mirror of
https://github.com/ollama/ollama.git
synced 2026-01-24 23:39:08 -05:00
Compare commits
8 Commits
v0.15.0-rc
...
main
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
465d124183 | ||
|
|
d310e56fa3 | ||
|
|
a1ca428c90 | ||
|
|
16750865d1 | ||
|
|
f3b476c592 | ||
|
|
5267d31d56 | ||
|
|
b44f56319f | ||
|
|
0209c268bb |
@@ -169,8 +169,10 @@ COPY . .
|
||||
RUN git clone --depth 1 --branch "$(cat MLX_VERSION)" https://github.com/ml-explore/mlx-c.git build/_deps/mlx-c-src
|
||||
ARG GOFLAGS="'-ldflags=-w -s'"
|
||||
ENV CGO_ENABLED=1
|
||||
ENV CGO_CFLAGS="-I/go/src/github.com/ollama/ollama/build/_deps/mlx-c-src"
|
||||
ARG CGO_CFLAGS
|
||||
ARG CGO_CXXFLAGS
|
||||
ENV CGO_CFLAGS="${CGO_CFLAGS} -I/go/src/github.com/ollama/ollama/build/_deps/mlx-c-src"
|
||||
ENV CGO_CXXFLAGS="${CGO_CXXFLAGS}"
|
||||
RUN --mount=type=cache,target=/root/.cache/go-build \
|
||||
go build -tags mlx -trimpath -buildmode=pie -o /bin/ollama .
|
||||
|
||||
|
||||
@@ -558,7 +558,7 @@ See the [API documentation](./docs/api.md) for all endpoints.
|
||||
- [LiteLLM](https://github.com/BerriAI/litellm)
|
||||
- [OllamaFarm for Go](https://github.com/presbrey/ollamafarm)
|
||||
- [OllamaSharp for .NET](https://github.com/awaescher/OllamaSharp)
|
||||
- [Ollama for Ruby](https://github.com/gbaptista/ollama-ai)
|
||||
- [Ollama for Ruby](https://github.com/crmne/ruby_llm)
|
||||
- [Ollama-rs for Rust](https://github.com/pepperoni21/ollama-rs)
|
||||
- [Ollama-hpp for C++](https://github.com/jmont-dev/ollama-hpp)
|
||||
- [Ollama4j for Java](https://github.com/ollama4j/ollama4j)
|
||||
|
||||
@@ -75,9 +75,9 @@ The `-dev` flag enables:
|
||||
CI builds with Xcode 14.1 for OS compatibility prior to v13. If you want to manually build v11+ support, you can download the older Xcode [here](https://developer.apple.com/services-account/download?path=/Developer_Tools/Xcode_14.1/Xcode_14.1.xip), extract, then `mv ./Xcode.app /Applications/Xcode_14.1.0.app` then activate with:
|
||||
|
||||
```
|
||||
export CGO_CFLAGS=-mmacosx-version-min=12.0
|
||||
export CGO_CXXFLAGS=-mmacosx-version-min=12.0
|
||||
export CGO_LDFLAGS=-mmacosx-version-min=12.0
|
||||
export CGO_CFLAGS="-O3 -mmacosx-version-min=12.0"
|
||||
export CGO_CXXFLAGS="-O3 -mmacosx-version-min=12.0"
|
||||
export CGO_LDFLAGS="-mmacosx-version-min=12.0"
|
||||
export SDKROOT=/Applications/Xcode_14.1.0.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk
|
||||
export DEVELOPER_DIR=/Applications/Xcode_14.1.0.app/Contents/Developer
|
||||
```
|
||||
|
||||
@@ -4,6 +4,8 @@ import (
|
||||
"fmt"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"runtime"
|
||||
)
|
||||
|
||||
// Claude implements Runner for Claude Code integration
|
||||
@@ -18,12 +20,32 @@ func (c *Claude) args(model string) []string {
|
||||
return nil
|
||||
}
|
||||
|
||||
func (c *Claude) findPath() (string, error) {
|
||||
if p, err := exec.LookPath("claude"); err == nil {
|
||||
return p, nil
|
||||
}
|
||||
home, err := os.UserHomeDir()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
name := "claude"
|
||||
if runtime.GOOS == "windows" {
|
||||
name = "claude.exe"
|
||||
}
|
||||
fallback := filepath.Join(home, ".claude", "local", name)
|
||||
if _, err := os.Stat(fallback); err != nil {
|
||||
return "", err
|
||||
}
|
||||
return fallback, nil
|
||||
}
|
||||
|
||||
func (c *Claude) Run(model string) error {
|
||||
if _, err := exec.LookPath("claude"); err != nil {
|
||||
claudePath, err := c.findPath()
|
||||
if err != nil {
|
||||
return fmt.Errorf("claude is not installed, install from https://code.claude.com/docs/en/quickstart")
|
||||
}
|
||||
|
||||
cmd := exec.Command("claude", c.args(model)...)
|
||||
cmd := exec.Command(claudePath, c.args(model)...)
|
||||
cmd.Stdin = os.Stdin
|
||||
cmd.Stdout = os.Stdout
|
||||
cmd.Stderr = os.Stderr
|
||||
|
||||
@@ -1,6 +1,9 @@
|
||||
package config
|
||||
|
||||
import (
|
||||
"os"
|
||||
"path/filepath"
|
||||
"runtime"
|
||||
"slices"
|
||||
"testing"
|
||||
)
|
||||
@@ -19,6 +22,62 @@ func TestClaudeIntegration(t *testing.T) {
|
||||
})
|
||||
}
|
||||
|
||||
func TestClaudeFindPath(t *testing.T) {
|
||||
c := &Claude{}
|
||||
|
||||
t.Run("finds claude in PATH", func(t *testing.T) {
|
||||
tmpDir := t.TempDir()
|
||||
name := "claude"
|
||||
if runtime.GOOS == "windows" {
|
||||
name = "claude.exe"
|
||||
}
|
||||
fakeBin := filepath.Join(tmpDir, name)
|
||||
os.WriteFile(fakeBin, []byte("#!/bin/sh\n"), 0o755)
|
||||
t.Setenv("PATH", tmpDir)
|
||||
|
||||
got, err := c.findPath()
|
||||
if err != nil {
|
||||
t.Fatalf("unexpected error: %v", err)
|
||||
}
|
||||
if got != fakeBin {
|
||||
t.Errorf("findPath() = %q, want %q", got, fakeBin)
|
||||
}
|
||||
})
|
||||
|
||||
t.Run("falls back to ~/.claude/local/claude", func(t *testing.T) {
|
||||
tmpDir := t.TempDir()
|
||||
setTestHome(t, tmpDir)
|
||||
t.Setenv("PATH", t.TempDir()) // empty dir, no claude binary
|
||||
|
||||
name := "claude"
|
||||
if runtime.GOOS == "windows" {
|
||||
name = "claude.exe"
|
||||
}
|
||||
fallback := filepath.Join(tmpDir, ".claude", "local", name)
|
||||
os.MkdirAll(filepath.Dir(fallback), 0o755)
|
||||
os.WriteFile(fallback, []byte("#!/bin/sh\n"), 0o755)
|
||||
|
||||
got, err := c.findPath()
|
||||
if err != nil {
|
||||
t.Fatalf("unexpected error: %v", err)
|
||||
}
|
||||
if got != fallback {
|
||||
t.Errorf("findPath() = %q, want %q", got, fallback)
|
||||
}
|
||||
})
|
||||
|
||||
t.Run("returns error when neither PATH nor fallback exists", func(t *testing.T) {
|
||||
tmpDir := t.TempDir()
|
||||
setTestHome(t, tmpDir)
|
||||
t.Setenv("PATH", t.TempDir()) // empty dir, no claude binary
|
||||
|
||||
_, err := c.findPath()
|
||||
if err == nil {
|
||||
t.Fatal("expected error, got nil")
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
func TestClaudeArgs(t *testing.T) {
|
||||
c := &Claude{}
|
||||
|
||||
|
||||
@@ -105,17 +105,26 @@ func (o *OpenCode) Edit(modelList []string) error {
|
||||
|
||||
for name, cfg := range models {
|
||||
if cfgMap, ok := cfg.(map[string]any); ok {
|
||||
if displayName, ok := cfgMap["name"].(string); ok {
|
||||
if strings.HasSuffix(displayName, "[Ollama]") && !selectedSet[name] {
|
||||
delete(models, name)
|
||||
}
|
||||
if isOllamaModel(cfgMap) && !selectedSet[name] {
|
||||
delete(models, name)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
for _, model := range modelList {
|
||||
if existing, ok := models[model].(map[string]any); ok {
|
||||
// migrate existing models without _launch marker
|
||||
if isOllamaModel(existing) {
|
||||
existing["_launch"] = true
|
||||
if name, ok := existing["name"].(string); ok {
|
||||
existing["name"] = strings.TrimSuffix(name, " [Ollama]")
|
||||
}
|
||||
}
|
||||
continue
|
||||
}
|
||||
models[model] = map[string]any{
|
||||
"name": fmt.Sprintf("%s [Ollama]", model),
|
||||
"name": model,
|
||||
"_launch": true,
|
||||
}
|
||||
}
|
||||
|
||||
@@ -201,3 +210,15 @@ func (o *OpenCode) Models() []string {
|
||||
slices.Sort(keys)
|
||||
return keys
|
||||
}
|
||||
|
||||
// isOllamaModel reports whether a model config entry is managed by us
|
||||
func isOllamaModel(cfg map[string]any) bool {
|
||||
if v, ok := cfg["_launch"].(bool); ok && v {
|
||||
return true
|
||||
}
|
||||
// previously used [Ollama] as a suffix for the model managed by ollama launch
|
||||
if name, ok := cfg["name"].(string); ok {
|
||||
return strings.HasSuffix(name, "[Ollama]")
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
@@ -161,6 +161,76 @@ func TestOpenCodeEdit(t *testing.T) {
|
||||
assertOpenCodeModelNotExists(t, configPath, "mistral")
|
||||
})
|
||||
|
||||
t.Run("preserve user customizations on managed models", func(t *testing.T) {
|
||||
cleanup()
|
||||
if err := o.Edit([]string{"llama3.2"}); err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
// Add custom fields to the model entry (simulating user edits)
|
||||
data, _ := os.ReadFile(configPath)
|
||||
var cfg map[string]any
|
||||
json.Unmarshal(data, &cfg)
|
||||
provider := cfg["provider"].(map[string]any)
|
||||
ollama := provider["ollama"].(map[string]any)
|
||||
models := ollama["models"].(map[string]any)
|
||||
entry := models["llama3.2"].(map[string]any)
|
||||
entry["_myPref"] = "custom-value"
|
||||
entry["_myNum"] = 42
|
||||
configData, _ := json.MarshalIndent(cfg, "", " ")
|
||||
os.WriteFile(configPath, configData, 0o644)
|
||||
|
||||
// Re-run Edit — should preserve custom fields
|
||||
if err := o.Edit([]string{"llama3.2"}); err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
data, _ = os.ReadFile(configPath)
|
||||
json.Unmarshal(data, &cfg)
|
||||
provider = cfg["provider"].(map[string]any)
|
||||
ollama = provider["ollama"].(map[string]any)
|
||||
models = ollama["models"].(map[string]any)
|
||||
entry = models["llama3.2"].(map[string]any)
|
||||
|
||||
if entry["_myPref"] != "custom-value" {
|
||||
t.Errorf("_myPref was lost: got %v", entry["_myPref"])
|
||||
}
|
||||
if entry["_myNum"] != float64(42) {
|
||||
t.Errorf("_myNum was lost: got %v", entry["_myNum"])
|
||||
}
|
||||
if v, ok := entry["_launch"].(bool); !ok || !v {
|
||||
t.Errorf("_launch marker missing or false: got %v", entry["_launch"])
|
||||
}
|
||||
})
|
||||
|
||||
t.Run("migrate legacy [Ollama] suffix entries", func(t *testing.T) {
|
||||
cleanup()
|
||||
// Write a config with a legacy entry (has [Ollama] suffix but no _launch marker)
|
||||
os.MkdirAll(configDir, 0o755)
|
||||
os.WriteFile(configPath, []byte(`{"provider":{"ollama":{"models":{"llama3.2":{"name":"llama3.2 [Ollama]"}}}}}`), 0o644)
|
||||
|
||||
if err := o.Edit([]string{"llama3.2"}); err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
data, _ := os.ReadFile(configPath)
|
||||
var cfg map[string]any
|
||||
json.Unmarshal(data, &cfg)
|
||||
provider := cfg["provider"].(map[string]any)
|
||||
ollama := provider["ollama"].(map[string]any)
|
||||
models := ollama["models"].(map[string]any)
|
||||
entry := models["llama3.2"].(map[string]any)
|
||||
|
||||
// _launch marker should be added
|
||||
if v, ok := entry["_launch"].(bool); !ok || !v {
|
||||
t.Errorf("_launch marker not added during migration: got %v", entry["_launch"])
|
||||
}
|
||||
// [Ollama] suffix should be stripped
|
||||
if name, ok := entry["name"].(string); !ok || name != "llama3.2" {
|
||||
t.Errorf("name suffix not stripped: got %q", entry["name"])
|
||||
}
|
||||
})
|
||||
|
||||
t.Run("remove model preserves non-ollama models", func(t *testing.T) {
|
||||
cleanup()
|
||||
os.MkdirAll(configDir, 0o755)
|
||||
|
||||
@@ -4,16 +4,6 @@ title: Anthropic compatibility
|
||||
|
||||
Ollama provides compatibility with the [Anthropic Messages API](https://docs.anthropic.com/en/api/messages) to help connect existing applications to Ollama, including tools like Claude Code.
|
||||
|
||||
## Recommended models
|
||||
|
||||
For coding use cases, models like `glm-4.7:cloud`, `minimax-m2.1:cloud`, and `qwen3-coder` are recommended.
|
||||
|
||||
Pull a model before use:
|
||||
```shell
|
||||
ollama pull qwen3-coder
|
||||
ollama pull glm-4.7:cloud
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
### Environment variables
|
||||
@@ -22,8 +12,8 @@ To use Ollama with tools that expect the Anthropic API (like Claude Code), set t
|
||||
|
||||
```shell
|
||||
export ANTHROPIC_AUTH_TOKEN=ollama # required but ignored
|
||||
export ANTHROPIC_API_KEY="" # required but ignored
|
||||
export ANTHROPIC_BASE_URL=http://localhost:11434
|
||||
export ANTHROPIC_API_KEY=ollama # required but ignored
|
||||
```
|
||||
|
||||
### Simple `/v1/messages` example
|
||||
@@ -245,10 +235,41 @@ curl -X POST http://localhost:11434/v1/messages \
|
||||
|
||||
## Using with Claude Code
|
||||
|
||||
[Claude Code](https://code.claude.com/docs/en/overview) can be configured to use Ollama as its backend:
|
||||
[Claude Code](https://code.claude.com/docs/en/overview) can be configured to use Ollama as its backend.
|
||||
|
||||
### Recommended models
|
||||
|
||||
For coding use cases, models like `glm-4.7`, `minimax-m2.1`, and `qwen3-coder` are recommended.
|
||||
|
||||
Download a model before use:
|
||||
|
||||
```shell
|
||||
ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_API_KEY=ollama claude --model qwen3-coder
|
||||
ollama pull qwen3-coder
|
||||
```
|
||||
> Note: Qwen 3 coder is a 30B parameter model requiring at least 24GB of VRAM to run smoothly. More is required for longer context lengths.
|
||||
|
||||
```shell
|
||||
ollama pull glm-4.7:cloud
|
||||
```
|
||||
|
||||
### Quick setup
|
||||
|
||||
```shell
|
||||
ollama launch claude
|
||||
```
|
||||
|
||||
This will prompt you to select a model, configure Claude Code automatically, and launch it. To configure without launching:
|
||||
|
||||
```shell
|
||||
ollama launch claude --config
|
||||
```
|
||||
|
||||
### Manual setup
|
||||
|
||||
Set the environment variables and run Claude Code:
|
||||
|
||||
```shell
|
||||
ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_API_KEY="" claude --model qwen3-coder
|
||||
```
|
||||
|
||||
Or set the environment variables in your shell profile:
|
||||
@@ -256,19 +277,13 @@ Or set the environment variables in your shell profile:
|
||||
```shell
|
||||
export ANTHROPIC_AUTH_TOKEN=ollama
|
||||
export ANTHROPIC_BASE_URL=http://localhost:11434
|
||||
export ANTHROPIC_API_KEY=ollama
|
||||
export ANTHROPIC_API_KEY=""
|
||||
```
|
||||
|
||||
Then run Claude Code with any Ollama model:
|
||||
|
||||
```shell
|
||||
# Local models
|
||||
claude --model qwen3-coder
|
||||
claude --model gpt-oss:20b
|
||||
|
||||
# Cloud models
|
||||
claude --model glm-4.7:cloud
|
||||
claude --model minimax-m2.1:cloud
|
||||
```
|
||||
|
||||
## Endpoints
|
||||
|
||||
41
docs/cli.mdx
41
docs/cli.mdx
@@ -8,6 +8,47 @@ title: CLI Reference
|
||||
ollama run gemma3
|
||||
```
|
||||
|
||||
### Launch integrations
|
||||
|
||||
```
|
||||
ollama launch
|
||||
```
|
||||
|
||||
Configure and launch external applications to use Ollama models. This provides an interactive way to set up and start integrations with supported apps.
|
||||
|
||||
#### Supported integrations
|
||||
|
||||
- **OpenCode** - Open-source coding assistant
|
||||
- **Claude Code** - Anthropic's agentic coding tool
|
||||
- **Codex** - OpenAI's coding assistant
|
||||
- **Droid** - Factory's AI coding agent
|
||||
|
||||
#### Examples
|
||||
|
||||
Launch an integration interactively:
|
||||
|
||||
```
|
||||
ollama launch
|
||||
```
|
||||
|
||||
Launch a specific integration:
|
||||
|
||||
```
|
||||
ollama launch claude
|
||||
```
|
||||
|
||||
Launch with a specific model:
|
||||
|
||||
```
|
||||
ollama launch claude --model qwen3-coder
|
||||
```
|
||||
|
||||
Configure without launching:
|
||||
|
||||
```
|
||||
ollama launch droid --config
|
||||
```
|
||||
|
||||
#### Multiline input
|
||||
|
||||
For multiline input, you can wrap text with `"""`:
|
||||
|
||||
@@ -3,8 +3,6 @@ title: Cloud
|
||||
sidebarTitle: Cloud
|
||||
---
|
||||
|
||||
<Info>Ollama's cloud is currently in preview.</Info>
|
||||
|
||||
## Cloud Models
|
||||
|
||||
Ollama's cloud models are a new kind of model in Ollama that can run without a powerful GPU. Instead, cloud models are automatically offloaded to Ollama's cloud service while offering the same capabilities as local models, making it possible to keep using your local tools while running larger models that wouldn't fit on a personal computer.
|
||||
|
||||
@@ -8,7 +8,7 @@ Context length is the maximum number of tokens that the model has access to in m
|
||||
The default context length in Ollama is 4096 tokens.
|
||||
</Note>
|
||||
|
||||
Tasks which require large context like web search, agents, and coding tools should be set to at least 32000 tokens.
|
||||
Tasks which require large context like web search, agents, and coding tools should be set to at least 64000 tokens.
|
||||
|
||||
## Setting context length
|
||||
|
||||
@@ -24,7 +24,7 @@ Change the slider in the Ollama app under settings to your desired context lengt
|
||||
### CLI
|
||||
If editing the context length for Ollama is not possible, the context length can also be updated when serving Ollama.
|
||||
```
|
||||
OLLAMA_CONTEXT_LENGTH=32000 ollama serve
|
||||
OLLAMA_CONTEXT_LENGTH=64000 ollama serve
|
||||
```
|
||||
|
||||
### Check allocated context length and model offloading
|
||||
|
||||
@@ -102,18 +102,19 @@
|
||||
"group": "Integrations",
|
||||
"pages": [
|
||||
"/integrations/claude-code",
|
||||
"/integrations/vscode",
|
||||
"/integrations/jetbrains",
|
||||
"/integrations/codex",
|
||||
"/integrations/cline",
|
||||
"/integrations/codex",
|
||||
"/integrations/droid",
|
||||
"/integrations/goose",
|
||||
"/integrations/zed",
|
||||
"/integrations/roo-code",
|
||||
"/integrations/jetbrains",
|
||||
"/integrations/marimo",
|
||||
"/integrations/n8n",
|
||||
"/integrations/xcode",
|
||||
"/integrations/onyx",
|
||||
"/integrations/marimo"
|
||||
"/integrations/opencode",
|
||||
"/integrations/roo-code",
|
||||
"/integrations/vscode",
|
||||
"/integrations/xcode",
|
||||
"/integrations/zed"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -9,7 +9,7 @@ sidebarTitle: Welcome
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Quickstart" icon="rocket" href="/quickstart">
|
||||
Get up and running with your first model
|
||||
Get up and running with your first model or integrate Ollama with your favorite tools
|
||||
</Card>
|
||||
<Card
|
||||
title="Download Ollama"
|
||||
|
||||
@@ -4,7 +4,7 @@ title: Claude Code
|
||||
|
||||
Claude Code is Anthropic's agentic coding tool that can read, modify, and execute code in your working directory.
|
||||
|
||||
Open models can be used with Claude Code through Ollama's Anthropic-compatible API, enabling you to use models such as `qwen3-coder`, `gpt-oss:20b`, or other models.
|
||||
Open models can be used with Claude Code through Ollama's Anthropic-compatible API, enabling you to use models such as `glm-4.7`, `qwen3-coder`, `gpt-oss`.
|
||||
|
||||
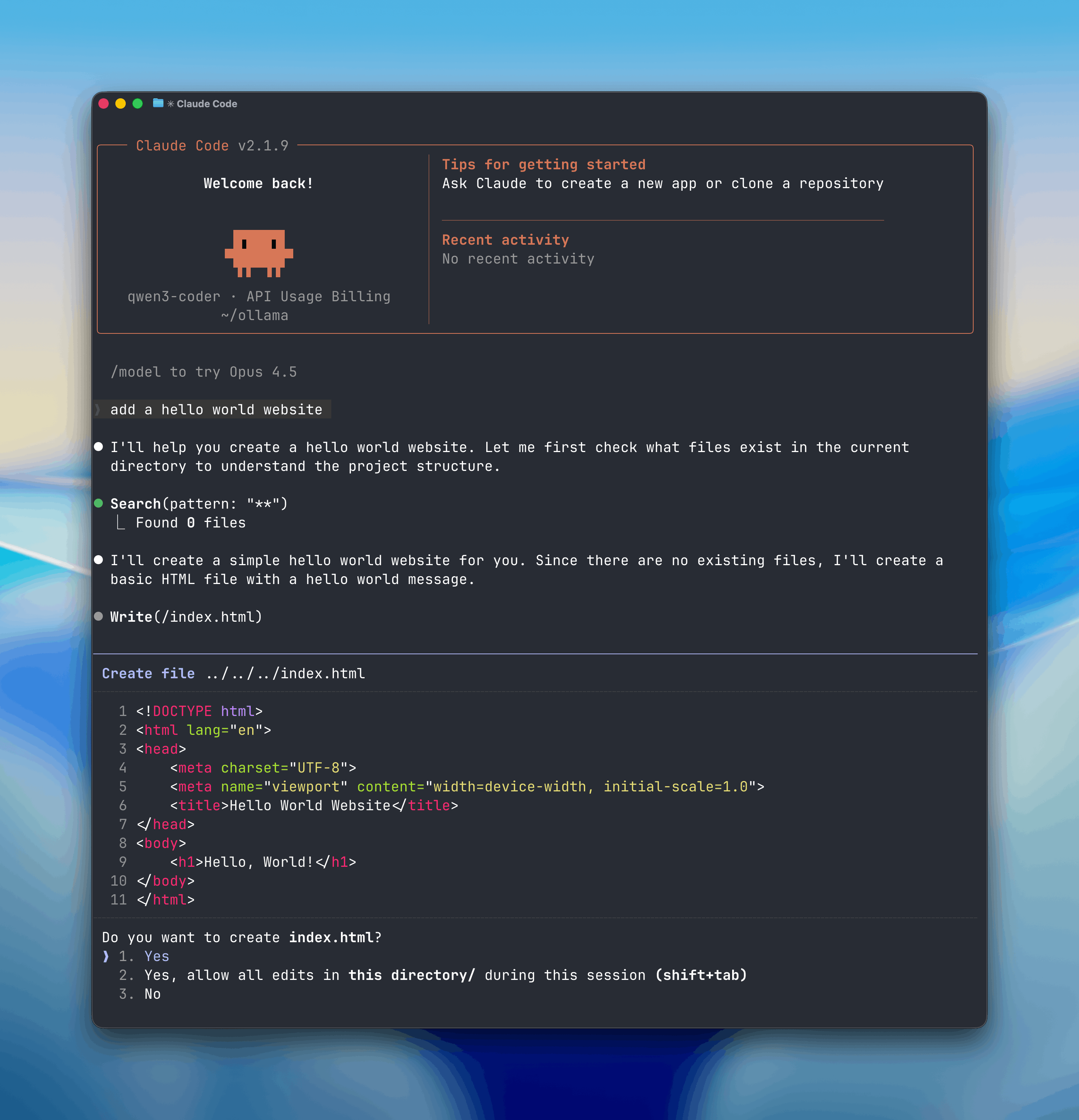
|
||||
|
||||
@@ -26,12 +26,27 @@ irm https://claude.ai/install.ps1 | iex
|
||||
|
||||
## Usage with Ollama
|
||||
|
||||
### Quick setup
|
||||
|
||||
```shell
|
||||
ollama launch claude
|
||||
```
|
||||
|
||||
To configure without launching:
|
||||
|
||||
```shell
|
||||
ollama launch claude --config
|
||||
```
|
||||
|
||||
### Manual setup
|
||||
|
||||
Claude Code connects to Ollama using the Anthropic-compatible API.
|
||||
|
||||
1. Set the environment variables:
|
||||
|
||||
```shell
|
||||
export ANTHROPIC_AUTH_TOKEN=ollama
|
||||
export ANTHROPIC_API_KEY=""
|
||||
export ANTHROPIC_BASE_URL=http://localhost:11434
|
||||
```
|
||||
|
||||
@@ -44,35 +59,17 @@ claude --model gpt-oss:20b
|
||||
Or run with environment variables inline:
|
||||
|
||||
```shell
|
||||
ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_BASE_URL=http://localhost:11434 claude --model gpt-oss:20b
|
||||
ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_API_KEY="" claude --model qwen3-coder
|
||||
```
|
||||
|
||||
**Note:** Claude Code requires a large context window. We recommend at least 32K tokens. See the [context length documentation](/context-length) for how to adjust context length in Ollama.
|
||||
|
||||
## Connecting to ollama.com
|
||||
|
||||
1. Create an [API key](https://ollama.com/settings/keys) on ollama.com
|
||||
2. Set the environment variables:
|
||||
|
||||
```shell
|
||||
export ANTHROPIC_BASE_URL=https://ollama.com
|
||||
export ANTHROPIC_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
3. Run Claude Code with a cloud model:
|
||||
|
||||
```shell
|
||||
claude --model glm-4.7:cloud
|
||||
```
|
||||
**Note:** Claude Code requires a large context window. We recommend at least 64k tokens. See the [context length documentation](/context-length) for how to adjust context length in Ollama.
|
||||
|
||||
## Recommended Models
|
||||
|
||||
### Cloud models
|
||||
- `glm-4.7:cloud` - High-performance cloud model
|
||||
- `minimax-m2.1:cloud` - Fast cloud model
|
||||
- `qwen3-coder:480b` - Large coding model
|
||||
- `qwen3-coder`
|
||||
- `glm-4.7`
|
||||
- `gpt-oss:20b`
|
||||
- `gpt-oss:120b`
|
||||
|
||||
Cloud models are also available at [ollama.com/search?c=cloud](https://ollama.com/search?c=cloud).
|
||||
|
||||
### Local models
|
||||
- `qwen3-coder` - Excellent for coding tasks
|
||||
- `gpt-oss:20b` - Strong general-purpose model
|
||||
- `gpt-oss:120b` - Larger general-purpose model for more complex tasks
|
||||
@@ -13,7 +13,21 @@ npm install -g @openai/codex
|
||||
|
||||
## Usage with Ollama
|
||||
|
||||
<Note>Codex requires a larger context window. It is recommended to use a context window of at least 32K tokens.</Note>
|
||||
<Note>Codex requires a larger context window. It is recommended to use a context window of at least 64k tokens.</Note>
|
||||
|
||||
### Quick setup
|
||||
|
||||
```
|
||||
ollama launch codex
|
||||
```
|
||||
|
||||
To configure without launching:
|
||||
|
||||
```shell
|
||||
ollama launch codex --config
|
||||
```
|
||||
|
||||
### Manual setup
|
||||
|
||||
To use `codex` with Ollama, use the `--oss` flag:
|
||||
|
||||
|
||||
@@ -11,10 +11,24 @@ Install the [Droid CLI](https://factory.ai/):
|
||||
curl -fsSL https://app.factory.ai/cli | sh
|
||||
```
|
||||
|
||||
<Note>Droid requires a larger context window. It is recommended to use a context window of at least 32K tokens. See [Context length](/context-length) for more information.</Note>
|
||||
<Note>Droid requires a larger context window. It is recommended to use a context window of at least 64k tokens. See [Context length](/context-length) for more information.</Note>
|
||||
|
||||
## Usage with Ollama
|
||||
|
||||
### Quick setup
|
||||
|
||||
```bash
|
||||
ollama launch droid
|
||||
```
|
||||
|
||||
To configure without launching:
|
||||
|
||||
```shell
|
||||
ollama launch droid --config
|
||||
```
|
||||
|
||||
### Manual setup
|
||||
|
||||
Add a local configuration block to `~/.factory/config.json`:
|
||||
|
||||
```json
|
||||
@@ -73,4 +87,4 @@ Add the cloud configuration block to `~/.factory/config.json`:
|
||||
}
|
||||
```
|
||||
|
||||
Run `droid` in a new terminal to load the new settings.
|
||||
Run `droid` in a new terminal to load the new settings.
|
||||
|
||||
106
docs/integrations/opencode.mdx
Normal file
106
docs/integrations/opencode.mdx
Normal file
@@ -0,0 +1,106 @@
|
||||
---
|
||||
title: OpenCode
|
||||
---
|
||||
|
||||
OpenCode is an open-source AI coding assistant that runs in your terminal.
|
||||
|
||||
## Install
|
||||
|
||||
Install the [OpenCode CLI](https://opencode.ai):
|
||||
|
||||
```bash
|
||||
curl -fsSL https://opencode.ai/install.sh | bash
|
||||
```
|
||||
|
||||
<Note>OpenCode requires a larger context window. It is recommended to use a context window of at least 64k tokens. See [Context length](/context-length) for more information.</Note>
|
||||
|
||||
## Usage with Ollama
|
||||
|
||||
### Quick setup
|
||||
|
||||
```bash
|
||||
ollama launch opencode
|
||||
```
|
||||
|
||||
To configure without launching:
|
||||
|
||||
```shell
|
||||
ollama launch opencode --config
|
||||
```
|
||||
|
||||
### Manual setup
|
||||
|
||||
Add a configuration block to `~/.config/opencode/opencode.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"$schema": "https://opencode.ai/config.json",
|
||||
"provider": {
|
||||
"ollama": {
|
||||
"npm": "@ai-sdk/openai-compatible",
|
||||
"name": "Ollama",
|
||||
"options": {
|
||||
"baseURL": "http://localhost:11434/v1"
|
||||
},
|
||||
"models": {
|
||||
"qwen3-coder": {
|
||||
"name": "qwen3-coder"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Cloud Models
|
||||
|
||||
`glm-4.7:cloud` is the recommended model for use with OpenCode.
|
||||
|
||||
Add the cloud configuration to `~/.config/opencode/opencode.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"$schema": "https://opencode.ai/config.json",
|
||||
"provider": {
|
||||
"ollama": {
|
||||
"npm": "@ai-sdk/openai-compatible",
|
||||
"name": "Ollama",
|
||||
"options": {
|
||||
"baseURL": "http://localhost:11434/v1"
|
||||
},
|
||||
"models": {
|
||||
"glm-4.7:cloud": {
|
||||
"name": "glm-4.7:cloud"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Connecting to ollama.com
|
||||
|
||||
1. Create an [API key](https://ollama.com/settings/keys) from ollama.com and export it as `OLLAMA_API_KEY`.
|
||||
2. Update `~/.config/opencode/opencode.json` to point to ollama.com:
|
||||
|
||||
```json
|
||||
{
|
||||
"$schema": "https://opencode.ai/config.json",
|
||||
"provider": {
|
||||
"ollama": {
|
||||
"npm": "@ai-sdk/openai-compatible",
|
||||
"name": "Ollama Cloud",
|
||||
"options": {
|
||||
"baseURL": "https://ollama.com/v1"
|
||||
},
|
||||
"models": {
|
||||
"glm-4.7:cloud": {
|
||||
"name": "glm-4.7:cloud"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Run `opencode` in a new terminal to load the new settings.
|
||||
@@ -18,13 +18,13 @@ This quickstart will walk your through running your first model with Ollama. To
|
||||
<Tab title="CLI">
|
||||
Open a terminal and run the command:
|
||||
|
||||
```
|
||||
```sh
|
||||
ollama run gemma3
|
||||
```
|
||||
|
||||
</Tab>
|
||||
<Tab title="cURL">
|
||||
```
|
||||
```sh
|
||||
ollama pull gemma3
|
||||
```
|
||||
|
||||
@@ -45,13 +45,13 @@ This quickstart will walk your through running your first model with Ollama. To
|
||||
<Tab title="Python">
|
||||
Start by downloading a model:
|
||||
|
||||
```
|
||||
```sh
|
||||
ollama pull gemma3
|
||||
```
|
||||
|
||||
Then install Ollama's Python library:
|
||||
|
||||
```
|
||||
```sh
|
||||
pip install ollama
|
||||
```
|
||||
|
||||
@@ -101,3 +101,42 @@ This quickstart will walk your through running your first model with Ollama. To
|
||||
</Tabs>
|
||||
|
||||
See a full list of available models [here](https://ollama.com/models).
|
||||
|
||||
## Coding
|
||||
|
||||
For coding use cases, we recommend using the `glm-4.7-flash` model.
|
||||
|
||||
Note: this model requires 23 GB of VRAM with 64000 tokens context length.
|
||||
```sh
|
||||
ollama pull glm-4.7-flash
|
||||
```
|
||||
|
||||
Alternatively, you can use a more powerful cloud model (with full context length):
|
||||
```sh
|
||||
ollama pull glm-4.7:cloud
|
||||
```
|
||||
|
||||
Use `ollama launch` to quickly set up a coding tool with Ollama models:
|
||||
|
||||
```sh
|
||||
ollama launch
|
||||
```
|
||||
|
||||
### Supported integrations
|
||||
|
||||
- [OpenCode](/integrations/opencode) - Open-source coding assistant
|
||||
- [Claude Code](/integrations/claude-code) - Anthropic's agentic coding tool
|
||||
- [Codex](/integrations/codex) - OpenAI's coding assistant
|
||||
- [Droid](/integrations/droid) - Factory's AI coding agent
|
||||
|
||||
### Launch with a specific model
|
||||
|
||||
```sh
|
||||
ollama launch claude --model glm-4.7-flash
|
||||
```
|
||||
|
||||
### Configure without launching
|
||||
|
||||
```sh
|
||||
ollama launch claude --config
|
||||
```
|
||||
|
||||
@@ -17,21 +17,22 @@ CUDA changes:
|
||||
- Add tile configs for (576, 512, 4) and (576, 512, 8)
|
||||
- Add MMA config cases for ncols 4
|
||||
- Add template instances for ncols2=4
|
||||
- Fix nbatch_fa values in nvidia_fp32 config (32->64)
|
||||
---
|
||||
ggml/src/ggml-cuda/fattn-mma-f16.cuh | 15 ++++++++++++---
|
||||
ggml/src/ggml-cuda/fattn-tile.cuh | 18 +++++++++++++++++-
|
||||
ggml/src/ggml-cuda/fattn.cu | 12 ++++++++----
|
||||
...attn-mma-f16-instance-ncols1_16-ncols2_4.cu | 1 +
|
||||
...fattn-mma-f16-instance-ncols1_2-ncols2_4.cu | 1 +
|
||||
...fattn-mma-f16-instance-ncols1_4-ncols2_4.cu | 1 +
|
||||
...fattn-mma-f16-instance-ncols1_8-ncols2_4.cu | 1 +
|
||||
ggml/src/ggml-metal/ggml-metal-device.m | 8 ++------
|
||||
ggml/src/ggml-metal/ggml-metal-ops.cpp | 2 +-
|
||||
ggml/src/ggml-metal/ggml-metal.metal | 1 +
|
||||
10 files changed, 45 insertions(+), 15 deletions(-)
|
||||
ggml/src/ggml-cuda/fattn-mma-f16.cuh | 40 +++++++++++++++----
|
||||
ggml/src/ggml-cuda/fattn-tile.cuh | 16 ++++++++
|
||||
ggml/src/ggml-cuda/fattn.cu | 12 ++++--
|
||||
...ttn-mma-f16-instance-ncols1_16-ncols2_4.cu | 1 +
|
||||
...attn-mma-f16-instance-ncols1_2-ncols2_4.cu | 1 +
|
||||
...attn-mma-f16-instance-ncols1_4-ncols2_4.cu | 1 +
|
||||
...attn-mma-f16-instance-ncols1_8-ncols2_4.cu | 1 +
|
||||
ggml/src/ggml-metal/ggml-metal-device.m | 8 +---
|
||||
ggml/src/ggml-metal/ggml-metal-ops.cpp | 2 +-
|
||||
ggml/src/ggml-metal/ggml-metal.metal | 1 +
|
||||
10 files changed, 64 insertions(+), 19 deletions(-)
|
||||
|
||||
diff --git a/ggml/src/ggml-cuda/fattn-mma-f16.cuh b/ggml/src/ggml-cuda/fattn-mma-f16.cuh
|
||||
index 7bd1044c1..a627302f9 100644
|
||||
index 7bd1044c1..3dea2205e 100644
|
||||
--- a/ggml/src/ggml-cuda/fattn-mma-f16.cuh
|
||||
+++ b/ggml/src/ggml-cuda/fattn-mma-f16.cuh
|
||||
@@ -66,7 +66,8 @@ static constexpr __host__ __device__ fattn_mma_config ggml_cuda_fattn_mma_get_co
|
||||
@@ -64,18 +65,78 @@ index 7bd1044c1..a627302f9 100644
|
||||
GGML_CUDA_FATTN_MMA_CONFIG_CASE(576, 512, 16, 64, 4, 32, 288, 256, 64, 1, false);
|
||||
GGML_CUDA_FATTN_MMA_CONFIG_CASE(576, 512, 32, 128, 2, 32, 160, 128, 64, 1, false);
|
||||
GGML_CUDA_FATTN_MMA_CONFIG_CASE(576, 512, 64, 256, 1, 32, 160, 128, 64, 1, false);
|
||||
@@ -1585,3 +1588,9 @@ DECL_FATTN_MMA_F16_CASE_ALL_NCOLS2(256, 256, 64)
|
||||
@@ -397,7 +400,7 @@ static __device__ __forceinline__ void flash_attn_ext_f16_iter(
|
||||
constexpr int ncols = ncols1 * ncols2;
|
||||
constexpr int cols_per_warp = T_B_KQ::I;
|
||||
constexpr int cols_per_thread = 2; // This is specifically KQ columns, Volta only has a single VKQ column.
|
||||
- constexpr int np = nwarps * (cols_per_warp/ncols2) / ncols1; // Number of parallel CUDA warps per Q column.
|
||||
+ constexpr int np = cols_per_warp > ncols ? nwarps : nwarps * cols_per_warp/ncols; // Number of parallel CUDA warps per Q column.
|
||||
constexpr int nbatch_fa = ggml_cuda_fattn_mma_get_nbatch_fa(DKQ, DV, ncols);
|
||||
constexpr int nbatch_K2 = ggml_cuda_fattn_mma_get_nbatch_K2(DKQ, DV, ncols);
|
||||
constexpr int nbatch_V2 = ggml_cuda_fattn_mma_get_nbatch_V2(DKQ, DV, ncols);
|
||||
@@ -467,7 +470,6 @@ static __device__ __forceinline__ void flash_attn_ext_f16_iter(
|
||||
}
|
||||
}
|
||||
} else {
|
||||
- static_assert(cols_per_warp != 8, "cols_per_warp == 8 not implemented");
|
||||
#pragma unroll
|
||||
for (int k_KQ_0 = k0_start; k_KQ_0 < k0_stop; k_KQ_0 += T_A_KQ::J) {
|
||||
load_ldmatrix(Q_B[0], tile_Q + (threadIdx.y / np)*(T_B_KQ::I*stride_tile_Q) + k_KQ_0, stride_tile_Q);
|
||||
@@ -479,8 +481,18 @@ static __device__ __forceinline__ void flash_attn_ext_f16_iter(
|
||||
T_A_KQ K_A;
|
||||
load_ldmatrix(K_A, tile_K + i_KQ_0*stride_tile_K + (k_KQ_0 - k0_start), stride_tile_K);
|
||||
|
||||
- // Wide version of KQ_C is column-major => swap A and B.
|
||||
- mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], Q_B[0], K_A);
|
||||
+ if constexpr (cols_per_warp == 8) {
|
||||
+ mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], K_A, Q_B[0]);
|
||||
+ } else {
|
||||
+ // Wide version of KQ_C is column-major
|
||||
+#if defined(AMD_WMMA_AVAILABLE)
|
||||
+ // RDNA matrix C is column-major.
|
||||
+ mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], K_A, Q_B[0]);
|
||||
+#else
|
||||
+ // swap A and B for CUDA.
|
||||
+ mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], Q_B[0], K_A);
|
||||
+#endif // defined(AMD_WMMA_AVAILABLE)
|
||||
+ }
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -841,7 +853,7 @@ static __device__ __forceinline__ void flash_attn_ext_f16_process_tile(
|
||||
|
||||
constexpr int cols_per_warp = T_B_KQ::I;
|
||||
constexpr int cols_per_thread = 2; // This is specifically KQ columns, Volta only has a single VKQ column.
|
||||
- constexpr int np = nwarps * (cols_per_warp/ncols2) / ncols1; // Number of parallel CUDA warps per Q column.
|
||||
+ constexpr int np = cols_per_warp > ncols ? nwarps : nwarps * cols_per_warp/ncols; // Number of parallel CUDA warps per Q column.
|
||||
constexpr int nbatch_fa = ggml_cuda_fattn_mma_get_nbatch_fa (DKQ, DV, ncols);
|
||||
constexpr int nbatch_K2 = ggml_cuda_fattn_mma_get_nbatch_K2 (DKQ, DV, ncols);
|
||||
constexpr int nbatch_V2 = ggml_cuda_fattn_mma_get_nbatch_V2 (DKQ, DV, ncols);
|
||||
@@ -1353,6 +1365,13 @@ static __global__ void flash_attn_ext_f16(
|
||||
NO_DEVICE_CODE;
|
||||
return;
|
||||
}
|
||||
+#ifdef VOLTA_MMA_AVAILABLE
|
||||
+ if (ncols1*ncols2 < 32) {
|
||||
+ NO_DEVICE_CODE;
|
||||
+ return;
|
||||
+ }
|
||||
+#endif // VOLTA_MMA_AVAILABLE
|
||||
+
|
||||
#if __CUDA_ARCH__ == GGML_CUDA_CC_TURING
|
||||
if (ncols1*ncols2 > 32) {
|
||||
NO_DEVICE_CODE;
|
||||
@@ -1585,3 +1604,8 @@ DECL_FATTN_MMA_F16_CASE_ALL_NCOLS2(256, 256, 64)
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 1, 16);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 2, 16);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 4, 16);
|
||||
+
|
||||
+// GLM 4.7 Flash uses gqa_ratio 4:
|
||||
+extern DECL_FATTN_MMA_F16_CASE(576, 512, 2, 4);
|
||||
+extern DECL_FATTN_MMA_F16_CASE(576, 512, 4, 4);
|
||||
+extern DECL_FATTN_MMA_F16_CASE(576, 512, 8, 4);
|
||||
+extern DECL_FATTN_MMA_F16_CASE(576, 512, 16, 4);
|
||||
+// For GLM 4.7 Flash
|
||||
+extern DECL_FATTN_MMA_F16_CASE(576, 512, 4, 4);
|
||||
+extern DECL_FATTN_MMA_F16_CASE(576, 512, 8, 4);
|
||||
+extern DECL_FATTN_MMA_F16_CASE(576, 512, 16, 4);
|
||||
diff --git a/ggml/src/ggml-cuda/fattn-tile.cuh b/ggml/src/ggml-cuda/fattn-tile.cuh
|
||||
index 7c4d6fe67..6389ba5c4 100644
|
||||
index 7c4d6fe67..371be7442 100644
|
||||
--- a/ggml/src/ggml-cuda/fattn-tile.cuh
|
||||
+++ b/ggml/src/ggml-cuda/fattn-tile.cuh
|
||||
@@ -68,6 +68,8 @@ static constexpr __host__ __device__ uint32_t ggml_cuda_fattn_tile_get_config_nv
|
||||
@@ -85,19 +146,17 @@ index 7c4d6fe67..6389ba5c4 100644
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 4, 128, 2, 64, 64)
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 8, 256, 2, 64, 64)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 16, 256, 2, 64, 64)
|
||||
|
||||
return 0;
|
||||
@@ -122,7 +124,9 @@ static constexpr __host__ __device__ uint32_t ggml_cuda_fattn_tile_get_config_nv
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 16, 256, 2, 32, 128)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 32, 256, 2, 32, 64)
|
||||
|
||||
- GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 16, 256, 2, 32, 64)
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 4, 128, 2, 32, 64)
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 8, 256, 2, 32, 64)
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 16, 256, 2, 32, 64)
|
||||
|
||||
return 0;
|
||||
}
|
||||
@@ -122,6 +124,8 @@ static constexpr __host__ __device__ uint32_t ggml_cuda_fattn_tile_get_config_nv
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 16, 256, 2, 32, 128)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 32, 256, 2, 32, 64)
|
||||
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 4, 128, 2, 32, 64)
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 8, 256, 2, 32, 64)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 16, 256, 2, 32, 64)
|
||||
|
||||
return 0;
|
||||
@@ -183,6 +187,8 @@ static constexpr __host__ __device__ uint32_t ggml_cuda_fattn_tile_get_config_am
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 16, 256, 2, 32, 128)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 32, 256, 2, 32, 128)
|
||||
@@ -106,11 +165,11 @@ index 7c4d6fe67..6389ba5c4 100644
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 8, 256, 2, 64, 64)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 16, 256, 2, 64, 64)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 32, 512, 1, 128, 64)
|
||||
|
||||
|
||||
@@ -245,6 +251,8 @@ static constexpr __host__ __device__ uint32_t ggml_cuda_fattn_tile_get_config_am
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 16, 256, 5, 32, 256)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(256, 256, 32, 256, 3, 64, 128)
|
||||
|
||||
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 4, 128, 2, 64, 64)
|
||||
+ GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 8, 256, 2, 64, 64)
|
||||
GGML_CUDA_FATTN_TILE_CONFIG_CASE(576, 512, 16, 256, 4, 64, 64)
|
||||
|
||||
@@ -400,7 +400,7 @@ static __device__ __forceinline__ void flash_attn_ext_f16_iter(
|
||||
constexpr int ncols = ncols1 * ncols2;
|
||||
constexpr int cols_per_warp = T_B_KQ::I;
|
||||
constexpr int cols_per_thread = 2; // This is specifically KQ columns, Volta only has a single VKQ column.
|
||||
constexpr int np = nwarps * (cols_per_warp/ncols2) / ncols1; // Number of parallel CUDA warps per Q column.
|
||||
constexpr int np = cols_per_warp > ncols ? nwarps : nwarps * cols_per_warp/ncols; // Number of parallel CUDA warps per Q column.
|
||||
constexpr int nbatch_fa = ggml_cuda_fattn_mma_get_nbatch_fa(DKQ, DV, ncols);
|
||||
constexpr int nbatch_K2 = ggml_cuda_fattn_mma_get_nbatch_K2(DKQ, DV, ncols);
|
||||
constexpr int nbatch_V2 = ggml_cuda_fattn_mma_get_nbatch_V2(DKQ, DV, ncols);
|
||||
@@ -470,7 +470,6 @@ static __device__ __forceinline__ void flash_attn_ext_f16_iter(
|
||||
}
|
||||
}
|
||||
} else {
|
||||
static_assert(cols_per_warp != 8, "cols_per_warp == 8 not implemented");
|
||||
#pragma unroll
|
||||
for (int k_KQ_0 = k0_start; k_KQ_0 < k0_stop; k_KQ_0 += T_A_KQ::J) {
|
||||
load_ldmatrix(Q_B[0], tile_Q + (threadIdx.y / np)*(T_B_KQ::I*stride_tile_Q) + k_KQ_0, stride_tile_Q);
|
||||
@@ -482,8 +481,18 @@ static __device__ __forceinline__ void flash_attn_ext_f16_iter(
|
||||
T_A_KQ K_A;
|
||||
load_ldmatrix(K_A, tile_K + i_KQ_0*stride_tile_K + (k_KQ_0 - k0_start), stride_tile_K);
|
||||
|
||||
// Wide version of KQ_C is column-major => swap A and B.
|
||||
mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], Q_B[0], K_A);
|
||||
if constexpr (cols_per_warp == 8) {
|
||||
mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], K_A, Q_B[0]);
|
||||
} else {
|
||||
// Wide version of KQ_C is column-major
|
||||
#if defined(AMD_WMMA_AVAILABLE)
|
||||
// RDNA matrix C is column-major.
|
||||
mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], K_A, Q_B[0]);
|
||||
#else
|
||||
// swap A and B for CUDA.
|
||||
mma(KQ_C[i_KQ_00/(np*T_A_KQ::I)], Q_B[0], K_A);
|
||||
#endif // defined(AMD_WMMA_AVAILABLE)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -844,7 +853,7 @@ static __device__ __forceinline__ void flash_attn_ext_f16_process_tile(
|
||||
|
||||
constexpr int cols_per_warp = T_B_KQ::I;
|
||||
constexpr int cols_per_thread = 2; // This is specifically KQ columns, Volta only has a single VKQ column.
|
||||
constexpr int np = nwarps * (cols_per_warp/ncols2) / ncols1; // Number of parallel CUDA warps per Q column.
|
||||
constexpr int np = cols_per_warp > ncols ? nwarps : nwarps * cols_per_warp/ncols; // Number of parallel CUDA warps per Q column.
|
||||
constexpr int nbatch_fa = ggml_cuda_fattn_mma_get_nbatch_fa (DKQ, DV, ncols);
|
||||
constexpr int nbatch_K2 = ggml_cuda_fattn_mma_get_nbatch_K2 (DKQ, DV, ncols);
|
||||
constexpr int nbatch_V2 = ggml_cuda_fattn_mma_get_nbatch_V2 (DKQ, DV, ncols);
|
||||
@@ -1356,6 +1365,13 @@ static __global__ void flash_attn_ext_f16(
|
||||
NO_DEVICE_CODE;
|
||||
return;
|
||||
}
|
||||
#ifdef VOLTA_MMA_AVAILABLE
|
||||
if (ncols1*ncols2 < 32) {
|
||||
NO_DEVICE_CODE;
|
||||
return;
|
||||
}
|
||||
#endif // VOLTA_MMA_AVAILABLE
|
||||
|
||||
#if __CUDA_ARCH__ == GGML_CUDA_CC_TURING
|
||||
if (ncols1*ncols2 > 32) {
|
||||
NO_DEVICE_CODE;
|
||||
@@ -1589,8 +1605,7 @@ extern DECL_FATTN_MMA_F16_CASE(576, 512, 1, 16);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 2, 16);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 4, 16);
|
||||
|
||||
// GLM 4.7 Flash uses gqa_ratio 4:
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 2, 4);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 4, 4);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 8, 4);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 16, 4);
|
||||
// For GLM 4.7 Flash
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 4, 4);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 8, 4);
|
||||
extern DECL_FATTN_MMA_F16_CASE(576, 512, 16, 4);
|
||||
|
||||
@@ -223,12 +223,7 @@ func New(c fs.Config) (model.Model, error) {
|
||||
|
||||
keyLength := int(c.Uint("attention.key_length"))
|
||||
valueLength := int(c.Uint("attention.value_length"))
|
||||
kvLoraRank := int(c.Uint("attention.kv_lora_rank"))
|
||||
qkRopeHeadDim := int(c.Uint("rope.dimension_count"))
|
||||
|
||||
// For MLA absorption, the effective key dimension is kvLoraRank + qkRopeHeadDim
|
||||
mlaKeyLength := kvLoraRank + qkRopeHeadDim
|
||||
kqScale := 1.0 / math.Sqrt(float64(mlaKeyLength))
|
||||
kqScale := 1.0 / math.Sqrt(float64(keyLength))
|
||||
|
||||
var pre []string
|
||||
switch c.String("tokenizer.ggml.pre") {
|
||||
@@ -246,7 +241,7 @@ func New(c fs.Config) (model.Model, error) {
|
||||
Values: c.Strings("tokenizer.ggml.tokens"),
|
||||
Types: c.Ints("tokenizer.ggml.token_type"),
|
||||
Merges: c.Strings("tokenizer.ggml.merges"),
|
||||
AddBOS: c.Bool("tokenizer.ggml.add_bos_token", true),
|
||||
AddBOS: c.Bool("tokenizer.ggml.add_bos_token", false),
|
||||
BOS: []int32{int32(c.Uint("tokenizer.ggml.bos_token_id"))},
|
||||
AddEOS: c.Bool("tokenizer.ggml.add_eos_token", false),
|
||||
EOS: append(
|
||||
|
||||
@@ -14,8 +14,8 @@
|
||||
VOL_NAME=${VOL_NAME:-"Ollama"}
|
||||
export VERSION=${VERSION:-$(git describe --tags --first-parent --abbrev=7 --long --dirty --always | sed -e "s/^v//g")}
|
||||
export GOFLAGS="'-ldflags=-w -s \"-X=github.com/ollama/ollama/version.Version=${VERSION#v}\" \"-X=github.com/ollama/ollama/server.mode=release\"'"
|
||||
export CGO_CFLAGS="-mmacosx-version-min=14.0"
|
||||
export CGO_CXXFLAGS="-mmacosx-version-min=14.0"
|
||||
export CGO_CFLAGS="-O3 -mmacosx-version-min=14.0"
|
||||
export CGO_CXXFLAGS="-O3 -mmacosx-version-min=14.0"
|
||||
export CGO_LDFLAGS="-mmacosx-version-min=14.0"
|
||||
|
||||
set -e
|
||||
|
||||
@@ -56,6 +56,12 @@ function checkEnv {
|
||||
|
||||
$script:DIST_DIR="${script:SRC_DIR}\dist\windows-${script:TARGET_ARCH}"
|
||||
$env:CGO_ENABLED="1"
|
||||
if (-not $env:CGO_CFLAGS) {
|
||||
$env:CGO_CFLAGS = "-O3"
|
||||
}
|
||||
if (-not $env:CGO_CXXFLAGS) {
|
||||
$env:CGO_CXXFLAGS = "-O3"
|
||||
}
|
||||
Write-Output "Checking version"
|
||||
if (!$env:VERSION) {
|
||||
$data=(git describe --tags --first-parent --abbrev=7 --long --dirty --always)
|
||||
|
||||
@@ -95,6 +95,13 @@ func getTensorNewType(kv fsggml.KV, qs *quantizeState, newType fsggml.TensorType
|
||||
// for the 8-expert model, bumping this to Q8_0 trades just ~128MB
|
||||
newType = fsggml.TensorTypeQ8_0
|
||||
}
|
||||
} else if strings.Contains(name, "attn_k_b.weight") ||
|
||||
strings.Contains(name, "attn_v_b.weight") ||
|
||||
strings.Contains(name, "attn_kv_a_mqa.weight") ||
|
||||
strings.Contains(name, "attn_q_a.weight") ||
|
||||
strings.Contains(name, "attn_q_b.weight") {
|
||||
// MLA tensors need higher precision to avoid quality degradation
|
||||
newType = fsggml.TensorTypeQ8_0
|
||||
} else if strings.Contains(name, "ffn_down") {
|
||||
iLayer := qs.iFfnDown
|
||||
n_layer := qs.nFfnDown
|
||||
|
||||
Reference in New Issue
Block a user