mirror of
https://github.com/Facepunch/sbox-public.git
synced 2026-04-20 14:28:17 -04:00
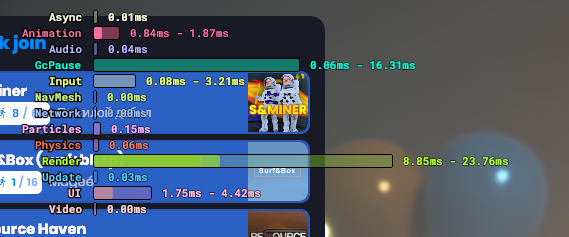
Fixes timing scopes to more accurately represent a per-frame main thread breakdown, and prevents spikes when GC is executed. - **GcPause** - New separate timing scope showing time spent in GC per frame - GC pause time is subtracted from all other scopes, so each scope now only tracks its own code execution and no longer includes GC overhead - e.g. when GC occurs during the audio scope, the audio scope no longer spikes to 20ms - **AudioMixingThread** removed from the main scopes - Runs on a separate thread, so its timings are effectively meaningless in the main thread view - All other scopes are main thread only - No longer relevant given the audio optimisation work done over the past months - **Scene** scope removed - Didn't make much sense as it was an aggregate wrapping many other timing scopes - Replaced with a finer `Update` scope that tracks `Component.FixedUpdate`/`Update` - **Editor** scope no longer shows in-game - Scopes reschuffled - e.g. verlet rope physics traces are now tracked under the physics scope - Audio occlusion queries are now tracked under the audio scope https://files.facepunch.com/lolleko/2026/March/02_12-59-QuixoticMarten.png
{kind=link}
130 lines
4.1 KiB
C#
130 lines
4.1 KiB
C#
using Sandbox.Utility;
|
|
using System.Collections.Concurrent;
|
|
|
|
namespace Sandbox;
|
|
|
|
[Expose]
|
|
public sealed class SceneAnimationSystem : GameObjectSystem<SceneAnimationSystem>
|
|
{
|
|
private HashSetEx<SkinnedModelRenderer> SkinnedRenderers { get; } = new();
|
|
|
|
internal void AddRenderer( SkinnedModelRenderer renderer )
|
|
{
|
|
SkinnedRenderers.Add( renderer );
|
|
}
|
|
|
|
internal void RemoveRenderer( SkinnedModelRenderer renderer )
|
|
{
|
|
SkinnedRenderers.Remove( renderer );
|
|
}
|
|
|
|
private ConcurrentQueue<GameTransform> ChangedTransforms { get; } = new();
|
|
|
|
// Reusable lists to avoid per-frame allocations from Parallel.ForEach with IEnumerable<T>.
|
|
// Parallel.ForEach on IEnumerable uses a dynamic partitioner that allocates KeyValuePair<long, T>[]
|
|
// chunks internally; passing an IList<T> uses the static range partitioner instead.
|
|
private readonly List<SkinnedModelRenderer> _rootRenderers = new();
|
|
private readonly List<SkinnedModelRenderer> _boneMergeRoots = new();
|
|
private readonly List<SkinnedModelRenderer> _physRenderers = new();
|
|
|
|
private static int _animThreadCount = Math.Max( 1, Environment.ProcessorCount - 1 );
|
|
|
|
private static ParallelOptions _animParallelOptions = new()
|
|
{
|
|
MaxDegreeOfParallelism = _animThreadCount
|
|
};
|
|
|
|
public SceneAnimationSystem( Scene scene ) : base( scene )
|
|
{
|
|
Listen( Stage.UpdateBones, 0, UpdateAnimation, "UpdateAnimation" );
|
|
Listen( Stage.FinishUpdate, 0, FinishUpdate, "FinishUpdate" );
|
|
Listen( Stage.PhysicsStep, 0, PhysicsStep, "PhysicsStep" );
|
|
}
|
|
|
|
void UpdateAnimation()
|
|
{
|
|
using ( PerformanceStats.Timings.Animation.Scope() )
|
|
{
|
|
_rootRenderers.Clear();
|
|
_boneMergeRoots.Clear();
|
|
|
|
foreach ( var renderer in SkinnedRenderers.EnumerateLocked() )
|
|
{
|
|
if ( renderer.IsRootRenderer )
|
|
_rootRenderers.Add( renderer );
|
|
|
|
if ( !renderer.BoneMergeTarget.IsValid() && renderer.HasBoneMergeChildren )
|
|
_boneMergeRoots.Add( renderer );
|
|
}
|
|
|
|
// Skip out if we have a parent that is a skinned model, because we need to move relative to that
|
|
// and their bones haven't been worked out yet. They will get worked out after our parent is.
|
|
// Use a load-balanced partitioner: work per root is highly uneven (clothed characters have many
|
|
// bone-merged children), so static range partitioning would cause severe thread idle time.
|
|
System.Threading.Tasks.Parallel.ForEach( Partitioner.Create( _rootRenderers, loadBalance: true ), _animParallelOptions, ProcessRenderer );
|
|
|
|
// This is a good time to maintain decode caches
|
|
// Will copy local caches to the global cache and handle LRU eviction
|
|
// Can do this in a background task as nothing is touching these caches until next frame
|
|
Task.Run( g_pAnimationSystemUtils.MaintainDecodeCaches );
|
|
|
|
// Now merge any descendants without allocating per-merge delegates
|
|
System.Threading.Tasks.Parallel.ForEach( Partitioner.Create( _boneMergeRoots, loadBalance: true ), _animParallelOptions, renderer => renderer.MergeDescendants( ChangedTransforms ) );
|
|
|
|
while ( ChangedTransforms.TryDequeue( out var tx ) )
|
|
{
|
|
tx.TransformChanged( true );
|
|
}
|
|
|
|
//
|
|
// Run events in the main thread
|
|
//
|
|
foreach ( var x in SkinnedRenderers.EnumerateLocked() )
|
|
{
|
|
x.DispatchEvents();
|
|
}
|
|
}
|
|
}
|
|
|
|
void ProcessRenderer( SkinnedModelRenderer renderer )
|
|
{
|
|
if ( !renderer.IsValid() || !renderer.Enabled )
|
|
return;
|
|
|
|
if ( renderer.AnimationUpdate() )
|
|
{
|
|
ChangedTransforms.Enqueue( renderer.Transform );
|
|
}
|
|
|
|
foreach ( var child in renderer.SkinnedChildren )
|
|
{
|
|
ProcessRenderer( child );
|
|
}
|
|
}
|
|
|
|
void FinishUpdate()
|
|
{
|
|
using var _ = PerformanceStats.Timings.Animation.Scope();
|
|
|
|
foreach ( var renderer in SkinnedRenderers.EnumerateLocked() )
|
|
{
|
|
renderer.FinishUpdate();
|
|
}
|
|
}
|
|
|
|
void PhysicsStep()
|
|
{
|
|
using var _ = PerformanceStats.Timings.Animation.Scope();
|
|
|
|
_physRenderers.Clear();
|
|
|
|
foreach ( var renderer in SkinnedRenderers.EnumerateLocked() )
|
|
{
|
|
if ( renderer.Physics != null )
|
|
_physRenderers.Add( renderer );
|
|
}
|
|
|
|
System.Threading.Tasks.Parallel.ForEach( Partitioner.Create( _physRenderers, loadBalance: true ), _animParallelOptions, renderer => renderer.Physics.Step() );
|
|
}
|
|
}
|