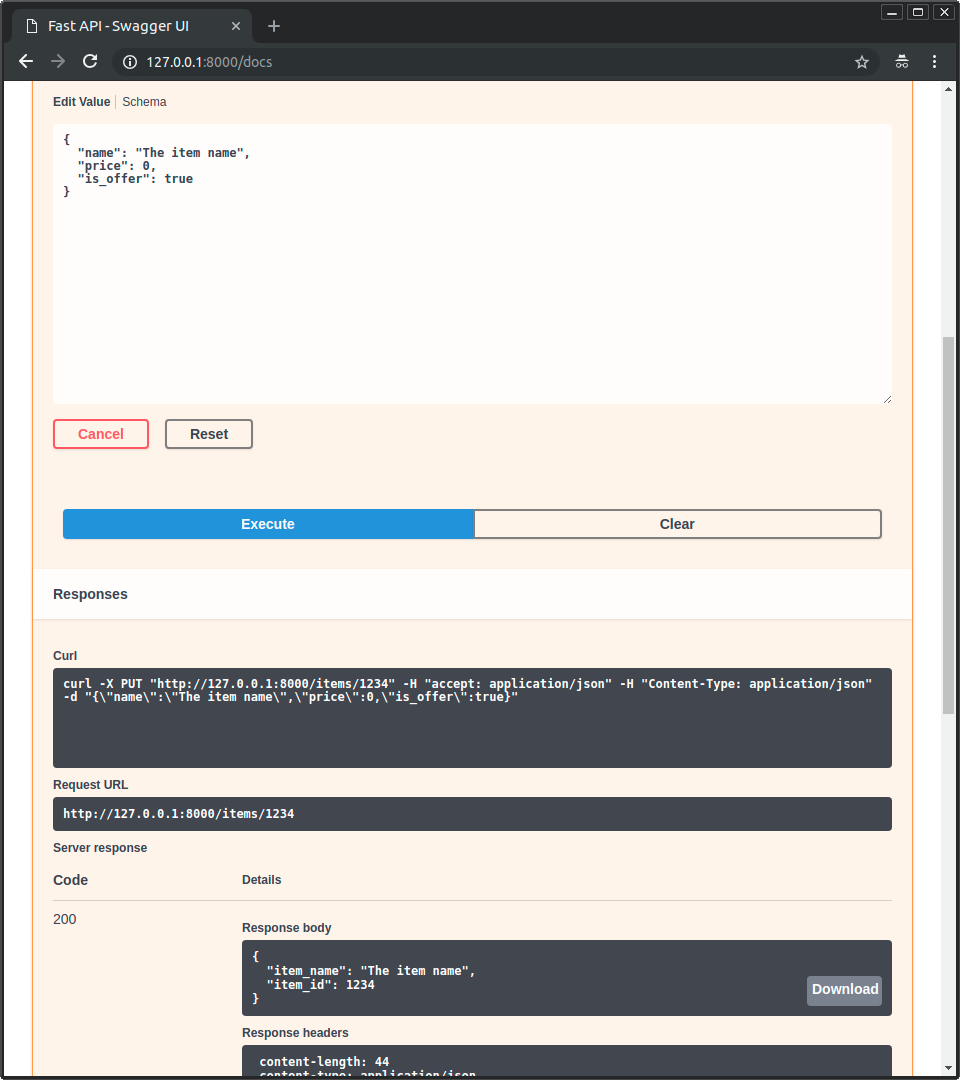
|
||||
|
||||
### Actualización de la Documentación Alternativa de la API { #alternative-api-docs-upgrade }
|
||||
### Actualización de la documentación alternativa de la API { #alternative-api-docs-upgrade }
|
||||
|
||||
Y ahora, ve a <a href="http://127.0.0.1:8000/redoc" class="external-link" target="_blank">http://127.0.0.1:8000/redoc</a>.
|
||||
|
||||
@@ -393,13 +399,13 @@ Volviendo al ejemplo de código anterior, **FastAPI**:
|
||||
* Validará que haya un `item_id` en el path para requests `GET` y `PUT`.
|
||||
* Validará que el `item_id` sea del tipo `int` para requests `GET` y `PUT`.
|
||||
* Si no lo es, el cliente verá un error útil y claro.
|
||||
* Comprobará si hay un parámetro de query opcional llamado `q` (como en `http://127.0.0.1:8000/items/foo?q=somequery`) para requests `GET`.
|
||||
* Revisa si hay un parámetro de query opcional llamado `q` (como en `http://127.0.0.1:8000/items/foo?q=somequery`) para requests `GET`.
|
||||
* Como el parámetro `q` está declarado con `= None`, es opcional.
|
||||
* Sin el `None` sería requerido (como lo es el body en el caso con `PUT`).
|
||||
* Para requests `PUT` a `/items/{item_id}`, leerá el body como JSON:
|
||||
* Comprobará que tiene un atributo requerido `name` que debe ser un `str`.
|
||||
* Comprobará que tiene un atributo requerido `price` que debe ser un `float`.
|
||||
* Comprobará que tiene un atributo opcional `is_offer`, que debe ser un `bool`, si está presente.
|
||||
* Revisa que tiene un atributo requerido `name` que debe ser un `str`.
|
||||
* Revisa que tiene un atributo requerido `price` que debe ser un `float`.
|
||||
* Revisa que tiene un atributo opcional `is_offer`, que debe ser un `bool`, si está presente.
|
||||
* Todo esto también funcionaría para objetos JSON profundamente anidados.
|
||||
* Convertirá de y a JSON automáticamente.
|
||||
* Documentará todo con OpenAPI, que puede ser usado por:
|
||||
|
||||
@@ -56,7 +56,7 @@ from app.routers import items
|
||||
|
||||
La misma estructura de archivos con comentarios:
|
||||
|
||||
```
|
||||
```bash
|
||||
.
|
||||
├── app # "app" es un paquete de Python
|
||||
│ ├── __init__.py # este archivo hace que "app" sea un "paquete de Python"
|
||||
@@ -185,7 +185,7 @@ El resultado final es que los paths de item son ahora:
|
||||
* Todos incluirán las `responses` predefinidas.
|
||||
* Todas estas *path operations* tendrán la lista de `dependencies` evaluadas/ejecutadas antes de ellas.
|
||||
* Si también declaras dependencias en una *path operation* específica, **también se ejecutarán**.
|
||||
* Las dependencias del router se ejecutan primero, luego las [dependencias en el decorador](dependencies/dependencies-in-path-operation-decorators.md){.internal-link target=_blank}, y luego las dependencias de parámetros normales.
|
||||
* Las dependencias del router se ejecutan primero, luego las [`dependencies` en el decorador](dependencies/dependencies-in-path-operation-decorators.md){.internal-link target=_blank}, y luego las dependencias de parámetros normales.
|
||||
* También puedes agregar [dependencias de `Security` con `scopes`](../advanced/security/oauth2-scopes.md){.internal-link target=_blank}.
|
||||
|
||||
/// tip | Consejo
|
||||
@@ -214,7 +214,7 @@ Así que usamos un import relativo con `..` para las dependencias:
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
Si sabes perfectamente cómo funcionan los imports, continúa a la siguiente sección.
|
||||
Si sabes perfectamente cómo funcionan los imports, continúa a la siguiente sección abajo.
|
||||
|
||||
///
|
||||
|
||||
@@ -271,7 +271,7 @@ eso significaría:
|
||||
|
||||
Eso se referiría a algún paquete arriba de `app/`, con su propio archivo `__init__.py`, etc. Pero no tenemos eso. Así que, eso lanzaría un error en nuestro ejemplo. 🚨
|
||||
|
||||
Pero ahora sabes cómo funciona, para que puedas usar imports relativos en tus propias aplicaciones sin importar cuán complejas sean. 🤓
|
||||
Pero ahora sabes cómo funciona, para que puedas usar imports relativos en tus propias apps sin importar cuán complejas sean. 🤓
|
||||
|
||||
### Agregar algunos `tags`, `responses`, y `dependencies` personalizados { #add-some-custom-tags-responses-and-dependencies }
|
||||
|
||||
@@ -283,7 +283,7 @@ Pero aún podemos agregar _más_ `tags` que se aplicarán a una *path operation*
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
Esta última *path operation* tendrá la combinación de tags: `["items", "custom"]`.
|
||||
Esta última path operation tendrá la combinación de tags: `["items", "custom"]`.
|
||||
|
||||
Y también tendrá ambas responses en la documentación, una para `404` y otra para `403`.
|
||||
|
||||
@@ -301,7 +301,7 @@ Y como la mayor parte de tu lógica ahora vivirá en su propio módulo específi
|
||||
|
||||
### Importar `FastAPI` { #import-fastapi }
|
||||
|
||||
Importas y creas una clase `FastAPI` como de costumbre.
|
||||
Importas y creas una clase `FastAPI` como normalmente.
|
||||
|
||||
Y podemos incluso declarar [dependencias globales](dependencies/global-dependencies.md){.internal-link target=_blank} que se combinarán con las dependencias para cada `APIRouter`:
|
||||
|
||||
@@ -398,7 +398,7 @@ Incluirá todas las rutas de ese router como parte de ella.
|
||||
|
||||
En realidad creará internamente una *path operation* para cada *path operation* que fue declarada en el `APIRouter`.
|
||||
|
||||
Así, detrás de escena, funcionará como si todo fuera la misma única aplicación.
|
||||
Así, detrás de escena, funcionará como si todo fuera la misma única app.
|
||||
|
||||
///
|
||||
|
||||
@@ -430,20 +430,20 @@ Podemos declarar todo eso sin tener que modificar el `APIRouter` original pasand
|
||||
|
||||
De esa manera, el `APIRouter` original permanecerá sin modificar, por lo que aún podemos compartir ese mismo archivo `app/internal/admin.py` con otros proyectos en la organización.
|
||||
|
||||
El resultado es que, en nuestra aplicación, cada una de las *path operations* del módulo `admin` tendrá:
|
||||
El resultado es que, en nuestra app, cada una de las *path operations* del módulo `admin` tendrá:
|
||||
|
||||
* El prefix `/admin`.
|
||||
* El tag `admin`.
|
||||
* La dependencia `get_token_header`.
|
||||
* La response `418`. 🍵
|
||||
|
||||
Pero eso solo afectará a ese `APIRouter` en nuestra aplicación, no en ningún otro código que lo utilice.
|
||||
Pero eso solo afectará a ese `APIRouter` en nuestra app, no en ningún otro código que lo utilice.
|
||||
|
||||
Así, por ejemplo, otros proyectos podrían usar el mismo `APIRouter` con un método de autenticación diferente.
|
||||
|
||||
### Incluir una *path operation* { #include-a-path-operation }
|
||||
|
||||
También podemos agregar *path operations* directamente a la aplicación de `FastAPI`.
|
||||
También podemos agregar *path operations* directamente a la app de `FastAPI`.
|
||||
|
||||
Aquí lo hacemos... solo para mostrar que podemos 🤷:
|
||||
|
||||
@@ -461,13 +461,13 @@ Los `APIRouter`s no están "montados", no están aislados del resto de la aplica
|
||||
|
||||
Esto se debe a que queremos incluir sus *path operations* en el esquema de OpenAPI y las interfaces de usuario.
|
||||
|
||||
Como no podemos simplemente aislarlos y "montarlos" independientemente del resto, se "clonan" las *path operations* (se vuelven a crear), no se incluyen directamente.
|
||||
Como no podemos simplemente aislarlos y "montarlos" independientemente del resto, las *path operations* se "clonan" (se vuelven a crear), no se incluyen directamente.
|
||||
|
||||
///
|
||||
|
||||
## Revisa la documentación automática de la API { #check-the-automatic-api-docs }
|
||||
|
||||
Ahora, ejecuta tu aplicación:
|
||||
Ahora, ejecuta tu app:
|
||||
|
||||
<div class="termy">
|
||||
|
||||
@@ -481,7 +481,7 @@ $ fastapi dev app/main.py
|
||||
|
||||
Y abre la documentación en <a href="http://127.0.0.1:8000/docs" class="external-link" target="_blank">http://127.0.0.1:8000/docs</a>.
|
||||
|
||||
Verás la documentación automática de la API, incluyendo los paths de todos los submódulos, usando los paths correctos (y prefijos) y las tags correctas:
|
||||
Verás la documentación automática de la API, incluyendo los paths de todos los submódulos, usando los paths correctos (y prefijos) y los tags correctos:
|
||||
|
||||
<img src="/img/tutorial/bigger-applications/image01.png">
|
||||
|
||||
@@ -501,4 +501,4 @@ De la misma manera que puedes incluir un `APIRouter` en una aplicación `FastAPI
|
||||
router.include_router(other_router)
|
||||
```
|
||||
|
||||
Asegúrate de hacerlo antes de incluir `router` en la aplicación de `FastAPI`, para que las *path operations* de `other_router` también se incluyan.
|
||||
Asegúrate de hacerlo antes de incluir `router` en la app de `FastAPI`, para que las *path operations* de `other_router` también se incluyan.
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# Cuerpo - Actualizaciones { #body-updates }
|
||||
# Body - Actualizaciones { #body-updates }
|
||||
|
||||
## Actualización reemplazando con `PUT` { #update-replacing-with-put }
|
||||
|
||||
@@ -50,14 +50,6 @@ Si quieres recibir actualizaciones parciales, es muy útil usar el parámetro `e
|
||||
|
||||
Como `item.model_dump(exclude_unset=True)`.
|
||||
|
||||
/// info | Información
|
||||
|
||||
En Pydantic v1 el método se llamaba `.dict()`, fue deprecado (pero aún soportado) en Pydantic v2, y renombrado a `.model_dump()`.
|
||||
|
||||
Los ejemplos aquí usan `.dict()` para compatibilidad con Pydantic v1, pero deberías usar `.model_dump()` si puedes usar Pydantic v2.
|
||||
|
||||
///
|
||||
|
||||
Eso generaría un `dict` solo con los datos que se establecieron al crear el modelo `item`, excluyendo los valores por defecto.
|
||||
|
||||
Luego puedes usar esto para generar un `dict` solo con los datos que se establecieron (enviados en el request), omitiendo los valores por defecto:
|
||||
@@ -68,14 +60,6 @@ Luego puedes usar esto para generar un `dict` solo con los datos que se establec
|
||||
|
||||
Ahora, puedes crear una copia del modelo existente usando `.model_copy()`, y pasar el parámetro `update` con un `dict` que contenga los datos a actualizar.
|
||||
|
||||
/// info | Información
|
||||
|
||||
En Pydantic v1 el método se llamaba `.copy()`, fue deprecado (pero aún soportado) en Pydantic v2, y renombrado a `.model_copy()`.
|
||||
|
||||
Los ejemplos aquí usan `.copy()` para compatibilidad con Pydantic v1, pero deberías usar `.model_copy()` si puedes usar Pydantic v2.
|
||||
|
||||
///
|
||||
|
||||
Como `stored_item_model.model_copy(update=update_data)`:
|
||||
|
||||
{* ../../docs_src/body_updates/tutorial002_py310.py hl[33] *}
|
||||
@@ -90,9 +74,9 @@ En resumen, para aplicar actualizaciones parciales deberías:
|
||||
* Generar un `dict` sin valores por defecto del modelo de entrada (usando `exclude_unset`).
|
||||
* De esta manera puedes actualizar solo los valores realmente establecidos por el usuario, en lugar de sobrescribir valores ya almacenados con valores por defecto en tu modelo.
|
||||
* Crear una copia del modelo almacenado, actualizando sus atributos con las actualizaciones parciales recibidas (usando el parámetro `update`).
|
||||
* Convertir el modelo copiado en algo que pueda almacenarse en tu base de datos (por ejemplo, usando el `jsonable_encoder`).
|
||||
* Convertir el modelo copiado en algo que pueda almacenarse en tu DB (por ejemplo, usando el `jsonable_encoder`).
|
||||
* Esto es comparable a usar el método `.model_dump()` del modelo de nuevo, pero asegura (y convierte) los valores a tipos de datos que pueden convertirse a JSON, por ejemplo, `datetime` a `str`.
|
||||
* Guardar los datos en tu base de datos.
|
||||
* Guardar los datos en tu DB.
|
||||
* Devolver el modelo actualizado.
|
||||
|
||||
{* ../../docs_src/body_updates/tutorial002_py310.py hl[28:35] *}
|
||||
|
||||
@@ -32,7 +32,8 @@ Usa tipos estándar de Python para todos los atributos:
|
||||
|
||||
{* ../../docs_src/body/tutorial001_py310.py hl[5:9] *}
|
||||
|
||||
Al igual que al declarar parámetros de query, cuando un atributo del modelo tiene un valor por defecto, no es obligatorio. De lo contrario, es obligatorio. Usa `None` para hacerlo opcional.
|
||||
|
||||
Al igual que al declarar parámetros de query, cuando un atributo del modelo tiene un valor por defecto, no es obligatorio. De lo contrario, es obligatorio. Usa `None` para hacerlo solo opcional.
|
||||
|
||||
Por ejemplo, el modelo anterior declara un “`object`” JSON (o `dict` en Python) como:
|
||||
|
||||
@@ -127,14 +128,6 @@ Dentro de la función, puedes acceder a todos los atributos del objeto modelo di
|
||||
|
||||
{* ../../docs_src/body/tutorial002_py310.py *}
|
||||
|
||||
/// info | Información
|
||||
|
||||
En Pydantic v1 el método se llamaba `.dict()`, se marcó como obsoleto (pero sigue soportado) en Pydantic v2, y se renombró a `.model_dump()`.
|
||||
|
||||
Los ejemplos aquí usan `.dict()` por compatibilidad con Pydantic v1, pero deberías usar `.model_dump()` si puedes usar Pydantic v2.
|
||||
|
||||
///
|
||||
|
||||
## Request body + parámetros de path { #request-body-path-parameters }
|
||||
|
||||
Puedes declarar parámetros de path y request body al mismo tiempo.
|
||||
@@ -143,6 +136,7 @@ Puedes declarar parámetros de path y request body al mismo tiempo.
|
||||
|
||||
{* ../../docs_src/body/tutorial003_py310.py hl[15:16] *}
|
||||
|
||||
|
||||
## Request body + path + parámetros de query { #request-body-path-query-parameters }
|
||||
|
||||
También puedes declarar parámetros de **body**, **path** y **query**, todos al mismo tiempo.
|
||||
@@ -155,7 +149,7 @@ Los parámetros de la función se reconocerán de la siguiente manera:
|
||||
|
||||
* Si el parámetro también se declara en el **path**, se utilizará como un parámetro de path.
|
||||
* Si el parámetro es de un **tipo singular** (como `int`, `float`, `str`, `bool`, etc.), se interpretará como un parámetro de **query**.
|
||||
* Si el parámetro se declara como del tipo de un **modelo de Pydantic**, se interpretará como un **request body**.
|
||||
* Si el parámetro se declara como del tipo de un **modelo de Pydantic**, se interpretará como un **body** de request.
|
||||
|
||||
/// note | Nota
|
||||
|
||||
|
||||
@@ -22,21 +22,13 @@ Aquí tienes una idea general de cómo podrían ser los modelos con sus campos d
|
||||
|
||||
{* ../../docs_src/extra_models/tutorial001_py310.py hl[7,9,14,20,22,27:28,31:33,38:39] *}
|
||||
|
||||
/// info | Información
|
||||
### Acerca de `**user_in.model_dump()` { #about-user-in-model-dump }
|
||||
|
||||
En Pydantic v1 el método se llamaba `.dict()`, fue deprecado (pero aún soportado) en Pydantic v2, y renombrado a `.model_dump()`.
|
||||
|
||||
Los ejemplos aquí usan `.dict()` para compatibilidad con Pydantic v1, pero deberías usar `.model_dump()` en su lugar si puedes usar Pydantic v2.
|
||||
|
||||
///
|
||||
|
||||
### Acerca de `**user_in.dict()` { #about-user-in-dict }
|
||||
|
||||
#### `.dict()` de Pydantic { #pydantics-dict }
|
||||
#### `.model_dump()` de Pydantic { #pydantics-model-dump }
|
||||
|
||||
`user_in` es un modelo Pydantic de la clase `UserIn`.
|
||||
|
||||
Los modelos Pydantic tienen un método `.dict()` que devuelve un `dict` con los datos del modelo.
|
||||
Los modelos Pydantic tienen un método `.model_dump()` que devuelve un `dict` con los datos del modelo.
|
||||
|
||||
Así que, si creamos un objeto Pydantic `user_in` como:
|
||||
|
||||
@@ -47,7 +39,7 @@ user_in = UserIn(username="john", password="secret", email="john.doe@example.com
|
||||
y luego llamamos a:
|
||||
|
||||
```Python
|
||||
user_dict = user_in.dict()
|
||||
user_dict = user_in.model_dump()
|
||||
```
|
||||
|
||||
ahora tenemos un `dict` con los datos en la variable `user_dict` (es un `dict` en lugar de un objeto modelo Pydantic).
|
||||
@@ -58,7 +50,7 @@ Y si llamamos a:
|
||||
print(user_dict)
|
||||
```
|
||||
|
||||
obtendremos un `dict` de Python con:
|
||||
obtendríamos un `dict` de Python con:
|
||||
|
||||
```Python
|
||||
{
|
||||
@@ -103,20 +95,20 @@ UserInDB(
|
||||
|
||||
#### Un modelo Pydantic a partir del contenido de otro { #a-pydantic-model-from-the-contents-of-another }
|
||||
|
||||
Como en el ejemplo anterior obtuvimos `user_dict` de `user_in.dict()`, este código:
|
||||
Como en el ejemplo anterior obtuvimos `user_dict` de `user_in.model_dump()`, este código:
|
||||
|
||||
```Python
|
||||
user_dict = user_in.dict()
|
||||
user_dict = user_in.model_dump()
|
||||
UserInDB(**user_dict)
|
||||
```
|
||||
|
||||
sería equivalente a:
|
||||
|
||||
```Python
|
||||
UserInDB(**user_in.dict())
|
||||
UserInDB(**user_in.model_dump())
|
||||
```
|
||||
|
||||
...porque `user_in.dict()` es un `dict`, y luego hacemos que Python lo "desempaquete" al pasarlo a `UserInDB` con el prefijo `**`.
|
||||
...porque `user_in.model_dump()` es un `dict`, y luego hacemos que Python lo "desempaquete" al pasarlo a `UserInDB` con el prefijo `**`.
|
||||
|
||||
Así, obtenemos un modelo Pydantic a partir de los datos en otro modelo Pydantic.
|
||||
|
||||
@@ -125,7 +117,7 @@ Así, obtenemos un modelo Pydantic a partir de los datos en otro modelo Pydantic
|
||||
Y luego agregando el argumento de palabra clave adicional `hashed_password=hashed_password`, como en:
|
||||
|
||||
```Python
|
||||
UserInDB(**user_in.dict(), hashed_password=hashed_password)
|
||||
UserInDB(**user_in.model_dump(), hashed_password=hashed_password)
|
||||
```
|
||||
|
||||
...termina siendo como:
|
||||
@@ -156,7 +148,7 @@ Y estos modelos están compartiendo muchos de los datos y duplicando nombres y t
|
||||
|
||||
Podríamos hacerlo mejor.
|
||||
|
||||
Podemos declarar un modelo `UserBase` que sirva como base para nuestros otros modelos. Y luego podemos hacer subclases de ese modelo que heredan sus atributos (anotaciones de tipos, validación, etc).
|
||||
Podemos declarar un modelo `UserBase` que sirva como base para nuestros otros modelos. Y luego podemos hacer subclases de ese modelo que heredan sus atributos (declaraciones de tipos, validación, etc).
|
||||
|
||||
Toda la conversión de datos, validación, documentación, etc. seguirá funcionando normalmente.
|
||||
|
||||
@@ -180,20 +172,19 @@ Al definir una <a href="https://docs.pydantic.dev/latest/concepts/types/#unions"
|
||||
|
||||
{* ../../docs_src/extra_models/tutorial003_py310.py hl[1,14:15,18:20,33] *}
|
||||
|
||||
|
||||
### `Union` en Python 3.10 { #union-in-python-3-10 }
|
||||
|
||||
En este ejemplo pasamos `Union[PlaneItem, CarItem]` como el valor del argumento `response_model`.
|
||||
|
||||
Porque lo estamos pasando como un **valor a un argumento** en lugar de ponerlo en **anotaciones de tipos**, tenemos que usar `Union` incluso en Python 3.10.
|
||||
Porque lo estamos pasando como un **valor a un argumento** en lugar de ponerlo en una **anotación de tipos**, tenemos que usar `Union` incluso en Python 3.10.
|
||||
|
||||
Si estuviera en anotaciones de tipos podríamos haber usado la barra vertical, como:
|
||||
Si estuviera en una anotación de tipos podríamos haber usado la barra vertical, como:
|
||||
|
||||
```Python
|
||||
some_variable: PlaneItem | CarItem
|
||||
```
|
||||
|
||||
Pero si ponemos eso en la asignación `response_model=PlaneItem | CarItem` obtendríamos un error, porque Python intentaría realizar una **operación inválida** entre `PlaneItem` y `CarItem` en lugar de interpretar eso como anotaciones de tipos.
|
||||
Pero si ponemos eso en la asignación `response_model=PlaneItem | CarItem` obtendríamos un error, porque Python intentaría realizar una **operación inválida** entre `PlaneItem` y `CarItem` en lugar de interpretar eso como una anotación de tipos.
|
||||
|
||||
## Lista de modelos { #list-of-models }
|
||||
|
||||
@@ -203,7 +194,6 @@ Para eso, usa el `typing.List` estándar de Python (o simplemente `list` en Pyth
|
||||
|
||||
{* ../../docs_src/extra_models/tutorial004_py39.py hl[18] *}
|
||||
|
||||
|
||||
## Response con `dict` arbitrario { #response-with-arbitrary-dict }
|
||||
|
||||
También puedes declarar un response usando un `dict` arbitrario plano, declarando solo el tipo de las claves y valores, sin usar un modelo Pydantic.
|
||||
@@ -214,7 +204,6 @@ En este caso, puedes usar `typing.Dict` (o solo `dict` en Python 3.9 y posterior
|
||||
|
||||
{* ../../docs_src/extra_models/tutorial005_py39.py hl[6] *}
|
||||
|
||||
|
||||
## Recapitulación { #recap }
|
||||
|
||||
Usa múltiples modelos Pydantic y hereda libremente para cada caso.
|
||||
|
||||
@@ -109,7 +109,7 @@ FastAPI ahora:
|
||||
|
||||
## Alternativa (antigua): `Query` como valor por defecto { #alternative-old-query-as-the-default-value }
|
||||
|
||||
Versiones anteriores de FastAPI (antes de <abbr title="antes de 2023-03">0.95.0</abbr>) requerían que usaras `Query` como el valor por defecto de tu parámetro, en lugar de ponerlo en `Annotated`, hay una alta probabilidad de que veas código usándolo alrededor, así que te lo explicaré.
|
||||
Versiones anteriores de FastAPI (antes de <abbr title="before 2023-03 - antes de 2023-03">0.95.0</abbr>) requerían que usaras `Query` como el valor por defecto de tu parámetro, en lugar de ponerlo en `Annotated`, hay una alta probabilidad de que veas código usándolo alrededor, así que te lo explicaré.
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
@@ -192,7 +192,7 @@ También puedes agregar un parámetro `min_length`:
|
||||
|
||||
## Agregar expresiones regulares { #add-regular-expressions }
|
||||
|
||||
Puedes definir un <abbr title="Una expresión regular, regex o regexp es una secuencia de caracteres que define un patrón de búsqueda para strings.">expresión regular</abbr> `pattern` que el parámetro debe coincidir:
|
||||
Puedes definir una <abbr title="Una expresión regular, regex o regexp es una secuencia de caracteres que define un patrón de búsqueda para strings.">expresión regular</abbr> `pattern` que el parámetro debe coincidir:
|
||||
|
||||
{* ../../docs_src/query_params_str_validations/tutorial004_an_py310.py hl[11] *}
|
||||
|
||||
@@ -206,20 +206,6 @@ Si te sientes perdido con todas estas ideas de **"expresión regular"**, no te p
|
||||
|
||||
Ahora sabes que cuando las necesites puedes usarlas en **FastAPI**.
|
||||
|
||||
### Pydantic v1 `regex` en lugar de `pattern` { #pydantic-v1-regex-instead-of-pattern }
|
||||
|
||||
Antes de la versión 2 de Pydantic y antes de FastAPI 0.100.0, el parámetro se llamaba `regex` en lugar de `pattern`, pero ahora está en desuso.
|
||||
|
||||
Todavía podrías ver algo de código que lo usa:
|
||||
|
||||
//// tab | Pydantic v1
|
||||
|
||||
{* ../../docs_src/query_params_str_validations/tutorial004_regex_an_py310.py hl[11] *}
|
||||
|
||||
////
|
||||
|
||||
Pero que sepas que esto está deprecado y debería actualizarse para usar el nuevo parámetro `pattern`. 🤓
|
||||
|
||||
## Valores por defecto { #default-values }
|
||||
|
||||
Puedes, por supuesto, usar valores por defecto diferentes de `None`.
|
||||
@@ -280,7 +266,7 @@ Entonces, con una URL como:
|
||||
http://localhost:8000/items/?q=foo&q=bar
|
||||
```
|
||||
|
||||
recibirías los múltiples valores del *query parameter* `q` (`foo` y `bar`) en una `list` de Python dentro de tu *path operation function*, en el *parámetro de función* `q`.
|
||||
recibirías los múltiples valores de los *query parameters* `q` (`foo` y `bar`) en una `list` de Python dentro de tu *path operation function*, en el *parámetro de función* `q`.
|
||||
|
||||
Entonces, el response a esa URL sería:
|
||||
|
||||
@@ -386,7 +372,7 @@ Entonces puedes declarar un `alias`, y ese alias será usado para encontrar el v
|
||||
|
||||
Ahora digamos que ya no te gusta este parámetro.
|
||||
|
||||
Tienes que dejarlo allí por un tiempo porque hay clientes usándolo, pero quieres que la documentación lo muestre claramente como <abbr title="obsoleto, se recomienda no usarlo">deprecated</abbr>.
|
||||
Tienes que dejarlo allí por un tiempo porque hay clientes usándolo, pero quieres que la documentación lo muestre claramente como <abbr title="obsolete, recommended not to use it - obsoleto, se recomienda no usarlo">deprecated</abbr>.
|
||||
|
||||
Luego pasa el parámetro `deprecated=True` a `Query`:
|
||||
|
||||
@@ -416,7 +402,7 @@ Pydantic también tiene <a href="https://docs.pydantic.dev/latest/concepts/valid
|
||||
|
||||
///
|
||||
|
||||
Por ejemplo, este validador personalizado comprueba que el ID del ítem empiece con `isbn-` para un número de libro <abbr title="International Standard Book Number – Número Estándar Internacional de Libro">ISBN</abbr> o con `imdb-` para un ID de URL de película de <abbr title="IMDB (Internet Movie Database) es un sitio web con información sobre películas">IMDB</abbr>:
|
||||
Por ejemplo, este validador personalizado comprueba que el ID del ítem empiece con `isbn-` para un número de libro <abbr title="ISBN means International Standard Book Number - ISBN significa International Standard Book Number">ISBN</abbr> o con `imdb-` para un ID de URL de película de <abbr title="IMDB (Internet Movie Database) is a website with information about movies - IMDB (Internet Movie Database) es un sitio web con información sobre películas">IMDB</abbr>:
|
||||
|
||||
{* ../../docs_src/query_params_str_validations/tutorial015_an_py310.py hl[5,16:19,24] *}
|
||||
|
||||
@@ -450,7 +436,7 @@ Pero si te da curiosidad este ejemplo de código específico y sigues entretenid
|
||||
|
||||
#### Un ítem aleatorio { #a-random-item }
|
||||
|
||||
Con `data.items()` obtenemos un <abbr title="Algo que podemos iterar con un for, como una list, set, etc.">objeto iterable</abbr> con tuplas que contienen la clave y el valor para cada elemento del diccionario.
|
||||
Con `data.items()` obtenemos un <abbr title="Algo que podemos iterar con un for loop, como una list, set, etc.">objeto iterable</abbr> con tuplas que contienen la clave y el valor para cada elemento del diccionario.
|
||||
|
||||
Convertimos este objeto iterable en una `list` propiamente dicha con `list(data.items())`.
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
Puedes declarar el tipo utilizado para el response anotando el **tipo de retorno** de la *path operation function*.
|
||||
|
||||
Puedes utilizar **anotaciones de tipos** de la misma manera que lo harías para datos de entrada en **parámetros** de función, puedes utilizar modelos de Pydantic, list, diccionarios, valores escalares como enteros, booleanos, etc.
|
||||
Puedes utilizar **anotaciones de tipos** de la misma manera que lo harías para datos de entrada en **parámetros** de función, puedes utilizar modelos de Pydantic, lists, diccionarios, valores escalares como enteros, booleanos, etc.
|
||||
|
||||
{* ../../docs_src/response_model/tutorial001_01_py310.py hl[16,21] *}
|
||||
|
||||
@@ -27,7 +27,7 @@ Por ejemplo, podrías querer **devolver un diccionario** u objeto de base de dat
|
||||
|
||||
Si añadiste la anotación del tipo de retorno, las herramientas y editores se quejarían con un error (correcto) diciéndote que tu función está devolviendo un tipo (por ejemplo, un dict) que es diferente de lo que declaraste (por ejemplo, un modelo de Pydantic).
|
||||
|
||||
En esos casos, puedes usar el parámetro del decorador de path operation `response_model` en lugar del tipo de retorno.
|
||||
En esos casos, puedes usar el parámetro del *decorador de path operation* `response_model` en lugar del tipo de retorno.
|
||||
|
||||
Puedes usar el parámetro `response_model` en cualquiera de las *path operations*:
|
||||
|
||||
@@ -153,7 +153,7 @@ Primero vamos a ver cómo los editores, mypy y otras herramientas verían esto.
|
||||
|
||||
`BaseUser` tiene los campos base. Luego `UserIn` hereda de `BaseUser` y añade el campo `password`, por lo que incluirá todos los campos de ambos modelos.
|
||||
|
||||
Anotamos el tipo de retorno de la función como `BaseUser`, pero en realidad estamos devolviendo un instance de `UserIn`.
|
||||
Anotamos el tipo de retorno de la función como `BaseUser`, pero en realidad estamos devolviendo un `UserIn` instance.
|
||||
|
||||
El editor, mypy y otras herramientas no se quejarán de esto porque, en términos de tipificación, `UserIn` es una subclase de `BaseUser`, lo que significa que es un tipo *válido* cuando se espera algo que es un `BaseUser`.
|
||||
|
||||
@@ -252,20 +252,6 @@ Entonces, si envías un request a esa *path operation* para el ítem con ID `foo
|
||||
|
||||
/// info | Información
|
||||
|
||||
En Pydantic v1 el método se llamaba `.dict()`, fue deprecado (pero aún soportado) en Pydantic v2, y renombrado a `.model_dump()`.
|
||||
|
||||
Los ejemplos aquí usan `.dict()` para compatibilidad con Pydantic v1, pero deberías usar `.model_dump()` en su lugar si puedes usar Pydantic v2.
|
||||
|
||||
///
|
||||
|
||||
/// info | Información
|
||||
|
||||
FastAPI usa el método `.dict()` del modelo de Pydantic con <a href="https://docs.pydantic.dev/1.10/usage/exporting_models/#modeldict" class="external-link" target="_blank">su parámetro `exclude_unset`</a> para lograr esto.
|
||||
|
||||
///
|
||||
|
||||
/// info | Información
|
||||
|
||||
También puedes usar:
|
||||
|
||||
* `response_model_exclude_defaults=True`
|
||||
|
||||
@@ -8,35 +8,13 @@ Aquí tienes varias formas de hacerlo.
|
||||
|
||||
Puedes declarar `examples` para un modelo de Pydantic que se añadirá al JSON Schema generado.
|
||||
|
||||
//// tab | Pydantic v2
|
||||
|
||||
{* ../../docs_src/schema_extra_example/tutorial001_py310.py hl[13:24] *}
|
||||
|
||||
////
|
||||
Esa información extra se añadirá tal cual al **JSON Schema** resultante para ese modelo, y se usará en la documentación de la API.
|
||||
|
||||
//// tab | Pydantic v1
|
||||
Puedes usar el atributo `model_config` que toma un `dict` como se describe en <a href="https://docs.pydantic.dev/latest/api/config/" class="external-link" target="_blank">la documentación de Pydantic: Configuración</a>.
|
||||
|
||||
{* ../../docs_src/schema_extra_example/tutorial001_pv1_py310.py hl[13:23] *}
|
||||
|
||||
////
|
||||
|
||||
Esa información extra se añadirá tal cual al **JSON Schema** generado para ese modelo, y se usará en la documentación de la API.
|
||||
|
||||
//// tab | Pydantic v2
|
||||
|
||||
En Pydantic versión 2, usarías el atributo `model_config`, que toma un `dict` como se describe en <a href="https://docs.pydantic.dev/latest/api/config/" class="external-link" target="_blank">la documentación de Pydantic: Configuración</a>.
|
||||
|
||||
Puedes establecer `"json_schema_extra"` con un `dict` que contenga cualquier dato adicional que desees que aparezca en el JSON Schema generado, incluyendo `examples`.
|
||||
|
||||
////
|
||||
|
||||
//// tab | Pydantic v1
|
||||
|
||||
En Pydantic versión 1, usarías una clase interna `Config` y `schema_extra`, como se describe en <a href="https://docs.pydantic.dev/1.10/usage/schema/#schema-customization" class="external-link" target="_blank">la documentación de Pydantic: Personalización de Esquema</a>.
|
||||
|
||||
Puedes establecer `schema_extra` con un `dict` que contenga cualquier dato adicional que desees que aparezca en el JSON Schema generado, incluyendo `examples`.
|
||||
|
||||
////
|
||||
Puedes establecer `"json_schema_extra"` con un `dict` que contenga cualquier dato adicional que te gustaría que aparezca en el JSON Schema generado, incluyendo `examples`.
|
||||
|
||||
/// tip | Consejo
|
||||
|
||||
@@ -50,7 +28,7 @@ Por ejemplo, podrías usarlo para añadir metadatos para una interfaz de usuario
|
||||
|
||||
OpenAPI 3.1.0 (usado desde FastAPI 0.99.0) añadió soporte para `examples`, que es parte del estándar de **JSON Schema**.
|
||||
|
||||
Antes de eso, solo soportaba la palabra clave `example` con un solo ejemplo. Eso aún es soportado por OpenAPI 3.1.0, pero está obsoleto y no es parte del estándar de JSON Schema. Así que se recomienda migrar de `example` a `examples`. 🤓
|
||||
Antes de eso, solo soportaba la palabra clave `example` con un solo ejemplo. Eso aún es soportado por OpenAPI 3.1.0, pero está obsoleto y no es parte del estándar de JSON Schema. Así que se te anima a migrar `example` a `examples`. 🤓
|
||||
|
||||
Puedes leer más al final de esta página.
|
||||
|
||||
@@ -94,7 +72,7 @@ Por supuesto, también puedes pasar múltiples `examples`:
|
||||
|
||||
{* ../../docs_src/schema_extra_example/tutorial004_an_py310.py hl[23:38] *}
|
||||
|
||||
Cuando haces esto, los ejemplos serán parte del **JSON Schema** interno para esos datos de body.
|
||||
Cuando haces esto, los ejemplos serán parte del **JSON Schema** interno para esos datos del body.
|
||||
|
||||
Sin embargo, al <abbr title="2023-08-26">momento de escribir esto</abbr>, Swagger UI, la herramienta encargada de mostrar la interfaz de documentación, no soporta mostrar múltiples ejemplos para los datos en **JSON Schema**. Pero lee más abajo para una solución alternativa.
|
||||
|
||||
@@ -203,17 +181,17 @@ Debido a eso, las versiones de FastAPI anteriores a 0.99.0 todavía usaban versi
|
||||
|
||||
### `examples` de Pydantic y FastAPI { #pydantic-and-fastapi-examples }
|
||||
|
||||
Cuando añades `examples` dentro de un modelo de Pydantic, usando `schema_extra` o `Field(examples=["algo"])`, ese ejemplo se añade al **JSON Schema** para ese modelo de Pydantic.
|
||||
Cuando añades `examples` dentro de un modelo de Pydantic, usando `schema_extra` o `Field(examples=["something"])`, ese ejemplo se añade al **JSON Schema** para ese modelo de Pydantic.
|
||||
|
||||
Y ese **JSON Schema** del modelo de Pydantic se incluye en el **OpenAPI** de tu API, y luego se usa en la interfaz de documentación.
|
||||
|
||||
En las versiones de FastAPI antes de 0.99.0 (0.99.0 y superior usan el nuevo OpenAPI 3.1.0) cuando usabas `example` o `examples` con cualquiera de las otras utilidades (`Query()`, `Body()`, etc.) esos ejemplos no se añadían al JSON Schema que describe esos datos (ni siquiera a la propia versión de JSON Schema de OpenAPI), se añadían directamente a la declaración de la *path operation* en OpenAPI (fuera de las partes de OpenAPI que usan JSON Schema).
|
||||
En las versiones de FastAPI antes de 0.99.0 (0.99.0 y superiores usan el nuevo OpenAPI 3.1.0) cuando usabas `example` o `examples` con cualquiera de las otras utilidades (`Query()`, `Body()`, etc.) esos ejemplos no se añadían al JSON Schema que describe esos datos (ni siquiera a la propia versión de JSON Schema de OpenAPI), se añadían directamente a la declaración de la *path operation* en OpenAPI (fuera de las partes de OpenAPI que usan JSON Schema).
|
||||
|
||||
Pero ahora que FastAPI 0.99.0 y superiores usa OpenAPI 3.1.0, que usa JSON Schema 2020-12, y Swagger UI 5.0.0 y superiores, todo es más consistente y los ejemplos se incluyen en JSON Schema.
|
||||
|
||||
### Swagger UI y `examples` específicos de OpenAPI { #swagger-ui-and-openapi-specific-examples }
|
||||
|
||||
Ahora, como Swagger UI no soportaba múltiples ejemplos de JSON Schema (a fecha de 2023-08-26), los usuarios no tenían una forma de mostrar múltiples ejemplos en los documentos.
|
||||
Ahora, como Swagger UI no soportaba múltiples ejemplos de JSON Schema (a fecha de 2023-08-26), los usuarios no tenían una forma de mostrar múltiples ejemplos en la documentación.
|
||||
|
||||
Para resolver eso, FastAPI `0.103.0` **añadió soporte** para declarar el mismo viejo campo **específico de OpenAPI** `examples` con el nuevo parámetro `openapi_examples`. 🤓
|
||||
|
||||
|
||||
@@ -6,123 +6,127 @@ Language code: fr.
|
||||
|
||||
### Grammar to use when talking to the reader
|
||||
|
||||
Use the formal grammar (use «vous» instead of «tu»).
|
||||
Use the formal grammar (use `vous` instead of `tu`).
|
||||
|
||||
Additionally, in instructional sentences, prefer the present tense for obligations:
|
||||
|
||||
- Prefer `vous devez …` over `vous devrez …`, unless the English source explicitly refers to a future requirement.
|
||||
|
||||
- When translating “make sure (that) … is …”, prefer the indicative after `vous assurer que` (e.g. `Vous devez vous assurer qu'il est …`) instead of the subjunctive (e.g. `qu'il soit …`).
|
||||
|
||||
### Quotes
|
||||
|
||||
1) Convert neutral double quotes («"») and English double typographic quotes («“» and «”») to French guillemets (««» and «»»).
|
||||
- Convert neutral double quotes (`"`) to French guillemets (`«` and `»`).
|
||||
|
||||
2) In the French docs, guillemets are written without extra spaces: use «texte», not « texte ».
|
||||
|
||||
3) Do not convert quotes inside code blocks, inline code, paths, URLs, or anything wrapped in backticks.
|
||||
- Do not convert quotes inside code blocks, inline code, paths, URLs, or anything wrapped in backticks.
|
||||
|
||||
Examples:
|
||||
|
||||
Source (English):
|
||||
Source (English):
|
||||
|
||||
«««
|
||||
"Hello world"
|
||||
“Hello Universe”
|
||||
"He said: 'Hello'"
|
||||
"The module is `__main__`"
|
||||
»»»
|
||||
```
|
||||
"Hello world"
|
||||
“Hello Universe”
|
||||
"He said: 'Hello'"
|
||||
"The module is `__main__`"
|
||||
```
|
||||
|
||||
Result (French):
|
||||
Result (French):
|
||||
|
||||
«««
|
||||
«Hello world»
|
||||
«Hello Universe»
|
||||
«He said: 'Hello'»
|
||||
«The module is `__main__`»
|
||||
»»»
|
||||
```
|
||||
"Hello world"
|
||||
“Hello Universe”
|
||||
"He said: 'Hello'"
|
||||
"The module is `__main__`"
|
||||
```
|
||||
|
||||
### Ellipsis
|
||||
|
||||
1) Make sure there is a space between an ellipsis and a word following or preceding the ellipsis.
|
||||
- Make sure there is a space between an ellipsis and a word following or preceding the ellipsis.
|
||||
|
||||
Examples:
|
||||
|
||||
Source (English):
|
||||
Source (English):
|
||||
|
||||
«««
|
||||
...as we intended.
|
||||
...this would work:
|
||||
...etc.
|
||||
others...
|
||||
More to come...
|
||||
»»»
|
||||
```
|
||||
...as we intended.
|
||||
...this would work:
|
||||
...etc.
|
||||
others...
|
||||
More to come...
|
||||
```
|
||||
|
||||
Result (French):
|
||||
Result (French):
|
||||
|
||||
«««
|
||||
... comme prévu.
|
||||
... cela fonctionnerait :
|
||||
... etc.
|
||||
D'autres ...
|
||||
La suite ...
|
||||
»»»
|
||||
```
|
||||
... comme prévu.
|
||||
... cela fonctionnerait :
|
||||
... etc.
|
||||
D'autres ...
|
||||
La suite ...
|
||||
```
|
||||
|
||||
2) This does not apply in URLs, code blocks, and code snippets. Do not remove or add spaces there.
|
||||
- This does not apply in URLs, code blocks, and code snippets. Do not remove or add spaces there.
|
||||
|
||||
### Headings
|
||||
|
||||
1) Prefer translating headings using the infinitive form (as is common in the existing French docs): «Créer…», «Utiliser…», «Ajouter…».
|
||||
- Prefer translating headings using the infinitive form (as is common in the existing French docs): `Créer…`, `Utiliser…`, `Ajouter…`.
|
||||
|
||||
2) For headings that are instructions written in imperative in English (e.g. “Go check …”), keep them in imperative in French, using the formal grammar (e.g. «Allez voir …»).
|
||||
|
||||
3) Keep heading punctuation as in the source. In particular, keep occurrences of literal « - » (space-hyphen-space) as « - » (the existing French docs use a hyphen here).
|
||||
- For headings that are instructions written in imperative in English (e.g. `Go check …`), keep them in imperative in French, using the formal grammar (e.g. `Allez voir …`).
|
||||
|
||||
### French instructions about technical terms
|
||||
|
||||
Do not try to translate everything. In particular, keep common programming terms when that is the established usage in the French docs (e.g. «framework», «endpoint», «plug-in», «payload»). Use French where the existing docs already consistently use French (e.g. «requête», «réponse»).
|
||||
Do not try to translate everything. In particular, keep common programming terms (e.g. `framework`, `endpoint`, `plug-in`, `payload`).
|
||||
|
||||
Keep class names, function names, modules, file names, and CLI commands unchanged.
|
||||
|
||||
### List of English terms and their preferred French translations
|
||||
|
||||
Below is a list of English terms and their preferred French translations, separated by a colon («:»). Use these translations, do not use your own. If an existing translation does not use these terms, update it to use them.
|
||||
Below is a list of English terms and their preferred French translations, separated by a colon (:). Use these translations, do not use your own. If an existing translation does not use these terms, update it to use them.
|
||||
|
||||
* «/// note | Technical Details»: «/// note | Détails techniques»
|
||||
* «/// note»: «/// note | Remarque»
|
||||
* «/// tip»: «/// tip | Astuce»
|
||||
* «/// warning»: «/// warning | Attention»
|
||||
* «/// check»: «/// check | vérifier»
|
||||
* «/// info»: «/// info»
|
||||
- /// note | Technical Details»: /// note | Détails techniques
|
||||
- /// note: /// note | Remarque
|
||||
- /// tip: /// tip | Astuce
|
||||
- /// warning: /// warning | Alertes
|
||||
- /// check: /// check | Vérifications
|
||||
- /// info: /// info
|
||||
|
||||
* «the docs»: «les documents»
|
||||
* «the documentation»: «la documentation»
|
||||
- the docs: les documents
|
||||
- the documentation: la documentation
|
||||
|
||||
* «framework»: «framework» (do not translate to «cadre»)
|
||||
* «performance»: «performance»
|
||||
- Exclude from OpenAPI: Exclusion d'OpenAPI
|
||||
|
||||
* «type hints»: «annotations de type»
|
||||
* «type annotations»: «annotations de type»
|
||||
- framework: framework (do not translate to cadre)
|
||||
- performance: performance
|
||||
|
||||
* «autocomplete»: «autocomplétion»
|
||||
* «autocompletion»: «autocomplétion»
|
||||
- type hints: annotations de type
|
||||
- type annotations: annotations de type
|
||||
|
||||
* «the request» (what the client sends to the server): «la requête»
|
||||
* «the response» (what the server sends back to the client): «la réponse»
|
||||
- autocomplete: autocomplétion
|
||||
- autocompletion: autocomplétion
|
||||
|
||||
* «the request body»: «le corps de la requête»
|
||||
* «the response body»: «le corps de la réponse»
|
||||
- the request (what the client sends to the server): la requête
|
||||
- the response (what the server sends back to the client): la réponse
|
||||
|
||||
* «path operation»: «opération de chemin»
|
||||
* «path operations» (plural): «opérations de chemin»
|
||||
* «path operation function»: «fonction de chemin»
|
||||
* «path operation decorator»: «décorateur d'opération de chemin»
|
||||
- the request body: le corps de la requête
|
||||
- the response body: le corps de la réponse
|
||||
|
||||
* «path parameter»: «paramètre de chemin»
|
||||
* «query parameter»: «paramètre de requête»
|
||||
- path operation: chemin d'accès
|
||||
- path operations (plural): chemins d'accès
|
||||
- path operation function: fonction de chemin d'accès
|
||||
- path operation decorator: décorateur de chemin d'accès
|
||||
|
||||
* «the `Request`»: «`Request`» (keep as code identifier)
|
||||
* «the `Response`»: «`Response`» (keep as code identifier)
|
||||
- path parameter: paramètre de chemin
|
||||
- query parameter: paramètre de requête
|
||||
|
||||
* «deployment»: «déploiement»
|
||||
* «to upgrade»: «mettre à niveau»
|
||||
- the `Request`: `Request` (keep as code identifier)
|
||||
- the `Response`: `Response` (keep as code identifier)
|
||||
|
||||
* «deprecated»: «déprécié»
|
||||
* «to deprecate»: «déprécier»
|
||||
- deployment: déploiement
|
||||
- to upgrade: mettre à niveau
|
||||
|
||||
* «cheat sheet»: «aide-mémoire»
|
||||
* «plug-in»: «plug-in»
|
||||
- deprecated: déprécié
|
||||
- to deprecate: déprécier
|
||||
|
||||
- cheat sheet: aide-mémoire
|
||||
- plug-in: plug-in
|
||||
|
||||
@@ -123,6 +123,68 @@ all = [
|
||||
[project.scripts]
|
||||
fastapi = "fastapi.cli:main"
|
||||
|
||||
[dependency-groups]
|
||||
dev = [
|
||||
{ include-group = "tests" },
|
||||
{ include-group = "docs" },
|
||||
{ include-group = "translations" },
|
||||
"playwright>=1.57.0",
|
||||
"prek==0.2.22",
|
||||
]
|
||||
docs = [
|
||||
{ include-group = "docs-tests" },
|
||||
"black==25.1.0",
|
||||
"cairosvg==2.8.2",
|
||||
"griffe-typingdoc==0.3.0",
|
||||
"griffe-warnings-deprecated==1.1.0",
|
||||
"jieba==0.42.1",
|
||||
"markdown-include-variants==0.0.8",
|
||||
"mdx-include>=1.4.1,<2.0.0",
|
||||
"mkdocs-macros-plugin==1.4.1",
|
||||
"mkdocs-material==9.7.0",
|
||||
"mkdocs-redirects>=1.2.1,<1.3.0",
|
||||
"mkdocstrings[python]==0.30.1",
|
||||
"pillow==11.3.0",
|
||||
"python-slugify==8.0.4",
|
||||
"pyyaml>=5.3.1,<7.0.0",
|
||||
"typer==0.16.0",
|
||||
]
|
||||
docs-tests = [
|
||||
"httpx>=0.23.0,<1.0.0",
|
||||
"ruff==0.14.3",
|
||||
]
|
||||
github-actions = [
|
||||
"httpx>=0.27.0,<1.0.0",
|
||||
"pydantic>=2.5.3,<3.0.0",
|
||||
"pydantic-settings>=2.1.0,<3.0.0",
|
||||
"pygithub>=2.3.0,<3.0.0",
|
||||
"pyyaml>=5.3.1,<7.0.0",
|
||||
"smokeshow>=0.5.0",
|
||||
]
|
||||
tests = [
|
||||
{ include-group = "docs-tests" },
|
||||
"anyio[trio]>=3.2.1,<5.0.0",
|
||||
"coverage[toml]>=6.5.0,<8.0",
|
||||
"dirty-equals==0.9.0",
|
||||
"flask>=1.1.2,<4.0.0",
|
||||
"inline-snapshot>=0.21.1",
|
||||
"mypy==1.14.1",
|
||||
"pwdlib[argon2]>=0.2.1",
|
||||
"pyjwt==2.9.0",
|
||||
"pytest>=7.1.3,<9.0.0",
|
||||
"pytest-codspeed==4.2.0",
|
||||
"pyyaml>=5.3.1,<7.0.0",
|
||||
"sqlmodel==0.0.27",
|
||||
"strawberry-graphql>=0.200.0,<1.0.0",
|
||||
"types-orjson==3.6.2",
|
||||
"types-ujson==5.10.0.20240515",
|
||||
]
|
||||
translations = [
|
||||
"gitpython==3.1.45",
|
||||
"pydantic-ai==0.4.10",
|
||||
"pygithub==2.8.1",
|
||||
]
|
||||
|
||||
[tool.pdm]
|
||||
version = { source = "file", path = "fastapi/__init__.py" }
|
||||
distribution = true
|
||||
@@ -131,11 +193,10 @@ distribution = true
|
||||
source-includes = [
|
||||
"tests/",
|
||||
"docs_src/",
|
||||
"requirements*.txt",
|
||||
"scripts/",
|
||||
# For a test
|
||||
"docs/en/docs/img/favicon.png",
|
||||
]
|
||||
]
|
||||
|
||||
[tool.tiangolo._internal-slim-build.packages.fastapi-slim.project]
|
||||
name = "fastapi-slim"
|
||||
|
||||
@@ -1,4 +0,0 @@
|
||||
# For mkdocstrings and tests
|
||||
httpx >=0.23.0,<1.0.0
|
||||
# For linting and generating docs versions
|
||||
ruff ==0.14.3
|
||||
@@ -1,21 +0,0 @@
|
||||
-e .
|
||||
-r requirements-docs-tests.txt
|
||||
mkdocs-material==9.7.0
|
||||
mdx-include >=1.4.1,<2.0.0
|
||||
mkdocs-redirects>=1.2.1,<1.3.0
|
||||
typer == 0.16.0
|
||||
pyyaml >=5.3.1,<7.0.0
|
||||
# For Material for MkDocs, Chinese search
|
||||
jieba==0.42.1
|
||||
# For image processing by Material for MkDocs
|
||||
pillow==11.3.0
|
||||
# For image processing by Material for MkDocs
|
||||
cairosvg==2.8.2
|
||||
mkdocstrings[python]==0.30.1
|
||||
griffe-typingdoc==0.3.0
|
||||
griffe-warnings-deprecated==1.1.0
|
||||
# For griffe, it formats with black
|
||||
black==25.1.0
|
||||
mkdocs-macros-plugin==1.4.1
|
||||
markdown-include-variants==0.0.8
|
||||
python-slugify==8.0.4
|
||||
@@ -1,6 +0,0 @@
|
||||
PyGithub>=2.3.0,<3.0.0
|
||||
pydantic>=2.5.3,<3.0.0
|
||||
pydantic-settings>=2.1.0,<3.0.0
|
||||
httpx>=0.27.0,<1.0.0
|
||||
pyyaml >=5.3.1,<7.0.0
|
||||
smokeshow
|
||||
@@ -1,18 +0,0 @@
|
||||
-e .[all]
|
||||
-r requirements-docs-tests.txt
|
||||
pytest >=7.1.3,<9.0.0
|
||||
coverage[toml] >= 6.5.0,< 8.0
|
||||
mypy ==1.14.1
|
||||
dirty-equals ==0.9.0
|
||||
sqlmodel==0.0.27
|
||||
flask >=1.1.2,<4.0.0
|
||||
strawberry-graphql >=0.200.0,< 1.0.0
|
||||
anyio[trio] >=3.2.1,<5.0.0
|
||||
PyJWT==2.9.0
|
||||
pyyaml >=5.3.1,<7.0.0
|
||||
pwdlib[argon2] >=0.2.1
|
||||
inline-snapshot>=0.21.1
|
||||
pytest-codspeed==4.2.0
|
||||
# types
|
||||
types-ujson ==5.10.0.20240515
|
||||
types-orjson ==3.6.2
|
||||
@@ -1,3 +0,0 @@
|
||||
pydantic-ai==0.4.10
|
||||
GitPython==3.1.45
|
||||
pygithub==2.8.1
|
||||
@@ -1,7 +0,0 @@
|
||||
-e .[all]
|
||||
-r requirements-tests.txt
|
||||
-r requirements-docs.txt
|
||||
-r requirements-translations.txt
|
||||
prek==0.2.22
|
||||
# For generating screenshots
|
||||
playwright
|
||||
733
scripts/doc_parsing_utils.py
Normal file
733
scripts/doc_parsing_utils.py
Normal file
@@ -0,0 +1,733 @@
|
||||
import re
|
||||
from typing import TypedDict, Union
|
||||
|
||||
CODE_INCLUDE_RE = re.compile(r"^\{\*\s*(\S+)\s*(.*)\*\}$")
|
||||
CODE_INCLUDE_PLACEHOLDER = "<CODE_INCLUDE>"
|
||||
|
||||
HEADER_WITH_PERMALINK_RE = re.compile(r"^(#{1,6}) (.+?)(\s*\{\s*#.*\s*\})?\s*$")
|
||||
HEADER_LINE_RE = re.compile(r"^(#{1,6}) (.+?)(?:\s*\{\s*(#.*)\s*\})?\s*$")
|
||||
|
||||
TIANGOLO_COM = "https://fastapi.tiangolo.com"
|
||||
ASSETS_URL_PREFIXES = ("/img/", "/css/", "/js/")
|
||||
|
||||
MARKDOWN_LINK_RE = re.compile(
|
||||
r"(?<!\\)(?<!\!)" # not an image ![...] and not escaped \[...]
|
||||
r"\[(?P<text>.*?)\]" # link text (non-greedy)
|
||||
r"\("
|
||||
r"(?P<url>[^)\s]+)" # url (no spaces and `)`)
|
||||
r'(?:\s+["\'](?P<title>.*?)["\'])?' # optional title in "" or ''
|
||||
r"\)"
|
||||
r"(?:\s*\{(?P<attrs>[^}]*)\})?" # optional attributes in {}
|
||||
)
|
||||
|
||||
HTML_LINK_RE = re.compile(r"<a\s+[^>]*>.*?</a>")
|
||||
HTML_LINK_TEXT_RE = re.compile(r"<a\b([^>]*)>(.*?)</a>")
|
||||
HTML_LINK_OPEN_TAG_RE = re.compile(r"<a\b([^>]*)>")
|
||||
HTML_ATTR_RE = re.compile(r'(\w+)\s*=\s*([\'"])(.*?)\2')
|
||||
|
||||
CODE_BLOCK_LANG_RE = re.compile(r"^`{3,4}([\w-]*)", re.MULTILINE)
|
||||
|
||||
SLASHES_COMMENT_RE = re.compile(
|
||||
r"^(?P<code>.*?)(?P<comment>(?:(?<= )// .*)|(?:^// .*))?$"
|
||||
)
|
||||
|
||||
HASH_COMMENT_RE = re.compile(r"^(?P<code>.*?)(?P<comment>(?:(?<= )# .*)|(?:^# .*))?$")
|
||||
|
||||
|
||||
class CodeIncludeInfo(TypedDict):
|
||||
line_no: int
|
||||
line: str
|
||||
|
||||
|
||||
class HeaderPermalinkInfo(TypedDict):
|
||||
line_no: int
|
||||
hashes: str
|
||||
title: str
|
||||
permalink: str
|
||||
|
||||
|
||||
class MarkdownLinkInfo(TypedDict):
|
||||
line_no: int
|
||||
url: str
|
||||
text: str
|
||||
title: Union[str, None]
|
||||
attributes: Union[str, None]
|
||||
full_match: str
|
||||
|
||||
|
||||
class HTMLLinkAttribute(TypedDict):
|
||||
name: str
|
||||
quote: str
|
||||
value: str
|
||||
|
||||
|
||||
class HtmlLinkInfo(TypedDict):
|
||||
line_no: int
|
||||
full_tag: str
|
||||
attributes: list[HTMLLinkAttribute]
|
||||
text: str
|
||||
|
||||
|
||||
class MultilineCodeBlockInfo(TypedDict):
|
||||
lang: str
|
||||
start_line_no: int
|
||||
content: list[str]
|
||||
|
||||
|
||||
# Code includes
|
||||
# --------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def extract_code_includes(lines: list[str]) -> list[CodeIncludeInfo]:
|
||||
"""
|
||||
Extract lines that contain code includes.
|
||||
|
||||
Return list of CodeIncludeInfo, where each dict contains:
|
||||
- `line_no` - line number (1-based)
|
||||
- `line` - text of the line
|
||||
"""
|
||||
|
||||
includes: list[CodeIncludeInfo] = []
|
||||
for line_no, line in enumerate(lines, start=1):
|
||||
if CODE_INCLUDE_RE.match(line):
|
||||
includes.append(CodeIncludeInfo(line_no=line_no, line=line))
|
||||
return includes
|
||||
|
||||
|
||||
def replace_code_includes_with_placeholders(text: list[str]) -> list[str]:
|
||||
"""
|
||||
Replace code includes with placeholders.
|
||||
"""
|
||||
|
||||
modified_text = text.copy()
|
||||
includes = extract_code_includes(text)
|
||||
for include in includes:
|
||||
modified_text[include["line_no"] - 1] = CODE_INCLUDE_PLACEHOLDER
|
||||
return modified_text
|
||||
|
||||
|
||||
def replace_placeholders_with_code_includes(
|
||||
text: list[str], original_includes: list[CodeIncludeInfo]
|
||||
) -> list[str]:
|
||||
"""
|
||||
Replace code includes placeholders with actual code includes from the original (English) document.
|
||||
Fail if the number of placeholders does not match the number of original includes.
|
||||
"""
|
||||
|
||||
code_include_lines = [
|
||||
line_no
|
||||
for line_no, line in enumerate(text)
|
||||
if line.strip() == CODE_INCLUDE_PLACEHOLDER
|
||||
]
|
||||
|
||||
if len(code_include_lines) != len(original_includes):
|
||||
raise ValueError(
|
||||
"Number of code include placeholders does not match the number of code includes "
|
||||
"in the original document "
|
||||
f"({len(code_include_lines)} vs {len(original_includes)})"
|
||||
)
|
||||
|
||||
modified_text = text.copy()
|
||||
for i, line_no in enumerate(code_include_lines):
|
||||
modified_text[line_no] = original_includes[i]["line"]
|
||||
|
||||
return modified_text
|
||||
|
||||
|
||||
# Header permalinks
|
||||
# --------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def extract_header_permalinks(lines: list[str]) -> list[HeaderPermalinkInfo]:
|
||||
"""
|
||||
Extract list of header permalinks from the given lines.
|
||||
|
||||
Return list of HeaderPermalinkInfo, where each dict contains:
|
||||
- `line_no` - line number (1-based)
|
||||
- `hashes` - string of hashes representing header level (e.g., "###")
|
||||
- `permalink` - permalink string (e.g., "{#permalink}")
|
||||
"""
|
||||
|
||||
headers: list[HeaderPermalinkInfo] = []
|
||||
in_code_block3 = False
|
||||
in_code_block4 = False
|
||||
|
||||
for line_no, line in enumerate(lines, start=1):
|
||||
if not (in_code_block3 or in_code_block4):
|
||||
if line.startswith("```"):
|
||||
count = len(line) - len(line.lstrip("`"))
|
||||
if count == 3:
|
||||
in_code_block3 = True
|
||||
continue
|
||||
elif count >= 4:
|
||||
in_code_block4 = True
|
||||
continue
|
||||
|
||||
header_match = HEADER_WITH_PERMALINK_RE.match(line)
|
||||
if header_match:
|
||||
hashes, title, permalink = header_match.groups()
|
||||
headers.append(
|
||||
HeaderPermalinkInfo(
|
||||
hashes=hashes, line_no=line_no, permalink=permalink, title=title
|
||||
)
|
||||
)
|
||||
|
||||
elif in_code_block3:
|
||||
if line.startswith("```"):
|
||||
count = len(line) - len(line.lstrip("`"))
|
||||
if count == 3:
|
||||
in_code_block3 = False
|
||||
continue
|
||||
|
||||
elif in_code_block4:
|
||||
if line.startswith("````"):
|
||||
count = len(line) - len(line.lstrip("`"))
|
||||
if count >= 4:
|
||||
in_code_block4 = False
|
||||
continue
|
||||
|
||||
return headers
|
||||
|
||||
|
||||
def remove_header_permalinks(lines: list[str]) -> list[str]:
|
||||
"""
|
||||
Remove permalinks from headers in the given lines.
|
||||
"""
|
||||
|
||||
modified_lines: list[str] = []
|
||||
for line in lines:
|
||||
header_match = HEADER_WITH_PERMALINK_RE.match(line)
|
||||
if header_match:
|
||||
hashes, title, _permalink = header_match.groups()
|
||||
modified_line = f"{hashes} {title}"
|
||||
modified_lines.append(modified_line)
|
||||
else:
|
||||
modified_lines.append(line)
|
||||
return modified_lines
|
||||
|
||||
|
||||
def replace_header_permalinks(
|
||||
text: list[str],
|
||||
header_permalinks: list[HeaderPermalinkInfo],
|
||||
original_header_permalinks: list[HeaderPermalinkInfo],
|
||||
) -> list[str]:
|
||||
"""
|
||||
Replace permalinks in the given text with the permalinks from the original document.
|
||||
|
||||
Fail if the number or level of headers does not match the original.
|
||||
"""
|
||||
|
||||
modified_text: list[str] = text.copy()
|
||||
|
||||
if len(header_permalinks) != len(original_header_permalinks):
|
||||
raise ValueError(
|
||||
"Number of headers with permalinks does not match the number in the "
|
||||
"original document "
|
||||
f"({len(header_permalinks)} vs {len(original_header_permalinks)})"
|
||||
)
|
||||
|
||||
for header_no in range(len(header_permalinks)):
|
||||
header_info = header_permalinks[header_no]
|
||||
original_header_info = original_header_permalinks[header_no]
|
||||
|
||||
if header_info["hashes"] != original_header_info["hashes"]:
|
||||
raise ValueError(
|
||||
"Header levels do not match between document and original document"
|
||||
f" (found {header_info['hashes']}, expected {original_header_info['hashes']})"
|
||||
f" for header №{header_no + 1} in line {header_info['line_no']}"
|
||||
)
|
||||
line_no = header_info["line_no"] - 1
|
||||
hashes = header_info["hashes"]
|
||||
title = header_info["title"]
|
||||
permalink = original_header_info["permalink"]
|
||||
modified_text[line_no] = f"{hashes} {title}{permalink}"
|
||||
|
||||
return modified_text
|
||||
|
||||
|
||||
# Markdown links
|
||||
# --------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def extract_markdown_links(lines: list[str]) -> list[MarkdownLinkInfo]:
|
||||
"""
|
||||
Extract all markdown links from the given lines.
|
||||
|
||||
Return list of MarkdownLinkInfo, where each dict contains:
|
||||
- `line_no` - line number (1-based)
|
||||
- `url` - link URL
|
||||
- `text` - link text
|
||||
- `title` - link title (if any)
|
||||
"""
|
||||
|
||||
links: list[MarkdownLinkInfo] = []
|
||||
for line_no, line in enumerate(lines, start=1):
|
||||
for m in MARKDOWN_LINK_RE.finditer(line):
|
||||
links.append(
|
||||
MarkdownLinkInfo(
|
||||
line_no=line_no,
|
||||
url=m.group("url"),
|
||||
text=m.group("text"),
|
||||
title=m.group("title"),
|
||||
attributes=m.group("attrs"),
|
||||
full_match=m.group(0),
|
||||
)
|
||||
)
|
||||
return links
|
||||
|
||||
|
||||
def _add_lang_code_to_url(url: str, lang_code: str) -> str:
|
||||
if url.startswith(TIANGOLO_COM):
|
||||
rel_url = url[len(TIANGOLO_COM) :]
|
||||
if not rel_url.startswith(ASSETS_URL_PREFIXES):
|
||||
url = url.replace(TIANGOLO_COM, f"{TIANGOLO_COM}/{lang_code}")
|
||||
return url
|
||||
|
||||
|
||||
def _construct_markdown_link(
|
||||
url: str,
|
||||
text: str,
|
||||
title: Union[str, None],
|
||||
attributes: Union[str, None],
|
||||
lang_code: str,
|
||||
) -> str:
|
||||
"""
|
||||
Construct a markdown link, adjusting the URL for the given language code if needed.
|
||||
"""
|
||||
url = _add_lang_code_to_url(url, lang_code)
|
||||
|
||||
if title:
|
||||
link = f'[{text}]({url} "{title}")'
|
||||
else:
|
||||
link = f"[{text}]({url})"
|
||||
|
||||
if attributes:
|
||||
link += f"{{{attributes}}}"
|
||||
|
||||
return link
|
||||
|
||||
|
||||
def replace_markdown_links(
|
||||
text: list[str],
|
||||
links: list[MarkdownLinkInfo],
|
||||
original_links: list[MarkdownLinkInfo],
|
||||
lang_code: str,
|
||||
) -> list[str]:
|
||||
"""
|
||||
Replace markdown links in the given text with the original links.
|
||||
|
||||
Fail if the number of links does not match the original.
|
||||
"""
|
||||
|
||||
if len(links) != len(original_links):
|
||||
raise ValueError(
|
||||
"Number of markdown links does not match the number in the "
|
||||
"original document "
|
||||
f"({len(links)} vs {len(original_links)})"
|
||||
)
|
||||
|
||||
modified_text = text.copy()
|
||||
for i, link_info in enumerate(links):
|
||||
link_text = link_info["text"]
|
||||
link_title = link_info["title"]
|
||||
original_link_info = original_links[i]
|
||||
|
||||
# Replace
|
||||
replacement_link = _construct_markdown_link(
|
||||
url=original_link_info["url"],
|
||||
text=link_text,
|
||||
title=link_title,
|
||||
attributes=original_link_info["attributes"],
|
||||
lang_code=lang_code,
|
||||
)
|
||||
line_no = link_info["line_no"] - 1
|
||||
modified_line = modified_text[line_no]
|
||||
modified_line = modified_line.replace(
|
||||
link_info["full_match"], replacement_link, 1
|
||||
)
|
||||
modified_text[line_no] = modified_line
|
||||
|
||||
return modified_text
|
||||
|
||||
|
||||
# HTML links
|
||||
# --------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def extract_html_links(lines: list[str]) -> list[HtmlLinkInfo]:
|
||||
"""
|
||||
Extract all HTML links from the given lines.
|
||||
|
||||
Return list of HtmlLinkInfo, where each dict contains:
|
||||
- `line_no` - line number (1-based)
|
||||
- `full_tag` - full HTML link tag
|
||||
- `attributes` - list of HTMLLinkAttribute (name, quote, value)
|
||||
- `text` - link text
|
||||
"""
|
||||
|
||||
links = []
|
||||
for line_no, line in enumerate(lines, start=1):
|
||||
for html_link in HTML_LINK_RE.finditer(line):
|
||||
link_str = html_link.group(0)
|
||||
|
||||
link_text_match = HTML_LINK_TEXT_RE.match(link_str)
|
||||
assert link_text_match is not None
|
||||
link_text = link_text_match.group(2)
|
||||
assert isinstance(link_text, str)
|
||||
|
||||
link_open_tag_match = HTML_LINK_OPEN_TAG_RE.match(link_str)
|
||||
assert link_open_tag_match is not None
|
||||
link_open_tag = link_open_tag_match.group(1)
|
||||
assert isinstance(link_open_tag, str)
|
||||
|
||||
attributes: list[HTMLLinkAttribute] = []
|
||||
for attr_name, attr_quote, attr_value in re.findall(
|
||||
HTML_ATTR_RE, link_open_tag
|
||||
):
|
||||
assert isinstance(attr_name, str)
|
||||
assert isinstance(attr_quote, str)
|
||||
assert isinstance(attr_value, str)
|
||||
attributes.append(
|
||||
HTMLLinkAttribute(
|
||||
name=attr_name, quote=attr_quote, value=attr_value
|
||||
)
|
||||
)
|
||||
links.append(
|
||||
HtmlLinkInfo(
|
||||
line_no=line_no,
|
||||
full_tag=link_str,
|
||||
attributes=attributes,
|
||||
text=link_text,
|
||||
)
|
||||
)
|
||||
return links
|
||||
|
||||
|
||||
def _construct_html_link(
|
||||
link_text: str,
|
||||
attributes: list[HTMLLinkAttribute],
|
||||
lang_code: str,
|
||||
) -> str:
|
||||
"""
|
||||
Reconstruct HTML link, adjusting the URL for the given language code if needed.
|
||||
"""
|
||||
|
||||
attributes_upd: list[HTMLLinkAttribute] = []
|
||||
for attribute in attributes:
|
||||
if attribute["name"] == "href":
|
||||
original_url = attribute["value"]
|
||||
url = _add_lang_code_to_url(original_url, lang_code)
|
||||
attributes_upd.append(
|
||||
HTMLLinkAttribute(name="href", quote=attribute["quote"], value=url)
|
||||
)
|
||||
else:
|
||||
attributes_upd.append(attribute)
|
||||
|
||||
attrs_str = " ".join(
|
||||
f"{attribute['name']}={attribute['quote']}{attribute['value']}{attribute['quote']}"
|
||||
for attribute in attributes_upd
|
||||
)
|
||||
return f"<a {attrs_str}>{link_text}</a>"
|
||||
|
||||
|
||||
def replace_html_links(
|
||||
text: list[str],
|
||||
links: list[HtmlLinkInfo],
|
||||
original_links: list[HtmlLinkInfo],
|
||||
lang_code: str,
|
||||
) -> list[str]:
|
||||
"""
|
||||
Replace HTML links in the given text with the links from the original document.
|
||||
|
||||
Adjust URLs for the given language code.
|
||||
Fail if the number of links does not match the original.
|
||||
"""
|
||||
|
||||
if len(links) != len(original_links):
|
||||
raise ValueError(
|
||||
"Number of HTML links does not match the number in the "
|
||||
"original document "
|
||||
f"({len(links)} vs {len(original_links)})"
|
||||
)
|
||||
|
||||
modified_text = text.copy()
|
||||
for link_index, link in enumerate(links):
|
||||
original_link_info = original_links[link_index]
|
||||
|
||||
# Replace in the document text
|
||||
replacement_link = _construct_html_link(
|
||||
link_text=link["text"],
|
||||
attributes=original_link_info["attributes"],
|
||||
lang_code=lang_code,
|
||||
)
|
||||
line_no = link["line_no"] - 1
|
||||
modified_text[line_no] = modified_text[line_no].replace(
|
||||
link["full_tag"], replacement_link, 1
|
||||
)
|
||||
|
||||
return modified_text
|
||||
|
||||
|
||||
# Multiline code blocks
|
||||
# --------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def get_code_block_lang(line: str) -> str:
|
||||
match = CODE_BLOCK_LANG_RE.match(line)
|
||||
if match:
|
||||
return match.group(1)
|
||||
return ""
|
||||
|
||||
|
||||
def extract_multiline_code_blocks(text: list[str]) -> list[MultilineCodeBlockInfo]:
|
||||
blocks: list[MultilineCodeBlockInfo] = []
|
||||
|
||||
in_code_block3 = False
|
||||
in_code_block4 = False
|
||||
current_block_lang = ""
|
||||
current_block_start_line = -1
|
||||
current_block_lines = []
|
||||
|
||||
for line_no, line in enumerate(text, start=1):
|
||||
stripped = line.lstrip()
|
||||
|
||||
# --- Detect opening fence ---
|
||||
if not (in_code_block3 or in_code_block4):
|
||||
if stripped.startswith("```"):
|
||||
current_block_start_line = line_no
|
||||
count = len(stripped) - len(stripped.lstrip("`"))
|
||||
if count == 3:
|
||||
in_code_block3 = True
|
||||
current_block_lang = get_code_block_lang(stripped)
|
||||
current_block_lines = [line]
|
||||
continue
|
||||
elif count >= 4:
|
||||
in_code_block4 = True
|
||||
current_block_lang = get_code_block_lang(stripped)
|
||||
current_block_lines = [line]
|
||||
continue
|
||||
|
||||
# --- Detect closing fence ---
|
||||
elif in_code_block3:
|
||||
if stripped.startswith("```"):
|
||||
count = len(stripped) - len(stripped.lstrip("`"))
|
||||
if count == 3:
|
||||
current_block_lines.append(line)
|
||||
blocks.append(
|
||||
MultilineCodeBlockInfo(
|
||||
lang=current_block_lang,
|
||||
start_line_no=current_block_start_line,
|
||||
content=current_block_lines,
|
||||
)
|
||||
)
|
||||
in_code_block3 = False
|
||||
current_block_lang = ""
|
||||
current_block_start_line = -1
|
||||
current_block_lines = []
|
||||
continue
|
||||
current_block_lines.append(line)
|
||||
|
||||
elif in_code_block4:
|
||||
if stripped.startswith("````"):
|
||||
count = len(stripped) - len(stripped.lstrip("`"))
|
||||
if count >= 4:
|
||||
current_block_lines.append(line)
|
||||
blocks.append(
|
||||
MultilineCodeBlockInfo(
|
||||
lang=current_block_lang,
|
||||
start_line_no=current_block_start_line,
|
||||
content=current_block_lines,
|
||||
)
|
||||
)
|
||||
in_code_block4 = False
|
||||
current_block_lang = ""
|
||||
current_block_start_line = -1
|
||||
current_block_lines = []
|
||||
continue
|
||||
current_block_lines.append(line)
|
||||
|
||||
return blocks
|
||||
|
||||
|
||||
def _split_hash_comment(line: str) -> tuple[str, Union[str, None]]:
|
||||
match = HASH_COMMENT_RE.match(line)
|
||||
if match:
|
||||
code = match.group("code").rstrip()
|
||||
comment = match.group("comment")
|
||||
return code, comment
|
||||
return line.rstrip(), None
|
||||
|
||||
|
||||
def _split_slashes_comment(line: str) -> tuple[str, Union[str, None]]:
|
||||
match = SLASHES_COMMENT_RE.match(line)
|
||||
if match:
|
||||
code = match.group("code").rstrip()
|
||||
comment = match.group("comment")
|
||||
return code, comment
|
||||
return line, None
|
||||
|
||||
|
||||
def replace_multiline_code_block(
|
||||
block_a: MultilineCodeBlockInfo, block_b: MultilineCodeBlockInfo
|
||||
) -> list[str]:
|
||||
"""
|
||||
Replace multiline code block `a` with block `b` leaving comments intact.
|
||||
|
||||
Syntax of comments depends on the language of the code block.
|
||||
Raises ValueError if the blocks are not compatible (different languages or different number of lines).
|
||||
"""
|
||||
|
||||
start_line = block_a["start_line_no"]
|
||||
end_line_no = start_line + len(block_a["content"]) - 1
|
||||
|
||||
if block_a["lang"] != block_b["lang"]:
|
||||
raise ValueError(
|
||||
f"Code block (lines {start_line}-{end_line_no}) "
|
||||
"has different language than the original block "
|
||||
f"('{block_a['lang']}' vs '{block_b['lang']}')"
|
||||
)
|
||||
if len(block_a["content"]) != len(block_b["content"]):
|
||||
raise ValueError(
|
||||
f"Code block (lines {start_line}-{end_line_no}) "
|
||||
"has different number of lines than the original block "
|
||||
f"({len(block_a['content'])} vs {len(block_b['content'])})"
|
||||
)
|
||||
|
||||
block_language = block_a["lang"].lower()
|
||||
if block_language in {"mermaid"}:
|
||||
if block_a != block_b:
|
||||
print(
|
||||
f"Skipping mermaid code block replacement (lines {start_line}-{end_line_no}). "
|
||||
"This should be checked manually."
|
||||
)
|
||||
return block_a["content"].copy() # We don't handle mermaid code blocks for now
|
||||
|
||||
code_block: list[str] = []
|
||||
for line_a, line_b in zip(block_a["content"], block_b["content"]):
|
||||
line_a_comment: Union[str, None] = None
|
||||
line_b_comment: Union[str, None] = None
|
||||
|
||||
# Handle comments based on language
|
||||
if block_language in {
|
||||
"python",
|
||||
"py",
|
||||
"sh",
|
||||
"bash",
|
||||
"dockerfile",
|
||||
"requirements",
|
||||
"gitignore",
|
||||
"toml",
|
||||
"yaml",
|
||||
"yml",
|
||||
"hash-style-comments",
|
||||
}:
|
||||
_line_a_code, line_a_comment = _split_hash_comment(line_a)
|
||||
_line_b_code, line_b_comment = _split_hash_comment(line_b)
|
||||
res_line = line_b
|
||||
if line_b_comment:
|
||||
res_line = res_line.replace(line_b_comment, line_a_comment, 1)
|
||||
code_block.append(res_line)
|
||||
elif block_language in {"console", "json", "slash-style-comments"}:
|
||||
_line_a_code, line_a_comment = _split_slashes_comment(line_a)
|
||||
_line_b_code, line_b_comment = _split_slashes_comment(line_b)
|
||||
res_line = line_b
|
||||
if line_b_comment:
|
||||
res_line = res_line.replace(line_b_comment, line_a_comment, 1)
|
||||
code_block.append(res_line)
|
||||
else:
|
||||
code_block.append(line_b)
|
||||
|
||||
return code_block
|
||||
|
||||
|
||||
def replace_multiline_code_blocks_in_text(
|
||||
text: list[str],
|
||||
code_blocks: list[MultilineCodeBlockInfo],
|
||||
original_code_blocks: list[MultilineCodeBlockInfo],
|
||||
) -> list[str]:
|
||||
"""
|
||||
Update each code block in `text` with the corresponding code block from
|
||||
`original_code_blocks` with comments taken from `code_blocks`.
|
||||
|
||||
Raises ValueError if the number, language, or shape of code blocks do not match.
|
||||
"""
|
||||
|
||||
if len(code_blocks) != len(original_code_blocks):
|
||||
raise ValueError(
|
||||
"Number of code blocks does not match the number in the original document "
|
||||
f"({len(code_blocks)} vs {len(original_code_blocks)})"
|
||||
)
|
||||
|
||||
modified_text = text.copy()
|
||||
for block, original_block in zip(code_blocks, original_code_blocks):
|
||||
updated_content = replace_multiline_code_block(block, original_block)
|
||||
|
||||
start_line_index = block["start_line_no"] - 1
|
||||
for i, updated_line in enumerate(updated_content):
|
||||
modified_text[start_line_index + i] = updated_line
|
||||
|
||||
return modified_text
|
||||
|
||||
|
||||
# All checks
|
||||
# --------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def check_translation(
|
||||
doc_lines: list[str],
|
||||
en_doc_lines: list[str],
|
||||
lang_code: str,
|
||||
auto_fix: bool,
|
||||
path: str,
|
||||
) -> list[str]:
|
||||
# Fix code includes
|
||||
en_code_includes = extract_code_includes(en_doc_lines)
|
||||
doc_lines_with_placeholders = replace_code_includes_with_placeholders(doc_lines)
|
||||
fixed_doc_lines = replace_placeholders_with_code_includes(
|
||||
doc_lines_with_placeholders, en_code_includes
|
||||
)
|
||||
if auto_fix and (fixed_doc_lines != doc_lines):
|
||||
print(f"Fixing code includes in: {path}")
|
||||
doc_lines = fixed_doc_lines
|
||||
|
||||
# Fix permalinks
|
||||
en_permalinks = extract_header_permalinks(en_doc_lines)
|
||||
doc_permalinks = extract_header_permalinks(doc_lines)
|
||||
fixed_doc_lines = replace_header_permalinks(
|
||||
doc_lines, doc_permalinks, en_permalinks
|
||||
)
|
||||
if auto_fix and (fixed_doc_lines != doc_lines):
|
||||
print(f"Fixing header permalinks in: {path}")
|
||||
doc_lines = fixed_doc_lines
|
||||
|
||||
# Fix markdown links
|
||||
en_markdown_links = extract_markdown_links(en_doc_lines)
|
||||
doc_markdown_links = extract_markdown_links(doc_lines)
|
||||
fixed_doc_lines = replace_markdown_links(
|
||||
doc_lines, doc_markdown_links, en_markdown_links, lang_code
|
||||
)
|
||||
if auto_fix and (fixed_doc_lines != doc_lines):
|
||||
print(f"Fixing markdown links in: {path}")
|
||||
doc_lines = fixed_doc_lines
|
||||
|
||||
# Fix HTML links
|
||||
en_html_links = extract_html_links(en_doc_lines)
|
||||
doc_html_links = extract_html_links(doc_lines)
|
||||
fixed_doc_lines = replace_html_links(
|
||||
doc_lines, doc_html_links, en_html_links, lang_code
|
||||
)
|
||||
if auto_fix and (fixed_doc_lines != doc_lines):
|
||||
print(f"Fixing HTML links in: {path}")
|
||||
doc_lines = fixed_doc_lines
|
||||
|
||||
# Fix multiline code blocks
|
||||
en_code_blocks = extract_multiline_code_blocks(en_doc_lines)
|
||||
doc_code_blocks = extract_multiline_code_blocks(doc_lines)
|
||||
fixed_doc_lines = replace_multiline_code_blocks_in_text(
|
||||
doc_lines, doc_code_blocks, en_code_blocks
|
||||
)
|
||||
if auto_fix and (fixed_doc_lines != doc_lines):
|
||||
print(f"Fixing multiline code blocks in: {path}")
|
||||
doc_lines = fixed_doc_lines
|
||||
|
||||
return doc_lines
|
||||
@@ -239,7 +239,7 @@ def generate_readme() -> None:
|
||||
Generate README.md content from main index.md
|
||||
"""
|
||||
readme_path = Path("README.md")
|
||||
old_content = readme_path.read_text()
|
||||
old_content = readme_path.read_text("utf-8")
|
||||
new_content = generate_readme_content()
|
||||
if new_content != old_content:
|
||||
print("README.md outdated from the latest index.md")
|
||||
|
||||
@@ -316,7 +316,7 @@ def main() -> None:
|
||||
raise RuntimeError(
|
||||
f"No github event file available at: {settings.github_event_path}"
|
||||
)
|
||||
contents = settings.github_event_path.read_text()
|
||||
contents = settings.github_event_path.read_text("utf-8")
|
||||
github_event = PartialGitHubEvent.model_validate_json(contents)
|
||||
logging.info(f"Using GitHub event: {github_event}")
|
||||
number = (
|
||||
|
||||
@@ -4,4 +4,4 @@ set -e
|
||||
set -x
|
||||
|
||||
export PYTHONPATH=./docs_src
|
||||
coverage run -m pytest tests ${@}
|
||||
coverage run -m pytest tests scripts/tests/ ${@}
|
||||
|
||||
42
scripts/tests/test_translation_fixer/conftest.py
Normal file
42
scripts/tests/test_translation_fixer/conftest.py
Normal file
@@ -0,0 +1,42 @@
|
||||
import shutil
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
skip_on_windows = pytest.mark.skipif(
|
||||
sys.platform == "win32", reason="Skipping on Windows"
|
||||
)
|
||||
|
||||
|
||||
def pytest_collection_modifyitems(items: list[pytest.Item]) -> None:
|
||||
for item in items:
|
||||
item.add_marker(skip_on_windows)
|
||||
|
||||
|
||||
@pytest.fixture(name="runner")
|
||||
def get_runner():
|
||||
runner = CliRunner()
|
||||
with runner.isolated_filesystem():
|
||||
yield runner
|
||||
|
||||
|
||||
@pytest.fixture(name="root_dir")
|
||||
def prepare_paths(runner):
|
||||
docs_dir = Path("docs")
|
||||
en_docs_dir = docs_dir / "en" / "docs"
|
||||
lang_docs_dir = docs_dir / "lang" / "docs"
|
||||
en_docs_dir.mkdir(parents=True, exist_ok=True)
|
||||
lang_docs_dir.mkdir(parents=True, exist_ok=True)
|
||||
yield Path.cwd()
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def copy_test_files(root_dir: Path, request: pytest.FixtureRequest):
|
||||
en_file_path = Path(request.param[0])
|
||||
translation_file_path = Path(request.param[1])
|
||||
shutil.copy(str(en_file_path), str(root_dir / "docs" / "en" / "docs" / "doc.md"))
|
||||
shutil.copy(
|
||||
str(translation_file_path), str(root_dir / "docs" / "lang" / "docs" / "doc.md")
|
||||
)
|
||||
@@ -0,0 +1,44 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
```toml
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Mermaid diagram
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,45 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
```toml
|
||||
# Extra line
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,45 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
The following block is missing first line:
|
||||
|
||||
```toml
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,44 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
```toml
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,44 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
```toml
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|требует| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,50 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
```toml
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
Extra code block
|
||||
|
||||
```
|
||||
$ cd my_project
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,41 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
Missing code block...
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,46 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
The following block has wrong language code (should be TOML):
|
||||
|
||||
```yaml
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,46 @@
|
||||
# Code blocks { #code-blocks }
|
||||
|
||||
Some text
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
Some more text
|
||||
|
||||
The following block has wrong language code (should be TOML):
|
||||
|
||||
```
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
And more text
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
And even more text
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
Диаграма Mermaid
|
||||
|
||||
```mermaid
|
||||
flowchart LR
|
||||
stone(philosophers-stone) -->|requires| harry-1[harry v1]
|
||||
```
|
||||
@@ -0,0 +1,58 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_code_blocks/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_lines_number_gt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_gt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_lines_number_gt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Code block (lines 14-18) has different number of lines than the original block (5 vs 4)"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_lines_number_lt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_lt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
# assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_lines_number_lt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Code block (lines 16-18) has different number of lines than the original block (3 vs 4)"
|
||||
) in result.output
|
||||
@@ -0,0 +1,59 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_code_blocks/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_mermaid_translated.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_translated(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 0, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(
|
||||
f"{data_path}/translated_doc_mermaid_translated.md"
|
||||
).read_text("utf-8")
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert (
|
||||
"Skipping mermaid code block replacement (lines 41-44). This should be checked manually."
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[
|
||||
(
|
||||
f"{data_path}/en_doc.md",
|
||||
f"{data_path}/translated_doc_mermaid_not_translated.md",
|
||||
)
|
||||
],
|
||||
indirect=True,
|
||||
)
|
||||
def test_not_translated(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 0, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(
|
||||
f"{data_path}/translated_doc_mermaid_not_translated.md"
|
||||
).read_text("utf-8")
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert ("Skipping mermaid code block replacement") not in result.output
|
||||
@@ -0,0 +1,60 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_code_blocks/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_gt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_gt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_gt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of code blocks does not match the number "
|
||||
"in the original document (6 vs 5)"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_lt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_lt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
# assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_lt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of code blocks does not match the number "
|
||||
"in the original document (4 vs 5)"
|
||||
) in result.output
|
||||
@@ -0,0 +1,58 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_code_blocks/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_wrong_lang_code.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_wrong_lang_code_1(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_wrong_lang_code.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Code block (lines 16-19) has different language than the original block ('yaml' vs 'toml')"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_wrong_lang_code_2.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_wrong_lang_code_2(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(
|
||||
f"{data_path}/translated_doc_wrong_lang_code_2.md"
|
||||
).read_text("utf-8")
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Code block (lines 16-19) has different language than the original block ('' vs 'toml')"
|
||||
) in result.output
|
||||
@@ -0,0 +1,13 @@
|
||||
# Header
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
Some text
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
Some more text
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] hl[31:33] *}
|
||||
|
||||
And even more text
|
||||
@@ -0,0 +1,15 @@
|
||||
# Header
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
Some text
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
Some more text
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] hl[31:33] *}
|
||||
|
||||
And even more text
|
||||
|
||||
{* ../../docs_src/python_types/tutorial001_py39.py *}
|
||||
@@ -0,0 +1,13 @@
|
||||
# Header
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
Some text
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
Some more text
|
||||
|
||||
...
|
||||
|
||||
And even more text
|
||||
@@ -0,0 +1,60 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_code_includes/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_gt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_gt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_gt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of code include placeholders does not match the number of code includes "
|
||||
"in the original document (4 vs 3)"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_lt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_lt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_lt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of code include placeholders does not match the number of code includes "
|
||||
"in the original document (2 vs 3)"
|
||||
) in result.output
|
||||
@@ -0,0 +1,244 @@
|
||||
# Test translation fixer tool { #test-translation-fixer }
|
||||
|
||||
## Code blocks with and without comments { #code-blocks-with-and-without-comments }
|
||||
|
||||
This is a test page for the translation fixer tool.
|
||||
|
||||
### Code blocks with comments { #code-blocks-with-comments }
|
||||
|
||||
The following code blocks include comments in different styles.
|
||||
Fixer tool should fix content, but preserve comments correctly.
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
# Comment with indentation
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
```toml
|
||||
# This is a sample TOML code block
|
||||
title = "TOML Example" # Title of the document
|
||||
```
|
||||
|
||||
```console
|
||||
// Use the command "live" and pass the language code as a CLI argument
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
// This is a sample JSON code block
|
||||
"greeting": "Hello, world!" // Greeting
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Code blocks with comments where language uses different comment styles { #code-blocks-with-different-comment-styles }
|
||||
|
||||
The following code blocks include comments in different styles based on the language.
|
||||
Fixer tool will not preserve comments in these blocks.
|
||||
|
||||
```json
|
||||
{
|
||||
# This is a sample JSON code block
|
||||
"greeting": "Hello, world!" # Print greeting
|
||||
}
|
||||
```
|
||||
|
||||
```console
|
||||
# This is a sample console code block
|
||||
$ echo "Hello, world!" # Print greeting
|
||||
```
|
||||
|
||||
```toml
|
||||
// This is a sample TOML code block
|
||||
title = "TOML Example" // Title of the document
|
||||
```
|
||||
|
||||
|
||||
### Code blocks with comments with unsupported languages or without language specified { #code-blocks-with-unsupported-languages }
|
||||
|
||||
The following code blocks use unsupported languages for comment preservation.
|
||||
Fixer tool will not preserve comments in these blocks.
|
||||
|
||||
```javascript
|
||||
// This is a sample JavaScript code block
|
||||
console.log("Hello, world!"); // Print greeting
|
||||
```
|
||||
|
||||
```
|
||||
# This is a sample console code block
|
||||
$ echo "Hello, world!" # Print greeting
|
||||
```
|
||||
|
||||
```
|
||||
// This is a sample console code block
|
||||
$ echo "Hello, world!" // Print greeting
|
||||
```
|
||||
|
||||
|
||||
### Code blocks with comments that don't follow pattern { #code-blocks-with-comments-without-pattern }
|
||||
|
||||
Fixer tool expects comments that follow specific pattern:
|
||||
|
||||
- For hash-style comments: comment starts with `# ` (hash following by whitespace) in the beginning of the string or after a whitespace.
|
||||
- For slash-style comments: comment starts with `// ` (two slashes following by whitespace) in the beginning of the string or after a whitespace.
|
||||
|
||||
If comment doesn't follow this pattern, fixer tool will not preserve it.
|
||||
|
||||
```python
|
||||
#Function declaration
|
||||
def hello_world():# Print greeting
|
||||
print("Hello, world!") #Print greeting without space after hash
|
||||
```
|
||||
|
||||
```console
|
||||
//Function declaration
|
||||
def hello_world():// Print greeting
|
||||
print("Hello, world!") //Print greeting without space after slashes
|
||||
```
|
||||
|
||||
## Code blocks with quadruple backticks { #code-blocks-with-quadruple-backticks }
|
||||
|
||||
The following code block uses quadruple backticks.
|
||||
|
||||
````python
|
||||
# Hello world function
|
||||
def hello_world():
|
||||
print("Hello, world!") # Print greeting
|
||||
````
|
||||
|
||||
### Backticks number mismatch is fixable { #backticks-number-mismatch-is-fixable }
|
||||
|
||||
The following code block has triple backticks in the original document, but quadruple backticks in the translated document.
|
||||
It will be fixed by the fixer tool (will convert to triple backticks).
|
||||
|
||||
```Python
|
||||
# Some Python code
|
||||
```
|
||||
|
||||
### Triple backticks inside quadruple backticks { #triple-backticks-inside-quadruple-backticks }
|
||||
|
||||
Comments inside nested code block will NOT be preserved.
|
||||
|
||||
````
|
||||
Here is a code block with quadruple backticks that contains triple backticks inside:
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
````
|
||||
|
||||
# Code includes { #code-includes }
|
||||
|
||||
## Simple code includes { #simple-code-includes }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial001_py39.py *}
|
||||
|
||||
{* ../../docs_src/python_types/tutorial002_py39.py *}
|
||||
|
||||
|
||||
## Code includes with highlighting { #code-includes-with-highlighting }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial002_py39.py hl[1] *}
|
||||
|
||||
{* ../../docs_src/python_types/tutorial006_py39.py hl[10] *}
|
||||
|
||||
|
||||
## Code includes with line ranges { #code-includes-with-line-ranges }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] *}
|
||||
|
||||
|
||||
## Code includes with line ranges and highlighting { #code-includes-with-line-ranges-and-highlighting }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] hl[31:33] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial015_an_py310.py ln[10:15] hl[12:14] *}
|
||||
|
||||
|
||||
## Code includes qith title { #code-includes-with-title }
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/routers/users.py hl[1,3] title["app/routers/users.py"] *}
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
## Code includes with unknown attributes { #code-includes-with-unknown-attributes }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial001_py39.py unknown[123] *}
|
||||
|
||||
## Some more code includes to test fixing { #some-more-code-includes-to-test-fixing }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] hl[31:33] *}
|
||||
|
||||
|
||||
|
||||
# Links { #links }
|
||||
|
||||
## Markdown-style links { #markdown-style-links }
|
||||
|
||||
This is a [Markdown link](https://example.com) to an external site.
|
||||
|
||||
This is a link with attributes: [**FastAPI** Project Generators](project-generation.md){.internal-link target=_blank}
|
||||
|
||||
This is a link to the main FastAPI site: [FastAPI](https://fastapi.tiangolo.com) - tool should add language code to the URL.
|
||||
|
||||
This is a link to one of the pages on FastAPI site: [How to](https://fastapi.tiangolo.com/how-to/) - tool should add language code to the URL.
|
||||
|
||||
Link to test wrong attribute: [**FastAPI** Project Generators](project-generation.md){.internal-link} - tool should fix the attribute.
|
||||
|
||||
Link with a title: [Example](https://example.com "Example site") - URL will be fixed, title preserved.
|
||||
|
||||
### Markdown link to static assets { #markdown-link-to-static-assets }
|
||||
|
||||
These are links to static assets:
|
||||
|
||||
* [FastAPI Logo](https://fastapi.tiangolo.com/img/fastapi-logo.png)
|
||||
* [FastAPI CSS](https://fastapi.tiangolo.com/css/fastapi.css)
|
||||
* [FastAPI JS](https://fastapi.tiangolo.com/js/fastapi.js)
|
||||
|
||||
Tool should NOT add language code to their URLs.
|
||||
|
||||
## HTML-style links { #html-style-links }
|
||||
|
||||
This is an <a href="https://example.com" target="_blank" class="external-link">HTML link</a> to an external site.
|
||||
|
||||
This is an <a href="https://fastapi.tiangolo.com">link to the main FastAPI site</a> - tool should add language code to the URL.
|
||||
|
||||
This is an <a href="https://fastapi.tiangolo.com/how-to/">link to one of the pages on FastAPI site</a> - tool should add language code to the URL.
|
||||
|
||||
Link to test wrong attribute: <a href="project-generation.md" class="internal-link">**FastAPI** Project Generators</a> - tool should fix the attribute.
|
||||
|
||||
### HTML links to static assets { #html-links-to-static-assets }
|
||||
|
||||
These are links to static assets:
|
||||
|
||||
* <a href="https://fastapi.tiangolo.com/img/fastapi-logo.png">FastAPI Logo</a>
|
||||
* <a href="https://fastapi.tiangolo.com/css/fastapi.css">FastAPI CSS</a>
|
||||
* <a href="https://fastapi.tiangolo.com/js/fastapi.js">FastAPI JS</a>
|
||||
|
||||
Tool should NOT add language code to their URLs.
|
||||
|
||||
# Header (with HTML link to <a href="https://tiangolo.com">tiangolo.com</a>) { #header-with-html-link-to-tiangolo-com }
|
||||
|
||||
#Not a header
|
||||
|
||||
```Python
|
||||
# Also not a header
|
||||
```
|
||||
|
||||
Some text
|
||||
@@ -0,0 +1,240 @@
|
||||
# Тестовый инструмент исправления переводов { #test-translation-fixer }
|
||||
|
||||
## Блоки кода с комментариями и без комментариев { #code-blocks-with-and-without-comments }
|
||||
|
||||
Это тестовая страница для инструмента исправления переводов.
|
||||
|
||||
### Блоки кода с комментариями { #code-blocks-with-comments }
|
||||
|
||||
Следующие блоки кода содержат комментарии в разных стилях.
|
||||
Инструмент исправления должен исправлять содержимое, но корректно сохранять комментарии.
|
||||
|
||||
```python
|
||||
# Это пример блока кода на Python
|
||||
def hello_world():
|
||||
# Комментарий с отступом
|
||||
print("Hello, world!") # Печать приветствия
|
||||
```
|
||||
|
||||
```toml
|
||||
# Это пример блока кода на TOML
|
||||
title = "TOML Example" # Заголовок документа
|
||||
```
|
||||
|
||||
```console
|
||||
// Используйте команду "live" и передайте код языка в качестве аргумента CLI
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
// Это пример блока кода на JSON
|
||||
"greeting": "Hello, world!" // Печать приветствия
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Блоки кода с комментариями, где язык использует другие стили комментариев { #code-blocks-with-different-comment-styles }
|
||||
|
||||
Следующие блоки кода содержат комментарии в разных стилях в зависимости от языка.
|
||||
Инструмент исправления не будет сохранять комментарии в этих блоках.
|
||||
|
||||
```json
|
||||
{
|
||||
# Это пример блока кода на JSON
|
||||
"greeting": "Hello, world!" # Печать приветствия
|
||||
}
|
||||
```
|
||||
|
||||
```console
|
||||
# Это пример блока кода консоли
|
||||
$ echo "Hello, world!" # Печать приветствия
|
||||
```
|
||||
|
||||
```toml
|
||||
// Это пример блока кода на TOML
|
||||
title = "TOML Example" // Заголовок документа
|
||||
```
|
||||
|
||||
### Блоки кода с комментариями на неподдерживаемых языках или без указания языка { #code-blocks-with-unsupported-languages }
|
||||
|
||||
Следующие блоки кода используют неподдерживаемые языки для сохранения комментариев.
|
||||
Инструмент исправления не будет сохранять комментарии в этих блоках.
|
||||
|
||||
```javascript
|
||||
// Это пример блока кода на JavaScript
|
||||
console.log("Hello, world!"); // Печать приветствия
|
||||
```
|
||||
|
||||
```
|
||||
# Это пример блока кода консоли
|
||||
$ echo "Hello, world!" # Печать приветствия
|
||||
```
|
||||
|
||||
```
|
||||
// Это пример блока кода консоли
|
||||
$ echo "Hello, world!" // Печать приветствия
|
||||
```
|
||||
|
||||
### Блоки кода с комментариями, которые не соответствуют шаблону { #code-blocks-with-comments-without-pattern }
|
||||
|
||||
Инструмент исправления ожидает комментарии, которые соответствуют определённому шаблону:
|
||||
|
||||
- Для комментариев в стиле с решёткой: комментарий начинается с `# ` (решётка, затем пробел) в начале строки или после пробела.
|
||||
- Для комментариев в стиле со слешами: комментарий начинается с `// ` (два слеша, затем пробел) в начале строки или после пробела.
|
||||
|
||||
Если комментарий не соответствует этому шаблону, инструмент исправления не будет его сохранять.
|
||||
|
||||
```python
|
||||
#Объявление функции
|
||||
def hello_world():# Печать приветствия
|
||||
print("Hello, world!") #Печать приветствия без пробела после решётки
|
||||
```
|
||||
|
||||
```console
|
||||
//Объявление функции
|
||||
def hello_world():// Печать приветствия
|
||||
print("Hello, world!") //Печать приветствия без пробела после слешей
|
||||
```
|
||||
|
||||
## Блок кода с четырёхкратными обратными кавычками { #code-blocks-with-quadruple-backticks }
|
||||
|
||||
Следующий блок кода содержит четырёхкратные обратные кавычки.
|
||||
|
||||
````python
|
||||
# Функция приветствия
|
||||
def hello_world():
|
||||
print("Hello, world") # Печать приветствия
|
||||
````
|
||||
|
||||
### Несоответствие обратных кавычек фиксится { #backticks-number-mismatch-is-fixable }
|
||||
|
||||
Следующий блок кода имеет тройные обратные кавычки в оригинальном документе, но четырёхкратные обратные кавычки в переведённом документе.
|
||||
Это будет исправлено инструментом исправления (будет преобразовано в тройные обратные кавычки).
|
||||
|
||||
````Python
|
||||
# Немного кода на Python
|
||||
````
|
||||
|
||||
### Блок кода в тройных обратных кавычка внутри блока кода в четырёхкратных обратных кавычках { #triple-backticks-inside-quadruple-backticks }
|
||||
|
||||
Комментарии внутри вложенного блока кода в тройных обратных кавычках НЕ БУДУТ сохранены.
|
||||
|
||||
````
|
||||
Here is a code block with quadruple backticks that contains triple backticks inside:
|
||||
|
||||
```python
|
||||
# Этот комментарий НЕ будет сохранён
|
||||
def hello_world():
|
||||
print("Hello, world") # Как и этот комментарий
|
||||
```
|
||||
|
||||
````
|
||||
|
||||
# Включения кода { #code-includes }
|
||||
|
||||
## Простые включения кода { #simple-code-includes }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial001_py39.py *}
|
||||
|
||||
{* ../../docs_src/python_types/tutorial002_py39.py *}
|
||||
|
||||
|
||||
## Включения кода с подсветкой { #code-includes-with-highlighting }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial002_py39.py hl[1] *}
|
||||
|
||||
{* ../../docs_src/python_types/tutorial006_py39.py hl[10] *}
|
||||
|
||||
|
||||
## Включения кода с диапазонами строк { #code-includes-with-line-ranges }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] *}
|
||||
|
||||
|
||||
## Включения кода с диапазонами строк и подсветкой { #code-includes-with-line-ranges-and-highlighting }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] hl[31:33] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial015_an_py310.py ln[10:15] hl[12:14] *}
|
||||
|
||||
|
||||
## Включения кода с заголовком { #code-includes-with-title }
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/routers/users.py hl[1,3] title["app/routers/users.py"] *}
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
## Включения кода с неизвестными атрибутами { #code-includes-with-unknown-attributes }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial001_py39.py unknown[123] *}
|
||||
|
||||
## Ещё включения кода для тестирования исправления { #some-more-code-includes-to-test-fixing }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19 : 21] *}
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/wrong.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[1:30] hl[1:10] *}
|
||||
|
||||
# Ссылки { #links }
|
||||
|
||||
## Ссылки в стиле Markdown { #markdown-style-links }
|
||||
|
||||
Это [Markdown-ссылка](https://example.com) на внешний сайт.
|
||||
|
||||
Это ссылка с атрибутами: [**FastAPI** генераторы проектов](project-generation.md){.internal-link target=_blank}
|
||||
|
||||
Это ссылка на основной сайт FastAPI: [FastAPI](https://fastapi.tiangolo.com) — инструмент должен добавить код языка в URL.
|
||||
|
||||
Это ссылка на одну из страниц на сайте FastAPI: [How to](https://fastapi.tiangolo.com/how-to) — инструмент должен добавить код языка в URL.
|
||||
|
||||
Ссылка для тестирования неправильного атрибута: [**FastAPI** генераторы проектов](project-generation.md){.external-link} - инструмент должен исправить атрибут.
|
||||
|
||||
Ссылка с заголовком: [Пример](http://example.com/ "Сайт для примера") - URL будет исправлен инструментом, заголовок сохранится.
|
||||
|
||||
### Markdown ссылки на статические ресурсы { #markdown-link-to-static-assets }
|
||||
|
||||
Это ссылки на статические ресурсы:
|
||||
|
||||
* [FastAPI Logo](https://fastapi.tiangolo.com/img/fastapi-logo.png)
|
||||
* [FastAPI CSS](https://fastapi.tiangolo.com/css/fastapi.css)
|
||||
* [FastAPI JS](https://fastapi.tiangolo.com/js/fastapi.js)
|
||||
|
||||
Инструмент НЕ должен добавлять код языка в их URL.
|
||||
|
||||
## Ссылки в стиле HTML { #html-style-links }
|
||||
|
||||
Это <a href="https://example.com" target="_blank" class="external-link">HTML-ссылка</a> на внешний сайт.
|
||||
|
||||
Это <a href="https://fastapi.tiangolo.com">ссылка на основной сайт FastAPI</a> — инструмент должен добавить код языка в URL.
|
||||
|
||||
Это <a href="https://fastapi.tiangolo.com/how-to/">ссылка на одну из страниц на сайте FastAPI</a> — инструмент должен добавить код языка в URL.
|
||||
|
||||
Ссылка для тестирования неправильного атрибута: <a href="project-generation.md" class="external-link">**FastAPI** генераторы проектов</a> - инструмент должен исправить атрибут.
|
||||
|
||||
### HTML ссылки на статические ресурсы { #html-links-to-static-assets }
|
||||
|
||||
Это ссылки на статические ресурсы:
|
||||
|
||||
* <a href="https://fastapi.tiangolo.com/img/fastapi-logo.png">FastAPI Logo</a>
|
||||
* <a href="https://fastapi.tiangolo.com/css/fastapi.css">FastAPI CSS</a>
|
||||
* <a href="https://fastapi.tiangolo.com/js/fastapi.js">FastAPI JS</a>
|
||||
|
||||
Инструмент НЕ должен добавлять код языка в их URL.
|
||||
|
||||
# Заголовок (с HTML ссылкой на <a href="https://tiangolo.com">tiangolo.com</a>) { #header-5 }
|
||||
|
||||
#Не заголовок
|
||||
|
||||
```Python
|
||||
# Также не заголовок
|
||||
```
|
||||
|
||||
Немного текста
|
||||
@@ -0,0 +1,240 @@
|
||||
# Тестовый инструмент исправления переводов { #test-translation-fixer }
|
||||
|
||||
## Блоки кода с комментариями и без комментариев { #code-blocks-with-and-without-comments }
|
||||
|
||||
Это тестовая страница для инструмента исправления переводов.
|
||||
|
||||
### Блоки кода с комментариями { #code-blocks-with-comments }
|
||||
|
||||
Следующие блоки кода содержат комментарии в разных стилях.
|
||||
Инструмент исправления должен исправлять содержимое, но корректно сохранять комментарии.
|
||||
|
||||
```python
|
||||
# Это пример блока кода на Python
|
||||
def hello_world():
|
||||
# Комментарий с отступом
|
||||
print("Hello, world!") # Печать приветствия
|
||||
```
|
||||
|
||||
```toml
|
||||
# Это пример блока кода на TOML
|
||||
title = "TOML Example" # Заголовок документа
|
||||
```
|
||||
|
||||
```console
|
||||
// Используйте команду "live" и передайте код языка в качестве аргумента CLI
|
||||
$ python ./scripts/docs.py live es
|
||||
|
||||
<span style="color: green;">[INFO]</span> Serving on http://127.0.0.1:8008
|
||||
<span style="color: green;">[INFO]</span> Start watching changes
|
||||
<span style="color: green;">[INFO]</span> Start detecting changes
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
// Это пример блока кода на JSON
|
||||
"greeting": "Hello, world!" // Печать приветствия
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Блоки кода с комментариями, где язык использует другие стили комментариев { #code-blocks-with-different-comment-styles }
|
||||
|
||||
Следующие блоки кода содержат комментарии в разных стилях в зависимости от языка.
|
||||
Инструмент исправления не будет сохранять комментарии в этих блоках.
|
||||
|
||||
```json
|
||||
{
|
||||
# This is a sample JSON code block
|
||||
"greeting": "Hello, world!" # Print greeting
|
||||
}
|
||||
```
|
||||
|
||||
```console
|
||||
# This is a sample console code block
|
||||
$ echo "Hello, world!" # Print greeting
|
||||
```
|
||||
|
||||
```toml
|
||||
// This is a sample TOML code block
|
||||
title = "TOML Example" // Title of the document
|
||||
```
|
||||
|
||||
### Блоки кода с комментариями на неподдерживаемых языках или без указания языка { #code-blocks-with-unsupported-languages }
|
||||
|
||||
Следующие блоки кода используют неподдерживаемые языки для сохранения комментариев.
|
||||
Инструмент исправления не будет сохранять комментарии в этих блоках.
|
||||
|
||||
```javascript
|
||||
// This is a sample JavaScript code block
|
||||
console.log("Hello, world!"); // Print greeting
|
||||
```
|
||||
|
||||
```
|
||||
# This is a sample console code block
|
||||
$ echo "Hello, world!" # Print greeting
|
||||
```
|
||||
|
||||
```
|
||||
// This is a sample console code block
|
||||
$ echo "Hello, world!" // Print greeting
|
||||
```
|
||||
|
||||
### Блоки кода с комментариями, которые не соответствуют шаблону { #code-blocks-with-comments-without-pattern }
|
||||
|
||||
Инструмент исправления ожидает комментарии, которые соответствуют определённому шаблону:
|
||||
|
||||
- Для комментариев в стиле с решёткой: комментарий начинается с `# ` (решётка, затем пробел) в начале строки или после пробела.
|
||||
- Для комментариев в стиле со слешами: комментарий начинается с `// ` (два слеша, затем пробел) в начале строки или после пробела.
|
||||
|
||||
Если комментарий не соответствует этому шаблону, инструмент исправления не будет его сохранять.
|
||||
|
||||
```python
|
||||
#Function declaration
|
||||
def hello_world():# Print greeting
|
||||
print("Hello, world!") #Print greeting without space after hash
|
||||
```
|
||||
|
||||
```console
|
||||
//Function declaration
|
||||
def hello_world():// Print greeting
|
||||
print("Hello, world!") //Print greeting without space after slashes
|
||||
```
|
||||
|
||||
## Блок кода с четырёхкратными обратными кавычками { #code-blocks-with-quadruple-backticks }
|
||||
|
||||
Следующий блок кода содержит четырёхкратные обратные кавычки.
|
||||
|
||||
````python
|
||||
# Функция приветствия
|
||||
def hello_world():
|
||||
print("Hello, world!") # Печать приветствия
|
||||
````
|
||||
|
||||
### Несоответствие обратных кавычек фиксится { #backticks-number-mismatch-is-fixable }
|
||||
|
||||
Следующий блок кода имеет тройные обратные кавычки в оригинальном документе, но четырёхкратные обратные кавычки в переведённом документе.
|
||||
Это будет исправлено инструментом исправления (будет преобразовано в тройные обратные кавычки).
|
||||
|
||||
```Python
|
||||
# Немного кода на Python
|
||||
```
|
||||
|
||||
### Блок кода в тройных обратных кавычка внутри блока кода в четырёхкратных обратных кавычках { #triple-backticks-inside-quadruple-backticks }
|
||||
|
||||
Комментарии внутри вложенного блока кода в тройных обратных кавычках НЕ БУДУТ сохранены.
|
||||
|
||||
````
|
||||
Here is a code block with quadruple backticks that contains triple backticks inside:
|
||||
|
||||
```python
|
||||
# This is a sample Python code block
|
||||
def hello_world():
|
||||
print("Hello, world!") # Print greeting
|
||||
```
|
||||
|
||||
````
|
||||
|
||||
# Включения кода { #code-includes }
|
||||
|
||||
## Простые включения кода { #simple-code-includes }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial001_py39.py *}
|
||||
|
||||
{* ../../docs_src/python_types/tutorial002_py39.py *}
|
||||
|
||||
|
||||
## Включения кода с подсветкой { #code-includes-with-highlighting }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial002_py39.py hl[1] *}
|
||||
|
||||
{* ../../docs_src/python_types/tutorial006_py39.py hl[10] *}
|
||||
|
||||
|
||||
## Включения кода с диапазонами строк { #code-includes-with-line-ranges }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] *}
|
||||
|
||||
|
||||
## Включения кода с диапазонами строк и подсветкой { #code-includes-with-line-ranges-and-highlighting }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] hl[31:33] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial015_an_py310.py ln[10:15] hl[12:14] *}
|
||||
|
||||
|
||||
## Включения кода с заголовком { #code-includes-with-title }
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/routers/users.py hl[1,3] title["app/routers/users.py"] *}
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
## Включения кода с неизвестными атрибутами { #code-includes-with-unknown-attributes }
|
||||
|
||||
{* ../../docs_src/python_types/tutorial001_py39.py unknown[123] *}
|
||||
|
||||
## Ещё включения кода для тестирования исправления { #some-more-code-includes-to-test-fixing }
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[19:21] *}
|
||||
|
||||
{* ../../docs_src/bigger_applications/app_an_py39/internal/admin.py hl[3] title["app/internal/admin.py"] *}
|
||||
|
||||
{* ../../docs_src/dependencies/tutorial013_an_py310.py ln[30:38] hl[31:33] *}
|
||||
|
||||
# Ссылки { #links }
|
||||
|
||||
## Ссылки в стиле Markdown { #markdown-style-links }
|
||||
|
||||
Это [Markdown-ссылка](https://example.com) на внешний сайт.
|
||||
|
||||
Это ссылка с атрибутами: [**FastAPI** генераторы проектов](project-generation.md){.internal-link target=_blank}
|
||||
|
||||
Это ссылка на основной сайт FastAPI: [FastAPI](https://fastapi.tiangolo.com/lang) — инструмент должен добавить код языка в URL.
|
||||
|
||||
Это ссылка на одну из страниц на сайте FastAPI: [How to](https://fastapi.tiangolo.com/lang/how-to/) — инструмент должен добавить код языка в URL.
|
||||
|
||||
Ссылка для тестирования неправильного атрибута: [**FastAPI** генераторы проектов](project-generation.md){.internal-link} - инструмент должен исправить атрибут.
|
||||
|
||||
Ссылка с заголовком: [Пример](https://example.com "Сайт для примера") - URL будет исправлен инструментом, заголовок сохранится.
|
||||
|
||||
### Markdown ссылки на статические ресурсы { #markdown-link-to-static-assets }
|
||||
|
||||
Это ссылки на статические ресурсы:
|
||||
|
||||
* [FastAPI Logo](https://fastapi.tiangolo.com/img/fastapi-logo.png)
|
||||
* [FastAPI CSS](https://fastapi.tiangolo.com/css/fastapi.css)
|
||||
* [FastAPI JS](https://fastapi.tiangolo.com/js/fastapi.js)
|
||||
|
||||
Инструмент НЕ должен добавлять код языка в их URL.
|
||||
|
||||
## Ссылки в стиле HTML { #html-style-links }
|
||||
|
||||
Это <a href="https://example.com" target="_blank" class="external-link">HTML-ссылка</a> на внешний сайт.
|
||||
|
||||
Это <a href="https://fastapi.tiangolo.com/lang">ссылка на основной сайт FastAPI</a> — инструмент должен добавить код языка в URL.
|
||||
|
||||
Это <a href="https://fastapi.tiangolo.com/lang/how-to/">ссылка на одну из страниц на сайте FastAPI</a> — инструмент должен добавить код языка в URL.
|
||||
|
||||
Ссылка для тестирования неправильного атрибута: <a href="project-generation.md" class="internal-link">**FastAPI** генераторы проектов</a> - инструмент должен исправить атрибут.
|
||||
|
||||
### HTML ссылки на статические ресурсы { #html-links-to-static-assets }
|
||||
|
||||
Это ссылки на статические ресурсы:
|
||||
|
||||
* <a href="https://fastapi.tiangolo.com/img/fastapi-logo.png">FastAPI Logo</a>
|
||||
* <a href="https://fastapi.tiangolo.com/css/fastapi.css">FastAPI CSS</a>
|
||||
* <a href="https://fastapi.tiangolo.com/js/fastapi.js">FastAPI JS</a>
|
||||
|
||||
Инструмент НЕ должен добавлять код языка в их URL.
|
||||
|
||||
# Заголовок (с HTML ссылкой на <a href="https://tiangolo.com">tiangolo.com</a>) { #header-with-html-link-to-tiangolo-com }
|
||||
|
||||
#Не заголовок
|
||||
|
||||
```Python
|
||||
# Также не заголовок
|
||||
```
|
||||
|
||||
Немного текста
|
||||
@@ -0,0 +1,30 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_complex_doc/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_fix(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 0, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = (data_path / "translated_doc_expected.md").read_text("utf-8")
|
||||
assert fixed_content == expected_content
|
||||
|
||||
assert "Fixing multiline code blocks in" in result.output
|
||||
assert "Fixing markdown links in" in result.output
|
||||
@@ -0,0 +1,19 @@
|
||||
# Header 1 { #header-1 }
|
||||
|
||||
Some text
|
||||
|
||||
## Header 2 { #header-2 }
|
||||
|
||||
Some more text
|
||||
|
||||
### Header 3 { #header-3 }
|
||||
|
||||
Even more text
|
||||
|
||||
# Header 4 { #header-4 }
|
||||
|
||||
A bit more text
|
||||
|
||||
#Not a header
|
||||
|
||||
Final portion of text
|
||||
@@ -0,0 +1,19 @@
|
||||
# Header 1 { #header-1 }
|
||||
|
||||
Some text
|
||||
|
||||
# Header 2 { #header-2 }
|
||||
|
||||
Some more text
|
||||
|
||||
### Header 3 { #header-3 }
|
||||
|
||||
Even more text
|
||||
|
||||
# Header 4 { #header-4 }
|
||||
|
||||
A bit more text
|
||||
|
||||
#Not a header
|
||||
|
||||
Final portion of text
|
||||
@@ -0,0 +1,19 @@
|
||||
# Header 1 { #header-1 }
|
||||
|
||||
Some text
|
||||
|
||||
## Header 2 { #header-2 }
|
||||
|
||||
Some more text
|
||||
|
||||
### Header 3 { #header-3 }
|
||||
|
||||
Even more text
|
||||
|
||||
## Header 4 { #header-4 }
|
||||
|
||||
A bit more text
|
||||
|
||||
#Not a header
|
||||
|
||||
Final portion of text
|
||||
@@ -0,0 +1,19 @@
|
||||
# Header 1 { #header-1 }
|
||||
|
||||
Some text
|
||||
|
||||
## Header 2 { #header-2 }
|
||||
|
||||
Some more text
|
||||
|
||||
### Header 3 { #header-3 }
|
||||
|
||||
Even more text
|
||||
|
||||
# Header 4 { #header-4 }
|
||||
|
||||
A bit more text
|
||||
|
||||
# Extra header
|
||||
|
||||
Final portion of text
|
||||
@@ -0,0 +1,19 @@
|
||||
# Header 1 { #header-1 }
|
||||
|
||||
Some text
|
||||
|
||||
## Header 2 { #header-2 }
|
||||
|
||||
Some more text
|
||||
|
||||
### Header 3 { #header-3 }
|
||||
|
||||
Even more text
|
||||
|
||||
Header 4 is missing
|
||||
|
||||
A bit more text
|
||||
|
||||
#Not a header
|
||||
|
||||
Final portion of text
|
||||
@@ -0,0 +1,60 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_header_permalinks/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_level_mismatch_1.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_level_mismatch_1(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(
|
||||
f"{data_path}/translated_doc_level_mismatch_1.md"
|
||||
).read_text("utf-8")
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Header levels do not match between document and original document"
|
||||
" (found #, expected ##) for header №2 in line 5"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_level_mismatch_2.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_level_mismatch_2(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(
|
||||
f"{data_path}/translated_doc_level_mismatch_2.md"
|
||||
).read_text("utf-8")
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Header levels do not match between document and original document"
|
||||
" (found ##, expected #) for header №4 in line 13"
|
||||
) in result.output
|
||||
@@ -0,0 +1,60 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_header_permalinks/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_gt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_gt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_gt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of headers with permalinks does not match the number "
|
||||
"in the original document (5 vs 4)"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_lt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_lt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_lt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of headers with permalinks does not match the number "
|
||||
"in the original document (3 vs 4)"
|
||||
) in result.output
|
||||
@@ -0,0 +1,19 @@
|
||||
# Header 1 { #header-1 }
|
||||
|
||||
Some text with a link to <a href="https://fastapi.tiangolo.com">FastAPI</a>.
|
||||
|
||||
## Header 2 { #header-2 }
|
||||
|
||||
Two links here: <a href="https://fastapi.tiangolo.com/how-to/">How to</a> and <a href="project-generation.md" class="internal-link" target="_blank">Project Generators</a>.
|
||||
|
||||
### Header 3 { #header-3 }
|
||||
|
||||
Another link: <a href="project-generation.md" class="internal-link" target="_blank" title="Link title">**FastAPI** Project Generators</a> with title.
|
||||
|
||||
# Header 4 { #header-4 }
|
||||
|
||||
Link to anchor: <a href="#header-2">Header 2</a>
|
||||
|
||||
# Header with <a href="http://example.com">link</a> { #header-with-link }
|
||||
|
||||
Some text
|
||||
@@ -0,0 +1,21 @@
|
||||
# Заголовок 1 { #header-1 }
|
||||
|
||||
Немного текста со ссылкой на <a href="https://fastapi.tiangolo.com">FastAPI</a>.
|
||||
|
||||
## Заголовок 2 { #header-2 }
|
||||
|
||||
Две ссылки здесь: <a href="https://fastapi.tiangolo.com/how-to/">How to</a> и <a href="project-generation.md" class="internal-link" target="_blank">Project Generators</a>.
|
||||
|
||||
### Заголовок 3 { #header-3 }
|
||||
|
||||
Ещё ссылка: <a href="project-generation.md" class="internal-link" target="_blank" title="Тайтл">**FastAPI** Генераторы Проектов</a> с тайтлом.
|
||||
|
||||
И ещё одна <a href="https://github.com">экстра ссылка</a>.
|
||||
|
||||
# Заголовок 4 { #header-4 }
|
||||
|
||||
Ссылка на якорь: <a href="#header-2">Заголовок 2</a>
|
||||
|
||||
# Заголовок со <a href="http://example.com">ссылкой</a> { #header-with-link }
|
||||
|
||||
Немного текста
|
||||
@@ -0,0 +1,19 @@
|
||||
# Заголовок 1 { #header-1 }
|
||||
|
||||
Немного текста со ссылкой на <a href="https://fastapi.tiangolo.com">FastAPI</a>.
|
||||
|
||||
## Заголовок 2 { #header-2 }
|
||||
|
||||
Две ссылки здесь: <a href="https://fastapi.tiangolo.com/how-to/">How to</a> и <a href="project-generation.md" class="internal-link" target="_blank">Project Generators</a>.
|
||||
|
||||
### Заголовок 3 { #header-3 }
|
||||
|
||||
Ещё ссылка: <a href="project-generation.md" class="internal-link" target="_blank" title="Тайтл">**FastAPI** Генераторы Проектов</a> с тайтлом.
|
||||
|
||||
# Заголовок 4 { #header-4 }
|
||||
|
||||
Ссылка на якорь: <a href="#header-2">Заголовок 2</a>
|
||||
|
||||
# Заголовок с потерянной ссылкой { #header-with-link }
|
||||
|
||||
Немного текста
|
||||
@@ -0,0 +1,58 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path("scripts/tests/test_translation_fixer/test_html_links/data").absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_gt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_gt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_gt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of HTML links does not match the number "
|
||||
"in the original document (7 vs 6)"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_lt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_lt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
# assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_lt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of HTML links does not match the number "
|
||||
"in the original document (5 vs 6)"
|
||||
) in result.output
|
||||
@@ -0,0 +1,19 @@
|
||||
# Header 1 { #header-1 }
|
||||
|
||||
Some text with a link to [FastAPI](https://fastapi.tiangolo.com).
|
||||
|
||||
## Header 2 { #header-2 }
|
||||
|
||||
Two links here: [How to](https://fastapi.tiangolo.com/how-to/) and [Project Generators](project-generation.md){.internal-link target=_blank}.
|
||||
|
||||
### Header 3 { #header-3 }
|
||||
|
||||
Another link: [**FastAPI** Project Generators](project-generation.md "Link title"){.internal-link target=_blank} with title.
|
||||
|
||||
# Header 4 { #header-4 }
|
||||
|
||||
Link to anchor: [Header 2](#header-2)
|
||||
|
||||
# Header with [link](http://example.com) { #header-with-link }
|
||||
|
||||
Some text
|
||||
@@ -0,0 +1,19 @@
|
||||
# Заголовок 1 { #header-1 }
|
||||
|
||||
Немного текста со ссылкой на [FastAPI](https://fastapi.tiangolo.com).
|
||||
|
||||
## Заголовок 2 { #header-2 }
|
||||
|
||||
Две ссылки здесь: [How to](https://fastapi.tiangolo.com/how-to/) и [Project Generators](project-generation.md){.internal-link target=_blank}.
|
||||
|
||||
### Заголовок 3 { #header-3 }
|
||||
|
||||
Ещё ссылка: [**FastAPI** Генераторы Проектов](project-generation.md "Тайтл"){.internal-link target=_blank} с тайтлом.
|
||||
|
||||
# Заголовок 4 { #header-4 }
|
||||
|
||||
Ссылка на якорь: [Заголовок 2](#header-2)
|
||||
|
||||
# Заголовок со [ссылкой](http://example.com) { #header-with-link }
|
||||
|
||||
Немного текста
|
||||
@@ -0,0 +1,21 @@
|
||||
# Заголовок 1 { #header-1 }
|
||||
|
||||
Немного текста со ссылкой на [FastAPI](https://fastapi.tiangolo.com).
|
||||
|
||||
## Заголовок 2 { #header-2 }
|
||||
|
||||
Две ссылки здесь: [How to](https://fastapi.tiangolo.com/how-to/) и [Project Generators](project-generation.md){.internal-link target=_blank}.
|
||||
|
||||
### Заголовок 3 { #header-3 }
|
||||
|
||||
Ещё ссылка: [**FastAPI** Генераторы Проектов](project-generation.md "Тайтл"){.internal-link target=_blank} с тайтлом.
|
||||
|
||||
И ещё одна [экстра ссылка](https://github.com).
|
||||
|
||||
# Заголовок 4 { #header-4 }
|
||||
|
||||
Ссылка на якорь: [Заголовок 2](#header-2)
|
||||
|
||||
# Заголовок со [ссылкой](http://example.com) { #header-with-link }
|
||||
|
||||
Немного текста
|
||||
@@ -0,0 +1,19 @@
|
||||
# Заголовок 1 { #header-1 }
|
||||
|
||||
Немного текста со ссылкой на [FastAPI](https://fastapi.tiangolo.com).
|
||||
|
||||
## Заголовок 2 { #header-2 }
|
||||
|
||||
Две ссылки здесь: [How to](https://fastapi.tiangolo.com/how-to/) и [Project Generators](project-generation.md){.internal-link target=_blank}.
|
||||
|
||||
### Заголовок 3 { #header-3 }
|
||||
|
||||
Ещё ссылка: [**FastAPI** Генераторы Проектов](project-generation.md "Тайтл"){.internal-link target=_blank} с тайтлом.
|
||||
|
||||
# Заголовок 4 { #header-4 }
|
||||
|
||||
Ссылка на якорь: [Заголовок 2](#header-2)
|
||||
|
||||
# Заголовок с потерянной ссылкой { #header-with-link }
|
||||
|
||||
Немного текста
|
||||
@@ -0,0 +1,60 @@
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from scripts.translation_fixer import cli
|
||||
|
||||
data_path = Path(
|
||||
"scripts/tests/test_translation_fixer/test_markdown_links/data"
|
||||
).absolute()
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_gt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_gt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_gt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of markdown links does not match the number "
|
||||
"in the original document (7 vs 6)"
|
||||
) in result.output
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"copy_test_files",
|
||||
[(f"{data_path}/en_doc.md", f"{data_path}/translated_doc_number_lt.md")],
|
||||
indirect=True,
|
||||
)
|
||||
def test_lt(runner: CliRunner, root_dir: Path, copy_test_files):
|
||||
result = runner.invoke(
|
||||
cli,
|
||||
["fix-pages", "docs/lang/docs/doc.md"],
|
||||
)
|
||||
# assert result.exit_code == 1, result.output
|
||||
|
||||
fixed_content = (root_dir / "docs" / "lang" / "docs" / "doc.md").read_text("utf-8")
|
||||
expected_content = Path(f"{data_path}/translated_doc_number_lt.md").read_text(
|
||||
"utf-8"
|
||||
)
|
||||
|
||||
assert fixed_content == expected_content # Translated doc remains unchanged
|
||||
assert "Error processing docs/lang/docs/doc.md" in result.output
|
||||
assert (
|
||||
"Number of markdown links does not match the number "
|
||||
"in the original document (5 vs 6)"
|
||||
) in result.output
|
||||
@@ -25,7 +25,7 @@ non_translated_sections = (
|
||||
"contributing.md",
|
||||
)
|
||||
|
||||
general_prompt_path = Path(__file__).absolute().parent / "llm-general-prompt.md"
|
||||
general_prompt_path = Path(__file__).absolute().parent / "general-llm-prompt.md"
|
||||
general_prompt = general_prompt_path.read_text(encoding="utf-8")
|
||||
|
||||
app = typer.Typer()
|
||||
@@ -360,6 +360,9 @@ def make_pr(
|
||||
command: Annotated[str | None, typer.Option(envvar="COMMAND")] = None,
|
||||
github_token: Annotated[str, typer.Option(envvar="GITHUB_TOKEN")],
|
||||
github_repository: Annotated[str, typer.Option(envvar="GITHUB_REPOSITORY")],
|
||||
commit_in_place: Annotated[
|
||||
bool, typer.Option(envvar="COMMIT_IN_PLACE", show_default=True)
|
||||
] = False,
|
||||
) -> None:
|
||||
print("Setting up GitHub Actions git user")
|
||||
repo = git.Repo(Path(__file__).absolute().parent.parent)
|
||||
@@ -371,14 +374,22 @@ def make_pr(
|
||||
["git", "config", "user.email", "github-actions[bot]@users.noreply.github.com"],
|
||||
check=True,
|
||||
)
|
||||
branch_name = "translate"
|
||||
if language:
|
||||
branch_name += f"-{language}"
|
||||
if command:
|
||||
branch_name += f"-{command}"
|
||||
branch_name += f"-{secrets.token_hex(4)}"
|
||||
print(f"Creating a new branch {branch_name}")
|
||||
subprocess.run(["git", "checkout", "-b", branch_name], check=True)
|
||||
current_branch = repo.active_branch.name
|
||||
if current_branch == "master" and commit_in_place:
|
||||
print("Can't commit directly to master")
|
||||
raise typer.Exit(code=1)
|
||||
|
||||
if not commit_in_place:
|
||||
branch_name = "translate"
|
||||
if language:
|
||||
branch_name += f"-{language}"
|
||||
if command:
|
||||
branch_name += f"-{command}"
|
||||
branch_name += f"-{secrets.token_hex(4)}"
|
||||
print(f"Creating a new branch {branch_name}")
|
||||
subprocess.run(["git", "checkout", "-b", branch_name], check=True)
|
||||
else:
|
||||
print(f"Committing in place on branch {current_branch}")
|
||||
print("Adding updated files")
|
||||
git_path = Path("docs")
|
||||
subprocess.run(["git", "add", str(git_path)], check=True)
|
||||
@@ -391,17 +402,20 @@ def make_pr(
|
||||
subprocess.run(["git", "commit", "-m", message], check=True)
|
||||
print("Pushing branch")
|
||||
subprocess.run(["git", "push", "origin", branch_name], check=True)
|
||||
print("Creating PR")
|
||||
g = Github(github_token)
|
||||
gh_repo = g.get_repo(github_repository)
|
||||
body = (
|
||||
message
|
||||
+ "\n\nThis PR was created automatically using LLMs."
|
||||
+ f"\n\nIt uses the prompt file https://github.com/fastapi/fastapi/blob/master/docs/{language}/llm-prompt.md."
|
||||
+ "\n\nIn most cases, it's better to make PRs updating that file so that the LLM can do a better job generating the translations than suggesting changes in this PR."
|
||||
)
|
||||
pr = gh_repo.create_pull(title=message, body=body, base="master", head=branch_name)
|
||||
print(f"Created PR: {pr.number}")
|
||||
if not commit_in_place:
|
||||
print("Creating PR")
|
||||
g = Github(github_token)
|
||||
gh_repo = g.get_repo(github_repository)
|
||||
body = (
|
||||
message
|
||||
+ "\n\nThis PR was created automatically using LLMs."
|
||||
+ f"\n\nIt uses the prompt file https://github.com/fastapi/fastapi/blob/master/docs/{language}/llm-prompt.md."
|
||||
+ "\n\nIn most cases, it's better to make PRs updating that file so that the LLM can do a better job generating the translations than suggesting changes in this PR."
|
||||
)
|
||||
pr = gh_repo.create_pull(
|
||||
title=message, body=body, base="master", head=branch_name
|
||||
)
|
||||
print(f"Created PR: {pr.number}")
|
||||
print("Finished")
|
||||
|
||||
|
||||
|
||||
132
scripts/translation_fixer.py
Normal file
132
scripts/translation_fixer.py
Normal file
@@ -0,0 +1,132 @@
|
||||
import os
|
||||
from collections.abc import Iterable
|
||||
from pathlib import Path
|
||||
from typing import Annotated
|
||||
|
||||
import typer
|
||||
|
||||
from scripts.doc_parsing_utils import check_translation
|
||||
|
||||
non_translated_sections = (
|
||||
f"reference{os.sep}",
|
||||
"release-notes.md",
|
||||
"fastapi-people.md",
|
||||
"external-links.md",
|
||||
"newsletter.md",
|
||||
"management-tasks.md",
|
||||
"management.md",
|
||||
"contributing.md",
|
||||
)
|
||||
|
||||
|
||||
cli = typer.Typer()
|
||||
|
||||
|
||||
@cli.callback()
|
||||
def callback():
|
||||
pass
|
||||
|
||||
|
||||
def iter_all_lang_paths(lang_path_root: Path) -> Iterable[Path]:
|
||||
"""
|
||||
Iterate on the markdown files to translate in order of priority.
|
||||
"""
|
||||
|
||||
first_dirs = [
|
||||
lang_path_root / "learn",
|
||||
lang_path_root / "tutorial",
|
||||
lang_path_root / "advanced",
|
||||
lang_path_root / "about",
|
||||
lang_path_root / "how-to",
|
||||
]
|
||||
first_parent = lang_path_root
|
||||
yield from first_parent.glob("*.md")
|
||||
for dir_path in first_dirs:
|
||||
yield from dir_path.rglob("*.md")
|
||||
first_dirs_str = tuple(str(d) for d in first_dirs)
|
||||
for path in lang_path_root.rglob("*.md"):
|
||||
if str(path).startswith(first_dirs_str):
|
||||
continue
|
||||
if path.parent == first_parent:
|
||||
continue
|
||||
yield path
|
||||
|
||||
|
||||
def get_all_paths(lang: str):
|
||||
res: list[str] = []
|
||||
lang_docs_root = Path("docs") / lang / "docs"
|
||||
for path in iter_all_lang_paths(lang_docs_root):
|
||||
relpath = path.relative_to(lang_docs_root)
|
||||
if not str(relpath).startswith(non_translated_sections):
|
||||
res.append(str(relpath))
|
||||
return res
|
||||
|
||||
|
||||
def process_one_page(path: Path) -> bool:
|
||||
"""
|
||||
Fix one translated document by comparing it to the English version.
|
||||
|
||||
Returns True if processed successfully, False otherwise.
|
||||
"""
|
||||
|
||||
try:
|
||||
lang_code = path.parts[1]
|
||||
if lang_code == "en":
|
||||
print(f"Skipping English document: {path}")
|
||||
return True
|
||||
|
||||
en_doc_path = Path("docs") / "en" / Path(*path.parts[2:])
|
||||
|
||||
doc_lines = path.read_text(encoding="utf-8").splitlines()
|
||||
en_doc_lines = en_doc_path.read_text(encoding="utf-8").splitlines()
|
||||
|
||||
doc_lines = check_translation(
|
||||
doc_lines=doc_lines,
|
||||
en_doc_lines=en_doc_lines,
|
||||
lang_code=lang_code,
|
||||
auto_fix=True,
|
||||
path=str(path),
|
||||
)
|
||||
|
||||
# Write back the fixed document
|
||||
doc_lines.append("") # Ensure file ends with a newline
|
||||
path.write_text("\n".join(doc_lines), encoding="utf-8")
|
||||
|
||||
except ValueError as e:
|
||||
print(f"Error processing {path}: {e}")
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
@cli.command()
|
||||
def fix_all(ctx: typer.Context, language: str):
|
||||
docs = get_all_paths(language)
|
||||
|
||||
all_good = True
|
||||
for page in docs:
|
||||
doc_path = Path("docs") / language / "docs" / page
|
||||
res = process_one_page(doc_path)
|
||||
all_good = all_good and res
|
||||
|
||||
if not all_good:
|
||||
raise typer.Exit(code=1)
|
||||
|
||||
|
||||
@cli.command()
|
||||
def fix_pages(
|
||||
doc_paths: Annotated[
|
||||
list[Path],
|
||||
typer.Argument(help="List of paths to documents."),
|
||||
],
|
||||
):
|
||||
all_good = True
|
||||
for path in doc_paths:
|
||||
res = process_one_page(path)
|
||||
all_good = all_good and res
|
||||
|
||||
if not all_good:
|
||||
raise typer.Exit(code=1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
cli()
|
||||
Reference in New Issue
Block a user