mirror of
https://github.com/mudler/LocalAI.git
synced 2026-02-03 03:02:38 -05:00
Compare commits
51 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ef1306f703 | ||
|
|
3196967995 | ||
|
|
3875e5e0e5 | ||
|
|
fc8423392f | ||
|
|
f1f6035967 | ||
|
|
ddd21f1644 | ||
|
|
d0a6a35b55 | ||
|
|
e0632f2ce2 | ||
|
|
37e6974afe | ||
|
|
e23e490455 | ||
|
|
f76bb8954b | ||
|
|
d168c7c9dc | ||
|
|
fd9d060c94 | ||
|
|
d8b17795d7 | ||
|
|
ea7b33b0d2 | ||
|
|
8ace0a9ba7 | ||
|
|
98ad93d53e | ||
|
|
38e4ec0b2a | ||
|
|
f083a901fe | ||
|
|
df13ba655c | ||
|
|
7678b25755 | ||
|
|
c87ca4f320 | ||
|
|
3c24a70a1b | ||
|
|
e46db63e06 | ||
|
|
1c57f8d077 | ||
|
|
16cebf0390 | ||
|
|
555bc02665 | ||
|
|
c1bae1ee81 | ||
|
|
f2ed3df3da | ||
|
|
abd678e147 | ||
|
|
6ac5d814fb | ||
|
|
f928899338 | ||
|
|
5a6fd98839 | ||
|
|
072f71dfb7 | ||
|
|
670cee8274 | ||
|
|
9f1be45552 | ||
|
|
f1846ae5ac | ||
|
|
ac19998e5e | ||
|
|
cb7512734d | ||
|
|
3733250b3c | ||
|
|
da3cd8993d | ||
|
|
7690caf020 | ||
|
|
5e335eaead | ||
|
|
d5d82ba344 | ||
|
|
efe2883c5d | ||
|
|
47237c7c3c | ||
|
|
697c769b64 | ||
|
|
94261b1717 | ||
|
|
eaf85a30f9 | ||
|
|
6a88b030ea | ||
|
|
f538416fb3 |
14
.github/workflows/image-pr.yml
vendored
14
.github/workflows/image-pr.yml
vendored
@@ -21,6 +21,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -39,6 +40,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -48,6 +50,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
core-image-build:
|
||||
uses: ./.github/workflows/image_build.yml
|
||||
with:
|
||||
@@ -60,6 +63,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -75,6 +79,15 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: 'sycl-f16-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -84,3 +97,4 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
|
||||
46
.github/workflows/image.yml
vendored
46
.github/workflows/image.yml
vendored
@@ -25,6 +25,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -44,6 +45,7 @@ jobs:
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: ''
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
@@ -51,6 +53,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
cuda-minor-version: "7"
|
||||
@@ -60,6 +63,7 @@ jobs:
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -69,6 +73,7 @@ jobs:
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
cuda-minor-version: "7"
|
||||
@@ -78,6 +83,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -87,6 +93,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: ''
|
||||
#platforms: 'linux/amd64,linux/arm64'
|
||||
platforms: 'linux/amd64'
|
||||
@@ -94,6 +101,7 @@ jobs:
|
||||
tag-suffix: ''
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'arc-runner-set'
|
||||
core-image-build:
|
||||
uses: ./.github/workflows/image_build.yml
|
||||
@@ -107,6 +115,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -121,7 +130,40 @@ jobs:
|
||||
tag-suffix: '-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f16-core'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f32'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f32-core'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f16-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f32'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f32-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
cuda-minor-version: "7"
|
||||
@@ -130,6 +172,7 @@ jobs:
|
||||
tag-suffix: '-cublas-cuda11-core'
|
||||
ffmpeg: ''
|
||||
image-type: 'core'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
@@ -139,6 +182,7 @@ jobs:
|
||||
tag-suffix: '-cublas-cuda12-core'
|
||||
ffmpeg: ''
|
||||
image-type: 'core'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
@@ -149,6 +193,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -158,3 +203,4 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
|
||||
83
.github/workflows/image_build.yml
vendored
83
.github/workflows/image_build.yml
vendored
@@ -4,6 +4,11 @@ name: 'build container images (reusable)'
|
||||
on:
|
||||
workflow_call:
|
||||
inputs:
|
||||
base-image:
|
||||
description: 'Base image'
|
||||
required: false
|
||||
default: ''
|
||||
type: string
|
||||
build-type:
|
||||
description: 'Build type'
|
||||
default: ''
|
||||
@@ -64,42 +69,47 @@ jobs:
|
||||
&& sudo apt-get install -y git
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
# - name: Release space from worker
|
||||
# run: |
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# df -h
|
||||
# echo
|
||||
# sudo apt-get remove -y '^llvm-.*|^libllvm.*' || true
|
||||
# sudo apt-get remove --auto-remove android-sdk-platform-tools || true
|
||||
# sudo apt-get purge --auto-remove android-sdk-platform-tools || true
|
||||
# sudo rm -rf /usr/local/lib/android
|
||||
# sudo apt-get remove -y '^dotnet-.*|^aspnetcore-.*' || true
|
||||
# sudo rm -rf /usr/share/dotnet
|
||||
# sudo apt-get remove -y '^mono-.*' || true
|
||||
# sudo apt-get remove -y '^ghc-.*' || true
|
||||
# sudo apt-get remove -y '.*jdk.*|.*jre.*' || true
|
||||
# sudo apt-get remove -y 'php.*' || true
|
||||
# sudo apt-get remove -y hhvm powershell firefox monodoc-manual msbuild || true
|
||||
# sudo apt-get remove -y '^google-.*' || true
|
||||
# sudo apt-get remove -y azure-cli || true
|
||||
# sudo apt-get remove -y '^mongo.*-.*|^postgresql-.*|^mysql-.*|^mssql-.*' || true
|
||||
# sudo apt-get remove -y '^gfortran-.*' || true
|
||||
# sudo apt-get remove -y microsoft-edge-stable || true
|
||||
# sudo apt-get remove -y firefox || true
|
||||
# sudo apt-get remove -y powershell || true
|
||||
# sudo apt-get remove -y r-base-core || true
|
||||
# sudo apt-get autoremove -y
|
||||
# sudo apt-get clean
|
||||
# echo
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# sudo rm -rfv build || true
|
||||
# df -h
|
||||
- name: Release space from worker
|
||||
if: inputs.runs-on == 'ubuntu-latest'
|
||||
run: |
|
||||
echo "Listing top largest packages"
|
||||
pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
head -n 30 <<< "${pkgs}"
|
||||
echo
|
||||
df -h
|
||||
echo
|
||||
sudo apt-get remove -y '^llvm-.*|^libllvm.*' || true
|
||||
sudo apt-get remove --auto-remove android-sdk-platform-tools || true
|
||||
sudo apt-get purge --auto-remove android-sdk-platform-tools || true
|
||||
sudo rm -rf /usr/local/lib/android
|
||||
sudo apt-get remove -y '^dotnet-.*|^aspnetcore-.*' || true
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo apt-get remove -y '^mono-.*' || true
|
||||
sudo apt-get remove -y '^ghc-.*' || true
|
||||
sudo apt-get remove -y '.*jdk.*|.*jre.*' || true
|
||||
sudo apt-get remove -y 'php.*' || true
|
||||
sudo apt-get remove -y hhvm powershell firefox monodoc-manual msbuild || true
|
||||
sudo apt-get remove -y '^google-.*' || true
|
||||
sudo apt-get remove -y azure-cli || true
|
||||
sudo apt-get remove -y '^mongo.*-.*|^postgresql-.*|^mysql-.*|^mssql-.*' || true
|
||||
sudo apt-get remove -y '^gfortran-.*' || true
|
||||
sudo apt-get remove -y microsoft-edge-stable || true
|
||||
sudo apt-get remove -y firefox || true
|
||||
sudo apt-get remove -y powershell || true
|
||||
sudo apt-get remove -y r-base-core || true
|
||||
sudo apt-get autoremove -y
|
||||
sudo apt-get clean
|
||||
echo
|
||||
echo "Listing top largest packages"
|
||||
pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
head -n 30 <<< "${pkgs}"
|
||||
echo
|
||||
sudo rm -rfv build || true
|
||||
sudo rm -rf /usr/share/dotnet || true
|
||||
sudo rm -rf /opt/ghc || true
|
||||
sudo rm -rf "/usr/local/share/boost" || true
|
||||
sudo rm -rf "$AGENT_TOOLSDIRECTORY" || true
|
||||
df -h
|
||||
- name: Docker meta
|
||||
id: meta
|
||||
uses: docker/metadata-action@v5
|
||||
@@ -149,6 +159,7 @@ jobs:
|
||||
CUDA_MINOR_VERSION=${{ inputs.cuda-minor-version }}
|
||||
FFMPEG=${{ inputs.ffmpeg }}
|
||||
IMAGE_TYPE=${{ inputs.image-type }}
|
||||
BASE_IMAGE=${{ inputs.base-image }}
|
||||
context: .
|
||||
file: ./Dockerfile
|
||||
platforms: ${{ inputs.platforms }}
|
||||
|
||||
94
.github/workflows/test-extra.yml
vendored
94
.github/workflows/test-extra.yml
vendored
@@ -164,34 +164,74 @@ jobs:
|
||||
|
||||
|
||||
|
||||
tests-bark:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Clone
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: true
|
||||
- name: Dependencies
|
||||
run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get install build-essential ffmpeg
|
||||
curl https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc | gpg --dearmor > conda.gpg && \
|
||||
sudo install -o root -g root -m 644 conda.gpg /usr/share/keyrings/conda-archive-keyring.gpg && \
|
||||
gpg --keyring /usr/share/keyrings/conda-archive-keyring.gpg --no-default-keyring --fingerprint 34161F5BF5EB1D4BFBBB8F0A8AEB4F8B29D82806 && \
|
||||
sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" > /etc/apt/sources.list.d/conda.list' && \
|
||||
sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" | tee -a /etc/apt/sources.list.d/conda.list' && \
|
||||
sudo apt-get update && \
|
||||
sudo apt-get install -y conda
|
||||
sudo apt-get install -y ca-certificates cmake curl patch
|
||||
sudo apt-get install -y libopencv-dev && sudo ln -s /usr/include/opencv4/opencv2 /usr/include/opencv2
|
||||
# tests-bark:
|
||||
# runs-on: ubuntu-latest
|
||||
# steps:
|
||||
# - name: Release space from worker
|
||||
# run: |
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# df -h
|
||||
# echo
|
||||
# sudo apt-get remove -y '^llvm-.*|^libllvm.*' || true
|
||||
# sudo apt-get remove --auto-remove android-sdk-platform-tools || true
|
||||
# sudo apt-get purge --auto-remove android-sdk-platform-tools || true
|
||||
# sudo rm -rf /usr/local/lib/android
|
||||
# sudo apt-get remove -y '^dotnet-.*|^aspnetcore-.*' || true
|
||||
# sudo rm -rf /usr/share/dotnet
|
||||
# sudo apt-get remove -y '^mono-.*' || true
|
||||
# sudo apt-get remove -y '^ghc-.*' || true
|
||||
# sudo apt-get remove -y '.*jdk.*|.*jre.*' || true
|
||||
# sudo apt-get remove -y 'php.*' || true
|
||||
# sudo apt-get remove -y hhvm powershell firefox monodoc-manual msbuild || true
|
||||
# sudo apt-get remove -y '^google-.*' || true
|
||||
# sudo apt-get remove -y azure-cli || true
|
||||
# sudo apt-get remove -y '^mongo.*-.*|^postgresql-.*|^mysql-.*|^mssql-.*' || true
|
||||
# sudo apt-get remove -y '^gfortran-.*' || true
|
||||
# sudo apt-get remove -y microsoft-edge-stable || true
|
||||
# sudo apt-get remove -y firefox || true
|
||||
# sudo apt-get remove -y powershell || true
|
||||
# sudo apt-get remove -y r-base-core || true
|
||||
# sudo apt-get autoremove -y
|
||||
# sudo apt-get clean
|
||||
# echo
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# sudo rm -rfv build || true
|
||||
# sudo rm -rf /usr/share/dotnet || true
|
||||
# sudo rm -rf /opt/ghc || true
|
||||
# sudo rm -rf "/usr/local/share/boost" || true
|
||||
# sudo rm -rf "$AGENT_TOOLSDIRECTORY" || true
|
||||
# df -h
|
||||
# - name: Clone
|
||||
# uses: actions/checkout@v4
|
||||
# with:
|
||||
# submodules: true
|
||||
# - name: Dependencies
|
||||
# run: |
|
||||
# sudo apt-get update
|
||||
# sudo apt-get install build-essential ffmpeg
|
||||
# curl https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc | gpg --dearmor > conda.gpg && \
|
||||
# sudo install -o root -g root -m 644 conda.gpg /usr/share/keyrings/conda-archive-keyring.gpg && \
|
||||
# gpg --keyring /usr/share/keyrings/conda-archive-keyring.gpg --no-default-keyring --fingerprint 34161F5BF5EB1D4BFBBB8F0A8AEB4F8B29D82806 && \
|
||||
# sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" > /etc/apt/sources.list.d/conda.list' && \
|
||||
# sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" | tee -a /etc/apt/sources.list.d/conda.list' && \
|
||||
# sudo apt-get update && \
|
||||
# sudo apt-get install -y conda
|
||||
# sudo apt-get install -y ca-certificates cmake curl patch
|
||||
# sudo apt-get install -y libopencv-dev && sudo ln -s /usr/include/opencv4/opencv2 /usr/include/opencv2
|
||||
|
||||
sudo rm -rfv /usr/bin/conda || true
|
||||
# sudo rm -rfv /usr/bin/conda || true
|
||||
|
||||
- name: Test bark
|
||||
run: |
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
make -C backend/python/bark
|
||||
make -C backend/python/bark test
|
||||
# - name: Test bark
|
||||
# run: |
|
||||
# export PATH=$PATH:/opt/conda/bin
|
||||
# make -C backend/python/bark
|
||||
# make -C backend/python/bark test
|
||||
|
||||
|
||||
# Below tests needs GPU. Commented out for now
|
||||
@@ -274,4 +314,4 @@ jobs:
|
||||
run: |
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
make -C backend/python/coqui
|
||||
make -C backend/python/coqui test
|
||||
make -C backend/python/coqui test
|
||||
|
||||
24
Dockerfile
24
Dockerfile
@@ -1,10 +1,11 @@
|
||||
ARG GO_VERSION=1.21-bullseye
|
||||
ARG GO_VERSION=1.21
|
||||
ARG IMAGE_TYPE=extras
|
||||
ARG BASE_IMAGE=ubuntu:22.04
|
||||
|
||||
# extras or core
|
||||
FROM ${BASE_IMAGE} as requirements-core
|
||||
|
||||
|
||||
FROM golang:$GO_VERSION as requirements-core
|
||||
|
||||
ARG GO_VERSION=1.21.7
|
||||
ARG BUILD_TYPE
|
||||
ARG CUDA_MAJOR_VERSION=11
|
||||
ARG CUDA_MINOR_VERSION=7
|
||||
@@ -12,14 +13,17 @@ ARG TARGETARCH
|
||||
ARG TARGETVARIANT
|
||||
|
||||
ENV BUILD_TYPE=${BUILD_TYPE}
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
ENV EXTERNAL_GRPC_BACKENDS="coqui:/build/backend/python/coqui/run.sh,huggingface-embeddings:/build/backend/python/sentencetransformers/run.sh,petals:/build/backend/python/petals/run.sh,transformers:/build/backend/python/transformers/run.sh,sentencetransformers:/build/backend/python/sentencetransformers/run.sh,autogptq:/build/backend/python/autogptq/run.sh,bark:/build/backend/python/bark/run.sh,diffusers:/build/backend/python/diffusers/run.sh,exllama:/build/backend/python/exllama/run.sh,vall-e-x:/build/backend/python/vall-e-x/run.sh,vllm:/build/backend/python/vllm/run.sh,mamba:/build/backend/python/mamba/run.sh,exllama2:/build/backend/python/exllama2/run.sh,transformers-musicgen:/build/backend/python/transformers-musicgen/run.sh"
|
||||
|
||||
ARG GO_TAGS="stablediffusion tinydream tts"
|
||||
|
||||
RUN apt-get update && \
|
||||
apt-get install -y ca-certificates curl patch pip cmake && apt-get clean
|
||||
apt-get install -y ca-certificates curl patch pip cmake git && apt-get clean
|
||||
|
||||
# Install Go
|
||||
RUN curl -L -s https://go.dev/dl/go$GO_VERSION.linux-$TARGETARCH.tar.gz | tar -v -C /usr/local -xz
|
||||
ENV PATH $PATH:/usr/local/go/bin
|
||||
|
||||
COPY --chmod=644 custom-ca-certs/* /usr/local/share/ca-certificates/
|
||||
RUN update-ca-certificates
|
||||
@@ -31,13 +35,13 @@ RUN echo "Target Variant: $TARGETVARIANT"
|
||||
# CuBLAS requirements
|
||||
RUN if [ "${BUILD_TYPE}" = "cublas" ]; then \
|
||||
apt-get install -y software-properties-common && \
|
||||
apt-add-repository contrib && \
|
||||
curl -O https://developer.download.nvidia.com/compute/cuda/repos/debian11/x86_64/cuda-keyring_1.0-1_all.deb && \
|
||||
dpkg -i cuda-keyring_1.0-1_all.deb && \
|
||||
rm -f cuda-keyring_1.0-1_all.deb && \
|
||||
curl -O https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb && \
|
||||
dpkg -i cuda-keyring_1.1-1_all.deb && \
|
||||
rm -f cuda-keyring_1.1-1_all.deb && \
|
||||
apt-get update && \
|
||||
apt-get install -y cuda-nvcc-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcublas-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusparse-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusolver-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} && apt-get clean \
|
||||
; fi
|
||||
|
||||
ENV PATH /usr/local/cuda/bin:${PATH}
|
||||
|
||||
# OpenBLAS requirements and stable diffusion
|
||||
|
||||
83
Makefile
83
Makefile
@@ -8,15 +8,12 @@ GOLLAMA_VERSION?=aeba71ee842819da681ea537e78846dc75949ac0
|
||||
|
||||
GOLLAMA_STABLE_VERSION?=50cee7712066d9e38306eccadcfbb44ea87df4b7
|
||||
|
||||
CPPLLAMA_VERSION?=381ee195721d8e747ee31a60c0751822b3072f02
|
||||
CPPLLAMA_VERSION?=4b7b38bef5addbd31f453871d79647fbae6bec8a
|
||||
|
||||
# gpt4all version
|
||||
GPT4ALL_REPO?=https://github.com/nomic-ai/gpt4all
|
||||
GPT4ALL_VERSION?=27a8b020c36b0df8f8b82a252d261cda47cf44b8
|
||||
|
||||
# go-ggml-transformers version
|
||||
GOGGMLTRANSFORMERS_VERSION?=ffb09d7dd71e2cbc6c5d7d05357d230eea6f369a
|
||||
|
||||
# go-rwkv version
|
||||
RWKV_REPO?=https://github.com/donomii/go-rwkv.cpp
|
||||
RWKV_VERSION?=633c5a3485c403cb2520693dc0991a25dace9f0f
|
||||
@@ -31,7 +28,7 @@ BERT_VERSION?=6abe312cded14042f6b7c3cd8edf082713334a4d
|
||||
PIPER_VERSION?=d6b6275ba037dabdba4a8b65dfdf6b2a73a67f07
|
||||
|
||||
# stablediffusion version
|
||||
STABLEDIFFUSION_VERSION?=902db5f066fd137697e3b69d0fa10d4782bd2c2f
|
||||
STABLEDIFFUSION_VERSION?=d5d2be8e7e395c2d73ceef61e6fe8d240f2cd831
|
||||
|
||||
# tinydream version
|
||||
TINYDREAM_VERSION?=772a9c0d9aaf768290e63cca3c904fe69faf677a
|
||||
@@ -145,7 +142,16 @@ ifeq ($(findstring tts,$(GO_TAGS)),tts)
|
||||
OPTIONAL_GRPC+=backend-assets/grpc/piper
|
||||
endif
|
||||
|
||||
ALL_GRPC_BACKENDS=backend-assets/grpc/langchain-huggingface backend-assets/grpc/falcon-ggml backend-assets/grpc/bert-embeddings backend-assets/grpc/llama backend-assets/grpc/llama-cpp backend-assets/grpc/llama-ggml backend-assets/grpc/gpt4all backend-assets/grpc/dolly backend-assets/grpc/gpt2 backend-assets/grpc/gptj backend-assets/grpc/gptneox backend-assets/grpc/mpt backend-assets/grpc/replit backend-assets/grpc/starcoder backend-assets/grpc/rwkv backend-assets/grpc/whisper $(OPTIONAL_GRPC)
|
||||
ALL_GRPC_BACKENDS=backend-assets/grpc/langchain-huggingface
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/bert-embeddings
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/llama
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/llama-cpp
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/llama-ggml
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/gpt4all
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/rwkv
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/whisper
|
||||
ALL_GRPC_BACKENDS+=$(OPTIONAL_GRPC)
|
||||
|
||||
GRPC_BACKENDS?=$(ALL_GRPC_BACKENDS) $(OPTIONAL_GRPC)
|
||||
|
||||
# If empty, then we build all
|
||||
@@ -217,14 +223,6 @@ backend-assets/espeak-ng-data: sources/go-piper
|
||||
sources/gpt4all/gpt4all-bindings/golang/libgpt4all.a: sources/gpt4all
|
||||
$(MAKE) -C sources/gpt4all/gpt4all-bindings/golang/ libgpt4all.a
|
||||
|
||||
## CEREBRAS GPT
|
||||
sources/go-ggml-transformers:
|
||||
git clone --recurse-submodules https://github.com/go-skynet/go-ggml-transformers.cpp sources/go-ggml-transformers
|
||||
cd sources/go-ggml-transformers && git checkout -b build $(GOGPT2_VERSION) && git submodule update --init --recursive --depth 1
|
||||
|
||||
sources/go-ggml-transformers/libtransformers.a: sources/go-ggml-transformers
|
||||
$(MAKE) -C sources/go-ggml-transformers BUILD_TYPE=$(BUILD_TYPE) libtransformers.a
|
||||
|
||||
sources/whisper.cpp:
|
||||
git clone https://github.com/ggerganov/whisper.cpp.git sources/whisper.cpp
|
||||
cd sources/whisper.cpp && git checkout -b build $(WHISPER_CPP_VERSION) && git submodule update --init --recursive --depth 1
|
||||
@@ -252,12 +250,11 @@ sources/go-piper/libpiper_binding.a: sources/go-piper
|
||||
backend/cpp/llama/llama.cpp:
|
||||
LLAMA_VERSION=$(CPPLLAMA_VERSION) $(MAKE) -C backend/cpp/llama llama.cpp
|
||||
|
||||
get-sources: backend/cpp/llama/llama.cpp sources/go-llama sources/go-llama-ggml sources/go-ggml-transformers sources/gpt4all sources/go-piper sources/go-rwkv sources/whisper.cpp sources/go-bert sources/go-stable-diffusion sources/go-tiny-dream
|
||||
get-sources: backend/cpp/llama/llama.cpp sources/go-llama sources/go-llama-ggml sources/gpt4all sources/go-piper sources/go-rwkv sources/whisper.cpp sources/go-bert sources/go-stable-diffusion sources/go-tiny-dream
|
||||
touch $@
|
||||
|
||||
replace:
|
||||
$(GOCMD) mod edit -replace github.com/nomic-ai/gpt4all/gpt4all-bindings/golang=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-ggml-transformers.cpp=$(CURDIR)/sources/go-ggml-transformers
|
||||
$(GOCMD) mod edit -replace github.com/donomii/go-rwkv.cpp=$(CURDIR)/sources/go-rwkv
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp=$(CURDIR)/sources/whisper.cpp
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp/bindings/go=$(CURDIR)/sources/whisper.cpp/bindings/go
|
||||
@@ -276,7 +273,6 @@ rebuild: ## Rebuilds the project
|
||||
$(MAKE) -C sources/go-llama clean
|
||||
$(MAKE) -C sources/go-llama-ggml clean
|
||||
$(MAKE) -C sources/gpt4all/gpt4all-bindings/golang/ clean
|
||||
$(MAKE) -C sources/go-ggml-transformers clean
|
||||
$(MAKE) -C sources/go-rwkv clean
|
||||
$(MAKE) -C sources/whisper.cpp clean
|
||||
$(MAKE) -C sources/go-stable-diffusion clean
|
||||
@@ -321,7 +317,7 @@ run: prepare ## run local-ai
|
||||
test-models/testmodel:
|
||||
mkdir test-models
|
||||
mkdir test-dir
|
||||
wget -q https://huggingface.co/nnakasato/ggml-model-test/resolve/main/ggml-model-q4.bin -O test-models/testmodel
|
||||
wget -q https://huggingface.co/TheBloke/orca_mini_3B-GGML/resolve/main/orca-mini-3b.ggmlv3.q4_0.bin -O test-models/testmodel
|
||||
wget -q https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-base.en.bin -O test-models/whisper-en
|
||||
wget -q https://huggingface.co/mudler/all-MiniLM-L6-v2/resolve/main/ggml-model-q4_0.bin -O test-models/bert
|
||||
wget -q https://cdn.openai.com/whisper/draft-20220913a/micro-machines.wav -O test-dir/audio.wav
|
||||
@@ -505,38 +501,6 @@ backend-assets/grpc/gpt4all: backend-assets/grpc backend-assets/gpt4all sources/
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang/ LIBRARY_PATH=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang/ \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gpt4all ./backend/go/llm/gpt4all/
|
||||
|
||||
backend-assets/grpc/dolly: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/dolly ./backend/go/llm/dolly/
|
||||
|
||||
backend-assets/grpc/gpt2: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gpt2 ./backend/go/llm/gpt2/
|
||||
|
||||
backend-assets/grpc/gptj: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gptj ./backend/go/llm/gptj/
|
||||
|
||||
backend-assets/grpc/gptneox: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gptneox ./backend/go/llm/gptneox/
|
||||
|
||||
backend-assets/grpc/mpt: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/mpt ./backend/go/llm/mpt/
|
||||
|
||||
backend-assets/grpc/replit: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/replit ./backend/go/llm/replit/
|
||||
|
||||
backend-assets/grpc/falcon-ggml: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/falcon-ggml ./backend/go/llm/falcon-ggml/
|
||||
|
||||
backend-assets/grpc/starcoder: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/starcoder ./backend/go/llm/starcoder/
|
||||
|
||||
backend-assets/grpc/rwkv: backend-assets/grpc sources/go-rwkv/librwkv.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-rwkv LIBRARY_PATH=$(CURDIR)/sources/go-rwkv \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/rwkv ./backend/go/llm/rwkv
|
||||
@@ -568,3 +532,22 @@ backend-assets/grpc/whisper: backend-assets/grpc sources/whisper.cpp/libwhisper.
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/whisper ./backend/go/transcribe/
|
||||
|
||||
grpcs: prepare $(GRPC_BACKENDS)
|
||||
|
||||
DOCKER_IMAGE?=local-ai
|
||||
IMAGE_TYPE?=core
|
||||
BASE_IMAGE?=ubuntu:22.04
|
||||
|
||||
docker:
|
||||
docker build \
|
||||
--build-arg BASE_IMAGE=$(BASE_IMAGE) \
|
||||
--build-arg IMAGE_TYPE=$(IMAGE_TYPE) \
|
||||
--build-arg GO_TAGS=$(GO_TAGS) \
|
||||
--build-arg BUILD_TYPE=$(BUILD_TYPE) \
|
||||
-t $(DOCKER_IMAGE) .
|
||||
|
||||
docker-image-intel:
|
||||
docker build \
|
||||
--build-arg BASE_IMAGE=intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04 \
|
||||
--build-arg IMAGE_TYPE=$(IMAGE_TYPE) \
|
||||
--build-arg GO_TAGS="none" \
|
||||
--build-arg BUILD_TYPE=sycl_f16 -t $(DOCKER_IMAGE) .
|
||||
@@ -43,6 +43,8 @@
|
||||
|
||||
[Roadmap](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
|
||||
- Intel GPU support (sycl): https://github.com/mudler/LocalAI/issues/1653
|
||||
- Deprecation of old backends: https://github.com/mudler/LocalAI/issues/1651
|
||||
- Mamba support: https://github.com/mudler/LocalAI/pull/1589
|
||||
- Start and share models with config file: https://github.com/mudler/LocalAI/pull/1522
|
||||
- 🐸 Coqui: https://github.com/mudler/LocalAI/pull/1489
|
||||
@@ -62,7 +64,7 @@ If you want to help and contribute, issues up for grabs: https://github.com/mudl
|
||||
For a detailed step-by-step introduction, refer to the [Getting Started](https://localai.io/basics/getting_started/index.html) guide. For those in a hurry, here's a straightforward one-liner to launch a LocalAI instance with [phi-2](https://huggingface.co/microsoft/phi-2) using `docker`:
|
||||
|
||||
```
|
||||
docker run -ti -p 8080:8080 localai/localai:v2.5.1-ffmpeg-core phi-2
|
||||
docker run -ti -p 8080:8080 localai/localai:v2.7.0-ffmpeg-core phi-2
|
||||
```
|
||||
|
||||
## 🚀 [Features](https://localai.io/features/)
|
||||
@@ -109,10 +111,10 @@ Other:
|
||||
|
||||
### 🔗 Resources
|
||||
|
||||
- 🆕 New! [LLM finetuning guide](https://localai.io/advanced/fine-tuning/)
|
||||
- 🆕 New! [LLM finetuning guide](https://localai.io/docs/advanced/fine-tuning/)
|
||||
- [How to build locally](https://localai.io/basics/build/index.html)
|
||||
- [How to install in Kubernetes](https://localai.io/basics/getting_started/index.html#run-localai-in-kubernetes)
|
||||
- [Projects integrating LocalAI](https://localai.io/integrations/)
|
||||
- [Projects integrating LocalAI](https://localai.io/docs/integrations/)
|
||||
- [How tos section](https://io.midori-ai.xyz/howtos/) (curated by our community)
|
||||
|
||||
## :book: 🎥 [Media, Blogs, Social](https://localai.io/basics/news/#media-blogs-social)
|
||||
@@ -176,7 +178,6 @@ LocalAI couldn't have been built without the help of great software already avai
|
||||
- https://github.com/ggerganov/whisper.cpp
|
||||
- https://github.com/saharNooby/rwkv.cpp
|
||||
- https://github.com/rhasspy/piper
|
||||
- https://github.com/cmp-nct/ggllm.cpp
|
||||
|
||||
## 🤗 Contributors
|
||||
|
||||
|
||||
@@ -37,7 +37,7 @@ func Startup(opts ...options.AppOption) (*options.Option, *config.ConfigLoader,
|
||||
log.Info().Msgf("Starting LocalAI using %d threads, with models path: %s", options.Threads, options.Loader.ModelPath)
|
||||
log.Info().Msgf("LocalAI version: %s", internal.PrintableVersion())
|
||||
|
||||
startup.PreloadModelsConfigurations(options.Loader.ModelPath, options.ModelsURL...)
|
||||
startup.PreloadModelsConfigurations(options.ModelLibraryURL, options.Loader.ModelPath, options.ModelsURL...)
|
||||
|
||||
cl := config.NewConfigLoader()
|
||||
if err := cl.LoadConfigs(options.Loader.ModelPath); err != nil {
|
||||
@@ -216,6 +216,11 @@ func App(opts ...options.AppOption) (*fiber.App, error) {
|
||||
}{Version: internal.PrintableVersion()})
|
||||
})
|
||||
|
||||
// Make sure directories exists
|
||||
os.MkdirAll(options.ImageDir, 0755)
|
||||
os.MkdirAll(options.AudioDir, 0755)
|
||||
os.MkdirAll(options.Loader.ModelPath, 0755)
|
||||
|
||||
modelGalleryService := localai.CreateModelGalleryService(options.Galleries, options.Loader.ModelPath, galleryService)
|
||||
app.Post("/models/apply", auth, modelGalleryService.ApplyModelGalleryEndpoint())
|
||||
app.Get("/models/available", auth, modelGalleryService.ListModelFromGalleryEndpoint())
|
||||
|
||||
@@ -29,6 +29,15 @@ import (
|
||||
"github.com/sashabaranov/go-openai/jsonschema"
|
||||
)
|
||||
|
||||
const testPrompt = `### System:
|
||||
You are an AI assistant that follows instruction extremely well. Help as much as you can.
|
||||
|
||||
### User:
|
||||
|
||||
Can you help rephrasing sentences?
|
||||
|
||||
### Response:`
|
||||
|
||||
type modelApplyRequest struct {
|
||||
ID string `json:"id"`
|
||||
URL string `json:"url"`
|
||||
@@ -629,28 +638,28 @@ var _ = Describe("API test", func() {
|
||||
Expect(len(models.Models)).To(Equal(6)) // If "config.yaml" should be included, this should be 8?
|
||||
})
|
||||
It("can generate completions", func() {
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "testmodel", Prompt: "abcdedfghikl"})
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "testmodel", Prompt: testPrompt})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Text).ToNot(BeEmpty())
|
||||
})
|
||||
|
||||
It("can generate chat completions ", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "testmodel", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "testmodel", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
})
|
||||
|
||||
It("can generate completions from model configs", func() {
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "gpt4all", Prompt: "abcdedfghikl"})
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "gpt4all", Prompt: testPrompt})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Text).ToNot(BeEmpty())
|
||||
})
|
||||
|
||||
It("can generate chat completions from model configs", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "gpt4all-2", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "gpt4all-2", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
@@ -658,7 +667,7 @@ var _ = Describe("API test", func() {
|
||||
|
||||
It("returns errors", func() {
|
||||
backends := len(model.AutoLoadBackends) + 1 // +1 for huggingface
|
||||
_, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "foomodel", Prompt: "abcdedfghikl"})
|
||||
_, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "foomodel", Prompt: testPrompt})
|
||||
Expect(err).To(HaveOccurred())
|
||||
Expect(err.Error()).To(ContainSubstring(fmt.Sprintf("error, status code: 500, message: could not load model - all backends returned error: %d errors occurred:", backends)))
|
||||
})
|
||||
@@ -834,13 +843,13 @@ var _ = Describe("API test", func() {
|
||||
app.Shutdown()
|
||||
})
|
||||
It("can generate chat completions from config file (list1)", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list1", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list1", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
})
|
||||
It("can generate chat completions from config file (list2)", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list2", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list2", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
|
||||
@@ -41,7 +41,7 @@ func ModelEmbedding(s string, tokens []int, loader *model.ModelLoader, c config.
|
||||
|
||||
var fn func() ([]float32, error)
|
||||
switch model := inferenceModel.(type) {
|
||||
case *grpc.Client:
|
||||
case grpc.Backend:
|
||||
fn = func() ([]float32, error) {
|
||||
predictOptions := gRPCPredictOpts(c, loader.ModelPath)
|
||||
if len(tokens) > 0 {
|
||||
|
||||
@@ -31,7 +31,7 @@ func ModelInference(ctx context.Context, s string, images []string, loader *mode
|
||||
|
||||
grpcOpts := gRPCModelOpts(c)
|
||||
|
||||
var inferenceModel *grpc.Client
|
||||
var inferenceModel grpc.Backend
|
||||
var err error
|
||||
|
||||
opts := modelOpts(c, o, []model.Option{
|
||||
|
||||
@@ -63,6 +63,8 @@ func gRPCModelOpts(c config.Config) *pb.ModelOptions {
|
||||
F16Memory: c.F16,
|
||||
MLock: c.MMlock,
|
||||
RopeFreqBase: c.RopeFreqBase,
|
||||
RopeScaling: c.RopeScaling,
|
||||
Type: c.ModelType,
|
||||
RopeFreqScale: c.RopeFreqScale,
|
||||
NUMA: c.NUMA,
|
||||
Embeddings: c.Embeddings,
|
||||
|
||||
@@ -128,7 +128,9 @@ type LLMConfig struct {
|
||||
Quantization string `yaml:"quantization"`
|
||||
MMProj string `yaml:"mmproj"`
|
||||
|
||||
RopeScaling string `yaml:"rope_scaling"`
|
||||
RopeScaling string `yaml:"rope_scaling"`
|
||||
ModelType string `yaml:"type"`
|
||||
|
||||
YarnExtFactor float32 `yaml:"yarn_ext_factor"`
|
||||
YarnAttnFactor float32 `yaml:"yarn_attn_factor"`
|
||||
YarnBetaFast float32 `yaml:"yarn_beta_fast"`
|
||||
|
||||
@@ -28,6 +28,8 @@ type Option struct {
|
||||
ApiKeys []string
|
||||
Metrics *metrics.Metrics
|
||||
|
||||
ModelLibraryURL string
|
||||
|
||||
Galleries []gallery.Gallery
|
||||
|
||||
BackendAssets embed.FS
|
||||
@@ -78,6 +80,12 @@ func WithCors(b bool) AppOption {
|
||||
}
|
||||
}
|
||||
|
||||
func WithModelLibraryURL(url string) AppOption {
|
||||
return func(o *Option) {
|
||||
o.ModelLibraryURL = url
|
||||
}
|
||||
}
|
||||
|
||||
var EnableWatchDog = func(o *Option) {
|
||||
o.WatchDog = true
|
||||
}
|
||||
|
||||
@@ -134,6 +134,8 @@ message ModelOptions {
|
||||
float YarnAttnFactor = 45;
|
||||
float YarnBetaFast = 46;
|
||||
float YarnBetaSlow = 47;
|
||||
|
||||
string Type = 49;
|
||||
}
|
||||
|
||||
message Result {
|
||||
|
||||
457
backend/backend_grpc.pb.go
Normal file
457
backend/backend_grpc.pb.go
Normal file
@@ -0,0 +1,457 @@
|
||||
// Code generated by protoc-gen-go-grpc. DO NOT EDIT.
|
||||
// versions:
|
||||
// - protoc-gen-go-grpc v1.2.0
|
||||
// - protoc v4.23.4
|
||||
// source: backend/backend.proto
|
||||
|
||||
package proto
|
||||
|
||||
import (
|
||||
context "context"
|
||||
grpc "google.golang.org/grpc"
|
||||
codes "google.golang.org/grpc/codes"
|
||||
status "google.golang.org/grpc/status"
|
||||
)
|
||||
|
||||
// This is a compile-time assertion to ensure that this generated file
|
||||
// is compatible with the grpc package it is being compiled against.
|
||||
// Requires gRPC-Go v1.32.0 or later.
|
||||
const _ = grpc.SupportPackageIsVersion7
|
||||
|
||||
// BackendClient is the client API for Backend service.
|
||||
//
|
||||
// For semantics around ctx use and closing/ending streaming RPCs, please refer to https://pkg.go.dev/google.golang.org/grpc/?tab=doc#ClientConn.NewStream.
|
||||
type BackendClient interface {
|
||||
Health(ctx context.Context, in *HealthMessage, opts ...grpc.CallOption) (*Reply, error)
|
||||
Predict(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (*Reply, error)
|
||||
LoadModel(ctx context.Context, in *ModelOptions, opts ...grpc.CallOption) (*Result, error)
|
||||
PredictStream(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (Backend_PredictStreamClient, error)
|
||||
Embedding(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (*EmbeddingResult, error)
|
||||
GenerateImage(ctx context.Context, in *GenerateImageRequest, opts ...grpc.CallOption) (*Result, error)
|
||||
AudioTranscription(ctx context.Context, in *TranscriptRequest, opts ...grpc.CallOption) (*TranscriptResult, error)
|
||||
TTS(ctx context.Context, in *TTSRequest, opts ...grpc.CallOption) (*Result, error)
|
||||
TokenizeString(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (*TokenizationResponse, error)
|
||||
Status(ctx context.Context, in *HealthMessage, opts ...grpc.CallOption) (*StatusResponse, error)
|
||||
}
|
||||
|
||||
type backendClient struct {
|
||||
cc grpc.ClientConnInterface
|
||||
}
|
||||
|
||||
func NewBackendClient(cc grpc.ClientConnInterface) BackendClient {
|
||||
return &backendClient{cc}
|
||||
}
|
||||
|
||||
func (c *backendClient) Health(ctx context.Context, in *HealthMessage, opts ...grpc.CallOption) (*Reply, error) {
|
||||
out := new(Reply)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/Health", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) Predict(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (*Reply, error) {
|
||||
out := new(Reply)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/Predict", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) LoadModel(ctx context.Context, in *ModelOptions, opts ...grpc.CallOption) (*Result, error) {
|
||||
out := new(Result)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/LoadModel", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) PredictStream(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (Backend_PredictStreamClient, error) {
|
||||
stream, err := c.cc.NewStream(ctx, &Backend_ServiceDesc.Streams[0], "/backend.Backend/PredictStream", opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
x := &backendPredictStreamClient{stream}
|
||||
if err := x.ClientStream.SendMsg(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if err := x.ClientStream.CloseSend(); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return x, nil
|
||||
}
|
||||
|
||||
type Backend_PredictStreamClient interface {
|
||||
Recv() (*Reply, error)
|
||||
grpc.ClientStream
|
||||
}
|
||||
|
||||
type backendPredictStreamClient struct {
|
||||
grpc.ClientStream
|
||||
}
|
||||
|
||||
func (x *backendPredictStreamClient) Recv() (*Reply, error) {
|
||||
m := new(Reply)
|
||||
if err := x.ClientStream.RecvMsg(m); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return m, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) Embedding(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (*EmbeddingResult, error) {
|
||||
out := new(EmbeddingResult)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/Embedding", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) GenerateImage(ctx context.Context, in *GenerateImageRequest, opts ...grpc.CallOption) (*Result, error) {
|
||||
out := new(Result)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/GenerateImage", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) AudioTranscription(ctx context.Context, in *TranscriptRequest, opts ...grpc.CallOption) (*TranscriptResult, error) {
|
||||
out := new(TranscriptResult)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/AudioTranscription", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) TTS(ctx context.Context, in *TTSRequest, opts ...grpc.CallOption) (*Result, error) {
|
||||
out := new(Result)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/TTS", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) TokenizeString(ctx context.Context, in *PredictOptions, opts ...grpc.CallOption) (*TokenizationResponse, error) {
|
||||
out := new(TokenizationResponse)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/TokenizeString", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
func (c *backendClient) Status(ctx context.Context, in *HealthMessage, opts ...grpc.CallOption) (*StatusResponse, error) {
|
||||
out := new(StatusResponse)
|
||||
err := c.cc.Invoke(ctx, "/backend.Backend/Status", in, out, opts...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return out, nil
|
||||
}
|
||||
|
||||
// BackendServer is the server API for Backend service.
|
||||
// All implementations must embed UnimplementedBackendServer
|
||||
// for forward compatibility
|
||||
type BackendServer interface {
|
||||
Health(context.Context, *HealthMessage) (*Reply, error)
|
||||
Predict(context.Context, *PredictOptions) (*Reply, error)
|
||||
LoadModel(context.Context, *ModelOptions) (*Result, error)
|
||||
PredictStream(*PredictOptions, Backend_PredictStreamServer) error
|
||||
Embedding(context.Context, *PredictOptions) (*EmbeddingResult, error)
|
||||
GenerateImage(context.Context, *GenerateImageRequest) (*Result, error)
|
||||
AudioTranscription(context.Context, *TranscriptRequest) (*TranscriptResult, error)
|
||||
TTS(context.Context, *TTSRequest) (*Result, error)
|
||||
TokenizeString(context.Context, *PredictOptions) (*TokenizationResponse, error)
|
||||
Status(context.Context, *HealthMessage) (*StatusResponse, error)
|
||||
mustEmbedUnimplementedBackendServer()
|
||||
}
|
||||
|
||||
// UnimplementedBackendServer must be embedded to have forward compatible implementations.
|
||||
type UnimplementedBackendServer struct {
|
||||
}
|
||||
|
||||
func (UnimplementedBackendServer) Health(context.Context, *HealthMessage) (*Reply, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method Health not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) Predict(context.Context, *PredictOptions) (*Reply, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method Predict not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) LoadModel(context.Context, *ModelOptions) (*Result, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method LoadModel not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) PredictStream(*PredictOptions, Backend_PredictStreamServer) error {
|
||||
return status.Errorf(codes.Unimplemented, "method PredictStream not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) Embedding(context.Context, *PredictOptions) (*EmbeddingResult, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method Embedding not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) GenerateImage(context.Context, *GenerateImageRequest) (*Result, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method GenerateImage not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) AudioTranscription(context.Context, *TranscriptRequest) (*TranscriptResult, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method AudioTranscription not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) TTS(context.Context, *TTSRequest) (*Result, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method TTS not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) TokenizeString(context.Context, *PredictOptions) (*TokenizationResponse, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method TokenizeString not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) Status(context.Context, *HealthMessage) (*StatusResponse, error) {
|
||||
return nil, status.Errorf(codes.Unimplemented, "method Status not implemented")
|
||||
}
|
||||
func (UnimplementedBackendServer) mustEmbedUnimplementedBackendServer() {}
|
||||
|
||||
// UnsafeBackendServer may be embedded to opt out of forward compatibility for this service.
|
||||
// Use of this interface is not recommended, as added methods to BackendServer will
|
||||
// result in compilation errors.
|
||||
type UnsafeBackendServer interface {
|
||||
mustEmbedUnimplementedBackendServer()
|
||||
}
|
||||
|
||||
func RegisterBackendServer(s grpc.ServiceRegistrar, srv BackendServer) {
|
||||
s.RegisterService(&Backend_ServiceDesc, srv)
|
||||
}
|
||||
|
||||
func _Backend_Health_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(HealthMessage)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).Health(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/Health",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).Health(ctx, req.(*HealthMessage))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_Predict_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(PredictOptions)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).Predict(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/Predict",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).Predict(ctx, req.(*PredictOptions))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_LoadModel_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(ModelOptions)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).LoadModel(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/LoadModel",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).LoadModel(ctx, req.(*ModelOptions))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_PredictStream_Handler(srv interface{}, stream grpc.ServerStream) error {
|
||||
m := new(PredictOptions)
|
||||
if err := stream.RecvMsg(m); err != nil {
|
||||
return err
|
||||
}
|
||||
return srv.(BackendServer).PredictStream(m, &backendPredictStreamServer{stream})
|
||||
}
|
||||
|
||||
type Backend_PredictStreamServer interface {
|
||||
Send(*Reply) error
|
||||
grpc.ServerStream
|
||||
}
|
||||
|
||||
type backendPredictStreamServer struct {
|
||||
grpc.ServerStream
|
||||
}
|
||||
|
||||
func (x *backendPredictStreamServer) Send(m *Reply) error {
|
||||
return x.ServerStream.SendMsg(m)
|
||||
}
|
||||
|
||||
func _Backend_Embedding_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(PredictOptions)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).Embedding(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/Embedding",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).Embedding(ctx, req.(*PredictOptions))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_GenerateImage_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(GenerateImageRequest)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).GenerateImage(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/GenerateImage",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).GenerateImage(ctx, req.(*GenerateImageRequest))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_AudioTranscription_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(TranscriptRequest)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).AudioTranscription(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/AudioTranscription",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).AudioTranscription(ctx, req.(*TranscriptRequest))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_TTS_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(TTSRequest)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).TTS(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/TTS",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).TTS(ctx, req.(*TTSRequest))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_TokenizeString_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(PredictOptions)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).TokenizeString(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/TokenizeString",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).TokenizeString(ctx, req.(*PredictOptions))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
func _Backend_Status_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
|
||||
in := new(HealthMessage)
|
||||
if err := dec(in); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if interceptor == nil {
|
||||
return srv.(BackendServer).Status(ctx, in)
|
||||
}
|
||||
info := &grpc.UnaryServerInfo{
|
||||
Server: srv,
|
||||
FullMethod: "/backend.Backend/Status",
|
||||
}
|
||||
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
|
||||
return srv.(BackendServer).Status(ctx, req.(*HealthMessage))
|
||||
}
|
||||
return interceptor(ctx, in, info, handler)
|
||||
}
|
||||
|
||||
// Backend_ServiceDesc is the grpc.ServiceDesc for Backend service.
|
||||
// It's only intended for direct use with grpc.RegisterService,
|
||||
// and not to be introspected or modified (even as a copy)
|
||||
var Backend_ServiceDesc = grpc.ServiceDesc{
|
||||
ServiceName: "backend.Backend",
|
||||
HandlerType: (*BackendServer)(nil),
|
||||
Methods: []grpc.MethodDesc{
|
||||
{
|
||||
MethodName: "Health",
|
||||
Handler: _Backend_Health_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "Predict",
|
||||
Handler: _Backend_Predict_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "LoadModel",
|
||||
Handler: _Backend_LoadModel_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "Embedding",
|
||||
Handler: _Backend_Embedding_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "GenerateImage",
|
||||
Handler: _Backend_GenerateImage_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "AudioTranscription",
|
||||
Handler: _Backend_AudioTranscription_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "TTS",
|
||||
Handler: _Backend_TTS_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "TokenizeString",
|
||||
Handler: _Backend_TokenizeString_Handler,
|
||||
},
|
||||
{
|
||||
MethodName: "Status",
|
||||
Handler: _Backend_Status_Handler,
|
||||
},
|
||||
},
|
||||
Streams: []grpc.StreamDesc{
|
||||
{
|
||||
StreamName: "PredictStream",
|
||||
Handler: _Backend_PredictStream_Handler,
|
||||
ServerStreams: true,
|
||||
},
|
||||
},
|
||||
Metadata: "backend/backend.proto",
|
||||
}
|
||||
@@ -70,7 +70,7 @@ add_library(hw_grpc_proto
|
||||
${hw_proto_srcs}
|
||||
${hw_proto_hdrs} )
|
||||
|
||||
add_executable(${TARGET} grpc-server.cpp json.hpp )
|
||||
add_executable(${TARGET} grpc-server.cpp utils.hpp json.hpp)
|
||||
target_link_libraries(${TARGET} PRIVATE common llama myclip ${CMAKE_THREAD_LIBS_INIT} absl::flags hw_grpc_proto
|
||||
absl::flags_parse
|
||||
gRPC::${_REFLECTION}
|
||||
|
||||
@@ -3,6 +3,7 @@ LLAMA_VERSION?=
|
||||
|
||||
CMAKE_ARGS?=
|
||||
BUILD_TYPE?=
|
||||
ONEAPI_VARS?=/opt/intel/oneapi/setvars.sh
|
||||
|
||||
# If build type is cublas, then we set -DLLAMA_CUBLAS=ON to CMAKE_ARGS automatically
|
||||
ifeq ($(BUILD_TYPE),cublas)
|
||||
@@ -19,6 +20,14 @@ else ifeq ($(BUILD_TYPE),hipblas)
|
||||
CMAKE_ARGS+=-DLLAMA_HIPBLAS=ON
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),sycl_f16)
|
||||
CMAKE_ARGS+=-DLLAMA_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx -DLLAMA_SYCL_F16=ON
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),sycl_f32)
|
||||
CMAKE_ARGS+=-DLLAMA_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx
|
||||
endif
|
||||
|
||||
llama.cpp:
|
||||
git clone --recurse-submodules https://github.com/ggerganov/llama.cpp llama.cpp
|
||||
if [ -z "$(LLAMA_VERSION)" ]; then \
|
||||
@@ -31,6 +40,7 @@ llama.cpp/examples/grpc-server:
|
||||
cp -r $(abspath ./)/CMakeLists.txt llama.cpp/examples/grpc-server/
|
||||
cp -r $(abspath ./)/grpc-server.cpp llama.cpp/examples/grpc-server/
|
||||
cp -rfv $(abspath ./)/json.hpp llama.cpp/examples/grpc-server/
|
||||
cp -rfv $(abspath ./)/utils.hpp llama.cpp/examples/grpc-server/
|
||||
echo "add_subdirectory(grpc-server)" >> llama.cpp/examples/CMakeLists.txt
|
||||
## XXX: In some versions of CMake clip wasn't being built before llama.
|
||||
## This is an hack for now, but it should be fixed in the future.
|
||||
@@ -49,5 +59,10 @@ clean:
|
||||
rm -rf grpc-server
|
||||
|
||||
grpc-server: llama.cpp llama.cpp/examples/grpc-server
|
||||
ifneq (,$(findstring sycl,$(BUILD_TYPE)))
|
||||
bash -c "source $(ONEAPI_VARS); \
|
||||
cd llama.cpp && mkdir -p build && cd build && cmake .. $(CMAKE_ARGS) && cmake --build . --config Release"
|
||||
else
|
||||
cd llama.cpp && mkdir -p build && cd build && cmake .. $(CMAKE_ARGS) && cmake --build . --config Release
|
||||
endif
|
||||
cp llama.cpp/build/bin/grpc-server .
|
||||
File diff suppressed because it is too large
Load Diff
510
backend/cpp/llama/utils.hpp
Normal file
510
backend/cpp/llama/utils.hpp
Normal file
@@ -0,0 +1,510 @@
|
||||
// https://github.com/ggerganov/llama.cpp/blob/master/examples/server/utils.hpp
|
||||
|
||||
#pragma once
|
||||
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <set>
|
||||
#include <mutex>
|
||||
#include <condition_variable>
|
||||
#include <unordered_map>
|
||||
|
||||
#include "json.hpp"
|
||||
|
||||
#include "../llava/clip.h"
|
||||
|
||||
using json = nlohmann::json;
|
||||
|
||||
extern bool server_verbose;
|
||||
|
||||
#ifndef SERVER_VERBOSE
|
||||
#define SERVER_VERBOSE 1
|
||||
#endif
|
||||
|
||||
#if SERVER_VERBOSE != 1
|
||||
#define LOG_VERBOSE(MSG, ...)
|
||||
#else
|
||||
#define LOG_VERBOSE(MSG, ...) \
|
||||
do \
|
||||
{ \
|
||||
if (server_verbose) \
|
||||
{ \
|
||||
server_log("VERBOSE", __func__, __LINE__, MSG, __VA_ARGS__); \
|
||||
} \
|
||||
} while (0)
|
||||
#endif
|
||||
|
||||
#define LOG_ERROR( MSG, ...) server_log("ERROR", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
#define LOG_WARNING(MSG, ...) server_log("WARNING", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
#define LOG_INFO( MSG, ...) server_log("INFO", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
|
||||
//
|
||||
// parallel
|
||||
//
|
||||
|
||||
enum server_state {
|
||||
SERVER_STATE_LOADING_MODEL, // Server is starting up, model not fully loaded yet
|
||||
SERVER_STATE_READY, // Server is ready and model is loaded
|
||||
SERVER_STATE_ERROR // An error occurred, load_model failed
|
||||
};
|
||||
|
||||
enum task_type {
|
||||
TASK_TYPE_COMPLETION,
|
||||
TASK_TYPE_CANCEL,
|
||||
TASK_TYPE_NEXT_RESPONSE
|
||||
};
|
||||
|
||||
struct task_server {
|
||||
int id = -1; // to be filled by llama_server_queue
|
||||
int target_id;
|
||||
task_type type;
|
||||
json data;
|
||||
bool infill_mode = false;
|
||||
bool embedding_mode = false;
|
||||
int multitask_id = -1;
|
||||
};
|
||||
|
||||
struct task_result {
|
||||
int id;
|
||||
int multitask_id = -1;
|
||||
bool stop;
|
||||
bool error;
|
||||
json result_json;
|
||||
};
|
||||
|
||||
struct task_multi {
|
||||
int id;
|
||||
std::set<int> subtasks_remaining{};
|
||||
std::vector<task_result> results{};
|
||||
};
|
||||
|
||||
// TODO: can become bool if we can't find use of more states
|
||||
enum slot_state
|
||||
{
|
||||
IDLE,
|
||||
PROCESSING,
|
||||
};
|
||||
|
||||
enum slot_command
|
||||
{
|
||||
NONE,
|
||||
LOAD_PROMPT,
|
||||
RELEASE,
|
||||
};
|
||||
|
||||
struct slot_params
|
||||
{
|
||||
bool stream = true;
|
||||
bool cache_prompt = false; // remember the prompt to avoid reprocessing all prompt
|
||||
|
||||
uint32_t seed = -1; // RNG seed
|
||||
int32_t n_keep = 0; // number of tokens to keep from initial prompt
|
||||
int32_t n_predict = -1; // new tokens to predict
|
||||
|
||||
std::vector<std::string> antiprompt;
|
||||
|
||||
json input_prefix;
|
||||
json input_suffix;
|
||||
};
|
||||
|
||||
struct slot_image
|
||||
{
|
||||
int32_t id;
|
||||
|
||||
bool request_encode_image = false;
|
||||
float * image_embedding = nullptr;
|
||||
int32_t image_tokens = 0;
|
||||
|
||||
clip_image_u8 * img_data;
|
||||
|
||||
std::string prefix_prompt; // before of this image
|
||||
};
|
||||
|
||||
// completion token output with probabilities
|
||||
struct completion_token_output
|
||||
{
|
||||
struct token_prob
|
||||
{
|
||||
llama_token tok;
|
||||
float prob;
|
||||
};
|
||||
|
||||
std::vector<token_prob> probs;
|
||||
llama_token tok;
|
||||
std::string text_to_send;
|
||||
};
|
||||
|
||||
static inline void server_log(const char *level, const char *function, int line,
|
||||
const char *message, const nlohmann::ordered_json &extra)
|
||||
{
|
||||
nlohmann::ordered_json log
|
||||
{
|
||||
{"timestamp", time(nullptr)},
|
||||
{"level", level},
|
||||
{"function", function},
|
||||
{"line", line},
|
||||
{"message", message},
|
||||
};
|
||||
|
||||
if (!extra.empty())
|
||||
{
|
||||
log.merge_patch(extra);
|
||||
}
|
||||
|
||||
const std::string str = log.dump(-1, ' ', false, json::error_handler_t::replace);
|
||||
printf("%.*s\n", (int)str.size(), str.data());
|
||||
fflush(stdout);
|
||||
}
|
||||
|
||||
//
|
||||
// server utils
|
||||
//
|
||||
|
||||
template <typename T>
|
||||
static T json_value(const json &body, const std::string &key, const T &default_value)
|
||||
{
|
||||
// Fallback null to default value
|
||||
return body.contains(key) && !body.at(key).is_null()
|
||||
? body.value(key, default_value)
|
||||
: default_value;
|
||||
}
|
||||
|
||||
inline std::string format_chatml(std::vector<json> messages)
|
||||
{
|
||||
std::ostringstream chatml_msgs;
|
||||
|
||||
for (auto it = messages.begin(); it != messages.end(); ++it) {
|
||||
chatml_msgs << "<|im_start|>"
|
||||
<< json_value(*it, "role", std::string("user")) << '\n';
|
||||
chatml_msgs << json_value(*it, "content", std::string(""))
|
||||
<< "<|im_end|>\n";
|
||||
}
|
||||
|
||||
chatml_msgs << "<|im_start|>assistant" << '\n';
|
||||
|
||||
return chatml_msgs.str();
|
||||
}
|
||||
|
||||
//
|
||||
// work queue utils
|
||||
//
|
||||
|
||||
struct llama_server_queue {
|
||||
int id = 0;
|
||||
std::mutex mutex_tasks;
|
||||
// queues
|
||||
std::vector<task_server> queue_tasks;
|
||||
std::vector<task_server> queue_tasks_deferred;
|
||||
std::vector<task_multi> queue_multitasks;
|
||||
std::condition_variable condition_tasks;
|
||||
// callback functions
|
||||
std::function<void(task_server&)> callback_new_task;
|
||||
std::function<void(task_multi&)> callback_finish_multitask;
|
||||
std::function<void(void)> callback_all_task_finished;
|
||||
|
||||
// Add a new task to the end of the queue
|
||||
int post(task_server task) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (task.id == -1) {
|
||||
task.id = id++;
|
||||
}
|
||||
queue_tasks.push_back(std::move(task));
|
||||
condition_tasks.notify_one();
|
||||
return task.id;
|
||||
}
|
||||
|
||||
// Add a new task, but defer until one slot is available
|
||||
void defer(task_server task) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
queue_tasks_deferred.push_back(std::move(task));
|
||||
}
|
||||
|
||||
// Get the next id for creating anew task
|
||||
int get_new_id() {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
return id++;
|
||||
}
|
||||
|
||||
// Register function to process a new task
|
||||
void on_new_task(std::function<void(task_server&)> callback) {
|
||||
callback_new_task = callback;
|
||||
}
|
||||
|
||||
// Register function to process a multitask
|
||||
void on_finish_multitask(std::function<void(task_multi&)> callback) {
|
||||
callback_finish_multitask = callback;
|
||||
}
|
||||
|
||||
// Register the function to be called when the batch of tasks is finished
|
||||
void on_all_tasks_finished(std::function<void(void)> callback) {
|
||||
callback_all_task_finished = callback;
|
||||
}
|
||||
|
||||
// Call when the state of one slot is changed
|
||||
void notify_slot_changed() {
|
||||
// move deferred tasks back to main loop
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
for (auto & task : queue_tasks_deferred) {
|
||||
queue_tasks.push_back(std::move(task));
|
||||
}
|
||||
queue_tasks_deferred.clear();
|
||||
}
|
||||
|
||||
// Start the main loop. This call is blocking
|
||||
[[noreturn]]
|
||||
void start_loop() {
|
||||
while (true) {
|
||||
// new task arrived
|
||||
LOG_VERBOSE("have new task", {});
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (queue_tasks.empty()) {
|
||||
lock.unlock();
|
||||
break;
|
||||
}
|
||||
task_server task = queue_tasks.front();
|
||||
queue_tasks.erase(queue_tasks.begin());
|
||||
lock.unlock();
|
||||
LOG_VERBOSE("callback_new_task", {});
|
||||
callback_new_task(task);
|
||||
}
|
||||
LOG_VERBOSE("callback_all_task_finished", {});
|
||||
// process and update all the multitasks
|
||||
auto queue_iterator = queue_multitasks.begin();
|
||||
while (queue_iterator != queue_multitasks.end())
|
||||
{
|
||||
if (queue_iterator->subtasks_remaining.empty())
|
||||
{
|
||||
// all subtasks done == multitask is done
|
||||
task_multi current_multitask = *queue_iterator;
|
||||
callback_finish_multitask(current_multitask);
|
||||
// remove this multitask
|
||||
queue_iterator = queue_multitasks.erase(queue_iterator);
|
||||
}
|
||||
else
|
||||
{
|
||||
++queue_iterator;
|
||||
}
|
||||
}
|
||||
// all tasks in the current loop is finished
|
||||
callback_all_task_finished();
|
||||
}
|
||||
LOG_VERBOSE("wait for new task", {});
|
||||
// wait for new task
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (queue_tasks.empty()) {
|
||||
condition_tasks.wait(lock, [&]{
|
||||
return !queue_tasks.empty();
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
//
|
||||
// functions to manage multitasks
|
||||
//
|
||||
|
||||
// add a multitask by specifying the id of all subtask (subtask is a task_server)
|
||||
void add_multitask(int multitask_id, std::vector<int>& sub_ids)
|
||||
{
|
||||
std::lock_guard<std::mutex> lock(mutex_tasks);
|
||||
task_multi multi;
|
||||
multi.id = multitask_id;
|
||||
std::copy(sub_ids.begin(), sub_ids.end(), std::inserter(multi.subtasks_remaining, multi.subtasks_remaining.end()));
|
||||
queue_multitasks.push_back(multi);
|
||||
}
|
||||
|
||||
// updatethe remaining subtasks, while appending results to multitask
|
||||
void update_multitask(int multitask_id, int subtask_id, task_result& result)
|
||||
{
|
||||
std::lock_guard<std::mutex> lock(mutex_tasks);
|
||||
for (auto& multitask : queue_multitasks)
|
||||
{
|
||||
if (multitask.id == multitask_id)
|
||||
{
|
||||
multitask.subtasks_remaining.erase(subtask_id);
|
||||
multitask.results.push_back(result);
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct llama_server_response {
|
||||
typedef std::function<void(int, int, task_result&)> callback_multitask_t;
|
||||
callback_multitask_t callback_update_multitask;
|
||||
// for keeping track of all tasks waiting for the result
|
||||
std::set<int> waiting_task_ids;
|
||||
// the main result queue
|
||||
std::vector<task_result> queue_results;
|
||||
std::mutex mutex_results;
|
||||
std::condition_variable condition_results;
|
||||
|
||||
void add_waiting_task_id(int task_id) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
waiting_task_ids.insert(task_id);
|
||||
}
|
||||
|
||||
void remove_waiting_task_id(int task_id) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
waiting_task_ids.erase(task_id);
|
||||
}
|
||||
|
||||
// This function blocks the thread until there is a response for this task_id
|
||||
task_result recv(int task_id) {
|
||||
while (true)
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
condition_results.wait(lock, [&]{
|
||||
return !queue_results.empty();
|
||||
});
|
||||
LOG_VERBOSE("condition_results unblock", {});
|
||||
|
||||
for (int i = 0; i < (int) queue_results.size(); i++)
|
||||
{
|
||||
if (queue_results[i].id == task_id)
|
||||
{
|
||||
assert(queue_results[i].multitask_id == -1);
|
||||
task_result res = queue_results[i];
|
||||
queue_results.erase(queue_results.begin() + i);
|
||||
return res;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// should never reach here
|
||||
}
|
||||
|
||||
// Register the function to update multitask
|
||||
void on_multitask_update(callback_multitask_t callback) {
|
||||
callback_update_multitask = callback;
|
||||
}
|
||||
|
||||
// Send a new result to a waiting task_id
|
||||
void send(task_result result) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
LOG_VERBOSE("send new result", {});
|
||||
for (auto& task_id : waiting_task_ids) {
|
||||
// LOG_TEE("waiting task id %i \n", task_id);
|
||||
// for now, tasks that have associated parent multitasks just get erased once multitask picks up the result
|
||||
if (result.multitask_id == task_id)
|
||||
{
|
||||
LOG_VERBOSE("callback_update_multitask", {});
|
||||
callback_update_multitask(task_id, result.id, result);
|
||||
continue;
|
||||
}
|
||||
|
||||
if (result.id == task_id)
|
||||
{
|
||||
LOG_VERBOSE("queue_results.push_back", {});
|
||||
queue_results.push_back(result);
|
||||
condition_results.notify_one();
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
//
|
||||
// base64 utils (TODO: move to common in the future)
|
||||
//
|
||||
|
||||
static const std::string base64_chars =
|
||||
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
|
||||
"abcdefghijklmnopqrstuvwxyz"
|
||||
"0123456789+/";
|
||||
|
||||
static inline bool is_base64(uint8_t c)
|
||||
{
|
||||
return (isalnum(c) || (c == '+') || (c == '/'));
|
||||
}
|
||||
|
||||
static inline std::vector<uint8_t> base64_decode(const std::string & encoded_string)
|
||||
{
|
||||
int i = 0;
|
||||
int j = 0;
|
||||
int in_ = 0;
|
||||
|
||||
int in_len = encoded_string.size();
|
||||
|
||||
uint8_t char_array_4[4];
|
||||
uint8_t char_array_3[3];
|
||||
|
||||
std::vector<uint8_t> ret;
|
||||
|
||||
while (in_len-- && (encoded_string[in_] != '=') && is_base64(encoded_string[in_]))
|
||||
{
|
||||
char_array_4[i++] = encoded_string[in_]; in_++;
|
||||
if (i == 4)
|
||||
{
|
||||
for (i = 0; i <4; i++)
|
||||
{
|
||||
char_array_4[i] = base64_chars.find(char_array_4[i]);
|
||||
}
|
||||
|
||||
char_array_3[0] = ((char_array_4[0] ) << 2) + ((char_array_4[1] & 0x30) >> 4);
|
||||
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
|
||||
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
|
||||
|
||||
for (i = 0; (i < 3); i++)
|
||||
{
|
||||
ret.push_back(char_array_3[i]);
|
||||
}
|
||||
i = 0;
|
||||
}
|
||||
}
|
||||
|
||||
if (i)
|
||||
{
|
||||
for (j = i; j <4; j++)
|
||||
{
|
||||
char_array_4[j] = 0;
|
||||
}
|
||||
|
||||
for (j = 0; j <4; j++)
|
||||
{
|
||||
char_array_4[j] = base64_chars.find(char_array_4[j]);
|
||||
}
|
||||
|
||||
char_array_3[0] = ((char_array_4[0] ) << 2) + ((char_array_4[1] & 0x30) >> 4);
|
||||
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
|
||||
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
|
||||
|
||||
for (j = 0; (j < i - 1); j++)
|
||||
{
|
||||
ret.push_back(char_array_3[j]);
|
||||
}
|
||||
}
|
||||
|
||||
return ret;
|
||||
}
|
||||
|
||||
//
|
||||
// random string / id
|
||||
//
|
||||
|
||||
static std::string random_string()
|
||||
{
|
||||
static const std::string str("0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz");
|
||||
|
||||
std::random_device rd;
|
||||
std::mt19937 generator(rd());
|
||||
|
||||
std::string result(32, ' ');
|
||||
|
||||
for (int i = 0; i < 32; ++i) {
|
||||
result[i] = str[generator() % str.size()];
|
||||
}
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
static std::string gen_chatcmplid()
|
||||
{
|
||||
std::stringstream chatcmplid;
|
||||
chatcmplid << "chatcmpl-" << random_string();
|
||||
return chatcmplid.str();
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.Falcon{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.GPT2{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.Starcoder{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,44 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Dolly struct {
|
||||
base.SingleThread
|
||||
|
||||
dolly *transformers.Dolly
|
||||
}
|
||||
|
||||
func (llm *Dolly) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewDolly(opts.ModelFile)
|
||||
llm.dolly = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Dolly) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.dolly.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Dolly) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
|
||||
go func() {
|
||||
res, err := llm.dolly.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
|
||||
return nil
|
||||
}
|
||||
@@ -1,43 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Falcon struct {
|
||||
base.SingleThread
|
||||
|
||||
falcon *transformers.Falcon
|
||||
}
|
||||
|
||||
func (llm *Falcon) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewFalcon(opts.ModelFile)
|
||||
llm.falcon = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Falcon) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.falcon.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Falcon) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.falcon.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type GPT2 struct {
|
||||
base.SingleThread
|
||||
|
||||
gpt2 *transformers.GPT2
|
||||
}
|
||||
|
||||
func (llm *GPT2) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.New(opts.ModelFile)
|
||||
llm.gpt2 = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *GPT2) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.gpt2.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *GPT2) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.gpt2.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type GPTJ struct {
|
||||
base.SingleThread
|
||||
|
||||
gptj *transformers.GPTJ
|
||||
}
|
||||
|
||||
func (llm *GPTJ) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewGPTJ(opts.ModelFile)
|
||||
llm.gptj = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *GPTJ) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.gptj.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *GPTJ) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.gptj.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type GPTNeoX struct {
|
||||
base.SingleThread
|
||||
|
||||
gptneox *transformers.GPTNeoX
|
||||
}
|
||||
|
||||
func (llm *GPTNeoX) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewGPTNeoX(opts.ModelFile)
|
||||
llm.gptneox = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *GPTNeoX) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.gptneox.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *GPTNeoX) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.gptneox.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type MPT struct {
|
||||
base.SingleThread
|
||||
|
||||
mpt *transformers.MPT
|
||||
}
|
||||
|
||||
func (llm *MPT) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewMPT(opts.ModelFile)
|
||||
llm.mpt = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *MPT) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.mpt.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *MPT) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.mpt.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,26 +0,0 @@
|
||||
package transformers
|
||||
|
||||
import (
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
func buildPredictOptions(opts *pb.PredictOptions) []transformers.PredictOption {
|
||||
predictOptions := []transformers.PredictOption{
|
||||
transformers.SetTemperature(float64(opts.Temperature)),
|
||||
transformers.SetTopP(float64(opts.TopP)),
|
||||
transformers.SetTopK(int(opts.TopK)),
|
||||
transformers.SetTokens(int(opts.Tokens)),
|
||||
transformers.SetThreads(int(opts.Threads)),
|
||||
}
|
||||
|
||||
if opts.Batch != 0 {
|
||||
predictOptions = append(predictOptions, transformers.SetBatch(int(opts.Batch)))
|
||||
}
|
||||
|
||||
if opts.Seed != 0 {
|
||||
predictOptions = append(predictOptions, transformers.SetSeed(int(opts.Seed)))
|
||||
}
|
||||
|
||||
return predictOptions
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Replit struct {
|
||||
base.SingleThread
|
||||
|
||||
replit *transformers.Replit
|
||||
}
|
||||
|
||||
func (llm *Replit) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewReplit(opts.ModelFile)
|
||||
llm.replit = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Replit) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.replit.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Replit) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.replit.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,43 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Starcoder struct {
|
||||
base.SingleThread
|
||||
|
||||
starcoder *transformers.Starcoder
|
||||
}
|
||||
|
||||
func (llm *Starcoder) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewStarcoder(opts.ModelFile)
|
||||
llm.starcoder = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Starcoder) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.starcoder.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Starcoder) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.starcoder.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
|
||||
return nil
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@@ -15,8 +15,8 @@ import backend_pb2_grpc
|
||||
|
||||
import grpc
|
||||
import torch
|
||||
|
||||
from transformers import AutoTokenizer, AutoModel
|
||||
import torch.cuda
|
||||
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM, set_seed
|
||||
|
||||
_ONE_DAY_IN_SECONDS = 60 * 60 * 24
|
||||
|
||||
@@ -68,16 +68,19 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
"""
|
||||
model_name = request.Model
|
||||
try:
|
||||
self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True) # trust_remote_code is needed to use the encode method with embeddings models like jinai-v2
|
||||
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
if request.Type == "AutoModelForCausalLM":
|
||||
self.model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
|
||||
else:
|
||||
self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
|
||||
|
||||
if request.CUDA:
|
||||
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
self.CUDA = False
|
||||
|
||||
if request.CUDA or torch.cuda.is_available():
|
||||
try:
|
||||
# TODO: also tensorflow, make configurable
|
||||
import torch.cuda
|
||||
if torch.cuda.is_available():
|
||||
print("Loading model", model_name, "to CUDA.", file=sys.stderr)
|
||||
self.model = self.model.to("cuda")
|
||||
print("Loading model", model_name, "to CUDA.", file=sys.stderr)
|
||||
self.model = self.model.to("cuda")
|
||||
self.CUDA = True
|
||||
except Exception as err:
|
||||
print("Not using CUDA:", err, file=sys.stderr)
|
||||
except Exception as err:
|
||||
@@ -98,6 +101,7 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
An EmbeddingResult object that contains the calculated embeddings.
|
||||
"""
|
||||
|
||||
set_seed(request.Seed)
|
||||
# Tokenize input
|
||||
max_length = 512
|
||||
if request.Tokens != 0:
|
||||
@@ -113,6 +117,51 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
print("Embeddings:", sentence_embeddings, file=sys.stderr)
|
||||
return backend_pb2.EmbeddingResult(embeddings=sentence_embeddings)
|
||||
|
||||
def Predict(self, request, context):
|
||||
"""
|
||||
Generates text based on the given prompt and sampling parameters.
|
||||
|
||||
Args:
|
||||
request: The predict request.
|
||||
context: The gRPC context.
|
||||
|
||||
Returns:
|
||||
backend_pb2.Reply: The predict result.
|
||||
"""
|
||||
set_seed(request.Seed)
|
||||
if request.TopP == 0:
|
||||
request.TopP = 0.9
|
||||
|
||||
max_tokens = 200
|
||||
if request.Tokens > 0:
|
||||
max_tokens = request.Tokens
|
||||
|
||||
inputs = self.tokenizer(request.Prompt, return_tensors="pt").input_ids
|
||||
if self.CUDA:
|
||||
inputs = inputs.to("cuda")
|
||||
|
||||
outputs = self.model.generate(inputs,max_new_tokens=max_tokens, temperature=request.Temperature, top_p=request.TopP)
|
||||
|
||||
generated_text = self.tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
|
||||
# Remove prompt from response if present
|
||||
if request.Prompt in generated_text:
|
||||
generated_text = generated_text.replace(request.Prompt, "")
|
||||
|
||||
return backend_pb2.Reply(message=bytes(generated_text, encoding='utf-8'))
|
||||
|
||||
def PredictStream(self, request, context):
|
||||
"""
|
||||
Generates text based on the given prompt and sampling parameters, and streams the results.
|
||||
|
||||
Args:
|
||||
request: The predict stream request.
|
||||
context: The gRPC context.
|
||||
|
||||
Returns:
|
||||
backend_pb2.Result: The predict stream result.
|
||||
"""
|
||||
yield self.Predict(request, context)
|
||||
|
||||
|
||||
def serve(address):
|
||||
server = grpc.server(futures.ThreadPoolExecutor(max_workers=MAX_WORKERS))
|
||||
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@@ -23,7 +23,7 @@ Fine-tuning a language model is a process that requires a lot of computational p
|
||||
|
||||
Currently LocalAI doesn't support the fine-tuning endpoint as LocalAI but there are are [plans](https://github.com/mudler/LocalAI/issues/596) to support that. For the time being a guide is proposed here to give a simple starting point on how to fine-tune a model and use it with LocalAI (but also with llama.cpp).
|
||||
|
||||
There is an e2e example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler) available [here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/).
|
||||
There is an e2e example of fine-tuning a LLM model to use with [LocalAI](https://github.com/mudler/LocalAI) written by [@mudler](https://github.com/mudler) available [here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/).
|
||||
|
||||
The steps involved are:
|
||||
|
||||
|
||||
@@ -15,9 +15,45 @@ This section contains instruction on how to use LocalAI with GPU acceleration.
|
||||
For accelleration for AMD or Metal HW there are no specific container images, see the [build]({{%relref "docs/getting-started/build#Acceleration" %}})
|
||||
{{% /alert %}}
|
||||
|
||||
### CUDA(NVIDIA) acceleration
|
||||
|
||||
#### Requirements
|
||||
## Model configuration
|
||||
|
||||
Depending on the model architecture and backend used, there might be different ways to enable GPU acceleration. It is required to configure the model you intend to use with a YAML config file. For example, for `llama.cpp` workloads a configuration file might look like this (where `gpu_layers` is the number of layers to offload to the GPU):
|
||||
|
||||
```yaml
|
||||
name: my-model-name
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: llama.cpp-model.ggmlv3.q5_K_M.bin
|
||||
|
||||
context_size: 1024
|
||||
threads: 1
|
||||
|
||||
f16: true # enable with GPU acceleration
|
||||
gpu_layers: 22 # GPU Layers (only used when built with cublas)
|
||||
|
||||
```
|
||||
|
||||
For diffusers instead, it might look like this instead:
|
||||
|
||||
```yaml
|
||||
name: stablediffusion
|
||||
parameters:
|
||||
model: toonyou_beta6.safetensors
|
||||
backend: diffusers
|
||||
step: 30
|
||||
f16: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionPipeline
|
||||
cuda: true
|
||||
enable_parameters: "negative_prompt,num_inference_steps,clip_skip"
|
||||
scheduler_type: "k_dpmpp_sde"
|
||||
```
|
||||
|
||||
## CUDA(NVIDIA) acceleration
|
||||
|
||||
### Requirements
|
||||
|
||||
Requirement: nvidia-container-toolkit (installation instructions [1](https://www.server-world.info/en/note?os=Ubuntu_22.04&p=nvidia&f=2) [2](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html))
|
||||
|
||||
@@ -74,37 +110,21 @@ llama_model_load_internal: total VRAM used: 1598 MB
|
||||
llama_init_from_file: kv self size = 512.00 MB
|
||||
```
|
||||
|
||||
#### Model configuration
|
||||
## Intel acceleration (sycl)
|
||||
|
||||
Depending on the model architecture and backend used, there might be different ways to enable GPU acceleration. It is required to configure the model you intend to use with a YAML config file. For example, for `llama.cpp` workloads a configuration file might look like this (where `gpu_layers` is the number of layers to offload to the GPU):
|
||||
#### Requirements
|
||||
|
||||
```yaml
|
||||
name: my-model-name
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: llama.cpp-model.ggmlv3.q5_K_M.bin
|
||||
Requirement: [Intel oneAPI Base Toolkit](https://software.intel.com/content/www/us/en/develop/tools/oneapi/base-toolkit/download.html)
|
||||
|
||||
context_size: 1024
|
||||
threads: 1
|
||||
To use SYCL, use the images with the `sycl-f16` or `sycl-f32` tag, for example `{{< version >}}-sycl-f32-core`, `{{< version >}}-sycl-f16-ffmpeg-core`, ...
|
||||
|
||||
f16: true # enable with GPU acceleration
|
||||
gpu_layers: 22 # GPU Layers (only used when built with cublas)
|
||||
The image list is on [quay](https://quay.io/repository/go-skynet/local-ai?tab=tags).
|
||||
|
||||
### Notes
|
||||
|
||||
In addition to the commands to run LocalAI normally, you need to specify `--device /dev/dri` to docker, for example:
|
||||
|
||||
```bash
|
||||
docker run --rm -ti --device /dev/dri -p 8080:8080 -e DEBUG=true -e MODELS_PATH=/models -e THREADS=1 -v $PWD/models:/models quay.io/go-skynet/local-ai:{{< version >}}-sycl-f16-ffmpeg-core
|
||||
```
|
||||
|
||||
For diffusers instead, it might look like this instead:
|
||||
|
||||
```yaml
|
||||
name: stablediffusion
|
||||
parameters:
|
||||
model: toonyou_beta6.safetensors
|
||||
backend: diffusers
|
||||
step: 30
|
||||
f16: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionPipeline
|
||||
cuda: true
|
||||
enable_parameters: "negative_prompt,num_inference_steps,clip_skip"
|
||||
scheduler_type: "k_dpmpp_sde"
|
||||
```
|
||||
@@ -6,10 +6,6 @@ weight = 14
|
||||
url = "/features/gpt-vision/"
|
||||
+++
|
||||
|
||||
{{% alert note %}}
|
||||
Available only on `master` builds
|
||||
{{% /alert %}}
|
||||
|
||||
LocalAI supports understanding images by using [LLaVA](https://llava.hliu.cc/), and implements the [GPT Vision API](https://platform.openai.com/docs/guides/vision) from OpenAI.
|
||||
|
||||

|
||||
@@ -28,4 +24,4 @@ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/jso
|
||||
|
||||
### Setup
|
||||
|
||||
To setup the LLaVa models, follow the full example in the [configuration examples](https://github.com/mudler/LocalAI/blob/master/examples/configurations/README.md#llava).
|
||||
To setup the LLaVa models, follow the full example in the [configuration examples](https://github.com/mudler/LocalAI/blob/master/examples/configurations/README.md#llava).
|
||||
|
||||
@@ -83,7 +83,7 @@ Here is the list of the variables available that can be used to customize the bu
|
||||
|
||||
| Variable | Default | Description |
|
||||
| ---------------------| ------- | ----------- |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas` |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas`, `sycl_f16`, `sycl_f32` |
|
||||
| `GO_TAGS` | `tts stablediffusion` | Go tags. Available: `stablediffusion`, `tts`, `tinydream` |
|
||||
| `CLBLAST_DIR` | | Specify a CLBlast directory |
|
||||
| `CUDA_LIBPATH` | | Specify a CUDA library path |
|
||||
@@ -225,6 +225,17 @@ make BUILD_TYPE=clblas build
|
||||
|
||||
To specify a clblast dir set: `CLBLAST_DIR`
|
||||
|
||||
#### Intel GPU acceleration
|
||||
|
||||
Intel GPU acceleration is supported via SYCL.
|
||||
|
||||
Requirements: [Intel oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html) (see also [llama.cpp setup installations instructions](https://github.com/ggerganov/llama.cpp/blob/d71ac90985854b0905e1abba778e407e17f9f887/README-sycl.md?plain=1#L56))
|
||||
|
||||
```
|
||||
make BUILD_TYPE=sycl_f16 build # for float16
|
||||
make BUILD_TYPE=sycl_f32 build # for float32
|
||||
```
|
||||
|
||||
#### Metal (Apple Silicon)
|
||||
|
||||
```
|
||||
|
||||
@@ -26,6 +26,8 @@ Here's an example to initiate the **phi-2** model:
|
||||
docker run -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core https://gist.githubusercontent.com/mudler/ad601a0488b497b69ec549150d9edd18/raw/a8a8869ef1bb7e3830bf5c0bae29a0cce991ff8d/phi-2.yaml
|
||||
```
|
||||
|
||||
You can also check all the embedded models configurations [here](https://github.com/mudler/LocalAI/tree/master/embedded/models).
|
||||
|
||||
{{% alert icon="" %}}
|
||||
The model configurations used in the quickstart are accessible here: [https://github.com/mudler/LocalAI/tree/master/embedded/models](https://github.com/mudler/LocalAI/tree/master/embedded/models). Contributions are welcome; please feel free to submit a Pull Request.
|
||||
|
||||
|
||||
@@ -40,7 +40,7 @@ There are different categories of models: [LLMs]({{%relref "docs/features/text-g
|
||||
|
||||
{{% alert icon="💡" %}}
|
||||
|
||||
To customize the models, see [Model customization]({{%relref "docs/getting-started/customize-model" %}}). For more model configurations, visit the [Examples Section](https://github.com/mudler/LocalAI/tree/master/examples/configurations).
|
||||
To customize the models, see [Model customization]({{%relref "docs/getting-started/customize-model" %}}). For more model configurations, visit the [Examples Section](https://github.com/mudler/LocalAI/tree/master/examples/configurations) and the configurations for the models below is available [here](https://github.com/mudler/LocalAI/tree/master/embedded/models).
|
||||
{{% /alert %}}
|
||||
|
||||
{{< tabs tabTotal="3" >}}
|
||||
@@ -64,6 +64,10 @@ To customize the models, see [Model customization]({{%relref "docs/getting-start
|
||||
| [tinyllama-chat](https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF) [original model](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v0.3) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core tinyllama-chat``` |
|
||||
| [dolphin-2.5-mixtral-8x7b](https://huggingface.co/TheBloke/dolphin-2.5-mixtral-8x7b-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core dolphin-2.5-mixtral-8x7b``` |
|
||||
| 🐍 [mamba](https://github.com/state-spaces/mamba) | [LLM]({{%relref "docs/features/text-generation" %}}) | GPU-only |
|
||||
| animagine-xl | [Text to Image]({{%relref "docs/features/image-generation" %}}) | GPU-only |
|
||||
| transformers-tinyllama | [LLM]({{%relref "docs/features/text-generation" %}}) | GPU-only |
|
||||
| [codellama-7b](https://huggingface.co/codellama/CodeLlama-7b-hf) (with transformers) | [LLM]({{%relref "docs/features/text-generation" %}}) | GPU-only |
|
||||
| [codellama-7b-gguf](https://huggingface.co/TheBloke/CodeLlama-7B-GGUF) (with llama.cpp) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 localai/localai:{{< version >}}-ffmpeg-core codellama-7b-gguf``` |
|
||||
{{% /tab %}}
|
||||
{{% tab tabName="GPU (CUDA 11)" %}}
|
||||
|
||||
@@ -86,7 +90,10 @@ To customize the models, see [Model customization]({{%relref "docs/getting-start
|
||||
| [tinyllama-chat](https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF) [original model](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v0.3) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core tinyllama-chat``` |
|
||||
| [dolphin-2.5-mixtral-8x7b](https://huggingface.co/TheBloke/dolphin-2.5-mixtral-8x7b-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core dolphin-2.5-mixtral-8x7b``` |
|
||||
| 🐍 [mamba](https://github.com/state-spaces/mamba) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 mamba-chat``` |
|
||||
|
||||
| animagine-xl | [Text to Image]({{%relref "docs/features/image-generation" %}}) | ```docker run -ti -p 8080:8080 -e COMPEL=0 --gpus all localai/localai:{{< version >}}-cublas-cuda11 animagine-xl``` |
|
||||
| transformers-tinyllama | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 transformers-tinyllama``` |
|
||||
| [codellama-7b](https://huggingface.co/codellama/CodeLlama-7b-hf) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11 codellama-7b``` |
|
||||
| [codellama-7b-gguf](https://huggingface.co/TheBloke/CodeLlama-7B-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda11-core codellama-7b-gguf``` |
|
||||
{{% /tab %}}
|
||||
|
||||
|
||||
@@ -110,6 +117,10 @@ To customize the models, see [Model customization]({{%relref "docs/getting-start
|
||||
| [tinyllama-chat](https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF) [original model](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v0.3) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core tinyllama-chat``` |
|
||||
| [dolphin-2.5-mixtral-8x7b](https://huggingface.co/TheBloke/dolphin-2.5-mixtral-8x7b-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core dolphin-2.5-mixtral-8x7b``` |
|
||||
| 🐍 [mamba](https://github.com/state-spaces/mamba) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 mamba-chat``` |
|
||||
| animagine-xl | [Text to Image]({{%relref "docs/features/image-generation" %}}) | ```docker run -ti -p 8080:8080 -e COMPEL=0 --gpus all localai/localai:{{< version >}}-cublas-cuda12 animagine-xl``` |
|
||||
| transformers-tinyllama | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 transformers-tinyllama``` |
|
||||
| [codellama-7b](https://huggingface.co/codellama/CodeLlama-7b-hf) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12 codellama-7b``` |
|
||||
| [codellama-7b-gguf](https://huggingface.co/TheBloke/CodeLlama-7B-GGUF) | [LLM]({{%relref "docs/features/text-generation" %}}) | ```docker run -ti -p 8080:8080 --gpus all localai/localai:{{< version >}}-cublas-cuda12-core codellama-7b-gguf``` |
|
||||
{{% /tab %}}
|
||||
|
||||
{{< /tabs >}}
|
||||
|
||||
@@ -24,5 +24,6 @@ The list below is a list of software that integrates with LocalAI.
|
||||
- https://github.com/mattermost/openops
|
||||
- https://github.com/charmbracelet/mods
|
||||
- https://github.com/cedriking/spark
|
||||
|
||||
- [Big AGI](https://github.com/enricoros/big-agi) is a powerful web interface entirely running in the browser, supporting LocalAI
|
||||
|
||||
Feel free to open up a Pull request (by clicking at the "Edit page" below) to get a page for your project made or if you see a error on one of the pages!
|
||||
|
||||
@@ -74,14 +74,6 @@ Note that this started just as a fun weekend project by [mudler](https://github.
|
||||
- 🖼️ [Download Models directly from Huggingface ](https://localai.io/models/)
|
||||
- 🆕 [Vision API](https://localai.io/features/gpt-vision/)
|
||||
|
||||
## How does it work?
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||
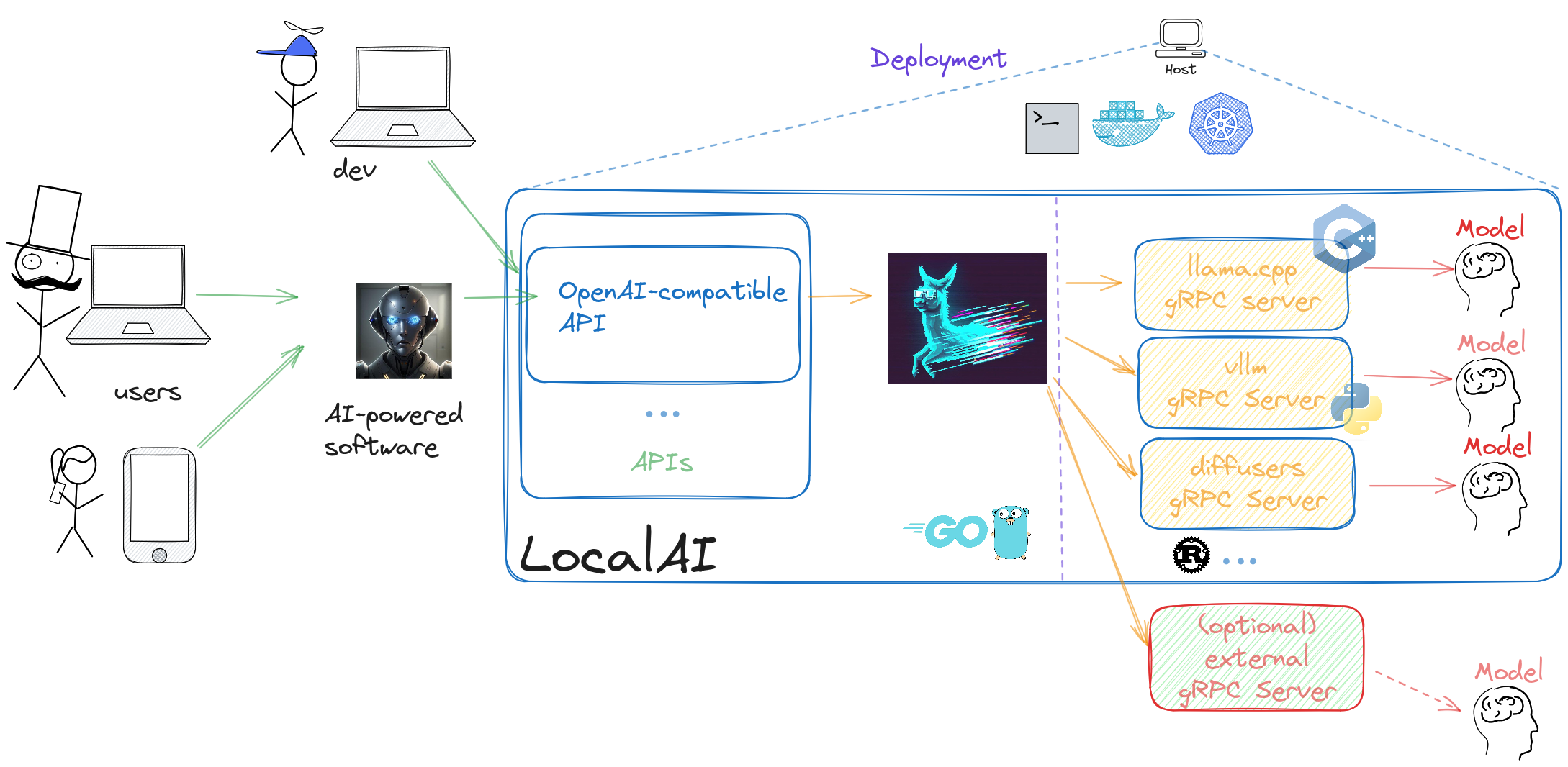
|
||||
|
||||
## Contribute and help
|
||||
|
||||
To help the project you can:
|
||||
@@ -112,21 +104,6 @@ LocalAI couldn't have been built without the help of great software already avai
|
||||
- https://github.com/ggerganov/whisper.cpp
|
||||
- https://github.com/saharNooby/rwkv.cpp
|
||||
- https://github.com/rhasspy/piper
|
||||
- https://github.com/cmp-nct/ggllm.cpp
|
||||
|
||||
|
||||
|
||||
## Backstory
|
||||
|
||||
As much as typical open source projects starts, I, [mudler](https://github.com/mudler/), was fiddling around with [llama.cpp](https://github.com/ggerganov/llama.cpp) over my long nights and wanted to have a way to call it from `go`, as I am a Golang developer and use it extensively. So I've created `LocalAI` (or what was initially known as `llama-cli`) and added an API to it.
|
||||
|
||||
But guess what? The more I dived into this rabbit hole, the more I realized that I had stumbled upon something big. With all the fantastic C++ projects floating around the community, it dawned on me that I could piece them together to create a full-fledged OpenAI replacement. So, ta-da! LocalAI was born, and it quickly overshadowed its humble origins.
|
||||
|
||||
Now, why did I choose to go with C++ bindings, you ask? Well, I wanted to keep LocalAI snappy and lightweight, allowing it to run like a champ on any system and avoid any Golang penalties of the GC, and, most importantly built on shoulders of giants like `llama.cpp`. Go is good at backends and API and is easy to maintain. And hey, don't forget that I'm all about sharing the love. That's why I made LocalAI MIT licensed, so everyone can hop on board and benefit from it.
|
||||
|
||||
As if that wasn't exciting enough, as the project gained traction, [mkellerman](https://github.com/mkellerman) and [Aisuko](https://github.com/Aisuko) jumped in to lend a hand. mkellerman helped set up some killer examples, while Aisuko is becoming our community maestro. The community now is growing even more with new contributors and users, and I couldn't be happier about it!
|
||||
|
||||
Oh, and let's not forget the real MVP here—[llama.cpp](https://github.com/ggerganov/llama.cpp). Without this extraordinary piece of software, LocalAI wouldn't even exist. So, a big shoutout to the community for making this magic happen!
|
||||
|
||||
## 🤗 Contributors
|
||||
|
||||
|
||||
25
docs/content/docs/reference/architecture.md
Normal file
25
docs/content/docs/reference/architecture.md
Normal file
@@ -0,0 +1,25 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Architecture"
|
||||
weight = 25
|
||||
+++
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||

|
||||
|
||||
|
||||
## Backstory
|
||||
|
||||
As much as typical open source projects starts, I, [mudler](https://github.com/mudler/), was fiddling around with [llama.cpp](https://github.com/ggerganov/llama.cpp) over my long nights and wanted to have a way to call it from `go`, as I am a Golang developer and use it extensively. So I've created `LocalAI` (or what was initially known as `llama-cli`) and added an API to it.
|
||||
|
||||
But guess what? The more I dived into this rabbit hole, the more I realized that I had stumbled upon something big. With all the fantastic C++ projects floating around the community, it dawned on me that I could piece them together to create a full-fledged OpenAI replacement. So, ta-da! LocalAI was born, and it quickly overshadowed its humble origins.
|
||||
|
||||
Now, why did I choose to go with C++ bindings, you ask? Well, I wanted to keep LocalAI snappy and lightweight, allowing it to run like a champ on any system and avoid any Golang penalties of the GC, and, most importantly built on shoulders of giants like `llama.cpp`. Go is good at backends and API and is easy to maintain. And hey, don't forget that I'm all about sharing the love. That's why I made LocalAI MIT licensed, so everyone can hop on board and benefit from it.
|
||||
|
||||
As if that wasn't exciting enough, as the project gained traction, [mkellerman](https://github.com/mkellerman) and [Aisuko](https://github.com/Aisuko) jumped in to lend a hand. mkellerman helped set up some killer examples, while Aisuko is becoming our community maestro. The community now is growing even more with new contributors and users, and I couldn't be happier about it!
|
||||
|
||||
Oh, and let's not forget the real MVP here—[llama.cpp](https://github.com/ggerganov/llama.cpp). Without this extraordinary piece of software, LocalAI wouldn't even exist. So, a big shoutout to the community for making this magic happen!
|
||||
@@ -16,18 +16,16 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
|
||||
| Backend and Bindings | Compatible models | Completion/Chat endpoint | Capability | Embeddings support | Token stream support | Acceleration |
|
||||
|----------------------------------------------------------------------------------|-----------------------|--------------------------|---------------------------|-----------------------------------|----------------------|--------------|
|
||||
| [llama.cpp]({{%relref "docs/features/text-generation#llama.cpp" %}}) | Vicuna, Alpaca, LLaMa | yes | GPT and Functions | yes** | yes | CUDA, openCL, cuBLAS, Metal |
|
||||
| [llama.cpp]({{%relref "docs/features/text-generation#llama.cpp" %}}) | Vicuna, Alpaca, LLaMa, Falcon, Starcoder, GPT-2, [and many others](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#description) | yes | GPT and Functions | yes** | yes | CUDA, openCL, cuBLAS, Metal |
|
||||
| [gpt4all-llama](https://github.com/nomic-ai/gpt4all) | Vicuna, Alpaca, LLaMa | yes | GPT | no | yes | N/A |
|
||||
| [gpt4all-mpt](https://github.com/nomic-ai/gpt4all) | MPT | yes | GPT | no | yes | N/A |
|
||||
| [gpt4all-j](https://github.com/nomic-ai/gpt4all) | GPT4ALL-J | yes | GPT | no | yes | N/A |
|
||||
| [falcon-ggml](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Falcon (*) | yes | GPT | no | no | N/A |
|
||||
| [gpt2](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | GPT2, Cerebras | yes | GPT | no | no | N/A |
|
||||
| [dolly](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Dolly | yes | GPT | no | no | N/A |
|
||||
| [gptj](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | GPTJ | yes | GPT | no | no | N/A |
|
||||
| [mpt](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | MPT | yes | GPT | no | no | N/A |
|
||||
| [replit](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Replit | yes | GPT | no | no | N/A |
|
||||
| [gptneox](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | GPT NeoX, RedPajama, StableLM | yes | GPT | no | no | N/A |
|
||||
| [starcoder](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Starcoder | yes | GPT | no | no | N/A|
|
||||
| [bloomz](https://github.com/NouamaneTazi/bloomz.cpp) ([binding](https://github.com/go-skynet/bloomz.cpp)) | Bloom | yes | GPT | no | no | N/A |
|
||||
| [rwkv](https://github.com/saharNooby/rwkv.cpp) ([binding](https://github.com/donomii/go-rwkv.cpp)) | rwkv | yes | GPT | no | yes | N/A |
|
||||
| [bert](https://github.com/skeskinen/bert.cpp) ([binding](https://github.com/go-skynet/go-bert.cpp)) | bert | no | Embeddings only | yes | no | N/A |
|
||||
@@ -35,7 +33,6 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
| [stablediffusion](https://github.com/EdVince/Stable-Diffusion-NCNN) ([binding](https://github.com/mudler/go-stable-diffusion)) | stablediffusion | no | Image | no | no | N/A |
|
||||
| [langchain-huggingface](https://github.com/tmc/langchaingo) | Any text generators available on HuggingFace through API | yes | GPT | no | no | N/A |
|
||||
| [piper](https://github.com/rhasspy/piper) ([binding](https://github.com/mudler/go-piper)) | Any piper onnx model | no | Text to voice | no | no | N/A |
|
||||
| [falcon](https://github.com/cmp-nct/ggllm.cpp/tree/c12b2d65f732a0d8846db2244e070f0f3e73505c) ([binding](https://github.com/mudler/go-ggllm.cpp)) | Falcon *** | yes | GPT | no | yes | CUDA |
|
||||
| [sentencetransformers](https://github.com/UKPLab/sentence-transformers) | BERT | no | Embeddings only | yes | no | N/A |
|
||||
| `bark` | bark | no | Audio generation | no | no | yes |
|
||||
| `autogptq` | GPTQ | yes | GPT | yes | no | N/A |
|
||||
@@ -48,6 +45,7 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
| [tinydream](https://github.com/symisc/tiny-dream#tiny-dreaman-embedded-header-only-stable-diffusion-inference-c-librarypixlabiotiny-dream) | stablediffusion | no | Image | no | no | N/A |
|
||||
| `coqui` | Coqui | no | Audio generation and Voice cloning | no | no | CPU/CUDA |
|
||||
| `petals` | Various GPTs and quantization formats | yes | GPT | no | no | CPU/CUDA |
|
||||
| `transformers` | Various GPTs and quantization formats | yes | GPT, embeddings | yes | no | CPU/CUDA |
|
||||
|
||||
Note: any backend name listed above can be used in the `backend` field of the model configuration file (See [the advanced section]({{%relref "docs/advanced" %}})).
|
||||
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
{
|
||||
"version": "v2.5.1"
|
||||
"version": "v2.7.0"
|
||||
}
|
||||
|
||||
@@ -6,6 +6,8 @@ import (
|
||||
"slices"
|
||||
"strings"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/downloader"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/assets"
|
||||
"gopkg.in/yaml.v3"
|
||||
)
|
||||
@@ -30,6 +32,19 @@ func init() {
|
||||
yaml.Unmarshal(modelLibrary, &modelShorteners)
|
||||
}
|
||||
|
||||
func GetRemoteLibraryShorteners(url string) (map[string]string, error) {
|
||||
remoteLibrary := map[string]string{}
|
||||
|
||||
err := downloader.GetURI(url, func(_ string, i []byte) error {
|
||||
return yaml.Unmarshal(i, &remoteLibrary)
|
||||
})
|
||||
if err != nil {
|
||||
return nil, fmt.Errorf("error downloading remote library: %s", err.Error())
|
||||
}
|
||||
|
||||
return remoteLibrary, err
|
||||
}
|
||||
|
||||
// ExistsInModelsLibrary checks if a model exists in the embedded models library
|
||||
func ExistsInModelsLibrary(s string) bool {
|
||||
f := fmt.Sprintf("%s.yaml", s)
|
||||
|
||||
17
embedded/models/animagine-xl.yaml
Normal file
17
embedded/models/animagine-xl.yaml
Normal file
@@ -0,0 +1,17 @@
|
||||
name: animagine-xl
|
||||
parameters:
|
||||
model: Linaqruf/animagine-xl
|
||||
backend: diffusers
|
||||
f16: true
|
||||
diffusers:
|
||||
scheduler_type: euler_a
|
||||
|
||||
usage: |
|
||||
curl http://localhost:8080/v1/images/generations \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"prompt": "<positive prompt>|<negative prompt>",
|
||||
"model": "animagine-xl",
|
||||
"step": 51,
|
||||
"size": "1024x1024"
|
||||
}'
|
||||
16
embedded/models/codellama-7b-gguf.yaml
Normal file
16
embedded/models/codellama-7b-gguf.yaml
Normal file
@@ -0,0 +1,16 @@
|
||||
name: codellama-7b-gguf
|
||||
backend: transformers
|
||||
parameters:
|
||||
model: huggingface://TheBloke/CodeLlama-7B-GGUF/codellama-7b.Q4_K_M.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
seed: -1
|
||||
top_p: 0.95
|
||||
context_size: 4096
|
||||
f16: true
|
||||
gpu_layers: 90
|
||||
usage: |
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "codellama-7b-gguf",
|
||||
"prompt": "import socket\n\ndef ping_exponential_backoff(host: str):"
|
||||
}'
|
||||
14
embedded/models/codellama-7b.yaml
Normal file
14
embedded/models/codellama-7b.yaml
Normal file
@@ -0,0 +1,14 @@
|
||||
name: codellama-7b
|
||||
backend: transformers
|
||||
type: AutoModelForCausalLM
|
||||
parameters:
|
||||
model: codellama/CodeLlama-7b-hf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
|
||||
usage: |
|
||||
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "codellama-7b",
|
||||
"prompt": "import socket\n\ndef ping_exponential_backoff(host: str):"
|
||||
}'
|
||||
@@ -1,10 +1,11 @@
|
||||
name: dolphin-mixtral-8x7b
|
||||
mmap: true
|
||||
parameters:
|
||||
model: huggingface://TheBloke/dolphin-2.5-mixtral-8x7b-GGUF/blob/main/dolphin-2.5-mixtral-8x7b.Q2_K.gguf
|
||||
model: huggingface://TheBloke/dolphin-2.5-mixtral-8x7b-GGUF/dolphin-2.5-mixtral-8x7b.Q2_K.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
seed: -1
|
||||
template:
|
||||
chat_message: |
|
||||
<|im_start|>{{if eq .RoleName "assistant"}}assistant{{else if eq .RoleName "system"}}system{{else if eq .RoleName "user"}}user{{end}}
|
||||
|
||||
@@ -17,6 +17,7 @@ parameters:
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
seed: -1
|
||||
|
||||
template:
|
||||
chat: |
|
||||
|
||||
21
embedded/models/mamba-bagel.yaml
Normal file
21
embedded/models/mamba-bagel.yaml
Normal file
@@ -0,0 +1,21 @@
|
||||
name: bagel
|
||||
backend: mamba
|
||||
parameters:
|
||||
model: "jondurbin/bagel-dpo-2.8b-v0.2"
|
||||
systemPrompt: "You are a helpful, unbiased, uncensored assistant."
|
||||
template:
|
||||
chat_message: |
|
||||
{{if eq .RoleName "assistant"}}{{.Content}}{{else}}
|
||||
[INST]
|
||||
{{if .SystemPrompt}}{{.SystemPrompt}}{{else if eq .RoleName "system"}}<<SYS>>{{.Content}}<</SYS>>
|
||||
|
||||
{{else if .Content}}{{.Content}}{{end}}
|
||||
[/INST]
|
||||
{{end}}
|
||||
completion: |
|
||||
{{.Input}}
|
||||
usage: |
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "bagel",
|
||||
"messages": [{"role": "user", "content": "how are you doing"}],
|
||||
}'
|
||||
@@ -5,6 +5,7 @@ parameters:
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
seed: -1
|
||||
template:
|
||||
chat_message: |
|
||||
<|im_start|>{{if eq .RoleName "assistant"}}assistant{{else if eq .RoleName "system"}}system{{else if eq .RoleName "user"}}user{{end}}
|
||||
|
||||
@@ -4,6 +4,7 @@ parameters:
|
||||
model: huggingface://TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/mixtral-8x7b-instruct-v0.1.Q2_K.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
seed: -1
|
||||
top_p: 0.95
|
||||
template:
|
||||
chat: &chat |
|
||||
|
||||
@@ -4,6 +4,7 @@ parameters:
|
||||
model: huggingface://TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF/tinyllama-1.1b-chat-v0.3.Q8_0.gguf
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
seed: -1
|
||||
top_p: 0.95
|
||||
template:
|
||||
chat_message: |
|
||||
|
||||
31
embedded/models/transformers-tinyllama.yaml
Normal file
31
embedded/models/transformers-tinyllama.yaml
Normal file
@@ -0,0 +1,31 @@
|
||||
name: tinyllama-chat
|
||||
backend: transformers
|
||||
type: AutoModelForCausalLM
|
||||
|
||||
parameters:
|
||||
model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
max_tokens: 4096
|
||||
|
||||
template:
|
||||
chat_message: |
|
||||
<|im_start|>{{if eq .RoleName "assistant"}}assistant{{else if eq .RoleName "system"}}system{{else if eq .RoleName "user"}}user{{end}}
|
||||
{{if .Content}}{{.Content}}{{end}}<|im_end|>
|
||||
chat: |
|
||||
{{.Input}}
|
||||
<|im_start|>assistant
|
||||
|
||||
completion: |
|
||||
{{.Input}}
|
||||
|
||||
stopwords:
|
||||
- <|im_end|>
|
||||
|
||||
usage: |
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "tinyllama-chat",
|
||||
"messages": [{"role": "user", "content": "Say this is a test!"}],
|
||||
"temperature": 0.7
|
||||
}'
|
||||
@@ -10,8 +10,16 @@ parameters:
|
||||
temperature: 0.2
|
||||
top_k: 40
|
||||
top_p: 0.95
|
||||
seed: -1
|
||||
template:
|
||||
chat: &template |
|
||||
Instruct: {{.Input}}
|
||||
Output:
|
||||
completion: *template
|
||||
completion: *template
|
||||
|
||||
usage: |
|
||||
To use this model, interact with the API (in another terminal) with curl for instance:
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "phi-2",
|
||||
"messages": [{"role": "user", "content": "How are you doing?", "temperature": 0.1}]
|
||||
}'
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
This is an example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler).
|
||||
This is an example of fine-tuning a LLM model to use with [LocalAI](https://github.com/mudler/LocalAI) written by [@mudler](https://github.com/mudler).
|
||||
|
||||
Specifically, this example shows how to use [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) to fine-tune a LLM model to consume with LocalAI as a `gguf` model.
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
"source": [
|
||||
"## Finetuning a model and using it with LocalAI\n",
|
||||
"\n",
|
||||
"This is an example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler).\n",
|
||||
"This is an example of fine-tuning a LLM model to use with [LocalAI](https://github.com/mudler/LocalAI) written by [@mudler](https://github.com/mudler).\n",
|
||||
"\n",
|
||||
"Specifically, this example shows how to use [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) to fine-tune a LLM model to consume with LocalAI as a `gguf` model."
|
||||
]
|
||||
|
||||
11
main.go
11
main.go
@@ -26,6 +26,10 @@ import (
|
||||
"github.com/urfave/cli/v2"
|
||||
)
|
||||
|
||||
const (
|
||||
remoteLibraryURL = "https://raw.githubusercontent.com/mudler/LocalAI/master/embedded/model_library.yaml"
|
||||
)
|
||||
|
||||
func main() {
|
||||
log.Logger = log.Output(zerolog.ConsoleWriter{Out: os.Stderr})
|
||||
// clean up process
|
||||
@@ -94,6 +98,12 @@ func main() {
|
||||
Usage: "JSON list of galleries",
|
||||
EnvVars: []string{"GALLERIES"},
|
||||
},
|
||||
&cli.StringFlag{
|
||||
Name: "remote-library",
|
||||
Usage: "A LocalAI remote library URL",
|
||||
EnvVars: []string{"REMOTE_LIBRARY"},
|
||||
Value: remoteLibraryURL,
|
||||
},
|
||||
&cli.StringFlag{
|
||||
Name: "preload-models",
|
||||
Usage: "A List of models to apply in JSON at start",
|
||||
@@ -219,6 +229,7 @@ For a list of compatible model, check out: https://localai.io/model-compatibilit
|
||||
options.WithAudioDir(ctx.String("audio-path")),
|
||||
options.WithF16(ctx.Bool("f16")),
|
||||
options.WithStringGalleries(ctx.String("galleries")),
|
||||
options.WithModelLibraryURL(ctx.String("remote-library")),
|
||||
options.WithDisableMessage(false),
|
||||
options.WithCors(ctx.Bool("cors")),
|
||||
options.WithCorsAllowOrigins(ctx.String("cors-allow-origins")),
|
||||
|
||||
46
pkg/grpc/backend.go
Normal file
46
pkg/grpc/backend.go
Normal file
@@ -0,0 +1,46 @@
|
||||
package grpc
|
||||
|
||||
import (
|
||||
"context"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
"google.golang.org/grpc"
|
||||
)
|
||||
|
||||
var embeds = map[string]*embedBackend{}
|
||||
|
||||
func Provide(addr string, llm LLM) {
|
||||
embeds[addr] = &embedBackend{s: &server{llm: llm}}
|
||||
}
|
||||
|
||||
func NewClient(address string, parallel bool, wd WatchDog, enableWatchDog bool) Backend {
|
||||
if bc, ok := embeds[address]; ok {
|
||||
return bc
|
||||
}
|
||||
return NewGrpcClient(address, parallel, wd, enableWatchDog)
|
||||
}
|
||||
|
||||
func NewGrpcClient(address string, parallel bool, wd WatchDog, enableWatchDog bool) Backend {
|
||||
if !enableWatchDog {
|
||||
wd = nil
|
||||
}
|
||||
return &Client{
|
||||
address: address,
|
||||
parallel: parallel,
|
||||
wd: wd,
|
||||
}
|
||||
}
|
||||
|
||||
type Backend interface {
|
||||
IsBusy() bool
|
||||
HealthCheck(ctx context.Context) (bool, error)
|
||||
Embeddings(ctx context.Context, in *pb.PredictOptions, opts ...grpc.CallOption) (*pb.EmbeddingResult, error)
|
||||
Predict(ctx context.Context, in *pb.PredictOptions, opts ...grpc.CallOption) (*pb.Reply, error)
|
||||
LoadModel(ctx context.Context, in *pb.ModelOptions, opts ...grpc.CallOption) (*pb.Result, error)
|
||||
PredictStream(ctx context.Context, in *pb.PredictOptions, f func(s []byte), opts ...grpc.CallOption) error
|
||||
GenerateImage(ctx context.Context, in *pb.GenerateImageRequest, opts ...grpc.CallOption) (*pb.Result, error)
|
||||
TTS(ctx context.Context, in *pb.TTSRequest, opts ...grpc.CallOption) (*pb.Result, error)
|
||||
AudioTranscription(ctx context.Context, in *pb.TranscriptRequest, opts ...grpc.CallOption) (*schema.Result, error)
|
||||
TokenizeString(ctx context.Context, in *pb.PredictOptions, opts ...grpc.CallOption) (*pb.TokenizationResponse, error)
|
||||
Status(ctx context.Context) (*pb.StatusResponse, error)
|
||||
}
|
||||
@@ -27,17 +27,6 @@ type WatchDog interface {
|
||||
UnMark(address string)
|
||||
}
|
||||
|
||||
func NewClient(address string, parallel bool, wd WatchDog, enableWatchDog bool) *Client {
|
||||
if !enableWatchDog {
|
||||
wd = nil
|
||||
}
|
||||
return &Client{
|
||||
address: address,
|
||||
parallel: parallel,
|
||||
wd: wd,
|
||||
}
|
||||
}
|
||||
|
||||
func (c *Client) IsBusy() bool {
|
||||
c.Lock()
|
||||
defer c.Unlock()
|
||||
|
||||
121
pkg/grpc/embed.go
Normal file
121
pkg/grpc/embed.go
Normal file
@@ -0,0 +1,121 @@
|
||||
package grpc
|
||||
|
||||
import (
|
||||
"context"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
"google.golang.org/grpc"
|
||||
"google.golang.org/grpc/metadata"
|
||||
"time"
|
||||
)
|
||||
|
||||
var _ Backend = new(embedBackend)
|
||||
var _ pb.Backend_PredictStreamServer = new(embedBackendServerStream)
|
||||
|
||||
type embedBackend struct {
|
||||
s *server
|
||||
}
|
||||
|
||||
func (e *embedBackend) IsBusy() bool {
|
||||
return e.s.llm.Busy()
|
||||
}
|
||||
|
||||
func (e *embedBackend) HealthCheck(ctx context.Context) (bool, error) {
|
||||
return true, nil
|
||||
}
|
||||
|
||||
func (e *embedBackend) Embeddings(ctx context.Context, in *pb.PredictOptions, opts ...grpc.CallOption) (*pb.EmbeddingResult, error) {
|
||||
return e.s.Embedding(ctx, in)
|
||||
}
|
||||
|
||||
func (e *embedBackend) Predict(ctx context.Context, in *pb.PredictOptions, opts ...grpc.CallOption) (*pb.Reply, error) {
|
||||
return e.s.Predict(ctx, in)
|
||||
}
|
||||
|
||||
func (e *embedBackend) LoadModel(ctx context.Context, in *pb.ModelOptions, opts ...grpc.CallOption) (*pb.Result, error) {
|
||||
return e.s.LoadModel(ctx, in)
|
||||
}
|
||||
|
||||
func (e *embedBackend) PredictStream(ctx context.Context, in *pb.PredictOptions, f func(s []byte), opts ...grpc.CallOption) error {
|
||||
bs := &embedBackendServerStream{
|
||||
ctx: ctx,
|
||||
fn: f,
|
||||
}
|
||||
return e.s.PredictStream(in, bs)
|
||||
}
|
||||
|
||||
func (e *embedBackend) GenerateImage(ctx context.Context, in *pb.GenerateImageRequest, opts ...grpc.CallOption) (*pb.Result, error) {
|
||||
return e.s.GenerateImage(ctx, in)
|
||||
}
|
||||
|
||||
func (e *embedBackend) TTS(ctx context.Context, in *pb.TTSRequest, opts ...grpc.CallOption) (*pb.Result, error) {
|
||||
return e.s.TTS(ctx, in)
|
||||
}
|
||||
|
||||
func (e *embedBackend) AudioTranscription(ctx context.Context, in *pb.TranscriptRequest, opts ...grpc.CallOption) (*schema.Result, error) {
|
||||
r, err := e.s.AudioTranscription(ctx, in)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
tr := &schema.Result{}
|
||||
for _, s := range r.Segments {
|
||||
var tks []int
|
||||
for _, t := range s.Tokens {
|
||||
tks = append(tks, int(t))
|
||||
}
|
||||
tr.Segments = append(tr.Segments,
|
||||
schema.Segment{
|
||||
Text: s.Text,
|
||||
Id: int(s.Id),
|
||||
Start: time.Duration(s.Start),
|
||||
End: time.Duration(s.End),
|
||||
Tokens: tks,
|
||||
})
|
||||
}
|
||||
tr.Text = r.Text
|
||||
return tr, err
|
||||
}
|
||||
|
||||
func (e *embedBackend) TokenizeString(ctx context.Context, in *pb.PredictOptions, opts ...grpc.CallOption) (*pb.TokenizationResponse, error) {
|
||||
return e.s.TokenizeString(ctx, in)
|
||||
}
|
||||
|
||||
func (e *embedBackend) Status(ctx context.Context) (*pb.StatusResponse, error) {
|
||||
return e.s.Status(ctx, &pb.HealthMessage{})
|
||||
}
|
||||
|
||||
type embedBackendServerStream struct {
|
||||
ctx context.Context
|
||||
fn func(s []byte)
|
||||
}
|
||||
|
||||
func (e *embedBackendServerStream) Send(reply *pb.Reply) error {
|
||||
e.fn(reply.GetMessage())
|
||||
return nil
|
||||
}
|
||||
|
||||
func (e *embedBackendServerStream) SetHeader(md metadata.MD) error {
|
||||
return nil
|
||||
}
|
||||
|
||||
func (e *embedBackendServerStream) SendHeader(md metadata.MD) error {
|
||||
return nil
|
||||
}
|
||||
|
||||
func (e *embedBackendServerStream) SetTrailer(md metadata.MD) {
|
||||
}
|
||||
|
||||
func (e *embedBackendServerStream) Context() context.Context {
|
||||
return e.ctx
|
||||
}
|
||||
|
||||
func (e *embedBackendServerStream) SendMsg(m any) error {
|
||||
if x, ok := m.(*pb.Reply); ok {
|
||||
return e.Send(x)
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (e *embedBackendServerStream) RecvMsg(m any) error {
|
||||
return nil
|
||||
}
|
||||
@@ -1,7 +1,7 @@
|
||||
// Code generated by protoc-gen-go. DO NOT EDIT.
|
||||
// versions:
|
||||
// protoc-gen-go v1.28.1
|
||||
// protoc v3.6.1
|
||||
// protoc-gen-go v1.26.0
|
||||
// protoc v4.23.4
|
||||
// source: backend.proto
|
||||
|
||||
package proto
|
||||
@@ -567,8 +567,7 @@ type ModelOptions struct {
|
||||
CLIPSubfolder string `protobuf:"bytes,32,opt,name=CLIPSubfolder,proto3" json:"CLIPSubfolder,omitempty"`
|
||||
CLIPSkip int32 `protobuf:"varint,33,opt,name=CLIPSkip,proto3" json:"CLIPSkip,omitempty"`
|
||||
ControlNet string `protobuf:"bytes,48,opt,name=ControlNet,proto3" json:"ControlNet,omitempty"`
|
||||
// RWKV
|
||||
Tokenizer string `protobuf:"bytes,34,opt,name=Tokenizer,proto3" json:"Tokenizer,omitempty"`
|
||||
Tokenizer string `protobuf:"bytes,34,opt,name=Tokenizer,proto3" json:"Tokenizer,omitempty"`
|
||||
// LLM (llama.cpp)
|
||||
LoraBase string `protobuf:"bytes,35,opt,name=LoraBase,proto3" json:"LoraBase,omitempty"`
|
||||
LoraAdapter string `protobuf:"bytes,36,opt,name=LoraAdapter,proto3" json:"LoraAdapter,omitempty"`
|
||||
@@ -584,6 +583,7 @@ type ModelOptions struct {
|
||||
YarnAttnFactor float32 `protobuf:"fixed32,45,opt,name=YarnAttnFactor,proto3" json:"YarnAttnFactor,omitempty"`
|
||||
YarnBetaFast float32 `protobuf:"fixed32,46,opt,name=YarnBetaFast,proto3" json:"YarnBetaFast,omitempty"`
|
||||
YarnBetaSlow float32 `protobuf:"fixed32,47,opt,name=YarnBetaSlow,proto3" json:"YarnBetaSlow,omitempty"`
|
||||
Type string `protobuf:"bytes,49,opt,name=Type,proto3" json:"Type,omitempty"`
|
||||
}
|
||||
|
||||
func (x *ModelOptions) Reset() {
|
||||
@@ -954,6 +954,13 @@ func (x *ModelOptions) GetYarnBetaSlow() float32 {
|
||||
return 0
|
||||
}
|
||||
|
||||
func (x *ModelOptions) GetType() string {
|
||||
if x != nil {
|
||||
return x.Type
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
type Result struct {
|
||||
state protoimpl.MessageState
|
||||
sizeCache protoimpl.SizeCache
|
||||
@@ -1696,7 +1703,7 @@ var file_backend_proto_rawDesc = []byte{
|
||||
0x65, 0x73, 0x18, 0x2a, 0x20, 0x03, 0x28, 0x09, 0x52, 0x06, 0x49, 0x6d, 0x61, 0x67, 0x65, 0x73,
|
||||
0x22, 0x21, 0x0a, 0x05, 0x52, 0x65, 0x70, 0x6c, 0x79, 0x12, 0x18, 0x0a, 0x07, 0x6d, 0x65, 0x73,
|
||||
0x73, 0x61, 0x67, 0x65, 0x18, 0x01, 0x20, 0x01, 0x28, 0x0c, 0x52, 0x07, 0x6d, 0x65, 0x73, 0x73,
|
||||
0x61, 0x67, 0x65, 0x22, 0xcc, 0x0b, 0x0a, 0x0c, 0x4d, 0x6f, 0x64, 0x65, 0x6c, 0x4f, 0x70, 0x74,
|
||||
0x61, 0x67, 0x65, 0x22, 0xe0, 0x0b, 0x0a, 0x0c, 0x4d, 0x6f, 0x64, 0x65, 0x6c, 0x4f, 0x70, 0x74,
|
||||
0x69, 0x6f, 0x6e, 0x73, 0x12, 0x14, 0x0a, 0x05, 0x4d, 0x6f, 0x64, 0x65, 0x6c, 0x18, 0x01, 0x20,
|
||||
0x01, 0x28, 0x09, 0x52, 0x05, 0x4d, 0x6f, 0x64, 0x65, 0x6c, 0x12, 0x20, 0x0a, 0x0b, 0x43, 0x6f,
|
||||
0x6e, 0x74, 0x65, 0x78, 0x74, 0x53, 0x69, 0x7a, 0x65, 0x18, 0x02, 0x20, 0x01, 0x28, 0x05, 0x52,
|
||||
@@ -1789,131 +1796,132 @@ var file_backend_proto_rawDesc = []byte{
|
||||
0x52, 0x0c, 0x59, 0x61, 0x72, 0x6e, 0x42, 0x65, 0x74, 0x61, 0x46, 0x61, 0x73, 0x74, 0x12, 0x22,
|
||||
0x0a, 0x0c, 0x59, 0x61, 0x72, 0x6e, 0x42, 0x65, 0x74, 0x61, 0x53, 0x6c, 0x6f, 0x77, 0x18, 0x2f,
|
||||
0x20, 0x01, 0x28, 0x02, 0x52, 0x0c, 0x59, 0x61, 0x72, 0x6e, 0x42, 0x65, 0x74, 0x61, 0x53, 0x6c,
|
||||
0x6f, 0x77, 0x22, 0x3c, 0x0a, 0x06, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x12, 0x18, 0x0a, 0x07,
|
||||
0x6d, 0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x18, 0x01, 0x20, 0x01, 0x28, 0x09, 0x52, 0x07, 0x6d,
|
||||
0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x12, 0x18, 0x0a, 0x07, 0x73, 0x75, 0x63, 0x63, 0x65, 0x73,
|
||||
0x73, 0x18, 0x02, 0x20, 0x01, 0x28, 0x08, 0x52, 0x07, 0x73, 0x75, 0x63, 0x63, 0x65, 0x73, 0x73,
|
||||
0x22, 0x31, 0x0a, 0x0f, 0x45, 0x6d, 0x62, 0x65, 0x64, 0x64, 0x69, 0x6e, 0x67, 0x52, 0x65, 0x73,
|
||||
0x75, 0x6c, 0x74, 0x12, 0x1e, 0x0a, 0x0a, 0x65, 0x6d, 0x62, 0x65, 0x64, 0x64, 0x69, 0x6e, 0x67,
|
||||
0x73, 0x18, 0x01, 0x20, 0x03, 0x28, 0x02, 0x52, 0x0a, 0x65, 0x6d, 0x62, 0x65, 0x64, 0x64, 0x69,
|
||||
0x6e, 0x67, 0x73, 0x22, 0x5b, 0x0a, 0x11, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70,
|
||||
0x74, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x12, 0x10, 0x0a, 0x03, 0x64, 0x73, 0x74, 0x18,
|
||||
0x02, 0x20, 0x01, 0x28, 0x09, 0x52, 0x03, 0x64, 0x73, 0x74, 0x12, 0x1a, 0x0a, 0x08, 0x6c, 0x61,
|
||||
0x6e, 0x67, 0x75, 0x61, 0x67, 0x65, 0x18, 0x03, 0x20, 0x01, 0x28, 0x09, 0x52, 0x08, 0x6c, 0x61,
|
||||
0x6e, 0x67, 0x75, 0x61, 0x67, 0x65, 0x12, 0x18, 0x0a, 0x07, 0x74, 0x68, 0x72, 0x65, 0x61, 0x64,
|
||||
0x73, 0x18, 0x04, 0x20, 0x01, 0x28, 0x0d, 0x52, 0x07, 0x74, 0x68, 0x72, 0x65, 0x61, 0x64, 0x73,
|
||||
0x22, 0x5e, 0x0a, 0x10, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70, 0x74, 0x52, 0x65,
|
||||
0x73, 0x75, 0x6c, 0x74, 0x12, 0x36, 0x0a, 0x08, 0x73, 0x65, 0x67, 0x6d, 0x65, 0x6e, 0x74, 0x73,
|
||||
0x18, 0x01, 0x20, 0x03, 0x28, 0x0b, 0x32, 0x1a, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64,
|
||||
0x2e, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70, 0x74, 0x53, 0x65, 0x67, 0x6d, 0x65,
|
||||
0x6e, 0x74, 0x52, 0x08, 0x73, 0x65, 0x67, 0x6d, 0x65, 0x6e, 0x74, 0x73, 0x12, 0x12, 0x0a, 0x04,
|
||||
0x74, 0x65, 0x78, 0x74, 0x18, 0x02, 0x20, 0x01, 0x28, 0x09, 0x52, 0x04, 0x74, 0x65, 0x78, 0x74,
|
||||
0x22, 0x77, 0x0a, 0x11, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70, 0x74, 0x53, 0x65,
|
||||
0x67, 0x6d, 0x65, 0x6e, 0x74, 0x12, 0x0e, 0x0a, 0x02, 0x69, 0x64, 0x18, 0x01, 0x20, 0x01, 0x28,
|
||||
0x05, 0x52, 0x02, 0x69, 0x64, 0x12, 0x14, 0x0a, 0x05, 0x73, 0x74, 0x61, 0x72, 0x74, 0x18, 0x02,
|
||||
0x20, 0x01, 0x28, 0x03, 0x52, 0x05, 0x73, 0x74, 0x61, 0x72, 0x74, 0x12, 0x10, 0x0a, 0x03, 0x65,
|
||||
0x6e, 0x64, 0x18, 0x03, 0x20, 0x01, 0x28, 0x03, 0x52, 0x03, 0x65, 0x6e, 0x64, 0x12, 0x12, 0x0a,
|
||||
0x04, 0x74, 0x65, 0x78, 0x74, 0x18, 0x04, 0x20, 0x01, 0x28, 0x09, 0x52, 0x04, 0x74, 0x65, 0x78,
|
||||
0x74, 0x12, 0x16, 0x0a, 0x06, 0x74, 0x6f, 0x6b, 0x65, 0x6e, 0x73, 0x18, 0x05, 0x20, 0x03, 0x28,
|
||||
0x05, 0x52, 0x06, 0x74, 0x6f, 0x6b, 0x65, 0x6e, 0x73, 0x22, 0xbe, 0x02, 0x0a, 0x14, 0x47, 0x65,
|
||||
0x6e, 0x65, 0x72, 0x61, 0x74, 0x65, 0x49, 0x6d, 0x61, 0x67, 0x65, 0x52, 0x65, 0x71, 0x75, 0x65,
|
||||
0x73, 0x74, 0x12, 0x16, 0x0a, 0x06, 0x68, 0x65, 0x69, 0x67, 0x68, 0x74, 0x18, 0x01, 0x20, 0x01,
|
||||
0x28, 0x05, 0x52, 0x06, 0x68, 0x65, 0x69, 0x67, 0x68, 0x74, 0x12, 0x14, 0x0a, 0x05, 0x77, 0x69,
|
||||
0x64, 0x74, 0x68, 0x18, 0x02, 0x20, 0x01, 0x28, 0x05, 0x52, 0x05, 0x77, 0x69, 0x64, 0x74, 0x68,
|
||||
0x12, 0x12, 0x0a, 0x04, 0x6d, 0x6f, 0x64, 0x65, 0x18, 0x03, 0x20, 0x01, 0x28, 0x05, 0x52, 0x04,
|
||||
0x6d, 0x6f, 0x64, 0x65, 0x12, 0x12, 0x0a, 0x04, 0x73, 0x74, 0x65, 0x70, 0x18, 0x04, 0x20, 0x01,
|
||||
0x28, 0x05, 0x52, 0x04, 0x73, 0x74, 0x65, 0x70, 0x12, 0x12, 0x0a, 0x04, 0x73, 0x65, 0x65, 0x64,
|
||||
0x18, 0x05, 0x20, 0x01, 0x28, 0x05, 0x52, 0x04, 0x73, 0x65, 0x65, 0x64, 0x12, 0x27, 0x0a, 0x0f,
|
||||
0x70, 0x6f, 0x73, 0x69, 0x74, 0x69, 0x76, 0x65, 0x5f, 0x70, 0x72, 0x6f, 0x6d, 0x70, 0x74, 0x18,
|
||||
0x06, 0x20, 0x01, 0x28, 0x09, 0x52, 0x0e, 0x70, 0x6f, 0x73, 0x69, 0x74, 0x69, 0x76, 0x65, 0x50,
|
||||
0x72, 0x6f, 0x6d, 0x70, 0x74, 0x12, 0x27, 0x0a, 0x0f, 0x6e, 0x65, 0x67, 0x61, 0x74, 0x69, 0x76,
|
||||
0x65, 0x5f, 0x70, 0x72, 0x6f, 0x6d, 0x70, 0x74, 0x18, 0x07, 0x20, 0x01, 0x28, 0x09, 0x52, 0x0e,
|
||||
0x6e, 0x65, 0x67, 0x61, 0x74, 0x69, 0x76, 0x65, 0x50, 0x72, 0x6f, 0x6d, 0x70, 0x74, 0x12, 0x10,
|
||||
0x0a, 0x03, 0x64, 0x73, 0x74, 0x18, 0x08, 0x20, 0x01, 0x28, 0x09, 0x52, 0x03, 0x64, 0x73, 0x74,
|
||||
0x12, 0x10, 0x0a, 0x03, 0x73, 0x72, 0x63, 0x18, 0x09, 0x20, 0x01, 0x28, 0x09, 0x52, 0x03, 0x73,
|
||||
0x72, 0x63, 0x12, 0x2a, 0x0a, 0x10, 0x45, 0x6e, 0x61, 0x62, 0x6c, 0x65, 0x50, 0x61, 0x72, 0x61,
|
||||
0x6d, 0x65, 0x74, 0x65, 0x72, 0x73, 0x18, 0x0a, 0x20, 0x01, 0x28, 0x09, 0x52, 0x10, 0x45, 0x6e,
|
||||
0x61, 0x62, 0x6c, 0x65, 0x50, 0x61, 0x72, 0x61, 0x6d, 0x65, 0x74, 0x65, 0x72, 0x73, 0x12, 0x1a,
|
||||
0x0a, 0x08, 0x43, 0x4c, 0x49, 0x50, 0x53, 0x6b, 0x69, 0x70, 0x18, 0x0b, 0x20, 0x01, 0x28, 0x05,
|
||||
0x52, 0x08, 0x43, 0x4c, 0x49, 0x50, 0x53, 0x6b, 0x69, 0x70, 0x22, 0x48, 0x0a, 0x0a, 0x54, 0x54,
|
||||
0x53, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x12, 0x12, 0x0a, 0x04, 0x74, 0x65, 0x78, 0x74,
|
||||
0x18, 0x01, 0x20, 0x01, 0x28, 0x09, 0x52, 0x04, 0x74, 0x65, 0x78, 0x74, 0x12, 0x14, 0x0a, 0x05,
|
||||
0x6d, 0x6f, 0x64, 0x65, 0x6c, 0x18, 0x02, 0x20, 0x01, 0x28, 0x09, 0x52, 0x05, 0x6d, 0x6f, 0x64,
|
||||
0x65, 0x6c, 0x12, 0x10, 0x0a, 0x03, 0x64, 0x73, 0x74, 0x18, 0x03, 0x20, 0x01, 0x28, 0x09, 0x52,
|
||||
0x03, 0x64, 0x73, 0x74, 0x22, 0x46, 0x0a, 0x14, 0x54, 0x6f, 0x6b, 0x65, 0x6e, 0x69, 0x7a, 0x61,
|
||||
0x74, 0x69, 0x6f, 0x6e, 0x52, 0x65, 0x73, 0x70, 0x6f, 0x6e, 0x73, 0x65, 0x12, 0x16, 0x0a, 0x06,
|
||||
0x6c, 0x65, 0x6e, 0x67, 0x74, 0x68, 0x18, 0x01, 0x20, 0x01, 0x28, 0x05, 0x52, 0x06, 0x6c, 0x65,
|
||||
0x6e, 0x67, 0x74, 0x68, 0x12, 0x16, 0x0a, 0x06, 0x74, 0x6f, 0x6b, 0x65, 0x6e, 0x73, 0x18, 0x02,
|
||||
0x20, 0x03, 0x28, 0x05, 0x52, 0x06, 0x74, 0x6f, 0x6b, 0x65, 0x6e, 0x73, 0x22, 0xac, 0x01, 0x0a,
|
||||
0x0f, 0x4d, 0x65, 0x6d, 0x6f, 0x72, 0x79, 0x55, 0x73, 0x61, 0x67, 0x65, 0x44, 0x61, 0x74, 0x61,
|
||||
0x12, 0x14, 0x0a, 0x05, 0x74, 0x6f, 0x74, 0x61, 0x6c, 0x18, 0x01, 0x20, 0x01, 0x28, 0x04, 0x52,
|
||||
0x05, 0x74, 0x6f, 0x74, 0x61, 0x6c, 0x12, 0x45, 0x0a, 0x09, 0x62, 0x72, 0x65, 0x61, 0x6b, 0x64,
|
||||
0x6f, 0x77, 0x6e, 0x18, 0x02, 0x20, 0x03, 0x28, 0x0b, 0x32, 0x27, 0x2e, 0x62, 0x61, 0x63, 0x6b,
|
||||
0x65, 0x6e, 0x64, 0x2e, 0x4d, 0x65, 0x6d, 0x6f, 0x72, 0x79, 0x55, 0x73, 0x61, 0x67, 0x65, 0x44,
|
||||
0x61, 0x74, 0x61, 0x2e, 0x42, 0x72, 0x65, 0x61, 0x6b, 0x64, 0x6f, 0x77, 0x6e, 0x45, 0x6e, 0x74,
|
||||
0x72, 0x79, 0x52, 0x09, 0x62, 0x72, 0x65, 0x61, 0x6b, 0x64, 0x6f, 0x77, 0x6e, 0x1a, 0x3c, 0x0a,
|
||||
0x0e, 0x42, 0x72, 0x65, 0x61, 0x6b, 0x64, 0x6f, 0x77, 0x6e, 0x45, 0x6e, 0x74, 0x72, 0x79, 0x12,
|
||||
0x10, 0x0a, 0x03, 0x6b, 0x65, 0x79, 0x18, 0x01, 0x20, 0x01, 0x28, 0x09, 0x52, 0x03, 0x6b, 0x65,
|
||||
0x79, 0x12, 0x14, 0x0a, 0x05, 0x76, 0x61, 0x6c, 0x75, 0x65, 0x18, 0x02, 0x20, 0x01, 0x28, 0x04,
|
||||
0x52, 0x05, 0x76, 0x61, 0x6c, 0x75, 0x65, 0x3a, 0x02, 0x38, 0x01, 0x22, 0xbc, 0x01, 0x0a, 0x0e,
|
||||
0x53, 0x74, 0x61, 0x74, 0x75, 0x73, 0x52, 0x65, 0x73, 0x70, 0x6f, 0x6e, 0x73, 0x65, 0x12, 0x33,
|
||||
0x0a, 0x05, 0x73, 0x74, 0x61, 0x74, 0x65, 0x18, 0x01, 0x20, 0x01, 0x28, 0x0e, 0x32, 0x1d, 0x2e,
|
||||
0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x53, 0x74, 0x61, 0x74, 0x75, 0x73, 0x52, 0x65,
|
||||
0x73, 0x70, 0x6f, 0x6e, 0x73, 0x65, 0x2e, 0x53, 0x74, 0x61, 0x74, 0x65, 0x52, 0x05, 0x73, 0x74,
|
||||
0x61, 0x74, 0x65, 0x12, 0x30, 0x0a, 0x06, 0x6d, 0x65, 0x6d, 0x6f, 0x72, 0x79, 0x18, 0x02, 0x20,
|
||||
0x01, 0x28, 0x0b, 0x32, 0x18, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x4d, 0x65,
|
||||
0x6d, 0x6f, 0x72, 0x79, 0x55, 0x73, 0x61, 0x67, 0x65, 0x44, 0x61, 0x74, 0x61, 0x52, 0x06, 0x6d,
|
||||
0x65, 0x6d, 0x6f, 0x72, 0x79, 0x22, 0x43, 0x0a, 0x05, 0x53, 0x74, 0x61, 0x74, 0x65, 0x12, 0x11,
|
||||
0x0a, 0x0d, 0x55, 0x4e, 0x49, 0x4e, 0x49, 0x54, 0x49, 0x41, 0x4c, 0x49, 0x5a, 0x45, 0x44, 0x10,
|
||||
0x00, 0x12, 0x08, 0x0a, 0x04, 0x42, 0x55, 0x53, 0x59, 0x10, 0x01, 0x12, 0x09, 0x0a, 0x05, 0x52,
|
||||
0x45, 0x41, 0x44, 0x59, 0x10, 0x02, 0x12, 0x12, 0x0a, 0x05, 0x45, 0x52, 0x52, 0x4f, 0x52, 0x10,
|
||||
0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x01, 0x32, 0xf4, 0x04, 0x0a, 0x07, 0x42,
|
||||
0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x12, 0x32, 0x0a, 0x06, 0x48, 0x65, 0x61, 0x6c, 0x74, 0x68,
|
||||
0x12, 0x16, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x48, 0x65, 0x61, 0x6c, 0x74,
|
||||
0x68, 0x4d, 0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x1a, 0x0e, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65,
|
||||
0x6e, 0x64, 0x2e, 0x52, 0x65, 0x70, 0x6c, 0x79, 0x22, 0x00, 0x12, 0x34, 0x0a, 0x07, 0x50, 0x72,
|
||||
0x65, 0x64, 0x69, 0x63, 0x74, 0x12, 0x17, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e,
|
||||
0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x4f, 0x70, 0x74, 0x69, 0x6f, 0x6e, 0x73, 0x1a, 0x0e,
|
||||
0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x52, 0x65, 0x70, 0x6c, 0x79, 0x22, 0x00,
|
||||
0x12, 0x35, 0x0a, 0x09, 0x4c, 0x6f, 0x61, 0x64, 0x4d, 0x6f, 0x64, 0x65, 0x6c, 0x12, 0x15, 0x2e,
|
||||
0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x4d, 0x6f, 0x64, 0x65, 0x6c, 0x4f, 0x70, 0x74,
|
||||
0x69, 0x6f, 0x6e, 0x73, 0x1a, 0x0f, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x52,
|
||||
0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x3c, 0x0a, 0x0d, 0x50, 0x72, 0x65, 0x64, 0x69,
|
||||
0x63, 0x74, 0x53, 0x74, 0x72, 0x65, 0x61, 0x6d, 0x12, 0x17, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65,
|
||||
0x6e, 0x64, 0x2e, 0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x4f, 0x70, 0x74, 0x69, 0x6f, 0x6e,
|
||||
0x73, 0x1a, 0x0e, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x52, 0x65, 0x70, 0x6c,
|
||||
0x79, 0x22, 0x00, 0x30, 0x01, 0x12, 0x40, 0x0a, 0x09, 0x45, 0x6d, 0x62, 0x65, 0x64, 0x64, 0x69,
|
||||
0x6e, 0x67, 0x12, 0x17, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x50, 0x72, 0x65,
|
||||
0x64, 0x69, 0x63, 0x74, 0x4f, 0x70, 0x74, 0x69, 0x6f, 0x6e, 0x73, 0x1a, 0x18, 0x2e, 0x62, 0x61,
|
||||
0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x45, 0x6d, 0x62, 0x65, 0x64, 0x64, 0x69, 0x6e, 0x67, 0x52,
|
||||
0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x41, 0x0a, 0x0d, 0x47, 0x65, 0x6e, 0x65, 0x72,
|
||||
0x61, 0x74, 0x65, 0x49, 0x6d, 0x61, 0x67, 0x65, 0x12, 0x1d, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65,
|
||||
0x6e, 0x64, 0x2e, 0x47, 0x65, 0x6e, 0x65, 0x72, 0x61, 0x74, 0x65, 0x49, 0x6d, 0x61, 0x67, 0x65,
|
||||
0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x1a, 0x0f, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e,
|
||||
0x64, 0x2e, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x4d, 0x0a, 0x12, 0x41, 0x75,
|
||||
0x64, 0x69, 0x6f, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70, 0x74, 0x69, 0x6f, 0x6e,
|
||||
0x12, 0x1a, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54, 0x72, 0x61, 0x6e, 0x73,
|
||||
0x63, 0x72, 0x69, 0x70, 0x74, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x1a, 0x19, 0x2e, 0x62,
|
||||
0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70,
|
||||
0x74, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x2d, 0x0a, 0x03, 0x54, 0x54, 0x53,
|
||||
0x12, 0x13, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54, 0x54, 0x53, 0x52, 0x65,
|
||||
0x71, 0x75, 0x65, 0x73, 0x74, 0x1a, 0x0f, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e,
|
||||
0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x4a, 0x0a, 0x0e, 0x54, 0x6f, 0x6b, 0x65,
|
||||
0x6e, 0x69, 0x7a, 0x65, 0x53, 0x74, 0x72, 0x69, 0x6e, 0x67, 0x12, 0x17, 0x2e, 0x62, 0x61, 0x63,
|
||||
0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x4f, 0x70, 0x74, 0x69,
|
||||
0x6f, 0x6e, 0x73, 0x1a, 0x1d, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54, 0x6f,
|
||||
0x6b, 0x65, 0x6e, 0x69, 0x7a, 0x61, 0x74, 0x69, 0x6f, 0x6e, 0x52, 0x65, 0x73, 0x70, 0x6f, 0x6e,
|
||||
0x73, 0x65, 0x22, 0x00, 0x12, 0x3b, 0x0a, 0x06, 0x53, 0x74, 0x61, 0x74, 0x75, 0x73, 0x12, 0x16,
|
||||
0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x48, 0x65, 0x61, 0x6c, 0x74, 0x68, 0x4d,
|
||||
0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x1a, 0x17, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64,
|
||||
0x2e, 0x53, 0x74, 0x61, 0x74, 0x75, 0x73, 0x52, 0x65, 0x73, 0x70, 0x6f, 0x6e, 0x73, 0x65, 0x22,
|
||||
0x00, 0x42, 0x5a, 0x0a, 0x19, 0x69, 0x6f, 0x2e, 0x73, 0x6b, 0x79, 0x6e, 0x65, 0x74, 0x2e, 0x6c,
|
||||
0x6f, 0x63, 0x61, 0x6c, 0x61, 0x69, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x42, 0x0e,
|
||||
0x4c, 0x6f, 0x63, 0x61, 0x6c, 0x41, 0x49, 0x42, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x50, 0x01,
|
||||
0x5a, 0x2b, 0x67, 0x69, 0x74, 0x68, 0x75, 0x62, 0x2e, 0x63, 0x6f, 0x6d, 0x2f, 0x67, 0x6f, 0x2d,
|
||||
0x73, 0x6b, 0x79, 0x6e, 0x65, 0x74, 0x2f, 0x4c, 0x6f, 0x63, 0x61, 0x6c, 0x41, 0x49, 0x2f, 0x70,
|
||||
0x6b, 0x67, 0x2f, 0x67, 0x72, 0x70, 0x63, 0x2f, 0x70, 0x72, 0x6f, 0x74, 0x6f, 0x62, 0x06, 0x70,
|
||||
0x72, 0x6f, 0x74, 0x6f, 0x33,
|
||||
0x6f, 0x77, 0x12, 0x12, 0x0a, 0x04, 0x54, 0x79, 0x70, 0x65, 0x18, 0x31, 0x20, 0x01, 0x28, 0x09,
|
||||
0x52, 0x04, 0x54, 0x79, 0x70, 0x65, 0x22, 0x3c, 0x0a, 0x06, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74,
|
||||
0x12, 0x18, 0x0a, 0x07, 0x6d, 0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x18, 0x01, 0x20, 0x01, 0x28,
|
||||
0x09, 0x52, 0x07, 0x6d, 0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x12, 0x18, 0x0a, 0x07, 0x73, 0x75,
|
||||
0x63, 0x63, 0x65, 0x73, 0x73, 0x18, 0x02, 0x20, 0x01, 0x28, 0x08, 0x52, 0x07, 0x73, 0x75, 0x63,
|
||||
0x63, 0x65, 0x73, 0x73, 0x22, 0x31, 0x0a, 0x0f, 0x45, 0x6d, 0x62, 0x65, 0x64, 0x64, 0x69, 0x6e,
|
||||
0x67, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x12, 0x1e, 0x0a, 0x0a, 0x65, 0x6d, 0x62, 0x65, 0x64,
|
||||
0x64, 0x69, 0x6e, 0x67, 0x73, 0x18, 0x01, 0x20, 0x03, 0x28, 0x02, 0x52, 0x0a, 0x65, 0x6d, 0x62,
|
||||
0x65, 0x64, 0x64, 0x69, 0x6e, 0x67, 0x73, 0x22, 0x5b, 0x0a, 0x11, 0x54, 0x72, 0x61, 0x6e, 0x73,
|
||||
0x63, 0x72, 0x69, 0x70, 0x74, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x12, 0x10, 0x0a, 0x03,
|
||||
0x64, 0x73, 0x74, 0x18, 0x02, 0x20, 0x01, 0x28, 0x09, 0x52, 0x03, 0x64, 0x73, 0x74, 0x12, 0x1a,
|
||||
0x0a, 0x08, 0x6c, 0x61, 0x6e, 0x67, 0x75, 0x61, 0x67, 0x65, 0x18, 0x03, 0x20, 0x01, 0x28, 0x09,
|
||||
0x52, 0x08, 0x6c, 0x61, 0x6e, 0x67, 0x75, 0x61, 0x67, 0x65, 0x12, 0x18, 0x0a, 0x07, 0x74, 0x68,
|
||||
0x72, 0x65, 0x61, 0x64, 0x73, 0x18, 0x04, 0x20, 0x01, 0x28, 0x0d, 0x52, 0x07, 0x74, 0x68, 0x72,
|
||||
0x65, 0x61, 0x64, 0x73, 0x22, 0x5e, 0x0a, 0x10, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69,
|
||||
0x70, 0x74, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x12, 0x36, 0x0a, 0x08, 0x73, 0x65, 0x67, 0x6d,
|
||||
0x65, 0x6e, 0x74, 0x73, 0x18, 0x01, 0x20, 0x03, 0x28, 0x0b, 0x32, 0x1a, 0x2e, 0x62, 0x61, 0x63,
|
||||
0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70, 0x74, 0x53,
|
||||
0x65, 0x67, 0x6d, 0x65, 0x6e, 0x74, 0x52, 0x08, 0x73, 0x65, 0x67, 0x6d, 0x65, 0x6e, 0x74, 0x73,
|
||||
0x12, 0x12, 0x0a, 0x04, 0x74, 0x65, 0x78, 0x74, 0x18, 0x02, 0x20, 0x01, 0x28, 0x09, 0x52, 0x04,
|
||||
0x74, 0x65, 0x78, 0x74, 0x22, 0x77, 0x0a, 0x11, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69,
|
||||
0x70, 0x74, 0x53, 0x65, 0x67, 0x6d, 0x65, 0x6e, 0x74, 0x12, 0x0e, 0x0a, 0x02, 0x69, 0x64, 0x18,
|
||||
0x01, 0x20, 0x01, 0x28, 0x05, 0x52, 0x02, 0x69, 0x64, 0x12, 0x14, 0x0a, 0x05, 0x73, 0x74, 0x61,
|
||||
0x72, 0x74, 0x18, 0x02, 0x20, 0x01, 0x28, 0x03, 0x52, 0x05, 0x73, 0x74, 0x61, 0x72, 0x74, 0x12,
|
||||
0x10, 0x0a, 0x03, 0x65, 0x6e, 0x64, 0x18, 0x03, 0x20, 0x01, 0x28, 0x03, 0x52, 0x03, 0x65, 0x6e,
|
||||
0x64, 0x12, 0x12, 0x0a, 0x04, 0x74, 0x65, 0x78, 0x74, 0x18, 0x04, 0x20, 0x01, 0x28, 0x09, 0x52,
|
||||
0x04, 0x74, 0x65, 0x78, 0x74, 0x12, 0x16, 0x0a, 0x06, 0x74, 0x6f, 0x6b, 0x65, 0x6e, 0x73, 0x18,
|
||||
0x05, 0x20, 0x03, 0x28, 0x05, 0x52, 0x06, 0x74, 0x6f, 0x6b, 0x65, 0x6e, 0x73, 0x22, 0xbe, 0x02,
|
||||
0x0a, 0x14, 0x47, 0x65, 0x6e, 0x65, 0x72, 0x61, 0x74, 0x65, 0x49, 0x6d, 0x61, 0x67, 0x65, 0x52,
|
||||
0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x12, 0x16, 0x0a, 0x06, 0x68, 0x65, 0x69, 0x67, 0x68, 0x74,
|
||||
0x18, 0x01, 0x20, 0x01, 0x28, 0x05, 0x52, 0x06, 0x68, 0x65, 0x69, 0x67, 0x68, 0x74, 0x12, 0x14,
|
||||
0x0a, 0x05, 0x77, 0x69, 0x64, 0x74, 0x68, 0x18, 0x02, 0x20, 0x01, 0x28, 0x05, 0x52, 0x05, 0x77,
|
||||
0x69, 0x64, 0x74, 0x68, 0x12, 0x12, 0x0a, 0x04, 0x6d, 0x6f, 0x64, 0x65, 0x18, 0x03, 0x20, 0x01,
|
||||
0x28, 0x05, 0x52, 0x04, 0x6d, 0x6f, 0x64, 0x65, 0x12, 0x12, 0x0a, 0x04, 0x73, 0x74, 0x65, 0x70,
|
||||
0x18, 0x04, 0x20, 0x01, 0x28, 0x05, 0x52, 0x04, 0x73, 0x74, 0x65, 0x70, 0x12, 0x12, 0x0a, 0x04,
|
||||
0x73, 0x65, 0x65, 0x64, 0x18, 0x05, 0x20, 0x01, 0x28, 0x05, 0x52, 0x04, 0x73, 0x65, 0x65, 0x64,
|
||||
0x12, 0x27, 0x0a, 0x0f, 0x70, 0x6f, 0x73, 0x69, 0x74, 0x69, 0x76, 0x65, 0x5f, 0x70, 0x72, 0x6f,
|
||||
0x6d, 0x70, 0x74, 0x18, 0x06, 0x20, 0x01, 0x28, 0x09, 0x52, 0x0e, 0x70, 0x6f, 0x73, 0x69, 0x74,
|
||||
0x69, 0x76, 0x65, 0x50, 0x72, 0x6f, 0x6d, 0x70, 0x74, 0x12, 0x27, 0x0a, 0x0f, 0x6e, 0x65, 0x67,
|
||||
0x61, 0x74, 0x69, 0x76, 0x65, 0x5f, 0x70, 0x72, 0x6f, 0x6d, 0x70, 0x74, 0x18, 0x07, 0x20, 0x01,
|
||||
0x28, 0x09, 0x52, 0x0e, 0x6e, 0x65, 0x67, 0x61, 0x74, 0x69, 0x76, 0x65, 0x50, 0x72, 0x6f, 0x6d,
|
||||
0x70, 0x74, 0x12, 0x10, 0x0a, 0x03, 0x64, 0x73, 0x74, 0x18, 0x08, 0x20, 0x01, 0x28, 0x09, 0x52,
|
||||
0x03, 0x64, 0x73, 0x74, 0x12, 0x10, 0x0a, 0x03, 0x73, 0x72, 0x63, 0x18, 0x09, 0x20, 0x01, 0x28,
|
||||
0x09, 0x52, 0x03, 0x73, 0x72, 0x63, 0x12, 0x2a, 0x0a, 0x10, 0x45, 0x6e, 0x61, 0x62, 0x6c, 0x65,
|
||||
0x50, 0x61, 0x72, 0x61, 0x6d, 0x65, 0x74, 0x65, 0x72, 0x73, 0x18, 0x0a, 0x20, 0x01, 0x28, 0x09,
|
||||
0x52, 0x10, 0x45, 0x6e, 0x61, 0x62, 0x6c, 0x65, 0x50, 0x61, 0x72, 0x61, 0x6d, 0x65, 0x74, 0x65,
|
||||
0x72, 0x73, 0x12, 0x1a, 0x0a, 0x08, 0x43, 0x4c, 0x49, 0x50, 0x53, 0x6b, 0x69, 0x70, 0x18, 0x0b,
|
||||
0x20, 0x01, 0x28, 0x05, 0x52, 0x08, 0x43, 0x4c, 0x49, 0x50, 0x53, 0x6b, 0x69, 0x70, 0x22, 0x48,
|
||||
0x0a, 0x0a, 0x54, 0x54, 0x53, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x12, 0x12, 0x0a, 0x04,
|
||||
0x74, 0x65, 0x78, 0x74, 0x18, 0x01, 0x20, 0x01, 0x28, 0x09, 0x52, 0x04, 0x74, 0x65, 0x78, 0x74,
|
||||
0x12, 0x14, 0x0a, 0x05, 0x6d, 0x6f, 0x64, 0x65, 0x6c, 0x18, 0x02, 0x20, 0x01, 0x28, 0x09, 0x52,
|
||||
0x05, 0x6d, 0x6f, 0x64, 0x65, 0x6c, 0x12, 0x10, 0x0a, 0x03, 0x64, 0x73, 0x74, 0x18, 0x03, 0x20,
|
||||
0x01, 0x28, 0x09, 0x52, 0x03, 0x64, 0x73, 0x74, 0x22, 0x46, 0x0a, 0x14, 0x54, 0x6f, 0x6b, 0x65,
|
||||
0x6e, 0x69, 0x7a, 0x61, 0x74, 0x69, 0x6f, 0x6e, 0x52, 0x65, 0x73, 0x70, 0x6f, 0x6e, 0x73, 0x65,
|
||||
0x12, 0x16, 0x0a, 0x06, 0x6c, 0x65, 0x6e, 0x67, 0x74, 0x68, 0x18, 0x01, 0x20, 0x01, 0x28, 0x05,
|
||||
0x52, 0x06, 0x6c, 0x65, 0x6e, 0x67, 0x74, 0x68, 0x12, 0x16, 0x0a, 0x06, 0x74, 0x6f, 0x6b, 0x65,
|
||||
0x6e, 0x73, 0x18, 0x02, 0x20, 0x03, 0x28, 0x05, 0x52, 0x06, 0x74, 0x6f, 0x6b, 0x65, 0x6e, 0x73,
|
||||
0x22, 0xac, 0x01, 0x0a, 0x0f, 0x4d, 0x65, 0x6d, 0x6f, 0x72, 0x79, 0x55, 0x73, 0x61, 0x67, 0x65,
|
||||
0x44, 0x61, 0x74, 0x61, 0x12, 0x14, 0x0a, 0x05, 0x74, 0x6f, 0x74, 0x61, 0x6c, 0x18, 0x01, 0x20,
|
||||
0x01, 0x28, 0x04, 0x52, 0x05, 0x74, 0x6f, 0x74, 0x61, 0x6c, 0x12, 0x45, 0x0a, 0x09, 0x62, 0x72,
|
||||
0x65, 0x61, 0x6b, 0x64, 0x6f, 0x77, 0x6e, 0x18, 0x02, 0x20, 0x03, 0x28, 0x0b, 0x32, 0x27, 0x2e,
|
||||
0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x4d, 0x65, 0x6d, 0x6f, 0x72, 0x79, 0x55, 0x73,
|
||||
0x61, 0x67, 0x65, 0x44, 0x61, 0x74, 0x61, 0x2e, 0x42, 0x72, 0x65, 0x61, 0x6b, 0x64, 0x6f, 0x77,
|
||||
0x6e, 0x45, 0x6e, 0x74, 0x72, 0x79, 0x52, 0x09, 0x62, 0x72, 0x65, 0x61, 0x6b, 0x64, 0x6f, 0x77,
|
||||
0x6e, 0x1a, 0x3c, 0x0a, 0x0e, 0x42, 0x72, 0x65, 0x61, 0x6b, 0x64, 0x6f, 0x77, 0x6e, 0x45, 0x6e,
|
||||
0x74, 0x72, 0x79, 0x12, 0x10, 0x0a, 0x03, 0x6b, 0x65, 0x79, 0x18, 0x01, 0x20, 0x01, 0x28, 0x09,
|
||||
0x52, 0x03, 0x6b, 0x65, 0x79, 0x12, 0x14, 0x0a, 0x05, 0x76, 0x61, 0x6c, 0x75, 0x65, 0x18, 0x02,
|
||||
0x20, 0x01, 0x28, 0x04, 0x52, 0x05, 0x76, 0x61, 0x6c, 0x75, 0x65, 0x3a, 0x02, 0x38, 0x01, 0x22,
|
||||
0xbc, 0x01, 0x0a, 0x0e, 0x53, 0x74, 0x61, 0x74, 0x75, 0x73, 0x52, 0x65, 0x73, 0x70, 0x6f, 0x6e,
|
||||
0x73, 0x65, 0x12, 0x33, 0x0a, 0x05, 0x73, 0x74, 0x61, 0x74, 0x65, 0x18, 0x01, 0x20, 0x01, 0x28,
|
||||
0x0e, 0x32, 0x1d, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x53, 0x74, 0x61, 0x74,
|
||||
0x75, 0x73, 0x52, 0x65, 0x73, 0x70, 0x6f, 0x6e, 0x73, 0x65, 0x2e, 0x53, 0x74, 0x61, 0x74, 0x65,
|
||||
0x52, 0x05, 0x73, 0x74, 0x61, 0x74, 0x65, 0x12, 0x30, 0x0a, 0x06, 0x6d, 0x65, 0x6d, 0x6f, 0x72,
|
||||
0x79, 0x18, 0x02, 0x20, 0x01, 0x28, 0x0b, 0x32, 0x18, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e,
|
||||
0x64, 0x2e, 0x4d, 0x65, 0x6d, 0x6f, 0x72, 0x79, 0x55, 0x73, 0x61, 0x67, 0x65, 0x44, 0x61, 0x74,
|
||||
0x61, 0x52, 0x06, 0x6d, 0x65, 0x6d, 0x6f, 0x72, 0x79, 0x22, 0x43, 0x0a, 0x05, 0x53, 0x74, 0x61,
|
||||
0x74, 0x65, 0x12, 0x11, 0x0a, 0x0d, 0x55, 0x4e, 0x49, 0x4e, 0x49, 0x54, 0x49, 0x41, 0x4c, 0x49,
|
||||
0x5a, 0x45, 0x44, 0x10, 0x00, 0x12, 0x08, 0x0a, 0x04, 0x42, 0x55, 0x53, 0x59, 0x10, 0x01, 0x12,
|
||||
0x09, 0x0a, 0x05, 0x52, 0x45, 0x41, 0x44, 0x59, 0x10, 0x02, 0x12, 0x12, 0x0a, 0x05, 0x45, 0x52,
|
||||
0x52, 0x4f, 0x52, 0x10, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x01, 0x32, 0xf4,
|
||||
0x04, 0x0a, 0x07, 0x42, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x12, 0x32, 0x0a, 0x06, 0x48, 0x65,
|
||||
0x61, 0x6c, 0x74, 0x68, 0x12, 0x16, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x48,
|
||||
0x65, 0x61, 0x6c, 0x74, 0x68, 0x4d, 0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x1a, 0x0e, 0x2e, 0x62,
|
||||
0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x52, 0x65, 0x70, 0x6c, 0x79, 0x22, 0x00, 0x12, 0x34,
|
||||
0x0a, 0x07, 0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x12, 0x17, 0x2e, 0x62, 0x61, 0x63, 0x6b,
|
||||
0x65, 0x6e, 0x64, 0x2e, 0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x4f, 0x70, 0x74, 0x69, 0x6f,
|
||||
0x6e, 0x73, 0x1a, 0x0e, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x52, 0x65, 0x70,
|
||||
0x6c, 0x79, 0x22, 0x00, 0x12, 0x35, 0x0a, 0x09, 0x4c, 0x6f, 0x61, 0x64, 0x4d, 0x6f, 0x64, 0x65,
|
||||
0x6c, 0x12, 0x15, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x4d, 0x6f, 0x64, 0x65,
|
||||
0x6c, 0x4f, 0x70, 0x74, 0x69, 0x6f, 0x6e, 0x73, 0x1a, 0x0f, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65,
|
||||
0x6e, 0x64, 0x2e, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x3c, 0x0a, 0x0d, 0x50,
|
||||
0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x53, 0x74, 0x72, 0x65, 0x61, 0x6d, 0x12, 0x17, 0x2e, 0x62,
|
||||
0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x4f, 0x70,
|
||||
0x74, 0x69, 0x6f, 0x6e, 0x73, 0x1a, 0x0e, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e,
|
||||
0x52, 0x65, 0x70, 0x6c, 0x79, 0x22, 0x00, 0x30, 0x01, 0x12, 0x40, 0x0a, 0x09, 0x45, 0x6d, 0x62,
|
||||
0x65, 0x64, 0x64, 0x69, 0x6e, 0x67, 0x12, 0x17, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64,
|
||||
0x2e, 0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74, 0x4f, 0x70, 0x74, 0x69, 0x6f, 0x6e, 0x73, 0x1a,
|
||||
0x18, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x45, 0x6d, 0x62, 0x65, 0x64, 0x64,
|
||||
0x69, 0x6e, 0x67, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x41, 0x0a, 0x0d, 0x47,
|
||||
0x65, 0x6e, 0x65, 0x72, 0x61, 0x74, 0x65, 0x49, 0x6d, 0x61, 0x67, 0x65, 0x12, 0x1d, 0x2e, 0x62,
|
||||
0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x47, 0x65, 0x6e, 0x65, 0x72, 0x61, 0x74, 0x65, 0x49,
|
||||
0x6d, 0x61, 0x67, 0x65, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x1a, 0x0f, 0x2e, 0x62, 0x61,
|
||||
0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x4d,
|
||||
0x0a, 0x12, 0x41, 0x75, 0x64, 0x69, 0x6f, 0x54, 0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70,
|
||||
0x74, 0x69, 0x6f, 0x6e, 0x12, 0x1a, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54,
|
||||
0x72, 0x61, 0x6e, 0x73, 0x63, 0x72, 0x69, 0x70, 0x74, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74,
|
||||
0x1a, 0x19, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54, 0x72, 0x61, 0x6e, 0x73,
|
||||
0x63, 0x72, 0x69, 0x70, 0x74, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x2d, 0x0a,
|
||||
0x03, 0x54, 0x54, 0x53, 0x12, 0x13, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x54,
|
||||
0x54, 0x53, 0x52, 0x65, 0x71, 0x75, 0x65, 0x73, 0x74, 0x1a, 0x0f, 0x2e, 0x62, 0x61, 0x63, 0x6b,
|
||||
0x65, 0x6e, 0x64, 0x2e, 0x52, 0x65, 0x73, 0x75, 0x6c, 0x74, 0x22, 0x00, 0x12, 0x4a, 0x0a, 0x0e,
|
||||
0x54, 0x6f, 0x6b, 0x65, 0x6e, 0x69, 0x7a, 0x65, 0x53, 0x74, 0x72, 0x69, 0x6e, 0x67, 0x12, 0x17,
|
||||
0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x50, 0x72, 0x65, 0x64, 0x69, 0x63, 0x74,
|
||||
0x4f, 0x70, 0x74, 0x69, 0x6f, 0x6e, 0x73, 0x1a, 0x1d, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e,
|
||||
0x64, 0x2e, 0x54, 0x6f, 0x6b, 0x65, 0x6e, 0x69, 0x7a, 0x61, 0x74, 0x69, 0x6f, 0x6e, 0x52, 0x65,
|
||||
0x73, 0x70, 0x6f, 0x6e, 0x73, 0x65, 0x22, 0x00, 0x12, 0x3b, 0x0a, 0x06, 0x53, 0x74, 0x61, 0x74,
|
||||
0x75, 0x73, 0x12, 0x16, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x48, 0x65, 0x61,
|
||||
0x6c, 0x74, 0x68, 0x4d, 0x65, 0x73, 0x73, 0x61, 0x67, 0x65, 0x1a, 0x17, 0x2e, 0x62, 0x61, 0x63,
|
||||
0x6b, 0x65, 0x6e, 0x64, 0x2e, 0x53, 0x74, 0x61, 0x74, 0x75, 0x73, 0x52, 0x65, 0x73, 0x70, 0x6f,
|
||||
0x6e, 0x73, 0x65, 0x22, 0x00, 0x42, 0x5a, 0x0a, 0x19, 0x69, 0x6f, 0x2e, 0x73, 0x6b, 0x79, 0x6e,
|
||||
0x65, 0x74, 0x2e, 0x6c, 0x6f, 0x63, 0x61, 0x6c, 0x61, 0x69, 0x2e, 0x62, 0x61, 0x63, 0x6b, 0x65,
|
||||
0x6e, 0x64, 0x42, 0x0e, 0x4c, 0x6f, 0x63, 0x61, 0x6c, 0x41, 0x49, 0x42, 0x61, 0x63, 0x6b, 0x65,
|
||||
0x6e, 0x64, 0x50, 0x01, 0x5a, 0x2b, 0x67, 0x69, 0x74, 0x68, 0x75, 0x62, 0x2e, 0x63, 0x6f, 0x6d,
|
||||
0x2f, 0x67, 0x6f, 0x2d, 0x73, 0x6b, 0x79, 0x6e, 0x65, 0x74, 0x2f, 0x4c, 0x6f, 0x63, 0x61, 0x6c,
|
||||
0x41, 0x49, 0x2f, 0x70, 0x6b, 0x67, 0x2f, 0x67, 0x72, 0x70, 0x63, 0x2f, 0x70, 0x72, 0x6f, 0x74,
|
||||
0x6f, 0x62, 0x06, 0x70, 0x72, 0x6f, 0x74, 0x6f, 0x33,
|
||||
}
|
||||
|
||||
var (
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
// Code generated by protoc-gen-go-grpc. DO NOT EDIT.
|
||||
// versions:
|
||||
// - protoc-gen-go-grpc v1.2.0
|
||||
// - protoc v3.6.1
|
||||
// - protoc v4.23.4
|
||||
// source: backend.proto
|
||||
|
||||
package proto
|
||||
|
||||
@@ -181,3 +181,23 @@ func StartServer(address string, model LLM) error {
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func RunServer(address string, model LLM) (func() error, error) {
|
||||
lis, err := net.Listen("tcp", address)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
s := grpc.NewServer()
|
||||
pb.RegisterBackendServer(s, &server{llm: model})
|
||||
log.Printf("gRPC Server listening at %v", lis.Addr())
|
||||
if err = s.Serve(lis); err != nil {
|
||||
return func() error {
|
||||
return lis.Close()
|
||||
}, err
|
||||
}
|
||||
|
||||
return func() error {
|
||||
s.GracefulStop()
|
||||
return nil
|
||||
}, nil
|
||||
}
|
||||
|
||||
@@ -23,18 +23,10 @@ const (
|
||||
GoLlamaBackend = "llama"
|
||||
LlamaGGML = "llama-ggml"
|
||||
LLamaCPP = "llama-cpp"
|
||||
StarcoderBackend = "starcoder"
|
||||
GPTJBackend = "gptj"
|
||||
DollyBackend = "dolly"
|
||||
MPTBackend = "mpt"
|
||||
GPTNeoXBackend = "gptneox"
|
||||
ReplitBackend = "replit"
|
||||
Gpt2Backend = "gpt2"
|
||||
Gpt4AllLlamaBackend = "gpt4all-llama"
|
||||
Gpt4AllMptBackend = "gpt4all-mpt"
|
||||
Gpt4AllJBackend = "gpt4all-j"
|
||||
Gpt4All = "gpt4all"
|
||||
FalconGGMLBackend = "falcon-ggml"
|
||||
|
||||
BertEmbeddingsBackend = "bert-embeddings"
|
||||
RwkvBackend = "rwkv"
|
||||
@@ -53,15 +45,7 @@ var AutoLoadBackends []string = []string{
|
||||
LlamaGGML,
|
||||
GoLlamaBackend,
|
||||
Gpt4All,
|
||||
GPTNeoXBackend,
|
||||
BertEmbeddingsBackend,
|
||||
FalconGGMLBackend,
|
||||
GPTJBackend,
|
||||
Gpt2Backend,
|
||||
DollyBackend,
|
||||
MPTBackend,
|
||||
ReplitBackend,
|
||||
StarcoderBackend,
|
||||
RwkvBackend,
|
||||
WhisperBackend,
|
||||
StableDiffusionBackend,
|
||||
@@ -166,7 +150,7 @@ func (ml *ModelLoader) grpcModel(backend string, o *Options) func(string, string
|
||||
}
|
||||
}
|
||||
|
||||
func (ml *ModelLoader) resolveAddress(addr ModelAddress, parallel bool) (*grpc.Client, error) {
|
||||
func (ml *ModelLoader) resolveAddress(addr ModelAddress, parallel bool) (grpc.Backend, error) {
|
||||
if parallel {
|
||||
return addr.GRPC(parallel, ml.wd), nil
|
||||
}
|
||||
@@ -177,7 +161,7 @@ func (ml *ModelLoader) resolveAddress(addr ModelAddress, parallel bool) (*grpc.C
|
||||
return ml.grpcClients[string(addr)], nil
|
||||
}
|
||||
|
||||
func (ml *ModelLoader) BackendLoader(opts ...Option) (client *grpc.Client, err error) {
|
||||
func (ml *ModelLoader) BackendLoader(opts ...Option) (client grpc.Backend, err error) {
|
||||
o := NewOptions(opts...)
|
||||
|
||||
if o.model != "" {
|
||||
@@ -220,7 +204,7 @@ func (ml *ModelLoader) BackendLoader(opts ...Option) (client *grpc.Client, err e
|
||||
return ml.resolveAddress(addr, o.parallelRequests)
|
||||
}
|
||||
|
||||
func (ml *ModelLoader) GreedyLoader(opts ...Option) (*grpc.Client, error) {
|
||||
func (ml *ModelLoader) GreedyLoader(opts ...Option) (grpc.Backend, error) {
|
||||
o := NewOptions(opts...)
|
||||
|
||||
ml.mu.Lock()
|
||||
|
||||
@@ -59,7 +59,7 @@ type ModelLoader struct {
|
||||
ModelPath string
|
||||
mu sync.Mutex
|
||||
// TODO: this needs generics
|
||||
grpcClients map[string]*grpc.Client
|
||||
grpcClients map[string]grpc.Backend
|
||||
models map[string]ModelAddress
|
||||
grpcProcesses map[string]*process.Process
|
||||
templates map[TemplateType]map[string]*template.Template
|
||||
@@ -68,7 +68,7 @@ type ModelLoader struct {
|
||||
|
||||
type ModelAddress string
|
||||
|
||||
func (m ModelAddress) GRPC(parallel bool, wd *WatchDog) *grpc.Client {
|
||||
func (m ModelAddress) GRPC(parallel bool, wd *WatchDog) grpc.Backend {
|
||||
enableWD := false
|
||||
if wd != nil {
|
||||
enableWD = true
|
||||
@@ -79,7 +79,7 @@ func (m ModelAddress) GRPC(parallel bool, wd *WatchDog) *grpc.Client {
|
||||
func NewModelLoader(modelPath string) *ModelLoader {
|
||||
nml := &ModelLoader{
|
||||
ModelPath: modelPath,
|
||||
grpcClients: make(map[string]*grpc.Client),
|
||||
grpcClients: make(map[string]grpc.Backend),
|
||||
models: make(map[string]ModelAddress),
|
||||
templates: make(map[TemplateType]map[string]*template.Template),
|
||||
grpcProcesses: make(map[string]*process.Process),
|
||||
@@ -163,7 +163,7 @@ func (ml *ModelLoader) StopModel(modelName string) error {
|
||||
}
|
||||
|
||||
func (ml *ModelLoader) CheckIsLoaded(s string) ModelAddress {
|
||||
var client *grpc.Client
|
||||
var client grpc.Backend
|
||||
if m, ok := ml.models[s]; ok {
|
||||
log.Debug().Msgf("Model already loaded in memory: %s", s)
|
||||
if c, ok := ml.grpcClients[s]; ok {
|
||||
|
||||
@@ -14,10 +14,22 @@ import (
|
||||
// PreloadModelsConfigurations will preload models from the given list of URLs
|
||||
// It will download the model if it is not already present in the model path
|
||||
// It will also try to resolve if the model is an embedded model YAML configuration
|
||||
func PreloadModelsConfigurations(modelPath string, models ...string) {
|
||||
func PreloadModelsConfigurations(modelLibraryURL string, modelPath string, models ...string) {
|
||||
for _, url := range models {
|
||||
url = embedded.ModelShortURL(url)
|
||||
|
||||
// As a best effort, try to resolve the model from the remote library
|
||||
// if it's not resolved we try with the other method below
|
||||
if modelLibraryURL != "" {
|
||||
lib, err := embedded.GetRemoteLibraryShorteners(modelLibraryURL)
|
||||
if err == nil {
|
||||
if lib[url] != "" {
|
||||
log.Debug().Msgf("[startup] model configuration is defined remotely: %s (%s)", url, lib[url])
|
||||
url = lib[url]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
url = embedded.ModelShortURL(url)
|
||||
switch {
|
||||
case embedded.ExistsInModelsLibrary(url):
|
||||
modelYAML, err := embedded.ResolveContent(url)
|
||||
|
||||
@@ -15,13 +15,29 @@ import (
|
||||
var _ = Describe("Preload test", func() {
|
||||
|
||||
Context("Preloading from strings", func() {
|
||||
It("loads from remote url", func() {
|
||||
tmpdir, err := os.MkdirTemp("", "")
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
libraryURL := "https://raw.githubusercontent.com/mudler/LocalAI/master/embedded/model_library.yaml"
|
||||
fileName := fmt.Sprintf("%s.yaml", "1701d57f28d47552516c2b6ecc3cc719")
|
||||
|
||||
PreloadModelsConfigurations(libraryURL, tmpdir, "phi-2")
|
||||
|
||||
resultFile := filepath.Join(tmpdir, fileName)
|
||||
|
||||
content, err := os.ReadFile(resultFile)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
|
||||
Expect(string(content)).To(ContainSubstring("name: phi-2"))
|
||||
})
|
||||
|
||||
It("loads from embedded full-urls", func() {
|
||||
tmpdir, err := os.MkdirTemp("", "")
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
url := "https://raw.githubusercontent.com/mudler/LocalAI/master/examples/configurations/phi-2.yaml"
|
||||
fileName := fmt.Sprintf("%s.yaml", utils.MD5(url))
|
||||
|
||||
PreloadModelsConfigurations(tmpdir, url)
|
||||
PreloadModelsConfigurations("", tmpdir, url)
|
||||
|
||||
resultFile := filepath.Join(tmpdir, fileName)
|
||||
|
||||
@@ -35,7 +51,7 @@ var _ = Describe("Preload test", func() {
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
url := "phi-2"
|
||||
|
||||
PreloadModelsConfigurations(tmpdir, url)
|
||||
PreloadModelsConfigurations("", tmpdir, url)
|
||||
|
||||
entry, err := os.ReadDir(tmpdir)
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
@@ -53,7 +69,7 @@ var _ = Describe("Preload test", func() {
|
||||
url := "mistral-openorca"
|
||||
fileName := fmt.Sprintf("%s.yaml", utils.MD5(url))
|
||||
|
||||
PreloadModelsConfigurations(tmpdir, url)
|
||||
PreloadModelsConfigurations("", tmpdir, url)
|
||||
|
||||
resultFile := filepath.Join(tmpdir, fileName)
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
top_p: 80
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
context_size: 10
|
||||
context_size: 200
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
@@ -20,7 +20,7 @@
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
model: testmodel
|
||||
context_size: 10
|
||||
context_size: 200
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
|
||||
@@ -4,7 +4,7 @@ parameters:
|
||||
top_p: 80
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
context_size: 10
|
||||
context_size: 200
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
|
||||
@@ -4,7 +4,7 @@ parameters:
|
||||
top_p: 80
|
||||
top_k: 0.9
|
||||
temperature: 0.1
|
||||
context_size: 10
|
||||
context_size: 200
|
||||
stopwords:
|
||||
- "HUMAN:"
|
||||
- "### Response:"
|
||||
|
||||
Reference in New Issue
Block a user