mirror of
https://github.com/mudler/LocalAI.git
synced 2026-02-03 03:02:38 -05:00
Compare commits
62 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ff88c390bb | ||
|
|
d825821a22 | ||
|
|
cbed6ab1bb | ||
|
|
6fc122fa1a | ||
|
|
feba38be36 | ||
|
|
ba85d0bcad | ||
|
|
ad3623dd8d | ||
|
|
8292781045 | ||
|
|
54ec6348fa | ||
|
|
255748bcba | ||
|
|
594eb468df | ||
|
|
960d314e4f | ||
|
|
ed3b50622b | ||
|
|
9f2235c208 | ||
|
|
4ec50bfc41 | ||
|
|
51b67a247a | ||
|
|
01205fd4c0 | ||
|
|
c72808f18b | ||
|
|
6b539a2972 | ||
|
|
2151d21862 | ||
|
|
fb0a4c5d9a | ||
|
|
e690bf387a | ||
|
|
5e155fb081 | ||
|
|
39a6b562cf | ||
|
|
c56b6ddb1c | ||
|
|
2e61ff32ad | ||
|
|
02f6e18adc | ||
|
|
4436e62cf1 | ||
|
|
6e0eb96c61 | ||
|
|
fd68bf7084 | ||
|
|
58cdf97361 | ||
|
|
53dbe36f32 | ||
|
|
081bd07fd1 | ||
|
|
ef1306f703 | ||
|
|
3196967995 | ||
|
|
3875e5e0e5 | ||
|
|
fc8423392f | ||
|
|
f1f6035967 | ||
|
|
ddd21f1644 | ||
|
|
d0a6a35b55 | ||
|
|
e0632f2ce2 | ||
|
|
37e6974afe | ||
|
|
e23e490455 | ||
|
|
f76bb8954b | ||
|
|
d168c7c9dc | ||
|
|
fd9d060c94 | ||
|
|
d8b17795d7 | ||
|
|
ea7b33b0d2 | ||
|
|
8ace0a9ba7 | ||
|
|
98ad93d53e | ||
|
|
38e4ec0b2a | ||
|
|
f083a901fe | ||
|
|
df13ba655c | ||
|
|
7678b25755 | ||
|
|
c87ca4f320 | ||
|
|
3c24a70a1b | ||
|
|
e46db63e06 | ||
|
|
1c57f8d077 | ||
|
|
16cebf0390 | ||
|
|
555bc02665 | ||
|
|
c1bae1ee81 | ||
|
|
f2ed3df3da |
22
.github/workflows/image-pr.yml
vendored
22
.github/workflows/image-pr.yml
vendored
@@ -21,6 +21,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -39,6 +40,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -48,6 +50,15 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'hipblas'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-hipblas'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'extras'
|
||||
base-image: "rocm/dev-ubuntu-22.04:6.0-complete"
|
||||
runs-on: 'arc-runner-set'
|
||||
core-image-build:
|
||||
uses: ./.github/workflows/image_build.yml
|
||||
with:
|
||||
@@ -60,6 +71,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -75,6 +87,15 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: 'sycl-f16-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -84,3 +105,4 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
|
||||
78
.github/workflows/image.yml
vendored
78
.github/workflows/image.yml
vendored
@@ -25,6 +25,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -44,6 +45,7 @@ jobs:
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: ''
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
@@ -51,6 +53,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
cuda-minor-version: "7"
|
||||
@@ -60,6 +63,7 @@ jobs:
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -69,6 +73,7 @@ jobs:
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
cuda-minor-version: "7"
|
||||
@@ -78,6 +83,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -87,6 +93,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
runs-on: 'arc-runner-set'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: ''
|
||||
#platforms: 'linux/amd64,linux/arm64'
|
||||
platforms: 'linux/amd64'
|
||||
@@ -94,6 +101,23 @@ jobs:
|
||||
tag-suffix: ''
|
||||
ffmpeg: ''
|
||||
image-type: 'extras'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'hipblas'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-hipblas-ffmpeg'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'extras'
|
||||
base-image: "rocm/dev-ubuntu-22.04:6.0-complete"
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'hipblas'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-hipblas'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'extras'
|
||||
base-image: "rocm/dev-ubuntu-22.04:6.0-complete"
|
||||
runs-on: 'arc-runner-set'
|
||||
core-image-build:
|
||||
uses: ./.github/workflows/image_build.yml
|
||||
@@ -107,6 +131,7 @@ jobs:
|
||||
cuda-minor-version: ${{ matrix.cuda-minor-version }}
|
||||
platforms: ${{ matrix.platforms }}
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
base-image: ${{ matrix.base-image }}
|
||||
secrets:
|
||||
dockerUsername: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
dockerPassword: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
@@ -115,13 +140,62 @@ jobs:
|
||||
strategy:
|
||||
matrix:
|
||||
include:
|
||||
- build-type: 'hipblas'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-hipblas-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
base-image: "rocm/dev-ubuntu-22.04:6.0-complete"
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'hipblas'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-hipblas-core'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'core'
|
||||
base-image: "rocm/dev-ubuntu-22.04:6.0-complete"
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: ''
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: '-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f16-core'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f32'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f32-core'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f16-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f32'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
base-image: "intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04"
|
||||
tag-suffix: '-sycl-f32-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
cuda-minor-version: "7"
|
||||
@@ -130,6 +204,7 @@ jobs:
|
||||
tag-suffix: '-cublas-cuda11-core'
|
||||
ffmpeg: ''
|
||||
image-type: 'core'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
@@ -139,6 +214,7 @@ jobs:
|
||||
tag-suffix: '-cublas-cuda12-core'
|
||||
ffmpeg: ''
|
||||
image-type: 'core'
|
||||
base-image: "ubuntu:22.04"
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
@@ -149,6 +225,7 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
@@ -158,3 +235,4 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
base-image: "ubuntu:22.04"
|
||||
|
||||
83
.github/workflows/image_build.yml
vendored
83
.github/workflows/image_build.yml
vendored
@@ -4,6 +4,11 @@ name: 'build container images (reusable)'
|
||||
on:
|
||||
workflow_call:
|
||||
inputs:
|
||||
base-image:
|
||||
description: 'Base image'
|
||||
required: false
|
||||
default: ''
|
||||
type: string
|
||||
build-type:
|
||||
description: 'Build type'
|
||||
default: ''
|
||||
@@ -64,42 +69,47 @@ jobs:
|
||||
&& sudo apt-get install -y git
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
# - name: Release space from worker
|
||||
# run: |
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# df -h
|
||||
# echo
|
||||
# sudo apt-get remove -y '^llvm-.*|^libllvm.*' || true
|
||||
# sudo apt-get remove --auto-remove android-sdk-platform-tools || true
|
||||
# sudo apt-get purge --auto-remove android-sdk-platform-tools || true
|
||||
# sudo rm -rf /usr/local/lib/android
|
||||
# sudo apt-get remove -y '^dotnet-.*|^aspnetcore-.*' || true
|
||||
# sudo rm -rf /usr/share/dotnet
|
||||
# sudo apt-get remove -y '^mono-.*' || true
|
||||
# sudo apt-get remove -y '^ghc-.*' || true
|
||||
# sudo apt-get remove -y '.*jdk.*|.*jre.*' || true
|
||||
# sudo apt-get remove -y 'php.*' || true
|
||||
# sudo apt-get remove -y hhvm powershell firefox monodoc-manual msbuild || true
|
||||
# sudo apt-get remove -y '^google-.*' || true
|
||||
# sudo apt-get remove -y azure-cli || true
|
||||
# sudo apt-get remove -y '^mongo.*-.*|^postgresql-.*|^mysql-.*|^mssql-.*' || true
|
||||
# sudo apt-get remove -y '^gfortran-.*' || true
|
||||
# sudo apt-get remove -y microsoft-edge-stable || true
|
||||
# sudo apt-get remove -y firefox || true
|
||||
# sudo apt-get remove -y powershell || true
|
||||
# sudo apt-get remove -y r-base-core || true
|
||||
# sudo apt-get autoremove -y
|
||||
# sudo apt-get clean
|
||||
# echo
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# sudo rm -rfv build || true
|
||||
# df -h
|
||||
- name: Release space from worker
|
||||
if: inputs.runs-on == 'ubuntu-latest'
|
||||
run: |
|
||||
echo "Listing top largest packages"
|
||||
pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
head -n 30 <<< "${pkgs}"
|
||||
echo
|
||||
df -h
|
||||
echo
|
||||
sudo apt-get remove -y '^llvm-.*|^libllvm.*' || true
|
||||
sudo apt-get remove --auto-remove android-sdk-platform-tools || true
|
||||
sudo apt-get purge --auto-remove android-sdk-platform-tools || true
|
||||
sudo rm -rf /usr/local/lib/android
|
||||
sudo apt-get remove -y '^dotnet-.*|^aspnetcore-.*' || true
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo apt-get remove -y '^mono-.*' || true
|
||||
sudo apt-get remove -y '^ghc-.*' || true
|
||||
sudo apt-get remove -y '.*jdk.*|.*jre.*' || true
|
||||
sudo apt-get remove -y 'php.*' || true
|
||||
sudo apt-get remove -y hhvm powershell firefox monodoc-manual msbuild || true
|
||||
sudo apt-get remove -y '^google-.*' || true
|
||||
sudo apt-get remove -y azure-cli || true
|
||||
sudo apt-get remove -y '^mongo.*-.*|^postgresql-.*|^mysql-.*|^mssql-.*' || true
|
||||
sudo apt-get remove -y '^gfortran-.*' || true
|
||||
sudo apt-get remove -y microsoft-edge-stable || true
|
||||
sudo apt-get remove -y firefox || true
|
||||
sudo apt-get remove -y powershell || true
|
||||
sudo apt-get remove -y r-base-core || true
|
||||
sudo apt-get autoremove -y
|
||||
sudo apt-get clean
|
||||
echo
|
||||
echo "Listing top largest packages"
|
||||
pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
head -n 30 <<< "${pkgs}"
|
||||
echo
|
||||
sudo rm -rfv build || true
|
||||
sudo rm -rf /usr/share/dotnet || true
|
||||
sudo rm -rf /opt/ghc || true
|
||||
sudo rm -rf "/usr/local/share/boost" || true
|
||||
sudo rm -rf "$AGENT_TOOLSDIRECTORY" || true
|
||||
df -h
|
||||
- name: Docker meta
|
||||
id: meta
|
||||
uses: docker/metadata-action@v5
|
||||
@@ -149,6 +159,7 @@ jobs:
|
||||
CUDA_MINOR_VERSION=${{ inputs.cuda-minor-version }}
|
||||
FFMPEG=${{ inputs.ffmpeg }}
|
||||
IMAGE_TYPE=${{ inputs.image-type }}
|
||||
BASE_IMAGE=${{ inputs.base-image }}
|
||||
context: .
|
||||
file: ./Dockerfile
|
||||
platforms: ${{ inputs.platforms }}
|
||||
|
||||
28
.github/workflows/release.yaml
vendored
28
.github/workflows/release.yaml
vendored
@@ -20,6 +20,10 @@ jobs:
|
||||
defines: '-DLLAMA_AVX2=OFF'
|
||||
- build: 'avx512'
|
||||
defines: '-DLLAMA_AVX512=ON'
|
||||
- build: 'cuda12'
|
||||
defines: ''
|
||||
- build: 'cuda11'
|
||||
defines: ''
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Clone
|
||||
@@ -33,7 +37,18 @@ jobs:
|
||||
run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get install build-essential ffmpeg
|
||||
|
||||
- name: Install CUDA Dependencies
|
||||
if: ${{ matrix.build == 'cuda12' || matrix.build == 'cuda11' }}
|
||||
run: |
|
||||
if [ "${{ matrix.build }}" == "cuda12" ]; then
|
||||
export CUDA_VERSION=12-3
|
||||
else
|
||||
export CUDA_VERSION=11-7
|
||||
fi
|
||||
curl -O https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
|
||||
sudo dpkg -i cuda-keyring_1.1-1_all.deb
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y cuda-nvcc-${CUDA_VERSION} libcublas-dev-${CUDA_VERSION}
|
||||
- name: Cache grpc
|
||||
id: cache-grpc
|
||||
uses: actions/cache@v3
|
||||
@@ -50,14 +65,19 @@ jobs:
|
||||
- name: Install gRPC
|
||||
run: |
|
||||
cd grpc && cd cmake/build && sudo make -j12 install
|
||||
|
||||
- name: Build
|
||||
id: build
|
||||
env:
|
||||
CMAKE_ARGS: "${{ matrix.defines }}"
|
||||
BUILD_ID: "${{ matrix.build }}"
|
||||
run: |
|
||||
STATIC=true make dist
|
||||
if [ "${{ matrix.build }}" == "cuda12" ] || [ "${{ matrix.build }}" == "cuda11" ]; then
|
||||
export BUILD_TYPE=cublas
|
||||
export PATH=/usr/local/cuda/bin:$PATH
|
||||
make dist
|
||||
else
|
||||
STATIC=true make dist
|
||||
fi
|
||||
- uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: ${{ matrix.build }}
|
||||
@@ -109,4 +129,4 @@ jobs:
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
with:
|
||||
files: |
|
||||
release/*
|
||||
release/*
|
||||
|
||||
94
.github/workflows/test-extra.yml
vendored
94
.github/workflows/test-extra.yml
vendored
@@ -164,34 +164,74 @@ jobs:
|
||||
|
||||
|
||||
|
||||
tests-bark:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Clone
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: true
|
||||
- name: Dependencies
|
||||
run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get install build-essential ffmpeg
|
||||
curl https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc | gpg --dearmor > conda.gpg && \
|
||||
sudo install -o root -g root -m 644 conda.gpg /usr/share/keyrings/conda-archive-keyring.gpg && \
|
||||
gpg --keyring /usr/share/keyrings/conda-archive-keyring.gpg --no-default-keyring --fingerprint 34161F5BF5EB1D4BFBBB8F0A8AEB4F8B29D82806 && \
|
||||
sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" > /etc/apt/sources.list.d/conda.list' && \
|
||||
sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" | tee -a /etc/apt/sources.list.d/conda.list' && \
|
||||
sudo apt-get update && \
|
||||
sudo apt-get install -y conda
|
||||
sudo apt-get install -y ca-certificates cmake curl patch
|
||||
sudo apt-get install -y libopencv-dev && sudo ln -s /usr/include/opencv4/opencv2 /usr/include/opencv2
|
||||
# tests-bark:
|
||||
# runs-on: ubuntu-latest
|
||||
# steps:
|
||||
# - name: Release space from worker
|
||||
# run: |
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# df -h
|
||||
# echo
|
||||
# sudo apt-get remove -y '^llvm-.*|^libllvm.*' || true
|
||||
# sudo apt-get remove --auto-remove android-sdk-platform-tools || true
|
||||
# sudo apt-get purge --auto-remove android-sdk-platform-tools || true
|
||||
# sudo rm -rf /usr/local/lib/android
|
||||
# sudo apt-get remove -y '^dotnet-.*|^aspnetcore-.*' || true
|
||||
# sudo rm -rf /usr/share/dotnet
|
||||
# sudo apt-get remove -y '^mono-.*' || true
|
||||
# sudo apt-get remove -y '^ghc-.*' || true
|
||||
# sudo apt-get remove -y '.*jdk.*|.*jre.*' || true
|
||||
# sudo apt-get remove -y 'php.*' || true
|
||||
# sudo apt-get remove -y hhvm powershell firefox monodoc-manual msbuild || true
|
||||
# sudo apt-get remove -y '^google-.*' || true
|
||||
# sudo apt-get remove -y azure-cli || true
|
||||
# sudo apt-get remove -y '^mongo.*-.*|^postgresql-.*|^mysql-.*|^mssql-.*' || true
|
||||
# sudo apt-get remove -y '^gfortran-.*' || true
|
||||
# sudo apt-get remove -y microsoft-edge-stable || true
|
||||
# sudo apt-get remove -y firefox || true
|
||||
# sudo apt-get remove -y powershell || true
|
||||
# sudo apt-get remove -y r-base-core || true
|
||||
# sudo apt-get autoremove -y
|
||||
# sudo apt-get clean
|
||||
# echo
|
||||
# echo "Listing top largest packages"
|
||||
# pkgs=$(dpkg-query -Wf '${Installed-Size}\t${Package}\t${Status}\n' | awk '$NF == "installed"{print $1 "\t" $2}' | sort -nr)
|
||||
# head -n 30 <<< "${pkgs}"
|
||||
# echo
|
||||
# sudo rm -rfv build || true
|
||||
# sudo rm -rf /usr/share/dotnet || true
|
||||
# sudo rm -rf /opt/ghc || true
|
||||
# sudo rm -rf "/usr/local/share/boost" || true
|
||||
# sudo rm -rf "$AGENT_TOOLSDIRECTORY" || true
|
||||
# df -h
|
||||
# - name: Clone
|
||||
# uses: actions/checkout@v4
|
||||
# with:
|
||||
# submodules: true
|
||||
# - name: Dependencies
|
||||
# run: |
|
||||
# sudo apt-get update
|
||||
# sudo apt-get install build-essential ffmpeg
|
||||
# curl https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc | gpg --dearmor > conda.gpg && \
|
||||
# sudo install -o root -g root -m 644 conda.gpg /usr/share/keyrings/conda-archive-keyring.gpg && \
|
||||
# gpg --keyring /usr/share/keyrings/conda-archive-keyring.gpg --no-default-keyring --fingerprint 34161F5BF5EB1D4BFBBB8F0A8AEB4F8B29D82806 && \
|
||||
# sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" > /etc/apt/sources.list.d/conda.list' && \
|
||||
# sudo /bin/bash -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/conda-archive-keyring.gpg] https://repo.anaconda.com/pkgs/misc/debrepo/conda stable main" | tee -a /etc/apt/sources.list.d/conda.list' && \
|
||||
# sudo apt-get update && \
|
||||
# sudo apt-get install -y conda
|
||||
# sudo apt-get install -y ca-certificates cmake curl patch
|
||||
# sudo apt-get install -y libopencv-dev && sudo ln -s /usr/include/opencv4/opencv2 /usr/include/opencv2
|
||||
|
||||
sudo rm -rfv /usr/bin/conda || true
|
||||
# sudo rm -rfv /usr/bin/conda || true
|
||||
|
||||
- name: Test bark
|
||||
run: |
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
make -C backend/python/bark
|
||||
make -C backend/python/bark test
|
||||
# - name: Test bark
|
||||
# run: |
|
||||
# export PATH=$PATH:/opt/conda/bin
|
||||
# make -C backend/python/bark
|
||||
# make -C backend/python/bark test
|
||||
|
||||
|
||||
# Below tests needs GPU. Commented out for now
|
||||
@@ -274,4 +314,4 @@ jobs:
|
||||
run: |
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
make -C backend/python/coqui
|
||||
make -C backend/python/coqui test
|
||||
make -C backend/python/coqui test
|
||||
|
||||
31
Dockerfile
31
Dockerfile
@@ -1,10 +1,10 @@
|
||||
ARG GO_VERSION=1.21-bullseye
|
||||
ARG IMAGE_TYPE=extras
|
||||
ARG BASE_IMAGE=ubuntu:22.04
|
||||
|
||||
# extras or core
|
||||
FROM ${BASE_IMAGE} as requirements-core
|
||||
|
||||
|
||||
FROM golang:$GO_VERSION as requirements-core
|
||||
|
||||
ARG GO_VERSION=1.21.7
|
||||
ARG BUILD_TYPE
|
||||
ARG CUDA_MAJOR_VERSION=11
|
||||
ARG CUDA_MINOR_VERSION=7
|
||||
@@ -12,14 +12,17 @@ ARG TARGETARCH
|
||||
ARG TARGETVARIANT
|
||||
|
||||
ENV BUILD_TYPE=${BUILD_TYPE}
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
ENV EXTERNAL_GRPC_BACKENDS="coqui:/build/backend/python/coqui/run.sh,huggingface-embeddings:/build/backend/python/sentencetransformers/run.sh,petals:/build/backend/python/petals/run.sh,transformers:/build/backend/python/transformers/run.sh,sentencetransformers:/build/backend/python/sentencetransformers/run.sh,autogptq:/build/backend/python/autogptq/run.sh,bark:/build/backend/python/bark/run.sh,diffusers:/build/backend/python/diffusers/run.sh,exllama:/build/backend/python/exllama/run.sh,vall-e-x:/build/backend/python/vall-e-x/run.sh,vllm:/build/backend/python/vllm/run.sh,mamba:/build/backend/python/mamba/run.sh,exllama2:/build/backend/python/exllama2/run.sh,transformers-musicgen:/build/backend/python/transformers-musicgen/run.sh"
|
||||
|
||||
ARG GO_TAGS="stablediffusion tinydream tts"
|
||||
|
||||
RUN apt-get update && \
|
||||
apt-get install -y ca-certificates curl patch pip cmake && apt-get clean
|
||||
apt-get install -y ca-certificates curl patch pip cmake git && apt-get clean
|
||||
|
||||
# Install Go
|
||||
RUN curl -L -s https://go.dev/dl/go$GO_VERSION.linux-$TARGETARCH.tar.gz | tar -v -C /usr/local -xz
|
||||
ENV PATH $PATH:/usr/local/go/bin
|
||||
|
||||
COPY --chmod=644 custom-ca-certs/* /usr/local/share/ca-certificates/
|
||||
RUN update-ca-certificates
|
||||
@@ -31,15 +34,19 @@ RUN echo "Target Variant: $TARGETVARIANT"
|
||||
# CuBLAS requirements
|
||||
RUN if [ "${BUILD_TYPE}" = "cublas" ]; then \
|
||||
apt-get install -y software-properties-common && \
|
||||
apt-add-repository contrib && \
|
||||
curl -O https://developer.download.nvidia.com/compute/cuda/repos/debian11/x86_64/cuda-keyring_1.0-1_all.deb && \
|
||||
dpkg -i cuda-keyring_1.0-1_all.deb && \
|
||||
rm -f cuda-keyring_1.0-1_all.deb && \
|
||||
curl -O https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb && \
|
||||
dpkg -i cuda-keyring_1.1-1_all.deb && \
|
||||
rm -f cuda-keyring_1.1-1_all.deb && \
|
||||
apt-get update && \
|
||||
apt-get install -y cuda-nvcc-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcublas-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusparse-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusolver-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} && apt-get clean \
|
||||
apt-get install -y cuda-nvcc-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcurand-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcublas-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusparse-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusolver-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} && apt-get clean \
|
||||
; fi
|
||||
|
||||
# Cuda
|
||||
ENV PATH /usr/local/cuda/bin:${PATH}
|
||||
|
||||
# HipBLAS requirements
|
||||
ENV PATH /opt/rocm/bin:${PATH}
|
||||
|
||||
# OpenBLAS requirements and stable diffusion
|
||||
RUN apt-get install -y \
|
||||
libopenblas-dev \
|
||||
@@ -66,7 +73,9 @@ RUN curl https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc | gpg --dearmo
|
||||
apt-get install -y conda && apt-get clean
|
||||
|
||||
ENV PATH="/root/.cargo/bin:${PATH}"
|
||||
RUN apt-get install -y python3-pip && apt-get clean
|
||||
RUN pip install --upgrade pip
|
||||
|
||||
RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
|
||||
RUN apt-get install -y espeak-ng espeak && apt-get clean
|
||||
|
||||
|
||||
87
Makefile
87
Makefile
@@ -8,15 +8,12 @@ GOLLAMA_VERSION?=aeba71ee842819da681ea537e78846dc75949ac0
|
||||
|
||||
GOLLAMA_STABLE_VERSION?=50cee7712066d9e38306eccadcfbb44ea87df4b7
|
||||
|
||||
CPPLLAMA_VERSION?=6db2b41a76ee78d5efdd5c3cddd5d7ad3f646855
|
||||
CPPLLAMA_VERSION?=fd43d66f46ee3b5345fb8a74a252d86ccd34a409
|
||||
|
||||
# gpt4all version
|
||||
GPT4ALL_REPO?=https://github.com/nomic-ai/gpt4all
|
||||
GPT4ALL_VERSION?=27a8b020c36b0df8f8b82a252d261cda47cf44b8
|
||||
|
||||
# go-ggml-transformers version
|
||||
GOGGMLTRANSFORMERS_VERSION?=ffb09d7dd71e2cbc6c5d7d05357d230eea6f369a
|
||||
|
||||
# go-rwkv version
|
||||
RWKV_REPO?=https://github.com/donomii/go-rwkv.cpp
|
||||
RWKV_VERSION?=633c5a3485c403cb2520693dc0991a25dace9f0f
|
||||
@@ -31,7 +28,7 @@ BERT_VERSION?=6abe312cded14042f6b7c3cd8edf082713334a4d
|
||||
PIPER_VERSION?=d6b6275ba037dabdba4a8b65dfdf6b2a73a67f07
|
||||
|
||||
# stablediffusion version
|
||||
STABLEDIFFUSION_VERSION?=902db5f066fd137697e3b69d0fa10d4782bd2c2f
|
||||
STABLEDIFFUSION_VERSION?=d5d2be8e7e395c2d73ceef61e6fe8d240f2cd831
|
||||
|
||||
# tinydream version
|
||||
TINYDREAM_VERSION?=772a9c0d9aaf768290e63cca3c904fe69faf677a
|
||||
@@ -100,6 +97,8 @@ endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),hipblas)
|
||||
ROCM_HOME ?= /opt/rocm
|
||||
ROCM_PATH ?= /opt/rocm
|
||||
LD_LIBRARY_PATH ?= /opt/rocm/lib:/opt/rocm/llvm/lib
|
||||
export CXX=$(ROCM_HOME)/llvm/bin/clang++
|
||||
export CC=$(ROCM_HOME)/llvm/bin/clang
|
||||
# llama-ggml has no hipblas support, so override it here.
|
||||
@@ -108,7 +107,7 @@ ifeq ($(BUILD_TYPE),hipblas)
|
||||
GPU_TARGETS ?= gfx900,gfx90a,gfx1030,gfx1031,gfx1100
|
||||
AMDGPU_TARGETS ?= "$(GPU_TARGETS)"
|
||||
CMAKE_ARGS+=-DLLAMA_HIPBLAS=ON -DAMDGPU_TARGETS="$(AMDGPU_TARGETS)" -DGPU_TARGETS="$(GPU_TARGETS)"
|
||||
CGO_LDFLAGS += -O3 --rtlib=compiler-rt -unwindlib=libgcc -lhipblas -lrocblas --hip-link
|
||||
CGO_LDFLAGS += -O3 --rtlib=compiler-rt -unwindlib=libgcc -lhipblas -lrocblas --hip-link -L${ROCM_HOME}/lib/llvm/lib
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),metal)
|
||||
@@ -145,7 +144,16 @@ ifeq ($(findstring tts,$(GO_TAGS)),tts)
|
||||
OPTIONAL_GRPC+=backend-assets/grpc/piper
|
||||
endif
|
||||
|
||||
ALL_GRPC_BACKENDS=backend-assets/grpc/langchain-huggingface backend-assets/grpc/falcon-ggml backend-assets/grpc/bert-embeddings backend-assets/grpc/llama backend-assets/grpc/llama-cpp backend-assets/grpc/llama-ggml backend-assets/grpc/gpt4all backend-assets/grpc/dolly backend-assets/grpc/gpt2 backend-assets/grpc/gptj backend-assets/grpc/gptneox backend-assets/grpc/mpt backend-assets/grpc/replit backend-assets/grpc/starcoder backend-assets/grpc/rwkv backend-assets/grpc/whisper $(OPTIONAL_GRPC)
|
||||
ALL_GRPC_BACKENDS=backend-assets/grpc/langchain-huggingface
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/bert-embeddings
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/llama
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/llama-cpp
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/llama-ggml
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/gpt4all
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/rwkv
|
||||
ALL_GRPC_BACKENDS+=backend-assets/grpc/whisper
|
||||
ALL_GRPC_BACKENDS+=$(OPTIONAL_GRPC)
|
||||
|
||||
GRPC_BACKENDS?=$(ALL_GRPC_BACKENDS) $(OPTIONAL_GRPC)
|
||||
|
||||
# If empty, then we build all
|
||||
@@ -217,14 +225,6 @@ backend-assets/espeak-ng-data: sources/go-piper
|
||||
sources/gpt4all/gpt4all-bindings/golang/libgpt4all.a: sources/gpt4all
|
||||
$(MAKE) -C sources/gpt4all/gpt4all-bindings/golang/ libgpt4all.a
|
||||
|
||||
## CEREBRAS GPT
|
||||
sources/go-ggml-transformers:
|
||||
git clone --recurse-submodules https://github.com/go-skynet/go-ggml-transformers.cpp sources/go-ggml-transformers
|
||||
cd sources/go-ggml-transformers && git checkout -b build $(GOGPT2_VERSION) && git submodule update --init --recursive --depth 1
|
||||
|
||||
sources/go-ggml-transformers/libtransformers.a: sources/go-ggml-transformers
|
||||
$(MAKE) -C sources/go-ggml-transformers BUILD_TYPE=$(BUILD_TYPE) libtransformers.a
|
||||
|
||||
sources/whisper.cpp:
|
||||
git clone https://github.com/ggerganov/whisper.cpp.git sources/whisper.cpp
|
||||
cd sources/whisper.cpp && git checkout -b build $(WHISPER_CPP_VERSION) && git submodule update --init --recursive --depth 1
|
||||
@@ -252,12 +252,11 @@ sources/go-piper/libpiper_binding.a: sources/go-piper
|
||||
backend/cpp/llama/llama.cpp:
|
||||
LLAMA_VERSION=$(CPPLLAMA_VERSION) $(MAKE) -C backend/cpp/llama llama.cpp
|
||||
|
||||
get-sources: backend/cpp/llama/llama.cpp sources/go-llama sources/go-llama-ggml sources/go-ggml-transformers sources/gpt4all sources/go-piper sources/go-rwkv sources/whisper.cpp sources/go-bert sources/go-stable-diffusion sources/go-tiny-dream
|
||||
get-sources: backend/cpp/llama/llama.cpp sources/go-llama sources/go-llama-ggml sources/gpt4all sources/go-piper sources/go-rwkv sources/whisper.cpp sources/go-bert sources/go-stable-diffusion sources/go-tiny-dream
|
||||
touch $@
|
||||
|
||||
replace:
|
||||
$(GOCMD) mod edit -replace github.com/nomic-ai/gpt4all/gpt4all-bindings/golang=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang
|
||||
$(GOCMD) mod edit -replace github.com/go-skynet/go-ggml-transformers.cpp=$(CURDIR)/sources/go-ggml-transformers
|
||||
$(GOCMD) mod edit -replace github.com/donomii/go-rwkv.cpp=$(CURDIR)/sources/go-rwkv
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp=$(CURDIR)/sources/whisper.cpp
|
||||
$(GOCMD) mod edit -replace github.com/ggerganov/whisper.cpp/bindings/go=$(CURDIR)/sources/whisper.cpp/bindings/go
|
||||
@@ -276,7 +275,6 @@ rebuild: ## Rebuilds the project
|
||||
$(MAKE) -C sources/go-llama clean
|
||||
$(MAKE) -C sources/go-llama-ggml clean
|
||||
$(MAKE) -C sources/gpt4all/gpt4all-bindings/golang/ clean
|
||||
$(MAKE) -C sources/go-ggml-transformers clean
|
||||
$(MAKE) -C sources/go-rwkv clean
|
||||
$(MAKE) -C sources/whisper.cpp clean
|
||||
$(MAKE) -C sources/go-stable-diffusion clean
|
||||
@@ -321,7 +319,7 @@ run: prepare ## run local-ai
|
||||
test-models/testmodel:
|
||||
mkdir test-models
|
||||
mkdir test-dir
|
||||
wget -q https://huggingface.co/nnakasato/ggml-model-test/resolve/main/ggml-model-q4.bin -O test-models/testmodel
|
||||
wget -q https://huggingface.co/TheBloke/orca_mini_3B-GGML/resolve/main/orca-mini-3b.ggmlv3.q4_0.bin -O test-models/testmodel
|
||||
wget -q https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-base.en.bin -O test-models/whisper-en
|
||||
wget -q https://huggingface.co/mudler/all-MiniLM-L6-v2/resolve/main/ggml-model-q4_0.bin -O test-models/bert
|
||||
wget -q https://cdn.openai.com/whisper/draft-20220913a/micro-machines.wav -O test-dir/audio.wav
|
||||
@@ -505,38 +503,6 @@ backend-assets/grpc/gpt4all: backend-assets/grpc backend-assets/gpt4all sources/
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang/ LIBRARY_PATH=$(CURDIR)/sources/gpt4all/gpt4all-bindings/golang/ \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gpt4all ./backend/go/llm/gpt4all/
|
||||
|
||||
backend-assets/grpc/dolly: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/dolly ./backend/go/llm/dolly/
|
||||
|
||||
backend-assets/grpc/gpt2: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gpt2 ./backend/go/llm/gpt2/
|
||||
|
||||
backend-assets/grpc/gptj: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gptj ./backend/go/llm/gptj/
|
||||
|
||||
backend-assets/grpc/gptneox: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/gptneox ./backend/go/llm/gptneox/
|
||||
|
||||
backend-assets/grpc/mpt: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/mpt ./backend/go/llm/mpt/
|
||||
|
||||
backend-assets/grpc/replit: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/replit ./backend/go/llm/replit/
|
||||
|
||||
backend-assets/grpc/falcon-ggml: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/falcon-ggml ./backend/go/llm/falcon-ggml/
|
||||
|
||||
backend-assets/grpc/starcoder: backend-assets/grpc sources/go-ggml-transformers/libtransformers.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-ggml-transformers LIBRARY_PATH=$(CURDIR)/sources/go-ggml-transformers \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/starcoder ./backend/go/llm/starcoder/
|
||||
|
||||
backend-assets/grpc/rwkv: backend-assets/grpc sources/go-rwkv/librwkv.a
|
||||
CGO_LDFLAGS="$(CGO_LDFLAGS)" C_INCLUDE_PATH=$(CURDIR)/sources/go-rwkv LIBRARY_PATH=$(CURDIR)/sources/go-rwkv \
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/rwkv ./backend/go/llm/rwkv
|
||||
@@ -568,3 +534,22 @@ backend-assets/grpc/whisper: backend-assets/grpc sources/whisper.cpp/libwhisper.
|
||||
$(GOCMD) build -ldflags "$(LD_FLAGS)" -tags "$(GO_TAGS)" -o backend-assets/grpc/whisper ./backend/go/transcribe/
|
||||
|
||||
grpcs: prepare $(GRPC_BACKENDS)
|
||||
|
||||
DOCKER_IMAGE?=local-ai
|
||||
IMAGE_TYPE?=core
|
||||
BASE_IMAGE?=ubuntu:22.04
|
||||
|
||||
docker:
|
||||
docker build \
|
||||
--build-arg BASE_IMAGE=$(BASE_IMAGE) \
|
||||
--build-arg IMAGE_TYPE=$(IMAGE_TYPE) \
|
||||
--build-arg GO_TAGS=$(GO_TAGS) \
|
||||
--build-arg BUILD_TYPE=$(BUILD_TYPE) \
|
||||
-t $(DOCKER_IMAGE) .
|
||||
|
||||
docker-image-intel:
|
||||
docker build \
|
||||
--build-arg BASE_IMAGE=intel/oneapi-basekit:2024.0.1-devel-ubuntu22.04 \
|
||||
--build-arg IMAGE_TYPE=$(IMAGE_TYPE) \
|
||||
--build-arg GO_TAGS="none" \
|
||||
--build-arg BUILD_TYPE=sycl_f32 -t $(DOCKER_IMAGE) .
|
||||
|
||||
25
README.md
25
README.md
@@ -43,18 +43,23 @@
|
||||
|
||||
[Roadmap](https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3Aroadmap)
|
||||
|
||||
- Parallel function calling: https://github.com/mudler/LocalAI/pull/1726
|
||||
- Upload file API: https://github.com/mudler/LocalAI/pull/1703
|
||||
- Tools API support: https://github.com/mudler/LocalAI/pull/1715
|
||||
- LLaVa 1.6: https://github.com/mudler/LocalAI/pull/1714
|
||||
- ROCm container images: https://github.com/mudler/LocalAI/pull/1595
|
||||
- Intel GPU support (sycl): https://github.com/mudler/LocalAI/issues/1653
|
||||
- Deprecation of old backends: https://github.com/mudler/LocalAI/issues/1651
|
||||
- Mamba support: https://github.com/mudler/LocalAI/pull/1589
|
||||
- Start and share models with config file: https://github.com/mudler/LocalAI/pull/1522
|
||||
- 🐸 Coqui: https://github.com/mudler/LocalAI/pull/1489
|
||||
- Inline templates: https://github.com/mudler/LocalAI/pull/1452
|
||||
- Mixtral: https://github.com/mudler/LocalAI/pull/1449
|
||||
- Img2vid https://github.com/mudler/LocalAI/pull/1442
|
||||
- Musicgen https://github.com/mudler/LocalAI/pull/1387
|
||||
|
||||
Hot topics (looking for contributors):
|
||||
- Backends v2: https://github.com/mudler/LocalAI/issues/1126
|
||||
- Improving UX v2: https://github.com/mudler/LocalAI/issues/1373
|
||||
|
||||
- Assistant API: https://github.com/mudler/LocalAI/issues/1273
|
||||
|
||||
If you want to help and contribute, issues up for grabs: https://github.com/mudler/LocalAI/issues?q=is%3Aissue+is%3Aopen+label%3A%22up+for+grabs%22
|
||||
|
||||
## 💻 [Getting started](https://localai.io/basics/getting_started/index.html)
|
||||
@@ -62,7 +67,7 @@ If you want to help and contribute, issues up for grabs: https://github.com/mudl
|
||||
For a detailed step-by-step introduction, refer to the [Getting Started](https://localai.io/basics/getting_started/index.html) guide. For those in a hurry, here's a straightforward one-liner to launch a LocalAI instance with [phi-2](https://huggingface.co/microsoft/phi-2) using `docker`:
|
||||
|
||||
```
|
||||
docker run -ti -p 8080:8080 localai/localai:v2.5.1-ffmpeg-core phi-2
|
||||
docker run -ti -p 8080:8080 localai/localai:v2.7.0-ffmpeg-core phi-2
|
||||
```
|
||||
|
||||
## 🚀 [Features](https://localai.io/features/)
|
||||
@@ -93,9 +98,8 @@ WebUIs:
|
||||
Model galleries
|
||||
- https://github.com/go-skynet/model-gallery
|
||||
|
||||
Auto Docker / Model setup
|
||||
- https://io.midori-ai.xyz/howtos/easy-localai-installer/
|
||||
- https://io.midori-ai.xyz/howtos/easy-model-installer/
|
||||
UI / Management Programs
|
||||
- [LocalAI Manager](https://io.midori-ai.xyz/howtos/easy-model-installer/)
|
||||
|
||||
Other:
|
||||
- Helm chart https://github.com/go-skynet/helm-charts
|
||||
@@ -109,10 +113,10 @@ Other:
|
||||
|
||||
### 🔗 Resources
|
||||
|
||||
- 🆕 New! [LLM finetuning guide](https://localai.io/advanced/fine-tuning/)
|
||||
- 🆕 New! [LLM finetuning guide](https://localai.io/docs/advanced/fine-tuning/)
|
||||
- [How to build locally](https://localai.io/basics/build/index.html)
|
||||
- [How to install in Kubernetes](https://localai.io/basics/getting_started/index.html#run-localai-in-kubernetes)
|
||||
- [Projects integrating LocalAI](https://localai.io/integrations/)
|
||||
- [Projects integrating LocalAI](https://localai.io/docs/integrations/)
|
||||
- [How tos section](https://io.midori-ai.xyz/howtos/) (curated by our community)
|
||||
|
||||
## :book: 🎥 [Media, Blogs, Social](https://localai.io/basics/news/#media-blogs-social)
|
||||
@@ -176,7 +180,6 @@ LocalAI couldn't have been built without the help of great software already avai
|
||||
- https://github.com/ggerganov/whisper.cpp
|
||||
- https://github.com/saharNooby/rwkv.cpp
|
||||
- https://github.com/rhasspy/piper
|
||||
- https://github.com/cmp-nct/ggllm.cpp
|
||||
|
||||
## 🤗 Contributors
|
||||
|
||||
|
||||
43
api/ctx/fiber.go
Normal file
43
api/ctx/fiber.go
Normal file
@@ -0,0 +1,43 @@
|
||||
package fiberContext
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"strings"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
)
|
||||
|
||||
// ModelFromContext returns the model from the context
|
||||
// If no model is specified, it will take the first available
|
||||
// Takes a model string as input which should be the one received from the user request.
|
||||
// It returns the model name resolved from the context and an error if any.
|
||||
func ModelFromContext(ctx *fiber.Ctx, loader *model.ModelLoader, modelInput string, firstModel bool) (string, error) {
|
||||
if ctx.Params("model") != "" {
|
||||
modelInput = ctx.Params("model")
|
||||
}
|
||||
|
||||
// Set model from bearer token, if available
|
||||
bearer := strings.TrimLeft(ctx.Get("authorization"), "Bearer ")
|
||||
bearerExists := bearer != "" && loader.ExistsInModelPath(bearer)
|
||||
|
||||
// If no model was specified, take the first available
|
||||
if modelInput == "" && !bearerExists && firstModel {
|
||||
models, _ := loader.ListModels()
|
||||
if len(models) > 0 {
|
||||
modelInput = models[0]
|
||||
log.Debug().Msgf("No model specified, using: %s", modelInput)
|
||||
} else {
|
||||
log.Debug().Msgf("No model specified, returning error")
|
||||
return "", fmt.Errorf("no model specified")
|
||||
}
|
||||
}
|
||||
|
||||
// If a model is found in bearer token takes precedence
|
||||
if bearerExists {
|
||||
log.Debug().Msgf("Using model from bearer token: %s", bearer)
|
||||
modelInput = bearer
|
||||
}
|
||||
return modelInput, nil
|
||||
}
|
||||
@@ -5,10 +5,10 @@ import (
|
||||
"fmt"
|
||||
"strings"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
|
||||
|
||||
@@ -11,7 +11,7 @@ import (
|
||||
json "github.com/json-iterator/go"
|
||||
"gopkg.in/yaml.v3"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/pkg/gallery"
|
||||
"github.com/go-skynet/LocalAI/pkg/utils"
|
||||
|
||||
|
||||
@@ -1,10 +1,12 @@
|
||||
package localai
|
||||
|
||||
import (
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
fiberContext "github.com/go-skynet/LocalAI/api/ctx"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/rs/zerolog/log"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
)
|
||||
|
||||
@@ -18,12 +20,31 @@ func TTSEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
return func(c *fiber.Ctx) error {
|
||||
|
||||
input := new(TTSRequest)
|
||||
|
||||
// Get input data from the request body
|
||||
if err := c.BodyParser(input); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
filePath, _, err := backend.ModelTTS(input.Backend, input.Input, input.Model, o.Loader, o)
|
||||
modelFile, err := fiberContext.ModelFromContext(c, o.Loader, input.Model, false)
|
||||
if err != nil {
|
||||
modelFile = input.Model
|
||||
log.Warn().Msgf("Model not found in context: %s", input.Model)
|
||||
}
|
||||
cfg, err := config.Load(modelFile, o.Loader.ModelPath, cm, false, 0, 0, false)
|
||||
if err != nil {
|
||||
modelFile = input.Model
|
||||
log.Warn().Msgf("Model not found in context: %s", input.Model)
|
||||
} else {
|
||||
modelFile = cfg.Model
|
||||
}
|
||||
log.Debug().Msgf("Request for model: %s", modelFile)
|
||||
|
||||
if input.Backend != "" {
|
||||
cfg.Backend = input.Backend
|
||||
}
|
||||
|
||||
filePath, _, err := backend.ModelTTS(cfg.Backend, input.Input, modelFile, o.Loader, o, *cfg)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
@@ -8,10 +8,10 @@ import (
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
"github.com/go-skynet/LocalAI/pkg/grammar"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/go-skynet/LocalAI/pkg/utils"
|
||||
@@ -55,15 +55,111 @@ func ChatEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
})
|
||||
close(responses)
|
||||
}
|
||||
processTools := func(noAction string, prompt string, req *schema.OpenAIRequest, config *config.Config, loader *model.ModelLoader, responses chan schema.OpenAIResponse) {
|
||||
result := ""
|
||||
_, tokenUsage, _ := ComputeChoices(req, prompt, config, o, loader, func(s string, c *[]schema.Choice) {}, func(s string, usage backend.TokenUsage) bool {
|
||||
result += s
|
||||
// TODO: Change generated BNF grammar to be compliant with the schema so we can
|
||||
// stream the result token by token here.
|
||||
return true
|
||||
})
|
||||
|
||||
results := parseFunctionCall(result, config.FunctionsConfig.ParallelCalls)
|
||||
noActionToRun := len(results) > 0 && results[0].name == noAction
|
||||
|
||||
switch {
|
||||
case noActionToRun:
|
||||
initialMessage := schema.OpenAIResponse{
|
||||
ID: id,
|
||||
Created: created,
|
||||
Model: req.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: []schema.Choice{{Delta: &schema.Message{Role: "assistant", Content: &emptyMessage}}},
|
||||
Object: "chat.completion.chunk",
|
||||
}
|
||||
responses <- initialMessage
|
||||
|
||||
result, err := handleQuestion(config, req, o, results[0].arguments, prompt)
|
||||
if err != nil {
|
||||
log.Error().Msgf("error handling question: %s", err.Error())
|
||||
return
|
||||
}
|
||||
|
||||
resp := schema.OpenAIResponse{
|
||||
ID: id,
|
||||
Created: created,
|
||||
Model: req.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: []schema.Choice{{Delta: &schema.Message{Content: &result}, Index: 0}},
|
||||
Object: "chat.completion.chunk",
|
||||
Usage: schema.OpenAIUsage{
|
||||
PromptTokens: tokenUsage.Prompt,
|
||||
CompletionTokens: tokenUsage.Completion,
|
||||
TotalTokens: tokenUsage.Prompt + tokenUsage.Completion,
|
||||
},
|
||||
}
|
||||
|
||||
responses <- resp
|
||||
|
||||
default:
|
||||
for i, ss := range results {
|
||||
name, args := ss.name, ss.arguments
|
||||
|
||||
initialMessage := schema.OpenAIResponse{
|
||||
ID: id,
|
||||
Created: created,
|
||||
Model: req.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: []schema.Choice{{
|
||||
Delta: &schema.Message{
|
||||
Role: "assistant",
|
||||
ToolCalls: []schema.ToolCall{
|
||||
{
|
||||
Index: i,
|
||||
ID: id,
|
||||
Type: "function",
|
||||
FunctionCall: schema.FunctionCall{
|
||||
Name: name,
|
||||
},
|
||||
},
|
||||
},
|
||||
}}},
|
||||
Object: "chat.completion.chunk",
|
||||
}
|
||||
responses <- initialMessage
|
||||
|
||||
responses <- schema.OpenAIResponse{
|
||||
ID: id,
|
||||
Created: created,
|
||||
Model: req.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: []schema.Choice{{
|
||||
Delta: &schema.Message{
|
||||
Role: "assistant",
|
||||
ToolCalls: []schema.ToolCall{
|
||||
{
|
||||
Index: i,
|
||||
ID: id,
|
||||
Type: "function",
|
||||
FunctionCall: schema.FunctionCall{
|
||||
Arguments: args,
|
||||
},
|
||||
},
|
||||
},
|
||||
}}},
|
||||
Object: "chat.completion.chunk",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
close(responses)
|
||||
}
|
||||
|
||||
return func(c *fiber.Ctx) error {
|
||||
processFunctions := false
|
||||
funcs := grammar.Functions{}
|
||||
modelFile, input, err := readInput(c, o, true)
|
||||
modelFile, input, err := readRequest(c, o, true)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
config, input, err := readConfig(modelFile, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
config, input, err := mergeRequestWithConfig(modelFile, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
@@ -116,13 +212,13 @@ func ChatEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
|
||||
// Update input grammar
|
||||
jsStruct := funcs.ToJSONStructure()
|
||||
config.Grammar = jsStruct.Grammar("")
|
||||
config.Grammar = jsStruct.Grammar("", config.FunctionsConfig.ParallelCalls)
|
||||
} else if input.JSONFunctionGrammarObject != nil {
|
||||
config.Grammar = input.JSONFunctionGrammarObject.Grammar("")
|
||||
config.Grammar = input.JSONFunctionGrammarObject.Grammar("", config.FunctionsConfig.ParallelCalls)
|
||||
}
|
||||
|
||||
// functions are not supported in stream mode (yet?)
|
||||
toStream := input.Stream && !processFunctions
|
||||
toStream := input.Stream
|
||||
|
||||
log.Debug().Msgf("Parameters: %+v", config)
|
||||
|
||||
@@ -145,6 +241,7 @@ func ChatEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
}
|
||||
r := config.Roles[role]
|
||||
contentExists := i.Content != nil && i.StringContent != ""
|
||||
|
||||
// First attempt to populate content via a chat message specific template
|
||||
if config.TemplateConfig.ChatMessage != "" {
|
||||
chatMessageData := model.ChatMessageTemplateData{
|
||||
@@ -152,6 +249,7 @@ func ChatEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
Role: r,
|
||||
RoleName: role,
|
||||
Content: i.StringContent,
|
||||
FunctionName: i.Name,
|
||||
MessageIndex: messageIndex,
|
||||
}
|
||||
templatedChatMessage, err := o.Loader.EvaluateTemplateForChatMessage(config.TemplateConfig.ChatMessage, chatMessageData)
|
||||
@@ -254,17 +352,24 @@ func ChatEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
log.Debug().Msgf("Grammar: %+v", config.Grammar)
|
||||
}
|
||||
|
||||
if toStream {
|
||||
switch {
|
||||
case toStream:
|
||||
responses := make(chan schema.OpenAIResponse)
|
||||
|
||||
go process(predInput, input, config, o.Loader, responses)
|
||||
if !processFunctions {
|
||||
go process(predInput, input, config, o.Loader, responses)
|
||||
} else {
|
||||
go processTools(noActionName, predInput, input, config, o.Loader, responses)
|
||||
}
|
||||
|
||||
c.Context().SetBodyStreamWriter(fasthttp.StreamWriter(func(w *bufio.Writer) {
|
||||
|
||||
usage := &schema.OpenAIUsage{}
|
||||
|
||||
toolsCalled := false
|
||||
for ev := range responses {
|
||||
usage = &ev.Usage // Copy a pointer to the latest usage chunk so that the stop message can reference it
|
||||
if len(ev.Choices[0].Delta.ToolCalls) > 0 {
|
||||
toolsCalled = true
|
||||
}
|
||||
var buf bytes.Buffer
|
||||
enc := json.NewEncoder(&buf)
|
||||
enc.Encode(ev)
|
||||
@@ -278,13 +383,20 @@ func ChatEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
w.Flush()
|
||||
}
|
||||
|
||||
finishReason := "stop"
|
||||
if toolsCalled {
|
||||
finishReason = "tool_calls"
|
||||
} else if toolsCalled && len(input.Tools) == 0 {
|
||||
finishReason = "function_call"
|
||||
}
|
||||
|
||||
resp := &schema.OpenAIResponse{
|
||||
ID: id,
|
||||
Created: created,
|
||||
Model: input.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: []schema.Choice{
|
||||
{
|
||||
FinishReason: "stop",
|
||||
FinishReason: finishReason,
|
||||
Index: 0,
|
||||
Delta: &schema.Message{Content: &emptyMessage},
|
||||
}},
|
||||
@@ -298,102 +410,182 @@ func ChatEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx)
|
||||
w.Flush()
|
||||
}))
|
||||
return nil
|
||||
}
|
||||
|
||||
result, tokenUsage, err := ComputeChoices(input, predInput, config, o, o.Loader, func(s string, c *[]schema.Choice) {
|
||||
if processFunctions {
|
||||
// As we have to change the result before processing, we can't stream the answer (yet?)
|
||||
ss := map[string]interface{}{}
|
||||
// This prevent newlines to break JSON parsing for clients
|
||||
s = utils.EscapeNewLines(s)
|
||||
json.Unmarshal([]byte(s), &ss)
|
||||
log.Debug().Msgf("Function return: %s %+v", s, ss)
|
||||
// no streaming mode
|
||||
default:
|
||||
result, tokenUsage, err := ComputeChoices(input, predInput, config, o, o.Loader, func(s string, c *[]schema.Choice) {
|
||||
if !processFunctions {
|
||||
// no function is called, just reply and use stop as finish reason
|
||||
*c = append(*c, schema.Choice{FinishReason: "stop", Index: 0, Message: &schema.Message{Role: "assistant", Content: &s}})
|
||||
return
|
||||
}
|
||||
|
||||
// The grammar defines the function name as "function", while OpenAI returns "name"
|
||||
func_name := ss["function"]
|
||||
// Similarly, while here arguments is a map[string]interface{}, OpenAI actually want a stringified object
|
||||
args := ss["arguments"] // arguments needs to be a string, but we return an object from the grammar result (TODO: fix)
|
||||
d, _ := json.Marshal(args)
|
||||
results := parseFunctionCall(s, config.FunctionsConfig.ParallelCalls)
|
||||
noActionsToRun := len(results) > 0 && results[0].name == noActionName
|
||||
|
||||
ss["arguments"] = string(d)
|
||||
ss["name"] = func_name
|
||||
switch {
|
||||
case noActionsToRun:
|
||||
result, err := handleQuestion(config, input, o, results[0].arguments, predInput)
|
||||
if err != nil {
|
||||
log.Error().Msgf("error handling question: %s", err.Error())
|
||||
return
|
||||
}
|
||||
*c = append(*c, schema.Choice{
|
||||
Message: &schema.Message{Role: "assistant", Content: &result}})
|
||||
default:
|
||||
toolChoice := schema.Choice{
|
||||
Message: &schema.Message{
|
||||
Role: "assistant",
|
||||
},
|
||||
}
|
||||
|
||||
// if do nothing, reply with a message
|
||||
if func_name == noActionName {
|
||||
log.Debug().Msgf("nothing to do, computing a reply")
|
||||
if len(input.Tools) > 0 {
|
||||
toolChoice.FinishReason = "tool_calls"
|
||||
}
|
||||
|
||||
// If there is a message that the LLM already sends as part of the JSON reply, use it
|
||||
arguments := map[string]interface{}{}
|
||||
json.Unmarshal([]byte(d), &arguments)
|
||||
m, exists := arguments["message"]
|
||||
if exists {
|
||||
switch message := m.(type) {
|
||||
case string:
|
||||
if message != "" {
|
||||
log.Debug().Msgf("Reply received from LLM: %s", message)
|
||||
message = backend.Finetune(*config, predInput, message)
|
||||
log.Debug().Msgf("Reply received from LLM(finetuned): %s", message)
|
||||
|
||||
*c = append(*c, schema.Choice{Message: &schema.Message{Role: "assistant", Content: &message}})
|
||||
return
|
||||
}
|
||||
for _, ss := range results {
|
||||
name, args := ss.name, ss.arguments
|
||||
if len(input.Tools) > 0 {
|
||||
// If we are using tools, we condense the function calls into
|
||||
// a single response choice with all the tools
|
||||
toolChoice.Message.ToolCalls = append(toolChoice.Message.ToolCalls,
|
||||
schema.ToolCall{
|
||||
ID: id,
|
||||
Type: "function",
|
||||
FunctionCall: schema.FunctionCall{
|
||||
Name: name,
|
||||
Arguments: args,
|
||||
},
|
||||
},
|
||||
)
|
||||
} else {
|
||||
// otherwise we return more choices directly
|
||||
*c = append(*c, schema.Choice{
|
||||
FinishReason: "function_call",
|
||||
Message: &schema.Message{
|
||||
Role: "assistant",
|
||||
FunctionCall: map[string]interface{}{
|
||||
"name": name,
|
||||
"arguments": args,
|
||||
},
|
||||
},
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
log.Debug().Msgf("No action received from LLM, without a message, computing a reply")
|
||||
// Otherwise ask the LLM to understand the JSON output and the context, and return a message
|
||||
// Note: This costs (in term of CPU) another computation
|
||||
config.Grammar = ""
|
||||
images := []string{}
|
||||
for _, m := range input.Messages {
|
||||
images = append(images, m.StringImages...)
|
||||
if len(input.Tools) > 0 {
|
||||
// we need to append our result if we are using tools
|
||||
*c = append(*c, toolChoice)
|
||||
}
|
||||
predFunc, err := backend.ModelInference(input.Context, predInput, images, o.Loader, *config, o, nil)
|
||||
if err != nil {
|
||||
log.Error().Msgf("inference error: %s", err.Error())
|
||||
return
|
||||
}
|
||||
|
||||
prediction, err := predFunc()
|
||||
if err != nil {
|
||||
log.Error().Msgf("inference error: %s", err.Error())
|
||||
return
|
||||
}
|
||||
|
||||
fineTunedResponse := backend.Finetune(*config, predInput, prediction.Response)
|
||||
*c = append(*c, schema.Choice{Message: &schema.Message{Role: "assistant", Content: &fineTunedResponse}})
|
||||
} else {
|
||||
// otherwise reply with the function call
|
||||
*c = append(*c, schema.Choice{
|
||||
FinishReason: "function_call",
|
||||
Message: &schema.Message{Role: "assistant", FunctionCall: ss},
|
||||
})
|
||||
}
|
||||
|
||||
return
|
||||
}, nil)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
*c = append(*c, schema.Choice{FinishReason: "stop", Index: 0, Message: &schema.Message{Role: "assistant", Content: &s}})
|
||||
}, nil)
|
||||
if err != nil {
|
||||
return err
|
||||
|
||||
resp := &schema.OpenAIResponse{
|
||||
ID: id,
|
||||
Created: created,
|
||||
Model: input.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: result,
|
||||
Object: "chat.completion",
|
||||
Usage: schema.OpenAIUsage{
|
||||
PromptTokens: tokenUsage.Prompt,
|
||||
CompletionTokens: tokenUsage.Completion,
|
||||
TotalTokens: tokenUsage.Prompt + tokenUsage.Completion,
|
||||
},
|
||||
}
|
||||
respData, _ := json.Marshal(resp)
|
||||
log.Debug().Msgf("Response: %s", respData)
|
||||
|
||||
// Return the prediction in the response body
|
||||
return c.JSON(resp)
|
||||
}
|
||||
|
||||
resp := &schema.OpenAIResponse{
|
||||
ID: id,
|
||||
Created: created,
|
||||
Model: input.Model, // we have to return what the user sent here, due to OpenAI spec.
|
||||
Choices: result,
|
||||
Object: "chat.completion",
|
||||
Usage: schema.OpenAIUsage{
|
||||
PromptTokens: tokenUsage.Prompt,
|
||||
CompletionTokens: tokenUsage.Completion,
|
||||
TotalTokens: tokenUsage.Prompt + tokenUsage.Completion,
|
||||
},
|
||||
}
|
||||
respData, _ := json.Marshal(resp)
|
||||
log.Debug().Msgf("Response: %s", respData)
|
||||
|
||||
// Return the prediction in the response body
|
||||
return c.JSON(resp)
|
||||
}
|
||||
}
|
||||
|
||||
func handleQuestion(config *config.Config, input *schema.OpenAIRequest, o *options.Option, args, prompt string) (string, error) {
|
||||
log.Debug().Msgf("nothing to do, computing a reply")
|
||||
|
||||
// If there is a message that the LLM already sends as part of the JSON reply, use it
|
||||
arguments := map[string]interface{}{}
|
||||
json.Unmarshal([]byte(args), &arguments)
|
||||
m, exists := arguments["message"]
|
||||
if exists {
|
||||
switch message := m.(type) {
|
||||
case string:
|
||||
if message != "" {
|
||||
log.Debug().Msgf("Reply received from LLM: %s", message)
|
||||
message = backend.Finetune(*config, prompt, message)
|
||||
log.Debug().Msgf("Reply received from LLM(finetuned): %s", message)
|
||||
|
||||
return message, nil
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
log.Debug().Msgf("No action received from LLM, without a message, computing a reply")
|
||||
// Otherwise ask the LLM to understand the JSON output and the context, and return a message
|
||||
// Note: This costs (in term of CPU/GPU) another computation
|
||||
config.Grammar = ""
|
||||
images := []string{}
|
||||
for _, m := range input.Messages {
|
||||
images = append(images, m.StringImages...)
|
||||
}
|
||||
|
||||
predFunc, err := backend.ModelInference(input.Context, prompt, images, o.Loader, *config, o, nil)
|
||||
if err != nil {
|
||||
log.Error().Msgf("inference error: %s", err.Error())
|
||||
return "", err
|
||||
}
|
||||
|
||||
prediction, err := predFunc()
|
||||
if err != nil {
|
||||
log.Error().Msgf("inference error: %s", err.Error())
|
||||
return "", err
|
||||
}
|
||||
return backend.Finetune(*config, prompt, prediction.Response), nil
|
||||
}
|
||||
|
||||
type funcCallResults struct {
|
||||
name string
|
||||
arguments string
|
||||
}
|
||||
|
||||
func parseFunctionCall(llmresult string, multipleResults bool) []funcCallResults {
|
||||
results := []funcCallResults{}
|
||||
|
||||
// TODO: use generics to avoid this code duplication
|
||||
if multipleResults {
|
||||
ss := []map[string]interface{}{}
|
||||
s := utils.EscapeNewLines(llmresult)
|
||||
json.Unmarshal([]byte(s), &ss)
|
||||
log.Debug().Msgf("Function return: %s %+v", s, ss)
|
||||
|
||||
for _, s := range ss {
|
||||
func_name := s["function"]
|
||||
args := s["arguments"]
|
||||
d, _ := json.Marshal(args)
|
||||
results = append(results, funcCallResults{name: func_name.(string), arguments: string(d)})
|
||||
}
|
||||
} else {
|
||||
// As we have to change the result before processing, we can't stream the answer token-by-token (yet?)
|
||||
ss := map[string]interface{}{}
|
||||
// This prevent newlines to break JSON parsing for clients
|
||||
s := utils.EscapeNewLines(llmresult)
|
||||
json.Unmarshal([]byte(s), &ss)
|
||||
log.Debug().Msgf("Function return: %s %+v", s, ss)
|
||||
|
||||
// The grammar defines the function name as "function", while OpenAI returns "name"
|
||||
func_name := ss["function"]
|
||||
// Similarly, while here arguments is a map[string]interface{}, OpenAI actually want a stringified object
|
||||
args := ss["arguments"] // arguments needs to be a string, but we return an object from the grammar result (TODO: fix)
|
||||
d, _ := json.Marshal(args)
|
||||
|
||||
results = append(results, funcCallResults{name: func_name.(string), arguments: string(d)})
|
||||
}
|
||||
|
||||
return results
|
||||
}
|
||||
|
||||
@@ -8,10 +8,10 @@ import (
|
||||
"fmt"
|
||||
"time"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
"github.com/go-skynet/LocalAI/pkg/grammar"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
@@ -53,14 +53,14 @@ func CompletionEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fibe
|
||||
}
|
||||
|
||||
return func(c *fiber.Ctx) error {
|
||||
modelFile, input, err := readInput(c, o, true)
|
||||
modelFile, input, err := readRequest(c, o, true)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
log.Debug().Msgf("`input`: %+v", input)
|
||||
|
||||
config, input, err := readConfig(modelFile, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
config, input, err := mergeRequestWithConfig(modelFile, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
@@ -5,10 +5,10 @@ import (
|
||||
"fmt"
|
||||
"time"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/google/uuid"
|
||||
@@ -18,12 +18,12 @@ import (
|
||||
|
||||
func EditEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
modelFile, input, err := readInput(c, o, true)
|
||||
modelFile, input, err := readRequest(c, o, true)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
config, input, err := readConfig(modelFile, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
config, input, err := mergeRequestWithConfig(modelFile, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
@@ -5,12 +5,12 @@ import (
|
||||
"fmt"
|
||||
"time"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
"github.com/google/uuid"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
)
|
||||
@@ -18,12 +18,12 @@ import (
|
||||
// https://platform.openai.com/docs/api-reference/embeddings
|
||||
func EmbeddingsEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
model, input, err := readInput(c, o, true)
|
||||
model, input, err := readRequest(c, o, true)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
config, input, err := readConfig(model, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
config, input, err := mergeRequestWithConfig(model, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
218
api/openai/files.go
Normal file
218
api/openai/files.go
Normal file
@@ -0,0 +1,218 @@
|
||||
package openai
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"fmt"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"time"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/pkg/utils"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
)
|
||||
|
||||
var uploadedFiles []File
|
||||
|
||||
const uploadedFilesFile = "uploadedFiles.json"
|
||||
|
||||
// File represents the structure of a file object from the OpenAI API.
|
||||
type File struct {
|
||||
ID string `json:"id"` // Unique identifier for the file
|
||||
Object string `json:"object"` // Type of the object (e.g., "file")
|
||||
Bytes int `json:"bytes"` // Size of the file in bytes
|
||||
CreatedAt time.Time `json:"created_at"` // The time at which the file was created
|
||||
Filename string `json:"filename"` // The name of the file
|
||||
Purpose string `json:"purpose"` // The purpose of the file (e.g., "fine-tune", "classifications", etc.)
|
||||
}
|
||||
|
||||
func saveUploadConfig(uploadDir string) {
|
||||
file, err := json.MarshalIndent(uploadedFiles, "", " ")
|
||||
if err != nil {
|
||||
log.Error().Msgf("Failed to JSON marshal the uploadedFiles: %s", err)
|
||||
}
|
||||
|
||||
err = os.WriteFile(filepath.Join(uploadDir, uploadedFilesFile), file, 0644)
|
||||
if err != nil {
|
||||
log.Error().Msgf("Failed to save uploadedFiles to file: %s", err)
|
||||
}
|
||||
}
|
||||
|
||||
func LoadUploadConfig(uploadPath string) {
|
||||
uploadFilePath := filepath.Join(uploadPath, uploadedFilesFile)
|
||||
|
||||
_, err := os.Stat(uploadFilePath)
|
||||
if os.IsNotExist(err) {
|
||||
log.Debug().Msgf("No uploadedFiles file found at %s", uploadFilePath)
|
||||
return
|
||||
}
|
||||
|
||||
file, err := os.ReadFile(uploadFilePath)
|
||||
if err != nil {
|
||||
log.Error().Msgf("Failed to read file: %s", err)
|
||||
} else {
|
||||
err = json.Unmarshal(file, &uploadedFiles)
|
||||
if err != nil {
|
||||
log.Error().Msgf("Failed to JSON unmarshal the file into uploadedFiles: %s", err)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// UploadFilesEndpoint https://platform.openai.com/docs/api-reference/files/create
|
||||
func UploadFilesEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
file, err := c.FormFile("file")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
// Check the file size
|
||||
if file.Size > int64(o.UploadLimitMB*1024*1024) {
|
||||
return c.Status(fiber.StatusBadRequest).SendString(fmt.Sprintf("File size %d exceeds upload limit %d", file.Size, o.UploadLimitMB))
|
||||
}
|
||||
|
||||
purpose := c.FormValue("purpose", "") //TODO put in purpose dirs
|
||||
if purpose == "" {
|
||||
return c.Status(fiber.StatusBadRequest).SendString("Purpose is not defined")
|
||||
}
|
||||
|
||||
// Sanitize the filename to prevent directory traversal
|
||||
filename := utils.SanitizeFileName(file.Filename)
|
||||
|
||||
savePath := filepath.Join(o.UploadDir, filename)
|
||||
|
||||
// Check if file already exists
|
||||
if _, err := os.Stat(savePath); !os.IsNotExist(err) {
|
||||
return c.Status(fiber.StatusBadRequest).SendString("File already exists")
|
||||
}
|
||||
|
||||
err = c.SaveFile(file, savePath)
|
||||
if err != nil {
|
||||
return c.Status(fiber.StatusInternalServerError).SendString("Failed to save file: " + err.Error())
|
||||
}
|
||||
|
||||
f := File{
|
||||
ID: fmt.Sprintf("file-%d", time.Now().Unix()),
|
||||
Object: "file",
|
||||
Bytes: int(file.Size),
|
||||
CreatedAt: time.Now(),
|
||||
Filename: file.Filename,
|
||||
Purpose: purpose,
|
||||
}
|
||||
|
||||
uploadedFiles = append(uploadedFiles, f)
|
||||
saveUploadConfig(o.UploadDir)
|
||||
return c.Status(fiber.StatusOK).JSON(f)
|
||||
}
|
||||
}
|
||||
|
||||
// ListFilesEndpoint https://platform.openai.com/docs/api-reference/files/list
|
||||
func ListFilesEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
type ListFiles struct {
|
||||
Data []File
|
||||
Object string
|
||||
}
|
||||
|
||||
return func(c *fiber.Ctx) error {
|
||||
var listFiles ListFiles
|
||||
|
||||
purpose := c.Query("purpose")
|
||||
if purpose == "" {
|
||||
listFiles.Data = uploadedFiles
|
||||
} else {
|
||||
for _, f := range uploadedFiles {
|
||||
if purpose == f.Purpose {
|
||||
listFiles.Data = append(listFiles.Data, f)
|
||||
}
|
||||
}
|
||||
}
|
||||
listFiles.Object = "list"
|
||||
return c.Status(fiber.StatusOK).JSON(listFiles)
|
||||
}
|
||||
}
|
||||
|
||||
func getFileFromRequest(c *fiber.Ctx) (*File, error) {
|
||||
id := c.Params("file_id")
|
||||
if id == "" {
|
||||
return nil, fmt.Errorf("file_id parameter is required")
|
||||
}
|
||||
|
||||
for _, f := range uploadedFiles {
|
||||
if id == f.ID {
|
||||
return &f, nil
|
||||
}
|
||||
}
|
||||
|
||||
return nil, fmt.Errorf("unable to find file id %s", id)
|
||||
}
|
||||
|
||||
// GetFilesEndpoint https://platform.openai.com/docs/api-reference/files/retrieve
|
||||
func GetFilesEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
file, err := getFileFromRequest(c)
|
||||
if err != nil {
|
||||
return c.Status(fiber.StatusInternalServerError).SendString(err.Error())
|
||||
}
|
||||
|
||||
return c.JSON(file)
|
||||
}
|
||||
}
|
||||
|
||||
// DeleteFilesEndpoint https://platform.openai.com/docs/api-reference/files/delete
|
||||
func DeleteFilesEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
type DeleteStatus struct {
|
||||
Id string
|
||||
Object string
|
||||
Deleted bool
|
||||
}
|
||||
|
||||
return func(c *fiber.Ctx) error {
|
||||
file, err := getFileFromRequest(c)
|
||||
if err != nil {
|
||||
return c.Status(fiber.StatusInternalServerError).SendString(err.Error())
|
||||
}
|
||||
|
||||
err = os.Remove(filepath.Join(o.UploadDir, file.Filename))
|
||||
if err != nil {
|
||||
// If the file doesn't exist then we should just continue to remove it
|
||||
if !errors.Is(err, os.ErrNotExist) {
|
||||
return c.Status(fiber.StatusInternalServerError).SendString(fmt.Sprintf("Unable to delete file: %s, %v", file.Filename, err))
|
||||
}
|
||||
}
|
||||
|
||||
// Remove upload from list
|
||||
for i, f := range uploadedFiles {
|
||||
if f.ID == file.ID {
|
||||
uploadedFiles = append(uploadedFiles[:i], uploadedFiles[i+1:]...)
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
saveUploadConfig(o.UploadDir)
|
||||
return c.JSON(DeleteStatus{
|
||||
Id: file.ID,
|
||||
Object: "file",
|
||||
Deleted: true,
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
// GetFilesContentsEndpoint https://platform.openai.com/docs/api-reference/files/retrieve-contents
|
||||
func GetFilesContentsEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
file, err := getFileFromRequest(c)
|
||||
if err != nil {
|
||||
return c.Status(fiber.StatusInternalServerError).SendString(err.Error())
|
||||
}
|
||||
|
||||
fileContents, err := os.ReadFile(filepath.Join(o.UploadDir, file.Filename))
|
||||
if err != nil {
|
||||
return c.Status(fiber.StatusInternalServerError).SendString(err.Error())
|
||||
}
|
||||
|
||||
return c.Send(fileContents)
|
||||
}
|
||||
}
|
||||
287
api/openai/files_test.go
Normal file
287
api/openai/files_test.go
Normal file
@@ -0,0 +1,287 @@
|
||||
package openai
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"io"
|
||||
"mime/multipart"
|
||||
"net/http"
|
||||
"net/http/httptest"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
utils2 "github.com/go-skynet/LocalAI/pkg/utils"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/stretchr/testify/assert"
|
||||
|
||||
"testing"
|
||||
)
|
||||
|
||||
type ListFiles struct {
|
||||
Data []File
|
||||
Object string
|
||||
}
|
||||
|
||||
func startUpApp() (app *fiber.App, option *options.Option, loader *config.ConfigLoader) {
|
||||
// Preparing the mocked objects
|
||||
loader = &config.ConfigLoader{}
|
||||
|
||||
option = &options.Option{
|
||||
UploadLimitMB: 10,
|
||||
UploadDir: "test_dir",
|
||||
}
|
||||
|
||||
_ = os.RemoveAll(option.UploadDir)
|
||||
|
||||
app = fiber.New(fiber.Config{
|
||||
BodyLimit: 20 * 1024 * 1024, // sets the limit to 20MB.
|
||||
})
|
||||
|
||||
// Create a Test Server
|
||||
app.Post("/files", UploadFilesEndpoint(loader, option))
|
||||
app.Get("/files", ListFilesEndpoint(loader, option))
|
||||
app.Get("/files/:file_id", GetFilesEndpoint(loader, option))
|
||||
app.Delete("/files/:file_id", DeleteFilesEndpoint(loader, option))
|
||||
app.Get("/files/:file_id/content", GetFilesContentsEndpoint(loader, option))
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
func TestUploadFileExceedSizeLimit(t *testing.T) {
|
||||
// Preparing the mocked objects
|
||||
loader := &config.ConfigLoader{}
|
||||
|
||||
option := &options.Option{
|
||||
UploadLimitMB: 10,
|
||||
UploadDir: "test_dir",
|
||||
}
|
||||
|
||||
_ = os.RemoveAll(option.UploadDir)
|
||||
|
||||
app := fiber.New(fiber.Config{
|
||||
BodyLimit: 20 * 1024 * 1024, // sets the limit to 20MB.
|
||||
})
|
||||
|
||||
// Create a Test Server
|
||||
app.Post("/files", UploadFilesEndpoint(loader, option))
|
||||
app.Get("/files", ListFilesEndpoint(loader, option))
|
||||
app.Get("/files/:file_id", GetFilesEndpoint(loader, option))
|
||||
app.Delete("/files/:file_id", DeleteFilesEndpoint(loader, option))
|
||||
app.Get("/files/:file_id/content", GetFilesContentsEndpoint(loader, option))
|
||||
|
||||
t.Run("UploadFilesEndpoint file size exceeds limit", func(t *testing.T) {
|
||||
resp, err := CallFilesUploadEndpoint(t, app, "foo.txt", "file", "fine-tune", 11, option)
|
||||
assert.NoError(t, err)
|
||||
|
||||
assert.Equal(t, fiber.StatusBadRequest, resp.StatusCode)
|
||||
assert.Contains(t, bodyToString(resp, t), "exceeds upload limit")
|
||||
})
|
||||
t.Run("UploadFilesEndpoint purpose not defined", func(t *testing.T) {
|
||||
resp, _ := CallFilesUploadEndpoint(t, app, "foo.txt", "file", "", 5, option)
|
||||
|
||||
assert.Equal(t, fiber.StatusBadRequest, resp.StatusCode)
|
||||
assert.Contains(t, bodyToString(resp, t), "Purpose is not defined")
|
||||
})
|
||||
t.Run("UploadFilesEndpoint file already exists", func(t *testing.T) {
|
||||
f1 := CallFilesUploadEndpointWithCleanup(t, app, "foo.txt", "file", "fine-tune", 5, option)
|
||||
|
||||
resp, err := CallFilesUploadEndpoint(t, app, "foo.txt", "file", "fine-tune", 5, option)
|
||||
fmt.Println(f1)
|
||||
fmt.Printf("ERror: %v", err)
|
||||
|
||||
assert.Equal(t, fiber.StatusBadRequest, resp.StatusCode)
|
||||
assert.Contains(t, bodyToString(resp, t), "File already exists")
|
||||
})
|
||||
t.Run("UploadFilesEndpoint file uploaded successfully", func(t *testing.T) {
|
||||
file := CallFilesUploadEndpointWithCleanup(t, app, "test.txt", "file", "fine-tune", 5, option)
|
||||
|
||||
// Check if file exists in the disk
|
||||
filePath := filepath.Join(option.UploadDir, utils2.SanitizeFileName("test.txt"))
|
||||
_, err := os.Stat(filePath)
|
||||
|
||||
assert.False(t, os.IsNotExist(err))
|
||||
assert.Equal(t, file.Bytes, 5242880)
|
||||
assert.NotEmpty(t, file.CreatedAt)
|
||||
assert.Equal(t, file.Filename, "test.txt")
|
||||
assert.Equal(t, file.Purpose, "fine-tune")
|
||||
})
|
||||
t.Run("ListFilesEndpoint without purpose parameter", func(t *testing.T) {
|
||||
resp, err := CallListFilesEndpoint(t, app, "")
|
||||
assert.NoError(t, err)
|
||||
|
||||
assert.Equal(t, 200, resp.StatusCode)
|
||||
|
||||
listFiles := responseToListFile(t, resp)
|
||||
if len(listFiles.Data) != len(uploadedFiles) {
|
||||
t.Errorf("Expected %v files, got %v files", len(uploadedFiles), len(listFiles.Data))
|
||||
}
|
||||
})
|
||||
t.Run("ListFilesEndpoint with valid purpose parameter", func(t *testing.T) {
|
||||
_ = CallFilesUploadEndpointWithCleanup(t, app, "test.txt", "file", "fine-tune", 5, option)
|
||||
|
||||
resp, err := CallListFilesEndpoint(t, app, "fine-tune")
|
||||
assert.NoError(t, err)
|
||||
|
||||
listFiles := responseToListFile(t, resp)
|
||||
if len(listFiles.Data) != 1 {
|
||||
t.Errorf("Expected 1 file, got %v files", len(listFiles.Data))
|
||||
}
|
||||
})
|
||||
t.Run("ListFilesEndpoint with invalid query parameter", func(t *testing.T) {
|
||||
resp, err := CallListFilesEndpoint(t, app, "not-so-fine-tune")
|
||||
assert.NoError(t, err)
|
||||
assert.Equal(t, 200, resp.StatusCode)
|
||||
|
||||
listFiles := responseToListFile(t, resp)
|
||||
|
||||
if len(listFiles.Data) != 0 {
|
||||
t.Errorf("Expected 0 file, got %v files", len(listFiles.Data))
|
||||
}
|
||||
})
|
||||
t.Run("GetFilesContentsEndpoint get file content", func(t *testing.T) {
|
||||
req := httptest.NewRequest("GET", "/files", nil)
|
||||
resp, _ := app.Test(req)
|
||||
assert.Equal(t, 200, resp.StatusCode)
|
||||
|
||||
var listFiles ListFiles
|
||||
if err := json.Unmarshal(bodyToByteArray(resp, t), &listFiles); err != nil {
|
||||
t.Errorf("Failed to decode response: %v", err)
|
||||
return
|
||||
}
|
||||
|
||||
if len(listFiles.Data) != 0 {
|
||||
t.Errorf("Expected 0 file, got %v files", len(listFiles.Data))
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
func CallListFilesEndpoint(t *testing.T, app *fiber.App, purpose string) (*http.Response, error) {
|
||||
var target string
|
||||
if purpose != "" {
|
||||
target = fmt.Sprintf("/files?purpose=%s", purpose)
|
||||
} else {
|
||||
target = "/files"
|
||||
}
|
||||
req := httptest.NewRequest("GET", target, nil)
|
||||
return app.Test(req)
|
||||
}
|
||||
|
||||
func CallFilesContentEndpoint(t *testing.T, app *fiber.App, fileId string) (*http.Response, error) {
|
||||
request := httptest.NewRequest("GET", "/files?file_id="+fileId, nil)
|
||||
return app.Test(request)
|
||||
}
|
||||
|
||||
func CallFilesUploadEndpoint(t *testing.T, app *fiber.App, fileName, tag, purpose string, fileSize int, o *options.Option) (*http.Response, error) {
|
||||
// Create a file that exceeds the limit
|
||||
file := createTestFile(t, fileName, fileSize, o)
|
||||
|
||||
// Creating a new HTTP Request
|
||||
body, writer := newMultipartFile(file.Name(), tag, purpose)
|
||||
|
||||
req := httptest.NewRequest(http.MethodPost, "/files", body)
|
||||
req.Header.Set(fiber.HeaderContentType, writer.FormDataContentType())
|
||||
return app.Test(req)
|
||||
}
|
||||
|
||||
func CallFilesUploadEndpointWithCleanup(t *testing.T, app *fiber.App, fileName, tag, purpose string, fileSize int, o *options.Option) File {
|
||||
// Create a file that exceeds the limit
|
||||
file := createTestFile(t, fileName, fileSize, o)
|
||||
|
||||
// Creating a new HTTP Request
|
||||
body, writer := newMultipartFile(file.Name(), tag, purpose)
|
||||
|
||||
req := httptest.NewRequest(http.MethodPost, "/files", body)
|
||||
req.Header.Set(fiber.HeaderContentType, writer.FormDataContentType())
|
||||
resp, err := app.Test(req)
|
||||
assert.NoError(t, err)
|
||||
f := responseToFile(t, resp)
|
||||
|
||||
id := f.ID
|
||||
t.Cleanup(func() {
|
||||
_, err := CallFilesDeleteEndpoint(t, app, id)
|
||||
assert.NoError(t, err)
|
||||
})
|
||||
|
||||
return f
|
||||
|
||||
}
|
||||
|
||||
func CallFilesDeleteEndpoint(t *testing.T, app *fiber.App, fileId string) (*http.Response, error) {
|
||||
target := fmt.Sprintf("/files/%s", fileId)
|
||||
req := httptest.NewRequest(http.MethodDelete, target, nil)
|
||||
return app.Test(req)
|
||||
}
|
||||
|
||||
// Helper to create multi-part file
|
||||
func newMultipartFile(filePath, tag, purpose string) (*strings.Reader, *multipart.Writer) {
|
||||
body := new(strings.Builder)
|
||||
writer := multipart.NewWriter(body)
|
||||
file, _ := os.Open(filePath)
|
||||
defer file.Close()
|
||||
part, _ := writer.CreateFormFile(tag, filepath.Base(filePath))
|
||||
io.Copy(part, file)
|
||||
|
||||
if purpose != "" {
|
||||
_ = writer.WriteField("purpose", purpose)
|
||||
}
|
||||
|
||||
writer.Close()
|
||||
return strings.NewReader(body.String()), writer
|
||||
}
|
||||
|
||||
// Helper to create test files
|
||||
func createTestFile(t *testing.T, name string, sizeMB int, option *options.Option) *os.File {
|
||||
err := os.MkdirAll(option.UploadDir, 0755)
|
||||
if err != nil {
|
||||
|
||||
t.Fatalf("Error MKDIR: %v", err)
|
||||
}
|
||||
|
||||
file, _ := os.Create(name)
|
||||
file.WriteString(strings.Repeat("a", sizeMB*1024*1024)) // sizeMB MB File
|
||||
|
||||
t.Cleanup(func() {
|
||||
os.Remove(name)
|
||||
os.RemoveAll(option.UploadDir)
|
||||
})
|
||||
return file
|
||||
}
|
||||
|
||||
func bodyToString(resp *http.Response, t *testing.T) string {
|
||||
return string(bodyToByteArray(resp, t))
|
||||
}
|
||||
|
||||
func bodyToByteArray(resp *http.Response, t *testing.T) []byte {
|
||||
bodyBytes, err := io.ReadAll(resp.Body)
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
return bodyBytes
|
||||
}
|
||||
|
||||
func responseToFile(t *testing.T, resp *http.Response) File {
|
||||
var file File
|
||||
responseToString := bodyToString(resp, t)
|
||||
|
||||
err := json.NewDecoder(strings.NewReader(responseToString)).Decode(&file)
|
||||
if err != nil {
|
||||
t.Errorf("Failed to decode response: %s", err)
|
||||
}
|
||||
|
||||
return file
|
||||
}
|
||||
|
||||
func responseToListFile(t *testing.T, resp *http.Response) ListFiles {
|
||||
var listFiles ListFiles
|
||||
responseToString := bodyToString(resp, t)
|
||||
|
||||
err := json.NewDecoder(strings.NewReader(responseToString)).Decode(&listFiles)
|
||||
if err != nil {
|
||||
fmt.Printf("Failed to decode response: %s", err)
|
||||
}
|
||||
|
||||
return listFiles
|
||||
}
|
||||
@@ -13,12 +13,12 @@ import (
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
"github.com/google/uuid"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
@@ -61,7 +61,7 @@ func downloadFile(url string) (string, error) {
|
||||
*/
|
||||
func ImageEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
m, input, err := readInput(c, o, false)
|
||||
m, input, err := readRequest(c, o, false)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
@@ -71,7 +71,7 @@ func ImageEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx
|
||||
}
|
||||
log.Debug().Msgf("Loading model: %+v", m)
|
||||
|
||||
config, input, err := readConfig(m, input, cm, o.Loader, o.Debug, 0, 0, false)
|
||||
config, input, err := mergeRequestWithConfig(m, input, cm, o.Loader, o.Debug, 0, 0, false)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
package openai
|
||||
|
||||
import (
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
)
|
||||
|
||||
|
||||
@@ -3,8 +3,8 @@ package openai
|
||||
import (
|
||||
"regexp"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
)
|
||||
|
||||
@@ -7,20 +7,19 @@ import (
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"net/http"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
options "github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
fiberContext "github.com/go-skynet/LocalAI/api/ctx"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
options "github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
"github.com/go-skynet/LocalAI/pkg/grammar"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
)
|
||||
|
||||
func readInput(c *fiber.Ctx, o *options.Option, randomModel bool) (string, *schema.OpenAIRequest, error) {
|
||||
loader := o.Loader
|
||||
func readRequest(c *fiber.Ctx, o *options.Option, firstModel bool) (string, *schema.OpenAIRequest, error) {
|
||||
input := new(schema.OpenAIRequest)
|
||||
ctx, cancel := context.WithCancel(o.Context)
|
||||
input.Context = ctx
|
||||
@@ -30,38 +29,13 @@ func readInput(c *fiber.Ctx, o *options.Option, randomModel bool) (string, *sche
|
||||
return "", nil, fmt.Errorf("failed parsing request body: %w", err)
|
||||
}
|
||||
|
||||
modelFile := input.Model
|
||||
|
||||
if c.Params("model") != "" {
|
||||
modelFile = c.Params("model")
|
||||
}
|
||||
|
||||
received, _ := json.Marshal(input)
|
||||
|
||||
log.Debug().Msgf("Request received: %s", string(received))
|
||||
|
||||
// Set model from bearer token, if available
|
||||
bearer := strings.TrimLeft(c.Get("authorization"), "Bearer ")
|
||||
bearerExists := bearer != "" && loader.ExistsInModelPath(bearer)
|
||||
modelFile, err := fiberContext.ModelFromContext(c, o.Loader, input.Model, firstModel)
|
||||
|
||||
// If no model was specified, take the first available
|
||||
if modelFile == "" && !bearerExists && randomModel {
|
||||
models, _ := loader.ListModels()
|
||||
if len(models) > 0 {
|
||||
modelFile = models[0]
|
||||
log.Debug().Msgf("No model specified, using: %s", modelFile)
|
||||
} else {
|
||||
log.Debug().Msgf("No model specified, returning error")
|
||||
return "", nil, fmt.Errorf("no model specified")
|
||||
}
|
||||
}
|
||||
|
||||
// If a model is found in bearer token takes precedence
|
||||
if bearerExists {
|
||||
log.Debug().Msgf("Using model from bearer token: %s", bearer)
|
||||
modelFile = bearer
|
||||
}
|
||||
return modelFile, input, nil
|
||||
return modelFile, input, err
|
||||
}
|
||||
|
||||
// this function check if the string is an URL, if it's an URL downloads the image in memory
|
||||
@@ -95,7 +69,7 @@ func getBase64Image(s string) (string, error) {
|
||||
return "", fmt.Errorf("not valid string")
|
||||
}
|
||||
|
||||
func updateConfig(config *config.Config, input *schema.OpenAIRequest) {
|
||||
func updateRequestConfig(config *config.Config, input *schema.OpenAIRequest) {
|
||||
if input.Echo {
|
||||
config.Echo = input.Echo
|
||||
}
|
||||
@@ -163,6 +137,20 @@ func updateConfig(config *config.Config, input *schema.OpenAIRequest) {
|
||||
}
|
||||
}
|
||||
|
||||
if len(input.Tools) > 0 {
|
||||
for _, tool := range input.Tools {
|
||||
input.Functions = append(input.Functions, tool.Function)
|
||||
}
|
||||
}
|
||||
|
||||
if input.ToolsChoice != nil {
|
||||
var toolChoice grammar.Tool
|
||||
json.Unmarshal([]byte(input.ToolsChoice.(string)), &toolChoice)
|
||||
input.FunctionCall = map[string]interface{}{
|
||||
"name": toolChoice.Function.Name,
|
||||
}
|
||||
}
|
||||
|
||||
// Decode each request's message content
|
||||
index := 0
|
||||
for i, m := range input.Messages {
|
||||
@@ -282,55 +270,11 @@ func updateConfig(config *config.Config, input *schema.OpenAIRequest) {
|
||||
}
|
||||
}
|
||||
|
||||
func readConfig(modelFile string, input *schema.OpenAIRequest, cm *config.ConfigLoader, loader *model.ModelLoader, debug bool, threads, ctx int, f16 bool) (*config.Config, *schema.OpenAIRequest, error) {
|
||||
// Load a config file if present after the model name
|
||||
modelConfig := filepath.Join(loader.ModelPath, modelFile+".yaml")
|
||||
|
||||
var cfg *config.Config
|
||||
|
||||
defaults := func() {
|
||||
cfg = config.DefaultConfig(modelFile)
|
||||
cfg.ContextSize = ctx
|
||||
cfg.Threads = threads
|
||||
cfg.F16 = f16
|
||||
cfg.Debug = debug
|
||||
}
|
||||
|
||||
cfgExisting, exists := cm.GetConfig(modelFile)
|
||||
if !exists {
|
||||
if _, err := os.Stat(modelConfig); err == nil {
|
||||
if err := cm.LoadConfig(modelConfig); err != nil {
|
||||
return nil, nil, fmt.Errorf("failed loading model config (%s) %s", modelConfig, err.Error())
|
||||
}
|
||||
cfgExisting, exists = cm.GetConfig(modelFile)
|
||||
if exists {
|
||||
cfg = &cfgExisting
|
||||
} else {
|
||||
defaults()
|
||||
}
|
||||
} else {
|
||||
defaults()
|
||||
}
|
||||
} else {
|
||||
cfg = &cfgExisting
|
||||
}
|
||||
func mergeRequestWithConfig(modelFile string, input *schema.OpenAIRequest, cm *config.ConfigLoader, loader *model.ModelLoader, debug bool, threads, ctx int, f16 bool) (*config.Config, *schema.OpenAIRequest, error) {
|
||||
cfg, err := config.Load(modelFile, loader.ModelPath, cm, debug, threads, ctx, f16)
|
||||
|
||||
// Set the parameters for the language model prediction
|
||||
updateConfig(cfg, input)
|
||||
updateRequestConfig(cfg, input)
|
||||
|
||||
// Don't allow 0 as setting
|
||||
if cfg.Threads == 0 {
|
||||
if threads != 0 {
|
||||
cfg.Threads = threads
|
||||
} else {
|
||||
cfg.Threads = 4
|
||||
}
|
||||
}
|
||||
|
||||
// Enforce debug flag if passed from CLI
|
||||
if debug {
|
||||
cfg.Debug = true
|
||||
}
|
||||
|
||||
return cfg, input, nil
|
||||
return cfg, input, err
|
||||
}
|
||||
|
||||
@@ -8,9 +8,9 @@ import (
|
||||
"path"
|
||||
"path/filepath"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
|
||||
"github.com/gofiber/fiber/v2"
|
||||
"github.com/rs/zerolog/log"
|
||||
@@ -19,12 +19,12 @@ import (
|
||||
// https://platform.openai.com/docs/api-reference/audio/create
|
||||
func TranscriptEndpoint(cm *config.ConfigLoader, o *options.Option) func(c *fiber.Ctx) error {
|
||||
return func(c *fiber.Ctx) error {
|
||||
m, input, err := readInput(c, o, false)
|
||||
m, input, err := readRequest(c, o, false)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
config, input, err := readConfig(m, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
config, input, err := mergeRequestWithConfig(m, input, cm, o.Loader, o.Debug, o.Threads, o.ContextSize, o.F16)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed reading parameters from request:%w", err)
|
||||
}
|
||||
|
||||
@@ -2,16 +2,20 @@
|
||||
## XXX: In some versions of CMake clip wasn't being built before llama.
|
||||
## This is an hack for now, but it should be fixed in the future.
|
||||
set(TARGET myclip)
|
||||
add_library(${TARGET} clip.cpp clip.h)
|
||||
add_library(${TARGET} clip.cpp clip.h llava.cpp llava.h)
|
||||
install(TARGETS ${TARGET} LIBRARY)
|
||||
target_link_libraries(${TARGET} PRIVATE common ggml ${CMAKE_THREAD_LIBS_INIT})
|
||||
target_include_directories(myclip PUBLIC .)
|
||||
target_include_directories(myclip PUBLIC ../..)
|
||||
target_include_directories(myclip PUBLIC ../../common)
|
||||
target_link_libraries(${TARGET} PRIVATE common ggml llama ${CMAKE_THREAD_LIBS_INIT})
|
||||
target_compile_features(${TARGET} PRIVATE cxx_std_11)
|
||||
if (NOT MSVC)
|
||||
target_compile_options(${TARGET} PRIVATE -Wno-cast-qual) # stb_image.h
|
||||
endif()
|
||||
# END CLIP hack
|
||||
|
||||
|
||||
set(TARGET grpc-server)
|
||||
# END CLIP hack
|
||||
set(CMAKE_CXX_STANDARD 17)
|
||||
cmake_minimum_required(VERSION 3.15)
|
||||
set(TARGET grpc-server)
|
||||
@@ -70,7 +74,7 @@ add_library(hw_grpc_proto
|
||||
${hw_proto_srcs}
|
||||
${hw_proto_hdrs} )
|
||||
|
||||
add_executable(${TARGET} grpc-server.cpp json.hpp )
|
||||
add_executable(${TARGET} grpc-server.cpp utils.hpp json.hpp)
|
||||
target_link_libraries(${TARGET} PRIVATE common llama myclip ${CMAKE_THREAD_LIBS_INIT} absl::flags hw_grpc_proto
|
||||
absl::flags_parse
|
||||
gRPC::${_REFLECTION}
|
||||
|
||||
@@ -3,6 +3,7 @@ LLAMA_VERSION?=
|
||||
|
||||
CMAKE_ARGS?=
|
||||
BUILD_TYPE?=
|
||||
ONEAPI_VARS?=/opt/intel/oneapi/setvars.sh
|
||||
|
||||
# If build type is cublas, then we set -DLLAMA_CUBLAS=ON to CMAKE_ARGS automatically
|
||||
ifeq ($(BUILD_TYPE),cublas)
|
||||
@@ -19,6 +20,14 @@ else ifeq ($(BUILD_TYPE),hipblas)
|
||||
CMAKE_ARGS+=-DLLAMA_HIPBLAS=ON
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),sycl_f16)
|
||||
CMAKE_ARGS+=-DLLAMA_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx -DLLAMA_SYCL_F16=ON
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),sycl_f32)
|
||||
CMAKE_ARGS+=-DLLAMA_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx
|
||||
endif
|
||||
|
||||
llama.cpp:
|
||||
git clone --recurse-submodules https://github.com/ggerganov/llama.cpp llama.cpp
|
||||
if [ -z "$(LLAMA_VERSION)" ]; then \
|
||||
@@ -31,10 +40,14 @@ llama.cpp/examples/grpc-server:
|
||||
cp -r $(abspath ./)/CMakeLists.txt llama.cpp/examples/grpc-server/
|
||||
cp -r $(abspath ./)/grpc-server.cpp llama.cpp/examples/grpc-server/
|
||||
cp -rfv $(abspath ./)/json.hpp llama.cpp/examples/grpc-server/
|
||||
cp -rfv $(abspath ./)/utils.hpp llama.cpp/examples/grpc-server/
|
||||
echo "add_subdirectory(grpc-server)" >> llama.cpp/examples/CMakeLists.txt
|
||||
## XXX: In some versions of CMake clip wasn't being built before llama.
|
||||
## This is an hack for now, but it should be fixed in the future.
|
||||
cp -rfv llama.cpp/examples/llava/clip.h llama.cpp/examples/grpc-server/clip.h
|
||||
cp -rfv llama.cpp/examples/llava/llava.cpp llama.cpp/examples/grpc-server/llava.cpp
|
||||
echo '#include "llama.h"' > llama.cpp/examples/grpc-server/llava.h
|
||||
cat llama.cpp/examples/llava/llava.h >> llama.cpp/examples/grpc-server/llava.h
|
||||
cp -rfv llama.cpp/examples/llava/clip.cpp llama.cpp/examples/grpc-server/clip.cpp
|
||||
|
||||
rebuild:
|
||||
@@ -49,5 +62,10 @@ clean:
|
||||
rm -rf grpc-server
|
||||
|
||||
grpc-server: llama.cpp llama.cpp/examples/grpc-server
|
||||
ifneq (,$(findstring sycl,$(BUILD_TYPE)))
|
||||
bash -c "source $(ONEAPI_VARS); \
|
||||
cd llama.cpp && mkdir -p build && cd build && cmake .. $(CMAKE_ARGS) && cmake --build . --config Release"
|
||||
else
|
||||
cd llama.cpp && mkdir -p build && cd build && cmake .. $(CMAKE_ARGS) && cmake --build . --config Release
|
||||
endif
|
||||
cp llama.cpp/build/bin/grpc-server .
|
||||
File diff suppressed because it is too large
Load Diff
510
backend/cpp/llama/utils.hpp
Normal file
510
backend/cpp/llama/utils.hpp
Normal file
@@ -0,0 +1,510 @@
|
||||
// https://github.com/ggerganov/llama.cpp/blob/master/examples/server/utils.hpp
|
||||
|
||||
#pragma once
|
||||
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <set>
|
||||
#include <mutex>
|
||||
#include <condition_variable>
|
||||
#include <unordered_map>
|
||||
|
||||
#include "json.hpp"
|
||||
|
||||
#include "../llava/clip.h"
|
||||
|
||||
using json = nlohmann::json;
|
||||
|
||||
extern bool server_verbose;
|
||||
|
||||
#ifndef SERVER_VERBOSE
|
||||
#define SERVER_VERBOSE 1
|
||||
#endif
|
||||
|
||||
#if SERVER_VERBOSE != 1
|
||||
#define LOG_VERBOSE(MSG, ...)
|
||||
#else
|
||||
#define LOG_VERBOSE(MSG, ...) \
|
||||
do \
|
||||
{ \
|
||||
if (server_verbose) \
|
||||
{ \
|
||||
server_log("VERBOSE", __func__, __LINE__, MSG, __VA_ARGS__); \
|
||||
} \
|
||||
} while (0)
|
||||
#endif
|
||||
|
||||
#define LOG_ERROR( MSG, ...) server_log("ERROR", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
#define LOG_WARNING(MSG, ...) server_log("WARNING", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
#define LOG_INFO( MSG, ...) server_log("INFO", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
|
||||
//
|
||||
// parallel
|
||||
//
|
||||
|
||||
enum server_state {
|
||||
SERVER_STATE_LOADING_MODEL, // Server is starting up, model not fully loaded yet
|
||||
SERVER_STATE_READY, // Server is ready and model is loaded
|
||||
SERVER_STATE_ERROR // An error occurred, load_model failed
|
||||
};
|
||||
|
||||
enum task_type {
|
||||
TASK_TYPE_COMPLETION,
|
||||
TASK_TYPE_CANCEL,
|
||||
TASK_TYPE_NEXT_RESPONSE
|
||||
};
|
||||
|
||||
struct task_server {
|
||||
int id = -1; // to be filled by llama_server_queue
|
||||
int target_id;
|
||||
task_type type;
|
||||
json data;
|
||||
bool infill_mode = false;
|
||||
bool embedding_mode = false;
|
||||
int multitask_id = -1;
|
||||
};
|
||||
|
||||
struct task_result {
|
||||
int id;
|
||||
int multitask_id = -1;
|
||||
bool stop;
|
||||
bool error;
|
||||
json result_json;
|
||||
};
|
||||
|
||||
struct task_multi {
|
||||
int id;
|
||||
std::set<int> subtasks_remaining{};
|
||||
std::vector<task_result> results{};
|
||||
};
|
||||
|
||||
// TODO: can become bool if we can't find use of more states
|
||||
enum slot_state
|
||||
{
|
||||
IDLE,
|
||||
PROCESSING,
|
||||
};
|
||||
|
||||
enum slot_command
|
||||
{
|
||||
NONE,
|
||||
LOAD_PROMPT,
|
||||
RELEASE,
|
||||
};
|
||||
|
||||
struct slot_params
|
||||
{
|
||||
bool stream = true;
|
||||
bool cache_prompt = false; // remember the prompt to avoid reprocessing all prompt
|
||||
|
||||
uint32_t seed = -1; // RNG seed
|
||||
int32_t n_keep = 0; // number of tokens to keep from initial prompt
|
||||
int32_t n_predict = -1; // new tokens to predict
|
||||
|
||||
std::vector<std::string> antiprompt;
|
||||
|
||||
json input_prefix;
|
||||
json input_suffix;
|
||||
};
|
||||
|
||||
struct slot_image
|
||||
{
|
||||
int32_t id;
|
||||
|
||||
bool request_encode_image = false;
|
||||
float * image_embedding = nullptr;
|
||||
int32_t image_tokens = 0;
|
||||
|
||||
clip_image_u8 * img_data;
|
||||
|
||||
std::string prefix_prompt; // before of this image
|
||||
};
|
||||
|
||||
// completion token output with probabilities
|
||||
struct completion_token_output
|
||||
{
|
||||
struct token_prob
|
||||
{
|
||||
llama_token tok;
|
||||
float prob;
|
||||
};
|
||||
|
||||
std::vector<token_prob> probs;
|
||||
llama_token tok;
|
||||
std::string text_to_send;
|
||||
};
|
||||
|
||||
static inline void server_log(const char *level, const char *function, int line,
|
||||
const char *message, const nlohmann::ordered_json &extra)
|
||||
{
|
||||
nlohmann::ordered_json log
|
||||
{
|
||||
{"timestamp", time(nullptr)},
|
||||
{"level", level},
|
||||
{"function", function},
|
||||
{"line", line},
|
||||
{"message", message},
|
||||
};
|
||||
|
||||
if (!extra.empty())
|
||||
{
|
||||
log.merge_patch(extra);
|
||||
}
|
||||
|
||||
const std::string str = log.dump(-1, ' ', false, json::error_handler_t::replace);
|
||||
printf("%.*s\n", (int)str.size(), str.data());
|
||||
fflush(stdout);
|
||||
}
|
||||
|
||||
//
|
||||
// server utils
|
||||
//
|
||||
|
||||
template <typename T>
|
||||
static T json_value(const json &body, const std::string &key, const T &default_value)
|
||||
{
|
||||
// Fallback null to default value
|
||||
return body.contains(key) && !body.at(key).is_null()
|
||||
? body.value(key, default_value)
|
||||
: default_value;
|
||||
}
|
||||
|
||||
inline std::string format_chatml(std::vector<json> messages)
|
||||
{
|
||||
std::ostringstream chatml_msgs;
|
||||
|
||||
for (auto it = messages.begin(); it != messages.end(); ++it) {
|
||||
chatml_msgs << "<|im_start|>"
|
||||
<< json_value(*it, "role", std::string("user")) << '\n';
|
||||
chatml_msgs << json_value(*it, "content", std::string(""))
|
||||
<< "<|im_end|>\n";
|
||||
}
|
||||
|
||||
chatml_msgs << "<|im_start|>assistant" << '\n';
|
||||
|
||||
return chatml_msgs.str();
|
||||
}
|
||||
|
||||
//
|
||||
// work queue utils
|
||||
//
|
||||
|
||||
struct llama_server_queue {
|
||||
int id = 0;
|
||||
std::mutex mutex_tasks;
|
||||
// queues
|
||||
std::vector<task_server> queue_tasks;
|
||||
std::vector<task_server> queue_tasks_deferred;
|
||||
std::vector<task_multi> queue_multitasks;
|
||||
std::condition_variable condition_tasks;
|
||||
// callback functions
|
||||
std::function<void(task_server&)> callback_new_task;
|
||||
std::function<void(task_multi&)> callback_finish_multitask;
|
||||
std::function<void(void)> callback_all_task_finished;
|
||||
|
||||
// Add a new task to the end of the queue
|
||||
int post(task_server task) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (task.id == -1) {
|
||||
task.id = id++;
|
||||
}
|
||||
queue_tasks.push_back(std::move(task));
|
||||
condition_tasks.notify_one();
|
||||
return task.id;
|
||||
}
|
||||
|
||||
// Add a new task, but defer until one slot is available
|
||||
void defer(task_server task) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
queue_tasks_deferred.push_back(std::move(task));
|
||||
}
|
||||
|
||||
// Get the next id for creating anew task
|
||||
int get_new_id() {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
return id++;
|
||||
}
|
||||
|
||||
// Register function to process a new task
|
||||
void on_new_task(std::function<void(task_server&)> callback) {
|
||||
callback_new_task = callback;
|
||||
}
|
||||
|
||||
// Register function to process a multitask
|
||||
void on_finish_multitask(std::function<void(task_multi&)> callback) {
|
||||
callback_finish_multitask = callback;
|
||||
}
|
||||
|
||||
// Register the function to be called when the batch of tasks is finished
|
||||
void on_all_tasks_finished(std::function<void(void)> callback) {
|
||||
callback_all_task_finished = callback;
|
||||
}
|
||||
|
||||
// Call when the state of one slot is changed
|
||||
void notify_slot_changed() {
|
||||
// move deferred tasks back to main loop
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
for (auto & task : queue_tasks_deferred) {
|
||||
queue_tasks.push_back(std::move(task));
|
||||
}
|
||||
queue_tasks_deferred.clear();
|
||||
}
|
||||
|
||||
// Start the main loop. This call is blocking
|
||||
[[noreturn]]
|
||||
void start_loop() {
|
||||
while (true) {
|
||||
// new task arrived
|
||||
LOG_VERBOSE("have new task", {});
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (queue_tasks.empty()) {
|
||||
lock.unlock();
|
||||
break;
|
||||
}
|
||||
task_server task = queue_tasks.front();
|
||||
queue_tasks.erase(queue_tasks.begin());
|
||||
lock.unlock();
|
||||
LOG_VERBOSE("callback_new_task", {});
|
||||
callback_new_task(task);
|
||||
}
|
||||
LOG_VERBOSE("callback_all_task_finished", {});
|
||||
// process and update all the multitasks
|
||||
auto queue_iterator = queue_multitasks.begin();
|
||||
while (queue_iterator != queue_multitasks.end())
|
||||
{
|
||||
if (queue_iterator->subtasks_remaining.empty())
|
||||
{
|
||||
// all subtasks done == multitask is done
|
||||
task_multi current_multitask = *queue_iterator;
|
||||
callback_finish_multitask(current_multitask);
|
||||
// remove this multitask
|
||||
queue_iterator = queue_multitasks.erase(queue_iterator);
|
||||
}
|
||||
else
|
||||
{
|
||||
++queue_iterator;
|
||||
}
|
||||
}
|
||||
// all tasks in the current loop is finished
|
||||
callback_all_task_finished();
|
||||
}
|
||||
LOG_VERBOSE("wait for new task", {});
|
||||
// wait for new task
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (queue_tasks.empty()) {
|
||||
condition_tasks.wait(lock, [&]{
|
||||
return !queue_tasks.empty();
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
//
|
||||
// functions to manage multitasks
|
||||
//
|
||||
|
||||
// add a multitask by specifying the id of all subtask (subtask is a task_server)
|
||||
void add_multitask(int multitask_id, std::vector<int>& sub_ids)
|
||||
{
|
||||
std::lock_guard<std::mutex> lock(mutex_tasks);
|
||||
task_multi multi;
|
||||
multi.id = multitask_id;
|
||||
std::copy(sub_ids.begin(), sub_ids.end(), std::inserter(multi.subtasks_remaining, multi.subtasks_remaining.end()));
|
||||
queue_multitasks.push_back(multi);
|
||||
}
|
||||
|
||||
// updatethe remaining subtasks, while appending results to multitask
|
||||
void update_multitask(int multitask_id, int subtask_id, task_result& result)
|
||||
{
|
||||
std::lock_guard<std::mutex> lock(mutex_tasks);
|
||||
for (auto& multitask : queue_multitasks)
|
||||
{
|
||||
if (multitask.id == multitask_id)
|
||||
{
|
||||
multitask.subtasks_remaining.erase(subtask_id);
|
||||
multitask.results.push_back(result);
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct llama_server_response {
|
||||
typedef std::function<void(int, int, task_result&)> callback_multitask_t;
|
||||
callback_multitask_t callback_update_multitask;
|
||||
// for keeping track of all tasks waiting for the result
|
||||
std::set<int> waiting_task_ids;
|
||||
// the main result queue
|
||||
std::vector<task_result> queue_results;
|
||||
std::mutex mutex_results;
|
||||
std::condition_variable condition_results;
|
||||
|
||||
void add_waiting_task_id(int task_id) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
waiting_task_ids.insert(task_id);
|
||||
}
|
||||
|
||||
void remove_waiting_task_id(int task_id) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
waiting_task_ids.erase(task_id);
|
||||
}
|
||||
|
||||
// This function blocks the thread until there is a response for this task_id
|
||||
task_result recv(int task_id) {
|
||||
while (true)
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
condition_results.wait(lock, [&]{
|
||||
return !queue_results.empty();
|
||||
});
|
||||
LOG_VERBOSE("condition_results unblock", {});
|
||||
|
||||
for (int i = 0; i < (int) queue_results.size(); i++)
|
||||
{
|
||||
if (queue_results[i].id == task_id)
|
||||
{
|
||||
assert(queue_results[i].multitask_id == -1);
|
||||
task_result res = queue_results[i];
|
||||
queue_results.erase(queue_results.begin() + i);
|
||||
return res;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// should never reach here
|
||||
}
|
||||
|
||||
// Register the function to update multitask
|
||||
void on_multitask_update(callback_multitask_t callback) {
|
||||
callback_update_multitask = callback;
|
||||
}
|
||||
|
||||
// Send a new result to a waiting task_id
|
||||
void send(task_result result) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
LOG_VERBOSE("send new result", {});
|
||||
for (auto& task_id : waiting_task_ids) {
|
||||
// LOG_TEE("waiting task id %i \n", task_id);
|
||||
// for now, tasks that have associated parent multitasks just get erased once multitask picks up the result
|
||||
if (result.multitask_id == task_id)
|
||||
{
|
||||
LOG_VERBOSE("callback_update_multitask", {});
|
||||
callback_update_multitask(task_id, result.id, result);
|
||||
continue;
|
||||
}
|
||||
|
||||
if (result.id == task_id)
|
||||
{
|
||||
LOG_VERBOSE("queue_results.push_back", {});
|
||||
queue_results.push_back(result);
|
||||
condition_results.notify_one();
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
//
|
||||
// base64 utils (TODO: move to common in the future)
|
||||
//
|
||||
|
||||
static const std::string base64_chars =
|
||||
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
|
||||
"abcdefghijklmnopqrstuvwxyz"
|
||||
"0123456789+/";
|
||||
|
||||
static inline bool is_base64(uint8_t c)
|
||||
{
|
||||
return (isalnum(c) || (c == '+') || (c == '/'));
|
||||
}
|
||||
|
||||
static inline std::vector<uint8_t> base64_decode(const std::string & encoded_string)
|
||||
{
|
||||
int i = 0;
|
||||
int j = 0;
|
||||
int in_ = 0;
|
||||
|
||||
int in_len = encoded_string.size();
|
||||
|
||||
uint8_t char_array_4[4];
|
||||
uint8_t char_array_3[3];
|
||||
|
||||
std::vector<uint8_t> ret;
|
||||
|
||||
while (in_len-- && (encoded_string[in_] != '=') && is_base64(encoded_string[in_]))
|
||||
{
|
||||
char_array_4[i++] = encoded_string[in_]; in_++;
|
||||
if (i == 4)
|
||||
{
|
||||
for (i = 0; i <4; i++)
|
||||
{
|
||||
char_array_4[i] = base64_chars.find(char_array_4[i]);
|
||||
}
|
||||
|
||||
char_array_3[0] = ((char_array_4[0] ) << 2) + ((char_array_4[1] & 0x30) >> 4);
|
||||
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
|
||||
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
|
||||
|
||||
for (i = 0; (i < 3); i++)
|
||||
{
|
||||
ret.push_back(char_array_3[i]);
|
||||
}
|
||||
i = 0;
|
||||
}
|
||||
}
|
||||
|
||||
if (i)
|
||||
{
|
||||
for (j = i; j <4; j++)
|
||||
{
|
||||
char_array_4[j] = 0;
|
||||
}
|
||||
|
||||
for (j = 0; j <4; j++)
|
||||
{
|
||||
char_array_4[j] = base64_chars.find(char_array_4[j]);
|
||||
}
|
||||
|
||||
char_array_3[0] = ((char_array_4[0] ) << 2) + ((char_array_4[1] & 0x30) >> 4);
|
||||
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
|
||||
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
|
||||
|
||||
for (j = 0; (j < i - 1); j++)
|
||||
{
|
||||
ret.push_back(char_array_3[j]);
|
||||
}
|
||||
}
|
||||
|
||||
return ret;
|
||||
}
|
||||
|
||||
//
|
||||
// random string / id
|
||||
//
|
||||
|
||||
static std::string random_string()
|
||||
{
|
||||
static const std::string str("0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz");
|
||||
|
||||
std::random_device rd;
|
||||
std::mt19937 generator(rd());
|
||||
|
||||
std::string result(32, ' ');
|
||||
|
||||
for (int i = 0; i < 32; ++i) {
|
||||
result[i] = str[generator() % str.size()];
|
||||
}
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
static std::string gen_chatcmplid()
|
||||
{
|
||||
std::stringstream chatcmplid;
|
||||
chatcmplid << "chatcmpl-" << random_string();
|
||||
return chatcmplid.str();
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.Dolly{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.Falcon{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.GPT2{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.GPTJ{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.GPTNeoX{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.MPT{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.Replit{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,23 +0,0 @@
|
||||
package main
|
||||
|
||||
// Note: this is started internally by LocalAI and a server is allocated for each model
|
||||
|
||||
import (
|
||||
"flag"
|
||||
|
||||
transformers "github.com/go-skynet/LocalAI/backend/go/llm/transformers"
|
||||
|
||||
grpc "github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
)
|
||||
|
||||
var (
|
||||
addr = flag.String("addr", "localhost:50051", "the address to connect to")
|
||||
)
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if err := grpc.StartServer(*addr, &transformers.Starcoder{}); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
@@ -1,44 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Dolly struct {
|
||||
base.SingleThread
|
||||
|
||||
dolly *transformers.Dolly
|
||||
}
|
||||
|
||||
func (llm *Dolly) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewDolly(opts.ModelFile)
|
||||
llm.dolly = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Dolly) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.dolly.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Dolly) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
|
||||
go func() {
|
||||
res, err := llm.dolly.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
|
||||
return nil
|
||||
}
|
||||
@@ -1,43 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Falcon struct {
|
||||
base.SingleThread
|
||||
|
||||
falcon *transformers.Falcon
|
||||
}
|
||||
|
||||
func (llm *Falcon) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewFalcon(opts.ModelFile)
|
||||
llm.falcon = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Falcon) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.falcon.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Falcon) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.falcon.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type GPT2 struct {
|
||||
base.SingleThread
|
||||
|
||||
gpt2 *transformers.GPT2
|
||||
}
|
||||
|
||||
func (llm *GPT2) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.New(opts.ModelFile)
|
||||
llm.gpt2 = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *GPT2) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.gpt2.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *GPT2) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.gpt2.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type GPTJ struct {
|
||||
base.SingleThread
|
||||
|
||||
gptj *transformers.GPTJ
|
||||
}
|
||||
|
||||
func (llm *GPTJ) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewGPTJ(opts.ModelFile)
|
||||
llm.gptj = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *GPTJ) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.gptj.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *GPTJ) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.gptj.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type GPTNeoX struct {
|
||||
base.SingleThread
|
||||
|
||||
gptneox *transformers.GPTNeoX
|
||||
}
|
||||
|
||||
func (llm *GPTNeoX) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewGPTNeoX(opts.ModelFile)
|
||||
llm.gptneox = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *GPTNeoX) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.gptneox.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *GPTNeoX) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.gptneox.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type MPT struct {
|
||||
base.SingleThread
|
||||
|
||||
mpt *transformers.MPT
|
||||
}
|
||||
|
||||
func (llm *MPT) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewMPT(opts.ModelFile)
|
||||
llm.mpt = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *MPT) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.mpt.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *MPT) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.mpt.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,26 +0,0 @@
|
||||
package transformers
|
||||
|
||||
import (
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
func buildPredictOptions(opts *pb.PredictOptions) []transformers.PredictOption {
|
||||
predictOptions := []transformers.PredictOption{
|
||||
transformers.SetTemperature(float64(opts.Temperature)),
|
||||
transformers.SetTopP(float64(opts.TopP)),
|
||||
transformers.SetTopK(int(opts.TopK)),
|
||||
transformers.SetTokens(int(opts.Tokens)),
|
||||
transformers.SetThreads(int(opts.Threads)),
|
||||
}
|
||||
|
||||
if opts.Batch != 0 {
|
||||
predictOptions = append(predictOptions, transformers.SetBatch(int(opts.Batch)))
|
||||
}
|
||||
|
||||
if opts.Seed != 0 {
|
||||
predictOptions = append(predictOptions, transformers.SetSeed(int(opts.Seed)))
|
||||
}
|
||||
|
||||
return predictOptions
|
||||
}
|
||||
@@ -1,42 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Replit struct {
|
||||
base.SingleThread
|
||||
|
||||
replit *transformers.Replit
|
||||
}
|
||||
|
||||
func (llm *Replit) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewReplit(opts.ModelFile)
|
||||
llm.replit = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Replit) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.replit.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Replit) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.replit.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
return nil
|
||||
}
|
||||
@@ -1,43 +0,0 @@
|
||||
package transformers
|
||||
|
||||
// This is a wrapper to statisfy the GRPC service interface
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
|
||||
transformers "github.com/go-skynet/go-ggml-transformers.cpp"
|
||||
)
|
||||
|
||||
type Starcoder struct {
|
||||
base.SingleThread
|
||||
|
||||
starcoder *transformers.Starcoder
|
||||
}
|
||||
|
||||
func (llm *Starcoder) Load(opts *pb.ModelOptions) error {
|
||||
model, err := transformers.NewStarcoder(opts.ModelFile)
|
||||
llm.starcoder = model
|
||||
return err
|
||||
}
|
||||
|
||||
func (llm *Starcoder) Predict(opts *pb.PredictOptions) (string, error) {
|
||||
return llm.starcoder.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
}
|
||||
|
||||
// fallback to Predict
|
||||
func (llm *Starcoder) PredictStream(opts *pb.PredictOptions, results chan string) error {
|
||||
go func() {
|
||||
res, err := llm.starcoder.Predict(opts.Prompt, buildPredictOptions(opts)...)
|
||||
|
||||
if err != nil {
|
||||
fmt.Println("err: ", err)
|
||||
}
|
||||
results <- res
|
||||
close(results)
|
||||
}()
|
||||
|
||||
return nil
|
||||
}
|
||||
@@ -8,7 +8,7 @@ import (
|
||||
|
||||
"github.com/ggerganov/whisper.cpp/bindings/go/pkg/whisper"
|
||||
"github.com/go-audio/wav"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
)
|
||||
|
||||
func sh(c string) (string, error) {
|
||||
|
||||
@@ -4,7 +4,7 @@ package main
|
||||
// It is meant to be used by the main executable that is the server for the specific backend type (falcon, gpt3, etc)
|
||||
import (
|
||||
"github.com/ggerganov/whisper.cpp/bindings/go/pkg/whisper"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/base"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
)
|
||||
|
||||
@@ -4,6 +4,10 @@ ifeq ($(BUILD_TYPE), cublas)
|
||||
CONDA_ENV_PATH = "transformers-nvidia.yml"
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE), hipblas)
|
||||
CONDA_ENV_PATH = "transformers-rocm.yml"
|
||||
endif
|
||||
|
||||
.PHONY: transformers
|
||||
transformers:
|
||||
@echo "Installing $(CONDA_ENV_PATH)..."
|
||||
|
||||
@@ -33,6 +33,7 @@ dependencies:
|
||||
- boto3==1.28.61
|
||||
- botocore==1.31.61
|
||||
- certifi==2023.7.22
|
||||
- TTS==0.22.0
|
||||
- charset-normalizer==3.3.0
|
||||
- datasets==2.14.5
|
||||
- sentence-transformers==2.2.2
|
||||
|
||||
109
backend/python/common-env/transformers/transformers-rocm.yml
Normal file
109
backend/python/common-env/transformers/transformers-rocm.yml
Normal file
@@ -0,0 +1,109 @@
|
||||
name: transformers
|
||||
channels:
|
||||
- defaults
|
||||
dependencies:
|
||||
- _libgcc_mutex=0.1=main
|
||||
- _openmp_mutex=5.1=1_gnu
|
||||
- bzip2=1.0.8=h7b6447c_0
|
||||
- ca-certificates=2023.08.22=h06a4308_0
|
||||
- ld_impl_linux-64=2.38=h1181459_1
|
||||
- libffi=3.4.4=h6a678d5_0
|
||||
- libgcc-ng=11.2.0=h1234567_1
|
||||
- libgomp=11.2.0=h1234567_1
|
||||
- libstdcxx-ng=11.2.0=h1234567_1
|
||||
- libuuid=1.41.5=h5eee18b_0
|
||||
- ncurses=6.4=h6a678d5_0
|
||||
- openssl=3.0.11=h7f8727e_2
|
||||
- pip=23.2.1=py311h06a4308_0
|
||||
- python=3.11.5=h955ad1f_0
|
||||
- readline=8.2=h5eee18b_0
|
||||
- setuptools=68.0.0=py311h06a4308_0
|
||||
- sqlite=3.41.2=h5eee18b_0
|
||||
- tk=8.6.12=h1ccaba5_0
|
||||
- wheel=0.41.2=py311h06a4308_0
|
||||
- xz=5.4.2=h5eee18b_0
|
||||
- zlib=1.2.13=h5eee18b_0
|
||||
- pip:
|
||||
- --pre
|
||||
- --extra-index-url https://download.pytorch.org/whl/nightly/
|
||||
- accelerate==0.23.0
|
||||
- aiohttp==3.8.5
|
||||
- aiosignal==1.3.1
|
||||
- async-timeout==4.0.3
|
||||
- attrs==23.1.0
|
||||
- bark==0.1.5
|
||||
- boto3==1.28.61
|
||||
- botocore==1.31.61
|
||||
- certifi==2023.7.22
|
||||
- TTS==0.22.0
|
||||
- charset-normalizer==3.3.0
|
||||
- datasets==2.14.5
|
||||
- sentence-transformers==2.2.2
|
||||
- sentencepiece==0.1.99
|
||||
- dill==0.3.7
|
||||
- einops==0.7.0
|
||||
- encodec==0.1.1
|
||||
- filelock==3.12.4
|
||||
- frozenlist==1.4.0
|
||||
- fsspec==2023.6.0
|
||||
- funcy==2.0
|
||||
- grpcio==1.59.0
|
||||
- huggingface-hub
|
||||
- idna==3.4
|
||||
- jinja2==3.1.2
|
||||
- jmespath==1.0.1
|
||||
- markupsafe==2.1.3
|
||||
- mpmath==1.3.0
|
||||
- multidict==6.0.4
|
||||
- multiprocess==0.70.15
|
||||
- networkx
|
||||
- numpy==1.26.0
|
||||
- packaging==23.2
|
||||
- pandas
|
||||
- peft==0.5.0
|
||||
- protobuf==4.24.4
|
||||
- psutil==5.9.5
|
||||
- pyarrow==13.0.0
|
||||
- python-dateutil==2.8.2
|
||||
- pytz==2023.3.post1
|
||||
- pyyaml==6.0.1
|
||||
- regex==2023.10.3
|
||||
- requests==2.31.0
|
||||
- rouge==1.0.1
|
||||
- s3transfer==0.7.0
|
||||
- safetensors==0.3.3
|
||||
- scipy==1.11.3
|
||||
- six==1.16.0
|
||||
- sympy==1.12
|
||||
- tokenizers
|
||||
- torch
|
||||
- torchaudio
|
||||
- tqdm==4.66.1
|
||||
- triton==2.1.0
|
||||
- typing-extensions==4.8.0
|
||||
- tzdata==2023.3
|
||||
- auto-gptq==0.6.0
|
||||
- urllib3==1.26.17
|
||||
- xxhash==3.4.1
|
||||
- yarl==1.9.2
|
||||
- soundfile
|
||||
- langid
|
||||
- wget
|
||||
- unidecode
|
||||
- pyopenjtalk-prebuilt
|
||||
- pypinyin
|
||||
- inflect
|
||||
- cn2an
|
||||
- jieba
|
||||
- eng_to_ipa
|
||||
- openai-whisper
|
||||
- matplotlib
|
||||
- gradio==3.41.2
|
||||
- nltk
|
||||
- sudachipy
|
||||
- sudachidict_core
|
||||
- vocos
|
||||
- vllm==0.2.7
|
||||
- transformers>=4.36.0 # Required for Mixtral.
|
||||
- xformers==0.0.23.post1
|
||||
prefix: /opt/conda/envs/transformers
|
||||
@@ -1,8 +1,13 @@
|
||||
export CONDA_ENV_PATH = "diffusers.yml"
|
||||
|
||||
ifeq ($(BUILD_TYPE), hipblas)
|
||||
export CONDA_ENV_PATH = "diffusers-rocm.yml"
|
||||
endif
|
||||
|
||||
.PHONY: diffusers
|
||||
diffusers:
|
||||
@echo "Creating virtual environment..."
|
||||
@conda env create --name diffusers --file diffusers.yml
|
||||
@echo "Virtual environment created."
|
||||
@echo "Installing $(CONDA_ENV_PATH)..."
|
||||
bash install.sh $(CONDA_ENV_PATH)
|
||||
|
||||
.PHONY: run
|
||||
run:
|
||||
@@ -11,4 +16,4 @@ run:
|
||||
@echo "Diffusers run."
|
||||
|
||||
test:
|
||||
bash test.sh
|
||||
bash test.sh
|
||||
|
||||
64
backend/python/diffusers/diffusers-rocm.yml
Normal file
64
backend/python/diffusers/diffusers-rocm.yml
Normal file
@@ -0,0 +1,64 @@
|
||||
name: diffusers
|
||||
channels:
|
||||
- defaults
|
||||
dependencies:
|
||||
- _libgcc_mutex=0.1=main
|
||||
- _openmp_mutex=5.1=1_gnu
|
||||
- bzip2=1.0.8=h7b6447c_0
|
||||
- ca-certificates=2023.08.22=h06a4308_0
|
||||
- ld_impl_linux-64=2.38=h1181459_1
|
||||
- libffi=3.4.4=h6a678d5_0
|
||||
- libgcc-ng=11.2.0=h1234567_1
|
||||
- libgomp=11.2.0=h1234567_1
|
||||
- libstdcxx-ng=11.2.0=h1234567_1
|
||||
- libuuid=1.41.5=h5eee18b_0
|
||||
- ncurses=6.4=h6a678d5_0
|
||||
- openssl=3.0.11=h7f8727e_2
|
||||
- pip=23.2.1=py311h06a4308_0
|
||||
- python=3.11.5=h955ad1f_0
|
||||
- readline=8.2=h5eee18b_0
|
||||
- setuptools=68.0.0=py311h06a4308_0
|
||||
- sqlite=3.41.2=h5eee18b_0
|
||||
- tk=8.6.12=h1ccaba5_0
|
||||
- tzdata=2023c=h04d1e81_0
|
||||
- wheel=0.41.2=py311h06a4308_0
|
||||
- xz=5.4.2=h5eee18b_0
|
||||
- zlib=1.2.13=h5eee18b_0
|
||||
- pip:
|
||||
- --pre
|
||||
- --extra-index-url https://download.pytorch.org/whl/nightly/
|
||||
- accelerate>=0.11.0
|
||||
- certifi==2023.7.22
|
||||
- charset-normalizer==3.3.0
|
||||
- compel==2.0.2
|
||||
- diffusers==0.24.0
|
||||
- filelock==3.12.4
|
||||
- fsspec==2023.9.2
|
||||
- grpcio==1.59.0
|
||||
- huggingface-hub>=0.19.4
|
||||
- idna==3.4
|
||||
- importlib-metadata==6.8.0
|
||||
- jinja2==3.1.2
|
||||
- markupsafe==2.1.3
|
||||
- mpmath==1.3.0
|
||||
- networkx==3.1
|
||||
- numpy==1.26.0
|
||||
- omegaconf
|
||||
- packaging==23.2
|
||||
- pillow==10.0.1
|
||||
- protobuf==4.24.4
|
||||
- psutil==5.9.5
|
||||
- pyparsing==3.1.1
|
||||
- pyyaml==6.0.1
|
||||
- regex==2023.10.3
|
||||
- requests==2.31.0
|
||||
- safetensors==0.4.0
|
||||
- sympy==1.12
|
||||
- tqdm==4.66.1
|
||||
- transformers>=4.25.1
|
||||
- triton==2.1.0
|
||||
- typing-extensions==4.8.0
|
||||
- urllib3==2.0.6
|
||||
- zipp==3.17.0
|
||||
- torch
|
||||
prefix: /opt/conda/envs/diffusers
|
||||
@@ -71,4 +71,4 @@ dependencies:
|
||||
- typing-extensions==4.8.0
|
||||
- urllib3==2.0.6
|
||||
- zipp==3.17.0
|
||||
prefix: /opt/conda/envs/diffusers
|
||||
prefix: /opt/conda/envs/diffusers
|
||||
|
||||
24
backend/python/diffusers/install.sh
Executable file
24
backend/python/diffusers/install.sh
Executable file
@@ -0,0 +1,24 @@
|
||||
#!/bin/bash
|
||||
set -ex
|
||||
|
||||
# Check if environment exist
|
||||
conda_env_exists(){
|
||||
! conda list --name "${@}" >/dev/null 2>/dev/null
|
||||
}
|
||||
|
||||
if conda_env_exists "diffusers" ; then
|
||||
echo "Creating virtual environment..."
|
||||
conda env create --name diffusers --file $1
|
||||
echo "Virtual environment created."
|
||||
else
|
||||
echo "Virtual environment already exists."
|
||||
fi
|
||||
|
||||
if [ "$PIP_CACHE_PURGE" = true ] ; then
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
# Activate conda environment
|
||||
source activate diffusers
|
||||
|
||||
pip cache purge
|
||||
fi
|
||||
@@ -1,15 +1,25 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
##
|
||||
## A bash script installs the required dependencies of VALL-E-X and prepares the environment
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
export SHA=c0ddebaaaf8ffd1b3529c2bb654e650bce2f790f
|
||||
|
||||
# Activate conda environment
|
||||
source activate transformers
|
||||
|
||||
echo $CONDA_PREFIX
|
||||
|
||||
git clone https://github.com/turboderp/exllamav2 $CONDA_PREFIX/exllamav2 && pushd $CONDA_PREFIX/exllamav2 && pip install -r requirements.txt && popd
|
||||
git clone https://github.com/turboderp/exllamav2 $CONDA_PREFIX/exllamav2
|
||||
|
||||
pushd $CONDA_PREFIX/exllamav2
|
||||
|
||||
git checkout -b build $SHA
|
||||
|
||||
# TODO: this needs to be pinned within the conda environments
|
||||
pip install -r requirements.txt
|
||||
|
||||
popd
|
||||
|
||||
cp -rfv $CONDA_PREFIX/exllamav2/* ./
|
||||
|
||||
|
||||
2
backend/python/mamba/install.sh
Normal file → Executable file
2
backend/python/mamba/install.sh
Normal file → Executable file
@@ -1,5 +1,5 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
##
|
||||
## A bash script installs the required dependencies of VALL-E-X and prepares the environment
|
||||
export PATH=$PATH:/opt/conda/bin
|
||||
|
||||
@@ -10,7 +10,7 @@ source activate transformers
|
||||
|
||||
echo $CONDA_PREFIX
|
||||
|
||||
git clone https://github.com/Plachtaa/VALL-E-X.git $CONDA_PREFIX/vall-e-x && pushd $CONDA_PREFIX/vall-e-x && git checkout -b build $SHA && pip install -r requirements.txt && popd
|
||||
git clone https://github.com/Plachtaa/VALL-E-X.git $CONDA_PREFIX/vall-e-x && pushd $CONDA_PREFIX/vall-e-x && git checkout -b build $SHA && popd
|
||||
|
||||
cp -rfv $CONDA_PREFIX/vall-e-x/* ./
|
||||
|
||||
|
||||
@@ -55,6 +55,7 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
print("Preparing models, please wait", file=sys.stderr)
|
||||
# download and load all models
|
||||
preload_models()
|
||||
self.clonedVoice = False
|
||||
# Assume directory from request.ModelFile.
|
||||
# Only if request.LoraAdapter it's not an absolute path
|
||||
if request.AudioPath and request.ModelFile != "" and not os.path.isabs(request.AudioPath):
|
||||
@@ -65,6 +66,7 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
if request.AudioPath != "":
|
||||
print("Generating model", file=sys.stderr)
|
||||
make_prompt(name=model_name, audio_prompt_path=request.AudioPath)
|
||||
self.clonedVoice = True
|
||||
### Use given transcript
|
||||
##make_prompt(name=model_name, audio_prompt_path="paimon_prompt.wav",
|
||||
## transcript="Just, what was that? Paimon thought we were gonna get eaten.")
|
||||
@@ -91,6 +93,8 @@ class BackendServicer(backend_pb2_grpc.BackendServicer):
|
||||
try:
|
||||
audio_array = None
|
||||
if model != "":
|
||||
if self.clonedVoice:
|
||||
model = os.path.basename(request.model)
|
||||
audio_array = generate_audio(request.text, prompt=model)
|
||||
else:
|
||||
audio_array = generate_audio(request.text)
|
||||
|
||||
@@ -3,8 +3,8 @@ package backend
|
||||
import (
|
||||
"fmt"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
)
|
||||
@@ -1,8 +1,8 @@
|
||||
package backend
|
||||
|
||||
import (
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
)
|
||||
@@ -8,8 +8,8 @@ import (
|
||||
"sync"
|
||||
"unicode/utf8"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/pkg/gallery"
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
@@ -7,8 +7,8 @@ import (
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
)
|
||||
|
||||
func modelOpts(c config.Config, o *options.Option, opts []model.Option) []model.Option {
|
||||
@@ -4,10 +4,10 @@ import (
|
||||
"context"
|
||||
"fmt"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
)
|
||||
@@ -6,8 +6,8 @@ import (
|
||||
"os"
|
||||
"path/filepath"
|
||||
|
||||
api_config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
model "github.com/go-skynet/LocalAI/pkg/model"
|
||||
"github.com/go-skynet/LocalAI/pkg/utils"
|
||||
@@ -29,16 +29,20 @@ func generateUniqueFileName(dir, baseName, ext string) string {
|
||||
}
|
||||
}
|
||||
|
||||
func ModelTTS(backend, text, modelFile string, loader *model.ModelLoader, o *options.Option) (string, *proto.Result, error) {
|
||||
func ModelTTS(backend, text, modelFile string, loader *model.ModelLoader, o *options.Option, c config.Config) (string, *proto.Result, error) {
|
||||
bb := backend
|
||||
if bb == "" {
|
||||
bb = model.PiperBackend
|
||||
}
|
||||
opts := modelOpts(api_config.Config{}, o, []model.Option{
|
||||
|
||||
grpcOpts := gRPCModelOpts(c)
|
||||
|
||||
opts := modelOpts(config.Config{}, o, []model.Option{
|
||||
model.WithBackendString(bb),
|
||||
model.WithModel(modelFile),
|
||||
model.WithContext(o.Context),
|
||||
model.WithAssetDir(o.AssetsDestination),
|
||||
model.WithLoadGRPCLoadModelOpts(grpcOpts),
|
||||
})
|
||||
piperModel, err := o.Loader.BackendLoader(opts...)
|
||||
if err != nil {
|
||||
@@ -1,4 +1,4 @@
|
||||
package api_config
|
||||
package config
|
||||
|
||||
import (
|
||||
"errors"
|
||||
@@ -148,6 +148,7 @@ type Functions struct {
|
||||
DisableNoAction bool `yaml:"disable_no_action"`
|
||||
NoActionFunctionName string `yaml:"no_action_function_name"`
|
||||
NoActionDescriptionName string `yaml:"no_action_description_name"`
|
||||
ParallelCalls bool `yaml:"parallel_calls"`
|
||||
}
|
||||
|
||||
type TemplateConfig struct {
|
||||
@@ -183,6 +184,60 @@ func (c *Config) FunctionToCall() string {
|
||||
return c.functionCallNameString
|
||||
}
|
||||
|
||||
// Load a config file for a model
|
||||
func Load(modelName, modelPath string, cm *ConfigLoader, debug bool, threads, ctx int, f16 bool) (*Config, error) {
|
||||
// Load a config file if present after the model name
|
||||
modelConfig := filepath.Join(modelPath, modelName+".yaml")
|
||||
|
||||
var cfg *Config
|
||||
|
||||
defaults := func() {
|
||||
cfg = DefaultConfig(modelName)
|
||||
cfg.ContextSize = ctx
|
||||
cfg.Threads = threads
|
||||
cfg.F16 = f16
|
||||
cfg.Debug = debug
|
||||
}
|
||||
|
||||
cfgExisting, exists := cm.GetConfig(modelName)
|
||||
if !exists {
|
||||
if _, err := os.Stat(modelConfig); err == nil {
|
||||
if err := cm.LoadConfig(modelConfig); err != nil {
|
||||
return nil, fmt.Errorf("failed loading model config (%s) %s", modelConfig, err.Error())
|
||||
}
|
||||
cfgExisting, exists = cm.GetConfig(modelName)
|
||||
if exists {
|
||||
cfg = &cfgExisting
|
||||
} else {
|
||||
defaults()
|
||||
}
|
||||
} else {
|
||||
defaults()
|
||||
}
|
||||
} else {
|
||||
cfg = &cfgExisting
|
||||
}
|
||||
|
||||
// Set the parameters for the language model prediction
|
||||
//updateConfig(cfg, input)
|
||||
|
||||
// Don't allow 0 as setting
|
||||
if cfg.Threads == 0 {
|
||||
if threads != 0 {
|
||||
cfg.Threads = threads
|
||||
} else {
|
||||
cfg.Threads = 4
|
||||
}
|
||||
}
|
||||
|
||||
// Enforce debug flag if passed from CLI
|
||||
if debug {
|
||||
cfg.Debug = true
|
||||
}
|
||||
|
||||
return cfg, nil
|
||||
}
|
||||
|
||||
func defaultPredictOptions(modelFile string) PredictionOptions {
|
||||
return PredictionOptions{
|
||||
TopP: 0.7,
|
||||
@@ -1,10 +1,10 @@
|
||||
package api_config_test
|
||||
package config_test
|
||||
|
||||
import (
|
||||
"os"
|
||||
|
||||
. "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
. "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/pkg/model"
|
||||
. "github.com/onsi/ginkgo/v2"
|
||||
. "github.com/onsi/gomega"
|
||||
@@ -1,4 +1,4 @@
|
||||
package api_config
|
||||
package config
|
||||
|
||||
type PredictionOptions struct {
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
package api
|
||||
package http
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
@@ -7,11 +7,11 @@ import (
|
||||
"os"
|
||||
"strings"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/localai"
|
||||
"github.com/go-skynet/LocalAI/api/openai"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
"github.com/go-skynet/LocalAI/internal"
|
||||
"github.com/go-skynet/LocalAI/metrics"
|
||||
"github.com/go-skynet/LocalAI/pkg/assets"
|
||||
@@ -146,7 +146,11 @@ func App(opts ...options.AppOption) (*fiber.App, error) {
|
||||
}
|
||||
|
||||
// Default middleware config
|
||||
app.Use(recover.New())
|
||||
|
||||
if !options.Debug {
|
||||
app.Use(recover.New())
|
||||
}
|
||||
|
||||
if options.Metrics != nil {
|
||||
app.Use(metrics.APIMiddleware(options.Metrics))
|
||||
}
|
||||
@@ -219,8 +223,12 @@ func App(opts ...options.AppOption) (*fiber.App, error) {
|
||||
// Make sure directories exists
|
||||
os.MkdirAll(options.ImageDir, 0755)
|
||||
os.MkdirAll(options.AudioDir, 0755)
|
||||
os.MkdirAll(options.UploadDir, 0755)
|
||||
os.MkdirAll(options.Loader.ModelPath, 0755)
|
||||
|
||||
// Load upload json
|
||||
openai.LoadUploadConfig(options.UploadDir)
|
||||
|
||||
modelGalleryService := localai.CreateModelGalleryService(options.Galleries, options.Loader.ModelPath, galleryService)
|
||||
app.Post("/models/apply", auth, modelGalleryService.ApplyModelGalleryEndpoint())
|
||||
app.Get("/models/available", auth, modelGalleryService.ListModelFromGalleryEndpoint())
|
||||
@@ -240,6 +248,18 @@ func App(opts ...options.AppOption) (*fiber.App, error) {
|
||||
app.Post("/v1/edits", auth, openai.EditEndpoint(cl, options))
|
||||
app.Post("/edits", auth, openai.EditEndpoint(cl, options))
|
||||
|
||||
// files
|
||||
app.Post("/v1/files", auth, openai.UploadFilesEndpoint(cl, options))
|
||||
app.Post("/files", auth, openai.UploadFilesEndpoint(cl, options))
|
||||
app.Get("/v1/files", auth, openai.ListFilesEndpoint(cl, options))
|
||||
app.Get("/files", auth, openai.ListFilesEndpoint(cl, options))
|
||||
app.Get("/v1/files/:file_id", auth, openai.GetFilesEndpoint(cl, options))
|
||||
app.Get("/files/:file_id", auth, openai.GetFilesEndpoint(cl, options))
|
||||
app.Delete("/v1/files/:file_id", auth, openai.DeleteFilesEndpoint(cl, options))
|
||||
app.Delete("/files/:file_id", auth, openai.DeleteFilesEndpoint(cl, options))
|
||||
app.Get("/v1/files/:file_id/content", auth, openai.GetFilesContentsEndpoint(cl, options))
|
||||
app.Get("/files/:file_id/content", auth, openai.GetFilesContentsEndpoint(cl, options))
|
||||
|
||||
// completion
|
||||
app.Post("/v1/completions", auth, openai.CompletionEndpoint(cl, options))
|
||||
app.Post("/completions", auth, openai.CompletionEndpoint(cl, options))
|
||||
@@ -1,4 +1,4 @@
|
||||
package api_test
|
||||
package http_test
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
@@ -13,8 +13,8 @@ import (
|
||||
"path/filepath"
|
||||
"runtime"
|
||||
|
||||
. "github.com/go-skynet/LocalAI/api"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
. "github.com/go-skynet/LocalAI/core/http"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/metrics"
|
||||
"github.com/go-skynet/LocalAI/pkg/downloader"
|
||||
"github.com/go-skynet/LocalAI/pkg/gallery"
|
||||
@@ -29,6 +29,15 @@ import (
|
||||
"github.com/sashabaranov/go-openai/jsonschema"
|
||||
)
|
||||
|
||||
const testPrompt = `### System:
|
||||
You are an AI assistant that follows instruction extremely well. Help as much as you can.
|
||||
|
||||
### User:
|
||||
|
||||
Can you help rephrasing sentences?
|
||||
|
||||
### Response:`
|
||||
|
||||
type modelApplyRequest struct {
|
||||
ID string `json:"id"`
|
||||
URL string `json:"url"`
|
||||
@@ -629,28 +638,28 @@ var _ = Describe("API test", func() {
|
||||
Expect(len(models.Models)).To(Equal(6)) // If "config.yaml" should be included, this should be 8?
|
||||
})
|
||||
It("can generate completions", func() {
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "testmodel", Prompt: "abcdedfghikl"})
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "testmodel", Prompt: testPrompt})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Text).ToNot(BeEmpty())
|
||||
})
|
||||
|
||||
It("can generate chat completions ", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "testmodel", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "testmodel", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
})
|
||||
|
||||
It("can generate completions from model configs", func() {
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "gpt4all", Prompt: "abcdedfghikl"})
|
||||
resp, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "gpt4all", Prompt: testPrompt})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Text).ToNot(BeEmpty())
|
||||
})
|
||||
|
||||
It("can generate chat completions from model configs", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "gpt4all-2", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "gpt4all-2", Messages: []openai.ChatCompletionMessage{openai.ChatCompletionMessage{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
@@ -658,7 +667,7 @@ var _ = Describe("API test", func() {
|
||||
|
||||
It("returns errors", func() {
|
||||
backends := len(model.AutoLoadBackends) + 1 // +1 for huggingface
|
||||
_, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "foomodel", Prompt: "abcdedfghikl"})
|
||||
_, err := client.CreateCompletion(context.TODO(), openai.CompletionRequest{Model: "foomodel", Prompt: testPrompt})
|
||||
Expect(err).To(HaveOccurred())
|
||||
Expect(err.Error()).To(ContainSubstring(fmt.Sprintf("error, status code: 500, message: could not load model - all backends returned error: %d errors occurred:", backends)))
|
||||
})
|
||||
@@ -834,13 +843,13 @@ var _ = Describe("API test", func() {
|
||||
app.Shutdown()
|
||||
})
|
||||
It("can generate chat completions from config file (list1)", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list1", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list1", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
})
|
||||
It("can generate chat completions from config file (list2)", func() {
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list2", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: "abcdedfghikl"}}})
|
||||
resp, err := client.CreateChatCompletion(context.TODO(), openai.ChatCompletionRequest{Model: "list2", Messages: []openai.ChatCompletionMessage{{Role: "user", Content: testPrompt}}})
|
||||
Expect(err).ToNot(HaveOccurred())
|
||||
Expect(len(resp.Choices)).To(Equal(1))
|
||||
Expect(resp.Choices[0].Message.Content).ToNot(BeEmpty())
|
||||
@@ -1,4 +1,4 @@
|
||||
package api_test
|
||||
package http_test
|
||||
|
||||
import (
|
||||
"testing"
|
||||
@@ -21,6 +21,7 @@ type Option struct {
|
||||
Debug, DisableMessage bool
|
||||
ImageDir string
|
||||
AudioDir string
|
||||
UploadDir string
|
||||
CORS bool
|
||||
PreloadJSONModels string
|
||||
PreloadModelsFromPath string
|
||||
@@ -249,6 +250,12 @@ func WithImageDir(imageDir string) AppOption {
|
||||
}
|
||||
}
|
||||
|
||||
func WithUploadDir(uploadDir string) AppOption {
|
||||
return func(o *Option) {
|
||||
o.UploadDir = uploadDir
|
||||
}
|
||||
}
|
||||
|
||||
func WithApiKeys(apiKeys []string) AppOption {
|
||||
return func(o *Option) {
|
||||
o.ApiKeys = apiKeys
|
||||
@@ -3,7 +3,7 @@ package schema
|
||||
import (
|
||||
"context"
|
||||
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
|
||||
"github.com/go-skynet/LocalAI/pkg/grammar"
|
||||
)
|
||||
@@ -68,6 +68,10 @@ type ContentURL struct {
|
||||
type Message struct {
|
||||
// The message role
|
||||
Role string `json:"role,omitempty" yaml:"role"`
|
||||
|
||||
// The message name (used for tools calls)
|
||||
Name string `json:"name,omitempty" yaml:"name"`
|
||||
|
||||
// The message content
|
||||
Content interface{} `json:"content" yaml:"content"`
|
||||
|
||||
@@ -76,6 +80,20 @@ type Message struct {
|
||||
|
||||
// A result of a function call
|
||||
FunctionCall interface{} `json:"function_call,omitempty" yaml:"function_call,omitempty"`
|
||||
|
||||
ToolCalls []ToolCall `json:"tool_calls,omitempty" yaml:"tool_call,omitempty"`
|
||||
}
|
||||
|
||||
type ToolCall struct {
|
||||
Index int `json:"index"`
|
||||
ID string `json:"id"`
|
||||
Type string `json:"type"`
|
||||
FunctionCall FunctionCall `json:"function"`
|
||||
}
|
||||
|
||||
type FunctionCall struct {
|
||||
Name string `json:"name,omitempty"`
|
||||
Arguments string `json:"arguments"`
|
||||
}
|
||||
|
||||
type OpenAIModel struct {
|
||||
@@ -117,6 +135,9 @@ type OpenAIRequest struct {
|
||||
Functions []grammar.Function `json:"functions" yaml:"functions"`
|
||||
FunctionCall interface{} `json:"function_call" yaml:"function_call"` // might be a string or an object
|
||||
|
||||
Tools []grammar.Tool `json:"tools,omitempty" yaml:"tools"`
|
||||
ToolsChoice interface{} `json:"tool_choice,omitempty" yaml:"tool_choice"`
|
||||
|
||||
Stream bool `json:"stream"`
|
||||
|
||||
// Image (not supported by OpenAI)
|
||||
@@ -23,7 +23,7 @@ Fine-tuning a language model is a process that requires a lot of computational p
|
||||
|
||||
Currently LocalAI doesn't support the fine-tuning endpoint as LocalAI but there are are [plans](https://github.com/mudler/LocalAI/issues/596) to support that. For the time being a guide is proposed here to give a simple starting point on how to fine-tune a model and use it with LocalAI (but also with llama.cpp).
|
||||
|
||||
There is an e2e example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler) available [here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/).
|
||||
There is an e2e example of fine-tuning a LLM model to use with [LocalAI](https://github.com/mudler/LocalAI) written by [@mudler](https://github.com/mudler) available [here](https://github.com/mudler/LocalAI/tree/master/examples/e2e-fine-tuning/).
|
||||
|
||||
The steps involved are:
|
||||
|
||||
|
||||
@@ -15,9 +15,45 @@ This section contains instruction on how to use LocalAI with GPU acceleration.
|
||||
For accelleration for AMD or Metal HW there are no specific container images, see the [build]({{%relref "docs/getting-started/build#Acceleration" %}})
|
||||
{{% /alert %}}
|
||||
|
||||
### CUDA(NVIDIA) acceleration
|
||||
|
||||
#### Requirements
|
||||
## Model configuration
|
||||
|
||||
Depending on the model architecture and backend used, there might be different ways to enable GPU acceleration. It is required to configure the model you intend to use with a YAML config file. For example, for `llama.cpp` workloads a configuration file might look like this (where `gpu_layers` is the number of layers to offload to the GPU):
|
||||
|
||||
```yaml
|
||||
name: my-model-name
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: llama.cpp-model.ggmlv3.q5_K_M.bin
|
||||
|
||||
context_size: 1024
|
||||
threads: 1
|
||||
|
||||
f16: true # enable with GPU acceleration
|
||||
gpu_layers: 22 # GPU Layers (only used when built with cublas)
|
||||
|
||||
```
|
||||
|
||||
For diffusers instead, it might look like this instead:
|
||||
|
||||
```yaml
|
||||
name: stablediffusion
|
||||
parameters:
|
||||
model: toonyou_beta6.safetensors
|
||||
backend: diffusers
|
||||
step: 30
|
||||
f16: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionPipeline
|
||||
cuda: true
|
||||
enable_parameters: "negative_prompt,num_inference_steps,clip_skip"
|
||||
scheduler_type: "k_dpmpp_sde"
|
||||
```
|
||||
|
||||
## CUDA(NVIDIA) acceleration
|
||||
|
||||
### Requirements
|
||||
|
||||
Requirement: nvidia-container-toolkit (installation instructions [1](https://www.server-world.info/en/note?os=Ubuntu_22.04&p=nvidia&f=2) [2](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html))
|
||||
|
||||
@@ -74,37 +110,32 @@ llama_model_load_internal: total VRAM used: 1598 MB
|
||||
llama_init_from_file: kv self size = 512.00 MB
|
||||
```
|
||||
|
||||
#### Model configuration
|
||||
## Intel acceleration (sycl)
|
||||
|
||||
Depending on the model architecture and backend used, there might be different ways to enable GPU acceleration. It is required to configure the model you intend to use with a YAML config file. For example, for `llama.cpp` workloads a configuration file might look like this (where `gpu_layers` is the number of layers to offload to the GPU):
|
||||
### Requirements
|
||||
|
||||
```yaml
|
||||
name: my-model-name
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: llama.cpp-model.ggmlv3.q5_K_M.bin
|
||||
If building from source, you need to install [Intel oneAPI Base Toolkit](https://software.intel.com/content/www/us/en/develop/tools/oneapi/base-toolkit/download.html) and have the Intel drivers available in the system.
|
||||
|
||||
context_size: 1024
|
||||
threads: 1
|
||||
### Container images
|
||||
|
||||
f16: true # enable with GPU acceleration
|
||||
gpu_layers: 22 # GPU Layers (only used when built with cublas)
|
||||
To use SYCL, use the images with the `sycl-f16` or `sycl-f32` tag, for example `{{< version >}}-sycl-f32-core`, `{{< version >}}-sycl-f16-ffmpeg-core`, ...
|
||||
|
||||
The image list is on [quay](https://quay.io/repository/go-skynet/local-ai?tab=tags).
|
||||
|
||||
#### Example
|
||||
|
||||
To run LocalAI with Docker and sycl starting `phi-2`, you can use the following command as an example:
|
||||
|
||||
```bash
|
||||
docker run -e DEBUG=true --privileged -ti -v $PWD/models:/build/models -p 8080:8080 -v /dev/dri:/dev/dri --rm quay.io/go-skynet/local-ai:master-sycl-f32-ffmpeg-core phi-2
|
||||
```
|
||||
|
||||
For diffusers instead, it might look like this instead:
|
||||
### Notes
|
||||
|
||||
```yaml
|
||||
name: stablediffusion
|
||||
parameters:
|
||||
model: toonyou_beta6.safetensors
|
||||
backend: diffusers
|
||||
step: 30
|
||||
f16: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionPipeline
|
||||
cuda: true
|
||||
enable_parameters: "negative_prompt,num_inference_steps,clip_skip"
|
||||
scheduler_type: "k_dpmpp_sde"
|
||||
```
|
||||
In addition to the commands to run LocalAI normally, you need to specify `--device /dev/dri` to docker, for example:
|
||||
|
||||
```bash
|
||||
docker run --rm -ti --device /dev/dri -p 8080:8080 -e DEBUG=true -e MODELS_PATH=/models -e THREADS=1 -v $PWD/models:/models quay.io/go-skynet/local-ai:{{< version >}}-sycl-f16-ffmpeg-core
|
||||
```
|
||||
|
||||
Note also that sycl does have a known issue to hang with `mmap: true`. You have to disable it in the model configuration if explicitly enabled.
|
||||
|
||||
@@ -144,15 +144,15 @@ parameters:
|
||||
model: "cloned-voice"
|
||||
vall-e:
|
||||
# The path to the audio file to be cloned
|
||||
# relative to the models directory
|
||||
audio_path: "path-to-wav-source.wav"
|
||||
# relative to the models directory
|
||||
# Max 15s
|
||||
audio_path: "audio-sample.wav"
|
||||
```
|
||||
|
||||
Then you can specify the model name in the requests:
|
||||
|
||||
```
|
||||
curl http://localhost:8080/tts -H "Content-Type: application/json" -d '{
|
||||
"backend": "vall-e-x",
|
||||
"model": "cloned-voice",
|
||||
"input":"Hello!"
|
||||
}' | aplay
|
||||
|
||||
@@ -83,7 +83,7 @@ Here is the list of the variables available that can be used to customize the bu
|
||||
|
||||
| Variable | Default | Description |
|
||||
| ---------------------| ------- | ----------- |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas` |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas`, `sycl_f16`, `sycl_f32` |
|
||||
| `GO_TAGS` | `tts stablediffusion` | Go tags. Available: `stablediffusion`, `tts`, `tinydream` |
|
||||
| `CLBLAST_DIR` | | Specify a CLBlast directory |
|
||||
| `CUDA_LIBPATH` | | Specify a CUDA library path |
|
||||
@@ -225,6 +225,17 @@ make BUILD_TYPE=clblas build
|
||||
|
||||
To specify a clblast dir set: `CLBLAST_DIR`
|
||||
|
||||
#### Intel GPU acceleration
|
||||
|
||||
Intel GPU acceleration is supported via SYCL.
|
||||
|
||||
Requirements: [Intel oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html) (see also [llama.cpp setup installations instructions](https://github.com/ggerganov/llama.cpp/blob/d71ac90985854b0905e1abba778e407e17f9f887/README-sycl.md?plain=1#L56))
|
||||
|
||||
```
|
||||
make BUILD_TYPE=sycl_f16 build # for float16
|
||||
make BUILD_TYPE=sycl_f32 build # for float32
|
||||
```
|
||||
|
||||
#### Metal (Apple Silicon)
|
||||
|
||||
```
|
||||
|
||||
@@ -24,5 +24,6 @@ The list below is a list of software that integrates with LocalAI.
|
||||
- https://github.com/mattermost/openops
|
||||
- https://github.com/charmbracelet/mods
|
||||
- https://github.com/cedriking/spark
|
||||
|
||||
- [Big AGI](https://github.com/enricoros/big-agi) is a powerful web interface entirely running in the browser, supporting LocalAI
|
||||
|
||||
Feel free to open up a Pull request (by clicking at the "Edit page" below) to get a page for your project made or if you see a error on one of the pages!
|
||||
|
||||
@@ -74,14 +74,6 @@ Note that this started just as a fun weekend project by [mudler](https://github.
|
||||
- 🖼️ [Download Models directly from Huggingface ](https://localai.io/models/)
|
||||
- 🆕 [Vision API](https://localai.io/features/gpt-vision/)
|
||||
|
||||
## How does it work?
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||
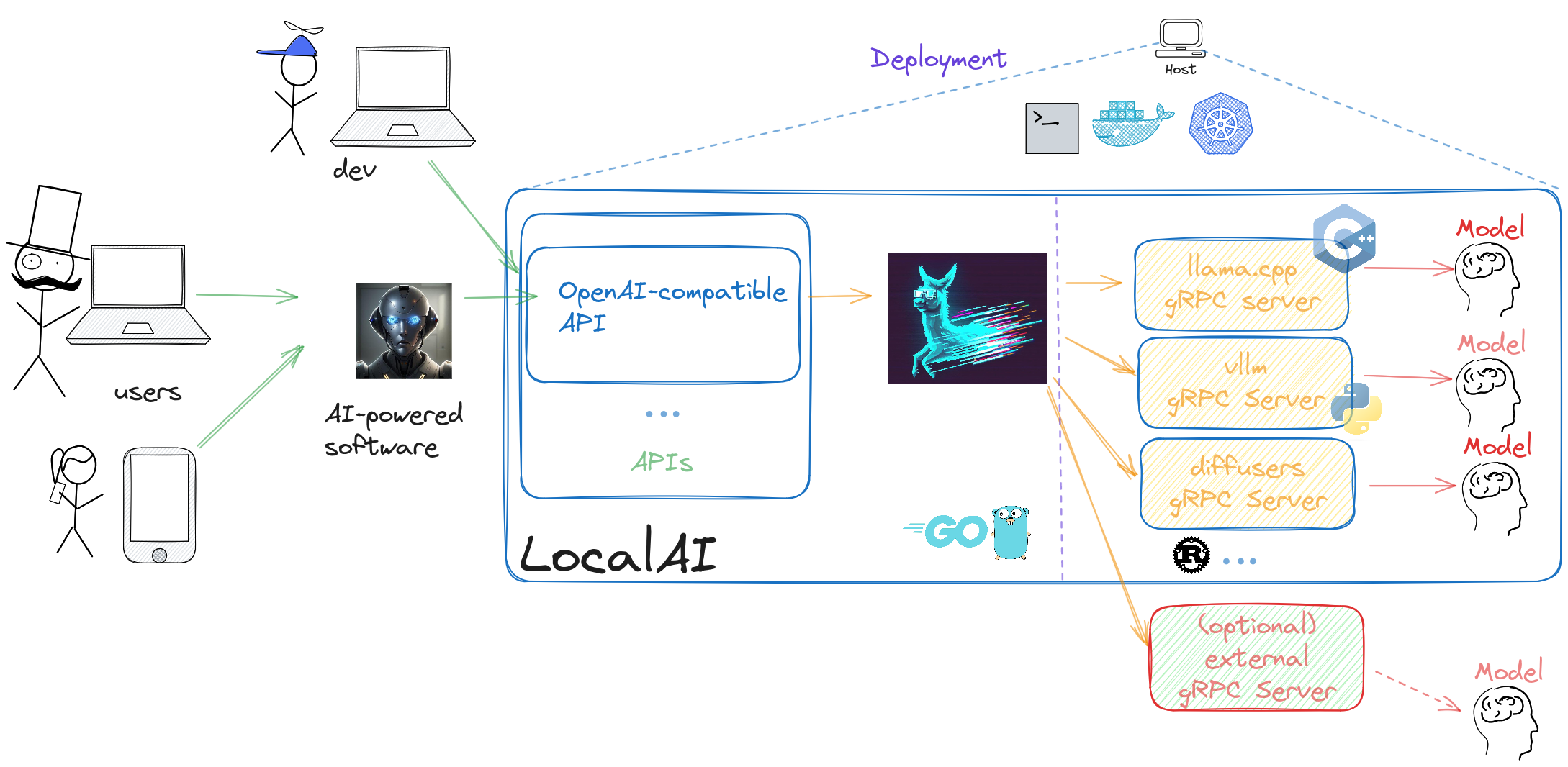
|
||||
|
||||
## Contribute and help
|
||||
|
||||
To help the project you can:
|
||||
@@ -112,21 +104,6 @@ LocalAI couldn't have been built without the help of great software already avai
|
||||
- https://github.com/ggerganov/whisper.cpp
|
||||
- https://github.com/saharNooby/rwkv.cpp
|
||||
- https://github.com/rhasspy/piper
|
||||
- https://github.com/cmp-nct/ggllm.cpp
|
||||
|
||||
|
||||
|
||||
## Backstory
|
||||
|
||||
As much as typical open source projects starts, I, [mudler](https://github.com/mudler/), was fiddling around with [llama.cpp](https://github.com/ggerganov/llama.cpp) over my long nights and wanted to have a way to call it from `go`, as I am a Golang developer and use it extensively. So I've created `LocalAI` (or what was initially known as `llama-cli`) and added an API to it.
|
||||
|
||||
But guess what? The more I dived into this rabbit hole, the more I realized that I had stumbled upon something big. With all the fantastic C++ projects floating around the community, it dawned on me that I could piece them together to create a full-fledged OpenAI replacement. So, ta-da! LocalAI was born, and it quickly overshadowed its humble origins.
|
||||
|
||||
Now, why did I choose to go with C++ bindings, you ask? Well, I wanted to keep LocalAI snappy and lightweight, allowing it to run like a champ on any system and avoid any Golang penalties of the GC, and, most importantly built on shoulders of giants like `llama.cpp`. Go is good at backends and API and is easy to maintain. And hey, don't forget that I'm all about sharing the love. That's why I made LocalAI MIT licensed, so everyone can hop on board and benefit from it.
|
||||
|
||||
As if that wasn't exciting enough, as the project gained traction, [mkellerman](https://github.com/mkellerman) and [Aisuko](https://github.com/Aisuko) jumped in to lend a hand. mkellerman helped set up some killer examples, while Aisuko is becoming our community maestro. The community now is growing even more with new contributors and users, and I couldn't be happier about it!
|
||||
|
||||
Oh, and let's not forget the real MVP here—[llama.cpp](https://github.com/ggerganov/llama.cpp). Without this extraordinary piece of software, LocalAI wouldn't even exist. So, a big shoutout to the community for making this magic happen!
|
||||
|
||||
## 🤗 Contributors
|
||||
|
||||
|
||||
25
docs/content/docs/reference/architecture.md
Normal file
25
docs/content/docs/reference/architecture.md
Normal file
@@ -0,0 +1,25 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Architecture"
|
||||
weight = 25
|
||||
+++
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||

|
||||
|
||||
|
||||
## Backstory
|
||||
|
||||
As much as typical open source projects starts, I, [mudler](https://github.com/mudler/), was fiddling around with [llama.cpp](https://github.com/ggerganov/llama.cpp) over my long nights and wanted to have a way to call it from `go`, as I am a Golang developer and use it extensively. So I've created `LocalAI` (or what was initially known as `llama-cli`) and added an API to it.
|
||||
|
||||
But guess what? The more I dived into this rabbit hole, the more I realized that I had stumbled upon something big. With all the fantastic C++ projects floating around the community, it dawned on me that I could piece them together to create a full-fledged OpenAI replacement. So, ta-da! LocalAI was born, and it quickly overshadowed its humble origins.
|
||||
|
||||
Now, why did I choose to go with C++ bindings, you ask? Well, I wanted to keep LocalAI snappy and lightweight, allowing it to run like a champ on any system and avoid any Golang penalties of the GC, and, most importantly built on shoulders of giants like `llama.cpp`. Go is good at backends and API and is easy to maintain. And hey, don't forget that I'm all about sharing the love. That's why I made LocalAI MIT licensed, so everyone can hop on board and benefit from it.
|
||||
|
||||
As if that wasn't exciting enough, as the project gained traction, [mkellerman](https://github.com/mkellerman) and [Aisuko](https://github.com/Aisuko) jumped in to lend a hand. mkellerman helped set up some killer examples, while Aisuko is becoming our community maestro. The community now is growing even more with new contributors and users, and I couldn't be happier about it!
|
||||
|
||||
Oh, and let's not forget the real MVP here—[llama.cpp](https://github.com/ggerganov/llama.cpp). Without this extraordinary piece of software, LocalAI wouldn't even exist. So, a big shoutout to the community for making this magic happen!
|
||||
@@ -16,18 +16,16 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
|
||||
| Backend and Bindings | Compatible models | Completion/Chat endpoint | Capability | Embeddings support | Token stream support | Acceleration |
|
||||
|----------------------------------------------------------------------------------|-----------------------|--------------------------|---------------------------|-----------------------------------|----------------------|--------------|
|
||||
| [llama.cpp]({{%relref "docs/features/text-generation#llama.cpp" %}}) | Vicuna, Alpaca, LLaMa | yes | GPT and Functions | yes** | yes | CUDA, openCL, cuBLAS, Metal |
|
||||
| [llama.cpp]({{%relref "docs/features/text-generation#llama.cpp" %}}) | Vicuna, Alpaca, LLaMa, Falcon, Starcoder, GPT-2, [and many others](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#description) | yes | GPT and Functions | yes** | yes | CUDA, openCL, cuBLAS, Metal |
|
||||
| [gpt4all-llama](https://github.com/nomic-ai/gpt4all) | Vicuna, Alpaca, LLaMa | yes | GPT | no | yes | N/A |
|
||||
| [gpt4all-mpt](https://github.com/nomic-ai/gpt4all) | MPT | yes | GPT | no | yes | N/A |
|
||||
| [gpt4all-j](https://github.com/nomic-ai/gpt4all) | GPT4ALL-J | yes | GPT | no | yes | N/A |
|
||||
| [falcon-ggml](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Falcon (*) | yes | GPT | no | no | N/A |
|
||||
| [gpt2](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | GPT2, Cerebras | yes | GPT | no | no | N/A |
|
||||
| [dolly](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Dolly | yes | GPT | no | no | N/A |
|
||||
| [gptj](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | GPTJ | yes | GPT | no | no | N/A |
|
||||
| [mpt](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | MPT | yes | GPT | no | no | N/A |
|
||||
| [replit](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Replit | yes | GPT | no | no | N/A |
|
||||
| [gptneox](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | GPT NeoX, RedPajama, StableLM | yes | GPT | no | no | N/A |
|
||||
| [starcoder](https://github.com/ggerganov/ggml) ([binding](https://github.com/go-skynet/go-ggml-transformers.cpp)) | Starcoder | yes | GPT | no | no | N/A|
|
||||
| [bloomz](https://github.com/NouamaneTazi/bloomz.cpp) ([binding](https://github.com/go-skynet/bloomz.cpp)) | Bloom | yes | GPT | no | no | N/A |
|
||||
| [rwkv](https://github.com/saharNooby/rwkv.cpp) ([binding](https://github.com/donomii/go-rwkv.cpp)) | rwkv | yes | GPT | no | yes | N/A |
|
||||
| [bert](https://github.com/skeskinen/bert.cpp) ([binding](https://github.com/go-skynet/go-bert.cpp)) | bert | no | Embeddings only | yes | no | N/A |
|
||||
@@ -35,7 +33,6 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
| [stablediffusion](https://github.com/EdVince/Stable-Diffusion-NCNN) ([binding](https://github.com/mudler/go-stable-diffusion)) | stablediffusion | no | Image | no | no | N/A |
|
||||
| [langchain-huggingface](https://github.com/tmc/langchaingo) | Any text generators available on HuggingFace through API | yes | GPT | no | no | N/A |
|
||||
| [piper](https://github.com/rhasspy/piper) ([binding](https://github.com/mudler/go-piper)) | Any piper onnx model | no | Text to voice | no | no | N/A |
|
||||
| [falcon](https://github.com/cmp-nct/ggllm.cpp/tree/c12b2d65f732a0d8846db2244e070f0f3e73505c) ([binding](https://github.com/mudler/go-ggllm.cpp)) | Falcon *** | yes | GPT | no | yes | CUDA |
|
||||
| [sentencetransformers](https://github.com/UKPLab/sentence-transformers) | BERT | no | Embeddings only | yes | no | N/A |
|
||||
| `bark` | bark | no | Audio generation | no | no | yes |
|
||||
| `autogptq` | GPTQ | yes | GPT | yes | no | N/A |
|
||||
@@ -48,6 +45,7 @@ LocalAI will attempt to automatically load models which are not explicitly confi
|
||||
| [tinydream](https://github.com/symisc/tiny-dream#tiny-dreaman-embedded-header-only-stable-diffusion-inference-c-librarypixlabiotiny-dream) | stablediffusion | no | Image | no | no | N/A |
|
||||
| `coqui` | Coqui | no | Audio generation and Voice cloning | no | no | CPU/CUDA |
|
||||
| `petals` | Various GPTs and quantization formats | yes | GPT | no | no | CPU/CUDA |
|
||||
| `transformers` | Various GPTs and quantization formats | yes | GPT, embeddings | yes | no | CPU/CUDA |
|
||||
|
||||
Note: any backend name listed above can be used in the `backend` field of the model configuration file (See [the advanced section]({{%relref "docs/advanced" %}})).
|
||||
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
{
|
||||
"version": "v2.6.1"
|
||||
"version": "v2.8.2"
|
||||
}
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
name: codellama-7b
|
||||
backend: transformers
|
||||
type: AutoModelForCausalLM
|
||||
parameters:
|
||||
model: codellama/CodeLlama-7b-hf
|
||||
temperature: 0.2
|
||||
|
||||
21
embedded/models/mamba-bagel.yaml
Normal file
21
embedded/models/mamba-bagel.yaml
Normal file
@@ -0,0 +1,21 @@
|
||||
name: bagel
|
||||
backend: mamba
|
||||
parameters:
|
||||
model: "jondurbin/bagel-dpo-2.8b-v0.2"
|
||||
systemPrompt: "You are a helpful, unbiased, uncensored assistant."
|
||||
template:
|
||||
chat_message: |
|
||||
{{if eq .RoleName "assistant"}}{{.Content}}{{else}}
|
||||
[INST]
|
||||
{{if .SystemPrompt}}{{.SystemPrompt}}{{else if eq .RoleName "system"}}<<SYS>>{{.Content}}<</SYS>>
|
||||
|
||||
{{else if .Content}}{{.Content}}{{end}}
|
||||
[/INST]
|
||||
{{end}}
|
||||
completion: |
|
||||
{{.Input}}
|
||||
usage: |
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "bagel",
|
||||
"messages": [{"role": "user", "content": "how are you doing"}],
|
||||
}'
|
||||
@@ -11,20 +11,18 @@ template:
|
||||
<|im_start|>{{if eq .RoleName "assistant"}}assistant{{else if eq .RoleName "system"}}system{{else if eq .RoleName "user"}}user{{end}}
|
||||
{{if .Content}}{{.Content}}{{end}}
|
||||
<|im_end|>
|
||||
|
||||
chat: |
|
||||
{{.Input}}
|
||||
<|im_start|>assistant
|
||||
|
||||
completion: |
|
||||
{{.Input}}
|
||||
context_size: 4096
|
||||
f16: true
|
||||
stopwords:
|
||||
- <|im_end|>
|
||||
|
||||
- <dummy32000>
|
||||
usage: |
|
||||
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
|
||||
"model": "mistral-openorca",
|
||||
"messages": [{"role": "user", "content": "How are you doing?", "temperature": 0.1}]
|
||||
}'
|
||||
}'
|
||||
|
||||
@@ -12,7 +12,7 @@ parameters:
|
||||
top_p: 0.95
|
||||
seed: -1
|
||||
template:
|
||||
chat: &template |
|
||||
chat: &template |-
|
||||
Instruct: {{.Input}}
|
||||
Output:
|
||||
completion: *template
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
This is an example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler).
|
||||
This is an example of fine-tuning a LLM model to use with [LocalAI](https://github.com/mudler/LocalAI) written by [@mudler](https://github.com/mudler).
|
||||
|
||||
Specifically, this example shows how to use [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) to fine-tune a LLM model to consume with LocalAI as a `gguf` model.
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
"source": [
|
||||
"## Finetuning a model and using it with LocalAI\n",
|
||||
"\n",
|
||||
"This is an example of fine-tuning a LLM model to use with [LocalAI](https://github/mudler/LocalAI) written by [@mudler](https://github.com/mudler).\n",
|
||||
"This is an example of fine-tuning a LLM model to use with [LocalAI](https://github.com/mudler/LocalAI) written by [@mudler](https://github.com/mudler).\n",
|
||||
"\n",
|
||||
"Specifically, this example shows how to use [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) to fine-tune a LLM model to consume with LocalAI as a `gguf` model."
|
||||
]
|
||||
|
||||
68
examples/kubernetes/deployment-intel-arc.yaml
Normal file
68
examples/kubernetes/deployment-intel-arc.yaml
Normal file
@@ -0,0 +1,68 @@
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: local-ai
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: models-pvc
|
||||
namespace: local-ai
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 20Gi
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
labels:
|
||||
app: local-ai
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: local-ai
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: local-ai
|
||||
name: local-ai
|
||||
spec:
|
||||
containers:
|
||||
- args:
|
||||
- phi-2
|
||||
env:
|
||||
- name: DEBUG
|
||||
value: "true"
|
||||
name: local-ai
|
||||
image: quay.io/go-skynet/local-ai:master-sycl-f32-ffmpeg-core
|
||||
imagePullPolicy: Always
|
||||
resources:
|
||||
limits:
|
||||
gpu.intel.com/i915: 1
|
||||
volumeMounts:
|
||||
- name: models-volume
|
||||
mountPath: /build/models
|
||||
volumes:
|
||||
- name: models-volume
|
||||
persistentVolumeClaim:
|
||||
claimName: models-pvc
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
spec:
|
||||
selector:
|
||||
app: local-ai
|
||||
type: LoadBalancer
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
65
examples/kubernetes/deployment.yaml
Normal file
65
examples/kubernetes/deployment.yaml
Normal file
@@ -0,0 +1,65 @@
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: local-ai
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: models-pvc
|
||||
namespace: local-ai
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
labels:
|
||||
app: local-ai
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: local-ai
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: local-ai
|
||||
name: local-ai
|
||||
spec:
|
||||
containers:
|
||||
- args:
|
||||
- phi-2
|
||||
env:
|
||||
- name: DEBUG
|
||||
value: "true"
|
||||
name: local-ai
|
||||
image: quay.io/go-skynet/local-ai:master-ffmpeg-core
|
||||
imagePullPolicy: IfNotPresent
|
||||
volumeMounts:
|
||||
- name: models-volume
|
||||
mountPath: /build/models
|
||||
volumes:
|
||||
- name: models-volume
|
||||
persistentVolumeClaim:
|
||||
claimName: models-pvc
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: local-ai
|
||||
namespace: local-ai
|
||||
spec:
|
||||
selector:
|
||||
app: local-ai
|
||||
type: LoadBalancer
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
4
go.mod
4
go.mod
@@ -8,7 +8,6 @@ require (
|
||||
github.com/ggerganov/whisper.cpp/bindings/go v0.0.0-20230628193450-85ed71aaec8e
|
||||
github.com/go-audio/wav v1.1.0
|
||||
github.com/go-skynet/go-bert.cpp v0.0.0-20230716133540-6abe312cded1
|
||||
github.com/go-skynet/go-ggml-transformers.cpp v0.0.0-20230714203132-ffb09d7dd71e
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20231009155254-aeba71ee8428
|
||||
github.com/gofiber/fiber/v2 v2.50.0
|
||||
github.com/google/uuid v1.3.1
|
||||
@@ -28,6 +27,7 @@ require (
|
||||
github.com/rs/zerolog v1.31.0
|
||||
github.com/sashabaranov/go-openai v1.16.0
|
||||
github.com/schollz/progressbar/v3 v3.13.1
|
||||
github.com/stretchr/testify v1.8.4
|
||||
github.com/tmc/langchaingo v0.0.0-20231019140956-c636b3da7701
|
||||
github.com/urfave/cli/v2 v2.25.7
|
||||
github.com/valyala/fasthttp v1.50.0
|
||||
@@ -55,6 +55,7 @@ require (
|
||||
require (
|
||||
github.com/beorn7/perks v1.0.1 // indirect
|
||||
github.com/cespare/xxhash/v2 v2.2.0 // indirect
|
||||
github.com/davecgh/go-spew v1.1.1 // indirect
|
||||
github.com/dlclark/regexp2 v1.8.1 // indirect
|
||||
github.com/dsnet/compress v0.0.2-0.20210315054119-f66993602bf5 // indirect
|
||||
github.com/go-logr/stdr v1.2.2 // indirect
|
||||
@@ -68,6 +69,7 @@ require (
|
||||
github.com/nwaples/rardecode v1.1.0 // indirect
|
||||
github.com/pierrec/lz4/v4 v4.1.2 // indirect
|
||||
github.com/pkoukk/tiktoken-go v0.1.2 // indirect
|
||||
github.com/pmezard/go-difflib v1.0.0 // indirect
|
||||
github.com/prometheus/client_model v0.4.1-0.20230718164431-9a2bf3000d16 // indirect
|
||||
github.com/prometheus/common v0.44.0 // indirect
|
||||
github.com/prometheus/procfs v0.11.1 // indirect
|
||||
|
||||
2
go.sum
2
go.sum
@@ -43,8 +43,6 @@ github.com/go-ole/go-ole v1.2.6 h1:/Fpf6oFPoeFik9ty7siob0G6Ke8QvQEuVcuChpwXzpY=
|
||||
github.com/go-ole/go-ole v1.2.6/go.mod h1:pprOEPIfldk/42T2oK7lQ4v4JSDwmV0As9GaiUsvbm0=
|
||||
github.com/go-skynet/go-bert.cpp v0.0.0-20230716133540-6abe312cded1 h1:yXvc7QfGtoZ51tUW/YVjoTwAfh8HG88XU7UOrbNlz5Y=
|
||||
github.com/go-skynet/go-bert.cpp v0.0.0-20230716133540-6abe312cded1/go.mod h1:fYjkCDRzC+oRLHSjQoajmYK6AmeJnmEanV27CClAcDc=
|
||||
github.com/go-skynet/go-ggml-transformers.cpp v0.0.0-20230714203132-ffb09d7dd71e h1:4reMY29i1eOZaRaSTMPNyXI7X8RMNxCTfDDBXYzrbr0=
|
||||
github.com/go-skynet/go-ggml-transformers.cpp v0.0.0-20230714203132-ffb09d7dd71e/go.mod h1:31j1odgFXP8hDSUVfH0zErKI5aYVP18ddYnPkwCso2A=
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20231009155254-aeba71ee8428 h1:WYjkXL0Nw7dN2uDBMVCWQ8xLavrIhjF/DLczuh5L9TY=
|
||||
github.com/go-skynet/go-llama.cpp v0.0.0-20231009155254-aeba71ee8428/go.mod h1:iub0ugfTnflE3rcIuqV2pQSo15nEw3GLW/utm5gyERo=
|
||||
github.com/go-task/slim-sprig v0.0.0-20210107165309-348f09dbbbc0/go.mod h1:fyg7847qk6SyHyPtNmDHnmrv/HOrqktSC+C9fM+CJOE=
|
||||
|
||||
17
main.go
17
main.go
@@ -12,10 +12,10 @@ import (
|
||||
"syscall"
|
||||
"time"
|
||||
|
||||
api "github.com/go-skynet/LocalAI/api"
|
||||
"github.com/go-skynet/LocalAI/api/backend"
|
||||
config "github.com/go-skynet/LocalAI/api/config"
|
||||
"github.com/go-skynet/LocalAI/api/options"
|
||||
"github.com/go-skynet/LocalAI/core/backend"
|
||||
config "github.com/go-skynet/LocalAI/core/config"
|
||||
api "github.com/go-skynet/LocalAI/core/http"
|
||||
"github.com/go-skynet/LocalAI/core/options"
|
||||
"github.com/go-skynet/LocalAI/internal"
|
||||
"github.com/go-skynet/LocalAI/metrics"
|
||||
"github.com/go-skynet/LocalAI/pkg/gallery"
|
||||
@@ -142,6 +142,12 @@ func main() {
|
||||
EnvVars: []string{"AUDIO_PATH"},
|
||||
Value: "/tmp/generated/audio",
|
||||
},
|
||||
&cli.StringFlag{
|
||||
Name: "upload-path",
|
||||
Usage: "Path to store uploads from files api",
|
||||
EnvVars: []string{"UPLOAD_PATH"},
|
||||
Value: "/tmp/localai/upload",
|
||||
},
|
||||
&cli.StringFlag{
|
||||
Name: "backend-assets-path",
|
||||
Usage: "Path used to extract libraries that are required by some of the backends in runtime.",
|
||||
@@ -227,6 +233,7 @@ For a list of compatible model, check out: https://localai.io/model-compatibilit
|
||||
options.WithDebug(ctx.Bool("debug")),
|
||||
options.WithImageDir(ctx.String("image-path")),
|
||||
options.WithAudioDir(ctx.String("audio-path")),
|
||||
options.WithUploadDir(ctx.String("upload-path")),
|
||||
options.WithF16(ctx.Bool("f16")),
|
||||
options.WithStringGalleries(ctx.String("galleries")),
|
||||
options.WithModelLibraryURL(ctx.String("remote-library")),
|
||||
@@ -404,7 +411,7 @@ For a list of compatible model, check out: https://localai.io/model-compatibilit
|
||||
|
||||
defer opts.Loader.StopAllGRPC()
|
||||
|
||||
filePath, _, err := backend.ModelTTS(backendOption, text, modelOption, opts.Loader, opts)
|
||||
filePath, _, err := backend.ModelTTS(backendOption, text, modelOption, opts.Loader, opts, config.Config{})
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
@@ -11,6 +11,12 @@ type Function struct {
|
||||
}
|
||||
type Functions []Function
|
||||
|
||||
type Tool struct {
|
||||
Type string `json:"type"`
|
||||
Function Function `json:"function,omitempty"`
|
||||
}
|
||||
type Tools []Tool
|
||||
|
||||
func (f Functions) ToJSONStructure() JSONFunctionStructure {
|
||||
js := JSONFunctionStructure{}
|
||||
for _, function := range f {
|
||||
|
||||
@@ -105,11 +105,28 @@ func (sc *JSONSchemaConverter) addRule(name, rule string) string {
|
||||
return key
|
||||
}
|
||||
|
||||
func (sc *JSONSchemaConverter) formatGrammar() string {
|
||||
const array = `arr ::=
|
||||
"[\n" (
|
||||
realvalue
|
||||
(",\n" realvalue)*
|
||||
)? "]"`
|
||||
|
||||
func (sc *JSONSchemaConverter) finalizeGrammar(maybeArray bool) string {
|
||||
var lines []string
|
||||
// write down the computed rules.
|
||||
// if maybeArray is true, we need to add the array rule and slightly tweak the root rule
|
||||
for name, rule := range sc.rules {
|
||||
if maybeArray && name == "root" {
|
||||
name = "realvalue"
|
||||
}
|
||||
lines = append(lines, fmt.Sprintf("%s ::= %s", name, rule))
|
||||
}
|
||||
|
||||
if maybeArray {
|
||||
lines = append(lines, fmt.Sprintf("%s ::= %s", "root", "arr | realvalue"))
|
||||
lines = append(lines, array)
|
||||
}
|
||||
|
||||
return strings.Join(lines, "\n")
|
||||
}
|
||||
|
||||
@@ -234,15 +251,15 @@ func (sc *JSONSchemaConverter) resolveReference(ref string, rootSchema map[strin
|
||||
|
||||
return def
|
||||
}
|
||||
func (sc *JSONSchemaConverter) Grammar(schema map[string]interface{}) string {
|
||||
func (sc *JSONSchemaConverter) Grammar(schema map[string]interface{}, maybeArray bool) string {
|
||||
sc.visit(schema, "", schema)
|
||||
return sc.formatGrammar()
|
||||
return sc.finalizeGrammar(maybeArray)
|
||||
}
|
||||
|
||||
func (sc *JSONSchemaConverter) GrammarFromBytes(b []byte) string {
|
||||
func (sc *JSONSchemaConverter) GrammarFromBytes(b []byte, maybeArray bool) string {
|
||||
var schema map[string]interface{}
|
||||
_ = json.Unmarshal(b, &schema)
|
||||
return sc.Grammar(schema)
|
||||
return sc.Grammar(schema, maybeArray)
|
||||
}
|
||||
|
||||
func jsonString(v interface{}) string {
|
||||
@@ -275,7 +292,7 @@ type JSONFunctionStructure struct {
|
||||
Defs map[string]interface{} `json:"$defs,omitempty"`
|
||||
}
|
||||
|
||||
func (j JSONFunctionStructure) Grammar(propOrder string) string {
|
||||
func (j JSONFunctionStructure) Grammar(propOrder string, maybeArray bool) string {
|
||||
dat, _ := json.Marshal(j)
|
||||
return NewJSONSchemaConverter(propOrder).GrammarFromBytes(dat)
|
||||
return NewJSONSchemaConverter(propOrder).GrammarFromBytes(dat, maybeArray)
|
||||
}
|
||||
|
||||
@@ -52,13 +52,32 @@ string ::= "\"" (
|
||||
[^"\\] |
|
||||
"\\" (["\\/bfnrt] | "u" [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F])
|
||||
)* "\"" space
|
||||
root-1-function ::= "\"search\""`
|
||||
|
||||
inputResult2 = `root-0-function ::= "\"create_event\""
|
||||
root-0 ::= "{" space "\"arguments\"" space ":" space root-0-arguments "," space "\"function\"" space ":" space root-0-function "}" space
|
||||
root-1-arguments ::= "{" space "\"query\"" space ":" space string "}" space
|
||||
realvalue ::= root-0 | root-1
|
||||
root ::= arr | realvalue
|
||||
space ::= " "?
|
||||
root-0-arguments ::= "{" space "\"date\"" space ":" space string "," space "\"time\"" space ":" space string "," space "\"title\"" space ":" space string "}" space
|
||||
root-1 ::= "{" space "\"arguments\"" space ":" space root-1-arguments "," space "\"function\"" space ":" space root-1-function "}" space
|
||||
string ::= "\"" (
|
||||
[^"\\] |
|
||||
"\\" (["\\/bfnrt] | "u" [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F])
|
||||
)* "\"" space
|
||||
arr ::=
|
||||
"[\n" (
|
||||
realvalue
|
||||
(",\n" realvalue)*
|
||||
)? "]"
|
||||
root-1-function ::= "\"search\""`
|
||||
)
|
||||
|
||||
var _ = Describe("JSON schema grammar tests", func() {
|
||||
Context("JSON", func() {
|
||||
It("generates a valid grammar from JSON schema", func() {
|
||||
grammar := NewJSONSchemaConverter("").GrammarFromBytes([]byte(testInput1))
|
||||
grammar := NewJSONSchemaConverter("").GrammarFromBytes([]byte(testInput1), false)
|
||||
results := strings.Split(inputResult1, "\n")
|
||||
for _, r := range results {
|
||||
if r != "" {
|
||||
@@ -103,7 +122,7 @@ var _ = Describe("JSON schema grammar tests", func() {
|
||||
},
|
||||
}}
|
||||
|
||||
grammar := structuredGrammar.Grammar("")
|
||||
grammar := structuredGrammar.Grammar("", false)
|
||||
results := strings.Split(inputResult1, "\n")
|
||||
for _, r := range results {
|
||||
if r != "" {
|
||||
@@ -112,5 +131,50 @@ var _ = Describe("JSON schema grammar tests", func() {
|
||||
}
|
||||
Expect(len(results)).To(Equal(len(strings.Split(grammar, "\n"))))
|
||||
})
|
||||
|
||||
It("generates a valid grammar from JSON Objects for multiple function return", func() {
|
||||
structuredGrammar := JSONFunctionStructure{
|
||||
OneOf: []Item{
|
||||
{
|
||||
Type: "object",
|
||||
Properties: Properties{
|
||||
Function: FunctionName{
|
||||
Const: "create_event",
|
||||
},
|
||||
Arguments: Argument{ // this is OpenAI's parameter
|
||||
Type: "object",
|
||||
Properties: map[string]interface{}{
|
||||
"title": map[string]string{"type": "string"},
|
||||
"date": map[string]string{"type": "string"},
|
||||
"time": map[string]string{"type": "string"},
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
{
|
||||
Type: "object",
|
||||
Properties: Properties{
|
||||
Function: FunctionName{
|
||||
Const: "search",
|
||||
},
|
||||
Arguments: Argument{
|
||||
Type: "object",
|
||||
Properties: map[string]interface{}{
|
||||
"query": map[string]string{"type": "string"},
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
}}
|
||||
|
||||
grammar := structuredGrammar.Grammar("", true)
|
||||
results := strings.Split(inputResult2, "\n")
|
||||
for _, r := range results {
|
||||
if r != "" {
|
||||
Expect(grammar).To(ContainSubstring(r))
|
||||
}
|
||||
}
|
||||
Expect(len(results)).To(Equal(len(strings.Split(grammar, "\n"))), grammar)
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
@@ -2,7 +2,8 @@ package grpc
|
||||
|
||||
import (
|
||||
"context"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
"google.golang.org/grpc"
|
||||
)
|
||||
|
||||
@@ -6,7 +6,7 @@ import (
|
||||
"fmt"
|
||||
"os"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
gopsutil "github.com/shirou/gopsutil/v3/process"
|
||||
)
|
||||
|
||||
@@ -7,7 +7,7 @@ import (
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
"google.golang.org/grpc"
|
||||
"google.golang.org/grpc/credentials/insecure"
|
||||
|
||||
@@ -2,11 +2,12 @@ package grpc
|
||||
|
||||
import (
|
||||
"context"
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"time"
|
||||
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
"google.golang.org/grpc"
|
||||
"google.golang.org/grpc/metadata"
|
||||
"time"
|
||||
)
|
||||
|
||||
var _ Backend = new(embedBackend)
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
package grpc
|
||||
|
||||
import (
|
||||
"github.com/go-skynet/LocalAI/api/schema"
|
||||
"github.com/go-skynet/LocalAI/core/schema"
|
||||
pb "github.com/go-skynet/LocalAI/pkg/grpc/proto"
|
||||
)
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user