mirror of
https://github.com/mudler/LocalAI.git
synced 2026-06-10 09:46:34 -04:00
Compare commits
16 Commits
docs/impro
...
copilot/fi
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
eae90cafac | ||
|
|
d2ed2b48a8 | ||
|
|
22d8b48fd1 | ||
|
|
f2ba636290 | ||
|
|
95b6c9bb5a | ||
|
|
2cc4809b0d | ||
|
|
77bbeed57e | ||
|
|
3152611184 | ||
|
|
30f992f241 | ||
|
|
2709220b84 | ||
|
|
4278506876 | ||
|
|
1dd1d12da1 | ||
|
|
3a5b3bb0a6 | ||
|
|
94d9fc923f | ||
|
|
6fcf2c50b6 | ||
|
|
7cbd4a2f18 |
3
.gitmodules
vendored
3
.gitmodules
vendored
@@ -1,6 +1,3 @@
|
||||
[submodule "docs/themes/hugo-theme-relearn"]
|
||||
path = docs/themes/hugo-theme-relearn
|
||||
url = https://github.com/McShelby/hugo-theme-relearn.git
|
||||
[submodule "docs/themes/lotusdocs"]
|
||||
path = docs/themes/lotusdocs
|
||||
url = https://github.com/colinwilson/lotusdocs
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
LLAMA_VERSION?=80deff3648b93727422461c41c7279ef1dac7452
|
||||
LLAMA_VERSION?=10e9780154365b191fb43ca4830659ef12def80f
|
||||
LLAMA_REPO?=https://github.com/ggerganov/llama.cpp
|
||||
|
||||
CMAKE_ARGS?=
|
||||
|
||||
@@ -14,6 +14,8 @@ cp -r grpc-server.cpp llama.cpp/tools/grpc-server/
|
||||
cp -rfv llama.cpp/vendor/nlohmann/json.hpp llama.cpp/tools/grpc-server/
|
||||
cp -rfv llama.cpp/tools/server/utils.hpp llama.cpp/tools/grpc-server/
|
||||
cp -rfv llama.cpp/vendor/cpp-httplib/httplib.h llama.cpp/tools/grpc-server/
|
||||
cp -rfv llama.cpp/tools/server/server-http.cpp llama.cpp/tools/grpc-server/
|
||||
cp -rfv llama.cpp/tools/server/server-http.h llama.cpp/tools/grpc-server/
|
||||
|
||||
set +e
|
||||
if grep -q "grpc-server" llama.cpp/tools/CMakeLists.txt; then
|
||||
|
||||
@@ -8,7 +8,7 @@ JOBS?=$(shell nproc --ignore=1)
|
||||
|
||||
# whisper.cpp version
|
||||
WHISPER_REPO?=https://github.com/ggml-org/whisper.cpp
|
||||
WHISPER_CPP_VERSION?=d9b7613b34a343848af572cc14467fc5e82fc788
|
||||
WHISPER_CPP_VERSION?=b12abefa9be2abae39a73fa903322af135024a36
|
||||
SO_TARGET?=libgowhisper.so
|
||||
|
||||
CMAKE_ARGS+=-DBUILD_SHARED_LIBS=OFF
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
package config
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"regexp"
|
||||
"slices"
|
||||
@@ -475,7 +476,7 @@ func (cfg *ModelConfig) SetDefaults(opts ...ConfigLoaderOption) {
|
||||
cfg.syncKnownUsecasesFromString()
|
||||
}
|
||||
|
||||
func (c *ModelConfig) Validate() bool {
|
||||
func (c *ModelConfig) Validate() (bool, error) {
|
||||
downloadedFileNames := []string{}
|
||||
for _, f := range c.DownloadFiles {
|
||||
downloadedFileNames = append(downloadedFileNames, f.Filename)
|
||||
@@ -489,17 +490,20 @@ func (c *ModelConfig) Validate() bool {
|
||||
}
|
||||
if strings.HasPrefix(n, string(os.PathSeparator)) ||
|
||||
strings.Contains(n, "..") {
|
||||
return false
|
||||
return false, fmt.Errorf("invalid file path: %s", n)
|
||||
}
|
||||
}
|
||||
|
||||
if c.Backend != "" {
|
||||
// a regex that checks that is a string name with no special characters, except '-' and '_'
|
||||
re := regexp.MustCompile(`^[a-zA-Z0-9-_]+$`)
|
||||
return re.MatchString(c.Backend)
|
||||
if !re.MatchString(c.Backend) {
|
||||
return false, fmt.Errorf("invalid backend name: %s", c.Backend)
|
||||
}
|
||||
return true, nil
|
||||
}
|
||||
|
||||
return true
|
||||
return true, nil
|
||||
}
|
||||
|
||||
func (c *ModelConfig) HasTemplate() bool {
|
||||
@@ -534,7 +538,8 @@ const (
|
||||
|
||||
func GetAllModelConfigUsecases() map[string]ModelConfigUsecases {
|
||||
return map[string]ModelConfigUsecases{
|
||||
"FLAG_ANY": FLAG_ANY,
|
||||
// Note: FLAG_ANY is intentionally excluded from this map
|
||||
// because it's 0 and would always match in HasUsecases checks
|
||||
"FLAG_CHAT": FLAG_CHAT,
|
||||
"FLAG_COMPLETION": FLAG_COMPLETION,
|
||||
"FLAG_EDIT": FLAG_EDIT,
|
||||
@@ -636,7 +641,7 @@ func (c *ModelConfig) GuessUsecases(u ModelConfigUsecases) bool {
|
||||
}
|
||||
}
|
||||
if (u & FLAG_TTS) == FLAG_TTS {
|
||||
ttsBackends := []string{"bark-cpp", "piper", "transformers-musicgen"}
|
||||
ttsBackends := []string{"bark-cpp", "piper", "transformers-musicgen", "kokoro"}
|
||||
if !slices.Contains(ttsBackends, c.Backend) {
|
||||
return false
|
||||
}
|
||||
|
||||
@@ -169,7 +169,7 @@ func (bcl *ModelConfigLoader) LoadMultipleModelConfigsSingleFile(file string, op
|
||||
}
|
||||
|
||||
for _, cc := range c {
|
||||
if cc.Validate() {
|
||||
if valid, _ := cc.Validate(); valid {
|
||||
bcl.configs[cc.Name] = *cc
|
||||
}
|
||||
}
|
||||
@@ -184,7 +184,7 @@ func (bcl *ModelConfigLoader) ReadModelConfig(file string, opts ...ConfigLoaderO
|
||||
return fmt.Errorf("ReadModelConfig cannot read config file %q: %w", file, err)
|
||||
}
|
||||
|
||||
if c.Validate() {
|
||||
if valid, _ := c.Validate(); valid {
|
||||
bcl.configs[c.Name] = *c
|
||||
} else {
|
||||
return fmt.Errorf("config is not valid")
|
||||
@@ -362,7 +362,7 @@ func (bcl *ModelConfigLoader) LoadModelConfigsFromPath(path string, opts ...Conf
|
||||
log.Error().Err(err).Str("File Name", file.Name()).Msgf("LoadModelConfigsFromPath cannot read config file")
|
||||
continue
|
||||
}
|
||||
if c.Validate() {
|
||||
if valid, _ := c.Validate(); valid {
|
||||
bcl.configs[c.Name] = *c
|
||||
} else {
|
||||
log.Error().Err(err).Str("Name", c.Name).Msgf("config is not valid")
|
||||
|
||||
@@ -28,7 +28,9 @@ known_usecases:
|
||||
config, err := readModelConfigFromFile(tmp.Name())
|
||||
Expect(err).To(BeNil())
|
||||
Expect(config).ToNot(BeNil())
|
||||
Expect(config.Validate()).To(BeFalse())
|
||||
valid, err := config.Validate()
|
||||
Expect(err).To(HaveOccurred())
|
||||
Expect(valid).To(BeFalse())
|
||||
Expect(config.KnownUsecases).ToNot(BeNil())
|
||||
})
|
||||
It("Test Validate", func() {
|
||||
@@ -46,7 +48,9 @@ parameters:
|
||||
Expect(config).ToNot(BeNil())
|
||||
// two configs in config.yaml
|
||||
Expect(config.Name).To(Equal("bar-baz"))
|
||||
Expect(config.Validate()).To(BeTrue())
|
||||
valid, err := config.Validate()
|
||||
Expect(err).To(BeNil())
|
||||
Expect(valid).To(BeTrue())
|
||||
|
||||
// download https://raw.githubusercontent.com/mudler/LocalAI/v2.25.0/embedded/models/hermes-2-pro-mistral.yaml
|
||||
httpClient := http.Client{}
|
||||
@@ -63,7 +67,9 @@ parameters:
|
||||
Expect(config).ToNot(BeNil())
|
||||
// two configs in config.yaml
|
||||
Expect(config.Name).To(Equal("hermes-2-pro-mistral"))
|
||||
Expect(config.Validate()).To(BeTrue())
|
||||
valid, err = config.Validate()
|
||||
Expect(err).To(BeNil())
|
||||
Expect(valid).To(BeTrue())
|
||||
})
|
||||
})
|
||||
It("Properly handles backend usecase matching", func() {
|
||||
@@ -160,4 +166,76 @@ parameters:
|
||||
Expect(i.HasUsecases(FLAG_COMPLETION)).To(BeTrue())
|
||||
Expect(i.HasUsecases(FLAG_CHAT)).To(BeTrue())
|
||||
})
|
||||
|
||||
It("Handles multiple configs with same model file but different names", func() {
|
||||
// Create a temporary directory for test configs
|
||||
tmpDir, err := os.MkdirTemp("", "config_test_*")
|
||||
Expect(err).To(BeNil())
|
||||
defer os.RemoveAll(tmpDir)
|
||||
|
||||
// Write first config without MCP
|
||||
config1Path := tmpDir + "/model-without-mcp.yaml"
|
||||
err = os.WriteFile(config1Path, []byte(`name: model-without-mcp
|
||||
backend: llama-cpp
|
||||
parameters:
|
||||
model: shared-model.gguf
|
||||
`), 0644)
|
||||
Expect(err).To(BeNil())
|
||||
|
||||
// Write second config with MCP
|
||||
config2Path := tmpDir + "/model-with-mcp.yaml"
|
||||
err = os.WriteFile(config2Path, []byte(`name: model-with-mcp
|
||||
backend: llama-cpp
|
||||
parameters:
|
||||
model: shared-model.gguf
|
||||
mcp:
|
||||
stdio: |
|
||||
mcpServers:
|
||||
test:
|
||||
command: echo
|
||||
args: ["hello"]
|
||||
`), 0644)
|
||||
Expect(err).To(BeNil())
|
||||
|
||||
// Load all configs
|
||||
loader := NewModelConfigLoader(tmpDir)
|
||||
err = loader.LoadModelConfigsFromPath(tmpDir)
|
||||
Expect(err).To(BeNil())
|
||||
|
||||
// Verify both configs are loaded
|
||||
cfg1, exists1 := loader.GetModelConfig("model-without-mcp")
|
||||
Expect(exists1).To(BeTrue())
|
||||
Expect(cfg1.Name).To(Equal("model-without-mcp"))
|
||||
Expect(cfg1.Model).To(Equal("shared-model.gguf"))
|
||||
Expect(cfg1.MCP.Stdio).To(Equal(""))
|
||||
Expect(cfg1.MCP.Servers).To(Equal(""))
|
||||
|
||||
cfg2, exists2 := loader.GetModelConfig("model-with-mcp")
|
||||
Expect(exists2).To(BeTrue())
|
||||
Expect(cfg2.Name).To(Equal("model-with-mcp"))
|
||||
Expect(cfg2.Model).To(Equal("shared-model.gguf"))
|
||||
Expect(cfg2.MCP.Stdio).ToNot(Equal(""))
|
||||
|
||||
// Verify both configs are in the list
|
||||
allConfigs := loader.GetAllModelsConfigs()
|
||||
Expect(len(allConfigs)).To(Equal(2))
|
||||
|
||||
// Find each config in the list
|
||||
foundWithoutMCP := false
|
||||
foundWithMCP := false
|
||||
for _, cfg := range allConfigs {
|
||||
if cfg.Name == "model-without-mcp" {
|
||||
foundWithoutMCP = true
|
||||
Expect(cfg.Model).To(Equal("shared-model.gguf"))
|
||||
Expect(cfg.MCP.Stdio).To(Equal(""))
|
||||
}
|
||||
if cfg.Name == "model-with-mcp" {
|
||||
foundWithMCP = true
|
||||
Expect(cfg.Model).To(Equal("shared-model.gguf"))
|
||||
Expect(cfg.MCP.Stdio).ToNot(Equal(""))
|
||||
}
|
||||
}
|
||||
Expect(foundWithoutMCP).To(BeTrue())
|
||||
Expect(foundWithMCP).To(BeTrue())
|
||||
})
|
||||
})
|
||||
|
||||
@@ -164,7 +164,7 @@ func InstallBackend(ctx context.Context, systemState *system.SystemState, modelL
|
||||
return fmt.Errorf("failed copying: %w", err)
|
||||
}
|
||||
} else {
|
||||
uri := downloader.URI(config.URI)
|
||||
log.Debug().Str("uri", config.URI).Str("backendPath", backendPath).Msg("Downloading backend")
|
||||
if err := uri.DownloadFileWithContext(ctx, backendPath, "", 1, 1, downloadStatus); err != nil {
|
||||
success := false
|
||||
// Try to download from mirrors
|
||||
@@ -177,16 +177,27 @@ func InstallBackend(ctx context.Context, systemState *system.SystemState, modelL
|
||||
}
|
||||
if err := downloader.URI(mirror).DownloadFileWithContext(ctx, backendPath, "", 1, 1, downloadStatus); err == nil {
|
||||
success = true
|
||||
log.Debug().Str("uri", config.URI).Str("backendPath", backendPath).Msg("Downloaded backend")
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if !success {
|
||||
log.Error().Str("uri", config.URI).Str("backendPath", backendPath).Err(err).Msg("Failed to download backend")
|
||||
return fmt.Errorf("failed to download backend %q: %v", config.URI, err)
|
||||
}
|
||||
} else {
|
||||
log.Debug().Str("uri", config.URI).Str("backendPath", backendPath).Msg("Downloaded backend")
|
||||
}
|
||||
}
|
||||
|
||||
// sanity check - check if runfile is present
|
||||
runFile := filepath.Join(backendPath, runFile)
|
||||
if _, err := os.Stat(runFile); os.IsNotExist(err) {
|
||||
log.Error().Str("runFile", runFile).Msg("Run file not found")
|
||||
return fmt.Errorf("not a valid backend: run file not found %q", runFile)
|
||||
}
|
||||
|
||||
// Create metadata for the backend
|
||||
metadata := &BackendMetadata{
|
||||
Name: name,
|
||||
|
||||
@@ -563,8 +563,8 @@ var _ = Describe("Gallery Backends", func() {
|
||||
)
|
||||
Expect(err).NotTo(HaveOccurred())
|
||||
err = InstallBackend(context.TODO(), systemState, ml, &backend, nil)
|
||||
Expect(err).To(HaveOccurred()) // Will fail due to invalid URI, but path should be created
|
||||
Expect(newPath).To(BeADirectory())
|
||||
Expect(err).To(HaveOccurred()) // Will fail due to invalid URI, but path should be created
|
||||
})
|
||||
|
||||
It("should overwrite existing backend", func() {
|
||||
|
||||
@@ -6,11 +6,13 @@ import (
|
||||
"os"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/lithammer/fuzzysearch/fuzzy"
|
||||
"github.com/mudler/LocalAI/core/config"
|
||||
"github.com/mudler/LocalAI/pkg/downloader"
|
||||
"github.com/mudler/LocalAI/pkg/system"
|
||||
"github.com/mudler/LocalAI/pkg/xsync"
|
||||
"github.com/rs/zerolog/log"
|
||||
|
||||
"gopkg.in/yaml.v2"
|
||||
@@ -19,7 +21,7 @@ import (
|
||||
func GetGalleryConfigFromURL[T any](url string, basePath string) (T, error) {
|
||||
var config T
|
||||
uri := downloader.URI(url)
|
||||
err := uri.DownloadWithCallback(basePath, func(url string, d []byte) error {
|
||||
err := uri.ReadWithCallback(basePath, func(url string, d []byte) error {
|
||||
return yaml.Unmarshal(d, &config)
|
||||
})
|
||||
if err != nil {
|
||||
@@ -32,7 +34,7 @@ func GetGalleryConfigFromURL[T any](url string, basePath string) (T, error) {
|
||||
func GetGalleryConfigFromURLWithContext[T any](ctx context.Context, url string, basePath string) (T, error) {
|
||||
var config T
|
||||
uri := downloader.URI(url)
|
||||
err := uri.DownloadWithAuthorizationAndCallback(ctx, basePath, "", func(url string, d []byte) error {
|
||||
err := uri.ReadWithAuthorizationAndCallback(ctx, basePath, "", func(url string, d []byte) error {
|
||||
return yaml.Unmarshal(d, &config)
|
||||
})
|
||||
if err != nil {
|
||||
@@ -141,7 +143,7 @@ func AvailableGalleryModels(galleries []config.Gallery, systemState *system.Syst
|
||||
|
||||
// Get models from galleries
|
||||
for _, gallery := range galleries {
|
||||
galleryModels, err := getGalleryElements[*GalleryModel](gallery, systemState.Model.ModelsPath, func(model *GalleryModel) bool {
|
||||
galleryModels, err := getGalleryElements(gallery, systemState.Model.ModelsPath, func(model *GalleryModel) bool {
|
||||
if _, err := os.Stat(filepath.Join(systemState.Model.ModelsPath, fmt.Sprintf("%s.yaml", model.GetName()))); err == nil {
|
||||
return true
|
||||
}
|
||||
@@ -182,7 +184,7 @@ func AvailableBackends(galleries []config.Gallery, systemState *system.SystemSta
|
||||
func findGalleryURLFromReferenceURL(url string, basePath string) (string, error) {
|
||||
var refFile string
|
||||
uri := downloader.URI(url)
|
||||
err := uri.DownloadWithCallback(basePath, func(url string, d []byte) error {
|
||||
err := uri.ReadWithCallback(basePath, func(url string, d []byte) error {
|
||||
refFile = string(d)
|
||||
if len(refFile) == 0 {
|
||||
return fmt.Errorf("invalid reference file at url %s: %s", url, d)
|
||||
@@ -194,6 +196,17 @@ func findGalleryURLFromReferenceURL(url string, basePath string) (string, error)
|
||||
return refFile, err
|
||||
}
|
||||
|
||||
type galleryCacheEntry struct {
|
||||
yamlEntry []byte
|
||||
lastUpdated time.Time
|
||||
}
|
||||
|
||||
func (entry galleryCacheEntry) hasExpired() bool {
|
||||
return entry.lastUpdated.Before(time.Now().Add(-1 * time.Hour))
|
||||
}
|
||||
|
||||
var galleryCache = xsync.NewSyncedMap[string, galleryCacheEntry]()
|
||||
|
||||
func getGalleryElements[T GalleryElement](gallery config.Gallery, basePath string, isInstalledCallback func(T) bool) ([]T, error) {
|
||||
var models []T = []T{}
|
||||
|
||||
@@ -204,16 +217,37 @@ func getGalleryElements[T GalleryElement](gallery config.Gallery, basePath strin
|
||||
return models, err
|
||||
}
|
||||
}
|
||||
|
||||
cacheKey := fmt.Sprintf("%s-%s", gallery.Name, gallery.URL)
|
||||
if galleryCache.Exists(cacheKey) {
|
||||
entry := galleryCache.Get(cacheKey)
|
||||
// refresh if last updated is more than 1 hour ago
|
||||
if !entry.hasExpired() {
|
||||
err := yaml.Unmarshal(entry.yamlEntry, &models)
|
||||
if err != nil {
|
||||
return models, err
|
||||
}
|
||||
} else {
|
||||
galleryCache.Delete(cacheKey)
|
||||
}
|
||||
}
|
||||
|
||||
uri := downloader.URI(gallery.URL)
|
||||
|
||||
err := uri.DownloadWithCallback(basePath, func(url string, d []byte) error {
|
||||
return yaml.Unmarshal(d, &models)
|
||||
})
|
||||
if err != nil {
|
||||
if yamlErr, ok := err.(*yaml.TypeError); ok {
|
||||
log.Debug().Msgf("YAML errors: %s\n\nwreckage of models: %+v", strings.Join(yamlErr.Errors, "\n"), models)
|
||||
if len(models) == 0 {
|
||||
err := uri.ReadWithCallback(basePath, func(url string, d []byte) error {
|
||||
galleryCache.Set(cacheKey, galleryCacheEntry{
|
||||
yamlEntry: d,
|
||||
lastUpdated: time.Now(),
|
||||
})
|
||||
return yaml.Unmarshal(d, &models)
|
||||
})
|
||||
if err != nil {
|
||||
if yamlErr, ok := err.(*yaml.TypeError); ok {
|
||||
log.Debug().Msgf("YAML errors: %s\n\nwreckage of models: %+v", strings.Join(yamlErr.Errors, "\n"), models)
|
||||
}
|
||||
return models, fmt.Errorf("failed to read gallery elements: %w", err)
|
||||
}
|
||||
return models, err
|
||||
}
|
||||
|
||||
// Add gallery to models
|
||||
|
||||
@@ -2,11 +2,16 @@ package importers
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"os"
|
||||
"strings"
|
||||
|
||||
"github.com/rs/zerolog/log"
|
||||
"gopkg.in/yaml.v3"
|
||||
|
||||
"github.com/mudler/LocalAI/core/config"
|
||||
"github.com/mudler/LocalAI/core/gallery"
|
||||
"github.com/mudler/LocalAI/pkg/downloader"
|
||||
hfapi "github.com/mudler/LocalAI/pkg/huggingface-api"
|
||||
)
|
||||
|
||||
@@ -28,6 +33,10 @@ type Importer interface {
|
||||
Import(details Details) (gallery.ModelConfig, error)
|
||||
}
|
||||
|
||||
func hasYAMLExtension(uri string) bool {
|
||||
return strings.HasSuffix(uri, ".yaml") || strings.HasSuffix(uri, ".yml")
|
||||
}
|
||||
|
||||
func DiscoverModelConfig(uri string, preferences json.RawMessage) (gallery.ModelConfig, error) {
|
||||
var err error
|
||||
var modelConfig gallery.ModelConfig
|
||||
@@ -42,20 +51,61 @@ func DiscoverModelConfig(uri string, preferences json.RawMessage) (gallery.Model
|
||||
if err != nil {
|
||||
// maybe not a HF repository
|
||||
// TODO: maybe we can check if the URI is a valid HF repository
|
||||
log.Debug().Str("uri", uri).Msg("Failed to get model details, maybe not a HF repository")
|
||||
log.Debug().Str("uri", uri).Str("hfrepoID", hfrepoID).Msg("Failed to get model details, maybe not a HF repository")
|
||||
} else {
|
||||
log.Debug().Str("uri", uri).Msg("Got model details")
|
||||
log.Debug().Any("details", hfDetails).Msg("Model details")
|
||||
}
|
||||
|
||||
// handle local config files ("/my-model.yaml" or "file://my-model.yaml")
|
||||
localURI := uri
|
||||
if strings.HasPrefix(uri, downloader.LocalPrefix) {
|
||||
localURI = strings.TrimPrefix(uri, downloader.LocalPrefix)
|
||||
}
|
||||
|
||||
// if a file exists or it's an url that ends with .yaml or .yml, read the config file directly
|
||||
if _, e := os.Stat(localURI); hasYAMLExtension(localURI) && (e == nil || downloader.URI(localURI).LooksLikeURL()) {
|
||||
var modelYAML []byte
|
||||
if downloader.URI(localURI).LooksLikeURL() {
|
||||
err := downloader.URI(localURI).ReadWithCallback(localURI, func(url string, i []byte) error {
|
||||
modelYAML = i
|
||||
return nil
|
||||
})
|
||||
if err != nil {
|
||||
log.Error().Err(err).Str("filepath", localURI).Msg("error reading model definition")
|
||||
return gallery.ModelConfig{}, err
|
||||
}
|
||||
} else {
|
||||
modelYAML, err = os.ReadFile(localURI)
|
||||
if err != nil {
|
||||
log.Error().Err(err).Str("filepath", localURI).Msg("error reading model definition")
|
||||
return gallery.ModelConfig{}, err
|
||||
}
|
||||
}
|
||||
|
||||
var modelConfig config.ModelConfig
|
||||
if e := yaml.Unmarshal(modelYAML, &modelConfig); e != nil {
|
||||
return gallery.ModelConfig{}, e
|
||||
}
|
||||
|
||||
configFile, err := yaml.Marshal(modelConfig)
|
||||
return gallery.ModelConfig{
|
||||
Description: modelConfig.Description,
|
||||
Name: modelConfig.Name,
|
||||
ConfigFile: string(configFile),
|
||||
}, err
|
||||
}
|
||||
|
||||
details := Details{
|
||||
HuggingFace: hfDetails,
|
||||
URI: uri,
|
||||
Preferences: preferences,
|
||||
}
|
||||
|
||||
importerMatched := false
|
||||
for _, importer := range defaultImporters {
|
||||
if importer.Match(details) {
|
||||
importerMatched = true
|
||||
modelConfig, err = importer.Import(details)
|
||||
if err != nil {
|
||||
continue
|
||||
@@ -63,5 +113,8 @@ func DiscoverModelConfig(uri string, preferences json.RawMessage) (gallery.Model
|
||||
break
|
||||
}
|
||||
}
|
||||
return modelConfig, err
|
||||
if !importerMatched {
|
||||
return gallery.ModelConfig{}, fmt.Errorf("no importer matched for %s", uri)
|
||||
}
|
||||
return modelConfig, nil
|
||||
}
|
||||
|
||||
@@ -3,6 +3,8 @@ package importers_test
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"os"
|
||||
"path/filepath"
|
||||
|
||||
"github.com/mudler/LocalAI/core/gallery/importers"
|
||||
. "github.com/onsi/ginkgo/v2"
|
||||
@@ -212,4 +214,139 @@ var _ = Describe("DiscoverModelConfig", func() {
|
||||
Expect(modelConfig.Name).To(BeEmpty())
|
||||
})
|
||||
})
|
||||
|
||||
Context("with local YAML config files", func() {
|
||||
var tempDir string
|
||||
|
||||
BeforeEach(func() {
|
||||
var err error
|
||||
tempDir, err = os.MkdirTemp("", "importers-test-*")
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
})
|
||||
|
||||
AfterEach(func() {
|
||||
os.RemoveAll(tempDir)
|
||||
})
|
||||
|
||||
It("should read local YAML file with file:// prefix", func() {
|
||||
yamlContent := `name: test-model
|
||||
backend: llama-cpp
|
||||
description: Test model from local YAML
|
||||
parameters:
|
||||
model: /path/to/model.gguf
|
||||
temperature: 0.7
|
||||
`
|
||||
yamlFile := filepath.Join(tempDir, "test-model.yaml")
|
||||
err := os.WriteFile(yamlFile, []byte(yamlContent), 0644)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
uri := "file://" + yamlFile
|
||||
preferences := json.RawMessage(`{}`)
|
||||
|
||||
modelConfig, err := importers.DiscoverModelConfig(uri, preferences)
|
||||
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(modelConfig.Name).To(Equal("test-model"))
|
||||
Expect(modelConfig.Description).To(Equal("Test model from local YAML"))
|
||||
Expect(modelConfig.ConfigFile).To(ContainSubstring("backend: llama-cpp"))
|
||||
Expect(modelConfig.ConfigFile).To(ContainSubstring("name: test-model"))
|
||||
})
|
||||
|
||||
It("should read local YAML file without file:// prefix (direct path)", func() {
|
||||
yamlContent := `name: direct-path-model
|
||||
backend: mlx
|
||||
description: Test model from direct path
|
||||
parameters:
|
||||
model: /path/to/model.safetensors
|
||||
`
|
||||
yamlFile := filepath.Join(tempDir, "direct-model.yaml")
|
||||
err := os.WriteFile(yamlFile, []byte(yamlContent), 0644)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
uri := yamlFile
|
||||
preferences := json.RawMessage(`{}`)
|
||||
|
||||
modelConfig, err := importers.DiscoverModelConfig(uri, preferences)
|
||||
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(modelConfig.Name).To(Equal("direct-path-model"))
|
||||
Expect(modelConfig.Description).To(Equal("Test model from direct path"))
|
||||
Expect(modelConfig.ConfigFile).To(ContainSubstring("backend: mlx"))
|
||||
})
|
||||
|
||||
It("should read local YAML file with .yml extension", func() {
|
||||
yamlContent := `name: yml-extension-model
|
||||
backend: transformers
|
||||
description: Test model with .yml extension
|
||||
parameters:
|
||||
model: /path/to/model
|
||||
`
|
||||
yamlFile := filepath.Join(tempDir, "test-model.yml")
|
||||
err := os.WriteFile(yamlFile, []byte(yamlContent), 0644)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
uri := "file://" + yamlFile
|
||||
preferences := json.RawMessage(`{}`)
|
||||
|
||||
modelConfig, err := importers.DiscoverModelConfig(uri, preferences)
|
||||
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(modelConfig.Name).To(Equal("yml-extension-model"))
|
||||
Expect(modelConfig.Description).To(Equal("Test model with .yml extension"))
|
||||
Expect(modelConfig.ConfigFile).To(ContainSubstring("backend: transformers"))
|
||||
})
|
||||
|
||||
It("should ignore preferences when reading YAML files directly", func() {
|
||||
yamlContent := `name: yaml-model
|
||||
backend: llama-cpp
|
||||
description: Original description
|
||||
parameters:
|
||||
model: /path/to/model.gguf
|
||||
`
|
||||
yamlFile := filepath.Join(tempDir, "prefs-test.yaml")
|
||||
err := os.WriteFile(yamlFile, []byte(yamlContent), 0644)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
uri := "file://" + yamlFile
|
||||
// Preferences should be ignored when reading YAML directly
|
||||
preferences := json.RawMessage(`{"name": "custom-name", "description": "Custom description", "backend": "mlx"}`)
|
||||
|
||||
modelConfig, err := importers.DiscoverModelConfig(uri, preferences)
|
||||
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
// Should use values from YAML file, not preferences
|
||||
Expect(modelConfig.Name).To(Equal("yaml-model"))
|
||||
Expect(modelConfig.Description).To(Equal("Original description"))
|
||||
Expect(modelConfig.ConfigFile).To(ContainSubstring("backend: llama-cpp"))
|
||||
})
|
||||
|
||||
It("should return error when local YAML file doesn't exist", func() {
|
||||
nonExistentFile := filepath.Join(tempDir, "nonexistent.yaml")
|
||||
uri := "file://" + nonExistentFile
|
||||
preferences := json.RawMessage(`{}`)
|
||||
|
||||
modelConfig, err := importers.DiscoverModelConfig(uri, preferences)
|
||||
|
||||
Expect(err).To(HaveOccurred())
|
||||
Expect(modelConfig.Name).To(BeEmpty())
|
||||
})
|
||||
|
||||
It("should return error when YAML file is invalid/malformed", func() {
|
||||
invalidYaml := `name: invalid-model
|
||||
backend: llama-cpp
|
||||
invalid: yaml: content: [unclosed bracket
|
||||
`
|
||||
yamlFile := filepath.Join(tempDir, "invalid.yaml")
|
||||
err := os.WriteFile(yamlFile, []byte(invalidYaml), 0644)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
uri := "file://" + yamlFile
|
||||
preferences := json.RawMessage(`{}`)
|
||||
|
||||
modelConfig, err := importers.DiscoverModelConfig(uri, preferences)
|
||||
|
||||
Expect(err).To(HaveOccurred())
|
||||
Expect(modelConfig.Name).To(BeEmpty())
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
@@ -9,7 +9,9 @@ import (
|
||||
"github.com/mudler/LocalAI/core/config"
|
||||
"github.com/mudler/LocalAI/core/gallery"
|
||||
"github.com/mudler/LocalAI/core/schema"
|
||||
"github.com/mudler/LocalAI/pkg/downloader"
|
||||
"github.com/mudler/LocalAI/pkg/functions"
|
||||
"github.com/rs/zerolog/log"
|
||||
"go.yaml.in/yaml/v2"
|
||||
)
|
||||
|
||||
@@ -20,14 +22,22 @@ type LlamaCPPImporter struct{}
|
||||
func (i *LlamaCPPImporter) Match(details Details) bool {
|
||||
preferences, err := details.Preferences.MarshalJSON()
|
||||
if err != nil {
|
||||
log.Error().Err(err).Msg("failed to marshal preferences")
|
||||
return false
|
||||
}
|
||||
|
||||
preferencesMap := make(map[string]any)
|
||||
err = json.Unmarshal(preferences, &preferencesMap)
|
||||
if err != nil {
|
||||
return false
|
||||
|
||||
if len(preferences) > 0 {
|
||||
err = json.Unmarshal(preferences, &preferencesMap)
|
||||
if err != nil {
|
||||
log.Error().Err(err).Msg("failed to unmarshal preferences")
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
uri := downloader.URI(details.URI)
|
||||
|
||||
if preferencesMap["backend"] == "llama-cpp" {
|
||||
return true
|
||||
}
|
||||
@@ -36,6 +46,10 @@ func (i *LlamaCPPImporter) Match(details Details) bool {
|
||||
return true
|
||||
}
|
||||
|
||||
if uri.LooksLikeOCI() {
|
||||
return true
|
||||
}
|
||||
|
||||
if details.HuggingFace != nil {
|
||||
for _, file := range details.HuggingFace.Files {
|
||||
if strings.HasSuffix(file.Path, ".gguf") {
|
||||
@@ -48,14 +62,19 @@ func (i *LlamaCPPImporter) Match(details Details) bool {
|
||||
}
|
||||
|
||||
func (i *LlamaCPPImporter) Import(details Details) (gallery.ModelConfig, error) {
|
||||
|
||||
log.Debug().Str("uri", details.URI).Msg("llama.cpp importer matched")
|
||||
|
||||
preferences, err := details.Preferences.MarshalJSON()
|
||||
if err != nil {
|
||||
return gallery.ModelConfig{}, err
|
||||
}
|
||||
preferencesMap := make(map[string]any)
|
||||
err = json.Unmarshal(preferences, &preferencesMap)
|
||||
if err != nil {
|
||||
return gallery.ModelConfig{}, err
|
||||
if len(preferences) > 0 {
|
||||
err = json.Unmarshal(preferences, &preferencesMap)
|
||||
if err != nil {
|
||||
return gallery.ModelConfig{}, err
|
||||
}
|
||||
}
|
||||
|
||||
name, ok := preferencesMap["name"].(string)
|
||||
@@ -108,7 +127,40 @@ func (i *LlamaCPPImporter) Import(details Details) (gallery.ModelConfig, error)
|
||||
Description: description,
|
||||
}
|
||||
|
||||
if strings.HasSuffix(details.URI, ".gguf") {
|
||||
uri := downloader.URI(details.URI)
|
||||
|
||||
switch {
|
||||
case uri.LooksLikeOCI():
|
||||
ociName := strings.TrimPrefix(string(uri), downloader.OCIPrefix)
|
||||
ociName = strings.TrimPrefix(ociName, downloader.OllamaPrefix)
|
||||
ociName = strings.ReplaceAll(ociName, "/", "__")
|
||||
ociName = strings.ReplaceAll(ociName, ":", "__")
|
||||
cfg.Files = append(cfg.Files, gallery.File{
|
||||
URI: details.URI,
|
||||
Filename: ociName,
|
||||
})
|
||||
modelConfig.PredictionOptions = schema.PredictionOptions{
|
||||
BasicModelRequest: schema.BasicModelRequest{
|
||||
Model: ociName,
|
||||
},
|
||||
}
|
||||
case uri.LooksLikeURL() && strings.HasSuffix(details.URI, ".gguf"):
|
||||
// Extract filename from URL
|
||||
fileName, e := uri.FilenameFromUrl()
|
||||
if e != nil {
|
||||
return gallery.ModelConfig{}, e
|
||||
}
|
||||
|
||||
cfg.Files = append(cfg.Files, gallery.File{
|
||||
URI: details.URI,
|
||||
Filename: fileName,
|
||||
})
|
||||
modelConfig.PredictionOptions = schema.PredictionOptions{
|
||||
BasicModelRequest: schema.BasicModelRequest{
|
||||
Model: fileName,
|
||||
},
|
||||
}
|
||||
case strings.HasSuffix(details.URI, ".gguf"):
|
||||
cfg.Files = append(cfg.Files, gallery.File{
|
||||
URI: details.URI,
|
||||
Filename: filepath.Base(details.URI),
|
||||
@@ -118,7 +170,7 @@ func (i *LlamaCPPImporter) Import(details Details) (gallery.ModelConfig, error)
|
||||
Model: filepath.Base(details.URI),
|
||||
},
|
||||
}
|
||||
} else if details.HuggingFace != nil {
|
||||
case details.HuggingFace != nil:
|
||||
// We want to:
|
||||
// Get first the chosen quants that match filenames
|
||||
// OR the first mmproj/gguf file found
|
||||
@@ -195,7 +247,6 @@ func (i *LlamaCPPImporter) Import(details Details) (gallery.ModelConfig, error)
|
||||
}
|
||||
break
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
data, err := yaml.Marshal(modelConfig)
|
||||
|
||||
@@ -9,7 +9,6 @@ import (
|
||||
"strings"
|
||||
|
||||
"dario.cat/mergo"
|
||||
"github.com/mudler/LocalAI/core/config"
|
||||
lconfig "github.com/mudler/LocalAI/core/config"
|
||||
"github.com/mudler/LocalAI/pkg/downloader"
|
||||
"github.com/mudler/LocalAI/pkg/model"
|
||||
@@ -17,7 +16,7 @@ import (
|
||||
"github.com/mudler/LocalAI/pkg/utils"
|
||||
|
||||
"github.com/rs/zerolog/log"
|
||||
"gopkg.in/yaml.v2"
|
||||
"gopkg.in/yaml.v3"
|
||||
)
|
||||
|
||||
/*
|
||||
@@ -74,7 +73,7 @@ type PromptTemplate struct {
|
||||
// Installs a model from the gallery
|
||||
func InstallModelFromGallery(
|
||||
ctx context.Context,
|
||||
modelGalleries, backendGalleries []config.Gallery,
|
||||
modelGalleries, backendGalleries []lconfig.Gallery,
|
||||
systemState *system.SystemState,
|
||||
modelLoader *model.ModelLoader,
|
||||
name string, req GalleryModel, downloadStatus func(string, string, string, float64), enforceScan, automaticallyInstallBackend bool) error {
|
||||
@@ -260,8 +259,8 @@ func InstallModel(ctx context.Context, systemState *system.SystemState, nameOver
|
||||
return nil, fmt.Errorf("failed to unmarshal updated config YAML: %v", err)
|
||||
}
|
||||
|
||||
if !modelConfig.Validate() {
|
||||
return nil, fmt.Errorf("failed to validate updated config YAML")
|
||||
if valid, err := modelConfig.Validate(); !valid {
|
||||
return nil, fmt.Errorf("failed to validate updated config YAML: %v", err)
|
||||
}
|
||||
|
||||
err = os.WriteFile(configFilePath, updatedConfigYAML, 0600)
|
||||
@@ -304,7 +303,7 @@ func DeleteModelFromSystem(systemState *system.SystemState, name string) error {
|
||||
// Galleryname is the name of the model in this case
|
||||
dat, err := os.ReadFile(configFile)
|
||||
if err == nil {
|
||||
modelConfig := &config.ModelConfig{}
|
||||
modelConfig := &lconfig.ModelConfig{}
|
||||
|
||||
err = yaml.Unmarshal(dat, &modelConfig)
|
||||
if err != nil {
|
||||
@@ -369,7 +368,7 @@ func DeleteModelFromSystem(systemState *system.SystemState, name string) error {
|
||||
|
||||
// This is ***NEVER*** going to be perfect or finished.
|
||||
// This is a BEST EFFORT function to surface known-vulnerable models to users.
|
||||
func SafetyScanGalleryModels(galleries []config.Gallery, systemState *system.SystemState) error {
|
||||
func SafetyScanGalleryModels(galleries []lconfig.Gallery, systemState *system.SystemState) error {
|
||||
galleryModels, err := AvailableGalleryModels(galleries, systemState)
|
||||
if err != nil {
|
||||
return err
|
||||
|
||||
@@ -87,7 +87,7 @@ func getModels(url string) ([]gallery.GalleryModel, error) {
|
||||
response := []gallery.GalleryModel{}
|
||||
uri := downloader.URI(url)
|
||||
// TODO: No tests currently seem to exercise file:// urls. Fix?
|
||||
err := uri.DownloadWithAuthorizationAndCallback(context.TODO(), "", bearerKey, func(url string, i []byte) error {
|
||||
err := uri.ReadWithAuthorizationAndCallback(context.TODO(), "", bearerKey, func(url string, i []byte) error {
|
||||
// Unmarshal YAML data into a struct
|
||||
return json.Unmarshal(i, &response)
|
||||
})
|
||||
@@ -513,6 +513,124 @@ var _ = Describe("API test", func() {
|
||||
})
|
||||
|
||||
})
|
||||
|
||||
Context("Importing models from URI", func() {
|
||||
var testYamlFile string
|
||||
|
||||
BeforeEach(func() {
|
||||
// Create a test YAML config file
|
||||
yamlContent := `name: test-import-model
|
||||
backend: llama-cpp
|
||||
description: Test model imported from file URI
|
||||
parameters:
|
||||
model: path/to/model.gguf
|
||||
temperature: 0.7
|
||||
`
|
||||
testYamlFile = filepath.Join(tmpdir, "test-import.yaml")
|
||||
err := os.WriteFile(testYamlFile, []byte(yamlContent), 0644)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
})
|
||||
|
||||
AfterEach(func() {
|
||||
err := os.Remove(testYamlFile)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
})
|
||||
|
||||
It("should import model from file:// URI pointing to local YAML config", func() {
|
||||
importReq := schema.ImportModelRequest{
|
||||
URI: "file://" + testYamlFile,
|
||||
Preferences: json.RawMessage(`{}`),
|
||||
}
|
||||
|
||||
var response schema.GalleryResponse
|
||||
err := postRequestResponseJSON("http://127.0.0.1:9090/models/import-uri", &importReq, &response)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(response.ID).ToNot(BeEmpty())
|
||||
|
||||
uuid := response.ID
|
||||
resp := map[string]interface{}{}
|
||||
Eventually(func() bool {
|
||||
response := getModelStatus("http://127.0.0.1:9090/models/jobs/" + uuid)
|
||||
resp = response
|
||||
return response["processed"].(bool)
|
||||
}, "360s", "10s").Should(Equal(true))
|
||||
|
||||
// Check that the model was imported successfully
|
||||
Expect(resp["message"]).ToNot(ContainSubstring("error"))
|
||||
Expect(resp["error"]).To(BeNil())
|
||||
|
||||
// Verify the model config file was created
|
||||
dat, err := os.ReadFile(filepath.Join(modelDir, "test-import-model.yaml"))
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
content := map[string]interface{}{}
|
||||
err = yaml.Unmarshal(dat, &content)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(content["name"]).To(Equal("test-import-model"))
|
||||
Expect(content["backend"]).To(Equal("llama-cpp"))
|
||||
})
|
||||
|
||||
It("should return error when file:// URI points to non-existent file", func() {
|
||||
nonExistentFile := filepath.Join(tmpdir, "nonexistent.yaml")
|
||||
importReq := schema.ImportModelRequest{
|
||||
URI: "file://" + nonExistentFile,
|
||||
Preferences: json.RawMessage(`{}`),
|
||||
}
|
||||
|
||||
var response schema.GalleryResponse
|
||||
err := postRequestResponseJSON("http://127.0.0.1:9090/models/import-uri", &importReq, &response)
|
||||
// The endpoint should return an error immediately
|
||||
Expect(err).To(HaveOccurred())
|
||||
Expect(err.Error()).To(ContainSubstring("failed to discover model config"))
|
||||
})
|
||||
})
|
||||
|
||||
Context("Importing models from URI can't point to absolute paths", func() {
|
||||
var testYamlFile string
|
||||
|
||||
BeforeEach(func() {
|
||||
// Create a test YAML config file
|
||||
yamlContent := `name: test-import-model
|
||||
backend: llama-cpp
|
||||
description: Test model imported from file URI
|
||||
parameters:
|
||||
model: /path/to/model.gguf
|
||||
temperature: 0.7
|
||||
`
|
||||
testYamlFile = filepath.Join(tmpdir, "test-import.yaml")
|
||||
err := os.WriteFile(testYamlFile, []byte(yamlContent), 0644)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
})
|
||||
|
||||
AfterEach(func() {
|
||||
err := os.Remove(testYamlFile)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
})
|
||||
|
||||
It("should fail to import model from file:// URI pointing to local YAML config", func() {
|
||||
importReq := schema.ImportModelRequest{
|
||||
URI: "file://" + testYamlFile,
|
||||
Preferences: json.RawMessage(`{}`),
|
||||
}
|
||||
|
||||
var response schema.GalleryResponse
|
||||
err := postRequestResponseJSON("http://127.0.0.1:9090/models/import-uri", &importReq, &response)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(response.ID).ToNot(BeEmpty())
|
||||
|
||||
uuid := response.ID
|
||||
resp := map[string]interface{}{}
|
||||
Eventually(func() bool {
|
||||
response := getModelStatus("http://127.0.0.1:9090/models/jobs/" + uuid)
|
||||
resp = response
|
||||
return response["processed"].(bool)
|
||||
}, "360s", "10s").Should(Equal(true))
|
||||
|
||||
// Check that the model was imported successfully
|
||||
Expect(resp["message"]).To(ContainSubstring("error"))
|
||||
Expect(resp["error"]).ToNot(BeNil())
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
Context("Model gallery", func() {
|
||||
|
||||
@@ -135,7 +135,7 @@ func EditModelEndpoint(cl *config.ModelConfigLoader, appConfig *config.Applicati
|
||||
}
|
||||
|
||||
// Validate the configuration
|
||||
if !req.Validate() {
|
||||
if valid, _ := req.Validate(); !valid {
|
||||
response := ModelResponse{
|
||||
Success: false,
|
||||
Error: "Validation failed",
|
||||
@@ -196,7 +196,7 @@ func EditModelEndpoint(cl *config.ModelConfigLoader, appConfig *config.Applicati
|
||||
func ReloadModelsEndpoint(cl *config.ModelConfigLoader, appConfig *config.ApplicationConfig) echo.HandlerFunc {
|
||||
return func(c echo.Context) error {
|
||||
// Reload configurations
|
||||
if err := cl.LoadModelConfigsFromPath(appConfig.SystemState.Model.ModelsPath); err != nil {
|
||||
if err := cl.LoadModelConfigsFromPath(appConfig.SystemState.Model.ModelsPath, appConfig.ToConfigLoaderOptions()...); err != nil {
|
||||
response := ModelResponse{
|
||||
Success: false,
|
||||
Error: "Failed to reload configurations: " + err.Error(),
|
||||
|
||||
@@ -148,7 +148,7 @@ func ImportModelEndpoint(cl *config.ModelConfigLoader, appConfig *config.Applica
|
||||
modelConfig.SetDefaults()
|
||||
|
||||
// Validate the configuration
|
||||
if !modelConfig.Validate() {
|
||||
if valid, _ := modelConfig.Validate(); !valid {
|
||||
response := ModelResponse{
|
||||
Success: false,
|
||||
Error: "Invalid configuration",
|
||||
@@ -185,7 +185,7 @@ func ImportModelEndpoint(cl *config.ModelConfigLoader, appConfig *config.Applica
|
||||
return c.JSON(http.StatusInternalServerError, response)
|
||||
}
|
||||
// Reload configurations
|
||||
if err := cl.LoadModelConfigsFromPath(appConfig.SystemState.Model.ModelsPath); err != nil {
|
||||
if err := cl.LoadModelConfigsFromPath(appConfig.SystemState.Model.ModelsPath, appConfig.ToConfigLoaderOptions()...); err != nil {
|
||||
response := ModelResponse{
|
||||
Success: false,
|
||||
Error: "Failed to reload configurations: " + err.Error(),
|
||||
|
||||
@@ -112,7 +112,7 @@ func newTranscriptionOnlyModel(pipeline *config.Pipeline, cl *config.ModelConfig
|
||||
return nil, nil, fmt.Errorf("failed to load backend config: %w", err)
|
||||
}
|
||||
|
||||
if !cfgVAD.Validate() {
|
||||
if valid, _ := cfgVAD.Validate(); !valid {
|
||||
return nil, nil, fmt.Errorf("failed to validate config: %w", err)
|
||||
}
|
||||
|
||||
@@ -128,7 +128,7 @@ func newTranscriptionOnlyModel(pipeline *config.Pipeline, cl *config.ModelConfig
|
||||
return nil, nil, fmt.Errorf("failed to load backend config: %w", err)
|
||||
}
|
||||
|
||||
if !cfgSST.Validate() {
|
||||
if valid, _ := cfgSST.Validate(); !valid {
|
||||
return nil, nil, fmt.Errorf("failed to validate config: %w", err)
|
||||
}
|
||||
|
||||
@@ -155,7 +155,7 @@ func newModel(pipeline *config.Pipeline, cl *config.ModelConfigLoader, ml *model
|
||||
return nil, fmt.Errorf("failed to load backend config: %w", err)
|
||||
}
|
||||
|
||||
if !cfgVAD.Validate() {
|
||||
if valid, _ := cfgVAD.Validate(); !valid {
|
||||
return nil, fmt.Errorf("failed to validate config: %w", err)
|
||||
}
|
||||
|
||||
@@ -172,7 +172,7 @@ func newModel(pipeline *config.Pipeline, cl *config.ModelConfigLoader, ml *model
|
||||
return nil, fmt.Errorf("failed to load backend config: %w", err)
|
||||
}
|
||||
|
||||
if !cfgSST.Validate() {
|
||||
if valid, _ := cfgSST.Validate(); !valid {
|
||||
return nil, fmt.Errorf("failed to validate config: %w", err)
|
||||
}
|
||||
|
||||
@@ -191,7 +191,7 @@ func newModel(pipeline *config.Pipeline, cl *config.ModelConfigLoader, ml *model
|
||||
return nil, fmt.Errorf("failed to load backend config: %w", err)
|
||||
}
|
||||
|
||||
if !cfgAnyToAny.Validate() {
|
||||
if valid, _ := cfgAnyToAny.Validate(); !valid {
|
||||
return nil, fmt.Errorf("failed to validate config: %w", err)
|
||||
}
|
||||
|
||||
@@ -218,7 +218,7 @@ func newModel(pipeline *config.Pipeline, cl *config.ModelConfigLoader, ml *model
|
||||
return nil, fmt.Errorf("failed to load backend config: %w", err)
|
||||
}
|
||||
|
||||
if !cfgLLM.Validate() {
|
||||
if valid, _ := cfgLLM.Validate(); !valid {
|
||||
return nil, fmt.Errorf("failed to validate config: %w", err)
|
||||
}
|
||||
|
||||
@@ -228,7 +228,7 @@ func newModel(pipeline *config.Pipeline, cl *config.ModelConfigLoader, ml *model
|
||||
return nil, fmt.Errorf("failed to load backend config: %w", err)
|
||||
}
|
||||
|
||||
if !cfgTTS.Validate() {
|
||||
if valid, _ := cfgTTS.Validate(); !valid {
|
||||
return nil, fmt.Errorf("failed to validate config: %w", err)
|
||||
}
|
||||
|
||||
|
||||
@@ -475,7 +475,7 @@ func mergeOpenAIRequestAndModelConfig(config *config.ModelConfig, input *schema.
|
||||
}
|
||||
}
|
||||
|
||||
if config.Validate() {
|
||||
if valid, _ := config.Validate(); valid {
|
||||
return nil
|
||||
}
|
||||
return fmt.Errorf("unable to validate configuration after merging")
|
||||
|
||||
@@ -1213,9 +1213,6 @@ async function promptGPT(systemPrompt, input) {
|
||||
document.getElementById("system_prompt").addEventListener("submit", submitSystemPrompt);
|
||||
document.getElementById("prompt").addEventListener("submit", submitPrompt);
|
||||
document.getElementById("input").focus();
|
||||
document.getElementById("input_image").addEventListener("change", readInputImage);
|
||||
document.getElementById("input_audio").addEventListener("change", readInputAudio);
|
||||
document.getElementById("input_file").addEventListener("change", readInputFile);
|
||||
|
||||
storesystemPrompt = localStorage.getItem("system_prompt");
|
||||
if (storesystemPrompt) {
|
||||
|
||||
@@ -629,11 +629,33 @@ function backendsGallery() {
|
||||
this.fetchBackends();
|
||||
}
|
||||
|
||||
if (jobData.error) {
|
||||
if (jobData.error || (jobData.message && jobData.message.startsWith('error:'))) {
|
||||
backend.processing = false;
|
||||
delete this.jobProgress[backend.jobID];
|
||||
const action = backend.isDeletion ? 'deleting' : 'installing';
|
||||
this.addNotification(`Error ${action} backend "${backend.name}": ${jobData.error}`, 'error');
|
||||
// Extract error message - handle both string and object errors
|
||||
let errorMessage = 'Unknown error';
|
||||
if (typeof jobData.error === 'string') {
|
||||
errorMessage = jobData.error;
|
||||
} else if (jobData.error && typeof jobData.error === 'object') {
|
||||
// Check if error object has any properties
|
||||
const errorKeys = Object.keys(jobData.error);
|
||||
if (errorKeys.length > 0) {
|
||||
// Try common error object properties
|
||||
errorMessage = jobData.error.message || jobData.error.error || jobData.error.Error || JSON.stringify(jobData.error);
|
||||
} else {
|
||||
// Empty object {}, fall back to message field
|
||||
errorMessage = jobData.message || 'Unknown error';
|
||||
}
|
||||
} else if (jobData.message) {
|
||||
// Use message field if error is not present or is empty
|
||||
errorMessage = jobData.message;
|
||||
}
|
||||
// Remove "error: " prefix if present
|
||||
if (errorMessage.startsWith('error: ')) {
|
||||
errorMessage = errorMessage.substring(7);
|
||||
}
|
||||
this.addNotification(`Error ${action} backend "${backend.name}": ${errorMessage}`, 'error');
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Error polling job:', error);
|
||||
|
||||
@@ -419,8 +419,7 @@ SOFTWARE.
|
||||
</template>
|
||||
|
||||
{{ if $model }}
|
||||
{{ $galleryConfig:= index $allGalleryConfigs $model}}
|
||||
{{ if $galleryConfig }}
|
||||
<!-- Check for MCP configuration independently of gallery config -->
|
||||
{{ $modelConfig := "" }}
|
||||
{{ range .ModelsConfig }}
|
||||
{{ if eq .Name $model }}
|
||||
@@ -449,7 +448,6 @@ SOFTWARE.
|
||||
</div>
|
||||
{{ end }}
|
||||
{{ end }}
|
||||
{{ end }}
|
||||
|
||||
<button
|
||||
@click="showPromptForm = !showPromptForm"
|
||||
|
||||
@@ -127,6 +127,7 @@
|
||||
imageFiles: [],
|
||||
audioFiles: [],
|
||||
textFiles: [],
|
||||
attachedFiles: [],
|
||||
currentPlaceholder: 'Send a message...',
|
||||
placeholderIndex: 0,
|
||||
charIndex: 0,
|
||||
@@ -241,6 +242,30 @@
|
||||
} else {
|
||||
this.resumeTyping();
|
||||
}
|
||||
},
|
||||
handleFileSelection(files, fileType) {
|
||||
Array.from(files).forEach(file => {
|
||||
// Check if file already exists
|
||||
const exists = this.attachedFiles.some(f => f.name === file.name && f.type === fileType);
|
||||
if (!exists) {
|
||||
this.attachedFiles.push({ name: file.name, type: fileType });
|
||||
}
|
||||
});
|
||||
},
|
||||
removeAttachedFile(fileType, fileName) {
|
||||
// Remove from attachedFiles array
|
||||
const index = this.attachedFiles.findIndex(f => f.name === fileName && f.type === fileType);
|
||||
if (index !== -1) {
|
||||
this.attachedFiles.splice(index, 1);
|
||||
}
|
||||
// Remove from corresponding file array
|
||||
if (fileType === 'image') {
|
||||
this.imageFiles = this.imageFiles.filter(f => f.name !== fileName);
|
||||
} else if (fileType === 'audio') {
|
||||
this.audioFiles = this.audioFiles.filter(f => f.name !== fileName);
|
||||
} else if (fileType === 'file') {
|
||||
this.textFiles = this.textFiles.filter(f => f.name !== fileName);
|
||||
}
|
||||
}
|
||||
}">
|
||||
<!-- Model Selector -->
|
||||
@@ -265,6 +290,24 @@
|
||||
|
||||
<!-- Input Bar -->
|
||||
<form @submit.prevent="startChat($event)" class="relative w-full">
|
||||
<!-- Attachment Tags - Show above input when files are attached -->
|
||||
<div x-show="attachedFiles.length > 0" class="mb-3 flex flex-wrap gap-2 items-center">
|
||||
<template x-for="(file, index) in attachedFiles" :key="index">
|
||||
<div class="inline-flex items-center gap-2 px-3 py-1.5 rounded-lg text-sm bg-[#38BDF8]/20 border border-[#38BDF8]/40 text-[#E5E7EB]">
|
||||
<i :class="file.type === 'image' ? 'fa-solid fa-image' : file.type === 'audio' ? 'fa-solid fa-microphone' : 'fa-solid fa-file'" class="text-[#38BDF8]"></i>
|
||||
<span x-text="file.name" class="max-w-[200px] truncate"></span>
|
||||
<button
|
||||
type="button"
|
||||
@click="attachedFiles.splice(index, 1); removeAttachedFile(file.type, file.name)"
|
||||
class="ml-1 text-[#94A3B8] hover:text-[#E5E7EB] transition-colors"
|
||||
title="Remove attachment"
|
||||
>
|
||||
<i class="fa-solid fa-times text-xs"></i>
|
||||
</button>
|
||||
</div>
|
||||
</template>
|
||||
</div>
|
||||
|
||||
<div class="relative w-full bg-[#1E293B] border border-[#38BDF8]/20 rounded-xl focus-within:ring-2 focus-within:ring-[#38BDF8]/50 focus-within:border-[#38BDF8] transition-all duration-200">
|
||||
<textarea
|
||||
x-model="inputValue"
|
||||
@@ -279,7 +322,6 @@
|
||||
@input="handleInput()"
|
||||
rows="2"
|
||||
></textarea>
|
||||
<span x-show="fileName" x-text="fileName" class="absolute right-16 top-3 text-[#94A3B8] text-xs mr-2"></span>
|
||||
|
||||
<!-- Attachment Buttons -->
|
||||
<button
|
||||
@@ -321,7 +363,7 @@
|
||||
multiple
|
||||
accept="image/*"
|
||||
style="display: none;"
|
||||
@change="imageFiles = Array.from($event.target.files); fileName = imageFiles.length > 0 ? imageFiles.length + ' image(s) selected' : ''"
|
||||
@change="imageFiles = Array.from($event.target.files); handleFileSelection($event.target.files, 'image')"
|
||||
/>
|
||||
<input
|
||||
id="index_input_audio"
|
||||
@@ -329,7 +371,7 @@
|
||||
multiple
|
||||
accept="audio/*"
|
||||
style="display: none;"
|
||||
@change="audioFiles = Array.from($event.target.files); fileName = audioFiles.length > 0 ? audioFiles.length + ' audio file(s) selected' : ''"
|
||||
@change="audioFiles = Array.from($event.target.files); handleFileSelection($event.target.files, 'audio')"
|
||||
/>
|
||||
<input
|
||||
id="index_input_file"
|
||||
@@ -337,7 +379,7 @@
|
||||
multiple
|
||||
accept=".txt,.md,.pdf"
|
||||
style="display: none;"
|
||||
@change="textFiles = Array.from($event.target.files); fileName = textFiles.length > 0 ? textFiles.length + ' file(s) selected' : ''"
|
||||
@change="textFiles = Array.from($event.target.files); handleFileSelection($event.target.files, 'file')"
|
||||
/>
|
||||
</div>
|
||||
|
||||
|
||||
@@ -279,10 +279,22 @@
|
||||
<!-- Backends Section -->
|
||||
<div class="mt-8">
|
||||
<div class="mb-6">
|
||||
<h2 class="text-2xl font-semibold text-[#E5E7EB] mb-1 flex items-center">
|
||||
<i class="fas fa-cogs mr-2 text-[#8B5CF6] text-sm"></i>
|
||||
Installed Backends
|
||||
</h2>
|
||||
<div class="flex items-center justify-between mb-1">
|
||||
<h2 class="text-2xl font-semibold text-[#E5E7EB] flex items-center">
|
||||
<i class="fas fa-cogs mr-2 text-[#8B5CF6] text-sm"></i>
|
||||
Installed Backends
|
||||
</h2>
|
||||
{{ if gt (len .InstalledBackends) 0 }}
|
||||
<button
|
||||
@click="reinstallAllBackends()"
|
||||
:disabled="reinstallingAll"
|
||||
class="inline-flex items-center bg-[#38BDF8] hover:bg-[#38BDF8]/80 disabled:opacity-50 disabled:cursor-not-allowed text-white py-1.5 px-3 rounded text-xs font-medium transition-colors"
|
||||
title="Reinstall all backends">
|
||||
<i class="fas fa-arrow-rotate-right mr-1.5 text-[10px]" :class="reinstallingAll ? 'fa-spin' : ''"></i>
|
||||
<span x-text="reinstallingAll ? 'Reinstalling...' : 'Reinstall All'"></span>
|
||||
</button>
|
||||
{{ end }}
|
||||
</div>
|
||||
<p class="text-sm text-[#94A3B8] mb-4">
|
||||
<span class="text-[#8B5CF6] font-medium">{{len .InstalledBackends}}</span> backend{{if gt (len .InstalledBackends) 1}}s{{end}} ready to use
|
||||
</p>
|
||||
@@ -324,7 +336,7 @@
|
||||
</thead>
|
||||
<tbody>
|
||||
{{ range .InstalledBackends }}
|
||||
<tr class="hover:bg-[#1E293B]/50 border-b border-[#1E293B] transition-colors">
|
||||
<tr class="hover:bg-[#1E293B]/50 border-b border-[#1E293B] transition-colors" data-backend-name="{{.Name}}" data-is-system="{{.IsSystem}}">
|
||||
<!-- Name Column -->
|
||||
<td class="p-2">
|
||||
<div class="flex items-center gap-2">
|
||||
@@ -378,6 +390,13 @@
|
||||
<td class="p-2">
|
||||
<div class="flex items-center justify-end gap-1">
|
||||
{{ if not .IsSystem }}
|
||||
<button
|
||||
@click="reinstallBackend('{{.Name}}')"
|
||||
:disabled="reinstallingBackends['{{.Name}}']"
|
||||
class="text-[#38BDF8]/60 hover:text-[#38BDF8] hover:bg-[#38BDF8]/10 disabled:opacity-50 disabled:cursor-not-allowed rounded p-1 transition-colors"
|
||||
title="Reinstall {{.Name}}">
|
||||
<i class="fas fa-arrow-rotate-right text-xs" :class="reinstallingBackends['{{.Name}}'] ? 'fa-spin' : ''"></i>
|
||||
</button>
|
||||
<button
|
||||
@click="deleteBackend('{{.Name}}')"
|
||||
class="text-red-400/60 hover:text-red-400 hover:bg-red-500/10 rounded p-1 transition-colors"
|
||||
@@ -406,9 +425,13 @@
|
||||
function indexDashboard() {
|
||||
return {
|
||||
notifications: [],
|
||||
reinstallingBackends: {},
|
||||
reinstallingAll: false,
|
||||
backendJobs: {},
|
||||
|
||||
init() {
|
||||
// Initialize component
|
||||
// Poll for job progress every 600ms
|
||||
setInterval(() => this.pollJobs(), 600);
|
||||
},
|
||||
|
||||
addNotification(message, type = 'success') {
|
||||
@@ -422,6 +445,137 @@ function indexDashboard() {
|
||||
this.notifications = this.notifications.filter(n => n.id !== id);
|
||||
},
|
||||
|
||||
async reinstallBackend(backendName) {
|
||||
if (this.reinstallingBackends[backendName]) {
|
||||
return; // Already reinstalling
|
||||
}
|
||||
|
||||
try {
|
||||
this.reinstallingBackends[backendName] = true;
|
||||
const response = await fetch(`/api/backends/install/${encodeURIComponent(backendName)}`, {
|
||||
method: 'POST'
|
||||
});
|
||||
|
||||
const data = await response.json();
|
||||
|
||||
if (response.ok && data.jobID) {
|
||||
this.backendJobs[backendName] = data.jobID;
|
||||
this.addNotification(`Reinstalling backend "${backendName}"...`, 'success');
|
||||
} else {
|
||||
this.reinstallingBackends[backendName] = false;
|
||||
this.addNotification(`Failed to start reinstall: ${data.error || 'Unknown error'}`, 'error');
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Error reinstalling backend:', error);
|
||||
this.reinstallingBackends[backendName] = false;
|
||||
this.addNotification(`Failed to reinstall backend: ${error.message}`, 'error');
|
||||
}
|
||||
},
|
||||
|
||||
async reinstallAllBackends() {
|
||||
if (this.reinstallingAll) {
|
||||
return; // Already reinstalling
|
||||
}
|
||||
|
||||
if (!confirm('Are you sure you want to reinstall all backends? This may take some time.')) {
|
||||
return;
|
||||
}
|
||||
|
||||
this.reinstallingAll = true;
|
||||
|
||||
// Get all non-system backends from the page using data attributes
|
||||
const backendRows = document.querySelectorAll('tr[data-backend-name]');
|
||||
const backendsToReinstall = [];
|
||||
|
||||
backendRows.forEach(row => {
|
||||
const backendName = row.getAttribute('data-backend-name');
|
||||
const isSystem = row.getAttribute('data-is-system') === 'true';
|
||||
if (backendName && !isSystem && !this.reinstallingBackends[backendName]) {
|
||||
backendsToReinstall.push(backendName);
|
||||
}
|
||||
});
|
||||
|
||||
if (backendsToReinstall.length === 0) {
|
||||
this.reinstallingAll = false;
|
||||
this.addNotification('No backends available to reinstall', 'error');
|
||||
return;
|
||||
}
|
||||
|
||||
this.addNotification(`Starting reinstall of ${backendsToReinstall.length} backend(s)...`, 'success');
|
||||
|
||||
// Reinstall all backends sequentially to avoid overwhelming the system
|
||||
for (const backendName of backendsToReinstall) {
|
||||
await this.reinstallBackend(backendName);
|
||||
// Small delay between installations
|
||||
await new Promise(resolve => setTimeout(resolve, 500));
|
||||
}
|
||||
|
||||
// Don't set reinstallingAll to false here - let pollJobs handle it when all jobs complete
|
||||
// This allows the UI to show the batch operation is in progress
|
||||
},
|
||||
|
||||
async pollJobs() {
|
||||
for (const [backendName, jobID] of Object.entries(this.backendJobs)) {
|
||||
try {
|
||||
const response = await fetch(`/api/backends/job/${jobID}`);
|
||||
const jobData = await response.json();
|
||||
|
||||
if (jobData.completed) {
|
||||
delete this.backendJobs[backendName];
|
||||
this.reinstallingBackends[backendName] = false;
|
||||
this.addNotification(`Backend "${backendName}" reinstalled successfully!`, 'success');
|
||||
|
||||
// Only reload if not in batch mode and no other jobs are running
|
||||
if (!this.reinstallingAll && Object.keys(this.backendJobs).length === 0) {
|
||||
setTimeout(() => {
|
||||
window.location.reload();
|
||||
}, 1500);
|
||||
}
|
||||
}
|
||||
|
||||
if (jobData.error || (jobData.message && jobData.message.startsWith('error:'))) {
|
||||
delete this.backendJobs[backendName];
|
||||
this.reinstallingBackends[backendName] = false;
|
||||
let errorMessage = 'Unknown error';
|
||||
if (typeof jobData.error === 'string') {
|
||||
errorMessage = jobData.error;
|
||||
} else if (jobData.error && typeof jobData.error === 'object') {
|
||||
const errorKeys = Object.keys(jobData.error);
|
||||
if (errorKeys.length > 0) {
|
||||
errorMessage = jobData.error.message || jobData.error.error || jobData.error.Error || JSON.stringify(jobData.error);
|
||||
} else {
|
||||
errorMessage = jobData.message || 'Unknown error';
|
||||
}
|
||||
} else if (jobData.message) {
|
||||
errorMessage = jobData.message;
|
||||
}
|
||||
if (errorMessage.startsWith('error: ')) {
|
||||
errorMessage = errorMessage.substring(7);
|
||||
}
|
||||
this.addNotification(`Error reinstalling backend "${backendName}": ${errorMessage}`, 'error');
|
||||
|
||||
// If batch mode and all jobs are done (completed or errored), reload
|
||||
if (this.reinstallingAll && Object.keys(this.backendJobs).length === 0) {
|
||||
this.reinstallingAll = false;
|
||||
setTimeout(() => {
|
||||
window.location.reload();
|
||||
}, 2000);
|
||||
}
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Error polling job:', error);
|
||||
}
|
||||
}
|
||||
|
||||
// If batch mode completed and no jobs left, reload
|
||||
if (this.reinstallingAll && Object.keys(this.backendJobs).length === 0) {
|
||||
this.reinstallingAll = false;
|
||||
setTimeout(() => {
|
||||
window.location.reload();
|
||||
}, 2000);
|
||||
}
|
||||
},
|
||||
|
||||
async deleteBackend(backendName) {
|
||||
if (!confirm(`Are you sure you want to delete the backend "${backendName}"?`)) {
|
||||
return;
|
||||
|
||||
@@ -77,18 +77,197 @@
|
||||
|
||||
<!-- URI Input -->
|
||||
<div>
|
||||
<label class="block text-sm font-medium text-[#94A3B8] mb-2">
|
||||
<i class="fas fa-link mr-2"></i>Model URI
|
||||
</label>
|
||||
<div class="flex items-center justify-between mb-2">
|
||||
<label class="block text-sm font-medium text-[#94A3B8]">
|
||||
<i class="fas fa-link mr-2"></i>Model URI
|
||||
</label>
|
||||
<div class="flex gap-2">
|
||||
<a href="https://huggingface.co/models?search=gguf&sort=trending"
|
||||
target="_blank"
|
||||
class="text-xs px-3 py-1.5 rounded-lg bg-purple-600/20 hover:bg-purple-600/30 text-purple-300 border border-purple-500/30 transition-all flex items-center gap-1.5">
|
||||
<i class="fab fa-huggingface"></i>
|
||||
<span>Search GGUF Models on Hugging Face</span>
|
||||
<i class="fas fa-external-link-alt text-xs"></i>
|
||||
</a>
|
||||
<a href="https://huggingface.co/models?sort=trending"
|
||||
target="_blank"
|
||||
class="text-xs px-3 py-1.5 rounded-lg bg-purple-600/20 hover:bg-purple-600/30 text-purple-300 border border-purple-500/30 transition-all flex items-center gap-1.5">
|
||||
<i class="fab fa-huggingface"></i>
|
||||
<span>Browse All Models on Hugging Face</span>
|
||||
<i class="fas fa-external-link-alt text-xs"></i>
|
||||
</a>
|
||||
</div>
|
||||
</div>
|
||||
<input
|
||||
x-model="importUri"
|
||||
type="text"
|
||||
placeholder="https://example.com/model.gguf or file:///path/to/model.gguf"
|
||||
placeholder="huggingface://TheBloke/Llama-2-7B-Chat-GGUF or https://example.com/model.gguf"
|
||||
class="w-full px-4 py-3 bg-[#101827] border border-[#1E293B] rounded-lg text-[#E5E7EB] focus:border-green-500 focus:ring-2 focus:ring-green-500/50 focus:outline-none transition-colors"
|
||||
:disabled="isSubmitting">
|
||||
<p class="mt-2 text-xs text-[#94A3B8]">
|
||||
Enter the URI or path to the model file you want to import
|
||||
</p>
|
||||
|
||||
<!-- URI Format Guide -->
|
||||
<div class="mt-4" x-data="{ showGuide: false }">
|
||||
<button @click="showGuide = !showGuide"
|
||||
class="flex items-center gap-2 text-sm text-[#94A3B8] hover:text-[#E5E7EB] transition-colors">
|
||||
<i class="fas" :class="showGuide ? 'fa-chevron-down' : 'fa-chevron-right'"></i>
|
||||
<i class="fas fa-info-circle"></i>
|
||||
<span>Supported URI Formats</span>
|
||||
</button>
|
||||
|
||||
<div x-show="showGuide"
|
||||
x-transition:enter="transition ease-out duration-200"
|
||||
x-transition:enter-start="opacity-0 transform -translate-y-2"
|
||||
x-transition:enter-end="opacity-100 transform translate-y-0"
|
||||
class="mt-3 p-4 bg-[#101827] border border-[#1E293B] rounded-lg space-y-4">
|
||||
|
||||
<!-- HuggingFace -->
|
||||
<div>
|
||||
<h4 class="text-sm font-semibold text-[#E5E7EB] mb-2 flex items-center gap-2">
|
||||
<i class="fab fa-huggingface text-purple-400"></i>
|
||||
HuggingFace
|
||||
</h4>
|
||||
<div class="space-y-1.5 text-xs text-[#94A3B8] font-mono pl-6">
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">huggingface://</code><span class="text-[#94A3B8]">TheBloke/Llama-2-7B-Chat-GGUF</span>
|
||||
<p class="text-[#6B7280] mt-0.5">Standard HuggingFace format</p>
|
||||
</div>
|
||||
</div>
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">hf://</code><span class="text-[#94A3B8]">TheBloke/Llama-2-7B-Chat-GGUF</span>
|
||||
<p class="text-[#6B7280] mt-0.5">Short HuggingFace format</p>
|
||||
</div>
|
||||
</div>
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">https://huggingface.co/</code><span class="text-[#94A3B8]">TheBloke/Llama-2-7B-Chat-GGUF</span>
|
||||
<p class="text-[#6B7280] mt-0.5">Full HuggingFace URL</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- HTTP/HTTPS -->
|
||||
<div>
|
||||
<h4 class="text-sm font-semibold text-[#E5E7EB] mb-2 flex items-center gap-2">
|
||||
<i class="fas fa-globe text-blue-400"></i>
|
||||
HTTP/HTTPS URLs
|
||||
</h4>
|
||||
<div class="space-y-1.5 text-xs text-[#94A3B8] font-mono pl-6">
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">https://</code><span class="text-[#94A3B8]">example.com/model.gguf</span>
|
||||
<p class="text-[#6B7280] mt-0.5">Direct download from any HTTPS URL</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- Local Files -->
|
||||
<div>
|
||||
<h4 class="text-sm font-semibold text-[#E5E7EB] mb-2 flex items-center gap-2">
|
||||
<i class="fas fa-file text-yellow-400"></i>
|
||||
Local Files
|
||||
</h4>
|
||||
<div class="space-y-1.5 text-xs text-[#94A3B8] font-mono pl-6">
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">file://</code><span class="text-[#94A3B8]">/path/to/model.gguf</span>
|
||||
<p class="text-[#6B7280] mt-0.5">Local file path (absolute)</p>
|
||||
</div>
|
||||
</div>
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#94A3B8]">/path/to/model.yaml</code>
|
||||
<p class="text-[#6B7280] mt-0.5">Direct local YAML config file</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- OCI -->
|
||||
<div>
|
||||
<h4 class="text-sm font-semibold text-[#E5E7EB] mb-2 flex items-center gap-2">
|
||||
<i class="fas fa-box text-cyan-400"></i>
|
||||
OCI Registry
|
||||
</h4>
|
||||
<div class="space-y-1.5 text-xs text-[#94A3B8] font-mono pl-6">
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">oci://</code><span class="text-[#94A3B8]">registry.example.com/model:tag</span>
|
||||
<p class="text-[#6B7280] mt-0.5">OCI container registry</p>
|
||||
</div>
|
||||
</div>
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">ocifile://</code><span class="text-[#94A3B8]">/path/to/image.tar</span>
|
||||
<p class="text-[#6B7280] mt-0.5">Local OCI tarball file</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- Ollama -->
|
||||
<div>
|
||||
<h4 class="text-sm font-semibold text-[#E5E7EB] mb-2 flex items-center gap-2">
|
||||
<i class="fas fa-cube text-indigo-400"></i>
|
||||
Ollama
|
||||
</h4>
|
||||
<div class="space-y-1.5 text-xs text-[#94A3B8] font-mono pl-6">
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#10B981]">ollama://</code><span class="text-[#94A3B8]">llama2:7b</span>
|
||||
<p class="text-[#6B7280] mt-0.5">Ollama model format</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- YAML Config Files -->
|
||||
<div>
|
||||
<h4 class="text-sm font-semibold text-[#E5E7EB] mb-2 flex items-center gap-2">
|
||||
<i class="fas fa-code text-pink-400"></i>
|
||||
YAML Configuration Files
|
||||
</h4>
|
||||
<div class="space-y-1.5 text-xs text-[#94A3B8] font-mono pl-6">
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#94A3B8]">https://example.com/model.yaml</code>
|
||||
<p class="text-[#6B7280] mt-0.5">Remote YAML config file</p>
|
||||
</div>
|
||||
</div>
|
||||
<div class="flex items-start gap-2">
|
||||
<span class="text-green-400">•</span>
|
||||
<div>
|
||||
<code class="text-[#94A3B8]">file:///path/to/config.yaml</code>
|
||||
<p class="text-[#6B7280] mt-0.5">Local YAML config file</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="pt-2 mt-3 border-t border-[#1E293B]">
|
||||
<p class="text-xs text-[#6B7280] italic">
|
||||
<i class="fas fa-lightbulb mr-1.5 text-yellow-400"></i>
|
||||
Tip: For HuggingFace models, you can use any of the three formats. The system will automatically detect and download the appropriate model files.
|
||||
</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- Preferences Section -->
|
||||
@@ -629,11 +808,33 @@ function importModel() {
|
||||
setTimeout(() => {
|
||||
window.location.reload();
|
||||
}, 2000);
|
||||
} else if (jobData.error) {
|
||||
} else if (jobData.error || (jobData.message && jobData.message.startsWith('error:'))) {
|
||||
clearInterval(this.jobPollInterval);
|
||||
this.isSubmitting = false;
|
||||
this.currentJobId = null;
|
||||
this.showAlert('error', 'Import failed: ' + jobData.error);
|
||||
// Extract error message - handle both string and object errors
|
||||
let errorMessage = 'Unknown error';
|
||||
if (typeof jobData.error === 'string') {
|
||||
errorMessage = jobData.error;
|
||||
} else if (jobData.error && typeof jobData.error === 'object') {
|
||||
// Check if error object has any properties
|
||||
const errorKeys = Object.keys(jobData.error);
|
||||
if (errorKeys.length > 0) {
|
||||
// Try common error object properties
|
||||
errorMessage = jobData.error.message || jobData.error.error || jobData.error.Error || JSON.stringify(jobData.error);
|
||||
} else {
|
||||
// Empty object {}, fall back to message field
|
||||
errorMessage = jobData.message || 'Unknown error';
|
||||
}
|
||||
} else if (jobData.message) {
|
||||
// Use message field if error is not present or is empty
|
||||
errorMessage = jobData.message;
|
||||
}
|
||||
// Remove "error: " prefix if present
|
||||
if (errorMessage.startsWith('error: ')) {
|
||||
errorMessage = errorMessage.substring(7);
|
||||
}
|
||||
this.showAlert('error', 'Import failed: ' + errorMessage);
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Error polling job status:', error);
|
||||
|
||||
@@ -714,11 +714,33 @@ function modelsGallery() {
|
||||
this.fetchModels();
|
||||
}
|
||||
|
||||
if (jobData.error) {
|
||||
if (jobData.error || (jobData.message && jobData.message.startsWith('error:'))) {
|
||||
model.processing = false;
|
||||
delete this.jobProgress[model.jobID];
|
||||
const action = model.isDeletion ? 'deleting' : 'installing';
|
||||
this.addNotification(`Error ${action} model "${model.name}": ${jobData.error}`, 'error');
|
||||
// Extract error message - handle both string and object errors
|
||||
let errorMessage = 'Unknown error';
|
||||
if (typeof jobData.error === 'string') {
|
||||
errorMessage = jobData.error;
|
||||
} else if (jobData.error && typeof jobData.error === 'object') {
|
||||
// Check if error object has any properties
|
||||
const errorKeys = Object.keys(jobData.error);
|
||||
if (errorKeys.length > 0) {
|
||||
// Try common error object properties
|
||||
errorMessage = jobData.error.message || jobData.error.error || jobData.error.Error || JSON.stringify(jobData.error);
|
||||
} else {
|
||||
// Empty object {}, fall back to message field
|
||||
errorMessage = jobData.message || 'Unknown error';
|
||||
}
|
||||
} else if (jobData.message) {
|
||||
// Use message field if error is not present or is empty
|
||||
errorMessage = jobData.message;
|
||||
}
|
||||
// Remove "error: " prefix if present
|
||||
if (errorMessage.startsWith('error: ')) {
|
||||
errorMessage = errorMessage.substring(7);
|
||||
}
|
||||
this.addNotification(`Error ${action} model "${model.name}": ${errorMessage}`, 'error');
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Error polling job:', error);
|
||||
|
||||
@@ -34,15 +34,14 @@
|
||||
<div class="border-b border-[#1E293B] p-5">
|
||||
<div class="flex flex-col sm:flex-row items-center justify-between gap-4">
|
||||
<!-- Model Selection -->
|
||||
<div class="flex items-center">
|
||||
<div class="flex items-center" x-data="{ link : '{{ if .Model }}tts/{{.Model}}{{ end }}' }">
|
||||
<label for="model-select" class="mr-3 text-[#94A3B8] font-medium">
|
||||
<i class="fas fa-microphone-lines text-[#8B5CF6] mr-2"></i>Model:
|
||||
</label>
|
||||
<select
|
||||
<select
|
||||
id="model-select"
|
||||
x-data="{ link : '' }"
|
||||
x-model="link"
|
||||
x-init="$watch('link', value => window.location = link)"
|
||||
x-model="link"
|
||||
@change="window.location = link"
|
||||
class="bg-[#101827] text-[#E5E7EB] border border-[#1E293B] focus:border-[#8B5CF6] focus:ring-2 focus:ring-[#8B5CF6]/50 rounded-lg shadow-sm p-2.5 appearance-none"
|
||||
>
|
||||
<option value="" disabled class="text-[#94A3B8]">Select a model</option>
|
||||
|
||||
@@ -85,7 +85,7 @@ func (g *GalleryService) modelHandler(op *GalleryOp[gallery.GalleryModel, galler
|
||||
}
|
||||
|
||||
// Reload models
|
||||
err = cl.LoadModelConfigsFromPath(systemState.Model.ModelsPath)
|
||||
err = cl.LoadModelConfigsFromPath(systemState.Model.ModelsPath, g.appConfig.ToConfigLoaderOptions()...)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
@@ -5,10 +5,6 @@ import (
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"fmt"
|
||||
"os"
|
||||
"path"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/google/uuid"
|
||||
@@ -16,12 +12,10 @@ import (
|
||||
"github.com/mudler/LocalAI/core/gallery"
|
||||
"github.com/mudler/LocalAI/core/gallery/importers"
|
||||
"github.com/mudler/LocalAI/core/services"
|
||||
"github.com/mudler/LocalAI/pkg/downloader"
|
||||
"github.com/mudler/LocalAI/pkg/model"
|
||||
"github.com/mudler/LocalAI/pkg/system"
|
||||
"github.com/mudler/LocalAI/pkg/utils"
|
||||
"github.com/rs/zerolog/log"
|
||||
"gopkg.in/yaml.v2"
|
||||
)
|
||||
|
||||
const (
|
||||
@@ -34,178 +28,59 @@ const (
|
||||
func InstallModels(ctx context.Context, galleryService *services.GalleryService, galleries, backendGalleries []config.Gallery, systemState *system.SystemState, modelLoader *model.ModelLoader, enforceScan, autoloadBackendGalleries bool, downloadStatus func(string, string, string, float64), models ...string) error {
|
||||
// create an error that groups all errors
|
||||
var err error
|
||||
|
||||
installBackend := func(modelPath string) error {
|
||||
// Then load the model file, and read the backend
|
||||
modelYAML, e := os.ReadFile(modelPath)
|
||||
if e != nil {
|
||||
log.Error().Err(e).Str("filepath", modelPath).Msg("error reading model definition")
|
||||
return e
|
||||
}
|
||||
|
||||
var model config.ModelConfig
|
||||
if e := yaml.Unmarshal(modelYAML, &model); e != nil {
|
||||
log.Error().Err(e).Str("filepath", modelPath).Msg("error unmarshalling model definition")
|
||||
return e
|
||||
}
|
||||
|
||||
if model.Backend == "" {
|
||||
log.Debug().Str("filepath", modelPath).Msg("no backend found in model definition")
|
||||
return nil
|
||||
}
|
||||
|
||||
if err := gallery.InstallBackendFromGallery(ctx, backendGalleries, systemState, modelLoader, model.Backend, downloadStatus, false); err != nil {
|
||||
log.Error().Err(err).Str("backend", model.Backend).Msg("error installing backend")
|
||||
return err
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
for _, url := range models {
|
||||
// As a best effort, try to resolve the model from the remote library
|
||||
// if it's not resolved we try with the other method below
|
||||
// Check if it's a model gallery, or print a warning
|
||||
e, found := installModel(ctx, galleries, backendGalleries, url, systemState, modelLoader, downloadStatus, enforceScan, autoloadBackendGalleries)
|
||||
if e != nil && found {
|
||||
log.Error().Err(err).Msgf("[startup] failed installing model '%s'", url)
|
||||
err = errors.Join(err, e)
|
||||
} else if !found {
|
||||
log.Debug().Msgf("[startup] model not found in the gallery '%s'", url)
|
||||
|
||||
uri := downloader.URI(url)
|
||||
|
||||
switch {
|
||||
case uri.LooksLikeOCI():
|
||||
log.Debug().Msgf("[startup] resolved OCI model to download: %s", url)
|
||||
|
||||
// convert OCI image name to a file name.
|
||||
ociName := strings.TrimPrefix(url, downloader.OCIPrefix)
|
||||
ociName = strings.TrimPrefix(ociName, downloader.OllamaPrefix)
|
||||
ociName = strings.ReplaceAll(ociName, "/", "__")
|
||||
ociName = strings.ReplaceAll(ociName, ":", "__")
|
||||
|
||||
// check if file exists
|
||||
if _, e := os.Stat(filepath.Join(systemState.Model.ModelsPath, ociName)); errors.Is(e, os.ErrNotExist) {
|
||||
modelDefinitionFilePath := filepath.Join(systemState.Model.ModelsPath, ociName)
|
||||
e := uri.DownloadFile(modelDefinitionFilePath, "", 0, 0, func(fileName, current, total string, percent float64) {
|
||||
utils.DisplayDownloadFunction(fileName, current, total, percent)
|
||||
})
|
||||
if e != nil {
|
||||
log.Error().Err(e).Str("url", url).Str("filepath", modelDefinitionFilePath).Msg("error downloading model")
|
||||
err = errors.Join(err, e)
|
||||
}
|
||||
if galleryService == nil {
|
||||
return fmt.Errorf("cannot start autoimporter, not sure how to handle this uri")
|
||||
}
|
||||
|
||||
log.Info().Msgf("[startup] installed model from OCI repository: %s", ociName)
|
||||
case uri.LooksLikeURL():
|
||||
log.Debug().Msgf("[startup] downloading %s", url)
|
||||
|
||||
// Extract filename from URL
|
||||
fileName, e := uri.FilenameFromUrl()
|
||||
if e != nil {
|
||||
log.Warn().Err(e).Str("url", url).Msg("error extracting filename from URL")
|
||||
err = errors.Join(err, e)
|
||||
// TODO: we should just use the discoverModelConfig here and default to this.
|
||||
modelConfig, discoverErr := importers.DiscoverModelConfig(url, json.RawMessage{})
|
||||
if discoverErr != nil {
|
||||
log.Error().Err(discoverErr).Msgf("[startup] failed to discover model config '%s'", url)
|
||||
err = errors.Join(discoverErr, fmt.Errorf("failed to discover model config: %w", err))
|
||||
continue
|
||||
}
|
||||
|
||||
modelPath := filepath.Join(systemState.Model.ModelsPath, fileName)
|
||||
|
||||
if e := utils.VerifyPath(fileName, modelPath); e != nil {
|
||||
log.Error().Err(e).Str("filepath", modelPath).Msg("error verifying path")
|
||||
err = errors.Join(err, e)
|
||||
uuid, uuidErr := uuid.NewUUID()
|
||||
if uuidErr != nil {
|
||||
err = errors.Join(uuidErr, fmt.Errorf("failed to generate UUID: %w", uuidErr))
|
||||
continue
|
||||
}
|
||||
|
||||
// check if file exists
|
||||
if _, e := os.Stat(modelPath); errors.Is(e, os.ErrNotExist) {
|
||||
e := uri.DownloadFile(modelPath, "", 0, 0, func(fileName, current, total string, percent float64) {
|
||||
utils.DisplayDownloadFunction(fileName, current, total, percent)
|
||||
})
|
||||
if e != nil {
|
||||
log.Error().Err(e).Str("url", url).Str("filepath", modelPath).Msg("error downloading model")
|
||||
err = errors.Join(err, e)
|
||||
}
|
||||
galleryService.ModelGalleryChannel <- services.GalleryOp[gallery.GalleryModel, gallery.ModelConfig]{
|
||||
Req: gallery.GalleryModel{
|
||||
Overrides: map[string]interface{}{},
|
||||
},
|
||||
ID: uuid.String(),
|
||||
GalleryElementName: modelConfig.Name,
|
||||
GalleryElement: &modelConfig,
|
||||
BackendGalleries: backendGalleries,
|
||||
}
|
||||
|
||||
// Check if we have the backend installed
|
||||
if autoloadBackendGalleries && path.Ext(modelPath) == YAML_EXTENSION {
|
||||
if err := installBackend(modelPath); err != nil {
|
||||
log.Error().Err(err).Str("filepath", modelPath).Msg("error installing backend")
|
||||
var status *services.GalleryOpStatus
|
||||
// wait for op to finish
|
||||
for {
|
||||
status = galleryService.GetStatus(uuid.String())
|
||||
if status != nil && status.Processed {
|
||||
break
|
||||
}
|
||||
time.Sleep(1 * time.Second)
|
||||
}
|
||||
default:
|
||||
if _, e := os.Stat(url); e == nil {
|
||||
log.Debug().Msgf("[startup] resolved local model: %s", url)
|
||||
// copy to modelPath
|
||||
md5Name := utils.MD5(url)
|
||||
|
||||
modelYAML, e := os.ReadFile(url)
|
||||
if e != nil {
|
||||
log.Error().Err(e).Str("filepath", url).Msg("error reading model definition")
|
||||
err = errors.Join(err, e)
|
||||
continue
|
||||
}
|
||||
|
||||
modelDefinitionFilePath := filepath.Join(systemState.Model.ModelsPath, md5Name) + YAML_EXTENSION
|
||||
if e := os.WriteFile(modelDefinitionFilePath, modelYAML, 0600); e != nil {
|
||||
log.Error().Err(err).Str("filepath", modelDefinitionFilePath).Msg("error loading model: %s")
|
||||
err = errors.Join(err, e)
|
||||
}
|
||||
|
||||
// Check if we have the backend installed
|
||||
if autoloadBackendGalleries && path.Ext(modelDefinitionFilePath) == YAML_EXTENSION {
|
||||
if err := installBackend(modelDefinitionFilePath); err != nil {
|
||||
log.Error().Err(err).Str("filepath", modelDefinitionFilePath).Msg("error installing backend")
|
||||
}
|
||||
}
|
||||
} else {
|
||||
// Check if it's a model gallery, or print a warning
|
||||
e, found := installModel(ctx, galleries, backendGalleries, url, systemState, modelLoader, downloadStatus, enforceScan, autoloadBackendGalleries)
|
||||
if e != nil && found {
|
||||
log.Error().Err(err).Msgf("[startup] failed installing model '%s'", url)
|
||||
err = errors.Join(err, e)
|
||||
} else if !found {
|
||||
log.Warn().Msgf("[startup] failed resolving model '%s'", url)
|
||||
|
||||
if galleryService == nil {
|
||||
err = errors.Join(err, fmt.Errorf("cannot start autoimporter, not sure how to handle this uri"))
|
||||
continue
|
||||
}
|
||||
|
||||
// TODO: we should just use the discoverModelConfig here and default to this.
|
||||
modelConfig, discoverErr := importers.DiscoverModelConfig(url, json.RawMessage{})
|
||||
if discoverErr != nil {
|
||||
err = errors.Join(discoverErr, fmt.Errorf("failed to discover model config: %w", err))
|
||||
continue
|
||||
}
|
||||
|
||||
uuid, uuidErr := uuid.NewUUID()
|
||||
if uuidErr != nil {
|
||||
err = errors.Join(uuidErr, fmt.Errorf("failed to generate UUID: %w", uuidErr))
|
||||
continue
|
||||
}
|
||||
|
||||
galleryService.ModelGalleryChannel <- services.GalleryOp[gallery.GalleryModel, gallery.ModelConfig]{
|
||||
Req: gallery.GalleryModel{
|
||||
Overrides: map[string]interface{}{},
|
||||
},
|
||||
ID: uuid.String(),
|
||||
GalleryElementName: modelConfig.Name,
|
||||
GalleryElement: &modelConfig,
|
||||
BackendGalleries: backendGalleries,
|
||||
}
|
||||
|
||||
var status *services.GalleryOpStatus
|
||||
// wait for op to finish
|
||||
for {
|
||||
status = galleryService.GetStatus(uuid.String())
|
||||
if status != nil && status.Processed {
|
||||
break
|
||||
}
|
||||
time.Sleep(1 * time.Second)
|
||||
}
|
||||
|
||||
if status.Error != nil {
|
||||
return status.Error
|
||||
}
|
||||
|
||||
log.Info().Msgf("[startup] imported model '%s' from '%s'", modelConfig.Name, url)
|
||||
}
|
||||
if status.Error != nil {
|
||||
log.Error().Err(status.Error).Msgf("[startup] failed to import model '%s' from '%s'", modelConfig.Name, url)
|
||||
return status.Error
|
||||
}
|
||||
|
||||
log.Info().Msgf("[startup] imported model '%s' from '%s'", modelConfig.Name, url)
|
||||
}
|
||||
}
|
||||
return err
|
||||
|
||||
@@ -7,6 +7,7 @@ import (
|
||||
"path/filepath"
|
||||
|
||||
"github.com/mudler/LocalAI/core/config"
|
||||
"github.com/mudler/LocalAI/core/services"
|
||||
. "github.com/mudler/LocalAI/core/startup"
|
||||
"github.com/mudler/LocalAI/pkg/model"
|
||||
"github.com/mudler/LocalAI/pkg/system"
|
||||
@@ -19,8 +20,11 @@ var _ = Describe("Preload test", func() {
|
||||
var tmpdir string
|
||||
var systemState *system.SystemState
|
||||
var ml *model.ModelLoader
|
||||
var ctx context.Context
|
||||
var cancel context.CancelFunc
|
||||
|
||||
BeforeEach(func() {
|
||||
ctx, cancel = context.WithCancel(context.Background())
|
||||
var err error
|
||||
tmpdir, err = os.MkdirTemp("", "")
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
@@ -29,13 +33,24 @@ var _ = Describe("Preload test", func() {
|
||||
ml = model.NewModelLoader(systemState, true)
|
||||
})
|
||||
|
||||
AfterEach(func() {
|
||||
cancel()
|
||||
})
|
||||
|
||||
Context("Preloading from strings", func() {
|
||||
It("loads from embedded full-urls", func() {
|
||||
url := "https://raw.githubusercontent.com/mudler/LocalAI-examples/main/configurations/phi-2.yaml"
|
||||
fileName := fmt.Sprintf("%s.yaml", "phi-2")
|
||||
|
||||
InstallModels(context.TODO(), nil, []config.Gallery{}, []config.Gallery{}, systemState, ml, true, true, nil, url)
|
||||
galleryService := services.NewGalleryService(&config.ApplicationConfig{
|
||||
SystemState: systemState,
|
||||
}, ml)
|
||||
galleryService.Start(ctx, config.NewModelConfigLoader(tmpdir), systemState)
|
||||
|
||||
err := InstallModels(ctx, galleryService, []config.Gallery{}, []config.Gallery{}, systemState, ml, true, true, func(s1, s2, s3 string, f float64) {
|
||||
fmt.Println(s1, s2, s3, f)
|
||||
}, url)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
resultFile := filepath.Join(tmpdir, fileName)
|
||||
|
||||
content, err := os.ReadFile(resultFile)
|
||||
@@ -47,13 +62,22 @@ var _ = Describe("Preload test", func() {
|
||||
url := "huggingface://TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF/tinyllama-1.1b-chat-v0.3.Q2_K.gguf"
|
||||
fileName := fmt.Sprintf("%s.gguf", "tinyllama-1.1b-chat-v0.3.Q2_K")
|
||||
|
||||
err := InstallModels(context.TODO(), nil, []config.Gallery{}, []config.Gallery{}, systemState, ml, true, true, nil, url)
|
||||
galleryService := services.NewGalleryService(&config.ApplicationConfig{
|
||||
SystemState: systemState,
|
||||
}, ml)
|
||||
galleryService.Start(ctx, config.NewModelConfigLoader(tmpdir), systemState)
|
||||
|
||||
err := InstallModels(ctx, galleryService, []config.Gallery{}, []config.Gallery{}, systemState, ml, true, true, func(s1, s2, s3 string, f float64) {
|
||||
fmt.Println(s1, s2, s3, f)
|
||||
}, url)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
resultFile := filepath.Join(tmpdir, fileName)
|
||||
dirs, err := os.ReadDir(tmpdir)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
_, err = os.Stat(resultFile)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(err).ToNot(HaveOccurred(), fmt.Sprintf("%+v", dirs))
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
208
docs/config.toml
208
docs/config.toml
@@ -1,208 +0,0 @@
|
||||
baseURL = "https://localai.io/"
|
||||
languageCode = "en-GB"
|
||||
contentDir = "content"
|
||||
enableEmoji = true
|
||||
enableGitInfo = true # N.B. .GitInfo does not currently function with git submodule content directories
|
||||
|
||||
defaultContentLanguage = 'en'
|
||||
|
||||
|
||||
[markup]
|
||||
defaultMarkdownHandler = "goldmark"
|
||||
[markup.tableOfContents]
|
||||
endLevel = 3
|
||||
startLevel = 1
|
||||
[markup.goldmark]
|
||||
[markup.goldmark.renderer]
|
||||
unsafe = true # https://jdhao.github.io/2019/12/29/hugo_html_not_shown/
|
||||
# [markup.highlight]
|
||||
# codeFences = false # disables Hugo's default syntax highlighting
|
||||
# [markup.goldmark.parser]
|
||||
# [markup.goldmark.parser.attribute]
|
||||
# block = true
|
||||
# title = true
|
||||
|
||||
|
||||
|
||||
[params]
|
||||
|
||||
google_fonts = [
|
||||
["Inter", "300, 400, 600, 700"],
|
||||
["Fira Code", "500, 700"]
|
||||
]
|
||||
|
||||
sans_serif_font = "Inter" # Default is System font
|
||||
secondary_font = "Inter" # Default is System font
|
||||
mono_font = "Fira Code" # Default is System font
|
||||
|
||||
[params.footer]
|
||||
copyright = "© 2023-2025 <a href='https://mudler.pm' target=_blank>Ettore Di Giacinto</a>"
|
||||
version = true # includes git commit info
|
||||
|
||||
[params.social]
|
||||
github = "mudler/LocalAI" # YOUR_GITHUB_ID or YOUR_GITHUB_URL
|
||||
twitter = "LocalAI_API" # YOUR_TWITTER_ID
|
||||
dicord = "uJAeKSAGDy"
|
||||
# instagram = "colinwilson" # YOUR_INSTAGRAM_ID
|
||||
rss = true # show rss icon with link
|
||||
|
||||
[params.docs] # Parameters for the /docs 'template'
|
||||
|
||||
logo = "https://raw.githubusercontent.com/mudler/LocalAI/refs/heads/master/core/http/static/logo.png"
|
||||
logo_text = ""
|
||||
title = "LocalAI" # default html title for documentation pages/sections
|
||||
|
||||
pathName = "docs" # path name for documentation site | default "docs"
|
||||
|
||||
# themeColor = "cyan" # (optional) - Set theme accent colour. Options include: blue (default), green, red, yellow, emerald, cardinal, magenta, cyan
|
||||
|
||||
darkMode = true # enable dark mode option? default false
|
||||
|
||||
prism = true # enable syntax highlighting via Prism
|
||||
|
||||
prismTheme = "solarized-light" # (optional) - Set theme for PrismJS. Options include: lotusdocs (default), solarized-light, twilight, lucario
|
||||
|
||||
# gitinfo
|
||||
repoURL = "https://github.com/mudler/LocalAI" # Git repository URL for your site [support for GitHub, GitLab, and BitBucket]
|
||||
repoBranch = "master"
|
||||
editPage = true # enable 'Edit this page' feature - default false
|
||||
lastMod = true # enable 'Last modified' date on pages - default false
|
||||
lastModRelative = true # format 'Last modified' time as relative - default true
|
||||
|
||||
sidebarIcons = true # enable sidebar icons? default false
|
||||
breadcrumbs = true # default is true
|
||||
backToTop = true # enable back-to-top button? default true
|
||||
|
||||
# ToC
|
||||
toc = true # enable table of contents? default is true
|
||||
tocMobile = true # enable table of contents in mobile view? default is true
|
||||
scrollSpy = true # enable scrollspy on ToC? default is true
|
||||
|
||||
# front matter
|
||||
descriptions = true # enable front matter descriptions under content title?
|
||||
titleIcon = true # enable front matter icon title prefix? default is false
|
||||
|
||||
# content navigation
|
||||
navDesc = true # include front matter descriptions in Prev/Next navigation cards
|
||||
navDescTrunc = 30 # Number of characters by which to truncate the Prev/Next descriptions
|
||||
|
||||
listDescTrunc = 100 # Number of characters by which to truncate the list card description
|
||||
|
||||
# Link behaviour
|
||||
intLinkTooltip = true # Enable a tooltip for internal links that displays info about the destination? default false
|
||||
# extLinkNewTab = false # Open external links in a new Tab? default true
|
||||
# logoLinkURL = "" # Set a custom URL destination for the top header logo link.
|
||||
|
||||
[params.flexsearch] # Parameters for FlexSearch
|
||||
enabled = true
|
||||
# tokenize = "full"
|
||||
# optimize = true
|
||||
# cache = 100
|
||||
# minQueryChar = 3 # default is 0 (disabled)
|
||||
# maxResult = 5 # default is 5
|
||||
# searchSectionsIndex = []
|
||||
|
||||
[params.docsearch] # Parameters for DocSearch
|
||||
# appID = "" # Algolia Application ID
|
||||
# apiKey = "" # Algolia Search-Only API (Public) Key
|
||||
# indexName = "" # Index Name to perform search on (or set env variable HUGO_PARAM_DOCSEARCH_indexName)
|
||||
|
||||
[params.analytics] # Parameters for Analytics (Google, Plausible)
|
||||
# google = "G-XXXXXXXXXX" # Replace with your Google Analytics ID
|
||||
# plausibleURL = "/docs/s" # (or set via env variable HUGO_PARAM_ANALYTICS_plausibleURL)
|
||||
# plausibleAPI = "/docs/s" # optional - (or set via env variable HUGO_PARAM_ANALYTICS_plausibleAPI)
|
||||
# plausibleDomain = "" # (or set via env variable HUGO_PARAM_ANALYTICS_plausibleDomain)
|
||||
|
||||
# [params.feedback]
|
||||
# enabled = true
|
||||
# emoticonTpl = true
|
||||
# eventDest = ["plausible","google"]
|
||||
# emoticonEventName = "Feedback"
|
||||
# positiveEventName = "Positive Feedback"
|
||||
# negativeEventName = "Negative Feedback"
|
||||
# positiveFormTitle = "What did you like?"
|
||||
# negativeFormTitle = "What went wrong?"
|
||||
# successMsg = "Thank you for helping to improve Lotus Docs' documentation!"
|
||||
# errorMsg = "Sorry! There was an error while attempting to submit your feedback!"
|
||||
# positiveForm = [
|
||||
# ["Accurate", "Accurately describes the feature or option."],
|
||||
# ["Solved my problem", "Helped me resolve an issue."],
|
||||
# ["Easy to understand", "Easy to follow and comprehend."],
|
||||
# ["Something else"]
|
||||
# ]
|
||||
# negativeForm = [
|
||||
# ["Inaccurate", "Doesn't accurately describe the feature or option."],
|
||||
# ["Couldn't find what I was looking for", "Missing important information."],
|
||||
# ["Hard to understand", "Too complicated or unclear."],
|
||||
# ["Code sample errors", "One or more code samples are incorrect."],
|
||||
# ["Something else"]
|
||||
# ]
|
||||
|
||||
[menu]
|
||||
[[menu.primary]]
|
||||
name = "Docs"
|
||||
url = "docs/"
|
||||
identifier = "docs"
|
||||
weight = 10
|
||||
[[menu.primary]]
|
||||
name = "Discord"
|
||||
url = "https://discord.gg/uJAeKSAGDy"
|
||||
identifier = "discord"
|
||||
weight = 20
|
||||
|
||||
[languages]
|
||||
[languages.en]
|
||||
title = "LocalAI"
|
||||
languageName = "English"
|
||||
weight = 10
|
||||
# [languages.fr]
|
||||
# title = "LocalAI documentation"
|
||||
# languageName = "Français"
|
||||
# contentDir = "content/fr"
|
||||
# weight = 20
|
||||
# [languages.de]
|
||||
# title = "LocalAI documentation"
|
||||
# languageName = "Deutsch"
|
||||
# contentDir = "content/de"
|
||||
# weight = 30
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# mounts are only needed in this showcase to access the publicly available screenshots;
|
||||
# remove this section if you don't need further mounts
|
||||
[module]
|
||||
replacements = "github.com/colinwilson/lotusdocs -> lotusdocs"
|
||||
[[module.mounts]]
|
||||
source = 'archetypes'
|
||||
target = 'archetypes'
|
||||
[[module.mounts]]
|
||||
source = 'assets'
|
||||
target = 'assets'
|
||||
[[module.mounts]]
|
||||
source = 'content'
|
||||
target = 'content'
|
||||
[[module.mounts]]
|
||||
source = 'data'
|
||||
target = 'data'
|
||||
[[module.mounts]]
|
||||
source = 'i18n'
|
||||
target = 'i18n'
|
||||
[[module.mounts]]
|
||||
source = '../images'
|
||||
target = 'static/images'
|
||||
[[module.mounts]]
|
||||
source = 'layouts'
|
||||
target = 'layouts'
|
||||
[[module.mounts]]
|
||||
source = 'static'
|
||||
target = 'static'
|
||||
# uncomment line below for temporary local development of module
|
||||
# or when using a 'theme' as a git submodule
|
||||
[[module.imports]]
|
||||
path = "github.com/colinwilson/lotusdocs"
|
||||
disable = false
|
||||
[[module.imports]]
|
||||
path = "github.com/gohugoio/hugo-mod-bootstrap-scss/v5"
|
||||
disable = false
|
||||
61
docs/content/_index.md
Normal file
61
docs/content/_index.md
Normal file
@@ -0,0 +1,61 @@
|
||||
+++
|
||||
title = "LocalAI"
|
||||
description = "The free, OpenAI, Anthropic alternative. Your All-in-One Complete AI Stack"
|
||||
type = "home"
|
||||
+++
|
||||
|
||||
**The free, OpenAI, Anthropic alternative. Your All-in-One Complete AI Stack** - Run powerful language models, autonomous agents, and document intelligence **locally** on your hardware.
|
||||
|
||||
**No cloud, no limits, no compromise.**
|
||||
|
||||
{{% notice tip %}}
|
||||
**[⭐ Star us on GitHub](https://github.com/mudler/LocalAI)** - 33.3k+ stars and growing!
|
||||
|
||||
**Drop-in replacement for OpenAI API** - modular suite of tools that work seamlessly together or independently.
|
||||
|
||||
Start with **[LocalAI](https://localai.io)**'s OpenAI-compatible API, extend with **[LocalAGI](https://github.com/mudler/LocalAGI)**'s autonomous agents, and enhance with **[LocalRecall](https://github.com/mudler/LocalRecall)**'s semantic search - all running locally on your hardware.
|
||||
|
||||
**Open Source** MIT Licensed.
|
||||
{{% /notice %}}
|
||||
|
||||
## Why Choose LocalAI?
|
||||
|
||||
**OpenAI API Compatible** - Run AI models locally with our modular ecosystem. From language models to autonomous agents and semantic search, build your complete AI stack without the cloud.
|
||||
|
||||
### Key Features
|
||||
|
||||
- **LLM Inferencing**: LocalAI is a free, **Open Source** OpenAI alternative. Run **LLMs**, generate **images**, **audio** and more **locally** with consumer grade hardware.
|
||||
- **Agentic-first**: Extend LocalAI with LocalAGI, an autonomous AI agent platform that runs locally, no coding required. Build and deploy autonomous agents with ease.
|
||||
- **Memory and Knowledge base**: Extend LocalAI with LocalRecall, A local rest api for semantic search and memory management. Perfect for AI applications.
|
||||
- **OpenAI Compatible**: Drop-in replacement for OpenAI API. Compatible with existing applications and libraries.
|
||||
- **No GPU Required**: Run on consumer grade hardware. No need for expensive GPUs or cloud services.
|
||||
- **Multiple Models**: Support for various model families including LLMs, image generation, and audio models. Supports multiple backends for inferencing.
|
||||
- **Privacy Focused**: Keep your data local. No data leaves your machine, ensuring complete privacy.
|
||||
- **Easy Setup**: Simple installation and configuration. Get started in minutes with Binaries installation, Docker, Podman, Kubernetes or local installation.
|
||||
- **Community Driven**: Active community support and regular updates. Contribute and help shape the future of LocalAI.
|
||||
|
||||
## Quick Start
|
||||
|
||||
**Docker is the recommended installation method** for most users:
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest
|
||||
```
|
||||
|
||||
For complete installation instructions, see the [Installation guide](/installation/).
|
||||
|
||||
## Get Started
|
||||
|
||||
1. **[Install LocalAI](/installation/)** - Choose your installation method (Docker recommended)
|
||||
2. **[Quickstart Guide](/getting-started/quickstart/)** - Get started quickly after installation
|
||||
3. **[Install and Run Models](/getting-started/models/)** - Learn how to work with AI models
|
||||
4. **[Try It Out](/getting-started/try-it-out/)** - Explore examples and use cases
|
||||
|
||||
## Learn More
|
||||
|
||||
- [Explore available models](https://models.localai.io)
|
||||
- [Model compatibility](/model-compatibility/)
|
||||
- [Try out examples](https://github.com/mudler/LocalAI-examples)
|
||||
- [Join the community](https://discord.gg/uJAeKSAGDy)
|
||||
- [Check the LocalAI Github repository](https://github.com/mudler/LocalAI)
|
||||
- [Check the LocalAGI Github repository](https://github.com/mudler/LocalAGI)
|
||||
12
docs/content/advanced/_index.en.md
Normal file
12
docs/content/advanced/_index.en.md
Normal file
@@ -0,0 +1,12 @@
|
||||
---
|
||||
weight: 20
|
||||
title: "Advanced"
|
||||
description: "Advanced usage"
|
||||
type: chapter
|
||||
icon: settings
|
||||
lead: ""
|
||||
date: 2020-10-06T08:49:15+00:00
|
||||
lastmod: 2020-10-06T08:49:15+00:00
|
||||
draft: false
|
||||
images: []
|
||||
---
|
||||
@@ -27,7 +27,7 @@ template:
|
||||
chat: chat
|
||||
```
|
||||
|
||||
For a complete reference of all available configuration options, see the [Model Configuration]({{%relref "docs/advanced/model-configuration" %}}) page.
|
||||
For a complete reference of all available configuration options, see the [Model Configuration]({{%relref "advanced/model-configuration" %}}) page.
|
||||
|
||||
**Configuration File Locations:**
|
||||
|
||||
@@ -108,7 +108,6 @@ Similarly it can be specified a path to a YAML configuration file containing a l
|
||||
```yaml
|
||||
- url: https://raw.githubusercontent.com/go-skynet/model-gallery/main/gpt4all-j.yaml
|
||||
name: gpt4all-j
|
||||
# ...
|
||||
```
|
||||
|
||||
### Automatic prompt caching
|
||||
@@ -119,7 +118,6 @@ To enable prompt caching, you can control the settings in the model config YAML
|
||||
|
||||
```yaml
|
||||
|
||||
# Enable prompt caching
|
||||
prompt_cache_path: "cache"
|
||||
prompt_cache_all: true
|
||||
|
||||
@@ -131,20 +129,18 @@ prompt_cache_all: true
|
||||
|
||||
By default LocalAI will try to autoload the model by trying all the backends. This might work for most of models, but some of the backends are NOT configured to autoload.
|
||||
|
||||
The available backends are listed in the [model compatibility table]({{%relref "docs/reference/compatibility-table" %}}).
|
||||
The available backends are listed in the [model compatibility table]({{%relref "reference/compatibility-table" %}}).
|
||||
|
||||
In order to specify a backend for your models, create a model config file in your `models` directory specifying the backend:
|
||||
|
||||
```yaml
|
||||
name: gpt-3.5-turbo
|
||||
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: ...
|
||||
|
||||
backend: llama-stable
|
||||
# ...
|
||||
```
|
||||
|
||||
### Connect external backends
|
||||
@@ -183,7 +179,6 @@ make -C backend/python/vllm
|
||||
When LocalAI runs in a container,
|
||||
there are additional environment variables available that modify the behavior of LocalAI on startup:
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Environment variable | Default | Description |
|
||||
|----------------------------|---------|------------------------------------------------------------------------------------------------------------|
|
||||
| `REBUILD` | `false` | Rebuild LocalAI on startup |
|
||||
@@ -193,20 +188,17 @@ there are additional environment variables available that modify the behavior of
|
||||
| `EXTRA_BACKENDS` | | A space separated list of backends to prepare. For example `EXTRA_BACKENDS="backend/python/diffusers backend/python/transformers"` prepares the python environment on start |
|
||||
| `DISABLE_AUTODETECT` | `false` | Disable autodetect of CPU flagset on start |
|
||||
| `LLAMACPP_GRPC_SERVERS` | | A list of llama.cpp workers to distribute the workload. For example `LLAMACPP_GRPC_SERVERS="address1:port,address2:port"` |
|
||||
{{< /table >}}
|
||||
|
||||
Here is how to configure these variables:
|
||||
|
||||
```bash
|
||||
# Option 1: command line
|
||||
docker run --env REBUILD=true localai
|
||||
# Option 2: set within an env file
|
||||
docker run --env-file .env localai
|
||||
```
|
||||
|
||||
### CLI Parameters
|
||||
|
||||
For a complete reference of all CLI parameters, environment variables, and command-line options, see the [CLI Reference]({{%relref "docs/reference/cli-reference" %}}) page.
|
||||
For a complete reference of all CLI parameters, environment variables, and command-line options, see the [CLI Reference]({{%relref "reference/cli-reference" %}}) page.
|
||||
|
||||
You can control LocalAI with command line arguments to specify a binding address, number of threads, model paths, and many other options. Any command line parameter can be specified via an environment variable.
|
||||
|
||||
@@ -282,20 +274,17 @@ A list of the environment variable that tweaks parallelism is the following:
|
||||
### Python backends GRPC max workers
|
||||
### Default number of workers for GRPC Python backends.
|
||||
### This actually controls wether a backend can process multiple requests or not.
|
||||
# PYTHON_GRPC_MAX_WORKERS=1
|
||||
|
||||
### Define the number of parallel LLAMA.cpp workers (Defaults to 1)
|
||||
# LLAMACPP_PARALLEL=1
|
||||
|
||||
### Enable to run parallel requests
|
||||
# LOCALAI_PARALLEL_REQUESTS=true
|
||||
```
|
||||
|
||||
Note that, for llama.cpp you need to set accordingly `LLAMACPP_PARALLEL` to the number of parallel processes your GPU/CPU can handle. For python-based backends (like vLLM) you can set `PYTHON_GRPC_MAX_WORKERS` to the number of parallel requests.
|
||||
|
||||
### VRAM and Memory Management
|
||||
|
||||
For detailed information on managing VRAM when running multiple models, see the dedicated [VRAM and Memory Management]({{%relref "docs/advanced/vram-management" %}}) page.
|
||||
For detailed information on managing VRAM when running multiple models, see the dedicated [VRAM and Memory Management]({{%relref "advanced/vram-management" %}}) page.
|
||||
|
||||
### Disable CPU flagset auto detection in llama.cpp
|
||||
|
||||
@@ -5,9 +5,9 @@ title = "Fine-tuning LLMs for text generation"
|
||||
weight = 22
|
||||
+++
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
Section under construction
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
This section covers how to fine-tune a language model for text generation and consume it in LocalAI.
|
||||
|
||||
@@ -74,12 +74,10 @@ Prepare a dataset, and upload it to your Google Drive in case you are using the
|
||||
### Install dependencies
|
||||
|
||||
```bash
|
||||
# Install axolotl and dependencies
|
||||
git clone https://github.com/OpenAccess-AI-Collective/axolotl && pushd axolotl && git checkout 797f3dd1de8fd8c0eafbd1c9fdb172abd9ff840a && popd #0.3.0
|
||||
pip install packaging
|
||||
pushd axolotl && pip install -e '.[flash-attn,deepspeed]' && popd
|
||||
|
||||
# https://github.com/oobabooga/text-generation-webui/issues/4238
|
||||
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.3.0/flash_attn-2.3.0+cu117torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
|
||||
```
|
||||
|
||||
@@ -96,19 +94,16 @@ We will need to configure axolotl. In this example is provided a file to use `ax
|
||||
If you have a big dataset, you can pre-tokenize it to speedup the fine-tuning process:
|
||||
|
||||
```bash
|
||||
# Optional pre-tokenize (run only if big dataset)
|
||||
python -m axolotl.cli.preprocess axolotl.yaml
|
||||
```
|
||||
|
||||
Now we are ready to start the fine-tuning process:
|
||||
```bash
|
||||
# Fine-tune
|
||||
accelerate launch -m axolotl.cli.train axolotl.yaml
|
||||
```
|
||||
|
||||
After we have finished the fine-tuning, we merge the Lora base with the model:
|
||||
```bash
|
||||
# Merge lora
|
||||
python3 -m axolotl.cli.merge_lora axolotl.yaml --lora_model_dir="./qlora-out" --load_in_8bit=False --load_in_4bit=False
|
||||
```
|
||||
|
||||
@@ -116,17 +111,11 @@ And we convert it to the gguf format that LocalAI can consume:
|
||||
|
||||
```bash
|
||||
|
||||
# Convert to gguf
|
||||
git clone https://github.com/ggerganov/llama.cpp.git
|
||||
pushd llama.cpp && cmake -B build -DGGML_CUDA=ON && cmake --build build --config Release && popd
|
||||
|
||||
# We need to convert the pytorch model into ggml for quantization
|
||||
# It crates 'ggml-model-f16.bin' in the 'merged' directory.
|
||||
pushd llama.cpp && python3 convert_hf_to_gguf.py ../qlora-out/merged && popd
|
||||
|
||||
# Start off by making a basic q4_0 4-bit quantization.
|
||||
# It's important to have 'ggml' in the name of the quant for some
|
||||
# software to recognize it's file format.
|
||||
pushd llama.cpp/build/bin && ./llama-quantize ../../../qlora-out/merged/Merged-33B-F16.gguf \
|
||||
../../../custom-model-q4_0.gguf q4_0
|
||||
|
||||
@@ -498,7 +498,7 @@ feature_flags:
|
||||
|
||||
## Related Documentation
|
||||
|
||||
- See [Advanced Usage]({{%relref "docs/advanced/advanced-usage" %}}) for other configuration options
|
||||
- See [Prompt Templates]({{%relref "docs/advanced/advanced-usage#prompt-templates" %}}) for template examples
|
||||
- See [CLI Reference]({{%relref "docs/reference/cli-reference" %}}) for command-line options
|
||||
- See [Advanced Usage]({{%relref "advanced/advanced-usage" %}}) for other configuration options
|
||||
- See [Prompt Templates]({{%relref "advanced/advanced-usage#prompt-templates" %}}) for template examples
|
||||
- See [CLI Reference]({{%relref "reference/cli-reference" %}}) for command-line options
|
||||
|
||||
@@ -23,10 +23,8 @@ The simplest approach is to ensure only one model is loaded at a time. When a ne
|
||||
### Configuration
|
||||
|
||||
```bash
|
||||
# Via command line
|
||||
./local-ai --single-active-backend
|
||||
|
||||
# Via environment variable
|
||||
LOCALAI_SINGLE_ACTIVE_BACKEND=true ./local-ai
|
||||
```
|
||||
|
||||
@@ -39,13 +37,10 @@ LOCALAI_SINGLE_ACTIVE_BACKEND=true ./local-ai
|
||||
### Example
|
||||
|
||||
```bash
|
||||
# Start LocalAI with single active backend
|
||||
LOCALAI_SINGLE_ACTIVE_BACKEND=true ./local-ai
|
||||
|
||||
# First request loads model A
|
||||
curl http://localhost:8080/v1/chat/completions -d '{"model": "model-a", ...}'
|
||||
|
||||
# Second request automatically unloads model A and loads model B
|
||||
curl http://localhost:8080/v1/chat/completions -d '{"model": "model-b", ...}'
|
||||
```
|
||||
|
||||
@@ -60,13 +55,10 @@ The idle watchdog monitors models that haven't been used for a specified period
|
||||
#### Configuration
|
||||
|
||||
```bash
|
||||
# Enable idle watchdog with default timeout (15 minutes)
|
||||
LOCALAI_WATCHDOG_IDLE=true ./local-ai
|
||||
|
||||
# Customize the idle timeout (e.g., 10 minutes)
|
||||
LOCALAI_WATCHDOG_IDLE=true LOCALAI_WATCHDOG_IDLE_TIMEOUT=10m ./local-ai
|
||||
|
||||
# Via command line
|
||||
./local-ai --enable-watchdog-idle --watchdog-idle-timeout=10m
|
||||
```
|
||||
|
||||
@@ -77,13 +69,10 @@ The busy watchdog monitors models that have been processing requests for an unus
|
||||
#### Configuration
|
||||
|
||||
```bash
|
||||
# Enable busy watchdog with default timeout (5 minutes)
|
||||
LOCALAI_WATCHDOG_BUSY=true ./local-ai
|
||||
|
||||
# Customize the busy timeout (e.g., 10 minutes)
|
||||
LOCALAI_WATCHDOG_BUSY=true LOCALAI_WATCHDOG_BUSY_TIMEOUT=10m ./local-ai
|
||||
|
||||
# Via command line
|
||||
./local-ai --enable-watchdog-busy --watchdog-busy-timeout=10m
|
||||
```
|
||||
|
||||
@@ -117,19 +106,15 @@ Or using command line flags:
|
||||
### Example
|
||||
|
||||
```bash
|
||||
# Start LocalAI with both watchdogs enabled
|
||||
LOCALAI_WATCHDOG_IDLE=true \
|
||||
LOCALAI_WATCHDOG_IDLE_TIMEOUT=10m \
|
||||
LOCALAI_WATCHDOG_BUSY=true \
|
||||
LOCALAI_WATCHDOG_BUSY_TIMEOUT=5m \
|
||||
./local-ai
|
||||
|
||||
# Load multiple models
|
||||
curl http://localhost:8080/v1/chat/completions -d '{"model": "model-a", ...}'
|
||||
curl http://localhost:8080/v1/chat/completions -d '{"model": "model-b", ...}'
|
||||
|
||||
# After 10 minutes of inactivity, model-a will be automatically unloaded
|
||||
# If a model gets stuck processing for more than 5 minutes, it will be terminated
|
||||
```
|
||||
|
||||
### Timeout Format
|
||||
@@ -154,7 +139,6 @@ LocalAI cannot reliably estimate VRAM usage of new models to load across differe
|
||||
If automatic management doesn't meet your needs, you can manually stop models using the LocalAI management API:
|
||||
|
||||
```bash
|
||||
# Stop a specific model
|
||||
curl -X POST http://localhost:8080/backend/shutdown \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{"model": "model-name"}'
|
||||
@@ -172,7 +156,7 @@ To stop all models, you'll need to call the endpoint for each loaded model indiv
|
||||
|
||||
## Related Documentation
|
||||
|
||||
- See [Advanced Usage]({{%relref "docs/advanced/advanced-usage" %}}) for other configuration options
|
||||
- See [GPU Acceleration]({{%relref "docs/features/GPU-acceleration" %}}) for GPU setup and configuration
|
||||
- See [Backend Flags]({{%relref "docs/advanced/advanced-usage#backend-flags" %}}) for all available backend configuration options
|
||||
- See [Advanced Usage]({{%relref "advanced/advanced-usage" %}}) for other configuration options
|
||||
- See [GPU Acceleration]({{%relref "features/GPU-acceleration" %}}) for GPU setup and configuration
|
||||
- See [Backend Flags]({{%relref "advanced/advanced-usage#backend-flags" %}}) for all available backend configuration options
|
||||
|
||||
@@ -1,38 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Advanced Configuration"
|
||||
weight = 20
|
||||
icon = "settings"
|
||||
description = "Advanced configuration and optimization for LocalAI"
|
||||
+++
|
||||
|
||||
This section covers advanced configuration, optimization, and fine-tuning options for LocalAI.
|
||||
|
||||
## Configuration
|
||||
|
||||
- **[Model Configuration]({{% relref "docs/advanced/model-configuration" %}})** - Complete model configuration reference
|
||||
- **[Advanced Usage]({{% relref "docs/advanced/advanced-usage" %}})** - Advanced configuration options
|
||||
- **[Installer Options]({{% relref "docs/advanced/installer" %}})** - Installer configuration and options
|
||||
|
||||
## Performance & Optimization
|
||||
|
||||
- **[Performance Tuning]({{% relref "docs/advanced/performance-tuning" %}})** - Optimize for maximum performance
|
||||
- **[VRAM Management]({{% relref "docs/advanced/vram-management" %}})** - Manage GPU memory efficiently
|
||||
|
||||
## Specialized Topics
|
||||
|
||||
- **[Fine-tuning]({{% relref "docs/advanced/fine-tuning" %}})** - Fine-tune models for LocalAI
|
||||
|
||||
## Before You Begin
|
||||
|
||||
Make sure you have:
|
||||
- LocalAI installed and running
|
||||
- Basic understanding of YAML configuration
|
||||
- Familiarity with your system's resources
|
||||
|
||||
## Related Documentation
|
||||
|
||||
- [Getting Started]({{% relref "docs/getting-started" %}}) - Installation and basics
|
||||
- [Model Configuration]({{% relref "docs/advanced/model-configuration" %}}) - Configuration reference
|
||||
- [Troubleshooting]({{% relref "docs/troubleshooting" %}}) - Common issues
|
||||
- [Performance Tuning]({{% relref "docs/advanced/performance-tuning" %}}) - Optimization guide
|
||||
@@ -1,52 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Installer options"
|
||||
weight = 24
|
||||
+++
|
||||
|
||||
An installation script is available for quick and hassle-free installations, streamlining the setup process for new users.
|
||||
|
||||
Can be used with the following command:
|
||||
```bash
|
||||
curl https://localai.io/install.sh | sh
|
||||
```
|
||||
|
||||
Installation can be configured with Environment variables, for example:
|
||||
|
||||
```bash
|
||||
curl https://localai.io/install.sh | VAR=value sh
|
||||
```
|
||||
|
||||
List of the Environment Variables:
|
||||
| Environment Variable | Description |
|
||||
|----------------------|--------------------------------------------------------------|
|
||||
| **DOCKER_INSTALL** | Set to "true" to enable the installation of Docker images. |
|
||||
| **USE_AIO** | Set to "true" to use the all-in-one LocalAI Docker image. |
|
||||
| **USE_VULKAN** | Set to "true" to use Vulkan GPU support. |
|
||||
| **API_KEY** | Specify an API key for accessing LocalAI, if required. |
|
||||
| **PORT** | Specifies the port on which LocalAI will run (default is 8080). |
|
||||
| **THREADS** | Number of processor threads the application should use. Defaults to the number of logical cores minus one. |
|
||||
| **VERSION** | Specifies the version of LocalAI to install. Defaults to the latest available version. |
|
||||
| **MODELS_PATH** | Directory path where LocalAI models are stored (default is /usr/share/local-ai/models). |
|
||||
| **P2P_TOKEN** | Token to use for the federation or for starting workers see [documentation]({{%relref "docs/features/distributed_inferencing" %}}) |
|
||||
| **WORKER** | Set to "true" to make the instance a worker (p2p token is required see [documentation]({{%relref "docs/features/distributed_inferencing" %}})) |
|
||||
| **FEDERATED** | Set to "true" to share the instance with the federation (p2p token is required see [documentation]({{%relref "docs/features/distributed_inferencing" %}})) |
|
||||
| **FEDERATED_SERVER** | Set to "true" to run the instance as a federation server which forwards requests to the federation (p2p token is required see [documentation]({{%relref "docs/features/distributed_inferencing" %}})) |
|
||||
|
||||
## Image Selection
|
||||
|
||||
The installer will automatically detect your GPU and select the appropriate image. By default, it uses the standard images without extra Python dependencies. You can customize the image selection using the following environment variables:
|
||||
|
||||
- `USE_AIO=true`: Use all-in-one images that include all dependencies
|
||||
- `USE_VULKAN=true`: Use Vulkan GPU support instead of vendor-specific GPU support
|
||||
|
||||
## Uninstallation
|
||||
|
||||
To uninstall, run:
|
||||
|
||||
```
|
||||
curl https://localai.io/install.sh | sh -s -- --uninstall
|
||||
```
|
||||
|
||||
We are looking into improving the installer, and as this is a first iteration any feedback is welcome! Open up an [issue](https://github.com/mudler/LocalAI/issues/new/choose) if something doesn't work for you!
|
||||
@@ -1,344 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Performance Tuning"
|
||||
weight = 22
|
||||
icon = "speed"
|
||||
description = "Optimize LocalAI for maximum performance"
|
||||
+++
|
||||
|
||||
This guide covers techniques to optimize LocalAI performance for your specific hardware and use case.
|
||||
|
||||
## Performance Metrics
|
||||
|
||||
Before optimizing, establish baseline metrics:
|
||||
|
||||
- **Tokens per second**: Measure inference speed
|
||||
- **Memory usage**: Monitor RAM and VRAM
|
||||
- **Latency**: Time to first token and total response time
|
||||
- **Throughput**: Requests per second
|
||||
|
||||
Enable debug mode to see performance stats:
|
||||
|
||||
```bash
|
||||
DEBUG=true local-ai
|
||||
```
|
||||
|
||||
Look for output like:
|
||||
```
|
||||
llm_load_tensors: tok/s: 45.23
|
||||
```
|
||||
|
||||
## CPU Optimization
|
||||
|
||||
### Thread Configuration
|
||||
|
||||
Match threads to CPU cores:
|
||||
|
||||
```yaml
|
||||
# Model configuration
|
||||
threads: 4 # For 4-core CPU
|
||||
```
|
||||
|
||||
**Guidelines**:
|
||||
- Use number of physical cores (not hyperthreads)
|
||||
- Leave 1-2 cores for system
|
||||
- Too many threads can hurt performance
|
||||
|
||||
### CPU Instructions
|
||||
|
||||
Enable appropriate CPU instructions:
|
||||
|
||||
```bash
|
||||
# Check available instructions
|
||||
cat /proc/cpuinfo | grep flags
|
||||
|
||||
# Build with optimizations
|
||||
CMAKE_ARGS="-DGGML_AVX2=ON -DGGML_AVX512=ON" make build
|
||||
```
|
||||
|
||||
### NUMA Optimization
|
||||
|
||||
For multi-socket systems:
|
||||
|
||||
```yaml
|
||||
numa: true
|
||||
```
|
||||
|
||||
### Memory Mapping
|
||||
|
||||
Enable memory mapping for faster model loading:
|
||||
|
||||
```yaml
|
||||
mmap: true
|
||||
mmlock: false # Set to true to lock in memory (faster but uses more RAM)
|
||||
```
|
||||
|
||||
## GPU Optimization
|
||||
|
||||
### Layer Offloading
|
||||
|
||||
Offload as many layers as GPU memory allows:
|
||||
|
||||
```yaml
|
||||
gpu_layers: 35 # Adjust based on GPU memory
|
||||
f16: true # Use FP16 for better performance
|
||||
```
|
||||
|
||||
**Finding optimal layers**:
|
||||
1. Start with 20 layers
|
||||
2. Monitor GPU memory: `nvidia-smi` or `rocm-smi`
|
||||
3. Gradually increase until near memory limit
|
||||
4. For maximum performance, offload all layers if possible
|
||||
|
||||
### Batch Processing
|
||||
|
||||
GPU excels at batch processing. Process multiple requests together when possible.
|
||||
|
||||
### Mixed Precision
|
||||
|
||||
Use FP16 when supported:
|
||||
|
||||
```yaml
|
||||
f16: true
|
||||
```
|
||||
|
||||
## Model Optimization
|
||||
|
||||
### Quantization
|
||||
|
||||
Choose appropriate quantization:
|
||||
|
||||
| Quantization | Speed | Quality | Memory | Use Case |
|
||||
|-------------|-------|---------|--------|----------|
|
||||
| Q8_0 | Slowest | Highest | Most | Maximum quality |
|
||||
| Q6_K | Slow | Very High | High | High quality |
|
||||
| Q4_K_M | Medium | High | Medium | **Recommended** |
|
||||
| Q4_K_S | Fast | Medium | Low | Balanced |
|
||||
| Q2_K | Fastest | Lower | Least | Speed priority |
|
||||
|
||||
### Context Size
|
||||
|
||||
Reduce context size for faster inference:
|
||||
|
||||
```yaml
|
||||
context_size: 2048 # Instead of 4096 or 8192
|
||||
```
|
||||
|
||||
**Trade-off**: Smaller context = faster but less conversation history
|
||||
|
||||
### Model Selection
|
||||
|
||||
Choose models appropriate for your hardware:
|
||||
|
||||
- **Small systems (4GB RAM)**: 1-3B parameter models
|
||||
- **Medium systems (8-16GB RAM)**: 3-7B parameter models
|
||||
- **Large systems (32GB+ RAM)**: 7B+ parameter models
|
||||
|
||||
## Configuration Optimizations
|
||||
|
||||
### Sampling Parameters
|
||||
|
||||
Optimize sampling for speed:
|
||||
|
||||
```yaml
|
||||
parameters:
|
||||
temperature: 0.7
|
||||
top_p: 0.9
|
||||
top_k: 40
|
||||
mirostat: 0 # Disable for speed (enabled by default)
|
||||
```
|
||||
|
||||
**Note**: Disabling mirostat improves speed but may reduce quality.
|
||||
|
||||
### Prompt Caching
|
||||
|
||||
Enable prompt caching for repeated queries:
|
||||
|
||||
```yaml
|
||||
prompt_cache_path: "cache"
|
||||
prompt_cache_all: true
|
||||
```
|
||||
|
||||
### Parallel Requests
|
||||
|
||||
LocalAI supports parallel requests. Configure appropriately:
|
||||
|
||||
```yaml
|
||||
# In model config
|
||||
parallel_requests: 4 # Adjust based on hardware
|
||||
```
|
||||
|
||||
## Storage Optimization
|
||||
|
||||
### Use SSD
|
||||
|
||||
Always use SSD for model storage:
|
||||
- HDD: Very slow model loading
|
||||
- SSD: Fast loading, better performance
|
||||
|
||||
### Disable MMAP on HDD
|
||||
|
||||
If stuck with HDD:
|
||||
|
||||
```yaml
|
||||
mmap: false # Loads entire model into RAM
|
||||
```
|
||||
|
||||
### Model Location
|
||||
|
||||
Store models on fastest storage:
|
||||
- Local SSD: Best performance
|
||||
- Network storage: Slower, but allows sharing
|
||||
- External drive: Slowest
|
||||
|
||||
## System-Level Optimizations
|
||||
|
||||
### Process Priority
|
||||
|
||||
Increase process priority (Linux):
|
||||
|
||||
```bash
|
||||
nice -n -10 local-ai
|
||||
```
|
||||
|
||||
### CPU Governor
|
||||
|
||||
Set CPU to performance mode (Linux):
|
||||
|
||||
```bash
|
||||
# Check current governor
|
||||
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
|
||||
|
||||
# Set to performance
|
||||
echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
|
||||
```
|
||||
|
||||
### Disable Swapping
|
||||
|
||||
Prevent swapping for better performance:
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
sudo swapoff -a
|
||||
|
||||
# Or set swappiness to 0
|
||||
echo 0 | sudo tee /proc/sys/vm/swappiness
|
||||
```
|
||||
|
||||
### Memory Allocation
|
||||
|
||||
For large models, consider huge pages (Linux):
|
||||
|
||||
```bash
|
||||
# Allocate huge pages
|
||||
echo 1024 | sudo tee /proc/sys/vm/nr_hugepages
|
||||
```
|
||||
|
||||
## Benchmarking
|
||||
|
||||
### Measure Performance
|
||||
|
||||
Create a benchmark script:
|
||||
|
||||
```python
|
||||
import time
|
||||
import requests
|
||||
|
||||
start = time.time()
|
||||
response = requests.post(
|
||||
"http://localhost:8080/v1/chat/completions",
|
||||
json={
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Hello"}]
|
||||
}
|
||||
)
|
||||
elapsed = time.time() - start
|
||||
|
||||
tokens = response.json()["usage"]["completion_tokens"]
|
||||
tokens_per_second = tokens / elapsed
|
||||
|
||||
print(f"Time: {elapsed:.2f}s")
|
||||
print(f"Tokens: {tokens}")
|
||||
print(f"Speed: {tokens_per_second:.2f} tok/s")
|
||||
```
|
||||
|
||||
### Compare Configurations
|
||||
|
||||
Test different configurations:
|
||||
1. Baseline: Default settings
|
||||
2. Optimized: Your optimizations
|
||||
3. Measure: Tokens/second, latency, memory
|
||||
|
||||
### Load Testing
|
||||
|
||||
Test under load:
|
||||
|
||||
```bash
|
||||
# Use Apache Bench or similar
|
||||
ab -n 100 -c 10 -p request.json -T application/json \
|
||||
http://localhost:8080/v1/chat/completions
|
||||
```
|
||||
|
||||
## Platform-Specific Tips
|
||||
|
||||
### Apple Silicon
|
||||
|
||||
- Metal acceleration is automatic
|
||||
- Use native builds (not Docker) for best performance
|
||||
- M1/M2/M3 have unified memory - optimize accordingly
|
||||
|
||||
### NVIDIA GPUs
|
||||
|
||||
- Use CUDA 12 for latest optimizations
|
||||
- Enable Tensor Cores with appropriate precision
|
||||
- Monitor with `nvidia-smi` for bottlenecks
|
||||
|
||||
### AMD GPUs
|
||||
|
||||
- Use ROCm/HIPBLAS backend
|
||||
- Check ROCm compatibility
|
||||
- Monitor with `rocm-smi`
|
||||
|
||||
### Intel GPUs
|
||||
|
||||
- Use oneAPI/SYCL backend
|
||||
- Check Intel GPU compatibility
|
||||
- Optimize for F16/F32 precision
|
||||
|
||||
## Common Performance Issues
|
||||
|
||||
### Slow First Response
|
||||
|
||||
**Cause**: Model loading
|
||||
**Solution**: Pre-load models or use model warming
|
||||
|
||||
### Degrading Performance
|
||||
|
||||
**Cause**: Memory fragmentation
|
||||
**Solution**: Restart LocalAI periodically
|
||||
|
||||
### Inconsistent Speed
|
||||
|
||||
**Cause**: System load, thermal throttling
|
||||
**Solution**: Monitor system resources, ensure cooling
|
||||
|
||||
## Performance Checklist
|
||||
|
||||
- [ ] Threads match CPU cores
|
||||
- [ ] GPU layers optimized
|
||||
- [ ] Appropriate quantization selected
|
||||
- [ ] Context size optimized
|
||||
- [ ] Models on SSD
|
||||
- [ ] MMAP enabled (if using SSD)
|
||||
- [ ] Mirostat disabled (if speed priority)
|
||||
- [ ] System resources monitored
|
||||
- [ ] Baseline metrics established
|
||||
- [ ] Optimizations tested and verified
|
||||
|
||||
## See Also
|
||||
|
||||
- [GPU Acceleration]({{% relref "docs/features/gpu-acceleration" %}}) - GPU setup
|
||||
- [VRAM Management]({{% relref "docs/advanced/vram-management" %}}) - GPU memory
|
||||
- [Model Configuration]({{% relref "docs/advanced/model-configuration" %}}) - Configuration options
|
||||
- [Troubleshooting]({{% relref "docs/troubleshooting" %}}) - Performance issues
|
||||
|
||||
@@ -1,215 +0,0 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "FAQ"
|
||||
weight = 24
|
||||
icon = "quiz"
|
||||
url = "/faq/"
|
||||
+++
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
Here are answers to some of the most common questions.
|
||||
|
||||
|
||||
### How do I get models?
|
||||
|
||||
There are several ways to get models for LocalAI:
|
||||
|
||||
1. **WebUI Import** (Easiest): Use the WebUI's model import interface:
|
||||
- Open `http://localhost:8080` and navigate to the Models tab
|
||||
- Click "Import Model" or "New Model"
|
||||
- Enter a model URI (Hugging Face, OCI, file path, etc.)
|
||||
- Configure preferences in Simple Mode or edit YAML in Advanced Mode
|
||||
- The WebUI provides syntax highlighting, validation, and a user-friendly interface
|
||||
|
||||
2. **Model Gallery** (Recommended): Use the built-in model gallery accessible via:
|
||||
- WebUI: Navigate to the Models tab in the LocalAI interface and browse available models
|
||||
- CLI: `local-ai models list` to see available models, then `local-ai models install <model-name>`
|
||||
- Online: Browse models at [models.localai.io](https://models.localai.io)
|
||||
|
||||
3. **Hugging Face**: Most GGUF-based models from Hugging Face work with LocalAI. You can install them via:
|
||||
- WebUI: Import using `huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf`
|
||||
- CLI: `local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf`
|
||||
|
||||
4. **Manual Installation**: Download model files and place them in your models directory. See [Install and Run Models]({{% relref "docs/getting-started/models" %}}) for details.
|
||||
|
||||
5. **OCI Registries**: Install models from OCI-compatible registries:
|
||||
- WebUI: Import using `ollama://gemma:2b` or `oci://localai/phi-2:latest`
|
||||
- CLI: `local-ai run ollama://gemma:2b` or `local-ai run oci://localai/phi-2:latest`
|
||||
|
||||
**Security Note**: Be cautious when downloading models from the internet. Always verify the source and use trusted repositories when possible.
|
||||
|
||||
### Where are models stored?
|
||||
|
||||
LocalAI stores downloaded models in the following locations by default:
|
||||
|
||||
- **Command line**: `./models` (relative to current working directory)
|
||||
- **Docker**: `/models` (inside the container, typically mounted to `./models` on host)
|
||||
- **Launcher application**: `~/.localai/models` (in your home directory)
|
||||
|
||||
You can customize the model storage location using the `LOCALAI_MODELS_PATH` environment variable or `--models-path` command line flag. This is useful if you want to store models outside your home directory for backup purposes or to avoid filling up your home directory with large model files.
|
||||
|
||||
### How much storage space do models require?
|
||||
|
||||
Model sizes vary significantly depending on the model and quantization level:
|
||||
|
||||
- **Small models (1-3B parameters)**: 1-3 GB
|
||||
- **Medium models (7-13B parameters)**: 4-8 GB
|
||||
- **Large models (30B+ parameters)**: 15-30+ GB
|
||||
|
||||
**Quantization levels** (smaller files, slightly reduced quality):
|
||||
- `Q4_K_M`: ~75% of original size
|
||||
- `Q4_K_S`: ~60% of original size
|
||||
- `Q2_K`: ~50% of original size
|
||||
|
||||
**Storage recommendations**:
|
||||
- Ensure you have at least 2-3x the model size available for downloads and temporary files
|
||||
- Use SSD storage for better performance
|
||||
- Consider the model size relative to your system RAM - models larger than your RAM may not run efficiently
|
||||
|
||||
### Benchmarking LocalAI and llama.cpp shows different results!
|
||||
|
||||
LocalAI applies a set of defaults when loading models with the llama.cpp backend, one of these is mirostat sampling - while it achieves better results, it slows down the inference. You can disable this by setting `mirostat: 0` in the model config file. See also the advanced section ({{%relref "docs/advanced/advanced-usage" %}}) for more information and [this issue](https://github.com/mudler/LocalAI/issues/2780).
|
||||
|
||||
### What's the difference with Serge, or XXX?
|
||||
|
||||
LocalAI is a multi-model solution that doesn't focus on a specific model type (e.g., llama.cpp or alpaca.cpp), and it handles all of these internally for faster inference, easy to set up locally and deploy to Kubernetes.
|
||||
|
||||
### Everything is slow, how is it possible?
|
||||
|
||||
There are few situation why this could occur. Some tips are:
|
||||
- Don't use HDD to store your models. Prefer SSD over HDD. In case you are stuck with HDD, disable `mmap` in the model config file so it loads everything in memory.
|
||||
- Watch out CPU overbooking. Ideally the `--threads` should match the number of physical cores. For instance if your CPU has 4 cores, you would ideally allocate `<= 4` threads to a model.
|
||||
- Run LocalAI with `DEBUG=true`. This gives more information, including stats on the token inference speed.
|
||||
- Check that you are actually getting an output: run a simple curl request with `"stream": true` to see how fast the model is responding.
|
||||
|
||||
### Can I use it with a Discord bot, or XXX?
|
||||
|
||||
Yes! If the client uses OpenAI and supports setting a different base URL to send requests to, you can use the LocalAI endpoint. This allows to use this with every application that was supposed to work with OpenAI, but without changing the application!
|
||||
|
||||
### Can this leverage GPUs?
|
||||
|
||||
There is GPU support, see {{%relref "docs/features/GPU-acceleration" %}}.
|
||||
|
||||
### Where is the webUI?
|
||||
|
||||
LocalAI includes a built-in WebUI that is automatically available when you start LocalAI. Simply navigate to `http://localhost:8080` in your web browser after starting LocalAI.
|
||||
|
||||
The WebUI provides:
|
||||
- Chat interface for interacting with models
|
||||
- Model gallery browser and installer
|
||||
- Backend management
|
||||
- Configuration tools
|
||||
|
||||
If you prefer a different interface, LocalAI is compatible with any OpenAI-compatible UI. You can find examples in the [LocalAI-examples repository](https://github.com/mudler/LocalAI-examples), including integrations with popular UIs like chatbot-ui.
|
||||
|
||||
### Does it work with AutoGPT?
|
||||
|
||||
Yes, see the [examples](https://github.com/mudler/LocalAI-examples)!
|
||||
|
||||
### How can I troubleshoot when something is wrong?
|
||||
|
||||
Enable the debug mode by setting `DEBUG=true` in the environment variables. This will give you more information on what's going on.
|
||||
You can also specify `--debug` in the command line.
|
||||
|
||||
### I'm getting 'invalid pitch' error when running with CUDA, what's wrong?
|
||||
|
||||
This typically happens when your prompt exceeds the context size. Try to reduce the prompt size, or increase the context size.
|
||||
|
||||
### I'm getting a 'SIGILL' error, what's wrong?
|
||||
|
||||
Your CPU probably does not have support for certain instructions that are compiled by default in the pre-built binaries. If you are running in a container, try setting `REBUILD=true` and disable the CPU instructions that are not compatible with your CPU. For instance: `CMAKE_ARGS="-DGGML_F16C=OFF -DGGML_AVX512=OFF -DGGML_AVX2=OFF -DGGML_FMA=OFF" make build`
|
||||
|
||||
Alternatively, you can use the backend management system to install a compatible backend for your CPU architecture. See [Backend Management]({{% relref "docs/features/backends" %}}) for more information.
|
||||
|
||||
### How do I install backends?
|
||||
|
||||
LocalAI now uses a backend management system where backends are automatically downloaded when needed. You can also manually install backends:
|
||||
|
||||
```bash
|
||||
# List available backends
|
||||
local-ai backends list
|
||||
|
||||
# Install a specific backend
|
||||
local-ai backends install llama-cpp
|
||||
|
||||
# Install a backend for a specific GPU type
|
||||
local-ai backends install llama-cpp --gpu-type nvidia
|
||||
```
|
||||
|
||||
For more details, see the [Backends documentation]({{% relref "docs/features/backends" %}}).
|
||||
|
||||
### How do I set up API keys for security?
|
||||
|
||||
You can secure your LocalAI instance by setting API keys using the `API_KEY` environment variable:
|
||||
|
||||
```bash
|
||||
# Single API key
|
||||
API_KEY=your-secret-key local-ai
|
||||
|
||||
# Multiple API keys (comma-separated)
|
||||
API_KEY=key1,key2,key3 local-ai
|
||||
```
|
||||
|
||||
When API keys are set, all requests must include the key in the `Authorization` header:
|
||||
```bash
|
||||
curl http://localhost:8080/v1/models \
|
||||
-H "Authorization: Bearer your-secret-key"
|
||||
```
|
||||
|
||||
**Important**: API keys provide full access to all LocalAI features (admin-level access). Make sure to protect your API keys and use HTTPS when exposing LocalAI remotely.
|
||||
|
||||
### My model is not loading or showing errors
|
||||
|
||||
Here are common issues and solutions:
|
||||
|
||||
1. **Backend not installed**: The required backend may not be installed. Check with `local-ai backends list` and install if needed.
|
||||
2. **Insufficient memory**: Large models require significant RAM. Check available memory and consider using a smaller quantized model.
|
||||
3. **Wrong backend specified**: Ensure the backend in your model configuration matches the model type. See the [Compatibility Table]({{% relref "docs/reference/compatibility-table" %}}).
|
||||
4. **Model file corruption**: Re-download the model file.
|
||||
5. **Check logs**: Enable debug mode (`DEBUG=true`) to see detailed error messages.
|
||||
|
||||
For more troubleshooting help, see the [Troubleshooting Guide]({{% relref "docs/troubleshooting" %}}).
|
||||
|
||||
### How do I use GPU acceleration?
|
||||
|
||||
LocalAI supports multiple GPU types:
|
||||
|
||||
- **NVIDIA (CUDA)**: Use `--gpus all` with Docker and CUDA-enabled images
|
||||
- **AMD (ROCm)**: Use images with `hipblas` tag
|
||||
- **Intel**: Use images with `intel` tag or Intel oneAPI
|
||||
- **Apple Silicon (Metal)**: Automatically detected on macOS
|
||||
|
||||
For detailed setup instructions, see [GPU Acceleration]({{% relref "docs/features/gpu-acceleration" %}}).
|
||||
|
||||
### Can I use LocalAI with LangChain, AutoGPT, or other frameworks?
|
||||
|
||||
Yes! LocalAI is compatible with any framework that supports OpenAI's API. Simply point the framework to your LocalAI endpoint:
|
||||
|
||||
```python
|
||||
# Example with LangChain
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
llm = OpenAI(
|
||||
openai_api_key="not-needed",
|
||||
openai_api_base="http://localhost:8080/v1"
|
||||
)
|
||||
```
|
||||
|
||||
See the [Integrations]({{% relref "docs/integrations" %}}) page for a list of compatible projects and examples.
|
||||
|
||||
### What's the difference between AIO images and standard images?
|
||||
|
||||
**AIO (All-in-One) images** come pre-configured with:
|
||||
- Pre-installed models ready to use
|
||||
- All necessary backends included
|
||||
- Quick start with no configuration needed
|
||||
|
||||
**Standard images** are:
|
||||
- Smaller in size
|
||||
- No pre-installed models
|
||||
- You install models and backends as needed
|
||||
- More flexible for custom setups
|
||||
|
||||
Choose AIO images for quick testing and standard images for production deployments. See [Container Images]({{% relref "docs/getting-started/container-images" %}}) for details.
|
||||
@@ -1,56 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Features"
|
||||
weight = 8
|
||||
icon = "feature_search"
|
||||
url = "/features/"
|
||||
description = "Explore all LocalAI capabilities and features"
|
||||
+++
|
||||
|
||||
LocalAI provides a comprehensive set of AI capabilities, all running locally with OpenAI-compatible APIs.
|
||||
|
||||
## Core Features
|
||||
|
||||
### Text Generation
|
||||
|
||||
- **[Text Generation]({{% relref "docs/features/text-generation" %}})** - Generate text with various LLMs
|
||||
- **[OpenAI Functions]({{% relref "docs/features/openai-functions" %}})** - Function calling and tools API
|
||||
- **[Constrained Grammars]({{% relref "docs/features/constrained_grammars" %}})** - Structured output generation
|
||||
- **[Model Context Protocol (MCP)]({{% relref "docs/features/mcp" %}})** - Agentic capabilities
|
||||
|
||||
### Multimodal
|
||||
|
||||
- **[GPT Vision]({{% relref "docs/features/gpt-vision" %}})** - Image understanding and analysis
|
||||
- **[Image Generation]({{% relref "docs/features/image-generation" %}})** - Create images from text
|
||||
- **[Object Detection]({{% relref "docs/features/object-detection" %}})** - Detect objects in images
|
||||
|
||||
### Audio
|
||||
|
||||
- **[Text to Audio]({{% relref "docs/features/text-to-audio" %}})** - Generate speech from text
|
||||
- **[Audio to Text]({{% relref "docs/features/audio-to-text" %}})** - Transcribe audio to text
|
||||
|
||||
### Data & Search
|
||||
|
||||
- **[Embeddings]({{% relref "docs/features/embeddings" %}})** - Generate vector embeddings
|
||||
- **[Reranker]({{% relref "docs/features/reranker" %}})** - Document relevance scoring
|
||||
- **[Stores]({{% relref "docs/features/stores" %}})** - Vector database storage
|
||||
|
||||
## Infrastructure
|
||||
|
||||
- **[Backends]({{% relref "docs/features/backends" %}})** - Backend management and installation
|
||||
- **[GPU Acceleration]({{% relref "docs/features/gpu-acceleration" %}})** - GPU support and optimization
|
||||
- **[Model Gallery]({{% relref "docs/features/model-gallery" %}})** - Browse and install models
|
||||
- **[Distributed Inferencing]({{% relref "docs/features/distributed_inferencing" %}})** - P2P and distributed inference
|
||||
|
||||
## Getting Started with Features
|
||||
|
||||
1. **Install LocalAI**: See [Getting Started]({{% relref "docs/getting-started" %}})
|
||||
2. **Install Models**: See [Setting Up Models]({{% relref "docs/tutorials/setting-up-models" %}})
|
||||
3. **Try Features**: See [Try It Out]({{% relref "docs/getting-started/try-it-out" %}})
|
||||
4. **Configure**: See [Advanced Configuration]({{% relref "docs/advanced" %}})
|
||||
|
||||
## Related Documentation
|
||||
|
||||
- [API Reference]({{% relref "docs/reference/api-reference" %}}) - Complete API documentation
|
||||
- [Compatibility Table]({{% relref "docs/reference/compatibility-table" %}}) - Supported models and backends
|
||||
- [Tutorials]({{% relref "docs/tutorials" %}}) - Step-by-step guides
|
||||
@@ -1,34 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "✍️ Constrained Grammars"
|
||||
weight = 15
|
||||
url = "/features/constrained_grammars/"
|
||||
+++
|
||||
|
||||
## Overview
|
||||
|
||||
The `chat` endpoint supports the `grammar` parameter, which allows users to specify a grammar in Backus-Naur Form (BNF). This feature enables the Large Language Model (LLM) to generate outputs adhering to a user-defined schema, such as `JSON`, `YAML`, or any other format that can be defined using BNF. For more details about BNF, see [Backus-Naur Form on Wikipedia](https://en.wikipedia.org/wiki/Backus%E2%80%93Naur_form).
|
||||
|
||||
{{% alert note %}}
|
||||
**Compatibility Notice:** This feature is only supported by models that use the [llama.cpp](https://github.com/ggerganov/llama.cpp) backend. For a complete list of compatible models, refer to the [Model Compatibility](docs/reference/compatibility-table) page. For technical details, see the related pull requests: [PR #1773](https://github.com/ggerganov/llama.cpp/pull/1773) and [PR #1887](https://github.com/ggerganov/llama.cpp/pull/1887).
|
||||
{{% /alert %}}
|
||||
|
||||
## Setup
|
||||
|
||||
To use this feature, follow the installation and setup instructions on the [LocalAI Functions](docs/features/openai-functions) page. Ensure that your local setup meets all the prerequisites specified for the llama.cpp backend.
|
||||
|
||||
## 💡 Usage Example
|
||||
|
||||
The following example demonstrates how to use the `grammar` parameter to constrain the model's output to either "yes" or "no". This can be particularly useful in scenarios where the response format needs to be strictly controlled.
|
||||
|
||||
### Example: Binary Response Constraint
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Do you like apples?"}],
|
||||
"grammar": "root ::= (\"yes\" | \"no\")"
|
||||
}'
|
||||
```
|
||||
|
||||
In this example, the `grammar` parameter is set to a simple choice between "yes" and "no", ensuring that the model's response adheres strictly to one of these options regardless of the context.
|
||||
@@ -1,49 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Getting Started"
|
||||
weight = 2
|
||||
icon = "rocket_launch"
|
||||
description = "Install LocalAI and run your first AI model"
|
||||
+++
|
||||
|
||||
Welcome to LocalAI! This section will guide you through installation and your first steps.
|
||||
|
||||
## Quick Start
|
||||
|
||||
**New to LocalAI?** Start here:
|
||||
|
||||
1. **[Quickstart]({{% relref "docs/getting-started/quickstart" %}})** - Get LocalAI running in minutes
|
||||
2. **[Your First Chat]({{% relref "docs/tutorials/first-chat" %}})** - Complete beginner tutorial
|
||||
3. **[Try It Out]({{% relref "docs/getting-started/try-it-out" %}})** - Test the API with examples
|
||||
|
||||
## Installation Options
|
||||
|
||||
Choose the installation method that works for you:
|
||||
|
||||
- **[Quickstart]({{% relref "docs/getting-started/quickstart" %}})** - Docker, installer, or binaries
|
||||
- **[Container Images]({{% relref "docs/getting-started/container-images" %}})** - Docker deployment options
|
||||
- **[Build from Source]({{% relref "docs/getting-started/build" %}})** - Compile LocalAI yourself
|
||||
- **[Kubernetes]({{% relref "docs/getting-started/kubernetes" %}})** - Deploy on Kubernetes
|
||||
|
||||
## Setting Up Models
|
||||
|
||||
Once LocalAI is installed:
|
||||
|
||||
- **[Install and Run Models]({{% relref "docs/getting-started/models" %}})** - Model installation guide
|
||||
- **[Setting Up Models Tutorial]({{% relref "docs/tutorials/setting-up-models" %}})** - Step-by-step model setup
|
||||
- **[Customize Models]({{% relref "docs/getting-started/customize-model" %}})** - Configure model behavior
|
||||
|
||||
## What's Next?
|
||||
|
||||
After installation:
|
||||
|
||||
- Explore [Features]({{% relref "docs/features" %}}) - See what LocalAI can do
|
||||
- Follow [Tutorials]({{% relref "docs/tutorials" %}}) - Learn step-by-step
|
||||
- Check [FAQ]({{% relref "docs/faq" %}}) - Common questions
|
||||
- Read [Documentation]({{% relref "docs" %}}) - Complete reference
|
||||
|
||||
## Need Help?
|
||||
|
||||
- [FAQ]({{% relref "docs/faq" %}}) - Common questions and answers
|
||||
- [Troubleshooting]({{% relref "docs/troubleshooting" %}}) - Solutions to problems
|
||||
- [Discord](https://discord.gg/uJAeKSAGDy) - Community support
|
||||
@@ -1,238 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Quickstart"
|
||||
weight = 3
|
||||
url = '/basics/getting_started/'
|
||||
icon = "rocket_launch"
|
||||
+++
|
||||
|
||||
**LocalAI** is a free, open-source alternative to OpenAI (Anthropic, etc.), functioning as a drop-in replacement REST API for local inferencing. It allows you to run [LLMs]({{% relref "docs/features/text-generation" %}}), generate images, and produce audio, all locally or on-premises with consumer-grade hardware, supporting multiple model families and architectures.
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
|
||||
**Security considerations**
|
||||
|
||||
If you are exposing LocalAI remotely, make sure you protect the API endpoints adequately with a mechanism which allows to protect from the incoming traffic or alternatively, run LocalAI with `API_KEY` to gate the access with an API key. The API key guarantees a total access to the features (there is no role separation), and it is to be considered as likely as an admin role.
|
||||
|
||||
{{% /alert %}}
|
||||
|
||||
## Quickstart
|
||||
|
||||
### Using the Bash Installer
|
||||
|
||||
```bash
|
||||
# Basic installation
|
||||
curl https://localai.io/install.sh | sh
|
||||
```
|
||||
|
||||
The bash installer, if docker is not detected, will install automatically as a systemd service.
|
||||
|
||||
See [Installer]({{% relref "docs/advanced/installer" %}}) for all the supported options
|
||||
|
||||
### macOS Download
|
||||
|
||||
For MacOS a DMG is available:
|
||||
|
||||
<a href="https://github.com/mudler/LocalAI/releases/latest/download/LocalAI.dmg">
|
||||
<img src="https://img.shields.io/badge/Download-macOS-blue?style=for-the-badge&logo=apple&logoColor=white" alt="Download LocalAI for macOS"/>
|
||||
</a>
|
||||
|
||||
> Note: the DMGs are not signed by Apple and shows quarantined after install. See https://github.com/mudler/LocalAI/issues/6268 for a workaround, fix is tracked here: https://github.com/mudler/LocalAI/issues/6244
|
||||
|
||||
### Run with docker
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
**Docker Run vs Docker Start**
|
||||
|
||||
- `docker run` creates and starts a new container. If a container with the same name already exists, this command will fail.
|
||||
- `docker start` starts an existing container that was previously created with `docker run`.
|
||||
|
||||
If you've already run LocalAI before and want to start it again, use: `docker start -i local-ai`
|
||||
{{% /alert %}}
|
||||
|
||||
The following commands will automatically start with a web interface and a Rest API on port `8080`.
|
||||
|
||||
#### CPU only image:
|
||||
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest
|
||||
```
|
||||
|
||||
#### NVIDIA GPU Images:
|
||||
|
||||
```bash
|
||||
# CUDA 12.0
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12
|
||||
|
||||
# CUDA 11.7
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-11
|
||||
|
||||
# NVIDIA Jetson (L4T) ARM64
|
||||
# First, you need to have installed the nvidia container toolkit: https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#installing-with-ap
|
||||
docker run -ti --name local-ai -p 8080:8080 --runtime nvidia --gpus all localai/localai:latest-nvidia-l4t-arm64
|
||||
```
|
||||
|
||||
#### AMD GPU Images (ROCm):
|
||||
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --device=/dev/kfd --device=/dev/dri --group-add=video localai/localai:latest-gpu-hipblas
|
||||
```
|
||||
|
||||
#### Intel GPU Images (oneAPI):
|
||||
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-gpu-intel
|
||||
```
|
||||
|
||||
#### Vulkan GPU Images:
|
||||
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-gpu-vulkan
|
||||
```
|
||||
|
||||
#### AIO Images (pre-downloaded models):
|
||||
|
||||
```bash
|
||||
# CPU version
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-cpu
|
||||
|
||||
# NVIDIA CUDA 12 version
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-aio-gpu-nvidia-cuda-12
|
||||
|
||||
# NVIDIA CUDA 11 version
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-aio-gpu-nvidia-cuda-11
|
||||
|
||||
# Intel GPU version
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-gpu-intel
|
||||
|
||||
# AMD GPU version
|
||||
docker run -ti --name local-ai -p 8080:8080 --device=/dev/kfd --device=/dev/dri --group-add=video localai/localai:latest-aio-gpu-hipblas
|
||||
```
|
||||
|
||||
### Downloading models on start
|
||||
|
||||
When starting LocalAI (either via Docker or via CLI) you can specify as argument a list of models to install automatically before starting the API, for example:
|
||||
|
||||
```bash
|
||||
# From the model gallery (see available models with `local-ai models list`, in the WebUI from the model tab, or visiting https://models.localai.io)
|
||||
local-ai run llama-3.2-1b-instruct:q4_k_m
|
||||
# Start LocalAI with the phi-2 model directly from huggingface
|
||||
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
|
||||
# Install and run a model from the Ollama OCI registry
|
||||
local-ai run ollama://gemma:2b
|
||||
# Run a model from a configuration file
|
||||
local-ai run https://gist.githubusercontent.com/.../phi-2.yaml
|
||||
# Install and run a model from a standard OCI registry (e.g., Docker Hub)
|
||||
local-ai run oci://localai/phi-2:latest
|
||||
```
|
||||
|
||||
{{% alert icon="⚡" %}}
|
||||
**Automatic Backend Detection**: When you install models from the gallery or YAML files, LocalAI automatically detects your system's GPU capabilities (NVIDIA, AMD, Intel) and downloads the appropriate backend. For advanced configuration options, see [GPU Acceleration]({{% relref "docs/features/gpu-acceleration#automatic-backend-detection" %}}).
|
||||
{{% /alert %}}
|
||||
|
||||
For a full list of options, you can run LocalAI with `--help` or refer to the [Installer Options]({{% relref "docs/advanced/installer" %}}) documentation.
|
||||
|
||||
Binaries can also be [manually downloaded]({{% relref "docs/reference/binaries" %}}).
|
||||
|
||||
## Using Homebrew on MacOS
|
||||
|
||||
{{% alert icon="⚠️" %}}
|
||||
The Homebrew formula currently doesn't have the same options than the bash script
|
||||
{{% /alert %}}
|
||||
|
||||
You can install Homebrew's [LocalAI](https://formulae.brew.sh/formula/localai) with the following command:
|
||||
|
||||
```
|
||||
brew install localai
|
||||
```
|
||||
|
||||
|
||||
## Using Container Images or Kubernetes
|
||||
|
||||
LocalAI is available as a container image compatible with various container engines such as Docker, Podman, and Kubernetes. Container images are published on [quay.io](https://quay.io/repository/go-skynet/local-ai?tab=tags&tag=latest) and [Docker Hub](https://hub.docker.com/r/localai/localai).
|
||||
|
||||
For detailed instructions, see [Using container images]({{% relref "docs/getting-started/container-images" %}}). For Kubernetes deployment, see [Run with Kubernetes]({{% relref "docs/getting-started/kubernetes" %}}).
|
||||
|
||||
## Running LocalAI with All-in-One (AIO) Images
|
||||
|
||||
> _Already have a model file? Skip to [Run models manually]({{% relref "docs/getting-started/models" %}})_.
|
||||
|
||||
LocalAI's All-in-One (AIO) images are pre-configured with a set of models and backends to fully leverage almost all the features of LocalAI. If pre-configured models are not required, you can use the standard [images]({{% relref "docs/getting-started/container-images" %}}).
|
||||
|
||||
These images are available for both CPU and GPU environments. AIO images are designed for ease of use and require no additional configuration.
|
||||
|
||||
It is recommended to use AIO images if you prefer not to configure the models manually or via the web interface. For running specific models, refer to the [manual method]({{% relref "docs/getting-started/models" %}}).
|
||||
|
||||
The AIO images come pre-configured with the following features:
|
||||
- Text to Speech (TTS)
|
||||
- Speech to Text
|
||||
- Function calling
|
||||
- Large Language Models (LLM) for text generation
|
||||
- Image generation
|
||||
- Embedding server
|
||||
|
||||
For instructions on using AIO images, see [Using container images]({{% relref "docs/getting-started/container-images#all-in-one-images" %}}).
|
||||
|
||||
## Using LocalAI and the full stack with LocalAGI
|
||||
|
||||
LocalAI is part of the Local family stack, along with LocalAGI and LocalRecall.
|
||||
|
||||
[LocalAGI](https://github.com/mudler/LocalAGI) is a powerful, self-hostable AI Agent platform designed for maximum privacy and flexibility which encompassess and uses all the software stack. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities, working entirely locally on consumer-grade hardware (CPU and GPU).
|
||||
|
||||
### Quick Start
|
||||
|
||||
```bash
|
||||
# Clone the repository
|
||||
git clone https://github.com/mudler/LocalAGI
|
||||
cd LocalAGI
|
||||
|
||||
# CPU setup (default)
|
||||
docker compose up
|
||||
|
||||
# NVIDIA GPU setup
|
||||
docker compose -f docker-compose.nvidia.yaml up
|
||||
|
||||
# Intel GPU setup (for Intel Arc and integrated GPUs)
|
||||
docker compose -f docker-compose.intel.yaml up
|
||||
|
||||
# Start with a specific model (see available models in models.localai.io, or localai.io to use any model in huggingface)
|
||||
MODEL_NAME=gemma-3-12b-it docker compose up
|
||||
|
||||
# NVIDIA GPU setup with custom multimodal and image models
|
||||
MODEL_NAME=gemma-3-12b-it \
|
||||
MULTIMODAL_MODEL=minicpm-v-4_5 \
|
||||
IMAGE_MODEL=flux.1-dev-ggml \
|
||||
docker compose -f docker-compose.nvidia.yaml up
|
||||
```
|
||||
|
||||
### Key Features
|
||||
|
||||
- **Privacy-Focused**: All processing happens locally, ensuring your data never leaves your machine
|
||||
- **Flexible Deployment**: Supports CPU, NVIDIA GPU, and Intel GPU configurations
|
||||
- **Multiple Model Support**: Compatible with various models from Hugging Face and other sources
|
||||
- **Web Interface**: User-friendly chat interface for interacting with AI agents
|
||||
- **Advanced Capabilities**: Supports multimodal models, image generation, and more
|
||||
- **Docker Integration**: Easy deployment using Docker Compose
|
||||
|
||||
### Environment Variables
|
||||
|
||||
You can customize your LocalAGI setup using the following environment variables:
|
||||
|
||||
- `MODEL_NAME`: Specify the model to use (e.g., `gemma-3-12b-it`)
|
||||
- `MULTIMODAL_MODEL`: Set a custom multimodal model
|
||||
- `IMAGE_MODEL`: Configure an image generation model
|
||||
|
||||
For more advanced configuration and API documentation, visit the [LocalAGI GitHub repository](https://github.com/mudler/LocalAGI).
|
||||
|
||||
## What's Next?
|
||||
|
||||
There is much more to explore with LocalAI! You can run any model from Hugging Face, perform video generation, and also voice cloning. For a comprehensive overview, check out the [features]({{% relref "docs/features" %}}) section.
|
||||
|
||||
Explore additional resources and community contributions:
|
||||
|
||||
- [Installer Options]({{% relref "docs/advanced/installer" %}})
|
||||
- [Run from Container images]({{% relref "docs/getting-started/container-images" %}})
|
||||
- [Examples to try from the CLI]({{% relref "docs/getting-started/try-it-out" %}})
|
||||
- [Build LocalAI and the container image]({{% relref "docs/getting-started/build" %}})
|
||||
- [Run models manually]({{% relref "docs/getting-started/models" %}})
|
||||
- [Examples](https://github.com/mudler/LocalAI/tree/master/examples#examples)
|
||||
@@ -1,445 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "API Reference"
|
||||
weight = 22
|
||||
icon = "api"
|
||||
description = "Complete API reference for LocalAI's OpenAI-compatible endpoints"
|
||||
+++
|
||||
|
||||
LocalAI provides a REST API that is compatible with OpenAI's API specification. This document provides a complete reference for all available endpoints.
|
||||
|
||||
## Base URL
|
||||
|
||||
All API requests should be made to:
|
||||
|
||||
```
|
||||
http://localhost:8080/v1
|
||||
```
|
||||
|
||||
For production deployments, replace `localhost:8080` with your server's address.
|
||||
|
||||
## Authentication
|
||||
|
||||
If API keys are configured (via `API_KEY` environment variable), include the key in the `Authorization` header:
|
||||
|
||||
```bash
|
||||
Authorization: Bearer your-api-key
|
||||
```
|
||||
|
||||
## Endpoints
|
||||
|
||||
### Chat Completions
|
||||
|
||||
Create a model response for the given chat conversation.
|
||||
|
||||
**Endpoint**: `POST /v1/chat/completions`
|
||||
|
||||
**Request Body**:
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "gpt-4",
|
||||
"messages": [
|
||||
{"role": "system", "content": "You are a helpful assistant."},
|
||||
{"role": "user", "content": "Hello!"}
|
||||
],
|
||||
"temperature": 0.7,
|
||||
"max_tokens": 100,
|
||||
"top_p": 1.0,
|
||||
"top_k": 40,
|
||||
"stream": false
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters**:
|
||||
|
||||
| Parameter | Type | Description | Default |
|
||||
|-----------|------|-------------|---------|
|
||||
| `model` | string | The model to use | Required |
|
||||
| `messages` | array | Array of message objects | Required |
|
||||
| `temperature` | number | Sampling temperature (0-2) | 0.7 |
|
||||
| `max_tokens` | integer | Maximum tokens to generate | Model default |
|
||||
| `top_p` | number | Nucleus sampling parameter | 1.0 |
|
||||
| `top_k` | integer | Top-k sampling parameter | 40 |
|
||||
| `stream` | boolean | Stream responses | false |
|
||||
| `tools` | array | Available tools/functions | - |
|
||||
| `tool_choice` | string | Tool selection mode | "auto" |
|
||||
|
||||
**Response**:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "chatcmpl-123",
|
||||
"object": "chat.completion",
|
||||
"created": 1677652288,
|
||||
"choices": [{
|
||||
"index": 0,
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "Hello! How can I help you today?"
|
||||
},
|
||||
"finish_reason": "stop"
|
||||
}],
|
||||
"usage": {
|
||||
"prompt_tokens": 9,
|
||||
"completion_tokens": 12,
|
||||
"total_tokens": 21
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Hello!"}]
|
||||
}'
|
||||
```
|
||||
|
||||
### Completions
|
||||
|
||||
Create a completion for the provided prompt.
|
||||
|
||||
**Endpoint**: `POST /v1/completions`
|
||||
|
||||
**Request Body**:
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "gpt-4",
|
||||
"prompt": "The capital of France is",
|
||||
"temperature": 0.7,
|
||||
"max_tokens": 10
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters**:
|
||||
|
||||
| Parameter | Type | Description |
|
||||
|-----------|------|-------------|
|
||||
| `model` | string | The model to use |
|
||||
| `prompt` | string | The prompt to complete |
|
||||
| `temperature` | number | Sampling temperature |
|
||||
| `max_tokens` | integer | Maximum tokens to generate |
|
||||
| `top_p` | number | Nucleus sampling |
|
||||
| `top_k` | integer | Top-k sampling |
|
||||
| `stream` | boolean | Stream responses |
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-4",
|
||||
"prompt": "The capital of France is",
|
||||
"max_tokens": 10
|
||||
}'
|
||||
```
|
||||
|
||||
### Edits
|
||||
|
||||
Create an edited version of the input.
|
||||
|
||||
**Endpoint**: `POST /v1/edits`
|
||||
|
||||
**Request Body**:
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "gpt-4",
|
||||
"instruction": "Make it more formal",
|
||||
"input": "Hey, how are you?",
|
||||
"temperature": 0.7
|
||||
}
|
||||
```
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/edits \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-4",
|
||||
"instruction": "Make it more formal",
|
||||
"input": "Hey, how are you?"
|
||||
}'
|
||||
```
|
||||
|
||||
### Embeddings
|
||||
|
||||
Get a vector representation of input text.
|
||||
|
||||
**Endpoint**: `POST /v1/embeddings`
|
||||
|
||||
**Request Body**:
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "text-embedding-ada-002",
|
||||
"input": "The food was delicious"
|
||||
}
|
||||
```
|
||||
|
||||
**Response**:
|
||||
|
||||
```json
|
||||
{
|
||||
"object": "list",
|
||||
"data": [{
|
||||
"object": "embedding",
|
||||
"embedding": [0.1, 0.2, 0.3, ...],
|
||||
"index": 0
|
||||
}],
|
||||
"usage": {
|
||||
"prompt_tokens": 4,
|
||||
"total_tokens": 4
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/embeddings \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "text-embedding-ada-002",
|
||||
"input": "The food was delicious"
|
||||
}'
|
||||
```
|
||||
|
||||
### Audio Transcription
|
||||
|
||||
Transcribe audio into the input language.
|
||||
|
||||
**Endpoint**: `POST /v1/audio/transcriptions`
|
||||
|
||||
**Request**: `multipart/form-data`
|
||||
|
||||
**Form Fields**:
|
||||
|
||||
| Field | Type | Description |
|
||||
|-------|------|-------------|
|
||||
| `file` | file | Audio file to transcribe |
|
||||
| `model` | string | Model to use (e.g., "whisper-1") |
|
||||
| `language` | string | Language code (optional) |
|
||||
| `prompt` | string | Optional text prompt |
|
||||
| `response_format` | string | Response format (json, text, etc.) |
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/audio/transcriptions \
|
||||
-H "Authorization: Bearer not-needed" \
|
||||
-F file="@audio.mp3" \
|
||||
-F model="whisper-1"
|
||||
```
|
||||
|
||||
### Audio Speech (Text-to-Speech)
|
||||
|
||||
Generate audio from text.
|
||||
|
||||
**Endpoint**: `POST /v1/audio/speech`
|
||||
|
||||
**Request Body**:
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "tts-1",
|
||||
"input": "Hello, this is a test",
|
||||
"voice": "alloy",
|
||||
"response_format": "mp3"
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters**:
|
||||
|
||||
| Parameter | Type | Description |
|
||||
|-----------|------|-------------|
|
||||
| `model` | string | TTS model to use |
|
||||
| `input` | string | Text to convert to speech |
|
||||
| `voice` | string | Voice to use (alloy, echo, fable, etc.) |
|
||||
| `response_format` | string | Audio format (mp3, opus, etc.) |
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/audio/speech \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "tts-1",
|
||||
"input": "Hello, this is a test",
|
||||
"voice": "alloy"
|
||||
}' \
|
||||
--output speech.mp3
|
||||
```
|
||||
|
||||
### Image Generation
|
||||
|
||||
Generate images from text prompts.
|
||||
|
||||
**Endpoint**: `POST /v1/images/generations`
|
||||
|
||||
**Request Body**:
|
||||
|
||||
```json
|
||||
{
|
||||
"prompt": "A cute baby sea otter",
|
||||
"n": 1,
|
||||
"size": "256x256",
|
||||
"response_format": "url"
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters**:
|
||||
|
||||
| Parameter | Type | Description |
|
||||
|-----------|------|-------------|
|
||||
| `prompt` | string | Text description of the image |
|
||||
| `n` | integer | Number of images to generate |
|
||||
| `size` | string | Image size (256x256, 512x512, etc.) |
|
||||
| `response_format` | string | Response format (url, b64_json) |
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/images/generations \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"prompt": "A cute baby sea otter",
|
||||
"size": "256x256"
|
||||
}'
|
||||
```
|
||||
|
||||
### List Models
|
||||
|
||||
List all available models.
|
||||
|
||||
**Endpoint**: `GET /v1/models`
|
||||
|
||||
**Query Parameters**:
|
||||
|
||||
| Parameter | Type | Description |
|
||||
|-----------|------|-------------|
|
||||
| `filter` | string | Filter models by name |
|
||||
| `excludeConfigured` | boolean | Exclude configured models |
|
||||
|
||||
**Response**:
|
||||
|
||||
```json
|
||||
{
|
||||
"object": "list",
|
||||
"data": [
|
||||
{
|
||||
"id": "gpt-4",
|
||||
"object": "model"
|
||||
},
|
||||
{
|
||||
"id": "gpt-4-vision-preview",
|
||||
"object": "model"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Example**:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/models
|
||||
```
|
||||
|
||||
## Streaming Responses
|
||||
|
||||
Many endpoints support streaming. Set `"stream": true` in the request:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Hello!"}],
|
||||
"stream": true
|
||||
}'
|
||||
```
|
||||
|
||||
Stream responses are sent as Server-Sent Events (SSE):
|
||||
|
||||
```
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk",...}
|
||||
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk",...}
|
||||
|
||||
data: [DONE]
|
||||
```
|
||||
|
||||
## Error Handling
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Error description",
|
||||
"type": "invalid_request_error",
|
||||
"code": 400
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Code | Description |
|
||||
|------|-------------|
|
||||
| 400 | Bad Request - Invalid parameters |
|
||||
| 401 | Unauthorized - Missing or invalid API key |
|
||||
| 404 | Not Found - Model or endpoint not found |
|
||||
| 429 | Too Many Requests - Rate limit exceeded |
|
||||
| 500 | Internal Server Error - Server error |
|
||||
| 503 | Service Unavailable - Model not loaded |
|
||||
|
||||
### Example Error Handling
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
try:
|
||||
response = requests.post(
|
||||
"http://localhost:8080/v1/chat/completions",
|
||||
json={"model": "gpt-4", "messages": [...]},
|
||||
timeout=30
|
||||
)
|
||||
response.raise_for_status()
|
||||
data = response.json()
|
||||
except requests.exceptions.HTTPError as e:
|
||||
if e.response.status_code == 404:
|
||||
print("Model not found")
|
||||
elif e.response.status_code == 503:
|
||||
print("Model not loaded")
|
||||
else:
|
||||
print(f"Error: {e}")
|
||||
```
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
LocalAI doesn't enforce rate limiting by default. For production deployments, implement rate limiting at the reverse proxy or application level.
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Use appropriate timeouts**: Set reasonable timeouts for requests
|
||||
2. **Handle errors gracefully**: Implement retry logic with exponential backoff
|
||||
3. **Monitor token usage**: Track `usage` fields in responses
|
||||
4. **Use streaming for long responses**: Enable streaming for better user experience
|
||||
5. **Cache embeddings**: Cache embedding results when possible
|
||||
6. **Batch requests**: Process multiple items together when possible
|
||||
|
||||
## See Also
|
||||
|
||||
- [OpenAI API Documentation](https://platform.openai.com/docs/api-reference) - Original OpenAI API reference
|
||||
- [Try It Out]({{% relref "docs/getting-started/try-it-out" %}}) - Interactive examples
|
||||
- [Integration Examples]({{% relref "docs/tutorials/integration-examples" %}}) - Framework integrations
|
||||
- [Troubleshooting]({{% relref "docs/troubleshooting" %}}) - API issues
|
||||
|
||||
@@ -1,318 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Security Best Practices"
|
||||
weight = 26
|
||||
icon = "security"
|
||||
description = "Security guidelines for deploying LocalAI"
|
||||
+++
|
||||
|
||||
This guide covers security best practices for deploying LocalAI in various environments, from local development to production.
|
||||
|
||||
## Overview
|
||||
|
||||
LocalAI processes sensitive data and may be exposed to networks. Follow these practices to secure your deployment.
|
||||
|
||||
## API Key Protection
|
||||
|
||||
### Always Use API Keys in Production
|
||||
|
||||
**Never expose LocalAI without API keys**:
|
||||
|
||||
```bash
|
||||
# Set API key
|
||||
API_KEY=your-secure-random-key local-ai
|
||||
|
||||
# Multiple keys (comma-separated)
|
||||
API_KEY=key1,key2,key3 local-ai
|
||||
```
|
||||
|
||||
### API Key Best Practices
|
||||
|
||||
1. **Generate strong keys**: Use cryptographically secure random strings
|
||||
```bash
|
||||
# Generate a secure key
|
||||
openssl rand -hex 32
|
||||
```
|
||||
|
||||
2. **Store securely**:
|
||||
- Use environment variables
|
||||
- Use secrets management (Kubernetes Secrets, HashiCorp Vault, etc.)
|
||||
- Never commit keys to version control
|
||||
|
||||
3. **Rotate regularly**: Change API keys periodically
|
||||
|
||||
4. **Use different keys**: Different keys for different services/clients
|
||||
|
||||
5. **Limit key scope**: Consider implementing key-based rate limiting
|
||||
|
||||
### Using API Keys
|
||||
|
||||
Include the key in requests:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/models \
|
||||
-H "Authorization: Bearer your-api-key"
|
||||
```
|
||||
|
||||
**Important**: API keys provide full access to all LocalAI features (admin-level). Protect them accordingly.
|
||||
|
||||
## Network Security
|
||||
|
||||
### Never Expose Directly to Internet
|
||||
|
||||
**Always use a reverse proxy** when exposing LocalAI:
|
||||
|
||||
```nginx
|
||||
# nginx example
|
||||
server {
|
||||
listen 443 ssl;
|
||||
server_name localai.example.com;
|
||||
|
||||
ssl_certificate /path/to/cert.pem;
|
||||
ssl_certificate_key /path/to/key.pem;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:8080;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header X-Forwarded-Proto $scheme;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Use HTTPS/TLS
|
||||
|
||||
**Always use HTTPS in production**:
|
||||
|
||||
1. Obtain SSL/TLS certificates (Let's Encrypt, etc.)
|
||||
2. Configure reverse proxy with TLS
|
||||
3. Enforce HTTPS redirects
|
||||
4. Use strong cipher suites
|
||||
|
||||
### Firewall Configuration
|
||||
|
||||
Restrict access with firewall rules:
|
||||
|
||||
```bash
|
||||
# Allow only specific IPs (example)
|
||||
ufw allow from 192.168.1.0/24 to any port 8080
|
||||
|
||||
# Or use iptables
|
||||
iptables -A INPUT -p tcp --dport 8080 -s 192.168.1.0/24 -j ACCEPT
|
||||
iptables -A INPUT -p tcp --dport 8080 -j DROP
|
||||
```
|
||||
|
||||
### VPN or Private Network
|
||||
|
||||
For sensitive deployments:
|
||||
- Use VPN for remote access
|
||||
- Deploy on private network only
|
||||
- Use network segmentation
|
||||
|
||||
## Model Security
|
||||
|
||||
### Model Source Verification
|
||||
|
||||
**Only use trusted model sources**:
|
||||
|
||||
1. **Official galleries**: Use LocalAI's model gallery
|
||||
2. **Verified repositories**: Hugging Face verified models
|
||||
3. **Verify checksums**: Check SHA256 hashes when provided
|
||||
4. **Scan for malware**: Scan downloaded files
|
||||
|
||||
### Model Isolation
|
||||
|
||||
- Run models in isolated environments
|
||||
- Use containers with limited permissions
|
||||
- Separate model storage from system
|
||||
|
||||
### Model Access Control
|
||||
|
||||
- Restrict file system access to models
|
||||
- Use appropriate file permissions
|
||||
- Consider read-only model storage
|
||||
|
||||
## Container Security
|
||||
|
||||
### Use Non-Root User
|
||||
|
||||
Run containers as non-root:
|
||||
|
||||
```yaml
|
||||
# Docker Compose
|
||||
services:
|
||||
localai:
|
||||
user: "1000:1000" # Non-root UID/GID
|
||||
```
|
||||
|
||||
### Limit Container Capabilities
|
||||
|
||||
```yaml
|
||||
services:
|
||||
localai:
|
||||
cap_drop:
|
||||
- ALL
|
||||
cap_add:
|
||||
- NET_BIND_SERVICE # Only what's needed
|
||||
```
|
||||
|
||||
### Resource Limits
|
||||
|
||||
Set resource limits to prevent resource exhaustion:
|
||||
|
||||
```yaml
|
||||
services:
|
||||
localai:
|
||||
deploy:
|
||||
resources:
|
||||
limits:
|
||||
cpus: '4'
|
||||
memory: 16G
|
||||
```
|
||||
|
||||
### Read-Only Filesystem
|
||||
|
||||
Where possible, use read-only filesystem:
|
||||
|
||||
```yaml
|
||||
services:
|
||||
localai:
|
||||
read_only: true
|
||||
tmpfs:
|
||||
- /tmp
|
||||
- /var/run
|
||||
```
|
||||
|
||||
## Input Validation
|
||||
|
||||
### Sanitize Inputs
|
||||
|
||||
Validate and sanitize all inputs:
|
||||
- Check input length limits
|
||||
- Validate data formats
|
||||
- Sanitize user prompts
|
||||
- Implement rate limiting
|
||||
|
||||
### File Upload Security
|
||||
|
||||
If accepting file uploads:
|
||||
- Validate file types
|
||||
- Limit file sizes
|
||||
- Scan for malware
|
||||
- Store in isolated location
|
||||
|
||||
## Logging and Monitoring
|
||||
|
||||
### Secure Logging
|
||||
|
||||
- Don't log sensitive data (API keys, user inputs)
|
||||
- Use secure log storage
|
||||
- Implement log rotation
|
||||
- Monitor for suspicious activity
|
||||
|
||||
### Monitoring
|
||||
|
||||
Monitor for:
|
||||
- Unusual API usage patterns
|
||||
- Failed authentication attempts
|
||||
- Resource exhaustion
|
||||
- Error rate spikes
|
||||
|
||||
## Updates and Maintenance
|
||||
|
||||
### Keep Updated
|
||||
|
||||
- Regularly update LocalAI
|
||||
- Update dependencies
|
||||
- Patch security vulnerabilities
|
||||
- Monitor security advisories
|
||||
|
||||
### Backup Security
|
||||
|
||||
- Encrypt backups
|
||||
- Secure backup storage
|
||||
- Test restore procedures
|
||||
- Limit backup access
|
||||
|
||||
## Deployment-Specific Security
|
||||
|
||||
### Kubernetes
|
||||
|
||||
- Use NetworkPolicies
|
||||
- Implement RBAC
|
||||
- Use Secrets for sensitive data
|
||||
- Enable Pod Security Policies
|
||||
- Use service mesh for mTLS
|
||||
|
||||
### Docker
|
||||
|
||||
- Use official images
|
||||
- Scan images for vulnerabilities
|
||||
- Keep images updated
|
||||
- Use Docker secrets
|
||||
- Implement health checks
|
||||
|
||||
### Systemd
|
||||
|
||||
- Run as dedicated user
|
||||
- Limit systemd service capabilities
|
||||
- Use PrivateTmp, ProtectSystem
|
||||
- Restrict network access
|
||||
|
||||
## Security Checklist
|
||||
|
||||
Before deploying to production:
|
||||
|
||||
- [ ] API keys configured and secured
|
||||
- [ ] HTTPS/TLS enabled
|
||||
- [ ] Reverse proxy configured
|
||||
- [ ] Firewall rules set
|
||||
- [ ] Network access restricted
|
||||
- [ ] Container security hardened
|
||||
- [ ] Resource limits configured
|
||||
- [ ] Logging configured securely
|
||||
- [ ] Monitoring in place
|
||||
- [ ] Updates planned
|
||||
- [ ] Backup security ensured
|
||||
- [ ] Incident response plan ready
|
||||
|
||||
## Incident Response
|
||||
|
||||
### If Compromised
|
||||
|
||||
1. **Isolate**: Immediately disconnect from network
|
||||
2. **Assess**: Determine scope of compromise
|
||||
3. **Contain**: Prevent further damage
|
||||
4. **Eradicate**: Remove threats
|
||||
5. **Recover**: Restore from clean backups
|
||||
6. **Learn**: Document and improve
|
||||
|
||||
### Security Contacts
|
||||
|
||||
- Report security issues: [GitHub Security](https://github.com/mudler/LocalAI/security)
|
||||
- Security discussions: [Discord](https://discord.gg/uJAeKSAGDy)
|
||||
|
||||
## Compliance Considerations
|
||||
|
||||
### Data Privacy
|
||||
|
||||
- Understand data processing
|
||||
- Implement data retention policies
|
||||
- Consider GDPR, CCPA requirements
|
||||
- Document data flows
|
||||
|
||||
### Audit Logging
|
||||
|
||||
- Log all API access
|
||||
- Track model usage
|
||||
- Monitor configuration changes
|
||||
- Retain logs appropriately
|
||||
|
||||
## See Also
|
||||
|
||||
- [Deploying to Production]({{% relref "docs/tutorials/deploying-production" %}}) - Production deployment
|
||||
- [API Reference]({{% relref "docs/reference/api-reference" %}}) - API security
|
||||
- [Troubleshooting]({{% relref "docs/troubleshooting" %}}) - Security issues
|
||||
- [FAQ]({{% relref "docs/faq" %}}) - Security questions
|
||||
|
||||
@@ -1,392 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Troubleshooting Guide"
|
||||
weight = 25
|
||||
icon = "bug_report"
|
||||
description = "Solutions to common problems and issues with LocalAI"
|
||||
+++
|
||||
|
||||
This guide helps you diagnose and fix common issues with LocalAI. If you can't find a solution here, check the [FAQ]({{% relref "docs/faq" %}}) or ask for help on [Discord](https://discord.gg/uJAeKSAGDy).
|
||||
|
||||
## Getting Help
|
||||
|
||||
Before asking for help, gather this information:
|
||||
|
||||
1. **LocalAI version**: `local-ai --version` or check container image tag
|
||||
2. **System information**: OS, CPU, RAM, GPU (if applicable)
|
||||
3. **Error messages**: Full error output with `DEBUG=true`
|
||||
4. **Configuration**: Relevant model configuration files
|
||||
5. **Logs**: Enable debug mode and capture logs
|
||||
|
||||
## Common Issues
|
||||
|
||||
### Model Not Loading
|
||||
|
||||
**Symptoms**: Model appears in list but fails to load or respond
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **Check backend installation**:
|
||||
```bash
|
||||
local-ai backends list
|
||||
local-ai backends install <backend-name> # if missing
|
||||
```
|
||||
|
||||
2. **Verify model file**:
|
||||
- Check file exists and is not corrupted
|
||||
- Verify file format (GGUF recommended)
|
||||
- Re-download if corrupted
|
||||
|
||||
3. **Check memory**:
|
||||
- Ensure sufficient RAM available
|
||||
- Try smaller quantization (Q4_K_S instead of Q8_0)
|
||||
- Reduce `context_size` in configuration
|
||||
|
||||
4. **Check logs**:
|
||||
```bash
|
||||
DEBUG=true local-ai
|
||||
```
|
||||
Look for specific error messages
|
||||
|
||||
5. **Verify backend compatibility**:
|
||||
- Check [Compatibility Table]({{% relref "docs/reference/compatibility-table" %}})
|
||||
- Ensure correct backend specified in model config
|
||||
|
||||
### Out of Memory Errors
|
||||
|
||||
**Symptoms**: Errors about memory, crashes, or very slow performance
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **Reduce model size**:
|
||||
- Use smaller quantization (Q2_K, Q4_K_S)
|
||||
- Use smaller models (1-3B instead of 7B+)
|
||||
|
||||
2. **Adjust configuration**:
|
||||
```yaml
|
||||
context_size: 1024 # Reduce from default
|
||||
gpu_layers: 20 # Reduce GPU layers if using GPU
|
||||
```
|
||||
|
||||
3. **Free system memory**:
|
||||
- Close other applications
|
||||
- Reduce number of loaded models
|
||||
- Use `--single-active-backend` flag
|
||||
|
||||
4. **Check system limits**:
|
||||
```bash
|
||||
# Linux
|
||||
free -h
|
||||
ulimit -a
|
||||
```
|
||||
|
||||
### Slow Performance
|
||||
|
||||
**Symptoms**: Very slow responses, low tokens/second
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **Check hardware**:
|
||||
- Use SSD instead of HDD for model storage
|
||||
- Ensure adequate CPU cores
|
||||
- Enable GPU acceleration if available
|
||||
|
||||
2. **Optimize configuration**:
|
||||
```yaml
|
||||
threads: 4 # Match CPU cores
|
||||
gpu_layers: 35 # Offload to GPU if available
|
||||
mmap: true # Enable memory mapping
|
||||
```
|
||||
|
||||
3. **Check for bottlenecks**:
|
||||
```bash
|
||||
# Monitor CPU
|
||||
top
|
||||
|
||||
# Monitor GPU (NVIDIA)
|
||||
nvidia-smi
|
||||
|
||||
# Monitor disk I/O
|
||||
iostat
|
||||
```
|
||||
|
||||
4. **Disable unnecessary features**:
|
||||
- Set `mirostat: 0` if not needed
|
||||
- Reduce context size
|
||||
- Use smaller models
|
||||
|
||||
5. **Check network**: If using remote models, check network latency
|
||||
|
||||
### GPU Not Working
|
||||
|
||||
**Symptoms**: GPU not detected, no GPU usage, or CUDA errors
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **Verify GPU drivers**:
|
||||
```bash
|
||||
# NVIDIA
|
||||
nvidia-smi
|
||||
|
||||
# AMD
|
||||
rocm-smi
|
||||
```
|
||||
|
||||
2. **Check Docker GPU access**:
|
||||
```bash
|
||||
docker run --rm --gpus all nvidia/cuda:12.0.0-base-ubuntu22.04 nvidia-smi
|
||||
```
|
||||
|
||||
3. **Use correct image**:
|
||||
- NVIDIA: `localai/localai:latest-gpu-nvidia-cuda-12`
|
||||
- AMD: `localai/localai:latest-gpu-hipblas`
|
||||
- Intel: `localai/localai:latest-gpu-intel`
|
||||
|
||||
4. **Configure GPU layers**:
|
||||
```yaml
|
||||
gpu_layers: 35 # Adjust based on GPU memory
|
||||
f16: true
|
||||
```
|
||||
|
||||
5. **Check CUDA version**: Ensure CUDA version matches (11.7 vs 12.0)
|
||||
|
||||
6. **Check logs**: Enable debug mode to see GPU initialization messages
|
||||
|
||||
### API Errors
|
||||
|
||||
**Symptoms**: 400, 404, 500, or 503 errors from API
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **404 - Model Not Found**:
|
||||
- Verify model name is correct
|
||||
- Check model is installed: `curl http://localhost:8080/v1/models`
|
||||
- Ensure model file exists in models directory
|
||||
|
||||
2. **503 - Service Unavailable**:
|
||||
- Model may not be loaded yet (wait a moment)
|
||||
- Check if model failed to load (check logs)
|
||||
- Verify backend is installed
|
||||
|
||||
3. **400 - Bad Request**:
|
||||
- Check request format matches API specification
|
||||
- Verify all required parameters are present
|
||||
- Check parameter types and values
|
||||
|
||||
4. **500 - Internal Server Error**:
|
||||
- Enable debug mode: `DEBUG=true`
|
||||
- Check logs for specific error
|
||||
- Verify model configuration is valid
|
||||
|
||||
5. **401 - Unauthorized**:
|
||||
- Check if API key is required
|
||||
- Verify API key is correct
|
||||
- Include Authorization header if needed
|
||||
|
||||
### Installation Issues
|
||||
|
||||
**Symptoms**: Installation fails or LocalAI won't start
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **Docker issues**:
|
||||
```bash
|
||||
# Check Docker is running
|
||||
docker ps
|
||||
|
||||
# Check image exists
|
||||
docker images | grep localai
|
||||
|
||||
# Pull latest image
|
||||
docker pull localai/localai:latest
|
||||
```
|
||||
|
||||
2. **Permission issues**:
|
||||
```bash
|
||||
# Check file permissions
|
||||
ls -la models/
|
||||
|
||||
# Fix permissions if needed
|
||||
chmod -R 755 models/
|
||||
```
|
||||
|
||||
3. **Port already in use**:
|
||||
```bash
|
||||
# Find process using port
|
||||
lsof -i :8080
|
||||
|
||||
# Use different port
|
||||
docker run -p 8081:8080 ...
|
||||
```
|
||||
|
||||
4. **Binary not found**:
|
||||
- Verify binary is in PATH
|
||||
- Check binary has execute permissions
|
||||
- Reinstall if needed
|
||||
|
||||
### Backend Issues
|
||||
|
||||
**Symptoms**: Backend fails to install or load
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **Check backend availability**:
|
||||
```bash
|
||||
local-ai backends list
|
||||
```
|
||||
|
||||
2. **Manual installation**:
|
||||
```bash
|
||||
local-ai backends install <backend-name>
|
||||
```
|
||||
|
||||
3. **Check network**: Backend download requires internet connection
|
||||
|
||||
4. **Check disk space**: Ensure sufficient space for backend files
|
||||
|
||||
5. **Rebuild if needed**:
|
||||
```bash
|
||||
REBUILD=true local-ai
|
||||
```
|
||||
|
||||
### Configuration Issues
|
||||
|
||||
**Symptoms**: Models not working as expected, wrong behavior
|
||||
|
||||
**Solutions**:
|
||||
|
||||
1. **Validate YAML syntax**:
|
||||
```bash
|
||||
# Check YAML is valid
|
||||
yamllint model.yaml
|
||||
```
|
||||
|
||||
2. **Check configuration reference**:
|
||||
- See [Model Configuration]({{% relref "docs/advanced/model-configuration" %}})
|
||||
- Verify all parameters are correct
|
||||
|
||||
3. **Test with minimal config**:
|
||||
- Start with basic configuration
|
||||
- Add parameters one at a time
|
||||
|
||||
4. **Check template files**:
|
||||
- Verify template syntax
|
||||
- Check template matches model type
|
||||
|
||||
## Debugging Tips
|
||||
|
||||
### Enable Debug Mode
|
||||
|
||||
```bash
|
||||
# Environment variable
|
||||
DEBUG=true local-ai
|
||||
|
||||
# Command line flag
|
||||
local-ai --debug
|
||||
|
||||
# Docker
|
||||
docker run -e DEBUG=true ...
|
||||
```
|
||||
|
||||
### Check Logs
|
||||
|
||||
```bash
|
||||
# Docker logs
|
||||
docker logs local-ai
|
||||
|
||||
# Systemd logs
|
||||
journalctl -u localai -f
|
||||
|
||||
# Direct output
|
||||
local-ai 2>&1 | tee localai.log
|
||||
```
|
||||
|
||||
### Test API Endpoints
|
||||
|
||||
```bash
|
||||
# Health check
|
||||
curl http://localhost:8080/healthz
|
||||
|
||||
# Readiness check
|
||||
curl http://localhost:8080/readyz
|
||||
|
||||
# List models
|
||||
curl http://localhost:8080/v1/models
|
||||
|
||||
# Test chat
|
||||
curl http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{"model": "gpt-4", "messages": [{"role": "user", "content": "test"}]}'
|
||||
```
|
||||
|
||||
### Monitor Resources
|
||||
|
||||
```bash
|
||||
# CPU and memory
|
||||
htop
|
||||
|
||||
# GPU (NVIDIA)
|
||||
watch -n 1 nvidia-smi
|
||||
|
||||
# Disk usage
|
||||
df -h
|
||||
du -sh models/
|
||||
|
||||
# Network
|
||||
iftop
|
||||
```
|
||||
|
||||
## Performance Issues
|
||||
|
||||
### Slow Inference
|
||||
|
||||
1. **Check token speed**: Look for tokens/second in debug logs
|
||||
2. **Optimize threads**: Match CPU cores
|
||||
3. **Enable GPU**: Use GPU acceleration
|
||||
4. **Reduce context**: Smaller context = faster inference
|
||||
5. **Use quantization**: Q4_K_M is good balance
|
||||
|
||||
### High Memory Usage
|
||||
|
||||
1. **Use smaller models**: 1-3B instead of 7B+
|
||||
2. **Lower quantization**: Q2_K uses less memory
|
||||
3. **Reduce context size**: Smaller context = less memory
|
||||
4. **Disable mmap**: Set `mmap: false` (slower but uses less memory)
|
||||
5. **Unload unused models**: Only load models you're using
|
||||
|
||||
## Platform-Specific Issues
|
||||
|
||||
### macOS
|
||||
|
||||
- **Quarantine warnings**: See [FAQ]({{% relref "docs/faq" %}})
|
||||
- **Metal not working**: Ensure Xcode is installed
|
||||
- **Docker performance**: Consider building from source for better performance
|
||||
|
||||
### Linux
|
||||
|
||||
- **Permission denied**: Check file permissions and SELinux
|
||||
- **Missing libraries**: Install required system libraries
|
||||
- **Systemd issues**: Check service status and logs
|
||||
|
||||
### Windows/WSL
|
||||
|
||||
- **Slow model loading**: Ensure files are on Linux filesystem
|
||||
- **GPU access**: May require WSL2 with GPU support
|
||||
- **Path issues**: Use forward slashes in paths
|
||||
|
||||
## Getting More Help
|
||||
|
||||
If you've tried the solutions above and still have issues:
|
||||
|
||||
1. **Check GitHub Issues**: Search [GitHub Issues](https://github.com/mudler/LocalAI/issues)
|
||||
2. **Ask on Discord**: Join [Discord](https://discord.gg/uJAeKSAGDy)
|
||||
3. **Create an Issue**: Provide all debugging information
|
||||
4. **Check Documentation**: Review relevant documentation sections
|
||||
|
||||
## See Also
|
||||
|
||||
- [FAQ]({{% relref "docs/faq" %}}) - Common questions
|
||||
- [Performance Tuning]({{% relref "docs/advanced/performance-tuning" %}}) - Optimize performance
|
||||
- [VRAM Management]({{% relref "docs/advanced/vram-management" %}}) - GPU memory management
|
||||
- [Model Configuration]({{% relref "docs/advanced/model-configuration" %}}) - Configuration reference
|
||||
|
||||
@@ -1,34 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Tutorials"
|
||||
weight = 5
|
||||
icon = "school"
|
||||
description = "Step-by-step guides to help you get started with LocalAI"
|
||||
+++
|
||||
|
||||
Welcome to the LocalAI tutorials section! These step-by-step guides will help you learn how to use LocalAI effectively, from your first chat to deploying in production.
|
||||
|
||||
## Getting Started Tutorials
|
||||
|
||||
Start here if you're new to LocalAI:
|
||||
|
||||
1. **[Your First Chat]({{% relref "docs/tutorials/first-chat" %}})** - Learn how to install LocalAI and have your first conversation with an AI model
|
||||
2. **[Setting Up Models]({{% relref "docs/tutorials/setting-up-models" %}})** - A comprehensive guide to installing and configuring models
|
||||
3. **[Using GPU Acceleration]({{% relref "docs/tutorials/using-gpu" %}})** - Set up GPU support for faster inference
|
||||
|
||||
## Advanced Tutorials
|
||||
|
||||
Ready to take it further?
|
||||
|
||||
4. **[Deploying to Production]({{% relref "docs/tutorials/deploying-production" %}})** - Best practices for running LocalAI in production environments
|
||||
5. **[Integration Examples]({{% relref "docs/tutorials/integration-examples" %}})** - Learn how to integrate LocalAI with popular frameworks and tools
|
||||
|
||||
## What's Next?
|
||||
|
||||
After completing the tutorials, explore:
|
||||
|
||||
- [Features Documentation]({{% relref "docs/features" %}}) - Detailed information about all LocalAI capabilities
|
||||
- [Advanced Configuration]({{% relref "docs/advanced" %}}) - Fine-tune your setup
|
||||
- [API Reference]({{% relref "docs/reference/api-reference" %}}) - Complete API documentation
|
||||
- [Troubleshooting Guide]({{% relref "docs/troubleshooting" %}}) - Solutions to common problems
|
||||
|
||||
@@ -1,355 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Deploying to Production"
|
||||
weight = 4
|
||||
icon = "rocket_launch"
|
||||
description = "Best practices for running LocalAI in production environments"
|
||||
+++
|
||||
|
||||
This tutorial covers best practices for deploying LocalAI in production environments, including security, performance, monitoring, and reliability considerations.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- LocalAI installed and tested
|
||||
- Understanding of your deployment environment
|
||||
- Basic knowledge of Docker, Kubernetes, or your chosen deployment method
|
||||
|
||||
## Security Considerations
|
||||
|
||||
### 1. API Key Protection
|
||||
|
||||
**Always use API keys in production**:
|
||||
|
||||
```bash
|
||||
# Set API key
|
||||
API_KEY=your-secure-random-key local-ai
|
||||
|
||||
# Or multiple keys
|
||||
API_KEY=key1,key2,key3 local-ai
|
||||
```
|
||||
|
||||
**Best Practices**:
|
||||
- Use strong, randomly generated keys
|
||||
- Store keys securely (environment variables, secrets management)
|
||||
- Rotate keys regularly
|
||||
- Use different keys for different services/clients
|
||||
|
||||
### 2. Network Security
|
||||
|
||||
**Never expose LocalAI directly to the internet** without protection:
|
||||
|
||||
- Use a reverse proxy (nginx, Traefik, Caddy)
|
||||
- Enable HTTPS/TLS
|
||||
- Use firewall rules to restrict access
|
||||
- Consider VPN or private network access only
|
||||
|
||||
**Example nginx configuration**:
|
||||
|
||||
```nginx
|
||||
server {
|
||||
listen 443 ssl;
|
||||
server_name localai.example.com;
|
||||
|
||||
ssl_certificate /path/to/cert.pem;
|
||||
ssl_certificate_key /path/to/key.pem;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:8080;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3. Resource Limits
|
||||
|
||||
Set appropriate resource limits to prevent resource exhaustion:
|
||||
|
||||
```yaml
|
||||
# Docker Compose example
|
||||
services:
|
||||
localai:
|
||||
deploy:
|
||||
resources:
|
||||
limits:
|
||||
cpus: '4'
|
||||
memory: 16G
|
||||
reservations:
|
||||
cpus: '2'
|
||||
memory: 8G
|
||||
```
|
||||
|
||||
## Deployment Methods
|
||||
|
||||
### Docker Compose (Recommended for Small-Medium Deployments)
|
||||
|
||||
```yaml
|
||||
version: '3.8'
|
||||
|
||||
services:
|
||||
localai:
|
||||
image: localai/localai:latest
|
||||
ports:
|
||||
- "8080:8080"
|
||||
environment:
|
||||
- API_KEY=${API_KEY}
|
||||
- DEBUG=false
|
||||
- MODELS_PATH=/models
|
||||
volumes:
|
||||
- ./models:/models
|
||||
- ./config:/config
|
||||
restart: unless-stopped
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
|
||||
interval: 30s
|
||||
timeout: 10s
|
||||
retries: 3
|
||||
deploy:
|
||||
resources:
|
||||
limits:
|
||||
memory: 16G
|
||||
```
|
||||
|
||||
### Kubernetes
|
||||
|
||||
See the [Kubernetes Deployment Guide]({{% relref "docs/getting-started/kubernetes" %}}) for detailed instructions.
|
||||
|
||||
**Key considerations**:
|
||||
- Use ConfigMaps for configuration
|
||||
- Use Secrets for API keys
|
||||
- Set resource requests and limits
|
||||
- Configure health checks and liveness probes
|
||||
- Use PersistentVolumes for model storage
|
||||
|
||||
### Systemd Service (Linux)
|
||||
|
||||
Create a systemd service file:
|
||||
|
||||
```ini
|
||||
[Unit]
|
||||
Description=LocalAI Service
|
||||
After=network.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
User=localai
|
||||
Environment="API_KEY=your-key"
|
||||
Environment="MODELS_PATH=/var/lib/localai/models"
|
||||
ExecStart=/usr/local/bin/local-ai
|
||||
Restart=always
|
||||
RestartSec=10
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
## Performance Optimization
|
||||
|
||||
### 1. Model Selection
|
||||
|
||||
- Use quantized models (Q4_K_M) for production
|
||||
- Choose models appropriate for your hardware
|
||||
- Consider model size vs. quality trade-offs
|
||||
|
||||
### 2. Resource Allocation
|
||||
|
||||
```yaml
|
||||
# Model configuration
|
||||
name: production-model
|
||||
parameters:
|
||||
model: model.gguf
|
||||
context_size: 2048 # Adjust based on needs
|
||||
threads: 4 # Match CPU cores
|
||||
gpu_layers: 35 # If using GPU
|
||||
```
|
||||
|
||||
### 3. Caching
|
||||
|
||||
Enable prompt caching for repeated queries:
|
||||
|
||||
```yaml
|
||||
prompt_cache_path: "cache"
|
||||
prompt_cache_all: true
|
||||
```
|
||||
|
||||
### 4. Connection Pooling
|
||||
|
||||
If using a reverse proxy, configure connection pooling:
|
||||
|
||||
```nginx
|
||||
upstream localai {
|
||||
least_conn;
|
||||
server localhost:8080 max_fails=3 fail_timeout=30s;
|
||||
keepalive 32;
|
||||
}
|
||||
```
|
||||
|
||||
## Monitoring and Logging
|
||||
|
||||
### 1. Health Checks
|
||||
|
||||
LocalAI provides health check endpoints:
|
||||
|
||||
```bash
|
||||
# Readiness check
|
||||
curl http://localhost:8080/readyz
|
||||
|
||||
# Health check
|
||||
curl http://localhost:8080/healthz
|
||||
```
|
||||
|
||||
### 2. Logging
|
||||
|
||||
Configure appropriate log levels:
|
||||
|
||||
```bash
|
||||
# Production: minimal logging
|
||||
DEBUG=false local-ai
|
||||
|
||||
# Development: detailed logging
|
||||
DEBUG=true local-ai
|
||||
```
|
||||
|
||||
### 3. Metrics
|
||||
|
||||
Monitor key metrics:
|
||||
- Request rate
|
||||
- Response times
|
||||
- Error rates
|
||||
- Resource usage (CPU, memory, GPU)
|
||||
- Model loading times
|
||||
|
||||
### 4. Alerting
|
||||
|
||||
Set up alerts for:
|
||||
- Service downtime
|
||||
- High error rates
|
||||
- Resource exhaustion
|
||||
- Slow response times
|
||||
|
||||
## High Availability
|
||||
|
||||
### 1. Multiple Instances
|
||||
|
||||
Run multiple LocalAI instances behind a load balancer:
|
||||
|
||||
```yaml
|
||||
# Docker Compose with multiple instances
|
||||
services:
|
||||
localai1:
|
||||
image: localai/localai:latest
|
||||
# ... configuration
|
||||
|
||||
localai2:
|
||||
image: localai/localai:latest
|
||||
# ... configuration
|
||||
|
||||
nginx:
|
||||
image: nginx:alpine
|
||||
# Load balance between localai1 and localai2
|
||||
```
|
||||
|
||||
### 2. Model Replication
|
||||
|
||||
Ensure models are available on all instances:
|
||||
- Shared storage (NFS, S3, etc.)
|
||||
- Model synchronization
|
||||
- Consistent model versions
|
||||
|
||||
### 3. Graceful Shutdown
|
||||
|
||||
LocalAI supports graceful shutdown. Ensure your deployment method handles SIGTERM properly.
|
||||
|
||||
## Backup and Recovery
|
||||
|
||||
### 1. Model Backups
|
||||
|
||||
Regularly backup your models and configurations:
|
||||
|
||||
```bash
|
||||
# Backup models
|
||||
tar -czf models-backup-$(date +%Y%m%d).tar.gz models/
|
||||
|
||||
# Backup configurations
|
||||
tar -czf config-backup-$(date +%Y%m%d).tar.gz config/
|
||||
```
|
||||
|
||||
### 2. Configuration Management
|
||||
|
||||
Version control your configurations:
|
||||
- Use Git for YAML configurations
|
||||
- Document model versions
|
||||
- Track configuration changes
|
||||
|
||||
### 3. Disaster Recovery
|
||||
|
||||
Plan for:
|
||||
- Model storage recovery
|
||||
- Configuration restoration
|
||||
- Service restoration procedures
|
||||
|
||||
## Scaling Considerations
|
||||
|
||||
### Horizontal Scaling
|
||||
|
||||
- Run multiple instances
|
||||
- Use load balancing
|
||||
- Consider stateless design (shared model storage)
|
||||
|
||||
### Vertical Scaling
|
||||
|
||||
- Increase resources (CPU, RAM, GPU)
|
||||
- Use more powerful hardware
|
||||
- Optimize model configurations
|
||||
|
||||
## Maintenance
|
||||
|
||||
### 1. Updates
|
||||
|
||||
- Test updates in staging first
|
||||
- Plan maintenance windows
|
||||
- Have rollback procedures ready
|
||||
|
||||
### 2. Model Updates
|
||||
|
||||
- Test new models before production
|
||||
- Keep model versions documented
|
||||
- Have rollback capability
|
||||
|
||||
### 3. Monitoring
|
||||
|
||||
Regularly review:
|
||||
- Performance metrics
|
||||
- Error logs
|
||||
- Resource usage trends
|
||||
- User feedback
|
||||
|
||||
## Production Checklist
|
||||
|
||||
Before going live, ensure:
|
||||
|
||||
- [ ] API keys configured and secured
|
||||
- [ ] HTTPS/TLS enabled
|
||||
- [ ] Firewall rules configured
|
||||
- [ ] Resource limits set
|
||||
- [ ] Health checks configured
|
||||
- [ ] Monitoring in place
|
||||
- [ ] Logging configured
|
||||
- [ ] Backups scheduled
|
||||
- [ ] Documentation updated
|
||||
- [ ] Team trained on operations
|
||||
- [ ] Incident response plan ready
|
||||
|
||||
## What's Next?
|
||||
|
||||
- [Kubernetes Deployment]({{% relref "docs/getting-started/kubernetes" %}}) - Deploy on Kubernetes
|
||||
- [Performance Tuning]({{% relref "docs/advanced/performance-tuning" %}}) - Optimize performance
|
||||
- [Security Best Practices]({{% relref "docs/security" %}}) - Security guidelines
|
||||
- [Troubleshooting Guide]({{% relref "docs/troubleshooting" %}}) - Production issues
|
||||
|
||||
## See Also
|
||||
|
||||
- [Container Images]({{% relref "docs/getting-started/container-images" %}})
|
||||
- [Advanced Configuration]({{% relref "docs/advanced" %}})
|
||||
- [FAQ]({{% relref "docs/faq" %}})
|
||||
|
||||
@@ -1,171 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Your First Chat with LocalAI"
|
||||
weight = 1
|
||||
icon = "chat"
|
||||
description = "Get LocalAI running and have your first conversation in minutes"
|
||||
+++
|
||||
|
||||
This tutorial will guide you through installing LocalAI and having your first conversation with an AI model. By the end, you'll have LocalAI running and be able to chat with a local AI model.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A computer running Linux, macOS, or Windows (with WSL)
|
||||
- At least 4GB of RAM (8GB+ recommended)
|
||||
- Docker installed (optional, but recommended for easiest setup)
|
||||
|
||||
## Step 1: Install LocalAI
|
||||
|
||||
Choose the installation method that works best for you:
|
||||
|
||||
### Option A: Docker (Recommended for Beginners)
|
||||
|
||||
```bash
|
||||
# Run LocalAI with AIO (All-in-One) image - includes pre-configured models
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest-aio-cpu
|
||||
```
|
||||
|
||||
This will:
|
||||
- Download the LocalAI image
|
||||
- Start the API server on port 8080
|
||||
- Automatically download and configure models
|
||||
|
||||
### Option B: Quick Install Script (Linux)
|
||||
|
||||
```bash
|
||||
curl https://localai.io/install.sh | sh
|
||||
```
|
||||
|
||||
### Option C: macOS DMG
|
||||
|
||||
Download the DMG from [GitHub Releases](https://github.com/mudler/LocalAI/releases/latest/download/LocalAI.dmg) and install it.
|
||||
|
||||
For more installation options, see the [Quickstart Guide]({{% relref "docs/getting-started/quickstart" %}}).
|
||||
|
||||
## Step 2: Verify Installation
|
||||
|
||||
Once LocalAI is running, verify it's working:
|
||||
|
||||
```bash
|
||||
# Check if the API is responding
|
||||
curl http://localhost:8080/v1/models
|
||||
```
|
||||
|
||||
You should see a JSON response listing available models. If using the AIO image, you'll see models like `gpt-4`, `gpt-4-vision-preview`, etc.
|
||||
|
||||
## Step 3: Access the WebUI
|
||||
|
||||
Open your web browser and navigate to:
|
||||
|
||||
```
|
||||
http://localhost:8080
|
||||
```
|
||||
|
||||
You'll see the LocalAI WebUI with:
|
||||
- A chat interface
|
||||
- Model gallery
|
||||
- Backend management
|
||||
- Configuration options
|
||||
|
||||
## Step 4: Your First Chat
|
||||
|
||||
### Using the WebUI
|
||||
|
||||
1. In the WebUI, you'll see a chat interface
|
||||
2. Select a model from the dropdown (if multiple models are available)
|
||||
3. Type your message and press Enter
|
||||
4. Wait for the AI to respond!
|
||||
|
||||
### Using the API (Command Line)
|
||||
|
||||
You can also chat using curl:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Hello! Can you introduce yourself?"}
|
||||
],
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
### Using Python
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
response = requests.post(
|
||||
"http://localhost:8080/v1/chat/completions",
|
||||
json={
|
||||
"model": "gpt-4",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Hello! Can you introduce yourself?"}
|
||||
],
|
||||
"temperature": 0.7
|
||||
}
|
||||
)
|
||||
|
||||
print(response.json()["choices"][0]["message"]["content"])
|
||||
```
|
||||
|
||||
## Step 5: Try Different Models
|
||||
|
||||
If you're using the AIO image, you have several models pre-installed:
|
||||
|
||||
- `gpt-4` - Text generation
|
||||
- `gpt-4-vision-preview` - Vision and text
|
||||
- `tts-1` - Text to speech
|
||||
- `whisper-1` - Speech to text
|
||||
|
||||
Try asking the vision model about an image, or generate speech with the TTS model!
|
||||
|
||||
### Installing New Models via WebUI
|
||||
|
||||
To install additional models, you can use the WebUI's import interface:
|
||||
|
||||
1. In the WebUI, navigate to the "Models" tab
|
||||
2. Click "Import Model" or "New Model"
|
||||
3. Enter a model URI (e.g., `huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf`)
|
||||
4. Configure preferences or use Advanced Mode for YAML editing
|
||||
5. Click "Import Model" to start the installation
|
||||
|
||||
For more details, see [Setting Up Models]({{% relref "docs/tutorials/setting-up-models" %}}).
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Port 8080 is already in use
|
||||
|
||||
Change the port mapping:
|
||||
```bash
|
||||
docker run -p 8081:8080 --name local-ai -ti localai/localai:latest-aio-cpu
|
||||
```
|
||||
Then access at `http://localhost:8081`
|
||||
|
||||
### No models available
|
||||
|
||||
If you're using a standard (non-AIO) image, you need to install models. See [Setting Up Models]({{% relref "docs/tutorials/setting-up-models" %}}) tutorial.
|
||||
|
||||
### Slow responses
|
||||
|
||||
- Check if you have enough RAM
|
||||
- Consider using a smaller model
|
||||
- Enable GPU acceleration (see [Using GPU]({{% relref "docs/tutorials/using-gpu" %}}))
|
||||
|
||||
## What's Next?
|
||||
|
||||
Congratulations! You've successfully set up LocalAI and had your first chat. Here's what to explore next:
|
||||
|
||||
1. **[Setting Up Models]({{% relref "docs/tutorials/setting-up-models" %}})** - Learn how to install and configure different models
|
||||
2. **[Using GPU Acceleration]({{% relref "docs/tutorials/using-gpu" %}})** - Speed up inference with GPU support
|
||||
3. **[Try It Out]({{% relref "docs/getting-started/try-it-out" %}})** - Explore more API endpoints and features
|
||||
4. **[Features Documentation]({{% relref "docs/features" %}})** - Discover all LocalAI capabilities
|
||||
|
||||
## See Also
|
||||
|
||||
- [Quickstart Guide]({{% relref "docs/getting-started/quickstart" %}})
|
||||
- [FAQ]({{% relref "docs/faq" %}})
|
||||
- [Troubleshooting Guide]({{% relref "docs/troubleshooting" %}})
|
||||
|
||||
@@ -1,361 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Integration Examples"
|
||||
weight = 5
|
||||
icon = "sync"
|
||||
description = "Learn how to integrate LocalAI with popular frameworks and tools"
|
||||
+++
|
||||
|
||||
This tutorial shows you how to integrate LocalAI with popular AI frameworks and tools. LocalAI's OpenAI-compatible API makes it easy to use as a drop-in replacement.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- LocalAI running and accessible
|
||||
- Basic knowledge of the framework you want to integrate
|
||||
- Python, Node.js, or other runtime as needed
|
||||
|
||||
## Python Integrations
|
||||
|
||||
### LangChain
|
||||
|
||||
LangChain has built-in support for LocalAI:
|
||||
|
||||
```python
|
||||
from langchain.llms import OpenAI
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
|
||||
# For chat models
|
||||
llm = ChatOpenAI(
|
||||
openai_api_key="not-needed",
|
||||
openai_api_base="http://localhost:8080/v1",
|
||||
model_name="gpt-4"
|
||||
)
|
||||
|
||||
response = llm.predict("Hello, how are you?")
|
||||
print(response)
|
||||
```
|
||||
|
||||
### OpenAI Python SDK
|
||||
|
||||
The official OpenAI Python SDK works directly with LocalAI:
|
||||
|
||||
```python
|
||||
import openai
|
||||
|
||||
openai.api_base = "http://localhost:8080/v1"
|
||||
openai.api_key = "not-needed"
|
||||
|
||||
response = openai.ChatCompletion.create(
|
||||
model="gpt-4",
|
||||
messages=[
|
||||
{"role": "user", "content": "Hello!"}
|
||||
]
|
||||
)
|
||||
|
||||
print(response.choices[0].message.content)
|
||||
```
|
||||
|
||||
### LangChain with LocalAI Functions
|
||||
|
||||
```python
|
||||
from langchain.agents import initialize_agent, Tool
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
llm = OpenAI(
|
||||
openai_api_key="not-needed",
|
||||
openai_api_base="http://localhost:8080/v1"
|
||||
)
|
||||
|
||||
tools = [
|
||||
Tool(
|
||||
name="Calculator",
|
||||
func=lambda x: eval(x),
|
||||
description="Useful for mathematical calculations"
|
||||
)
|
||||
]
|
||||
|
||||
agent = initialize_agent(tools, llm, agent="zero-shot-react-description")
|
||||
result = agent.run("What is 25 * 4?")
|
||||
```
|
||||
|
||||
## JavaScript/TypeScript Integrations
|
||||
|
||||
### OpenAI Node.js SDK
|
||||
|
||||
```javascript
|
||||
import OpenAI from 'openai';
|
||||
|
||||
const openai = new OpenAI({
|
||||
baseURL: 'http://localhost:8080/v1',
|
||||
apiKey: 'not-needed',
|
||||
});
|
||||
|
||||
async function main() {
|
||||
const completion = await openai.chat.completions.create({
|
||||
model: 'gpt-4',
|
||||
messages: [{ role: 'user', content: 'Hello!' }],
|
||||
});
|
||||
|
||||
console.log(completion.choices[0].message.content);
|
||||
}
|
||||
|
||||
main();
|
||||
```
|
||||
|
||||
### LangChain.js
|
||||
|
||||
```javascript
|
||||
import { ChatOpenAI } from "langchain/chat_models/openai";
|
||||
|
||||
const model = new ChatOpenAI({
|
||||
openAIApiKey: "not-needed",
|
||||
configuration: {
|
||||
baseURL: "http://localhost:8080/v1",
|
||||
},
|
||||
modelName: "gpt-4",
|
||||
});
|
||||
|
||||
const response = await model.invoke("Hello, how are you?");
|
||||
console.log(response.content);
|
||||
```
|
||||
|
||||
## Integration with Specific Tools
|
||||
|
||||
### AutoGPT
|
||||
|
||||
AutoGPT can use LocalAI by setting the API base URL:
|
||||
|
||||
```bash
|
||||
export OPENAI_API_BASE=http://localhost:8080/v1
|
||||
export OPENAI_API_KEY=not-needed
|
||||
```
|
||||
|
||||
Then run AutoGPT normally.
|
||||
|
||||
### Flowise
|
||||
|
||||
Flowise supports LocalAI out of the box. In the Flowise UI:
|
||||
|
||||
1. Add a ChatOpenAI node
|
||||
2. Set the base URL to `http://localhost:8080/v1`
|
||||
3. Set API key to any value (or leave empty)
|
||||
4. Select your model
|
||||
|
||||
### Continue (VS Code Extension)
|
||||
|
||||
Configure Continue to use LocalAI:
|
||||
|
||||
```json
|
||||
{
|
||||
"models": [
|
||||
{
|
||||
"title": "LocalAI",
|
||||
"provider": "openai",
|
||||
"model": "gpt-4",
|
||||
"apiBase": "http://localhost:8080/v1",
|
||||
"apiKey": "not-needed"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### AnythingLLM
|
||||
|
||||
AnythingLLM has native LocalAI support:
|
||||
|
||||
1. Go to Settings > LLM Preference
|
||||
2. Select "LocalAI"
|
||||
3. Enter your LocalAI endpoint: `http://localhost:8080`
|
||||
4. Select your model
|
||||
|
||||
## REST API Examples
|
||||
|
||||
### cURL
|
||||
|
||||
```bash
|
||||
# Chat completion
|
||||
curl http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Hello!"}]
|
||||
}'
|
||||
|
||||
# List models
|
||||
curl http://localhost:8080/v1/models
|
||||
|
||||
# Embeddings
|
||||
curl http://localhost:8080/v1/embeddings \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "text-embedding-ada-002",
|
||||
"input": "Hello world"
|
||||
}'
|
||||
```
|
||||
|
||||
### Python Requests
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
response = requests.post(
|
||||
"http://localhost:8080/v1/chat/completions",
|
||||
json={
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Hello!"}]
|
||||
}
|
||||
)
|
||||
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
## Advanced Integrations
|
||||
|
||||
### Custom Wrapper
|
||||
|
||||
Create a custom wrapper for your application:
|
||||
|
||||
```python
|
||||
class LocalAIClient:
|
||||
def __init__(self, base_url="http://localhost:8080/v1"):
|
||||
self.base_url = base_url
|
||||
self.api_key = "not-needed"
|
||||
|
||||
def chat(self, messages, model="gpt-4", **kwargs):
|
||||
response = requests.post(
|
||||
f"{self.base_url}/chat/completions",
|
||||
json={
|
||||
"model": model,
|
||||
"messages": messages,
|
||||
**kwargs
|
||||
},
|
||||
headers={"Authorization": f"Bearer {self.api_key}"}
|
||||
)
|
||||
return response.json()
|
||||
|
||||
def embeddings(self, text, model="text-embedding-ada-002"):
|
||||
response = requests.post(
|
||||
f"{self.base_url}/embeddings",
|
||||
json={
|
||||
"model": model,
|
||||
"input": text
|
||||
}
|
||||
)
|
||||
return response.json()
|
||||
```
|
||||
|
||||
### Streaming Responses
|
||||
|
||||
```python
|
||||
import requests
|
||||
import json
|
||||
|
||||
def stream_chat(messages, model="gpt-4"):
|
||||
response = requests.post(
|
||||
"http://localhost:8080/v1/chat/completions",
|
||||
json={
|
||||
"model": model,
|
||||
"messages": messages,
|
||||
"stream": True
|
||||
},
|
||||
stream=True
|
||||
)
|
||||
|
||||
for line in response.iter_lines():
|
||||
if line:
|
||||
data = json.loads(line.decode('utf-8').replace('data: ', ''))
|
||||
if 'choices' in data:
|
||||
content = data['choices'][0].get('delta', {}).get('content', '')
|
||||
if content:
|
||||
yield content
|
||||
```
|
||||
|
||||
## Common Integration Patterns
|
||||
|
||||
### Error Handling
|
||||
|
||||
```python
|
||||
import requests
|
||||
from requests.exceptions import RequestException
|
||||
|
||||
def safe_chat_request(messages, model="gpt-4", retries=3):
|
||||
for attempt in range(retries):
|
||||
try:
|
||||
response = requests.post(
|
||||
"http://localhost:8080/v1/chat/completions",
|
||||
json={"model": model, "messages": messages},
|
||||
timeout=30
|
||||
)
|
||||
response.raise_for_status()
|
||||
return response.json()
|
||||
except RequestException as e:
|
||||
if attempt == retries - 1:
|
||||
raise
|
||||
time.sleep(2 ** attempt) # Exponential backoff
|
||||
```
|
||||
|
||||
### Rate Limiting
|
||||
|
||||
```python
|
||||
from functools import wraps
|
||||
import time
|
||||
|
||||
def rate_limit(calls_per_second=2):
|
||||
min_interval = 1.0 / calls_per_second
|
||||
last_called = [0.0]
|
||||
|
||||
def decorator(func):
|
||||
@wraps(func)
|
||||
def wrapper(*args, **kwargs):
|
||||
elapsed = time.time() - last_called[0]
|
||||
left_to_wait = min_interval - elapsed
|
||||
if left_to_wait > 0:
|
||||
time.sleep(left_to_wait)
|
||||
ret = func(*args, **kwargs)
|
||||
last_called[0] = time.time()
|
||||
return ret
|
||||
return wrapper
|
||||
return decorator
|
||||
|
||||
@rate_limit(calls_per_second=2)
|
||||
def chat_request(messages):
|
||||
# Your chat request here
|
||||
pass
|
||||
```
|
||||
|
||||
## Testing Integrations
|
||||
|
||||
### Unit Tests
|
||||
|
||||
```python
|
||||
import unittest
|
||||
from unittest.mock import patch, Mock
|
||||
import requests
|
||||
|
||||
class TestLocalAIIntegration(unittest.TestCase):
|
||||
@patch('requests.post')
|
||||
def test_chat_completion(self, mock_post):
|
||||
mock_response = Mock()
|
||||
mock_response.json.return_value = {
|
||||
"choices": [{
|
||||
"message": {"content": "Hello!"}
|
||||
}]
|
||||
}
|
||||
mock_post.return_value = mock_response
|
||||
|
||||
# Your integration code here
|
||||
# Assertions
|
||||
```
|
||||
|
||||
## What's Next?
|
||||
|
||||
- [API Reference]({{% relref "docs/reference/api-reference" %}}) - Complete API documentation
|
||||
- [Integrations]({{% relref "docs/integrations" %}}) - List of compatible projects
|
||||
- [Examples Repository](https://github.com/mudler/LocalAI-examples) - More integration examples
|
||||
|
||||
## See Also
|
||||
|
||||
- [Features Documentation]({{% relref "docs/features" %}}) - All LocalAI capabilities
|
||||
- [FAQ]({{% relref "docs/faq" %}}) - Common integration questions
|
||||
- [Troubleshooting]({{% relref "docs/troubleshooting" %}}) - Integration issues
|
||||
|
||||
@@ -1,267 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Setting Up Models"
|
||||
weight = 2
|
||||
icon = "hub"
|
||||
description = "Learn how to install, configure, and manage models in LocalAI"
|
||||
+++
|
||||
|
||||
This tutorial covers everything you need to know about installing and configuring models in LocalAI. You'll learn multiple methods to get models running.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- LocalAI installed and running (see [Your First Chat]({{% relref "docs/tutorials/first-chat" %}}) if you haven't set it up yet)
|
||||
- Basic understanding of command line usage
|
||||
|
||||
## Method 1: Using the Model Gallery (Easiest)
|
||||
|
||||
The Model Gallery is the simplest way to install models. It provides pre-configured models ready to use.
|
||||
|
||||
### Via WebUI
|
||||
|
||||
1. Open the LocalAI WebUI at `http://localhost:8080`
|
||||
2. Navigate to the "Models" tab
|
||||
3. Browse available models
|
||||
4. Click "Install" on any model you want
|
||||
5. Wait for installation to complete
|
||||
|
||||
## Method 1.5: Import Models via WebUI
|
||||
|
||||
The WebUI provides a powerful model import interface that supports both simple and advanced configuration:
|
||||
|
||||
### Simple Import Mode
|
||||
|
||||
1. Open the LocalAI WebUI at `http://localhost:8080`
|
||||
2. Click "Import Model"
|
||||
3. Enter the model URI (e.g., `https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct-GGUF`)
|
||||
4. Optionally configure preferences:
|
||||
- Backend selection
|
||||
- Model name
|
||||
- Description
|
||||
- Quantizations
|
||||
- Embeddings support
|
||||
- Custom preferences
|
||||
5. Click "Import Model" to start the import process
|
||||
|
||||
### Advanced Import Mode
|
||||
|
||||
For full control over model configuration:
|
||||
|
||||
1. In the WebUI, click "Import Model"
|
||||
2. Toggle to "Advanced Mode"
|
||||
3. Edit the YAML configuration directly in the code editor
|
||||
4. Use the "Validate" button to check your configuration
|
||||
5. Click "Create" or "Update" to save
|
||||
|
||||
The advanced editor includes:
|
||||
- Syntax highlighting
|
||||
- YAML validation
|
||||
- Format and copy tools
|
||||
- Full configuration options
|
||||
|
||||
This is especially useful for:
|
||||
- Custom model configurations
|
||||
- Fine-tuning model parameters
|
||||
- Setting up complex model setups
|
||||
- Editing existing model configurations
|
||||
|
||||
### Via CLI
|
||||
|
||||
```bash
|
||||
# List available models
|
||||
local-ai models list
|
||||
|
||||
# Install a specific model
|
||||
local-ai models install llama-3.2-1b-instruct:q4_k_m
|
||||
|
||||
# Start LocalAI with a model from the gallery
|
||||
local-ai run llama-3.2-1b-instruct:q4_k_m
|
||||
```
|
||||
|
||||
### Browse Online
|
||||
|
||||
Visit [models.localai.io](https://models.localai.io) to browse all available models in your browser.
|
||||
|
||||
## Method 2: Installing from Hugging Face
|
||||
|
||||
LocalAI can directly install models from Hugging Face:
|
||||
|
||||
```bash
|
||||
# Install and run a model from Hugging Face
|
||||
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
|
||||
```
|
||||
|
||||
The format is: `huggingface://<repository>/<model-file>`
|
||||
|
||||
## Method 3: Installing from OCI Registries
|
||||
|
||||
### Ollama Registry
|
||||
|
||||
```bash
|
||||
local-ai run ollama://gemma:2b
|
||||
```
|
||||
|
||||
### Standard OCI Registry
|
||||
|
||||
```bash
|
||||
local-ai run oci://localai/phi-2:latest
|
||||
```
|
||||
|
||||
## Method 4: Manual Installation
|
||||
|
||||
For full control, you can manually download and configure models.
|
||||
|
||||
### Step 1: Download a Model
|
||||
|
||||
Download a GGUF model file. Popular sources:
|
||||
- [Hugging Face](https://huggingface.co/models?search=gguf)
|
||||
|
||||
Example:
|
||||
```bash
|
||||
mkdir -p models
|
||||
wget https://huggingface.co/TheBloke/phi-2-GGUF/resolve/main/phi-2.Q4_K_M.gguf \
|
||||
-O models/phi-2.Q4_K_M.gguf
|
||||
```
|
||||
|
||||
### Step 2: Create a Configuration File (Optional)
|
||||
|
||||
Create a YAML file to configure the model:
|
||||
|
||||
```yaml
|
||||
# models/phi-2.yaml
|
||||
name: phi-2
|
||||
parameters:
|
||||
model: phi-2.Q4_K_M.gguf
|
||||
temperature: 0.7
|
||||
context_size: 2048
|
||||
threads: 4
|
||||
backend: llama-cpp
|
||||
```
|
||||
|
||||
### Step 3: Start LocalAI
|
||||
|
||||
```bash
|
||||
# With Docker
|
||||
docker run -p 8080:8080 -v $PWD/models:/models \
|
||||
localai/localai:latest
|
||||
|
||||
# Or with binary
|
||||
local-ai --models-path ./models
|
||||
```
|
||||
|
||||
## Understanding Model Files
|
||||
|
||||
### File Formats
|
||||
|
||||
- **GGUF**: Modern format, recommended for most use cases
|
||||
- **GGML**: Older format, still supported but deprecated
|
||||
|
||||
### Quantization Levels
|
||||
|
||||
Models come in different quantization levels (quality vs. size trade-off):
|
||||
|
||||
| Quantization | Size | Quality | Use Case |
|
||||
|-------------|------|---------|----------|
|
||||
| Q8_0 | Largest | Highest | Best quality, requires more RAM |
|
||||
| Q6_K | Large | Very High | High quality |
|
||||
| Q4_K_M | Medium | High | Balanced (recommended) |
|
||||
| Q4_K_S | Small | Medium | Lower RAM usage |
|
||||
| Q2_K | Smallest | Lower | Minimal RAM, lower quality |
|
||||
|
||||
### Choosing the Right Model
|
||||
|
||||
Consider:
|
||||
- **RAM available**: Larger models need more RAM
|
||||
- **Use case**: Different models excel at different tasks
|
||||
- **Speed**: Smaller quantizations are faster
|
||||
- **Quality**: Higher quantizations produce better output
|
||||
|
||||
## Model Configuration
|
||||
|
||||
### Basic Configuration
|
||||
|
||||
Create a YAML file in your models directory:
|
||||
|
||||
```yaml
|
||||
name: my-model
|
||||
parameters:
|
||||
model: model.gguf
|
||||
temperature: 0.7
|
||||
top_p: 0.9
|
||||
context_size: 2048
|
||||
threads: 4
|
||||
backend: llama-cpp
|
||||
```
|
||||
|
||||
### Advanced Configuration
|
||||
|
||||
See the [Model Configuration]({{% relref "docs/advanced/model-configuration" %}}) guide for all available options.
|
||||
|
||||
## Managing Models
|
||||
|
||||
### List Installed Models
|
||||
|
||||
```bash
|
||||
# Via API
|
||||
curl http://localhost:8080/v1/models
|
||||
|
||||
# Via CLI
|
||||
local-ai models list
|
||||
```
|
||||
|
||||
### Remove Models
|
||||
|
||||
Simply delete the model file and configuration from your models directory:
|
||||
|
||||
```bash
|
||||
rm models/model-name.gguf
|
||||
rm models/model-name.yaml # if exists
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Model Not Loading
|
||||
|
||||
1. **Check backend**: Ensure the required backend is installed
|
||||
```bash
|
||||
local-ai backends list
|
||||
local-ai backends install llama-cpp # if needed
|
||||
```
|
||||
|
||||
2. **Check logs**: Enable debug mode
|
||||
```bash
|
||||
DEBUG=true local-ai
|
||||
```
|
||||
|
||||
3. **Verify file**: Ensure the model file is not corrupted
|
||||
|
||||
### Out of Memory
|
||||
|
||||
- Use a smaller quantization (Q4_K_S or Q2_K)
|
||||
- Reduce `context_size` in configuration
|
||||
- Close other applications to free RAM
|
||||
|
||||
### Wrong Backend
|
||||
|
||||
Check the [Compatibility Table]({{% relref "docs/reference/compatibility-table" %}}) to ensure you're using the correct backend for your model.
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Start small**: Begin with smaller models to test your setup
|
||||
2. **Use quantized models**: Q4_K_M is a good balance for most use cases
|
||||
3. **Organize models**: Keep your models directory organized
|
||||
4. **Backup configurations**: Save your YAML configurations
|
||||
5. **Monitor resources**: Watch RAM and disk usage
|
||||
|
||||
## What's Next?
|
||||
|
||||
- [Using GPU Acceleration]({{% relref "docs/tutorials/using-gpu" %}}) - Speed up inference
|
||||
- [Model Configuration]({{% relref "docs/advanced/model-configuration" %}}) - Advanced configuration options
|
||||
- [Compatibility Table]({{% relref "docs/reference/compatibility-table" %}}) - Find compatible models and backends
|
||||
|
||||
## See Also
|
||||
|
||||
- [Model Gallery Documentation]({{% relref "docs/features/model-gallery" %}})
|
||||
- [Install and Run Models]({{% relref "docs/getting-started/models" %}})
|
||||
- [FAQ]({{% relref "docs/faq" %}})
|
||||
|
||||
@@ -1,254 +0,0 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Using GPU Acceleration"
|
||||
weight = 3
|
||||
icon = "memory"
|
||||
description = "Set up GPU acceleration for faster inference"
|
||||
+++
|
||||
|
||||
This tutorial will guide you through setting up GPU acceleration for LocalAI. GPU acceleration can significantly speed up model inference, especially for larger models.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A compatible GPU (NVIDIA, AMD, Intel, or Apple Silicon)
|
||||
- LocalAI installed
|
||||
- Basic understanding of your system's GPU setup
|
||||
|
||||
## Check Your GPU
|
||||
|
||||
First, verify you have a compatible GPU:
|
||||
|
||||
### NVIDIA
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
You should see your GPU information. Ensure you have CUDA 11.7 or 12.0+ installed.
|
||||
|
||||
### AMD
|
||||
|
||||
```bash
|
||||
rocminfo
|
||||
```
|
||||
|
||||
### Intel
|
||||
|
||||
```bash
|
||||
intel_gpu_top # if available
|
||||
```
|
||||
|
||||
### Apple Silicon (macOS)
|
||||
|
||||
Apple Silicon (M1/M2/M3) GPUs are automatically detected. No additional setup needed!
|
||||
|
||||
## Installation Methods
|
||||
|
||||
### Method 1: Docker with GPU Support (Recommended)
|
||||
|
||||
#### NVIDIA CUDA
|
||||
|
||||
```bash
|
||||
# CUDA 12.0
|
||||
docker run -p 8080:8080 --gpus all --name local-ai \
|
||||
-ti localai/localai:latest-gpu-nvidia-cuda-12
|
||||
|
||||
# CUDA 11.7
|
||||
docker run -p 8080:8080 --gpus all --name local-ai \
|
||||
-ti localai/localai:latest-gpu-nvidia-cuda-11
|
||||
```
|
||||
|
||||
**Prerequisites**: Install [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html)
|
||||
|
||||
#### AMD ROCm
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 \
|
||||
--device=/dev/kfd \
|
||||
--device=/dev/dri \
|
||||
--group-add=video \
|
||||
--name local-ai \
|
||||
-ti localai/localai:latest-gpu-hipblas
|
||||
```
|
||||
|
||||
#### Intel GPU
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 --name local-ai \
|
||||
-ti localai/localai:latest-gpu-intel
|
||||
```
|
||||
|
||||
#### Apple Silicon
|
||||
|
||||
GPU acceleration works automatically when running on macOS with Apple Silicon. Use the standard CPU image - Metal acceleration is built-in.
|
||||
|
||||
### Method 2: AIO Images with GPU
|
||||
|
||||
AIO images are also available with GPU support:
|
||||
|
||||
```bash
|
||||
# NVIDIA CUDA 12
|
||||
docker run -p 8080:8080 --gpus all --name local-ai \
|
||||
-ti localai/localai:latest-aio-gpu-nvidia-cuda-12
|
||||
|
||||
# AMD
|
||||
docker run -p 8080:8080 \
|
||||
--device=/dev/kfd --device=/dev/dri --group-add=video \
|
||||
--name local-ai \
|
||||
-ti localai/localai:latest-aio-gpu-hipblas
|
||||
```
|
||||
|
||||
### Method 3: Build from Source
|
||||
|
||||
For building with GPU support from source, see the [Build Guide]({{% relref "docs/getting-started/build" %}}).
|
||||
|
||||
## Configuring Models for GPU
|
||||
|
||||
### Automatic Detection
|
||||
|
||||
LocalAI automatically detects GPU capabilities and downloads the appropriate backend when you install models from the gallery.
|
||||
|
||||
### Manual Configuration
|
||||
|
||||
In your model YAML configuration, specify GPU layers:
|
||||
|
||||
```yaml
|
||||
name: my-model
|
||||
parameters:
|
||||
model: model.gguf
|
||||
backend: llama-cpp
|
||||
# Offload layers to GPU (adjust based on your GPU memory)
|
||||
f16: true
|
||||
gpu_layers: 35 # Number of layers to offload to GPU
|
||||
```
|
||||
|
||||
**GPU Layers Guidelines**:
|
||||
- **Small GPU (4-6GB)**: 20-30 layers
|
||||
- **Medium GPU (8-12GB)**: 30-40 layers
|
||||
- **Large GPU (16GB+)**: 40+ layers or set to model's total layer count
|
||||
|
||||
### Finding the Right Number of Layers
|
||||
|
||||
1. Start with a conservative number (e.g., 20)
|
||||
2. Monitor GPU memory usage: `nvidia-smi` (NVIDIA) or `rocminfo` (AMD)
|
||||
3. Gradually increase until you reach GPU memory limits
|
||||
4. For maximum performance, offload all layers if you have enough VRAM
|
||||
|
||||
## Verifying GPU Usage
|
||||
|
||||
### Check if GPU is Being Used
|
||||
|
||||
#### NVIDIA
|
||||
|
||||
```bash
|
||||
# Watch GPU usage in real-time
|
||||
watch -n 1 nvidia-smi
|
||||
```
|
||||
|
||||
You should see:
|
||||
- GPU utilization > 0%
|
||||
- Memory usage increasing
|
||||
- Processes running on GPU
|
||||
|
||||
#### AMD
|
||||
|
||||
```bash
|
||||
rocm-smi
|
||||
```
|
||||
|
||||
#### Check Logs
|
||||
|
||||
Enable debug mode to see GPU information in logs:
|
||||
|
||||
```bash
|
||||
DEBUG=true local-ai
|
||||
```
|
||||
|
||||
Look for messages indicating GPU initialization and layer offloading.
|
||||
|
||||
## Performance Tips
|
||||
|
||||
### 1. Optimize GPU Layers
|
||||
|
||||
- Offload as many layers as your GPU memory allows
|
||||
- Balance between GPU and CPU layers for best performance
|
||||
- Use `f16: true` for better GPU performance
|
||||
|
||||
### 2. Batch Processing
|
||||
|
||||
GPU excels at batch processing. Process multiple requests together when possible.
|
||||
|
||||
### 3. Model Quantization
|
||||
|
||||
Even with GPU, quantized models (Q4_K_M) often provide the best speed/quality balance.
|
||||
|
||||
### 4. Context Size
|
||||
|
||||
Larger context sizes use more GPU memory. Adjust based on your GPU:
|
||||
|
||||
```yaml
|
||||
context_size: 4096 # Adjust based on GPU memory
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### GPU Not Detected
|
||||
|
||||
1. **Check drivers**: Ensure GPU drivers are installed
|
||||
2. **Check Docker**: Verify Docker has GPU access
|
||||
```bash
|
||||
docker run --rm --gpus all nvidia/cuda:12.0.0-base-ubuntu22.04 nvidia-smi
|
||||
```
|
||||
3. **Check logs**: Enable debug mode and check for GPU-related errors
|
||||
|
||||
### Out of GPU Memory
|
||||
|
||||
- Reduce `gpu_layers` in model configuration
|
||||
- Use a smaller model or lower quantization
|
||||
- Reduce `context_size`
|
||||
- Close other GPU-using applications
|
||||
|
||||
### Slow Performance
|
||||
|
||||
- Ensure you're using the correct GPU image
|
||||
- Check that layers are actually offloaded (check logs)
|
||||
- Verify GPU drivers are up to date
|
||||
- Consider using a more powerful GPU or reducing model size
|
||||
|
||||
### CUDA Errors
|
||||
|
||||
- Ensure CUDA version matches (11.7 vs 12.0)
|
||||
- Check CUDA compatibility with your GPU
|
||||
- Try rebuilding with `REBUILD=true`
|
||||
|
||||
## Platform-Specific Notes
|
||||
|
||||
### NVIDIA Jetson (L4T)
|
||||
|
||||
Use the L4T-specific images:
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 --runtime nvidia --gpus all \
|
||||
--name local-ai \
|
||||
-ti localai/localai:latest-nvidia-l4t-arm64
|
||||
```
|
||||
|
||||
### Apple Silicon
|
||||
|
||||
- Metal acceleration is automatic
|
||||
- No special Docker flags needed
|
||||
- Use standard CPU images - Metal is built-in
|
||||
- For best performance, build from source on macOS
|
||||
|
||||
## What's Next?
|
||||
|
||||
- [GPU Acceleration Documentation]({{% relref "docs/features/gpu-acceleration" %}}) - Detailed GPU information
|
||||
- [Performance Tuning]({{% relref "docs/advanced/performance-tuning" %}}) - Optimize your setup
|
||||
- [VRAM Management]({{% relref "docs/advanced/vram-management" %}}) - Manage GPU memory efficiently
|
||||
|
||||
## See Also
|
||||
|
||||
- [Compatibility Table]({{% relref "docs/reference/compatibility-table" %}}) - GPU support by backend
|
||||
- [Build Guide]({{% relref "docs/getting-started/build" %}}) - Build with GPU support
|
||||
- [FAQ]({{% relref "docs/faq" %}}) - Common GPU questions
|
||||
|
||||
90
docs/content/faq.md
Normal file
90
docs/content/faq.md
Normal file
@@ -0,0 +1,90 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "FAQ"
|
||||
weight = 24
|
||||
icon = "quiz"
|
||||
url = "/faq/"
|
||||
+++
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
Here are answers to some of the most common questions.
|
||||
|
||||
|
||||
### How do I get models?
|
||||
|
||||
Most gguf-based models should work, but newer models may require additions to the API. If a model doesn't work, please feel free to open up issues. However, be cautious about downloading models from the internet and directly onto your machine, as there may be security vulnerabilities in lama.cpp or ggml that could be maliciously exploited. Some models can be found on Hugging Face: https://huggingface.co/models?search=gguf, or models from gpt4all are compatible too: https://github.com/nomic-ai/gpt4all.
|
||||
|
||||
### Where are models stored?
|
||||
|
||||
LocalAI stores downloaded models in the following locations by default:
|
||||
|
||||
- **Command line**: `./models` (relative to current working directory)
|
||||
- **Docker**: `/models` (inside the container, typically mounted to `./models` on host)
|
||||
- **Launcher application**: `~/.localai/models` (in your home directory)
|
||||
|
||||
You can customize the model storage location using the `LOCALAI_MODELS_PATH` environment variable or `--models-path` command line flag. This is useful if you want to store models outside your home directory for backup purposes or to avoid filling up your home directory with large model files.
|
||||
|
||||
### How much storage space do models require?
|
||||
|
||||
Model sizes vary significantly depending on the model and quantization level:
|
||||
|
||||
- **Small models (1-3B parameters)**: 1-3 GB
|
||||
- **Medium models (7-13B parameters)**: 4-8 GB
|
||||
- **Large models (30B+ parameters)**: 15-30+ GB
|
||||
|
||||
**Quantization levels** (smaller files, slightly reduced quality):
|
||||
- `Q4_K_M`: ~75% of original size
|
||||
- `Q4_K_S`: ~60% of original size
|
||||
- `Q2_K`: ~50% of original size
|
||||
|
||||
**Storage recommendations**:
|
||||
- Ensure you have at least 2-3x the model size available for downloads and temporary files
|
||||
- Use SSD storage for better performance
|
||||
- Consider the model size relative to your system RAM - models larger than your RAM may not run efficiently
|
||||
|
||||
### Benchmarking LocalAI and llama.cpp shows different results!
|
||||
|
||||
LocalAI applies a set of defaults when loading models with the llama.cpp backend, one of these is mirostat sampling - while it achieves better results, it slows down the inference. You can disable this by setting `mirostat: 0` in the model config file. See also the advanced section ({{%relref "advanced/advanced-usage" %}}) for more information and [this issue](https://github.com/mudler/LocalAI/issues/2780).
|
||||
|
||||
### What's the difference with Serge, or XXX?
|
||||
|
||||
LocalAI is a multi-model solution that doesn't focus on a specific model type (e.g., llama.cpp or alpaca.cpp), and it handles all of these internally for faster inference, easy to set up locally and deploy to Kubernetes.
|
||||
|
||||
### Everything is slow, how is it possible?
|
||||
|
||||
There are few situation why this could occur. Some tips are:
|
||||
- Don't use HDD to store your models. Prefer SSD over HDD. In case you are stuck with HDD, disable `mmap` in the model config file so it loads everything in memory.
|
||||
- Watch out CPU overbooking. Ideally the `--threads` should match the number of physical cores. For instance if your CPU has 4 cores, you would ideally allocate `<= 4` threads to a model.
|
||||
- Run LocalAI with `DEBUG=true`. This gives more information, including stats on the token inference speed.
|
||||
- Check that you are actually getting an output: run a simple curl request with `"stream": true` to see how fast the model is responding.
|
||||
|
||||
### Can I use it with a Discord bot, or XXX?
|
||||
|
||||
Yes! If the client uses OpenAI and supports setting a different base URL to send requests to, you can use the LocalAI endpoint. This allows to use this with every application that was supposed to work with OpenAI, but without changing the application!
|
||||
|
||||
### Can this leverage GPUs?
|
||||
|
||||
There is GPU support, see {{%relref "features/GPU-acceleration" %}}.
|
||||
|
||||
### Where is the webUI?
|
||||
|
||||
There is the availability of localai-webui and chatbot-ui in the examples section and can be setup as per the instructions. However as LocalAI is an API you can already plug it into existing projects that provides are UI interfaces to OpenAI's APIs. There are several already on Github, and should be compatible with LocalAI already (as it mimics the OpenAI API)
|
||||
|
||||
### Does it work with AutoGPT?
|
||||
|
||||
Yes, see the [examples](https://github.com/mudler/LocalAI-examples)!
|
||||
|
||||
### How can I troubleshoot when something is wrong?
|
||||
|
||||
Enable the debug mode by setting `DEBUG=true` in the environment variables. This will give you more information on what's going on.
|
||||
You can also specify `--debug` in the command line.
|
||||
|
||||
### I'm getting 'invalid pitch' error when running with CUDA, what's wrong?
|
||||
|
||||
This typically happens when your prompt exceeds the context size. Try to reduce the prompt size, or increase the context size.
|
||||
|
||||
### I'm getting a 'SIGILL' error, what's wrong?
|
||||
|
||||
Your CPU probably does not have support for certain instructions that are compiled by default in the pre-built binaries. If you are running in a container, try setting `REBUILD=true` and disable the CPU instructions that are not compatible with your CPU. For instance: `CMAKE_ARGS="-DGGML_F16C=OFF -DGGML_AVX512=OFF -DGGML_AVX2=OFF -DGGML_FMA=OFF" make build`
|
||||
@@ -5,15 +5,15 @@ weight = 9
|
||||
url = "/features/gpu-acceleration/"
|
||||
+++
|
||||
|
||||
{{% alert context="warning" %}}
|
||||
{{% notice context="warning" %}}
|
||||
Section under construction
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
This section contains instruction on how to use LocalAI with GPU acceleration.
|
||||
|
||||
{{% alert icon="⚡" context="warning" %}}
|
||||
For acceleration for AMD or Metal HW is still in development, for additional details see the [build]({{%relref "docs/getting-started/build#Acceleration" %}})
|
||||
{{% /alert %}}
|
||||
{{% notice icon="⚡" context="warning" %}}
|
||||
For acceleration for AMD or Metal HW is still in development, for additional details see the [build]({{%relref "installation/build#Acceleration" %}})
|
||||
{{% /notice %}}
|
||||
|
||||
## Automatic Backend Detection
|
||||
|
||||
@@ -32,7 +32,6 @@ Depending on the model architecture and backend used, there might be different w
|
||||
|
||||
```yaml
|
||||
name: my-model-name
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: llama.cpp-model.ggmlv3.q5_K_M.bin
|
||||
@@ -124,7 +123,7 @@ llama_init_from_file: kv self size = 512.00 MB
|
||||
|
||||
There are a limited number of tested configurations for ROCm systems however most newer deditated GPU consumer grade devices seem to be supported under the current ROCm6 implementation.
|
||||
|
||||
Due to the nature of ROCm it is best to run all implementations in containers as this limits the number of packages required for installation on host system, compatibility and package versions for dependencies across all variations of OS must be tested independently if desired, please refer to the [build]({{%relref "docs/getting-started/build#Acceleration" %}}) documentation.
|
||||
Due to the nature of ROCm it is best to run all implementations in containers as this limits the number of packages required for installation on host system, compatibility and package versions for dependencies across all variations of OS must be tested independently if desired, please refer to the [build]({{%relref "installation/build#Acceleration" %}}) documentation.
|
||||
|
||||
### Requirements
|
||||
|
||||
@@ -181,7 +180,6 @@ The devices in the following list have been tested with `hipblas` images running
|
||||
The following are examples of the ROCm specific configuration elements required.
|
||||
|
||||
```yaml
|
||||
# docker-compose.yaml
|
||||
# For full functionality select a non-'core' image, version locking the image is recommended for debug purposes.
|
||||
image: quay.io/go-skynet/local-ai:master-aio-gpu-hipblas
|
||||
environment:
|
||||
38
docs/content/features/_index.en.md
Normal file
38
docs/content/features/_index.en.md
Normal file
@@ -0,0 +1,38 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Features"
|
||||
weight = 8
|
||||
icon = "lightbulb"
|
||||
type = "chapter"
|
||||
url = "/features/"
|
||||
+++
|
||||
|
||||
LocalAI provides a comprehensive set of features for running AI models locally. This section covers all the capabilities and functionalities available in LocalAI.
|
||||
|
||||
## Core Features
|
||||
|
||||
- **[Text Generation](text-generation/)** - Generate text with GPT-compatible models using various backends
|
||||
- **[Image Generation](image-generation/)** - Create images with Stable Diffusion and other diffusion models
|
||||
- **[Audio Processing](audio-to-text/)** - Transcribe audio to text and generate speech from text
|
||||
- **[Embeddings](embeddings/)** - Generate vector embeddings for semantic search and RAG applications
|
||||
- **[GPT Vision](gpt-vision/)** - Analyze and understand images with vision-language models
|
||||
|
||||
## Advanced Features
|
||||
|
||||
- **[OpenAI Functions](openai-functions/)** - Use function calling and tools API with local models
|
||||
- **[Constrained Grammars](constrained_grammars/)** - Control model output format with BNF grammars
|
||||
- **[GPU Acceleration](GPU-acceleration/)** - Optimize performance with GPU support
|
||||
- **[Distributed Inference](distributed_inferencing/)** - Scale inference across multiple nodes
|
||||
- **[Model Context Protocol (MCP)](mcp/)** - Enable agentic capabilities with MCP integration
|
||||
|
||||
## Specialized Features
|
||||
|
||||
- **[Object Detection](object-detection/)** - Detect and locate objects in images
|
||||
- **[Reranker](reranker/)** - Improve retrieval accuracy with cross-encoder models
|
||||
- **[Stores](stores/)** - Vector similarity search for embeddings
|
||||
- **[Model Gallery](model-gallery/)** - Browse and install pre-configured models
|
||||
- **[Backends](backends/)** - Learn about available backends and how to manage them
|
||||
|
||||
## Getting Started
|
||||
|
||||
To start using these features, make sure you have [LocalAI installed](/installation/) and have [downloaded some models](/getting-started/models/). Then explore the feature pages above to learn how to use each capability.
|
||||
@@ -41,4 +41,4 @@ curl http://localhost:8080/v1/audio/transcriptions -H "Content-Type: multipart/f
|
||||
|
||||
## Result
|
||||
{"text":"My fellow Americans, this day has brought terrible news and great sadness to our country.At nine o'clock this morning, Mission Control in Houston lost contact with our Space ShuttleColumbia.A short time later, debris was seen falling from the skies above Texas.The Columbia's lost.There are no survivors.One board was a crew of seven.Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark, Captain DavidBrown, Commander William McCool, Dr. Kultna Shavla, and Elon Ramon, a colonel in the IsraeliAir Force.These men and women assumed great risk in the service to all humanity.In an age when spaceflight has come to seem almost routine, it is easy to overlook thedangers of travel by rocket and the difficulties of navigating the fierce outer atmosphere ofthe Earth.These astronauts knew the dangers, and they faced them willingly, knowing they had a highand noble purpose in life.Because of their courage and daring and idealism, we will miss them all the more.All Americans today are thinking as well of the families of these men and women who havebeen given this sudden shock and grief.You're not alone.Our entire nation agrees with you, and those you loved will always have the respect andgratitude of this country.The cause in which they died will continue.Mankind has led into the darkness beyond our world by the inspiration of discovery andthe longing to understand.Our journey into space will go on.In the skies today, we saw destruction and tragedy.As farther than we can see, there is comfort and hope.In the words of the prophet Isaiah, \"Lift your eyes and look to the heavens who createdall these, he who brings out the starry hosts one by one and calls them each by name.\"Because of his great power and mighty strength, not one of them is missing.The same creator who names the stars also knows the names of the seven souls we mourntoday.The crew of the shuttle Columbia did not return safely to Earth yet we can pray that all aresafely home.May God bless the grieving families and may God continue to bless America.[BLANK_AUDIO]"}
|
||||
```
|
||||
```
|
||||
@@ -1,11 +1,10 @@
|
||||
---
|
||||
title: "Backends"
|
||||
title: "⚙️ Backends"
|
||||
description: "Learn how to use, manage, and develop backends in LocalAI"
|
||||
weight: 4
|
||||
url: "/backends/"
|
||||
---
|
||||
|
||||
# Backends
|
||||
|
||||
LocalAI supports a variety of backends that can be used to run different types of AI models. There are core Backends which are included, and there are containerized applications that provide the runtime environment for specific model types, such as LLMs, diffusion models, or text-to-speech models.
|
||||
|
||||
@@ -53,7 +52,6 @@ Where URI is the path to an OCI container image.
|
||||
A backend gallery is a collection of YAML files, each defining a backend. Here's an example structure:
|
||||
|
||||
```yaml
|
||||
# backends/llm-backend.yaml
|
||||
name: "llm-backend"
|
||||
description: "A backend for running LLM models"
|
||||
uri: "quay.io/username/llm-backend:latest"
|
||||
72
docs/content/features/constrained_grammars.md
Normal file
72
docs/content/features/constrained_grammars.md
Normal file
@@ -0,0 +1,72 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "✍️ Constrained Grammars"
|
||||
weight = 15
|
||||
url = "/features/constrained_grammars/"
|
||||
+++
|
||||
|
||||
## Overview
|
||||
|
||||
The `chat` endpoint supports the `grammar` parameter, which allows users to specify a grammar in Backus-Naur Form (BNF). This feature enables the Large Language Model (LLM) to generate outputs adhering to a user-defined schema, such as `JSON`, `YAML`, or any other format that can be defined using BNF. For more details about BNF, see [Backus-Naur Form on Wikipedia](https://en.wikipedia.org/wiki/Backus%E2%80%93Naur_form).
|
||||
|
||||
{{% notice note %}}
|
||||
**Compatibility Notice:** This feature is only supported by models that use the [llama.cpp](https://github.com/ggerganov/llama.cpp) backend. For a complete list of compatible models, refer to the [Model Compatibility]({{%relref "reference/compatibility-table" %}}) page. For technical details, see the related pull requests: [PR #1773](https://github.com/ggerganov/llama.cpp/pull/1773) and [PR #1887](https://github.com/ggerganov/llama.cpp/pull/1887).
|
||||
{{% /notice %}}
|
||||
|
||||
## Setup
|
||||
|
||||
To use this feature, follow the installation and setup instructions on the [LocalAI Functions]({{%relref "features/openai-functions" %}}) page. Ensure that your local setup meets all the prerequisites specified for the llama.cpp backend.
|
||||
|
||||
## 💡 Usage Example
|
||||
|
||||
The following example demonstrates how to use the `grammar` parameter to constrain the model's output to either "yes" or "no". This can be particularly useful in scenarios where the response format needs to be strictly controlled.
|
||||
|
||||
### Example: Binary Response Constraint
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Do you like apples?"}],
|
||||
"grammar": "root ::= (\"yes\" | \"no\")"
|
||||
}'
|
||||
```
|
||||
|
||||
In this example, the `grammar` parameter is set to a simple choice between "yes" and "no", ensuring that the model's response adheres strictly to one of these options regardless of the context.
|
||||
|
||||
### Example: JSON Output Constraint
|
||||
|
||||
You can also use grammars to enforce JSON output format:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Generate a person object with name and age"}],
|
||||
"grammar": "root ::= \"{\" \"\\\"name\\\":\" string \",\\\"age\\\":\" number \"}\"\nstring ::= \"\\\"\" [a-z]+ \"\\\"\"\nnumber ::= [0-9]+"
|
||||
}'
|
||||
```
|
||||
|
||||
### Example: YAML Output Constraint
|
||||
|
||||
Similarly, you can enforce YAML format:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "gpt-4",
|
||||
"messages": [{"role": "user", "content": "Generate a YAML list of fruits"}],
|
||||
"grammar": "root ::= \"fruits:\" newline (\" - \" string newline)+\nstring ::= [a-z]+\nnewline ::= \"\\n\""
|
||||
}'
|
||||
```
|
||||
|
||||
## Advanced Usage
|
||||
|
||||
For more complex grammars, you can define multi-line BNF rules. The grammar parser supports:
|
||||
- Alternation (`|`)
|
||||
- Repetition (`*`, `+`)
|
||||
- Optional elements (`?`)
|
||||
- Character classes (`[a-z]`)
|
||||
- String literals (`"text"`)
|
||||
|
||||
## Related Features
|
||||
|
||||
- [OpenAI Functions]({{%relref "features/openai-functions" %}}) - Function calling with structured outputs
|
||||
- [Text Generation]({{%relref "features/text-generation" %}}) - General text generation capabilities
|
||||
@@ -49,11 +49,11 @@ The instructions are displayed in the "Swarm" section of the WebUI, guiding you
|
||||
|
||||
### Workers mode
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
This feature is available exclusively with llama-cpp compatible models.
|
||||
|
||||
This feature was introduced in [LocalAI pull request #2324](https://github.com/mudler/LocalAI/pull/2324) and is based on the upstream work in [llama.cpp pull request #6829](https://github.com/ggerganov/llama.cpp/pull/6829).
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
To connect multiple workers to a single LocalAI instance, start first a server in p2p mode:
|
||||
|
||||
@@ -90,7 +90,6 @@ Use the WebUI to guide you in the process of starting new workers. This example
|
||||
|
||||
```bash
|
||||
./local-ai run --p2p
|
||||
# Get the token in the Swarm section of the WebUI
|
||||
```
|
||||
|
||||
Copy the token from the WebUI or via API call (e.g., `curl http://localhost:8000/p2p/token`) and save it for later use.
|
||||
@@ -101,19 +100,6 @@ To reuse the same token later, restart the server with `--p2ptoken` or `P2P_TOKE
|
||||
|
||||
```bash
|
||||
TOKEN=XXX ./local-ai worker p2p-llama-cpp-rpc --llama-cpp-args="-m <memory>"
|
||||
# 1:06AM INF loading environment variables from file envFile=.env
|
||||
# 1:06AM INF Setting logging to info
|
||||
# {"level":"INFO","time":"2024-05-19T01:06:01.794+0200","caller":"config/config.go:288","message":"connmanager disabled\n"}
|
||||
# {"level":"INFO","time":"2024-05-19T01:06:01.794+0200","caller":"config/config.go:295","message":" go-libp2p resource manager protection enabled"}
|
||||
# {"level":"INFO","time":"2024-05-19T01:06:01.794+0200","caller":"config/config.go:409","message":"max connections: 100\n"}
|
||||
# 1:06AM INF Starting llama-cpp-rpc-server on '127.0.0.1:34371'
|
||||
# {"level":"INFO","time":"2024-05-19T01:06:01.794+0200","caller":"node/node.go:118","message":" Starting EdgeVPN network"}
|
||||
# create_backend: using CPU backend
|
||||
# Starting RPC server on 127.0.0.1:34371, backend memory: 31913 MB
|
||||
# 2024/05/19 01:06:01 failed to sufficiently increase receive buffer size (was: 208 kiB, wanted: 2048 kiB, got: 416 kiB). # See https://github.com/quic-go/quic-go/wiki/UDP-Buffer-Sizes for details.
|
||||
# {"level":"INFO","time":"2024-05-19T01:06:01.805+0200","caller":"node/node.go:172","message":" Node ID: 12D3KooWJ7WQAbCWKfJgjw2oMMGGss9diw3Sov5hVWi8t4DMgx92"}
|
||||
# {"level":"INFO","time":"2024-05-19T01:06:01.806+0200","caller":"node/node.go:173","message":" Node Addresses: [/ip4/127.0.0.1/tcp/44931 /ip4/127.0.0.1/udp/33251/quic-v1/webtransport/certhash/uEiAWAhZ-W9yx2ZHnKQm3BE_ft5jjoc468z5-Rgr9XdfjeQ/certhash/uEiB8Uwn0M2TQBELaV2m4lqypIAY2S-2ZMf7lt_N5LS6ojw /ip4/127.0.0.1/udp/35660/quic-v1 /ip4/192.168.68.110/tcp/44931 /ip4/192.168.68.110/udp/33251/quic-v1/webtransport/certhash/uEiAWAhZ-W9yx2ZHnKQm3BE_ft5jjoc468z5-Rgr9XdfjeQ/certhash/uEiB8Uwn0M2TQBELaV2m4lqypIAY2S-2ZMf7lt_N5LS6ojw /ip4/192.168.68.110/udp/35660/quic-v1 /ip6/::1/tcp/41289 /ip6/::1/udp/33160/quic-v1/webtransport/certhash/uEiAWAhZ-W9yx2ZHnKQm3BE_ft5jjoc468z5-Rgr9XdfjeQ/certhash/uEiB8Uwn0M2TQBELaV2m4lqypIAY2S-2ZMf7lt_N5LS6ojw /ip6/::1/udp/35701/quic-v1]"}
|
||||
# {"level":"INFO","time":"2024-05-19T01:06:01.806+0200","caller":"discovery/dht.go:104","message":" Bootstrapping DHT"}
|
||||
```
|
||||
|
||||
(Note: You can also supply the token via command-line arguments)
|
||||
@@ -129,7 +115,6 @@ The server logs should indicate that new workers are being discovered.
|
||||
|
||||
There are options that can be tweaked or parameters that can be set using environment variables
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Environment Variable | Description |
|
||||
|----------------------|-------------|
|
||||
| **LOCALAI_P2P** | Set to "true" to enable p2p |
|
||||
@@ -143,7 +128,6 @@ There are options that can be tweaked or parameters that can be set using enviro
|
||||
| **LOCALAI_P2P_TOKEN** | Set the token for the p2p network |
|
||||
| **LOCALAI_P2P_LOGLEVEL** | Set the loglevel for the LocalAI p2p stack (default: info) |
|
||||
| **LOCALAI_P2P_LIB_LOGLEVEL** | Set the loglevel for the underlying libp2p stack (default: fatal) |
|
||||
{{< /table >}}
|
||||
|
||||
|
||||
## Architecture
|
||||
@@ -167,6 +151,4 @@ LOCALAI_P2P_LOGLEVEL=debug LOCALAI_P2P_LIB_LOGLEVEL=debug LOCALAI_P2P_ENABLE_LIM
|
||||
- If running in p2p mode with container images, make sure you start the container with `--net host` or `network_mode: host` in the docker-compose file.
|
||||
- Only a single model is supported currently.
|
||||
- Ensure the server detects new workers before starting inference. Currently, additional workers cannot be added once inference has begun.
|
||||
- For more details on the implementation, refer to [LocalAI pull request #2343](https://github.com/mudler/LocalAI/pull/2343)
|
||||
|
||||
|
||||
- For more details on the implementation, refer to [LocalAI pull request #2343](https://github.com/mudler/LocalAI/pull/2343)
|
||||
@@ -24,7 +24,6 @@ parameters:
|
||||
model: <model_file>
|
||||
backend: "<backend>"
|
||||
embeddings: true
|
||||
# .. other parameters
|
||||
```
|
||||
|
||||
## Huggingface embeddings
|
||||
@@ -41,7 +40,7 @@ parameters:
|
||||
|
||||
The `sentencetransformers` backend uses Python [sentence-transformers](https://github.com/UKPLab/sentence-transformers). For a list of all pre-trained models available see here: https://github.com/UKPLab/sentence-transformers#pre-trained-models
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
|
||||
- The `sentencetransformers` backend is an optional backend of LocalAI and uses Python. If you are running `LocalAI` from the containers you are good to go and should be already configured for use.
|
||||
- For local execution, you also have to specify the extra backend in the `EXTERNAL_GRPC_BACKENDS` environment variable.
|
||||
@@ -49,7 +48,7 @@ The `sentencetransformers` backend uses Python [sentence-transformers](https://g
|
||||
- The `sentencetransformers` backend does support only embeddings of text, and not of tokens. If you need to embed tokens you can use the `bert` backend or `llama.cpp`.
|
||||
- No models are required to be downloaded before using the `sentencetransformers` backend. The models will be downloaded automatically the first time the API is used.
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
## Llama.cpp embeddings
|
||||
|
||||
@@ -61,7 +60,6 @@ backend: llama-cpp
|
||||
embeddings: true
|
||||
parameters:
|
||||
model: ggml-file.bin
|
||||
# ...
|
||||
```
|
||||
|
||||
Then you can use the API to generate embeddings:
|
||||
@@ -75,4 +73,4 @@ curl http://localhost:8080/embeddings -X POST -H "Content-Type: application/json
|
||||
|
||||
## 💡 Examples
|
||||
|
||||
- Example that uses LLamaIndex and LocalAI as embedding: [here](https://github.com/mudler/LocalAI-examples/tree/main/query_data).
|
||||
- Example that uses LLamaIndex and LocalAI as embedding: [here](https://github.com/mudler/LocalAI-examples/tree/main/query_data).
|
||||
@@ -34,5 +34,4 @@ Grammars and function tools can be used as well in conjunction with vision APIs:
|
||||
|
||||
All-in-One images have already shipped the llava model as `gpt-4-vision-preview`, so no setup is needed in this case.
|
||||
|
||||
To setup the LLaVa models, follow the full example in the [configuration examples](https://github.com/mudler/LocalAI-examples/blob/main/configurations/llava/llava.yaml).
|
||||
|
||||
To setup the LLaVa models, follow the full example in the [configuration examples](https://github.com/mudler/LocalAI-examples/blob/main/configurations/llava/llava.yaml).
|
||||
@@ -18,7 +18,6 @@ OpenAI docs: https://platform.openai.com/docs/api-reference/images/create
|
||||
To generate an image you can send a POST request to the `/v1/images/generations` endpoint with the instruction as the request body:
|
||||
|
||||
```bash
|
||||
# 512x512 is supported too
|
||||
curl http://localhost:8080/v1/images/generations -H "Content-Type: application/json" -d '{
|
||||
"prompt": "A cute baby sea otter",
|
||||
"size": "256x256"
|
||||
@@ -92,7 +91,6 @@ parameters:
|
||||
model: Linaqruf/animagine-xl
|
||||
backend: diffusers
|
||||
|
||||
# Force CPU usage - set to true for GPU
|
||||
f16: false
|
||||
diffusers:
|
||||
cuda: false # Enable for GPU usage (CUDA)
|
||||
@@ -101,7 +99,7 @@ diffusers:
|
||||
|
||||
#### Dependencies
|
||||
|
||||
This is an extra backend - in the container is already available and there is nothing to do for the setup. Do not use *core* images (ending with `-core`). If you are building manually, see the [build instructions]({{%relref "docs/getting-started/build" %}}).
|
||||
This is an extra backend - in the container is already available and there is nothing to do for the setup. Do not use *core* images (ending with `-core`). If you are building manually, see the [build instructions]({{%relref "installation/build" %}}).
|
||||
|
||||
#### Model setup
|
||||
|
||||
@@ -205,7 +203,6 @@ Additional arbitrarly parameters can be specified in the option field in key/val
|
||||
|
||||
```yaml
|
||||
name: animagine-xl
|
||||
# ...
|
||||
options:
|
||||
- "cfg_scale:6"
|
||||
```
|
||||
@@ -293,7 +290,6 @@ parameters:
|
||||
model: stabilityai/stable-diffusion-2-depth
|
||||
backend: diffusers
|
||||
step: 50
|
||||
# Force CPU usage
|
||||
f16: true
|
||||
cuda: true
|
||||
diffusers:
|
||||
@@ -317,7 +313,6 @@ parameters:
|
||||
model: stabilityai/stable-video-diffusion-img2vid
|
||||
backend: diffusers
|
||||
step: 25
|
||||
# Force CPU usage
|
||||
f16: true
|
||||
cuda: true
|
||||
diffusers:
|
||||
@@ -337,7 +332,6 @@ parameters:
|
||||
model: damo-vilab/text-to-video-ms-1.7b
|
||||
backend: diffusers
|
||||
step: 25
|
||||
# Force CPU usage
|
||||
f16: true
|
||||
cuda: true
|
||||
diffusers:
|
||||
@@ -348,4 +342,4 @@ diffusers:
|
||||
```bash
|
||||
(echo -n '{"prompt": "spiderman surfing","size": "512x512","model":"txt2vid"}') |
|
||||
curl -H "Content-Type: application/json" -X POST -d @- http://localhost:8080/v1/images/generations
|
||||
```
|
||||
```
|
||||
@@ -1,5 +1,5 @@
|
||||
+++
|
||||
title = "Model Context Protocol (MCP)"
|
||||
title = "🔗 Model Context Protocol (MCP)"
|
||||
weight = 20
|
||||
toc = true
|
||||
description = "Agentic capabilities with Model Context Protocol integration"
|
||||
@@ -7,7 +7,6 @@ tags = ["MCP", "Agents", "Tools", "Advanced"]
|
||||
categories = ["Features"]
|
||||
+++
|
||||
|
||||
# Model Context Protocol (MCP) Support
|
||||
|
||||
LocalAI now supports the **Model Context Protocol (MCP)**, enabling powerful agentic capabilities by connecting AI models to external tools and services. This feature allows your LocalAI models to interact with various MCP servers, providing access to real-time data, APIs, and specialized tools.
|
||||
|
||||
@@ -43,7 +42,6 @@ backend: llama-cpp
|
||||
parameters:
|
||||
model: qwen3-4b.gguf
|
||||
|
||||
# MCP Configuration
|
||||
mcp:
|
||||
remote: |
|
||||
{
|
||||
@@ -79,7 +77,6 @@ mcp:
|
||||
}
|
||||
}
|
||||
|
||||
# Agent Configuration
|
||||
agent:
|
||||
max_attempts: 3 # Maximum number of tool execution attempts
|
||||
max_iterations: 3 # Maximum number of reasoning iterations
|
||||
@@ -2,7 +2,6 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "🖼️ Model gallery"
|
||||
|
||||
weight = 18
|
||||
url = '/models'
|
||||
+++
|
||||
@@ -14,13 +13,13 @@ A list of the models available can also be browsed at [the Public LocalAI Galler
|
||||
LocalAI to ease out installations of models provide a way to preload models on start and downloading and installing them in runtime. You can install models manually by copying them over the `models` directory, or use the API or the Web interface to configure, download and verify the model assets for you.
|
||||
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
The models in this gallery are not directly maintained by LocalAI. If you find a model that is not working, please open an issue on the model gallery repository.
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
GPT and text generation models might have a license which is not permissive for commercial use or might be questionable or without any license at all. Please check the model license before using it. The official gallery contains only open licensed models.
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||

|
||||
|
||||
@@ -68,10 +67,10 @@ where `github:mudler/localai/gallery/index.yaml` will be expanded automatically
|
||||
|
||||
Note: the url are expanded automatically for `github` and `huggingface`, however `https://` and `http://` prefix works as well.
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
|
||||
If you want to build your own gallery, there is no documentation yet. However you can find the source of the default gallery in the [LocalAI repository](https://github.com/mudler/LocalAI/tree/master/gallery).
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
|
||||
### List Models
|
||||
@@ -85,13 +84,10 @@ curl http://localhost:8080/models/available
|
||||
To search for a model, you can use `jq`:
|
||||
|
||||
```bash
|
||||
# Get all information about models with a name that contains "replit"
|
||||
curl http://localhost:8080/models/available | jq '.[] | select(.name | contains("replit"))'
|
||||
|
||||
# Get the binary name of all local models (not hosted on Hugging Face)
|
||||
curl http://localhost:8080/models/available | jq '.[] | .name | select(contains("localmodels"))'
|
||||
|
||||
# Get all of the model URLs that contains "orca"
|
||||
curl http://localhost:8080/models/available | jq '.[] | .urls | select(. != null) | add | select(contains("orca"))'
|
||||
```
|
||||
|
||||
@@ -124,11 +120,9 @@ LOCALAI=http://localhost:8080
|
||||
curl $LOCALAI/models/apply -H "Content-Type: application/json" -d '{
|
||||
"config_url": "<MODEL_CONFIG_FILE_URL>"
|
||||
}'
|
||||
# or if from a repository
|
||||
curl $LOCALAI/models/apply -H "Content-Type: application/json" -d '{
|
||||
"id": "<GALLERY>@<MODEL_NAME>"
|
||||
}'
|
||||
# or from a gallery config
|
||||
curl $LOCALAI/models/apply -H "Content-Type: application/json" -d '{
|
||||
"url": "<MODEL_CONFIG_FILE_URL>"
|
||||
}'
|
||||
@@ -199,7 +193,7 @@ YAML:
|
||||
|
||||
</details>
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
|
||||
You can find already some open licensed models in the [LocalAI gallery](https://github.com/mudler/LocalAI/tree/master/gallery).
|
||||
|
||||
@@ -223,7 +217,7 @@ curl $LOCALAI/models/apply -H "Content-Type: application/json" -d '{
|
||||
|
||||
</details>
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
### Override a model name
|
||||
|
||||
@@ -117,7 +117,7 @@ The RF-DETR backend is implemented as a Python-based gRPC service that integrate
|
||||
|
||||
#### Available Models
|
||||
|
||||
Currently, the following model is available in the [Model Gallery]({{%relref "docs/features/model-gallery" %}}):
|
||||
Currently, the following model is available in the [Model Gallery]({{%relref "features/model-gallery" %}}):
|
||||
|
||||
- **rfdetr-base**: Base model with balanced performance and accuracy
|
||||
|
||||
@@ -128,7 +128,6 @@ You can browse and install this model through the LocalAI web interface or using
|
||||
### Basic Object Detection
|
||||
|
||||
```bash
|
||||
# Detect objects in an image from URL
|
||||
curl -X POST http://localhost:8080/v1/detection \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
@@ -140,7 +139,6 @@ curl -X POST http://localhost:8080/v1/detection \
|
||||
### Base64 Image Detection
|
||||
|
||||
```bash
|
||||
# Convert image to base64 and send
|
||||
base64_image=$(base64 -w 0 image.jpg)
|
||||
curl -X POST http://localhost:8080/v1/detection \
|
||||
-H "Content-Type: application/json" \
|
||||
@@ -187,7 +185,7 @@ Additional object detection models and backends will be added to this category i
|
||||
|
||||
## Related Features
|
||||
|
||||
- [🎨 Image generation]({{%relref "docs/features/image-generation" %}}): Generate images with AI
|
||||
- [📖 Text generation]({{%relref "docs/features/text-generation" %}}): Generate text with language models
|
||||
- [🔍 GPT Vision]({{%relref "docs/features/gpt-vision" %}}): Analyze images with language models
|
||||
- [🚀 GPU acceleration]({{%relref "docs/features/GPU-acceleration" %}}): Optimize performance with GPU acceleration
|
||||
- [🎨 Image generation]({{%relref "features/image-generation" %}}): Generate images with AI
|
||||
- [📖 Text generation]({{%relref "features/text-generation" %}}): Generate text with language models
|
||||
- [🔍 GPT Vision]({{%relref "features/gpt-vision" %}}): Analyze images with language models
|
||||
- [🚀 GPU acceleration]({{%relref "features/GPU-acceleration" %}}): Optimize performance with GPU acceleration
|
||||
@@ -42,8 +42,6 @@ To use the functions with the OpenAI client in python:
|
||||
```python
|
||||
from openai import OpenAI
|
||||
|
||||
# ...
|
||||
# Send the conversation and available functions to GPT
|
||||
messages = [{"role": "user", "content": "What is the weather like in Beijing now?"}]
|
||||
tools = [
|
||||
{
|
||||
@@ -263,4 +261,4 @@ Grammars and function tools can be used as well in conjunction with vision APIs:
|
||||
|
||||
## 💡 Examples
|
||||
|
||||
A full e2e example with `docker-compose` is available [here](https://github.com/mudler/LocalAI-examples/tree/main/functions).
|
||||
A full e2e example with `docker-compose` is available [here](https://github.com/mudler/LocalAI-examples/tree/main/functions).
|
||||
@@ -25,10 +25,6 @@ backend: rerankers
|
||||
parameters:
|
||||
model: cross-encoder
|
||||
|
||||
# optionally:
|
||||
# type: flashrank
|
||||
# diffusers:
|
||||
# pipeline_type: en # to specify the english language
|
||||
```
|
||||
|
||||
and test it with:
|
||||
@@ -54,4 +50,4 @@ and test it with:
|
||||
],
|
||||
"top_n": 3
|
||||
}'
|
||||
```
|
||||
```
|
||||
@@ -2,7 +2,6 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "💾 Stores"
|
||||
|
||||
weight = 18
|
||||
url = '/stores'
|
||||
+++
|
||||
@@ -6,7 +6,7 @@ weight = 10
|
||||
url = "/features/text-generation/"
|
||||
+++
|
||||
|
||||
LocalAI supports generating text with GPT with `llama.cpp` and other backends (such as `rwkv.cpp` as ) see also the [Model compatibility]({{%relref "docs/reference/compatibility-table" %}}) for an up-to-date list of the supported model families.
|
||||
LocalAI supports generating text with GPT with `llama.cpp` and other backends (such as `rwkv.cpp` as ) see also the [Model compatibility]({{%relref "reference/compatibility-table" %}}) for an up-to-date list of the supported model families.
|
||||
|
||||
Note:
|
||||
|
||||
@@ -82,19 +82,19 @@ RWKV support is available through llama.cpp (see below)
|
||||
|
||||
[llama.cpp](https://github.com/ggerganov/llama.cpp) is a popular port of Facebook's LLaMA model in C/C++.
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
|
||||
The `ggml` file format has been deprecated. If you are using `ggml` models and you are configuring your model with a YAML file, specify, use a LocalAI version older than v2.25.0. For `gguf` models, use the `llama` backend. The go backend is deprecated as well but still available as `go-llama`.
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
#### Features
|
||||
|
||||
The `llama.cpp` model supports the following features:
|
||||
- [📖 Text generation (GPT)]({{%relref "docs/features/text-generation" %}})
|
||||
- [🧠 Embeddings]({{%relref "docs/features/embeddings" %}})
|
||||
- [🔥 OpenAI functions]({{%relref "docs/features/openai-functions" %}})
|
||||
- [✍️ Constrained grammars]({{%relref "docs/features/constrained_grammars" %}})
|
||||
- [📖 Text generation (GPT)]({{%relref "features/text-generation" %}})
|
||||
- [🧠 Embeddings]({{%relref "features/embeddings" %}})
|
||||
- [🔥 OpenAI functions]({{%relref "features/openai-functions" %}})
|
||||
- [✍️ Constrained grammars]({{%relref "features/constrained_grammars" %}})
|
||||
|
||||
#### Setup
|
||||
|
||||
@@ -104,7 +104,7 @@ LocalAI supports `llama.cpp` models out of the box. You can use the `llama.cpp`
|
||||
|
||||
It is sufficient to copy the `ggml` or `gguf` model files in the `models` folder. You can refer to the model in the `model` parameter in the API calls.
|
||||
|
||||
[You can optionally create an associated YAML]({{%relref "docs/advanced" %}}) model config file to tune the model's parameters or apply a template to the prompt.
|
||||
[You can optionally create an associated YAML]({{%relref "advanced" %}}) model config file to tune the model's parameters or apply a template to the prompt.
|
||||
|
||||
Prompt templates are useful for models that are fine-tuned towards a specific prompt.
|
||||
|
||||
@@ -124,7 +124,7 @@ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/jso
|
||||
|
||||
LocalAI will automatically download and configure the model in the `model` directory.
|
||||
|
||||
Models can be also preloaded or downloaded on demand. To learn about model galleries, check out the [model gallery documentation]({{%relref "docs/features/model-gallery" %}}).
|
||||
Models can be also preloaded or downloaded on demand. To learn about model galleries, check out the [model gallery documentation]({{%relref "features/model-gallery" %}}).
|
||||
|
||||
#### YAML configuration
|
||||
|
||||
@@ -189,8 +189,6 @@ name: exllama
|
||||
parameters:
|
||||
model: WizardLM-7B-uncensored-GPTQ
|
||||
backend: exllama
|
||||
# Note: you can also specify "exllama2" if it's an exllama2 model here
|
||||
# ...
|
||||
```
|
||||
|
||||
Test with:
|
||||
@@ -220,22 +218,6 @@ backend: vllm
|
||||
parameters:
|
||||
model: "facebook/opt-125m"
|
||||
|
||||
# Uncomment to specify a quantization method (optional)
|
||||
# quantization: "awq"
|
||||
# Uncomment to limit the GPU memory utilization (vLLM default is 0.9 for 90%)
|
||||
# gpu_memory_utilization: 0.5
|
||||
# Uncomment to trust remote code from huggingface
|
||||
# trust_remote_code: true
|
||||
# Uncomment to enable eager execution
|
||||
# enforce_eager: true
|
||||
# Uncomment to specify the size of the CPU swap space per GPU (in GiB)
|
||||
# swap_space: 2
|
||||
# Uncomment to specify the maximum length of a sequence (including prompt and output)
|
||||
# max_model_len: 32768
|
||||
# Uncomment and specify the number of Tensor divisions.
|
||||
# Allows you to partition and run large models. Performance gains are limited.
|
||||
# https://github.com/vllm-project/vllm/issues/1435
|
||||
# tensor_parallel_size: 2
|
||||
```
|
||||
|
||||
The backend will automatically download the required files in order to run the model.
|
||||
@@ -401,4 +383,4 @@ template:
|
||||
|
||||
completion: |
|
||||
{{.Input}}
|
||||
```
|
||||
```
|
||||
@@ -213,4 +213,4 @@ curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
}'
|
||||
```
|
||||
|
||||
If a `response_format` is added in the query (other than `wav`) and ffmpeg is not available, the call will fail.
|
||||
If a `response_format` is added in the query (other than `wav`) and ffmpeg is not available, the call will fail.
|
||||
24
docs/content/getting-started/_index.en.md
Normal file
24
docs/content/getting-started/_index.en.md
Normal file
@@ -0,0 +1,24 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Getting started"
|
||||
weight = 3
|
||||
icon = "rocket_launch"
|
||||
type = "chapter"
|
||||
+++
|
||||
|
||||
Welcome to LocalAI! This section covers everything you need to know **after installation** to start using LocalAI effectively.
|
||||
|
||||
{{% notice tip %}}
|
||||
**Haven't installed LocalAI yet?**
|
||||
|
||||
See the [Installation guide](/installation/) to install LocalAI first. **Docker is the recommended installation method** for most users.
|
||||
{{% /notice %}}
|
||||
|
||||
## What's in This Section
|
||||
|
||||
- **[Quickstart Guide](quickstart/)** - Get started quickly with your first API calls and model downloads
|
||||
- **[Install and Run Models](models/)** - Learn how to install, configure, and run AI models
|
||||
- **[Customize Models](customize-model/)** - Customize model configurations and prompt templates
|
||||
- **[Container Images Reference](container-images/)** - Complete reference for available Docker images
|
||||
- **[Try It Out](try-it-out/)** - Explore examples and use cases
|
||||
12
docs/content/getting-started/build.md
Normal file
12
docs/content/getting-started/build.md
Normal file
@@ -0,0 +1,12 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Build LocalAI from source"
|
||||
weight = 6
|
||||
url = '/basics/build/'
|
||||
ico = "rocket_launch"
|
||||
+++
|
||||
|
||||
Building LocalAI from source is an installation method that allows you to compile LocalAI yourself, which is useful for custom configurations, development, or when you need specific build options.
|
||||
|
||||
For complete build instructions, see the [Build from Source](/installation/build/) documentation in the Installation section.
|
||||
@@ -10,16 +10,16 @@ LocalAI provides a variety of images to support different environments. These im
|
||||
|
||||
All-in-One images comes with a pre-configured set of models and backends, standard images instead do not have any model pre-configured and installed.
|
||||
|
||||
For GPU Acceleration support for Nvidia video graphic cards, use the Nvidia/CUDA images, if you don't have a GPU, use the CPU images. If you have AMD or Mac Silicon, see the [build section]({{%relref "docs/getting-started/build" %}}).
|
||||
For GPU Acceleration support for Nvidia video graphic cards, use the Nvidia/CUDA images, if you don't have a GPU, use the CPU images. If you have AMD or Mac Silicon, see the [build section]({{%relref "installation/build" %}}).
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
{{% notice tip %}}
|
||||
|
||||
**Available Images Types**:
|
||||
|
||||
- Images ending with `-core` are smaller images without predownload python dependencies. Use these images if you plan to use `llama.cpp`, `stablediffusion-ncn` or `rwkv` backends - if you are not sure which one to use, do **not** use these images.
|
||||
- Images containing the `aio` tag are all-in-one images with all the features enabled, and come with an opinionated set of configuration.
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
@@ -29,11 +29,88 @@ Before you begin, ensure you have a container engine installed if you are not us
|
||||
- [Install Podman (Linux)](https://podman.io/getting-started/installation)
|
||||
- [Install Docker engine (Servers)](https://docs.docker.com/engine/install/#get-started)
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
{{% notice tip %}}
|
||||
|
||||
**Hardware Requirements:** The hardware requirements for LocalAI vary based on the model size and quantization method used. For performance benchmarks with different backends, such as `llama.cpp`, visit [this link](https://github.com/ggerganov/llama.cpp#memorydisk-requirements). The `rwkv` backend is noted for its lower resource consumption.
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
## Standard container images
|
||||
|
||||
Standard container images do not have pre-installed models. Use these if you want to configure models manually.
|
||||
|
||||
{{< tabs >}}
|
||||
{{% tab title="Vanilla / CPU Images" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-----------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master` | `localai/localai:master` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest` | `localai/localai:latest` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}` | `localai/localai:{{< version >}}` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab title="GPU Images CUDA 11" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-nvidia-cuda-11` | `localai/localai:master-gpu-nvidia-cuda-11` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-nvidia-cuda-11` | `localai/localai:latest-gpu-nvidia-cuda-11` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-nvidia-cuda-11` | `localai/localai:{{< version >}}-gpu-nvidia-cuda-11` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab title="GPU Images CUDA 12" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-nvidia-cuda-12` | `localai/localai:master-gpu-nvidia-cuda-12` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-nvidia-cuda-12` | `localai/localai:latest-gpu-nvidia-cuda-12` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-nvidia-cuda-12` | `localai/localai:{{< version >}}-gpu-nvidia-cuda-12` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab title="Intel GPU" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-intel` | `localai/localai:master-gpu-intel` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-intel` | `localai/localai:latest-gpu-intel` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-intel` | `localai/localai:{{< version >}}-gpu-intel` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab title="AMD GPU" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-hipblas` | `localai/localai:master-gpu-hipblas` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-hipblas` | `localai/localai:latest-gpu-hipblas` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-hipblas` | `localai/localai:{{< version >}}-gpu-hipblas` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab title="Vulkan Images" %}}
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-vulkan` | `localai/localai:master-vulkan` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-vulkan` | `localai/localai:latest-gpu-vulkan` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-vulkan` | `localai/localai:{{< version >}}-vulkan` |
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab title="Nvidia Linux for tegra" %}}
|
||||
|
||||
These images are compatible with Nvidia ARM64 devices, such as the Jetson Nano, Jetson Xavier NX, and Jetson AGX Xavier. For more information, see the [Nvidia L4T guide]({{%relref "reference/nvidia-l4t" %}}).
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-nvidia-l4t-arm64` | `localai/localai:master-nvidia-l4t-arm64` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-nvidia-l4t-arm64` | `localai/localai:latest-nvidia-l4t-arm64` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-nvidia-l4t-arm64` | `localai/localai:{{< version >}}-nvidia-l4t-arm64` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
## All-in-one images
|
||||
|
||||
@@ -41,7 +118,6 @@ All-In-One images are images that come pre-configured with a set of models and b
|
||||
|
||||
In the AIO images there are models configured with the names of OpenAI models, however, they are really backed by Open Source models. You can find the table below
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Category | Model name | Real model (CPU) | Real model (GPU) |
|
||||
| ---- | ---- | ---- | ---- |
|
||||
| Text Generation | `gpt-4` | `phi-2` | `hermes-2-pro-mistral` |
|
||||
@@ -50,18 +126,13 @@ In the AIO images there are models configured with the names of OpenAI models, h
|
||||
| Speech to Text | `whisper-1` | `whisper` with `whisper-base` model | <= same |
|
||||
| Text to Speech | `tts-1` | `en-us-amy-low.onnx` from `rhasspy/piper` | <= same |
|
||||
| Embeddings | `text-embedding-ada-002` | `all-MiniLM-L6-v2` in Q4 | `all-MiniLM-L6-v2` |
|
||||
{{< /table >}}
|
||||
|
||||
### Usage
|
||||
|
||||
Select the image (CPU or GPU) and start the container with Docker:
|
||||
|
||||
```bash
|
||||
# CPU example
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest-aio-cpu
|
||||
# For Nvidia GPUs:
|
||||
# docker run -p 8080:8080 --gpus all --name local-ai -ti localai/localai:latest-aio-gpu-nvidia-cuda-11
|
||||
# docker run -p 8080:8080 --gpus all --name local-ai -ti localai/localai:latest-aio-gpu-nvidia-cuda-12
|
||||
```
|
||||
|
||||
LocalAI will automatically download all the required models, and the API will be available at [localhost:8080](http://localhost:8080/v1/models).
|
||||
@@ -103,7 +174,7 @@ services:
|
||||
# capabilities: [gpu]
|
||||
```
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
{{% notice tip %}}
|
||||
|
||||
**Models caching**: The **AIO** image will download the needed models on the first run if not already present and store those in `/models` inside the container. The AIO models will be automatically updated with new versions of AIO images.
|
||||
|
||||
@@ -122,7 +193,7 @@ docker volume create localai-models
|
||||
docker run -p 8080:8080 --name local-ai -ti -v localai-models:/models localai/localai:latest-aio-cpu
|
||||
```
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
### Available AIO images
|
||||
|
||||
@@ -142,86 +213,8 @@ The AIO Images are inheriting the same environment variables as the base images
|
||||
| Variable | Default | Description |
|
||||
| ---------------------| ------- | ----------- |
|
||||
| `PROFILE` | Auto-detected | The size of the model to use. Available: `cpu`, `gpu-8g` |
|
||||
| `MODELS` | Auto-detected | A list of models YAML Configuration file URI/URL (see also [running models]({{%relref "docs/getting-started/models" %}})) |
|
||||
|
||||
|
||||
## Standard container images
|
||||
|
||||
Standard container images do not have pre-installed models.
|
||||
|
||||
{{< tabs tabTotal="8" >}}
|
||||
{{% tab tabName="Vanilla / CPU Images" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-----------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master` | `localai/localai:master` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest` | `localai/localai:latest` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}` | `localai/localai:{{< version >}}` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="GPU Images CUDA 11" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-nvidia-cuda-11` | `localai/localai:master-gpu-nvidia-cuda-11` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-nvidia-cuda-11` | `localai/localai:latest-gpu-nvidia-cuda-11` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-nvidia-cuda-11` | `localai/localai:{{< version >}}-gpu-nvidia-cuda-11` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="GPU Images CUDA 12" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-nvidia-cuda-12` | `localai/localai:master-gpu-nvidia-cuda-12` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-nvidia-cuda-12` | `localai/localai:latest-gpu-nvidia-cuda-12` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-nvidia-cuda-12` | `localai/localai:{{< version >}}-gpu-nvidia-cuda-12` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="Intel GPU" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-intel` | `localai/localai:master-gpu-intel` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-intel` | `localai/localai:latest-gpu-intel` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-intel` | `localai/localai:{{< version >}}-gpu-intel` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="AMD GPU" %}}
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-gpu-hipblas` | `localai/localai:master-gpu-hipblas` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-hipblas` | `localai/localai:latest-gpu-hipblas` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-gpu-hipblas` | `localai/localai:{{< version >}}-gpu-hipblas` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="Vulkan Images" %}}
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-vulkan` | `localai/localai:master-vulkan` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-gpu-vulkan` | `localai/localai:latest-gpu-vulkan` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-vulkan` | `localai/localai:{{< version >}}-vulkan` |
|
||||
{{% /tab %}}
|
||||
|
||||
{{% tab tabName="Nvidia Linux for tegra" %}}
|
||||
|
||||
These images are compatible with Nvidia ARM64 devices, such as the Jetson Nano, Jetson Xavier NX, and Jetson AGX Xavier. For more information, see the [Nvidia L4T guide]({{%relref "docs/reference/nvidia-l4t" %}}).
|
||||
|
||||
| Description | Quay | Docker Hub |
|
||||
| --- | --- |-------------------------------------------------------------|
|
||||
| Latest images from the branch (development) | `quay.io/go-skynet/local-ai:master-nvidia-l4t-arm64` | `localai/localai:master-nvidia-l4t-arm64` |
|
||||
| Latest tag | `quay.io/go-skynet/local-ai:latest-nvidia-l4t-arm64` | `localai/localai:latest-nvidia-l4t-arm64` |
|
||||
| Versioned image | `quay.io/go-skynet/local-ai:{{< version >}}-nvidia-l4t-arm64` | `localai/localai:{{< version >}}-nvidia-l4t-arm64` |
|
||||
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
| `MODELS` | Auto-detected | A list of models YAML Configuration file URI/URL (see also [running models]({{%relref "getting-started/models" %}})) |
|
||||
|
||||
## See Also
|
||||
|
||||
- [GPU acceleration]({{%relref "docs/features/gpu-acceleration" %}})
|
||||
- [GPU acceleration]({{%relref "features/gpu-acceleration" %}})
|
||||
@@ -2,21 +2,20 @@
|
||||
disableToc = false
|
||||
title = "Customizing the Model"
|
||||
weight = 5
|
||||
url = "/docs/getting-started/customize-model"
|
||||
icon = "rocket_launch"
|
||||
|
||||
+++
|
||||
|
||||
To customize the prompt template or the default settings of the model, a configuration file is utilized. This file must adhere to the LocalAI YAML configuration standards. For comprehensive syntax details, refer to the [advanced documentation]({{%relref "docs/advanced" %}}). The configuration file can be located either remotely (such as in a Github Gist) or within the local filesystem or a remote URL.
|
||||
To customize the prompt template or the default settings of the model, a configuration file is utilized. This file must adhere to the LocalAI YAML configuration standards. For comprehensive syntax details, refer to the [advanced documentation]({{%relref "advanced" %}}). The configuration file can be located either remotely (such as in a Github Gist) or within the local filesystem or a remote URL.
|
||||
|
||||
LocalAI can be initiated using either its container image or binary, with a command that includes URLs of model config files or utilizes a shorthand format (like `huggingface://` or `github://`), which is then expanded into complete URLs.
|
||||
|
||||
The configuration can also be set via an environment variable. For instance:
|
||||
|
||||
```
|
||||
# Command-Line Arguments
|
||||
local-ai github://owner/repo/file.yaml@branch
|
||||
|
||||
# Environment Variable
|
||||
MODELS="github://owner/repo/file.yaml@branch,github://owner/repo/file.yaml@branch" local-ai
|
||||
```
|
||||
|
||||
@@ -28,11 +27,11 @@ docker run -p 8080:8080 localai/localai:{{< version >}} https://gist.githubuserc
|
||||
|
||||
You can also check all the embedded models configurations [here](https://github.com/mudler/LocalAI/tree/master/embedded/models).
|
||||
|
||||
{{% alert icon="" %}}
|
||||
{{% notice tip %}}
|
||||
The model configurations used in the quickstart are accessible here: [https://github.com/mudler/LocalAI/tree/master/embedded/models](https://github.com/mudler/LocalAI/tree/master/embedded/models). Contributions are welcome; please feel free to submit a Pull Request.
|
||||
|
||||
The `phi-2` model configuration from the quickstart is expanded from [https://github.com/mudler/LocalAI/blob/master/examples/configurations/phi-2.yaml](https://github.com/mudler/LocalAI/blob/master/examples/configurations/phi-2.yaml).
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
## Example: Customizing the Prompt Template
|
||||
|
||||
@@ -69,5 +68,5 @@ docker run -p 8080:8080 localai/localai:{{< version >}} https://gist.githubuserc
|
||||
|
||||
## Next Steps
|
||||
|
||||
- Visit the [advanced section]({{%relref "docs/advanced" %}}) for more insights on prompt templates and configuration files.
|
||||
- To learn about fine-tuning an LLM model, check out the [fine-tuning section]({{%relref "docs/advanced/fine-tuning" %}}).
|
||||
- Visit the [advanced section]({{%relref "advanced" %}}) for more insights on prompt templates and configuration files.
|
||||
- To learn about fine-tuning an LLM model, check out the [fine-tuning section]({{%relref "advanced/fine-tuning" %}}).
|
||||
@@ -22,16 +22,10 @@ kubectl apply -f https://raw.githubusercontent.com/mudler/LocalAI-examples/refs/
|
||||
Alternatively, the [helm chart](https://github.com/go-skynet/helm-charts) can be used as well:
|
||||
|
||||
```bash
|
||||
# Install the helm repository
|
||||
helm repo add go-skynet https://go-skynet.github.io/helm-charts/
|
||||
# Update the repositories
|
||||
helm repo update
|
||||
# Get the values
|
||||
helm show values go-skynet/local-ai > values.yaml
|
||||
|
||||
# Edit the values if needed
|
||||
# vim values.yaml ...
|
||||
|
||||
# Install the helm chart
|
||||
helm install local-ai go-skynet/local-ai -f values.yaml
|
||||
```
|
||||
@@ -7,8 +7,7 @@ icon = "rocket_launch"
|
||||
|
||||
To install models with LocalAI, you can:
|
||||
|
||||
- **Import via WebUI** (Recommended for beginners): Use the WebUI's model import interface to import models from URIs with a user-friendly interface. Supports both simple mode (with preferences) and advanced mode (YAML editor). See the [Setting Up Models tutorial]({{% relref "docs/tutorials/setting-up-models" %}}) for details.
|
||||
- Browse the Model Gallery from the Web Interface and install models with a couple of clicks. For more details, refer to the [Gallery Documentation]({{% relref "docs/features/model-gallery" %}}).
|
||||
- Browse the Model Gallery from the Web Interface and install models with a couple of clicks. For more details, refer to the [Gallery Documentation]({{% relref "features/model-gallery" %}}).
|
||||
- Specify a model from the LocalAI gallery during startup, e.g., `local-ai run <model_gallery_name>`.
|
||||
- Use a URI to specify a model file (e.g., `huggingface://...`, `oci://`, or `ollama://`) when starting LocalAI, e.g., `local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf`.
|
||||
- Specify a URL to a model configuration file when starting LocalAI, e.g., `local-ai run https://gist.githubusercontent.com/.../phi-2.yaml`.
|
||||
@@ -30,49 +29,25 @@ To install only the model, use:
|
||||
local-ai models install hermes-2-theta-llama-3-8b
|
||||
```
|
||||
|
||||
Note: The galleries available in LocalAI can be customized to point to a different URL or a local directory. For more information on how to setup your own gallery, see the [Gallery Documentation]({{% relref "docs/features/model-gallery" %}}).
|
||||
Note: The galleries available in LocalAI can be customized to point to a different URL or a local directory. For more information on how to setup your own gallery, see the [Gallery Documentation]({{% relref "features/model-gallery" %}}).
|
||||
|
||||
## Import Models via WebUI
|
||||
## Run Models via URI
|
||||
|
||||
The easiest way to import models is through the WebUI's import interface:
|
||||
|
||||
1. Open the LocalAI WebUI at `http://localhost:8080`
|
||||
2. Navigate to the "Models" tab
|
||||
3. Click "Import Model" or "New Model"
|
||||
4. Choose your import method:
|
||||
- **Simple Mode**: Enter a model URI and configure preferences (backend, name, description, quantizations, etc.)
|
||||
- **Advanced Mode**: Edit YAML configuration directly with syntax highlighting and validation
|
||||
|
||||
The WebUI import supports all URI types:
|
||||
- `huggingface://repository_id/model_file`
|
||||
- `oci://container_image:tag`
|
||||
- `ollama://model_id:tag`
|
||||
- `file://path/to/model`
|
||||
- `https://...` (for configuration files)
|
||||
|
||||
For detailed instructions, see the [Setting Up Models tutorial]({{% relref "docs/tutorials/setting-up-models" %}}).
|
||||
|
||||
## Run Models via URI (CLI)
|
||||
|
||||
To run models via URI from the command line, specify a URI to a model file or a configuration file when starting LocalAI. Valid syntax includes:
|
||||
To run models via URI, specify a URI to a model file or a configuration file when starting LocalAI. Valid syntax includes:
|
||||
|
||||
- `file://path/to/model`
|
||||
- `huggingface://repository_id/model_file` (e.g., `huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf`)
|
||||
- From OCIs: `oci://container_image:tag`, `ollama://model_id:tag`
|
||||
- From configuration files: `https://gist.githubusercontent.com/.../phi-2.yaml`
|
||||
|
||||
Configuration files can be used to customize the model defaults and settings. For advanced configurations, refer to the [Customize Models section]({{% relref "docs/getting-started/customize-model" %}}).
|
||||
Configuration files can be used to customize the model defaults and settings. For advanced configurations, refer to the [Customize Models section]({{% relref "getting-started/customize-model" %}}).
|
||||
|
||||
### Examples
|
||||
|
||||
```bash
|
||||
# Start LocalAI with the phi-2 model
|
||||
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
|
||||
# Install and run a model from the Ollama OCI registry
|
||||
local-ai run ollama://gemma:2b
|
||||
# Run a model from a configuration file
|
||||
local-ai run https://gist.githubusercontent.com/.../phi-2.yaml
|
||||
# Install and run a model from a standard OCI registry (e.g., Docker Hub)
|
||||
local-ai run oci://localai/phi-2:latest
|
||||
```
|
||||
|
||||
@@ -81,38 +56,25 @@ local-ai run oci://localai/phi-2:latest
|
||||
Follow these steps to manually run models using LocalAI:
|
||||
|
||||
1. **Prepare Your Model and Configuration Files**:
|
||||
Ensure you have a model file and, if necessary, a configuration YAML file. Customize model defaults and settings with a configuration file. For advanced configurations, refer to the [Advanced Documentation]({{% relref "docs/advanced" %}}).
|
||||
Ensure you have a model file and, if necessary, a configuration YAML file. Customize model defaults and settings with a configuration file. For advanced configurations, refer to the [Advanced Documentation]({{% relref "advanced" %}}).
|
||||
|
||||
2. **GPU Acceleration**:
|
||||
For instructions on GPU acceleration, visit the [GPU Acceleration]({{% relref "docs/features/gpu-acceleration" %}}) page.
|
||||
For instructions on GPU acceleration, visit the [GPU Acceleration]({{% relref "features/gpu-acceleration" %}}) page.
|
||||
|
||||
3. **Run LocalAI**:
|
||||
Choose one of the following methods to run LocalAI:
|
||||
|
||||
{{< tabs tabTotal="5" >}}
|
||||
{{% tab tabName="Docker" %}}
|
||||
{{< tabs >}}
|
||||
{{% tab title="Docker" %}}
|
||||
|
||||
```bash
|
||||
# Prepare the models into the `models` directory
|
||||
mkdir models
|
||||
|
||||
# Copy your models to the directory
|
||||
cp your-model.gguf models/
|
||||
|
||||
# Run the LocalAI container
|
||||
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest --models-path /models --context-size 700 --threads 4
|
||||
|
||||
# Expected output:
|
||||
# ┌───────────────────────────────────────────────────┐
|
||||
# │ Fiber v2.42.0 │
|
||||
# │ http://127.0.0.1:8080 │
|
||||
# │ (bound on host 0.0.0.0 and port 8080) │
|
||||
# │ │
|
||||
# │ Handlers ............. 1 Processes ........... 1 │
|
||||
# │ Prefork ....... Disabled PID ................. 1 │
|
||||
# └───────────────────────────────────────────────────┘
|
||||
|
||||
# Test the endpoint with curl
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "your-model.gguf",
|
||||
"prompt": "A long time ago in a galaxy far, far away",
|
||||
@@ -120,68 +82,52 @@ curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d
|
||||
}'
|
||||
```
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
{{% notice tip %}}
|
||||
**Other Docker Images**:
|
||||
|
||||
For other Docker images, please refer to the table in [the container images section]({{% relref "docs/getting-started/container-images" %}}).
|
||||
{{% /alert %}}
|
||||
For other Docker images, please refer to the table in [the container images section]({{% relref "getting-started/container-images" %}}).
|
||||
{{% /notice %}}
|
||||
|
||||
### Example:
|
||||
|
||||
```bash
|
||||
mkdir models
|
||||
|
||||
# Download luna-ai-llama2 to models/
|
||||
wget https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGUF/resolve/main/luna-ai-llama2-uncensored.Q4_0.gguf -O models/luna-ai-llama2
|
||||
|
||||
# Use a template from the examples, if needed
|
||||
cp -rf prompt-templates/getting_started.tmpl models/luna-ai-llama2.tmpl
|
||||
|
||||
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest --models-path /models --context-size 700 --threads 4
|
||||
|
||||
# Now the API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
# {"object":"list","data":[{"id":"luna-ai-llama2","object":"model"}]}
|
||||
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "luna-ai-llama2",
|
||||
"messages": [{"role": "user", "content": "How are you?"}],
|
||||
"temperature": 0.9
|
||||
}'
|
||||
# {"model":"luna-ai-llama2","choices":[{"message":{"role":"assistant","content":"I'm doing well, thanks. How about you?"}}]}
|
||||
```
|
||||
|
||||
{{% alert note %}}
|
||||
- If running on Apple Silicon (ARM), it is **not** recommended to run on Docker due to emulation. Follow the [build instructions]({{% relref "docs/getting-started/build" %}}) to use Metal acceleration for full GPU support.
|
||||
{{% notice note %}}
|
||||
- If running on Apple Silicon (ARM), it is **not** recommended to run on Docker due to emulation. Follow the [build instructions]({{% relref "installation/build" %}}) to use Metal acceleration for full GPU support.
|
||||
- If you are running on Apple x86_64, you can use Docker without additional gain from building it from source.
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="Docker Compose" %}}
|
||||
{{% tab title="Docker Compose" %}}
|
||||
|
||||
```bash
|
||||
# Clone LocalAI
|
||||
git clone https://github.com/go-skynet/LocalAI
|
||||
|
||||
cd LocalAI
|
||||
|
||||
# (Optional) Checkout a specific LocalAI tag
|
||||
# git checkout -b build <TAG>
|
||||
|
||||
# Copy your models to the models directory
|
||||
cp your-model.gguf models/
|
||||
|
||||
# (Optional) Edit the .env file to set parameters like context size and threads
|
||||
# vim .env
|
||||
|
||||
# Start with Docker Compose
|
||||
docker compose up -d --pull always
|
||||
# Or build the images with:
|
||||
# docker compose up -d --build
|
||||
|
||||
# Now the API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
# {"object":"list","data":[{"id":"your-model.gguf","object":"model"}]}
|
||||
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "your-model.gguf",
|
||||
@@ -190,25 +136,25 @@ curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d
|
||||
}'
|
||||
```
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
{{% notice tip %}}
|
||||
**Other Docker Images**:
|
||||
|
||||
For other Docker images, please refer to the table in [Container Images]({{% relref "docs/getting-started/container-images" %}}).
|
||||
{{% /alert %}}
|
||||
For other Docker images, please refer to the table in [Getting Started](https://localai.io/basics/getting_started/#container-images).
|
||||
{{% /notice %}}
|
||||
|
||||
Note: If you are on Windows, ensure the project is on the Linux filesystem to avoid slow model loading. For more information, see the [Microsoft Docs](https://learn.microsoft.com/en-us/windows/wsl/filesystems).
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="Kubernetes" %}}
|
||||
{{% tab title="Kubernetes" %}}
|
||||
|
||||
For Kubernetes deployment, see the [Kubernetes section]({{% relref "docs/getting-started/kubernetes" %}}).
|
||||
For Kubernetes deployment, see the [Kubernetes installation guide]({{% relref "installation/kubernetes" %}}).
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="From Binary" %}}
|
||||
{{% tab title="From Binary" %}}
|
||||
|
||||
LocalAI binary releases are available on [GitHub](https://github.com/go-skynet/LocalAI/releases).
|
||||
|
||||
{{% alert icon="⚠️" %}}
|
||||
{{% notice tip %}}
|
||||
If installing on macOS, you might encounter a message saying:
|
||||
|
||||
> "local-ai-git-Darwin-arm64" (or the name you gave the binary) can't be opened because Apple cannot check it for malicious software.
|
||||
@@ -218,12 +164,12 @@ Hit OK, then go to Settings > Privacy & Security > Security and look for the mes
|
||||
> "local-ai-git-Darwin-arm64" was blocked from use because it is not from an identified developer.
|
||||
|
||||
Press "Allow Anyway."
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="From Source" %}}
|
||||
{{% tab title="From Source" %}}
|
||||
|
||||
For instructions on building LocalAI from source, see the [Build Section]({{% relref "docs/getting-started/build" %}}).
|
||||
For instructions on building LocalAI from source, see the [Build from Source guide]({{% relref "installation/build" %}}).
|
||||
|
||||
{{% /tab %}}
|
||||
{{< /tabs >}}
|
||||
107
docs/content/getting-started/quickstart.md
Normal file
107
docs/content/getting-started/quickstart.md
Normal file
@@ -0,0 +1,107 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Quickstart"
|
||||
weight = 3
|
||||
url = '/basics/getting_started/'
|
||||
icon = "rocket_launch"
|
||||
+++
|
||||
|
||||
**LocalAI** is a free, open-source alternative to OpenAI (Anthropic, etc.), functioning as a drop-in replacement REST API for local inferencing. It allows you to run [LLMs]({{% relref "features/text-generation" %}}), generate images, and produce audio, all locally or on-premises with consumer-grade hardware, supporting multiple model families and architectures.
|
||||
|
||||
{{% notice tip %}}
|
||||
|
||||
**Security considerations**
|
||||
|
||||
If you are exposing LocalAI remotely, make sure you protect the API endpoints adequately with a mechanism which allows to protect from the incoming traffic or alternatively, run LocalAI with `API_KEY` to gate the access with an API key. The API key guarantees a total access to the features (there is no role separation), and it is to be considered as likely as an admin role.
|
||||
|
||||
{{% /notice %}}
|
||||
|
||||
## Quickstart
|
||||
|
||||
This guide assumes you have already [installed LocalAI](/installation/). If you haven't installed it yet, see the [Installation guide](/installation/) first.
|
||||
|
||||
### Starting LocalAI
|
||||
|
||||
Once installed, start LocalAI. For Docker installations:
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest
|
||||
```
|
||||
|
||||
The API will be available at `http://localhost:8080`.
|
||||
|
||||
### Downloading models on start
|
||||
|
||||
When starting LocalAI (either via Docker or via CLI) you can specify as argument a list of models to install automatically before starting the API, for example:
|
||||
|
||||
```bash
|
||||
local-ai run llama-3.2-1b-instruct:q4_k_m
|
||||
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
|
||||
local-ai run ollama://gemma:2b
|
||||
local-ai run https://gist.githubusercontent.com/.../phi-2.yaml
|
||||
local-ai run oci://localai/phi-2:latest
|
||||
```
|
||||
|
||||
{{% notice tip %}}
|
||||
**Automatic Backend Detection**: When you install models from the gallery or YAML files, LocalAI automatically detects your system's GPU capabilities (NVIDIA, AMD, Intel) and downloads the appropriate backend. For advanced configuration options, see [GPU Acceleration]({{% relref "features/gpu-acceleration#automatic-backend-detection" %}}).
|
||||
{{% /notice %}}
|
||||
|
||||
For a full list of options, you can run LocalAI with `--help` or refer to the [Linux Installation guide]({{% relref "installation/linux" %}}) for installer configuration options.
|
||||
|
||||
## Using LocalAI and the full stack with LocalAGI
|
||||
|
||||
LocalAI is part of the Local family stack, along with LocalAGI and LocalRecall.
|
||||
|
||||
[LocalAGI](https://github.com/mudler/LocalAGI) is a powerful, self-hostable AI Agent platform designed for maximum privacy and flexibility which encompassess and uses all the software stack. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities, working entirely locally on consumer-grade hardware (CPU and GPU).
|
||||
|
||||
### Quick Start
|
||||
|
||||
```bash
|
||||
git clone https://github.com/mudler/LocalAGI
|
||||
cd LocalAGI
|
||||
|
||||
docker compose up
|
||||
|
||||
docker compose -f docker-compose.nvidia.yaml up
|
||||
|
||||
docker compose -f docker-compose.intel.yaml up
|
||||
|
||||
MODEL_NAME=gemma-3-12b-it docker compose up
|
||||
|
||||
MODEL_NAME=gemma-3-12b-it \
|
||||
MULTIMODAL_MODEL=minicpm-v-4_5 \
|
||||
IMAGE_MODEL=flux.1-dev-ggml \
|
||||
docker compose -f docker-compose.nvidia.yaml up
|
||||
```
|
||||
|
||||
### Key Features
|
||||
|
||||
- **Privacy-Focused**: All processing happens locally, ensuring your data never leaves your machine
|
||||
- **Flexible Deployment**: Supports CPU, NVIDIA GPU, and Intel GPU configurations
|
||||
- **Multiple Model Support**: Compatible with various models from Hugging Face and other sources
|
||||
- **Web Interface**: User-friendly chat interface for interacting with AI agents
|
||||
- **Advanced Capabilities**: Supports multimodal models, image generation, and more
|
||||
- **Docker Integration**: Easy deployment using Docker Compose
|
||||
|
||||
### Environment Variables
|
||||
|
||||
You can customize your LocalAGI setup using the following environment variables:
|
||||
|
||||
- `MODEL_NAME`: Specify the model to use (e.g., `gemma-3-12b-it`)
|
||||
- `MULTIMODAL_MODEL`: Set a custom multimodal model
|
||||
- `IMAGE_MODEL`: Configure an image generation model
|
||||
|
||||
For more advanced configuration and API documentation, visit the [LocalAGI GitHub repository](https://github.com/mudler/LocalAGI).
|
||||
|
||||
## What's Next?
|
||||
|
||||
There is much more to explore with LocalAI! You can run any model from Hugging Face, perform video generation, and also voice cloning. For a comprehensive overview, check out the [features]({{% relref "features" %}}) section.
|
||||
|
||||
Explore additional resources and community contributions:
|
||||
|
||||
- [Linux Installation Options]({{% relref "installation/linux" %}})
|
||||
- [Run from Container images]({{% relref "getting-started/container-images" %}})
|
||||
- [Examples to try from the CLI]({{% relref "getting-started/try-it-out" %}})
|
||||
- [Build LocalAI from source]({{% relref "installation/build" %}})
|
||||
- [Run models manually]({{% relref "getting-started/models" %}})
|
||||
- [Examples](https://github.com/mudler/LocalAI/tree/master/examples#examples)
|
||||
@@ -9,16 +9,16 @@ icon = "rocket_launch"
|
||||
|
||||
Once LocalAI is installed, you can start it (either by using docker, or the cli, or the systemd service).
|
||||
|
||||
By default the LocalAI WebUI should be accessible from http://localhost:8080. You can also use 3rd party projects to interact with LocalAI as you would use OpenAI (see also [Integrations]({{%relref "docs/integrations" %}}) ).
|
||||
By default the LocalAI WebUI should be accessible from http://localhost:8080. You can also use 3rd party projects to interact with LocalAI as you would use OpenAI (see also [Integrations]({{%relref "integrations" %}}) ).
|
||||
|
||||
After installation, install new models by navigating the model gallery, or by using the `local-ai` CLI.
|
||||
|
||||
{{% alert icon="🚀" %}}
|
||||
To install models with the WebUI, see the [Models section]({{%relref "docs/features/model-gallery" %}}).
|
||||
{{% notice tip %}}
|
||||
To install models with the WebUI, see the [Models section]({{%relref "features/model-gallery" %}}).
|
||||
With the CLI you can list the models with `local-ai models list` and install them with `local-ai models install <model-name>`.
|
||||
|
||||
You can also [run models manually]({{%relref "docs/getting-started/models" %}}) by copying files into the `models` directory.
|
||||
{{% /alert %}}
|
||||
You can also [run models manually]({{%relref "getting-started/models" %}}) by copying files into the `models` directory.
|
||||
{{% /notice %}}
|
||||
|
||||
You can test out the API endpoints using `curl`, few examples are listed below. The models we are referring here (`gpt-4`, `gpt-4-vision-preview`, `tts-1`, `whisper-1`) are the default models that come with the AIO images - you can also use any other model you have installed.
|
||||
|
||||
@@ -187,10 +187,10 @@ curl http://localhost:8080/embeddings \
|
||||
|
||||
</details>
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
{{% notice tip %}}
|
||||
|
||||
Don't use the model file as `model` in the request unless you want to handle the prompt template for yourself.
|
||||
|
||||
Use the model names like you would do with OpenAI like in the examples below. For instance `gpt-4-vision-preview`, or `gpt-4`.
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
41
docs/content/installation/_index.en.md
Normal file
41
docs/content/installation/_index.en.md
Normal file
@@ -0,0 +1,41 @@
|
||||
---
|
||||
weight: 2
|
||||
title: "Installation"
|
||||
description: "How to install LocalAI"
|
||||
type: chapter
|
||||
icon: download
|
||||
---
|
||||
|
||||
LocalAI can be installed in multiple ways depending on your platform and preferences.
|
||||
|
||||
{{% notice tip %}}
|
||||
**Recommended: Docker Installation**
|
||||
|
||||
**Docker is the recommended installation method** for most users as it works across all platforms (Linux, macOS, Windows) and provides the easiest setup experience. It's the fastest way to get started with LocalAI.
|
||||
{{% /notice %}}
|
||||
|
||||
## Installation Methods
|
||||
|
||||
Choose the installation method that best suits your needs:
|
||||
|
||||
1. **[Docker](docker/)** ⭐ **Recommended** - Works on all platforms, easiest setup
|
||||
2. **[macOS](macos/)** - Download and install the DMG application
|
||||
3. **[Linux](linux/)** - Install on Linux using the one-liner script or binaries
|
||||
4. **[Kubernetes](kubernetes/)** - Deploy LocalAI on Kubernetes clusters
|
||||
5. **[Build from Source](build/)** - Build LocalAI from source code
|
||||
|
||||
## Quick Start
|
||||
|
||||
**Recommended: Docker (works on all platforms)**
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest
|
||||
```
|
||||
|
||||
This will start LocalAI. The API will be available at `http://localhost:8080`. For images with pre-configured models, see [All-in-One images](/getting-started/container-images/#all-in-one-images).
|
||||
|
||||
For other platforms:
|
||||
- **macOS**: Download the [DMG](macos/)
|
||||
- **Linux**: Use the `curl https://localai.io/install.sh | sh` [one-liner](linux/)
|
||||
|
||||
For detailed instructions, see the [Docker installation guide](docker/).
|
||||
@@ -1,12 +1,12 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Build LocalAI from source"
|
||||
weight = 6
|
||||
title = "Build LocalAI"
|
||||
icon = "model_training"
|
||||
weight = 5
|
||||
url = '/basics/build/'
|
||||
ico = "rocket_launch"
|
||||
+++
|
||||
|
||||
|
||||
### Build
|
||||
|
||||
LocalAI can be built as a container image or as a single, portable binary. Note that some model architectures might require Python libraries, which are not included in the binary.
|
||||
@@ -27,8 +27,8 @@ In order to build LocalAI locally, you need the following requirements:
|
||||
|
||||
To install the dependencies follow the instructions below:
|
||||
|
||||
{{< tabs tabTotal="3" >}}
|
||||
{{% tab tabName="Apple" %}}
|
||||
{{< tabs >}}
|
||||
{{% tab title="Apple" %}}
|
||||
|
||||
Install `xcode` from the App Store
|
||||
|
||||
@@ -37,7 +37,7 @@ brew install go protobuf protoc-gen-go protoc-gen-go-grpc wget
|
||||
```
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="Debian" %}}
|
||||
{{% tab title="Debian" %}}
|
||||
|
||||
```bash
|
||||
apt install golang make protobuf-compiler-grpc
|
||||
@@ -52,7 +52,7 @@ go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@1958fcbe2ca8bd93af633f1
|
||||
```
|
||||
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="From source" %}}
|
||||
{{% tab title="From source" %}}
|
||||
|
||||
```bash
|
||||
make build
|
||||
@@ -81,7 +81,6 @@ Requirements:
|
||||
In order to build the `LocalAI` container image locally you can use `docker`, for example:
|
||||
|
||||
```
|
||||
# build the image
|
||||
docker build -t localai .
|
||||
docker run localai
|
||||
```
|
||||
@@ -95,30 +94,22 @@ The below has been tested by one mac user and found to work. Note that this does
|
||||
Install `xcode` from the Apps Store (needed for metalkit)
|
||||
|
||||
```
|
||||
# install build dependencies
|
||||
brew install abseil cmake go grpc protobuf wget protoc-gen-go protoc-gen-go-grpc
|
||||
|
||||
# clone the repo
|
||||
git clone https://github.com/go-skynet/LocalAI.git
|
||||
|
||||
cd LocalAI
|
||||
|
||||
# build the binary
|
||||
make build
|
||||
|
||||
# Download phi-2 to models/
|
||||
wget https://huggingface.co/TheBloke/phi-2-GGUF/resolve/main/phi-2.Q2_K.gguf -O models/phi-2.Q2_K
|
||||
|
||||
# Use a template from the examples
|
||||
cp -rf prompt-templates/ggml-gpt4all-j.tmpl models/phi-2.Q2_K.tmpl
|
||||
|
||||
# Install the llama-cpp backend
|
||||
./local-ai backends install llama-cpp
|
||||
|
||||
# Run LocalAI
|
||||
./local-ai --models-path=./models/ --debug=true
|
||||
|
||||
# Now API is accessible at localhost:8080
|
||||
curl http://localhost:8080/v1/models
|
||||
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
@@ -135,10 +126,8 @@ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/jso
|
||||
- After the installation of Xcode, if you receive a xcrun error `'xcrun: error: unable to find utility "metal", not a developer tool or in PATH'`. You might have installed the Xcode command line tools before installing Xcode, the former one is pointing to an incomplete SDK.
|
||||
|
||||
```
|
||||
# print /Library/Developer/CommandLineTools, if command line tools were installed in advance
|
||||
xcode-select --print-path
|
||||
|
||||
# point to a complete SDK
|
||||
sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer
|
||||
```
|
||||
|
||||
@@ -147,7 +136,6 @@ sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer
|
||||
- If you get a compile error: `error: only virtual member functions can be marked 'final'`, reinstall all the necessary brew packages, clean the build, and try again.
|
||||
|
||||
```
|
||||
# reinstall build dependencies
|
||||
brew reinstall go grpc protobuf wget
|
||||
|
||||
make clean
|
||||
@@ -168,10 +156,8 @@ In the LocalAI repository, for instance you can build `bark-cpp` by doing:
|
||||
```
|
||||
git clone https://github.com/go-skynet/LocalAI.git
|
||||
|
||||
# Build the bark-cpp backend (requires cmake)
|
||||
make -C LocalAI/backend/go/bark-cpp build package
|
||||
|
||||
# Build vllm backend (requires python)
|
||||
make -C LocalAI/backend/python/vllm
|
||||
```
|
||||
|
||||
@@ -184,7 +170,6 @@ In the LocalAI repository, you can build `bark-cpp` by doing:
|
||||
```
|
||||
git clone https://github.com/go-skynet/LocalAI.git
|
||||
|
||||
# Build the bark-cpp backend (requires docker)
|
||||
make docker-build-bark-cpp
|
||||
```
|
||||
|
||||
241
docs/content/installation/docker.md
Normal file
241
docs/content/installation/docker.md
Normal file
@@ -0,0 +1,241 @@
|
||||
---
|
||||
title: "Docker Installation"
|
||||
description: "Install LocalAI using Docker containers - the recommended installation method"
|
||||
weight: 1
|
||||
url: '/installation/docker/'
|
||||
---
|
||||
|
||||
{{% notice tip %}}
|
||||
**Recommended Installation Method**
|
||||
|
||||
Docker is the recommended way to install LocalAI as it works across all platforms (Linux, macOS, Windows) and provides the easiest setup experience.
|
||||
{{% /notice %}}
|
||||
|
||||
LocalAI provides Docker images that work with Docker, Podman, and other container engines. These images are available on [Docker Hub](https://hub.docker.com/r/localai/localai) and [Quay.io](https://quay.io/repository/go-skynet/local-ai).
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before you begin, ensure you have Docker or Podman installed:
|
||||
|
||||
- [Install Docker Desktop](https://docs.docker.com/get-docker/) (Mac, Windows, Linux)
|
||||
- [Install Podman](https://podman.io/getting-started/installation) (Linux alternative)
|
||||
- [Install Docker Engine](https://docs.docker.com/engine/install/) (Linux servers)
|
||||
|
||||
## Quick Start
|
||||
|
||||
The fastest way to get started is with the CPU image:
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest
|
||||
```
|
||||
|
||||
This will:
|
||||
- Start LocalAI (you'll need to install models separately)
|
||||
- Make the API available at `http://localhost:8080`
|
||||
|
||||
{{% notice tip %}}
|
||||
**Docker Run vs Docker Start**
|
||||
|
||||
- `docker run` creates and starts a new container. If a container with the same name already exists, this command will fail.
|
||||
- `docker start` starts an existing container that was previously created with `docker run`.
|
||||
|
||||
If you've already run LocalAI before and want to start it again, use: `docker start -i local-ai`
|
||||
{{% /notice %}}
|
||||
|
||||
## Image Types
|
||||
|
||||
LocalAI provides several image types to suit different needs:
|
||||
|
||||
### Standard Images
|
||||
|
||||
Standard images don't include pre-configured models. Use these if you want to configure models manually.
|
||||
|
||||
#### CPU Image
|
||||
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest
|
||||
```
|
||||
|
||||
#### GPU Images
|
||||
|
||||
**NVIDIA CUDA 12:**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12
|
||||
```
|
||||
|
||||
**NVIDIA CUDA 11:**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-11
|
||||
```
|
||||
|
||||
**AMD GPU (ROCm):**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --device=/dev/kfd --device=/dev/dri --group-add=video localai/localai:latest-gpu-hipblas
|
||||
```
|
||||
|
||||
**Intel GPU:**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-gpu-intel
|
||||
```
|
||||
|
||||
**Vulkan:**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-gpu-vulkan
|
||||
```
|
||||
|
||||
**NVIDIA Jetson (L4T ARM64):**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --runtime nvidia --gpus all localai/localai:latest-nvidia-l4t-arm64
|
||||
```
|
||||
|
||||
### All-in-One (AIO) Images
|
||||
|
||||
**Recommended for beginners** - These images come pre-configured with models and backends, ready to use immediately.
|
||||
|
||||
#### CPU Image
|
||||
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-cpu
|
||||
```
|
||||
|
||||
#### GPU Images
|
||||
|
||||
**NVIDIA CUDA 12:**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-aio-gpu-nvidia-cuda-12
|
||||
```
|
||||
|
||||
**NVIDIA CUDA 11:**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-aio-gpu-nvidia-cuda-11
|
||||
```
|
||||
|
||||
**AMD GPU (ROCm):**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 --device=/dev/kfd --device=/dev/dri --group-add=video localai/localai:latest-aio-gpu-hipblas
|
||||
```
|
||||
|
||||
**Intel GPU:**
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-gpu-intel
|
||||
```
|
||||
|
||||
## Using Docker Compose
|
||||
|
||||
For a more manageable setup, especially with persistent volumes, use Docker Compose:
|
||||
|
||||
```yaml
|
||||
version: "3.9"
|
||||
services:
|
||||
api:
|
||||
image: localai/localai:latest-aio-cpu
|
||||
# For GPU support, use one of:
|
||||
# image: localai/localai:latest-aio-gpu-nvidia-cuda-12
|
||||
# image: localai/localai:latest-aio-gpu-nvidia-cuda-11
|
||||
# image: localai/localai:latest-aio-gpu-hipblas
|
||||
# image: localai/localai:latest-aio-gpu-intel
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
|
||||
interval: 1m
|
||||
timeout: 20m
|
||||
retries: 5
|
||||
ports:
|
||||
- 8080:8080
|
||||
environment:
|
||||
- DEBUG=true
|
||||
volumes:
|
||||
- ./models:/models:cached
|
||||
# For NVIDIA GPUs, uncomment:
|
||||
# deploy:
|
||||
# resources:
|
||||
# reservations:
|
||||
# devices:
|
||||
# - driver: nvidia
|
||||
# count: 1
|
||||
# capabilities: [gpu]
|
||||
```
|
||||
|
||||
Save this as `docker-compose.yml` and run:
|
||||
|
||||
```bash
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
## Persistent Storage
|
||||
|
||||
To persist models and configurations, mount a volume:
|
||||
|
||||
```bash
|
||||
docker run -ti --name local-ai -p 8080:8080 \
|
||||
-v $PWD/models:/models \
|
||||
localai/localai:latest-aio-cpu
|
||||
```
|
||||
|
||||
Or use a named volume:
|
||||
|
||||
```bash
|
||||
docker volume create localai-models
|
||||
docker run -ti --name local-ai -p 8080:8080 \
|
||||
-v localai-models:/models \
|
||||
localai/localai:latest-aio-cpu
|
||||
```
|
||||
|
||||
## What's Included in AIO Images
|
||||
|
||||
All-in-One images come pre-configured with:
|
||||
|
||||
- **Text Generation**: LLM models for chat and completion
|
||||
- **Image Generation**: Stable Diffusion models
|
||||
- **Text to Speech**: TTS models
|
||||
- **Speech to Text**: Whisper models
|
||||
- **Embeddings**: Vector embedding models
|
||||
- **Function Calling**: Support for OpenAI-compatible function calling
|
||||
|
||||
The AIO images use OpenAI-compatible model names (like `gpt-4`, `gpt-4-vision-preview`) but are backed by open-source models. See the [container images documentation](/getting-started/container-images/#all-in-one-images) for the complete mapping.
|
||||
|
||||
## Next Steps
|
||||
|
||||
After installation:
|
||||
|
||||
1. Access the WebUI at `http://localhost:8080`
|
||||
2. Check available models: `curl http://localhost:8080/v1/models`
|
||||
3. [Install additional models](/getting-started/models/)
|
||||
4. [Try out examples](/getting-started/try-it-out/)
|
||||
|
||||
## Advanced Configuration
|
||||
|
||||
For detailed information about:
|
||||
- All available image tags and versions
|
||||
- Advanced Docker configuration options
|
||||
- Custom image builds
|
||||
- Backend management
|
||||
|
||||
See the [Container Images documentation](/getting-started/container-images/).
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Container won't start
|
||||
|
||||
- Check Docker is running: `docker ps`
|
||||
- Check port 8080 is available: `netstat -an | grep 8080` (Linux/Mac)
|
||||
- View logs: `docker logs local-ai`
|
||||
|
||||
### GPU not detected
|
||||
|
||||
- Ensure Docker has GPU access: `docker run --rm --gpus all nvidia/cuda:12.0.0-base-ubuntu22.04 nvidia-smi`
|
||||
- For NVIDIA: Install [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html)
|
||||
- For AMD: Ensure devices are accessible: `ls -la /dev/kfd /dev/dri`
|
||||
|
||||
### Models not downloading
|
||||
|
||||
- Check internet connection
|
||||
- Verify disk space: `df -h`
|
||||
- Check Docker logs for errors: `docker logs local-ai`
|
||||
|
||||
## See Also
|
||||
|
||||
- [Container Images Reference](/getting-started/container-images/) - Complete image reference
|
||||
- [Install Models](/getting-started/models/) - Install and configure models
|
||||
- [GPU Acceleration](/features/gpu-acceleration/) - GPU setup and optimization
|
||||
- [Kubernetes Installation](/installation/kubernetes/) - Deploy on Kubernetes
|
||||
|
||||
31
docs/content/installation/kubernetes.md
Normal file
31
docs/content/installation/kubernetes.md
Normal file
@@ -0,0 +1,31 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Run with Kubernetes"
|
||||
weight = 4
|
||||
url = '/basics/kubernetes/'
|
||||
ico = "rocket_launch"
|
||||
+++
|
||||
|
||||
|
||||
For installing LocalAI in Kubernetes, the deployment file from the `examples` can be used and customized as preferred:
|
||||
|
||||
```
|
||||
kubectl apply -f https://raw.githubusercontent.com/mudler/LocalAI-examples/refs/heads/main/kubernetes/deployment.yaml
|
||||
```
|
||||
|
||||
For Nvidia GPUs:
|
||||
|
||||
```
|
||||
kubectl apply -f https://raw.githubusercontent.com/mudler/LocalAI-examples/refs/heads/main/kubernetes/deployment-nvidia.yaml
|
||||
```
|
||||
|
||||
Alternatively, the [helm chart](https://github.com/go-skynet/helm-charts) can be used as well:
|
||||
|
||||
```bash
|
||||
helm repo add go-skynet https://go-skynet.github.io/helm-charts/
|
||||
helm repo update
|
||||
helm show values go-skynet/local-ai > values.yaml
|
||||
|
||||
|
||||
helm install local-ai go-skynet/local-ai -f values.yaml
|
||||
```
|
||||
105
docs/content/installation/linux.md
Normal file
105
docs/content/installation/linux.md
Normal file
@@ -0,0 +1,105 @@
|
||||
---
|
||||
title: "Linux Installation"
|
||||
description: "Install LocalAI on Linux using the installer script or binaries"
|
||||
weight: 3
|
||||
url: '/installation/linux/'
|
||||
---
|
||||
|
||||
|
||||
## One-Line Installer (Recommended)
|
||||
|
||||
The fastest way to install LocalAI on Linux is with the installation script:
|
||||
|
||||
```bash
|
||||
curl https://localai.io/install.sh | sh
|
||||
```
|
||||
|
||||
This script will:
|
||||
- Detect your system architecture
|
||||
- Download the appropriate LocalAI binary
|
||||
- Set up the necessary configuration
|
||||
- Start LocalAI automatically
|
||||
|
||||
### Installer Configuration Options
|
||||
|
||||
The installer can be configured using environment variables:
|
||||
|
||||
```bash
|
||||
curl https://localai.io/install.sh | VAR=value sh
|
||||
```
|
||||
|
||||
#### Environment Variables
|
||||
|
||||
| Environment Variable | Description |
|
||||
|----------------------|-------------|
|
||||
| **DOCKER_INSTALL** | Set to `"true"` to enable the installation of Docker images |
|
||||
| **USE_AIO** | Set to `"true"` to use the all-in-one LocalAI Docker image |
|
||||
| **USE_VULKAN** | Set to `"true"` to use Vulkan GPU support |
|
||||
| **API_KEY** | Specify an API key for accessing LocalAI, if required |
|
||||
| **PORT** | Specifies the port on which LocalAI will run (default is 8080) |
|
||||
| **THREADS** | Number of processor threads the application should use. Defaults to the number of logical cores minus one |
|
||||
| **VERSION** | Specifies the version of LocalAI to install. Defaults to the latest available version |
|
||||
| **MODELS_PATH** | Directory path where LocalAI models are stored (default is `/usr/share/local-ai/models`) |
|
||||
| **P2P_TOKEN** | Token to use for the federation or for starting workers. See [distributed inferencing documentation]({{%relref "features/distributed_inferencing" %}}) |
|
||||
| **WORKER** | Set to `"true"` to make the instance a worker (p2p token is required) |
|
||||
| **FEDERATED** | Set to `"true"` to share the instance with the federation (p2p token is required) |
|
||||
| **FEDERATED_SERVER** | Set to `"true"` to run the instance as a federation server which forwards requests to the federation (p2p token is required) |
|
||||
|
||||
#### Image Selection
|
||||
|
||||
The installer will automatically detect your GPU and select the appropriate image. By default, it uses the standard images without extra Python dependencies. You can customize the image selection:
|
||||
|
||||
- `USE_AIO=true`: Use all-in-one images that include all dependencies
|
||||
- `USE_VULKAN=true`: Use Vulkan GPU support instead of vendor-specific GPU support
|
||||
|
||||
#### Uninstallation
|
||||
|
||||
To uninstall LocalAI installed via the script:
|
||||
|
||||
```bash
|
||||
curl https://localai.io/install.sh | sh -s -- --uninstall
|
||||
```
|
||||
|
||||
## Manual Installation
|
||||
|
||||
### Download Binary
|
||||
|
||||
You can manually download the appropriate binary for your system from the [releases page](https://github.com/mudler/LocalAI/releases):
|
||||
|
||||
1. Go to [GitHub Releases](https://github.com/mudler/LocalAI/releases)
|
||||
2. Download the binary for your architecture (amd64, arm64, etc.)
|
||||
3. Make it executable:
|
||||
|
||||
```bash
|
||||
chmod +x local-ai-*
|
||||
```
|
||||
|
||||
4. Run LocalAI:
|
||||
|
||||
```bash
|
||||
./local-ai-*
|
||||
```
|
||||
|
||||
### System Requirements
|
||||
|
||||
Hardware requirements vary based on:
|
||||
- Model size
|
||||
- Quantization method
|
||||
- Backend used
|
||||
|
||||
For performance benchmarks with different backends like `llama.cpp`, visit [this link](https://github.com/ggerganov/llama.cpp#memorydisk-requirements).
|
||||
|
||||
## Configuration
|
||||
|
||||
After installation, you can:
|
||||
|
||||
- Access the WebUI at `http://localhost:8080`
|
||||
- Configure models in the models directory
|
||||
- Customize settings via environment variables or config files
|
||||
|
||||
## Next Steps
|
||||
|
||||
- [Try it out with examples](/basics/try/)
|
||||
- [Learn about available models](/models/)
|
||||
- [Configure GPU acceleration](/features/gpu-acceleration/)
|
||||
- [Customize your configuration](/advanced/model-configuration/)
|
||||
40
docs/content/installation/macos.md
Normal file
40
docs/content/installation/macos.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
title: "macOS Installation"
|
||||
description: "Install LocalAI on macOS using the DMG application"
|
||||
weight: 1
|
||||
---
|
||||
|
||||
|
||||
The easiest way to install LocalAI on macOS is using the DMG application.
|
||||
|
||||
## Download
|
||||
|
||||
Download the latest DMG from GitHub releases:
|
||||
|
||||
<a href="https://github.com/mudler/LocalAI/releases/latest/download/LocalAI.dmg">
|
||||
<img src="https://img.shields.io/badge/Download-macOS-blue?style=for-the-badge&logo=apple&logoColor=white" alt="Download LocalAI for macOS"/>
|
||||
</a>
|
||||
|
||||
## Installation Steps
|
||||
|
||||
1. Download the `LocalAI.dmg` file from the link above
|
||||
2. Open the downloaded DMG file
|
||||
3. Drag the LocalAI application to your Applications folder
|
||||
4. Launch LocalAI from your Applications folder
|
||||
|
||||
## Known Issues
|
||||
|
||||
> **Note**: The DMGs are not signed by Apple and may show as quarantined.
|
||||
>
|
||||
> **Workaround**: See [this issue](https://github.com/mudler/LocalAI/issues/6268) for details on how to bypass the quarantine.
|
||||
>
|
||||
> **Fix tracking**: The signing issue is being tracked in [this issue](https://github.com/mudler/LocalAI/issues/6244).
|
||||
|
||||
## Next Steps
|
||||
|
||||
After installing LocalAI, you can:
|
||||
|
||||
- Access the WebUI at `http://localhost:8080`
|
||||
- [Try it out with examples](/basics/try/)
|
||||
- [Learn about available models](/models/)
|
||||
- [Customize your configuration](/advanced/model-configuration/)
|
||||
@@ -5,11 +5,11 @@ toc = true
|
||||
description = "What is LocalAI?"
|
||||
tags = ["Beginners"]
|
||||
categories = [""]
|
||||
url = "/docs/overview"
|
||||
author = "Ettore Di Giacinto"
|
||||
icon = "info"
|
||||
+++
|
||||
|
||||
# Welcome to LocalAI
|
||||
|
||||
LocalAI is your complete AI stack for running AI models locally. It's designed to be simple, efficient, and accessible, providing a drop-in replacement for OpenAI's API while keeping your data private and secure.
|
||||
|
||||
@@ -51,34 +51,17 @@ LocalAI is more than just a single tool - it's a complete ecosystem:
|
||||
|
||||
## Getting Started
|
||||
|
||||
LocalAI can be installed in several ways. **Docker is the recommended installation method** for most users as it provides the easiest setup and works across all platforms.
|
||||
|
||||
### macOS Download
|
||||
### Recommended: Docker Installation
|
||||
|
||||
You can use the DMG application for Mac:
|
||||
|
||||
<a href="https://github.com/mudler/LocalAI/releases/latest/download/LocalAI.dmg">
|
||||
<img src="https://img.shields.io/badge/Download-macOS-blue?style=for-the-badge&logo=apple&logoColor=white" alt="Download LocalAI for macOS"/>
|
||||
</a>
|
||||
|
||||
> Note: the DMGs are not signed by Apple shows as quarantined. See https://github.com/mudler/LocalAI/issues/6268 for a workaround, fix is tracked here: https://github.com/mudler/LocalAI/issues/6244
|
||||
|
||||
## Docker
|
||||
|
||||
You can use Docker for a quick start:
|
||||
The quickest way to get started with LocalAI is using Docker:
|
||||
|
||||
```bash
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest-aio-cpu
|
||||
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest
|
||||
```
|
||||
|
||||
For more detailed installation options and configurations, see our [Getting Started guide]({{% relref "docs/getting-started/quickstart" %}}).
|
||||
|
||||
## One-liner
|
||||
|
||||
The fastest way to get started is with our one-line installer (Linux):
|
||||
|
||||
```bash
|
||||
curl https://localai.io/install.sh | sh
|
||||
```
|
||||
For complete installation instructions including Docker, macOS, Linux, Kubernetes, and building from source, see the [Installation guide](/installation/).
|
||||
|
||||
## Key Features
|
||||
|
||||
@@ -104,9 +87,9 @@ LocalAI is a community-driven project. You can:
|
||||
|
||||
Ready to dive in? Here are some recommended next steps:
|
||||
|
||||
1. [Install LocalAI]({{% relref "docs/getting-started/quickstart" %}})
|
||||
1. **[Install LocalAI](/installation/)** - Start with [Docker installation](/installation/docker/) (recommended) or choose another method
|
||||
2. [Explore available models](https://models.localai.io)
|
||||
3. [Model compatibility]({{% relref "docs/reference/compatibility-table" %}})
|
||||
3. [Model compatibility](/model-compatibility/)
|
||||
4. [Try out examples](https://github.com/mudler/LocalAI-examples)
|
||||
5. [Join the community](https://discord.gg/uJAeKSAGDy)
|
||||
6. [Check the LocalAI Github repository](https://github.com/mudler/LocalAI)
|
||||
@@ -2,6 +2,7 @@
|
||||
weight: 23
|
||||
title: "References"
|
||||
description: "Reference"
|
||||
type: chapter
|
||||
icon: menu_book
|
||||
lead: ""
|
||||
date: 2020-10-06T08:49:15+00:00
|
||||
@@ -7,7 +7,7 @@ weight = 25
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||
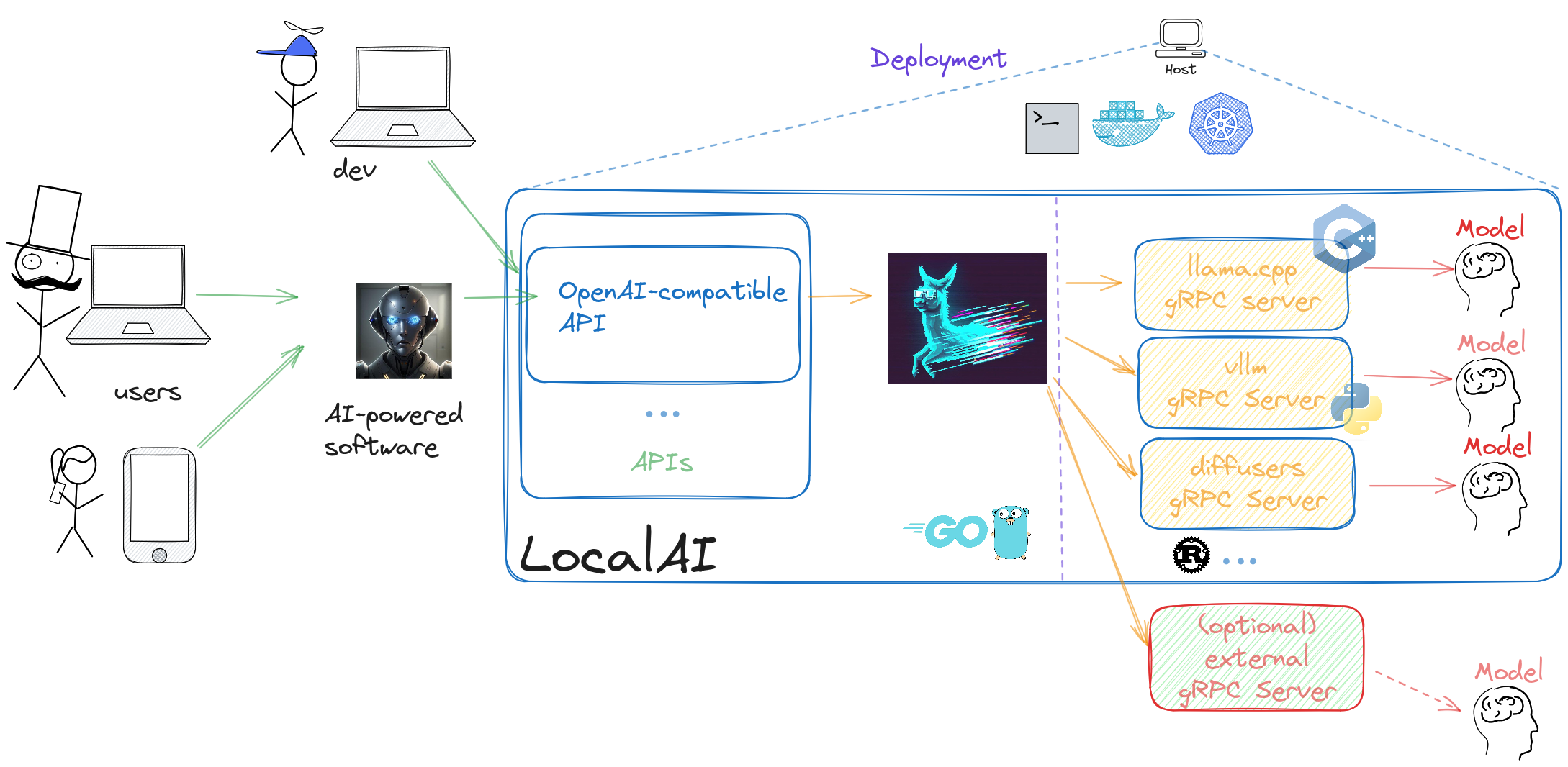
|
||||
|
||||
@@ -32,10 +32,10 @@ Otherwise, here are the links to the binaries:
|
||||
| MacOS (arm64) | [Download](https://github.com/mudler/LocalAI/releases/download/{{< version >}}/local-ai-Darwin-arm64) |
|
||||
|
||||
|
||||
{{% alert icon="⚡" context="warning" %}}
|
||||
{{% notice icon="⚡" context="warning" %}}
|
||||
Binaries do have limited support compared to container images:
|
||||
|
||||
- Python-based backends are not shipped with binaries (e.g. `bark`, `diffusers` or `transformers`)
|
||||
- MacOS binaries and Linux-arm64 do not ship TTS nor `stablediffusion-cpp` backends
|
||||
- Linux binaries do not ship `stablediffusion-cpp` backend
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
@@ -7,21 +7,18 @@ url = '/reference/cli-reference'
|
||||
|
||||
Complete reference for all LocalAI command-line interface (CLI) parameters and environment variables.
|
||||
|
||||
> **Note:** All CLI flags can also be set via environment variables. Environment variables take precedence over CLI flags. See [.env files]({{%relref "docs/advanced/advanced-usage#env-files" %}}) for configuration file support.
|
||||
> **Note:** All CLI flags can also be set via environment variables. Environment variables take precedence over CLI flags. See [.env files]({{%relref "advanced/advanced-usage#env-files" %}}) for configuration file support.
|
||||
|
||||
## Global Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `-h, --help` | | Show context-sensitive help | |
|
||||
| `--log-level` | `info` | Set the level of logs to output [error,warn,info,debug,trace] | `$LOCALAI_LOG_LEVEL` |
|
||||
| `--debug` | `false` | **DEPRECATED** - Use `--log-level=debug` instead. Enable debug logging | `$LOCALAI_DEBUG`, `$DEBUG` |
|
||||
{{< /table >}}
|
||||
|
||||
## Storage Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `--models-path` | `BASEPATH/models` | Path containing models used for inferencing | `$LOCALAI_MODELS_PATH`, `$MODELS_PATH` |
|
||||
@@ -30,11 +27,9 @@ Complete reference for all LocalAI command-line interface (CLI) parameters and e
|
||||
| `--localai-config-dir` | `BASEPATH/configuration` | Directory for dynamic loading of certain configuration files (currently api_keys.json and external_backends.json) | `$LOCALAI_CONFIG_DIR` |
|
||||
| `--localai-config-dir-poll-interval` | | Time duration to poll the LocalAI Config Dir if your system has broken fsnotify events (example: `1m`) | `$LOCALAI_CONFIG_DIR_POLL_INTERVAL` |
|
||||
| `--models-config-file` | | YAML file containing a list of model backend configs (alias: `--config-file`) | `$LOCALAI_MODELS_CONFIG_FILE`, `$CONFIG_FILE` |
|
||||
{{< /table >}}
|
||||
|
||||
## Backend Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `--backends-path` | `BASEPATH/backends` | Path containing backends used for inferencing | `$LOCALAI_BACKENDS_PATH`, `$BACKENDS_PATH` |
|
||||
@@ -50,13 +45,11 @@ Complete reference for all LocalAI command-line interface (CLI) parameters and e
|
||||
| `--watchdog-idle-timeout` | `15m` | Threshold beyond which an idle backend should be stopped | `$LOCALAI_WATCHDOG_IDLE_TIMEOUT`, `$WATCHDOG_IDLE_TIMEOUT` |
|
||||
| `--enable-watchdog-busy` | `false` | Enable watchdog for stopping backends that are busy longer than the watchdog-busy-timeout | `$LOCALAI_WATCHDOG_BUSY`, `$WATCHDOG_BUSY` |
|
||||
| `--watchdog-busy-timeout` | `5m` | Threshold beyond which a busy backend should be stopped | `$LOCALAI_WATCHDOG_BUSY_TIMEOUT`, `$WATCHDOG_BUSY_TIMEOUT` |
|
||||
{{< /table >}}
|
||||
|
||||
For more information on VRAM management, see [VRAM and Memory Management]({{%relref "docs/advanced/vram-management" %}}).
|
||||
For more information on VRAM management, see [VRAM and Memory Management]({{%relref "advanced/vram-management" %}}).
|
||||
|
||||
## Models Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `--galleries` | | JSON list of galleries | `$LOCALAI_GALLERIES`, `$GALLERIES` |
|
||||
@@ -65,23 +58,19 @@ For more information on VRAM management, see [VRAM and Memory Management]({{%rel
|
||||
| `--models` | | A list of model configuration URLs to load | `$LOCALAI_MODELS`, `$MODELS` |
|
||||
| `--preload-models-config` | | A list of models to apply at startup. Path to a YAML config file | `$LOCALAI_PRELOAD_MODELS_CONFIG`, `$PRELOAD_MODELS_CONFIG` |
|
||||
| `--load-to-memory` | | A list of models to load into memory at startup | `$LOCALAI_LOAD_TO_MEMORY`, `$LOAD_TO_MEMORY` |
|
||||
{{< /table >}}
|
||||
|
||||
> **Note:** You can also pass model configuration URLs as positional arguments: `local-ai run MODEL_URL1 MODEL_URL2 ...`
|
||||
|
||||
## Performance Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `--f16` | `false` | Enable GPU acceleration | `$LOCALAI_F16`, `$F16` |
|
||||
| `-t, --threads` | | Number of threads used for parallel computation. Usage of the number of physical cores in the system is suggested | `$LOCALAI_THREADS`, `$THREADS` |
|
||||
| `--context-size` | | Default context size for models | `$LOCALAI_CONTEXT_SIZE`, `$CONTEXT_SIZE` |
|
||||
{{< /table >}}
|
||||
|
||||
## API Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `--address` | `:8080` | Bind address for the API server | `$LOCALAI_ADDRESS`, `$ADDRESS` |
|
||||
@@ -94,11 +83,9 @@ For more information on VRAM management, see [VRAM and Memory Management]({{%rel
|
||||
| `--disable-gallery-endpoint` | `false` | Disable the gallery endpoints | `$LOCALAI_DISABLE_GALLERY_ENDPOINT`, `$DISABLE_GALLERY_ENDPOINT` |
|
||||
| `--disable-metrics-endpoint` | `false` | Disable the `/metrics` endpoint | `$LOCALAI_DISABLE_METRICS_ENDPOINT`, `$DISABLE_METRICS_ENDPOINT` |
|
||||
| `--machine-tag` | | If not empty, add that string to Machine-Tag header in each response. Useful to track response from different machines using multiple P2P federated nodes | `$LOCALAI_MACHINE_TAG`, `$MACHINE_TAG` |
|
||||
{{< /table >}}
|
||||
|
||||
## Hardening Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `--disable-predownload-scan` | `false` | If true, disables the best-effort security scanner before downloading any files | `$LOCALAI_DISABLE_PREDOWNLOAD_SCAN` |
|
||||
@@ -106,11 +93,9 @@ For more information on VRAM management, see [VRAM and Memory Management]({{%rel
|
||||
| `--use-subtle-key-comparison` | `false` | If true, API Key validation comparisons will be performed using constant-time comparisons rather than simple equality. This trades off performance on each request for resilience against timing attacks | `$LOCALAI_SUBTLE_KEY_COMPARISON` |
|
||||
| `--disable-api-key-requirement-for-http-get` | `false` | If true, a valid API key is not required to issue GET requests to portions of the web UI. This should only be enabled in secure testing environments | `$LOCALAI_DISABLE_API_KEY_REQUIREMENT_FOR_HTTP_GET` |
|
||||
| `--http-get-exempted-endpoints` | `^/$,^/browse/?$,^/talk/?$,^/p2p/?$,^/chat/?$,^/text2image/?$,^/tts/?$,^/static/.*$,^/swagger.*$` | If `--disable-api-key-requirement-for-http-get` is overridden to true, this is the list of endpoints to exempt. Only adjust this in case of a security incident or as a result of a personal security posture review | `$LOCALAI_HTTP_GET_EXEMPTED_ENDPOINTS` |
|
||||
{{< /table >}}
|
||||
|
||||
## P2P Flags
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Parameter | Default | Description | Environment Variable |
|
||||
|-----------|---------|-------------|----------------------|
|
||||
| `--p2p` | `false` | Enable P2P mode | `$LOCALAI_P2P`, `$P2P` |
|
||||
@@ -119,7 +104,6 @@ For more information on VRAM management, see [VRAM and Memory Management]({{%rel
|
||||
| `--p2ptoken` | | Token for P2P mode (optional) | `$LOCALAI_P2P_TOKEN`, `$P2P_TOKEN`, `$TOKEN` |
|
||||
| `--p2p-network-id` | | Network ID for P2P mode, can be set arbitrarily by the user for grouping a set of instances | `$LOCALAI_P2P_NETWORK_ID`, `$P2P_NETWORK_ID` |
|
||||
| `--federated` | `false` | Enable federated instance | `$LOCALAI_FEDERATED`, `$FEDERATED` |
|
||||
{{< /table >}}
|
||||
|
||||
## Other Commands
|
||||
|
||||
@@ -142,20 +126,16 @@ Use `local-ai <command> --help` for more information on each command.
|
||||
### Basic Usage
|
||||
|
||||
```bash
|
||||
# Start LocalAI with default settings
|
||||
./local-ai run
|
||||
|
||||
# Start with custom model path and address
|
||||
./local-ai run --models-path /path/to/models --address :9090
|
||||
|
||||
# Start with GPU acceleration
|
||||
./local-ai run --f16
|
||||
```
|
||||
|
||||
### Environment Variables
|
||||
|
||||
```bash
|
||||
# Using environment variables
|
||||
export LOCALAI_MODELS_PATH=/path/to/models
|
||||
export LOCALAI_ADDRESS=:9090
|
||||
export LOCALAI_F16=true
|
||||
@@ -165,7 +145,6 @@ export LOCALAI_F16=true
|
||||
### Advanced Configuration
|
||||
|
||||
```bash
|
||||
# Start with multiple models, watchdog, and P2P enabled
|
||||
./local-ai run \
|
||||
--models model1.yaml model2.yaml \
|
||||
--enable-watchdog-idle \
|
||||
@@ -176,6 +155,6 @@ export LOCALAI_F16=true
|
||||
|
||||
## Related Documentation
|
||||
|
||||
- See [Advanced Usage]({{%relref "docs/advanced/advanced-usage" %}}) for configuration examples
|
||||
- See [VRAM and Memory Management]({{%relref "docs/advanced/vram-management" %}}) for memory management options
|
||||
- See [Advanced Usage]({{%relref "advanced/advanced-usage" %}}) for configuration examples
|
||||
- See [VRAM and Memory Management]({{%relref "advanced/vram-management" %}}) for memory management options
|
||||
|
||||
@@ -8,29 +8,26 @@ url = "/model-compatibility/"
|
||||
|
||||
Besides llama based models, LocalAI is compatible also with other architectures. The table below lists all the backends, compatible models families and the associated repository.
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
|
||||
LocalAI will attempt to automatically load models which are not explicitly configured for a specific backend. You can specify the backend to use by configuring a model with a YAML file. See [the advanced section]({{%relref "docs/advanced" %}}) for more details.
|
||||
LocalAI will attempt to automatically load models which are not explicitly configured for a specific backend. You can specify the backend to use by configuring a model with a YAML file. See [the advanced section]({{%relref "advanced" %}}) for more details.
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
## Text Generation & Language Models
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Backend and Bindings | Compatible models | Completion/Chat endpoint | Capability | Embeddings support | Token stream support | Acceleration |
|
||||
|----------------------------------------------------------------------------------|-----------------------|--------------------------|---------------------------|-----------------------------------|----------------------|--------------|
|
||||
| [llama.cpp]({{%relref "docs/features/text-generation#llama.cpp" %}}) | LLama, Mamba, RWKV, Falcon, Starcoder, GPT-2, [and many others](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#description) | yes | GPT and Functions | yes | yes | CUDA 11/12, ROCm, Intel SYCL, Vulkan, Metal, CPU |
|
||||
| [llama.cpp]({{%relref "features/text-generation#llama.cpp" %}}) | LLama, Mamba, RWKV, Falcon, Starcoder, GPT-2, [and many others](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#description) | yes | GPT and Functions | yes | yes | CUDA 11/12, ROCm, Intel SYCL, Vulkan, Metal, CPU |
|
||||
| [vLLM](https://github.com/vllm-project/vllm) | Various GPTs and quantization formats | yes | GPT | no | no | CUDA 12, ROCm, Intel |
|
||||
| [transformers](https://github.com/huggingface/transformers) | Various GPTs and quantization formats | yes | GPT, embeddings, Audio generation | yes | yes* | CUDA 11/12, ROCm, Intel, CPU |
|
||||
| [exllama2](https://github.com/turboderp-org/exllamav2) | GPTQ | yes | GPT only | no | no | CUDA 12 |
|
||||
| [MLX](https://github.com/ml-explore/mlx-lm) | Various LLMs | yes | GPT | no | no | Metal (Apple Silicon) |
|
||||
| [MLX-VLM](https://github.com/Blaizzy/mlx-vlm) | Vision-Language Models | yes | Multimodal GPT | no | no | Metal (Apple Silicon) |
|
||||
| [langchain-huggingface](https://github.com/tmc/langchaingo) | Any text generators available on HuggingFace through API | yes | GPT | no | no | N/A |
|
||||
{{< /table >}}
|
||||
|
||||
## Audio & Speech Processing
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Backend and Bindings | Compatible models | Completion/Chat endpoint | Capability | Embeddings support | Token stream support | Acceleration |
|
||||
|----------------------------------------------------------------------------------|-----------------------|--------------------------|---------------------------|-----------------------------------|----------------------|--------------|
|
||||
| [whisper.cpp](https://github.com/ggml-org/whisper.cpp) | whisper | no | Audio transcription | no | no | CUDA 12, ROCm, Intel SYCL, Vulkan, CPU |
|
||||
@@ -45,28 +42,23 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
| [silero-vad](https://github.com/snakers4/silero-vad) with [Golang bindings](https://github.com/streamer45/silero-vad-go) | Silero VAD | no | Voice Activity Detection | no | no | CPU |
|
||||
| [neutts](https://github.com/neuphonic/neuttsair) | NeuTTSAir | no | Text-to-speech with voice cloning | no | no | CUDA 12, ROCm, CPU |
|
||||
| [mlx-audio](https://github.com/Blaizzy/mlx-audio) | MLX | no | Text-tospeech | no | no | Metal (Apple Silicon) |
|
||||
{{< /table >}}
|
||||
|
||||
## Image & Video Generation
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Backend and Bindings | Compatible models | Completion/Chat endpoint | Capability | Embeddings support | Token stream support | Acceleration |
|
||||
|----------------------------------------------------------------------------------|-----------------------|--------------------------|---------------------------|-----------------------------------|----------------------|--------------|
|
||||
| [stablediffusion.cpp](https://github.com/leejet/stable-diffusion.cpp) | stablediffusion-1, stablediffusion-2, stablediffusion-3, flux, PhotoMaker | no | Image | no | no | CUDA 12, Intel SYCL, Vulkan, CPU |
|
||||
| [diffusers](https://github.com/huggingface/diffusers) | SD, various diffusion models,... | no | Image/Video generation | no | no | CUDA 11/12, ROCm, Intel, Metal, CPU |
|
||||
| [transformers-musicgen](https://github.com/huggingface/transformers) | MusicGen | no | Audio generation | no | no | CUDA, CPU |
|
||||
{{< /table >}}
|
||||
|
||||
## Specialized AI Tasks
|
||||
|
||||
{{< table "table-responsive" >}}
|
||||
| Backend and Bindings | Compatible models | Completion/Chat endpoint | Capability | Embeddings support | Token stream support | Acceleration |
|
||||
|----------------------------------------------------------------------------------|-----------------------|--------------------------|---------------------------|-----------------------------------|----------------------|--------------|
|
||||
| [rfdetr](https://github.com/roboflow/rf-detr) | RF-DETR | no | Object Detection | no | no | CUDA 12, Intel, CPU |
|
||||
| [rerankers](https://github.com/AnswerDotAI/rerankers) | Reranking API | no | Reranking | no | no | CUDA 11/12, ROCm, Intel, CPU |
|
||||
| [local-store](https://github.com/mudler/LocalAI) | Vector database | no | Vector storage | yes | no | CPU |
|
||||
| [huggingface](https://huggingface.co/docs/hub/en/api) | HuggingFace API models | yes | Various AI tasks | yes | yes | API-based |
|
||||
{{< /table >}}
|
||||
|
||||
## Acceleration Support Summary
|
||||
|
||||
@@ -87,6 +79,6 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
- **Quantization**: 4-bit, 5-bit, 8-bit integer quantization support
|
||||
- **Mixed Precision**: F16/F32 mixed precision support
|
||||
|
||||
Note: any backend name listed above can be used in the `backend` field of the model configuration file (See [the advanced section]({{%relref "docs/advanced" %}})).
|
||||
Note: any backend name listed above can be used in the `backend` field of the model configuration file (See [the advanced section]({{%relref "advanced" %}})).
|
||||
|
||||
- \* Only for CUDA and OpenVINO CPU/XPU acceleration.
|
||||
@@ -1,60 +1,15 @@
|
||||
+++
|
||||
disableToc = false
|
||||
title = "What's New"
|
||||
title = "News"
|
||||
weight = 7
|
||||
url = '/basics/news/'
|
||||
icon = "newspaper"
|
||||
+++
|
||||
|
||||
Release notes have been moved to GitHub releases for the most up-to-date information.
|
||||
Release notes have been now moved completely over Github releases.
|
||||
|
||||
You can see all release notes [here](https://github.com/mudler/LocalAI/releases).
|
||||
You can see the release notes [here](https://github.com/mudler/LocalAI/releases).
|
||||
|
||||
## Recent Highlights
|
||||
|
||||
### 2025
|
||||
|
||||
**July 2025**: All backends migrated outside of the main binary. LocalAI is now more lightweight, small, and automatically downloads the required backend to run the model. [Read the release notes](https://github.com/mudler/LocalAI/releases/tag/v3.2.0)
|
||||
|
||||
**June 2025**: [Backend management](https://github.com/mudler/LocalAI/pull/5607) has been added. Attention: extras images are going to be deprecated from the next release! Read [the backend management PR](https://github.com/mudler/LocalAI/pull/5607).
|
||||
|
||||
**May 2025**: [Audio input](https://github.com/mudler/LocalAI/pull/5466) and [Reranking](https://github.com/mudler/LocalAI/pull/5396) in llama.cpp backend, [Realtime API](https://github.com/mudler/LocalAI/pull/5392), Support to Gemma, SmollVLM, and more multimodal models (available in the gallery).
|
||||
|
||||
**May 2025**: Important: image name changes [See release](https://github.com/mudler/LocalAI/releases/tag/v2.29.0)
|
||||
|
||||
**April 2025**: Rebrand, WebUI enhancements
|
||||
|
||||
**April 2025**: [LocalAGI](https://github.com/mudler/LocalAGI) and [LocalRecall](https://github.com/mudler/LocalRecall) join the LocalAI family stack.
|
||||
|
||||
**April 2025**: WebUI overhaul, AIO images updates
|
||||
|
||||
**February 2025**: Backend cleanup, Breaking changes, new backends (kokoro, OutelTTS, faster-whisper), Nvidia L4T images
|
||||
|
||||
**January 2025**: LocalAI model release: https://huggingface.co/mudler/LocalAI-functioncall-phi-4-v0.3, SANA support in diffusers: https://github.com/mudler/LocalAI/pull/4603
|
||||
|
||||
### 2024
|
||||
|
||||
**December 2024**: stablediffusion.cpp backend (ggml) added ( https://github.com/mudler/LocalAI/pull/4289 )
|
||||
|
||||
**November 2024**: Bark.cpp backend added ( https://github.com/mudler/LocalAI/pull/4287 )
|
||||
|
||||
**November 2024**: Voice activity detection models (**VAD**) added to the API: https://github.com/mudler/LocalAI/pull/4204
|
||||
|
||||
**October 2024**: Examples moved to [LocalAI-examples](https://github.com/mudler/LocalAI-examples)
|
||||
|
||||
**August 2024**: 🆕 FLUX-1, [P2P Explorer](https://explorer.localai.io)
|
||||
|
||||
**July 2024**: 🔥🔥 🆕 P2P Dashboard, LocalAI Federated mode and AI Swarms: https://github.com/mudler/LocalAI/pull/2723. P2P Global community pools: https://github.com/mudler/LocalAI/issues/3113
|
||||
|
||||
**May 2024**: 🔥🔥 Decentralized P2P llama.cpp: https://github.com/mudler/LocalAI/pull/2343 (peer2peer llama.cpp!) 👉 Docs https://localai.io/features/distribute/
|
||||
|
||||
**May 2024**: 🔥🔥 Distributed inferencing: https://github.com/mudler/LocalAI/pull/2324
|
||||
|
||||
**April 2024**: Reranker API: https://github.com/mudler/LocalAI/pull/2121
|
||||
|
||||
---
|
||||
|
||||
## Archive: Older Release Notes (2023 and earlier)
|
||||
|
||||
## 04-12-2023: __v2.0.0__
|
||||
|
||||
@@ -102,7 +57,7 @@ Thanks to @jespino now the local-ai binary has more subcommands allowing to mana
|
||||
|
||||
This is an exciting LocalAI release! Besides bug-fixes and enhancements this release brings the new backend to a whole new level by extending support to vllm and vall-e-x for audio generation!
|
||||
|
||||
Check out the documentation for vllm [here]({{% relref "docs/reference/compatibility-table" %}}) and Vall-E-X [here]({{% relref "docs/reference/compatibility-table" %}})
|
||||
Check out the documentation for vllm [here](https://localai.io/model-compatibility/vllm/) and Vall-E-X [here](https://localai.io/model-compatibility/vall-e-x/)
|
||||
|
||||
[Release notes](https://github.com/mudler/LocalAI/releases/tag/v1.30.0)
|
||||
|
||||
@@ -118,7 +73,7 @@ From this release the `llama` backend supports only `gguf` files (see {{< pr "94
|
||||
|
||||
### Image generation enhancements
|
||||
|
||||
The [Diffusers]({{%relref "docs/features/image-generation" %}}) backend got now various enhancements, including support to generate images from images, longer prompts, and support for more kernels schedulers. See the [Diffusers]({{%relref "docs/features/image-generation" %}}) documentation for more information.
|
||||
The [Diffusers]({{%relref "features/image-generation" %}}) backend got now various enhancements, including support to generate images from images, longer prompts, and support for more kernels schedulers. See the [Diffusers]({{%relref "features/image-generation" %}}) documentation for more information.
|
||||
|
||||
### Lora adapters
|
||||
|
||||
@@ -181,7 +136,7 @@ The full changelog is available [here](https://github.com/go-skynet/LocalAI/rele
|
||||
|
||||
## 🔥🔥🔥🔥 12-08-2023: __v1.24.0__ 🔥🔥🔥🔥
|
||||
|
||||
This is release brings four(!) new additional backends to LocalAI: [🐶 Bark]({{%relref "docs/features/text-to-audio#bark" %}}), 🦙 [AutoGPTQ]({{%relref "docs/features/text-generation#autogptq" %}}), [🧨 Diffusers]({{%relref "docs/features/image-generation" %}}), 🦙 [exllama]({{%relref "docs/features/text-generation#exllama" %}}) and a lot of improvements!
|
||||
This is release brings four(!) new additional backends to LocalAI: [🐶 Bark]({{%relref "features/text-to-audio#bark" %}}), 🦙 [AutoGPTQ]({{%relref "features/text-generation#autogptq" %}}), [🧨 Diffusers]({{%relref "features/image-generation" %}}), 🦙 [exllama]({{%relref "features/text-generation#exllama" %}}) and a lot of improvements!
|
||||
|
||||
### Major improvements:
|
||||
|
||||
@@ -193,23 +148,23 @@ This is release brings four(!) new additional backends to LocalAI: [🐶 Bark]({
|
||||
|
||||
### 🐶 Bark
|
||||
|
||||
[Bark]({{%relref "docs/features/text-to-audio#bark" %}}) is a text-prompted generative audio model - it combines GPT techniques to generate Audio from text. It is a great addition to LocalAI, and it's available in the container images by default.
|
||||
[Bark]({{%relref "features/text-to-audio#bark" %}}) is a text-prompted generative audio model - it combines GPT techniques to generate Audio from text. It is a great addition to LocalAI, and it's available in the container images by default.
|
||||
|
||||
It can also generate music, see the example: [lion.webm](https://user-images.githubusercontent.com/5068315/230684766-97f5ea23-ad99-473c-924b-66b6fab24289.webm)
|
||||
|
||||
### 🦙 AutoGPTQ
|
||||
|
||||
[AutoGPTQ]({{%relref "docs/features/text-generation#autogptq" %}}) is an easy-to-use LLMs quantization package with user-friendly apis, based on GPTQ algorithm.
|
||||
[AutoGPTQ]({{%relref "features/text-generation#autogptq" %}}) is an easy-to-use LLMs quantization package with user-friendly apis, based on GPTQ algorithm.
|
||||
|
||||
It is targeted mainly for GPU usage only. Check out the [ documentation]({{%relref "docs/features/text-generation" %}}) for usage.
|
||||
It is targeted mainly for GPU usage only. Check out the [ documentation]({{%relref "features/text-generation" %}}) for usage.
|
||||
|
||||
### 🦙 Exllama
|
||||
|
||||
[Exllama]({{%relref "docs/features/text-generation#exllama" %}}) is a "A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantized weights". It is a faster alternative to run LLaMA models on GPU.Check out the [Exllama documentation]({{%relref "docs/features/text-generation#exllama" %}}) for usage.
|
||||
[Exllama]({{%relref "features/text-generation#exllama" %}}) is a "A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantized weights". It is a faster alternative to run LLaMA models on GPU.Check out the [Exllama documentation]({{%relref "features/text-generation#exllama" %}}) for usage.
|
||||
|
||||
### 🧨 Diffusers
|
||||
|
||||
[Diffusers]({{%relref "docs/features/image-generation#diffusers" %}}) is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Currently it is experimental, and supports generation only of images so you might encounter some issues on models which weren't tested yet. Check out the [Diffusers documentation]({{%relref "docs/features/image-generation" %}}) for usage.
|
||||
[Diffusers]({{%relref "features/image-generation#diffusers" %}}) is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Currently it is experimental, and supports generation only of images so you might encounter some issues on models which weren't tested yet. Check out the [Diffusers documentation]({{%relref "features/image-generation" %}}) for usage.
|
||||
|
||||
### 🔑 API Keys
|
||||
|
||||
@@ -245,11 +200,11 @@ Most notably, this release brings important fixes for CUDA (and not only):
|
||||
* fix: select function calls if 'name' is set in the request by {{< github "mudler" >}} in {{< pr "827" >}}
|
||||
* fix: symlink libphonemize in the container by {{< github "mudler" >}} in {{< pr "831" >}}
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
|
||||
From this release [OpenAI functions]({{%relref "docs/features/openai-functions" %}}) are available in the `llama` backend. The `llama-grammar` has been deprecated. See also [OpenAI functions]({{%relref "docs/features/openai-functions" %}}).
|
||||
From this release [OpenAI functions]({{%relref "features/openai-functions" %}}) are available in the `llama` backend. The `llama-grammar` has been deprecated. See also [OpenAI functions]({{%relref "features/openai-functions" %}}).
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
The full [changelog is available here](https://github.com/go-skynet/LocalAI/releases/tag/v1.23.0)
|
||||
|
||||
@@ -263,15 +218,15 @@ The full [changelog is available here](https://github.com/go-skynet/LocalAI/rele
|
||||
* feat: backends improvements by {{< github "mudler" >}} in {{< pr "778" >}}
|
||||
* feat(llama2): add template for chat messages by {{< github "dave-gray101" >}} in {{< pr "782" >}}
|
||||
|
||||
{{% alert note %}}
|
||||
{{% notice note %}}
|
||||
|
||||
From this release to use the OpenAI functions you need to use the `llama-grammar` backend. It has been added a `llama` backend for tracking `llama.cpp` master and `llama-grammar` for the grammar functionalities that have not been merged yet upstream. See also [OpenAI functions]({{%relref "docs/features/openai-functions" %}}). Until the feature is merged we will have two llama backends.
|
||||
From this release to use the OpenAI functions you need to use the `llama-grammar` backend. It has been added a `llama` backend for tracking `llama.cpp` master and `llama-grammar` for the grammar functionalities that have not been merged yet upstream. See also [OpenAI functions]({{%relref "features/openai-functions" %}}). Until the feature is merged we will have two llama backends.
|
||||
|
||||
{{% /alert %}}
|
||||
{{% /notice %}}
|
||||
|
||||
## Huggingface embeddings
|
||||
|
||||
In this release is now possible to specify to LocalAI external `gRPC` backends that can be used for inferencing {{< pr "778" >}}. It is now possible to write internal backends in any language, and a `huggingface-embeddings` backend is now available in the container image to be used with https://github.com/UKPLab/sentence-transformers. See also [Embeddings]({{%relref "docs/features/embeddings" %}}).
|
||||
In this release is now possible to specify to LocalAI external `gRPC` backends that can be used for inferencing {{< pr "778" >}}. It is now possible to write internal backends in any language, and a `huggingface-embeddings` backend is now available in the container image to be used with https://github.com/UKPLab/sentence-transformers. See also [Embeddings]({{%relref "features/embeddings" %}}).
|
||||
|
||||
## LLaMa 2 has been released!
|
||||
|
||||
@@ -316,7 +271,7 @@ The former, ggml-based backend has been renamed to `falcon-ggml`.
|
||||
|
||||
### Default pre-compiled binaries
|
||||
|
||||
From this release the default behavior of images has changed. Compilation is not triggered on start automatically, to recompile `local-ai` from scratch on start and switch back to the old behavior, you can set `REBUILD=true` in the environment variables. Rebuilding can be necessary if your CPU and/or architecture is old and the pre-compiled binaries are not compatible with your platform. See the [build section]({{%relref "docs/getting-started/build" %}}) for more information.
|
||||
From this release the default behavior of images has changed. Compilation is not triggered on start automatically, to recompile `local-ai` from scratch on start and switch back to the old behavior, you can set `REBUILD=true` in the environment variables. Rebuilding can be necessary if your CPU and/or architecture is old and the pre-compiled binaries are not compatible with your platform. See the [build section]({{%relref "installation/build" %}}) for more information.
|
||||
|
||||
[Full release changelog](https://github.com/go-skynet/LocalAI/releases/tag/v1.21.0)
|
||||
|
||||
@@ -326,8 +281,8 @@ From this release the default behavior of images has changed. Compilation is not
|
||||
|
||||
### Exciting New Features 🎉
|
||||
|
||||
* Add Text-to-Audio generation with `go-piper` by {{< github "mudler" >}} in {{< pr "649" >}} See [API endpoints]({{%relref "docs/features/text-to-audio" %}}) in our documentation.
|
||||
* Add gallery repository by {{< github "mudler" >}} in {{< pr "663" >}}. See [models]({{%relref "docs/features/model-gallery" %}}) for documentation.
|
||||
* Add Text-to-Audio generation with `go-piper` by {{< github "mudler" >}} in {{< pr "649" >}} See [API endpoints]({{%relref "features/text-to-audio" %}}) in our documentation.
|
||||
* Add gallery repository by {{< github "mudler" >}} in {{< pr "663" >}}. See [models]({{%relref "features/model-gallery" %}}) for documentation.
|
||||
|
||||
### Container images
|
||||
- Standard (GPT + `stablediffusion`): `quay.io/go-skynet/local-ai:v1.20.0`
|
||||
@@ -339,7 +294,7 @@ From this release the default behavior of images has changed. Compilation is not
|
||||
|
||||
Updates to `llama.cpp`, `go-transformers`, `gpt4all.cpp` and `rwkv.cpp`.
|
||||
|
||||
The NUMA option was enabled by {{< github "mudler" >}} in {{< pr "684" >}}, along with many new parameters (`mmap`,`mmlock`, ..). See [advanced]({{%relref "docs/advanced" %}}) for the full list of parameters.
|
||||
The NUMA option was enabled by {{< github "mudler" >}} in {{< pr "684" >}}, along with many new parameters (`mmap`,`mmlock`, ..). See [advanced]({{%relref "advanced" %}}) for the full list of parameters.
|
||||
|
||||
### Gallery repositories
|
||||
|
||||
@@ -363,13 +318,13 @@ or a `tts` voice with:
|
||||
curl http://localhost:8080/models/apply -H "Content-Type: application/json" -d '{ "id": "model-gallery@voice-en-us-kathleen-low" }'
|
||||
```
|
||||
|
||||
See also [models]({{%relref "docs/features/model-gallery" %}}) for a complete documentation.
|
||||
See also [models]({{%relref "features/model-gallery" %}}) for a complete documentation.
|
||||
|
||||
### Text to Audio
|
||||
|
||||
Now `LocalAI` uses [piper](https://github.com/rhasspy/piper) and [go-piper](https://github.com/mudler/go-piper) to generate audio from text. This is an experimental feature, and it requires `GO_TAGS=tts` to be set during build. It is enabled by default in the pre-built container images.
|
||||
|
||||
To setup audio models, you can use the new galleries, or setup the models manually as described in [the API section of the documentation]({{%relref "docs/features/text-to-audio" %}}).
|
||||
To setup audio models, you can use the new galleries, or setup the models manually as described in [the API section of the documentation]({{%relref "features/text-to-audio" %}}).
|
||||
|
||||
You can check the full changelog in [Github](https://github.com/go-skynet/LocalAI/releases/tag/v1.20.0)
|
||||
|
||||
@@ -397,7 +352,7 @@ We now support a vast variety of models, while being backward compatible with pr
|
||||
### New features
|
||||
|
||||
- ✨ Added support for `falcon`-based model families (7b) ( [mudler](https://github.com/mudler) )
|
||||
- ✨ Experimental support for Metal Apple Silicon GPU - ( [mudler](https://github.com/mudler) and thanks to [Soleblaze](https://github.com/Soleblaze) for testing! ). See the [build section]({{%relref "docs/getting-started/build#Acceleration" %}}).
|
||||
- ✨ Experimental support for Metal Apple Silicon GPU - ( [mudler](https://github.com/mudler) and thanks to [Soleblaze](https://github.com/Soleblaze) for testing! ). See the [build section]({{%relref "installation/build#Acceleration" %}}).
|
||||
- ✨ Support for token stream in the `/v1/completions` endpoint ( [samm81](https://github.com/samm81) )
|
||||
- ✨ Added huggingface backend ( [Evilfreelancer](https://github.com/EvilFreelancer) )
|
||||
- 📷 Stablediffusion now can output `2048x2048` images size with `esrgan`! ( [mudler](https://github.com/mudler) )
|
||||
@@ -438,7 +393,7 @@ Two new projects offer now direct integration with LocalAI!
|
||||
|
||||
Support for OpenCL has been added while building from sources.
|
||||
|
||||
You can now build LocalAI from source with `BUILD_TYPE=clblas` to have an OpenCL build. See also the [build section]({{%relref "docs/getting-started/build#Acceleration" %}}).
|
||||
You can now build LocalAI from source with `BUILD_TYPE=clblas` to have an OpenCL build. See also the [build section]({{%relref "getting-started/build#Acceleration" %}}).
|
||||
|
||||
For instructions on how to install OpenCL/CLBlast see [here](https://github.com/ggerganov/llama.cpp#blas-build).
|
||||
|
||||
@@ -459,16 +414,13 @@ PRELOAD_MODELS=[{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml", "name":
|
||||
`llama.cpp` models now can also automatically save the prompt cache state as well by specifying in the model YAML configuration file:
|
||||
|
||||
```yaml
|
||||
# Enable prompt caching
|
||||
|
||||
# This is a file that will be used to save/load the cache. relative to the models directory.
|
||||
prompt_cache_path: "alpaca-cache"
|
||||
|
||||
# Always enable prompt cache
|
||||
prompt_cache_all: true
|
||||
```
|
||||
|
||||
See also the [advanced section]({{%relref "docs/advanced" %}}).
|
||||
See also the [advanced section]({{%relref "advanced" %}}).
|
||||
|
||||
## Media, Blogs, Social
|
||||
|
||||
@@ -481,7 +433,7 @@ See also the [advanced section]({{%relref "docs/advanced" %}}).
|
||||
|
||||
- 23-05-2023: __v1.15.0__ released. `go-gpt2.cpp` backend got renamed to `go-ggml-transformers.cpp` updated including https://github.com/ggerganov/llama.cpp/pull/1508 which breaks compatibility with older models. This impacts RedPajama, GptNeoX, MPT(not `gpt4all-mpt`), Dolly, GPT2 and Starcoder based models. [Binary releases available](https://github.com/go-skynet/LocalAI/releases), various fixes, including {{< pr "341" >}} .
|
||||
- 21-05-2023: __v1.14.0__ released. Minor updates to the `/models/apply` endpoint, `llama.cpp` backend updated including https://github.com/ggerganov/llama.cpp/pull/1508 which breaks compatibility with older models. `gpt4all` is still compatible with the old format.
|
||||
- 19-05-2023: __v1.13.0__ released! 🔥🔥 updates to the `gpt4all` and `llama` backend, consolidated CUDA support ( {{< pr "310" >}} thanks to @bubthegreat and @Thireus ), preliminar support for [installing models via API]({{%relref "docs/advanced#" %}}).
|
||||
- 19-05-2023: __v1.13.0__ released! 🔥🔥 updates to the `gpt4all` and `llama` backend, consolidated CUDA support ( {{< pr "310" >}} thanks to @bubthegreat and @Thireus ), preliminar support for [installing models via API]({{%relref "advanced#" %}}).
|
||||
- 17-05-2023: __v1.12.0__ released! 🔥🔥 Minor fixes, plus CUDA ({{< pr "258" >}}) support for `llama.cpp`-compatible models and image generation ({{< pr "272" >}}).
|
||||
- 16-05-2023: 🔥🔥🔥 Experimental support for CUDA ({{< pr "258" >}}) in the `llama.cpp` backend and Stable diffusion CPU image generation ({{< pr "272" >}}) in `master`.
|
||||
|
||||
@@ -40,7 +40,7 @@ hero:
|
||||
ctaButton:
|
||||
icon: rocket_launch
|
||||
btnText: "Get Started"
|
||||
url: "/basics/getting_started/"
|
||||
url: "/installation/"
|
||||
cta2Button:
|
||||
icon: code
|
||||
btnText: "View on GitHub"
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
module github.com/McShelby/hugo-theme-relearn.git
|
||||
module github.com/mudler/LocalAI/docs
|
||||
|
||||
go 1.19
|
||||
|
||||
110
docs/hugo.toml
Normal file
110
docs/hugo.toml
Normal file
@@ -0,0 +1,110 @@
|
||||
baseURL = 'https://localai.io/'
|
||||
languageCode = 'en-GB'
|
||||
defaultContentLanguage = 'en'
|
||||
|
||||
title = 'LocalAI'
|
||||
|
||||
# Theme configuration
|
||||
theme = 'hugo-theme-relearn'
|
||||
|
||||
# Enable Git info
|
||||
enableGitInfo = true
|
||||
enableEmoji = true
|
||||
|
||||
[outputs]
|
||||
home = ['html', 'rss', 'print', 'search']
|
||||
section = ['html', 'rss', 'print']
|
||||
page = ['html', 'print']
|
||||
|
||||
[markup]
|
||||
defaultMarkdownHandler = 'goldmark'
|
||||
[markup.tableOfContents]
|
||||
endLevel = 3
|
||||
startLevel = 1
|
||||
[markup.goldmark]
|
||||
[markup.goldmark.renderer]
|
||||
unsafe = true
|
||||
[markup.goldmark.parser.attribute]
|
||||
block = true
|
||||
title = true
|
||||
|
||||
[params]
|
||||
# Relearn theme parameters
|
||||
editURL = 'https://github.com/mudler/LocalAI/edit/master/docs/content/'
|
||||
description = 'LocalAI documentation'
|
||||
author = 'Ettore Di Giacinto'
|
||||
showVisitedLinks = true
|
||||
disableBreadcrumb = false
|
||||
disableNextPrev = false
|
||||
disableLandingPageButton = false
|
||||
titleSeparator = '::'
|
||||
disableSeoHiddenPages = true
|
||||
|
||||
# Additional theme options
|
||||
disableSearch = false
|
||||
disableGenerator = false
|
||||
disableLanguageSwitchingButton = true
|
||||
|
||||
# Theme variant - dark/blue style
|
||||
themeVariant = [ 'zen-dark' , 'neon', 'auto' ]
|
||||
|
||||
# ordersectionsby = 'weight'
|
||||
|
||||
[languages]
|
||||
[languages.en]
|
||||
title = 'LocalAI'
|
||||
languageName = 'English'
|
||||
weight = 10
|
||||
contentDir = 'content'
|
||||
[languages.en.params]
|
||||
landingPageName = '<i class="fa-fw fas fa-home"></i> Home'
|
||||
|
||||
# Menu shortcuts
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = '<i class="fas fa-fw fa-star"></i> Star us on GitHub'
|
||||
identifier = 'star-github'
|
||||
url = 'https://github.com/mudler/LocalAI'
|
||||
weight = 5
|
||||
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = '<i class="fab fa-fw fa-github"></i> GitHub'
|
||||
identifier = 'github'
|
||||
url = 'https://github.com/mudler/LocalAI'
|
||||
weight = 10
|
||||
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = '<i class="fab fa-fw fa-discord"></i> Discord'
|
||||
identifier = 'discord'
|
||||
url = 'https://discord.gg/uJAeKSAGDy'
|
||||
weight = 20
|
||||
|
||||
[[languages.en.menu.shortcuts]]
|
||||
name = '<i class="fab fa-fw fa-x-twitter"></i> X/Twitter'
|
||||
identifier = 'twitter'
|
||||
url = 'https://twitter.com/LocalAI_API'
|
||||
weight = 20
|
||||
|
||||
|
||||
# Module configuration for theme
|
||||
[module]
|
||||
[[module.mounts]]
|
||||
source = 'content'
|
||||
target = 'content'
|
||||
[[module.mounts]]
|
||||
source = 'static'
|
||||
target = 'static'
|
||||
[[module.mounts]]
|
||||
source = 'layouts'
|
||||
target = 'layouts'
|
||||
[[module.mounts]]
|
||||
source = 'data'
|
||||
target = 'data'
|
||||
[[module.mounts]]
|
||||
source = 'assets'
|
||||
target = 'assets'
|
||||
[[module.mounts]]
|
||||
source = '../images'
|
||||
target = 'static/images'
|
||||
[[module.mounts]]
|
||||
source = 'i18n'
|
||||
target = 'i18n'
|
||||
2
docs/layouts/partials/menu-footer.html
Normal file
2
docs/layouts/partials/menu-footer.html
Normal file
@@ -0,0 +1,2 @@
|
||||
<p>© 2023-2025 <a href="https://mudler.pm">Ettore Di Giacinto</a></p>
|
||||
|
||||
1
docs/themes/hugo-theme-relearn
vendored
1
docs/themes/hugo-theme-relearn
vendored
@@ -1 +0,0 @@
|
||||
9a020e7eadb7d8203f5b01b18756c72d94773ec9
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user